
Significant Improvement in Soil Organic Carbon Estimation Using Data-Driven Machine Learning Based on Habitat Patches
 ,
,
Abstract
:1. Introduction
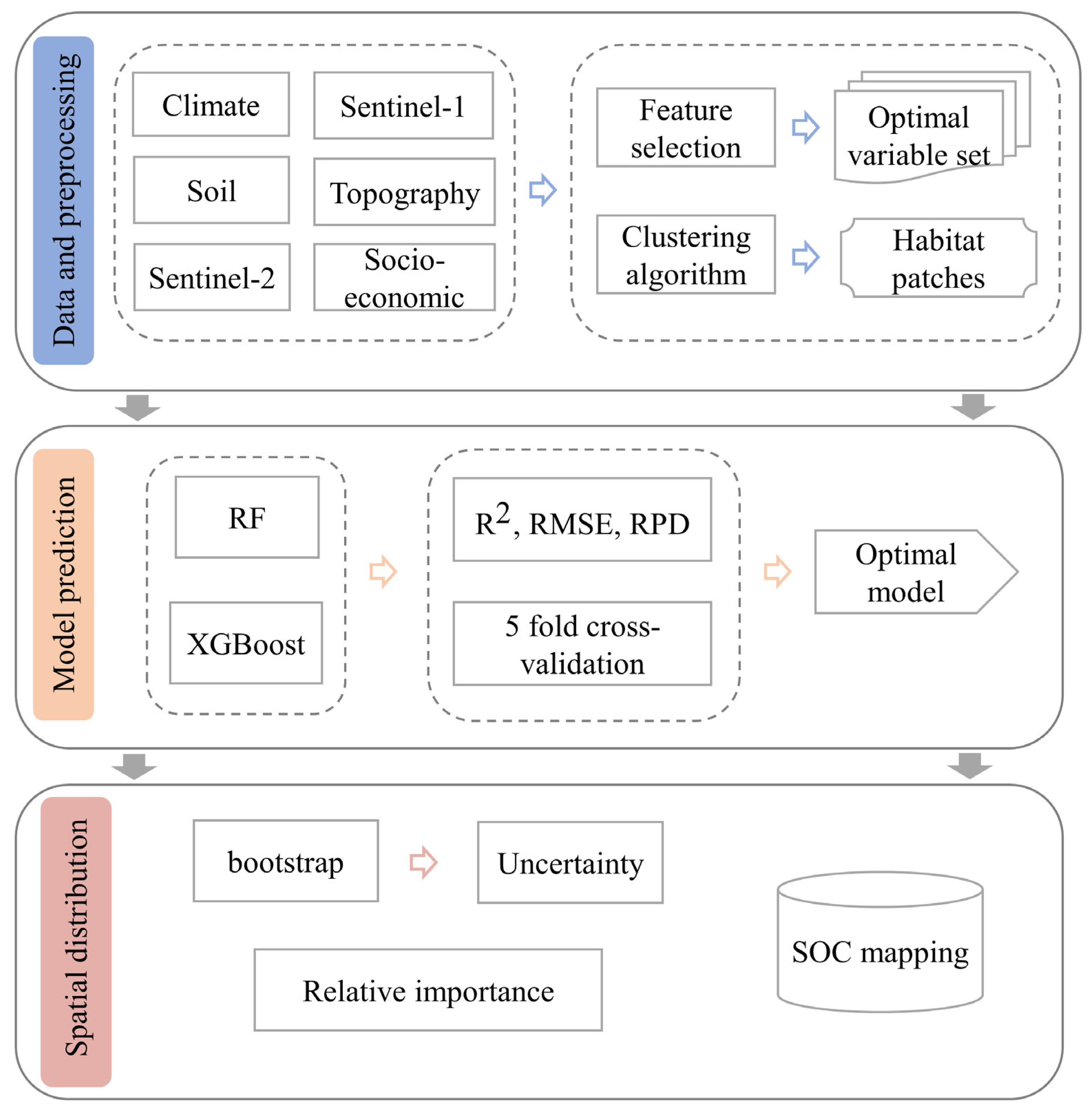
2. Materials and Methods
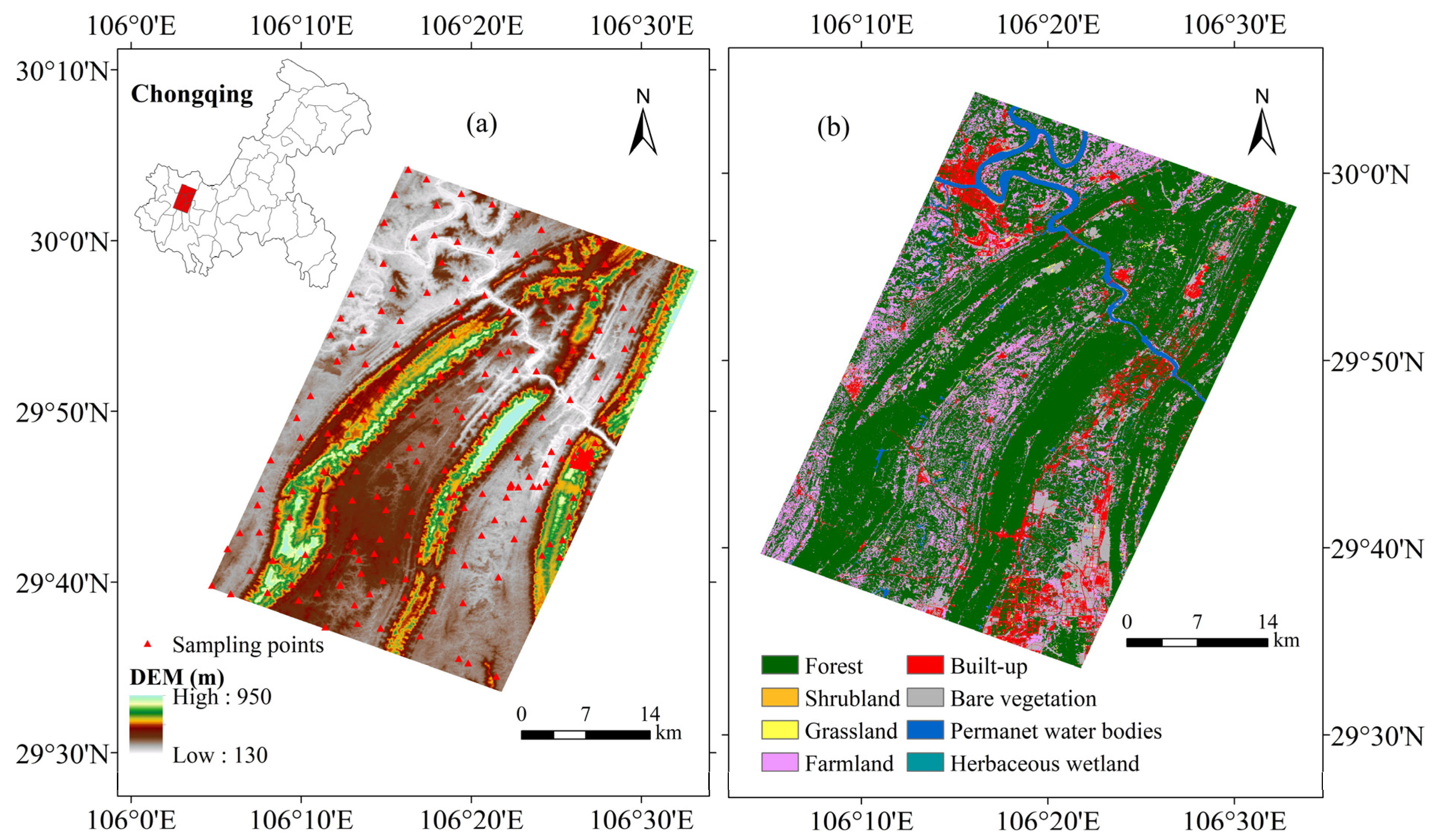
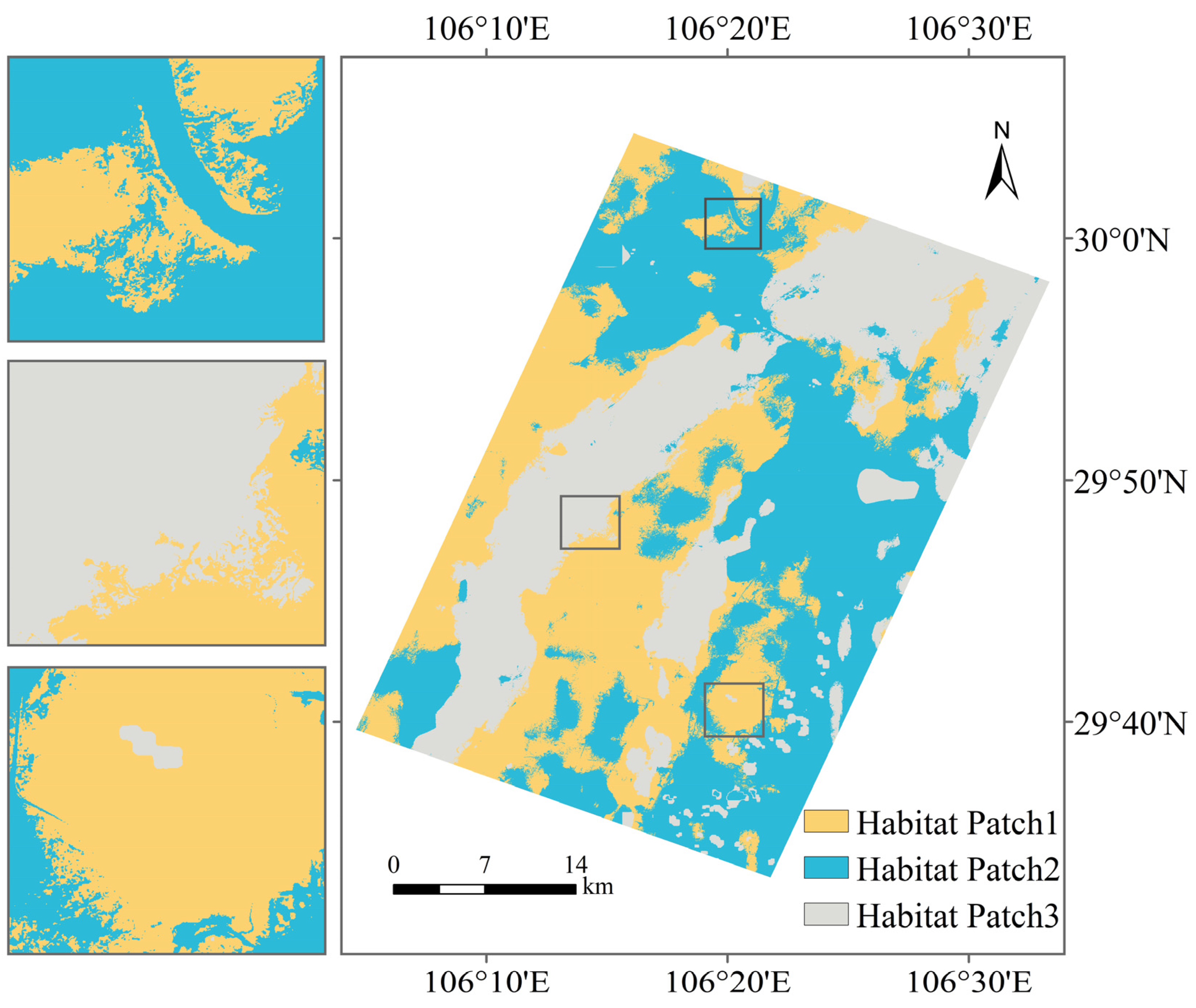
2.1. Study Area
2.2. Acquisition and Treatment of Data
2.2.1. Collection and Treatment of Soil Samples
2.2.2. Auxiliary Variables
2.3. Methods
2.3.1. Cluster Algorithm
2.3.2. Feature Selection Method
2.3.3. Prediction Models
2.3.4. Evaluation of Prediction Accuracy
2.3.5. Uncertainty Analyses
3. Results
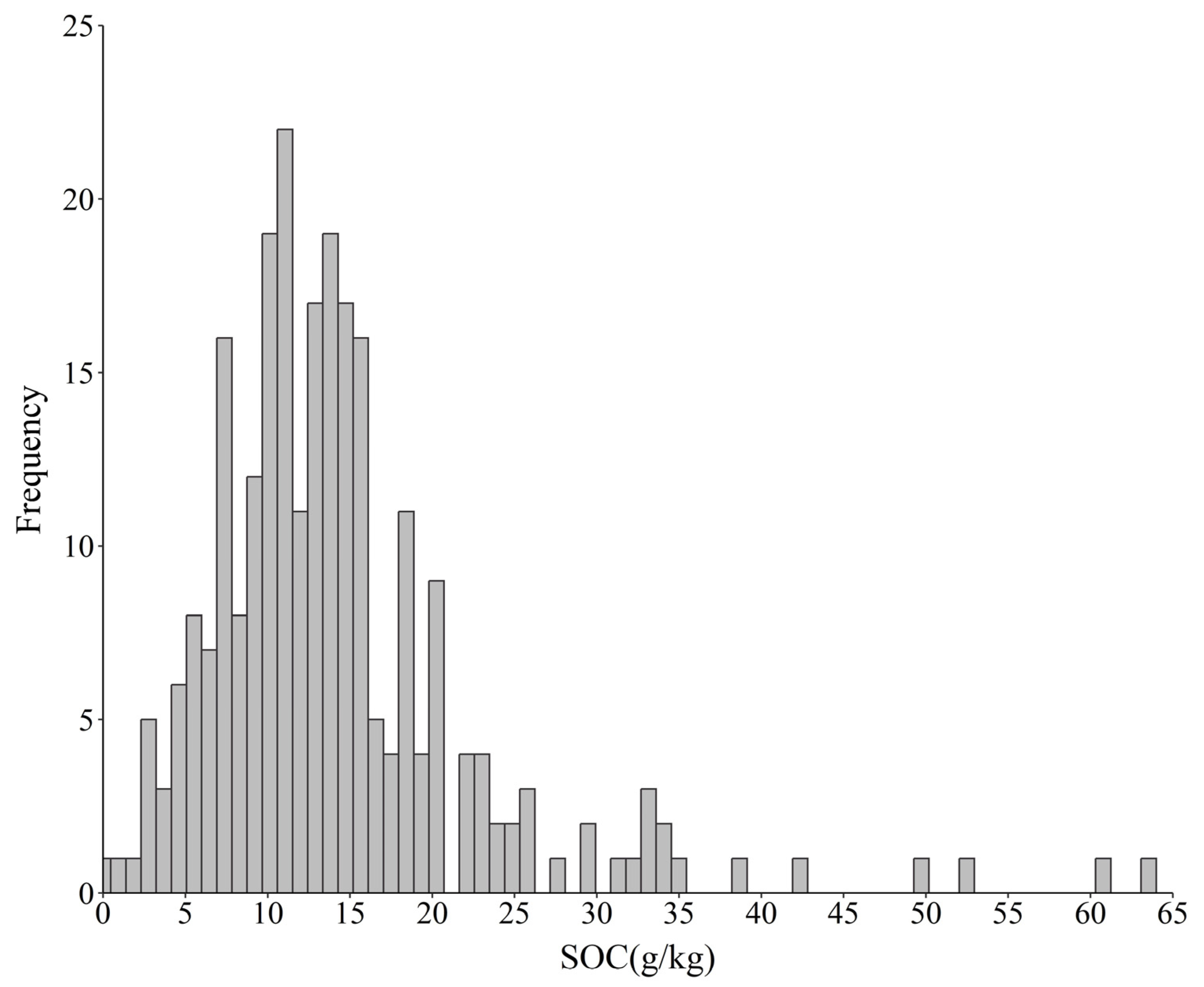
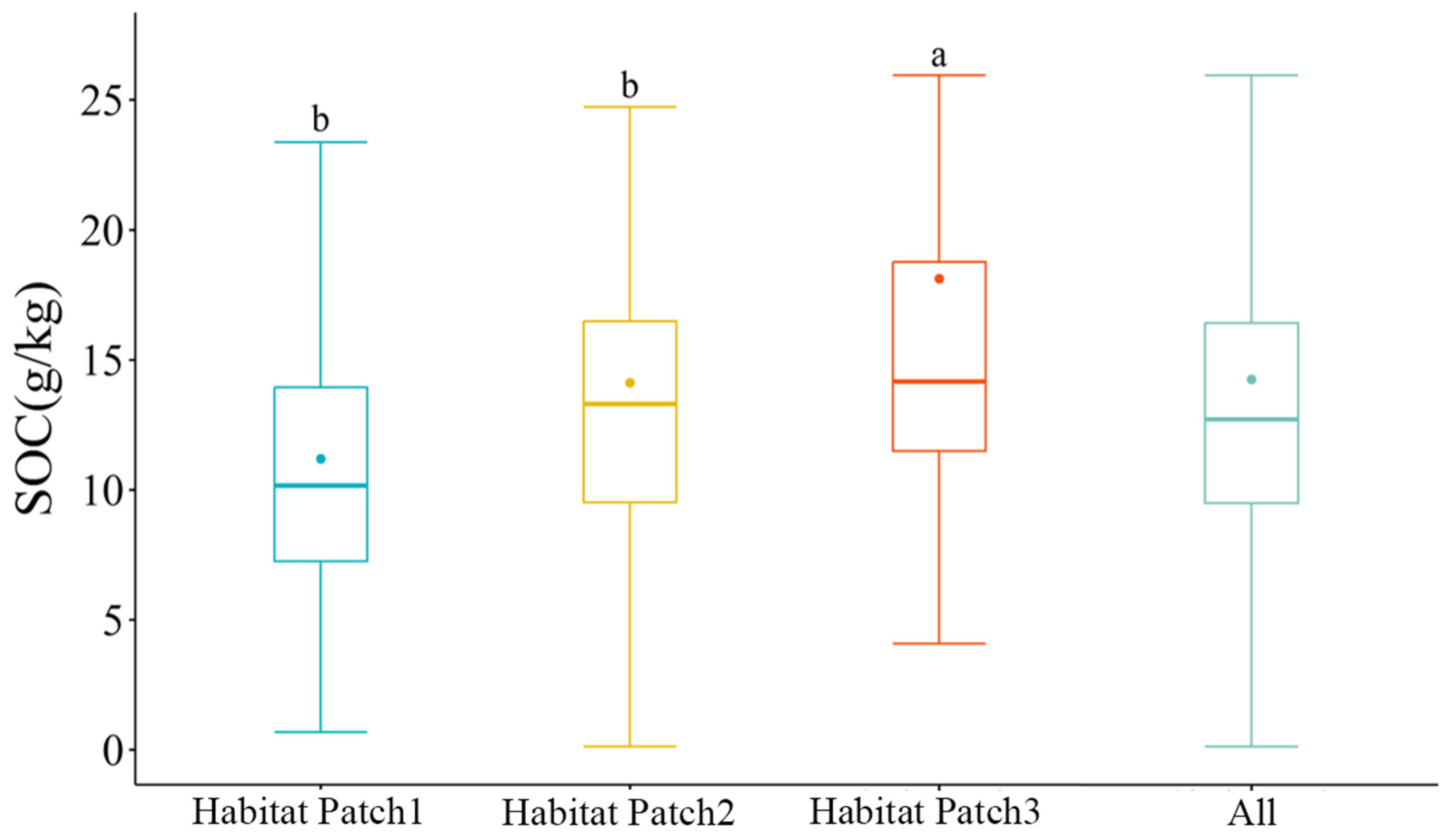
3.1. Descriptive Statistics of the SOC Content
3.2. Cluster Analysis and Feature Selection of Variables
3.3. Simulation Accuracy of the Predictive Models
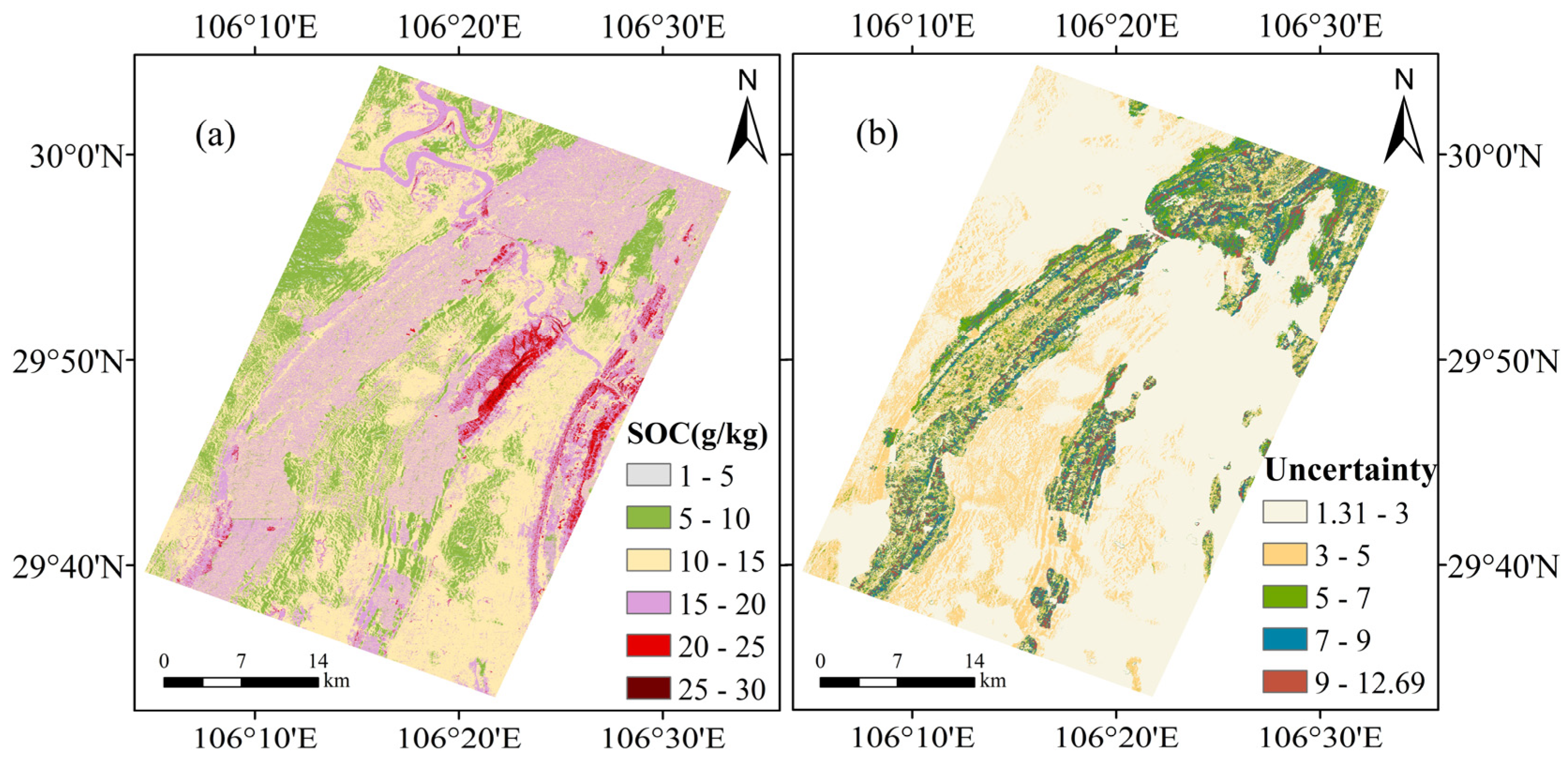
3.4. Spatial Distribution and Uncertainty of SOC Content
4. Discussion
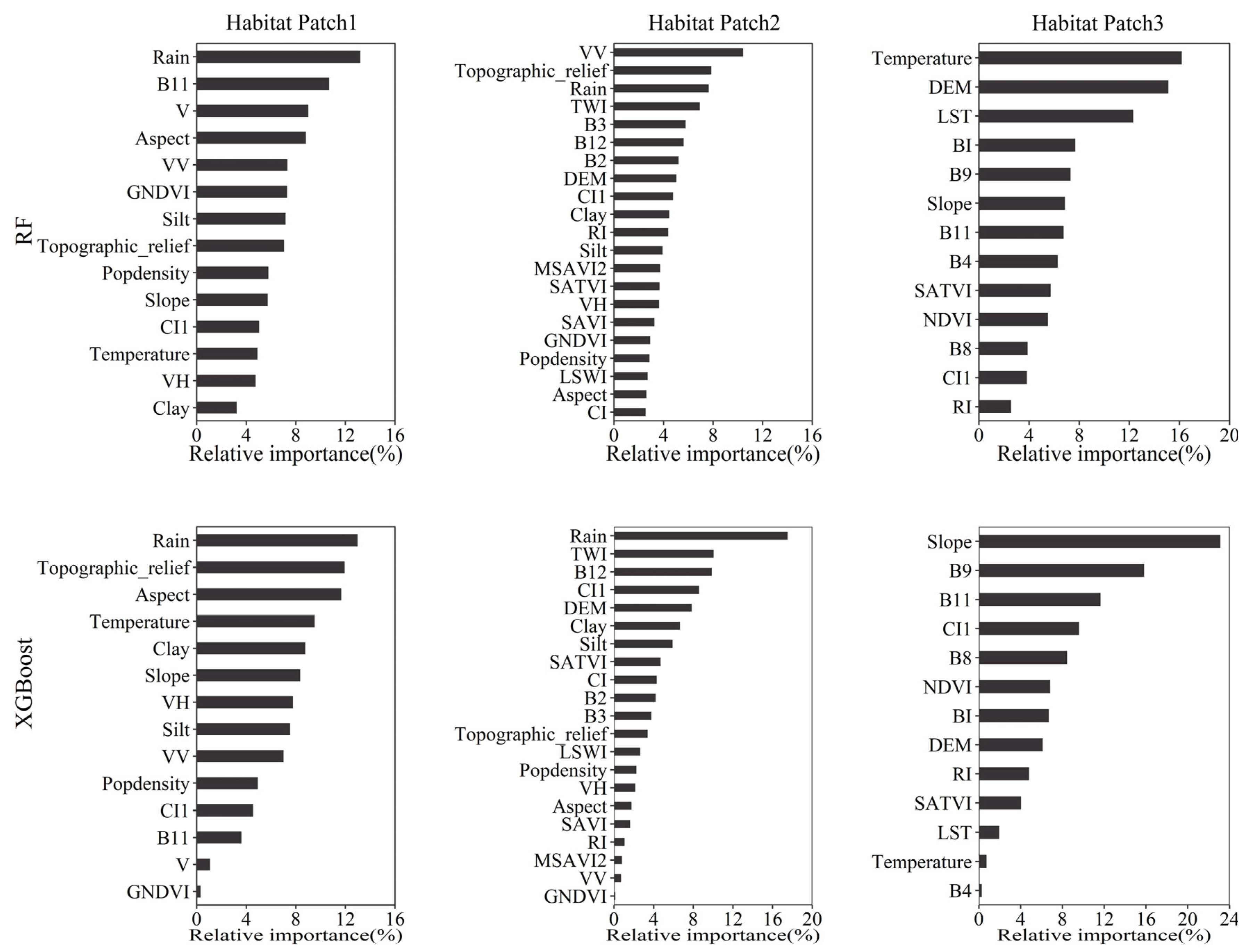
4.1. Variable Importance
4.2. Geographic Characteristics of the SOC Map and the Uncertainty
4.3. Limitations and Perspective
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Koarashi, J.; Atarashi Andoh, M.; Ishizuka, S.; Miura, S.; Saito, T.; Hirai, K. Quantitative aspects of heterogeneity in soil organic matter dynamics in a cool-temperate Japanese beech forest: A radiocarbon-based approach. Glob. Chang. Biol. 2009, 15, 631–642. [Google Scholar] [CrossRef]
- Lal, R. Sequestration of atmospheric CO2 in global carbon pools. Energy Environ. Sci. 2008, 1, 86–100. [Google Scholar] [CrossRef]
