
An Autonomous Framework for Real-Time Wrong-Way Driving Vehicle Detection from Closed-Circuit Televisions

Abstract
:1. Introduction
1.1. Statement of Problem
1.2. Wrong-Way Driving Detection
- The system can automatically and efficiently validate the correct direction of vehicles.
- The system can detect wrong-way driving vehicles on multiple lanes.
- The system can report the exact number of wrong and correct driving vehicles from each lane.
- The system should run at real-time speed.
1.3. IoT amd Embedded System
1.4. Road Lane Detection
- Identify areas of interest to remove the side road noises, such as vehicles parking or bicycle riding outside the interested road lane.
- Reduce the confusion in the system as we track vehicles on multiple lanes.
1.5. Evidence Capturing
1.6. WrongWay-LVDC Framework
- Improved road lane boundary detection from CCTV (improved RLB-CCTV)
- Direction validation and wrong-way driving vehicle detection using Distance-Based Direction Detection (DBDD)
- Inside Boundary Image Capturing (IBI capturing)
2. Materials and Methods
2.1. Input
- The road must be a straight line
- The road must have a clear side road line or a clear footpath line
- There should not be any objects blocking the side of the road
- The road must not be under construction
- The road should not have disturbing shadows from the side road objects.

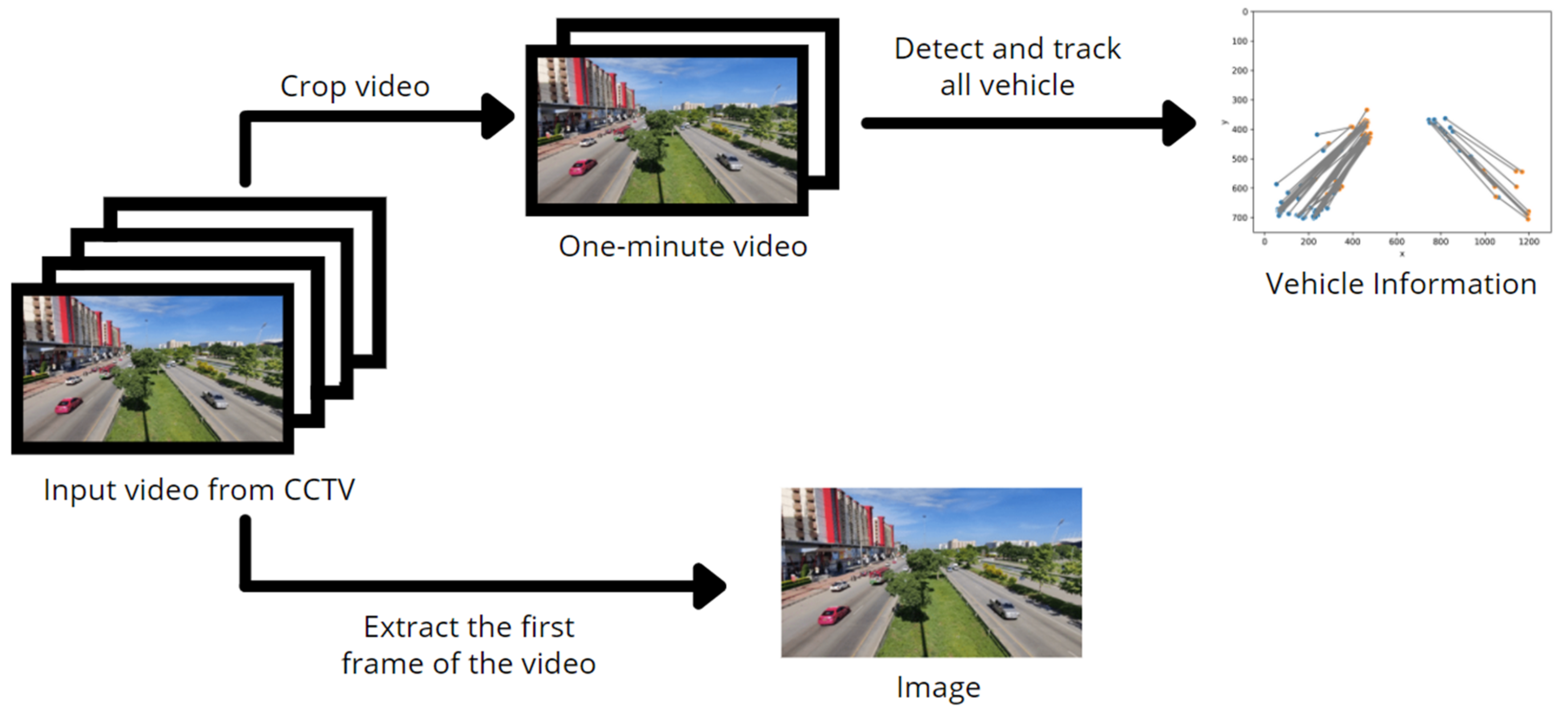
2.1.1. Image Input
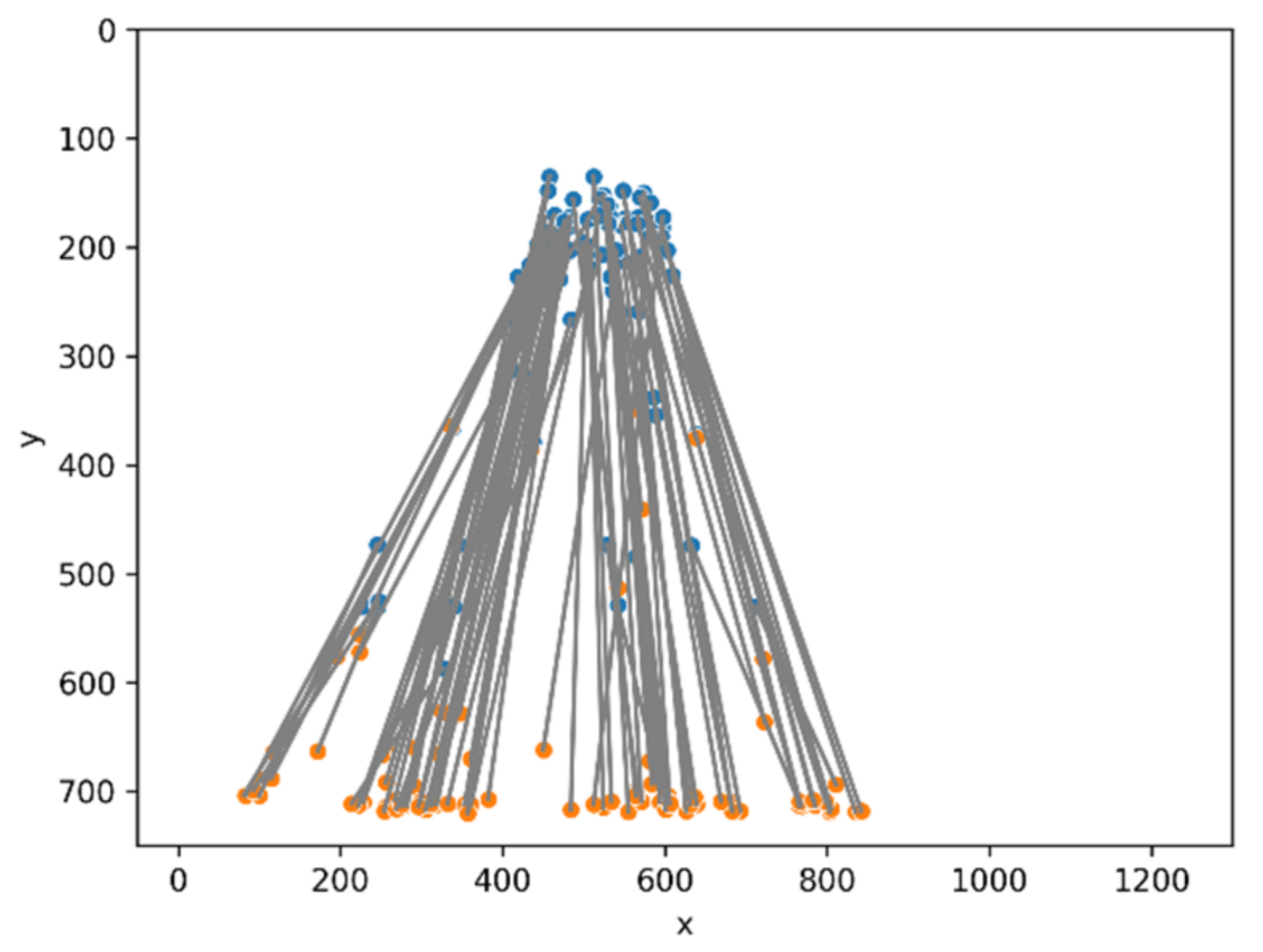
2.1.2. Vehicle Information
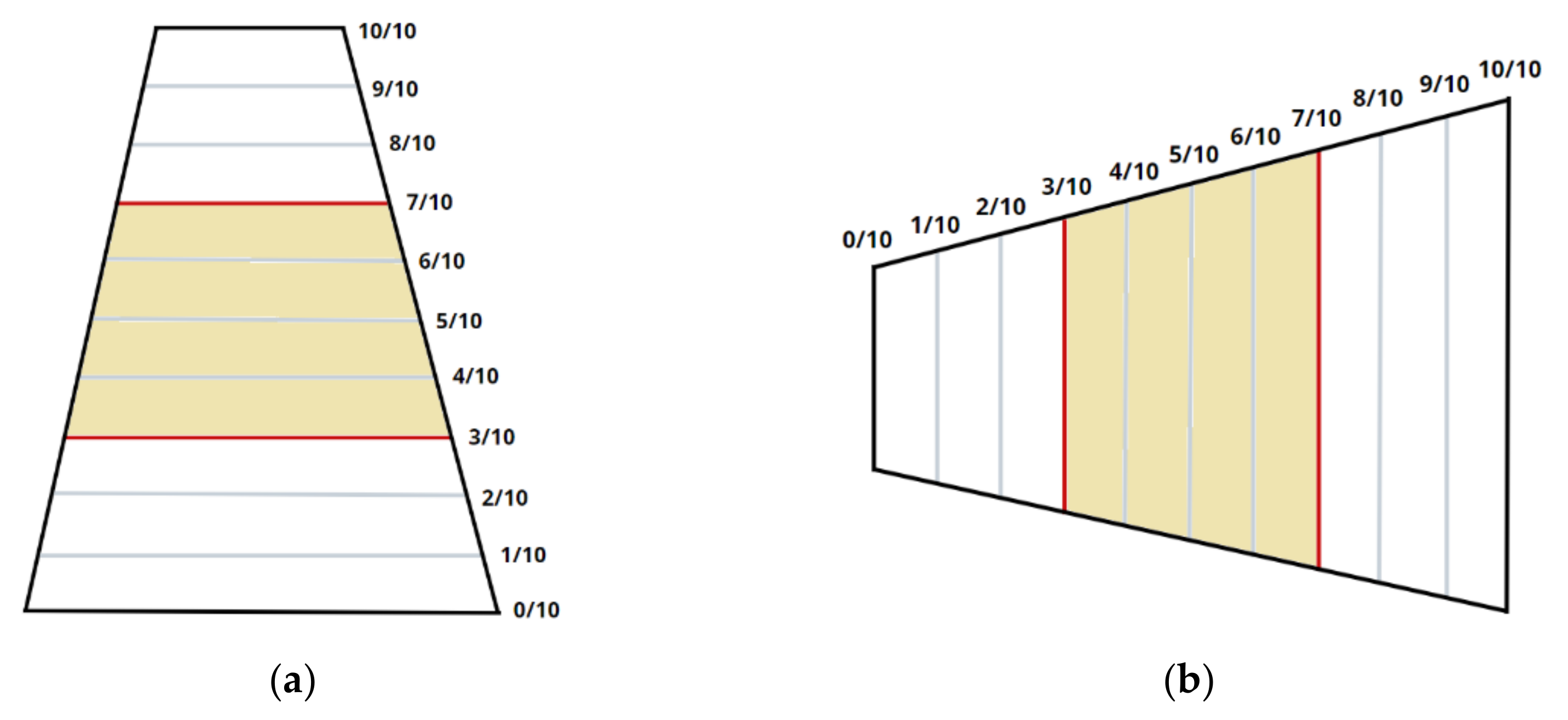
2.2. Improved Road Lane Boundaries Based on CCTV
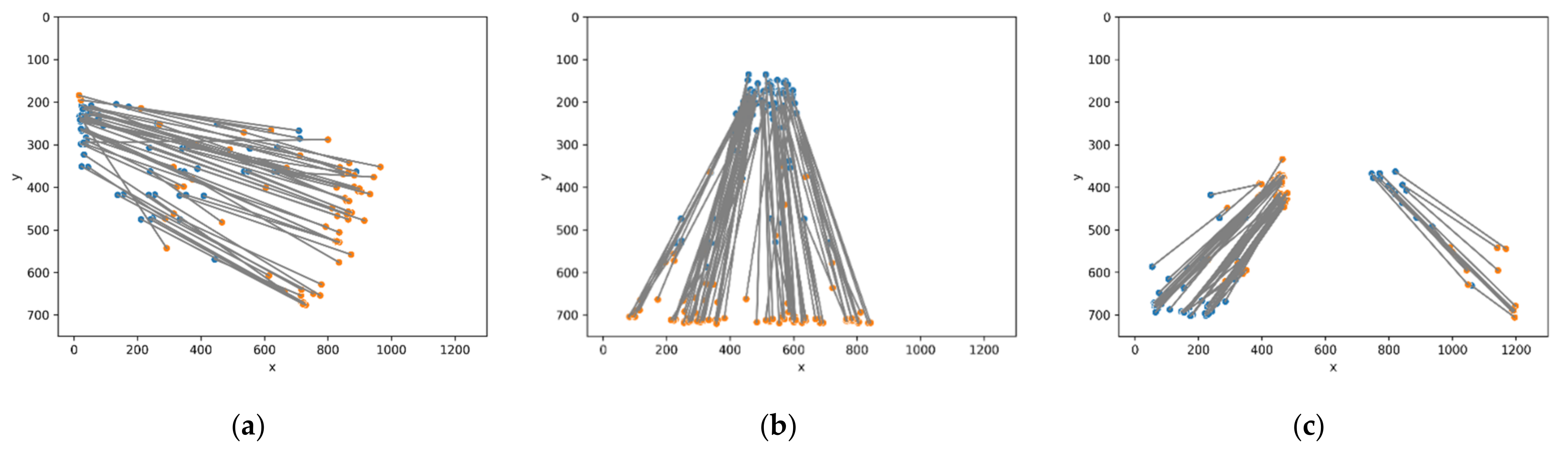
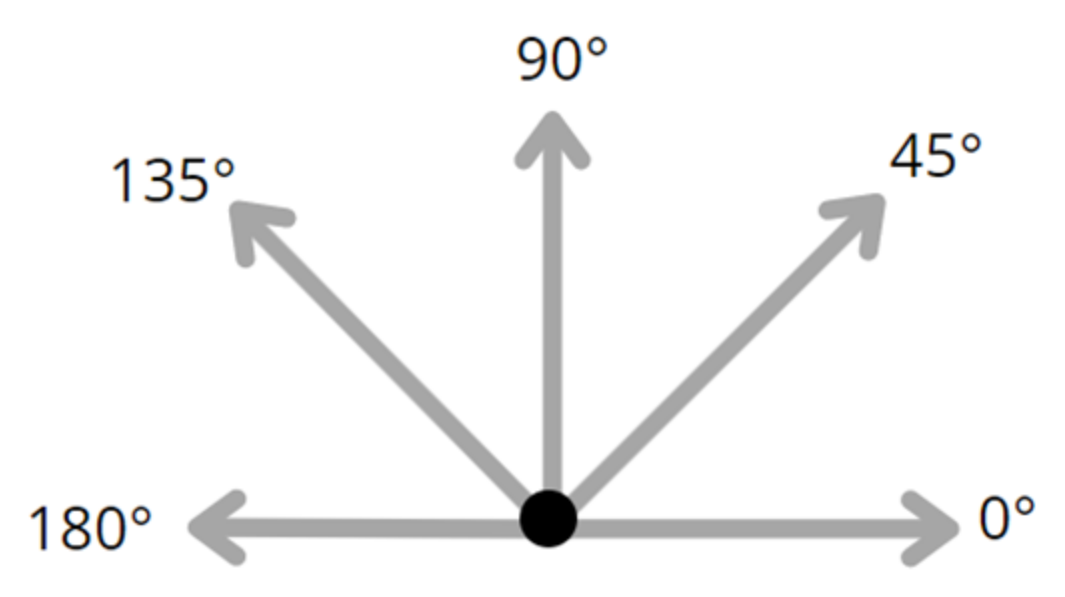
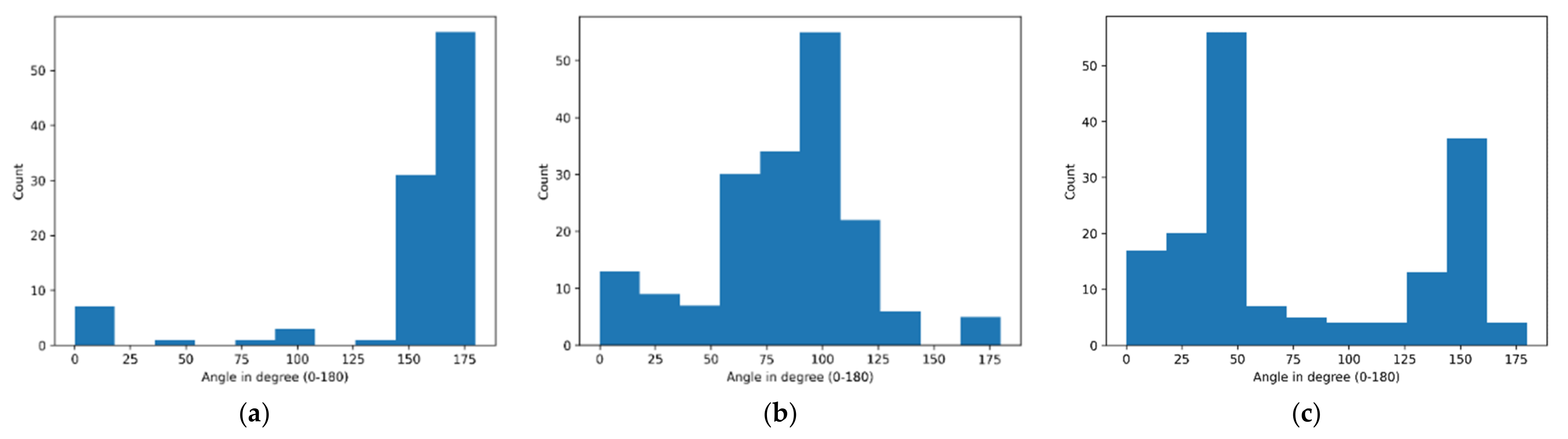
2.2.1. Orientation Decision
| Algorithm 1. Pseudo Code for the Orientation Decision Step | |
