

An Analysis of the Evolution of Public Sentiment and Spatio-Temporal Dynamics Regarding Building Collapse Accidents Based on Sina Weibo Data
Abstract
:1. Introduction
- (1)
- Instead of collecting comments from all relevant posts, this study chose to select comments from specific mainstream media as a novel research perspective. This avoids inappropriate comments that distort facts or maliciously spread false information, thereby ensuring that the comments are based on timely and genuine reporting, which enhances the reliability of the data. More importantly, selecting data from mainstream media facilitates the study of the relationship between the content they published and public sentiment, allowing for an exploration of the media’s role in guiding public opinion.
- (2)
- We not only focused on sentiment polarity and intensity but also considered factors related to media topics and the sentiment polarity of specific vocabulary. In addition, we integrated sentiment with spatial distribution and time series for a more comprehensive and detailed analysis, leading to more comprehensive conclusions.
- (3)
- To explore the geographical spatial differences in public sentiment, this study analyzed regional attention disparities and regional intensity differences in public sentiment. Additionally, by employing geographic detectors, it delved into the reasons behind these spatial disparities, providing a basis for relevant authorities to formulate differentiated regional strategies.
2. Data and Methods
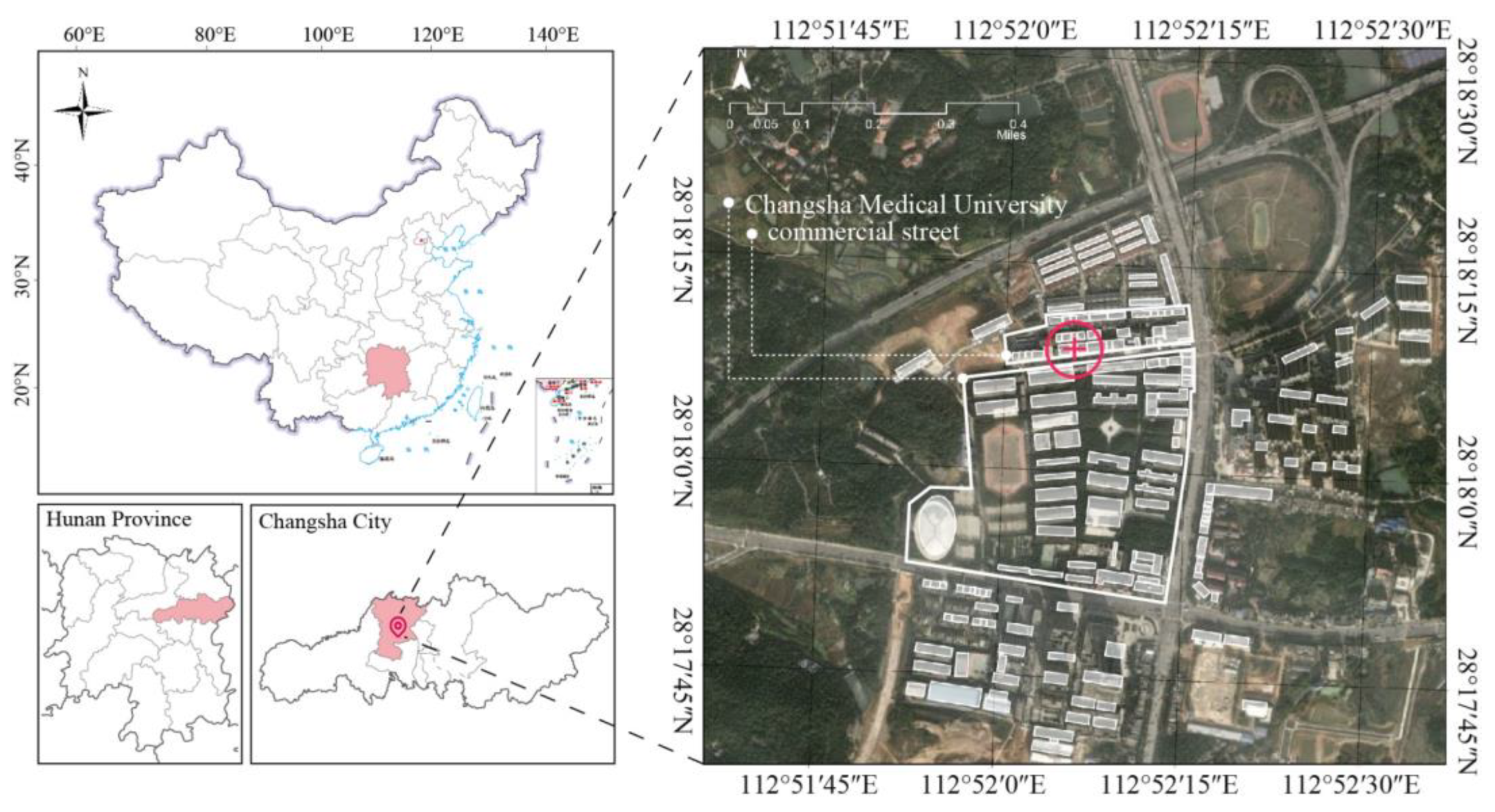
2.1. Case Presentation
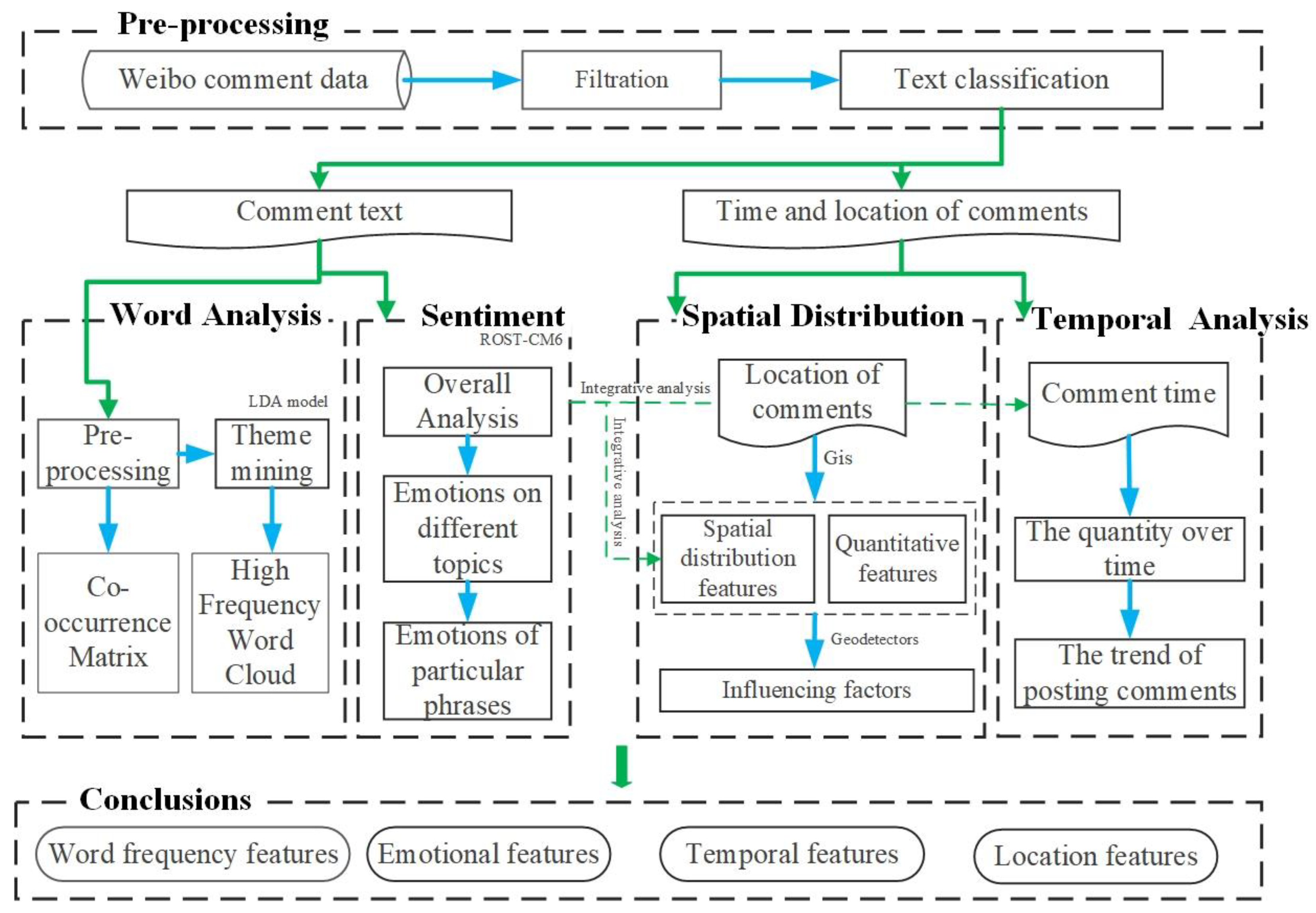
2.2. Research Framework
2.3. Data and Data Pre-Processing
2.4. Method
2.4.1. Co-Occurrence Matrix Analysis
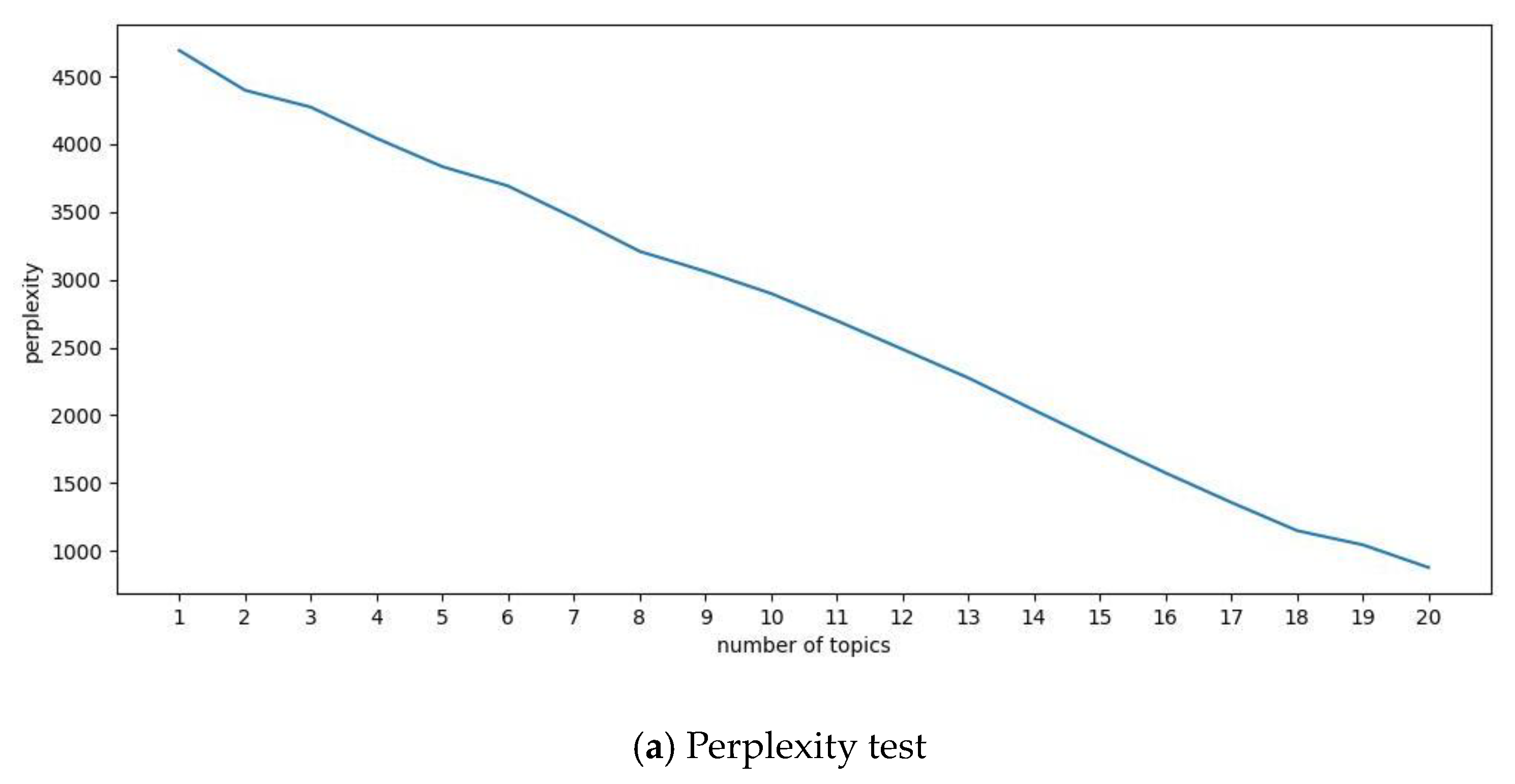
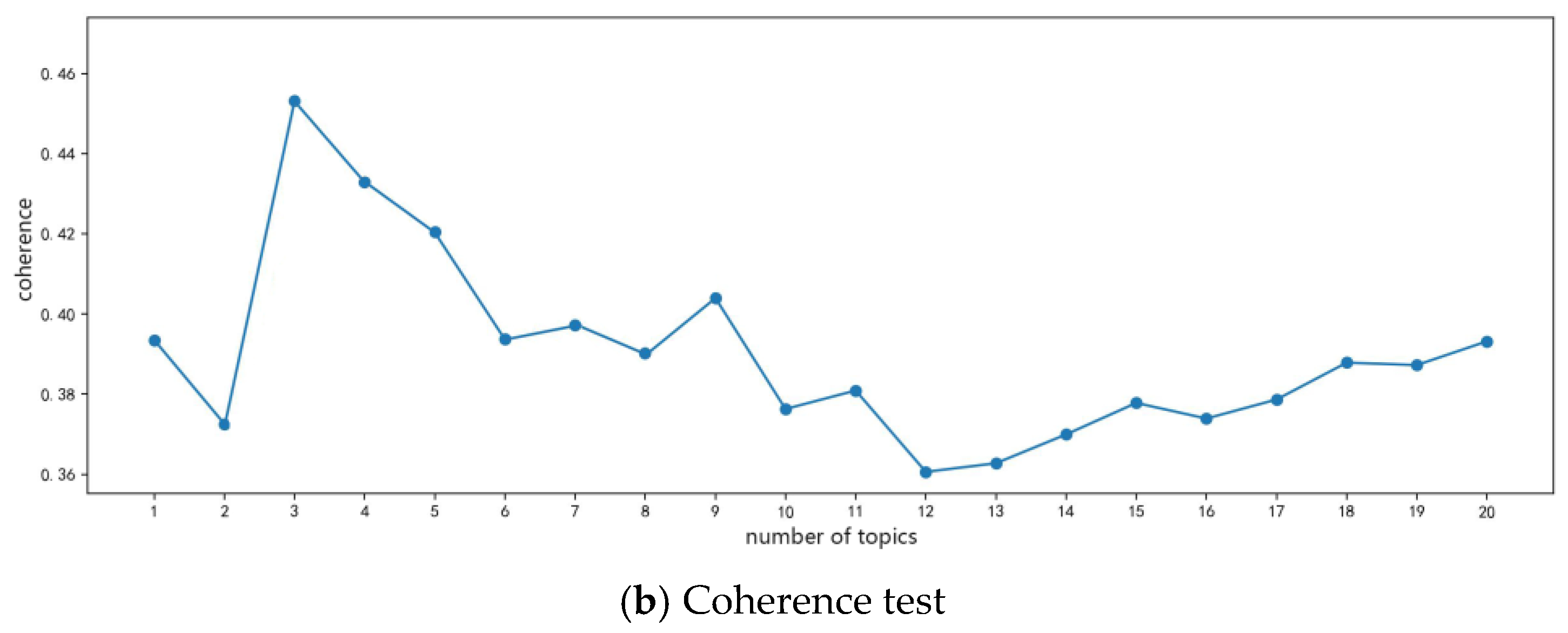
2.4.2. LDA Topic Model
2.4.3. Word Frequency Analysis
2.4.4. Sentiment Analysis Methods
2.4.5. Spatio-Temporal Analysis
