

A Comparative Analysis of Machine Learning Techniques for National Glacier Mapping: Evaluating Performance through Spatial Cross-Validation in Perú


Abstract
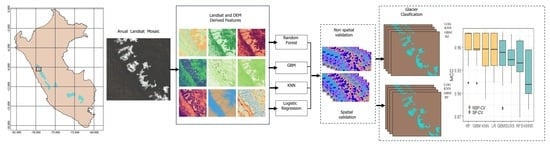
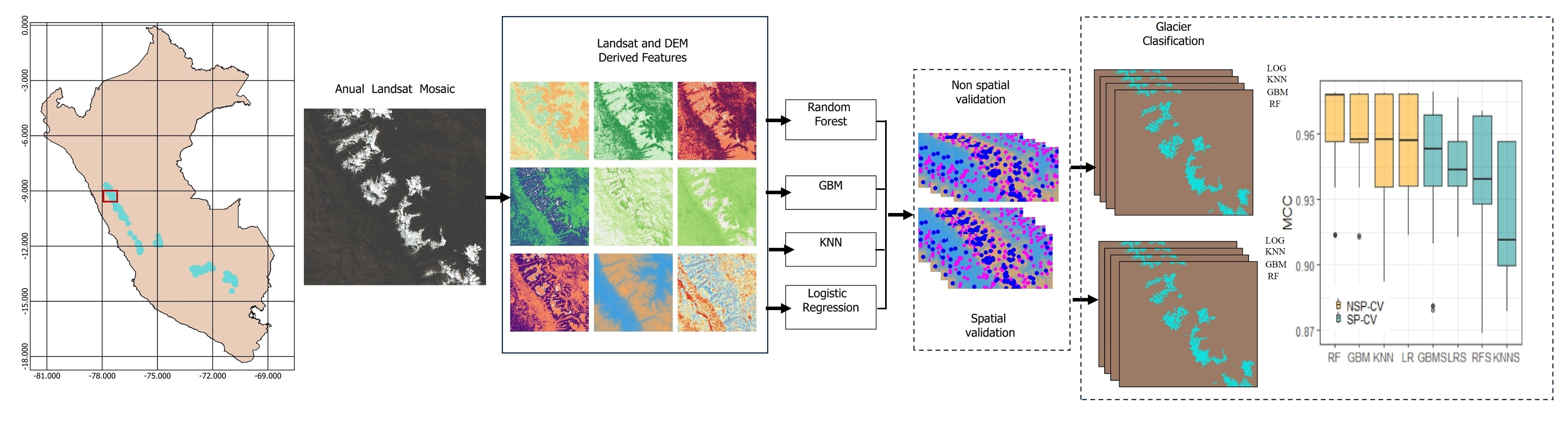
:
1. Introduction
2. Materials and Methods
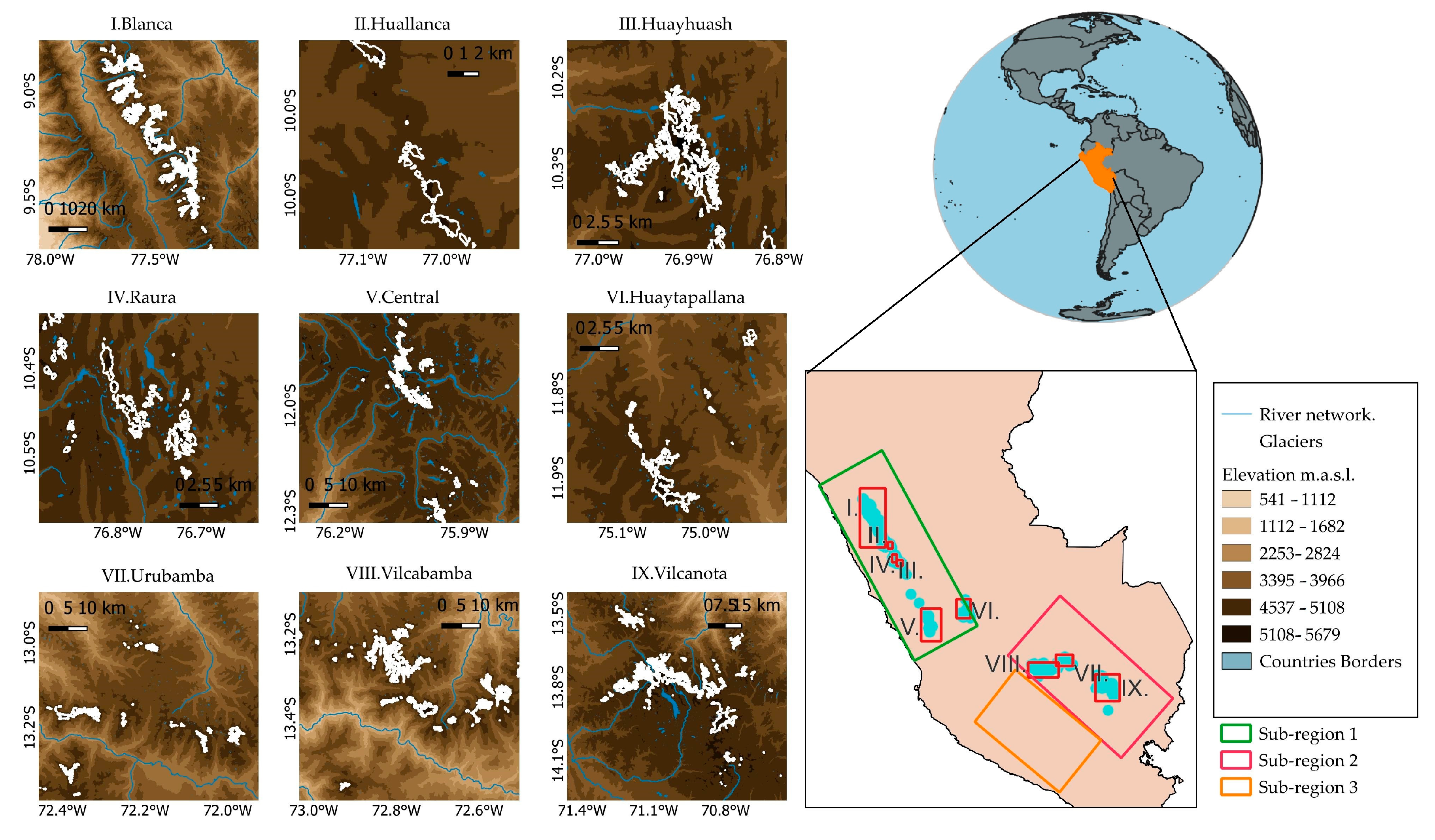
2.1. Study Area
- The sub-region situated in the northern wet outer tropics experiences a high mean annual humidity of 71%, minimal temperature seasonality, and a total annual precipitation of 815 mm. Sub-region 1 includes the Cordillera Blanca, Central, Huallanca, Huayhuash, Huaytapallana, and Raura. Sub-region 2, located in the southern wet outer tropics, has a moderate mean annual humidity of 59%, annual variability of the mean monthly temperature of approximately 4 °C, and a total annual precipitation of 723 mm. Sub-region 2 includes the Cordillera Vilcabamba, Urubamba, and Vilcanota. Sub-region 3 is characterized by a low mean annual humidity of 50%, a mean annual temperature of −4.0 °C, and a minimal total annual precipitation of 287 mm. The three subregions experience a dry season from May to September, coinciding with the austral winter, and a wet season from October to April, corresponding to the austral summer [44]. During the wet season, the glaciers predominantly accumulate mass, while the lower portions of the glaciers experience ablation consistently throughout the year.
