

高等学校化学学报 ›› 2022, Vol. 43 ›› Issue (10): 20220397.doi: 10.7503/cjcu20220397
武晴滢, 祝震予, 吴剑鸣( ), 徐昕
), 徐昕
收稿日期:2022-06-05
出版日期:2022-10-10
发布日期:2022-07-11
通讯作者:
吴剑鸣
E-mail:jianmingwu@fudan.edu.cn
基金资助:
WU Qingying, ZHU Zhenyu, WU Jianming(), XU Xin
Received:2022-06-05
Online:2022-10-10
Published:2022-07-11
Contact:
WU Jianming
E-mail:jianmingwu@fudan.edu.cn
Supported by:摘要:
在大数据机器学习时代, 选择更具代表性的数据集对于模型的训练和验证尤为重要. Kennard- Stone(KS)算法及其各种变种(泛KS算法)是一大类优异的数据集分割方法, 但其采样比例或采样数的选择仅能依靠经验或根据建模结果事后评判. KS算法依据原始文献的计算复杂度为
中图分类号:
TrendMD:
武晴滢, 祝震予, 吴剑鸣, 徐昕. 泛Kennard-Stone算法的数据集代表性度量与分块采样策略. 高等学校化学学报, 2022, 43(10): 20220397.
WU Qingying, ZHU Zhenyu, WU Jianming, XU Xin. A Dataset Representativeness Metric and A Slicing Sampling Strategy for the Kennard-Stone Algorithm. Chem. J. Chinese Universities, 2022, 43(10): 20220397.
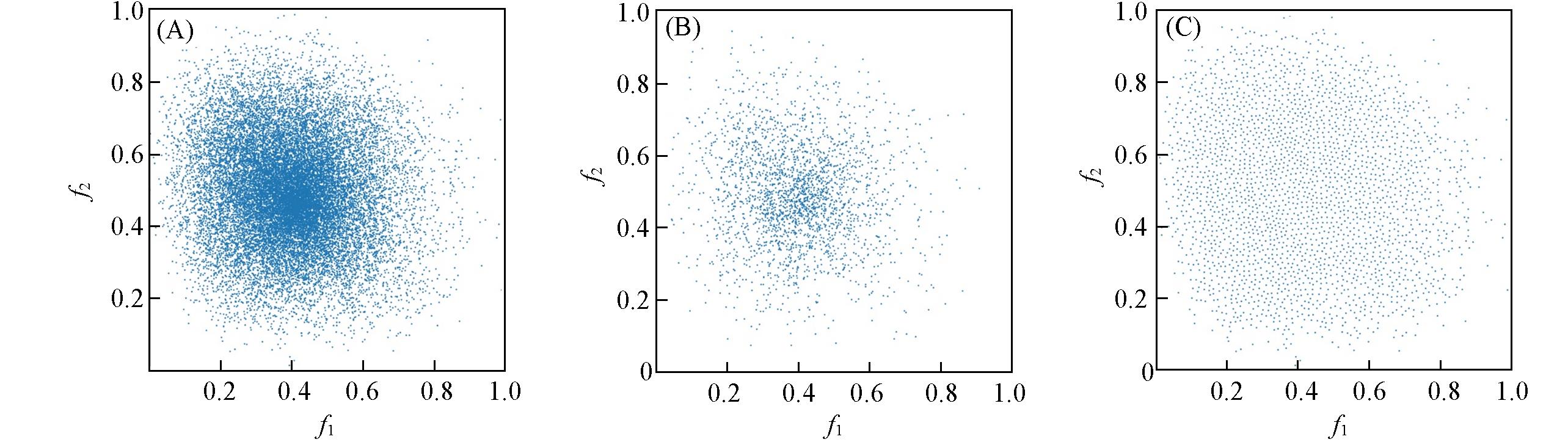
Fig.1 Feature distribution(2D) maps of the methane?based C—H bond dataset(A) All 21600 samples; (B) random selected 2431 samples; (C) KS algorithm selected subset with 2431 samples that shows P=50%.
