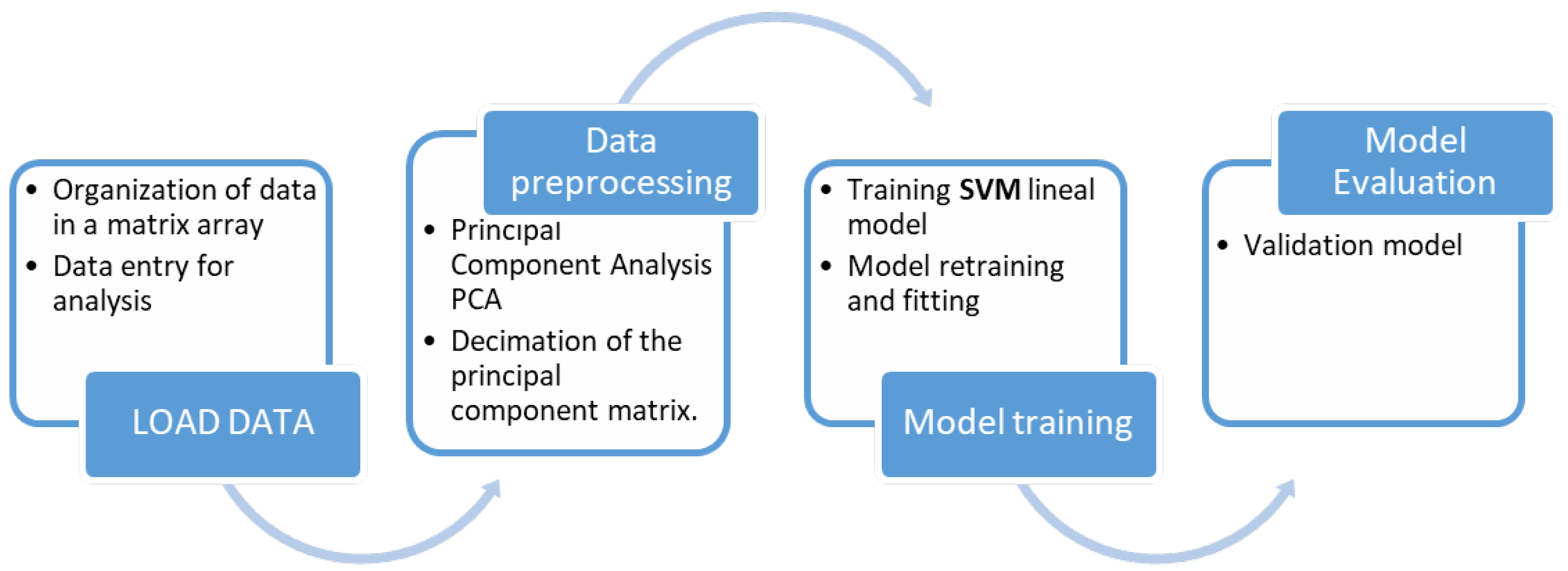
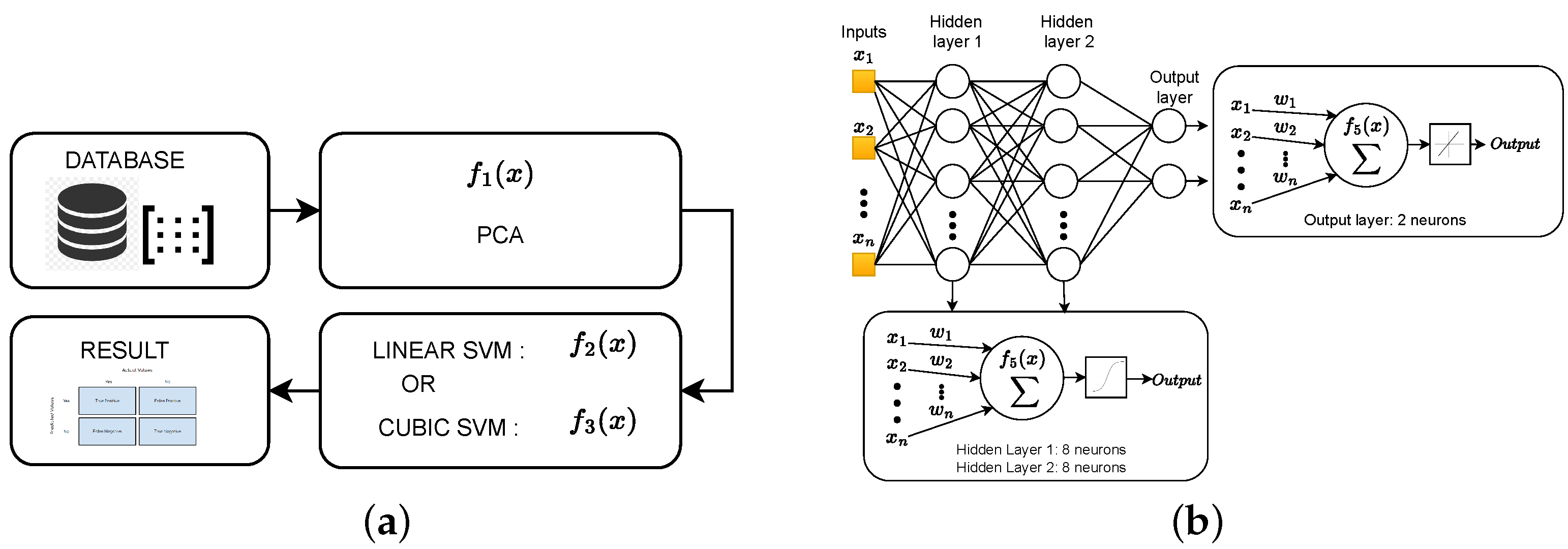
The first stage of this workflow is to load the samples obtained for each isotope pair into memory, creating the necessary data structure. The information stored in this structure corresponds to the label, the name of the isotope with which the data are associated, and the number of protons (Z) and neutrons (N) that compose it. Once this step is completed, the second stage, denoted in
Figure 2 as “Data preprocessing”, is performed. During this stage, the PCA technique is applied to reduce the number of features to be processed. This process is described in
Section 3.1. After the reduction of the sample space, an SVM-based classifier is trained (
Section 3.2). Finally, after the training phase, the generated model is applied to a new dataset to validate its estimation. All the coding works were implemented in Matlab, using the Statistics and Machine Learning Toolbox [
