Viruses.STRING: A Virus-Host Protein-Protein Interaction Database
by
 , ,
, ,
Helen Victoria Cook
1 ,
,
Nadezhda Tsankova Doncheva
1,2,
Damian Szklarczyk
3,
Christian Von Mering
3 and
Lars Juhl Jensen
1,* 1
Novo Nordisk Foundation Center for Protein Research, University of Copenhagen, DK-2200 Copenhagen N, Danmark
2
Center for Non-Coding RNA in Technology and Health, University of Copenhagen, 1870 Frederiksberg C, Danmark
3
Swiss Institute of Bioinformatics, University of Zurich, 8006 Zurich, Switzerland
*
Author to whom correspondence should be addressed.
Viruses 2018, 10(10), 519; https://doi.org/10.3390/v10100519
Submission received: 3 September 2018
/
Revised: 19 September 2018
/
Accepted: 20 September 2018
/
Published: 23 September 2018
Abstract
:As viruses continue to pose risks to global health, having a better understanding of virus–host protein–protein interactions aids in the development of treatments and vaccines. Here, we introduce Viruses.STRING, a protein–protein interaction database specifically catering to virus–virus and virus–host interactions. This database combines evidence from experimental and text-mining channels to provide combined probabilities for interactions between viral and host proteins. The database contains 177,425 interactions between 239 viruses and 319 hosts. The database is publicly available at viruses.string-db.org, and the interaction data can also be accessed through the latest version of the Cytoscape STRING app.
1. Introduction
Viruses are well known as global threats to human and animal welfare. Viral diseases such as hepatitis caused by Hepatitis C virus (HCV) and cervical cancer caused by Human papillomavirus (HPV) each cause more than a quarter of a million deaths worldwide each year [1]. Outbreaks also present an economic burden—the 2014 Ebola virus outbreak cost 2.2 billion USD to contain [2], and the annual response to Influenza virus costs five times this amount in medical expenses in the US alone [3]. Climate change and changing land use patterns are causing humans and livestock to be exposed to novel viruses for which there are currently no vaccines or antiviral drugs [4]. This trend will continue as the habitats of vectors that carry arboviruses expand [5], and as humans continue to come into contact with wildlife, creating opportunities for zoonosis [6].
As obligate intracellular parasites, viruses act as metabolic engineers of the cells they infect as they commandeer the cell’s protein synthesis mechanisms to replicate [7]. Thus, it is important to study their interactions with host cells in order to understand their biology, especially how their disruption of the host protein–protein interaction (PPI) network causes disease [8]. Antiviral drugs have been highly effective at preventing the progression of HIV infection to AIDS [9]; however, the effectiveness of antiviral drugs can decrease over time due to the development of drug resistant viral strains [10,11,12,13]. A more complete understanding of the host–virus protein–protein interaction network provides more potential viral drug targets, and also enables alternative strategies such as targeting host proteins to attenuate viral infection [14]. When available, vaccines are very effective at preventing diseases caused by viruses [15]; however, vaccines are not available for all viruses, including HIV-1 and HCV, and a universal Influenza vaccine is still elusive [16]. The development of modern vaccines such as subunit vaccines, which can be administered to immunocompromized patients, and which eliminate the chance that the vaccine could revert to an infectious virus [17], also hinges on understanding the protein–protein interactions between viruses and their hosts.
Novel protein–protein interaction information is disseminated primarily in the scientific literature, but it is not always organized in ways that make it easy to find, access, or extract. Databases such as VirusMentha [18] and HPIDB [19] make strong efforts to organize virus–virus and virus–host PPIs into databases, where this information is available in an easily parsable format. However, with the volume of the biomedical literature growing exponentially at 4% per year [20], it is not feasible for human curators to thoroughly review all new publications to add any new evidence to curated databases [21]. Automated text-mining methods are thus required to get a comprehensive picture of what is already known about the viruses we study.
We have expanded the popular database STRING [22] to include intra-virus and virus–host PPIs. The STRING database has been in constant development for 15 years, and the current version includes protein interaction data for over 2000 species; however, all of the interactions are exclusively intra-species. In this work, for the first time, we include cross species interactions into the STRING database. The PPIs reported by STRING represent functional associations between proteins. These interactions are not limited to physical interactions, and may also include interactions such as transcription factor binding, or the interaction may represent the fact that the associated proteins appear in the same biological pathway. In this paper, the terms “interaction” and “PPI” are used to refer to functional associations. STRING combines many different sources (channels) of information to give a confidence score that measures the probability that the interaction is true. In a similar fashion, we provide virus-related probabilistic interaction networks derived from text mining and experiment channels.
2. Materials and Methods
2.1. Text Mining Evidence
Text mining for virus species and proteins was conducted using the dictionary-based software described in [23], the same tool that is used for the STRING text mining pipeline. The dictionary for virus species was constructed from NCBI Taxonomy [24], with additional synonyms taken from Disease Ontology [25] and the ninth ICTV report on virus taxonomy [26] to give 173,767 names for 150,885 virus taxa. The virus protein dictionary was constructed from the 397 reference proteomes that were present in UniProt [27] on 31 August 2015. All virus protein names and aliases were expanded following a set of rules to generate variants. This gave 16,580 proteins with 112,013 names. This dictionary was evaluated against a benchmark corpus of 300 abstracts that were annotated by domain experts [28]. The host species and protein dictionaries were identical to those used during the text mining for STRING 10.5 [22]. The text mining was conducted over a corpus that contained the more than 26 million abstracts in PubMed [20], and more than 2.2 million full text articles. The text mining software tags locations at which a protein has been referred to by any of the names that represent it, and then it calculates co-occurrence scores for pairs of proteins. The co-occurrence scores are normalized to account for the fact that some proteins are mentioned very often [29]. The interactions found by this method represent functional associations between the identified proteins.
2.2. Experimental Evidence
Experimental data for virus–virus and virus–host PPIs was imported from BioGrid [30], MintAct [31], DIP [32], HPIDB [19] and VirusMentha [18]. These virus–host interactions were scored and then benchmarked against a gold standard set derived from the Kyoto Encyclopedia of Genes and Genomes, (KEGG). This creates a mapping between the number of interacitons mentioned in a study and the probability that they are true interactions according to the benchmark set [33]. The interactions found by this method represent physical interactions.