| Input: Vehicle Information Output: Road Orientation Auxiliary Variables: Horizontal Count, Vertical Count Initialization: Horizontal Count = 0, Vertical Count = 0 Begin Orientation Decision Algorithm | |
| 1 | for(Each Vehicle Movement ∈ Vehicle Information) do |
| 2 | Start location, Stop location = extract information (Each Vehicle Movement) |
| 3 | if (Start location (y) < Stop location(y)) then |
| 4 | Point 1 = Start location |
| 5 | Point 2 = Stop location |
| 6 | else |
| 7 | Point 1 = Stop location |
| 8 | Point 2 = Start location |
| 9 | end if |
| 10 | Each Angle = Find Angle (Point 1, Point 2) |
| 11 | if (Each Angle ≤ 180) AND (Each Angle > 155) OR (Each Angle ≥ 0) AND (Each Angle < 35) then |
| 12 | Horizontal Count = Horizontal Count + 1 |
| 13 | else if (Each Angle ≥ 35) OR (Each Angle ≤ 155) then |
| 14 | Vertical Count = Vertical Count + 1 |
| 15 | end if |
| 16 | end for |
| 17 | if Horizontal Orient > Vertical Orient then |
| 18 | Road Orientation = Horizontal |
| 19 | else |
| 20 | Road Orientation = Vertical |
| 21 | end if |
| 22 | return Road Orientation |
| End Orientation Decision Algorithm | |
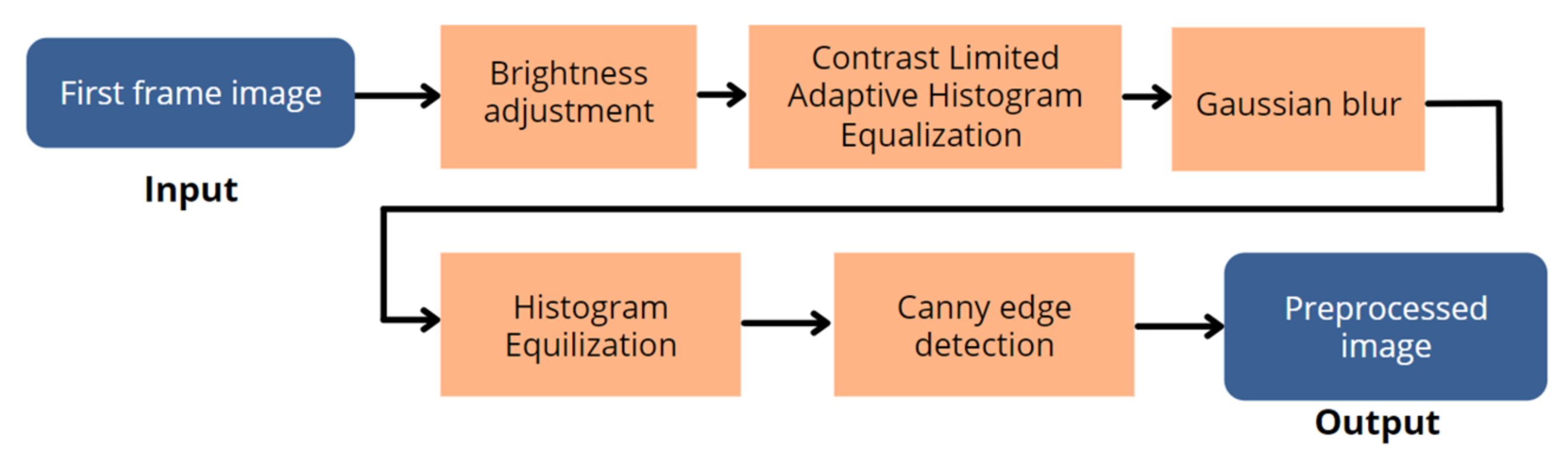
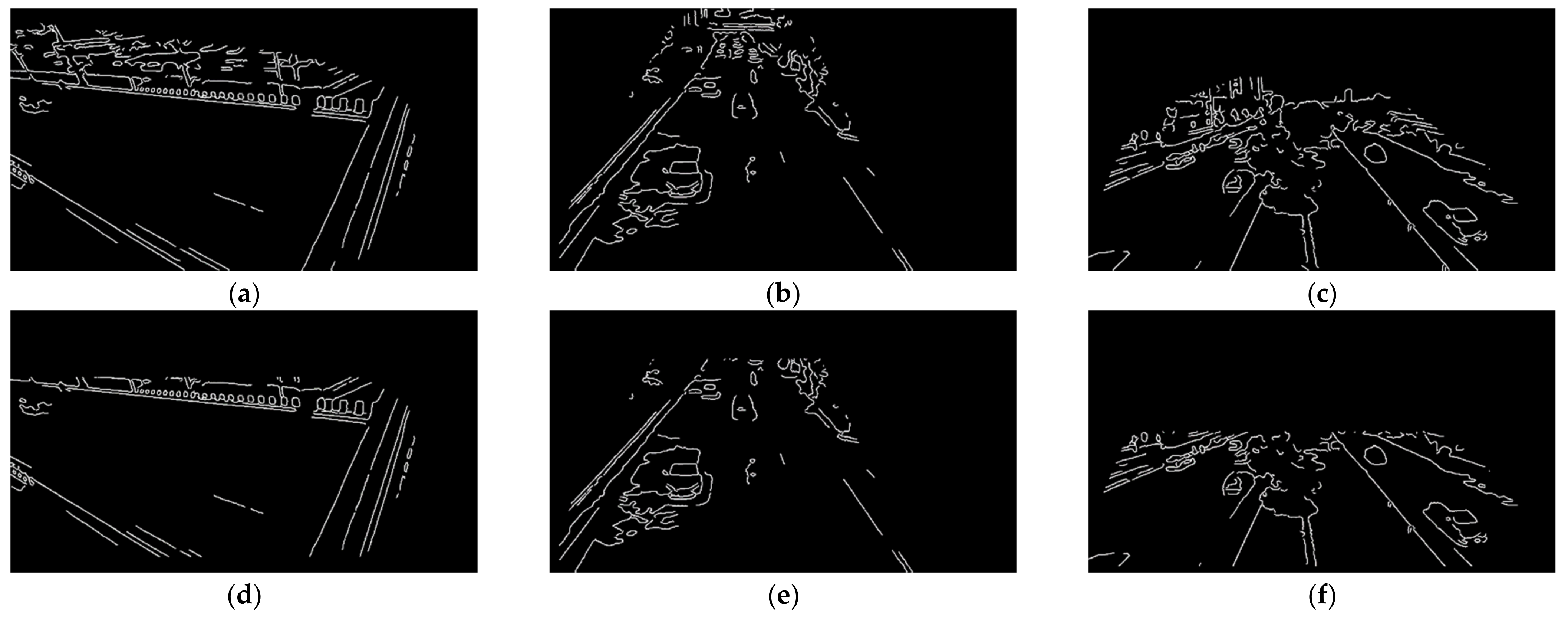
2.2.2. Image Preprocessing
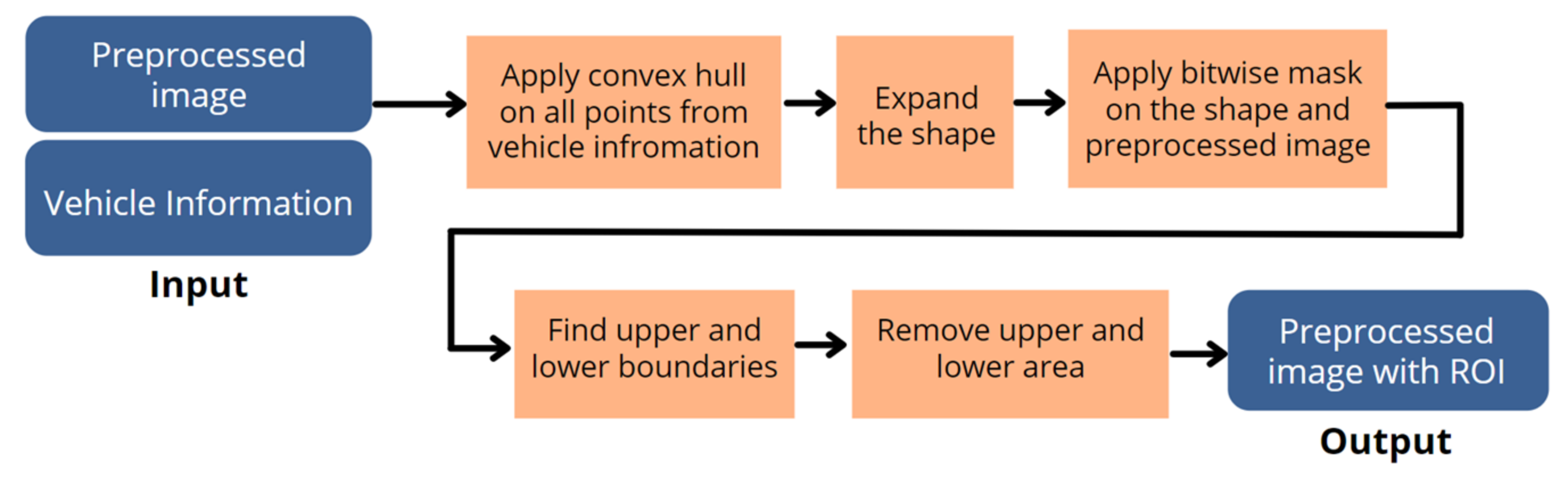
2.2.3. Area of Interest
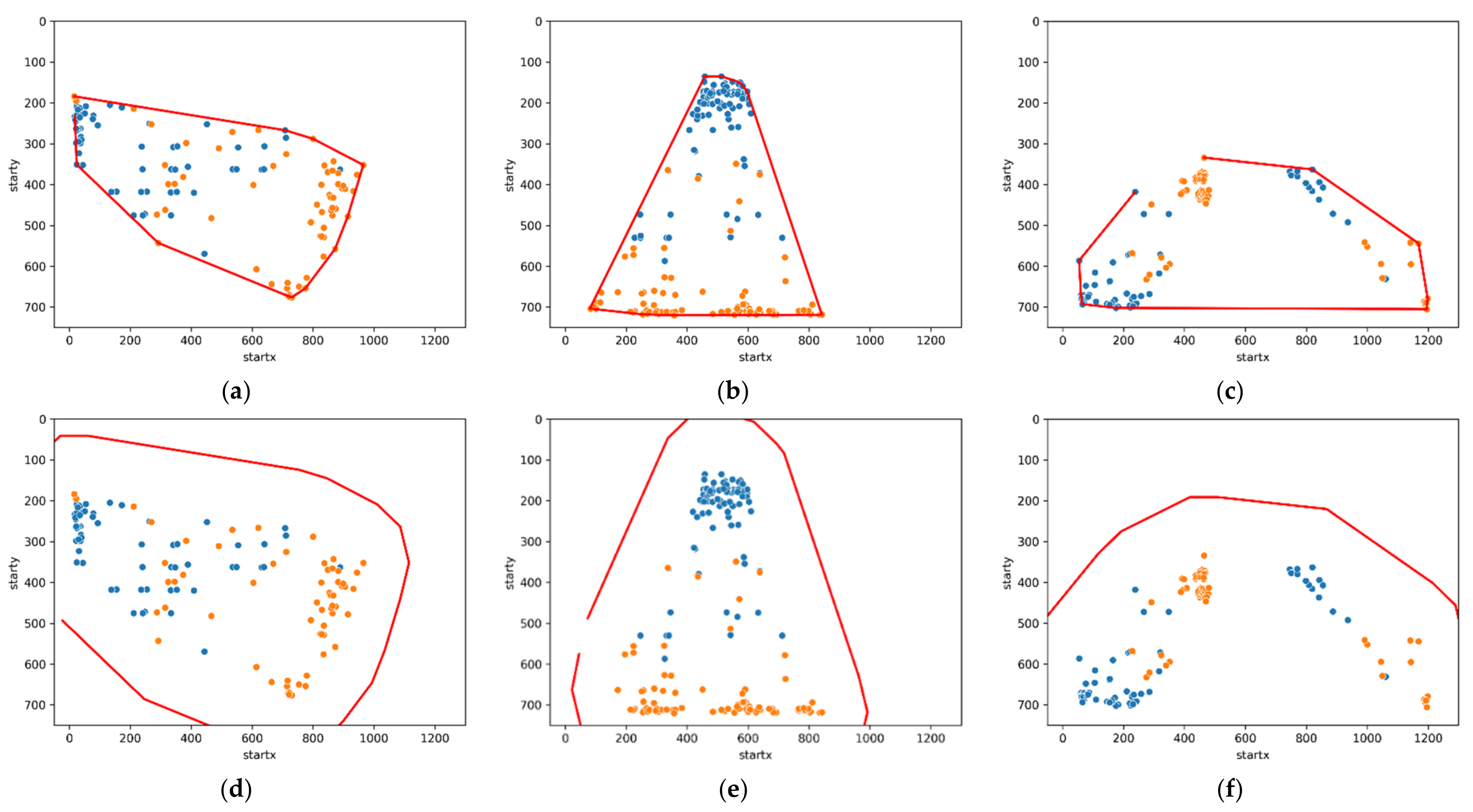
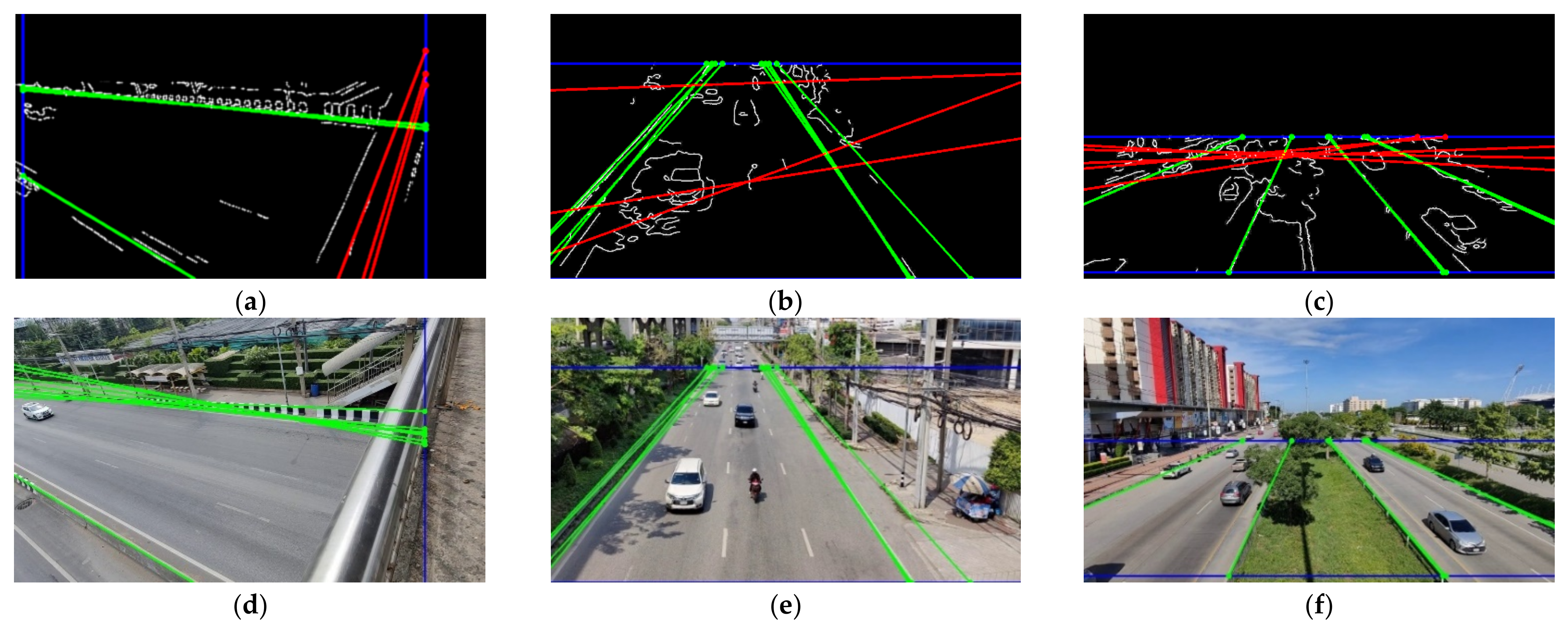
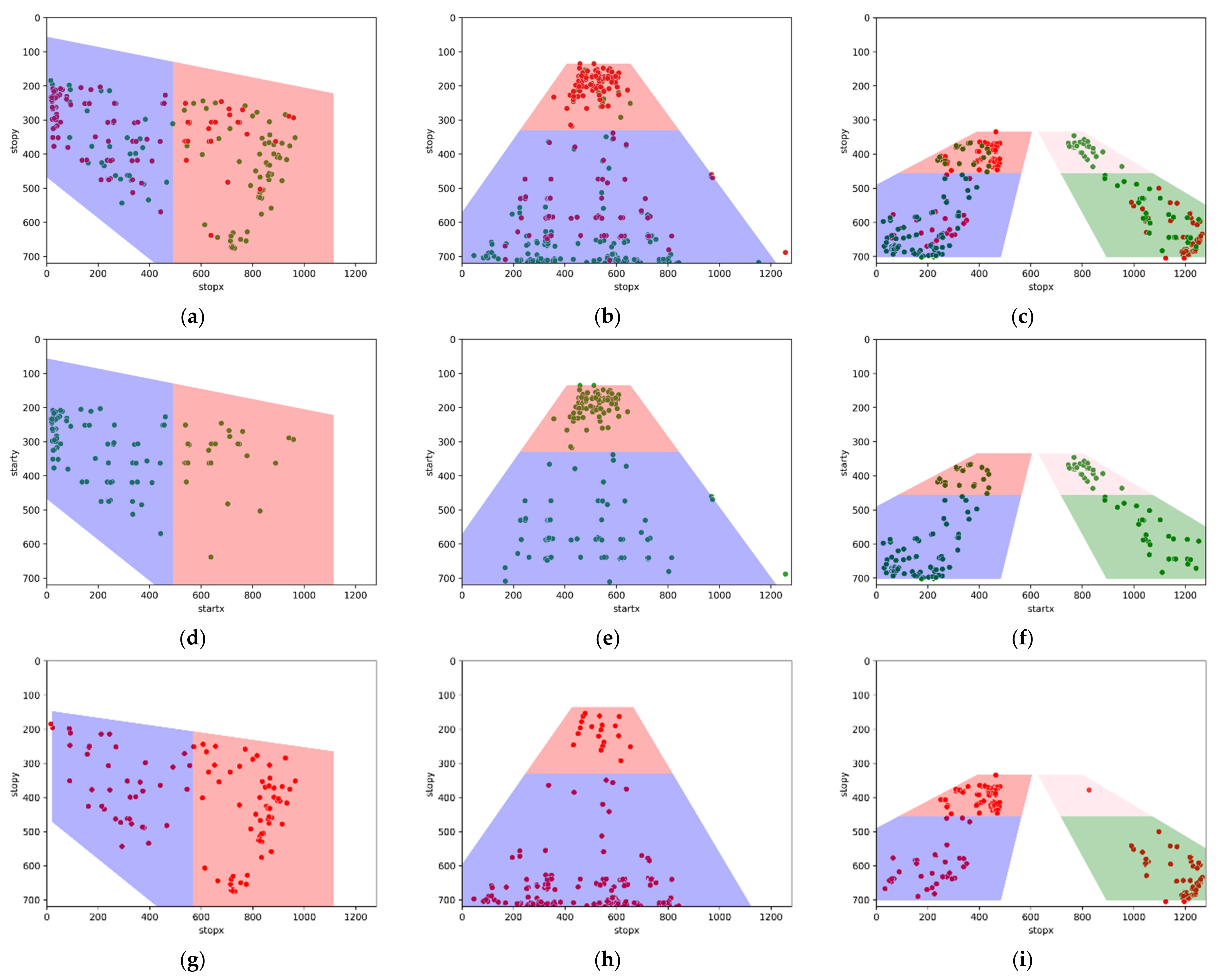
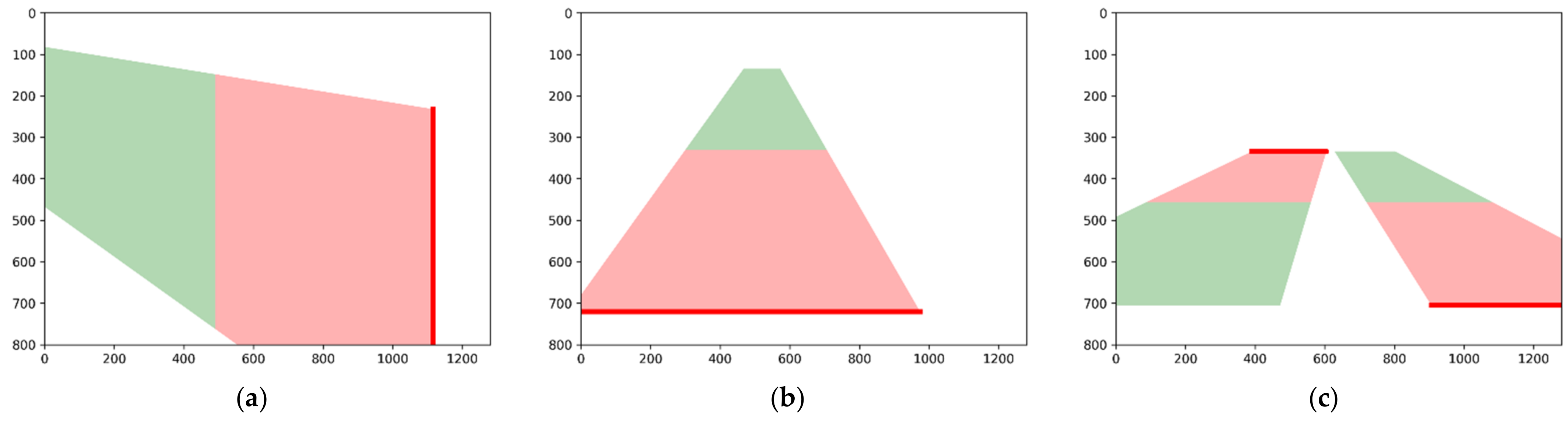
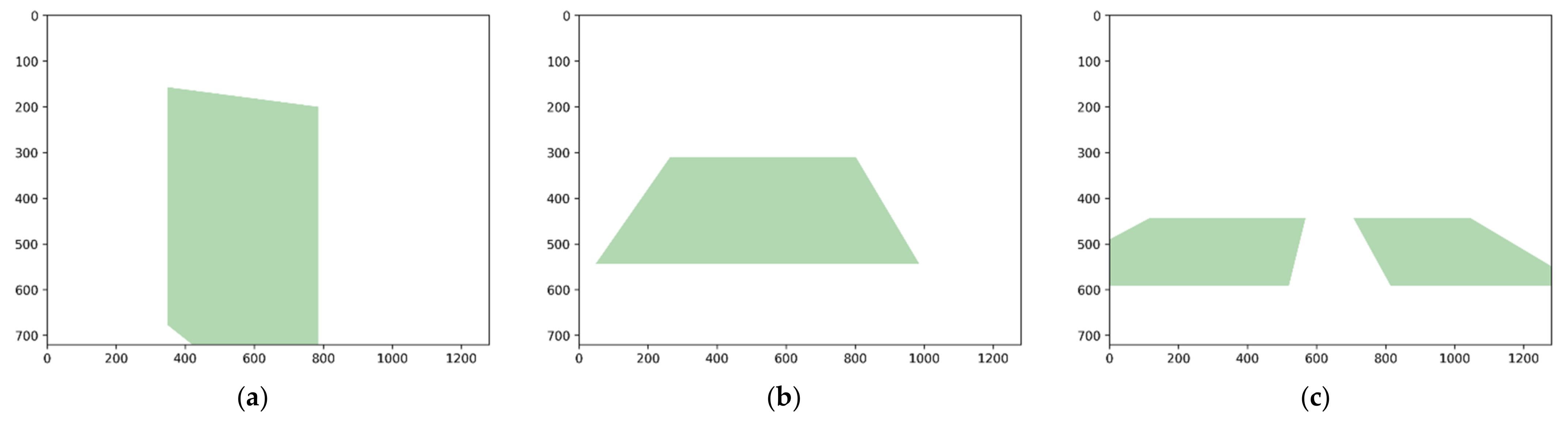
2.2.4. Boundary Detection


| Algorithm 2. Pseudo Code for Polygon Forming in Vertical Orientation | |
| Input: UX, LX, UY, LY Output: Polygon corners Auxiliary Variables: Polygon_list Initialization: Polygon_list = [] Begin Polygon Forming in Vertical Orientation | |
| 1 | While (element number in UX > 1) do |
| 2 | Current_intersect_1 = UX [0] |
| 3 | Current_intersect_2 = LX [0] |
| 4 | Next_intersect_1 = UX [1] |
| 5 | Next_intersect_2 = LX [1] |