33,
34].
3.1. Data Pre-Processing: Principal Component Analysis
Principal component analysis is a statistical-algebraic technique that allows the dimensionality of a dataset to be reduced while preserving the maximum amount of information. This is achieved by linearly converting the data into a new coordinate system in which a significant portion of the data’s variation can be explained using fewer dimensions than the original dataset. This enables a reduction in the memory footprint of a dataset and significantly simplifies the classification algorithm without compromising precision [
35]. For this work, the available dataset consists of the following feature vectors:
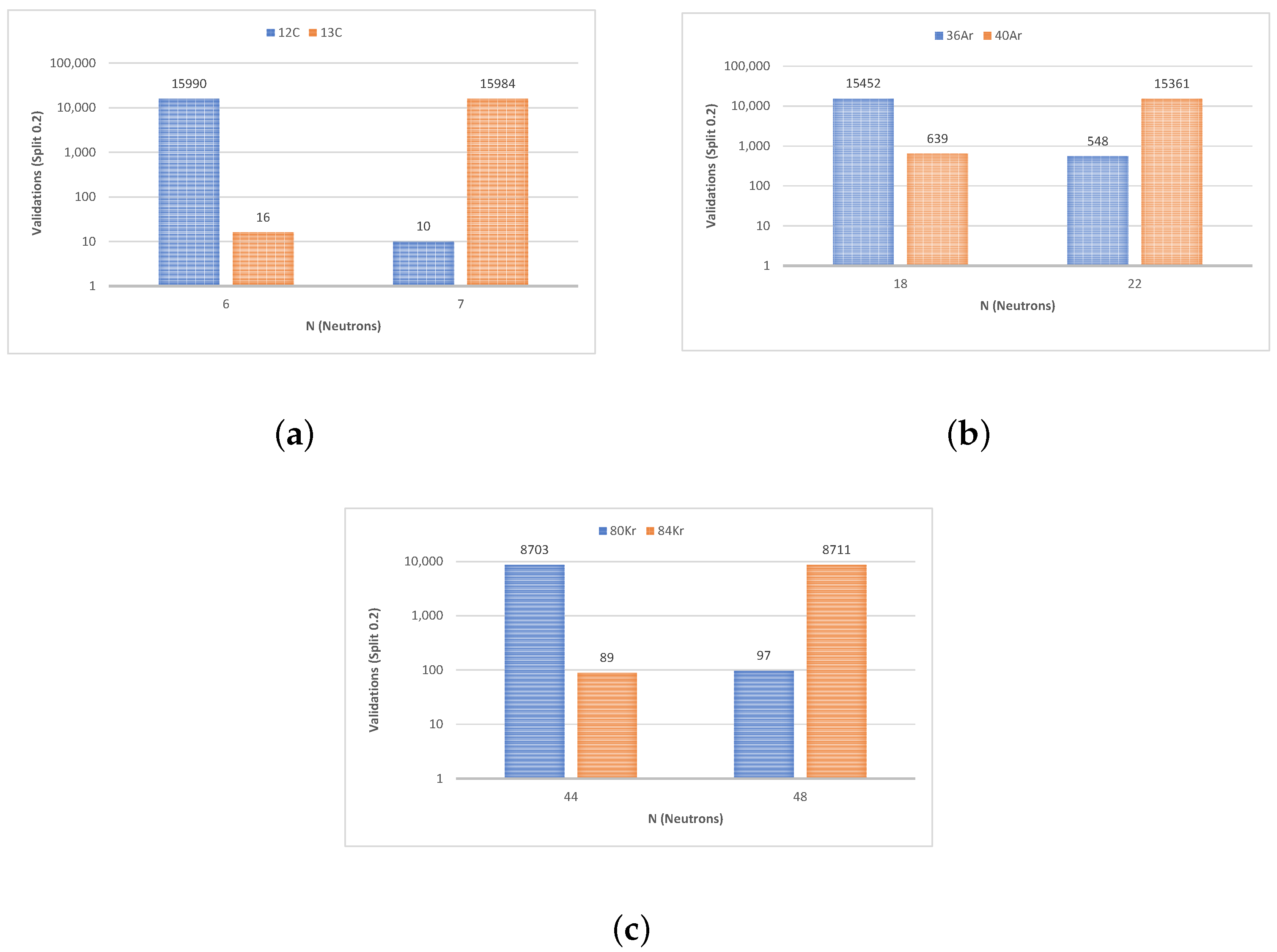
80Kr,1100 observations with 300 features
84Kr, 1100 observations with 300 features
36Ar, 2000 observations with 200 features
