1. Introduction
Geological hazards constitute one of the greatest impacts that global and local economies, as well as human settlements, may face [
1,
2]. In particular, landslides, which are defined as movements of soil, mud, debris, or rock, are the most common geological hazard in the world [
3]. Landslides are a major hazard to human life and property since they occur all over the world and are characterized by a vast effect, sudden onset, and multiple instances [
4]. They are commonly induced by natural events such as earthquakes or heavy rainfall, which occur in specific geological, geomorphological, and hydrological environments. In mountainous areas, landslides can have significant effects on topographic features, forests and soil, as well as on infrastructure such as roads and farming land.
The extent of these effects will depend on the magnitude of the landslides [
5,
6]. In the last two decades, efforts to assess landslides have focused on studying susceptible zones and understanding the mechanisms that govern landslides ([
7,
8]). This has made it possible to extract valuable knowledge from the analysis of geomorphological, tectonic, geological, climatic, and anthropomorphic characteristics ([
9]).
In Chile, landslides are one of the most common geological hazards, together with earthquakes, volcanic activity, and floods. The geological, geomorphological, tectonic, and climatic conditions of the country, characterized by the presence of the Andes Mountain Range on its eastern margin and the Coastal Mountain Range on its western margin, make it highly susceptible to the generation of mass movements such as landslides, rockfalls, flows, and falls [
10]. Within 52 declared events in Chile, there have been a total of 1010 fatal victims caused by landslides, corresponding to 882 deaths and 128 people missing between 1928 and 2017 (90 years) [
11]. The Atacama Region is characterized by a geomorphology that renders it susceptible to landslide events. According to documented records, this region has witnessed the highest number of fatalities resulting from flow-type events in the country, with a total of 132 people [
11]. In the area of study, the Salado River basin, situated in the Chañaral Province of the region, a landslide event occurred in 1940 that resulted in the destruction of houses and the interruption of roads, causing substantial disruption to the city of Chañaral. In 1972, another landslide affected Chañaral and towns upstream, which were flooded, and 700 people were affected in Chañaral and 400 people in El Salado. Another flood in 1983 affected the city due to a rise in the river level caused by an increase in rainfall [
12]. In Chañaral, there have been at least 15 major landslide events in the last 150 years [
13]. With regard to the reports of deadly events and economic damage provoked by landslides, the identification of areas prone to these types of events and the determination of their risk level are the most critical actions in the assessment of the hazard [
14].
In the last two decades, extensive research has been carried out on landslide methods using innovative technologies and tools to promote this field, such as in crisis management in mountain areas or near them [
15]. Therefore, in order to obtain a reliable and accurate vulnerability map, it is necessary to test and evaluate several quantitative methods for more effective management of mountainous areas [
16]. The use of Geographical Information Systems (GIS) in the elaboration of susceptibility maps constitutes an effective method to identify and delineate landslide-prone areas. This allows for the creation of a geospatial database of occurrences or an exhaustive inventory. By using GIS data repositories, the geospatial attributes of landslide-prone sites that can influence the potential stability of slopes, called landslide conditioning factors (LCFs), can be aggregated into a database.
Several methodologies and techniques have been developed for hazard susceptibility cartography around the world. The literature has classified them into ([
14,
17]):
Models founded on physical conditions [
18].
Models founded on expert knowledge ([
19,
20]).
Multivariate statistical methods. The examples are the statistical index (SI) [
21], the frequency ratio (FR) ([
22,
23]), and logistic regression ([
24,
25]).
Machine learning models, such as decision trees (DT) [
26], random forests (RF) [
27], support vector machines (SVM) [
28], artificial neural networks (ANN) [
22], and some hybrid methods, which include optimization algorithms ([
7,
16,
24,
29]).
Each of the methods described has its own unique strengths and limitations. Physical models, for example, require extensive field analysis and are currently considered unbeatable in terms of prediction accuracy, making them suitable for local-scale mapping. In order to work effectively, these models demand a complete knowledge of the landslide systems, obtained through meticulous observation and monitoring of the surface and the subsurface; this is essential in order to issue timely warnings of further slope collapse [
30]. However, when applied on a larger scale, the need for a large amount of substantial data to obtain reliable results becomes inconvenient due to the considerable financial and computational resources required. Therefore, the use of this technique for the segmentation of larger regions is not feasible. This has led to the proliferation of statistical and knowledge-based models for more than four decades [
31]. The knowledge-based models operate on the premise of building a framework with limited information, which is then parameterized by a system of weights assigned to factors according to expert judgment. Statistical models, on the other hand, have benefited from recent advances in GIS. This has paved the way for the successful application of a set of tools and quantitative methodologies for the modeling of landslides, improving in this way the understanding of the associated patterns and the causative agents [
32]. At the moment, the thin line that separates statistical models from machine learning is a subject of controversy ([
17,
33]). The synergy and differences between statistical methods and machine learning are not clearly explained in academic works, mainly because the approach for geoscientists is primarily to generate and refine accurate results in landslide susceptibility mapping (LSM) rather than algorithmic categorization. In essence, machine learning is characterized by its ability to extract knowledge from data without relying on rule-based functions, whereas statistical modeling aims to establish relationships between data variables through algebraic expressions. Although the two fields were once considered mutually exclusive, they have recently converged [
17]. A notable example is the adoption of the logistic regression (LR) algorithm, originally from statistics, to solve classification problems. Now, machine learning has adopted LR and has become one of the most widely used algorithms. However, machine learning is more concerned with optimization and efficiency, in contrast to the inferential approach of statistical models.
Machine learning methods have been used in engineering and science problems for more than two decades. This is the reason why the use of these techniques in the area of geosciences and remote sensing is quite new and limited. Machine learning focuses on the automatic extraction of information from data through computational and statistical methods. The areas of applicability are very diverse and involve different topics such as rock mass characterization, ocean products, vegetation indices, etc. At present, data analysis methods play a central role in geosciences and remote sensing. While collecting large volumes of data is essential in the field, the analysis of this information becomes a major challenge [
34]. Various machine learning techniques, including random forests (RF), support vector machines (SVM), and artificial neural networks (ANN), have proven to be effective in dealing with nonlinear data across different scales in areas such as identification, prediction, mitigation, and modeling. Studies like [
6,
35,
36] and others have demonstrated the success of these methods. Unlike traditional statistical models, which aim to infer relationships between variables, machine learning models autonomously identify logical criteria from input data to make highly accurate predictions [
35]. The primary benefits of machine learning are its accuracy and ability to capture nonlinear correlations, as well as its ability to successfully overcome the impacts of various data distributions [
37], flexibility (these models can be adapted to different types of data and problems), speed (they can process large amounts of data quickly and efficiently), and generalization (once the model is trained, it can be applied to new data to produce reliable predictions).