- Parras-Alcántara, L.; Lozano-García, B.; Keesstra, S.; Cerdà, A.; Brevik, E.C. Long-term effects of soil management on ecosystem services and soil loss estimation in olive grove top soils. Sci. Total Environ. 2016, 571, 498–506. [Google Scholar] [CrossRef] [PubMed]
- Post, W.M.; Peng, T.; Emanuel, W.R.; King, A.W.; Dale, V.H.; DeAngelis, D.L. The global carbon cycle. Am. Sci. 1990, 78, 310–326. [Google Scholar]
- Lal, R. Soil carbon sequestration impacts on global climate change and food security. Science 2004, 304, 1623–1627. [Google Scholar] [CrossRef] [PubMed]
- Liang, Q.; Liu, M. An automatic site survey approach for indoor localization using a smartphone. IEEE Trans. Autom. Sci. Eng. 2019, 17, 191–206. [Google Scholar] [CrossRef]
- Kheir, R.B.; Greve, M.H.; Bøcher, P.K.; Greve, M.B.; Larsen, R.; McCloy, K. Predictive mapping of soil organic carbon in wet cultivated lands using classification-tree based models: The case study of Denmark. J. Environ. Manag. 2010, 91, 1150–1160. [Google Scholar] [CrossRef]
- Moore, I.D.; Gessler, P.E.; Nielsen, G.; Peterson, G.A. Soil attribute prediction using terrain analysis. Soil Sci. Soc. Am. J. 1993, 57, 443–452. [Google Scholar] [CrossRef]
- Kaya, F.; Keshavarzi, A.; Francaviglia, R.; Kaplan, G.; Başayiğit, L.; Dedeoğlu, M. Assessing machine learning-based prediction under different agricultural practices for digital mapping of soil organic carbon and available phosphorus. Agriculture 2022, 12, 1062. [Google Scholar] [CrossRef]
- Wang, T.; Zhou, W.; Xiao, J.; Li, H.; Yao, L.; Xie, L.; Wang, K. Soil Organic Carbon Prediction Using Sentinel-2 Data and Environmental Variables in a Karst Trough Valley Area of Southwest China. Remote Sens. 2023, 15, 2118. [Google Scholar] [CrossRef]