| 6 | Polygon corners = [[Current_intersect_1, UY], [next_intersect_1, UY], [next_intersect_2, LY], [Current_intersect_2, LY]] |
| 7 | Polygon_list.append(Shapely.polygon(Polygon corners)) |
| 8 | Remove UX [0] from UX |
| 9 | Remove LX [0] from LX |
| 10 | end while |
| 11 | return Polygon_list |
| End Polygon Forming in Vertical Orientation | |
| Algorithm 3. Pseudo Code for Polygon Forming in Horizontal Orientation | |
| Input: LeftX, RightX, LeftY, RightY Output: Polygon corners Auxiliary Variables: Polygon_list Initialization: Polygon_list = [] Begin Polygon Forming in Horizontal Orientation | |
| 1 | While (element number in LeftY > 1) do |
| 2 | Cur_intersect_1 = LeftY [0] |
| 3 | Cur_intersect_2 = RightY [0] |
| 4 | Next_intersect_1 = LeftY [1] |
| 5 | Next_intersect_2 = RightY [1] |
| 6 | Polygon corners = [[XLeft, Cur_intersect_1], [XLeft, next_intersect_1], [XRight, next_intersect_2], [XRight, Cur_intersect_2]] |
| 7 | Polygon_list.append(Shapely.polygon(Polygon corners)) |
| 8 | Remove LeftY [0] from LeftY |
| 9 | Remove RightY [0] from RightY |
| 10 | end while |
| 11 | return Polygon_list |
| End Polygon Forming in Horizontal Orientation | |

2.3. Distance-Based Direction Detection
2.4. Inside Boundary Image Capturing Feature
2.4.1. Vertical Orientation
2.4.2. Horizontal Orientation
2.5. Framework’s Version
3. Results
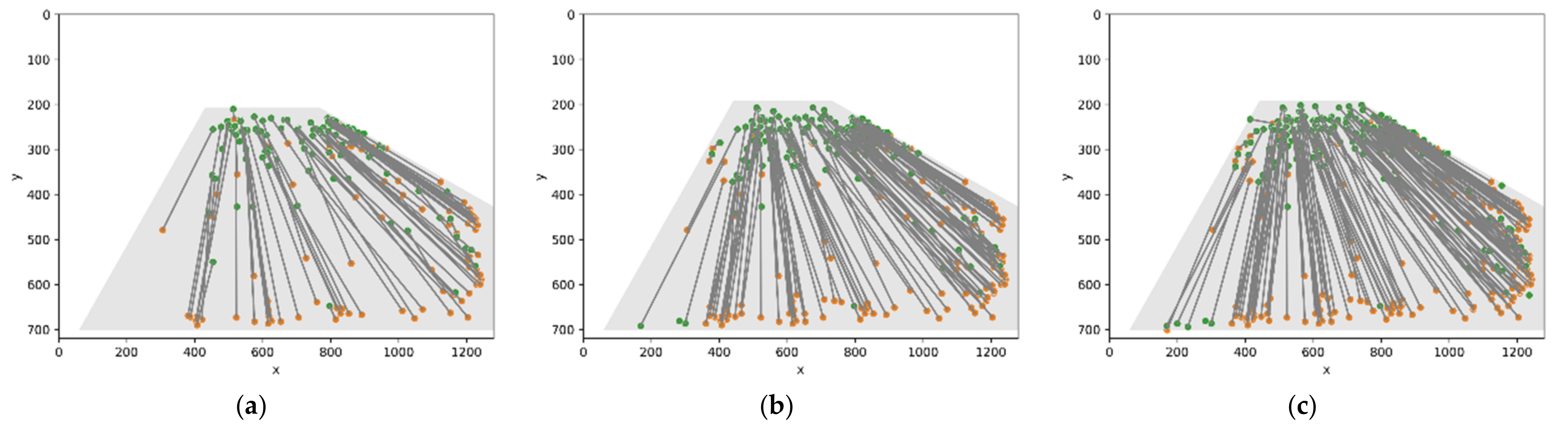
3.1. Object Detection
3.2. Result of the Framework
3.2.1. Improved RLB-CCTV Algorithm
3.2.2. DBDD Algorithm
3.2.3. IBI Capturing Feature
4. Discussion
4.1. Limitations
4.2. Challenging Constraints
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Road Traffic Injuries. Available online: https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries#:~:text=Road%20traffic%20injuries%20are%20the,pedestrians%2C%20cyclists%2C%20and%20motorcyclists (accessed on 6 August 2022).
