
Ranking Method of Intuitionistic Fuzzy Numbers and Multiple Attribute Decision Making Based on the Probabilistic Dominance Relationship

1
College of Economics and Management, China Three Gorges University, Yichang 443002, China
2
Economics and Management Department, Guangxi Minzu Normal University, Chongzuo 532200, China
3
College of Mathematics and Information Sciences, Guangxi University, Nanning 530004, China
4
Department of Mathematics and Physics, Liuzhou Institute of Technology, Liuzhou 545616, China
*
Author to whom correspondence should be addressed.
Symmetry 2023, 15(5), 1001; https://doi.org/10.3390/sym15051001
Submission received: 19 March 2023
/
Revised: 18 April 2023
/
Accepted: 24 April 2023
/
Published: 28 April 2023
(This article belongs to the Special Issue Fuzzy Set Theory and Uncertainty Theory—Volume II)
Abstract
:The uncertainty of intuitionistic fuzzy numbers (IFNs) is further enhanced by the existence of the degree of hesitation (DH). The shortcomings of existing researches are mainly reflected in the following situations: when comparing IFNs, the comparison rules of IFNs are difficult to apply to the comparison of any two IFNs, or the relevant methods do not fully consider the uncertainty expressed by DH. Thus, the rationality of the decision results needs to be improved. On the other hand, multi-attribute decision making (DADM) based on IFNs is often not objective due to the need to determine the attribute weight. Moreover, the strict condition of attribute aggregation of classical dominance relation makes it a method that fails considering the practical application. Aiming at the comparison problem of IFNs, this paper takes probability conversion as the starting point and proposes an IFN comparison method based on the area method, which can better deal with the comparison problem of “either superior or inferior” IFNs. In addition, aiming at the MADM problem of an intuitionistic fuzzy information system, we propose an intuitionistic fuzzy probabilistic dominance relation model and construct the MADM method under the probabilistic dominance relation. The series properties of IFNs and probabilistic dominance relation were summarized and proved, which theoretically ensured the scientificity and rigor of the method. The results show that the comparison and ranking method of IFNs proposed in this paper can be applied to the comparison of any two IFNs, and the dominance degree of IFNs is presented in the form of probability, which is more flexible and practical than the classical method. The probabilistic dominance relation method based on IFNs avoids the problem of determining attribute weights subjectively or objectively, and the decision maker can reflect decision preference by adjusting decision parameters to better match the actual problem. The application of this model to a campus express site evaluation further verifies the feasibility of the proposed method and the rationality of the results. In addition, various extension problems of the model and method proposed in this paper are discussed, which pave the way for future related research. This paper constructs a complete decision-making framework through theoretical analysis and application from practical problems, which provides a reference for enriching and improving uncertain decision-making theory and the MADM method.
1. Introduction
Since its birth in 1965, fuzzy sets theory [1] has been widely concerned by the academic community and has been widely applied in various fields subsequently as a uncertainty quantification model and method [2,3]. At present, the research on fuzzy sets theory in the academic circle has tended to be mature, and many new concepts and models of fuzzy sets extension have appeared, such as intuitionistic fuzzy sets (IFS) [4,5], hesitant fuzzy sets [6,7], etc. Some scholars integrate fuzzy sets theory with other theories to solve new problems, such as fuzzy rough sets [8,9,10,11], rough fuzzy sets [12,13,14], fuzzy soft sets [15], Pythagorean fuzzy sets [16,17], etc. Regarding the application of fuzzy sets, relevant scholars have also conducted extensive discussions, such as applying intuitionistic fuzzy sets to ensemble learning [18] and emergency logistics plan decision [19], applying hesitant fuzzy sets to sequence recognition [20] and product quality management [21], applying interval fuzzy sets to risk management [22] and transportation problems [23], etc., and achieving fruitful results in a series of studies.
IFS increase the uncertainty of information expression and applicability to practical problems because the uncertainty of fuzzy sets is described by the degree of membership (DM) and degree of non-membership (DN). Therefore, many scholars have conducted researches on IFS, such as distance measure [24,25,26] and similarity measure [27]. In addition, the model generalization of IFS is also studied, such as interval type IFS [28], Atanassov-type intuitionistic fuzzy [29], intuitionistic fuzzy soft sets [30,31], intuitionistic fuzzy rough sets [32,33], intuitionistic fuzzy set and three-way decision [34,35,36,37], intuitionistic fuzzy set and dominance relationship [38,39], and other series of achievements. At present, IFS have achieved good application results in fault diagnosis [40], multi-attribute decision-making [41], incomplete data decision-making [42], deep learning [43], imbalance learning [44], and other fields.
However, it is precisely because of the introduction of the degree of non-membership (DN) and the degree of hesitation (DH) in IFS, and there is no unified standard for the treatment of DH in the academic circle, so the comparison of intuitionistic fuzzy numbers (IFNs) has become a problem that researchers continue to explore. Atanassov K [4] defined the inclusion relation of fuzzy sets from the perspective of sets. Wei C P et al. [45] believed that the uncertainty of IFS was reflected in fuzziness and intuitionality. The fuzziness was determined by the difference between its DM and DN, while the intuitionality was determined by its DH, and the entropy measurement formula of IFS was proposed based on this. Sevastjanov P [46] proposed a new comparison method for intuitionistic fuzzy numbers that can deal with real, interval and fuzzy values. Some scholars often do not consider the influence of DH when measuring IFS. For example, Wang Y [47] and Zhao F X [48] only measured the distance between IFS with the difference between DM and DN; Li YH et al. [49] proposed a unified ranking method of intuitionistic fuzzy numbers and Pythagorean fuzzy numbers based on area characterization, but they also did not consider the influence of DH. Ye J [50] defined cosine similarity of IFS, but did not consider the influence of DH, so it is easy to get unreasonable comparison results. Xie J M et al. [51] put the DH in the same position as the DM and DN when considering the distance measure. Xu C L et al. [52] equally divided the DH into the DM and the DN, and proposed its distance measure by constructing a four-dimensional space.
In summary, the current research on IFS mainly has the following deficiencies: First, most literature does not consider the DH enough, or choose to ignore the DH, which may lead to information loss and unreasonable decision making. In other studies, DM, DN, and DH are processed in the same way. However, as DH is not completely independent of DM and DN, information redundancy will be caused to a certain extent. Second, most research results based on the integration of IFS and rough sets consider the inclusion relationship between fuzzy sets from the perspective of sets, calculate the upper approximation and lower approximation of concepts, or take classification as the purpose; in contrast, there are few studies for the purpose of evaluation and ranking.
Given the current academic research on IFS, this paper proposes a comparison method of intuitionistic fuzzy numbers considering the DH and then constructs a MADM method for intuitionistic fuzzy numbers based on probabilistic dominance relations. The main contributions of this paper are as follows:
(1) In view of the problem that the comparison and measurement of IFNs in the current research do not fully consider the DH, this paper proposes a comparison and ranking method of IFNs based on DN conversion, and by constructing the number of fuzzy intervals, the comparison of intervals based on the geometric area method is carried out and finally converted into the comparison probability of IFNs. This method can be applied to the comparison of any two IFNs, and fully considers the influence of the size of DH on the comparison of IFNs, expands the comparison method of IFNs, and obtains more reasonable results.
(2) The classical rough sets model of dominance relation often faces failure in practical decision-making problems due to the requirement of the construction of its dominance class to satisfy the condition that all attributes are simultaneously dominant. Therefore, for intuitionistic fuzzy information systems, this paper proposes a MADM method based on probabilistic dominance relations. By setting parameters α and β as the threshold of IFNs comparison and multi-attribute dominance class construction, respectively, the method can effectively solve the situation that the classical dominance relation is easy to fail, which makes the method more widely applied and robust. In addition, the method of element comparison based on the dominance class is improved and the decision steps are given. It is helpful to further develop the theory and method of uncertain decision-making theory and method based on fuzzy sets and rough sets, and improve the theory and application research of MADM.
The following chapters of this paper are arranged as follows: Section 2 is a review of basic knowledge, Section 3 is a comparison and ranking method for IFNs based on probability conversion and the area method, Section 4 is an intuitionistic fuzzy probabilistic dominance relationship and the MADM method, Section 5 is a case application analysis, Section 6 is a discussion, and Section 7 is a conclusion.
2. Basic Knowledge
In this section, the basic concept of IFS is reviewed briefly to lay a foundation for subsequent research.
Definition 1.
([4]). Let be a non-empty finite universe, and an IFS on is defined as , where indicate the degree of membership (DM) and degree of non-membership (DN) that element in belongs to IFS , and for , , : and : represent membership functions and non-membership functions of on , respectively. Let be the degree of hesitation (DH) of for set , and is obvious. For , is the intuitionistic fuzzy number (IFN) of under set .
For the sake of simplification, is generally used to represent the IFN; then, , and .
Definition 2.
Example 1.
If
,
and
are three IFNs, then it can be seen from Definition 2 that
and
are valid, but
and
cannot be compared according to Definition 2.
As shown in Example 1, there are two problems in the comparison of IFNs. First, this rule cannot give comparison results for any two IFNs, which greatly limits the application of IFNs in MADM. Secondly, for the IFNs that can be compared according to Definition 2, the comparison results are often irrational. This is because the existence of DH makes IFNs have greater uncertainty. If the DH is converted into DM or DN under certain conditions, the conclusion of is not always valid. If the DH of is converted into DM and the DH of is converted into DN, namely , , then and are available. Obviously, the comparison result at this time should be , although this conversion is not an inevitable result. However, the above example at least shows that there is a possibility of , and it cannot be directly determined that is satisfied with and .
3. Comparison of IFNs Based on the Area Method
Definition 3.
Let
and be two IFNs satisfying , , namely , . Therefore, if and only if and . In particular, if and only if and .
On the basis of Definition 2, Definition 3 makes a further strictly defined, that is, when there is no DH in IFNs, the comparison of IFNs can be made according to Definition 2.
In fact, in Definition 3, if and are satisfied, then there will be when . Therefore, for IFNs without DH, the IFN can be sorted by the comparison of DM directly.
Definition 4.
Let
be an IFN, . For , let be an -probability conversion of the IFN of . Obviously, satisfies .