- Han, J. Spatial clustering methods in data mining: A survey. In Geographic Data Mining and Knowledge Discovery; Taylor and Francis: London, UK, 2001; pp. 188–217. [Google Scholar]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; New York John Wiley&Sons: Hoboken, NY, USA, 2009. [Google Scholar]
- Fahrig, L. Rethinking patch size and isolation effects: The habitat amount hypothesis. J. Biogeogr. 2013, 40, 1649–1663. [Google Scholar] [CrossRef]
- Fahrig, L.; Arroyo-Rodríguez, V.; Bennett, J.R.; Boucher-Lalonde, V.; Cazetta, E.; Currie, D.J.; Eigenbrod, F.; Ford, A.T.; Harrison, S.P.; Jaeger, J.A. Is habitat fragmentation bad for biodiversity? Biol. Conserv. 2019, 230, 179–186. [Google Scholar] [CrossRef]
- McBratney, A.B.; Santos, M.M.; Minasny, B. On digital soil mapping. Geoderma 2003, 117, 3–52. [Google Scholar] [CrossRef]
- Heung, B.; Ho, H.C.; Zhang, J.; Knudby, A.; Bulmer, C.E.; Schmidt, M.G. An overview and comparison of machine-learning techniques for classification purposes in digital soil mapping. Geoderma 2016, 265, 62–77. [Google Scholar] [CrossRef]
- Zhang, Y.; Sui, B.; Shen, H.; Ouyang, L. Mapping stocks of soil total nitrogen using remote sensing data: A comparison of random forest models with different predictors. Comput. Electron. Agric. 2019, 160, 23–30. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Bui, D.T.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017, 151, 147–160. [Google Scholar] [CrossRef]
- Ain, Q.U.; Aleksandrova, A.; Roessler, F.D.; Ballester, P.J. Machine-learning scoring functions to improve structure-based binding affinity prediction and virtual screening. Wiley Interdiscip. Rev. Comput. Mol. Sci. 2015, 5, 405–424. [Google Scholar] [CrossRef] [PubMed]
