
Allocation of Eavesdropping Attacks for Multi-System Remote State Estimation


Shandong Key Laboratory of Industrial Control Technology, School of Automation, Qingdao University, Qingdao 266071, China
*
Author to whom correspondence should be addressed.
Sensors 2024, 24(3), 850; https://doi.org/10.3390/s24030850
Submission received: 5 January 2024
/
Revised: 23 January 2024
/
Accepted: 26 January 2024
/
Published: 28 January 2024
(This article belongs to the Section Sensor Networks)
Abstract
:In recent years, the problem of cyber–physical systems’ remote state estimations under eavesdropping attacks have been a source of concern. Aiming at the existence of eavesdroppers in multi-system CPSs, the optimal attack energy allocation problem based on a SINR (signal-to-noise ratio) remote state estimation is studied. Assume that there are N sensors, and these sensors use a shared wireless communication channel to send their state measurements to the remote estimator. Due to the limited power, eavesdroppers can only attack M channels out of N channels at most. Our goal is to use the Markov decision processes (MDP) method to maximize the eavesdropper’s state estimation error, so as to determine the eavesdropper’s optimal attack allocation. We propose a backward induction algorithm which uses MDP to obtain the optimal attack energy allocation strategy. Compared with the traditional induction algorithm, this algorithm has lower computational cost. Finally, the numerical simulation results verify the correctness of the theoretical analysis.
1. Introduction
Cyber–physical systems (CPS) are considered to be among the revolutionary technologies due to the continuous technological breakthroughs and innovations in information technology and in the manufacturing industry [1]. CPS is a multidimensional and complex system that deeply integrates control, communication and computing (that is, 3C technology composed of control, communication and computing)and can realizes large-scale information acquisition and intelligent control of the physical world through the cognition, communication and control of physical objects, so that the network can monitor the specific actions of a physical entity in a real-time, reliable, remote and safe way [2,3]. CPS is widely used in aerospace, industrial production, advanced automobile systems, energy reserve, environmental monitoring, national defense and military, infrastructure construction, intelligent building, smart grids, transportation systems and telemedicine [4]. With the rapid development of network, computing, sensing and control systems, CPS technology is more and more widely used, and the emerging network attacks make the wireless CPS system very fragile, and the security of CPS becomes the primary consideration [5,6,7].
For the security issues of a system’s remote state estimation, there are many forms of malicious network attacks, but they are divided into three main and common categories: denial of service (DoS) attacks, integrity (including replay and false data injection) attacks and eavesdropping attacks [8]. DoS attacks are designed to interfere with wireless communication channels. This attack will lead to a significant decline in the estimation accuracy in CPS [9]. Peng [10] and Zhang [11] formulated the problem as a Markov decision process (MDP) problem to consider the optimal attack power allocation for remote state estimation in a multi-system. Integrity attacks can disrupt the transmitted data packets with stealth constraint [12,13]. In Ref. [14], an important scenario is designed from the attacker’s point of view, in which the false data injection attack can completely and secretly destroy CPS. In addition, the channel may be subject to eavesdropping attacks, which can lead to serious economic losses and even pose a threat to human survival by eavesdropping on personal privacy data [15,16]. For example, in the intelligent transportation system, eavesdroppers infer the path planning of vehicles by monitoring the location information, and on this basis, eavesdropping attacks will easily succeed [17,18]. In terms of existing research, data encryption is the main method to protect system privacy from eavesdropping attacks [19,20,21].
Recently, the issue of remote state estimation in the presence of eavesdroppers has attracted widespread attention from researchers. The attack types of eavesdropping attacks are divided into passive eavesdropping attacks and active eavesdropping attacks. Some estimation and control problems have been studied in the presence of active attacks. Han [22] studied the problem of active eavesdropping on fading channels, and proposed an interference-assisted eavesdropping method to improve the probability of successful monitoring. Yuan [23] constructed a two-person non-zero-sum game between the sensor and the active eavesdropper with the goal of minimizing the covariance of the self-estimated error and maximizing the covariance of the opponent’s estimated error. Ding [24] took the trade-off between stealth and eavesdropping performance as a constrained MDP, and proposed an optimal strategy for active eavesdropping.
The above literatures indicate a certain breakthrough in the design of active eavesdropping solutions. This paper mainly studies the passive attacks of eavesdroppers. Tsiamis [25] proposed a confidentiality mechanism for randomly hiding sensor information, and explored the trade-off between user utility and control theory confidentiality through optimization methods. Huang [26] proposed a new encryption strategy and considered the cost of the encryption process. Then, the optimal determinism of the encryption strategy and the existence of the Markov strategy in the finite time horizon are proven. Wang [27] theoretically proved that there are some structural properties in the optimal transmission scheduling for known and unknown eavesdropper estimation errors. In reference [28], the transmission scheduling strategy of remote state estimation systems with eavesdroppers on packet-dropping links was studied. Yuan [29] transformed the system model into MDP in order to obtain the optimal transmission scheduling to minimize the AoI of CPS and keep the AoI of eavesdroppers above a certain level, and proved that the optimal transmission scheduling strategy is a threshold behavior on the CPS and AoI of eavesdroppers, respectively. In [30], the proposed problem is formulated as a Stackelberg game, and the strategy of maximizing the secure transmission rate between sensor and controller in the presence of malicious eavesdroppers and disruptors is studied. On the basis of analyzing the influence of different strategies on eavesdropping performance, Zhou [31] studied the multi-output system and proposed a decryption scheduling scheme to minimize the expected estimation error under the condition of energy constraint.