2.3. Transfer Evidence
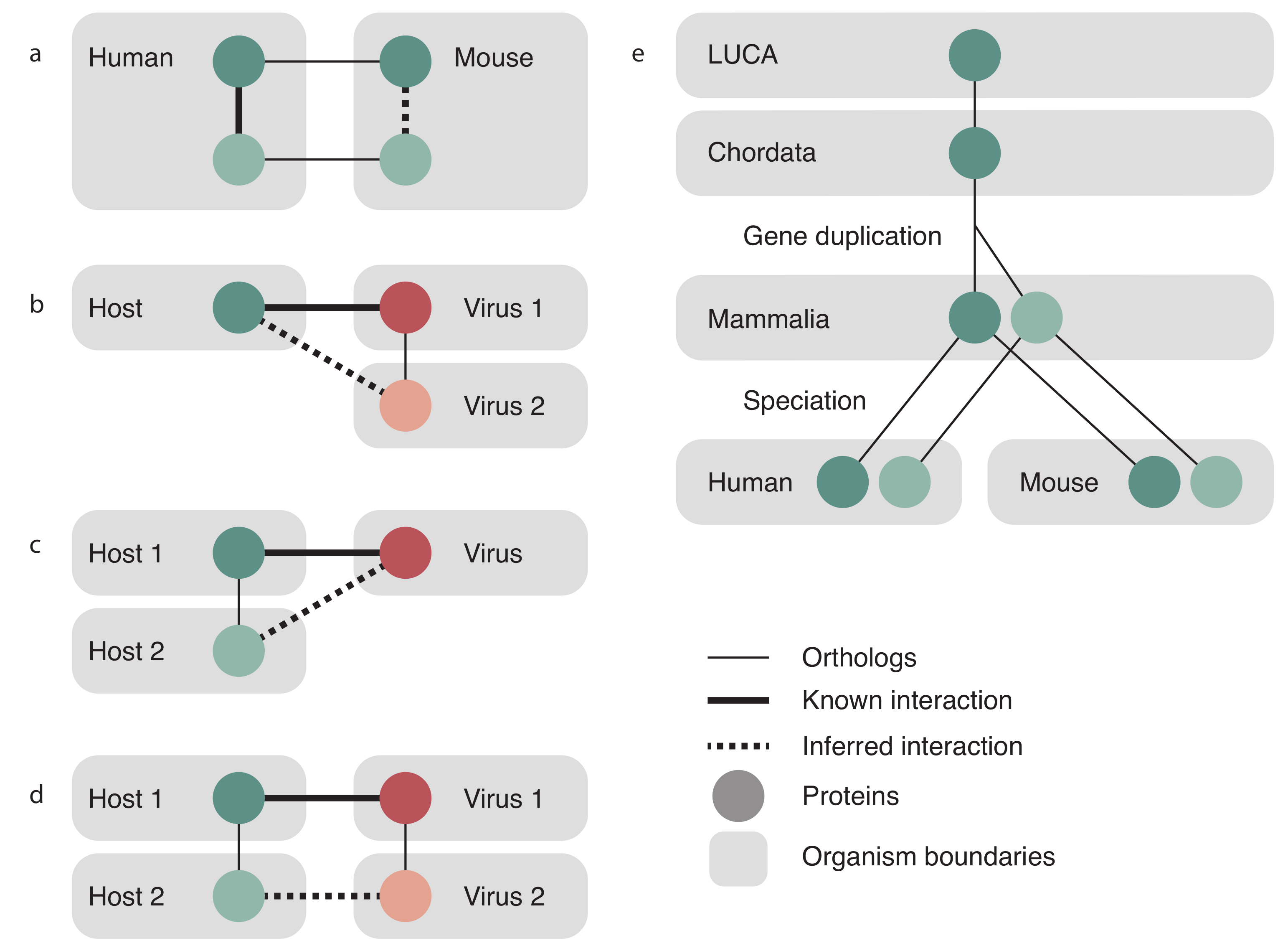
Orthologous relationships were used to transfer interactions following the same protocol that STRING uses, which is briefly described here and fully described in [29]. Both virus and host orthology relations were taken from EggNOG 4.5 [34]. STRING transfers an interaction between two proteins of the same species to two orthologous proteins in another species as is shown in Figure 1a, and exactly the same was done to also transfer virus–virus PPIs. For transfer of a host–virus PPI, three cases are possible and are illustrated in Figure 1b–d. The known interaction between a virus protein and host protein could be transferred to an orthologous virus protein in a different virus species (panel b), to an orthologous host protein in a different host (panel c), or both cases simultaneously, to both a new virus and a new host (panel d). Transfer is made only between viruses and the hosts they are known to infect; we do not predict new host–virus pairs based on orthology.
The score assigned to the transfer of evidence is a scaled fraction of the score for the original interaction, proportional to how distant the recipient species is. Distance here is calculated as a self normalized bit score, i.e., the bit score of the alignment of the pair of proteins divided by the bit score of the self-alignment of the shorter of the two proteins. Paralogs are considered to be orthologs for the purposes of calculating the score at levels lower than the gene duplication, but at levels higher than the gene duplication, the score is discounted. For virus–virus transfer, the paralog discount is calculated as the reciprocal of the product of the number of proteins of that species in the donor and target orthology groups. For the case of transferring a virus–host PPI, the paralog discount is calculated as the reciprocal of the product of the number of host proteins in the host orthology group and the number of viral proteins in the viral orthology group.
Figure 1e shows three orthology levels (Last universal common ancestor (LUCA), Chordata, Mammalia) and illustrates a gene that has duplicated after Chordata but prior to the last common ancestor of all mammals. Furthermore, there has been a speciation event after Mammalia, separating humans and mice into separate species. At the level of Mammalia, these two proteins are placed in different orthology groups, so any interactions that occur with the darker protein will not be transferred to interaction evidence for the lighter protein. However, at the level of Chordata, the light and dark proteins are in the same orthology group and so will both contribute their confidence to the resulting interaction. The contribution of these two proteins will be penalized since they are paralogs at a lower level. Although it is illustrated here for cellular organisms, this process is also applied to transfers involving viral orthology groups. The final transfer scores are then benchmarked the same way as the scores for the other channels.
3. Results
We were able to identify 177,425 protein–protein interactions for 239 viruses. Seventy-seven of these are human viruses, and the remainder infect a total of 318 other hosts. These interactions include more hosts than viruses since many viruses, such as arboviruses, infect multiple hosts. The median number of proteins coded for by these viruses is nine, with 24 viruses coding for more than 100 proteins, and 74 viruses coding for less than nine proteins. The majority of all types of interactions are between viruses and their hosts (as opposed to being intra-virus interactions), due to viral genomes encoding many fewer proteins than their host genomes and thus having fewer potential interactions. In this and the subsequent analysis, interactions are counted per channel, disregarding their scores. Excluding orthology transfer, 89% of the interactions are derived from text mining evidence, and the remaining untransferred evidence comes from curated experimental databases. For 154 viruses, representing 19.8% of all evidence in the database, only text mining evidence is present. This means that, although the interaction has not been curated into databases, we have found a protein from this virus mentioned together in the literature with either other proteins from this virus, or a protein from a host that this virus infects. For 77 viruses, representing 77.4% of all evidence, all of the experimental evidence is also supported by text mining evidence. The remaining eight viruses, representing 2.8% of evidence, have more experimental evidence than text mining, and likely represent opportunities to improve the text mining dictionaries. Despite the large efforts of database curators, the vast wealth of information on PPIs is accessible only in the literature. Furthermore, in addition to physical interactions, text mining will also uncover functional associations such as genetic interactions. As such, text mining provides a very important contribution to this database.