- Reddy, N.N.; Das, B.S. Digital soil mapping of key secondary soil properties using pedotransfer functions and Indian legacy soil data. Geoderma 2023, 429, 116265. [Google Scholar] [CrossRef]
- Huang, S.; Cai, N.; Pacheco, P.P.; Narrandes, S.; Wang, Y.; Xu, W. Applications of support vector machine (SVM) learning in cancer genomics. Cancer Genom. Proteom. 2018, 15, 41–51. [Google Scholar]
- Zhao, Z.; Chow, T.L.; Rees, H.W.; Yang, Q.; Xing, Z.; Meng, F. Predict soil texture distributions using an artificial neural network model. Comput. Electron. Agric. 2009, 65, 36–48. [Google Scholar] [CrossRef]
- Yang, J.; Wang, X.; Wang, R.; Wang, H. Combination of convolutional neural networks and recurrent neural networks for predicting soil properties using Vis–NIR spectroscopy. Geoderma 2020, 380, 114616. [Google Scholar] [CrossRef]
- Lamichhane, S.; Kumar, L.; Wilson, B. Digital soil mapping algorithms and covariates for soil organic carbon mapping and their implications: A review. Geoderma 2019, 352, 395–413. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, L.; Wu, G.; Wang, K.; Shangguan, Z. Large-scale soil organic carbon mapping based on multivariate modelling: The case of grasslands on the Loess Plateau. Land Degrad. Dev. 2018, 29, 26–37. [Google Scholar] [CrossRef]
- Zhou, W.; Xiao, J.; Li, H.; Chen, Q.; Wang, T.; Wang, Q.; Yue, T. Soil organic matter content prediction using Vis-NIRS based on different wavelength optimization algorithms and inversion models. J. Soils Sediments 2023, 23, 2506–2517. [Google Scholar] [CrossRef]
- Grinand, C.; Le Maire, G.; Vieilledent, G.; Razakamanarivo, H.; Razafimbelo, T.; Bernoux, M. Estimating temporal changes in soil carbon stocks at ecoregional scale in Madagascar using remote-sensing. Int. J. Appl. Earth Obs. Geoinf. 2017, 54, 1–14. [Google Scholar] [CrossRef]