Most of the existing literature studies the optimal transmission strategies of sensors from the remote estimator. Compared to [27,28], this paper studies the optimal attack energy allocation strategies from the perspective of eavesdroppers. Moreover, the previous literature mainly focuses on the situation that CPS has eavesdroppers in a single system and a finite time range, but does not pay too much attention to the situation when there are eavesdroppers in a multi-system and in an infinite time range. In this paper, the optimal attack allocation problem of remote state estimation in CPS with eavesdropping attacks in a multi-system in infinite time range is studied. Our goal is to maximize the state estimation error of the eavesdropper, so as to determine the optimal attack allocation of the eavesdropper. The contributions of this paper are as follows:
- We propose a multi-system eavesdropping attack model based on channel SINR, which reveals the relationship between attack power and packet arrival rate.
- In the infinite time horizon, under the condition of energy constraint, the optimal attack scheduling strategy is obtained by constructing MDP and using the Bellman equation.
- Finally, according to the given algorithm, the optimal attack energy allocation strategy is obtained, and then it is verified by simulation experiments.
Notations: The entire paper uses the following symbols. is the set of natural numbers. The n-dimensional Euclidean space is denoted by . () is the set of n by n positive semi-definite matricess (and positive definite matrices). is the trace of a matrix X, and is the transpose of X and denotes the inverse of matrix X. and represent that X is a positive definite matrix and positive semidefinite matrix, respectively. For functions and h, stands for the function composition and with . indicates taking the expected value of ′·′. denotes the probability of ′·′.
2. Problem Setup
2.1. System Model
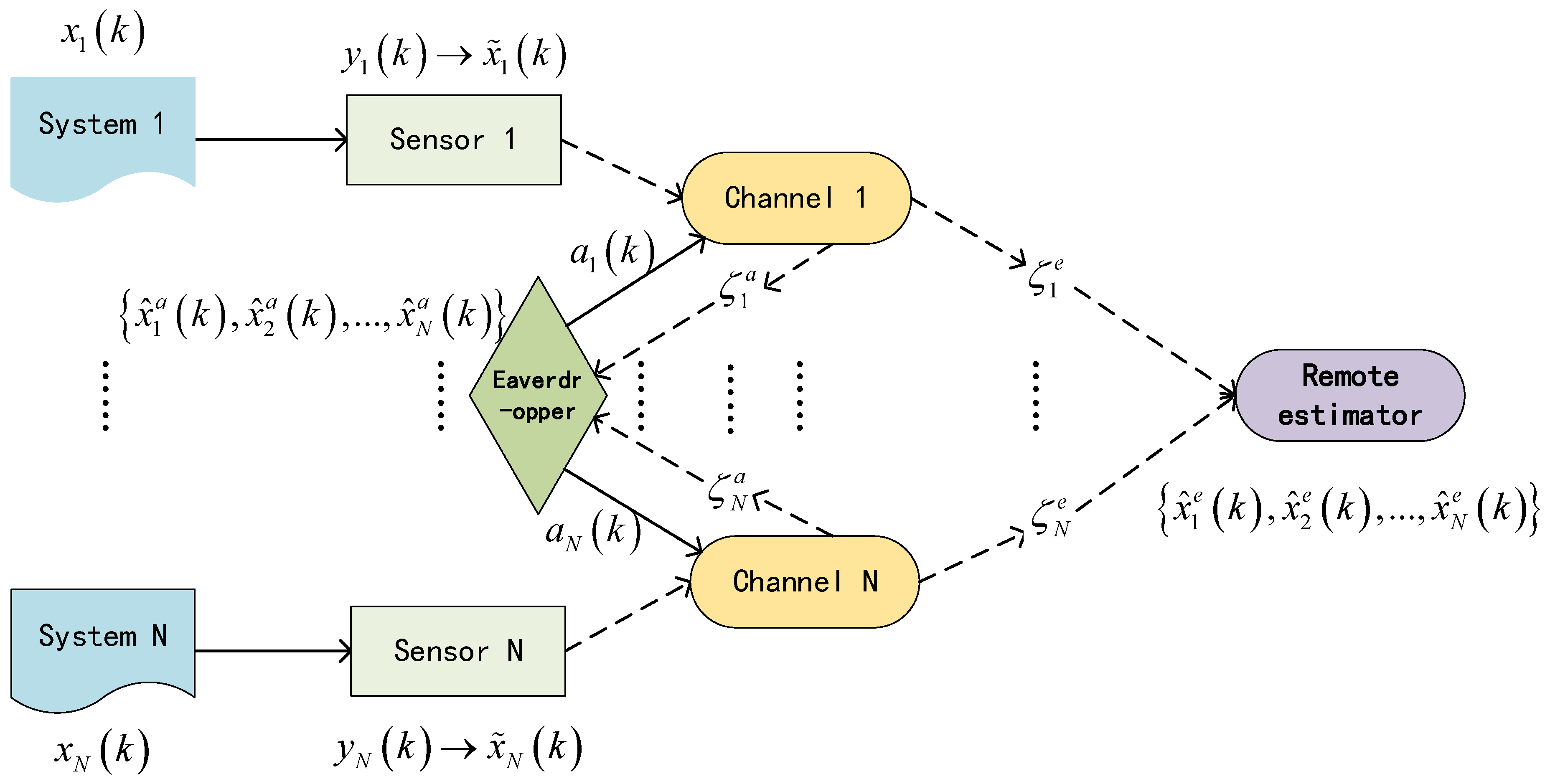
Figure 1 shows the system architecture. We consider N general discrete time-invariant stochastic system, which is given as follows
where is the time index and and refer to the state of the ith system and the system measurements vector taken by the sensor at time k, respectively. The process noise and the observation noise are assumed to be independent and identically distributed (i.i.d.) Gaussian noises with zero-mean and the covariances matrix and matrix , respectively. The initial state of the ith system is also a zero-mean Gaussian random variable independented and with covariance . We also assume that the pair is observable and is stabilizable. Assuming that the sensors in the system are intelligent sensors with certain computing powers, each sensor can first use the collected observation data to calculate the local state estimation, and then transmit the local state estimation value to the remote state estimator. Therefore, we use and to represent the ith sensor’s local minimum mean-squared error (MMSE) estimate of the state and the corresponding error covariance [32]:
which can be calculated based on a standard Kalman filter:
where
is the gain of the Kalman filter and the initial condition is .
For ease of representation, we can also define the Lyapunov and Riccati operators h, : → as
Under the assumptions of detectability and stability, it has been shown that the posterior estimation error covariance matrix of the Kalman filter converges exponentially from any initial condition to a unique value , [33], i.e., , , which is the steady-state error covariance, which is determined by the unique positive semi-definite solution of =X [34].