2.2. Data Acquisition
2.2.1. Glacier Inventory
2.2.2. Landsat Data and Processing
2.2.3. Digital Elevation Model (DEM)
2.3. Data Overlay
2.4. Machine Learning Classifiers
2.4.1. Logistic Regression
2.4.2. K-Nearest Neighbors
2.4.3. Random Forest
2.4.4. Gradient-Boosting Machines
2.5. Normalized Difference Snow Index (NDSI)
2.6. Model Evaluation Metrics
2.6.1. Matthews Correlation Coefficient (MCC)
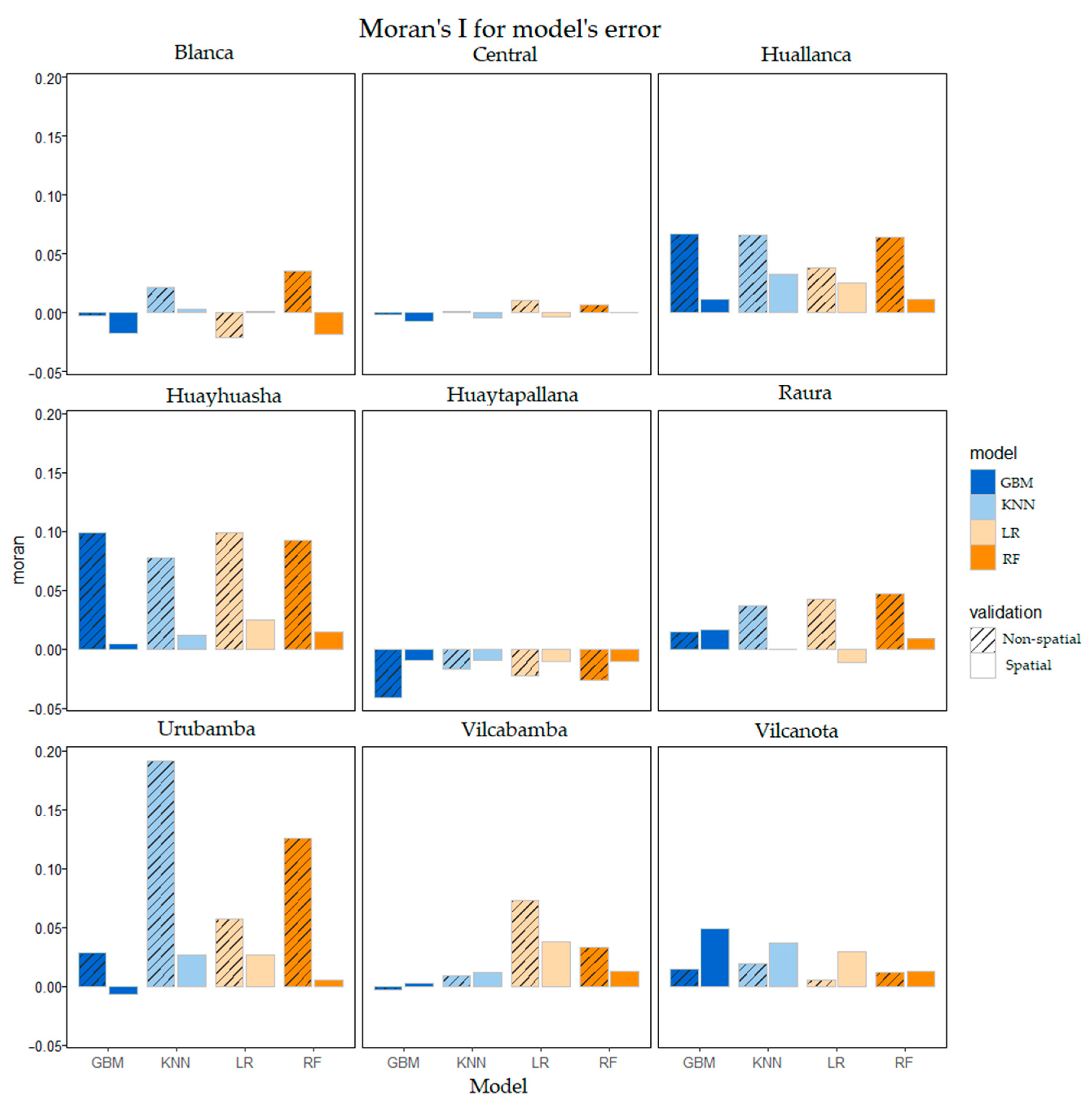
2.6.2. Moran’s I
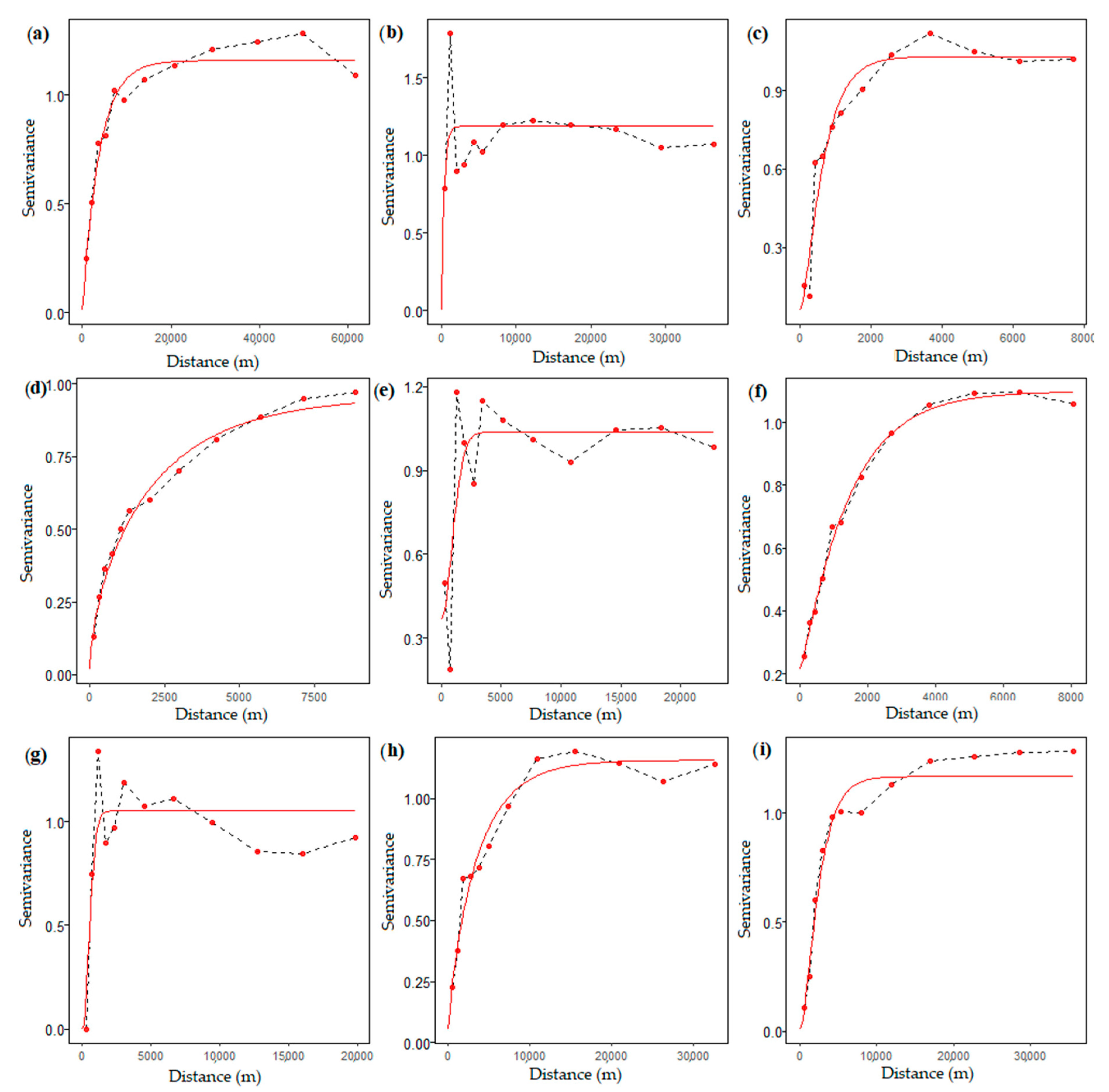
2.6.3. Indicator Variograms
2.7. Model Validation
2.7.1. K-Fold Cross-Validation
2.7.2. K-Fold Spatial Cross-Validation
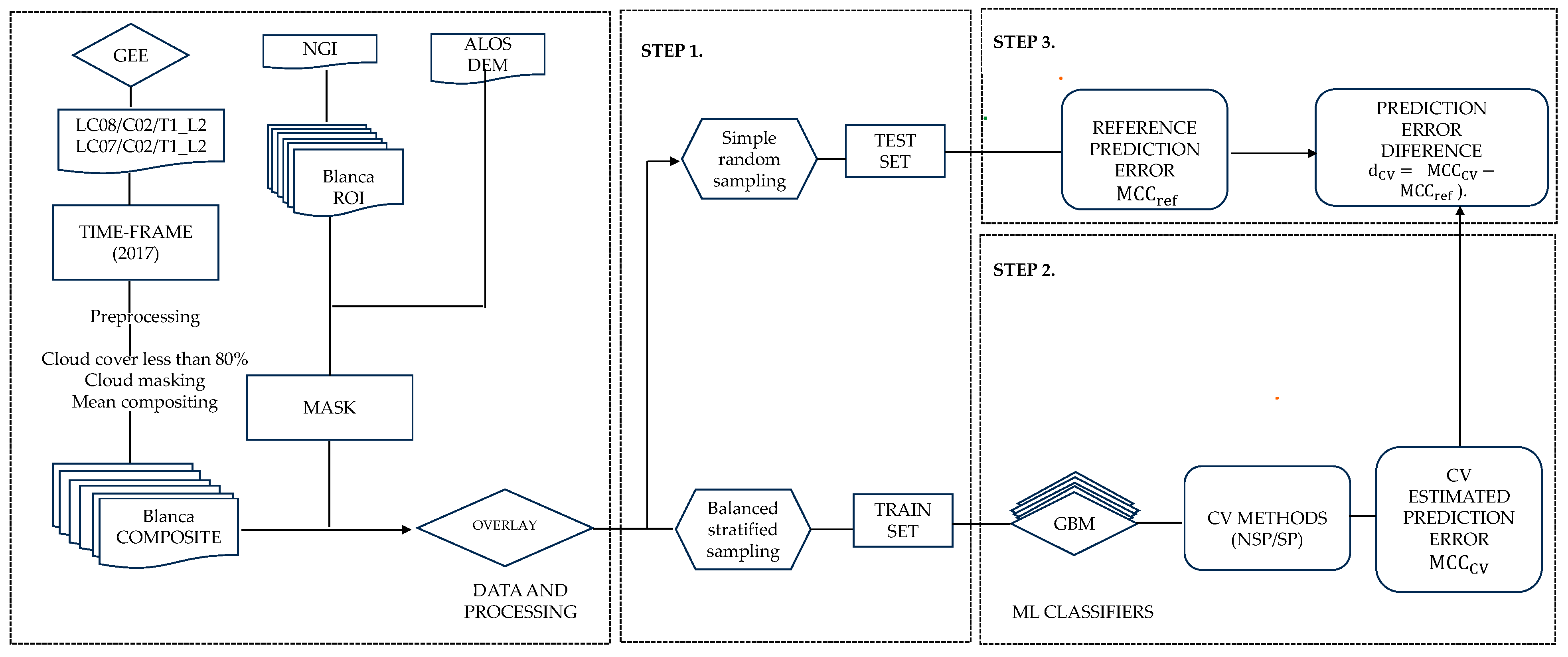
2.8. Experimental Benchmark
2.8.1. Step 1: Independent Data Test Prediction Error
2.8.2. Step 2: Compute the Prediction Error for Each CV Method
2.8.3. Step 3: Compute Differences in CV Prediction Errors
2.9. Satistical Comparison of Model Results
2.10. Software
3. Results and Discussion
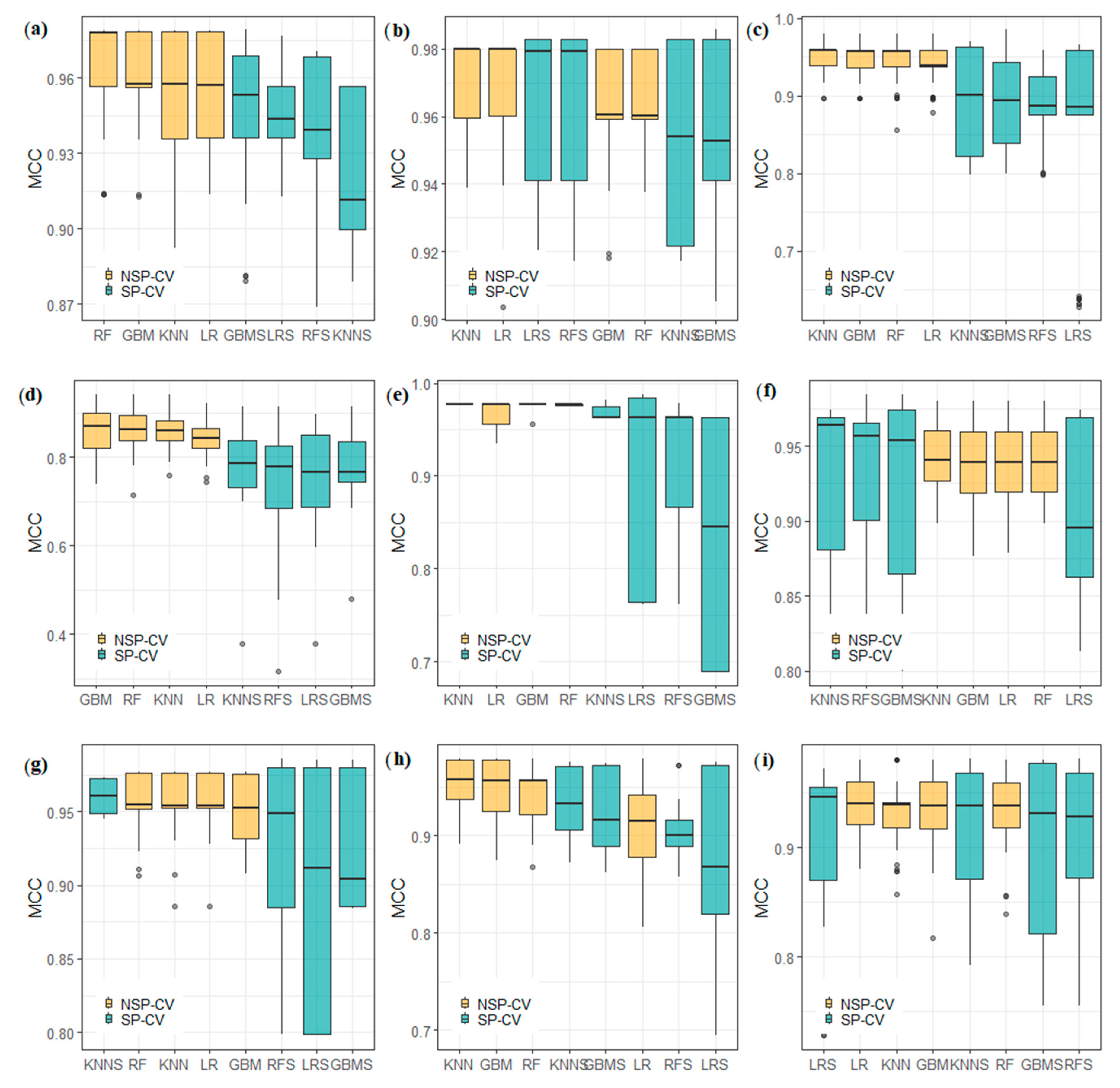
3.1. Classification Performance
3.1.1. Which Models Showed the Best Performance?
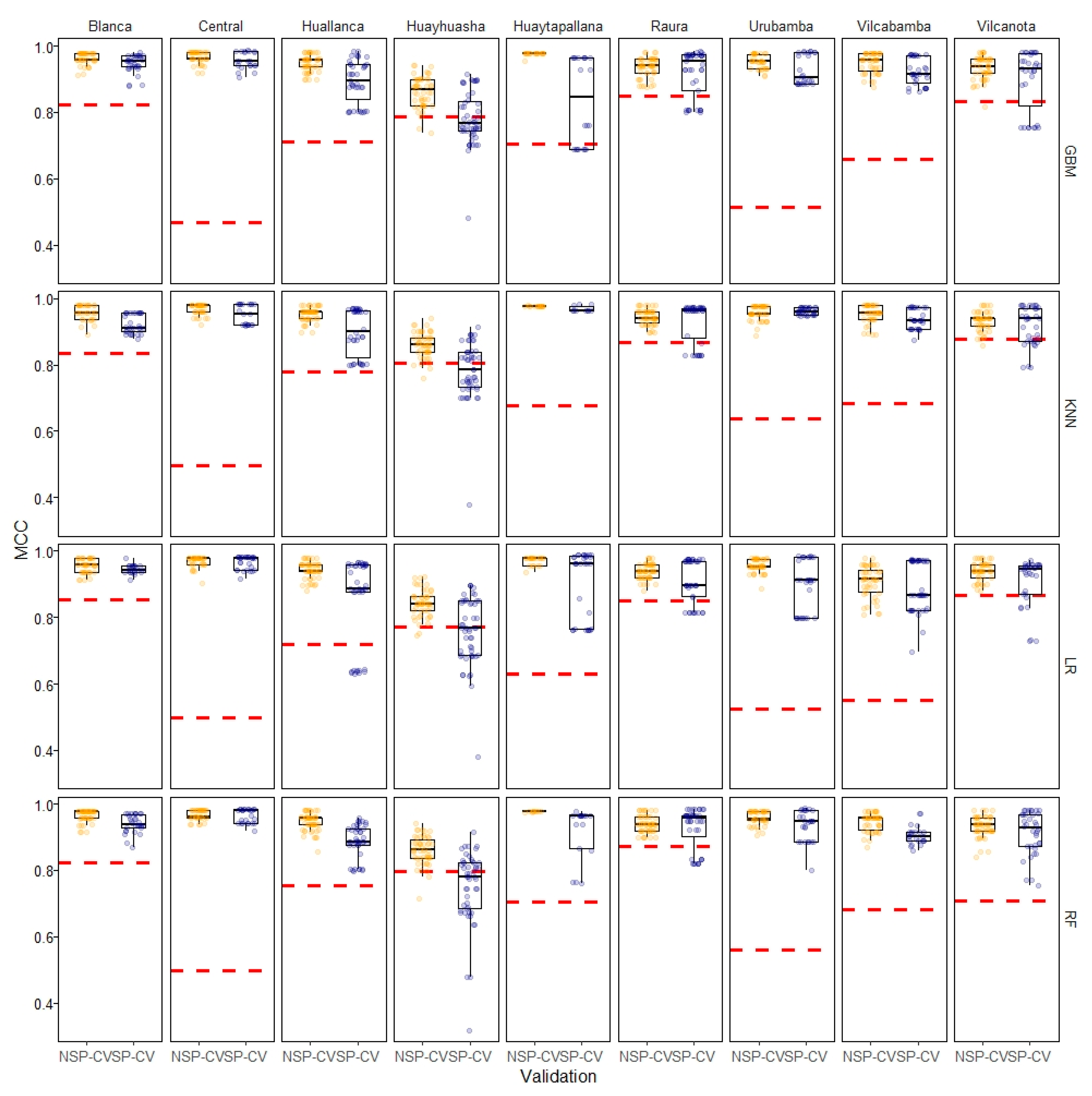
3.1.2. Effect of Spatial and Non-spatial Cross-Validation
3.1.3. Statistical Comparison of Model Results
3.2. Spatial Autocorrelation Assessment
3.2.1. Spatial Autocorrelation of Classes
3.2.2. Spatial Autocorrelation of Errors
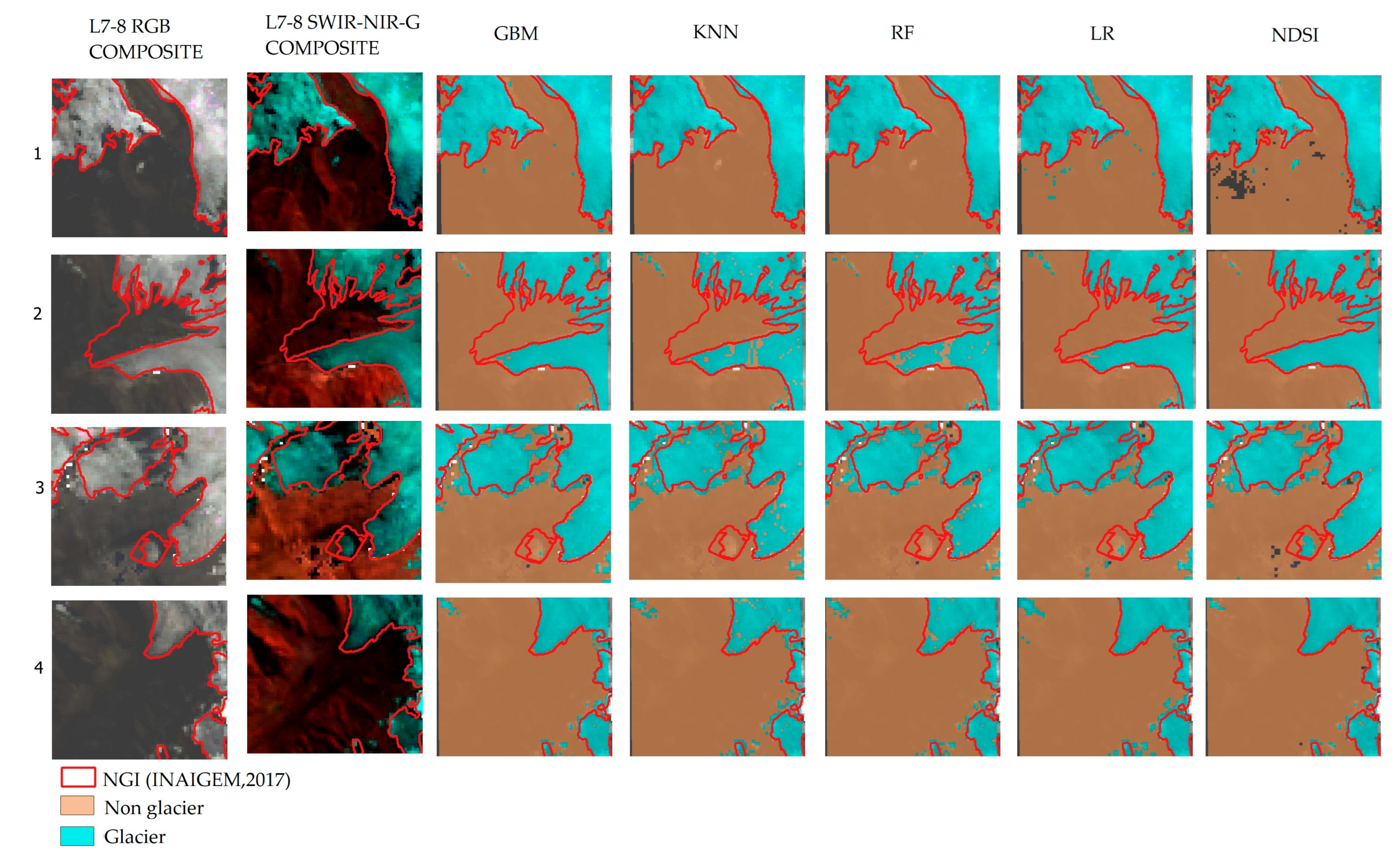
3.3. Spatial Predictions
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Veettil, B.K.; Kamp, U. Remote Sensing of Glaciers in the Tropical Andes: A Review. Int. J. Remote Sens. 2017, 38, 7101–7137. [Google Scholar] [CrossRef]
- Drenkhan, F.; Carey, M.; Huggel, C.; Seidel, J.; Oré, M.T. The Changing Water Cycle: Climatic and Socioeconomic Drivers of Water-related Changes in the Andes of Peru. WIREs Water 2015, 2, 715–733. [Google Scholar] [CrossRef]
- Salzmann, N.; Huggel, C.; Rohrer, M.; Silverio, W.; Mark, B.G.; Burns, P.; Portocarrero, C. Glacier Changes and Climate Trends Derived from Multiple Sources in the Data Scarce Cordillera Vilcanota Region, Southern Peruvian Andes. Cryosphere 2013, 7, 103–118. [Google Scholar] [CrossRef]
- Taylor, L.S.; Quincey, D.J.; Smith, M.W.; Potter, E.R.; Castro, J.; Fyffe, C.L. Multi-Decadal Glacier Area and Mass Balance Change in the Southern Peruvian Andes. Front. Earth Sci. 2022, 10, 863933. [Google Scholar] [CrossRef]
- Silverio, W.; Jaquet, J.-M. Glacial Cover Mapping (1987–1996) of the Cordillera Blanca (Peru) Using Satellite Imagery. Remote Sens. Environ. 2005, 95, 342–350. [Google Scholar] [CrossRef]
- Durán-Alarcón, C.; Gevaert, C.M.; Mattar, C.; Jiménez-Muñoz, J.C.; Pasapera-Gonzales, J.J.; Sobrino, J.A.; Silvia-Vidal, Y.; Fashé-Raymundo, O.; Chavez-Espiritu, T.W.; Santillan-Portilla, N. Recent Trends on Glacier Area Retreat over the Group of Nevados Caullaraju-Pastoruri (Cordillera Blanca, Peru) Using Landsat Imagery. J. S. Am. Earth Sci. 2015, 59, 19–26. [Google Scholar] [CrossRef]
- Juen, I.; Kaser, G.; Georges, C. Modelling Observed and Future Runoff from a Glacierized Tropical Catchment (Cordillera Blanca, Perú). Glob. Planet. Chang. 2007, 59, 37–48. [Google Scholar] [CrossRef]
- Buytaert, W.; Moulds, S.; Acosta, L.; De Bièvre, B.; Olmos, C.; Villacis, M.; Tovar, C.; Verbist, K.M.J. Glacial Melt Content of Water Use in the Tropical Andes. Environ. Res. Lett. 2017, 12, 114014. [Google Scholar] [CrossRef]
- Turpo Cayo, E.Y.; Borja, M.O.; Espinoza-Villar, R.; Moreno, N.; Camargo, R.; Almeida, C.; Hopfgartner, K.; Yarleque, C.; Souza, C.M. Mapping Three Decades of Changes in the Tropical Andean Glaciers Using Landsat Data Processed in the Earth Engine. Remote Sens. 2022, 14, 1974. [Google Scholar] [CrossRef]
