1. Introduction
To endure climate conditions and traffic loads, various types of bituminous mixes are used for roadway pavements which must be effectively designed as bitumen and aggregate mixtures. Inadequate mechanical characteristics could lead to a variety of problems in road pavements such as low temperature or fatigue cracks, stripping, permanent deformations, etc. Such failure mechanisms reduce the pavement’s service life and pose major safety concerns for road users [
1]. Consequently, it is critical to characterize the performance of mixtures in terms of their composition so that optimization based on performance might be done during the mix design process [
2,
3,
4]. Experimental methods are currently utilized to assess the performance of bituminous mixes [
5,
6,
7,
8,
9,
10], which necessitate costly laboratory experiments in conjunction with skilled labor. As a result, any change in the composition of mixtures, whether it be in bitumen content or type or aggregate gradation, necessitates additional laboratory testing, increasing cost and time in the design process.
Numerous researchers have been working on developing numerical or mathematical relationships for the mechanical behavior of bituminous mixes that can quickly produce reliable and accurate predicted results for bituminous mixes. Advanced machine learning (ML) methods allow in-depth and rational analysis of material responses [
11,
12,
13,
14,
15,
16,
17,
18,
19,
20]. ML techniques have gained significant popularity in research due to their high reliability and prediction capabilities despite the fact that they are not based on physical testing procedures and they are being utilized in modeling and forecasting the complex behaviors of several pavement engineering materials [
21,
22,
23,
24,
25,
26]. Data mining procedures in material, civil, and pavement engineering, in particular, have been reported widely in the previous two decades, thanks to the swift development in the approaches of ML [
27]. The soft computing methods (SCMs) or artificial intelligence techniques (AITs) that are developed recently, for example, artificial neural networks (ANNs) (sub-types are; multilayer perceptron neural network (MLPNN), Bayesian neural network (BNN), general regression neural network (GRNN), backpropagation neural network (BPNN), and k-nearest neighbor (KNN)), ANNs with their hybrid form, i.e., support vector machine (SVM), multivariate adaptive regression splines (MARS), eXtreme gradient boosting (XGBoost), adaptive neuro-fuzzy inference system (ANFIS), alternate decision trees), genetic algorithms (GAs), M5 model trees, evolutionary algorithms (EAs), ensemble random forest regression (ERFR), genetic expression programming (GEP), and MEP, have facilitated in the development of the various models in conjunction with conventional statistical models, e.g., regression, among many others [
25,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38]. Mechanistic learning has been frequently used to evaluate the estimating models for the development of intelligent structures [
39]. Moreover, Giustolisi et al. (2007) suggested the categorization of different mathematical models into grey, black, and white colors [
40]. The known parameters and variables, the white-box model (first type), are established on the basis of physical laws forming precise physical relationships, hence maximum transparency is provided. Although, it was argued by Shahin et al. (2009) that their underlying procedure is not entirely understood, making the formulation challenging and difficult [
41]. Additionally, black box models depend on regressive data-driven techniques with unidentified functional forms of relationships among respective parameters that must be estimated. Finally, in grey-box models, it can be labelled as logical systems where mathematical frameworks more successfully assess the system’s behavior. The ANFIS and ANN due to (i) low transparency, (ii) the incapability to describe the underlying physical process, explicitly, and (iii) the inability to develop expressions of closed-form, are both classified as “black-box” models [
42]. MEP, on the other hand, is categorized as a “grey-box model”, since its approach is simple and straightforward in order to conceptualize the physical phenomenon [
43]. In the field of pavement engineering, although it is considered that the performance of models based on is decent while using ANFIS and ANN, on the other hand, MEP has also shown very good results [
44], for which a comparative study needs to be conducted to verify the assumptions made and to gain further insights. With these uncertainties in sight, the current research study integrates ANN, ANFIS, and MEP to evaluate their ability to predict the MF and MS of asphalt pavements.
First and foremost, ANNs are problem-solving computational models, inspired by biological neural networks (NNs) that aim to mimic the biological structure of our nervous system and brain [
29,
45,
46]. ANNs explicitly record the link between the corresponding input and output variables of the models [
47], but they do not develop an empirical formulation, which limits their real-world applicability despite their better accuracy [
39,
48]. Secondly, Jang (1993) introduced ANFIS, a fuzzy inference system of the Sugeno or Takagi Sugeno Kang (TSK) type, based on the principle of ANNs [
49,
50]. ANFIS is a hybrid model that integrates both fuzzy algorithms and ANNs. It is vital to note that fuzzy logic (FL) incorporates elements of falsehood and truth and does not behave in the same way as 1′s and 0′s logic [
51]. Lastly, MEP, a method of genetic programming (GP), has been proven as an efficient and alternative approach in the prediction of complex and nonlinear problems [
44]. Oltean and Dumitrescu (2002) were the first ones to suggest the MEP approach [
52]. The problem of having several computer programs could be encoded into a single chromosome using this method. Through computation procedure, the best encoded predicting expression can be constructed and easily changed to meet the practical applications. The development of prediction models using the MEP approach has seen a rise in the previous decade due to its advantage of easy implementation, high efficiency, and prediction accuracy, in the field of material engineering. This method has been successfully used to forecast the tensile and compressive strength [
53], Marshall parameters [
44], classification of soil [
54], reloading and secant moduli of soil deformation [
55], peak ground acceleration [
56], etc. Hence, MEP is feasible to estimate the MS and MF of asphalt pavements, which is reinforced by past relevant research studies of this method on specific material engineering problems.
