
A Deep-Learning Method for the Classification of Apple Varieties via Leaf Images from Different Growth Periods in Natural Environment


Abstract
:1. Introduction
2. Materials and Methods
2.1. Apple-Leaf Image Data Analysis
2.2. Dataset Partitioning
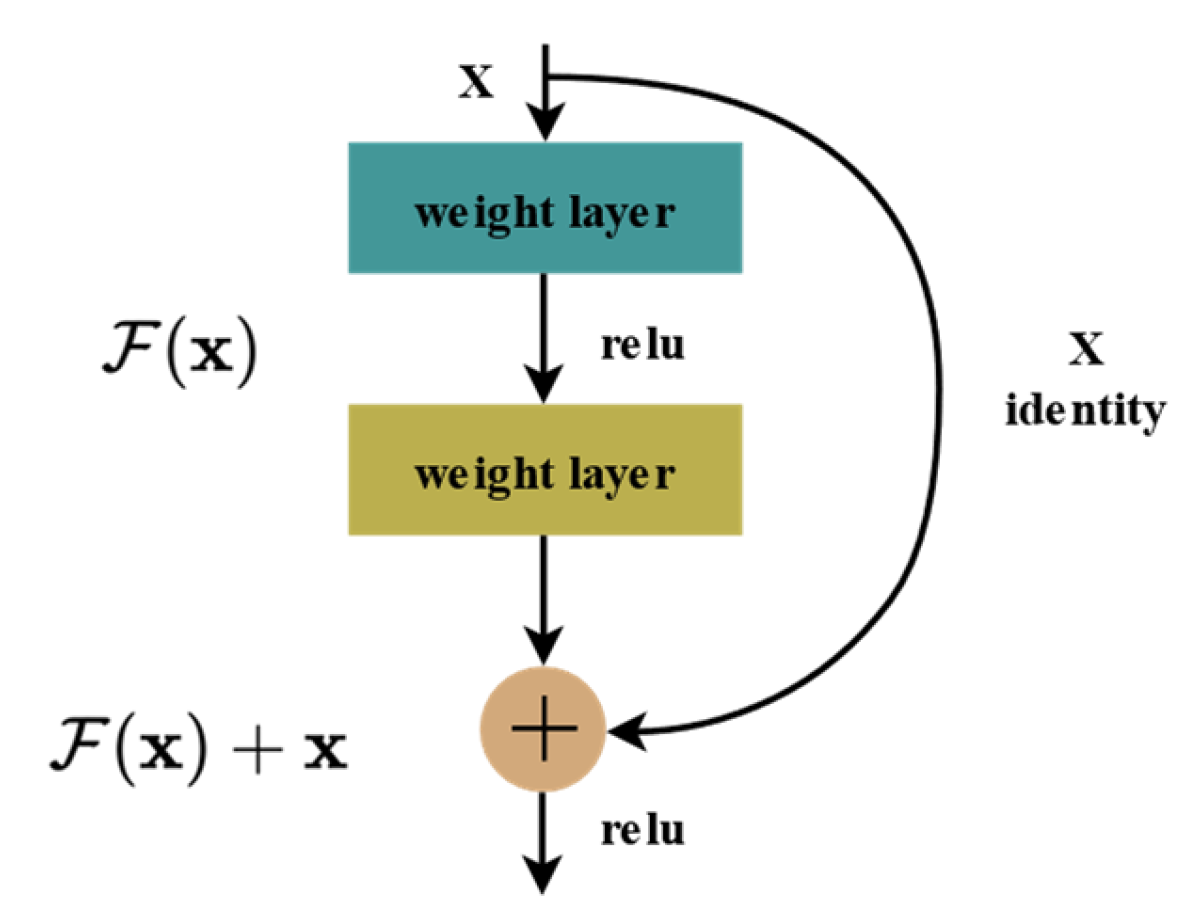
2.3. Network Structure of the Main Modules in MAFNet
2.4. Network Structure Design of MAFNet
2.5. Configuration of the Experimental Environment
3. Result
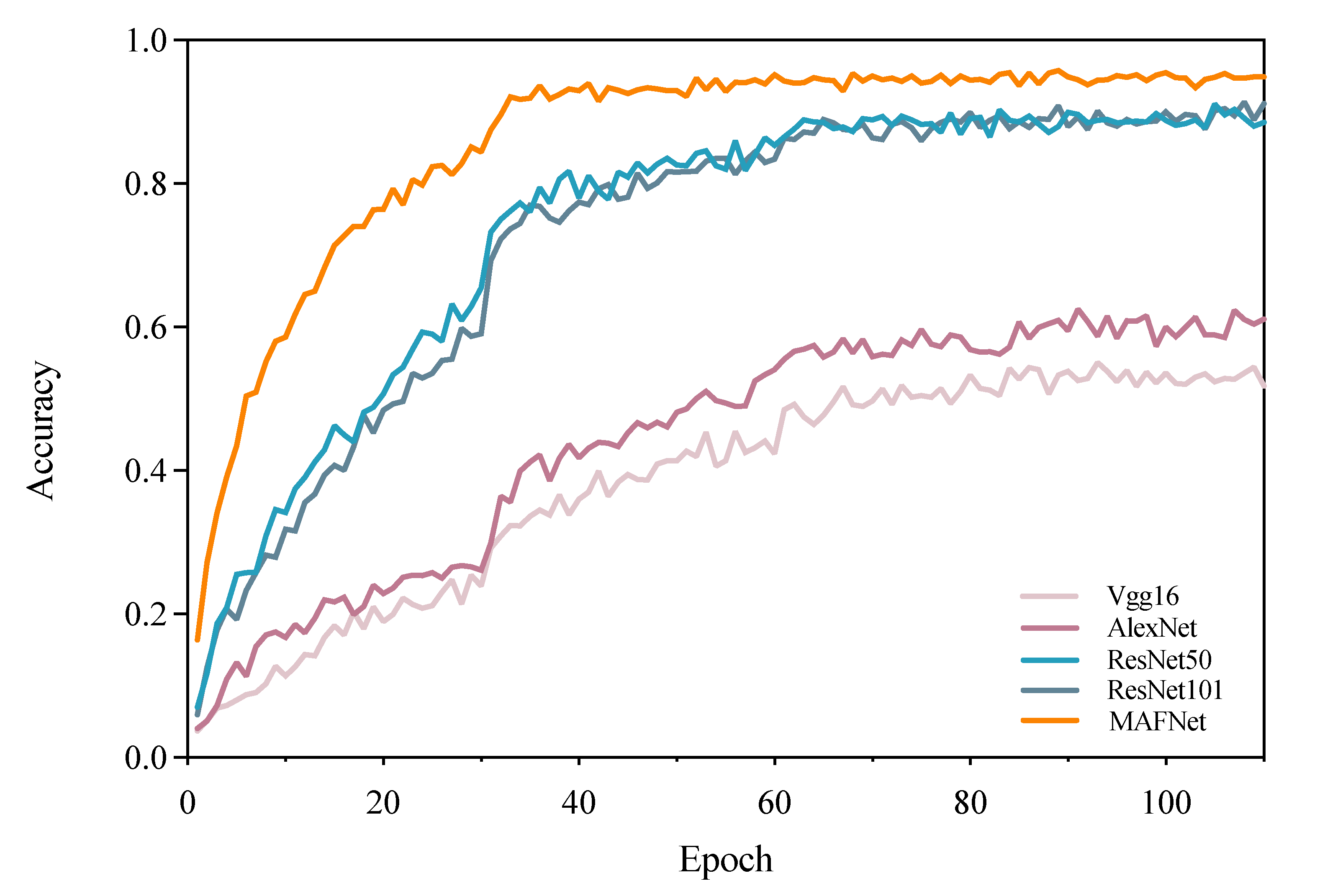
3.1. Performance Comparison of MAFNet with Other Models
3.2. Performance Evaluation of MAFNet on Apple Leaf Dataset
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Brown, S. Apple; Fruit Breeding; Springer: Boston, MA, USA, 2012; pp. 329–367. [Google Scholar] [CrossRef]
- Boyer, J.; Liu, R.H. Apple phytochemicals and their health benefits. Nutr. J. 2004, 3, 5–13. [Google Scholar] [CrossRef] [PubMed]
- Cong, P. Apple Varieties in China; China Agriculture Press: Beijing, China, 2015; pp. 2–3. [Google Scholar]
- Luo, W.; Huan, S.; Fu, H.; Wen, G.; Cheng, H.; Zhou, J.; Wu, H.; Shen, G.; Yu, R. Preliminary study on the application of near infrared spectroscopy and pattern recognition methods to classify different types of apple samples. Food Chem. 2011, 128, 555–561. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Wu, B.; Sun, J.; Li, M.; Du, H. Discrimination of Apples Using Near Infrared Spectroscopy and Sorting Discriminant Analysis. Int. J. Food Prop. 2016, 19, 1016–1028. [Google Scholar] [CrossRef]
- Ma, H.; Wang, R.; Cai, C.; Wang, D. Rapid Identification of Apple Varieties Based on Hyperspectral Imaging. Trans. Chin. Soc. Agric. Mach. 2017, 48, 305–312. [Google Scholar]
- Ni, J.; Yang, H.; Li, J.; Han, Z. Variety identification of peanut pod based on improved AlexNet. J. Peanut Sci. 2021, 50, 14–22. [Google Scholar] [CrossRef]
- Park, J.; Kim, D.; Kim, J.; Kim, H. CNN based modeling and classification for variety of apples. J. D-Cult. Arch. 2021, 4, 63–70. [Google Scholar]