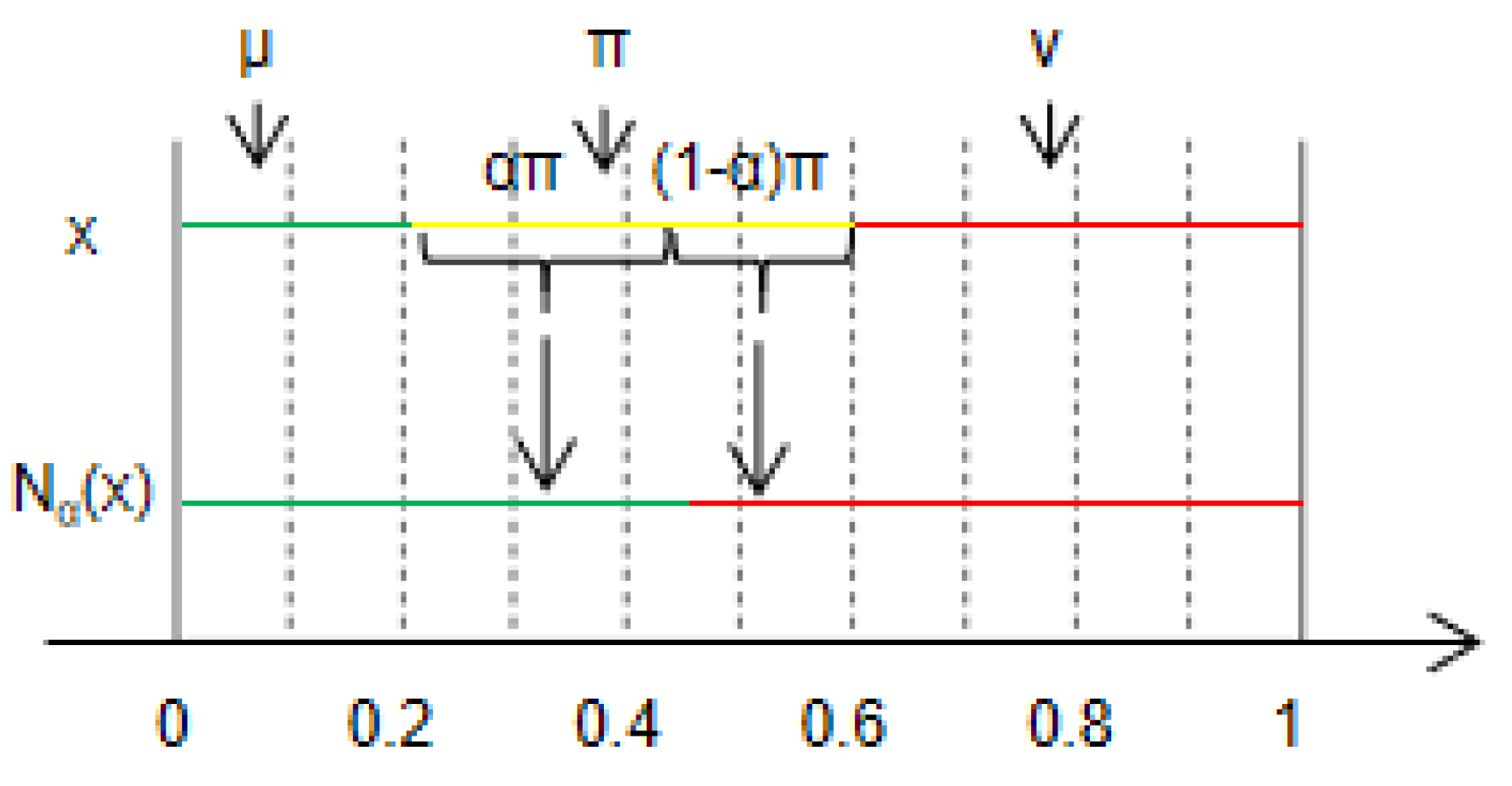
According to Definition 4, the DH of IFNs can be further clarified and converted into DM or DN of fuzzy numbers. As shown in Figure 1, the part near the left expresses the concept of certainty belonging, namely DM; the part near the right expresses the concept of certainty unbelonging, namely DN; and the middle part expresses the concept of uncertainty, namely DH. According to the assumption of probability conversion, if we convert part of π of DH into DM, the part of DM will become larger, and if we convert another part of π of DH into DN, the part of DN will also become larger. Through this probability conversion, the uncertain attribution problem of IFNs is eliminated to a certain extent, so as to enhance the comparability of IFNs.
It can be seen from Definition 4 that when , , that is all the DH is converted into DN, then the degree of “non-belonging” reaches the maximum. When , , that is the DH is completely converted into the DM, then the degree of “belonging” reaches the maximum. When , the DH is divided into two parts, which are converted into DM and DN using and , respectively.
Although all IFNs can be converted into another IFNs without DH according to Definition 4, then all IFNs without DH can be compared and sorted according to Definition 3. However, the actual problem is not so simple, because the conversion probability is difficult to determine; in other words, when the value of is different, different comparison and sorting results will be obtained, as shown in Example 2.
Example 2.
Let and be two IFNs. Obviously, and cannot be compared according to Definition 2. Take respectively, then:
, , there is .
, , there is .
, , there is .
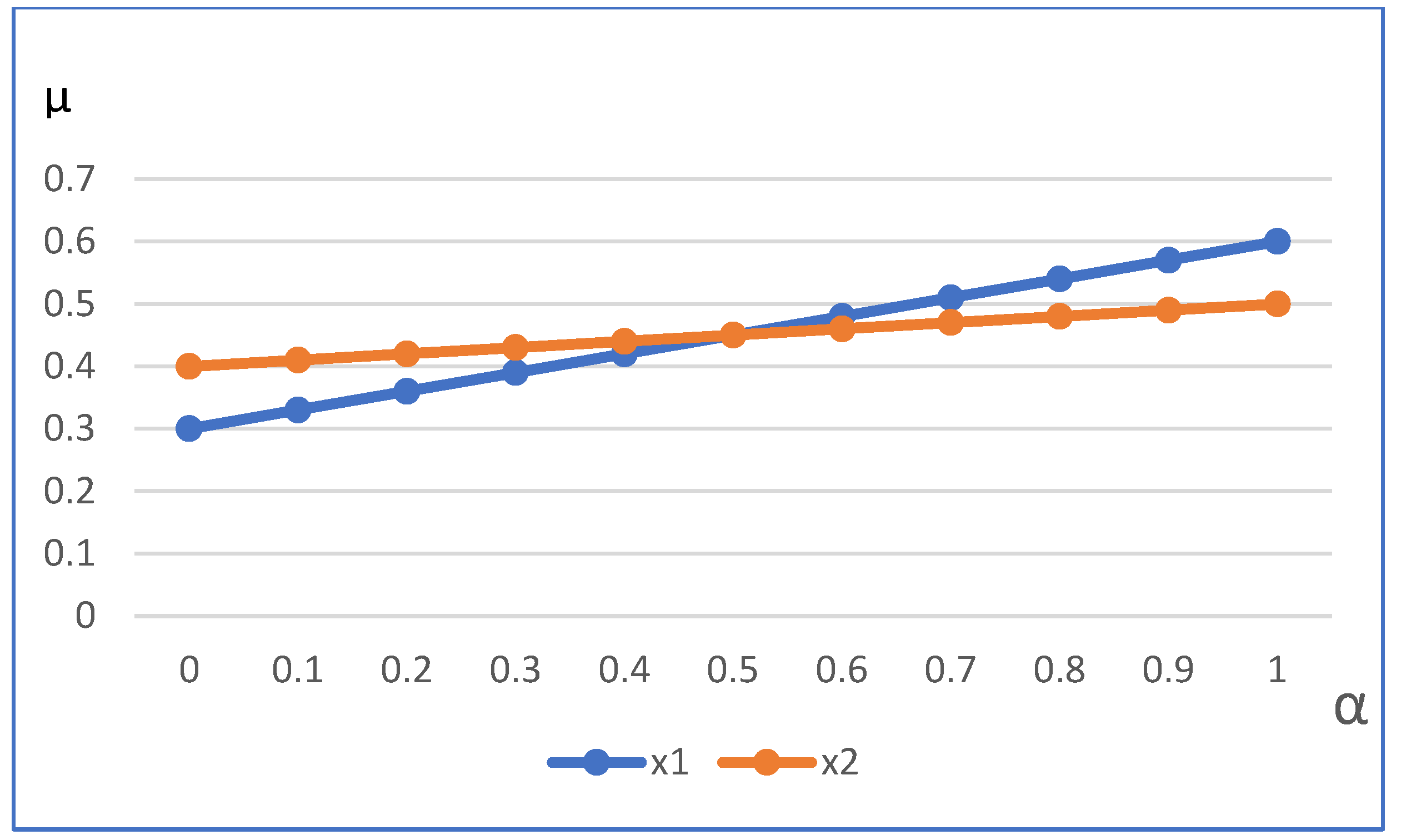
The result of Example 2 shows that when the conversion probability takes different values, completely different comparison results may be obtained. We can further draw the variation trend of DM of and after conversion with conversion probability through Figure 2. Since the probability conversion formula is linear, the conversion DM of and also follows a linear trend. The conversion DM of and increases with the increase of , which is monotonous. The relative comparison of conversion DM between and with 0.5 as the dividing line, when , there is , when , there is , if and only if , there is .
In view of this, we cannot artificially give the conversion probability, because it is difficult to give itself; in addition, for different IFNs, the conversion probability does not have to be the same. Therefore, the comparison of IFNs cannot be made simply using a given conversion probability. However, probability conversion still provides an effective idea for the comparison of IFNs. In practice, we can compare and analyze all possible conversion cases with an “exhaustive method”, and finally, give a reasonable conclusion for the comparison of IFNs in the form of probability.
Definition 5.
Let
and be two IFNs, , , denoting and as the DM conversion interval of IFNs and , then the dominance degree of relative to can be formalized as , Where is the joint probability density of random variables and , the value range of corresponds to , and the value range of corresponds to . is the integral region for comparing constructed via DM conversion interval and of IFNs and , namely .