Lemma 1
2.2. Attack Model Based on SINR
To simulate random data loss due to fading and interference, we assume that the communication between the sensor and the remote estimator or the eavesdropper is via an Additive White Gaussian Noise (AWGN) channel using quadrature amplitude modulation (QAM). Data packets sent by the sensor are quantized and mapped to QAM symbols. Then, digital communication theory reveals the relationship between symbol error rate (SER) and SINR as follows [5,36]:
where , and is a parameter. represents the remote estimator side, indicates the eavesdropper side.
Considering the remote estimator side first, the channel SINR for the remote estimator at time k is [24],
where is the channel gain of the ith communication channel between the sensor and the remote estimator. is the transmission power for the QAM symbol used by sensor i at time k and is the AWGN power of the ith channel between the sensor and the remote estimator. Define a random variable as to whether the remote estimator successfully receives the information at time k, i.e.,
Then, the packet arrival rate of the remote estimator is
Secondly, considering the eavesdropper side, we can know that the SINR of the channel at the eavesdropper side at time k can be expressed as
where is the channel gain of the ith communication channel between the sensor and the eavesdropper. indicates the attack power to the ith channel launched by the eavesdropper. is the AWGN power of the channel between the sensor and the eavesdropper. Similarly, we use a binary random variable to indicate whether the eavesdropper is successful in eavesdropping, i.e.,
Then, the probability that an eavesdropper can successfully eavesdrop is:
Hypothetical processes and are independent of each other.
2.3. Remote State Estimation
With the local estimate received by the remote estimator, we can determine the MMSE state estimate and the corresponding estimation error covariance of the remote estimator at time k, where and are obtained by the following iterative process:
Similarly, denote and as the MMSE state estimation and corresponding error covariance of the eavesdropper at time k, then and can be expressed as
Therefore,
Define S ≜, it is composed of all possible values of and .
2.4. Problem Formulation
Specifically, we consider the following problem: from the perspective of the eavesdropper, in an infinite time horizon, the eavesdropper finds the optimal attack allocation under the condition of limited energy to maximize the state estimation error of the eavesdropper, i.e.,
Problem 1.
where is an admissible attack policy with the attack power using a time-step . is an energy constraint for the attacker at each time. The infinite horizon average expectation of the remote estimation error covariance can be expressed by the following formula:
3. Optimal Attack Schedule
In this section, we formulate Problem 1 as a discrete time MDP to solve. In addition, we also give an algorithm for searching the optimal eavesdropping attack strategy.
3.1. MDP Formulation
For the convenience of notation, denote (or ) as the holding time from the estimator (or eavesdropper) to the continuous successful acquisition of data at time k, that is, the duration from the last successful transmission time to time k, which can be expressed by the following formula:
Obviously, (or ), then we can get:
Using MDP to describe the dynamic process of CPS under eavesdropping attacks, MDP is expressed mathematically as , and the specific elements are as follows.
