
Spatio-Temporal Information Fusion and Filtration for Human Action Recognition
1
College of Information Science and Technology & College of Artificial Intelligence, Nanjing Forestry University, Nanjing 210037, China
2
College of Social Sciences, University of Birmingham, Birmingham B15 2TT, UK
3
School of Computer and Information, Hohai University, Nanjing 211100, China
*
Author to whom correspondence should be addressed.
Symmetry 2023, 15(12), 2177; https://doi.org/10.3390/sym15122177
Submission received: 14 November 2023
/
Revised: 5 December 2023
/
Accepted: 6 December 2023
/
Published: 8 December 2023
(This article belongs to the Special Issue Advances in Computer Vision, Pattern Recognition, Machine Learning and Symmetry)
Abstract
:Human action recognition (HAR) as the most representative human-centred computer vision task is critical in human resource management (HRM), especially in human resource recruitment, performance appraisal, and employee training. Currently, prevailing approaches to human action recognition primarily emphasize either temporal or spatial features while overlooking the intricate interplay between these two dimensions. This oversight leads to less precise and robust action classification within complex human resource recruitment environments. In this paper, we propose a novel human action recognition methodology for human resource recruitment environments, which aims at symmetrically harnessing temporal and spatial information to enhance the performance of human action recognition. Specifically, we compute Depth Motion Maps (DMM) and Depth Temporal Maps (DTM) from depth video sequences as space and time descriptors, respectively. Subsequently, a novel feature fusion technique named Center Boundary Collaborative Canonical Correlation Analysis (CBCCCA) is designed to enhance the fusion of space and time features by collaboratively learning the center and boundary information of feature class space. We then introduce a spatio-temporal information filtration module to remove redundant information introduced by spatio-temporal fusion and retain discriminative details. Finally, a Support Vector Machine (SVM) is employed for human action recognition. Extensive experiments demonstrate that the proposed method has the ability to significantly improve human action recognition performance.
1. Introduction
In the realm of modern human resource management (HRM), precise human action recognition (HAR) has emerged as a fundamental element across several domains. These domains encompass human resource recruitment (HRR) [1], employee performance assessment (EPA) [2], and employee training (ET) [3]. In the context of HRM, it is important to explore effective and efficient HAR methods for recruitment selection, employee performance assessment, and providing personalized training.
Currently, HAR is categorized into three modalities based on data types: RGB sequence-based HAR (RGB-HAR) [4,5], skeleton sequence-based HAR (Skeleton-HAR) [6,7], and depth sequence-based HAR (Depth-HAR) [8,9,10]. RGB-HAR, although widely used in the early stages, is sensitive to variations in lighting conditions and environmental factors. Changes in illumination, the presence of shadows, and background interference can compromise its recognition accuracy, particularly in complex indoor settings. Skeleton-HAR relies on skeletal coordinate data obtained from depth sensors, encompassing the positions of key joint points such as the head, hands, shoulders, and hips. Acquiring skeletal sequences can be labor-intensive, requiring specialized pose estimation algorithms. In contrast, Depth-HAR involves the automatic identification and categorization of human action through the modeling of depth video sequences. These sequences are directly captured using a depth camera, with each frame of the depth image recording the object’s distance from the camera. Depth video sequences offer not only ease of acquisition but also resilience against variations in lighting conditions and environmental changes. Therefore, Depth-HAR is more appropriate for various HRM scenarios.
Depth video sequences record both temporal and spatial information. Spatial information records the coordinates, shapes, sizes, and positional relationships between body parts, which can clearly describe the static posture of human actions. Temporal information reflects the movement trajectory over time, which summarizes the dynamic movement of human actions. At present, mainstream approaches [10,11,12,13] to human action recognition tend to focus on capturing either spatial or temporal information in isolation, while ignoring the intricate interactions between these two dimensions. Symmetrically capturing space and time information and understanding the interactions between them are crucial for HAR tasks in complex HRM environments [1,2,3]. The temporal and spatial dimensions of movement are intertwined and together shape the characteristics and patterns of movement. For example, the action of a person lifting their hand includes not only the trajectory of the arm (temporal feature) but also the position and angle of the hand (spatial feature). This synthesis makes the interplay between temporal and spatial features a key factor in accurately recognizing and understanding human movements.
In this paper, we propose an efficient and effective HAR method tailored to HRM scenarios. Our approach symmetrically leverages both temporal and spatial information to enhance recognition accuracy. To begin, we extract DMM and DTM features from depth video sequences to characterize the temporal and spatial aspects of human actions, respectively. Subsequently, we design a novel feature fusion technique, CBCCCA, aimed at enhancing the fusion performance of space and time features by reconciling marginal and central information in the sample space. We then introduce a spatio-temporal information filtration module to eliminate redundant information introduced through spatio-temporal fusion, along with irrelevant information that does not contribute to action classification. Finally, we employ an SVM for human action recognition. Extensive and comprehensive experiments conducted on three representative human action datasets demonstrate that our method significantly improves the accuracy of action classification, thereby laying a solid foundation for the successful application of HAR technology within HRM scenarios.
Our main contributions are summarized as follows:
- We propose a novel Depth-HAR method tailored to HRM scenarios. To the best of our knowledge, the proposed method is the first HAR scheme that performs information fusion and filtration for symmetrically extracted space and time features.
- According to our technical contributions, we propose a new feature fusion algorithm called CBCCCA, which improves the feature fusion performance by collaboratively reconciling marginal and central information in the sample space.
- We construct a spatio-temporal information filtration module based on the information bottleneck theory, which can effectively remove redundant and irrelevant information to improve the discriminability of features.
The remainder of the paper is organized as follows. Section 2 presents related work. Section 3 introduces the proposed Depth-HAR method. Section 4 presents the experimental results and analysis. In Section 5, relevant issues with our approach are discussed. Finally, the paper presents the conclusions in Section 6.
2. Related Work
In this section, we first review Depth-HAR methods. Then, popular feature fusion techniques are briefly discussed.
2.1. Depth-Video-Based Human Action Recognition
In earlier works, Motion Energy Images (MEI) [9] and Motion History Images (MHI) [9] were introduced as temporal templates for human motion. MEI outlines the two-dimensional space contour of the action but does not contain time information. MHI collects both time information and space outlines through brightness attenuation. However, due to overlapping human actions occurring at the same spatial locations, the space and time information in MHI is incomplete. In [10], DMM is proposed as a representational method for human movements. DMM projects depth frames from three viewpoints and computes motion differences for each viewpoint, representing human action by accumulating these motion differences. In [17], DMM is employed to extract Local Binary Pattern (LBP) characteristics as descriptors. However, DMM cannot capture time information, which makes it difficult to distinguish actions with similar spatial trajectories but different time sequences. To address this problem, Hierarchical Pyramid Depth Motion Maps (HP-DMM) are investigated in [12]. HP-DMM extends DMM and combines time information. In [11], Three Motion History Images (MHIs) and Three Static History Images (SHIs) are introduced to integrate motion and static time information. In [18], Kamel et al. demonstrated that, with the aid of the Moving Joints Descriptor (MJD), effective recognition results can be achieved using only front-view Depth Motion Images (DMI) while maintaining lower computational complexity.
In addition to the above methods, deep learning algorithms are frequently applied in HAR research. Adrián et al. [19] proposed a 3D Fully Convolutional Neural Network (3D FCNN) that directly encodes spatiotemporal information from raw depth sequences for action classification. In [20], a Bidirectional Recurrent Neural Network (BRNN) network was introduced, which projects three-dimensional depth images onto three different two-dimensional planes and inputs them into separate BRNN modules for action classification. Keceli et al. [21] combined depth sequences with 2D CNN and 3D CNN models to generate a three-dimensional volume representation using the spatio-temporal information from depth sequences, which is then fed into a 3D CNN for human action recognition.