40Ar, 2000 observations with 200 features
12C, 2000 observations with 100 features
13C, 2000 observations with 100 features
Each observation corresponds to a sample vector with 300, 200, and 100 features for
80,84Kr,
36,40Ar, and
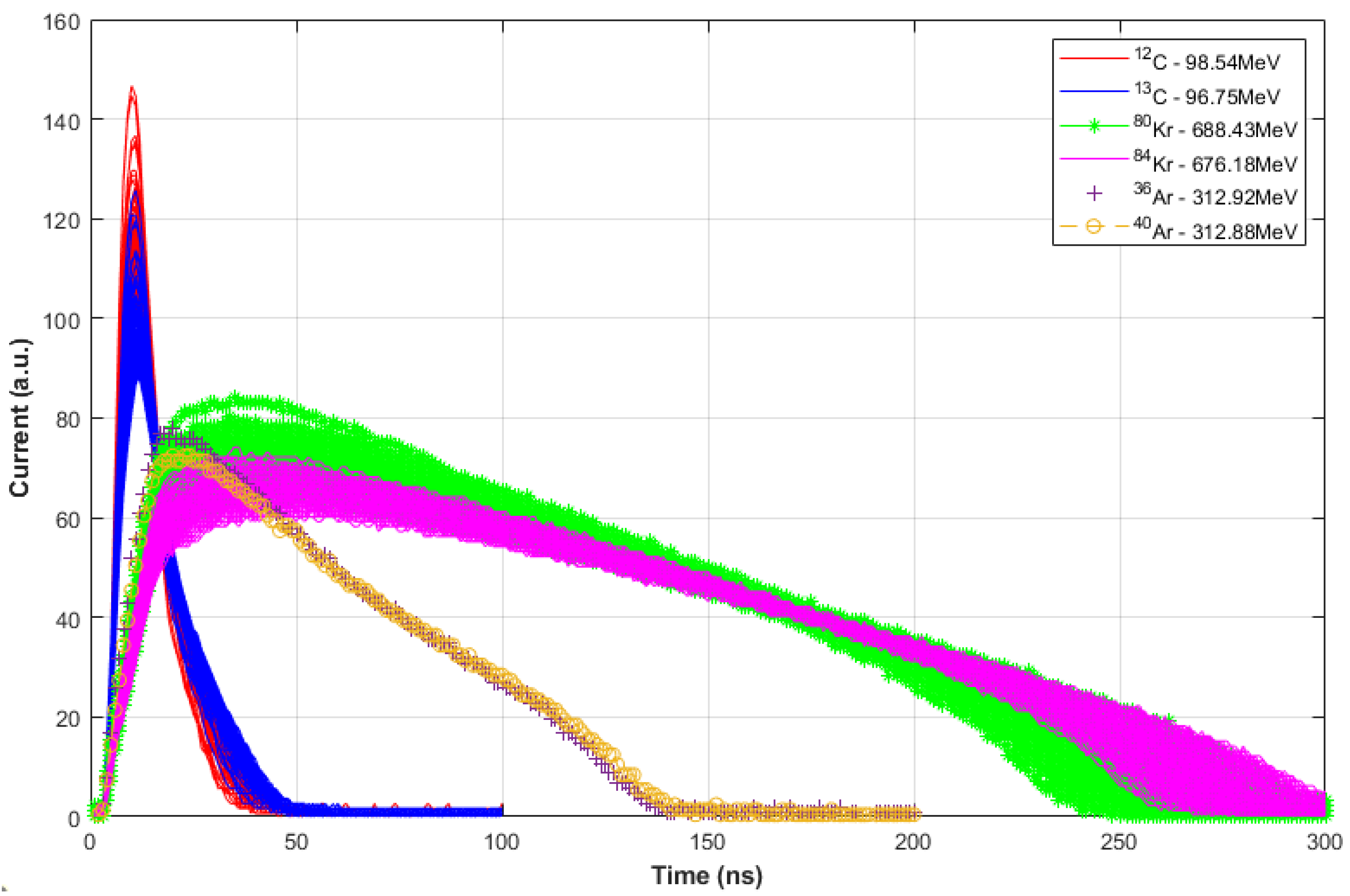
12,13C isotopes, respectively. Note that each of the features corresponds to a sample of the electric current acquired by the 8-bit ACQIRIS digitizer, operating with a sample period of 1 ns. These vectors are arranged in a matrix for each isotope pair. The digitizer provides the samples with an interval of 1 ns. Thus, each observation has a duration of 300 ns, 200 ns, and 100 ns for Kr, Ar, and C isotopes, respectively. The digitizer output for each isotope pair is plotted in
Figure 1. Note that the X-axis represents the time instant of the acquired sample and it can also be interpreted as the number of the sample, without loss of generality.