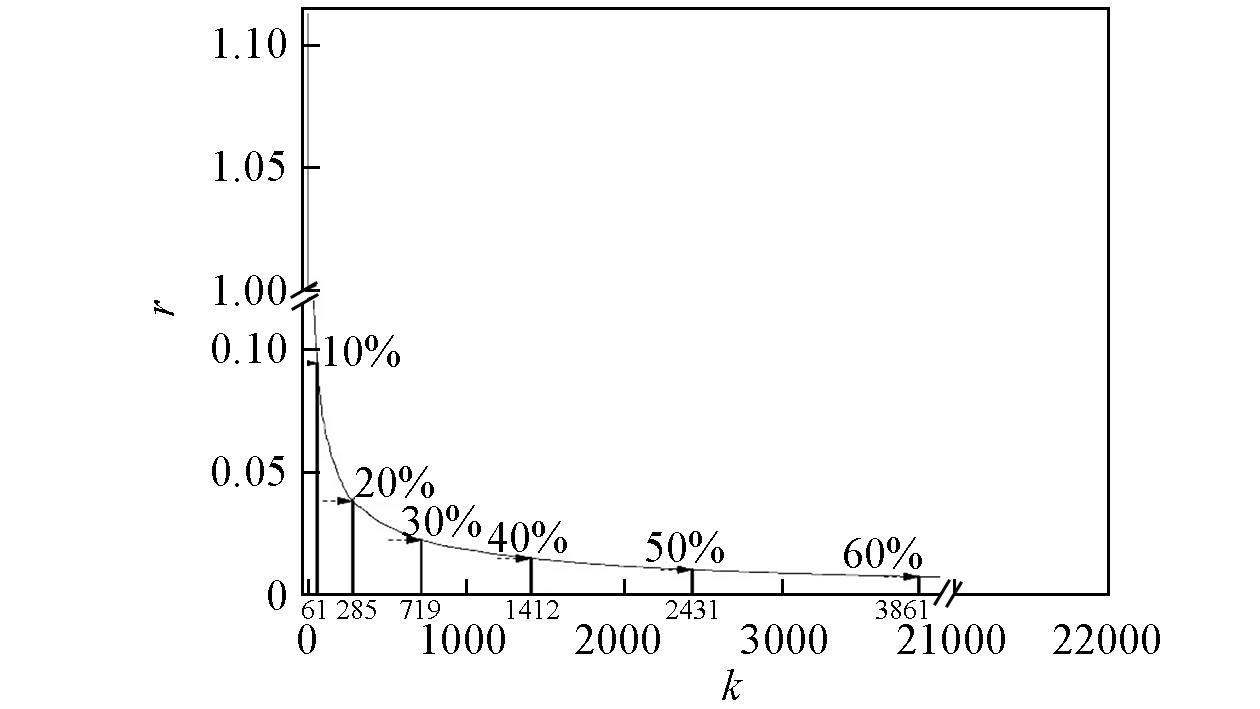
Fig.2 KS sampling distance(r) for methane?based C—H bond dataset as a function of sampling number(k)
| Data | bp50 b /℃ | d4052 c /(g·mL-1) | Total d (%) |
|---|---|---|---|
| Min | 197 | 0.7818 | 13.0 |
| Max | 293 | 0.8728 | 47.0 |
| Average | 259 | 0.8446 | 30.9 |
| Nos. | 389 | 385 | 392 |
Table 1 Dataset statistics of three diesel fuel properties a
| Data | bp50 b /℃ | d4052 c /(g·mL-1) | Total d (%) |
|---|---|---|---|
| Min | 197 | 0.7818 | 13.0 |
| Max | 293 | 0.8728 | 47.0 |
| Average | 259 | 0.8446 | 30.9 |
| Nos. | 389 | 385 | 392 |
| 20% a | 50% | 80% | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Property | bp50 b | d4052 c | Total d | bp50 | d4052 | Total | bp50 | d4052 | Total |
| Sample number for calibration e | 78 | 79 | 78 | 194 | 198 | 196 | 311 | 316 | 314 |
| Sample number for prediction f | 311 | 316 | 314 | 195 | 197 | 196 | 78 | 79 | 78 |
| F?value g | 1.17 | 1.17 | 1.17 | 1.10 | 1.10 | 1.10 | 1.08 | 1.08 | 1.08 |
| PKSh | 52.9% | 51.6% | 51.8% | 78.1% | 77.6% | 77.5% | 93.8% | 93.6% | 93.5% |
| R2KSi | 0.942 | 0.992 | 0.987 | 0.964 | 0.996 | 0.989 | 0.981 | 0.997 | 0.992 |
| Psequentialh | 48.5% | 46.5% | 46.5% | 74.4% | 75.2% | 73.8% | 92.7% | 92.8% | 91.7% |
| R | 0.953 | 0.992 | 0.986 | 0.972 | 0.995 | 0.988 | 0.986 | 0.996 | 0.990 |
| Prandom?Ah | 48.2% | 44.4% | 46.6% | 73.1% | 73.8% | 73.4% | 92.2% | 92.3% | 91.5% |
| R | 0.951 | 0.991 | 0.980 | 0.956 | 0.995 | 0.987 | 0.975 | 0.997 | 0.989 |
| Prandom?Bh | 47.2% | 46.3% | 44.9% | 72.6% | 74.1% | 72.6% | 91.4% | 91.8% | 91.5% |
| R | 0.952 | 0.988 | 0.979 | 0.961 | 0.995 | 0.986 | 0.968 | 0.997 | 0.988 |
| Prandom?Ch | 46.7% | 44.9% | 48.2% | 46.0% | 73.7% | 74.1% | 73.8% | 91.9% | 91.6% |
| R | 0.945 | 0.993 | 0.989 | 0.969 | 0.995 | 0.987 | 0.978 | 0.995 | 0.989 |