There are several research gaps in the modeling of landslide susceptibility using machine learning algorithms. Some of them are the following:
Integration of multiple factors: Most studies have focused on assessing a limited and repetitive set of factors. The integration of new factors needs to be explored to improve model accuracy and ensure a more complete assessment of susceptibility.
Development of interpretable models: Although machine learning models can achieve high accuracy in identifying landslide susceptibility, some of these models can be difficult to interpret and explain. There is a need to develop interpretable models that allow decision makers to understand how the data are being used and how susceptibility identification is being performed [
38].
The lack of simplification of the models in terms of the use of factors: Many models rely on multiple data sources, such as area-specific maps (geology, soils, roads, etc.), which hinder subsequent reproducibility and detract from some dynamic dimension of the model, which, if only satellite parameters and/or digital elevation were used, could be updated as these images become available.
In this work, we seek to fill one of the existing research gaps in the Central Andes, in the sense that there are few studies that characterize the susceptibility to landslides, which can help to understand the development of this phenomenon and thus apply the models generated in similar areas that have not yet been studied. For its part, the research question that this study seeks to address is how different machine learning techniques can be applied and compared to assess and predict susceptibility to landslides in a region of the Andes where no studies of this type have been carried out before.
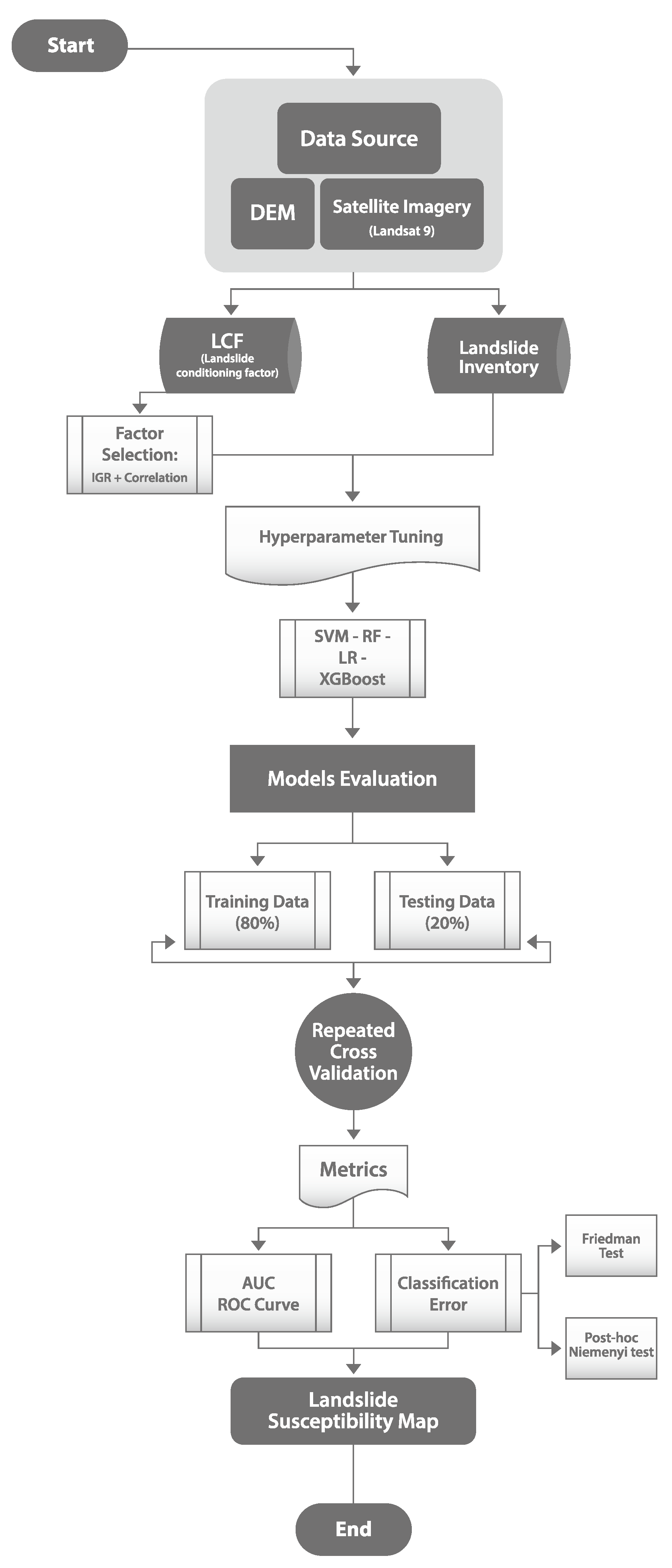
The objectives of the work are to build a susceptibility model of the Chañaral province to identify the areas most exposed to landslide risk by using machine learning algorithms (SVM, RF, XGBoost, and LR) and by comparing their performance; to build an inventory of landslides in the study area through historical records and the analysis of satellite images; and to determine the most relevant factors in susceptibility assessment by using indices based on information theory.
4. Discussion
The spatial prediction of landslides is considered to be one of the most complex tasks in natural hazard risk assessment. Despite the fact that numerous methodologies have been proposed, the accuracy of the predictions is still a controversial issue. Development in the field of machine learning and GIS platforms has led to the development of many new techniques and methods. However, further exploration of new methods is still necessary.
