
Grant-Free NOMA: A Low-Complexity Power Control through User Clustering

Computer, Electrical, and Mathematical Sciences & Engineering (CEMSE) Division, King Abdullah University of Science and Technology (KAUST), Thuwal 23955-6900, Saudi Arabia
Sensors 2023, 23(19), 8245; https://doi.org/10.3390/s23198245
Submission received: 7 September 2023
/
Revised: 24 September 2023
/
Accepted: 29 September 2023
/
Published: 4 October 2023
(This article belongs to the Special Issue Future Wireless Communication Networks (Volume II))
Abstract
:Non-orthogonal multiple access (NOMA) has emerged as a promising solution to support multiple devices on the same network resources, improving spectral efficiency and enabling massive connectivity required by ever-increasing Internet of Things devices. However, traditional NOMA schemes operate in a grant-based fashion and require channel-state information and power control, which hinders its implementation for massive machine-type communications. Accordingly, this paper proposes synchronous grant-free NOMA (GF-NOMA) frameworks that effectively integrate user equipment (UE) clustering and low-complexity power control to facilitate the power-reception disparity required by the power-domain NOMA. Although single-level GF-NOMA (SGF-NOMA) designates an identical transmit power for all UEs, multi-level GF-NOMA (MGF-NOMA) groups UEs into partitions based on the sounding reference signals strength and assigns partitions with different identical power levels. Based on the objective of interest (e.g., max–sum or max–min rate), the proposed UE clustering scheme iteratively admits UEs to form clusters whose size is dynamically determined based on the number of UEs and available resource blocks (RBs). Once the UEs are acknowledged with power levels and allocated RBs through random-access response (RAR) messages, UEs can transmit anytime without grant acquisition. Numerical results show that the proposed GF-NOMA frameworks can compute clusters in the order of milliseconds for hundreds of UEs. The MGF-NOMA can reach up to 96–99% of the optimal benchmark max–sum rate, and the SGF-NOMA reaches 87% of the optimal benchmark max–sum rate at the same power consumption. Since the MGF-NOMA and optimal benchmark enforce the strongest and weakest channel UEs to transmit at maximum and minimum transmit powers, respectively, the SGF-NOMA also offers a significantly higher energy consumption fairness and network lifetime as all UEs consume equal transmit powers. Although the MGF-NOMA delivers an inferior max–min rate performance, the SGF-NOMA is shown to reach 3e6 MbpJ energy efficiency compared to the 1e7 MbpJ benchmark.
1. Introduction
The ever-increasing demand for connectivity in today’s world is driving continuous evolution in wireless networks. With the advent of the digital age, there is an increasing emphasis on designing network architectures that can seamlessly integrate with various forms of communication and smart technologies. As envisioned by the International Telecommunication Union (ITU), future wireless networks are expected to be versatile enough to cater to the diverse quality of service (QoS) requirements for distinct types of network usage scenarios [1], which can be broadly categorized into three paradigms:
- Enhanced Mobile Broadband (eMBB): This primarily focuses on supporting traditional human-type communications (HTC), emphasizing high data rates, broadband services, and providing high-capacity connectivity [2].
- Massive Machine-Type Communications (mMTC): As we move towards a more interconnected world, there is a surge in the deployment of the Internet of Things (IoT) devices [3]. mMTC focuses on ensuring that cellular networks can handle the immense connectivity demand from billions of these devices. Unlike eMBB, the emphasis here is not on high data rates but on ensuring reliable, efficient communication for devices that might transmit data sporadically, often in very short packets [4].
- Ultra-Reliable Low-Latency Communications (URLLC): In applications like autonomous vehicles or industrial automation, it is crucial to have instantaneous communication with near-zero latency and ultra-high reliability [5]. URLLC has been tailored to meet reliability and latency requirements beyond the perception of a human.
Traditional cellular networks predominantly operated on contention-based channel access methods orthogonally allocate radio resource blocks (RBs) to devices/user equipment (UEs) through the physical random-access channel (PRACH), where the foundational mechanism a four-way handshake [6]: (1) Every device randomly chooses one out of the available preambles and sends it to the BS; (2) the BS sends a random-access response (RAR) message including information about allocated RBs and timing advance for synchronization; (3) following the RAR message reception, devices make a radio resource control (RRC) connection request through the Physical UL shared channel (PUSCH); and (4) the BS sets up RRC connection by sending information of allocated RBs to all devices by specifying their terminal identity. Although device and user equipment are terms typically preferred for MTC and HTC, respectively, this paper uses them interchangeably, as the proposed methods are not limited to the communication type. This handshake ensures not only the establishment of communication between the base station (BS) and the device but also addresses key requirements such as initial access, uplink synchronization, data transmission, acknowledgment responses, and handover management, among other functionalities [7].