The top GO terms that are enriched in the set of 1835 human proteins that interact with any virus protein with a confidence of 0.5 or greater are shown in Table 1. The fact that this list includes terms such as viral process, protein binding and cell surface receptor signaling pathways provides a sanity check that the human protein partners in the found interactions are valid.
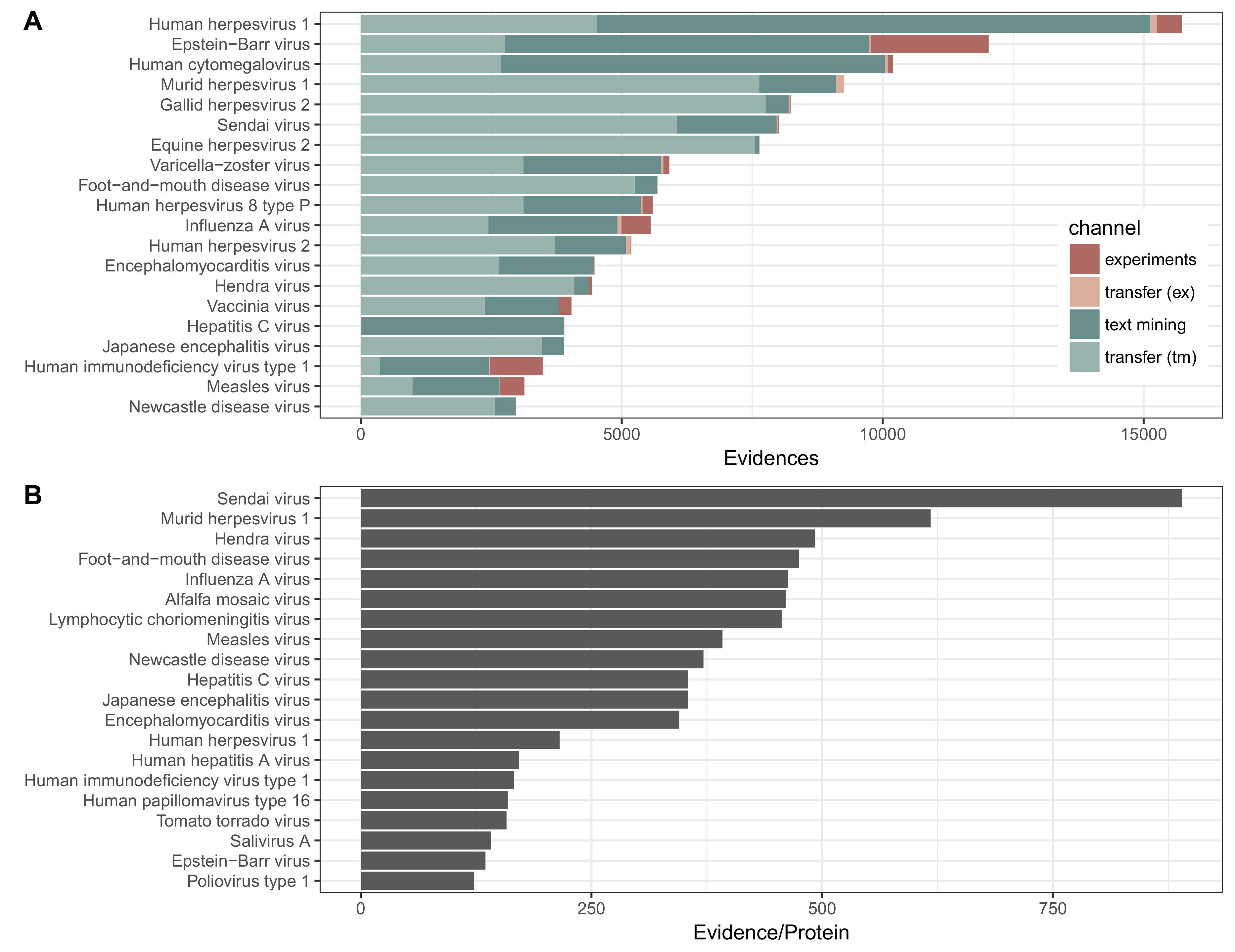
Orthology transfer gives a 2.7 times increase in the number of interactions with text mining results being more readily transferred than experimental results. A handful of well studied viruses (EBV, HIV-1, Influenza A) are the subjects of high-throughput studies that make up the bulk of the interactions in curated experimental databases. These viruses happen to have few close relatives (e.g., HIV, Influenza A), and infect a limited number of hosts (EBV, HIV), which is why their PPIs are not as readily transferred via orthology as interactions found by text mining for other virus proteins. Viruses with many close relatives will have more populated orthology groups, and thus more candidates to transfer evidence from and to. At the level of ssRNA viruses, the maximum size of any orthology group containing an Influenza A protein is 5, and at the level of retrotranscribing viruses the same for any HIV protein is 9. This is in contrast to the viruses that receive the most experimental transfer data, which have 193 (Swinepox virus), 16 (Canine oral papillomavirus) and 30 (Murine cytomegalovirus) proteins in their most populated orthology group. The viruses that receive the most text mining transfer data are Gallid herpesvirus, Murine cytomegalovirus and Equine herpesvirus 2, which at the level of dsDNA have maximum orthology group sizes of 62, 30 and 62 proteins, respectively.
More than half (55%) of pre-transfer evidence relates to human viruses. However, evidence transferred to humans comprises only 26% of all transferred experimental evidence and 18% of all transferred text mining evidence, which implies that the majority of transferred evidence is to a new host (panel c or d in Figure 1). This is due to the fact that gene duplication events occur less frequently in viruses compared to their host organisms [34], and additionally also because the viral taxonomic tree has overall been sequenced much less densely than the tree for cellular organisms, even though the viral tree has been extensively sequenced around specific human viruses [35]. In all, this makes potential transfer partners rarer for transfer between viruses than between hosts.