- Gholizadeh, A.; Žižala, D.; Saberioon, M.; Borůvka, L. Soil organic carbon and texture retrieving and mapping using proximal, airborne and Sentinel-2 spectral imaging. Remote Sens. Environ. 2018, 218, 89–103. [Google Scholar] [CrossRef]
- Zou, X.; Zhu, S.; Mõttus, M. Estimation of canopy structure of field crops using sentinel-2 bands with vegetation indices and machine learning algorithms. Remote Sens. 2022, 14, 2849. [Google Scholar] [CrossRef]
- Rajah, P.; Odindi, J.; Mutanga, O.; Kiala, Z. The utility of Sentinel-2 Vegetation Indices (VIs) and Sentinel-1 Synthetic Aperture Radar (SAR) for invasive alien species detection and mapping. Nat. Conserv. 2019, 35, 41–61. [Google Scholar] [CrossRef]
- Yang, R.; Guo, W. Using time-series Sentinel-1 data for soil prediction on invaded coastal wetlands. Environ. Monit. Assess. 2019, 191, 462. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Z.; Lian, Y.I.; Qin, X. Rocky desertification in Southwest China: Impacts, causes, and restoration. Earth Sci. Rev. 2014, 132, 1–12. [Google Scholar] [CrossRef]
- Huang, Y.; Lan, Y.; Thomson, S.J.; Fang, A.; Hoffmann, W.C.; Lacey, R.E. Development of soft computing and applications in agricultural and biological engineering. Comput. Electron. Agric. 2010, 71, 107–127. [Google Scholar] [CrossRef]
- Meersmans, J.; Van Wesemael, B.; Van Molle, M. Determining soil organic carbon for agricultural soils: A comparison between the Walkley & Black and the dry combustion methods (north Belgium). Soil Use Manag. 2009, 25, 346–353. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, Z.; Hu, T.; Wang, G.; He, G.; Zhang, Z.; Li, H.; Wu, Z.; Liu, X. An Efficient Framework for Producing Landsat-Based Land Surface Temperature Data Using Google Earth Engine. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2020, 13, 4689–4701. [Google Scholar] [CrossRef]