However, as efficient as this grant-based (GB) mechanism may seem for eMBB scenarios, where the sheer volume of data might overshadow the signaling overhead, it does show its limitations in the face of mMTC. Given the vast number of IoT devices transmitting short packets intermittently, the delay from this GB process becomes a critical performance bottleneck [8]. Non-orthogonal multiple access (NOMA) is a prospective multiple-access technique envisioned to augment spectral efficiency in wireless communication systems [9]. Unlike traditional orthogonal multiple-access (OMA) methods, where users are distinctly allocated resources to avert interference, NOMA facilitates the simultaneous transmission of multiple users over identical resources, such as time, frequency, and space, yielding various types of NOMA schemes [10]:
Power-domain NOMA (PD-NOMA) primarily relies on superimposing signals from multiple users in the power domain before actual transmission [11], which is made possible by assigning varying power levels to the signals of the different users. The receiver then employs a mechanism known as successive interference cancellation (SIC) to segregate the signals of the individual users [12]. The user signal with the highest power level is decoded first. Subsequently, its influence is removed from the combined signal, allowing the next user’s signal to be decoded. This process is reiterated until all signals are decoded. The allure of PD-NOMA emerges especially in scenarios characterized by heterogeneous user channel conditions, where it often demonstrates enhanced spectral efficiency compared to OMA techniques.
In parallel, code-domain NOMA (CD-NOMA) is another vibrant domain, occasionally referred to by names such as sparse code multiple access (SCMA) [13] or multi-user shared access (MUSA) [14], which hinge on employing distinct codebooks for different users. Essentially, the data of each UE is diffused across several resource elements, each having a specific spreading factor. On the receiving end, techniques leveraging multi-dimensional codebooks or multi-user detection come into play to extricate the overlapping users. The cardinal advantage of this method is its enablement of an overloading factor that allows more users to be served simultaneously than the orthogonal resources available. Such a characteristic provides the system with added flexibility and superior spectral efficiency.
Furthermore, spatial NOMA [15] incorporates the principles of multiple-input multiple-output (MIMO) technology by using the spatial domain, i.e., the multiple antennas at the transmitter and/or receiver, to serve multiple users simultaneously over the same frequency resource. The spatial differences of the users’ channels are exploited to differentiate and decode the overlapping signals. When combined with techniques from PD-NOMA or CD-NOMA, this spatial-based differentiation offers another dimension to improve spectral efficiency and user connectivity. In addition to these primary schemes, hybrid approaches amalgamating features from multiple topologies have also been explored by researchers [16]. Such hybrid strategies aim to assimilate various domains’ strengths, enhancing the robustness and efficiency of wireless communication systems.
PD-NOMA is the most studied and promising approach among these primary NOMA schemes. However, it brings forth its set of challenges, especially concerning the non-convex and combinatorial complexities of power control, user clustering, and the excessive signaling overhead due to the need for channel-state information (CSI) [17,18]. Grant-free NOMA (GF-NOMA) manifests as an evolved facet of the NOMA paradigm, designed meticulously to mitigate certain intrinsic challenges observed in GB-NOMA systems, predominantly in PD-NOMA. In mMTC, many IoT devices frequently exhibit sporadic data transmission patterns and often remain dormant for extended durations, transmitting exclusively upon detecting specific events. The aforementioned GB-NOMA schemes may demonstrably falter in efficiency in such traffic patterns. The consequent overhead spawned by this iterative request-grant protocol, particularly when dealing with concise data packets, emerges as a substantial bottleneck in networks with dense deployments. There are three main advantages of GF-NOMA schemes:
- Signaling Overhead Attenuation: A primary impetus propelling GF-NOMA’s inception is its prowess in truncating the signaling overhead, an inevitable byproduct of recurrent grant access requests in ultra-dense networks [19]. GF-NOMA can streamline network operations, allowing devices to transmit without waiting for prior scheduling, especially for short and sporadic data transmissions.