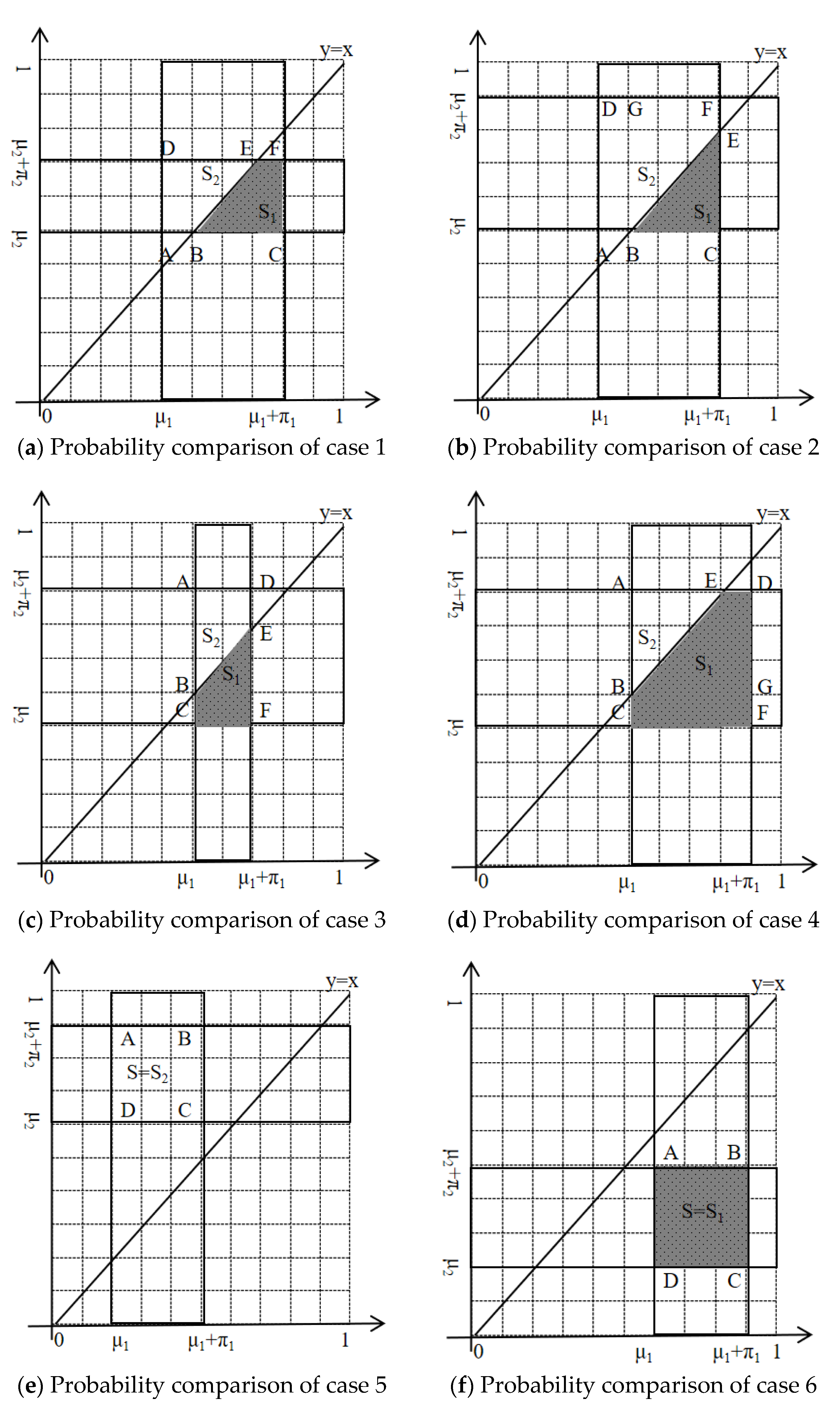
The specific expression of in Definition 5 explicitly depends on the relative size relationship between , which can be discussed in 6 cases as follows:
Case 1: ; currently, the position relationship is shown in Figure 3a. The rectangular ACFD is divided into two parts via the first quadrant diagonal . The area of the trapezoid EFCB in the lower right corner is denoted as , and the area of the trapezoid ABED in the upper left corner is denoted as , then , .
As shown in Figure 3a, , , so . Then , , , so . , , , then . There is:
, , it is easy to verify , .
Case 2: , the position relationship is shown in Figure 3b, and the other symbol marks and interpretation are the same as Case 1.
As shown in Figure 3b, , , so . Because , there is . The calculation of needs to divide the pentagon ABEFD into rectangular ABGD and trapezoidal EFGB, and , , so . Because , , , so , then . Thus,
Case 3: , and the position relationship is shown in Figure 3c.
As shown in Figure 3c, , , so . Because , , , so . With , , , then . Hence,
Case 4: , and the position relationship is shown in Figure 3d.
As shown in Figure 3d, , , so . The calculation of needs to divide the pentagonal BCFDE into rectangular BCFG and trapezoidal EDGB, and , , so . Because , , , so , . , . Hence,
Case 5: , the position relationship is shown in Figure 3e. Obviously, , , i.e., , .
Case 6: , the position relationship is shown in Figure 3f. Obviously, , , i.e., , .
By summarizing the above 6 cases, we can obtain:
From the above 6 cases, it is not difficult to see that case 3 has a “symmetric” relationship with case 1, case 4 has a “symmetric” relationship with case 2, and case 6 has a “symmetric” relationship with case 5. The concrete embodiment of this “symmetric” relationship is as follows: first, the position is symmetric about , and second, the probability value of comparison is symmetric and complementary.
In fact, according to the solution formula in 6 cases above, we can define the formal integral of probability comparison in Definition 5 as follows:
where is the joint probability density of random variables and under uniform distribution. Taking case 1 as an example, the above equation can be concretized as follows:
The calculation results are completely consistent with case 1 in Definition 5, and the remaining five cases can be solved in the form of integrals in the same way. Limited by space, we will not repeat them here.
Property 1.
Let , and be any three IFNs, then:
- (1)
- ;
- (2)
- ;
- (3)
- ;
- (4)
- if ;
- (5)
- if ;
- (6)
- if ;
- (7)
- if ;
- (8)
- if , , then ;
- (9)
- if , , then ;
- (10)
- if , , then .
Proof.
Properties (1) and (2) are obviously true from the six cases in the above equation.
(3) On the one hand, let , then there is , , . Substituting and into case 1 to case 4 in the above formula, the conclusion of can be obtained. On the other hand, according to property (2), let , there is also , i.e., .
(4) Adequacy: if , it conforms to case 5, i.e., , since , so . Necessity: If , then there is , which obviously conforms to case 5, then can be obtained.
(5) Adequacy: if , it conforms to case 6, that is . Because of , there is . Necessity can also be proved; this is omitted.
(6) Adequacy: if , it corresponds to part of cases 1 and 3. In case 1, it is satisfied that AB = EF, where,
, , and then there is , that is , i.e., . In case 3, BC = DE, with , , we have , that is , i.e., . Necessity can also be proved; this is omitted.
(7) Adequacy: It can be further verified on the basis of property (6). In case 1, if AB ≤ EF is satisfied, there is , and can be obtained via simplification. In case 3, if BC ≥ DE is satisfied, then we have , which is simplified to . Necessity can also be proved; this is omitted.
(8) According to property (4), if , then , and if , then . Obviously, , which is ; then, we have , so is true.
(9) According to property (5), if , then , and if , then . Obviously, , which is ; then, we have , so is true.
(10) According to property (7), if , then , and if , then . Obviously, , so is true. □
Definition 6.
Let
be a set of the universe containing IFNs. For , let represent the dominance degree of relative to , then represents the dominance matrix on , and further define the comprehensive dominance degree of each object as , where .
The IFNs on can be sorted and compared according to the value of .
4. Intuitionistic Fuzzy Probability Dominance Relation and Multi-Attribute Decision-Making
Definition 7.
We call
an intuitionistic fuzzy information system (IFIS), where is the non-empty finite universe, is the non-empty finite attribute set, , that is , is a IFN, is the intuitionistic fuzzy set of different objects under different attributes, and is a partial order set under attribute .
Definition 8.
Let
be the IFIS, for
,, denote
as the binary judgment of the probability dominance value of object relative to under attribute ; furthermore, let , and the intuitionistic fuzzy probability dominance relation (IFPDR) of on is defined as , where represents the number of attribute sets, and are the threshold of IFPDR, generally , .
Based on IFPDR, we can define the intuitionistic fuzzy probability dominance class of object under attribute sets as . For , its meaning is based on the probabilistic dominance comparison rule of IFNs. Under all attributes, is superior to with a probability of no less than and the attribute proportion is no less than . Similarly, the intuitionistic fuzzy probability inferiority class of object under attribute sets can be defined as .
Taking and as thresholds to define the IFPDR, the main starting point is based on the consideration of practical problems. In the realistic MADM, it is difficult to make objects meet the strict superiority and inferiority relationship under all attributes, and too strict parameter setting often leads to the decision failure. Therefore, relaxing the comparison requirement between objects is more helpful to obtain reasonable results for MADM problems.
In particular, when , it is required that the relationship of probabilistic superiority or probabilistic inferiority between objects is satisfied under all attributes; when , it is required that the IFNs themselves have an absolute relationship between superiority or inferiority; when , it means that the object represented by IFNs has an absolute relationship between superiority or inferiority under all attributes, which is difficult to satisfy in MADM. Therefore, by introducing parameters and as the decision threshold, decision-makers can adjust the threshold according to the actual situation in practical problems. According to the “half rule”, and should not be lower than 0.5.
Property 2.
Let be an IFIS. For , , , there is:
- (1)
- ;
- (2)
- ;
- (3)
- ;
- (4)
- .
The proof of property is obvious and omitted here.
Definition 9.
Let
be the
IFIS,
is the
IFPDR of
on , then
is the intuitionistic fuzzy probability dominance intercept matrix of
on
, where the corresponding relation between
and
is:
Definition 10.
Let
be the IFIS, is the intuitionistic fuzzy probability dominance intercept matrix of on , is the intuitionistic fuzzy probability dominance matrix of on , and be the average dominance degree of object .
The above definition of the dominance matrix is equivalent to , that is, the intersection of the object set dominated by and the object set not inferior to is taken as a measure of the degree to which is superior to . In MADM, all objects can be sorted according to the value of .