- Muñoz, R.; Huggel, C.; Drenkhan, F.; Vis, M.; Viviroli, D. Comparing Model Complexity for Glacio-Hydrological Simulation in the Data-Scarce Peruvian Andes. J. Hydrol. Reg. Stud. 2021, 37, 100932. [Google Scholar] [CrossRef]
- Veettil, B.K. Glacier Mapping in the Cordillera Blanca, Peru, Tropical Andes, Using Sentinel-2 and Landsat Data. Singap. J. Trop. Geogr. 2018, 39, 351–363. [Google Scholar] [CrossRef]
- Paul, F.; Barrand, N.E.; Baumann, S.; Berthier, E.; Bolch, T.; Casey, K.; Frey, H.; Joshi, S.P.; Konovalov, V.; Bris, R.L.; et al. On the Accuracy of Glacier Outlines Derived from Remote-Sensing Data. Ann. Glaciol. 2013, 54, 171–182. [Google Scholar] [CrossRef]
- López-Moreno, J.I.; Fontaneda, S.; Bazo, J.; Revuelto, J.; Azorin-Molina, C.; Valero-Garcés, B.; Morán-Tejeda, E.; Vicente-Serrano, S.M.; Zubieta, R.; Alejo-Cochachín, J. Recent Glacier Retreat and Climate Trends in Cordillera Huaytapallana, Peru. Glob. Planet. Chang. 2014, 112, 1–11. [Google Scholar] [CrossRef]
- INAIGEM. Manual Metodológico de Inventario Nacional de Glaciares; Instituto Nacional de Investigación en Glaciaresy Ecosistemas de Montaña: Huaraz, Peru, 2017. [Google Scholar]
- Raup, B.; Racoviteanu, A.; Khalsa, S.J.S.; Helm, C.; Armstrong, R.; Arnaud, Y. The GLIMS Geospatial Glacier Database: A New Tool for Studying Glacier Change. Glob. Planet. Chang. 2007, 56, 101–110. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2009; ISBN 978-0-387-84857-0. [Google Scholar]
- Schratz, P.; Becker, M.; Lang, M.; Brenning, A. Mlr3spatiotempcv: Spatiotemporal Resampling Methods for Machine Learning in R. arXiv 2021, arXiv:2110.12674. [Google Scholar]
- Alifu, H.; Vuillaume, J.-F.; Johnson, B.A.; Hirabayashi, Y. Machine-Learning Classification of Debris-Covered Glaciers Using a Combination of Sentinel-1/-2 (SAR/Optical), Landsat 8 (Thermal) and Digital Elevation Data. Geomorphology 2020, 369, 107365. [Google Scholar] [CrossRef]
- Lu, Y.; Zhang, Z.; Shangguan, D.; Yang, J. Novel Machine Learning Method Integrating Ensemble Learning and Deep Learning for Mapping Debris-Covered Glaciers. Remote Sens. 2021, 13, 2595. [Google Scholar] [CrossRef]
- Baraka, S.; Akera, B.; Aryal, B.; Sherpa, T.; Shresta, F.; Ortiz, A.; Sankaran, K.; Ferres, J.L.; Matin, M.; Bengio, Y. Machine Learning for Glacier Monitoring in the Hindu Kush Himalaya. arXiv 2020, arXiv:2012.05013. [Google Scholar]
- Caro, A.; Condom, T.; Rabatel, A. Climatic and Morphometric Explanatory Variables of Glacier Changes in the Andes (8–55°S): New Insights From Machine Learning Approaches. Front. Earth Sci. 2021, 9, 713011. [Google Scholar] [CrossRef]
- Li, X.; Wang, N.; Wu, Y. Automated Glacier Snow Line Altitude Calculation Method Using Landsat Series Images in the Google Earth Engine Platform. Remote Sens. 2022, 14, 2377. [Google Scholar] [CrossRef]
- Prieur, C.; Rabatel, A.; Thomas, J.-B.; Farup, I.; Chanussot, J. Machine Learning Approaches to Automatically Detect Glacier Snow Lines on Multi-Spectral Satellite Images. Remote Sens. 2022, 14, 3868. [Google Scholar] [CrossRef]
- Huang, Z. Extensions to the K-Means Algorithm for Clustering Large Data Sets with Categorical Values. Data Min. Knowl. Discov. 1998, 2, 283–304. [Google Scholar] [CrossRef]
- Khan, A.A.; Jamil, A.; Hussain, D.; Taj, M.; Jabeen, G.; Malik, M.K. Machine-Learning Algorithms for Mapping Debris-Covered Glaciers: The Hunza Basin Case Study. IEEE Access 2020, 8, 12725–12734. [Google Scholar] [CrossRef]
- Zhang, J.; Jia, L.; Menenti, M.; Hu, G. Glacier Facies Mapping Using a Machine-Learning Algorithm: The Parlung Zangbo Basin Case Study. Remote Sens. 2019, 11, 452. [Google Scholar] [CrossRef]
- Bierkens, M.F.P.; Burrough, P.A. The Indicator Approach to Categorical Soil Data. J. Soil Sci. 1993, 44, 361–368. [Google Scholar] [CrossRef]