2.2. Feature Fusion Techniques
Feature fusion allows for the better use of features with different characteristics and the joint modeling of these different features. The fusion of multiple different features provides a more comprehensive representation of the target sample. Even if the differences between some features in different categories of samples are small, other features can still be distinguished, so the whole algorithm is more robust. The key to successful fusion is to effectively utilize information from multiple perspectives. Canonical Correlation Analysis (CCA) et al. [22] is a multivariate statistical analysis method that uses the correlation between pairs of composite variables to reflect the overall correlation between two sets of data. Several attempts at correlation have been proposed. Rasiwasia et al. [23] proposed cluster canonical correlation analysis (cluster-CCA) for the joint dimensionality reduction of two sets of data points. Only correlations between samples from the same set or class are considered. Kan et al. [24] proposed a Multi-View Discriminant Analysis (MvDA) method, which seeks a discriminative common space by jointly learning multi-view-specific linear transformations for robust object recognition from multiple views in an unpaired manner. Kan et al. [25] extended MvDA to generate a deep network. In addition to this, some researchers have combined the idea of manifolds. Sun et al. [26] proposed local methods such as Local Linear Embedding (LLE) and Local Preserving Projection (LPP) to discover low-dimensional manifolds embedded in the original high-dimensional space. Shen et al. [27] proposed a unified multiset canonical correlation analysis framework based on graph embedding for dimensionality reduction (GbMCC-DR), which combines different discriminative methods with graph regularisation CCA in combination. Mungoli et al. [28] proposed Adaptive Feature Fusion (AFF) to bolster the generalization capacity of deep learning models through adaptively regulating the fusion procedure of feature representation. Hou et al. [29] proposed a novel local-aware spatiotemporal attention network with multi-stage feature fusion based on compact bilinear pooling for human action recognition.
3. Methodology
In this section, we first describe how to symmetrically extract space and time features of depth sequences. Then, a Center Boundary Collaborative Canonical Correlation Analysis (CBCCCA) is designed to efficiently fuse the space and time features. Next, a spatio-temporal information filtration module is introduced to filter the redundant and irrelevant information from the fused space and time features to improve the discriminative performance of the fused space and time features. Finally, the filtered spatio-temporal features are fed into an SVM in order to recognize human actions. Figure 1 shows the overall flowchart of our method.
3.1. Symmetric Extraction of Space and Time Features
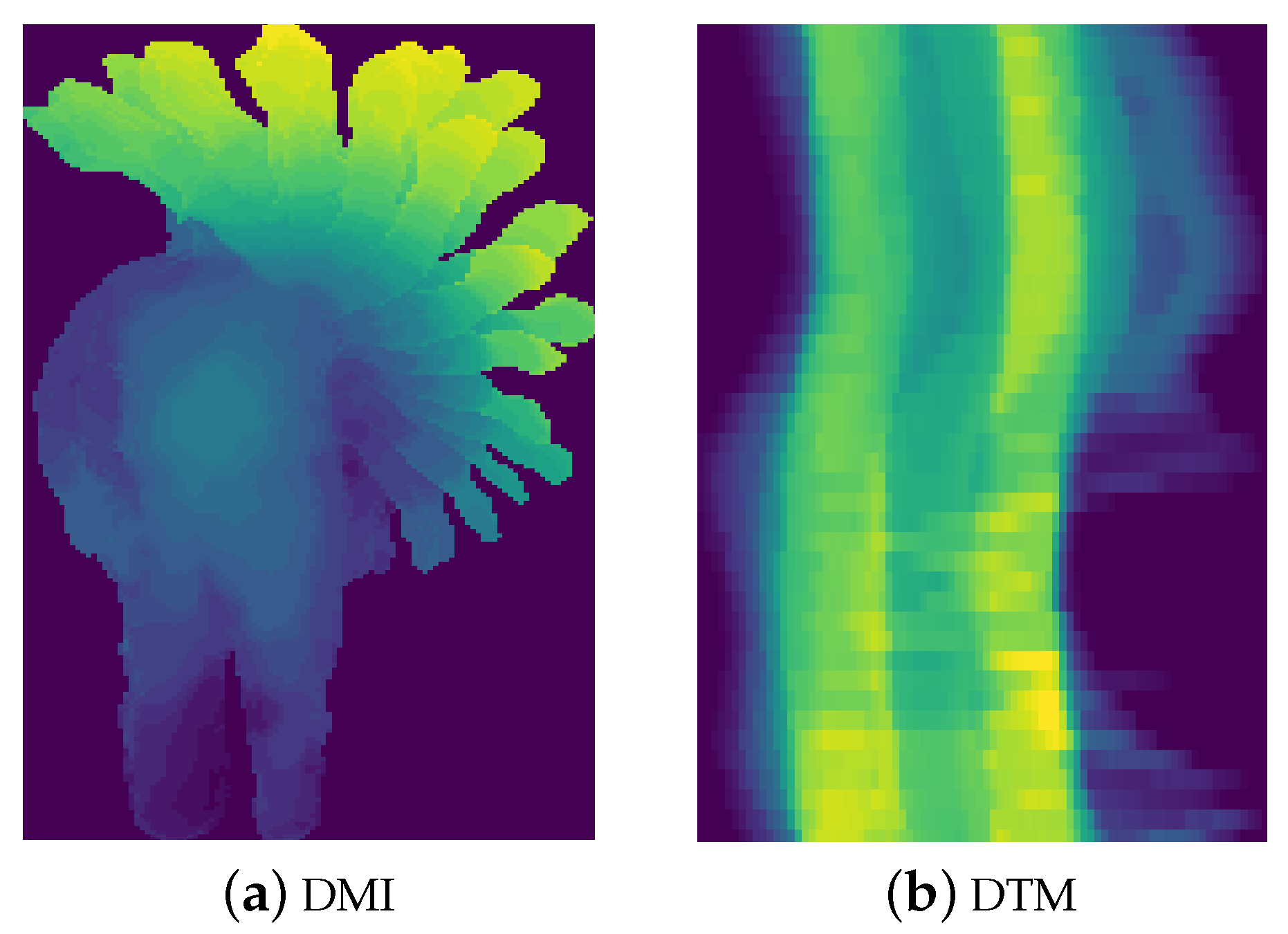
Spatial feature maps: As depicted in Figure 2a, Depth Motion Images (DMI) [18] characterize the spatial aspects of actions by identifying the most prominent appearance features from the same spatial location in all depth frames. This process results in a unified representation that encapsulates the specific spatial appearance of each action, offering distinct features for each action. The DMI is calculated as follows:
where represents the pixel value at the tth depth frame at pixel position . The variable t ranges from frame 1 to T, where T signifies the total number of frames. The pixel value in the is determined as the maximum value at the same pixel position, signifying the most salient appearance feature of the action within the depth sequence.
Temporal feature maps: The creation of Depth Temporal Maps (DTM) [13] is illustrated in Figure 2b. Each depth frame undergoes projection onto three views, and the resultant three 2D projection images are subsequently projected onto two axes. This projection involves computing the row and column sums for each 2D projection image, resulting in two 1D projection lists for each 2D projection image. With three projection views and two projection axes, a total of six 1D projection lists are obtained.
where is the projection axes, and corresponds to the Cartesian views. signifies the projected list of the kth video frame on view v and axis a. represents the projection image on projection view v. W and H denote the width and height of the projection images, respectively. refers to the kth row of the .
Finally, we use the Histogram of Oriented Gradient (HOG) algorithm to characterize the local shape of each and , forming space and time features denoted as and , respectively.
3.2. Center Boundary Collaborative Canonical Correlation Analysis (CBCCCA)
In the feature extraction phase, we symmetrically compute space and time features. To further capture the complex interaction between space and time dimensions, we design a novel feature fusion algorithm called CBCCCA in this paper.