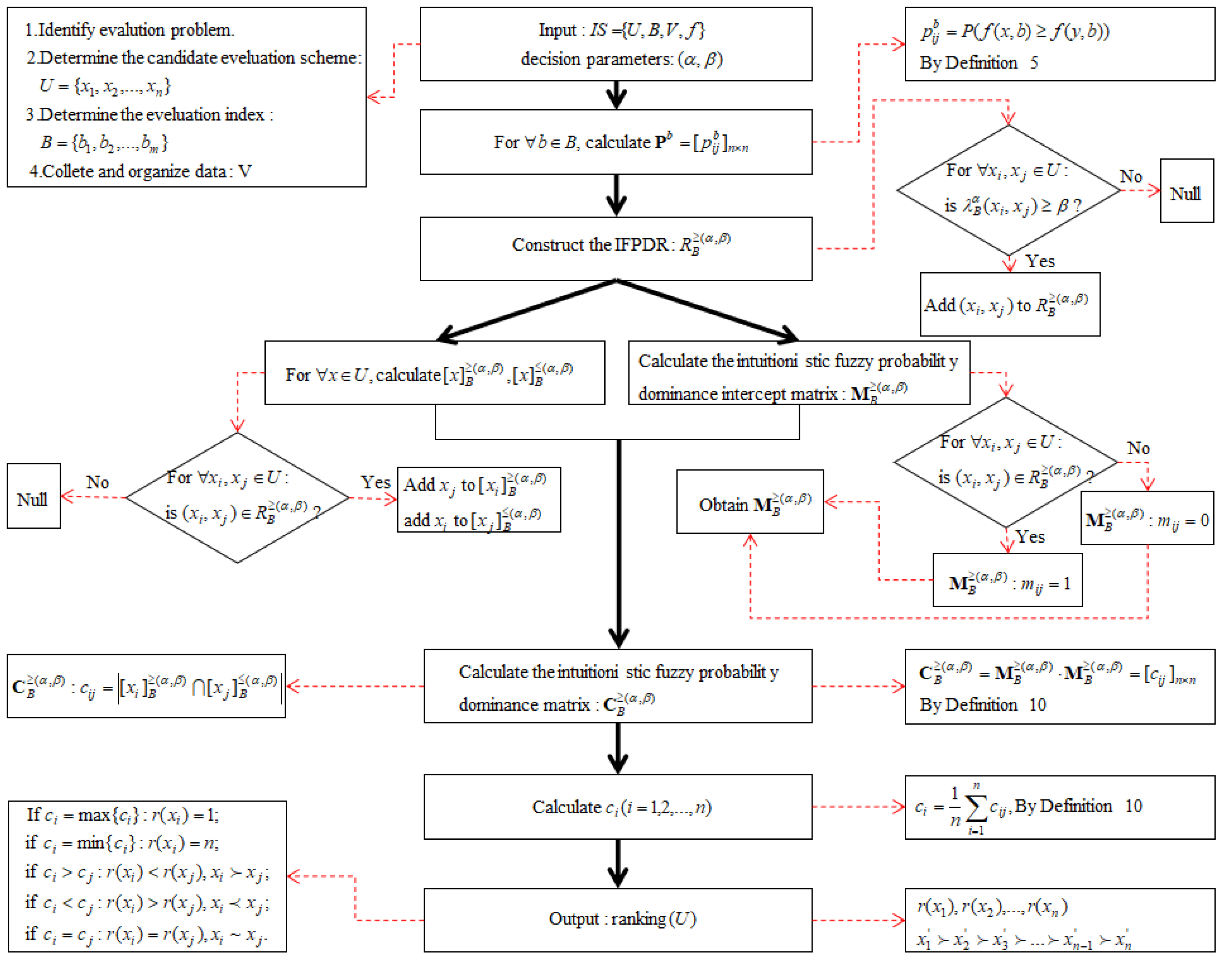
Combined with the above analysis, the steps of this paper’s probability dominance relation for MADM based on IFNs can be summarized as follows (as shown in Figure 4):
Step 1: For , calculate the dominance degree of pairwise comparison of objects in domain ;
Step 2: Construct the IFPDR and intuitionistic fuzzy probability dominance intercept matrix according to ;
Step 3: Calculate the intuitionistic fuzzy probability dominance matrix according to ;
Step 4: Calculate the average dominance degree according to , and sort the objects and schemes according to the value of .
5. Case Application and Analysis
With the rapid development of social economy, e-commerce has gradually become a new industry and a link between commodities and consumers all over the world. Online shopping has also increasingly become a new consumption mode for contemporary young people and is becoming increasingly popular. In particular, the prevalence of COVID-19 between 2019 and 2022 has further promoted the development of e-commerce. In online shopping choices, logistics and distribution problems often become the key factors for consumers to choose whether to buy or not. After all, we do not want to have the situation that there is no delivery a week after we place an order, or the embarrassment caused by the logistics delay that makes the online gift miss a friend’s birthday. Therefore, the quality of logistics services largely determines whether a region or consumer group chooses online consumption.
In order to evaluate the service quality of express delivery points in a university and provide reference for them to improve the service quality, we designed the corresponding questionnaire. Through field visits and observation, we found that there are altogether 10 express delivery companies settled in M university with branches. They are SF Express, YTO Express, ZTO Express, STO Express, Best Express, TTK Express, Yunda, CPEL, JD Express, and Jitu Express. Therefore, we took the service branches of these 10 express delivery companies as the investigation objects. The evaluation indexes of logistics service quality are obtained by referring to relevant literature, consulting experts in the field and communicating with teachers and students of M university. Finally, through discussion and screening, nine factors are determined as the evaluation indexes of logistics service quality. They are price, delivery speed, service attitude, service professionalism, timeliness of logistics information update, rationality of delivery time, integrity of products and packaging, remedial measures taken for service errors, and popularity of express companies. When constructing the information table, we mark the 10 service outlets of express enterprises to be evaluated as , and the 9 evaluation indexes affecting the quality of logistics service as .
In order to construct the data table in line with the form of IFNs as objectively as possible, when assigning values to the indexes of each express company, the questionnaire only sets three options for the attribute value of each index , which are respectively “good”, “poor” and “unclear”. If the respondents approve the performance of a courier company under this index, they choose “good”; if the respondents do not approve the performance of a courier company under this index, they choose “bad”; in particular, if the respondents have not used the relevant services of a courier company, or do not have a deep impression and understanding of a courier company so that it is difficult to judge, they can choose “unclear”.
Based on the above survey objectives and questionnaire design, a questionnaire was issued to teachers and students of M university to solve this problem. The questionnaire was made through the network and released through social software in December 2022. A total of 508 valid samples were collected. According to the number of respondents for each option, the proportions of “good”, “bad”, and “unclear” were calculated as the DM, DN, and DH of the IFNs, and the original data information table is shown in Table 1.
(1) Calculate the dominance degree under each attribute. Take as an example, and the results are as follows:
Taking the solution of as an example, the calculation process is briefly shown as follows:
In the attribute set of , the values of and are and respectively (The attribute tag is omitted here for convenience of expression). Further calculation of its DH can be seen as follows:
Since 0.51 < 0.69 < 051 + 0.30 < 0.69 + 0.22, case 4 in Definition 5 is satisfied, namely:
then can be calculated as follows:
Other data in can be similarly obtained.
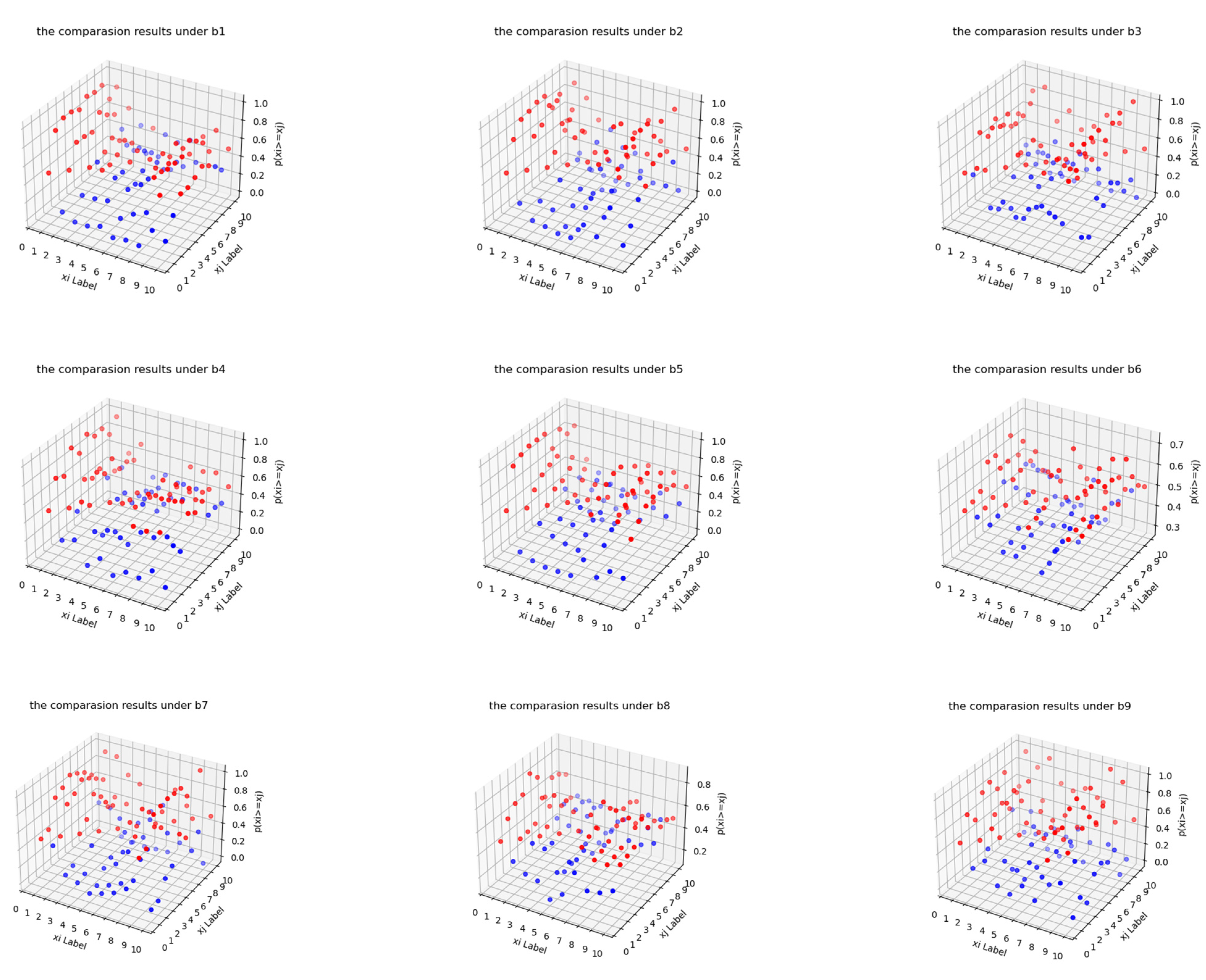
, ,..., can be obtained in the same way; this is omitted due to space limitations. However, in order to display the results more intuitively, we draw the 9 comparison matrix results of into the following figure (as shown in Figure 5), where the horizontal coordinate 1–10 represents from to , the vertical coordinate 1–10 represents from to , and the vertical coordinate represents the probability that the IFNs is greater than . In order to better distinguish the relationship between the advantages and disadvantages of objects, we use different colors for display. When , red marks are used; when , blue marks are used.