- Power Control Dynamics: Although classical PD-NOMA is profoundly reliant on power control to delineate users, in the GF-NOMA context, this emphasis is palpably attenuated, albeit not rendered obsolete [20]. Devices might necessitate intermittent power calibrations to ascertain the decodability of their signals at the receiver, especially in the presence of potential interference.
- Latency Minimization: Another salient advantage offered by GF-NOMA is its potential to curtail latency. By obviating the inherent latency in grant-based systems, devices experience expedited data relay, a facet paramount for applications with a penchant for URLLC [21].
In encapsulation, GF-NOMA epitomizes a pivot towards a more structured, adaptable, and efficient wireless communication, especially in network landscapes characterized by density and unpredictability. Although it embodies the promise of aligning with futuristic network aspirations, especially those overcrowded with many IoT devices, GF-NOMA is not devoid of challenges. Accordingly, this paper will focus on providing a fast yet efficient user clustering approach with implicit power control mechanisms, allowing grant-free operation of users.
1.1. Related Work
The GF-NOMA can be categorized into synchronous and asynchronous depending on whether it relies on the abovementioned PRACH mechanism. Once UEs perform PRACH and become aligned with the BS in the synchronous GF-NOMA, there is no need for further grant acquisition (GA). On the other hand, the asynchronous GF-NOMA does not need any access or GA processes. Noting that there exist various GF-NOMA schemes exploiting different domains of non-orthogonality (e.g., power, spreading, scrambling, interleaving, etc.) [22], we restrict this section with literature on power-domain GF-NOMA as it is the main focus of the paper. Early GF-NOMA schemes integrated slotted-ALOHA protocols with PD-NOMA [23,24,25], where the BS estimated the number of active devices by various statistical tools (e.g., hypothesis testing) and allow devices independently select predetermined power levels. Stochastic geometry has also been used as an effective tool to analyze the performance of GF-NOMA [26,27,28]. In [26], the authors proposed a semi-GF-NOMA scheme to improve spectral efficiency by multiplexing GB and GF devices on the same RB. By leveraging stochastic geometry techniques, they developed a dynamic protocol that reduces GF devices’ interference to a large extent compared to the open-loop protocol benchmark. This work was further studied in [27] to analyze ergodic rates by deriving the closed-form analytical and approximated expressions. In [28], Liu et al. exploited compressive sensing and stochastic geometry tools to model, analyze, and optimize the GF-NOMA scheme, where active devices were allowed to send preambles and data symbols without a need for GA. In [29], Fayaz et al. proposed an open-loop power control technique, where each UE acts as an agent and power levels are learned through a multi-agent deep Q-network. In [30], Abbas et al. developed a framework treating collisions as interference and deriving approximate expressions of the outage probability and throughput using Poisson point processes and ordered statistics. In [31], Dogan et al. introduced a GF approach for URLLC based on index modulation-based orthogonal frequency division multiplexing (OFDM-IM) to reduce the impact of the collision on the URLLC and achieved 99.999% success probability within 1 ms.
In recent years, there has been a considerable exploration into integrating deep-learning (DL) techniques with GF-NOMA schemes that can substantially improve efficiency and performance, especially for mMTC and URLLC. For instance, Liu et al. [32] introduced a novel learning framework for multiple configured-grants GF-NOMA systems designed to comply with URLLC requirements. They employed a cooperative Multi-Agent Double Deep Q-Network (MA-DDQN) to optimize channel resource allocations, which improved latency and reliability performance, underlining the potential of DL techniques in enhancing URLLC. The use of DL in dynamic resource configuration was further developed in [33], wherein Liu et al. developed an MA-DQN framework for signature-based GF-NOMA, demonstrating a significant improvement in heavy traffic performance for URLLC services. On the other hand, Zhang et al. [34] proposed two efficient Bayesian learning algorithms, which significantly reduced the computational complexity of GF-NOMA systems, showing the benefits of DL in computational efficiency. Their later work [35] further utilized Sparse Bayesian Learning (SBL) approaches to tackle the multi-user detection problem in GF-NOMA and demonstrated the capacity of DL to handle complex detection problems in mMTC.