In traditional Canonical Correlation Analysis (CCA) [22], the features to be fused are projected into a common semantic space. CCA is designed to learn projection matrices that maximize the correlation between the projected samples. In this paper, we introduce a novel feature fusion algorithm CBCCCA. CBCCCA enhances the fusion of spatial features ∈ and temporal features ∈ by collaboratively learning center and boundary information in class feature spaces; it can be formalized as follows:
where is the cross-correlation matrix between two center information matrices from space and time features, and and are the auto-correlation matrices of center information matrices. is the cross-correlation matrix between two boundary information matrices from space and time features, and and are the auto-correlation matrices of boundary information matrices. ∈ and ∈ are the projection matrices for and , and K is the number of projected dimensions. represents the identity matrix. is a tuning parameter that collaboratively reconciles the marginal and central information. The sensitivity regarding also indicates the level of noise in the training samples. A higher sensitivity value of corresponds to a greater level of noise. We adopt the same solution in [22]; in Equation (5) can be solved from the generalized eigenvalue decomposition as follows:
where is the eigenvalue in the generalized eigenvalue decomposition. After computing , solving for yields . Based on the projection matrices, we project the spatial features and temporal features into the common semantic space and concatenate them to obtain the fused spatio-temporal features .
The key to CBCCCA is knowing how to determine the center information matrices and boundary information matrices. In this paper, we adopt high-confidence center matrices as the center information matrices and use the original space and time feature matrices as the boundary information matrices. In CBCCCA, the collaborative reconciliation of centre and margin information mitigates the effect of outlier samples on spatio-temporal fusion. In the presence of outlier samples within the sample space, the location of the sample distribution centers is affected by these outlier sample points (called pseudo-centres). Obviously, the presence of pseudo-centres may adversely affect the feature fusion effect. To address this issue, we compute the high-confidence centers of each sample space. Taking the spatial feature as an example, we first use the maximum likelihood method to estimate the parameters for each feature dimension of each class in as described below:
where is the sample instance for each feature dimension of each class in and n is the number of sample instances. After obtaining and , i.e., the estimates of the mean and variance , we partition the feature dimension into three intervals using and as watersheds. The central interval [, ] is considered a high-confidence interval, due to the fact that outlier sample points are typically in the minority and tend to lie outside of this interval. Subsequently, we compute the mean of the values in [, ] at all dimensional locations and form them into a high-confidence center for the sample features. Finally, all samples in are replaced with the corresponding high-confidence centers to obtain the high-confidence center matrix.
3.3. The Spatio-Temporal Information Filtration Module
Multi-feature fusion strategy is the mainstream approach to improve the performance of recognition tasks. However, feature fusion operations inevitably generate a certain amount of redundant information. In this paper, we design a spatio-temporal information filtration module. On the one hand, the spatio-temporal information filtration module is used to remove the redundant information introduced by feature fusion. On the other hand, the spatio-temporal information filtration module is also utilized to filter useless information that is not relevant to the HAR task, such as body type information.
The spatio-temporal information filtration module adopts the idea of information bottleneck theory [30]. The spatio-temporal information filtration module wants to obtain a filtered spatio-temporal feature , which is desired to have as large a correlation as possible with the label but as small a correlation as possible with the initial fusion feature . Keeping the correlation with as large as possible ensures that has the ability to maximally retain useful information for action recognition. Keeping the correlation with as small as possible ensures that can maximally remove redundant information resulting from the fusion of spatio-temporal information. According to the information bottleneck theory [30], the spatio-temporal information filtration module can be formulated as follows:
where is Lagrange Multiplier. is the mutual information of and and is denoted as:
where denotes the joint probability of m and y, denotes the probability of y, and is the probability of y under condition m. Due to the uncertainty of m and the different dimensions of m and y, cannot be computed directly. We design an encoder and a decoder for such that , . Both the encoder and decoder consist of multilayer perceptrons. We compute as an approximation to (where ). Thus, can be written as:
Since our method is a type of supervised learning, the label y is known. Thus, and . Meanwhile, the structure of the spatio-temporal information filtration module can be viewed as . According to the Markov chain theory [31], . Therefore, Equation (13) can be written as:
As in Equation (12), can be written as:
Due to the uncertainty of m, is not computable. We compute as an approximation of . According to , we obtain the following:
Thus, Equation (15) can be expressed as:
Let ). According to [32], can be approximated as follows:
where is the Kullback–Leibler Divergence of with . According to Equation (18), L has a lower bound. We use L as a loss function to train the encoder and decoder. The initial fusion features are fed into the encoder, and then we can obtain the filtered spatio-temporal features .
Finally, we send the filtered spatio-temporal features to an SVM for action recognition.
4. Experiments
This section provides an overview of the datasets used in this paper. To evaluate the effectiveness of our proposed method, we select three widely recognized HAR datasets: the MSR Action3D [14], the UTD-MHAD [15], and the DHA [16]. Then, we thoroughly compare the proposed method with state-of-the-art methods. Finally, a series of ablation studies are implemented to further validate the contribution of each component of the proposed method.
4.1. Datasets
In order to simulate the HAR task in HRM scenarios, three widely used indoor human action datasets are selected for comparison experiments in this paper.
The MSR Action3D dataset [14] is one of the most popular action recognition datasets and contains 567 sequences formed by 10 subjects performing 20 different human actions. We use the same cross-subject testing configuration as in [14], using odd subjects for training and even subjects for testing.
The UTD-MHAD dataset [15] yields 861 samples of depth sequences containing 27 actions from eight subjects. Each subject performs each action four times. Our experimental setup is consistent with the configuration introduced in [15], i.e., half of the subjects are assigned to the training set and the remaining half constitute the test set. Figure 3 shows a depth video sequence of bowling from the UTD-MHAD dataset as an example of action samples.
The DHA dataset [16] has 483 depth sample sequences representing 23 different movements performed by 21 subjects. Each subject carried out each of the 23 actions once. We followed the experimental setup in [16], which contains all 23 actions. The actions of the odd-numbered subjects were used in the training set, and the actions of the even-numbered subjects were used in the test set.
4.2. Comparison with the State-of-the-Art Methods
To validate the effectiveness of our method, comparative experiments with state-of-the-art methods are conducted on three widely used human action datasets.
4.2.1. MSR Action3D Dataset
In the last decade, there are many Depth-HAR methods that validate their performance on the MSR Action3D dataset, including ROP, DMM-HOG, BSC, HP-DMM-CNN, P4Transformer, and PointMapNet. We summarize the results of these methods in Table 1. As shown in Table 1, our method achieves a recognition accuracy of 97.1% in the cross-subject setting, which is the highest compared to other methods. In the Baseline method [14], a straightforward yet efficient projection-based sampling scheme is proposed for extracting a set of 3D points from depth maps. Compared with the baseline method, we improve the extraction of space and time features and design a fusion and filtering scheme for space and time features to enhance the recognition performance. It is worth noting that, like our methods, DMM-HOG [10], and HP-DMM-CNN [12] also convert depth videos into feature maps and then perform HAR. However, these methods only focus on the extraction of spatial or temporal features individually and do not capture the complex interaction of temporal and spatial information. Recently, point cloud processing techniques have become more advanced. Point cloud sequence network methods are an extension of static point cloud techniques in 3D space to 4D time-space; they directly consume spatially disordered and temporally ordered point cloud sequences to identify human actions. However, point cloud sequence network methods, like PointLSTM-late [33], P4Transformer [34], PointMapNet [35], and SequentialPointNet [36], require a large number of samples and high computational cost for model training, which hinders the application of HAR techniques in HRM scenarios.