(2) Take and , then the IFPDR can be obtained.
The corresponding intuitionistic fuzzy probability dominance intercept matrix is as follows:
For example: because of , so , and , so (The first number in parentheses represents the row of the elements in the matrix , and the second number represents the column of the elements in the matrix).
(3) The intuitionistic fuzzy probability dominance matrix can be obtained from the calculation formula in step 3 as follows:
For example: denote the second row of as
denote the third column of as
then can be calculated as
Moreover, we can also compute it in terms of sets, as .
When
then , and .
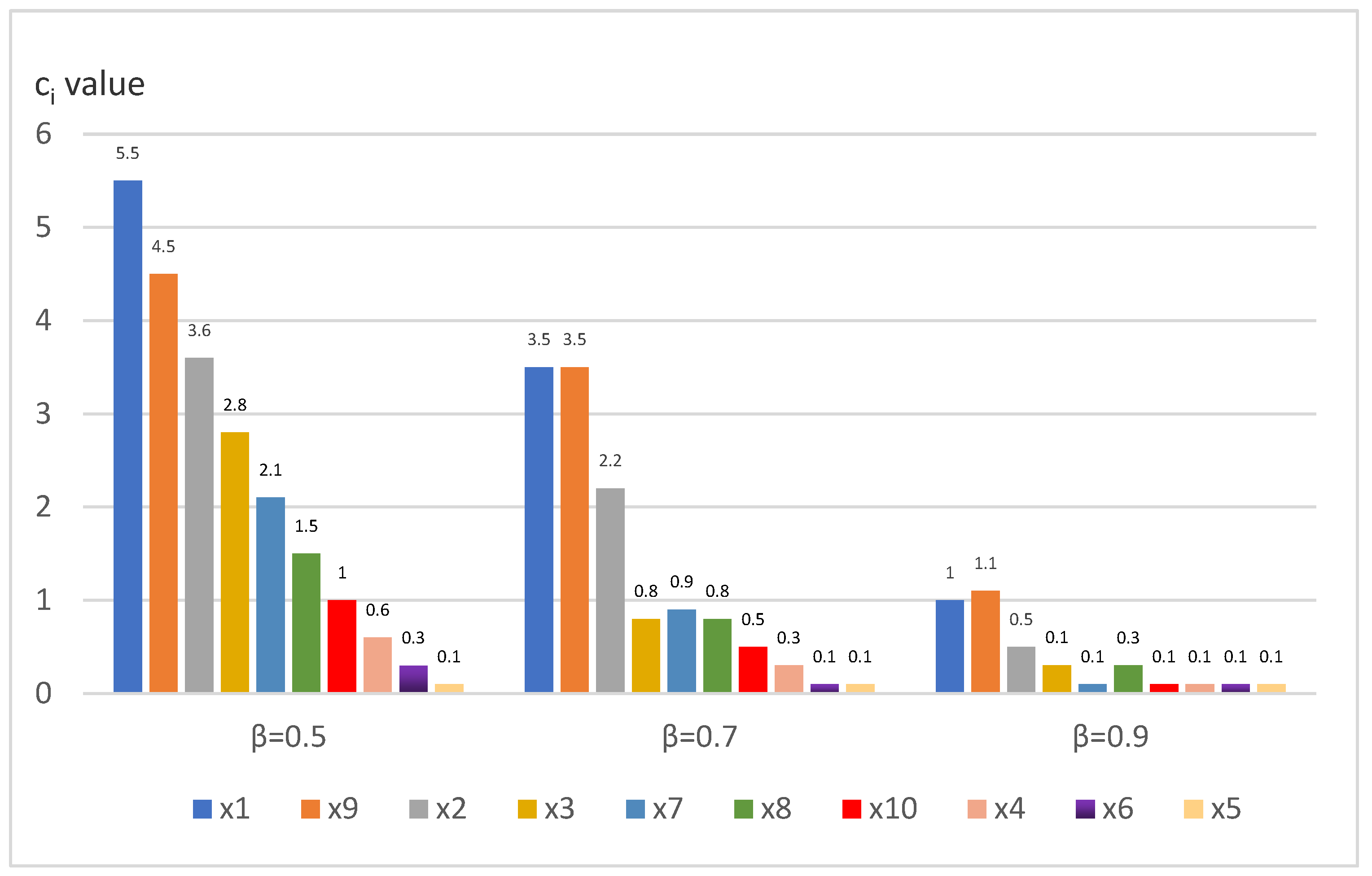
(4) By averaging all lines in by step 4, the comprehensive dominance degree of each object can be obtained. In order to further test the influence of parameter , is taken for repeated calculation, and the results are shown in Figure 6 and Figure 7.
For example: when , (as shown in Figure 6), other values can be obtained similarly.
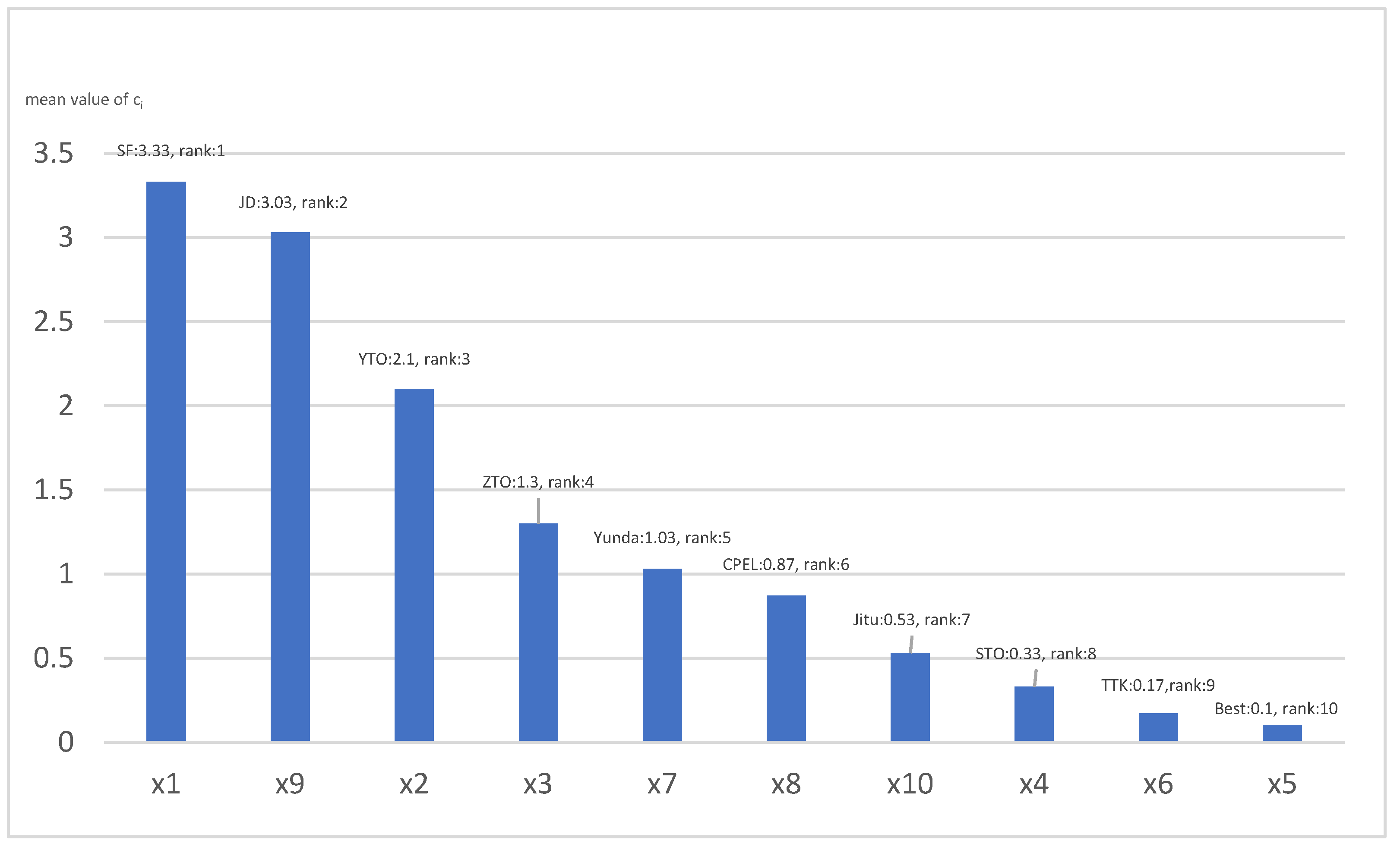
As can be seen from the results of Figure 6, when , it has the strongest differentiation ability and can better distinguish all objects without the situation of parallel ranking. When , , and are all the undifferentiated comparison results; when , and are all the undifferentiated comparison results. It can be seen that the larger is, the weaker the differentiation ability will be, and there will be many cases that cannot be compared. However, the sorting results under different values are not completely consistent, and even reverse order may exist. Therefore, the final result can be the average of the three scenarios. The ranking result is shown in Figure 7, that is, SF Express has the strongest overall strength, followed by JD Express, and Best Express has the worst ranking. This result is basically consistent with the value of the original data and the result of pair-to-pair comparison. Under most indexes, SF Express and JD Express have relatively large DM but relatively small DN while Best Express has relatively small DM and relatively large DN. In the pairwise comparison of objects, there are only five times of probability comparison value less than 0.5 in 90 comparisons of nine indexes of (SF Express), and only six times of probability comparison value less than 0.5 in 81 comparisons of (JD Express) with the exception of comparing to . In contrast, (Best Express) only had eight times of probability comparison value greater than 0.5. Therefore, we believe that this ranking result is in line with the actual situation and reasonable.