2.4.6. Exploring Spatial Heterogeneity of Comment Data Using a Geographical Detector
3. Results
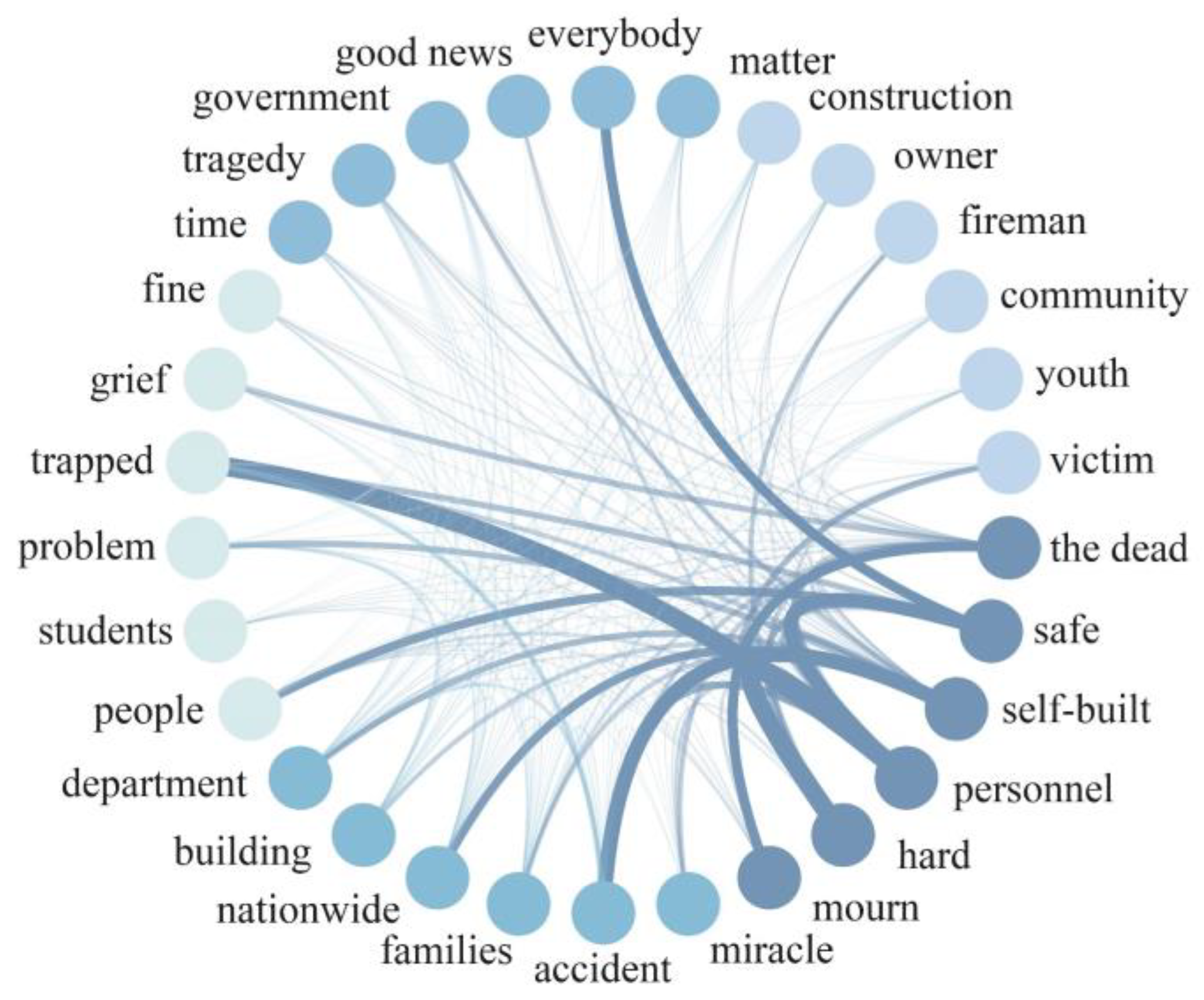
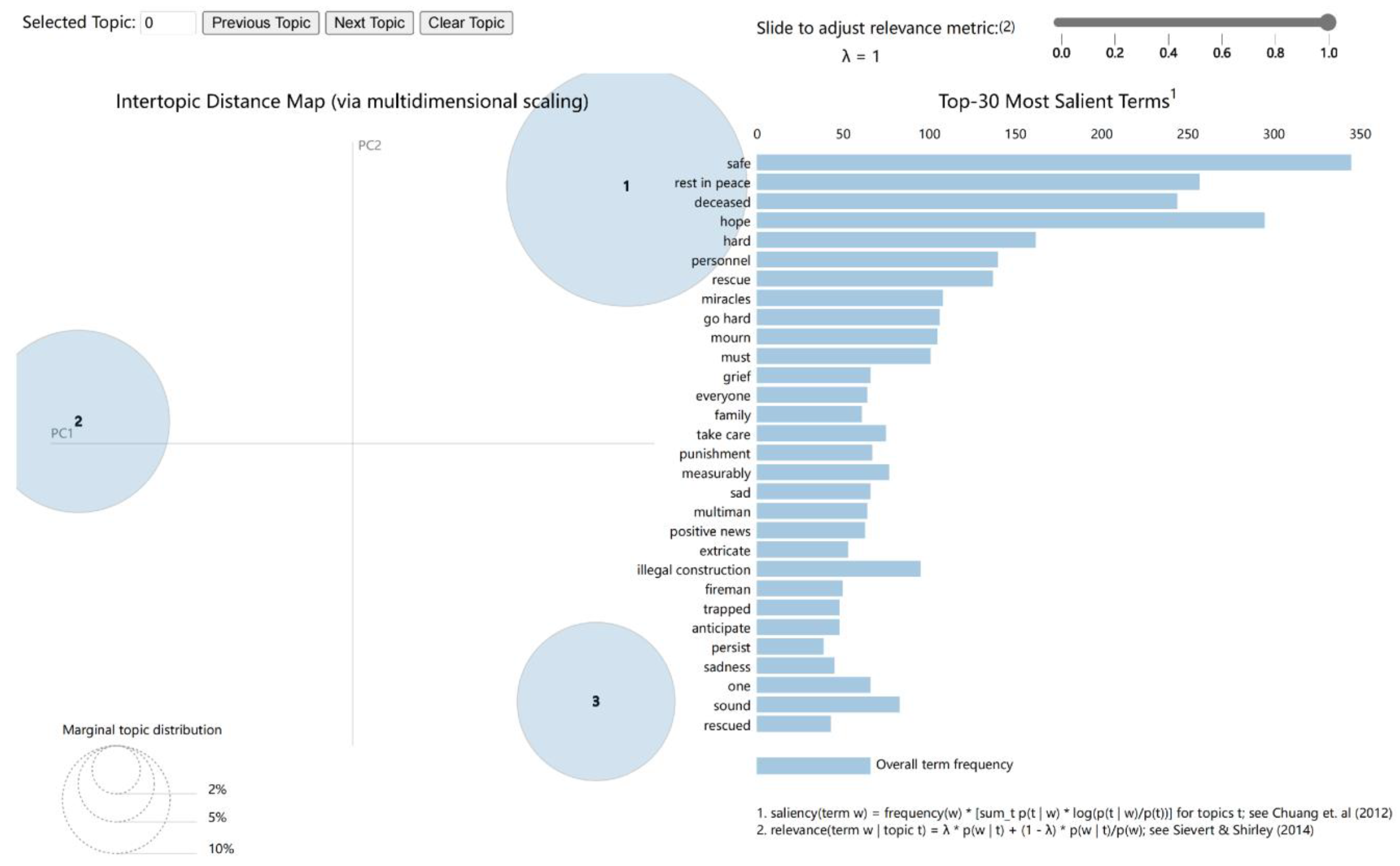
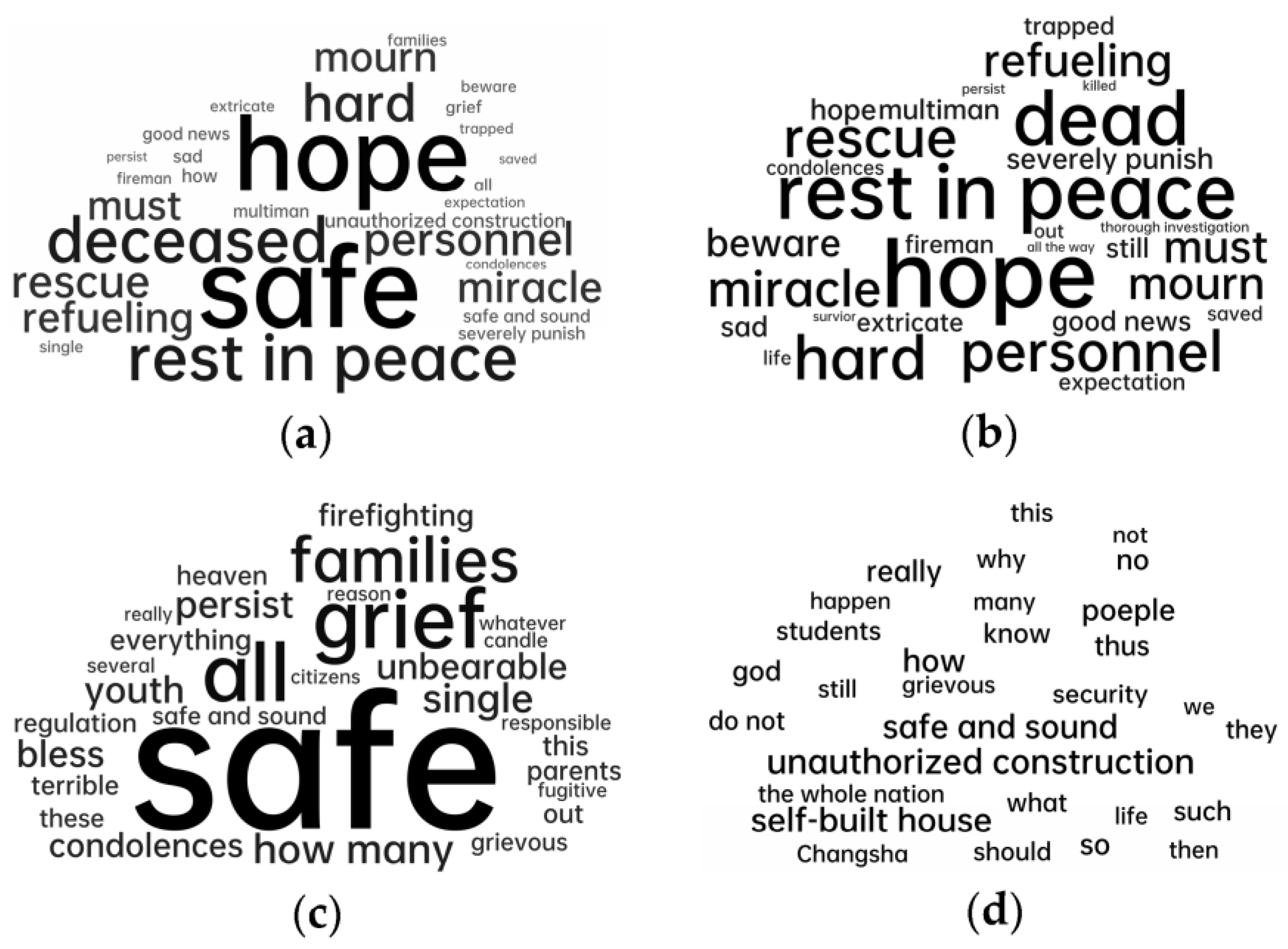
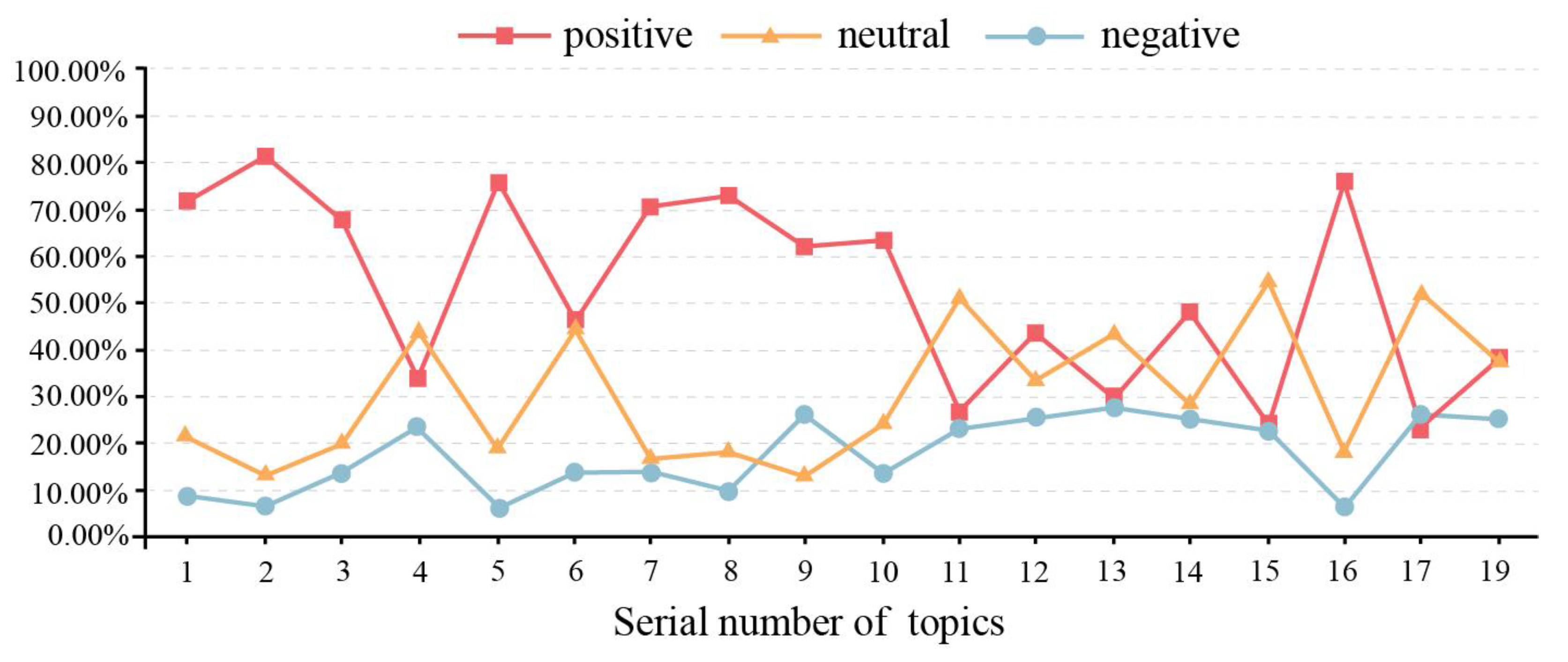
3.1. Topic Mining and Word Frequency Analysis
3.2. Sentiment Analysis
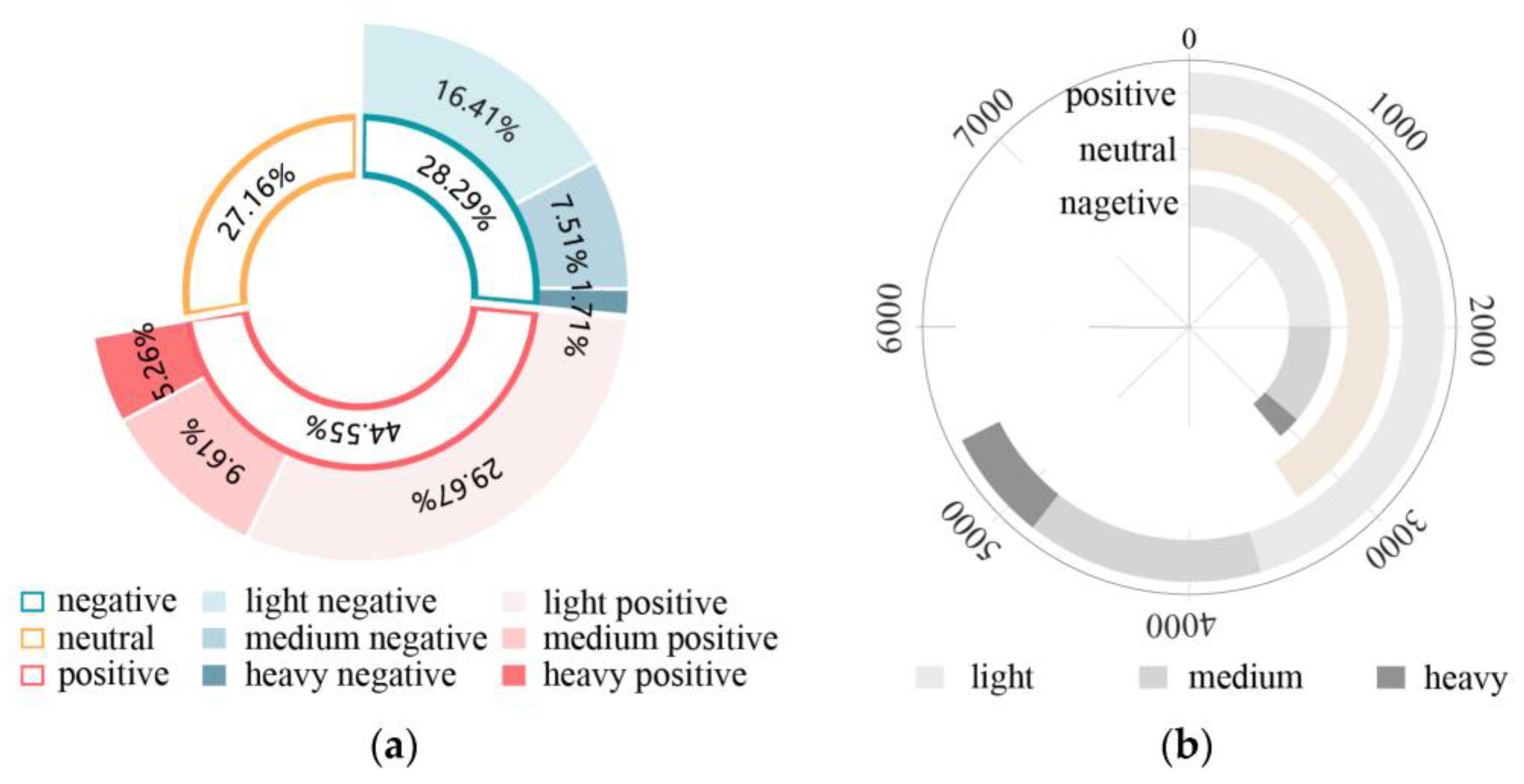
3.2.1. Overall Sentiment Analysis
3.2.2. Relationship between Emotional Polarity and Weibo Content Variation
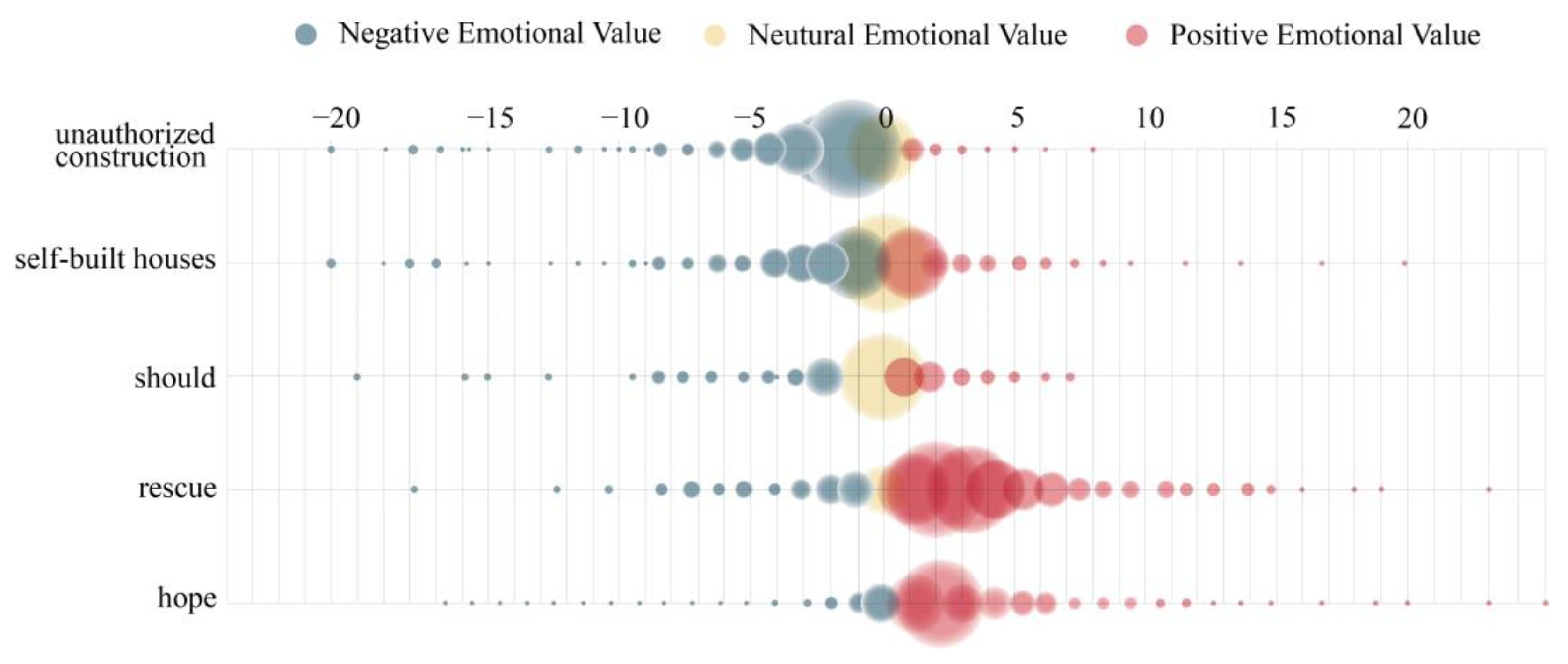
3.2.3. Sentiment Analysis of Specific Words
3.3. Analysis of Spatio-Temporal Distribution and Influencing Factors of Comment Texts
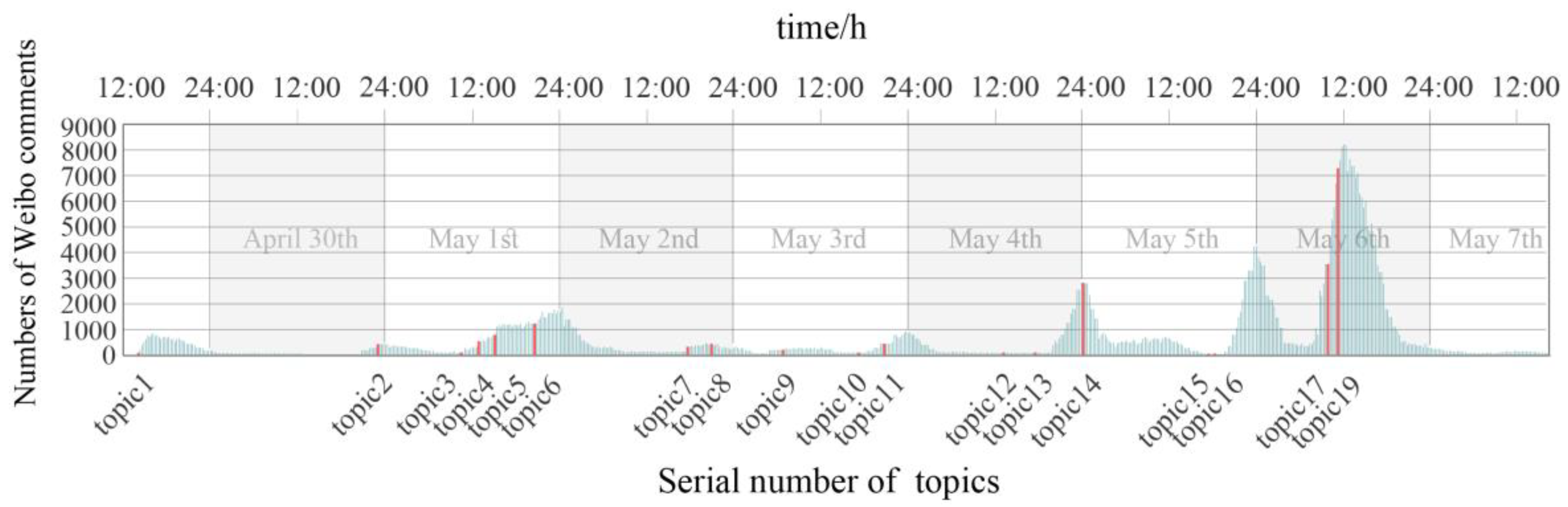
3.3.1. Temporal Distribution Characteristics of Weibo Comments
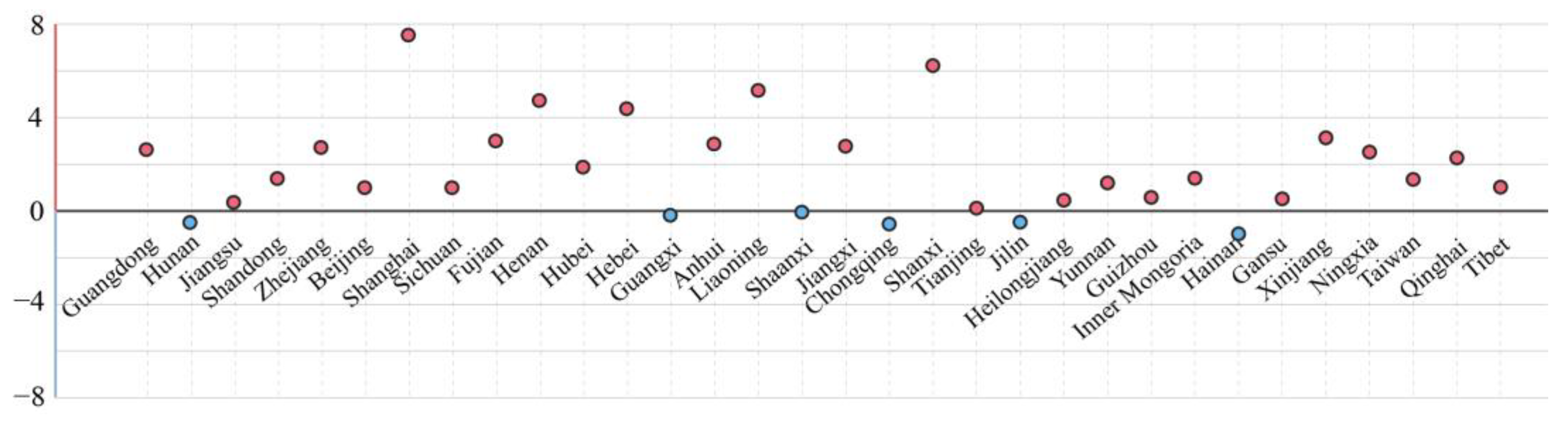
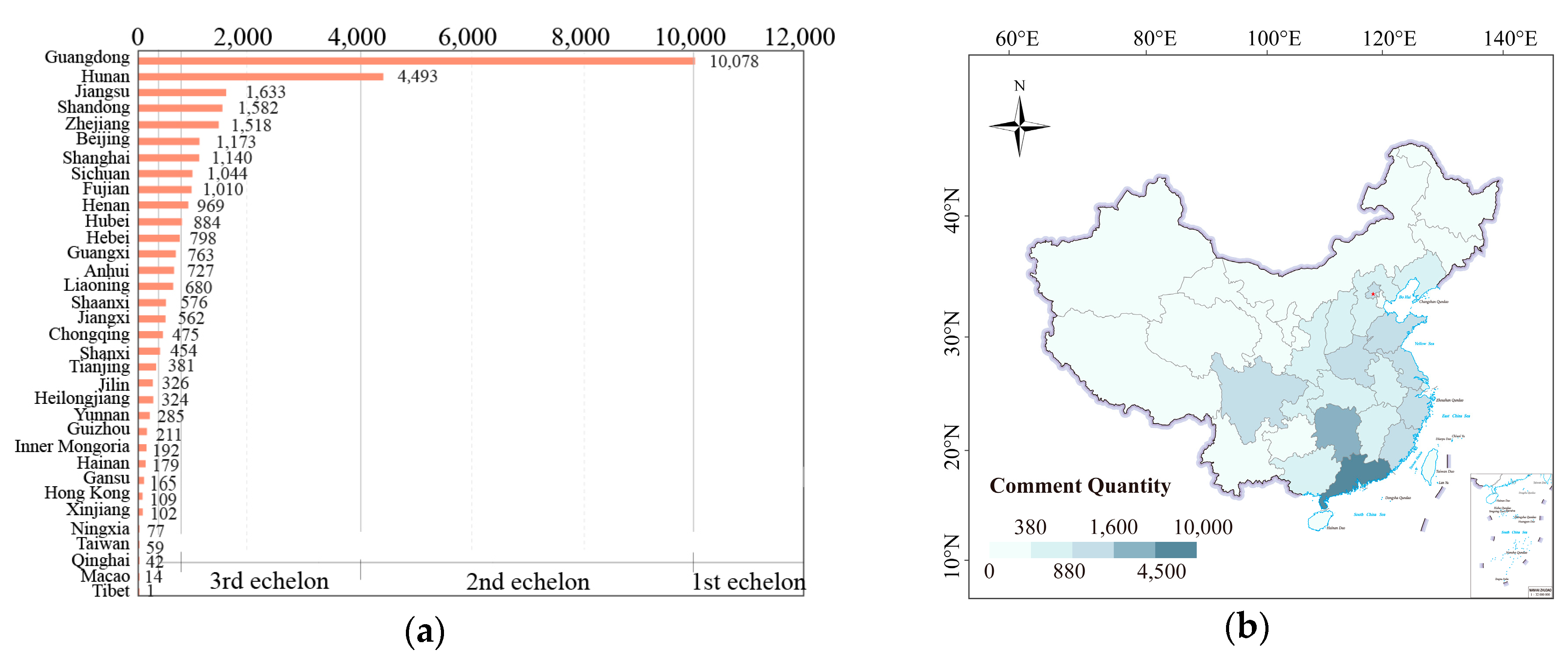
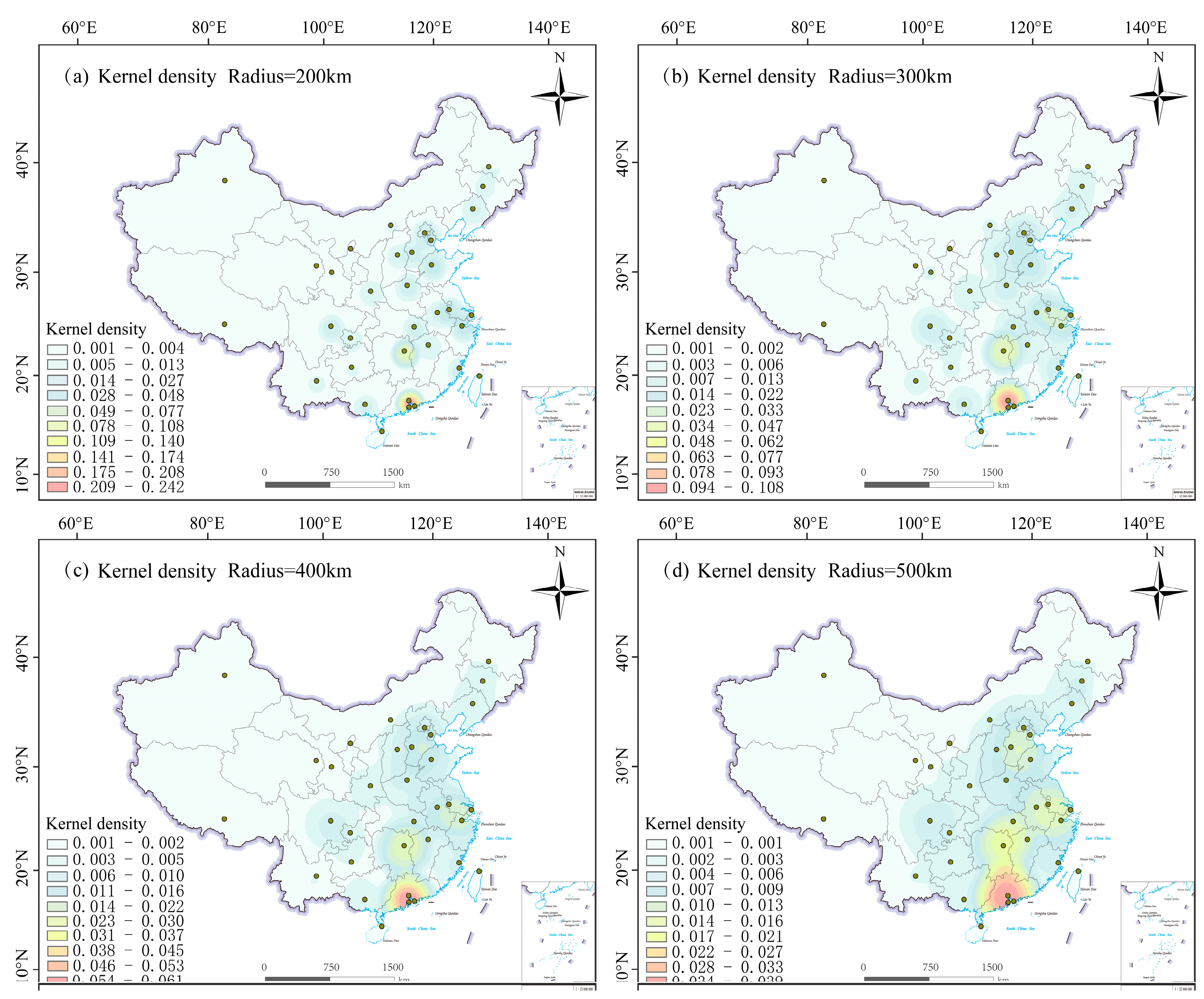
3.3.2. Spatial Distribution Characteristics of Weibo Comments
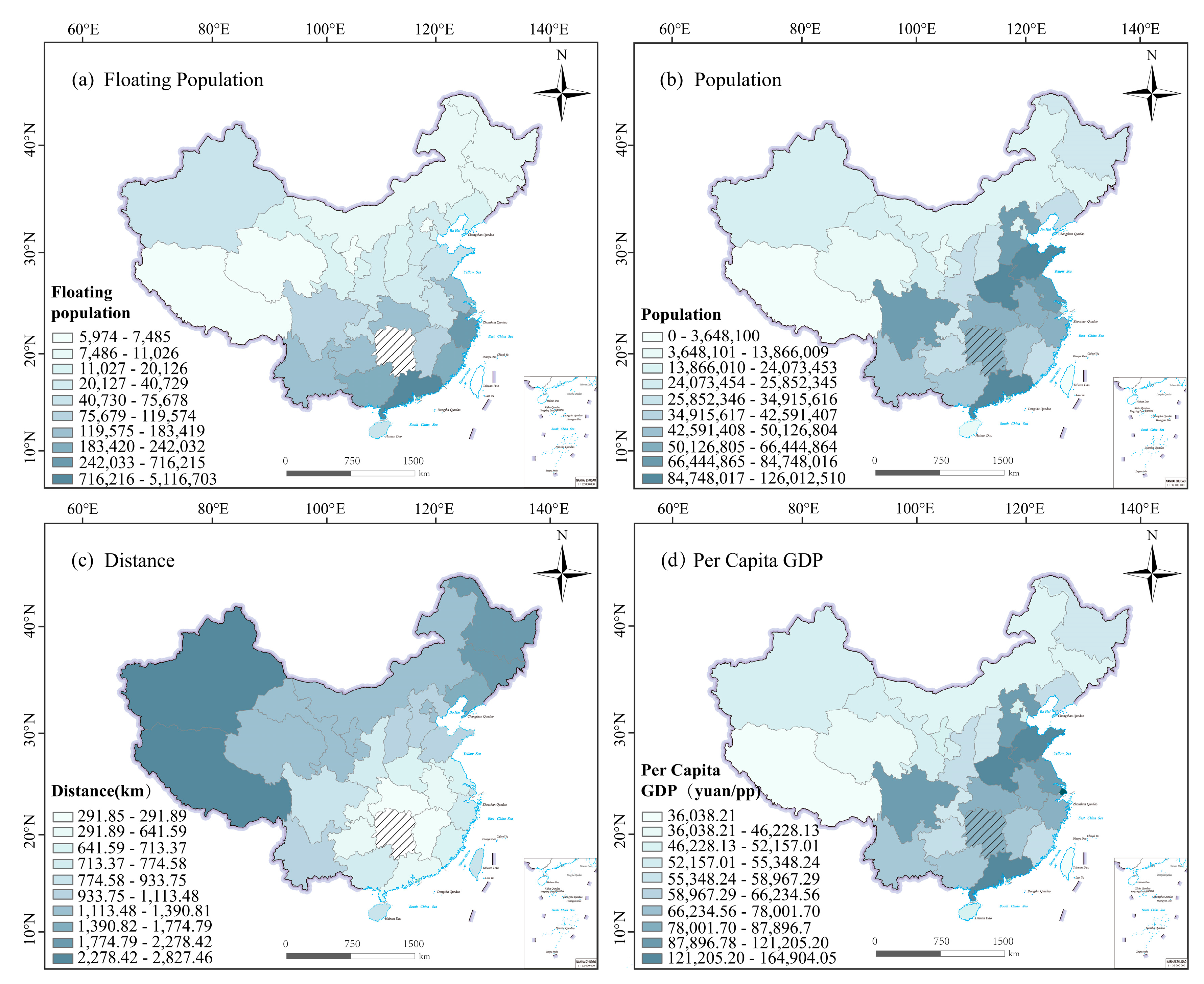
3.3.3. Analysis of Factors Influencing Spatial Divergence of Weibo Comments
4. Discussion
4.1. Analysis of Topic and Word Frequency
4.2. Sentiment Analysis
4.3. Spatio-Temporal Distribution Analysis of Weibo Comments and Influencing Factors
4.4. Integrated Analysis of Sentiment and Spatio-Temporal Features
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dai, W.H. Public cognition morale mechanism of unexpected incidents in cities and the responding strategies. Shanghai Chengshi Guanli 2014, 23, 34–37. [Google Scholar]
- Xiao, Y.; Du, N.; Chen, J.; Li, Y.L.; Qiu, Q.M.; Zhu, S.Y. Workplace violence against doctors in China: A case analysis of the Civil Aviation General Hospital incident. Front. Public Health 2022, 10, 2984. [Google Scholar] [CrossRef] [PubMed]
- Ding, Y. Public opinion analysis of traffic control during the epidemic based on social media data. Comput. Era 2022, 363, 78–82+95. [Google Scholar]
