
Open Access to Data about Silk Heritage: A Case Study in Digital Information Sustainability
 , ,
, ,  , , ,
, , ,  and
and
Abstract
:1. Introduction: From Silk Heritage to Digital, Public Humanities
- “Materials and Methods” offers an in-depth analysis of the existing information resources about textile heritage, with a main focus on silk fabrics. It also provides an updated look at the sector-wide trend towards open access to cultural heritage information. This is motivated, among other reasons, by the growing understanding that the long-term sustainability of heritage data can be best guaranteed by efforts focused on interoperability, open access and decentralized management.
- “Results and Discussion” shows some tools and resources created within the SILKNOW research project, that aimed at providing sustainable answers to the limitations of those existing resources. More specifically, a multilingual thesaurus to standardize textile terminology across four European languages; on ontology based on CIDOC CRM, created to allow the mapping and interoperability of data about silk textiles, coming from different catalogs and very heterogeneous in nature; some cross-lingual models that can automatically infer and provide annotations to complete missing properties of cataloging records and a tool for the spatiotemporal visualization of information associated with records gathered from independent repositories.
- “Conclusions” argues that in addition to the technical requirements and possibilities inherent in digital repositories for cultural heritage, institutional and intellectual issues also have paramount importance. Open access to cultural heritage data must be claimed and facilitated by everyone involved before the promise of truly public humanities can be fully accomplished.
Research Background and Literature Review
2. Materials and Methods
2.1. Access to Textile and Fashion Heritage: Some Approaches
2.1.1. “Universal” Repositories
- Opportunities for discovery: large databases can provide “windows” of visibility for less-known pieces, many times kept in storage, that are less likely to attract the attention of the general public, but which can be interesting for other experts or targeted audiences. This is the main benefit and one that “only” requires cataloging data in digital formats, adapting them to existing standards, and sharing them through available repositories.
- Workflow optimization: information generated primarily for institutional, internal usage can to a certain extent be repurposed for later, external reuse, instead of incurring the costs of time-consuming, one-off curated content publishing.
- Multilingualism: joint efforts are helping to overcome linguistic barriers. Thanks to automated translation and, in specialized contexts, multilingual thesauri, it is possible to gather information in different languages, and not just the language employed by the user to interrogate the system. Museum catalogs tend to be rather specialized resources that use scholarly terminology. Therefore, it will always be better to count on multilingual controlled vocabularies and not just general automated translation.
- Opportunities for automatization of some tasks. Large bodies of information (for instance, objects covering an entire period or style) are hard to grasp in their entirety, even for experts. Artificial intelligence and big data might be ready to help us in some cases, where computers can take care of repetitive and cumbersome tasks. For instance, searching for previously unknown shared features, or for unexpected patterns within large numbers of objects and records, both in visual analysis and in textual analysis. Automated annotation might be a great help for catalogers, providing suggestions based on comparison with many other instances, but always ensuring that the AI-generated content is curated and supervised by domain experts.
Europeana
Wikimedia Commons
2.1.2. National Databases
- Joconde is the classical model in this regard. This database, created and maintained by the French Ministry of Culture, as of 31 August 2023, gathers 667,466 records from more than 250 museums having received the legal status of “Musée de France” [13]. Its records are also shared through other platforms, notably, on POP, the Plateforme Ouverte du Patrimoine (https://pop.culture.gouv.fr/ (accessed on 12 September 2023)). By late 2020, some 21,000 of them were related to textiles and costumes [14].
- CERES, the Red Digital de Colecciones de Museos de España, offers a similar framework. It is built on an information system named Domus, developed by the Spanish Ministry of Culture and currently used by 195 museums throughout Spain, both public and private. While the system was originally built for the internal management of the collections, sharing the catalog records through the Ministry’s centralized repository is a permanent feature of the software. This repository is then made public online through the CERES website. It also relies on a set of common controlled vocabularies and cataloging rules. It covers large parts of Spanish heritage kept in museums, but it cannot be said to be fully comprehensive, either. Some regions have developed their own, independent systems. Even among museums contributing to CERES, the quantity and depth of their records on the platform can vary widely. Despite such shortcomings, it offers a tremendous amount of information and serves as an outstanding example of the feasibility and advantages of centralized repositories. In its current version, it offers more than 341,000 records from 118 museums (http://ceres.mcu.es/ (accessed on 12 September 2023)). It is particularly useful for small and medium institutions: among them, many specializing in textile heritage. They can benefit greatly from shared resources like Domus and CERES, as they usually lack the funding, human resources and expertise to embark on large digitization campaigns on their own.
- A partly similar approach lies at the basis of BeWeB, the census of heritage owned by Catholic dioceses and institutions from Italy (https://beweb.chiesacattolica.it/ (accessed on 12 September 2023)). While organized by a private institution, the Italian Bishops’ Conference (CEI—Ufficio Nazionale per i beni culturali ecclesiastici e l‘edilizia di culto), offers coverage even larger than the ones just mentioned. It contains records on more than 10 million objects, including archival documents and books, with historical and artistic objects exceeding 4 million [15]. Inevitably, the quality and standardization of all these records is quite a challenge and often offers ample room for improvement. The resource itself, however, is staggering in its ambition and reach and offers a good example for private owners of art historical heritage.
- The last two instances show, on the other hand, some of the limitations of the centralized model. Even when controlled vocabularies are available, cataloguers do not always follow them consistently. In CERES, identical pieces may be cataloged as either “Textiles” or “Tejidos” (or as any of their many subtypes), which makes systematic recovery quite unpredictable sometimes. Semantic web technologies can help to overcome these problems, but only to a certain extent. On the other hand, these repositories bring together records prepared over long periods of time (decades, sometimes), in widely different institutions, about very heterogeneous records, by catalogers with varying levels of expertise and dedication to the task. The resulting records are also dissimilar in quality, depth and scientific validity. In any case, the main advantages of these large repositories are, again, the new opportunities they provide for discovery into the less visible parts of our heritage, for the cross-reference of objects between institutions or across disciplines, for quantitative analysis and innovative visualizations.
2.1.3. Major Museums
- The Victoria and Albert Museum in London was created in the mid-19th century with a focus on the applied arts and science. Cataloging records on part of their collections are available on their website, numbering more than 1.2 million. Their holdings of textiles and fashion are truly impressive: their online presence almost reaches 80,000 pieces, not including embroidery and fashion items. They are also accessible through an API, an uncommon but forward-looking feature for museums (https://developers.vam.ac.uk/ (accessed on 12 September 2023)). Similar institutions in other European countries are the Musée des Arts Décoratifs in Paris and the Museum für angewandte Kunst in Vienna.
- The Musée des Tissus in Lyon (https://www.museedestissus.fr/ (accessed on 12 September 2023)), until recently known as the Musée des Tissus et des Arts Décoratifs. Widely considered the best European collection of historical silks, it is also exceptionally rich in fashion and other textiles, with 2.5 million pieces in total. Online access to such a vast collection is quite limited, however. As a private establishment, dependent on both public and private funding, it has suffered serious institutional crises in the last years that seem to have been overcome by now.
- The Metropolitan Museum of Art, in New York City, is an encyclopedic art museum, and a public/private partnership. It houses world-class collections of many kinds of fine and decorative arts. In the last decades, its Costume Institute has gained huge visibility for its temporary exhibitions and celebrity-oriented events, such as the annual Met Gala. Less known but equally important are the textile collections. It is a global leader in the field of open access to collections, providing full information and high-resolution images on some 400,000 pieces, from the total 1.5 million objects it holds (https://www.metmuseum.org/about-the-met/policies-and-documents/open-access (accessed on 12 September 2023)). Some 40,000 catalog records on textiles are freely available on its website.
- The Smithsonian Institution is a system of research centers, libraries and museums, part of the US federal administration. One of its 19 museums is the Cooper Hewitt Design Museum, located in New York City. While it may seem focused on modern design, it houses impressive historical collections, too, with textiles among them. It is also a champion of open access, as part of the Institution’s general policy, featuring an API (https://edan.si.edu/openaccess/apidocs/ (accessed on 12 September 2023)) and an image repository shared across all of the Smithsonian’s collections (https://www.si.edu/openaccess (accessed on 12 September 2023)).