Moreover, the use of DL has also been extended to address challenges in user activity detection and channel estimation in GF-NOMA. Yu et al. [36] introduced a novel DL architecture, UAD-CE-NN, which showed higher detection accuracy, especially with short preamble sequences. Meanwhile, Khan et al. [37] presented a Deep Neural Network (DNN)-based approach for active user detection in GF-NOMA with sparse spreading. Their active user enumeration and identification method demonstrated substantial performance improvements over traditional methods. Furthermore, Cao et al. have focused on the security aspects of semi-grant-free NOMA transmission [38], wherein they investigated passive and active eavesdropping attacks and proposed DL-based user scheduling schemes to enhance security, showing the flexibility and applicability of these techniques in GF-NOMA design.
Reconfigurable intelligent surfaces (RIS) have recently received attention owing to their ability to control wireless channels by changing impinging signals’ electromagnetic properties [39,40,41], wherein RIS control wireless channels to facilitate GF-NOMA by improving channel gain disparity among NOMA users and eliminate the need for power control, which is especially problematic for UL traffic. In [40], authors proposed a user pairing, RIS assignment, and phase shift alignment framework to utilize multiple RIS distributed across the cell area to realize a GF-NOMA network. In [41], authors optimally divided RIS into two partitions, each of which is aligned to one of the two NOMA users, and the size of each partition is adjusted to maximize the max–sum and max–min rate while satisfying UL and DL QoS requirements of bidirectional NOMA networks.
1.2. Paper Contributions and Novelty
This paper proposes synchronous GF-NOMA frameworks that substantially differ from the above works in that low-complexity power control and UE clustering are effectively integrated to facilitate the power-reception disparity required by the PD-NOMA. The main contributions of this paper can be summarized as follows:
- Two simple yet effective PD-NOMA schemes are proposed for the low-complexity power control required by the GF-NOMA concept. In single-level GF-NOMA (SGF-NOMA), all UEs are requested to transmit at the same power level through a broadcast RAR message. Even though all UEs transmit at the same power, the SGF-NOMA reaches power-reception disparity based on the channel gain disparity of UEs.
- To further improve SGF-NOMA, we propose a multi-level GF-NOMA (MGF-NOMA) approach that groups UEs into partitions based on sounding reference signals (SRS) signal strength. Then, partitions are assigned with different but identical power levels and shared with partition members through broadcast signals. The MGF-NOMA executes partitioning and power leveling dynamically depending on the available number of RBs and UEs awaiting admission. In addition to channel gain differences, the MGF-NOMA further improves the power-reception disparity by varying partitions’ power levels. Assuming channel reciprocity, the proposed schemes are also adopted to downlink (DL) power control for low-complexity operations.
- An iterative UE clustering scheme is proposed using the proposed low-complexity power control schemes as building blocks. The clustering algorithm iteratively pairs UEs awaiting admission with the available RBs to maximize the network sum or max–min rate. Therefore, the iterative clustering approach introduces extra power control while performing RB allocation. Finally, clustering information is shared with UEs by broadcasting RAR messages, and UEs can transmit on allocated RBs anytime without GA.