The distribution of interactions for the 20 viruses with the most interactions is shown in Figure 2. The viruses with the largest number of intra-virus interactions include the relatively large double-stranded DNA Herpesviruses and well studied RNA viruses including Influenza and HIV. The same viruses also show the highest proportion of interactions from the experimental channel. An example of two viruses that share interactions based on orthology transfer are human and murine cytomegalovirus (HCMV and MCMV, respectively). The majority of the evidence for HCMV is direct evidence, and conversely, the majority of evidence for MCMV is evidence from transfer, which has come from interactions with HCMV.
The virus–virus and virus–host PPI networks are made publicly accessible as a resource which is available at viruses.string-db.org. The data can be browsed online, downloaded from the website, or accessed through the REST API. Furthermore, the data can also be imported into Cytoscape directly [36] using the STRING Cytoscape app [22].
3.1. Utility and Examples
3.1.1. Web Interface
The Viruses.STRING website enables three variants of protein search: for the complete set of proteins in a virus, for a single protein in a virus, or for multiple proteins in a virus. Since most viral genomes encode only a small number of proteins (the viruses included in the database have a median of nine proteins), they can easily be displayed in a network together with the most strongly interacting host proteins.
The network interface has a similar appearance to STRING, but the visual styling has been modified to be more flat. The nodes in the network are coloured only based on their origin, either as viral proteins (brick red) or as host proteins (blue-green slate).
As is possible on the main STRING site, the viruses.STRING web interface provides more information about each protein, which is accessed by clicking on the node. Similarly, clicking on any edge displays a summary of the information that contributes to that interaction, and provides links to further inspect the evidence from each channel. Text mining evidence shows highlighted phrases from relevant publications, whereas experiments’ evidence shows the specific database and publication from which it was obtained.
3.1.2. Example: HIV-1
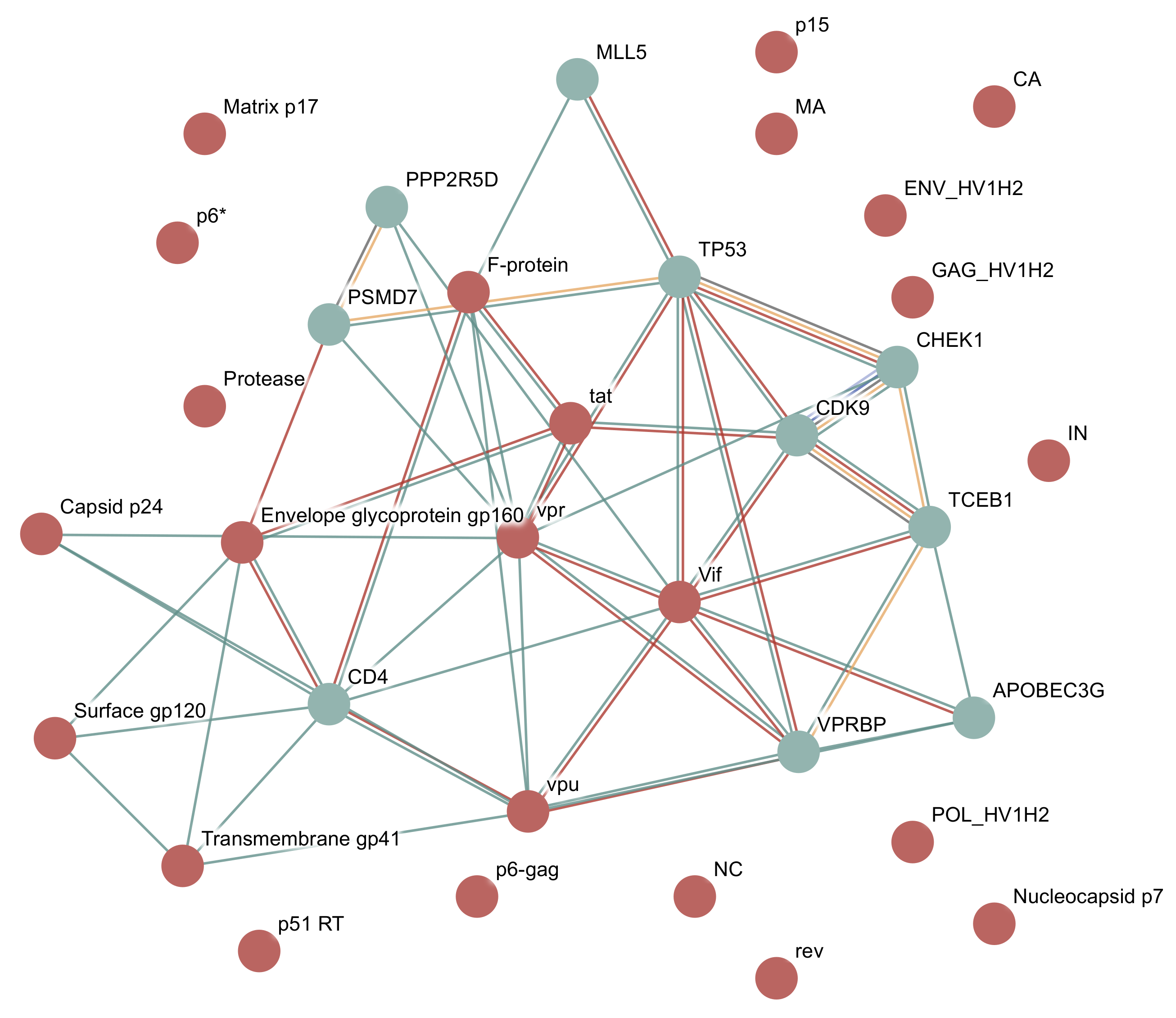
In this example, we will query for all proteins present in Human Immunodeficiency virus type 1. If the host field on the search page is left empty, the server will auto detect the host species with the most interactions with the specified virus, in this case, humans. An interaction network will then be shown for the virus proteins and for the 10 human proteins that have the highest interaction scores with these virus proteins, as shown in Figure 3. By default, only interaction scores with a confidence score greater than 0.4 will be shown, the same as the main STRING site. This confidence can be changed using the interface.
HIV-1 consists of 19 proteins, 10 of which are cleaved from three polyproteins. The polyproteins are translated as a single long protein, and then the long polyprotein is cleaved by the viral protease into functional protein units. The database includes 24 proteins as it includes some partial cleavage products, such as both gp160 and gp120, which is cleaved from gp160.
3.1.3. Cytoscape STRING App
The Viruses.STRING interaction data can also be queried from the Cytoscape STRING app. This requires version 3.6 of Cytoscape or greater and version 1.4 of the STRING app or greater, which is available for free in the Cytoscape app store (http://apps.cytoscape.org/apps/stringapp).