- Bivand, R.S.; Pebesma, E.; Gómez-Rubio, V. Applied Spatial Data Analysis with R; Springer: New York, NY, USA, 2013; ISBN 978-1-4614-7617-7. [Google Scholar]
- Burns, P.; Nolin, A. Using Atmospherically-Corrected Landsat Imagery to Measure Glacier Area Change in the Cordillera Blanca, Peru from 1987 to 2010—ScienceDirect. Remote Sens. Environ. 2014, 140, 165–178. [Google Scholar] [CrossRef]
- Cressie, N.A.C. Statistics for Spatial Data, Revised Edition; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2015; ISBN 978-1-119-11517-5. [Google Scholar]
- Easterling, W.; Apps, M. Assessing the Consequences of Climate Change for Food and Forest Resources: A View from the IPCC. In Increasing Climate Variability and Change; Salinger, J., Sivakumar, M.V.K., Motha, R.P., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 165–189. ISBN 978-1-4020-3354-4. [Google Scholar]
- Tsendbazar, N.-E.; De Bruin, S.; Fritz, S.; Herold, M. Spatial Accuracy Assessment and Integration of Global Land Cover Datasets. Remote Sens. 2015, 7, 15804–15821. [Google Scholar] [CrossRef]
- Brenning, A. Spatial Prediction Models for Landslide Hazards: Review, Comparison and Evaluation. Nat. Hazards Earth Syst. Sci. 2005, 5, 853–862. [Google Scholar] [CrossRef]
- De Bruin, S.; Brus, D.J.; Heuvelink, G.B.M.; Van Ebbenhorst Tengbergen, T.; Wadoux, A.M.J.-C. Dealing with Clustered Samples for Assessing Map Accuracy by Cross-Validation. Ecol. Inform. 2022, 69, 101665. [Google Scholar] [CrossRef]
- Schratz, P.; Muenchow, J.; Iturritxa, E.; Richter, J.; Brenning, A. Hyperparameter Tuning and Performance Assessment of Statistical and Machine-Learning Algorithms Using Spatial Data. Ecol. Model. 2019, 406, 109–120. [Google Scholar] [CrossRef]
- Kopczewska, K. Spatial Machine Learning: New Opportunities for Regional Science. Ann. Reg. Sci. 2022, 68, 713–755. [Google Scholar] [CrossRef]
- Ploton, P.; Mortier, F.; Réjou-Méchain, M.; Barbier, N.; Picard, N.; Rossi, V.; Dormann, C.; Cornu, G.; Viennois, G.; Bayol, N.; et al. Spatial Validation Reveals Poor Predictive Performance of Large-Scale Ecological Mapping Models. Nat. Commun. 2020, 11, 4540. [Google Scholar] [CrossRef] [PubMed]
- Brenning, A. Spatial Cross-Validation and Bootstrap for the Assessment of Prediction Rules in Remote Sensing: The R Package Sperrorest. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 5372–5375. [Google Scholar]
- Milà, C.; Mateu, J.; Pebesma, E.; Meyer, H. Nearest Neighbour Distance Matching Leave-One-Out Cross-Validation for Map Validation. Methods Ecol. Evol. 2022, 13, 1304–1316. [Google Scholar] [CrossRef]
- Roberts, D.R.; Bahn, V.; Ciuti, S.; Boyce, M.S.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.J.; Schröder, B.; Thuiller, W.; et al. Cross-Validation Strategies for Data with Temporal, Spatial, Hierarchical, or Phylogenetic Structure. Ecography 2017, 40, 913–929. [Google Scholar] [CrossRef]
- Rocha, A.; Groen, T.; Skidmore, A.; Darvishzadeh, R.; Willemen, L. Machine Learning Using Hyperspectral Data Inaccurately Predicts Plant Traits Under Spatial Dependency. Remote Sens. 2018, 10, 1263. [Google Scholar] [CrossRef]
- Meyer, H.; Pebesma, E. Machine Learning-Based Global Maps of Ecological Variables and the Challenge of Assessing Them. Nat. Commun. 2022, 13, 2208. [Google Scholar] [CrossRef] [PubMed]
- Seehaus, T.; Malz, P.; Sommer, C.; Lippl, S.; Cochachin, A.; Braun, M. Changes of the Tropical Glaciers throughout Peru between 2000 and 2016—Mass Balance and Area Fluctuations. Cryosphere 2019, 13, 2537–2556. [Google Scholar] [CrossRef]
- Sagredo, E.A.; Lowell, T.V. Climatology of Andean Glaciers: A Framework to Understand Glacier Response to Climate Change. Glob. Planet. Chang. 2012, 86–87, 101–109. [Google Scholar] [CrossRef]