- de Carvalho, V.D.H.; Nepomuceno, T.C.C.; Poleto, T.; Costa, A.P.C.S. The COVID-19 infodemic on Twitter: A space and time topic analysis of the Brazilian immunization program and public trust. Trop. Med. Infect. Dis. 2022, 7, 425. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Cheng, C. Temporal and spatial evolution and influencing factors of public sentiment in natural disasters—A case study of typhoon haiyan. ISPRS Int. J. Geo-Inf. 2021, 10, 299. [Google Scholar] [CrossRef]
- Justicia De La Torre, C.; Sánchez, D.; Blanco, I.; Martín-Bautista, M.J. Text mining: Techniques, applications, and challenges. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2018, 26, 553–582. [Google Scholar] [CrossRef]
- Silva, P.A.; Santos, R. An opinion mining methodology to analyse games for health. Multimed. Tools Appl. 2023, 82, 12957–12976. [Google Scholar] [CrossRef]
- Arbane, M.; Benlamri, R.; Brik, Y.; Alahmar, A.D. Social media-based COVID-19 sentiment classification model using Bi-LSTM. Expert Syst. Appl. 2023, 212, 118710. [Google Scholar] [CrossRef]
- Sun, R.; Budhwani, H. Negative sentiments toward novel coronavirus (COVID-19) vaccines. Vaccine 2022, 40, 6895–6899. [Google Scholar] [CrossRef]
- Sari, I.C.; Ruldeviyani, Y. Sentiment analysis of the COVID-19 virus infection in indonesian public transportation on twitter data: A case study of commuter line passengers. In Proceedings of the 2020 International Workshop on Big Data and Information Security (IWBIS), Depok, Indonesia, 17 October 2020. [Google Scholar]
- Fitri, V.A.; Andreswari, R.; Hasibuan, M.A. Sentiment analysis of social media Twitter with case of Anti-LGBT campaign in Indonesia using Naïve Bayes, decision tree, and random forest algorithm. Procedia Comput. Sci. 2019, 161, 765–772. [Google Scholar] [CrossRef]
- Arias, F.; Guerra-Adames, A.; Zambrano, M.; Quintero-Guerra, E.; Tejedor-Flores, N. Analyzing Spanish-language public sentiment in the context of a pandemic and social unrest: The Panama case. Int. J. Environ. Res. Public Health 2022, 19, 10328. [Google Scholar] [CrossRef] [PubMed]