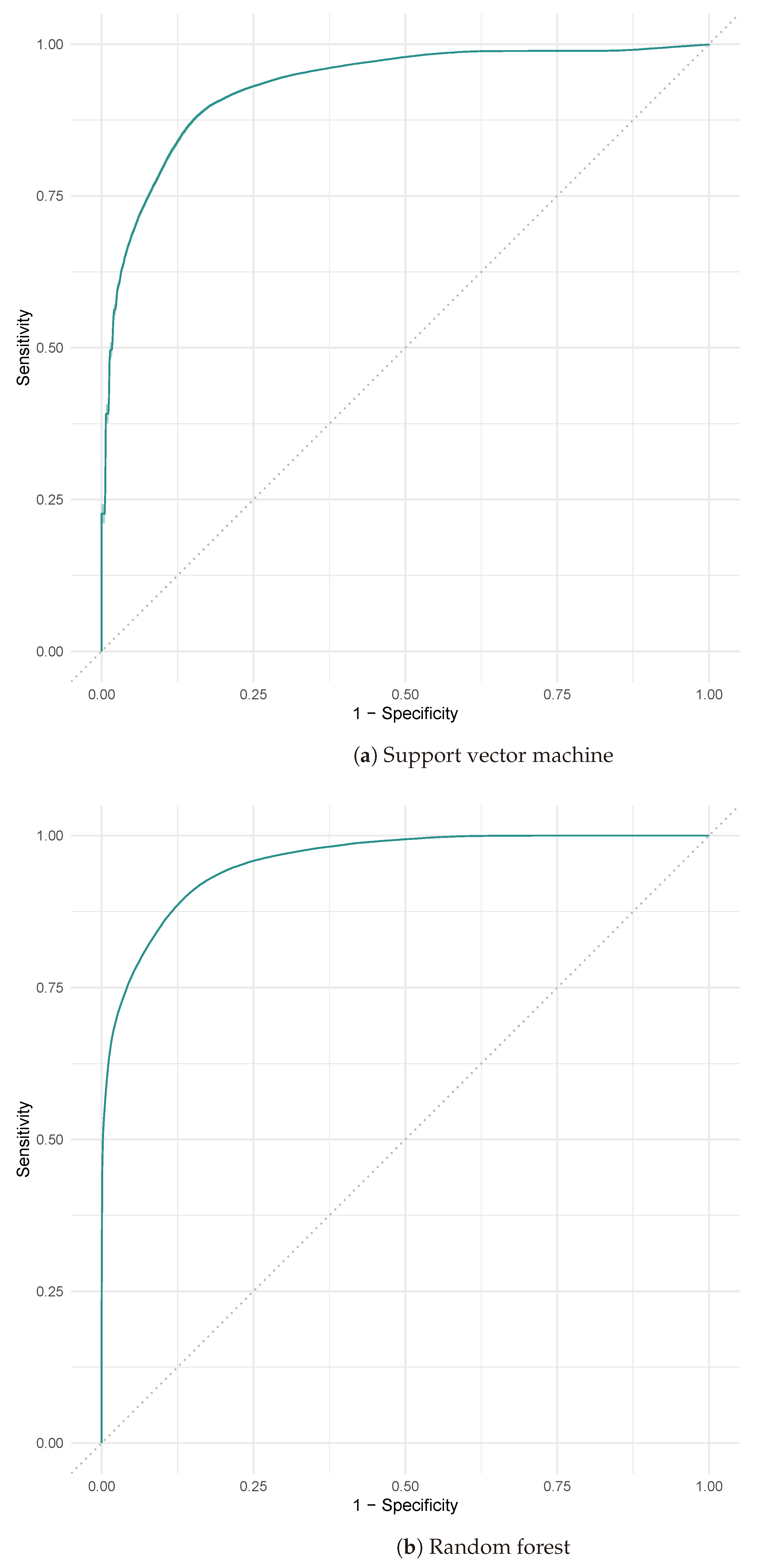
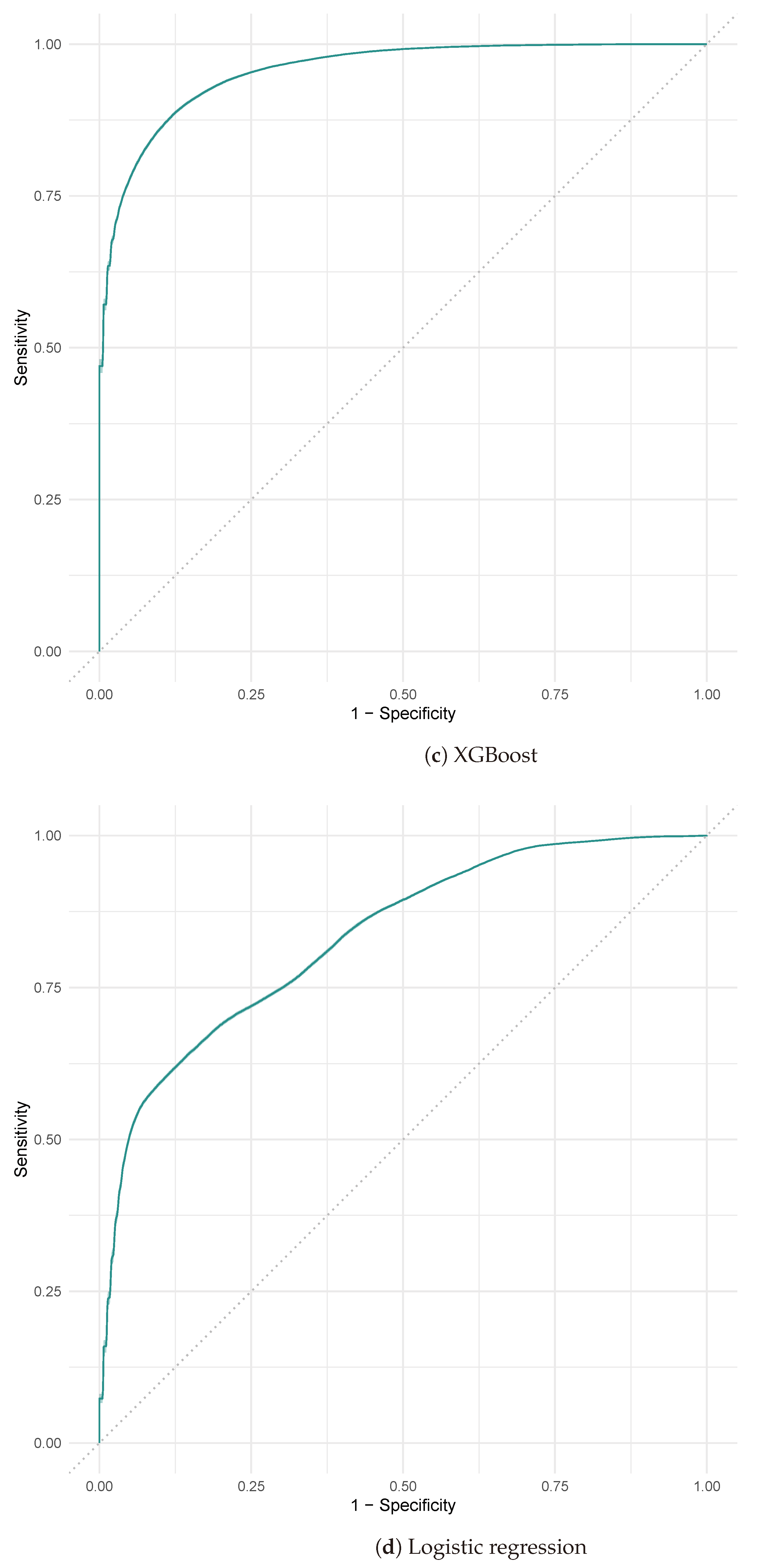
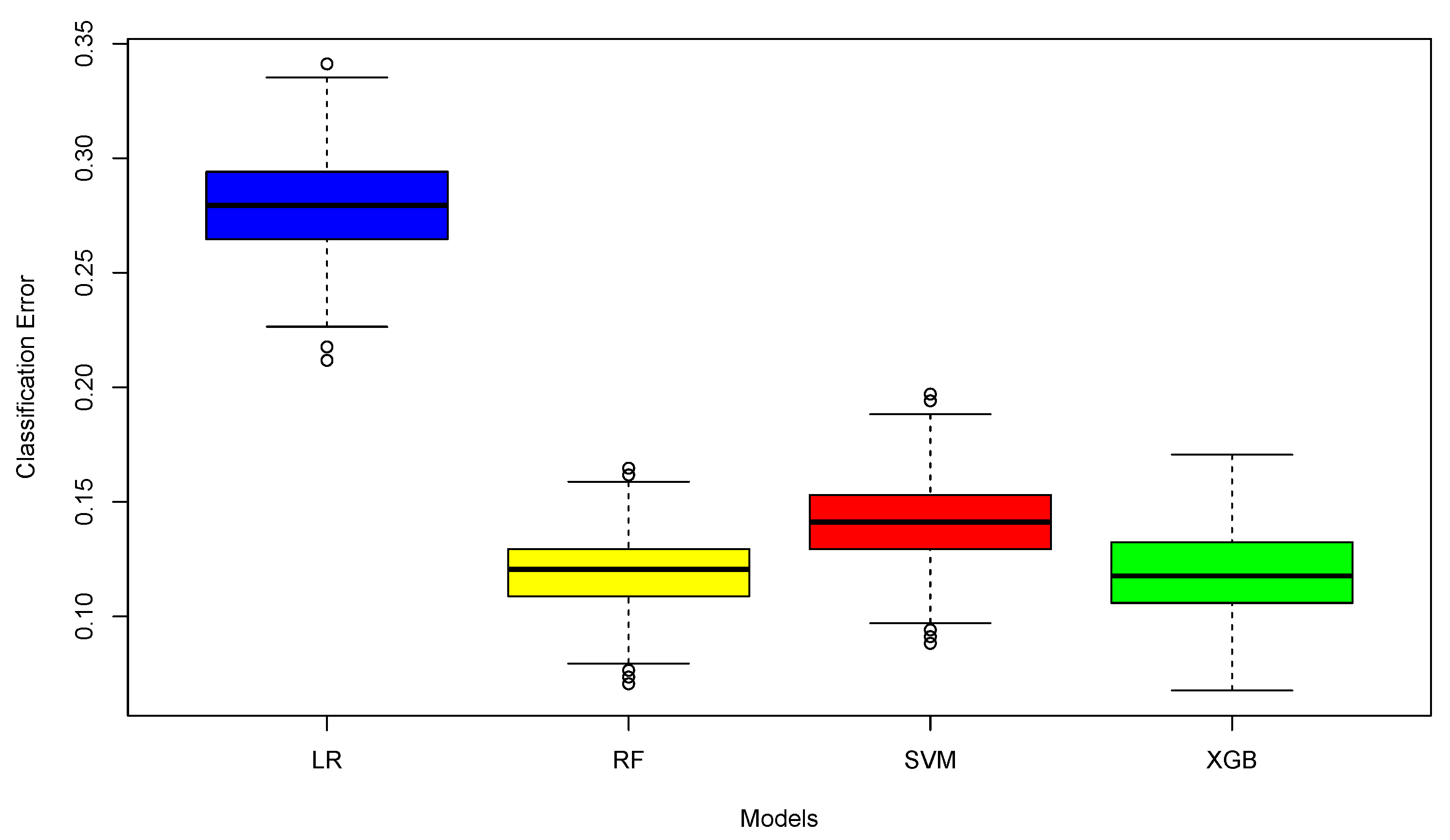
This research addresses this issue by evaluating and comparing four machine learning techniques. In general, RF outperforms the other models in terms of classification effectiveness. In terms of hyperparameter calibration, the available computational resources have been used to perform a grid search. In the case of RF and XGBoost, these algorithms need to adjust a larger set of parameters.
The machine learning models are suitable for solving the studied problem since they are able to handle the complex relationships between LCFs and landslide susceptibility and are robust in noisy environments [
88]. The algorithms presented in this paper have been widely used in the literature for the generation of landslide susceptibility maps. SVM has obtained AUROC values ranging from 0.768 to 0.946 ([
16,
24,
88,
89,
90]). Logistic regression, which is mainly used as a benchmark with which it is possible to make a comparison with other models, has obtained AUROC values ranging from 0.792 to 0.934 ([
25,
89,
90,
91,
92]). On the other hand, XGBoost, although it has been used in fewer publications than the other algorithms, has obtained promising results: in [
93], it obtained an AUROC of 0.96, while in [
91], it obtained an AUROC of 0.979. Finally, RF, which almost always achieves excellent results in this problem, has an AUROC ranging from 0.9 to 0.985 ([
25,
73,
89,
90,
91]), which is consistent with the results obtained and also supported by findings from previous studies ([
8,
89,
94]). One of the advantages that RF has in conjunction with XGBoost is that both are immune to multicollinearity that can occur due to the presence of multiple topographic derivatives as conditioning factors [