- Thai RSC. Available online: https://www.thairsc.com (accessed on 16 March 2022).
- World Life Expectancy, Road Traffic Accidents. Available online: https://www.worldlifeexpectancy.com/cause-of-death/road-traffic-accidents/by-country/ (accessed on 16 March 2022).
- 5 Major Areas in Bangkok that Still Have Wrong-Way Driving Motorcycles. Available online: https://www.pptvhd36.com/news/%E0%B8%9B%E0%B8%A3%E0%B8%B0%E0%B9%80%E0%B8%94%E0%B9%87%E0% (accessed on 16 March 2022).
- Usmankhujaev, S.; Baydadaev, S.; Woo, K.J. Real-Time, Deep Learning Based Wrong Direction Detection. Appl. Sci. 2020, 10, 2453. [Google Scholar] [CrossRef]
- Montella, C. The Kalman Filter and Related Algorithms: A Literature Review. 2011. Available online: https://www.researchgate.net/publication/236897001_The_Kalman_Filter_and_Related_Algorithms_A_Literature_Review (accessed on 17 July 2022).
- Joseph, R.; Ali, F. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Monteiro, G.; Ribeiro, M.; Marcos, J.; Batista, J. Wrongway Drivers Detection Based on Optical Flow. IEEE Int. Conf. Image Process. 2007, 5, 141–144. [Google Scholar] [CrossRef]
- Rahman, Z.; Ami, A.M.; Ullah, M.A. A Real-Time Wrong-Way Vehicle Detection Based on YOLO and Centroid Tracking. In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 June 2020; pp. 916–920. [Google Scholar] [CrossRef]
- Pudasaini, D.; Abhari, A. Scalable Object Detection, Tracking and Pattern Recognition Model Using Edge Computing. In Proceedings of the 2020 Spring Simulation Conference (SpringSim), Fairfax, VA, USA, 18–21 May 2020; pp. 1–11. [Google Scholar] [CrossRef]
- Gu, H.; Ge, Z.; Cao, E.; Chen, M.; Wei, T.; Fu, X.; Hu, S. A Collaborative and Sustainable Edge-Cloud Architecture for Object Tracking with Convolutional Siamese Networks. IEEE Trans. Sustain. Comput. 2021, 6, 144–154. [Google Scholar] [CrossRef]
- Coral. Available online: https://coral.ai/ (accessed on 16 March 2022).
- NVIDIA Jetson. Available online: https://developer.nvidia.com/embedded/jetson-modules (accessed on 16 March 2022).
- Raspberry Pi Foundation. Available online: https://www.raspberrypi.org/ (accessed on 16 March 2022).
- Zualkernan, I.; Dhou, S.; Judas, J.; Sajun, A.R.; Gomez, B.R.; Hussain, L.A. An IoT System Using Deep Learning to Classify Camera Trap Images on the Edge. Computers 2022, 11, 13. [Google Scholar] [CrossRef]
- Jetson Nano Developer Kit. Available online: https://developer.nvidia.com/embedded/jetson-nano-developer-kit (accessed on 16 March 2022).
- Liu, L.; Chen, X.; Zhu, S.; Tan, P. CondLaneNet: A Top-to-down Lane Detection Framework Based on Conditional Convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 3773–3782. [Google Scholar]
- Chen, L.; Xu, X.; Pan, L.; Cao, J.; Li, X. Real-time lane detection model based on non bottleneck skip residual connections and attention pyramids. PLoS ONE 2021, 16, e0252755. [Google Scholar] [CrossRef] [PubMed]
- Andrei, M.-A.; Boiangiu, C.-A.; Tarbă, N.; Voncilă, M.-L. Robust Lane Detection and Tracking Algorithm for Steering Assist Systems. Machines 2022, 10, 10. [Google Scholar] [CrossRef]
- Sharma, A.; Kumar, M.; Kumar, R. Lane detection using Python. In Proceedings of the 2021 3rd International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), Greater Noida, India, 17–18 December 2021; pp. 88–90. [Google Scholar]
- Rakotondrajao, F.; Jangsamsi, K. Road Boundary Detection for Straight Lane Lines Using Automatic Inverse Perspective Mapping. In Proceedings of the 2019 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Taipei, Taiwan, 3–6 December 2019; pp. 1–2. [Google Scholar] [CrossRef]
- Franco, F.; Santos, M.M.D.; Yoshino, R.T.; Yoshioka, L.R.; Justo, J.F. ROADLANE—The Modular Framework to Support Recognition Algorithms of Road Lane Markings. Appl. Sci. 2021, 11, 10783. [Google Scholar] [CrossRef]
- Ghazali, K.; Xiao, R.; Ma, J. Road Lane Detection Using H-Maxima and Improved Hough Transform. In Proceedings of the 2012 Fourth International Conference on Computational Intelligence, Modelling and Simulation, Kuantan, Malaysia, 25–27 September 2012; pp. 205–208. [Google Scholar] [CrossRef]
- Farag, W.; Saleh, Z. Road Lane-Lines Detection in Real-Time for Advanced Driving Assistance Systems. In Proceedings of the 2018 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Sakhier, Bahrain, 18–20 November 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Python. Available online: https://www.python.org/ (accessed on 6 August 2022).
- Linux. Available online: https://www.linux.com/ (accessed on 6 August 2022).
- OpenCV. Available online: https://opencv.org/ (accessed on 16 March 2022).
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- FastMOT: High-Performance Multiple Object Tracking Based on Deep SORT and KLT. Available online: https://github.com/GeekAlexis/FastMOT (accessed on 16 March 2022).