Traditional statistical studies were used to derive prior correlations for the MS and MF of asphalt pavements, which had shortcomings such as: (i) fewer data points, (ii) governing parameters had smaller correlations, and (iii) the absence of an integrated comparative evaluation, among others [
42]. Furthermore, the test of MS and MF takes time, while their determination in the laboratory is also time-consuming and costly [
57,
58]. A number of studies have previously employed basic input parameters for the prediction of the MS and MF of asphalt pavements using ANN and ANFIS approaches [
57,
59,
60,
61,
62,
63,
64,
65,
66]. As a result, the goal of this research study is the construction of models that reliably predict the MS and MF of asphalt pavements using major input parameters that are determined simply and economically. Three soft computing approaches, i.e., ANN, ANFIS, and MEP, were used to construct prediction expressions for MS and MF. Eight properties were used in input parameters, i.e., Percentage of Aggregates (P
s), Percentage Asphalt Content (P
b), Bulk Specific Gravity of Compacted Aggregate (G
mb), Bulk Specific Gravity of Aggregate (G
sb), Maximum Specific Gravity Paving Mix (G
mm), Percentage of Voids in Mineral Aggregate (VMA), Percentage of Air Voids (V
a), and Percentage Voids Filled by Bitumen (VFA). MS (Corrected Stability in Kg), and MF (Flow in 0.25 mm) were the output parameters of this study. The major objectives of this research study were (i) the construction of MEP-based prediction expressions, (ii) the investigation of the feasibility study for ANN and ANFIS approaches, and (iii) the comparison of the MEP-based model with models of ANN, and ANFIS, for prediction of MS and MF. The ANN, ANFIS, and MEP models were evaluated by means of several statistical error checks, such as root square error (RSE), Nash–Sutcliffe efficiency (NSE), mean absolute error (MAE), relative root mean square error (RRMSE), regression coefficient (R
2), and correlation coefficient (R). Furthermore, PA was performed, and results were evaluated to determine the negative and positive effects of input variables by employing sensitivity analysis.
2. Overview of Soft-Computing Approaches
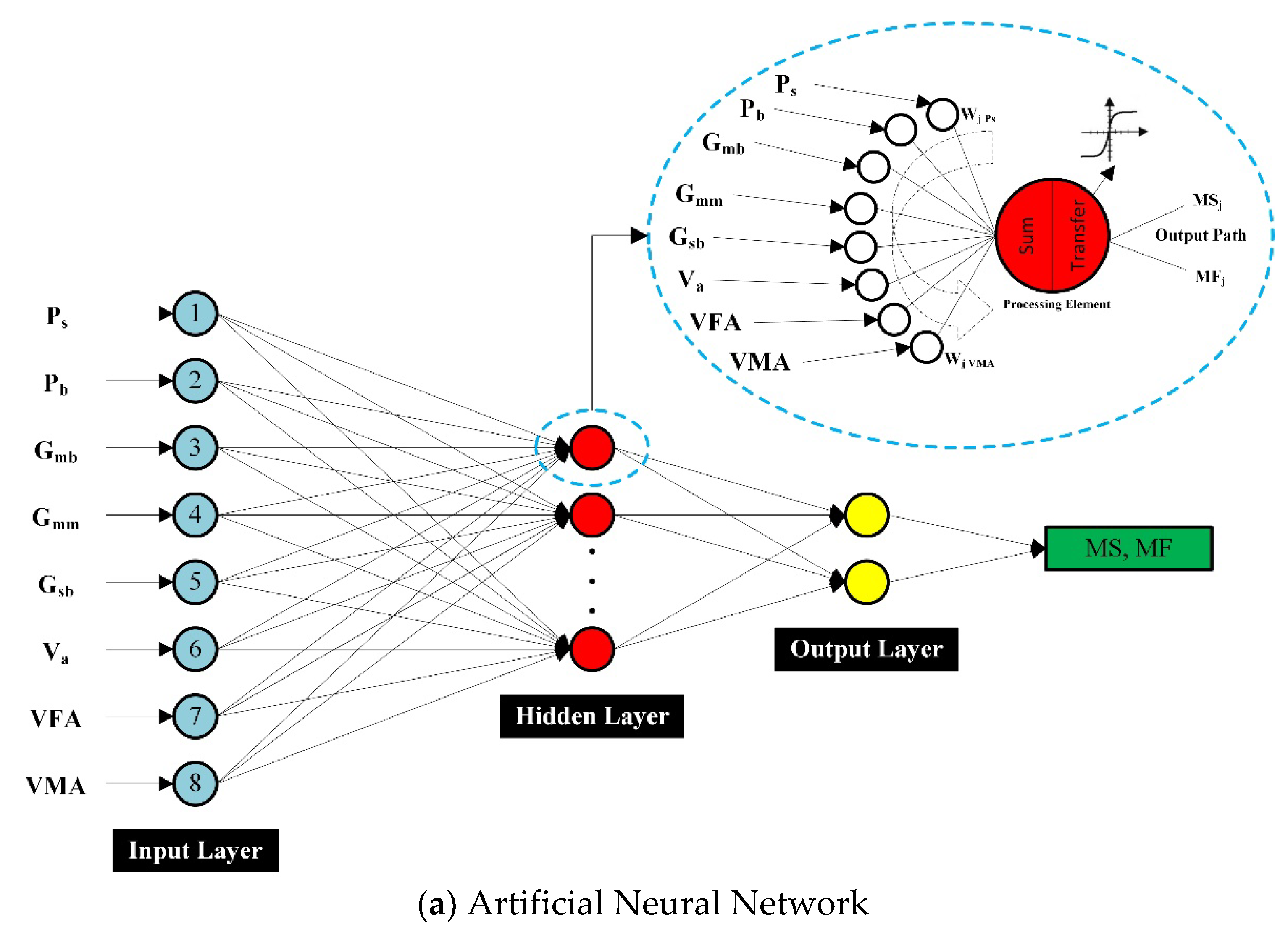
ANNs are computer algorithms that can accurately forecast and categorize data-processing challenges [
67,
68,
69]. They consist of mathematical models based on the properties of biological neuron networks that are similar to the human brain [
51,
70]. ANNs have layered structures which have diversified arrangements of processing elements (PEs) or nodes; (i) an input layer consisting of an independent set of parameters, (ii) a hidden layer(s) consisting of various hidden parameters better known as hidden neurons, and (iii) an output layer, which consists of target parameters (
Figure 1a) [
39,
71]. Eight different characteristics of asphalt concrete were chosen as the input parameter for the prediction of the corresponding output parameters, i.e., MS and MF, as shown in
Figure 1. Each individual input parameter in the preceding layer was multiplied by the appropriate connection weight, in a hidden layer. On each node, the sum of weighted input signals is added with a cutoff value (θ
j). The collected input (I
j) then goes through a transfer function (nonlinear) in the transfer phase. Linear, sigmoid, logistic, hyperbolic, and stepped are among the most frequently utilized activation transfer functions (ATFs) [
39,
72]. ATF is a major and significant characteristic of NNs, and it has a considerable impact on the functioning of the ANN model as it helps in the induction of nonlinearity to NNs, implying that selecting a feasible ATF is of critical importance [
73]. Multi-state activation functions (MSAFs) were previously utilized in the improvement of deep neural networks (DNNs) models [
74], softmax ATFs [
75], swish ATFs [
76], the tangent hyperbolic and logistic sigmoid ATFs [
77], ATFs of transcendental type parametric algebraic [
78], etc. In this research study, more specifically, PURELIN (linear–transfer–function), and TRANSIG (BPNN’s transfer functions with an output ranging from +1 to −1, and are related to bipolar sigmoid), are utilized in order to increase the number of the transfer function as well as neurons in each layer, thus helping to improve the statistical measures for the training set, but lowering the precision of testing and validation datasets [
79,
80,
81]. Dorofki et al. (2012) discovered, by applying several statistical parameters, that the performance of Log-sigmoid (transfer function) was determined as the best, as it is differentiable, bounded, and continuous. However, Purelin (transfer function) yielded even further improved results [
82]. Accordingly, PE (MSj or MFj) is acquired as the subsequent output parameter. It is essential to specify here that the output of the first PE contributes to the input of the next PE. For the output layer and hidden layer, each neuron performs the logistic function in Equation (1), which was utilized as the AF [
83]. Additionally, Equations (1)–(3) show the procedure mentioned above.