4.2.2. UTD-MHAD Dataset
The UTD-MHAD dataset is another widely used human action dataset. We compare the proposed method with a series of Depth-HAR methods, including Baseline [15], 3DHOT-MBC [47], HP-DMM-HOG [12], DTMMN [48], PointMapNet [35], and CBBMC [13]. The results of the comparison experiments are tabulated in Table 2. We can see from the table that our method has a huge lead over other methods. In the Baseline method [15], the DMM for the three projected views are computed and form a feature vector. Then, Principal Component Analysis (PCA) is used to reduce the dimension of the spliced features. However, characterizing human action using only the DMM cannot capture the complex interaction of temporal and spatial information. Similar to our method, CBBMC [13] symmetrically extracts space and time features and effectively fuses them together but does not perform information filtration on the fused space and time features. The information filtration operation used in our method removes redundant and irrelevant information and improves the recognition performance.
4.2.3. DHA Dataset
On the DHA dataset, we compare the proposed method with a series of Depth-HAR methods, including D-STV/ASM [16], DMM-LBP-DF [17], D-DMHI-PHOG [50], DMMS-FV [51], and CBBMC [13]. As shown in Table 3, our method obtains the best performance by a large margin, which further validates the effectiveness of the proposed method. In the Baseline method [16], the depth video is represented as overlapping spatio-temporal volumes. Each spatio-temporal volume is divided into a number of cubes and represented as descriptors. Then, a spatio-temporal feature vector is constructed by connecting the descriptors of all the cubes in the volume. The proposed method significantly improves the discriminability of spatio-temporal information compared to the Baseline method. The key to the success of our method lies in the effective fusion of symmetrically extracted spatio-temporal features. In this paper, the sample class center and boundary information are learned collaboratively, leading to the efficient fusion of spatio-temporal features while fully exploiting the complex interactions between them. In addition, the creative design of the spatio-temporal information filtration module further purifies the fused spatio-temporal information, which significantly improves the classification effect of the spatio-temporal features.
4.3. Ablation Study
In this section, comprehensive ablation experiments are conducted to affirm the contribution of various components in our methodology.
4.3.1. Effectiveness of Symmetric Extraction of Space and Time Information
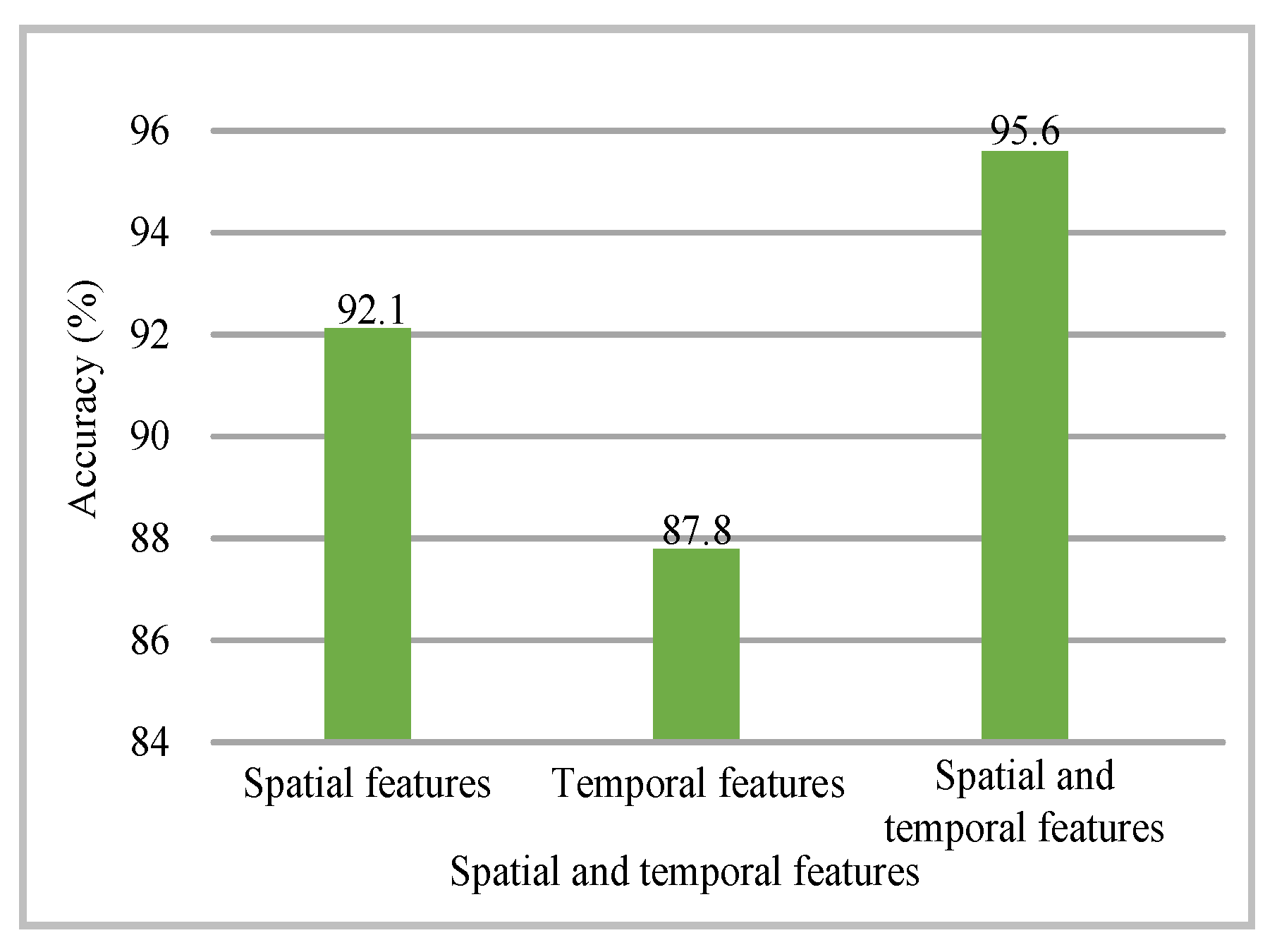
In the feature extraction phase, we symmetrically extract the space and time features of human actions. To validate the contribution of symmetrically extracting space and time information, we conduct experiments using only spatial or temporal features. It is essential to note that in this ablation study, the feature fusion algorithm is not utilized in any of the tests to ensure fairness, while the information filtration module is used. As shown in Figure 4, when using only spatial features, our method achieves a recognition rate of 92.1%. Using only temporal features results in a recognition rate of 87.8%. The symmetric use of both space and time features leads to a 3.5% increase in recognition accuracy, reaching 95.6%. The experimental results substantiate that symmetrically extracting space and time features significantly enhances the accuracy of HAR.
4.3.2. Fusion Performance Analysis of CBCCCA
In this paper, we present CBCCCA, a feature fusion algorithm designed to integrate space and time features. CBCCCA alleviates the effect of noisy samples on spatio-temporal fusion by reconciling central and marginal information in the sample space. In this subsection, we perform a sensitivity analysis on the parameters of CBCCCA. Subsequently, we qualitatively analyze the fusion performance of CBCCCA. Finally, we evaluate CBCCCA against other feature fusion algorithms to validate its effectiveness.