- Drenkhan, F.; Guardamino, L.; Huggel, C.; Frey, H. Current and Future Glacier and Lake Assessment in the Deglaciating Vilcanota-Urubamba Basin, Peruvian Andes. Glob. Planet. Chang. 2018, 169, 105–118. [Google Scholar] [CrossRef]
- Kozhikkodan Veettil, B.; de Souza, S.F. Study of 40-Year Glacier Retreat in the Northern Region of the Cordillera Vilcanota, Peru, Using Satellite Images: Preliminary Results. Remote Sens. Lett. 2017, 8, 78–85. [Google Scholar] [CrossRef]
- INAIGEM. Inventario Nacional de Glaciares; Instituto Nacional de Investigación en Glaciaresy Ecosistemas de Montaña: Huaraz, Peru, 2018. [Google Scholar]
- Vermote, E.; Justice, C.; Claverie, M.; Franch, B. Preliminary Analysis of the Performance of the Landsat 8/OLI Land Surface Reflectance Product. Remote Sens. Environ. 2016, 185, 46–56. [Google Scholar] [CrossRef] [PubMed]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-Scale Geospatial Analysis for Everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Paul, F.; Bolch, T.; Kääb, A.; Nagler, T.; Nuth, C.; Scharrer, K.; Shepherd, A.; Strozzi, T.; Ticconi, F.; Bhambri, R.; et al. The Glaciers Climate Change Initiative: Methods for Creating Glacier Area, Elevation Change and Velocity Products. Remote Sens. Environ. 2015, 162, 408–426. [Google Scholar] [CrossRef]
- Roy, D.P.; Kovalskyy, V.; Zhang, H.K.; Vermote, E.F.; Yan, L.; Kumar, S.S.; Egorov, A. Characterization of Landsat-7 to Landsat-8 Reflective Wavelength and Normalized Difference Vegetation Index Continuity. Remote Sens. Environ. 2016, 185, 57–70. [Google Scholar] [CrossRef] [PubMed]
- Paul, F.; Huggel, C.; Kääb, A. Combining Satellite Multispectral Image Data and a Digital Elevation Model for Mapping Debris-Covered Glaciers. Remote Sens. Environ. 2004, 89, 510–518. [Google Scholar] [CrossRef]
- Conrad, O.; Bechtel, B.; Bock, M.; Dietrich, H.; Fischer, E.; Gerlitz, L.; Wehberg, J.; Wichmann, V.; Böhner, J. System for Automated Geoscientific Analyses (SAGA) v. 2.1.4. Geosci. Model Dev. 2015, 8, 1991–2007. [Google Scholar] [CrossRef]
- Das, P.; Pandey, V. Use of Logistic Regression in Land-Cover Classification with Moderate-Resolution Multispectral Data. J. Indian Soc. Remote Sens. 2019, 47, 1443–1454. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Hengl, T.; Nussbaum, M.; Wright, M.N.; Heuvelink, G.B.M.; Gräler, B. Random Forest as a Generic Framework for Predictive Modeling of Spatial and Spatio-Temporal Variables. PeerJ 2018, 6, e5518. [Google Scholar] [CrossRef]
- Meyer, H.; Reudenbach, C.; Wöllauer, S.; Nauss, T. Importance of Spatial Predictor Variable Selection in Machine Learning Applications—Moving from Data Reproduction to Spatial Prediction. Ecol. Model. 2019, 411, 108815. [Google Scholar] [CrossRef]
- Gupta, S.; Papritz, A.; Lehmann, P.; Hengl, T.; Bonetti, S.; Or, D. Global Mapping of Soil Water Characteristics Parameters—Fusing Curated Data with Machine Learning and Environmental Covariates. Remote Sens. 2022, 14, 1947. [Google Scholar] [CrossRef]
- Chen, Q.; Miao, F.; Wang, H.; Xu, Z.; Tang, Z.; Yang, L.; Qi, S. Downscaling of Satellite Remote Sensing Soil Moisture Products Over the Tibetan Plateau Based on the Random Forest Algorithm: Preliminary Results. Earth Space Sci. 2020, 7, e2020EA001265. [Google Scholar] [CrossRef]
- de Graaf, I.E.M.; Sutanudjaja, E.H.; van Beek, L.P.H.; Bierkens, M.F.P. A High-Resolution Global-Scale Groundwater Model. Hydrol. Earth Syst. Sci. 2015, 19, 823–837. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Niang Gadiaga, A.; Linard, C.; Lennert, M.; Vanhuysse, S.; Mboga, N.; Wolff, E.; Kalogirou, S. Geographical Random Forests: A Spatial Extension of the Random Forest Algorithm to Address Spatial Heterogeneity in Remote Sensing and Population Modelling. Geocarto Int. 2021, 36, 121–136. [Google Scholar] [CrossRef]