The learning or training phase begins when the propagation of information is started by the ANNs from the input layer, and then weights are updated, consistent with the predefined rules, in order to find the best combination of weights to yield the least amount of error possible. Then a new testing set is utilized to validate the trained model. More details of the technique and the evolution of ANN modelling are explained in greater length elsewhere and are outside the scope of this study [
39,
46,
84,
85,
86,
87,
88].
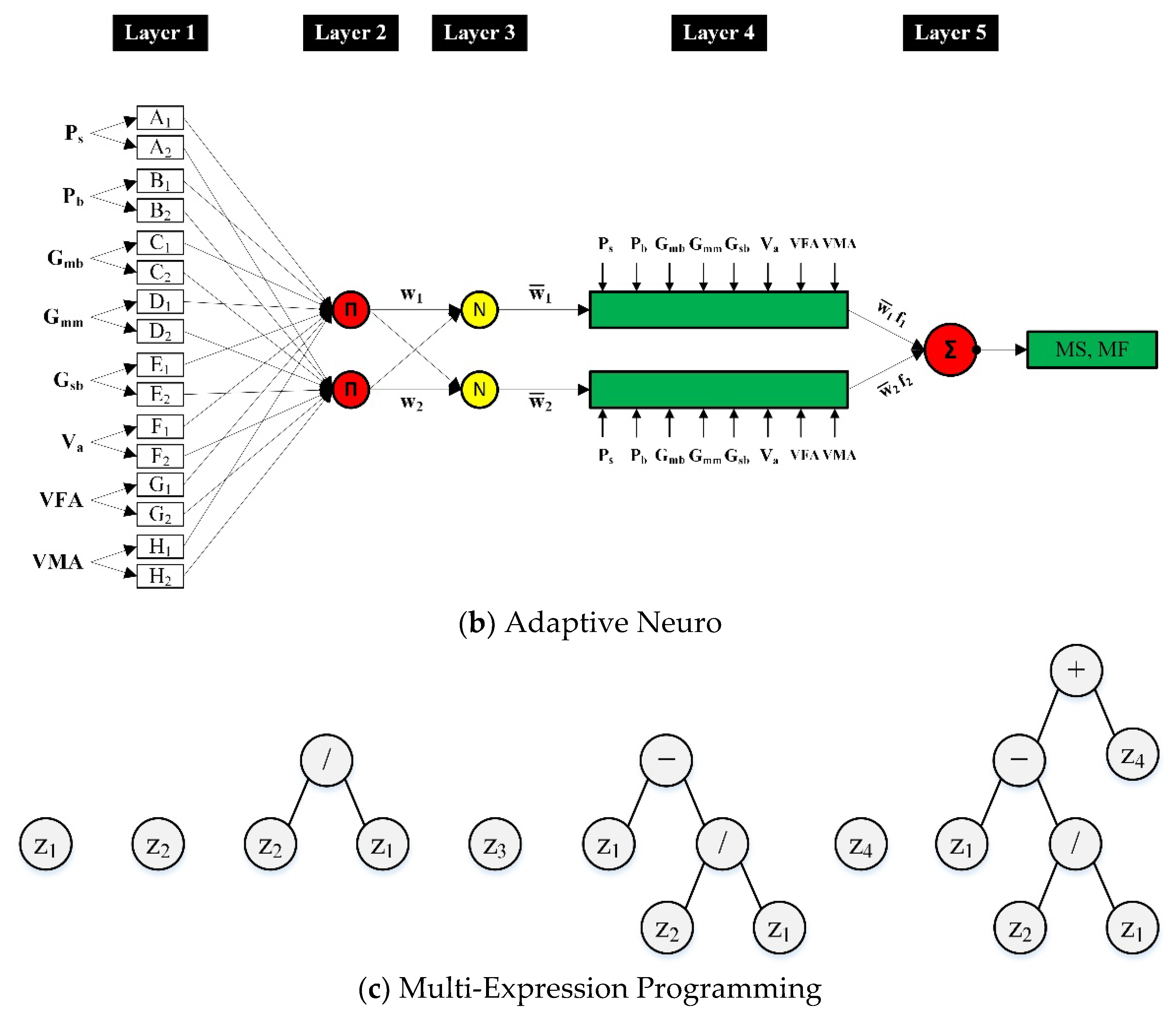
An intriguing computational intelligence modeling method, ANFIS, blends generalization capability of ANNs with FL’s reasoning capability. ANFIS has an enhanced estimating ability and is an effective substitute for the computation of complex and nonlinear problems with high accuracy [
89,
90,
91]. It uses training data for learning with any sophisticated mathematical model, then generates the results onto a fuzzy inference system (FIS), similar to ANNs [
70,
92]. Similar to the process used by ANNs, the ANFIS tool in MATLAB R2020b starts training output and input variables for the evaluation of output and input mapping. A simple FIS consists of several processes, one of which is the entering of inputs to aid the fuzzification of fuzzy sets according to the activation of linguistic rules. Following this, particular guidelines are either established by a professional or could be derived from arithmetic data. Inference is the succeeding step that involves the mapping of fuzzy sets according to predefined rules. The final output values are obtained once fuzzy sets have been defuzzified. To put it another way, the ANFIS approach is made up of five basic stages: (i) datasets, (ii) development of ANFIS, (iii) setting of variables, (iv) training and validating the datasets, and (v) outputs or results. Additionally,
Figure 1b, shows the architecture of ANFIS for eight input parameters (P
s, P
b, G
sb, G
mb, G
mm, VMA, V
a, and VFA) with circles and squares denoting the fixed and adaptive nodes, respectively. The first-order of the Sugeno model depicts ANFIS architecture, by using two IF-THEN rules.