The STRING app allows for more flexible queries than the Viruses.STRING website, such as choosing specific additional host proteins to be included in the network, and displaying multiple hosts and multiple viruses in the same network. In addition to the Viruses.STRING interaction data, the app automatically fetches node and edge information, which can be used for further analysis. The former includes the protein sequence for host and virus nodes, subcellular localization data from the COMPARTMENTS database for human proteins, and tissue expression data taken from the TISSUES database for human, mouse, rat and pig proteins [37]. Edge information includes the combined confidence score from all channels as a probability that the interaction is true.
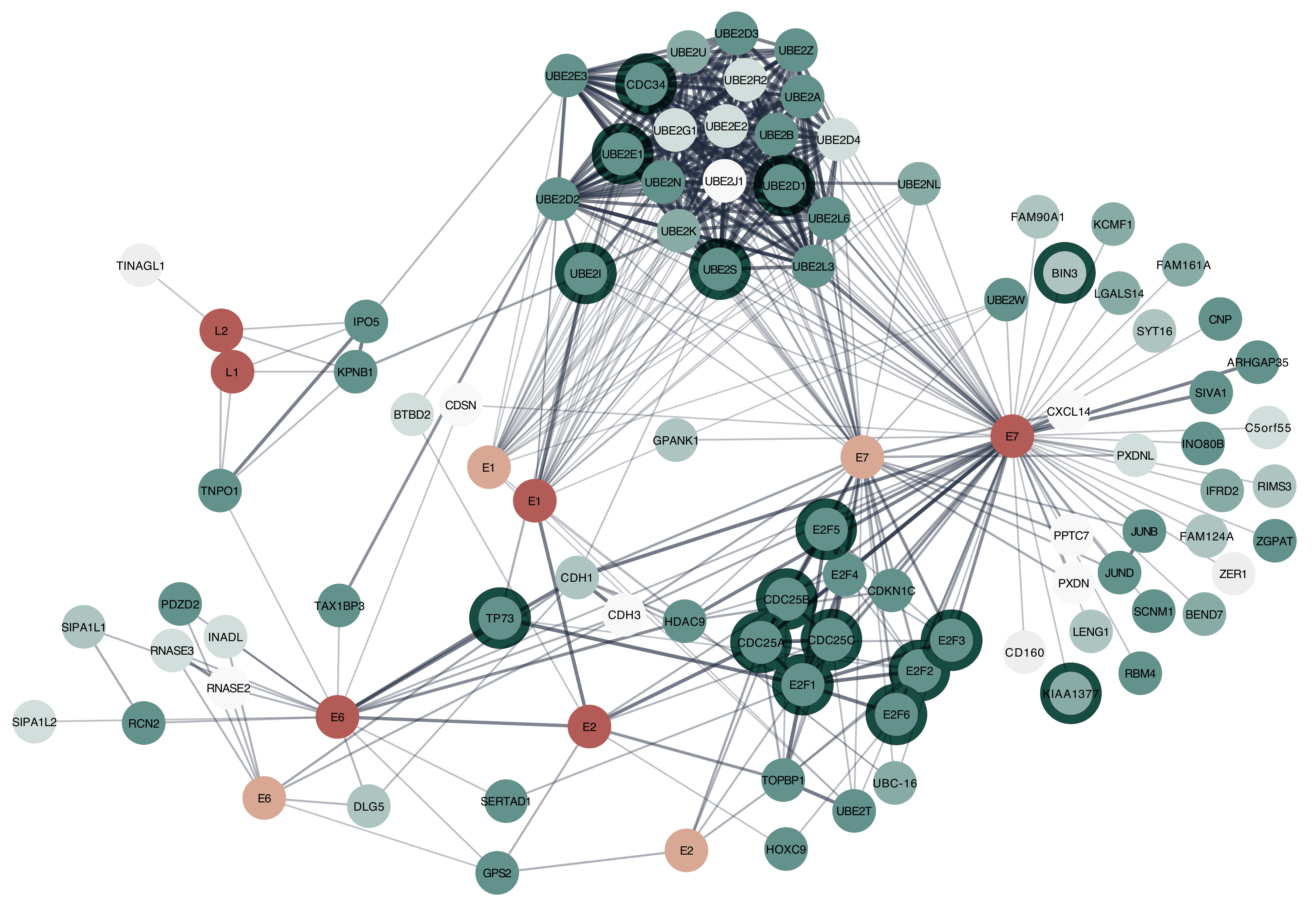
Figure 4 illustrates the combined interaction network for HPV 16 and HPV 1a proteins with the top 50 human proteins they interact with ranked by combined interaction score. Since HPV is known to disrupt the cell cycle [38], many of the proteins that interact with E6 and E7 are associated with the nucleus and the GO term for cell cycle. A tutorial to reproduce this network in Cytoscape is available at http://jensenlab.org/training/stringapp/.
4. Discussion
The Viruses.STRING database provides a single unified interface to virus–virus and host–virus PPIs from text mining and many experimental sources. With a simple web interface, the database can easily be queried to immediately retrieve the interaction partners for a protein of interest, and the corresponding evidence can be inspected. The Cytoscape STRINGapp, although it requires software to be installed, provides more versatility than the website, and can handle much larger networks—up to at least as large as the human interaction network. This provides the researcher with more opportunities to answer interesting biological questions about viruses and their hosts. For example, the virus–host network could potentially be used to select candidate host proteins as drug targets to inhibit viral infection, possibly by repurposing existing drugs. This approach would likely generate less viral resistance to the drug since the host protein is being targeted, instead of a viral protein that can mutate easily [14,39].
As this is the first iteration of Viruses.STRING, there are currently some limitations to the data. The virus data is provided only at the species level, with the exception of Dengue types 1–4, even though there is some evidence that different influenza strains show differential protein interactions [40]. This fine grained resolution will be added in a future version for those viruses where sufficient data is available, such as Influenza A.
Text mining reveals many more virus–host PPIs in the literature than have been collected into databases. The text mining gives good precision and recall for virus species, and good precision for virus proteins [28]. However, the method performs less well for virus proteins in terms of recall, meaning that many interactions may still be missed by this approach [28].
Both text mining and experimental evidence is transferred via orthology using the system designed for STRING for cellular organisms. Since viruses have a much higher mutation rate than cellular organisms, this transfer method may over-discount contributions from viruses that appear to be distant relatives but that have diverged relatively recently. This will result in lower transfer scores for viruses than we would see between cellular organisms that have diverged for the same amount of time.
Just as a having a broader view of intra-species PPIs has provided a deeper understanding of cellular function [41], having a similar understanding between pathogens and their hosts will provide new information to combat clinically and economically relevant viral infections and diseases.
Author Contributions
H.V.C. gathered and analyzed the data. N.T.D. integrated viruses into the STRINGapp. D.S., C.v.M., L.J.J. contributed to the design of the study and revised the manuscript. All authors read and approved the final manuscript.