2.1.4. Other Projects
- SilkMemory is, according to its own website https://silkmemory.ch/ (accessed on 12 September 2023), a “web portal [that] provides access to the archive database of the Lucerne School of Art and Design with digitized text and image sources about the silk industry of the Canton of Zurich”. Born after the commercial demise of the once-thriving Swiss silk industry, it was funded by the Zurich cantonal government and went online in 2018. It provides a thoughtful answer to a danger that is common to many European countries: the dispersal and loss of the valuable archival and material heritage generated by those industries, most of which have gone out of business during the last decades. It offers a database of fabrics, books and images kept in those archives, together with a selection of some personal or institutional stories obtained from the same archival fund.
- ART-CHERIE (Achieving and Retrieving Creativity Through European Fashion Cultural Heritage Inspiration—https://www.artcherie.eu/ (accessed on 12 September 2023)) was a project funded by the Erasmus programme of the European Commission, lasting from December 2016 to May 2019. It brought together partners from Belgium, Greece, Italy and the United Kingdom, from a quite broad scope, including an interesting connection to the training of fashion designers. Among other outputs, it aimed at providing a Digital Database or “Catalogue and Digitisation of Museo Prato Exhibits and Collection”. However, it is not openly accessible.
- María Judith Feliciano, an independent scholar specializing in Medieval Iberian textiles, is the principal investigator of the “Medieval Islamic Textiles in Iberia and the Mediterranean” research project (https://maxvanberchem.org/en/scientific-activities/projects/art-history/16-histoire-de-l-art/160-medieval-islamic-textiles-in-iberia-and-the-mediterranean-2 (accessed on 12 September 2023)). Funded by the Fondation Max van Berchem in 2016–17, it was a crossroads for a number of research projects from other scholars in the same field, like Ana Cabrera, Laura Rodríguez Peinado and Therese Martin. It reportedly aimed at producing a website and database to make available the results of the research carried out, but these have only been disseminated through articles and essays.
- Tetiana Brovarets is one case of an independent scholar working outside the usual funding schemes and doing valuable self-supported research. For example, she has published a database where textiles with embroidered verbal texts are collected: mostly rushnyks, Ukrainian towels from the late 19th and early 20th centuries (https://volkovicher.com/ (accessed on 12 September 2023)). Thanks to this database, it is possible to study different combinations of one and the same images and inscriptions on textiles, as shown in [16].
- IMATEX is the online database offering information about the collection of the Centre de Documentació i Museu Tèxtil de Terrassa (http://imatex.cdmt.cat/ (accessed on 12 September 2023)). Created in 1996, it was originally built as a gateway for designers searching for inspiration in CDMT’s historical collection and later transformed into a generic online information resource, open to everyone [17]. It is extremely rich in content, including costumes, accessories, designs, paraments, sample books, a library and an outstanding collection of more than 9000 textiles. Available in Catalan, Spanish and English, initially it was made possible by the European Regional Development Fund, and by the CDMT’s own budget afterward.
- The MINGEI project aims to explore the possibilities of representing and making accessible both tangible and intangible aspects of craft as cultural heritage (https://www.mingei-project.eu/ (accessed on 12 September 2023)). One of the crafts under study is silk weaving, led by one of the project partners, Haus der Seidenkultur in Krefeld. It is a Horizon 2020 project, led by FORTH, and it is being carried out between 2019 and 2022. The project does not directly intend to build a database, but rather a repository of innovative storytelling models, including interactive Augmented Reality and Mixed Reality. It does have a strong emphasis on developing content description tools that comply with existing semantic web standards, such as CIDOC-CRM.
- The PARVENUE project was recently funded by the German Federal Ministry for Education (https://www.parvenue-projekt.de/ (accessed on 12 September 2023)). Led by art historians from the Heinrich-Heine-Universität in Düsseldorf, it is built on a tight collaboration with the Deutsche Textilmuseum in Krefeld (https://www.deutschestextilmuseum.de/ (accessed on 12 September 2023)), one of the European capitals of the silk industry. One of the areas of the project is built on preliminary cataloging of the collection of 30,000 fabrics and costumes in the museum, not yet available online.
- Another recent initiative is the Restaging Fashion project, based in the Lipperheidesche Kostümbibliothek—Sammlung Modebild in Berlin, and the Fachhochschule Potsdam (https://uclab.fh-potsdam.de/projects/restaging-fashion/ (accessed on 12 September 2023)). Active between 2020 and 2023, and also funded by the German Federal Ministry for Education, it purports to build an online catalog of costumes, prints and drawings, held in different institutions, adding 3D visualizations of some of these objects.
- Finally, some authors of this article have been involved in three projects focused on the dissemination and sustainability of heritage via digital tools and platforms. One of them is, as already mentioned, SILKNOW, a Horizon 2020 project active between 2018 and 2021, that among other things has built ADASilk, a repository of some 40,000 records about silk-related objects from different museums and collections (https://ada.silknow.org/ (accessed on 12 September 2023)). The joint team of art historians and computer scientists in Universitat de València has also been working on SeMap (https://www.uv.es/semap/ (accessed on 12 September 2023)), a project funded by Fundación BBVA and built on the data from Spanish museums made available by CERES, the web portal of the Red Digital de Colecciones de Museos de España presented above. Finally, some members of the same team are currently working on the ClioViz project (https://www.uv.es/clioviz (accessed on 12 September 2023)), funded by the Spanish government (2022–2025). It explores advanced techniques for the visualization of historical information, thanks to the collaboration of the already-mentioned CERES national repository.
2.2. Sustainability of Heritage Information: Toward Open Access
- Ownership: public institutions (meaning state-owned), or collections owned by private organizations or individuals.
- Funding models: be they fee-based, paid through taxes, established as non-profits but aiming at sustainability, and many different mixed approaches.
- Intellectual property rights (moral and economic ones) connected to the works, or their associated documentation have varying consequences on the display, dissemination and reuse of all that information.
- Information tools: catalogs and inventories kept only for professional and scholarly (internal) use; sometimes slowly and partially published over decades or centuries; sometimes disseminated through exhibition catalogs or research journals.
- Digital availability: varying degrees of transition to digital tools and repositories for all that information, a true wealth of data kept by heritage institutions.