- Ding, J.; Wang, A.; Zhang, Q. Mining the vaccination willingness of China using social media data. Int. J. Med. Inform. 2023, 170, 104941. [Google Scholar] [CrossRef] [PubMed]
- Jabalameli, S.; Xu, Y.; Shetty, S. Spatial and sentiment analysis of public opinion toward COVID-19 pandemic using twitter data: At the early stage of vaccination. Int. J. Disaster Risk Reduct. 2022, 80, 103204. [Google Scholar] [CrossRef] [PubMed]
- Weng, Z.; Lin, A. Public opinion manipulation on social media: Social network analysis of twitter bots during the COVID-19 pandemic. Int. J. Environ. Res. Public Health 2022, 19, 16376. [Google Scholar] [CrossRef]
- Liu, C.; Guo, L.; Fan, Z.Y. Study on identification and governance countermeasures of the traffic problems in metropolis based on online public opinion: A case study of Wuhan City. Chengshi Wenti 2022, 323, 77–87. [Google Scholar]
- Chen, Y.; Niu, H.; Silva, E.A. The road to recovery: Sensing public opinion towards reopening measures with social media data in post-lockdown cities. Cities 2023, 132, 104054. [Google Scholar] [CrossRef]
- Pi, Z.; Feng, H. The evolution of public sentiment toward government management of emergencies: Social media analytics. Front. Ecol. Evol. 2022, 10, 1026175. [Google Scholar] [CrossRef]
- Zhang, P.; Zhang, H.; Kong, F.; Kong, B.L. A study on public opinion characteristics of rainstorm flooding disasters based on Sina Weibo data: Take the three rainstorm flooding disasters in China in 2021 as an example. Shuili Shuidian Jishu 2022, 54, 47–59. [Google Scholar]
- Liu, G.J.; Li, W.W.; Han, W.; Chen, A. Analysis on structural features of dissemination network of the ethnic factors-related online public opinion based on SNA: Taking the Kunming “3.1” violent and terrorist incident as an example. Anquan 2022, 43, 12–21. [Google Scholar]
- Lv, B.R.; Peng, L.; Chen, J.H.; Chen, R.N.; Ge, X.T. Analysis of Public Opinion Information Pulsation of Forest Fire on Social Media. Dili Xinxi Shijie 2021, 28, 61–66. [Google Scholar]