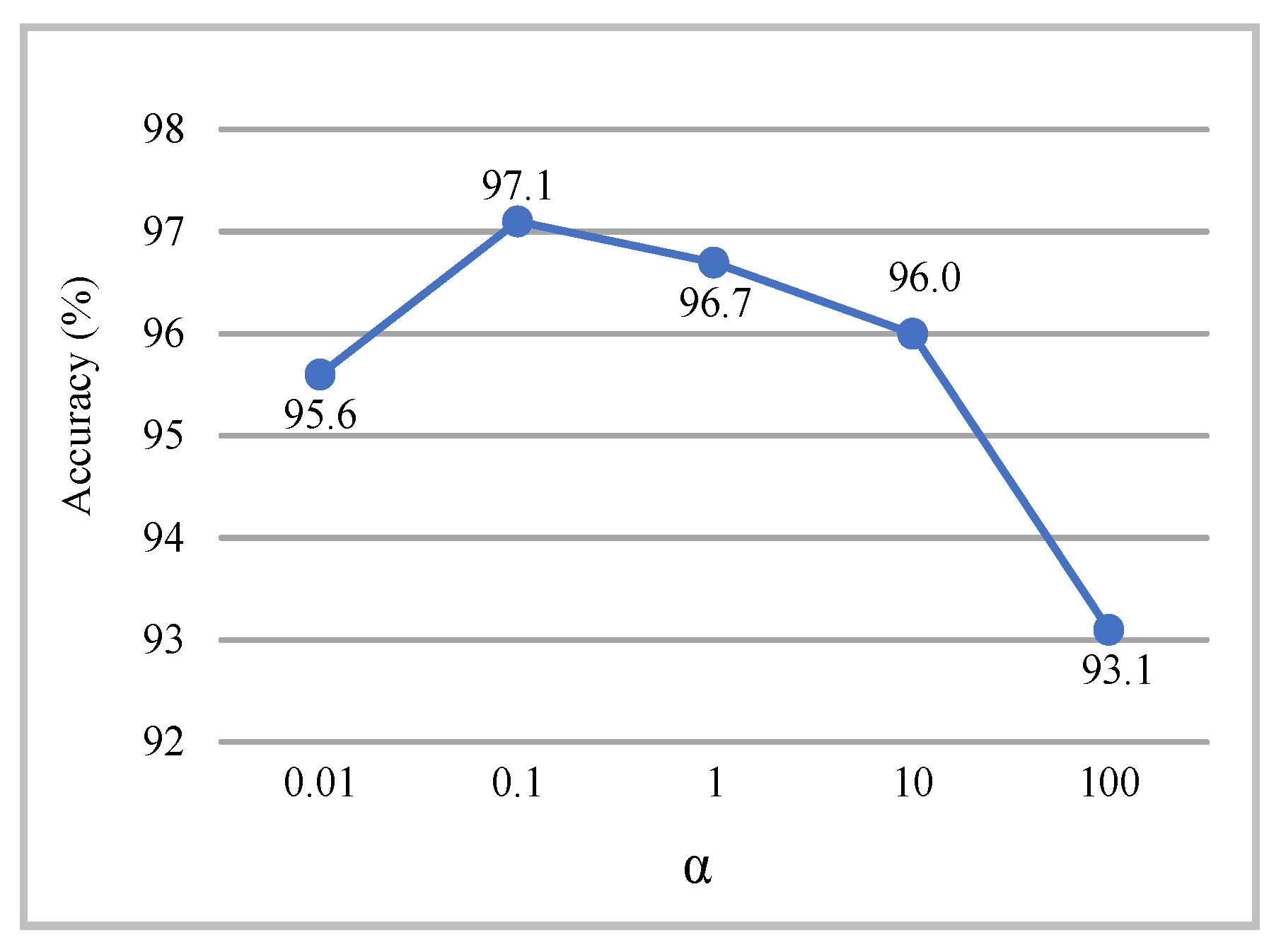
Parameter sensitivity analysis: CBCCCA contains the parameter that coordinates the marginal and central information in the sample space. The values of are in the range of {0.01, 0.1, 1, 10, and 100}. The performance of CBCCCA under different values of varies, as shown in Figure 5. The best performance is achieved when is set to 0.1. This optimal performance stems from the role of in reconciling marginal and central information. Too small a value fails to describe the class-centred information, which is critical to mitigating the effects of outlier samples. Conversely, too large a value weakens the decision margin information required for effective categorisation. Therefore, we fix the value of to 0.1.
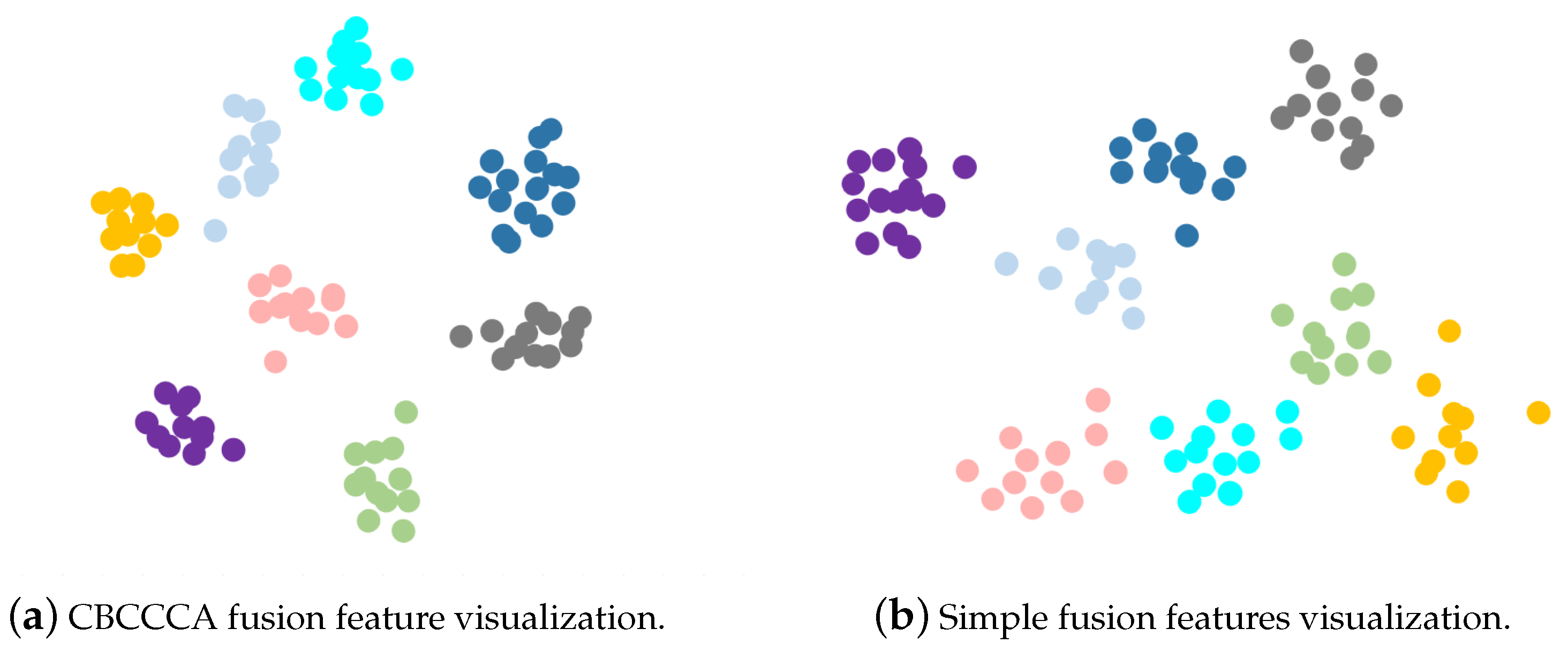
Qualitative analysis of fusion performance: In order to qualitatively analyze the temporal and spatial fusion effects, we show a visualisation of the semantic space of CBCCCA in Figure 6a. As a reference, simple fusion features obtained by direct splicing of space and time features are also visualized in Figure 6b. In this subsection, t-SNE [53] is used to reduce the high-dimensional semantic features to 2D features for visualization. Comparison experiments are performed on the MSR Action3D dataset, and the first eight classes of samples are visualized. From the figure, we can see that the fusion features produced by CBCCCA have smaller intra-class distances and larger inter-class distances in the semantic space than the simple fusion features. Therefore, we can obtain a conclusion that the fusion features obtained through CBCCCA are more discriminative than simple fusion features, thus indicating that CBCCCA has excellent feature fusion performance.