Funding
This work was supported by the Novo Nordisk Foundation (grant NNF14CC0001), and by SIB Swiss Bioinformatics Institute and the University of Zurich. The funding agencies had no role in the design, analysis, interpretation of the data or writing of the manuscript.
Acknowledgments
The authors would like to thank John ‘Scooter’ Morris for his continued work on the Cytoscape STRING app to support these changes. H.C. would like to thank the members of the Von Mering group for their hospitality during the summer over which the bulk of this work was conducted. This work was supported by the Novo Nordisk Foundation (Grant NNF14CC0001) (H.V.C., N.T.D., L.J.J.), SIB Swiss Bioinformatics Institute and the University of Zurich (D.S., C.v.M.).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| HCMV | Human cytomegalovirus |
| HIV | Human immunodeficiency virus |
| MCMV | Murine cytomegalovirus |
| PPI | Protein–protein interaction |
References
- WHO. WHO Fact Sheets: Influenza, HCV, HPV; WHO: Geneva, Switzerland, 2014. [Google Scholar]
- Ceters for Disease Control and Prevention, Ebola (Ebola Virus Disease). Cost of the Ebola Epidemic. Available online: https://www.cdc.gov/vhf/ebola/outbreaks/2014-west-africa/cost-of-ebola.html (accessed on 7 July 2017).
- Molinari, N.A.M.; Ortega-Sanchez, I.R.; Messonnier, M.L.; Thompson, W.W.; Wortley, P.M.; Weintraub, E.; Bridges, C.B. The annual impact of seasonal influenza in the US: Measuring disease burden and costs. Vaccine 2007, 25, 5086–5096. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mills, J.N.; Gage, K.L.; Khan, A.S. Potential influence of climate change on vector-borne and zoonotic diseases: A review and proposed research plan. Environ. Health Perspect. 2010, 118, 1507–1514. [Google Scholar] [CrossRef] [PubMed]
- Fauci, A.S.; Morens, D.M. Zika Virus in the Americas—Yet Another Arbovirus Threat. N. Engl. J. Med. 2016, 374, 601–604. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.F.; Crameri, G. Emerging zoonotic viral diseases. Rev. Sci. Tech. Off. Int. Epizoot. 2014, 33, 569–581. [Google Scholar] [CrossRef] [Green Version]
- Maynard, N.D.; Gutschow, M.V.; Birch, E.W.; Covert, M.W. The virus as metabolic engineer. Biotechnol. J. 2010, 5, 686–694. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gulbahce, N.; Yan, H.; Dricot, A.; Padi, M.; Byrdsong, D.; Franchi, R.; Lee, D.S.; Rozenblatt-Rosen, O.; Mar, J.C.; Calderwood, M.A.; et al. Viral Perturbations of Host Networks Reflect Disease Etiology. PLoS Comput. Biol. 2012, 8, e1002531. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arts, E.J.; Hazuda, D.J. HIV-1 antiretroviral drug therapy. Cold Spring Harb. Perspect. Med. 2012, 2, a007161. [Google Scholar] [CrossRef] [PubMed]
- Frentz, D.; Boucher, C.A.B.; Van De Vijver, D.A.M.C. Temporal changes in the epidemiology of transmission of drug-resistant HIV-1 across the world. AIDS Rev. 2012, 14, 17–27. [Google Scholar] [PubMed]
- Razonable, R.R. Antiviral drugs for viruses other than human immunodeficiency virus. Mayo Clin. Proc. 2011, 86, 1009–1026. [Google Scholar] [CrossRef] [PubMed]
- Pawlotsky, J.M. Hepatitis C Virus Resistance to Direct-Acting Antiviral Drugs in Interferon-Free Regimens. Gastroenterology 2016, 151, 70–86. [Google Scholar] [CrossRef] [PubMed]
- Piret, J.; Boivin, G. Herpesvirus Resistance to Antiviral Drugs. In Antimicrobial Drug Resistance; Number 18; Academic Press: New York, NY, USA, 2009; pp. 171–181. [Google Scholar]
- Murali, T.M.; Dyer, M.D.; Badger, D.; Tyler, B.M.; Katze, M.G. Network-based prediction and analysis of HIV dependency factors. PLoS Comput. Biol. 2011, 7, e1002164. [Google Scholar] [CrossRef] [PubMed]
- Ehreth, J. The global value of vaccination. Vaccine 2003, 21, 596–600. [Google Scholar] [CrossRef]
- Soema, P.C.; Kompier, R.; Amorij, J.P.; Kersten, G.F.A. Current and next generation influenza vaccines: Formulation and production strategies. Eur. J. Pharm. Biopharm. 2015, 94, 251–263. [Google Scholar] [CrossRef] [PubMed]
- Moyle, P.M.; Toth, I. Modern Subunit Vaccines: Development, Components, and Research Opportunities. ChemMedChem 2013, 8, 360–376. [Google Scholar] [CrossRef] [PubMed]
- Calderone, A.; Licata, L.; Cesareni, G. VirusMentha: A new resource for virus–host protein interactions. Nucleic Acids Res. 2014, 43, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Ammari, M.G.; Gresham, C.R.; McCarthy, F.M.; Nanduri, B. HPIDB 2.0: A curated database for host-pathogen interactions. Database 2016, 2016, baw103. [Google Scholar] [CrossRef] [PubMed]
- Lu, Z. PubMed and beyond: A survey of web tools for searching biomedical literature. Database 2011, 2011, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Attwood, T.; Agit, B.; Ellis, L. Longevity of Biological Databases. EMBnet J. 2015, 21, e803. [Google Scholar] [CrossRef]
- Szklarczyk, D.; Morris, J.H.; Cook, H.; Kuhn, M.; Wyder, S.; Simonovic, M.; Santos, A.; Doncheva, N.T.; Roth, A.; Bork, P.; et al. The STRING database in 2017: Quality-controlled protein–protein association networks, made broadly accessible. Nucleic Acids Res. 2016, 45, D362–D368. [Google Scholar] [CrossRef] [PubMed]
- Pafilis, E.; Frankild, S.P.; Fanini, L.; Faulwetter, S.; Pavloudi, C.; Vasileiadou, A.; Arvanitidis, C.; Jensen, L.J. The SPECIES and ORGANISMS Resources for Fast and Accurate Identification of Taxonomic Names in Text. PLoS ONE 2013, 8, 2–7. [Google Scholar] [CrossRef] [PubMed]
- Sayers, E.W.; Barrett, T.; Benson, D.A.; Bryant, S.H.; Canese, K.; Chetvernin, V.; Church, D.M.; DiCuccio, M.; Edgar, R.; Federhen, S.; et al. Database resources of the National Center for Biotechnology Information. Nucleic Acids Res. 2009, 37, D5–D15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kibbe, W.A.; Arze, C.; Felix, V.; Mitraka, E.; Bolton, E.; Fu, G.; Mungall, C.J.; Binder, J.X.; Malone, J.; Vasant, D.; et al. Disease Ontology 2015 update: An expanded and updated database of Human diseases for linking biomedical knowledge through disease data. Nucleic Acids Res. 2015, 43, D1071–D1078. [Google Scholar] [CrossRef] [PubMed]