Tue Rules:
Rule 1: IF (Ps is A1) and (Pb is B1)
Then, Equation (4) states that,
Rule 2: IF (Ps is A2) and (Pb is B2)
Then, according to Equation (5)
where f
n denotes the fuzzy output (MS and MF) for input (P
s, P
b, G
mb … VFA) to the fuzzy extent, A
n and B
n denote the sets of fuzzy, and p
n, r
n, and q
n denote the parameters for shape derived during the training period.
An ANFIS model is made up of five layers [
90], as can be shown. These layers and their functions are described in detail here.
Layer 1: the adaptive PEs in the first layer, known as the fuzzification layer, produce outputs in the form of Equations (6) and (7) which explains the functions of the fuzzy membership of the model’s input variables, and the base of initial fuzzy rule, as follows;
where
μ represents the weight obtained while linking the function of fuzzy membership, and
in conjunction with
discriminates the method of implementing the function of fuzzy membership. Equation (8) states
for a function of the bell-shaped membership,
where a
i, b
i, and c
i are the parameters impacting the function of the membership.
Layer 2: This layer’s output is predefined rules’ firing strength for a pattern of specified input. The nodes in the second layer perform basic multiplication and are constant, with output variables as follows (Equation (9)),
Layer 3: The nodes in this layer are fixed and are similar as they were in the second layer, such that the firing strengths of the preceding layer are normalized, and thus Equation (10) represents the outputs;
Layer 4: The adaptive nodes of this layer, and their outputs are characterized as products of a first-order polynomial, and normalized firing strength, with the first-order Sugeno model taken into account. Thus, the output is given by (Equation (11));
Layer 5: In the fifth layer, there is one fixed node (Σ) that performs the addition of weighted result of rules received from the subsequent layer, yielding the model’s output as Equation (12);
It is essential to note that only the first and fourth layers of the ANFIS architecture are adaptive. In the first layer, the three adaptive parameters, i.e., a
i, b
i, and c
i (premise-parameters) are linked to functions of input membership. Likewise, the three adaptable variables, i.e., p
i, q
i, and r
i, also known as consequent parameters, are found in the fourth layer, and are related to the first-order polynomial [
93,
94].
GAs are stochastic methods for finding and optimizing the solutions to a problem based on natural and genetic selection principles [
95]. GAs generate a chain of binary strings which express the solution using traditional optimization techniques. GP was introduced by Koza, in 1992, as an extension of GAs by developing string expressions into computer-friendly programs, such as functional programming or tree structures [
96,
97,
98]. GP is a symbolic technique of optimization that applies Darwin’s natural selection principle to computer programs for the solution of a problem. The major purpose of the GP is to find a program based on fitness function by the connection of known input parameters with known output parameters. Generally, there are three forms of GP: graph-based, linear-based, and tree-based [
99,
100]. The efficiency of linear-based GP is more than its other types since it does not require slow or expensive interpreters. Consequently, it allows a more appropriate value for the linear-based GP, in order to enhance the model’s precision in actual timeframes [
101,
102,
103].
While considering accuracy and efficiency, in this investigation, linear-based GP also known as MEP was utilized to forecast the MS and MF of asphalt pavements. The MEP encodes solutions using linear chromosomes. The MEP encodes solutions using linear chromosomes. A chromosome can store various solutions (computer programs). The best of the encoded solutions, which represent the chromosome, is chosen by comparing the fitness values of the computer programs. The algorithm of MEP begins by creating computer programs of a random population. To construct the best computer program, MEP continue to follow the below-mentioned steps until it achieves the termination condition [
52,
104]:
Using the binary tournament approach, two parents are chosen and recombined with a probability of fixed crossover.
By recombining the two parents, two offspring are obtained.
The mutation of the offspring takes place by the replacement of the best individual with the worst in the current population.
MEP is represented in the same way as C and Pascal compliers translate mathematical statements to machine code [
54,
99]. A string of expressions represents the genes of MEP. The length of the chromosome (length of code), which remains constant throughout the computation period, is used to determine the number of genes. Each gene has either one or two terminals (a constituent of terminal set T) as well as a function symbol (a constituent of function set F). To obtain a syntax accurate program, the first gene of the chromosome must be a terminal which is selected randomly from ‘T’. A pointer to function arguments is included in a gene containing a function. The generated terminal indices in a specific gene have lower values than the gene’s chromosome position.
The following is an illustration of the MEP chromosome:
G0: z1
G1: z2
G2: G1/G0
G3: z3
G4: G0 − G2
G5: z4
G6: G4 + G5
The terminal set T = {z
1, z
2, z
3, z
4}, and the function set F = {+, /, −} are utilized in this example. The genes of MEP can be converted into computer code by traversing the code of chromosomes from top to bottom.
Figure 1c shows the relevant gene trees. G
0 = z
1, G
1 = z
2, G
3 = z
3, and G
5 = z
4 are the genes that encode a single terminal. Gene 2 denotes the operation/(division) on the operands at chromosome positions 0 and 1 with the expression G
2 = z
2/z
1. Gene 4 denotes operation subtraction on the operands at positions 0 and 2 making the expression as
. Lastly,
. Hence, the chromosome could be visualized as a forest of gene trees (
Figure 1c) each of which has several expressions, after determining the fitness of entire expressions in the chromosome of MEP [
105].
