In this section, the general architecture of the proposed network is illustrated and each component of our approach is elaborated. We attempt to improve the domain generalization performance through a combination of AT and ST methods. However, distinguishing from existing work [
28,
29,
53], we are devoted to leveraging the idea of consistency regularization [
52,
54,
55] to preserve the output prediction consistency during the feature alignment process to mitigate the instability issues that are easily induced by the adversarial perturbation. Simultaneously, a confidence estimation mechanism is established to optimize the training direction for different complicated domain difference scenarios in RSIs. First, some preliminary work is introduced in
Section 3.1. Then, the proposed adversarial perturbation with consistency is described in
Section 3.2, and the proposed confidence estimation mechanism is described in
Section 3.3.
3.1. Preliminaries
In the DA semantic segmentation task, the source domain images are defined as
, where
, and its corresponding one-hot ground truth is
. Let us define the target domain images as
, where
, and the ground truth of the target domain cannot access the model. Typically, the annotated source domain data is used to train model
with parameters
, and then the trained weights are directly applied to the target domain. Supervisory losses are formulaic as follows:
where
and
is defined as the batch size of the source domain data input to the model at each iteration.
represents the loss entropy of minimizing the ground truth with respect to the predicted probability distribution. This method is set up as the multicategory cross-entropy. In general, the generalization ability of the model tends to perform poorly if domain discrepancies exist between the source and target domains, resulting in the model performance in the target domain usually being suboptimal.
Several strategies and methods [
25,
28,
41,
56] have been proposed to address the domain shift problem, among which AT and ST have become the two dominant DA methods [
57]. In ST, the model generates pseudolabels for the target domain images and iteratively transfers training for the model to be adapted to the target domain. The overall objective function is the linear combination of the supervised loss in the source domain and the unsupervised loss in the target domain
.
where
is the batch size of the target domain data for the input model,
is defined as the default confidence threshold, which is usually set at 0.9 to select high-quality pseudolabels for the target domain, and
represents the candidate pseudolabels from the target domain.
As a common concept in semi-supervised learning [
30,
51,
58], consistency regularization [
52,
55] typically imposes random perturbation information on unannotated data while constraining the model to maintain output prediction consistency. FixMatch [
30] uses weak-to-strong consistency regularization to assign different levels of perturbation augmentation, dubbed weak perturbation
and strong perturbation
, to each unannotated target domain images
. It is written as
where the teacher network
generates higher-quality pseudolabels from weakly perturbed target images, and the student network
serves as a trainable segmentation network to apply stronger perturbations to the same images for optimizing the model. In our method, the teacher network
and the student network
are designed to share weights.
AT obtains the domain-invariant feature space of the source and target domains via aligning the interdomain global feature distributions, which provides another effective method to alleviate the domain discrepancy problem. It generally consists of segmentation network
and discriminative network
. The segmentation network can be divided into the feature extractor
and the classifier
, where
. AT depends on the discriminative network
to align the feature distributions extracted by the segmentation network in the source and target domains. Specifically, the segmentation network
and the discriminative network
are optimized alternately and iteratively by the following two steps [
25,
28,
40]:
- (1)
First,
and
of the segmentation network are frozen, and only the determination network is optimized, which improves the domain discrimination ability of the discriminator
to distinguish the output features of different domains:
where
and
are feature extractors whose inputs are source images
and target images
. d denotes the domain indicator, where 0 denotes the source domain, and 1 denotes the target domain.
and
denote the output probability that discriminator
determines; the input comes from the source and target domains, respectively.
- (2)
The segmentation network G not only conducts supervised training tasks with labeled source domains, but also participates in the AT process. Specifically, the adversarial loss is as follows, and this process is achieved by fixing the discriminative network D and optimizing F and C of the segmentation network.
The main purpose of adversarial loss is to confuse the discriminator and encourage the segmentation network to perform interdomain alignment and learn domain invariant features.
In general, the ST method combined with consistency regularization shows better stability with small discrepancies in data distributions between source and target domains. However, in practical cases, the factors that cause the data distribution discrepancies in RSIs are often complicated. For complex domain discrepancy scenarios, the generalization performance of simple ST methods usually fails to meet the requirements due to the impact of pseudolabel noise. Deep AT methods aim to reduce domain discrepancies through feature space alignment. However, for the semantic segmentation task, fine-grained feature alignment in high-dimensional space is needed, which is prone to induce more noise disturbances causing the model to become over robust and affecting the stability of adversarial learning.