State space: let , where and can be considered as the state of process i at time at the remote estimator side and eavesdropper side, respectively. The state at time k is defined as , and its value range is a countable state space . Let .
Action space: we can know the action space is defined as , where , , is the maximum attack power to channel i. Thus, the action is .
Transition probability: let the state transition introduction matrix at time k be , which represents the probability of the state changing from to under action , where , . For simplicity, let the state at time k be . Then, the state transition probability matrix is as follows:
Payoff functions: let be the immediate cost function and define it as:
Obviously, the single-stage reward at time k is independent of the action behavior and only depends on the current state.
Note that the random decision rule of the eavesdropper is a mixed strategy sequence , where is the random kernel from to and definition is the set of all these feasible strategies. Based on the process state , the attacker chooses action , . Then, for the initial state , we can get the sum of expected reward following the action strategy :
and its optimal value is
Define the average value function under policy as the function V: . Therefore, we can get the following theorem.
Theorem 1.
According to the MDP theory, we can obtain the optimal value by solving the following optimality (Bellman) equation:
where s = is the initial state.
The optimal attack strategies of the eavesdropper is:
Proof (Proof of Theorem 1).
According to the eighth chapter in reference [37], Theorem 1 can be obtained by introducing our state transition probability matrix (27) and immediate cost function (28).
From Equation (8.4.2) in [37], we can get the following equation:
where is the strategy of the time k. r and are abbreviations. Many decision rules are contained in historical strategies. So, and can be decomposed into the following formula:
Therefore, we can get the following:
Then, we rewrite the finite-horizon optimality Equation (4.5.1) in [37] as
Remark 1.
It should be noted that for finite MDP, the action taken at time k is non-stationary and depends on the current state at time k.
3.2. Policy Iteration Algorithm
MDP proposed in this paper has infinite state space. However, according to the characteristics of state transition in the system model, we can find that when the eavesdropper’s attack energy is limited, the transition rule can effectively limit the system state in a limited time range. Therefore, in the MDP proposed in this paper, although it has infinite state space, we can treat it as an MDP with a finite time domain. This is convenient for us to design the algorithm of the optimal attack strategy.
In a finite time domain, the solution of the optimal equation is the optimal quality function from the decision time k to the decision time T at the end of the process. Based on the MDP problem constructed above, we provide a specific backward induction algorithm to solve it and provide the optimal attack strategy, i.e., Algorithm 1.
In Algorithm 1, we first calculate , the packet rate and the hold time , in step 1 and calculate the state transition matrix in step 2. Then, in step 3, set all and for all , compute by (31). Next, in step 4, we set , initialize . In step 5, let , compute by (31) and by (32). We assess that the best action 1 is found for state , so in step 6, if , then for all , let (34). After this, let , and go to Step 5. Otherwise, let , go to Step 5. Finally, in step 7, if , output and . Otherwise, go to Step 4.
| Algorithm 1 Backward induction algorithm for optimal allocation strategy |
| Require: . |
| Ensure: The optimal value ; optimal deterministic Markov policy |
| Step 1: Calculate , the packet rate and the holding time , |
| Step 2: Calculate state transition matrix |
| Step 3: Set all and for all , compute by (31). |
| Step 4: Set , initialize . |
| Step 5: Let , compute
|
| Step 6: If , then, for all , let
|
| let , and go to Step 5. Otherwise, let , go to Step 5. |
| Step 7: If , then output and . Otherwise, go to Step 4. |
Remark 3.
In the above Algorithm 1, it is assumed that in order to reduce the calculation cost and complexity compared with the traditional algorithm.
Remark 4.
We can derive the state estimation of the eavesdropper each time to ensure the feasibility of Algorithm 1.
4. Discussion and Illustrative Example
In this section, according to the above MDP model, we can provide some numerical simulations to show the optimal attack energy allocation strategy of problem 1. Consider systems and with . The parameters of the systems and channels are shown in Table 1.
Suppose the energy constraint is . In Table 1, indicates that the possible maximum attack power of channel 1 is 0, 5, 7 and 10, respectively, and another 0 means that there is no attack. in the same way. According to the number of existing systems and the number of channels that eavesdrop at the same time, we can divide them into the following three methods, such as numerical simulation. We use the Algorithm 1 to calculate the optimal attack energy allocation strategy and the optimal average return.
4.1. Single System
Let us first consider the case where there is only one system. When there is only one system, we consider the optimal attack energy allocation strategy when attacking this channel at different times. We can use the data in Table 1 about Sensor 1. The strategy set for the eavesdropper is , where means no attack, means use energy 10 to attack at the first moment and not to attack at the second moment and and have a similar meaning. Assume that the transmission power of the sensor is . Through the calculation, the error covariance of the steady state estimation is obtained, i.e., . Assume that the AWGN power of the channel between the sensor and the estimator is , and the AWGN power of the channel between the sensor and the eavesdropper is . This paper studies the infinite time domain, but in order to simplify the calculation, we use the truncated set . The optimal strategy is calculated through Algorithm 1.
In Figure 2, we use and to represent the state of the optimal strategy and the optimal strategy is shown, where the purple and red symbols represent policy 1 (policy 1 = (0, 0)) and policy 2 (policy 2 = (0, 10)).