Comparison with other fusion technologies: To further evaluate the fusion performance of CBCCCA, we compare CBCCCA with several classical fusion algorithms. The fusion algorithms involved include CCA [22], MeanCCA [23], and JFSSL [54]. The comparison experiments are performed on the MSR Actions3D and shown in Table 4. It should be noted that all tests in this experiment keep the same settings except for the fusion algorithms. Impressively, the proposed CBCCCA reaches the top accuracy of 97.1%. Compared with other fusion algorithms, CBCCCA collaboratively exploits the marginal and central information of the sample space and decreases the impact of outlier samples on spatio-temporal fusion.
4.3.3. Effectiveness of the Spatio-Temporal Information Filtration Module
In this paper, the spatio-temporal information filtration module is designed to perform information purification on the fused spatio-temporal features, which removes redundant information while reducing useless information that is not relevant to HAR. We analyze the recognition results of the two HAR frameworks. Framework A represents the complete method proposed in this paper. Framework B is the HAR method without using the spatio-temporal information filtration module. As shown in Table 5, the spatio-temporal information filtration module improves the recognition accuracy by 1.1%, which indicates that the spatio-temporal information filtration module can effectively contribute to the HAR performance.
4.3.4. Computational Efficiency Analysis
In order to analyze the real-time running efficiency of the proposed method, we show the running time of each step. The experimental results are shown in Table 6. It should be mentioned that the running time of all the modules is the model forward inference time. The experiment is conducted on a machine with an Intel(R) Xeon(R) W-3175X CPU.
From the table, we can see that the proposed method consumes only 0.089 s to classify a depth video much more than the real-time running requirement. Excellent running efficiency makes it possible to deploy the proposed approach in real time in HRM scenarios.
5. Discussion
In this section, we first compare the proposed method with other spatio-temporal feature extraction techniques. Then, we discuss the application of our method in HRM scenarios. Finally, the limitations and potential challenges of our method are analyzed.
Spatio-temporal feature extraction techniques in gesture recognition: Knowing how to extract and utilize the space and time information of human actions is the core problem of this paper. In the experimental section, we compare our proposed method with popular Depth-HAR methods on three widely used human action datasets. In addition to the Depth-HAR methods, various advanced spatio-temporal feature extraction techniques have been proposed in recognizing specific action tasks, such as gesture recognition [55,56,57,58,59]. In [55], seven types of spatio-temporal features such as 2D distances from face to hands and areas of face and hands intersection are combined into a single vector, which is then sent to the BiLSTM network for gesture recognition. Jiang et al. [56] use a 3DCNN network to extract spatio-temporal features from depth videos. In [57], a novel neural ensembler is introduced, incorporating various models (I3D, TimeSformer, and SPOTER) and diverse data sources (RGB, Masked RGB, Optical Flow, and Skeleton) for training the individual sources within the ensemble. These methods have been remarkably successful in recognizing specific actions and provide useful inspiration for subsequent improvements of our method.
Application in HRM scenarios: In this paper, we design a new Depth-HAR scheme for HRM scenarios. In HRM scenarios such as human resource recruitment (HRR), employee performance assessment (EPA), and employee training (ET), accurate and efficient HAR facilitates the development of each field. In HRR, HAR technology revolutionizes the interview process by analyzing candidates’ non-verbal cues, offering a comprehensive understanding of communication skills, emotional expression, and adaptability. This enhances the objectivity of candidate assessment, providing a scientific and objective approach to recruitment. In EPA, HAR methods offer crucial insights by monitoring workplace actions. This reduces subjective biases in evaluations, providing fair assessments and clear development directions for employees, fostering continuous improvement. In ET, HAR optimizes training effectiveness through personalized plans and real-time feedback. Tailored training content meets individual needs, while real-time feedback corrects unfavorable learning habits promptly, advancing talent development strategies. These applications showcase the versatile potential of HAR in HRM, introducing innovative and scientific approaches to several domain.
Limitations and potential challenges: Extensive experiments have verified that our method not only has outstanding HAR accuracy but also has excellent running efficiency. In this subsection, we try to discuss the limitations and potential shortcomings of our approach with respect to real-time deployment. The diversity of observational perspectives is a common challenge for all current HAR research. Due to differences in observation perspectives, sample data collected for the same action have large intra-class differences. In fact, we execute a series of operations in order to mitigate this issue. The depth video used in this paper is a type of 3D data that exerts a measure of observation perspective robustness. In addition, we perform the three-view projection for the depth video to simulate three different observation perspectives. However, it is worth mentioning that our approach does not completely avoid the impact of the diversity of observation perspectives on HAR, especially in the case of complex actions. In a practical deployment, cooperative sampling with multiple shooting positions would be an effective solution to this problem. However, it may degrade the real-time running performance of the proposed method.
6. Conclusions
HAR technology has shown promising versatile potential in numerous HRM scenarios. In this paper, we develop a novel HAR algorithm for HRM scenarios. To enhance the robustness and accuracy of the proposed algorithm, we symmetrically propose space and time features of human actions and design a feature fusion algorithm, CBCCCA, to capture the complex interactions between temporal and spatial dimensions. In addition, a creative spatio-temporal information filtration module is introduced to remove redundant and irrelevant information. We simulate human actions in HRM scenarios using three public human indoor action datasets and conduct extensive experiments. The experimental results verify that the proposed method has excellent recognition performance and real-time running efficiency. We can conclude that the proposed method is an excellent HAR scheme in HRM scenarios and introduces an innovative and scientific approach to HRM fields.
For future work, on the one hand, we will continue to explore more advanced HAR techniques, and on the other hand, we intend to further promote the development of human resource management based on HAR techniques.
Author Contributions
Conceptualization, M.Z. and X.L.; methodology, M.Z.; software, X.L. and Q.W.; validation, X.L. and M.Z.; formal analysis, M.Z.; investigation, X.L.; resources, X.L.; data curation, X.L.; writing—original draft preparation, M.Z.; writing—review and editing, M.Z.; visualization, Q.W.; supervision, M.Z.; project administration, M.Z.; funding acquisition, X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Research and Development Program of China grant number 2018YFC0407905.