- Laurencelle, J.; Logan, T.; Gens, R. ASF radiometrically terrain corrected ALOS PALSAR products. Alaska Satell. Facil. 2015, 1, 12. [Google Scholar]
- Liu, F.; Wu, H.; Zhao, Y.; Li, D.; Yang, J.; Song, X.; Shi, Z.; Zhu, A.; Zhang, G. Mapping high resolution national soil information grids of China. Sci. Bull. 2022, 67, 328–340. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Zhang, G.; Song, X.; Li, D.; Zhao, Y.; Yang, J.; Wu, H.; Yang, F. High-resolution and three-dimensional mapping of soil texture of China. Geoderma 2020, 361, 114061. [Google Scholar] [CrossRef]
- Escadafal, R. Remote sensing of arid soil surface color with Landsat thematic mapper. Adv. Space Res. 1989, 9, 159–163. [Google Scholar] [CrossRef]
- Hengl, T. A Practical Guide to Geostatistical Mapping; Office for Official Publications of the European Communities: Luxembourg, 2009. [Google Scholar]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Kaufman, Y.J.; Merzlyak, M.N. Use of a green channel in remote sensing of global vegetation from EOS-MODIS. Remote Sens. Environ. 1996, 58, 289–298. [Google Scholar] [CrossRef]
- Xiao, X.; Zhang, Q.; Braswell, B.; Urbanski, S.; Boles, S.; Wofsy, S.; Moore, B., III; Ojima, D. Modeling gross primary production of temperate deciduous broadleaf forest using satellite images and climate data. Remote Sens. Environ. 2004, 91, 256–270. [Google Scholar] [CrossRef]
- Qi, J.; Kerr, Y.; Chehbouni, A. External Factor Consideration in Vegetation Index Development; NASA: Val D’Isere, France, 1994.