- King, A.M.; Adams, M.J.; Carstens, E.B.; Lefkowitz, E.J. (Eds.) Virus Taxonomy: Classification and Nomenclature of Viruses: Ninth Report of the International Committee on Taxonomy of Viruses; Elsevier Academic Press: New York, NY, USA, 2012. [Google Scholar]
- The UniProt Consortium. UniProt: A hub for protein information. Nucleic Acids Res. 2014, 43, D204–D212. [Google Scholar] [CrossRef]
- Cook, H.V.; Berzins, R.; Rodriguez, C.L.; Cejuela, J.M.; Jensen, L.J. Creation and evaluation of a dictionary-based tagger for virus species and proteins. In Proceedings of the BioNLP 2017 Workshop, Association for Computational Linguistics, Vancouver, BC, Canada, 4 August 2017; pp. 91–98. [Google Scholar]
- Franceschini, A.; Szklarczyk, D.; Frankild, S.; Kuhn, M.; Simonovic, M.; Roth, A.; Lin, J.; Minguez, P.; Bork, P.; von Mering, C.; et al. STRING v9.1: Protein-protein interaction networks, with increased coverage and integration. Nucleic Acids Res. 2013, 41, D808–D15. [Google Scholar] [CrossRef] [PubMed]
- Chatr-Aryamontri, A.; Breitkreutz, B.J.; Oughtred, R.; Boucher, L.; Heinicke, S.; Chen, D.; Stark, C.; Breitkreutz, A.; Kolas, N.; O’Donnell, L.; et al. The BioGRID interaction database: 2015 update. Nucleic Acids Res. 2015, 43, D470–D478. [Google Scholar] [CrossRef] [PubMed]
- Orchard, S.; Ammari, M.; Aranda, B.; Breuza, L.; Briganti, L.; Broackes-Carter, F.; Campbell, N.H.; Chavali, G.; Chen, C.; Del-Toro, N.; et al. The MIntAct project - IntAct as a common curation platform for 11 molecular interaction databases. Nucleic Acids Res. 2014, 42, 358–363. [Google Scholar] [CrossRef] [PubMed]
- Xenarios, I.; Salwínski, L.; Duan, X.J.; Higney, P.; Kim, S.M.; Eisenberg, D. DIP, the Database of Interacting Proteins: A research tool for studying cellular networks of protein interactions. Nucleic Acids Res. 2002, 30, 303–305. [Google Scholar] [CrossRef] [PubMed]
- von Mering, C.; Jensen, L.J.; Snel, B.; Hooper, S.D.; Krupp, M.; Foglierini, M.; Jouffre, N.; Huynen, M.A.; Bork, P. STRING: Known and predicted protein–protein associations, integrated and transferred across organisms. Nucleic Acids Res. 2005, 33, 433–437. [Google Scholar] [CrossRef] [PubMed]
- Huerta-Cepas, J.; Szklarczyk, D.; Forslund, K.; Cook, H.; Heller, D.; Walter, M.C.; Rattei, T.; Mende, D.R.; Sunagawa, S.; Kuhn, M.; et al. eggNOG 4.5: A hierarchical orthology framework with improved functional annotations for eukaryotic, prokaryotic and viral sequences. Nucleic Acids Res. 2015, 44, 286–293. [Google Scholar] [CrossRef] [PubMed]
- Anthony, S.J.; Epstein, J.H.; Murray, K.A.; Navarrete-Macias, I.; Zambrana-Torrelio, C.; Soloyvov, A.; Ojeda-Flores, R.; Arrigio, N.C.; Islam, A.; Kahn, S.A.; et al. A Strategy to Estimate Unknown Viral Diversity in Mammals. mBio 2013, 4, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Shannon, P.; Markiel, A.; Ozier, O.; Baliga, N.S.; Wang, J.T.; Ramage, D.; Amin, N.; Schwikowski, B.; Ideker, T. Cytoscape: A software environment for integrated models of biomolecular interaction networks. Genome Res. 2003, 13, 2498–2504. [Google Scholar] [CrossRef] [PubMed]
- Palasca, O.; Santos, A.; Stolte, C.; Gorodkin, J.; Jensen, L.J. TISSUES 2.0: An integrative web resource on mammalian tissue expression. Database 2018, 2018, bay003. [Google Scholar] [CrossRef] [PubMed]
- Reinson, T.; Henno, L.; Toots, M.; Ustav, M.; Ustav, M. The cell cycle timing of human papillomavirus DNA replication. PLoS ONE 2015, 10, 1–16. [Google Scholar] [CrossRef] [PubMed]
- De Chassey, B.; Meyniel-Schicklin, L.; Vonderscher, J.; André, P.; Lotteau, V. Virus-host interactomics: New insights and opportunities for antiviral drug discovery. Genome Med. 2014, 6, 115. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Fu, B.; Li, W.; Patil, G.; Liu, L.; Dorf, M.E.; Li, S. Comparative influenza protein interactomes identify the role of plakophilin 2 in virus restriction. Nat. Commun. 2017, 8, 13876. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gaballa, A.; Newton, G.L.; Antelmann, H.; Parsonage, D.; Upton, H.; Rawat, M.; Claiborne, A.; Fahey, R.C.; Helmann, J.D. Biosynthesis and functions of bacillithiol, a major low-molecular-weight thiol in Bacilli. Proc. Natl. Acad. Sci. USA 2010, 107, 6482–6486. [Google Scholar] [CrossRef] [PubMed] [Green Version]
Figure 1.
Orthologous relationship transfer in Viruses.STRING. STRING intra-species interactions are transferred between organisms as shown in (a): an interaction between two proteins in species 1 (solid thick line) is transferred to two orthologous proteins in species 2 (dashed line). Orthologous relationships are indicated by solid thin lines. This relationship is identical to transferring an interaction between two virus proteins of one virus species to two orthologous proteins in another virus species. Cross species interactions are handled as one of three cases—same host to closely related virus (b), the same virus to closely related host (c), or both a new host and new virus at the same time (d). Note that we transfer only to already known virus–host pairs and that we are not predicting new virus–host relationships via orthology transfer; (e) shows the evolutionary history of a gene that underwent a gene duplication event after the last common ancestor of Chordata, but prior to the last common ancestor of mammals. There was subsequently a speciation event that resulted in the duplicated gene being present in both human and mouse. Orthology groups can be read by following the lines up the tree—at the level of Mammalia, the light and dark genes are in separate orthology groups, but at higher levels, they are in the same orthology group.