- Hu, L.; Chun, Y.; Griffith, D.A. Incorporating Spatial Autocorrelation into House Sale Price Prediction Using Random Forest Model. Trans. GIS 2022, 26, 2123–2144. [Google Scholar] [CrossRef]
- Sekulić, A.; Kilibarda, M.; Heuvelink, G.B.M.; Nikolić, M.; Bajat, B. Random Forest Spatial Interpolation. Remote Sens. 2020, 12, 1687. [Google Scholar] [CrossRef]
- Probst, P.; Wright, M.N.; Boulesteix, A. Hyperparameters and Tuning Strategies for Random Forest. WIREs Data Min. Knowl. Discov. 2019, 9, e1301. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic Gradient Boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Wang, J.; Tang, Z.; Deng, G.; Hu, G.; You, Y.; Zhao, Y. Landsat Satellites Observed Dynamics of Snowline Altitude at the End of the Melting Season, Himalayas, 1991–2022. Remote Sens. 2023, 15, 2534. [Google Scholar] [CrossRef]
- Wang, X.; Wang, J.; Che, T.; Huang, X.; Hao, X.; Li, H. Snow Cover Mapping for Complex Mountainous Forested Environments Based on a Multi-Index Technique. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1433–1441. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The Matthews Correlation Coefficient (MCC) Is More Informative Than Cohen’s Kappa and Brier Score in Binary Classification Assessment. IEEE Access 2021, 9, 78368–78381. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The Advantages of the Matthews Correlation Coefficient (MCC) over F1 Score and Accuracy in Binary Classification Evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed]
- Foody, G.M. Explaining the Unsuitability of the Kappa Coefficient in the Assessment and Comparison of the Accuracy of Thematic Maps Obtained by Image Classification. Remote Sens. Environ. 2020, 239, 111630. [Google Scholar] [CrossRef]
- Jiang, Z. A Survey on Spatial Prediction Methods. IEEE Trans. Knowl. Data Eng. 2019, 31, 1645–1664. [Google Scholar] [CrossRef]
- Liu, X.; Kounadi, O.; Zurita-Milla, R. Incorporating Spatial Autocorrelation in Machine Learning Models Using Spatial Lag and Eigenvector Spatial Filtering Features. ISPRS Int. J. Geo-Inf. 2022, 11, 242. [Google Scholar] [CrossRef]
- Goovaerts, P. AUTO-IK: A 2D Indicator Kriging Program for the Automated Non-Parametric Modeling of Local Uncertainty in Earth Sciences. Comput. Geosci. 2009, 35, 1255–1270. [Google Scholar] [CrossRef]
- Pebesma, E.; Bivand, R.S. Classes and Methods for Spatial Data: The Sp Package. R News 2005, 5, 9–13. [Google Scholar]
- Gräler, B.; Pebesma, E.; Heuvelink, G. Spatio-Temporal Interpolation Using Gstat. R J. 2016, 8, 204. [Google Scholar] [CrossRef]
- Brus, D.J.; Kempen, B.; Heuvelink, G.B.M. Sampling for Validation of Digital Soil Maps. Eur. J. Soil Sci. 2011, 62, 394–407. [Google Scholar] [CrossRef]
- Wadoux, A.M.J.-C.; Heuvelink, G.B.M.; de Bruin, S.; Brus, D.J. Spatial Cross-Validation Is Not the Right Way to Evaluate Map Accuracy. Ecol. Model. 2021, 457, 109692. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning: With Applications in R.; Springer Texts in Statistics; Springer: New York, NY, USA, 2013; ISBN 978-1-4614-7137-0. [Google Scholar]
- Gao, B.; Stein, A.; Wang, J. A Two-Point Machine Learning Method for the Spatial Prediction of Soil Pollution. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102742. [Google Scholar] [CrossRef]
- Wang, Y.; Khodadadzadeh, M.; Zurita-Milla, R. Spatial+: A New Cross-Validation Method to Evaluate Geospatial Machine Learning Models. Int. J. Appl. Earth Obs. Geoinf. 2023, 121, 103364. [Google Scholar] [CrossRef]