Naturally, the aim of applying PCA is to reduce the amount of features to process in the classification techniques without compromising the accuracy and, hence, improving its computational efficiency. This reduction of features to be processed is beneficial since these techniques, see PCA, act as an enabling technology for the implementation of the edge-computing paradigm in the field of nuclear physics research. This new approach opens up the potential for processing and analyzing data in proximity to the silicon detector, thereby decreasing the amount of valuable data that need to be transmitted in an experiment. Furthermore, in the specific case of PCA, the way to generate the most relevant features of a dataset allows the resulting data to be used as a visualization tool, thus improving the understanding of the obtained data.
Figure 3 shows a typical visual example that represents a dataset that could be the raw feature matrix corresponding to a certain isotope. Note that in this example, the matrix is composed of
n observations and each observation has
p features. Therefore, the sample space presents
p dimensions.
After applying PCA, the dimensionality of the dataset is reduced, generating a subset
, where
k is a number much smaller than the original features
p,
.
Figure 4 depicts the condensation of the information provided by multiple variables through PCA into just a few adjacent components.
Each principal component
is obtained by a linear combination of the original variables. They can be understood as new features obtained by combining the original features in a certain way. The first principal component of a group of variables (
,
, …,
) is the normalized linear combination of these features that has the highest variance (
1).
The coefficients are known as “loadings” and define each principal component, . The loadings are understood as the weight that each feature has in each principal component, and it tells us what kind of information each component collects. These coefficients correspond to the eigenvector and eigenvalue of the covariance matrix.
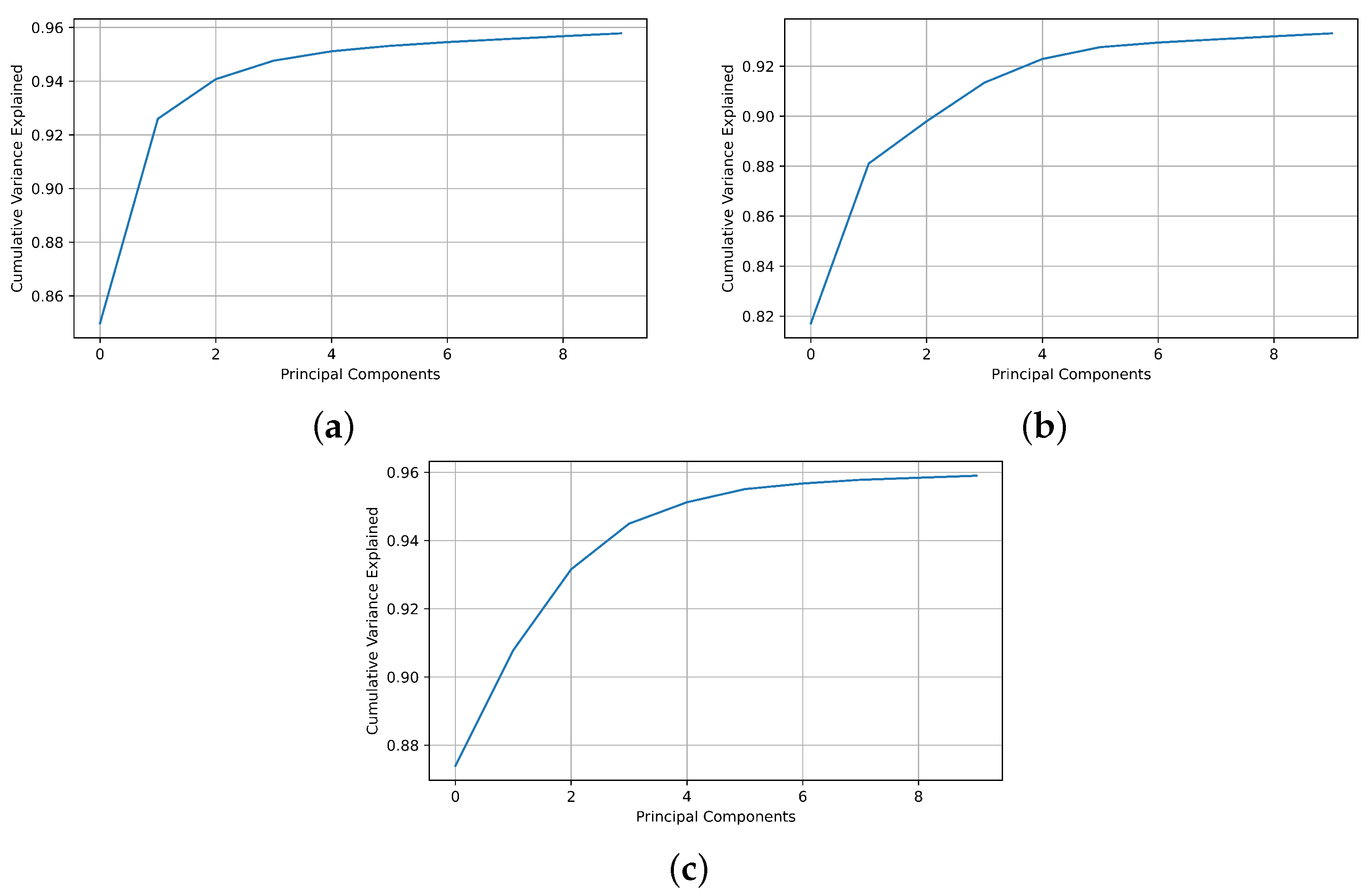
For the dataset used in this work, a matrix of principal components of the same dimensions as the original dataset is obtained. However, because the purpose of PCA is to reduce the amount of data and retain as much information as possible, a minimum number of principal components must be found that are sufficient to preserve and explain the original features. There is no standardized solution or method to select the optimal number of principal components. Nevertheless, a widely accepted criterion is to evaluate the proportion of cumulative explained variance and select the minimum number of components beyond which the increase in variance is no longer significant.