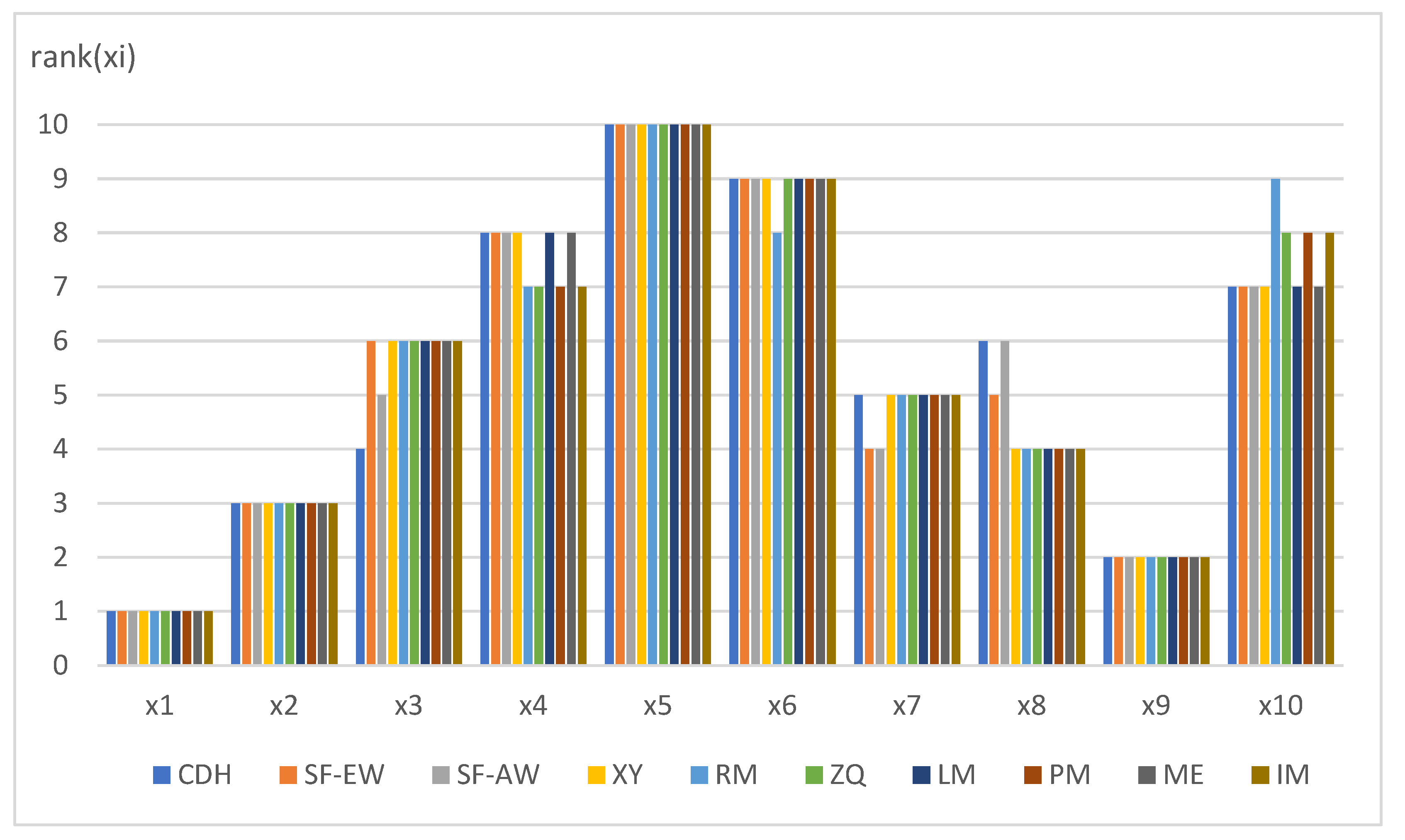
In order to further verify the rationality and effectiveness of the proposed algorithm, various algorithms mentioned in literature [28,53] are selected for comparative analysis, and the final ranking results are shown in Figure 8.
Note: The comparison algorithm in Figure 6 is explained as follows:
Method ① (CDH): The conversion of the DH model proposed in this paper, and the results are as shown in Figure 8.
Method ② (SF-EW): the score function with the entropy weight method, from the literature [28]. Firstly, the score function is calculated for the direct fuzzy number under each attribute. Then, based on the score function, the entropy weight method is used to calculate the weight. Finally, the scheme ranking results are obtained by calculating the comprehensive score function.
Method ③ (SF-AW): the score function with the average weight method, which was obtained from the literature [28]. The value of each attribute is aggregated via the average weight, and other parts are the same as the SF-EW.
Method ④~⑩ (XY, RM, ZQ, LM, PM, ME, and IM): They are all from the literature [53]; the comparison formula of intuitionistic fuzzy numbers refers to the original text. The attribute aggregation methods all adopt the addition principle of multiple intuitionistic fuzzy numbers. In the ZQ method, parameter k = 1.
From Figure 6, we can see that the ranking results of elements under most of the ranking methods are consistent, which also validates the effectiveness of various methods (for example, the ranking results of , , and under the 10 methods are unchanged, and the ranking results of , , and under different methods differ by 1 bit). It is worth noting that the ranking results of and in this paper differ by 2 bits from those of other comparison methods, and there is a reverse order between them. In other literature, the ranking result is , while the ranking result in this paper is , and we think the ranking result in this paper is more reasonable. As can be seen from the original data, according to the comparison results of this paper, all of the five attributes of meet , and the proportion of their dominance attributes is 5/9, exceeding the threshold of 0.5. Therefore, it is reasonable to determine the final result as .
6. Discussion
This paper mainly focuses on two aspects. First, aiming at the problem that the IFNs are difficult to compare, we convert the DH into the DM and DN and use the probability method to realize the comparison of IFNs. This method draws on the comparison rules of interval numbers to some extent, but it has strong applicability and can be compared against any IFNs. Secondly, for the MADM problem, we constructed the MADM method based on the probability dominance relation in the form of IFNs. This method does not need to give the weight of different attributes subjectively, the decision result is driven by the original data, and the threshold α and β can be adjusted according to the decision preference of the decision-maker. The proposed method can be well applied to real decision-making problems, and it has wide application prospects.
About the comparison of IFNs, the current research methods mainly propose various measurement formulas for a single IFN, such as score function, precision function and other indicators, and then calculate its indicator value for each IFN, so as to compare between different IFNs. Among these measurement indicators, the measurement formulas in many studies do not consider the influence of DH on the ranking of IFNs, or deal with DH in the same way as DM and DN, and do not fully consider the information uncertainty expressed by DH itself. Relevant scholars often lack an explanation of actual meaning in the measurement formulas they propose. Therefore, the comparison of IFNs in this paper does not measure a single IFN, but is based on the comparison of a pair of IFNs. In the form of paired comparison, the comparison result is not “either–or” ( or ), the comparison result of two IFNs is presented in the form of probability. This method provides a more widely applicable expression for the comparison of IFNs, so that decision makers can choose results under different decision thresholds rather than the only comparison results.
For the MADM problem, the current research mainly aggregates the values under different attributes by constructing various weight operators, but the weight determination is also a difficult problem in the decision-making process. Some scholars use the subjective method to determine the weight, only to verify the feasibility of the method from the perspective of examples, but rarely discuss the sensitivity of the influence of different weights on the decision results. In addition, some scholars adopt the objective weighting method. Common methods mainly include the optimization weight method and entropy weight method, but the optimization method is difficult to calculate the weight. In contrast, the MADM method constructed based on the probability dominance relationship in this paper calculates the proportion of attribute sets satisfying the comparison of advantages and disadvantages by setting thresholds, effectively avoiding the direct aggregation of attributes, and eliminating the need to manually determine attribute weights, thus making the decision results more objective. Compared with the classical dominance relation, the probabilistic dominance relation in this paper appropriately loosens the conditional restrictions, allowing decision-makers to reflect their personal preferences by adjusting the threshold within a certain range. Under extreme conditions, it can also degenerate into the classical dominance relation, which makes the decision results more widely applicable and avoids the decision failure situation, which is easy to exist in the classical dominance relation.
Regarding the two aspects of the research in this paper, further discussion and expansion can be carried out as follows: regarding the comparison of IFNs, this paper did not consider the distribution form of DH as a random variable when converting DH into DM and DN. In the actual analysis of this paper, we derived it according to the simplest uniform distribution form. In fact, if further research is carried out, we can assume the distribution form of random variables in the conversion of DH to be normal distribution, exponential distribution, T-distribution and other forms for more systematic exploration and research. In addition, when constructing the judgment matrix of pairwise comparison, we set the restriction condition of parameter α > 0.5, which requires at least half of the probability of dominance. For this purpose, we can also consider lowering the threshold α further, such as α > 0.3, because the conversion of DH itself has a large uncertainty, so we can assume that as long as has a 30% probability of superiority over , still has a high probability of defeating in the final “duel”. Alternatively, when the decision maker is particularly strict, they may set the threshold α as α > 0.8, which means that a very high probability of dominance is needed to ensure that is superior to . However, at this time, we will face a problem, that is, the intercept matrix induced by the dominant probability judgment matrix does not satisfy the symmetric complementarity, which makes part of the mathematical properties of the intercept matrix no longer maintained, but it still can give a decision result.
On the other hand, in the MADM model, we construct the decision method based on the probabilistic dominance relation. Here, we still need to determine another threshold β, that is, the lower limit of the proportion of the dominant object when two objects are compared. In this model, we take β > 0.5 as the basic principle. In the case application of Section 5, we discuss β = 0.5, β = 0.7, and β = 0.9, respectively. Similar to the threshold α, we can also consider lowering β below 0.5, which helps each object gain more dominance class elements, but when β is too small (e.g., β = 0.1), this condition becomes almost meaningless. In addition, regarding the setting of threshold α and β, we should follow a “When one is rising, the other is falling” principle, that is, when α is set high, β can be appropriately reduced; in contrast, if α is set low, β can be appropriately increased. If α and β are very low, they will make the dominance class of elements not have advantages, and the comparison is meaningless. Similarly, if α and β are both high, the judgment conditions will be too strict, and the dominance class construction is easy to fail in practical decision problems. Therefore, we give a reference criterion, that is, α + β ≥ 1.