3. Results and Discussion: Silk Heritage Resources and Tools from the SILKNOW Project
3.1. The SILKNOW Thesaurus
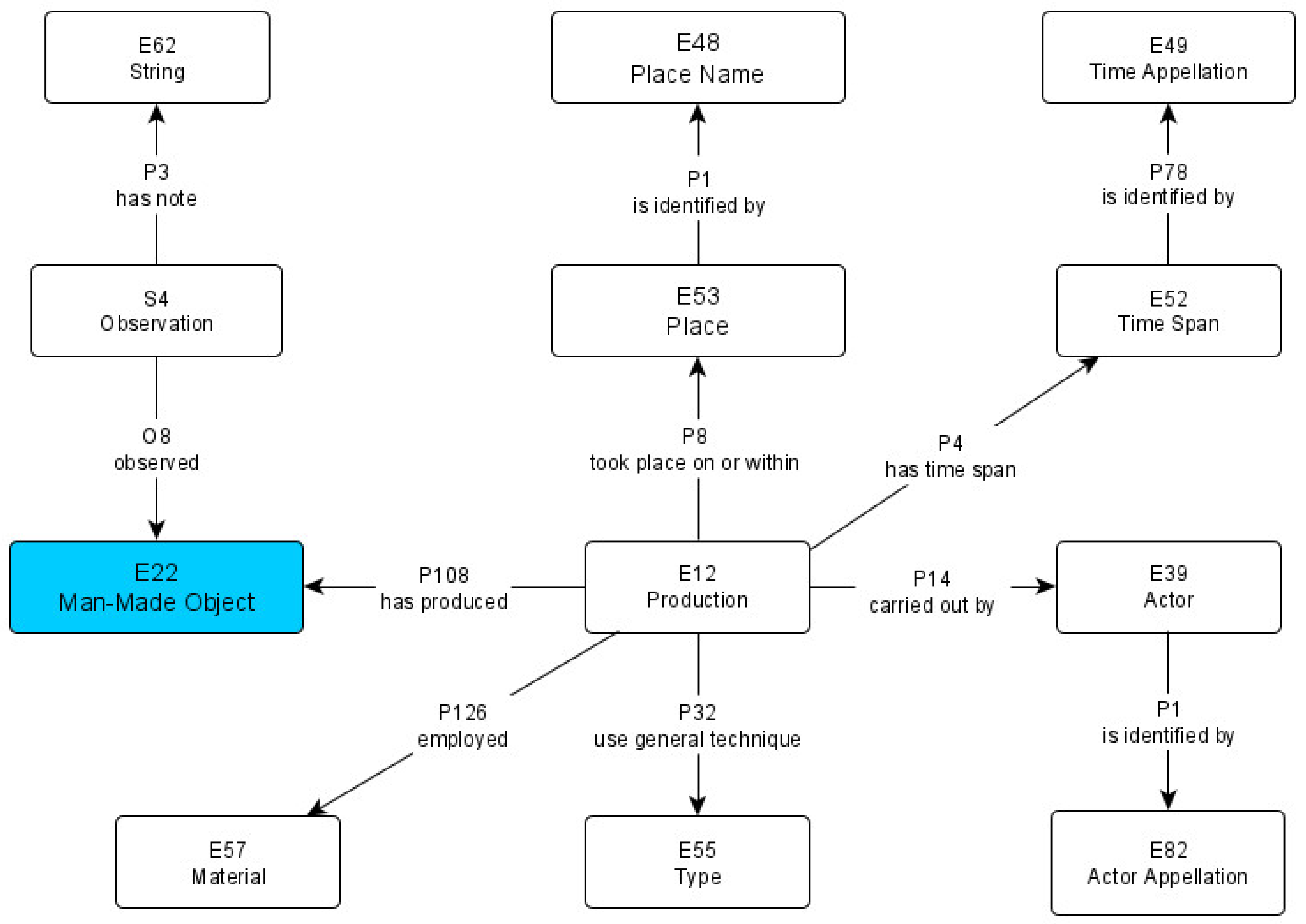
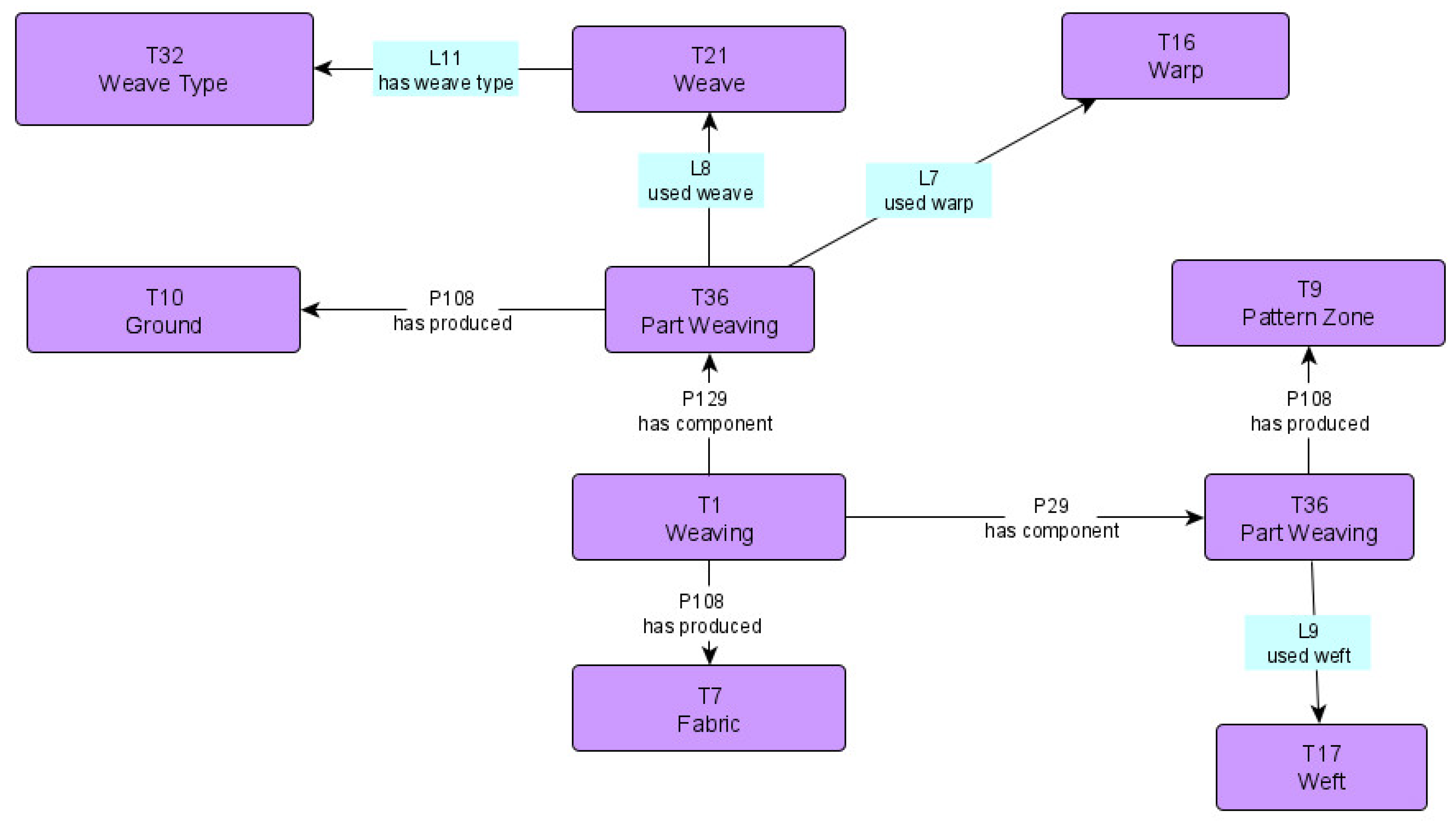
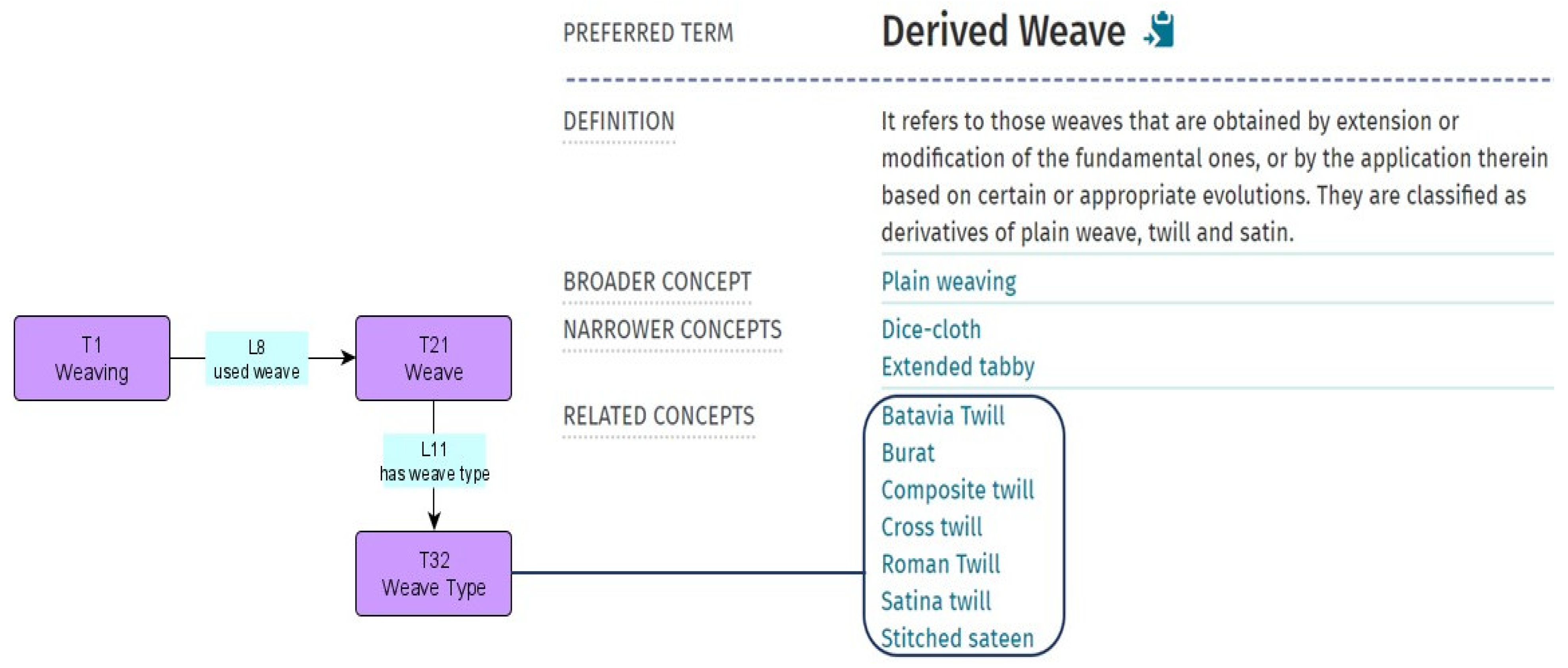
3.2. The SILKNOW Ontology
- tables and columns in the relational database are interpreted as entities;
- complete records are interpreted as entity instances;
- field names are interpreted as both relationships and entities;
- and field contents are interpreted as entity instances.