5. Conclusions
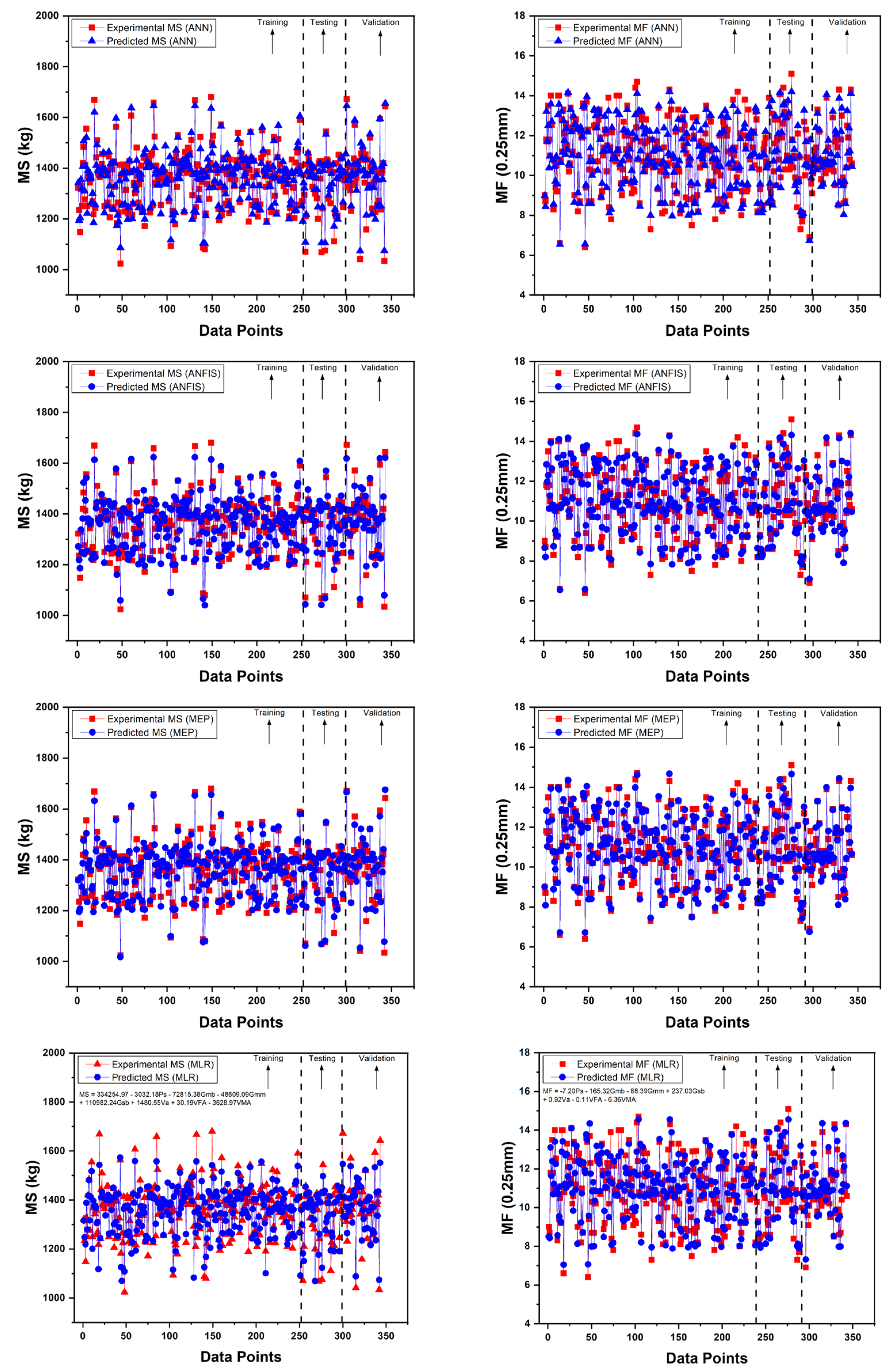
The conventional method for determining the Marshall Stability (MS) and Marshall Flow (MF) of asphalt pavements entails laborious, time-consuming, and expensive laboratory procedures. In this research study, three AI techniques, i.e., ANN, ANFIS, and MEP, are employed to determine the MS and MF of asphalt pavements. The findings of this work contribute to finding an appropriate AI strategy to quickly and precisely identify the MS and MF of the Marshall Parameters. The database for MS and MF was constructed from an extensive collection of the results from various construction companies working in Pakistan on different road projects.
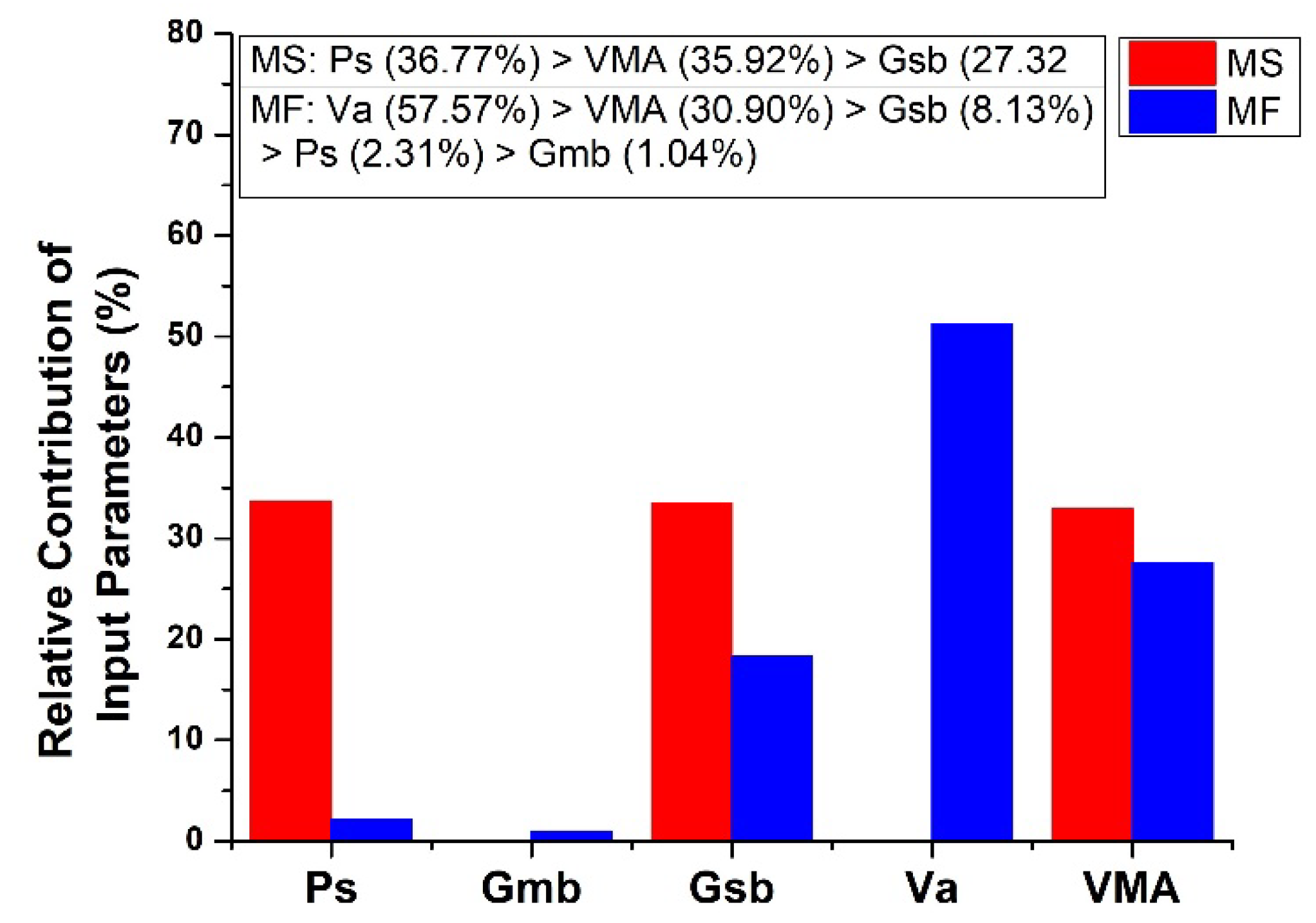
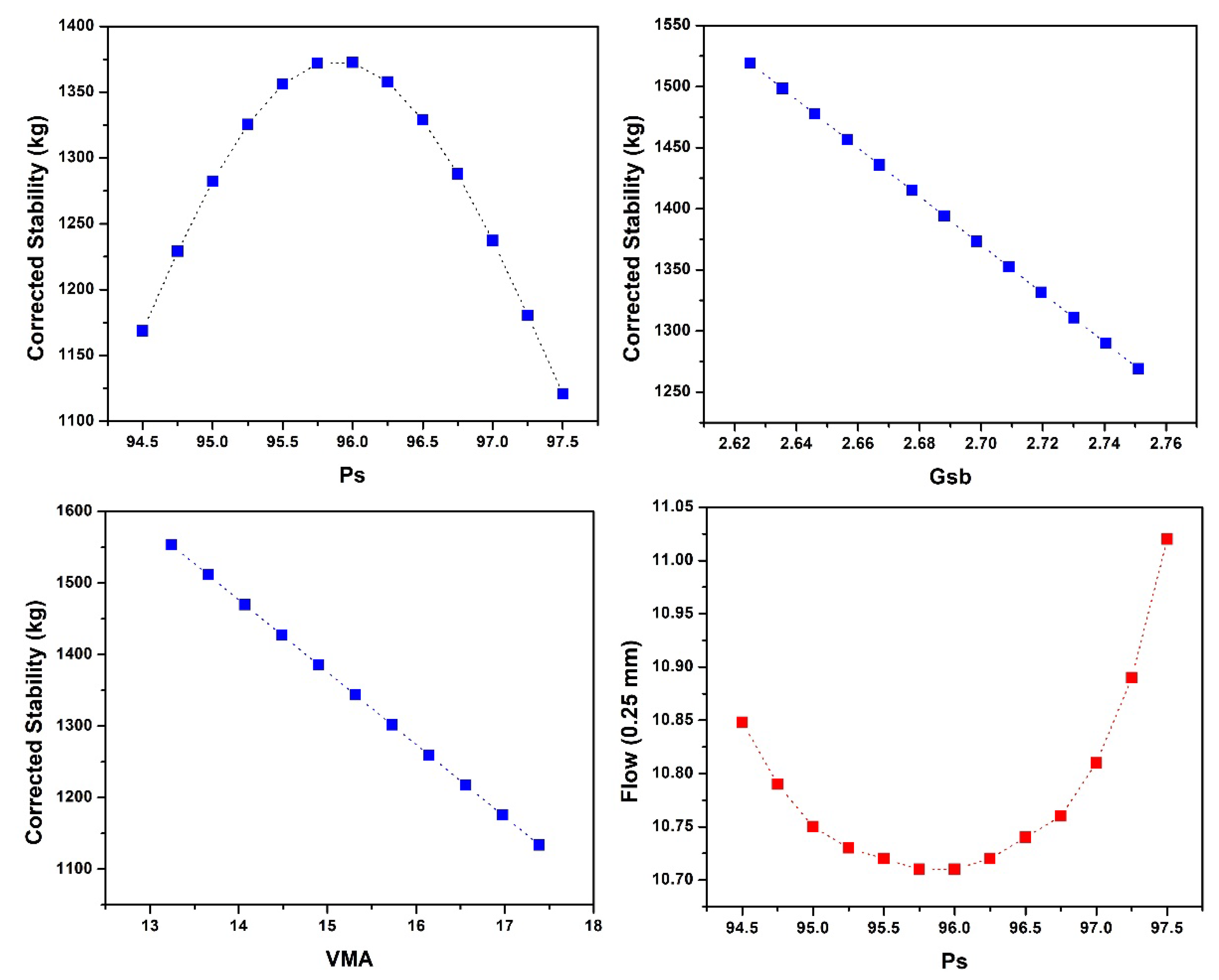
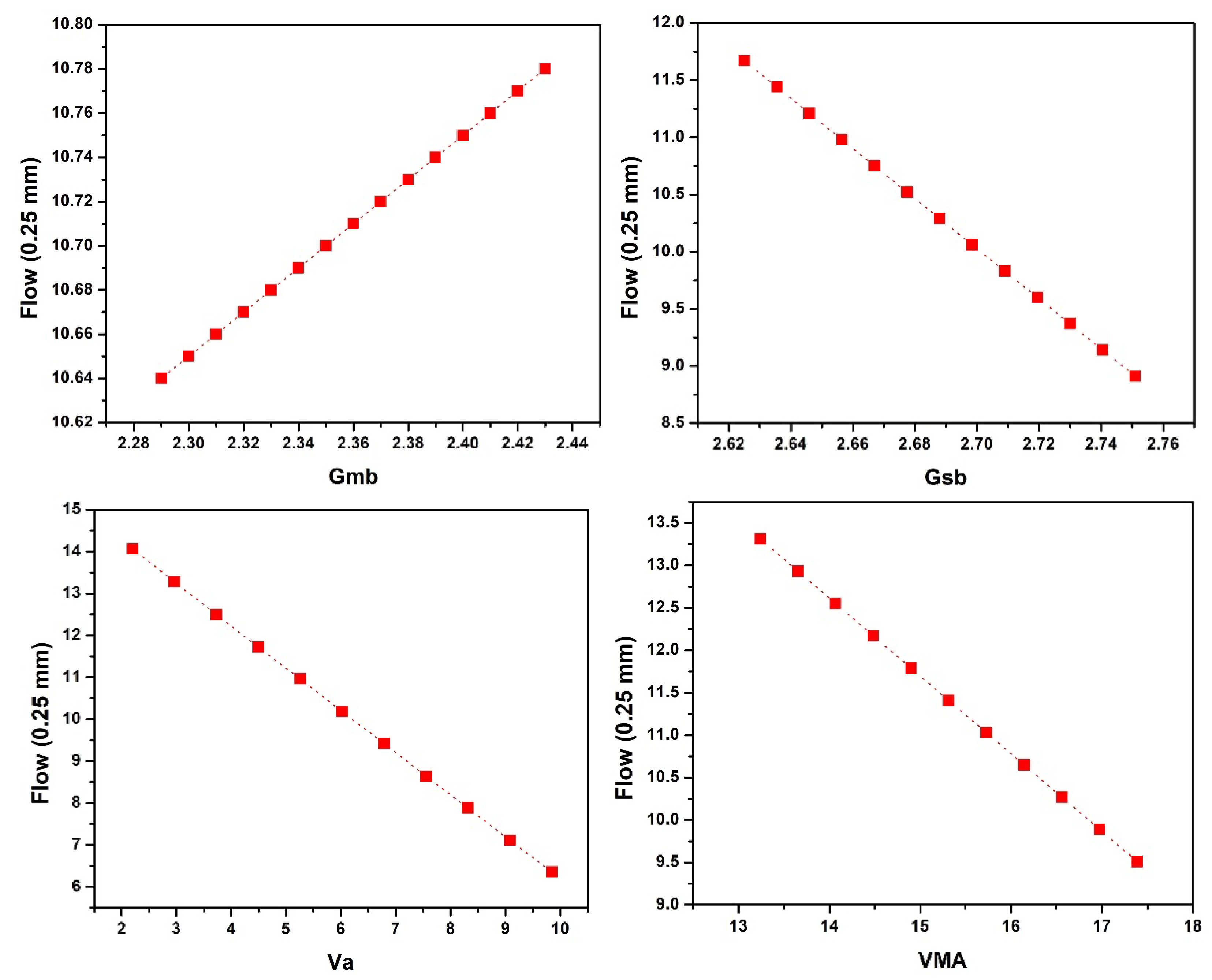
According to the investigation on the influence of input parameters on MS and MF, it was concluded that with the increase in Ps, the MS first increases then