- Pouget, M.; Madeira, J.; Le Floc, H.E.; Kamal, S. Caracteristiques spectrales des surfaces sableuses de la region cotiere nord-ouest de l’Egypte: Application aux donnees satellitaires SPOT. In Caractérisation et Suivi des Milieux Terrestres en Régions Arides et Tropicales, Proceedings of the 2e’me Journées Télédétection; ORSTOM: Bondy, Japan, 1991; pp. 27–38. [Google Scholar]
- Marsett, R.C.; Qi, J.; Heilman, P.; Biedenbender, S.H.; Watson, M.C.; Amer, S.; Weltz, M.; Goodrich, D.; Marsett, R. Remote sensing for grassland management in the arid southwest. Rangel. Ecol. Manag. 2006, 59, 530–540. [Google Scholar] [CrossRef]
- Huete, A.R. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Nellis, M.D.; Briggs, J.M. Transformed vegetation index for measuring spatial variation in drought impacted biomass on Konza Prairie, Kansas. Trans. Kans. Acad. Sci. 1992, 95, 93–99. [Google Scholar] [CrossRef]
- Jordan, C.F. Derivation of leaf-area index from quality of light on the forest floor. Ecology 1969, 50, 663–666. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Welikala, R.A.; Fraz, M.M.; Dehmeshki, J.; Hoppe, A.; Tah, V.; Mann, S.; Williamson, T.H.; Barman, S.A. Genetic algorithm based feature selection combined with dual classification for the automated detection of proliferative diabetic retinopathy. Comput. Med. Imaging Graph. 2015, 43, 64–77. [Google Scholar] [CrossRef] [PubMed]
- Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Hansen, L.K.; Salamon, P. Neural network ensembles. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 993–1001. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Fan, J.; Wang, X.; Wu, L.; Zhou, H.; Zhang, F.; Yu, X.; Lu, X.; Xiang, Y. Comparison of Support Vector Machine and Extreme Gradient Boosting for predicting daily global solar radiation using temperature and precipitation in humid subtropical climates: A case study in China. Energy Convers. Manag. 2018, 164, 102–111. [Google Scholar] [CrossRef]
- Yagli, G.M.; Yang, D.; Srinivasan, D. Automatic hourly solar forecasting using machine learning models. Renew. Sustain. Energy Rev. 2019, 105, 487–498. [Google Scholar] [CrossRef]
- Rossel, R.V.; McGlynn, R.N.; McBratney, A.B. Determining the composition of mineral-organic mixes using UV–vis–NIR diffuse reflectance spectroscopy. Geoderma 2006, 137, 70–82. [Google Scholar] [CrossRef]
- Rojas, R.; Feyen, L.; Dassargues, A. Conceptual model uncertainty in groundwater modeling: Combining generalized likelihood uncertainty estimation and Bayesian model averaging. Water Resour. Res. 2008, 44, W12418. [Google Scholar] [CrossRef]
- Malone, B.P.; Styc, Q.; Minasny, B.; McBratney, A.B. Digital soil mapping of soil carbon at the farm scale: A spatial downscaling approach in consideration of measured and uncertain data. Geoderma 2017, 290, 91–99. [Google Scholar] [CrossRef]
- Zeraatpisheh, M.; Garosi, Y.; Owliaie, H.R.; Ayoubi, S.; Taghizadeh-Mehrjardi, R.; Scholten, T.; Xu, M. Improving the spatial prediction of soil organic carbon using environmental covariates selection: A comparison of a group of environmental covariates. Catena 2022, 208, 105723. [Google Scholar] [CrossRef]
- Adhikari, K.; Hartemink, A.E. Digital mapping of topsoil carbon content and changes in the Driftless Area of Wisconsin, USA. Soil Sci. Soc. Am. J. 2015, 79, 155–164. [Google Scholar] [CrossRef]
- Ohlmacher, G.C.; Davis, J.C. Using multiple logistic regression and GIS technology to predict landslide hazard in northeast Kansas, USA. Eng. Geol. 2003, 69, 331–343. [Google Scholar] [CrossRef]
- Dong, L.; Zeng, W.; Wang, A.; Tang, J.; Yao, X.; Wang, W. Response of soil respiration and its components to warming and dominant species removal along an elevation gradient in alpine meadow of the Qinghai–Tibetan plateau. Environ. Sci. Technol. 2020, 54, 10472–10482. [Google Scholar] [CrossRef]
- Lal, R. Soil carbon sequestration to mitigate climate change. Geoderma 2004, 123, 1–22. [Google Scholar] [CrossRef]
- Ottoy, S.; Van Meerbeek, K.; Sindayihebura, A.; Hermy, M.; Van Orshoven, J. Assessing top-and subsoil organic carbon stocks of Low-Input High-Diversity systems using soil and vegetation characteristics. Sci. Total Environ. 2017, 589, 153–164. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Waters, C.; Orgill, S.; Gray, J.; Cowie, A.; Clark, A.; Liu, D.L. High resolution mapping of soil organic carbon stocks using remote sensing variables in the semi-arid rangelands of eastern Australia. Sci. Total Environ. 2018, 630, 367–378. [Google Scholar] [CrossRef]
- Schuur, E.A.; McGuire, A.D.; Schädel, C.; Grosse, G.; Harden, J.W.; Hayes, D.J.; Hugelius, G.; Koven, C.D.; Kuhry, P.; Lawrence, D.M. Climate change and the permafrost carbon feedback. Nature 2015, 520, 171–179. [Google Scholar] [CrossRef]
- Jobbágy, E.G.; Jackson, R.B. The vertical distribution of soil organic carbon and its relation to climate and vegetation. Ecol. Appl. 2000, 10, 423–436. [Google Scholar] [CrossRef]
- Bao, Y.; Lin, L.; Wu, S.; Deng, K.A.K.; Petropoulos, G.P. Surface soil moisture retrievals over partially vegetated areas from the synergy of Sentinel-1 and Landsat 8 data using a modified water-cloud model. Int. J. Appl. Earth Obs. Geoinf. 2018, 72, 76–85. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Pham, T.D.; Nguyen, C.T.; Delfos, J.; Archibald, R.; Dang, K.B.; Hoang, N.B.; Guo, W.; Ngo, H.H. A novel intelligence approach based active and ensemble learning for agricultural soil organic carbon prediction using multispectral and SAR data fusion. Sci. Total Environ. 2022, 804, 150187. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Geng, Y.; Chen, J.; Liu, M.; Haase, D.; Lausch, A. Mapping soil organic carbon content using multi-source remote sensing variables in the Heihe River Basin in China. Ecol. Indic. 2020, 114, 106288. [Google Scholar] [CrossRef]