3.3. Towards Automated Annotation through AI: Text Analysis
3.3.1. Data Description
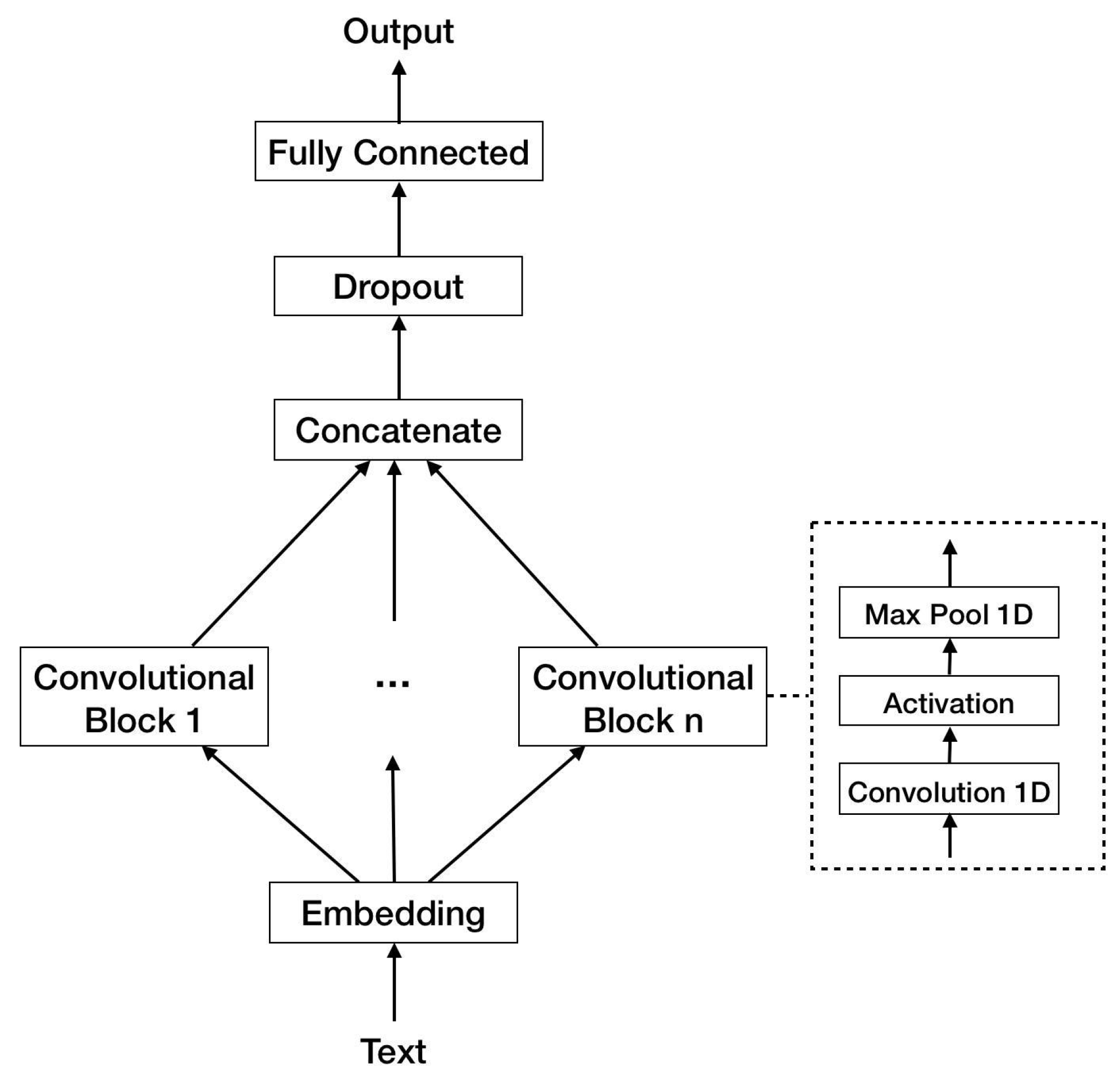
3.3.2. Methodology
3.3.3. Experiments and Results
- Given labeled data (digitized artifacts) from one catalog (e.g., a museum), can we infer those labels (properties) in non-labeled data in the same catalog? The practical applications of this include the ability to infer properties in a catalog from a subset of that catalog’s data which was semi-automatically or manually labeled, filling missing data, and semi-automatic conversion to a different ontology.
- Given labeled data from one catalog, can we infer the labels of non-labeled data in a different catalog? Practical applications include aligning the ontologies of two or more different catalogs, and, if one can be labeled with a standard ontology then that effort can be leveraged to provide those categorical labels to other catalogs.
- Given labeled data from one catalog, can we infer the labels of non-labeled data in a different language catalog? Applications are the same as in the previous case, but cross-lingual.
3.3.4. Text Analysis: Conclusions
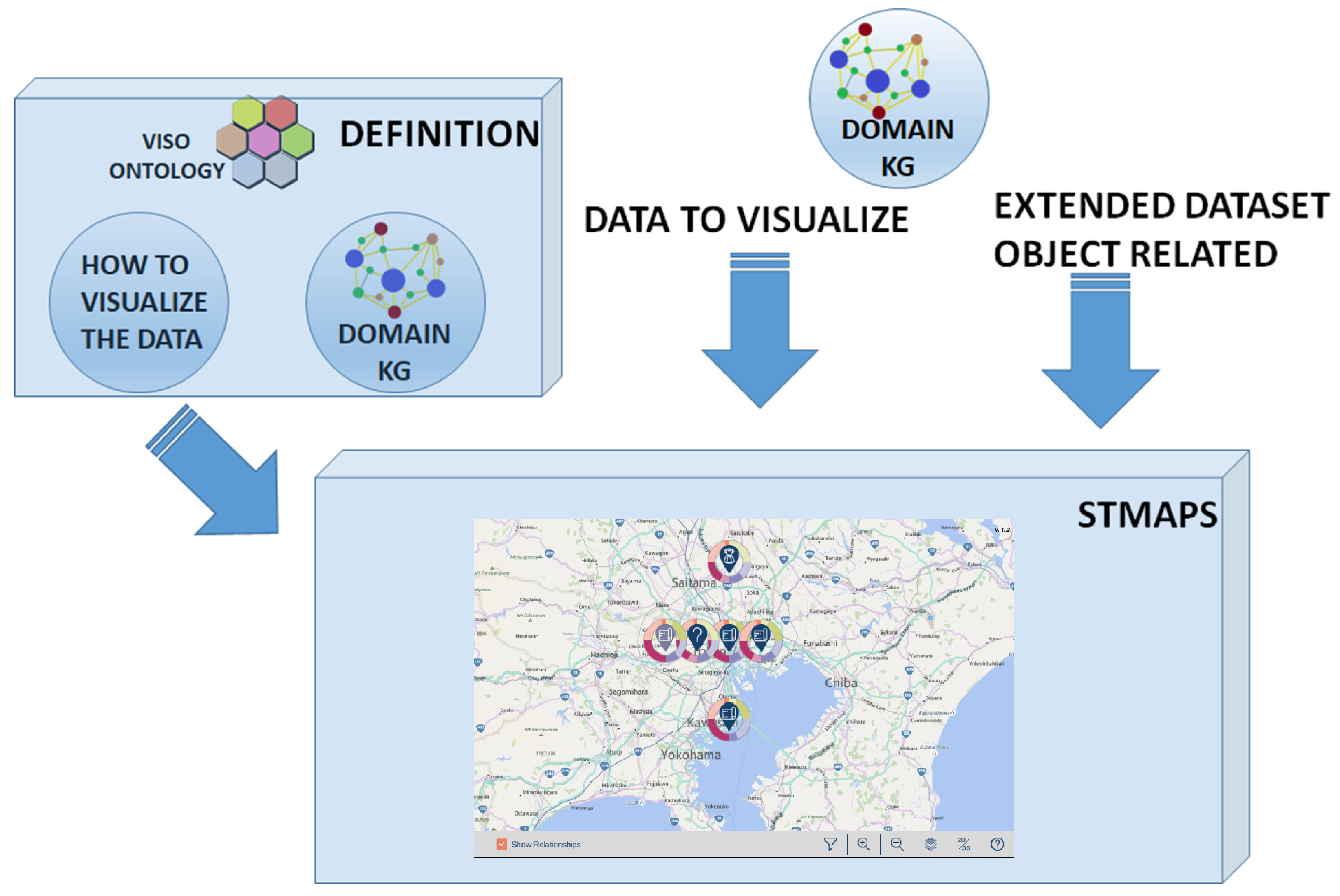
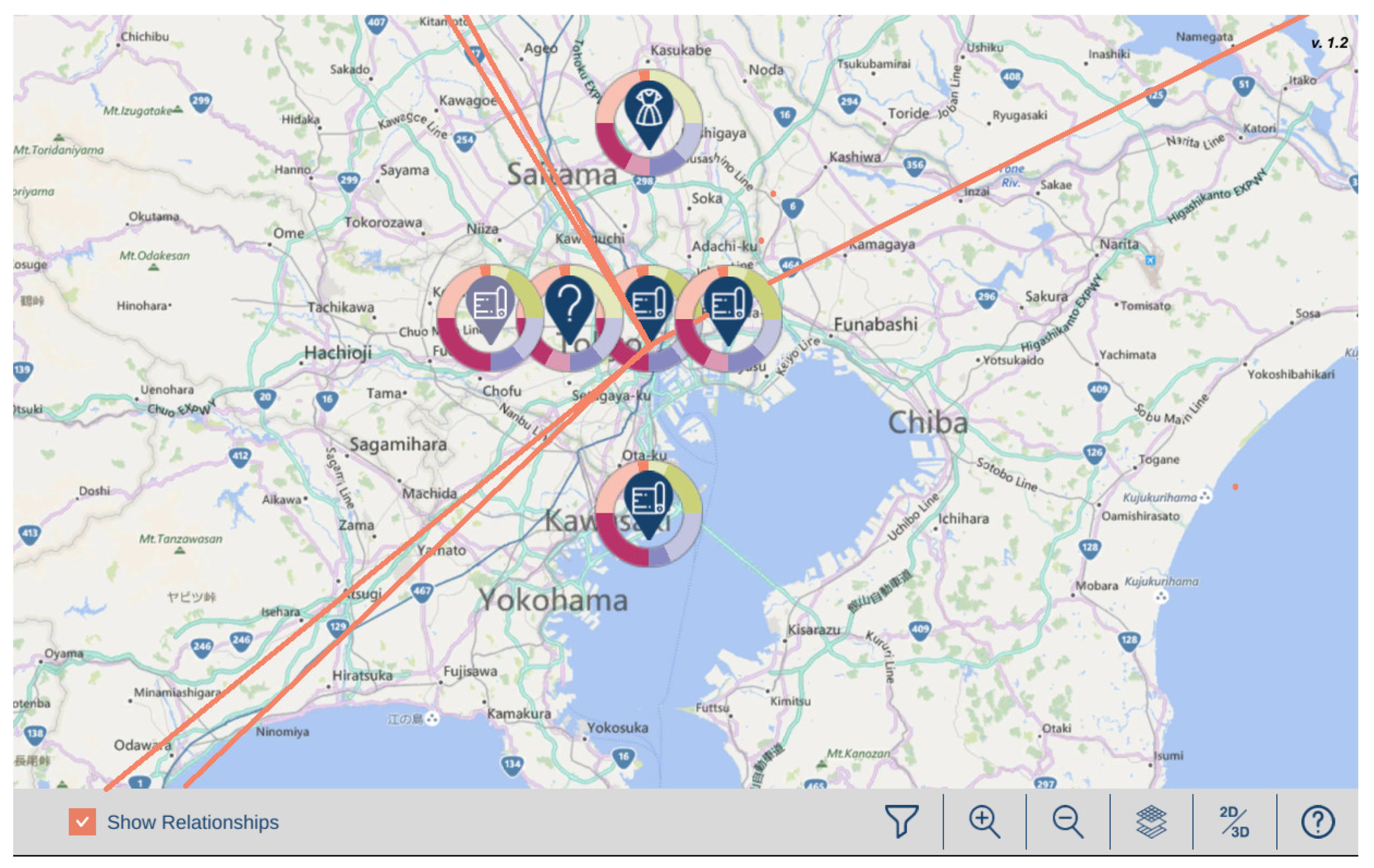
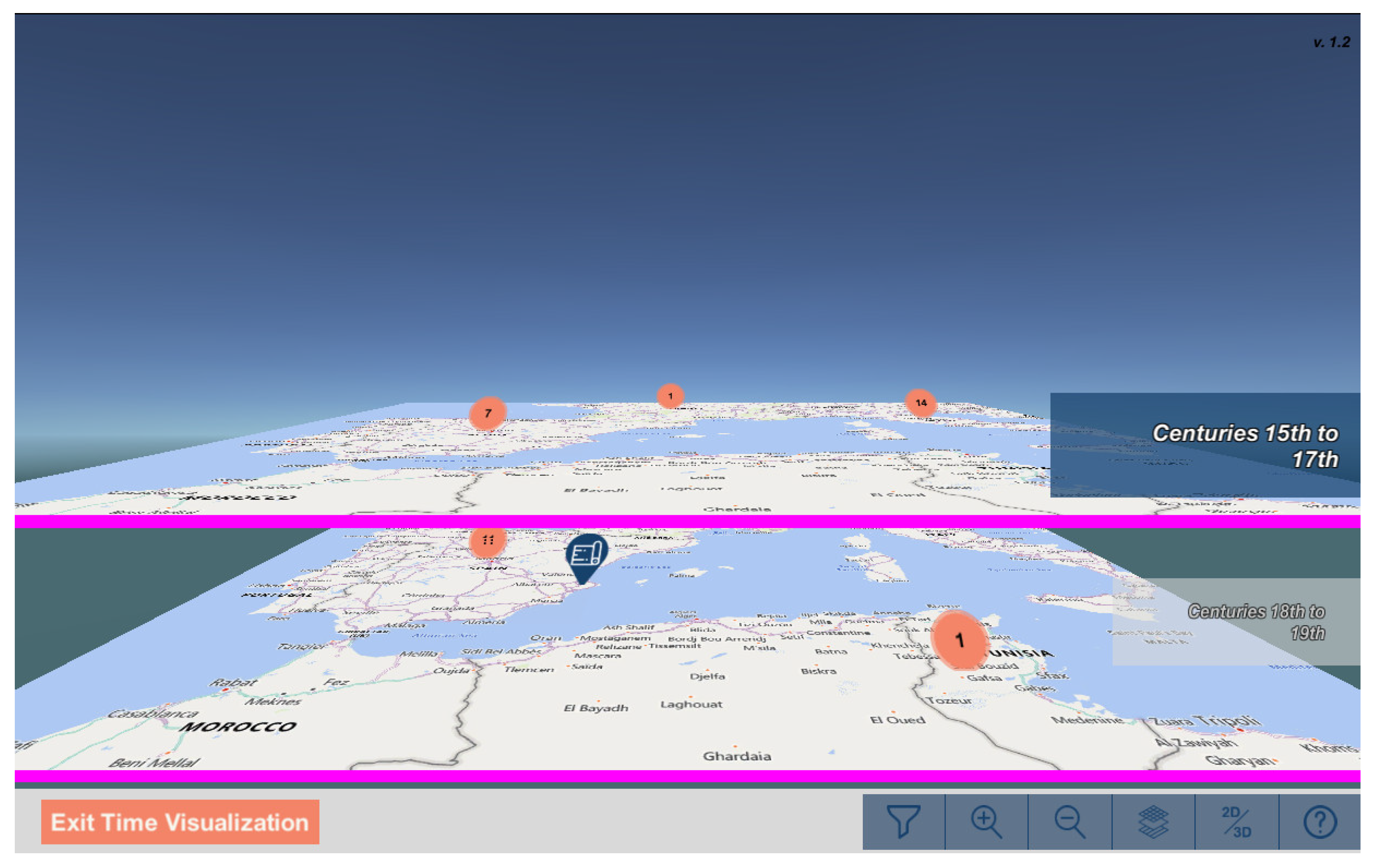
3.4. Spatiotemporal Visualization of Maps