- Geng, L.; Huang, Y.; Guo, Y. Apple Variety Classification Method Based on Fusion Attention Mechanism. Trans. Chin. Soc. Agric. Mach. 2022, 1–11. [Google Scholar]
- Al-Shawwa, M.O.; Abu-Naser, S.S. Classification of apple fruits by deep learning. Int. J. Acad. Eng. Res. (IJAER) 2020, 3, 1–6. [Google Scholar]
- Jeong, S.; Yoe, H. Fruit classification system using deep learning. J. Knowl. Inf. Technol. Syst. 2018, 13, 589–595. [Google Scholar]
- Grinblat, G.L.; Uzal, L.C.; Larese, M.G.; Granitto, P.M. Deep learning for plant identification using vein morphological patterns. Comput. Electron. Agric. 2016, 127, 418–424. [Google Scholar] [CrossRef]
- Baldi, A.; Pandolfi, C.; Mancuso, S.; Lenzi, A. A leaf-based back propagation neural network for oleander (Nerium oleander L.) cultivar identification. Comput. Electron. Agric. 2017, 142, 515–520. [Google Scholar] [CrossRef]
- Liu, C.; Han, J.; Chen, B.; Mao, J.; Xue, Z.; Li, S. A Novel Identification Method for Apple (Malus domestica Borkh.) Cultivars Based on a Deep Convolutional Neural Network with Leaf Image Input. Symmetry 2020, 12, 217. [Google Scholar] [CrossRef]
- Zhao, K.; Liu, X.; Ji, J. Automatic body condition scoring method for dairy cows based on EfficientNet and convex hull feature of point cloud. Trans. Chin. Soc. Agric. Mach. 2021, 52, 192–201. [Google Scholar]
- Zhu, Y.; Xia, J.; Zeng, R.; Zheng, K.; Du, J.; Liu, Z. Prediction model of rotary tillage power consumption in paddy stubble field based on discrete element method. Trans. Chin. Soc. Agric. Mach. 2020, 51, 42–50. [Google Scholar]
- Sun, J.; Chen, H.; Wang, Z.; Ou, Z.; Yang, Z.; Liu, Z.; Duan, J. Study on plowing performance of EDEM low-resistance animal bionic device based on red soil. Soil Tillage Res. 2020, 196, 104336. [Google Scholar] [CrossRef]
- Hu, H.; Li, H.; Li, C.; Wang, Q.; He, J.; Li, W.; Zhang, X. Design and experiment of broad width and precision minimal tillage wheat planter in rice stubble field. Trans. Chin. Soc. Agric. Eng. 2016, 32, 24–32. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual transformer networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 1. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; Volume 25. [Google Scholar]
