
An Extended TODIM Method and Applications for Multi-Attribute Group Decision-Making Based on Bonferroni Mean Operators under Probabilistic Linguistic Term Sets


Abstract
:1. Introduction
2. Preliminaries
2.1. Keyword Extraction Technique
2.2. Probabilistic Linguistic Term Sets
- (1)
- (2)
- (3)
- (4)
- (5)
- (6)
- .
2.3. Bonferroni Mean (BM) and Power Average (PA)
- (1)
- (2)
- (3)
3. Probabilistic Linguistic Weighted Dombi Bonferroni Mean Power Average Operators
3.1. PLDBMPA Operators
- (1)
- (2)
- (3)
- If , then .
3.2. PLWDBMPA Operators
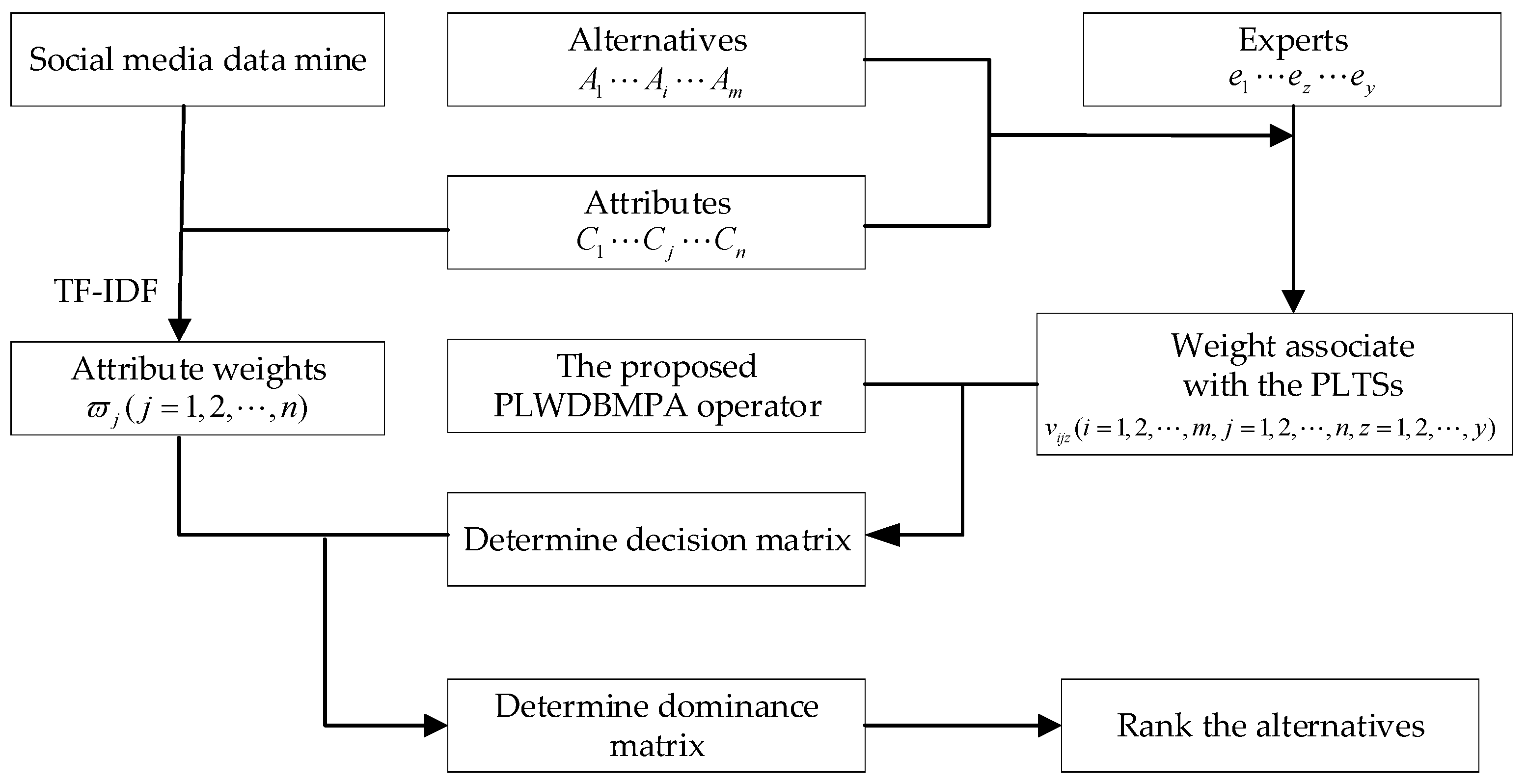
4. Solving Multi-Attribute Group Decision-Making Problem with the PLWDBMPA Operator
4.1. The Problem Description of MAGDM
4.2. The Decision Procedure
- (1)
- The deviation degree between and , which based on the matrix and Definition 5, is calculated as follows:where and are the subscripts of linguistic terms and respectively.