Table 2 Performance tests of different slicing KS sampling strategies
| 20% a | 50% | 80% | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Property | bp50 b | d4052 c | Total d | bp50 | d4052 | Total | bp50 | d4052 | Total |
| Sample number for calibration e | 78 | 79 | 78 | 194 | 198 | 196 | 311 | 316 | 314 |
| Sample number for prediction f | 311 | 316 | 314 | 195 | 197 | 196 | 78 | 79 | 78 |
| F?value g | 1.17 | 1.17 | 1.17 | 1.10 | 1.10 | 1.10 | 1.08 | 1.08 | 1.08 |
| PKSh | 52.9% | 51.6% | 51.8% | 78.1% | 77.6% | 77.5% | 93.8% | 93.6% | 93.5% |
| R2KSi | 0.942 | 0.992 | 0.987 | 0.964 | 0.996 | 0.989 | 0.981 | 0.997 | 0.992 |
| Psequentialh | 48.5% | 46.5% | 46.5% | 74.4% | 75.2% | 73.8% | 92.7% | 92.8% | 91.7% |
| R | 0.953 | 0.992 | 0.986 | 0.972 | 0.995 | 0.988 | 0.986 | 0.996 | 0.990 |
| Prandom?Ah | 48.2% | 44.4% | 46.6% | 73.1% | 73.8% | 73.4% | 92.2% | 92.3% | 91.5% |
| R | 0.951 | 0.991 | 0.980 | 0.956 | 0.995 | 0.987 | 0.975 | 0.997 | 0.989 |
| Prandom?Bh | 47.2% | 46.3% | 44.9% | 72.6% | 74.1% | 72.6% | 91.4% | 91.8% | 91.5% |
| R | 0.952 | 0.988 | 0.979 | 0.961 | 0.995 | 0.986 | 0.968 | 0.997 | 0.988 |
| Prandom?Ch | 46.7% | 44.9% | 48.2% | 46.0% | 73.7% | 74.1% | 73.8% | 91.9% | 91.6% |
| R | 0.945 | 0.993 | 0.989 | 0.969 | 0.995 | 0.987 | 0.978 | 0.995 | 0.989 |
| 1 | Huang B., von Lilienfeld O. A., Chem. Rev., 2021, 121, 10001—10036 |
| 2 | Kennard R. W., Stone L. A., Technometrics, 1969, 11, 137—148 |
| 3 | Rajer⁃Kanduč K., Zupan J., Majcen N., Chemometr. Intell. Lab. Syst., 2003, 65, 221—229 |
| 4 | Wu W., Walczak B., Massart D. L., Heuerding S., Erni F., Last I. R., Prebble K. A., Chemometr. Intell. Lab. Syst., 1996, 33, 35—46 |
| 5 | Henle J. J., Zahrt A. F., Rose B. T., Darrow W. T., Wang Y., Denmark S. E., J. Am. Chem. Soc., 2020, 142, 11578—11592 |