4.2. Dual System (Not Attacking or Attacking One Channel)
Consider that when there are two systems, neither of the two channels can attack or can only attack one channel.In the numerical solution, we consider the data in Table 1 and Table 2 and use a truncated set . We can assume that the eavesdropper’s strategy set is , i.e., Table 3. Where indicates that there is no attack on both channels. means that channel 1 is attacked with energy 5, 7 and 10, respectively, and channel 2 is not attacked; has the same meaning. Through our calculations, we can get , . and we take as random numbers.
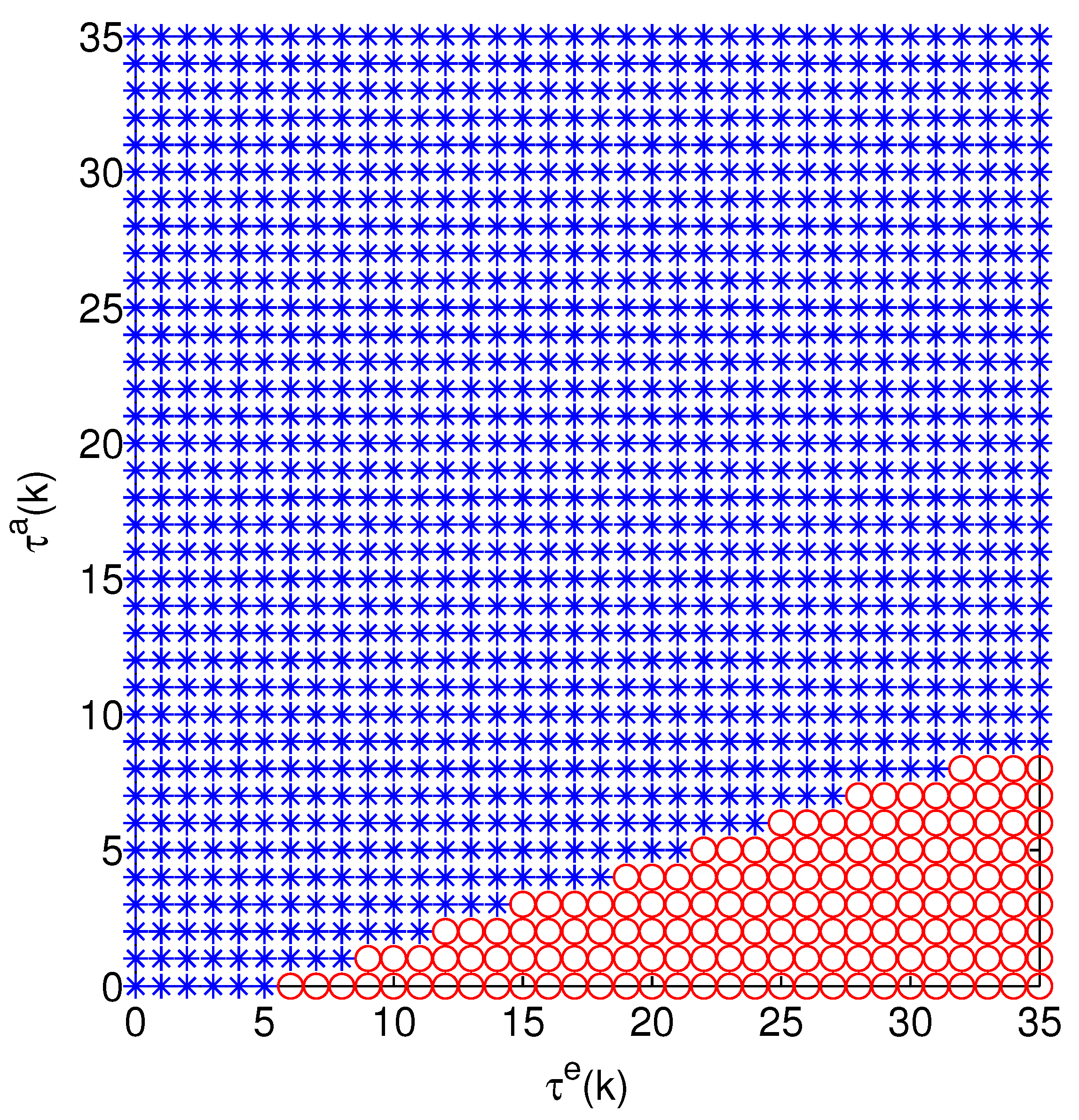
The optimal attack energy allocation strategy when there are two systems, neither of which attack or only one attacks, is shown in Figure 3 and Figure 4. In Figure 3, with an increase of , the optimal strategies cannot be clearly identified. Therefore, we use and in Figure 4 to represent the state of the optimal strategies. From Figure 4, we can see that the optimal action includes and .