3.4.1. Implementation
3.4.2. Functionality
4. Conclusions: Heritage Institutions Need to Focus on Information Sustainability and Open Access
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bradley, K. Defining Digital Sustainability. Libr. Trends 2007, 56, 148–163. [Google Scholar] [CrossRef]
- Stuermer, M.; Abu-Tayeh, G.; Myrach, T. Digital sustainability: Basic conditions for sustainable digital artifacts and their ecosystems. Sustain. Sci. 2017, 12, 247–262. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, G. Sustainability of digital information services. J. Doc. 2013, 69, 602–622. [Google Scholar] [CrossRef]
- Borkopp-Restle, B.; McNeil, P.; Martinetti, S.; Miller, L.; Riello, G. Museums and the Making of Textile Histories: Past, Present, and Future. Perspective 2016, 43–60. [Google Scholar] [CrossRef]
- Brovarets, T. Apocalyptic Motifs on Century-Old Ukrainian Rushnyks through Today’s Digital Folklore Communication. Colloq. Humanist. 2022, 1–21. [Google Scholar] [CrossRef]
- Haffner, D. A Textile Thesaurus—Merging and Enlarging the Existing Vocabularies. In Proceedings of the ICOM General Conference, Milan, Italy, 4 July 2016; Available online: http://cidoc.mini.icom.museum/wp-content/uploads/sites/6/2018/12/haffner-textile-thesaurus.pdf (accessed on 12 September 2023).