| 6 | Liu J., Sun S., Tan Z., Liu Y., Spectrochim. Acta A: Mol. Biomol., 2020, 242, 118718 |
| 7 | Sun J., Wu J., Song T., Hu L. H., Shan K. L., Chen G. H., J. Phys. Chem. A, 2014, 118, 9120—9131 |
| 8 | Rodrigues A. D. P., de Gois J. S., Costa M. A. J. L., da Silva C. S., Xavier V. L., Luna A. S., Chemometr. Intell. Lab. Syst., 2020, 206, 104168 |
| 9 | Saptoro A., Tadé M. O., Vuthaluru H. B., Chem. Prod. Process. Model., 2012, 7, 13 |
| 10 | Galvão R. K. H., Araujo M. C. U., José G. E., Pontes M. J. C., Silva E. C., Saldanha T. C. B., Talanta, 2005, 67, 736—740 |
| 11 | Chen D., Cai W., Shao X., Chemometr. Intell. Lab. Syst., 2007, 87, 312—318 |
| 12 | Gani W., Limam M., J. Stat. Comput. Simul., 2016, 86, 135—148 |
| 13 | Gao T., Hu L., Jia Z., Xia T., Fang C., Li H., Hu L., Lu Y., Li H., Cluster Comput., 2019, 22, 3069—3078 |
| 14 | Li W., Fang C., Liu J., Cui J., Li H., Gao T., Li H., Hu L., Lu Y., J. Chemom., 2019, 33, e3109 |
| 15 | Li T., Fong S., Wu Y., Tallón⁃Ballesteros A. J., Kennard⁃Stone Balance Algorithm for Time⁃series Big Data Stream Mining, ICDMW, 2020, 851—858 |
| 16 | Cook R. L., ACM Trans. Graph., 1986, 5, 51—72 |
| 17 | Bridson R., Fast Poisson Disk Sampling in Arbitrary Dimensions, ACM SIGGRAPH 2007 Sketches, 2007, 22 |
| 18 | Joseph V. R., Vakayil A., Technometrics, 2022, 64, 166—176 |
| 19 | Dong Y., Xiang B., Du D., J. Chem. Inf. Model., 2017, 57, 1055—1067 |
| 20 | Bowden G. J., Maier H. R., Dandy G. C., Water Resour., 2002, 38, 2⁃1⁃2⁃11 |
| 21 | Atkinson A. C., Chemometr. Intell. Lab. Syst., 1995, 28, 35—47 |
| 22 | Clark R. D., J. Chem. Inf. Comp. Sci., 1997, 37, 1181—1188 |
| 23 | Chen W. R., Yun Y. H., Wen M., Lu H. M., Zhang Z. M., Liang Y. Z., Anal. Methods, 2016, 8, 7225—7231 |
| 24 | Sander J., Ester M., Kriegel H. P., Xu X., Data Min. Knowl. Discov., 1998, 2, 169—194 |