4.3. Dual System (Not Attacking, Attacking One Channel or Attacking Two Channels)
Similarly, in this section, two systems are also considered, and we can consider three situations: no attack, only one channel attack and two channels attack at the same time. We can assume that the eavesdropper’s strategy set is , i.e., Table 4. Where indicates that there is no attack on both channels. means that channel 1 is attacked with energy 5 and 10, respectively, and channel 2 is not attacked; has the same meaning. represents an attack on channel 1 and channel 2 using energy 5 and energy 5, respectively; has the same meaning. In the numerical solution, we consider the data in Table 1 and Table 2 and use truncated set . and we take as random numbers. Through our calculations, we can get , .
Figure 5 and Figure 6 show the optimal attack energy allocation strategy when there are two systems, in which two channels are not attacked, only one channel is attacked and both channels are attacked. In Figure 5, with an increase of , the optimal strategies cannot be clearly identified. Therefore, we use and in Figure 6 to represent the state of the optimal strategies. From Figure 6, we can see that the optimal action includes , , and .
5. Conclusions
The optimal attack energy allocation of multi-system remote state estimation in CPS is studied when eavesdroppers exist in an infinite time domain. Based on the channel SINR, a wireless communication model is constructed. When the eavesdropper’s energy is limited, the optimal value of the eavesdropper and the optimal attack energy allocation strategy are found by using MDP theory. Finally, the research results are numerically simulated. According to the theoretical analysis and the numerical analysis, we can draw the following conclusions: in a multi-system, the optimal energy allocation strategy is to choose a higher attack energy to attack the channel when the estimation error covariance at the eavesdropper is large, and choose a lower attack energy to attack the channel when the estimation error covariance is small. And, we can see that the optimal attack strategy has an obvious threshold structure. In the future, we will prove the threshold structure of the optimal allocation strategy and study the situation when the detector exists.
Author Contributions
Conceptualization, X.C. and L.P.; methodology, X.C.; software, X.C. and L.P.; validation, X.C., S.Z. and L.P.; formal analysis, S.Z.; investigation, X.C.; writing—original draft preparation, X.C.; writing—review and editing, X.C. and L.P.; visualization, L.P.; supervision, S.Z.; project administration, L.P.; funding acquisition, L.P. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Natural Science Foundation of Shandong Province (No. ZR2023MF023), Natural Science Foundation postdoctoral project of Qingdao of China (No. QDBSH20230102058), Taishan Scholars Project of Shandong Province of China (No. tstp20230624), and the Science and Technology Plan for Youth Innovation of Universities in Shandong Province (No. 2022KJ301).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CPS | Cyber-physical systems |
| DoS | denial of service |
| SINR | signal-to-noise ratio |
| MDP | markov decision process |
| MMSE | minimum mean-squared error |
| AWGN | Additive White Gaussian Noise |
| QAM | quadrature amplitude modulation |
| AoI | age of information |
References
- Gunes, V.; Peter, S.; Givargis, T.; Vahid, F. A Survey on Concepts, Applications, and Challenges in Cyber-Physical Systems. KSII Trans. Int. Inf. Syst. 2014, 8, 4242–4268. [Google Scholar] [CrossRef]
- Peng, L.; Cao, X.; Sun, C. Optimal Transmit Power Allocation for an Energy-Harvesting Sensor in Wireless Cyber-Physical Systems. IEEE Trans. Cybern. 2021, 51, 779–788. [Google Scholar] [CrossRef]
- Kim, K.D.; Kumar, P.R. Cyber-Physical Systems: A Perspective at the Centennial. Proc. IEEE 2012, 100, 1287–1308. [Google Scholar] [CrossRef]
- Wei, J.; Ye, D. Multisensor Scheduling for Remote State Estimation Over a Temporally Correlated Channel. IEEE Trans. Ind. Inform. 2023, 19, 800–808. [Google Scholar] [CrossRef]
- Li, Y.; Quevedo, D.E.; Dey, S.; Shi, L. SINR-Based DoS Attack on Remote State Estimation: A Game-Theoretic Approach. IEEE Trans. Control Netw. Syst. 2017, 4, 632–642. [Google Scholar] [CrossRef]
- Zhao, L.; Li, W. Co-Design of Dual Security Control and Communication for Nonlinear CPS Under DoS Attack. IEEE Access 2020, 8, 19271–19285. [Google Scholar] [CrossRef]