- Hooland, S.; Verborgh, R. Linked Data for Libraries, Archives and Museums: How to Clean, Link and Publish Your Metadata; Facet Publishing: London, UK, 2014. [Google Scholar]
- Le Boeuf, P. Le Modèle conceptuel de référence du, CIDOC. De la sémantique des inventaires aux musées en dialogue. Cult. Et Musées 2014, 22, 89–111. [Google Scholar] [CrossRef]
- Dörr, M. CRM Family of Models. 2018. Available online: http://dataforhistory.org/sites/default/files/dfh20180525_doerr.pdf (accessed on 12 September 2023).
- Rosenberg, D.; Grafton, A. Cartographies of Time; Princeton Architectural Press: New York, NY, USA, 2012. [Google Scholar]
- Lippincott, K.; Eco, U.; Gombrich, E.H. El Tiempo a Través del Tiempo; Grijalbo: Barcelona, Spain, 2000. [Google Scholar]
- Sebastián Lozano, J. Mapping Art History in the Digital Era. Art Bull. 2021, 103, 6–16. [Google Scholar] [CrossRef]
- Nouvelles Notices Versées sur Joconde. 2023. Available online: https://www.culture.gouv.fr/Thematiques/Musees/Les-musees-en-France/Les-collections-des-musees-de-France/Joconde-catalogue-collectif-des-collections-des-musees-de-France/Nouvelles-notices-versees-sur-Joconde (accessed on 12 September 2023).
- Lettre d’Information Publiée par le Bureau de la Diffusion Numérique des Collections. Available online: https://www.culture.gouv.fr/Media/Medias-creation-rapide/lettre_info_41.pdf4 (accessed on 12 September 2023).
- D’Agnelli, F.M.; Rizzo, M.T. Raccontare il Patrimonio Religioso: Identità ed Etica Nella Restituzione sul Portale Beweb. In Nessuno Poteva Aprire il Libro… Miscellanea di Studi e Testimonianze per i Settant’anni di fr. Silvano Danieli, OSM; Guerrini, M., Ed.; Firenze University Press: Firenze, Italy, 2019; pp. 113–130. [Google Scholar]
- Brovarets, T. A Grave Cross on Eastern-Slavonic Ritual Towels. Eikon/Imago 2021, 10, 43–49. [Google Scholar] [CrossRef]
- Renovamos IMATEX. 2021. Available online: https://cdmt.cat/es/renovem-imatex-10_05_2021/ (accessed on 12 September 2023).
- Castells, M. The Rise of the Network Society, 2nd ed.; Oxford Blackwell Publishers: Oxford, UK, 2000. [Google Scholar]
- Wallace, A. Words Mean Things (A Glossary). Open GLAM 2020. Available online: https://openglam.pubpub.org/pub/the-glossary/release/1 (accessed on 12 September 2023).
- Wallace, A. Clarifying “Open”. Open GLAM 2020. Available online: https://openglam.pubpub.org/pub/clarifying-open/release/1 (accessed on 12 September 2023).
- Pekel, J.; Nilsson, K. Making Impact on a Small Budget. How the LSH Museet Shared Their Collection with the World. Europeana Pro 2015. Available online: https://pro.europeana.eu/post/making-impact-on-a-small-budget (accessed on 12 September 2023).
- Patti, E.; Quiviger, F. “Linking Venus”. New Technologies of Memory and the Reconfiguration of Space at the Warburg Library. Between 2014, 4, 1–29. [Google Scholar]
- Smeets, R. Language as a Vehicle of the Intangible Cultural Heritage. Mus. Int. 2004, 56, 156–165. [Google Scholar] [CrossRef]
- Schreiber, G.; Amin, A.; Aroyo, L.; van Assem, M.; de Boer, V.; Hardman, L.; Hildebrand, M.; Omelayenko, B.; van Osenbruggen, J.; Tordai, A.; et al. Semantic annotation and search of cultural-heritage collections: The MultimediaN E-Culture demonstrator. J. Web Semant. 2008, 6, 243–249. [Google Scholar] [CrossRef]
- Gunzburger, C.A. Talking about Textiles: The Making of The Textile Museum Thesaurus. In Textile Society of America Symposium Proceedings; Digital Commons University of Nebraska: Lincoln, NE, USA, 2006; Volume 302, pp. 72–78. Available online: https://digitalcommons.unl.edu/tsaconf/302/ (accessed on 12 September 2023).
- Gunzburger, C.A. The Textile Museum Thesaurus; Textile Museum: Washington, DC, USA, 2005. [Google Scholar]
- Van Steen, N. Europeana Fashion Thesaurus v1. Deliverable 2.3. 2012. Available online: https://cordis.europa.eu/docs/projects/cnect/7/297167/080/deliverables/002-EuropeanaFashionDeliverable23EuropeanaFashionThesaurusv1.pdf (accessed on 12 September 2023).
- Calderón, P.O.; Puerto, F.P.; Verhagen, P.; Prieto, A.J. Designing a Thesaurus about Historical Silk for Small and Medium-Sized Textile Museums. In Science and Digital Technology for Cultural Heritage—Interdisciplinary Approach to Diagnosis, Vulnerability, Risk Assessment and Graphic Information Models; CRC Press: Sevilla, Spain, 2009; pp. 187–190. [Google Scholar]
- Owens, L.A.; Cochrane, P.A. Thesaurus Evaluation. Cat. Classif. Q. 2004, 37, 87–102. [Google Scholar] [CrossRef]
- Isaac, A.; Zinn, C.; Matthezing, H.; Van de Meij, H.; Schlobach, S.; Wang, S. The Value of Usage Scenarios for Thesaurus Alignment in Cultural Heritage Context. 2007. Available online: https://api.semanticscholar.org/CorpusID:14684772 (accessed on 12 September 2023).
- Alba, E.; Gaitán, M.; León, A.; Mladenić, D.; Brank, J. Weaving words for textile museums: The development of the linked SILKNOW thesaurus. Herit. Sci. 2022, 10, 59. [Google Scholar] [CrossRef] [PubMed]
- Halevy, A. Why Your Data Won’t Mix: New tools and techniques can help ease the pain of reconciling schemas. Queue 2005, 3, 50–58. [Google Scholar] [CrossRef]
- Guarino, N. Understanding, building and using ontologies. Int. J. Hum. Comput. Stud. 1997, 46, 293–310. [Google Scholar] [CrossRef]
- Arrêté du 25 mai 2004 fixant les normes techniques relatives à la tenue de l’inventaire, du registre des biens déposés dans un musée de France et au récolement. J. Off. Lois Décrets 2004. Available online: https://www.legifrance.gouv.fr/loda/id/JORFTEXT000000604037 (accessed on 12 September 2023).