93], have the ability to handle large data sets, and are resistant to overfitting. Other advantages of RF are that it does not require assumptions on the statistical distribution of the conditioning factors, it takes into account interactions and nonlinear characteristics among the variables, and it has the ability to provide information on the influence of each variable in the final model ([
8,
25]). The differences between the models lie mainly in the fact that the principles they use to generate predictions are different. SVM is able to map low-dimensional features to high-dimensional spaces using a kernel to find a characteristic hyperplane to maximize the categorical space. The problem with this method is that the corresponding mapping may be poor for the prediction in question, and if the data are noisy or overlapping, the performance of SVM may decrease. RL characterizes the spatial relationship between the landslide events and the conditioning factors, looking for the best-fitting algorithm. However, it is very sensitive to multicollinearity, which limits its performance [
90], and also, as the amount of data increases, it may not be able to effectively model the relationship between variables, resulting in a decrease in accuracy. In the case of XGBoost, it can lead to overfitting if the number of trees is not carefully controlled [
95].
This study uses a 5-fold cross-validation with 100 replicates in order to calculate the prediction metrics, while most studies use a static data partition to then calculate the indices of interest. This methodology does not deal with the stochastic nature of the problem, so applying cross-validation with repetitions allows us to obtain more robust results. These benefits indicate that it is advisable to continue to use this methodology in future work related to susceptibility assessment.