- Jelodar, H.; Wang, Y.; Orji, R.; Huang, S. Deep sentiment classification and topic discovery on novel coronavirus or COVID-19 online discussions: NLP using LSTM recurrent neural network approach. IEEE J. Biomed. Health Inform. 2020, 24, 2733–2742. [Google Scholar] [CrossRef]
- Lyu, J.C.; Han, E.L.; Luli, G.K. COVID-19 vaccine–related discussion on Twitter: Topic modeling and sentiment analysis. J. Med. Internet Res. 2021, 23, e24435. [Google Scholar] [CrossRef]
- Chen, X.S.; Chang, T.Y.; Wang, H.Z.; Zhao, Z.L.; Zhang, J. Spatial and temporal analysis on public opinion evolution of epidemic situation about novel coronavirus pneumonia based on micro-blog data. J. Sichuan Univ. 2020, 57, 409–416. [Google Scholar]
- Hu, N. Sentiment analysis of texts on public health emergencies based on social media data mining. Comput. Math. Methods Med. 2022, 2022, 3964473. [Google Scholar] [CrossRef] [PubMed]
- Mane, H.; Yue, X.; Yu, W.; Doig, A.C.; Wei, H.; Delcid, N.; Harris, A.; Nguyen, T.N.; Nguyen, Q.C. Examination of the Public’s Reaction on Twitter to the Over-Turning of Roe v Wade and Abortion Bans. Healthcare 2022, 10, 2390. [Google Scholar] [CrossRef] [PubMed]
- Griffiths, T.L.; Steyvers, M. Finding scientific topics. Proc. Natl. Acad. Sci. USA 2004, 101, 5228–5235. [Google Scholar] [CrossRef] [PubMed]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Luo, L.X. Network text sentiment analysis method combining LDA text representation and GRU-CNN. Pers. Ubiquitous Comput. 2019, 23, 405–412. [Google Scholar] [CrossRef]
- Liu, J.W.; Zhang, S.Q. jiyu qinggan fenxi de weibo redian huati yanhua fenxi[Micro-blog hot topic evolution analysis based on sentiment analysis]. Xinxi Xitong Gongcheng 2022, 12, 137–140. [Google Scholar]
- Liu, Y.H.; Liu, W.T. Spatio-temporal characteristics of public opinion and emotion analysis of MS6.4Yunnan Yangbi earthquake based on Sina Weibbo data. Ziran Zaihai Xuebao 2022, 31, 168–178. [Google Scholar]