- Li, T.; Chen, B.; Yu, L.; Zhang, W.A. Active Security Control Approach Against DoS Attacks in Cyber-Physical Systems. IEEE Trans. Autom. Control 2021, 66, 4303–4310. [Google Scholar] [CrossRef]
- Wang, L.; Cao, X.; Sun, C. Optimal Offline Privacy Schedule for Remote State Estimation under an Eavesdropper. In Proceedings of the 2019 34rd Youth Academic Annual Conference of Chinese Association of Automation (YAC), Jinzhou, China, 6–8 June 2019; pp. 676–682. [Google Scholar] [CrossRef]
- Zhu, F.; Ding, S.; Zuo, Y.; Peng, L. Distributed Robust Filtering for Cyber-Physical Systems under Periodic Denial-of-Service Jamming Attacks. Proc. Inst. Mech. Eng. Part I J. Syst. Control Eng. 2022, 236, 1890–1907. [Google Scholar] [CrossRef]
- Peng, L.; Shi, L.; Cao, X.; Sun, C. Optimal Attack Energy Allocation against Remote State Estimation. IEEE Trans. Autom. Control 2018, 63, 2199–2205. [Google Scholar] [CrossRef]
- Zhang, S.; Peng, L.; Chang, X. Optimal Energy Allocation Based on SINR under DoS Attack. Neurocomputing 2024, 570, 127126. [Google Scholar] [CrossRef]
- Mo, Y.; Weerakkody, S.; Sinopoli, B. Physical Authentication of Control Systems: Designing Watermarked Control Inputs to Detect Counterfeit Sensor Outputs. IEEE Control Syst. Mag. 2015, 35, 93–109. [Google Scholar] [CrossRef]
- An, D.; Zhang, F.; Yang, Q.; Zhang, C. Data Integrity Attack in Dynamic State Estimation of Smart Grid: Attack Model and Countermeasures. IEEE Trans. Autom. Sci. Eng. 2022, 19, 1631–1644. [Google Scholar] [CrossRef]
- Zhang, T.Y.; Ye, D. False Data Injection Attacks with Complete Stealthiness in Cyber-Physical Systems: A Self-Generated Approach. Automatica 2020, 120, 109117. [Google Scholar] [CrossRef]
- Xu, Q.; Zhang, Z.; Yan, Y.; Xia, C. Security and Privacy with k-step Opacity for Finite Automata Via A Novel Algebraic Approach. IEEE Trans. Inst. Meas. Control 2021, 43, 3606–3614. [Google Scholar] [CrossRef]
- Yuan, Y.; Zhang, P.; Guo, L.; Yang, H. Towards Quantifying the Impact of randomly Occurred Attacks on A Class of Networked Control Systems. J. Frankl. Inst. 2021, 354, 4966–4988. [Google Scholar] [CrossRef]
- Wang, K.; Yuan, L.; Miyazaki, T.; Chen, Y.; Zhang, Y. Jamming and Eavesdropping Defense in Green Cyber-Physical Transportation Systems Using a Stackelberg Game. IEEE Trans. Ind. Inform. 2018, 4, 4232–4242. [Google Scholar] [CrossRef]
- Zhang, P.; Zhou, M.; Fortino, G. Security and Trust Issues in Fog Computing: A Survey. Future Gener. Comput. Syst. 2018, 88, 16–27. [Google Scholar] [CrossRef]
- Bayat-Sarmadi, S.; Kermani, M.M.; Azarderakhsh, R.; Lee, C.Y. Dual-Basis Superserial Multipliers for Secure Applications and Lightweight Cryptographic Architectures. IEEE Trans. Circuits Syst. II Express Briefs 2014, 61, 125–129. [Google Scholar] [CrossRef]
- Chen, Y.J.; Wang, L.C.; Liao, C.H. Eavesdropping Prevention for Network Coding Encrypted Cloud Storage Systems. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 2261–2273. [Google Scholar] [CrossRef]
- Yang, H.; Jiang, G.P. Reference-Modulated DCSK: A Novel Chaotic Communication Scheme. IEEE Trans. Circuits Syst. II Express Briefs 2013, 60, 232–236. [Google Scholar] [CrossRef]
- Han, Y.; Duan, L.; Zhang, R. Jamming-Assisted Eavesdropping Over Parallel Fading Channels. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2486–2499. [Google Scholar] [CrossRef]
- Yuan, H.; Xia, Y.; Yuan, Y.; Yang, H. Resilient Strategy Design for Cyber-Physical System under Active Eavesdropping Attack. J. Frankl. Inst. 2021, 358, 5281–5304. [Google Scholar] [CrossRef]
- Ding, K.; Ren, X.; Leong, A.S.; Quevedo, D.E.; Shi, L. Remote State Estimation in the Presence of an Active Eavesdropper. IEEE Trans. Autom. Control 2021, 66, 229–244. [Google Scholar] [CrossRef]
- Tsiamis, A.; Gatsis, K.; Pappas, G.J. State Estimation with Secrecyagainst Eavesdroppers. IFAC-PapersOnLine 2017, 50, 8385–8392. [Google Scholar] [CrossRef]
- Huang, L.; Leong, A.S.; Quevedo, D.E.; Shi, L. Finite Time Encryption Schedule in the Presence of an Eavesdropper with Operation Cost. In Proceedings of the 2019 American Control Conference (ACC), Philadelphia, PA, USA, 10–12 July 2019; pp. 4063–4068. [Google Scholar] [CrossRef]
- Wang, L.; Cao, X.; Sun, B.; Zhang, H.; Sun, C. Optimal Schedule of Secure Transmissions for Remote State Estimation Against Eavesdropping. IEEE Trans. Ind. Inform. 2021, 17, 1987–1997. [Google Scholar] [CrossRef]
- Leong, A.S.; Quevedo, D.E.; Dolz, D.; Dey, S. Transmission Scheduling for Remote State Estimation Over Packet Dropping Links in the Presence of an Eavesdropper. IEEE Trans. Autom. Control 2021, 64, 3732–3739. [Google Scholar] [CrossRef]