drops, while MF first decreases and then rises. Downward linear trends were found for Gsb and VMA in the case of MS and Gsb, and Va and VMA in the case of MF. While in the case of MF, Gmb followed the upward linear trend.
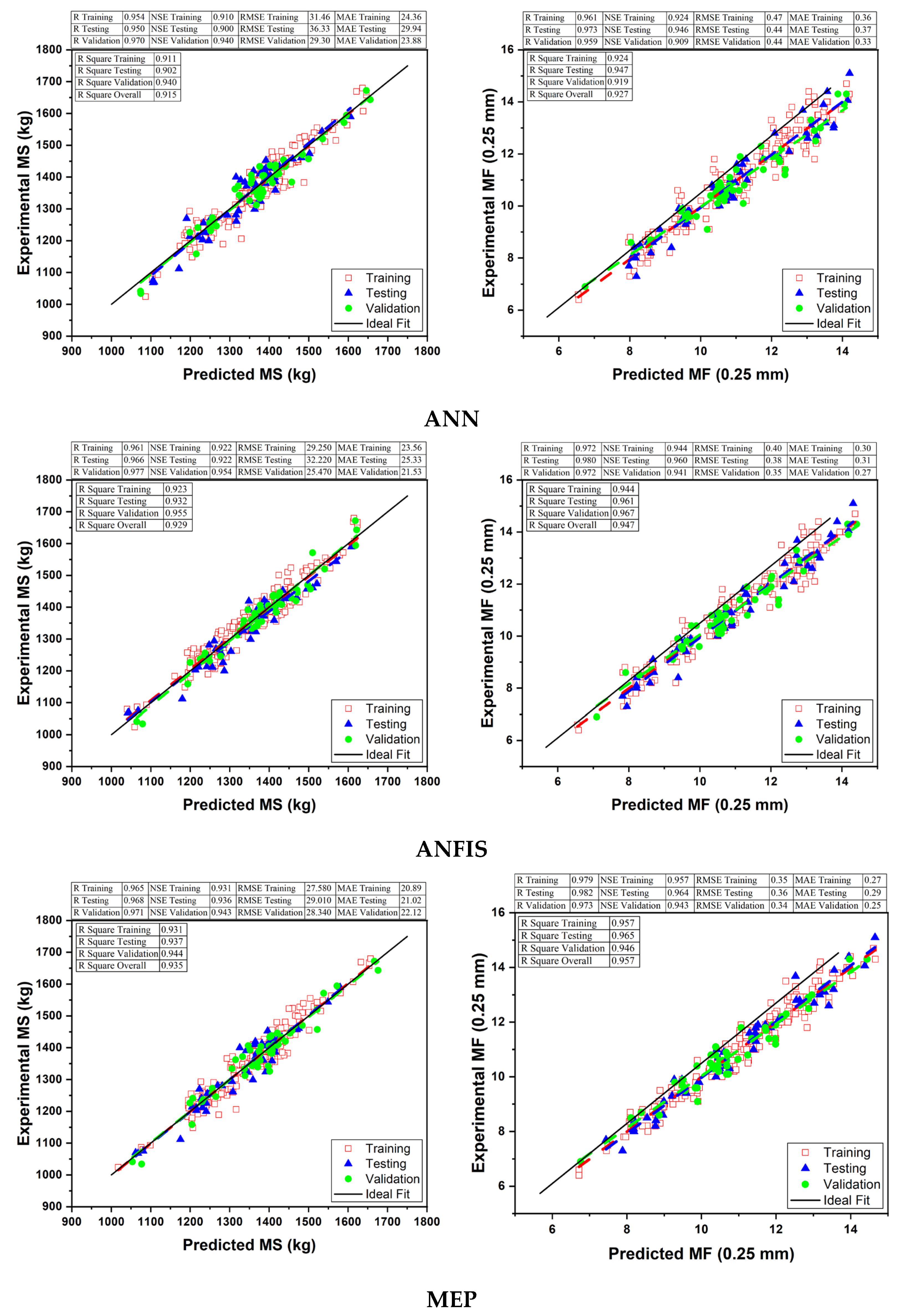
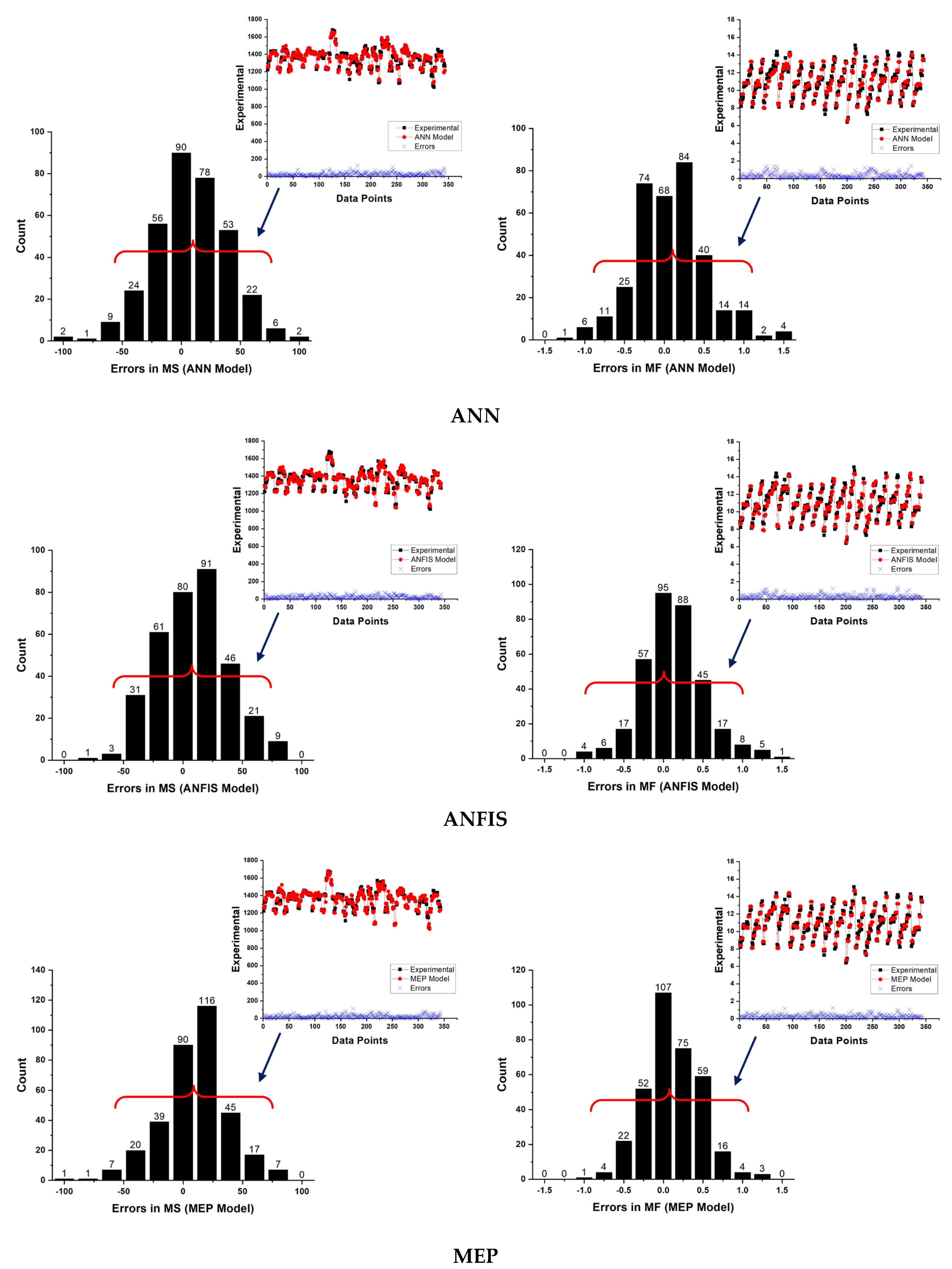
Models based on ANN, ANFIS, and MEP have the ability to predict MS and MF with higher accuracy. Additionally, the MS and MF predicted while employing the MEP technique is better than ANN and ANFIS. The MEP approach simplifies the derivation of MS and MF while maintaining a reasonable level of accuracy between simulated and experimental data.
To avoid the over-fitting of the employed approaches, i.e., ANN, ANFIS, and MEP, a variety of methods, including data division and preprocessing were utilized to minimize the complexity of the developed models. Sensitivity and parametric analysis were carried out, and are covered in length in the paper. The results of the parametric study were found to be inconsistent with the trends of previous research studies.