- Walvoort, D.J.J.; Brus, D.J.; de Gruijter, J.J. An R Package for Spatial Coverage Sampling and Random Sampling from Compact Geographical Strata by K-Means. Comput. Geosci. 2010, 36, 1261–1267. [Google Scholar] [CrossRef]
- Chabalala, Y.; Adam, E.; Ali, K.A. Exploring the Effect of Balanced and Imbalanced Multi-Class Distribution Data and Sampling Techniques on Fruit-Tree Crop Classification Using Different Machine Learning Classifiers. Geomatics 2023, 3, 70–92. [Google Scholar] [CrossRef]
- Nadeau, C.; Bengio, Y. Inference for the Generalization Error. Mach. Learn. 2003, 52, 239–281. [Google Scholar] [CrossRef]
- Guillén, A.; Martínez, J.; Carceller, J.M.; Herrera, L.J. A Comparative Analysis of Machine Learning Techniques for Muon Count in UHECR Extensive Air-Showers. Entropy 2020, 22, 1216. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- Uddin, S.; Haque, I.; Lu, H.; Moni, M.A.; Gide, E. Comparative Performance Analysis of K-Nearest Neighbour (KNN) Algorithm and Its Different Variants for Disease Prediction. Sci. Rep. 2022, 12, 6256. [Google Scholar] [CrossRef] [PubMed]
- Wright, M.N.; Ziegler, A. Ranger: A Fast Implementation of Random Forests for High Dimensional Data. J. Stat. Soft. 2017, 77, 1–17. [Google Scholar] [CrossRef]
- Pacheco, A.D.P.; Junior, J.A.D.S.; Ruiz-Armenteros, A.M.; Henriques, R.F.F. Assessment of K-Nearest Neighbor and Random Forest Classifiers for Mapping Forest Fire Areas in Central Portugal Using Landsat-8, Sentinel-2, and Terra Imagery. Remote Sens. 2021, 13, 1345. [Google Scholar] [CrossRef]
- Bansal, M.; Goyal, A.; Choudhary, A. A Comparative Analysis of K-Nearest Neighbor, Genetic, Support Vector Machine, Decision Tree, and Long Short Term Memory Algorithms in Machine Learning. Decis. Anal. J. 2022, 3, 100071. [Google Scholar] [CrossRef]
- Hoef, J.M.V.; Temesgen, H. A Comparison of the Spatial Linear Model to Nearest Neighbor (k-NN) Methods for Forestry Applications. PLoS ONE 2013, 8, e59129. [Google Scholar] [CrossRef]
- Vega Isuhuaylas, L.A.; Hirata, Y.; Ventura Santos, L.C.; Serrudo Torobeo, N. Natural Forest Mapping in the Andes (Peru): A Comparison of the Performance of Machine-Learning Algorithms. Remote Sens. 2018, 10, 782. [Google Scholar] [CrossRef]
- Behrens, T.; Viscarra Rossel, R.A. On the Interpretability of Predictors in Spatial Data Science: The Information Horizon. Sci. Rep. 2020, 10, 16737. [Google Scholar] [CrossRef]
- Saha, A.; Basu, S.; Datta, A. Random Forests for Spatially Dependent Data. J. Am. Stat. Assoc. 2023, 118, 665–683. [Google Scholar] [CrossRef]
- Meyer, H.; Reudenbach, C.; Hengl, T.; Katurji, M.; Nauss, T. Improving Performance of Spatio-Temporal Machine Learning Models Using Forward Feature Selection and Target-Oriented Validation. Environ. Model. Softw. 2018, 101, 1–9. [Google Scholar] [CrossRef]
- Kuhn, M. Building Predictive Models in R Using the Caret Package. J. Stat. Soft. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Kochtitzky, W.H.; Edwards, B.R.; Enderlin, E.M.; Marino, J.; Marinque, N. Improved Estimates of Glacier Change Rates at Nevado Coropuna Ice Cap, Peru. J. Glaciol. 2018, 64, 175–184. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cordillera | LS8-7 1 Composite Total Area (km2) | Path/Row | Available Scenes 2 |
|---|---|---|---|
| Cordillera Blanca | 13,963.1 | 8, 66 8, 67 | 30 |
| Cordillera Central | 5957.4 | 7, 68 | 53 |
| Cordillera Huallanca | 271.9 | 8, 67 | 21 |
| Cordillera Huayhuash | 344.5 | 8, 67 | 34 |
| Cordillera Huaytapallana | 2489.8 | 6, 68 | 9 |
| Cordillera Raura | 322.3 | 7, 67 | 34 |
| Cordillera Urubamba | 1818 | 4, 69 | 9 |
| Cordillera Vilcabamba | 4221.3 | 5, 69 4, 69 | 40 |
| Cordillera Vilcanota | 6179.7 | 3, 69 3, 70 | 52 |
| Total | 42,135 |