- Wang, J.F.; Xu, C.D. Geodetertor: Principle and prospective. Dili Xuebao 2017, 72, 116–134. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Principles | Representative Models | Applicable Scenarios | Advantages | Disadvantages |
|---|---|---|---|---|
| Based on probabilistic graph models | LDA | Large-scale text topic mining; applicable to fields such as news and research papers | Strong interpretability | Not very suitable for short texts |
| HDP | Adaptive topic number learning | Dynamically learning; handling multi-domain data | Higher computational complexity; requires large datasets; poor interpretability | |
| Based on matrix factorization | NMF | Tasks such as topic mining and text clustering | Simple and interpretable | Effectiveness may be influenced by initialization |
| Based on word embeddings | Word2Vec, Doc2Vec, FastText | Word sense representation and text similarity calculation, etc. | Capturing semantic relationships | May not be suitable for complex topic mining; may require a large amount of training data |
| Based on deep learning | BERT, CNN, RNN | Multi-task text analysis, sentiment analysis, etc. | Strong expressive capability | Training process can be slow; requires a large amount of data |
| Topic-based | Author-topic model, DTM | Analyzing the relationship between authors and topics, as well as how topics change over time | Considering contextual information | Requires additional information; relatively complex |
| Network-based embeddings | Node2Vec | Analyzing graph data | Considering graph structure relationships | Complexity |
| Serial Number | Date | Topic | Number of Comments | Number of Valid Comments |
|---|---|---|---|---|
| 1 | 29 April | #Collapse of a building in Changsha# | 2116 | 1403 |
| 2 | 30 April | #Hello, tomorrow# | 963 | 801 |
| 3 | 1 May | #Challenges in the rescue operation of the Changsha building collapse accident# | 754 | 493 |