- (2)
- Calculate the support of the alternative on attribute by the result of Definition 11 as follows:
- (3)
- Calculate the support of by all of other based on the result of Definition 11 as follows:
- (4)
- Then, the weight associated with the PLTS is as follows:
5. An Illustrative Example
5.1. Decision Analysis with the Proposed Approach
- (1)
- (2)
- (3)
- By Equation (22), we have the support of by all of other on the attributes , and , the results are as follows:
- (4)
- By Equation (23), we have the weight associated with the PLTS on , and , the results are as follows:
5.2. Comparative Analysis
5.2.1. Comparison with the PL-TOPSIS Method [43]
5.2.2. Comparison with the PLWA Method [43]
5.2.3. Comparison with the PROMETHEE Method [26]
5.2.4. Comparison with the SPOTIS Method [28]
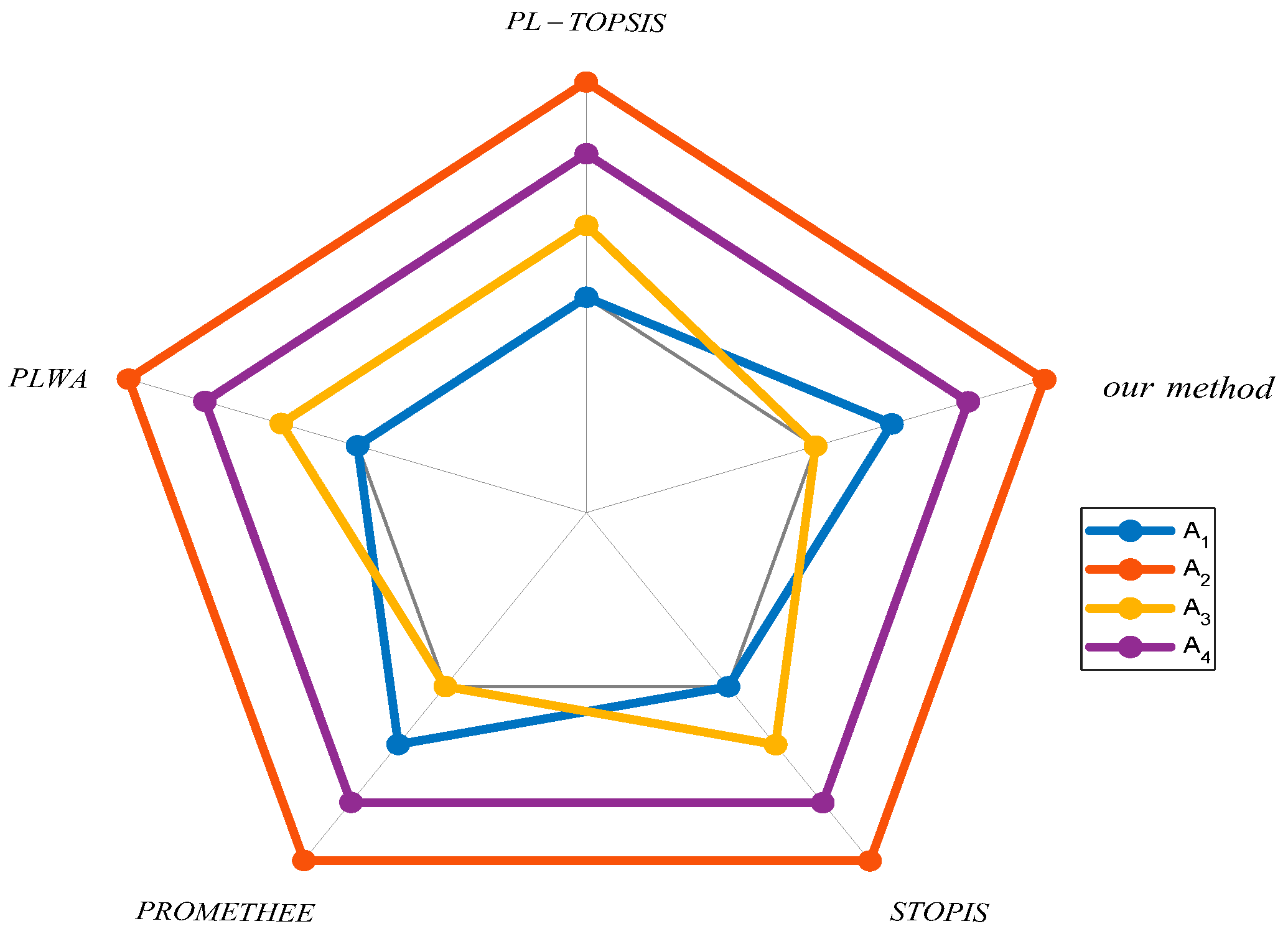
5.3. Visualization of Ranking Results
5.4. The Second Case Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B
References
- Ahmad, N.; Hasan, M.G.; Barbhuiya, R.K. Identification and prioritization of strategies to tackle COVID-19 outbreak: A group-BWM based MCDM approach. Appl. Soft Comput. 2021, 111, 107642. [Google Scholar] [CrossRef] [PubMed]
- Lin, H.; You, J.; Xu, T. Evaluation of Online Teaching Quality: An Extended Linguistic MAGDM Framework Based on Risk Preferences and Unknown Weight Information. Symmetry 2021, 13, 192. [Google Scholar] [CrossRef]
- Han, Q.; Li, W.; Song, Y.; Zhang, T.; Wang, R. A New Method for MAGDM Based on Improved TOPSIS and a Novel Pythagorean Fuzzy Soft Entropy. Symmetry 2019, 11, 905. [Google Scholar] [CrossRef]
- Peng, Y.; Tao, Y.; Wu, B.; Wang, X. Probabilistic Hesitant Intuitionistic Fuzzy Linguistic Term Sets and Their Application in Multiple Attribute Group Decision Making. Symmetry 2020, 12, 1932. [Google Scholar] [CrossRef]
- Wang, J.-X. A MAGDM Algorithm with Multi-Granular Probabilistic Linguistic Information. Symmetry 2019, 11, 127. [Google Scholar] [CrossRef]
- Wang, J.; Li, S.; Zhou, X. A Novel GDMD-PROMETHEE Algorithm Based on the Maximizing Deviation Method and Social Media Data Mining for Large Group Decision Making. Symmetry 2023, 15, 387. [Google Scholar] [CrossRef]
- Yan, L. EDAS-aided intelligent decision-making in interior decoration design quality assessment using 2-tuple linguistic pythagorean fuzzy sets. Int. J. Knowl.-Based Intell. Eng. Systems. 2023, 1–16, preprint. [Google Scholar] [CrossRef]
- Ziemba, P. Energy Security Assessment Based on a New Dynamic Multi-Criteria Decision-Making Framework. Energies 2022, 15, 9356. [Google Scholar] [CrossRef]