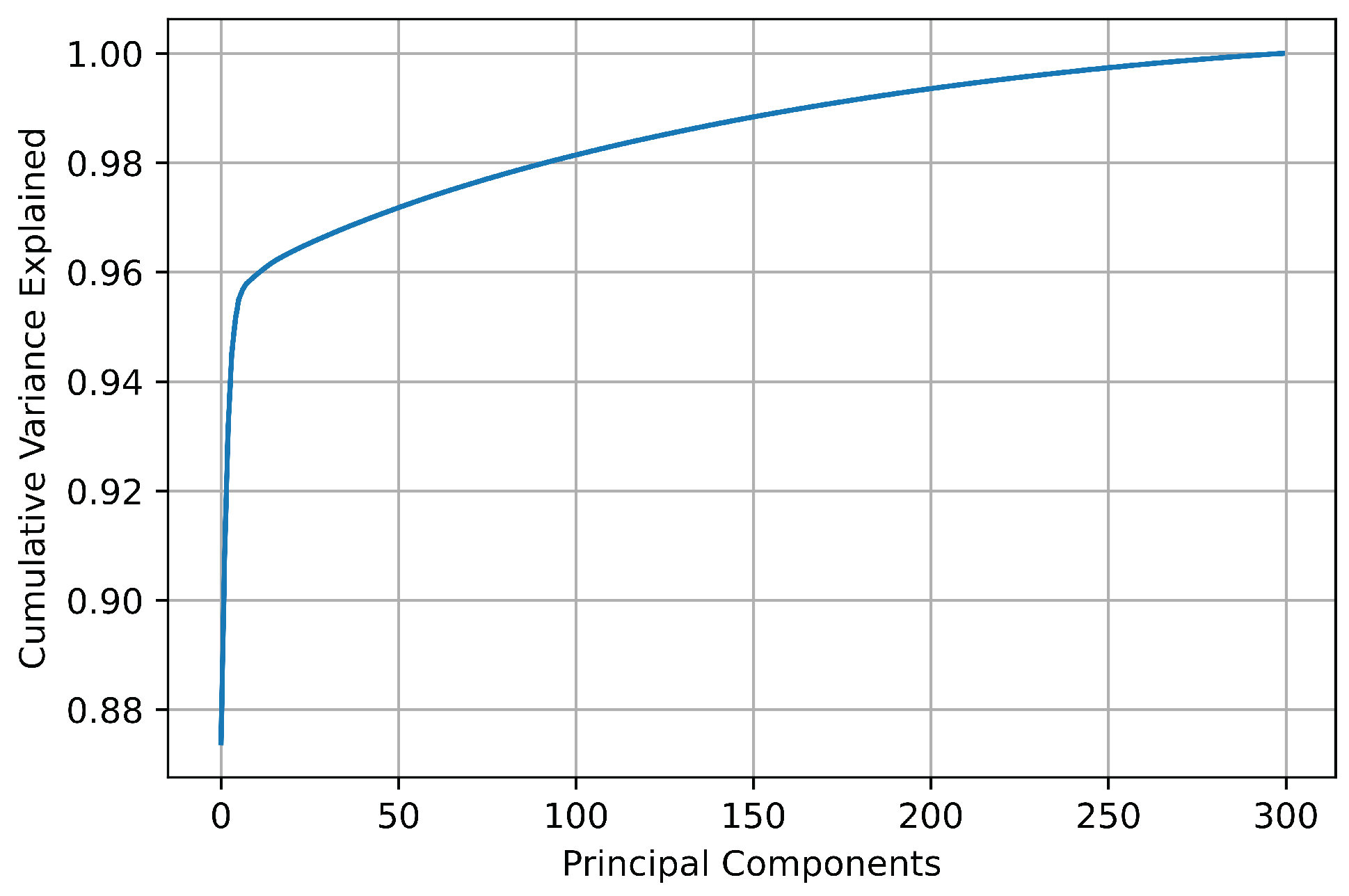
Figure 5 shows the cumulative explained variance of the principal components of the dataset for
80,84Kr. As can be observed, the greatest variation in the cumulative explained variance occurs in the first 20 principal components, where this parameter varies from 0.873959 for only one PC to 0.963423 for the first 20 PCs. From this number of principal components, the increase in the cumulative explained variance is not significant compared to the amount of data that must be processed.
3.2. Classifier: SVM
Support vector machines (SVMs) are a popular linear classifier based on supervised machine learning models [
36,
37], i.e., the sample dataset must be labeled to be used. Its effectiveness in classification, numerical prediction, and pattern recognition tasks has been exploited in this work to train an efficient model capable of identifying isotopes of similar energies. The aim of SVMs is to find a line or a hyperplane in dimensions greater than 2 between different classes of data such that the distance on either side of that line or hyperplane to the nearest data point is maximized. For this research, linear and cubic kernels are used.
In relation to the inputs of the model to be trained, these correspond to the characteristics generated by the PCA algorithm. Specifically, a series of principal components is evaluated that varies between 1 and 10. For each of these PCs, a different classifier model is trained. It is important to note that preprocessing the data with PCA not only contributes to reducing the number of characteristics of the observations, but also helps to maximize their variance; increasing the separation of some characteristics from others. A simple way to interpret this effect is from a geometrical point of view. The new features composed of the principal components occupy different positions in space and with greater separation between them. This allows for simplifying the line or hyperplane estimated by the SVM and, therefore, facilitating its classification.