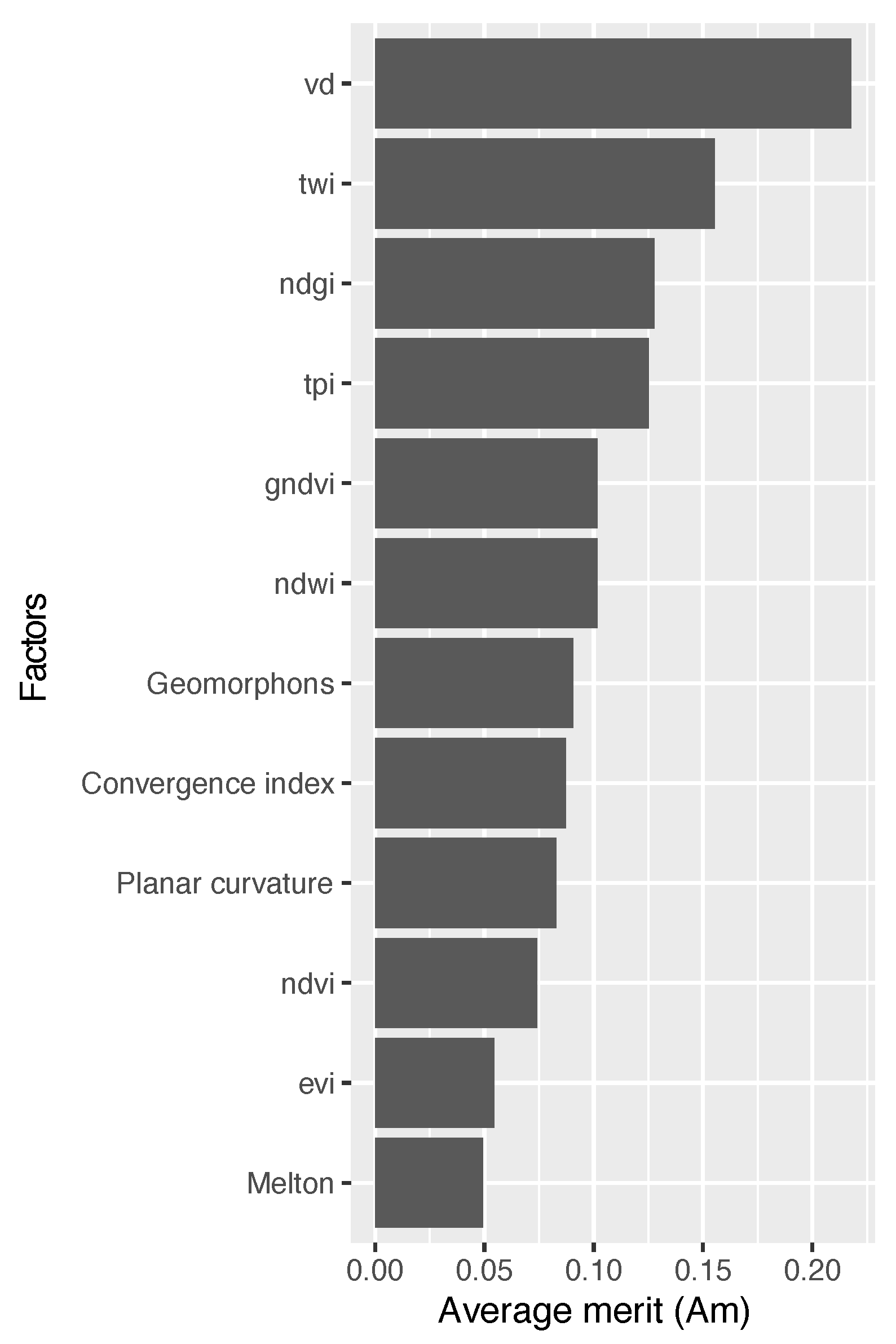
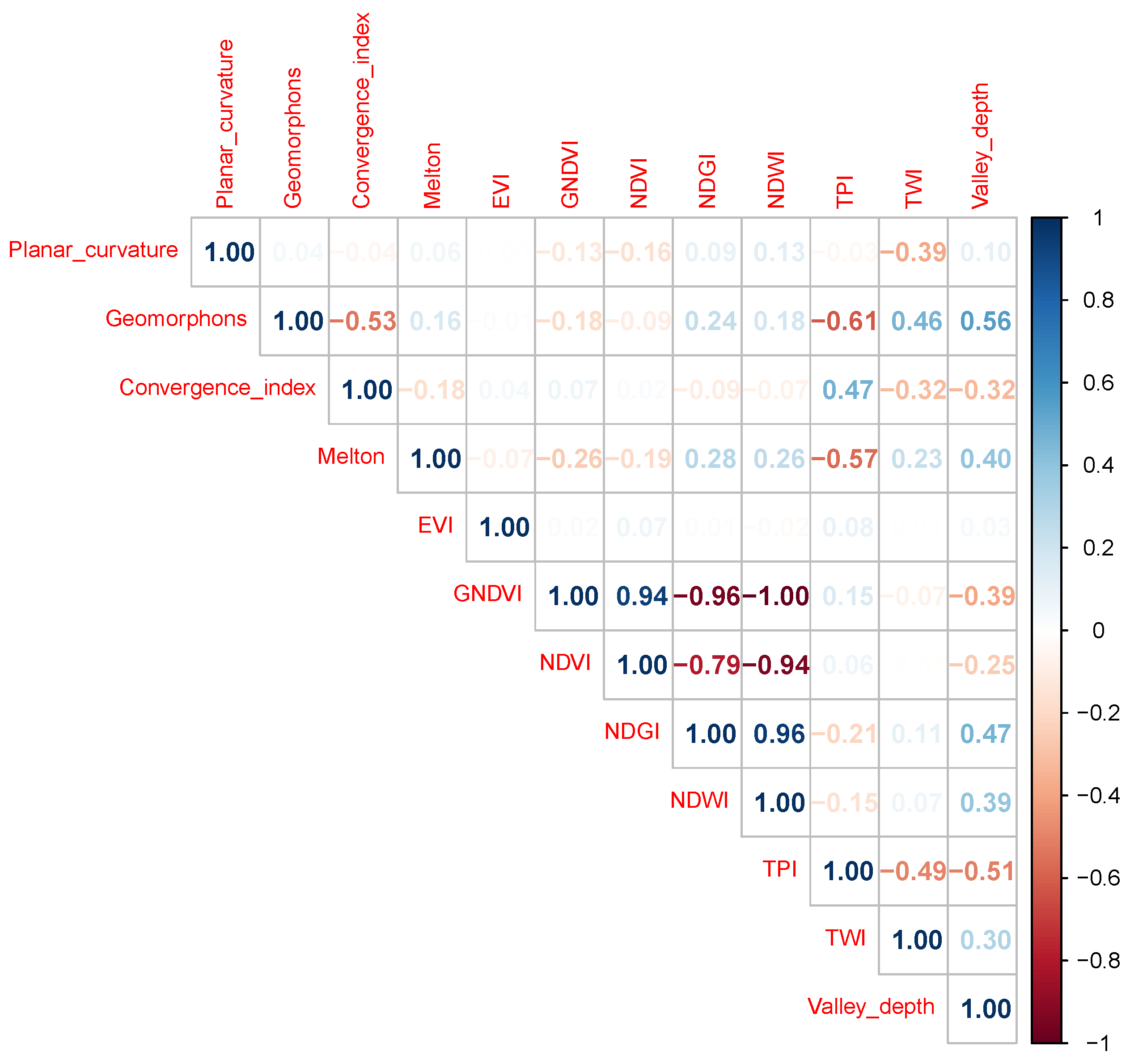
The choice of conditioning factors is a key aspect that influences the quality of susceptibility models [
96]. Although various methodologies for selecting factors have been proposed, including linear correlation [
31] and the Kolmogorov–Smirnov test [
96], there is still no universal criterion for making these selections, and the issue remains a topic for debate [
7]. In general, topographic, geologic, soil, hydrologic, geomorphologic, and anthropogenic factors have been accepted in the literature for most susceptibility models. In some cases, factors that do not have predictive capability cause noise, affecting the quality of the model. In addition, it is important to eliminate those factors that have a high correlation index between them to be able to apply cross-validation.