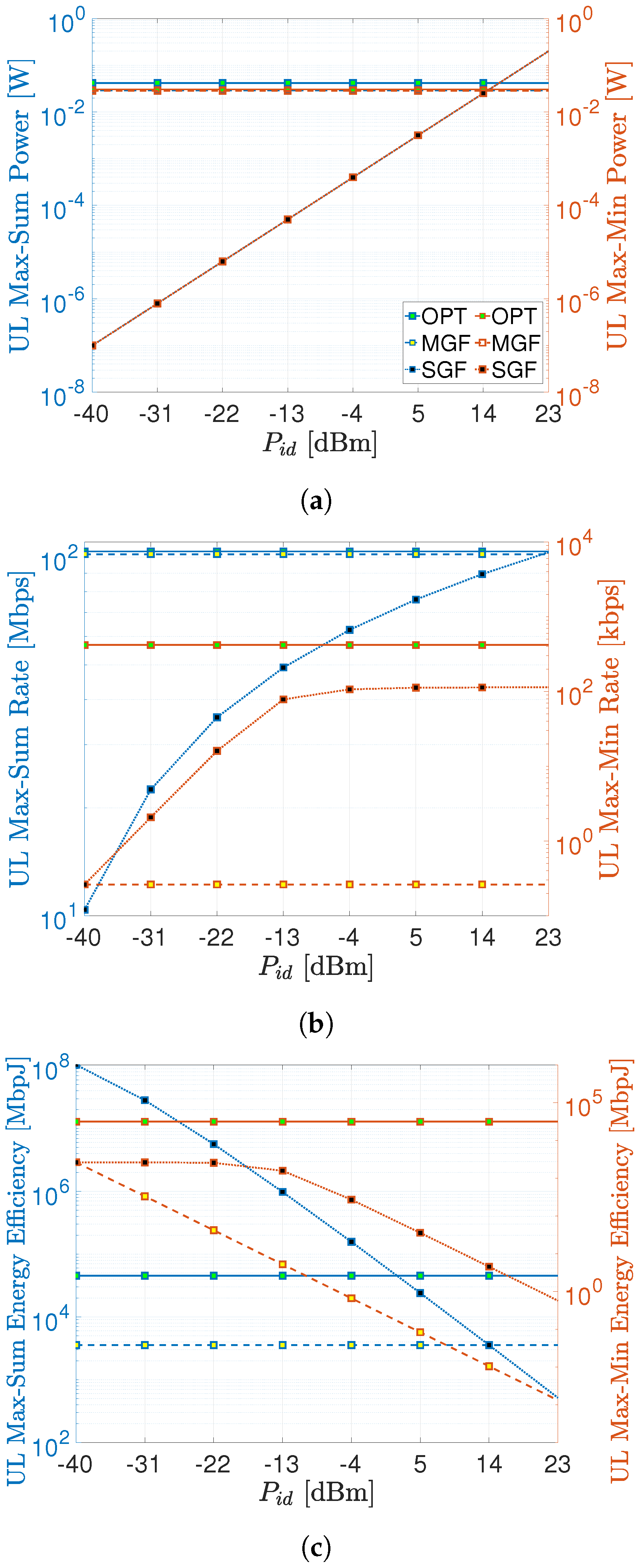
The MGF-NOMA is shown to provide a power control behavior very close to a GB benchmark with optimal power control and deliver 96–98% and 96–99.9% of the benchmark UL and DL max–sum rate. When the identical power level is set to match the same power consumption with other schemes, the SGF-NOMA is shown to deliver 87% and 88% UL max–sum rate of the MGF-NOMA and benchmark schemes, respectively. This clearly shows the efficacy of implicit power control imposed by the proposed UE clustering scheme, which only depends on readily available standard SRS signals and forms clusters in the order of milliseconds for a network with hundreds of UEs. From an energy-efficiency point of view, the SGF-NOMA is shown to deliver up to three orders of magnitude better max–sum rate performance, especially at transmission powers less than 5 dBm. Since the MGF-NOMA and optimal benchmarks enforce the strongest and weakest channel UEs to transmit at maximum and minimum transmit powers, respectively, the SGF-NOMA offers a significantly higher energy consumption fairness and network lifetime as all UEs consume equal transmit powers. If one also accounts for its low signal overhead and simplicity, the SGF-NOMA can be regarded as the best fit for low-power and low-complexity IoT devices. On the other hand, the MGF-NOMA is especially more suitable for DL transmission for three reasons: (1) the broadcasting of partitions’ power levels is redundant; (2) the BS exactly knows the active UEs, thus not affected by the MGF-NOMA’s dependence on the accurate estimation of active UEs to determine power levels; and (3) the MGF-NOMA’s relatively lower energy efficiency can be tolerated at the BS. Albeit its significant performance in max–sum rate, the MGF-NOMA turns an extremely low performance in max–min rate. This is mainly because max–min rate optimization requires all nodes to reach the same transmission rate, which does not comply with the leveled power approach. On the other hand, the SGF-NOMA delivers a much better max–min rate performance than the MGF-NOMA. Especially at low transmission power range up to −10 dBm, the SGF-NOMA yields MbpJ energy efficiency compared to MbpJ benchmark.
1.3. Notations and Paper Organization
Throughout the paper, sets and their cardinality are denoted with calligraphic and regular uppercase letters (e.g., ), respectively. Vectors and matrices are represented in lowercase and uppercase boldfaces (e.g., and ), respectively. The ith member of a vector and set is denoted by and , respectively. Likewise, matrix ’s entry on ith row and jth column is denoted by . Subscripts b, r, and u are used for indexing the BS, RB/cluster, and UEs, respectively. The most frequent symbols and notations are summarized in Table 1 for readers’ convenience.
The remainder of the paper is organized as follows: Section 2 presents the considered network model. Section 3 discusses the problem formulation and explains the proposed solution methodology. Section 4 introduces the optimal benchmark and the proposed low-complexity power control schemes. Section 5 presents the algorithmic implementation of the clustering approaches. Lastly, Section 6 presents numerical results, and Section 7 concludes the paper by remarking on the key findings.