The research method proposed in this paper can be widely used in other fields. As long as multiple attributes are involved and the value of attributes is uncertain, the IFNs-based information system can be constructed for MADM evaluation to some extent. For example, in the evaluation of investment schemes, firstly, the diversification of evaluation indicators makes it impossible to make decisions based on only one indicator, so it conforms to the characteristics of MADM. Secondly, any investment is risky, and its returns are not fixed. According to the different states of the market, we can convert the belonging, unbelonging, and uncertain parts of the indicators value into DM, DN, and DH, respectively, so as to construct the intuitionistic fuzzy information system for decision-making. For another example, in the emotion analysis of natural language processing (using an intelligent customer service chatbot), due to the diversity of language expression meanings, often a word can express both a positive emotion on one occasion and a negative emotion on another occasion. Therefore, the relationship between emotional words and emotional states can also be expressed via IFN, and then, the emotional state of the whole sentence can be expressed by aggregating multiple emotional words. Of course, it can still be expressed as an IFN. The proposed scheme can also be used for path following schemes of intelligent vehicles and multi-robots. In paths following control, road conditions faced by vehicles or robots are often complex, which is difficult to be directly expressed by accurate variables and data. In this case, IFNs provides a feasible scheme. In terms of the control of state variables such as path curvature, vehicle speed, turning angle, and obstacle safety distance, we designed multiple levels for them, expressed their actual values by membership function, which can be converted to DM, DN and DH, and then planned reasonable driving paths for them according to vehicle safety requirements to ensure the flexible response ability and high safety of the path following scheme. There are many other similar occasions, such as supplier selection and evaluation, construction safety and risk assessment, and so on. As long as we can express the data table in the form of IFNs, we can apply the model and method proposed in this paper to solve the corresponding problems.
There are some limitations of this work: firstly, there is limited discussion regarding the properties of IFNs comparison and ranking methods. Secondly, the constructors of the dominance relation and dominance class in the MADM method do not satisfy the monotonicity of the attribute sets (that is, the larger the attribute sets, the smaller the dominance relation and dominance class). Finally, in the case analysis and application section, we did not test a larger data set. These are things that we can try to do better in future studies.
7. Conclusions
The comparison of intuitionistic fuzzy numbers (IFNs) will have an important impact on the theory and method of multi-attribute decision-making (MADM), but the current research has not solved this problem well. Therefore, based on the conversion concept of degree of hesitation (DH), this paper proposes the probabilistic conversion comparison method of IFNs based on the area method, and then constructs the probability dominance relationship model based on IFNs, designs the corresponding MADM method, and finally verifies and applies the model and method through the evaluation problem of campus express stations. The results show that it is scientific and reasonable. However, the research of this paper still has some shortcomings, such as group decision-making problem and multi-granularity decision-making problem based on IFNs; designing better comparison and ranking methods is required in the future.
Author Contributions
Conceptualization, Z.H. and Y.L.; methodology, S.W.; software, H.L.; validation, S.W. and H.L.; formal analysis, Z.H.; investigation, S.W.; resources, Y.L.; data curation, H.L.; writing—original draft preparation, S.W. and Z.H.; writing—review and editing, S.W. and Y.L.; proofreading of language and text, S.W. and H.L.; supervision, Z.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Guangxi University Young and Middle-aged Teachers Basic Ability Improvement Project “Probability Numbers and its Application in Uncertain Decision Theory” (2022KY0764); Scientific Research Project of Guangxi Minzu Normal University “Multi-attribute Decision Making Method and Application Research of Fuzzy Interval Rough Numbers Information System”(2020YB007).
Data Availability Statement
Not applicable.
Acknowledgments
I would like to thank all the authors for their contributions to this paper and the funding from related projects.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| DH | Degree of Hesitation |
| DM | Degree of Membership |
| DN | Degree of Non-membership |
| IFIS | Intuitionistic Fuzzy Information System |
| IFN | Intuitionistic Fuzzy Number |
| IFNs | Intuitionistic Fuzzy Numbers |
| IFS | Intuitionistic Fuzzy Sets |
| IFPDR | Intuitionistic Fuzzy Probability Dominance Relation |
| MADM | Multi-Attribute Decision-Making |
References
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Wang, C.; Qiang, X.; Xu, M.H.; Wu, T. Recent Advances in Surrogate Modeling Methods for Uncertainty Quantification and Propagation. Symmetry 2022, 14, 1219. [Google Scholar] [CrossRef]
- Luo, M.X.; Li, W.L. Some new similarity measures on picture fuzzy sets and their applications. Soft Comput. 2023, 27, 6049–6067. [Google Scholar] [CrossRef]
- Atanassov, K.T. Intuitionistic Fuzzy Sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Dan, S.; Kar, M.B.; Majumder, S.; Roy, B.; Pamucar, D. Intuitionistic Type-2 Fuzzy Set and Its Properties. Symmetry 2019, 11, 808. [Google Scholar] [CrossRef]
- Torra, V. Hesitant Fuzzy Sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Alcantud JC, R.; Santos-Gacia, G.; Peng, X.D.; Zhan, J. Dual Extended Hesitant Fuzzy Sets. Symmetry 2019, 11, 714. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, W.; Chung, Y.; Tang, Z.; Xie, Y.; Ma, T.; Zhang, J.; Zhang, G.; Niyoyita, J.P. Adaptive Intrusion Detection via GA-GOGMM-based Pattern Learning with Fuzzy Rough Set-based Attribute Selection. Expert Syst. Appl. 2020, 139, 112845. [Google Scholar] [CrossRef]
- Syau, Y.R.; Lin, E.B.; Liau, C.J. Fuzzy Binary Rough Set. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2020, 28, 317–329. [Google Scholar] [CrossRef]
- Mathew, B.; John, S.J.; Alcantud, J.C.R. Multi-Granulation Picture Hesitant Fuzzy Rough Sets. Symmetry 2020, 12, 362. [Google Scholar] [CrossRef]
- Ayub, S.; Shabir, M.; Riaz, M.; Mahmood, W.; Bozanic, D.; Marinkovic, D. Linear Diophantine Fuzzy Rough Sets: A New Rough Set Approach with Decision Making. Symmetry 2022, 14, 525. [Google Scholar] [CrossRef]
- Gong, Z.T.; Wang, L.W. Covering-based variable precision rough fuzzy set models. J. Lanzhou Univ. Nat. Sci. 2019, 55, 105–112. [Google Scholar]
- Sun, B.; Ma, W.; Chen, X. Variable precision multigranulation rough fuzzy set approach to multiple attribute group decision-making based on λ-similarity relation. Comput. Ind. Eng. 2019, 127, 326–343. [Google Scholar] [CrossRef]
- Yang, J.; Huang, M.Y.; Chen, J. Neighborhood-based multi-granulation rough fuzzy sets and their uncertainty measure. J. Chongqing Univ. Posts Telecommun. (Nat. Sci. Ed.) 2020, 32, 898–908. [Google Scholar]
- Khalil, A.M.; Cao, D.Q.; Azzam, A.; Smarandache, F.; Alharbi, W.R. Combination of the Single-Valued Neutrosophic Fuzzy Set and the Soft Set with Applications in Decision-Making. Symmetry 2020, 12, 1361. [Google Scholar] [CrossRef]
- Pan, L.P.; Deng, Y.; Cheong, K.H. Quaternion model of Pythagorean fuzzy sets and its distance measure. Expert Syst. Appl. 2023, 213, e119222. [Google Scholar] [CrossRef]
- Kumar, K.; Chen, S.M. Group decision making based on entropy measure of Pythagorean fuzzy sets and Pythagorean fuzzy weighted arithmetic mean aggregation operator of Pythagorean fuzzy numbers. Inf. Sci. 2023, 624, 361–377. [Google Scholar] [CrossRef]
- Dai, Z.M.; Hu, K.; Xie, J.; Ya, G. Ensemble Learning Algorithm Based on Intuitionistic Fuzzy Sets. Comput. Sci. 2021, 48, 270–274, 280. [Google Scholar]
- Liu, L.M.; Gong, Y.L.; Cao, W.Z.; Yang, Y. Emergency logistics plan decision-making method based on linguistic intuitionistic fuzzy sets. Comput. Integr. Manuf. Syst. 2021, 27, 1494–1505. [Google Scholar]
- Li, S.M.; Guan, X.; Sun, G.D. Recognition method based on hesitant fuzzy set for unequal length sequences and its application. J. Commun. 2021, 42, 41–51. [Google Scholar]
- Wang, H.W.; Ran, Y.; Zhang, G.B. Comprehensive Evaluation Method for Quantitative Multi-indexes of Manufacturing Process Based on Hesitant Fuzzy Sets. J. Hunan Univ. (Nat. Sci.) 2021, 48, 59–70. [Google Scholar]
- Li, R.X.; Hu, W.X.; Qi, X.L. The Applications of Utility function and Entropy of Interval Type-2 Fuzzy Set in Risk Decision-Making. Oper. Res. Manag. Sci. 2021, 30, 102–109. [Google Scholar]