| Algorithm | Reference | Hyperparameter | Type | Default |
|---|---|---|---|---|
| Gradient-Boosting Machines (GBM) 1 | [65] | n.trees | Integer | 100 |
| n.minobsinnode | Integer | 10 | ||
| shrinkage | Numeric | 0.1 | ||
| distribution | Nominal | bernoulli | ||
| Random Forest (RF) | [55] | num.trees | Integer | 500 |
| mtry | Integer | Sqrt(p) | ||
| min.node.size | Integer | 1 | ||
| max.depth | Integer | 0 | ||
| Weighted K-Nearest Neighbors (KKN) | https://github.com/KlausVigo/kknn (accessed on 2 November 2023) | k | Integer | 10 |
| distance | Integer | 2 | ||
| kernel | Nominal | gaussian | ||
| Logistic Regression (LR) | family | Nominal | binomial |
| Glacier Region | SP-CV 1 MCC | NSP-CV 2 MCC |
|---|---|---|
| Cordillera Blanca | 0.928 (0.0845) 3 | 0.949 (0.1054) |
| Cordillera Central | 0.937 (0.446) | 0.954 (0.4624) |
| Cordillera Huallanca | 0.877 (0.1201) | 0.937 (0.1800) |
| Cordillera Huayhuash | 0.753 (0.0196) | 0.830 (0.0576) |
| Cordillera Huaytapallana | 0.904 (0.1979) | 0.968 (0.2617) |
| Cordillera Raura | 0.915 (0.0532) | 0.931 (0.0699) |
| Cordillera Urubamba | 0.906 (0.3082) | 0.930 (0.3317) |
| Cordillera Vilcabamba | 0.891 (0.2067) | 0.917 (0.2326) |
| Cordillera Vilcanota | 0.906 (0.0618) | 0.929 (0.0847) |
| Glacier Region | LR | RF | GBM | KNN |
|---|---|---|---|---|
| Cordillera Blanca | 0.05971 (0.4763) | 1.155 (0.1267) | 1.678 (0.04711) 1 | 2.061 (0.02229) 1 |
| Cordillera Central | 0.2374 (0.4066) | 0.8284 (0.2057) | 0.6774 (0.2506) | 1.391 (0.08516) |
| Cordillera Huallanca | 1.202 (0.1174) | 1.9135 (0.03076) 1 | 1.4590 (0.07545) | 1.366 (0.08895) |
| Cordillera Huayhuash | 1.44537 (0.07735) | 1.6833 (0.04933) 1 | 1.64397 (0.05329) | 1.64590 (0.0530) |
| Cordillera Huaytapallana | 1.3271 (0.09530) | 1.5579 (0.06284) | 1.910303 (0.03092) 1 | 253.484 (-) |
| Cordillera Raura | 0.76974 (0.2225) | 0.34939 (0.3641) | 0.4885 (0.3136) | 0.3651 (0.3582) |
| Cordillera Urubamba | 1.59805 (0.04823) 1 | 0.93018 (0.1784) | 1.2942 (0.1008) | 0.0655 (0.4739) |
| Cordillera Vilcabamba | 0.20655 (0.4186) | 1.61089 (0.04681) 1 | 0.9120 (0.1831) | 1.3423 (0.09283) |
| Cordillera Vilcanota | 0.84632 (0.2007) | 0.62994 (0.2658) | 0.7284 (0.2348) | 0.48702 (0.3142) |
| Cordillera | Model 1 | Range (m) | C0 2 | C 3 | Mat-κ 4 |
|---|---|---|---|---|---|
| Cordillera Blanca | Mat | 5428.204 | 3.57 × 10−4 | 0.0355 | 0.5 |
| Cordillera Central | Exp | 371.4613 | 0 | 0.00475 | - |
| Cordillera Huallanca | Mat | 874.5616 | 1.14 × 10−3 | 0.0184 | 1 |
| Cordillera Huayhuash | Mat | 3160.411 | 2.54 × 10−3 | 0.1477 | 0.3 |
| Cordillera Huaytapallana | Mat | 1320.108 | 2.21 × 10−3 | 0.004013 | 10 |
| Cordillera Raura | Mat | 1999.836 | 1.68 × 10−2 | 0.07002 | 0.6 |
| Cordillera Urubamba | Mat | 684.1284 | 0 | 0.00736 | 10 |
| Cordillera Vilcabamba | Mat | 5326.374 | 1.30 × 10−3 | 0.0264 | 0.4 |
| Cordillera Vilcanota | Mat | 3288.231 | 3.19 × 10−4 | 0.03816 | 1.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bueno, M.; Macera, B.; Montoya, N. A Comparative Analysis of Machine Learning Techniques for National Glacier Mapping: Evaluating Performance through Spatial Cross-Validation in Perú. Water 2023, 15, 4214. https://doi.org/10.3390/w15244214
Bueno M, Macera B, Montoya N. A Comparative Analysis of Machine Learning Techniques for National Glacier Mapping: Evaluating Performance through Spatial Cross-Validation in Perú. Water. 2023; 15(24):4214. https://doi.org/10.3390/w15244214
Chicago/Turabian StyleBueno, Marcelo, Briggitte Macera, and Nilton Montoya. 2023. "A Comparative Analysis of Machine Learning Techniques for National Glacier Mapping: Evaluating Performance through Spatial Cross-Validation in Perú" Water 15, no. 24: 4214. https://doi.org/10.3390/w15244214