2. Network Model
We consider a cellular network consisting of a BS serving U UEs over R available RBs, each with B Hz bandwidth, whose index sets are denoted by and , respectively. Based on the underlying traffic characteristics, the BS controls the network and allocates resources to achieve various performance goals, e.g., max–sum rate, max–min fair rate, etc. The UE accesses the allocated RB with probability , which also depends on traffic characteristics of its communication type, e.g., HTC, MTC. Through long-term observation of access requests, the BS is assumed to have an accurate estimate of . It is worth noting that exact information on active UEs in the DL direction is already available to the BS.
To demonstrate the massive connectivity capability of the proposed GF-NOMA schemes, we primarily focus on network scenarios satisfying such that an RB/cluster can admit up to UEs, which is referred to as the maximum cluster size. The set of UEs allocated to operate on RB is referred to as a cluster that is represented by set , where the binary clustering variable if UE is allocated to RB, otherwise, i.e., there is a one-to-one correspondence between RB and UE cluster, , which are used interchangeably throughout the paper. Since cluster members randomly access the channel, the set of cluster members currently active at the RB is given by , , where is the binary indicator of channel access following from and .
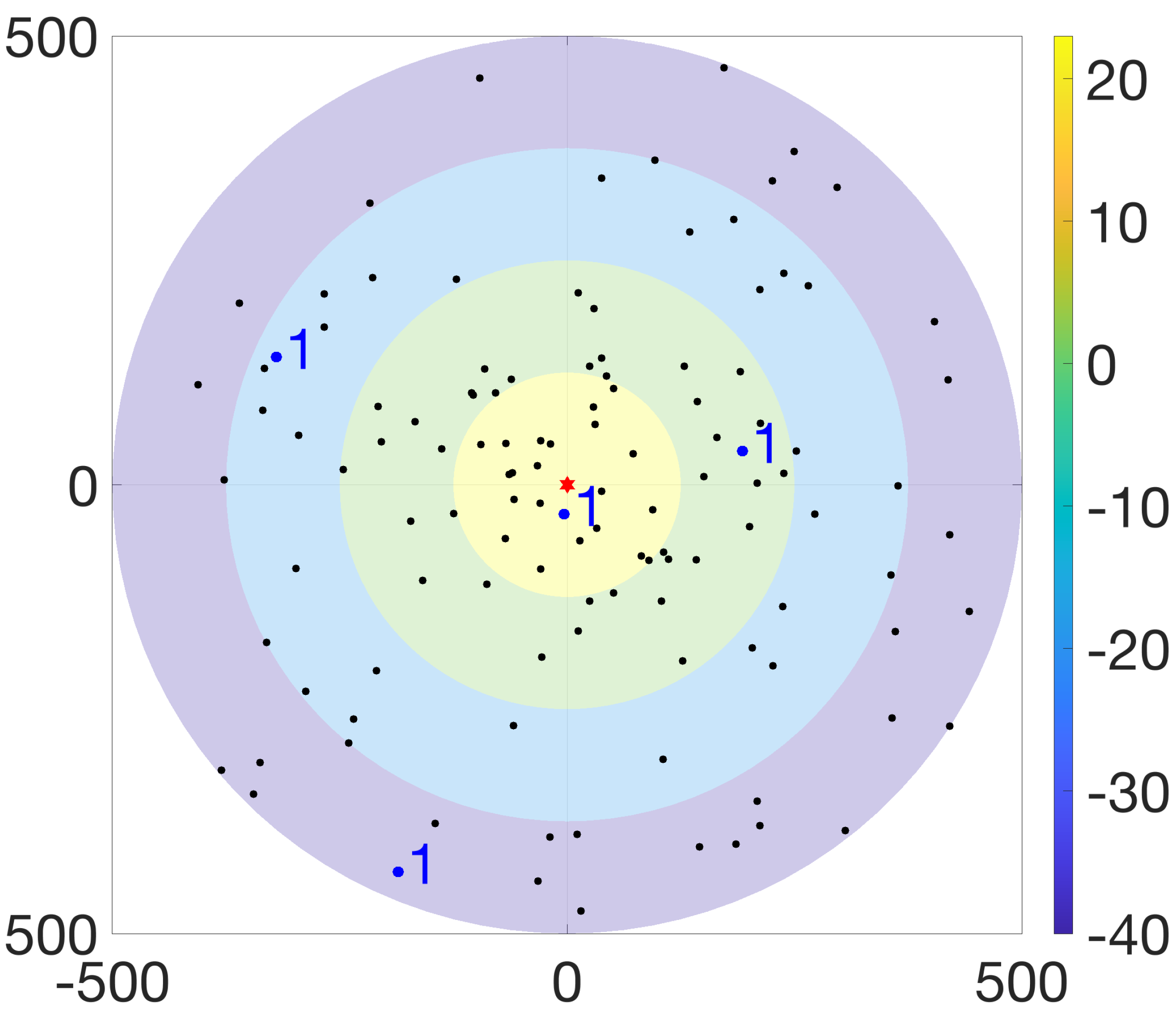
The BS and UEs operate in a single-input single-output (SISO) fashion, where the maximum transmission power of the BS is denoted by that is shared equally across all RBs. Moreover, the maximum and minimum transmission powers of UEs are represented by and , respectively. In the SGF-NOMA scheme, all UEs transmit at an identical power, denoted by . On the other hand, the MGF-NOMA divides the power control range into N levels and requires UEs placed at level to adjust its transmission power to . Figure 1 illustrates an aerial view of a network where the BS is located at the origin and serves 100 UEs over 25 RBs/clusters, each hosting 4 UEs. Although the rings represent four partitions, the ring colors indicate the transmission power of partitions such that UEs fall into yellow (level 1), green (level 2), blue (level 3), and purple (level 4) rings transmit at 23 dBm, 2 dBm, −19 dBm, and −40 dBm, respectively.
Channel Model
All channels are assumed to be quasi-static, i.e., channel coherence time is longer than the time-slot duration during which UEs experience flat-fading. For a generic transmitter node i and receiver node j, the composite channel gain is given by