Figure 1.
Orthologous relationship transfer in Viruses.STRING. STRING intra-species interactions are transferred between organisms as shown in (a): an interaction between two proteins in species 1 (solid thick line) is transferred to two orthologous proteins in species 2 (dashed line). Orthologous relationships are indicated by solid thin lines. This relationship is identical to transferring an interaction between two virus proteins of one virus species to two orthologous proteins in another virus species. Cross species interactions are handled as one of three cases—same host to closely related virus (b), the same virus to closely related host (c), or both a new host and new virus at the same time (d). Note that we transfer only to already known virus–host pairs and that we are not predicting new virus–host relationships via orthology transfer; (e) shows the evolutionary history of a gene that underwent a gene duplication event after the last common ancestor of Chordata, but prior to the last common ancestor of mammals. There was subsequently a speciation event that resulted in the duplicated gene being present in both human and mouse. Orthology groups can be read by following the lines up the tree—at the level of Mammalia, the light and dark genes are in separate orthology groups, but at higher levels, they are in the same orthology group.

Figure 2.
Intra- and intervirus interactions in viruses.STRING by species. (A) distribution of experimental (red) and text mining (green) interactions present in the database, further divided into direct (dark red and dark green) and transferred (light green and pink) evidence. Data is shown for the 20 viruses with the most evidence. Evidence may be between two proteins of one virus species, or between a virus protein and a host protein. Evidence is counted as interaction pairs per channel, such that an interaction that is supported by three channels will be counted as 3 evidences. The sources of evidence that is transferred may originate from experimental (abbreviated ex in the figure) or from text mining (tm) data; (B) amount of evidence normalized by the number of proteins coded for by that virus.
Figure 2.
Intra- and intervirus interactions in viruses.STRING by species. (A) distribution of experimental (red) and text mining (green) interactions present in the database, further divided into direct (dark red and dark green) and transferred (light green and pink) evidence. Data is shown for the 20 viruses with the most evidence. Evidence may be between two proteins of one virus species, or between a virus protein and a host protein. Evidence is counted as interaction pairs per channel, such that an interaction that is supported by three channels will be counted as 3 evidences. The sources of evidence that is transferred may originate from experimental (abbreviated ex in the figure) or from text mining (tm) data; (B) amount of evidence normalized by the number of proteins coded for by that virus.

Figure 3.
HIV-1 and Homo sapiens interaction network in viruses.STRING. HIV-1 and Homo sapiens interaction network downloaded as a vector image from viruses.STRING. The type of interaction is indicated by edge colour—green: text mining, red: experiments. Additional edge types can be found between host proteins, and come from the STRING database—yellow orange: pathway databases, light blue: protein homology, dark blue: gene co-occurrence, black: co-expression, light green: gene neighbourhoods, pink: gene fusions (last two not present in figure).
Figure 3.
HIV-1 and Homo sapiens interaction network in viruses.STRING. HIV-1 and Homo sapiens interaction network downloaded as a vector image from viruses.STRING. The type of interaction is indicated by edge colour—green: text mining, red: experiments. Additional edge types can be found between host proteins, and come from the STRING database—yellow orange: pathway databases, light blue: protein homology, dark blue: gene co-occurrence, black: co-expression, light green: gene neighbourhoods, pink: gene fusions (last two not present in figure).

Figure 4.
HPV and Homo sapiens interaction network in Cytoscape. Proteins from Human Papillomavirus type 16, and HPV type 1a with their human protein interaction partners. Virus proteins are coloured according to their species (dark red: HPV 16, light red: HPV 1a). The human proteins are coloured in shades of green with darker colours showing a stronger association with the nucleus. The dark halos around human proteins are those that are associated with the GO term for cell cycle. The HPV E6 and E7 proteins are known to interfere with the cell cycle. This analysis shows some of the data exploration and visualization flexibility that is easily possible within Cytoscape.
Figure 4.
HPV and Homo sapiens interaction network in Cytoscape. Proteins from Human Papillomavirus type 16, and HPV type 1a with their human protein interaction partners. Virus proteins are coloured according to their species (dark red: HPV 16, light red: HPV 1a). The human proteins are coloured in shades of green with darker colours showing a stronger association with the nucleus. The dark halos around human proteins are those that are associated with the GO term for cell cycle. The HPV E6 and E7 proteins are known to interfere with the cell cycle. This analysis shows some of the data exploration and visualization flexibility that is easily possible within Cytoscape.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Top gene ontology (GO) terms by false discovery rate (FDR) adjusted p-value that are enriched for the human proteins that interact with any virus protein.
Table 1.
Top gene ontology (GO) terms by false discovery rate (FDR) adjusted p-value that are enriched for the human proteins that interact with any virus protein.
| Number of Genes | FDR p-Value | GO Term |
|---|---|---|
| 549 | 2.28E-104 | positive regulation of macromolecule metabolic process |
| 718 | 5.96E-93 | positive regulation of cellular process |
| 452 | 3.02E-91 | cell surface receptor signaling pathway |
| 758 | 7.87E-91 | protein binding |
| 779 | 1.23E-90 | positive regulation of biological process |
| 539 | 1.61E-87 | positive regulation of cellular metabolic process |
| 459 | 3.86E-84 | multi-organism process |
| 277 | 4.56E-82 | innate immune response |
| 468 | 5.27E-82 | carbohydrate derivative binding |
| 595 | 1.99E-81 | response to stress |
| 240 | 2.07E-81 | multi-organism cellular process |
| 254 | 2.4E-81 | regulation of immune response |
| 239 | 2.55E-81 | viral process |
| 583 | 4.17E-81 | regulation of response to stimulus |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Cook, H.V.; Doncheva, N.T.; Szklarczyk, D.; Von Mering, C.; Jensen, L.J. Viruses.STRING: A Virus-Host Protein-Protein Interaction Database. Viruses 2018, 10, 519. https://doi.org/10.3390/v10100519
AMA Style
Cook HV, Doncheva NT, Szklarczyk D, Von Mering C, Jensen LJ. Viruses.STRING: A Virus-Host Protein-Protein Interaction Database. Viruses. 2018; 10(10):519. https://doi.org/10.3390/v10100519
Chicago/Turabian StyleCook, Helen Victoria, Nadezhda Tsankova Doncheva, Damian Szklarczyk, Christian Von Mering, and Lars Juhl Jensen. 2018. "Viruses.STRING: A Virus-Host Protein-Protein Interaction Database" Viruses 10, no. 10: 519. https://doi.org/10.3390/v10100519
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.