| 4 | 1 May | #9 people involved in the Changsha self-built building collapse accident have been criminally detained# | 925 | 430 |
| 5 | 1 May | #A trapped person is being rescued from the scene of the building collapse in Changsha# | 257 | 221 |
| 6 | 1 May | #Another trapped individual rescued in the collapse of a building in Changsha# | 3161 | 2546 |
| 7 | 1 May | #The seventh trapped individual was rescued from the scene of the building collapse in Changsha# | 1458 | 1125 |
| 8 | 2 May | #The rescue team responded that they would never give up until the last moment# | 402 | 305 |
| 9 | 2 May | #The eighth trapped individual was rescued# | 482 | 410 |
| 10 | 3 May | #The ninth trapped individual was rescued# | 528 | 465 |
| 11 | 3 May | #9 people involved in the Changsha self-built building collapse accident have been arrested# | 641 | 326 |
| 12 | 3 May | #The search and rescue approach for the collapse incident in Changsha has been adjusted# | 3071 | 1089 |
| 13 | 4 May | #Rescue personnel at the Changsha collapse site observe a moment of silence for the victims# | 7293 | 4594 |
| 14 | 5 May | #The 10th trapped individual has been rescued in the collapse incident in Changsha# | 894 | 393 |
| 15 | 5 May | #26 people confirmed dead in the Changsha self-built building collapse accident# | 8372 | 5137 |
| 16 | 5 May | #I knew the firefighters would come to rescue me# | 598 | 441 |
| 17 | 6 May | #53 people confirmed dead in the Changsha self-built building collapse accident# | 20,000 | 12,977 |
| 18 | 6 May | #The Changsha Municipal Committee and the Municipal Government apologize for the collapse incident# | 1013 | 6 |
| 19 | 6 May | #The State Council establishes an investigation team for the collapse incident of self-built houses in Changsha# | 1137 | 710 |
| Total | 33,878 |
| Sentiment | Date | Geolocation | Example of Comment Content |
|---|---|---|---|
| Positive sentiment | 29 April 17:05 | Hainan | Hope for safety. Rescuers, thank you for your hard work! |