- Ahmad, Q.S.; Khan, M.F.; Ahmad, N. Multi-Criteria Group Decision-Making Models in a Multi-Choice Environment. Axioms 2022, 11, 659. [Google Scholar] [CrossRef]
- Stević, Ž.; Zavadskas, E.K.; Tawfiq, F.M.O.; Tchier, F.; Davidov, T. Fuzzy Multicriteria Decision-Making Model Based on Z Numbers for the Evaluation of Information Technology for Order Picking in Warehouses. Appl. Sci. 2022, 12, 12533. [Google Scholar] [CrossRef]
- Dombi, J. A general class of fuzzy operators, the demorgan class of fuzzy operators and fuzziness measures induced by fuzzy operators. Fuzzy Sets Syst. 1982, 8, 149–163. [Google Scholar] [CrossRef]
- Liu, P.; Liu, J.; Chen, S.-M. Some intuitionistic fuzzy Dombi Bonferroni mean operators and their application to multi-attribute group decision making. J. Oper. Res. Society. 2018, 69, 1–24. [Google Scholar] [CrossRef]
- He, X. Typhoon disaster assessment based on Dombi hesitant fuzzy information aggregation operators. Nat. Hazards. 2018, 90, 1153–1175. [Google Scholar] [CrossRef]
- Bonferroni, C. Sulle medie multiple di potenze. Boll. Mat. Ital. 1950, 5, 267–270. [Google Scholar]
- Xu, Z.; Yager, R.R. Some geometric aggregation operators based on intuitionistic fuzzy sets. Int. J. Gen. Systems. 2006, 35, 417–433. [Google Scholar] [CrossRef]
- Liang, D.; Kobina, A.; Quan, W. Grey Relational Analysis Method for Probabilistic Linguistic Multi-criteria Group Decision-Making Based on Geometric Bonferroni Mean. Int. J. Fuzzy Systems. 2018, 20, 2234–2244. [Google Scholar] [CrossRef]
- Zhu, B.; Xu, Z.S. Hesitant fuzzy Bonferroni means for multi-criteria decision making. J. Oper. Res. Society. 2013, 64, 1831–1840. [Google Scholar] [CrossRef]
- Liu, P. Multi-attribute decision-making method research based on interval vague set and TOPSIS method. Ūkio Technol. Ekon. Vystym. 2009, 15, 453–463. [Google Scholar] [CrossRef]
- Yue, Z. An extended TOPSIS for determining weights of decision makers with interval numbers. Knowl Based Syst. 2011, 24, 146–153. [Google Scholar] [CrossRef]
- Opricovic, S.; Tzeng, G.-H. Compromise solution by MCDM methods: A comparative analysis of VIKOR and TOPSIS. Eur. J. Oper. Res. 2004, 156, 445–455. [Google Scholar] [CrossRef]
- Ren, Z.; Xu, Z.; Wang, H. Dual hesitant fuzzy VIKOR method for multi-criteria group decision making based on fuzzy measure and new comparison method. Inf. Sci. 2017, 388–389, 1–16. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, X. Research on the supplier selection of a supply chain based on entropy weight and improved ELECTRE-III method. Int. J. Prod. Res. 2011, 49, 637–646. [Google Scholar] [CrossRef]
- Akram, M.; Luqman, A.; Kahraman, C. Hesitant Pythagorean fuzzy ELECTRE-II method for multi-criteria decision-making problems. Appl. Soft Comput. 2021, 108, 107479. [Google Scholar] [CrossRef]