All the models were evaluated using RSE, MAE, NSE, RMSE, RRMSE, R2, and R. Overall, the comparison results show that all three approaches are effective and trustworthy for predicting the MS and MF of asphalt pavements; however, MEP technique outperformed ANN and ANFIS based on various statistical checks. MEP’s mathematical expressions (Equations (22) and (23)) are substantially simpler than the proposed models of ANN and ANFIS. The latter strategies, on the other hand, suffer from overfitting of data, NN’s limitations, and complexity in the network’s structure. It is suggested that the developed MEP models be used in everyday practice.
The existing models can be used to estimate the MS and MF of asphalt pavements using basic geotechnical indices, which is an efficient, cost-effective, reliable, and time-saving solution to deal with the hectic and time-consuming process involved in the determination of MS and MF, leading to sustainable construction.
Ultimately, it is crucial to note that, based on the finding of this research study, AI techniques are extremely useful and robust tools for solving issues with complicated mechanisms, notably in the field of pavement engineering. The mathematical expressions can be intelligently generalized to previous data which is unseen. The authors also suggest that the outcomes of this research study be validated using other AI approaches, such as SVM, Ensemble Random Forest (ERF), and Gradient Boosted (GB). Because of their intrinsic flaws, such as model uncertainty, knowledge extraction, and interpretability, soft computing techniques are still facing opposition. To acquire a better understanding of the learning process, special emphasis must be made on gaining advanced knowledge about the hidden physical process, based on human expertise, or engineering judgement.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}