Based on the above issues, we propose a novel DA method for high-resolution RSIs based on adversarial perturbation consistency. We provide directional feature perturbation through AT and align the source domain features with the target domain to improve the domain generalization ability of the model. Additionally, combining consistency regularization and the ST paradigm maintains the output prediction consistency after feature perturbation and improves the stability of AT. Moreover, to adapt to the complex domain discrepancy scenarios in RSIs, based on the complementary advantages of weak-to-strong and adversarial perturbation consistency, we further develop a confidence estimation mechanism for pseudolabels to constrain the direction of the decision boundary.
3.2. Adversarial Perturbations Consistency
To combine the AT and ST paradigms to improve the domain transfer performance of the model, and simultaneously ensure model stability during the training process, inspired by the consistency regularization idea of semi-supervised learning, we propose an adversarial perturbation consistency-based DA semantic segmentation method. Consistency regularization has achieved significant effects in the semi-supervised domain. However, it is difficult to achieve breakthrough performance improvement when applied directly to scenarios where large data distribution shifts exist between the source and target domains, mainly due to the lack of an effective feature alignment mechanism to reduce the interdomain discrepancies. AT is an effective interdomain feature alignment method, but it relies on fine-grained alignment in high-dimensional feature space, which is prone to generating ineffective feature perturbations and causing instability in the training process. Hence, AdvCDA considers the AT process as a single directional feature perturbation stream in consistency regularization to reduce the interdomain variance. Simultaneously, the output consistency is constrained by consistency loss to maintain AT stability.