- Krishankumar, R.; Ravichandran, K.S.; Saeid, A.B. A new extension to PROMETHEE under intuitionistic fuzzy environment for solving supplier selection problem with linguistic preferences. Appl. Soft Comput. 2017, 60, 564–576. [Google Scholar] [CrossRef]
- Akram, M.; Noreen, U.; Pamucar, D. Extended PROMETHEE approach with 2-tuple linguistic m-polar fuzzy sets for selection of elliptical cardio machine. Expert Systems. 2023, 40, e13178. [Google Scholar] [CrossRef]
- Li, P.; Xu, Z.; Wei, C.; Bai, Q.; Liu, J. A novel PROMETHEE method based on GRA-DEMATEL for PLTSs and its application in selecting renewable energies. Inf. Sci. 2022, 589, 142–161. [Google Scholar] [CrossRef]
- Wang, X.; Li, Y.; Xu, Z.; Luo, Y. Nested information representation of multi-dimensional decision: An improved PROMETHEE method based on NPLTSs. Inf. Sci. 2022, 607, 1224–1244. [Google Scholar] [CrossRef]
- Dezert, J.; Tchamova, A.; Han, D.; Tacnet, J.-M. The SPOTIS rank reversal free method for multi-criteria decision-making support. In Proceedings of the 2020 IEEE 23rd International Conference on Information Fusion (FUSION), Rustenburg, South Africa, 6–9 July 2020; pp. 1–8. [Google Scholar]
- Więckowski, J.; Król, R.; Wątróbski, J. Towards robust results in Multi-Criteria Decision Analysis: Ranking reversal free methods case study. Procedia Comput. Science 2022, 207, 4584–4592. [Google Scholar] [CrossRef]
- Sałabun, W.; Piegat, A.; Wątróbski, J.; Karczmarczyk, A.; Jankowski, J. The COMET method: The first MCDA method completely resistant to rank reversal paradox. Eur. Work. Group Series. 2019, 3, 10–16. [Google Scholar]
- Stoilova, S.; Munier, N. A Novel Fuzzy SIMUS Multicriteria Decision-Making Method. An Application in Railway Passenger Transport Planning. Symmetry. 2021, 13, 483. [Google Scholar] [CrossRef]
- Wątróbski, J.; Bączkiewicz, A.; Ziemba, E.; Sałabun, W. Sustainable cities and communities assessment using the DARIA-TOPSIS method. Sustain. Cities Society 2022, 83, 103926. [Google Scholar] [CrossRef]
- Gomes, L.; Lima, M. TODIMI: Basics and application to multicriteria ranking. Found. Comput. Decis. Sci. 1991, 16, 1–16. [Google Scholar]
- Liu, Y.; Bao, T.; Zhao, D.; Sang, H.; Fu, B. Evaluation of Student-Perceived Service Quality in Higher Education for Sustainable Development: A Fuzzy TODIM-ERA Method. Sustainability 2022, 14, 4761. [Google Scholar] [CrossRef]
- Liu, Y.-H.; Peng, H.-M.; Wang, T.-L.; Wang, X.-K.; Wang, J.-Q. Supplier Selection in the Nuclear Power Industry with an Integrated ANP-TODIM Method under Z-Number Circumstances. Symmetry 2020, 12, 1357. [Google Scholar] [CrossRef]