- Mahmoudabadi, E.; Karimi, A.; Haghnia, G.H.; Sepehr, A. Digital soil mapping using remote sensing indices, terrain attributes, and vegetation features in the rangelands of northeastern Iran. Environ. Monit. Assess. 2017, 189, 500. [Google Scholar] [CrossRef] [PubMed]
- Shi, J.; Wang, J.; Hsu, A.Y.; O’Neill, P.E.; Engman, E.T. Estimation of bare surface soil moisture and surface roughness parameter using L-band SAR image data. IEEE Trans. Geosci. Remote Sens. 1997, 35, 1254–1266. [Google Scholar]
- Wagner, W.; Scipal, K.; Pathe, C.; Gerten, D.; Lucht, W.; Rudolf, B. Evaluation of the agreement between the first global remotely sensed soil moisture data with model and precipitation data. J. Geophys. Res. Atmos. 2003, 108, 4611. [Google Scholar] [CrossRef]
- Yang, R.; Guo, W.; Zheng, J. Soil prediction for coastal wetlands following Spartina alterniflora invasion using Sentinel-1 imagery and structural equation modeling. Catena 2019, 173, 465–470. [Google Scholar] [CrossRef]
- Li, Q.; Yue, T.; Wang, C.; Zhang, W.; Yu, Y.; Li, B.; Yang, J.; Bai, G. Spatially distributed modeling of soil organic matter across China: An application of artificial neural network approach. Catena 2013, 104, 210–218. [Google Scholar] [CrossRef]
- Tsui, C.; Chen, Z.; Hsieh, C. Relationships between soil properties and slope position in a lowland rain forest of southern Taiwan. Geoderma 2004, 123, 131–142. [Google Scholar] [CrossRef]
- Siewert, M.B. High-resolution digital mapping of soil organic carbon in permafrost terrain using machine learning: A case study in a sub-Arctic peatland environment. Biogeosciences 2018, 15, 1663–1682. [Google Scholar] [CrossRef]
- Hengl, T.; Mendes De Jesus, J.; Heuvelink, G.B.M.; Ruiperez Gonzalez, M.; Kilibarda, M.; Blagotić, A.; Shangguan, W.; Wright, M.N.; Geng, X.; Bauer-Marschallinger, B.; et al. SoilGrids250m: Global gridded soil information based on machine learning. PLoS ONE 2017, 12, e169748. [Google Scholar] [CrossRef] [PubMed]
- Were, K.; Bui, D.T.; Dick, Ø.B.; Singh, B.R. A comparative assessment of support vector regression, artificial neural networks, and random forests for predicting and mapping soil organic carbon stocks across an Afromontane landscape. Ecol. Indic. 2015, 52, 394–403. [Google Scholar] [CrossRef]
- Wang, S.; Adhikari, K.; Wang, Q.; Jin, X.; Li, H. Role of environmental variables in the spatial distribution of soil carbon (C), nitrogen (N), and C: N ratio from the northeastern coastal agroecosystems in China. Ecol. Indic. 2018, 84, 263–272. [Google Scholar] [CrossRef]
- Tsui, C.; Tsai, C.; Chen, Z. Soil organic carbon stocks in relation to elevation gradients in volcanic ash soils of Taiwan. Geoderma. 2013, 209, 119–127. [Google Scholar] [CrossRef]
- Ulaby, F.T.; Moore, R.K.; Fung, A.K. Microwave Remote Sensing: Active and Passive. Volume 2-Radar Remote Sensing and Surface Scattering and Emission Theory; Addison-Wesley: Reading, MA, USA, 1982. [Google Scholar]
- Barrett, B.; Nitze, I.; Green, S.; Cawkwell, F. Assessment of multi-temporal, multi-sensor radar and ancillary spatial data for grasslands monitoring in Ireland using machine learning approaches. Remote Sens. Environ. 2014, 152, 109–124. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Definition | Reference |
|---|---|---|
| BI | [40] | |
| BI2 | [40] | |
| CI | ||
| CI1 | [41] | |
| GRVI | [42] | |
| GNDVI | [43] | |
| LSWI | [44] | |
| MSAVI2 | [45] | |
| MSI | ||
| NDVI | ||
| RI | [46] | |
| SATVI | [47] | |
| SAVI | [48] | |
| TVI | [49] | |
| V | [50] |
| Sample Type | Sample Number | Minimum (g·kg −1) | Maximum (g·kg −1) | Average (g·kg −1) | Standard Deviation (g·kg −1) | Coefficient of Variation (%) |
|---|---|---|---|---|---|---|
| Overall | 254 | 0.12 | 63.66 | 14.25 | 8.79 | 61.68 |
| Habitat Patch 1 | 80 | 0.67 | 34.27 | 11.19 | 5.91 | 52.81 |
| Habitat Patch 2 | 107 | 0.12 | 50.06 | 14.11 | 7.59 | 53.79 |
| Habitat Patch 3 | 67 | 4.07 | 63.66 | 18.11 | 11.63 | 64.22 |
| Sample Type | Sample Numbers | Models | RMSE | R2 | RPD |
|---|---|---|---|---|---|
| Habitat Patch 1 | 80 | RF | 3.69 | 0.23 | 1.07 |
| XGBoost | 2.89 | 0.55 | 1.48 | ||
| Habitat Patch 2 | 107 | RF | 4 | 0.41 | 1.21 |
| XGBoost | 3.95 | 0.35 | 1.14 | ||
| Habitat Patch 3 | 67 | RF | 5.98 | 0.36 | 1.06 |
| XGBoost | 3.94 | 0.47 | 1.16 | ||
| All | 254 | RF | 4.47 | 0.34 | 1.16 |
| XGBoost | 4.35 | 0.44 | 1.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, W.; Zhou, W.; Wang, T.; Xiao, J.; Peng, Y.; Li, H.; Li, Y. Significant Improvement in Soil Organic Carbon Estimation Using Data-Driven Machine Learning Based on Habitat Patches. Remote Sens. 2024, 16, 688. https://doi.org/10.3390/rs16040688
Yu W, Zhou W, Wang T, Xiao J, Peng Y, Li H, Li Y. Significant Improvement in Soil Organic Carbon Estimation Using Data-Driven Machine Learning Based on Habitat Patches. Remote Sensing. 2024; 16(4):688. https://doi.org/10.3390/rs16040688
Chicago/Turabian StyleYu, Wenping, Wei Zhou, Ting Wang, Jieyun Xiao, Yao Peng, Haoran Li, and Yuechen Li. 2024. "Significant Improvement in Soil Organic Carbon Estimation Using Data-Driven Machine Learning Based on Habitat Patches" Remote Sensing 16, no. 4: 688. https://doi.org/10.3390/rs16040688