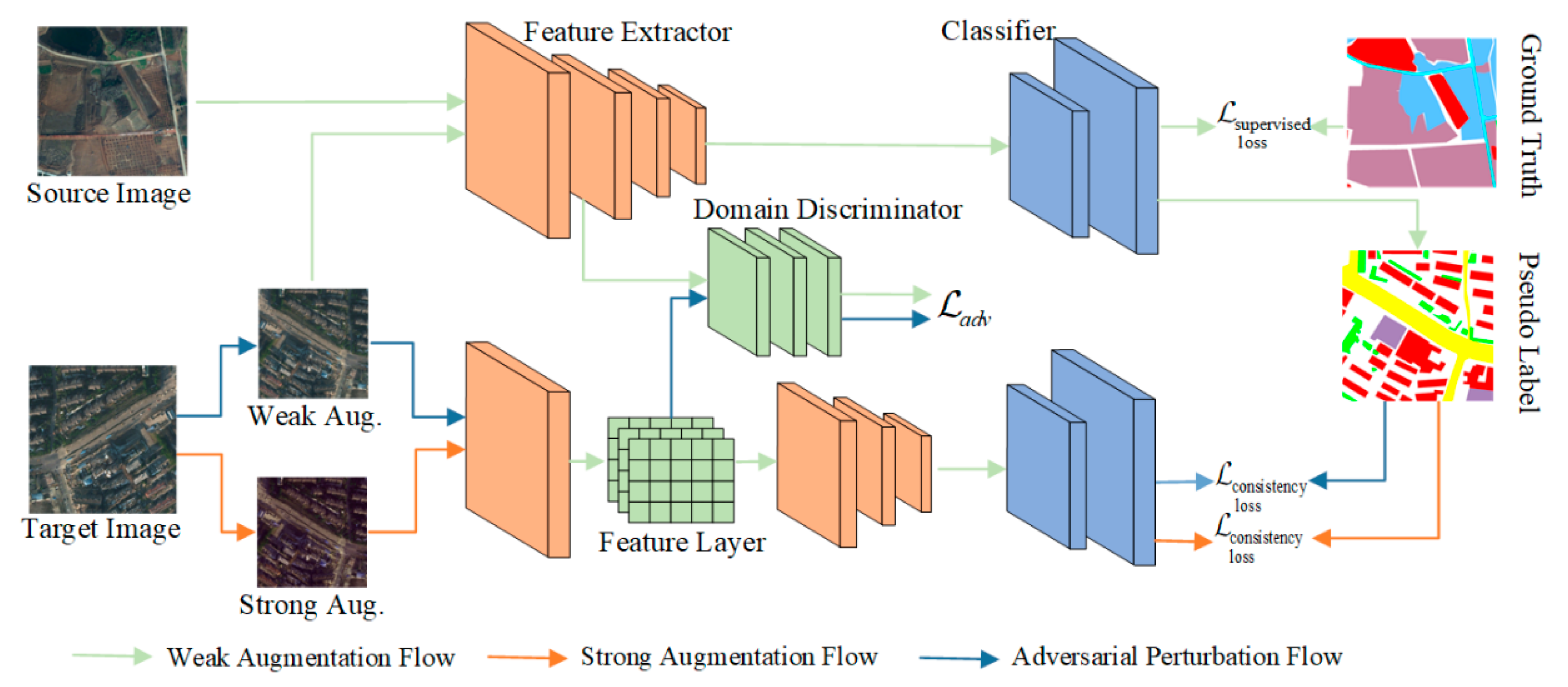
The framework of AdvCDA is shown in
Figure 2. For source images with ground truth, we use supervised loss to train the segmentation network and improve the semantic discrimination performance of the model for each category. For the target domain, we set up three branches to achieve domain transfer between the source and target images to improve the generalization of the model: the weak augmentation branch, the strong augmentation branch, and the adversarial perturbation branch, respectively. Similar to some existing semi-supervised methods [
30,
50], we provide different versions of input perturbations at the input level through weak and strong augmentation to improve the generalization of the model. However, due to domain shifts, consistency learning [
51] at only the input image level is often insufficient and requires the model to maintain consistency at multiple levels under various perturbations to fully exploit the ability of the model to learn generalized features. In particular, it is important to note that the goal of UDA is to align the feature space between different domains to reduce domain discrepancies.
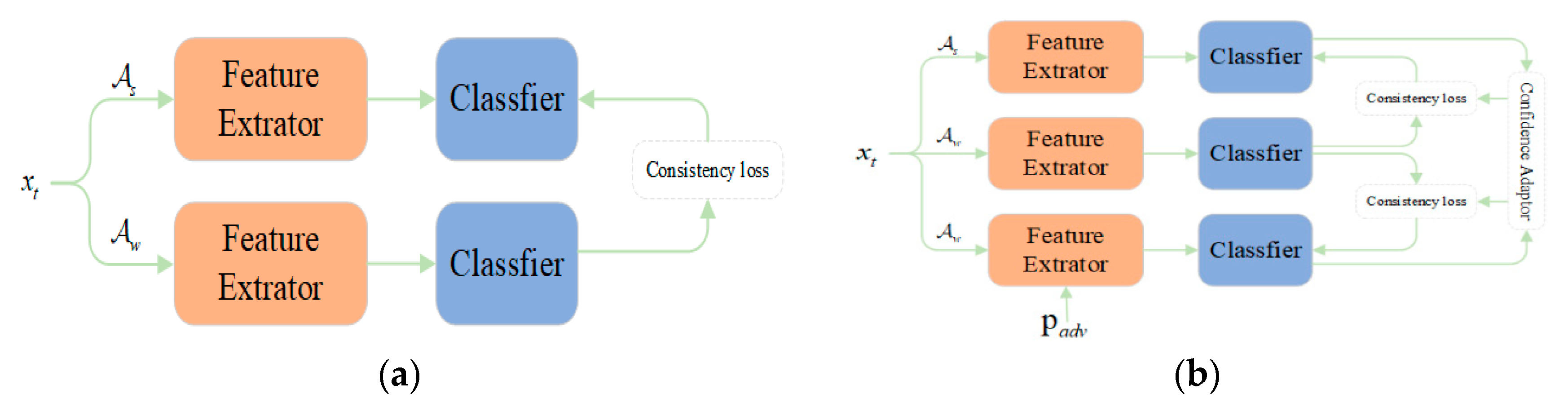
Therefore, based on weak-to-strong perturbation consistency learning [
30], as shown in
Figure 3a, we propose injecting adversarial perturbation information to maintain the consistency of the output prediction with the adversarial perturbation. Specifically, as shown in
Figure 3b, we separate image- and feature-level perturbations into individual network streams, allowing the model to directly achieve target consistency with each type of perturbation information.