- Rani, J.J.; Manivannan, A.; Dhanasekar, S. Interval Valued Intuitionistic Fuzzy Diagonal Optimal Algorithm to Solve Transportation Problems. Int. J. Fuzzy Syst. 2023. [Google Scholar] [CrossRef]
- Yang, Y.J.; Chiclana, F. Consistency of 2D and 3D distances of intuitionistic fuzzy sets. Expert Syst. Appl. 2012, 39, 8665–8670. [Google Scholar] [CrossRef]
- Guo, K.H.; Wang, Z.Q. Interval-valued Intuitionistic Fuzzy Knowledge Measure with Applications Based on Hamming-Hausdorff Distance. J. Softw. 2022, 33, 4251–4267. [Google Scholar]
- Sun, G.; Wang, M.X.; Li, X.P.; Huang, W. Distance measure and intuitionistic fuzzy TOPSIS method based on the centroid coordinate representation. J. Intell. Fuzzy Syst. 2023, 41, 555–571. [Google Scholar] [CrossRef]
- Ullah, K.; Mahmood, T.; Jan, N. Similarity Measures for T-Spherical Fuzzy Sets with Applications in Pattern Recognition. Symmetry 2018, 10, 193. [Google Scholar] [CrossRef]
- Pan, F.P.; Gong, R.C.; Tan, K.X. Multi-attribute group decision-making method for tourism projects based on interval intuitionistic fuzzy information. Stat. Decis. 2021, 37, 173–176. [Google Scholar]
- Deng, X.Y.; Yang, Y.; Jiang, W. Discrete choice models with Atanassov-type intuitionistic fuzzy membership degrees. Inf. Sci. 2023, 622, 46–67. [Google Scholar] [CrossRef]
- Qin, H.W.; Li, H.F.; Ma, X.Q.; Gong, Z.; Cheng, Y.; Fei, Q. Data Analysis Approach for Incomplete Interval-Valued Intuitionistic Fuzzy Soft Sets. Symmetry 2020, 12, 1061. [Google Scholar] [CrossRef]
- Das, A.K.; Granados, C. IFP-intuitionistic multi fuzzy N-soft set and its induced IFP-hesitant N-soft set in decision-making. J. Ambient Intell. Humaniz. Comput. 2022. [Google Scholar] [CrossRef]
- Guo, Z.L.; Yang, H.L.; Wang, J. Intuitionistic fuzzy probabilistic rough set model on two universes and its applications. Syst. Eng. Theory Pract. 2014, 34, 1828–1834. [Google Scholar]
- Huang, X.H.; Zhang, X.Y.; Yang, J.L. Two-Universe Multi-granularity Probability Rough Sets Based on Intuitionistic Fuzzy Relations. Pattern Recognit. Artif. Intell. 2022, 35, 439–450. [Google Scholar]
- Gong, Z.T.; Ta, G.P. Semantics of the soft set induced by intuitionistic fuzzy set and its three-way decision. J. Shandong Univ. (Nat. Sci.) 2022, 57, 68–76. [Google Scholar]
- Liu, J.B.; Peng, L.S.; Li, H.X.; Huang, B.; Zhou, X. Interval-valued Intuitionistic Fuzzy Three Way Group Decisions Considering The Unknown Weight Information. Oper. Res. Manag. Sci. 2022, 31, 50–57. [Google Scholar]
- Li, X.N.; Zhao, L.; Yi, H.J. Three-way decision of intuitionistic fuzzy information systems based on the weighted information entropy. Control Decis. 2022, 37, 2705–2713. [Google Scholar]
- Dai, J.H.; Chen, T.; Zhang, K. The intuitionistic fuzzy concept-oriented three-way decision model. Inf. Sci. 2023, 619, 52–83. [Google Scholar] [CrossRef]
- Chao, N.; Wan, R.X.; Miao, D.Q. Neighborhood Rough Set Based on Dominant Relation in Intuitionistic Fuzzy Information System. J. Shanxi Univ. (Nat. Sci. Ed.) 2023, 46, 62–68. [Google Scholar]
- Xue, Z.A.; Lv, M.J.; Han, D.J.; Xin, X. Multi-Granulation Graded Rough Intuitionistic Fuzzy Sets Models Based on Dominance Relation. Symmetry 2018, 10, 446. [Google Scholar] [CrossRef]
- Li, D.F.; Lin, P. An intuitionistic fuzzy Bayesian network bidirection reasoning model for stampede fault diagnosis analysis of scenic spots integrating the D-S evidence theory. Syst. Eng.-Theory Pract. 2022, 42, 1979–1992. [Google Scholar]
- Peng, Y.; Liu, X.H.; Sun, J.B. Interval-Valued Intuitionistic Fuzzy Multi-attribute Group Decision Making Approach Based on the Hesitancy Degrees and Correlation Coefficient. Chin. J. Manag. Sci. 2021, 29, 229–240. [Google Scholar]
- Batool, N.; Hussain, S.; Kausar, N.; Munir, M.; Li, R.; Khan, S. Decision Making under Incomplete Data: Intuitionistic Multi Fuzzy Ideals of Near-Ring Approach. Decis. Mak. Appl. Manag. Eng. 2023, 5, 67–89. [Google Scholar]
- Kong, R.; Zhao, N. Merchant Ranking based on Intuitionistic Fuzzy Sentiment and Dual-attention BILSTM[J/OL]. J. Syst. Manag. 2022, 1–21. Available online: http://kns.cnki.net/kcms/detail/31.1977.N.20221228.1659.002.html (accessed on 9 January 2023).
- Fu, C.; Zhou, S.S.; Zhang, D.; Chen, L. Relative Density-Based Intuitionistic Fuzzy SVM for Class Imbalance Learning. Entropy 2023, 25, 34. [Google Scholar] [CrossRef] [PubMed]
- Wei, C.P.; Liang, X.; Zhang, Y.Z. A Comparative Analysis and Improvement of Entropy Measure for Intuitionistic Fuzzy Sets. J. Syst. Sci. Math. Sci. 2012, 32, 1437–1448. [Google Scholar]
- Sevastjanov, P.; Dymova, L.; Kaczmarek, K. A new approach to the comparison of real, interval and fuzzy-valued intuitionistic fuzzy and Belief-Plausibility numbers. Int. J. Approx. Reason. 2023, 152, 262–281. [Google Scholar] [CrossRef]
- Wang, Y.; Lei, Y.J.; Lu, Y.L. Multiple attribute decision making method based on intuitionistic fuzzy sets. Syst. Eng. Electron. 2007, 29, 2060–2063. [Google Scholar]
- Zhao, F.X. Distances Between Interval-Valued Intuitionistic Fuzzy Sets. Microelectron. Comput. 2010, 27, 188–192. [Google Scholar]
- Li, Y.H.; Sun, G. A unified ranking method of intuitionistic fuzzy numbers and Pythagorean fuzzy numbers based on geometric area characterization. Comput. Appl. Math. 2023, 42, e16. [Google Scholar] [CrossRef]
- Ye, J. Cosine similarity measure for intuitionistic fuzzy sets and their applications. Math. Comput. Model. 2011, 53, 91–97. [Google Scholar] [CrossRef]
- Xie, J.M.; Liu, S.Y. Similarity Measure of Interval Valued Intuitionistic Fuzzy Sets and Its Application. Math. Pract. Theory 2018, 48, 249–255. [Google Scholar]
- Xu, C.L.; Chen, J.H. New distance between intuitionistic fuzzy sets and its applications in decision-making. Appl. Res. Comput. 2020, 37, 3627–3634. [Google Scholar]
- Liang, M.S.; Mi, J.S.; Zhang, S.P.; Jin, C. A novel approach for ranking intuitionistic fuzzy numbers and its application to decision making. J. Intell. Fuzzy Syst. 2023, 44, 661–672. [Google Scholar] [CrossRef]
Figure 1.
α-probability conversion of the IFN.

Figure 2.
The change trend of conversion DM of and with different conversion probabilities .

Figure 3.
Position relation of IFNs.

Figure 4.
MADM method block diagram.

Figure 5.
Dominance degree matrix under different attributes.

Figure 6.
Comparison of the ranking results at different values.

Figure 7.
The final raking result of express delivery points with mean value of .

Figure 8.
Comparison of ranking results of different algorithms.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Original data of express delivery evaluation in M university.
| U/B | b1 | b2 | b3 | b4 | b5 | b6 | b7 | b8 | b9 |
|---|---|---|---|---|---|---|---|---|---|
| x1 | (0.69, 0.09) | (0.67, 0.07) | (0.54, 0.12) | (0.73, 0.15) | (0.76, 0.13) | (0.47, 0.13) | (0.65, 0.10) | (0.51, 0.13) | (0.51, 0.13) |
| x2 | (0.51, 0.19) | (0.57, 0.16) | (0.65, 0.17) | (0.39, 0.10) | (0.50, 0.16) | (0.46, 0.13) | (0.63, 0.10) | (0.31, 0.10) | (0.31, 0.10) |
| x3 | (0.32, 0.22) | (0.37, 0.22) | (0.35, 0.21) | (0.51, 0.11) | (0.43, 0.19) | (0.41, 0.10) | (0.55, 0.21) | (0.43, 0.23) | (0.43, 0.23) |
| x4 | (0.33, 0.22) | (0.30, 0.24) | (0.51, 0.22) | (0.32, 0.22) | (0.38, 0.23) | (0.42, 0.20) | (0.52, 0.23) | (0.43, 0.25) | (0.43, 0.25) |
| x5 | (0.22, 0.16) | (0.30, 0.45) | (0.34, 0.22) | (0.26, 0.12) | (0.43, 0.29) | (0.36, 0.16) | (0.35, 0.27) | (0.27, 0.30) | (0.27, 0.30) |
| x6 | (0.30, 0.31) | (0.20, 0.38) | (0.31, 0.10) | (0.40, 0.27) | (0.30, 0.25) | (0.50, 0.15) | (0.40, 0.23) | (0.39, 0.27) | (0.39, 0.27) |
| x7 | (0.33, 0.25) | (0.46, 0.13) | (0.55, 0.20) | (0.49, 0.19) | (0.55, 0.11) | (0.37, 0.20) | (0.55, 0.23) | (0.43, 0.12) | (0.43, 0.12) |
| x8 | (0.48, 0.29) | (0.24, 0.15) | (0.52, 0.22) | (0.49, 0.20) | (0.33, 0.15) | (0.56, 0.27) | (0.34, 0.10) | (0.44, 0.22) | (0.44, 0.22) |
| x9 | (0.44, 0.10) | (0.70, 0.12) | (0.74, 0.16) | (0.45, 0.13) | (0.57, 0.13) | (0.50, 0.15) | (0.74, 0.13) | (0.38, 0.17) | (0.38, 0.17) |
| x10 | (0.21, 0.10) | (0.23, 0.15) | (0.30, 0.20) | (0.42, 0.20) | (0.46, 0.12) | (0.48, 0.10) | (0.43, 0.24) | (0.38, 0.13) | (0.38, 0.13) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Huang, Z.; Weng, S.; Lv, Y.; Liu, H. Ranking Method of Intuitionistic Fuzzy Numbers and Multiple Attribute Decision Making Based on the Probabilistic Dominance Relationship. Symmetry 2023, 15, 1001. https://doi.org/10.3390/sym15051001
AMA Style
Huang Z, Weng S, Lv Y, Liu H. Ranking Method of Intuitionistic Fuzzy Numbers and Multiple Attribute Decision Making Based on the Probabilistic Dominance Relationship. Symmetry. 2023; 15(5):1001. https://doi.org/10.3390/sym15051001
Chicago/Turabian StyleHuang, Zhengwei, Shizhou Weng, Yuejin Lv, and Huayuan Liu. 2023. "Ranking Method of Intuitionistic Fuzzy Numbers and Multiple Attribute Decision Making Based on the Probabilistic Dominance Relationship" Symmetry 15, no. 5: 1001. https://doi.org/10.3390/sym15051001
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.