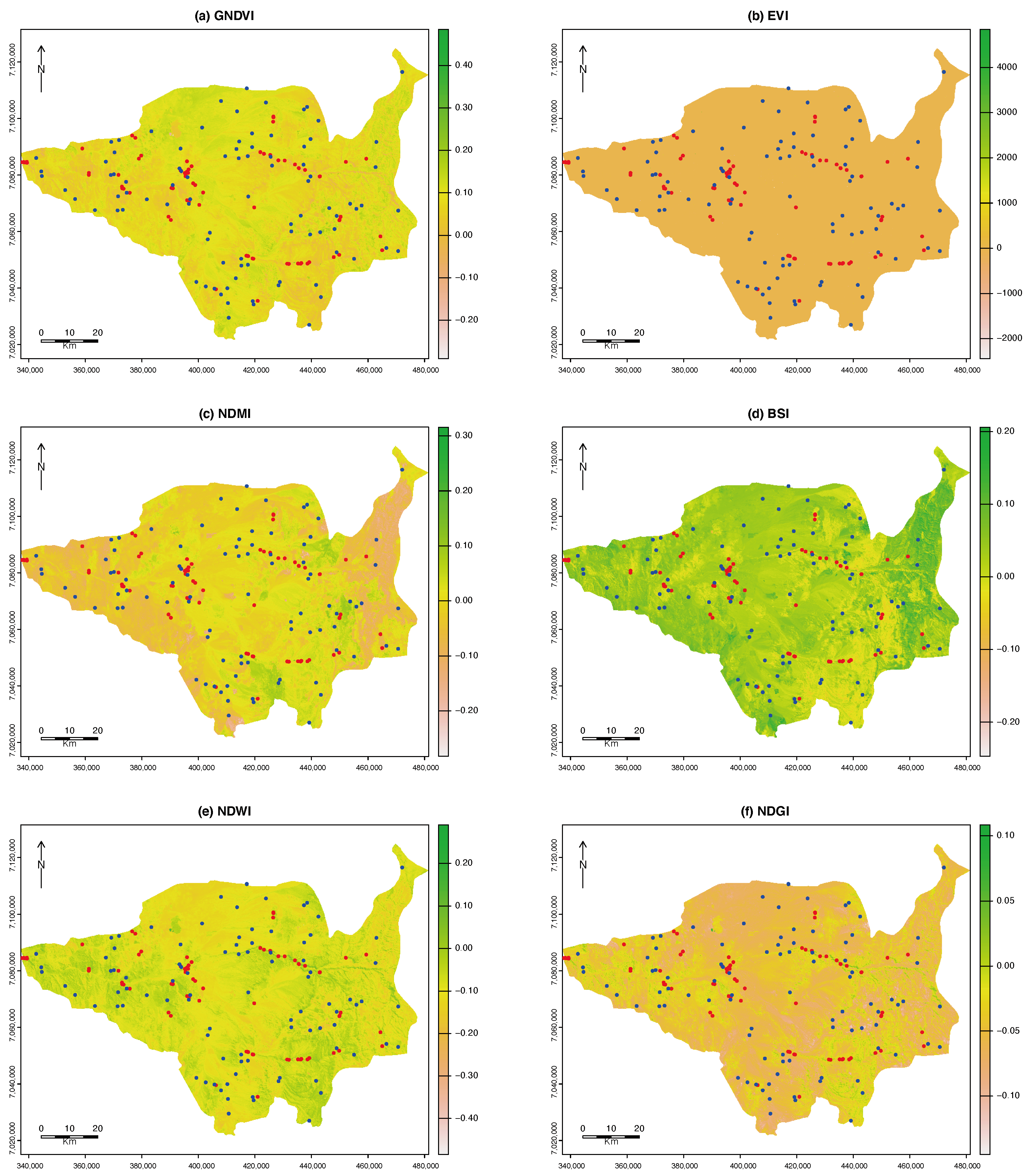
Instead of the widely used NDVI, our model employed the NDGI and EVI spectral indices. This is due to its significant limitations, such as its reliance on the specific time of day when the aerial images are captured, as it does not account for variations in the angle of solar radiation. Hence, this index yields imprecise outcomes. The EVI, calculated in a manner similar to the NDVI, incorporates extra wavelengths to rectify any inaccuracies in the NDVI measurement. This compensates for fluctuations in the solar angle, atmospheric aberrations induced by suspended particles, and land cover indications obscured by vegetation. Furthermore, the EVI may exhibit reduced sensitivity to the soil composition, rendering it more efficient in regions with limited vegetation, where the soil composition can exert a substantial impact on the NDVI. Within our model, the EVI variable exhibits a notable adverse impact, signifying its robust inverse correlation with the incidence of landslides. Higher EVI values suggest that areas with denser and healthier vegetation are less prone to landslides.
On the other hand, the NDGI, primarily utilized for glacier characterization, exhibits a strong predictive capability for susceptibility estimation, as indicated by the IGR. Consequently, it serves as a substitute for the NDVI. In regions with limited vegetation, the NDVI may not be as effective in distinguishing areas that are prone to landslides. On the contrary, the NDGI may be more efficient in semiarid regions or areas with less dense vegetation cover, where it concentrates on particular bands of the spectrum that accurately distinguish between vegetated areas and bare ground or snow. This makes it more suitable for identifying areas prone to landslides. Consequently, regions with sparse vegetation or uncovered soil, which typically exhibit elevated NDGI values in nonglacial settings, are more susceptible to landslides. A high NDGI value may suggest a significant disparity between exposed soil and plant life, potentially indicating regions with limited vegetation coverage. Hence, it is recommended to employ these indices in areas that are analogous to those examined in this study.