- Briatte, K. HADOC Modèle Harmonisé Pour la Production des Données Culturelles; Ministère de la Culture et de la Communication: Paris, France, 2012. [Google Scholar]
- International Guidelines for Museum Object Information: The CIDOC Information Categories; International Committee for Documentation of the International Council of Museums: Paris, France, 1995. Available online: https://cidoc.mini.icom.museum/wp-content/uploads/sites/6/2020/03/guidelines1995.pdf (accessed on 12 September 2023).
- Europeana. Europeana Data Model. Available online: https://pro.europeana.eu/page/edm-documentation (accessed on 12 September 2023).
- Kondylakis, H.; Doerr, M.; Plexousakis, D. Mapping Language for Information Integration. Technical Report 385 FORTH-ICS. 2006. Available online: https://www.cidoc-crm.org/sites/default/files/Mapping_TR385_December06.pdf (accessed on 12 September 2023).
- Doerr, M. Mapping a Data Structure to the CIDOC Conceptual Reference Model; ICS-FORTH: Heraklion, Greece, 2002. [Google Scholar]
- Beretta, F. OntoME, Ontology management environment. In Proceedings of the 2nd Data for History Workshop, Lyon, France, 24–25 May 2018. [Google Scholar]
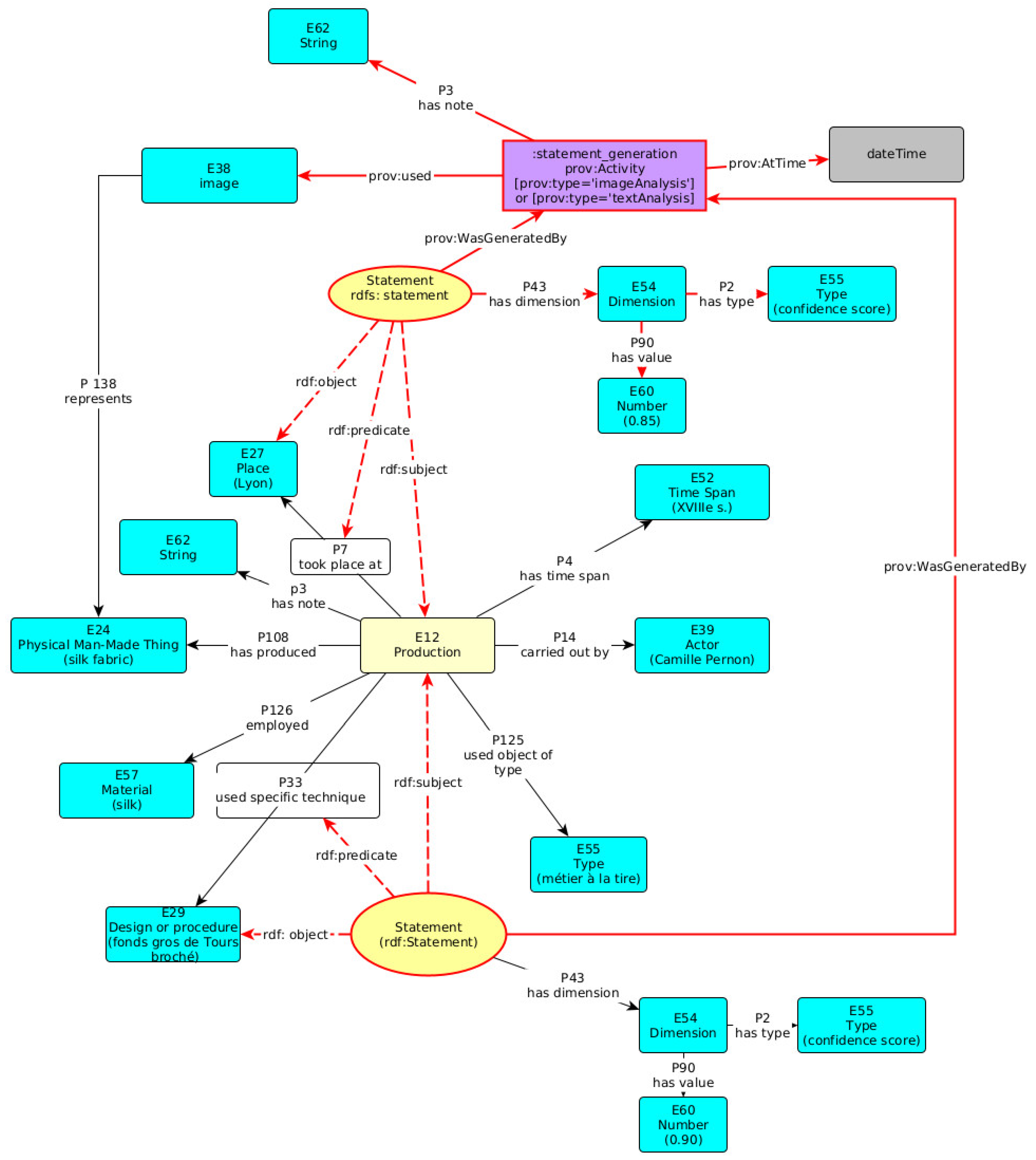
- Definition of the CRMsci. An Extension of CIDOC-CRM to Support Scientific Observation, Version 1.2.8. 2020. Available online: https://cidoc-crm.org/crmsci/ModelVersion/version-1.2.8 (accessed on 12 September 2023).
- The PROV Data Model, W3C Recommendation. 30 April 2013. Available online: https://www.w3.org/TR/prov-dm/ (accessed on 12 September 2023).
- Joulin, A.; Bojanowski, P.; Mikolov, T.; Jégou, H.; Grave, E. Loss in Translation: Learning Bilingual Word Mapping with a Retrieval Criterion. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2008; pp. 2979–2984. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 1746–1751. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2020, arXiv:1606.08415. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. arXiv 2017, arXiv:1706.02515. [Google Scholar] [CrossRef]
- Ruotsalo, T.; Aroyo, L.; Schreiber, G. Knowledge-Based Linguistic Annotation of Digital Cultural Heritage Collections. IEEE Intell. Syst. 2009, 24, 64–75. [Google Scholar] [CrossRef]
- Dorozynski, M.; Clermont, D.; Rottensteiner, F. Multi-task deep learning with incomplete training samples for the image-based prediction of variables describing silk fabrics. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, IV-2/W6, 47–54. [Google Scholar] [CrossRef]
- SILKNOW Text Classification Code Link. 2021. Available online: https://github.com/silknow/text-classification (accessed on 12 September 2023).
- Qin, X.; Luo, Y.; Tang, N.; Li, G. Making data visualization more efficient and effective: A survey. VLDB J. 2019, 29, 93–117. [Google Scholar] [CrossRef]
- Wang, J.; Hazarika, S.; Li, C.; Shen, H.W. Visualization and Visual Analysis of Ensemble Data: A Survey. IEEE Trans. Vis. Comput. Graph. 2018, 25, 2853–2872. [Google Scholar] [CrossRef]
- Alam, M.M.; Torgo, L.; Bifet, A. A Survey on Spatio-temporal Data Analytics Systems. ACM Comput. Surv. 2022, 54, 219. [Google Scholar] [CrossRef]
- Windhager, F.; Filipov, V.A.; Salisu, S.; Mayr, E. Visualizing Uncertainty in Cultural Heritage Collections. In EuroVis Workshop on Reproducibility, Verification, and Validation in Visualization (EuroRV3); The Eurographics Association: Saarbrücken, Germany, 2018. [Google Scholar] [CrossRef]
- Sevilla, J.; Casanova-Salas, P.; Casas-Yrurzum, S.; Portalés, C. Multi-Purpose Ontology-Based Visualization of Spatio-Temporal Data: A Case Study on Silk Heritage. Appl. Sci. 2021, 11, 1636. [Google Scholar] [CrossRef]
- STMAPS Github Repository. 2021. Available online: https://github.com/silknow/spatio-temporal-map (accessed on 12 September 2023).