The output of the classifier corresponds to the label associated with each of the observations. Thus, for each pair of isotopes, the classifier properly categorizes each one into its respective class and, once classified, assigns the corresponding number of neutrons and protons. These values are used in
Section 4 to compare these algorithms with other classification techniques.
To train each model, the 80–20% rule was applied, i.e., 80% of the dataset was used for the training while the remaining 20% was dedicated to evaluate the accuracy of the model generated. Note that the accuracy is defined as the true positive predictions that are correct over the total number of cases. Furthermore, to obtain an accurate and robust classifier, a k-fold cross-validation strategy was applied to the training dataset. The main purpose of this method is to divide the dataset into multiple subsets or “folds”, allowing for training and testing the model multiple times. Specifically, the training dataset was subdivided into 5 sections so that during each training iteration composed of 5 iterations, 4 of these sections were used to train the model and the remaining one was used to evaluate it. Note that k-fold-based training was chosen since the amount of available data was limited, and, in these cases, this technique contributes to reduce the risk of overfitting, offering a more reliable estimate of the model’s performance. Finally, 40 iterations were run to obtain the final model. This procedure was applied for each of the chosen methods: linear and cubic.
To determine the optimal number of principal components, three metrics were considered for their evaluation: accuracy, merit factor, and the performance previously achieved by the neural network that we aim to surpass. In the case of the first metric, the precision of the SVM classifier, the estimation of the number of principal components to be used was performed according to two criteria. First, the success–error rate obtained after evaluating the confusion matrix must be higher than 90%, a value similar to that of other scientific publications [
27,
28]. The second defined criterion is that an increase in the number of principal components should represent a negligible percentage improvement in the classification. For this purpose, a percentage of 1% was established as the improvement threshold. Below this threshold, the computational resources required to implement the PCA algorithm and the SVM classifier increase significantly, leading to an increase in the complexity and size of a possible hardware implementation.