| 25 | Smith J. S., Isayev O., Roitberg A. E., Chem. Sci., 2017, 8, 3192—3203 |
| 26 | Shang B., Apley D. W., J. Qual. Technol., 2021, 53, 173—196 |
| 27 | Diesel Fuel Data Sets, http://www.eigenvector.com/data/SWRI/index.html |
| 28 | Haaland D. M., Thomas E. V., Anal. Chem., 1988, 60, 1193—1202 |
| 29 | Mountrakis G., Xi B., ISPRS J. Photogramm. Remote Sens., 2013, 78, 129—147 |
| [1] | 张咪, 田亚锋, 高克利, 侯华, 王宝山. 三氟甲基磺酰氟绝缘介质理化特性的分子动力学模拟[J]. 高等学校化学学报, 2022, 43(11): 20220424. |
| [2] | 刘洋, 李旺昌, 张竹霞, 王芳, 杨文静, 郭臻, 崔鹏. Sc3C2@C80与[12]CPP纳米环之间非共价相互作用的理论研究[J]. 高等学校化学学报, 2022, 43(11): 20220457. |
| [3] | 王思佳 侯璐 李成龙 李文翠 陆安慧. 空腔型纳米炭的制备与应用[J]. 高等学校化学学报, 0, (): 20220637. |
| [4] | 王园月, 安梭梭, 郑旭明, 赵彦英. 5-巯基-1, 3, 4-噻二唑-2-硫酮微溶剂团簇的光谱和理论计算研究[J]. 高等学校化学学报, 2022, 43(10): 20220354. |
| [5] | 张伶育, 张继龙, 曲泽星. RDX分子内振动能量重分配的动力学研究[J]. 高等学校化学学报, 2022, 43(10): 20220393. |
| [6] | 沈琦 陈海瑶 高登辉 赵 熹 那日松 刘佳 黄旭日. 天然产物法卡林二醇与人类 GABAA 受体的相互作用机制研究[J]. 高等学校化学学报, 0, (): 0. |
| [7] | 陈少臣 程敏 王诗慧 吴金奎 罗磊 薛小雨 吉旭 张长春 周利. 预测金属有机骨架的甲烷和氢气输送能力的迁移学习建模[J]. 高等学校化学学报, 0, (): 20220459. |
| [8] | 彭辛哲, 葛娇阳, 王访丽, 余国静, 冉雪芹, 周栋, 杨磊, 解令海. 一种基于苯并噻吩平面格的张力与重组能的理论研究[J]. 高等学校化学学报, 0, (): 20220313. |
| [9] | 郭程, 张威, 唐云. 有序介孔材料: 历史、 现状与发展趋势[J]. 高等学校化学学报, 2022, 43(8): 20220167. |
| [10] | 汤乔伟 蔡小青 李江 诸颖 王丽华 田阳 樊春海 胡钧. 同步辐射X射线成像技术在脑成像研究中的应用[J]. 高等学校化学学报, 0, (): 20220379. |
| [11] | 杨丹, 刘旭, 戴翼虎, 祝艳, 杨艳辉. 金团簇电催化二氧化碳还原反应的研究进展[J]. 高等学校化学学报, 2022, 43(7): 20220198. |
| [12] | 戴卫, 侯华, 王宝山. 七氟异丁腈负离子结构与反应活性的理论研究[J]. 高等学校化学学报, 2022, 43(6): 20220044. |
| [13] | 施耐克, 张娅, SANSON Andrea, 王蕾, 陈骏. Zn(NCN)单轴的负热膨胀性及机理研究[J]. 高等学校化学学报, 2022, 43(6): 20220124. |
| [14] | 任娜娜, 薛洁, 王治钒, 姚晓霞, 王繁. 热力学数据对1, 3-丁二烯燃烧特性的影响[J]. 高等学校化学学报, 2022, 43(6): 20220151. |
| [15] | 高志伟, 李军委, 史赛, 付强, 贾钧儒, 安海龙. 基于分子动力学模拟的TRPM8通道门控特性分析[J]. 高等学校化学学报, 2022, 43(6): 20220080. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||