- Lee, Y.; Hwang, J.W.; Lee, S.; Bae, Y.; Park, J. An energy and GPU-computation efficient backbone network for real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Variety | Label | Variety |
| 1 | Fuji 2001 | 16 | Honey Crisp |
| 2 | Idared | 17 | Gala Mitchgla |
| 3 | Asta | 18 | Pinova |
| 4 | Chengji No. 1 | 19 | Ruixue |
| 5 | Gala | 20 | Ruiyang |
| 6 | GanHong | 21 | Shoufu 1 |
| 7 | Ruby | 22 | Taiga |
| 8 | Red General | 23 | MATO |
| 9 | Honglu | 24 | Orin |
| 10 | Golden Delicious | 25 | Rustless Goldspur |
| 11 | Huashuo | 26 | SinanoGold |
| 12 | Jingning No.1 | 27 | Jonagold |
| 13 | KCo8 | 28 | Yanfu 0 |
| 14 | Kuihua | 29 | Yanfu 3 |
| 15 | Liuyuexian | 30 | Indo |
| Configuration Information | |
|---|---|
| OS | Ubuntu 20.04.3 LTS |
| CPU | Intel(R)Xeon(R)[email protected] (4 Cores) |
| RAM | 16 GB |
| GPU | NVIDIA GeForce GTX 1080 |
| Video memory | 8 GB |
| Code management software | PyCharm Community 2022.1.2 |
| Language | Python 3.6.13 |
| Deep-learning framework | PyTorch 1.2.0 |
| Apple Cultivar | TP | FP | FN | TN | Precision | Recall | F1_score |
|---|---|---|---|---|---|---|---|
| Fuji 2001 | 238 | 2 | 17 | 6943 | 0.9917 | 0.9333 | 0.9616 |
| Idared | 236 | 4 | 4 | 6956 | 0.9833 | 0.9833 | 0.9833 |
| Asta | 235 | 5 | 3 | 6957 | 0.9792 | 0.9874 | 0.9833 |
| Chengji No.1 | 237 | 3 | 12 | 6948 | 0.9875 | 0.9518 | 0.9693 |
| Gala | 239 | 1 | 3 | 6957 | 0.9958 | 0.9876 | 0.9917 |
| GanHong | 232 | 8 | 1 | 6959 | 0.9667 | 0.9957 | 0.9810 |
| Ruby | 239 | 1 | 1 | 6959 | 0.9958 | 0.9958 | 0.9958 |
| Red General | 240 | 0 | 8 | 6952 | 1.0000 | 0.9677 | 0.9836 |
| Honglu | 229 | 11 | 4 | 6956 | 0.9542 | 0.9828 | 0.9683 |
| Golden Delicious | 239 | 1 | 3 | 6957 | 0.9958 | 0.9876 | 0.9917 |
| Huashuo | 227 | 13 | 0 | 6960 | 0.9458 | 1.0000 | 0.9722 |
| Jingning No.1 | 235 | 5 | 0 | 6960 | 0.9792 | 1.0000 | 0.9895 |