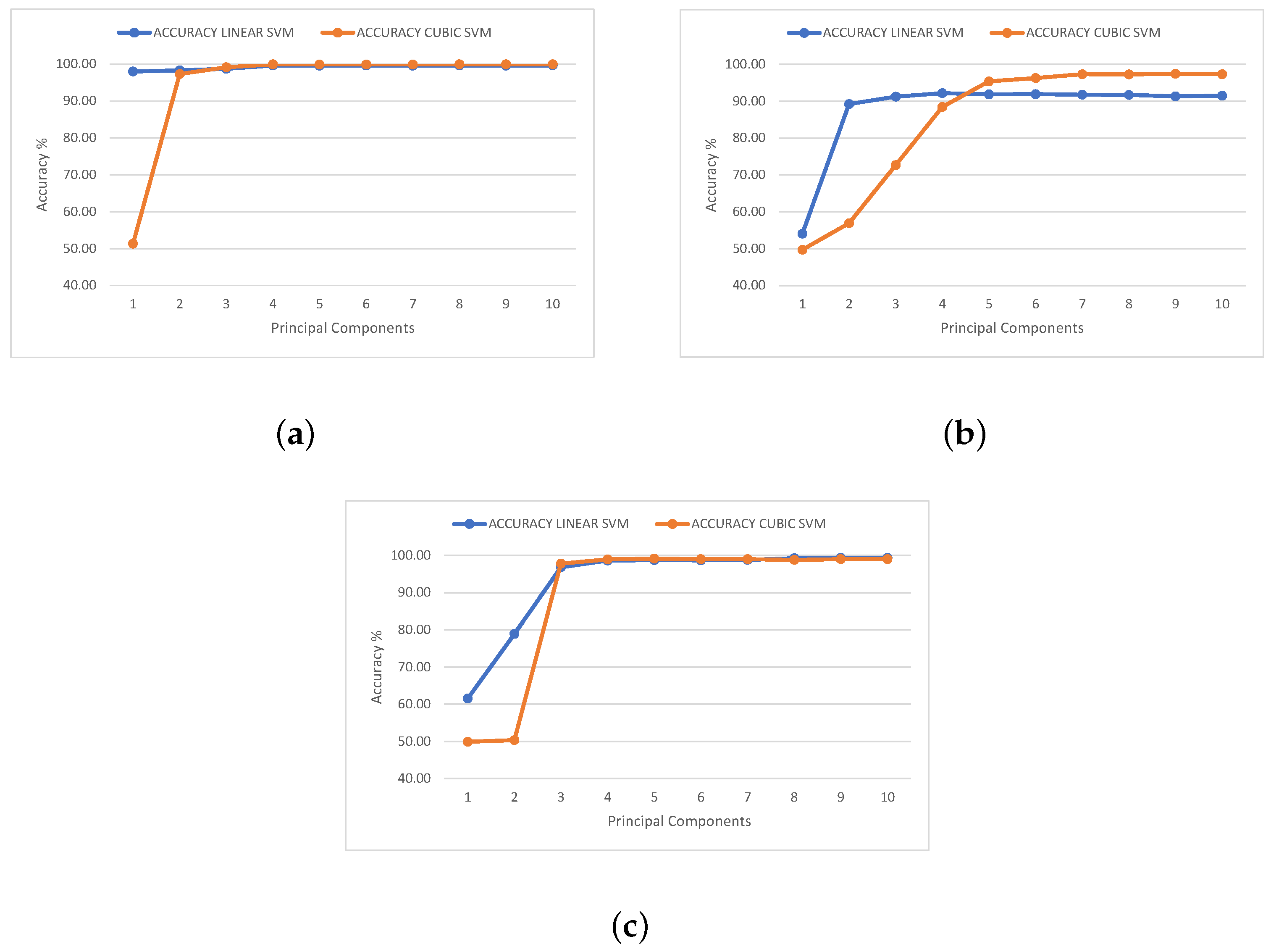
Figure 6 presents the accuracy achieved by the model as a function of the different principal components used. The data represented in
Figure 6 are summarized in
Table 1 and
Table 2.