First, we divide the model encoder into
and
parts, that is,
. We attempt to align the shallow feature space of the model in the source and target domains. This design explains that the domain discrepancies between the source and target domains are represented in the low-level feature information, such as spectral and textural differences, because of the geographic location, atmospheric radiation conditions, or seasons. These features are generally captured by the shallow layer of the feature extractor, so we decided to inject adversarial perturbation information into the shallow network features, which will capture domain-invariant features more accurately and simultaneously prevent excessive invalid perturbation information from affecting the stability of the model training process. The source and target domain images
and
are fed into the model to obtain the corresponding shallow features
and the predicted results:
Specifically, to reduce the domain discrepancies and improve the generalization performance of the model in the target domain, we attempt to align the feature distributions of the source and target domains through AT methods. Therefore, we apply a discriminator in the shallow feature space of the model for adversarial learning. The adversarial loss is as follows:
Training the discriminator is also required to improve the discriminant performance on source and target domains. Discriminatory loss is described as follows:
where 0 denotes the source domain and 1 denotes the target domain. The feature space of the target domain gradually converges to the source domain through AT to obtain the domain-invariant feature space. The alignment process in the source and target domains can be regarded as injecting a feature perturbation in the shallow feature space of the model and obtaining the new feature parameter, which is
. Furthermore, we can obtain the predicted results after feature perturbation by AT:
Fine-grained feature alignment in high-dimensional space can be more prone to generate adversarial noise [
59], leading to a lack of stability in training DA methods. Therefore, we constrain the model to maintain the consistency of the output predictions after noise perturbation based on the idea of consistency regularization, which helps to improve the stability of the model. Eventually, the unsupervised loss in the target domain is reformulated as
and
, where
denotes the weak-to-strong consistency loss and
denotes the adversarial perturbation consistency loss.
To adapt to the complicated domain discrepancies in RSIs, one can find that our framework is designed with a weak-to-strong consistency stream and an adversarial perturbation consistency stream, which skillfully combines the ST and AT methods to improve domain transfer performance while guaranteeing training stability. Specifically, AT plays a crucial role in the network to conduct interdomain alignment to reduce domain discrepancies. On the one hand, AT provides feature-level perturbations to allow the model to learn various consistent features with more abundant perturbation information. On the other hand, feature alignment is used to reduce the domain discrepancies between the source and target images to improve the domain generalization performance of the model. Meanwhile, consistency regularization enables the model to maintain strong stability during the co-learning process of ST and AT, which fully exploits the potential for domain generalization.
3.3. Confidence Estimation Mechanism
In general, for large domain discrepancy scenarios, feature alignment by AT plays the primary role in reducing the interdomain discrepancy and improving the generalization of the model. In contrast, ST methods are prone to pseudo-label noise that can lead to performance degradation [
46]. For scenarios with small domain discrepancies, such as semi-supervised domains, the ST method can be sufficient to attain satisfactory results for the model in the target domain. Therefore, for the weak-to-strong consistency and adversarial perturbation consistency stream, it is better to allow the model to adaptively optimize the learned weights of the two streams to meet uncertain domain discrepancy scenarios.
The design key of this method is how to evaluate the confidence estimation of each stream to guide the model for better transfer training. As we know, it is especially critical for ST methods to design confidence thresholds for pseudolabels, where labels lower than the confidence threshold are generally considered incorrect labels for prediction. In contrast, labels higher than the threshold will be involved as candidate labels in the next iterative training process to improve the performance of the model in the target domain. Based on this, as shown in
Figure 3b, we propose a confidence estimation mechanism that estimates the training confidence of the two streams by calculating the similarity of the outputs from the strong augmented branch, and the adversarial perturbation branch to the weakly augmented branch, thus constraining the model to assign more training weights to the higher-quality consistent network stream. In addition, it can be found that both of the proposed consistency regularization streams conduct consistently supervised learning based on weak augmentation. Intuitively, the weakly augmented branch is more prone to produce high-quality prediction results. We define the final target domain loss as:
where
and
are the key weights for estimating the confidence of the two streams. The weight values determine the influence level of the corresponding stream on the training and gradient optimization, guiding the optimization direction of the model. When
= 0, the model degenerates into a semi-supervised model, FixMatch [
30]. Specifically, we use the similarity of the logit outputs from the strongly augmented branch and the adversarial perturbation branch, with the weakly augmented branch, respectively, as a confidence estimation for the two streams:
where
and
are the confidence weights assigned to the two streams of weak-to-strong consistency and adversarial perturbation consistency, the higher weight value represents the higher confidence assigned to the corresponding stream, and the model tends to learn from the stream with high confidence. To avoid the instability problem caused by scale variation in weight values, we normalize the final weight values:
In this case, the final loss we use to train the segmentation network was , and as an adversarial loss will inject interdomain feature alignment perturbation information into the feature extractor before the gradient optimization of the segmentation network. The data distribution shifts between source and target images mainly manifest in the shallow information, so focuses primarily on the domain-invariant features in the shallow feature space, and is employed to individually train and optimize the discriminative network.