Data Availability Statement
The data sets used in this paper are public, free, and available at. UTD-MHAD dataset: https://www.utdallas.edu/~kehtar/UTD-MHAD.html (accessed at 1 November 2023).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yang, Y.; Wang, Y. Enterprise Human Resources Recruitment Management Model in the Era of Mobile Internet. Mob. Inf. Syst. 2022, 2022, 7607864. [Google Scholar] [CrossRef]
- Safrizal; Tanti, L.; Puspasari, R.; Triandi, B. Employee Performance Assessment with Profile Matching Method. In Proceedings of the 2018 6th International Conference on Cyber and IT Service Management (CITSM), Parapat, Indonesia, 7–9 August 2018; pp. 553–558. [Google Scholar]
- Gupta, A.; Chadha, A.; Tiwari, V.; Varma, A.; Pereira, V. Sustainable training practices: Predicting job satisfaction and employee behavior using machine learning techniques. Asian Bus. Manag. 2023, 22, 1913–1936. [Google Scholar] [CrossRef]
- Shen, Z.; Wu, X.J.; Xu, T. FEXNet: Foreground Extraction Network for Human Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 3141–3151. [Google Scholar] [CrossRef]
- Zheng, X.; Gong, T.; Lu, X.; Li, X. Human action recognition by multiple spatial clues network. Neurocomputing 2022, 483, 10–21. [Google Scholar] [CrossRef]
- Ko, K.E.; Sim, K.B. Deep convolutional framework for abnormal behavior detection in a smart surveillance system. Eng. Appl. Artif. Intell. 2018, 67, 226–234. [Google Scholar] [CrossRef]
- Rodomagoulakis, I.; Kardaris, N.; Pitsikalis, V.; Mavroudi, E.; Katsamanis, A.; Tsiami, A.; Maragos, P. Multimodal human action recognition in assistive human-robot interaction. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2702–2706. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, J.; Cai, J.; Xu, Z. Complex Network-based features extraction in RGB-D human action recognition. J. Vis. Commun. Image Represent. 2022, 82, 103371. [Google Scholar] [CrossRef]
- Bobick, A.; Davis, J. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, C.; Tian, Y. Recognizing Actions Using Depth Motion Maps-Based Histograms of Oriented Gradients; Association for Computing Machinery: New York, NY, USA, 2012. [Google Scholar] [CrossRef]
- Bulbul, M.F.; Islam, S.; Ali, H. 3D human action analysis and recognition through GLAC descriptor on 2D motion and static posture images. Multimed. Tools Appl. 2019, 78, 21085–21111. [Google Scholar] [CrossRef]
- Elmadany, N.E.D.; He, Y.; Guan, L. Information Fusion for Human Action Recognition via Biset/Multiset Globality Locality Preserving Canonical Correlation Analysis. IEEE Trans. Image Process. 2018, 27, 5275–5287. [Google Scholar] [CrossRef]
- Li, X.; Huang, Q.; Wang, Z. Spatial and temporal information fusion for human action recognition via Center Boundary Balancing Multimodal Classifier. J. Vis. Commun. Image Represent. 2023, 90, 103716. [Google Scholar] [CrossRef]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3d points. In Proceedings of the 2010 IEEE Computer Society Conference On Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 9–14. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Lin, Y.C.; Hu, M.C.; Cheng, W.H.; Hsieh, Y.H.; Chen, H.M. Human action recognition and retrieval using sole depth information. In Proceedings of the Acm International Conference on Multimedia, Hong Kong, China, 5–8 June 2012; p. 1053. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. Action Recognition from Depth Sequences Using Depth Motion Maps-based Local Binary Patterns. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 1092–1099. [Google Scholar]
- Kamel, A.; Sheng, B.; Yang, P.; Li, P.; Shen, R.; Feng, D.D. Deep Convolutional Neural Networks for Human Action Recognition Using Depth Maps and Postures. IEEE Trans. Syst. Man Cybern.-Syst. 2019, 49, 1806–1819. [Google Scholar] [CrossRef]
- Sanchez-Caballero, A.; de Lopez-Diz, S.; Fuentes-Jimenez, D.; Losada-Gutierrez, C.; Marron-Romera, M.; Casillas-Perez, D.; Sarker, M.I. 3DFCNN: Real-time action recognition using 3D deep neural networks with raw depth information. Multimed. Tools Appl. 2022, 81, 24119–24143. [Google Scholar] [CrossRef]
- Liu, X.; Li, Y.; Wang, Q. Multi-View Hierarchical Bidirectional Recurrent Neural Network for Depth Video Sequence Based Action Recognition. Int. J. Pattern Recognit. Artif. Intell. 2018, 32, 1850033. [Google Scholar] [CrossRef]
- Keceli, A.S.; Kaya, A.; Can, A.B. Combining 2D and 3D deep models for action recognition with depth information. Signal Image Video Process. 2018, 12, 1197–1205. [Google Scholar] [CrossRef]
- Hardoon, D.R.; Szedmák, S.; Shawe-Taylor, J. Canonical Correlation Analysis: An Overview with Application to Learning Methods. Neural Comput. 2004, 16, 2639–2664. [Google Scholar] [CrossRef]
- Rasiwasia, N.; Mahajan, D.; Mahadevan, V.; Aggarwal, G. Cluster Canonical Correlation Analysis. JMLR Workshop Conf. Proc. 2014, 33, 823–831. [Google Scholar]
- Kan, M.; Shan, S.; Zhang, H.; Lao, S.; Chen, X. Multi-View Discriminant Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 188–194. [Google Scholar] [CrossRef]
- Kan, M.; Shan, S.; Chen, X. Multi-view Deep Network for Cross-View Classification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 4847–4855. [Google Scholar] [CrossRef]
- Sun, T.; Chen, S. Locality preserving CCA with applications to data visualization and pose estimation. Image Vis. Comput. 2007, 25, 531–543. [Google Scholar] [CrossRef]
- Shen, X.; Sun, Q.; Yuan, Y. A unified multiset canonical correlation analysis framework based on graph embedding for multiple feature extraction. Neurocomputing 2015, 148, 397–408. [Google Scholar] [CrossRef]
- Mungoli, N. Adaptive Feature Fusion: Enhancing Generalization in Deep Learning Models. arXiv 2023, arXiv:2304.03290. [Google Scholar]
- Hou, Y.; Yu, H.; Zhou, D.; Wang, P.; Ge, H.; Zhang, J.; Zhang, Q. Local-aware spatio-temporal attention network with multi-stage feature fusion for human action recognition. Neural Comput. Appl. 2021, 33, 16439–16450. [Google Scholar] [CrossRef]
- Tishby, N.; Pereira, F.C.; Bialek, W. The Information Bottleneck Method. arXiv 2000, arXiv:2304.03290. [Google Scholar]
- Grewal, J.K.; Krzywinski, M.; Altman, N. Markov models-Markov chains. Nat. Methods 2019, 16, 663–664. [Google Scholar] [CrossRef]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep Variational Information Bottleneck. arXiv 2016, arXiv:1612.00410. [Google Scholar]
- Min, Y.; Zhang, Y.; Chai, X.; Chen, X. An Efficient PointLSTM for Point Clouds Based Gesture Recognition. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5760–5769. [Google Scholar] [CrossRef]
- Fan, H.; Yang, Y.; Kankanhalli, M. Point 4D Transformer Networks for Spatio-Temporal Modeling in Point Cloud Videos. In Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14199–14208. [Google Scholar] [CrossRef]
- Li, X.; Huang, Q.; Zhang, Y.; Yang, T.; Wang, Z. PointMapNet: Point Cloud Feature Map Network for 3D Human Action Recognition. Symmetry 2023, 15, 363. [Google Scholar] [CrossRef]
- Li, X.; Huang, Q.; Wang, Z.; Yang, T.; Hou, Z.; Miao, Z. Real-Time 3-D Human Action Recognition Based on Hyperpoint Sequence. IEEE Trans. Ind. Inform. 2023, 19, 8933–8942. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Z.; Chorowski, J.; Chen, Z.; Wu, Y. Robust 3D Action Recognition with Random Occupancy Patterns. Lect. Notes Comput. Sci. 2012, 7573, 872–885. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Mining Actionlet Ensemble for Action Recognition with Depth Cameras. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1290–1297. [Google Scholar] [CrossRef]