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef] [PubMed]
- Duda, R.O.; Hart, P.E. Use of the Hough Transformation to Detect Lines and Curves in Pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Gedraite, E.; Hadad, M. Investigation on the effect of a Gaussian Blur in image filtering and segmentation. In Proceedings of the ELMAR-2011, Zadar, Croatia, 14–16 September 2011; pp. 393–396. [Google Scholar]
- Suttiponpisarn, P.; Charnsripinyo, C.; Usanavasin, S.; Nakahara, H. An Enhanced System for Wrong-Way Driving Vehicle Detection with Road Boundary Detection Algorithm. In Proceedings of the 2022 International Conference on Industry Science and Computer Sciences Innovation, Oporto, Portugal, 9–11 March 2022. in press. [Google Scholar]
- ImageStat Module. Available online: https://pillow.readthedocs.io/en/stable/reference/ImageStat.html (accessed on 17 March 2022).
- HSL and HSV. Available online: https://en.wikipedia.org/wiki/HSL_and_HSV (accessed on 17 March 2022).
- Yadav, G.; Maheshwari, S.; Agarwal, A. Contrast limited adaptive histogram equalization based enhancement for real time video system. In Proceedings of the 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Delhi, India, 24–27 September 2014; pp. 2392–2397. [Google Scholar] [CrossRef]
- Patel, O.; Maravi, Y.; Sharma, S. A Comparative Study of Histogram Equalization Based Image Enhancement Techniques for Brightness Preservation and Contrast Enhancement. Signal Image Process. Int. J. 2013, 4, 11–25. [Google Scholar] [CrossRef]
- Sharif, M. A new approach to compute convex hull. Innov. Syst. Des. Eng. 2011, 2, 187–193. [Google Scholar]
- OpenCV Bitwise AND, OR, XOR, and NOT. Available online: https://pyimagesearch.com/2021/01/19/opencv-bitwise-and-or-xor-and-not/ (accessed on 17 March 2022).
- The Shapely User Manual. Available online: https://shapely.readthedocs.io/en/stable/manual.html (accessed on 17 March 2022).
- Suttiponpisarn, P.; Charnsripinyo, C.; Usanavasin, S.; Nakahara, H. Detection of Wrong Direction Vehicles on Two-Way Traffic. In Proceedings of the 13th International Conference on Knowledge and Systems Engineering, Bangkok, Thailand, 10–12 November 2021. [Google Scholar]
- Song, H.; Liang, H.; Li, H.; Dai, Z.; Yun, X. Vision-based vehicle detection and counting system using deep learning in highway scenes. Eur. Transp. Res. Rev. 2019, 11, 51. [Google Scholar] [CrossRef]
- Roszyk, K.; Nowicki, M.R.; Skrzypczyński, P. Adopting the YOLOv4 Architecture for Low-Latency Multispectral Pedestrian Detection in Autonomous Driving. Sensors 2022, 22, 1082. [Google Scholar] [CrossRef] [PubMed]



































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | AP | mAP | ||
|---|---|---|---|---|
| Motorcycle | Car | Big Vehicle | ||
| Results | 71.89% | 78.0% | 86.25% | 78.71% |
| Video | Length | Area | Number of Points | Area Type | ||
|---|---|---|---|---|---|---|
| Start | Stop | Prediction | Ground Truth | |||
| 1 | 2:12 min | Area 1 | 0 | 95 | Stop | Stop |
| Area 2 | 50 | 35 | Start | Start | ||
| Area 3 | 23 | 2 | Start | Start | ||
| Area 4 | 2 | 53 | Stop | Stop | ||
| 2 | 3:01 min | Area 1 | 0 | 28 | Stop | Stop |
| Area 2 | 18 | 1 | Start | Start | ||
| Area 3 | 21 | 0 | Start | Start | ||
| Area 4 | 0 | 23 | Stop | Stop | ||
| 3 | 5:00 min | Area 1 | 4 | 119 | Stop | Stop |
| Area 2 | 68 | 40 | Start | Start | ||
| 4 | 2:31 min | Area 1 | 2 | 64 | Stop | Stop |
| Area 2 | 46 | 31 | Start | Start | ||
| 5 | 2:59 min | Area 1 | 111 | 37 | Start | Start |
| Area 2 | 2 | 194 | Stop | Stop | ||
| 6 | 2:04 min | Area 1 | 100 | 35 | Start | Start |
| Area 2 | 4 | 228 | Stop | Stop | ||
| 7 | 4:07 min | Area 1 | 72 | 34 | Start | Start |
| Area 2 | 0 | 151 | Stop | Stop | ||
| 8 | 2:00 min | Area 1 | 3 | 88 | Stop | Stop |
| Area 2 | 43 | 35 | Start | Start | ||
| 9 | 2:03 min | Area 1 | 0 | 71 | Stop | Stop |
| Area 2 | 50 | 16 | Start | Start | ||
| 10 | 2:02 min | Area 1 | 3 | 41 | Stop | Stop |
| Area 2 | 105 | 21 | Start | Start | ||
| Video | Length | Lane | Ground Truth | Computer | Embedded System | ||||
|---|---|---|---|---|---|---|---|---|---|
| Correct Driving | Wrong Driving | Correct Driving | Wrong Driving | Correct Driving | Wrong Driving | FPS | |||
| 1 | 2:12 min | 1 | 9 | 1 | 9 | 1 | 9 | 1 | 22 |
| 2 | 6 | 0 | 5 | 0 | 6 | 1 | |||
| 2 | 3:01 min | 1 | 8 | 0 | 9 | 0 | 7 | 0 | 23 |
| 2 | 3 | 0 | 2 | 0 | 3 | 0 | |||
| 3 | 5:00 min | 1 | 51 | 15 | 51 | 15 | 49 | 17 | 27 |
| 4 | 2:31 min | 1 | 20 | 6 | 19 | 6 | 19 | 6 | 27 |
| 5 | 2:59 min | 1 | 44 | 4 | 46 | 5 | 47 | 3 | 18 |
| 6 | 2:04 min | 1 | 26 | 5 | 25 | 5 | 26 | 5 | 19 |
| 7 | 4:07 min | 1 | 70 | 1 | 68 | 1 | 68 | 1 | 26 |
| 8 | 2:00 min | 1 | 25 | 10 | 26 | 11 | 28 | 10 | 25 |
| 9 | 2:03 min | 1 | 32 | 2 | 29 | 2 | 33 | 2 | 32 |
| 10 | 2:02 min | 1 | 13 | 5 | 14 | 6 | 12 | 6 | 29 |
| Video Length (Frame) | Validation | Detection | |||||
|---|---|---|---|---|---|---|---|
| STD | Threshold | Time Taken (Seconds) | Speed (FPS) | Correct-Way Driving Vehicle | Wrong-Way Driving Vehicle | Speed (FPS) | |
| 1000 | 6.053 | 0 | 174 | 7 | 51 | 8 | 23 |
| 2000 | 6.130 | 7 | 303 | 7 | 52 | 12 | 20 |
| 3000 | 6.498 | 14 | 450 | 7 | 52 | 15 | 20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suttiponpisarn, P.; Charnsripinyo, C.; Usanavasin, S.; Nakahara, H. An Autonomous Framework for Real-Time Wrong-Way Driving Vehicle Detection from Closed-Circuit Televisions. Sustainability 2022, 14, 10232. https://doi.org/10.3390/su141610232
Suttiponpisarn P, Charnsripinyo C, Usanavasin S, Nakahara H. An Autonomous Framework for Real-Time Wrong-Way Driving Vehicle Detection from Closed-Circuit Televisions. Sustainability. 2022; 14(16):10232. https://doi.org/10.3390/su141610232
Chicago/Turabian StyleSuttiponpisarn, Pintusorn, Chalermpol Charnsripinyo, Sasiporn Usanavasin, and Hiro Nakahara. 2022. "An Autonomous Framework for Real-Time Wrong-Way Driving Vehicle Detection from Closed-Circuit Televisions" Sustainability 14, no. 16: 10232. https://doi.org/10.3390/su141610232