| KCo8 | 227 | 13 | 6 | 6954 | 0.9458 | 0.9742 | 0.9598 |
| Kuihua | 232 | 8 | 1 | 6959 | 0.9667 | 0.9957 | 0.9810 |
| Liuyuexian | 238 | 2 | 4 | 6956 | 0.9917 | 0.9835 | 0.9876 |
| Honey Crisp | 231 | 9 | 0 | 6960 | 0.9625 | 1.0000 | 0.9809 |
| Gala Mitchgla | 234 | 6 | 7 | 6953 | 0.9750 | 0.9710 | 0.9730 |
| Pinova | 238 | 2 | 5 | 6955 | 0.9917 | 0.9794 | 0.9855 |
| Ruixue | 239 | 1 | 5 | 6955 | 0.9958 | 0.9795 | 0.9876 |
| Ruiyang | 238 | 2 | 2 | 6958 | 0.9917 | 0.9917 | 0.9917 |
| Shoufu 1 | 226 | 14 | 3 | 6957 | 0.9417 | 0.9869 | 0.9638 |
| Taiga | 237 | 3 | 7 | 6953 | 0.9875 | 0.9713 | 0.9793 |
| MATO | 239 | 1 | 0 | 6960 | 0.9958 | 1.0000 | 0.9979 |
| Orin | 235 | 5 | 8 | 6952 | 0.9792 | 0.9671 | 0.9731 |
| Rustless Goldspur | 237 | 3 | 0 | 6960 | 0.9875 | 1.0000 | 0.9937 |
| SinanoGold | 240 | 0 | 0 | 6960 | 1.0000 | 1.0000 | 1.0000 |
| Jonagold | 240 | 0 | 0 | 6960 | 1.0000 | 1.0000 | 1.0000 |
| Yanfu 0 | 232 | 8 | 7 | 6953 | 0.9667 | 0.9707 | 0.9687 |
| Yanfu 3 | 238 | 2 | 18 | 6942 | 0.9917 | 0.9297 | 0.9597 |
| Indo | 239 | 1 | 5 | 6955 | 0.9958 | 0.9795 | 0.9876 |
| macro-P = 0.9814 | macro-R = 0.9818 | macro-F1 = 0.9814 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Han, J.; Liu, C.; Wang, Y.; Shen, H.; Li, L. A Deep-Learning Method for the Classification of Apple Varieties via Leaf Images from Different Growth Periods in Natural Environment. Symmetry 2022, 14, 1671. https://doi.org/10.3390/sym14081671
Chen J, Han J, Liu C, Wang Y, Shen H, Li L. A Deep-Learning Method for the Classification of Apple Varieties via Leaf Images from Different Growth Periods in Natural Environment. Symmetry. 2022; 14(8):1671. https://doi.org/10.3390/sym14081671
Chicago/Turabian StyleChen, Junkang, Junying Han, Chengzhong Liu, Yefeng Wang, Hangchi Shen, and Long Li. 2022. "A Deep-Learning Method for the Classification of Apple Varieties via Leaf Images from Different Growth Periods in Natural Environment" Symmetry 14, no. 8: 1671. https://doi.org/10.3390/sym14081671