- Xiao, F. Method for classroom teaching quality evaluation in college English based on the probabilistic uncertain linguistic multiple-attribute group decision-making. Int. J. Knowl. Based Intell. Eng. Systems 2023, 1, 1–13, preprint. [Google Scholar] [CrossRef]
- He, X.; Wu, J.; Wang, C.; Ye, M. Historical Earthquakes and Their Socioeconomic Consequences in China: 1950–2017. Int. J. Environ. Res. Public Health 2018, 15, 2728. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Ding, F.; Wang, Z.; Ren, J.; Zhao, J.; Wang, Y.; Tang, X.; Wang, Y.; Yao, J.; Li, Q. A Rapid Public Health Needs Assessment Framework for after Major Earthquakes Using High-Resolution Satellite Imagery. Int. J. Environ. Res. Public Health 2018, 15, 1111. [Google Scholar] [CrossRef] [PubMed]
- Trivedi, A. A multi-criteria decision approach based on DEMATEL to assess determinants of shelter site selection in disaster response. Int. J. Disaster Risk Reduct. 2018, 31, 722–728. [Google Scholar] [CrossRef]
- Xu, Y.; Wen, X.; Zhang, W. A two-stage consensus method for large-scale multi-attribute group decision making with an application to earthquake shelter selection. Comput. Ind. Eng. 2018, 116, 113–129. [Google Scholar] [CrossRef]
- Song, S.; Zhou, H.; Song, W. Sustainable shelter-site selection under uncertainty: A rough QUALIFLEX method. Comput. Ind. Eng. 2019, 128, 371–386. [Google Scholar] [CrossRef]
- Zhang, W.; Yoshida, T.; Tang, X. A comparative study of TF*IDF, LSI and multi-words for text classification. Expert Syst. Appl. 2011, 38, 2758–2765. [Google Scholar] [CrossRef]
- Pang, Q.; Wang, H.; Xu, Z. Probabilistic linguistic term sets in multi-attribute group decision making. Inf. Sci. 2016, 369, 128–143. [Google Scholar] [CrossRef]
- Gou, X.; Xu, Z. Novel basic operational laws for linguistic terms, hesitant fuzzy linguistic term sets and probabilistic linguistic term sets. Inf. Sci. 2016, 372, 407–427. [Google Scholar] [CrossRef]
- Yager, R.R. The power average operator. IEEE Trans. Syst. Man Cybern. Part A Syst. Humans 2001, 31, 724–731. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| 1 | 0.1925 | 0 | 0.1925 |
| 2 | 0.3227 | 0 | 0.3227 |
| 3 | 0.0962 | 0.1232 | 0.0981 |
| 4 | 0.2406 | 0.3081 | 0.0962 |
| 1 | 0.3081 | 0 | 0.3081 |
| 2 | 0.1984 | 0.1984 | 0 |
| 3 | 0.0962 | 0.1456 | 0.1848 |
| 4 | 0.1925 | 0.1925 | 0 |
| 1 | 0.1905 | 0 | 0.1905 |
| 2 | 0.3322 | 0.3322 | 0 |
| 3 | 0.3156 | 0.3156 | 0 |
| 4 | 0.0481 | 0 | 0.0481 |
| 1 | 0.5 | 1 | 0.5 |
| 2 | 0.5 | 1 | 0.5 |
| 3 | 0.6970 | 0.6120 | 0.6910 |
| 4 | 0.6270 | 0.5223 | 0.8508 |
| 1 | 0.5 | 1 | 0.5 |
| 2 | 0.5 | 0.5 | 1 |