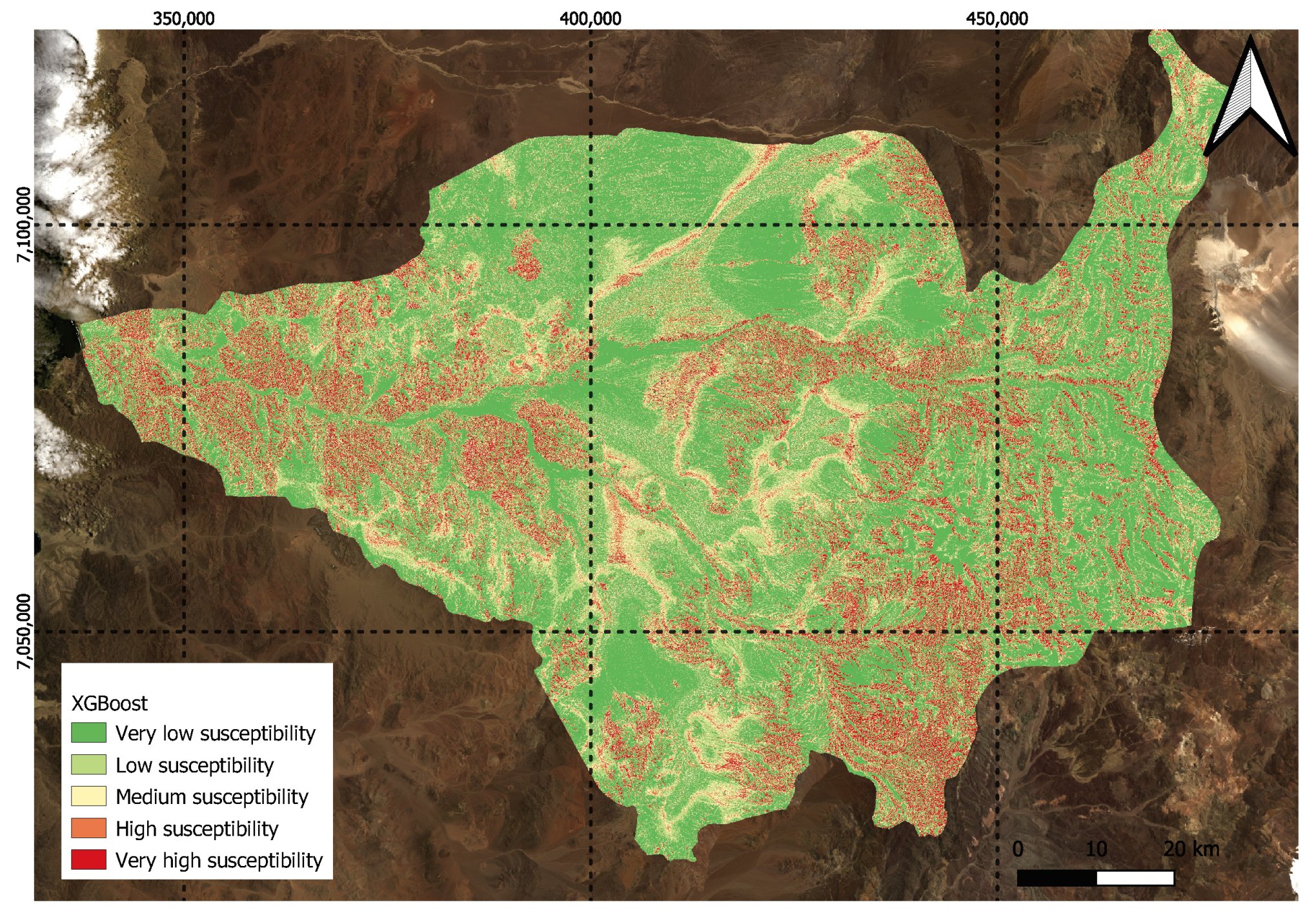
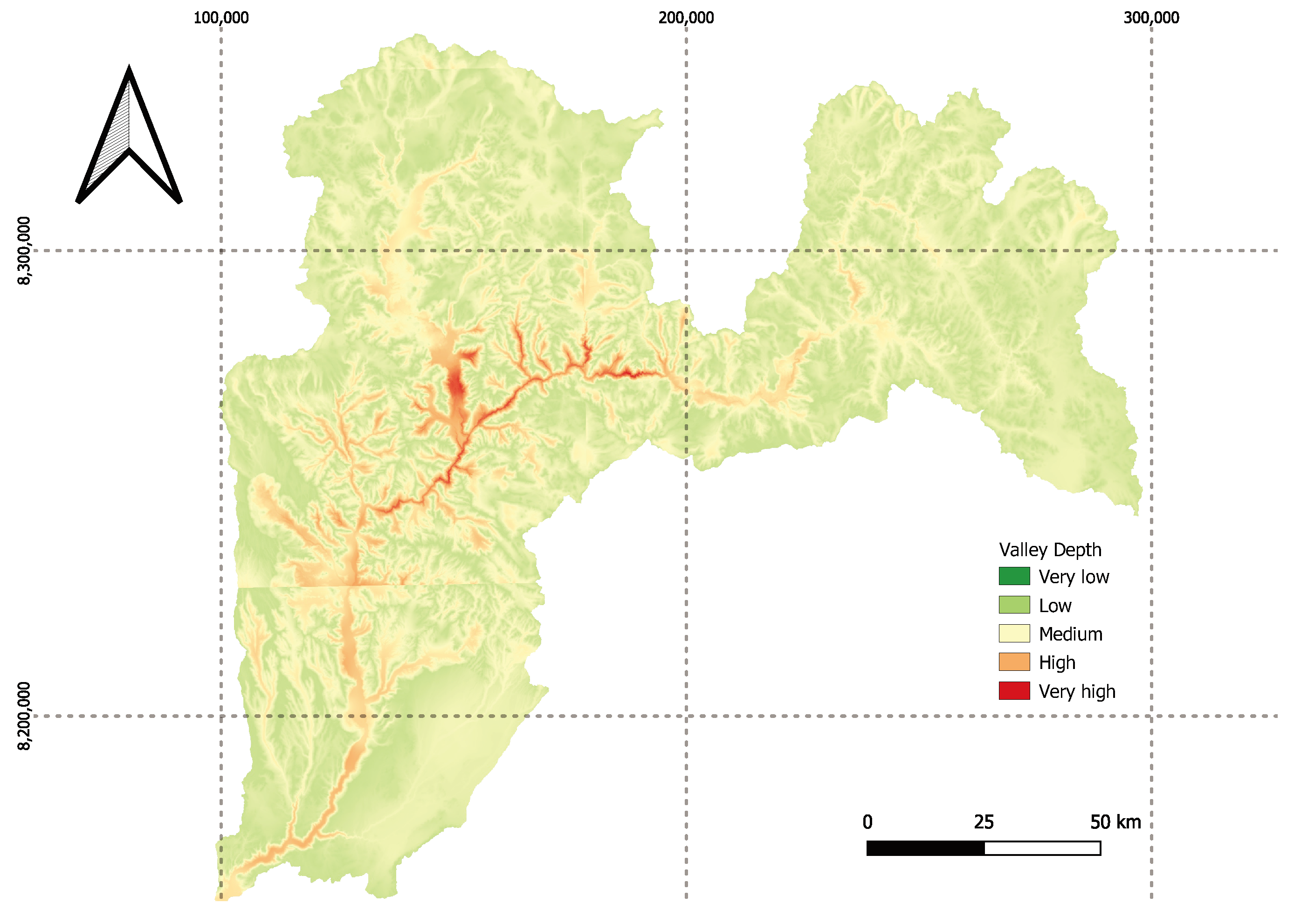
Among the factors studied in this work, two stand out with respect to the others in terms of their influence on the model: the valley depth index (VD) and the TWI. A high valley depth index may be related to a high susceptibility to landslides due to the steep topography and abrupt relief present in the study area, which may favor the occurrence of gravitational processes and increase the erosion rate on the slopes, while a high TWI indicates saturated soil, which implies an increase in the susceptibility to landslides.