| 29 April 14:23 | Shandong | May everyone be safe🙏🙏🙏 | |
| Neutral sentiment | 30 April 23:33 | Henan | Is it a prefabricated panel structure? |
| 30 April 23:33 | Fujian | Why are there so many people in the self-built house? Is it a homestay? | |
| Negative sentiment | 30 April 23:41 | Henan | The one next to it in the picture looks even more dangerous, it has not collapsed yet, but it’s just a matter of time! |
| 5 May 08:50 | Jiangsu | A completely avoidable accident, let us have a human sacrifice before the press conference. |
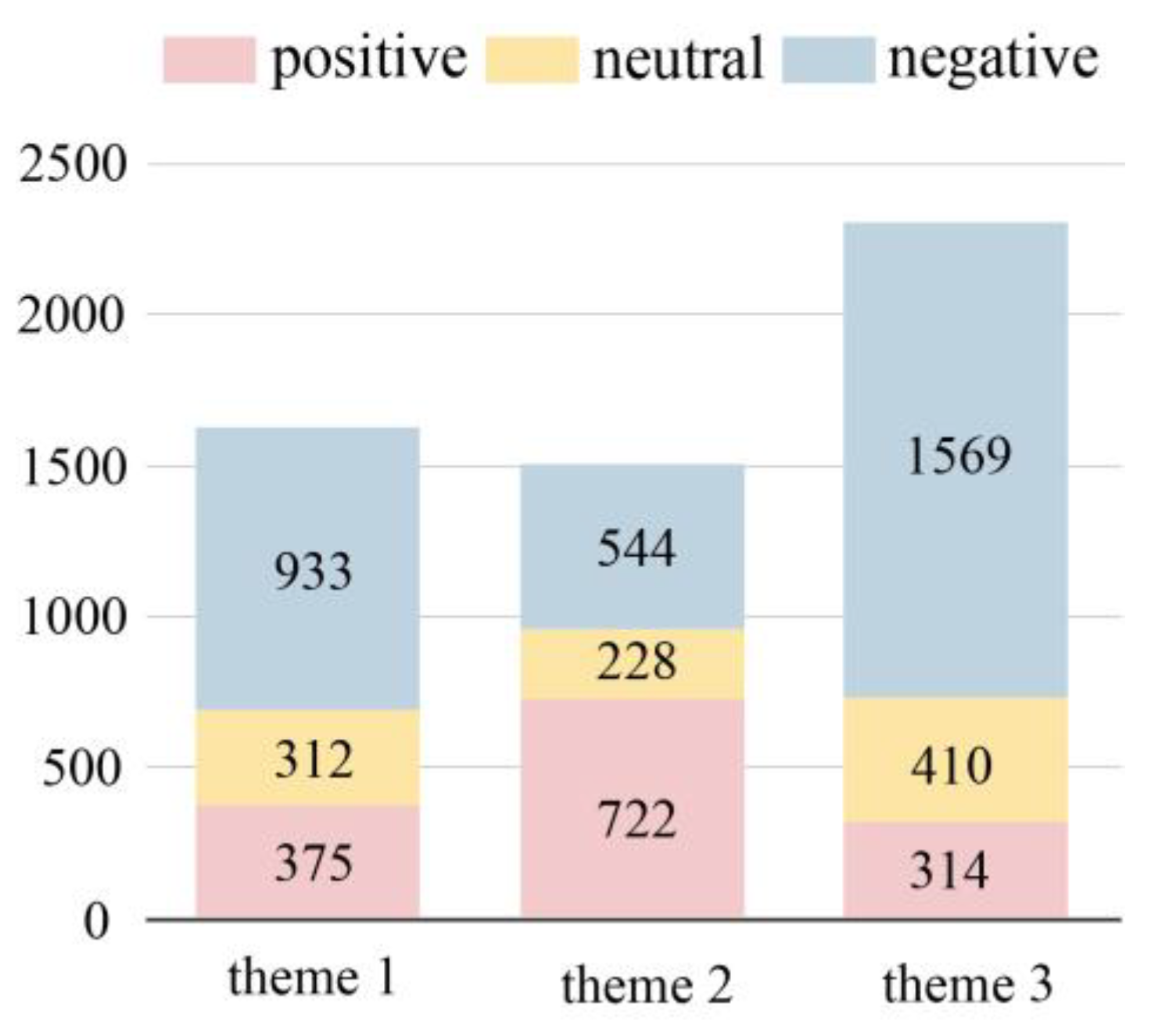
| Theme | Theme 1 | Theme 2 | Theme 3 |
| Rest in Peace for the Deceased | Wishing Everyone Safety | Thorough Investigation of Self-Built Houses | |
| Emotion Value | −3.32 | 3.39 | −5.96 |
| Floating Population | Population | Distance from Hunan Province | Per Capita GDP | |
|---|---|---|---|---|
| q statistic | 0.965099 | 0.258924 | 0.215676 | 0.963853 |
| p value | 0 | 0.79695 | 0.84563 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, D.; Zhang, C.; Zhao, L.; Huang, Q.; Liu, B. An Analysis of the Evolution of Public Sentiment and Spatio-Temporal Dynamics Regarding Building Collapse Accidents Based on Sina Weibo Data. ISPRS Int. J. Geo-Inf. 2023, 12, 388. https://doi.org/10.3390/ijgi12100388
Ma D, Zhang C, Zhao L, Huang Q, Liu B. An Analysis of the Evolution of Public Sentiment and Spatio-Temporal Dynamics Regarding Building Collapse Accidents Based on Sina Weibo Data. ISPRS International Journal of Geo-Information. 2023; 12(10):388. https://doi.org/10.3390/ijgi12100388
Chicago/Turabian StyleMa, Dongling, Chunhong Zhang, Liang Zhao, Qingji Huang, and Baoze Liu. 2023. "An Analysis of the Evolution of Public Sentiment and Spatio-Temporal Dynamics Regarding Building Collapse Accidents Based on Sina Weibo Data" ISPRS International Journal of Geo-Information 12, no. 10: 388. https://doi.org/10.3390/ijgi12100388