| 3 | 0.7745 | 0.6587 | 0.5668 |
| 4 | 0.5 | 0.5 | 1 |
| 1 | 0.5 | 1 | 0.5 |
| 2 | 0.5 | 0.5 | 1 |
| 3 | 0.5 | 0.5 | 1 |
| 4 | 0.5 | 1 | 0.5 |
| Attribute | Keywords Included | Number of Terms | |
|---|---|---|---|
| Scale and location | Contractor, building, campsite, city, etc. | 8 | 0.2581 |
| Accessibility | Security, aftershock, safeguard, hospital, etc. | 13 | 0.4193 |
| Resource availability | Supplies, assistance, container, contribution, etc. | 10 | 0.3226 |
| 0.5000 | 0.2543 | 0.5482 | 0.4180 | |
| 0.7457 | 0.5000 | 0.8460 | 0.7476 | |
| 0.4518 | 0.1540 | 0.5000 | 0.3268 | |
| 0.5820 | 0.2524 | 0.6732 | 0.5000 |
| 0.4301 | 0.5699 | −0.1398 | |
| 0.7098 | 0.2902 | 0.4197 | |
| 0.3582 | 0.6418 | −0.2836 | |
| 0.5019 | 0.4981 | 0.0038 |
| 0.645 | 0.805 | 0.455 | |
| 0.783 | 0.750 | 0.788 | |
| 0.600 | 0.628 | 0.800 | |
| 0.750 | 0.645 | 0.662 | |
| Weights | 0.3 | 0.3 | 0.4 |
| Types | Profit | Profit | Profit |
| Rank | |||||
|---|---|---|---|---|---|
| Our Method | 0.2799 | 1.0000 | 0.0000 | 0.5733 | |
| PL-TOPSIS | −0.6000 | 0.0000 | −0.4920 | −0.2880 | |
| PLWA | 0.2169 | 0.2570 | 0.2255 | 0.2258 | |
| PROMETHEE | −0.1398 | 0.4197 | −0.2836 | 0.0038 | |
| SPOTIS | 0.6264 | 0.1069 | 0.6000 | 0.4866 |
| Coefficient | PL-TOPSIS | PLWA | PROMETHEE | SPOTIS |
|---|---|---|---|---|
| WS | 0.917 | 0.917 | 1.000 | 0.917 |
| RW | 0.740 | 0.740 | 1.000 | 0.740 |
| Rank | |||||||
|---|---|---|---|---|---|---|---|
| Our Method | 0.9332 | 0.4354 | 1.0000 | 0.2378 | 0.0000 | 0.5151 | |
| PL-TOPSIS | −0.1223 | −0.5892 | 0.0000 | −0.5169 | −0.5568 | −0.1505 | |
| PLWA | 0.2397 | 0.2238 | 0.2468 | 0.2194 | 0.2156 | 0.2375 | |
| PROMETHEE | 0.0825 | −0.0413 | 0.1897 | −0.1096 | −0.1057 | −0.0155 | |
| SPOTIS | 0.3270 | 0.6749 | 0.3216 | 0.6865 | 0.6935 | 0.4410 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Zhou, X.; Li, S.; Hu, J. An Extended TODIM Method and Applications for Multi-Attribute Group Decision-Making Based on Bonferroni Mean Operators under Probabilistic Linguistic Term Sets. Symmetry 2023, 15, 1807. https://doi.org/10.3390/sym15101807
Wang J, Zhou X, Li S, Hu J. An Extended TODIM Method and Applications for Multi-Attribute Group Decision-Making Based on Bonferroni Mean Operators under Probabilistic Linguistic Term Sets. Symmetry. 2023; 15(10):1807. https://doi.org/10.3390/sym15101807
Chicago/Turabian StyleWang, Juxiang, Xiangyu Zhou, Si Li, and Jianwei Hu. 2023. "An Extended TODIM Method and Applications for Multi-Attribute Group Decision-Making Based on Bonferroni Mean Operators under Probabilistic Linguistic Term Sets" Symmetry 15, no. 10: 1807. https://doi.org/10.3390/sym15101807