It is also novel that the “Valley Depth” (VD) index is the one that provides the most information for the model. The variable VD (valley depth) in the study refers to the vertical distance to the base level of the hydrographic network. This index is calculated using an algorithm that involves interpolating the elevation of the base level of the hydrographic network and then subtracting this base level from the original elevations. This characteristic corresponds to the vertical distance to the base level of the hydrographic network. The algorithm that calculates this index consists of two steps, which involve the interpolation of the elevation of the base level of the hydrographic network and the subsequent subtraction of this base level from the original elevations [
97]. A high valley depth index may be related to a high susceptibility to landslides due to the steep topography and abrupt relief present in the study area, which favors the occurrence of gravitational processes and increases the rate of erosion on the slopes. This implies that the landslide and non-landslide sites in the area share similar values of VD, respectively. This aspect is important for morphologies such as that of the Salado River basin, which has a marked slope at the geographic transition as it crosses from the foothills to the intermediate depression and has a “funnel” shape [
12].
In summary, the novelty of this study consists of applying repeated cross-validation to obtain the metrics of the models and using the valley depth index, NDGI, and EVI to construct the susceptibility models. Another novelty is the use of the MLR3 package in solving the machine learning problem and the combination with other geospatial packages in R in order to produce the susceptibility maps. Also, the data sources used in the construction of the model proposed in our article come exclusively from satellite images and digital elevation models, unlike other studies, which consider sources of information with a greater number of data and are therefore more difficult for disaster risk management analysts to apply in practice. The method has the advantage in that it can enable the creation of systems that produce susceptibility maps based on the routine updating of satellite images, which can contribute to the development of a susceptibility monitoring system that technical agencies in the disaster area can implement.
After an extensive and updated literature review, we found few publications linked to susceptibility assessment in the Andes. In this regard, we found that in [
98], susceptibility mapping was performed in a different Andean area in terms of geomorphology and climate, but like our study, the most successful algorithm corresponds to the random forest. In [
99], they use GAM models for the calculation of susceptibility in areas near roads, and here, they note the importance of curvature, like in our study, as an important factor in the calculation of susceptibility. In [
100], they also found relevance in the curvature. Finally, in [
101], susceptibility maps are used using only the DEM of the zone, holding the results obtained in this work, which also uses satellite imagery. Also, they use a logistic regression model to calculate susceptibility in the Cordillera Blanca, achieving an AUC of 0.75. The region in question presents topographic similarities with the Salado Basin, so the model built in this study may have promising results in that area.
The applicability of the proposed model is determined by the climatic, topographic, and morphometric characteristics of the study area. Under that perspective, the model can be expected to be suitable in areas worldwide that are semiarid zones with a variable topography and a Mediterranean climate with a prolonged dry season, in addition to having narrow and deep valleys where the maximum susceptibility is concentrated. Examples of these zones that are recommended to use this model are the following:
Colca Valley, Peru: This region is located in southern Peru and has a rugged topography with narrow and deep valleys. The climate is semiarid with a prolonged dry season and has geomorphological characteristics similar to those of the Salado Basin.
Indo Valley, Pakistan: This valley is located in northern Pakistan and is a mountainous region with deep, narrow valleys. The climate is arid with a prolonged dry season, and the region has a geomorphology similar to the study zone.
Colorado River Valley, United States: This region is located in the southern part of the state of Colorado and in northern New Mexico. It is a semiarid area with a rugged and mountainous topography and narrow and deep valleys similar to those of the Salado Basin.
To demonstrate the usefulness of the model in other geographical areas, we include a map of the valley depth index in the basin associated with the Colca Valley in Peru (
Figure 12), because that factor is the most important in our model. What is interesting about this map is that it is very similar to the generated landslide susceptibility map obtained in [
65].
5. Conclusions
This study has comprehensively examined landslide susceptibility in Chañaral province, Chile, using a variety of machine learning algorithms. Our findings reveal a significant influence of topographic and satellite factors, such as the NDGI and EVI, on landslide prediction, bringing a new perspective to the existing literature. We performed a detailed comparison and evaluation of four machine learning models: random forest, support vector machine, XGBoost, and logistic Regression. To train and validate these models, 86 locations were identified as landslides and 86 locations as non-landslides, using 22 conditioning factors, of which 7 were chosen using feature selection techniques such as IGR and Pearson correlation. Furthermore, unlike traditional models, it only uses factors from two easily accessible data sources, which would allow this model to be easily placed in a temporal susceptibility monitoring system in the future.
Model validation was performed through a 5-fold cross-validation repeated 100 times. The metrics employed included the area under the ROC curve (AUC) and classification error to measure the level of accuracy of the models and to determine significant differences between them. The results indicate that the RF and XGBoost models obtain the highest AUC indices, at 0.957 and 0.955, respectively. Furthermore, nonparametric statistical tests indicated that there are no significant statistical differences between them. Maps were generated for these models, highlighting valley depth as the most relevant factor for susceptibility in this area, suggesting its usefulness in similar geographical regions.
The main limitations identified in this work include:
Integration of other factors: the study focuses only on topographic, hydrological, and satellite factors. Future research could incorporate anthropogenic, geological, or infrastructural factors.
Spatial resolution: The study area is considerably larger than those commonly analysed in this type of research. It is suggested to limit future studies to a sub-basin of interest and to work with a resolution higher than 30 m/pixel.
These findings offer valuable insights for informed decision making and policy formulation in landslide-prone regions. Overall, our study highlights the potential of machine learning models, especially XGBoost and RF, to accurately and reliably map landslide susceptibility, which is useful for identifying high-risk areas and implementing effective mitigation strategies, benefiting land-use planning authorities and stakeholders. By enhancing the prediction accuracy of landslide susceptibility, we proactively safeguard natural habitats, thereby preserving biodiversity and ecosystem services. Furthermore, the integration of our research into regional sustainability policies can catalyze informed decision making that aligns with sustainable development goals.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}