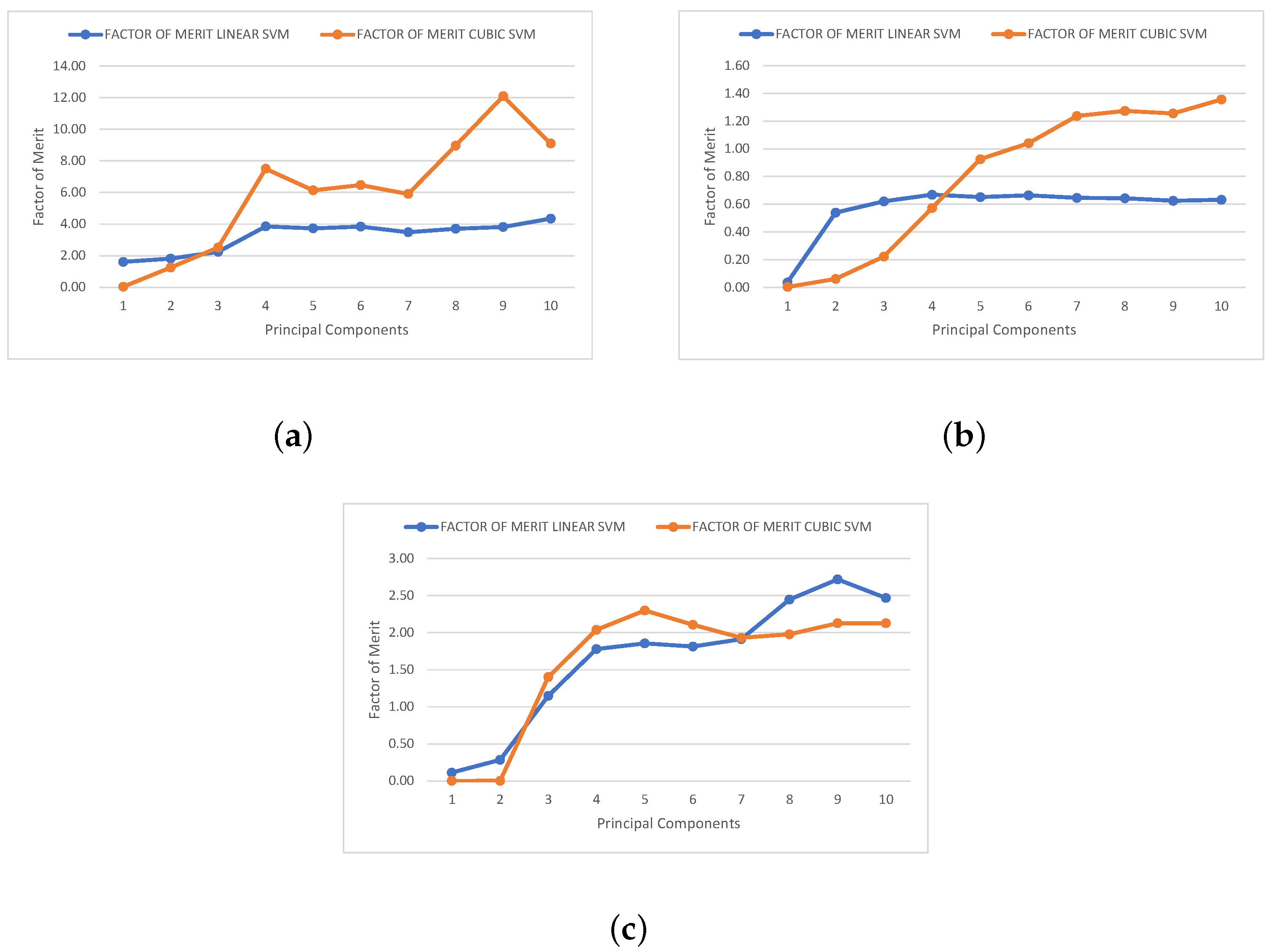
The second metric is the merit factor. This metric describes the ability of the proposed SVM classifiers to discriminate between isotopes with similar energy, which are the most challenging classification cases in this type of study. In order to quantify the classification efficiency of our trained SVM models, measurements were conducted by estimating the degree of overlap between neighboring clusters. A widely used merit factor (FOM)
M for gamma–neutron discrimination is presented in [
22,
38]. Equation (
2) represents the generalized two-dimensional form of the merit factor
M.
where
and
represent the corresponding two-dimensional centers and one-dimensional standard deviations of the classes, respectively [
28].
The merit factor is interpreted as follows: values of
can be associated with a good rejection rate, and when
, almost all events are completely separated. To ensure acceptable discrimination between a pair of isotopes, the FOM must exceed 0.75; with the linear SVM, this value is adequately surpassed, except for the case of
36,40Ar. However, with the cubic SVM model, this threshold is exceeded for all three pairs of isotopes, ensuring proper discrimination and, therefore, an acceptable rejection rate. The merit factor data obtained for different numbers of principal components are displayed in
Figure 7, and
Table 3 and
Table 4 represent these same results.
Finally, the third criterion for principal component selection is predicated on surpassing the previously established outcomes of the neural network referenced in this study. In other words, it is imperative that the merit factor value not only exceeds the minimum required by definition but also outperforms the classification capacity level of the reference neural network.
Based on the results collected under the aforementioned three criteria, it can be observed that in the case of the isotope pairs
12,13 C and
80,84 Kr, the requisite number of principal components is four to achieve the required accuracy of the SVM classifiers and surpass the neural network in the cubic case. However, for
36,40 Ar, it is necessary to increase the number of principal components to six in order to attain an accuracy exceeding 92%. Hence, these numbers of principal components are employed to generate the final models, thereby conserving computational resources through classifier model simplification. Furthermore, these results were substantiated by cumulative explained variance, as depicted in
Figure 8 for each isotope pair.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}