- Oreifej, O.; Liu, Z. HON4D: Histogram of Oriented 4D Normals for Activity Recognition from Depth Sequences. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 716–723. [Google Scholar] [CrossRef]
- Xia, L.; Aggarwal, J.K. Spatio-Temporal Depth Cuboid Similarity Feature for Activity Recognition Using Depth Camera. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2834–2841. [Google Scholar] [CrossRef]
- Tran, Q.D.; Ly, N.Q. Sparse Spatio-Temporal Representation of Joint Shape-Motion Cues for Human Action Recognition in Depth Sequences. In Proceedings of the 2013 RIVF International Conference on Computing & Communication Technologies—Research, Innovation, and Vision for Future (RIVF), Hanoi, Vietnam, 10–13 November 2013; pp. 253–258. [Google Scholar]
- Song, Y.; Tang, J.; Liu, F.; Yan, S. Body Surface Context: A New Robust Feature for Action Recognition From Depth Videos. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 952–964. [Google Scholar] [CrossRef]
- Lu, C.; Jia, J.; Tang, C.K. Range-Sample Depth Feature for Action Recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 772–779. [Google Scholar] [CrossRef]
- Elmadany, N.E.D.; He, Y.; Guan, L. Multimodal Learning for Human Action Recognition Via Bimodal/Multimodal Hybrid Centroid Canonical Correlation Analysis. IEEE Trans. Multimed. 2019, 21, 1317–1331. [Google Scholar] [CrossRef]
- Wu, H.; Ma, X.; Li, Y. Hierarchical dynamic depth projected difference images-based action recognition in videos with convolutional neural networks. Int. J. Adv. Robot. Syst. 2019, 16, 1729881418825093. [Google Scholar] [CrossRef]
- Azad, R.; Asadi-Aghbolaghi, M.; Kasaei, S.; Escalera, S. Dynamic 3D Hand Gesture Recognition by Learning Weighted Depth Motion Maps. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 1729–1740. [Google Scholar] [CrossRef]
- Zhang, B.; Yang, Y.; Chen, C.; Yang, L.; Han, J.; Shao, L. Action Recognition Using 3D Histograms of Texture and A Multi-Class Boosting Classifier. IEEE Trans. Image Process. 2017, 26, 4648–4660. [Google Scholar] [CrossRef] [PubMed]
- Qin, X.; Ge, Y.; Feng, J.; Yang, D.; Chen, F.; Huang, S.; Xu, L. DTMMN: Deep transfer multi -metric network for RGB-D action recognition. Neurocomputing 2020, 406, 127–134. [Google Scholar] [CrossRef]
- Yang, T.; Hou, Z.; Liang, J.; Gu, Y.; Chao, X. Depth Sequential Information Entropy Maps and Multi-Label Subspace Learning for Human Action Recognition. IEEE Access 2020, 8, 135118–135130. [Google Scholar] [CrossRef]
- Gao, Z.; Zhang, H.; Xu, G.P.; Xue, Y.B. Multi-perspective and multi-modality joint representation and recognition model for 3D action recognition. Neurocomputing 2015, 151, 554–564. [Google Scholar] [CrossRef]
- Liu, M.; Liu, H.; Chen, C. 3D Action Recognition Using Multiscale Energy-Based Global Ternary Image. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1824–1838. [Google Scholar] [CrossRef]
- Liu, H.; Tian, L.; Liu, M.; Tang, H. SDM-BSM: A fusing depth scheme for human action recognition. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 4674–4678. [Google Scholar]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European Conference On Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 305–321. [Google Scholar]
- Wang, K.; He, R.; Wang, L.; Wang, W.; Tan, T. Joint Feature Selection and Subspace Learning for Cross-Modal Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2010–2023. [Google Scholar] [CrossRef]
- Ryumin, D.; Ivanko, D.; Ryumina, E. Audio-Visual Speech and Gesture Recognition by Sensors of Mobile Devices. Sensors 2023, 23, 2284. [Google Scholar] [CrossRef]
- Jiang, S.; Sun, B.; Wang, L.; Bai, Y.; Li, K.; Fu, Y. Skeleton Aware Multi-modal Sign Language Recognition. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 3408–3418. [Google Scholar] [CrossRef]
- Hruz, M.; Gruber, I.; Kanis, J.; Bohacek, M.; Hlavac, M.; Krnoul, Z. One Model is Not Enough: Ensembles for Isolated Sign Language Recognition. Sensors 2022, 22, 5043. [Google Scholar] [CrossRef]
- Maxim, N.; Leonid, V.; Ruslan, M.; Dmitriy, M.; Iuliia, Z. Fine-tuning of sign language recognition models: A technical report. arXiv 2023, arXiv:2302.07693. [Google Scholar]
- Ryumin, D.; Ivanko, D.; Axyonov, A. Cross-Language Transfer Learning Using Visual Information for Automatic Sign Gesture Recognition. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Moscow, Russia, 24–26 April 2023. [Google Scholar] [CrossRef]
Figure 1.
The overall flowchart of the proposed method.

Figure 2.
Depth feature maps.

Figure 3.
The depth video of bowling in the UTD-MHAD dataset dataset.

Figure 4.
Comparison of different features on the MSR Action3D dataset dataset.

Figure 5.
Recognition accuracy at different on the MSR Action3D dataset.

Figure 6.
Visualization of different fusion features.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Recognition results of different methods on the MSR Action3D dataset.
| Methods | Accuracy |
|---|---|
| Baseline [14] | 74.7% |
| ROP [37] | 86.50% |
| DMM-HOG [10] | 88.7% |
| Actionlet ensemble [38] | 88.2% |
| HON4D [39] | 88.9% |
| DSTIP [40] | 89.30% |
| Tran et al. [41] | 91.9% |
| BSC [42] | 90.36% |
| Rang-Sample Feature [43] | 95.62% |
| Kamel et al. [12] | 94.51% |
| HP-DMM-CNN [12] | 92.31% |
| GMHI + GSHI + CRC [11] | 94.5% |
| Ahmad et al. [44] | 87.88% |
| DDPDI [45] | 96.15% |
| Azad et al. [46] | 95.24% |
| PointLSTM-late [33] | 95.38% |
| P4Transformer [34] | 90.94% |
| PointMapNet [35] | 91.91% |
| CBBMC [13] | 96.3% |
| SequentialPointNet [36] | 92.6% |
| Proposed | 97.1% |
Table 2.
Recognition results of different methods on the UTD-MHAD dataset.
| Method | Accuracy |
|---|---|
| Baseline [15] | 66.1% |
| 3DHOT-MBC [47] | 84.4% |
| HP-DMM-HOG [12] | 73.72% |
| DMI [18] | 82.79% |
| Yang et al. [49] | 88.37% |
| DTMMN [48] | 93.0% |
| PointMapNet [35] | 91.6% |
| CBBMC [13] | 94.4% |
| Proposed | 95.3% |
Table 3.
Recognition results of different methods on the DHA dataset.
| Method | Accuracy |
|---|---|
| Baseline [16] | 86.8% |
| DMM-LBP-DF [17] | 91.3% |
| SDM-BSM [52] | 89.5% |
| D-DMHI-PHOG [50] | 92.4% |
| DMMS-FV [51] | 95.44% |
| CBBMC [13] | 95.6% |
| Proposed | 96.2% |
Table 4.
Comparison of different fusion technologies on the MSR Action3D dataset.
| Method | Accuracy |
|---|---|
| CCA [22] | 93.1% |
| MeanCCA [23] | 94.6% |
| JFSSL [54] | 95.7% |
| CBCCCA | 97.1% |
Table 5.
Recognition results with and without spatio-temporal information filtration module.
| Method | Accuracy |
|---|---|
| Framework B | 96.0% |
| Framework A | 97.1% |
Table 6.
Running time per sample video on the MSR Action3D dataset.
| Step | Time |
|---|---|
| Feature extraction | 0.024 s |
| Feature fusion | 0.002 s |
| Feature Filtration | 0.007 s |
| Feature classification | 0.056 s |
| Total | 0.089 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhang, M.; Li, X.; Wu, Q. Spatio-Temporal Information Fusion and Filtration for Human Action Recognition. Symmetry 2023, 15, 2177. https://doi.org/10.3390/sym15122177
AMA Style
Zhang M, Li X, Wu Q. Spatio-Temporal Information Fusion and Filtration for Human Action Recognition. Symmetry. 2023; 15(12):2177. https://doi.org/10.3390/sym15122177
Chicago/Turabian StyleZhang, Man, Xing Li, and Qianhan Wu. 2023. "Spatio-Temporal Information Fusion and Filtration for Human Action Recognition" Symmetry 15, no. 12: 2177. https://doi.org/10.3390/sym15122177
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.