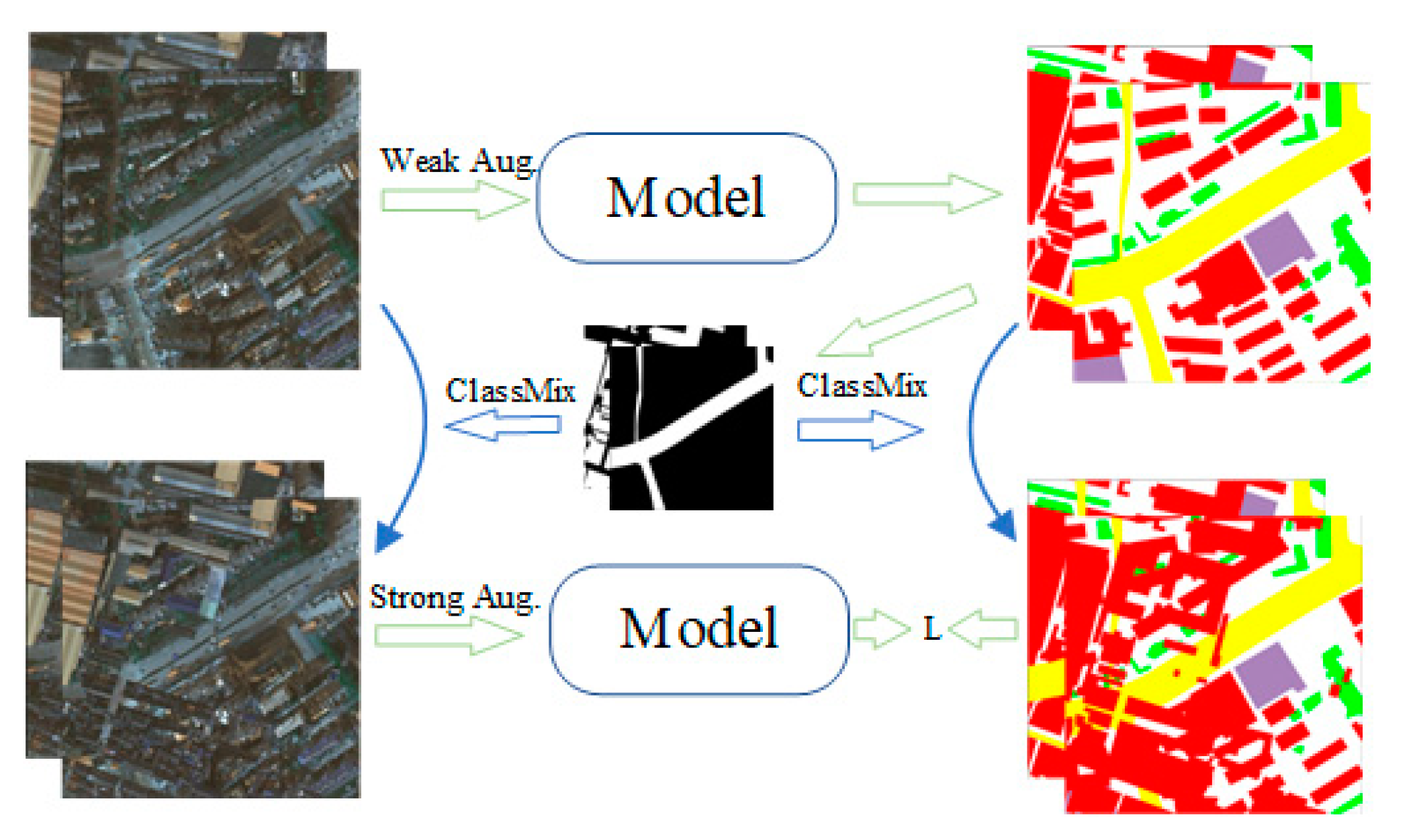
In addition, for weak-to-strong augmentation in consistency regularization learning, we leverage the ClassMix [
32] augmentation strategy in the strongly augmented perturbations by mixing the foreground and background regions of the image to provide more diverse information about the perturbations, as illustrated in
Figure 4. Compared to the commonly adopted CutMix [
60] strategy, ClassMix has more advantages in maintaining the semantic integrity and the boundary information of each object in the images.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}