- Yuan, F.; Tang, S.; Liu, D. AoI-Based Transmission Scheduling for Cyber-Physical Systems Over Fading Channel Against Eavesdropping. IEEE Internet Things J. 2024, 11, 5455–5466. [Google Scholar] [CrossRef]
- Yuan, L.; Wang, K.; Miyazaki, T.; Guo, S.; Wu, M. Optimal transmission strategy for sensors to defend against eavesdropping and jamming attacks. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Zhou, J.; Luo, Y.; Liu, Y.; Yang, W. Eavesdropping Strategies for Remote State Estimation Under Communication Constraints. IEEE Trans. Inf. Forensics Secur. 2023, 18, 2250–2261. [Google Scholar] [CrossRef]
- Sun, S.L.; Deng, Z.L. Multi-Sensor Optimal Information Fusion Kalman Filter. Automatica 2004, 40, 1017–1023. [Google Scholar] [CrossRef]
- Sinopoli, B.; Schenato, L.; Franceschetti, M.; Poolla, K.; Jordan, M.I.; Sastry, S.S. Kalman Filtering with Intermittent Observations. IEEE Trans. Autom. Control 2004, 9, 1453–1464. [Google Scholar] [CrossRef]
- Shi, L.; Cheng, P.; Chen, J. Sensor Data Scheduling for Optimal State Estimation with Communication Energy Constraint. Automatica 2011, 47, 1693–1698. [Google Scholar] [CrossRef]
- Wu, S.; Ding, K.; Cheng, P.; Shi, L. Optimal Scheduling of Multiple Sensors over Lossy and Bandwidth Limited Channels. IEEE Trans. Control Netw. Syst. 2020, 7, 1188–1200. [Google Scholar] [CrossRef]
- Zhang, H.; Qi, Y.; Wu, J.; Fu, L.; He, L. DoS Attack Energy Management Against Remote State Estimation. IEEE Trans. Control Netw. Syst. 2018, 5, 383–394. [Google Scholar] [CrossRef]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley and Sons Publishing House: New York, NY, USA, 2005; pp. 354–358. [Google Scholar]
Figure 1.
System architecture.

Figure 2.
A single system’s optimal energy allocation.

Figure 3.
Optimal action of state (not attacking or attacking one channel), where the blue stars and red circles represent the actions and , respectively.
Figure 3.
Optimal action of state (not attacking or attacking one channel), where the blue stars and red circles represent the actions and , respectively.

Figure 4.
Optimal action of (). The meaning of circles and stars is the same as in Figure 3.
Figure 4.
Optimal action of (). The meaning of circles and stars is the same as in Figure 3.

Figure 5.
Optimal action of state (not attacking, attacking one channel or attacking two channels), where the blue stars, green triangles, black pentagrams and red circles represent the actions , , and , respectively.
Figure 5.
Optimal action of state (not attacking, attacking one channel or attacking two channels), where the blue stars, green triangles, black pentagrams and red circles represent the actions , , and , respectively.

Figure 6.
Optimal action of (). The meaning of circles, triangles, pentagrams and stars is the same as in Figure 5.
Figure 6.
Optimal action of (). The meaning of circles, triangles, pentagrams and stars is the same as in Figure 5.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Parameters for sensors and attack power.
| Sensor 1 | Sensor 2 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Process 1 | Attack Power | Process 2 | Attack Power | ||||||||||||
| 1.8 | 1.5 | 0.8 | 1 | 0 | 5 | 7 | 10 | 1.2 | 1.0 | 0.9 | 0.8 | 0 | 3 | 5 | 10 |
Table 2.
AWGN power and Transmission power.
| AWGN Power | Transmission Power | ||
|---|---|---|---|
| 0.1 | 0.2 | 1 | 0.8 |
Table 3.
Attack power levels. Dual system (not attacking or attacking one channel).
| Not Attack | To Channel 1 | To Channel 2 | ||||
|---|---|---|---|---|---|---|
| (0,0) | ||||||
Table 4.
Attack power levels. Dual system (not attacking, attacking one channel or attacking two channels).
Table 4.
Attack power levels. Dual system (not attacking, attacking one channel or attacking two channels).
| Not Attack | Attacking One Channel | Attacking Two Channels | ||||
|---|---|---|---|---|---|---|
| (0,0) | To Channel 1 | To Channel 2 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Chang, X.; Peng, L.; Zhang, S. Allocation of Eavesdropping Attacks for Multi-System Remote State Estimation. Sensors 2024, 24, 850. https://doi.org/10.3390/s24030850
AMA Style
Chang X, Peng L, Zhang S. Allocation of Eavesdropping Attacks for Multi-System Remote State Estimation. Sensors. 2024; 24(3):850. https://doi.org/10.3390/s24030850
Chicago/Turabian StyleChang, Xiaoyan, Lianghong Peng, and Suzhen Zhang. 2024. "Allocation of Eavesdropping Attacks for Multi-System Remote State Estimation" Sensors 24, no. 3: 850. https://doi.org/10.3390/s24030850
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.