- Sevilla, J.; Samper, J.J.; Fernández, M.; León, A. Ontology and Software Tools for the Formalization of the Visualisation of Cultural Heritage Knowledge Graphs. Heritage 2023, 6, 4722–4736. [Google Scholar] [CrossRef]
- Polowinski, J.; Voigt, M. VISO: A Shared, Formal Knowledge Base as a Foundation for Semi-automatic InfoVis Systems. In Proceedings of the CHI ‘13 Extended Abstracts on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 1791–1796. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Acquisition and Legal Status Information Group |
|---|
| Definition: information about the acquisition and ownership of a cultural heritage object. Several such information groups can be available for one object depending on the history of the object. |
| Acquisition method |
| The method by which an object was acquired. |
| Ex: gift; purchase |
| Acquisition time-span |
| The timespan or the date of acquisition of the object. |
| ex: Before 1998; 1950 |
| Previous owner |
| The name of the person from whom, or organization from which, the object was acquired. |
| New owner |
| The name of the person who, or organization that, acquired the object. |
| Acquisition complement |
| Any additional information about the acquisition of the object. |
| Acquisition note |
| If necessary, additional comment on the acquisition of the object |
| Domain | Property | Range |
|---|---|---|
| E8_Acquisition | P14_carried out by | E39_Actor |
| E8_Acquisition | P22_transferred title to | E39_Actor |
| E8_Acquisition | P23 transferred title from | E39_Actor |
| E8_Acquisition | P24_transferred title | E22_Man-Made Object |
| E8_Acquisition | P7_took place | E53_Place |
| E8_Acquisition | P4_has time-span | E52_Time-Span |
| Fieldname | Content | Path |
|---|---|---|
| Denominación principal | Abundancia | E22_Man-Made Object P102 has title E35_Title |
| Fieldname | Content | Path |
|---|---|---|
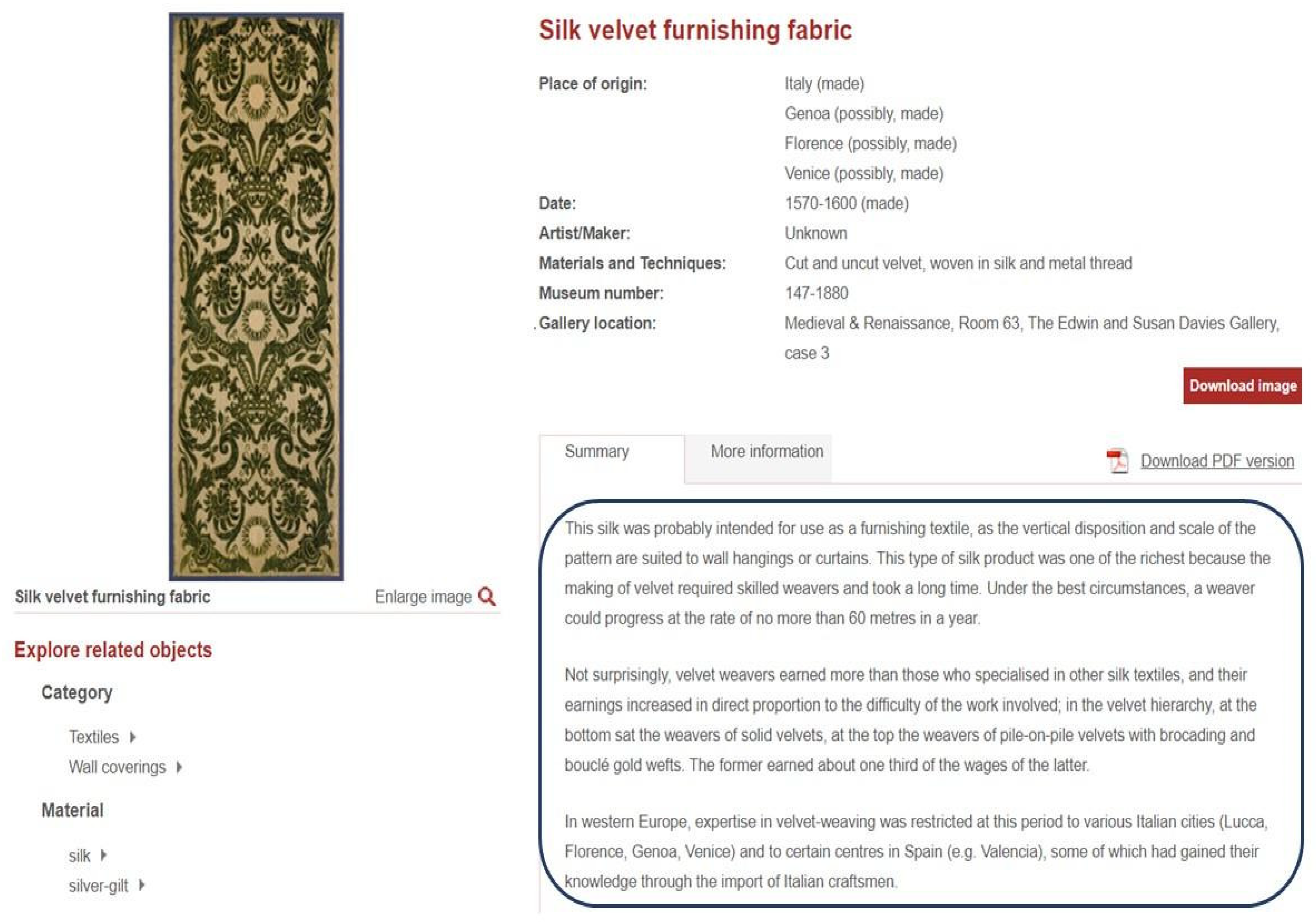
| Costruzione | fondo in raso da 5, diffalcamento 2, faccia ordito, prodotto da tutti i fili e da tutte le trame di fondo. Opera creata dal raso da 5, diffalcamento 3 faccia trama prodotto da tutti i fili e da tutte le trame di fondo, unitamente a 2 trame braccate […]. | S4_Observation O8_observed E22_Man-Made Object S4_Observation P3_has note E62_String S4_Observation P2_has type E55_Type (Costruzione) |
| Technique | Material Used | Production Place (Country) | Production Date (Century) | |
|---|---|---|---|---|
| Values | brocading, embroidering, knitting, lace, printing, sewing, velvet, weaving | cotton, leather, linen, metal_thread, wool, printed, other | Africa, AT, AZ, BE, UK, CN, FR, DE, GR, IR, IT, JP, NL, PT, RU, ES, SY, TR, US, South Asia | 10, 14, 15, 16, 17, 18, 19, 20 |
| Number of Samples | 3783 | 4058 | 8116 | 7765 |
| Technique | Material Used | Production Place | Production Date (Century) | |
|---|---|---|---|---|
| Scenario 1 (within museum) | 97.6% | 91.4% | 97.4% | 88.6% |
| Scenario 2 (across museums) | 88.3% | 77.7% | 24.22% | 48.2% |
| Scenario 3 (across museums and languages) | 54.9% | 59.8% | 86.4% | 20.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sebastián Lozano, J.; Alba Pagán, E.; Martínez Roig, E.; Gaitán Salvatella, M.; León Muñoz, A.; Sevilla Peris, J.; Vernus, P.; Puren, M.; Rei, L.; Mladenič, D. Open Access to Data about Silk Heritage: A Case Study in Digital Information Sustainability. Sustainability 2023, 15, 14340. https://doi.org/10.3390/su151914340
Sebastián Lozano J, Alba Pagán E, Martínez Roig E, Gaitán Salvatella M, León Muñoz A, Sevilla Peris J, Vernus P, Puren M, Rei L, Mladenič D. Open Access to Data about Silk Heritage: A Case Study in Digital Information Sustainability. Sustainability. 2023; 15(19):14340. https://doi.org/10.3390/su151914340
Chicago/Turabian StyleSebastián Lozano, Jorge, Ester Alba Pagán, Eliseo Martínez Roig, Mar Gaitán Salvatella, Arabella León Muñoz, Javier Sevilla Peris, Pierre Vernus, Marie Puren, Luis Rei, and Dunja Mladenič. 2023. "Open Access to Data about Silk Heritage: A Case Study in Digital Information Sustainability" Sustainability 15, no. 19: 14340. https://doi.org/10.3390/su151914340