where is the channel gain representing small-scale fading modeled by Rayleigh distribution and is the large-scale fading. Since man-made structures incur significant shadowing and scattering impact on the channel attenuation, the commonly exploited free-space path loss model is inadequate to capture real-life signal losses. Therefore, we consider the statistical features of the underlying urban environment, such as (i) the percentage of build-up area to the total land area, (ii) the number of buildings per unit area, and (iii) the statistical distribution of building heights. Accordingly, the spatial expectation of channel attenuation over the probabilities of having line-of-sight (LoS) and non-line-of-sight (NLoS) links is given by [42]
where refers to the mean value of the excessive path loss over the free-space path loss (FSPL) between transceivers, which is expressed as
where is the distance between transceivers, is the carrier frequency, and c is the speed of light. Denoting the heights by and , the probability of having an LoS transmission is given by
where and are the approximation parameters depending on /, the mean number of buildings per km, distribution of building heights, and the ratio of lands covered by buildings to the total land area [1]. The probability of having NLoS links directly follows from (3) as .
3. Problem Definition and Solution Methodology
In this section, we first provide joint power control and user clustering formulation of the optimal PD-NOMA scheme, then provide an overview of the proposed GF-NOMA frameworks.
3.1. Problem Definition
The DL sum rate maximization problem can be formulated as follows
where is the power allocation vector, ensures that the SINR of each UE, , satisfy the QoS requirement [bps], assures each UE is allocated at most one cluster, limits the cluster size by , is the constraint on total cluster transmission power, and specifies the domain and bounds on optimization variables. The UL sum rate maximization problem can be formulated as in (4) by omitting the constraint on total cluster transmission power, , as each UE has its own power source in the UL transmission. By introducing an auxiliary variable and enforcing all UEs to reach an SINR no less than , the DL max–min fair rate problem can be formulated as follows
which can be further reduced to the UL max–min fair rate problem by ignoring as in the max–sum rate problem. and are both mixed-integer non-linear programming (MINLP) problems, whose computational complexity is prohibitively high to employ in real life even for a moderate size of the network. Although the binary clustering variables cause the mixed-integer nature, the non-linearity results from power control variables. Given a certain clustering solution, the non-linear power control problem is indeed non-convex due to the interference terms in the SINR expressions, which are defined in the next section. Even though variations of these problems are studied extensively in the PD-NOMA literature, the underlying complexity of power control is not suitable to the spirit of GF-NOMA, as explained before. Therefore, we will benchmark the solution to these problems against the proposed low-complexity GF-NOMA frameworks presented next.
3.2. Solution Methodology
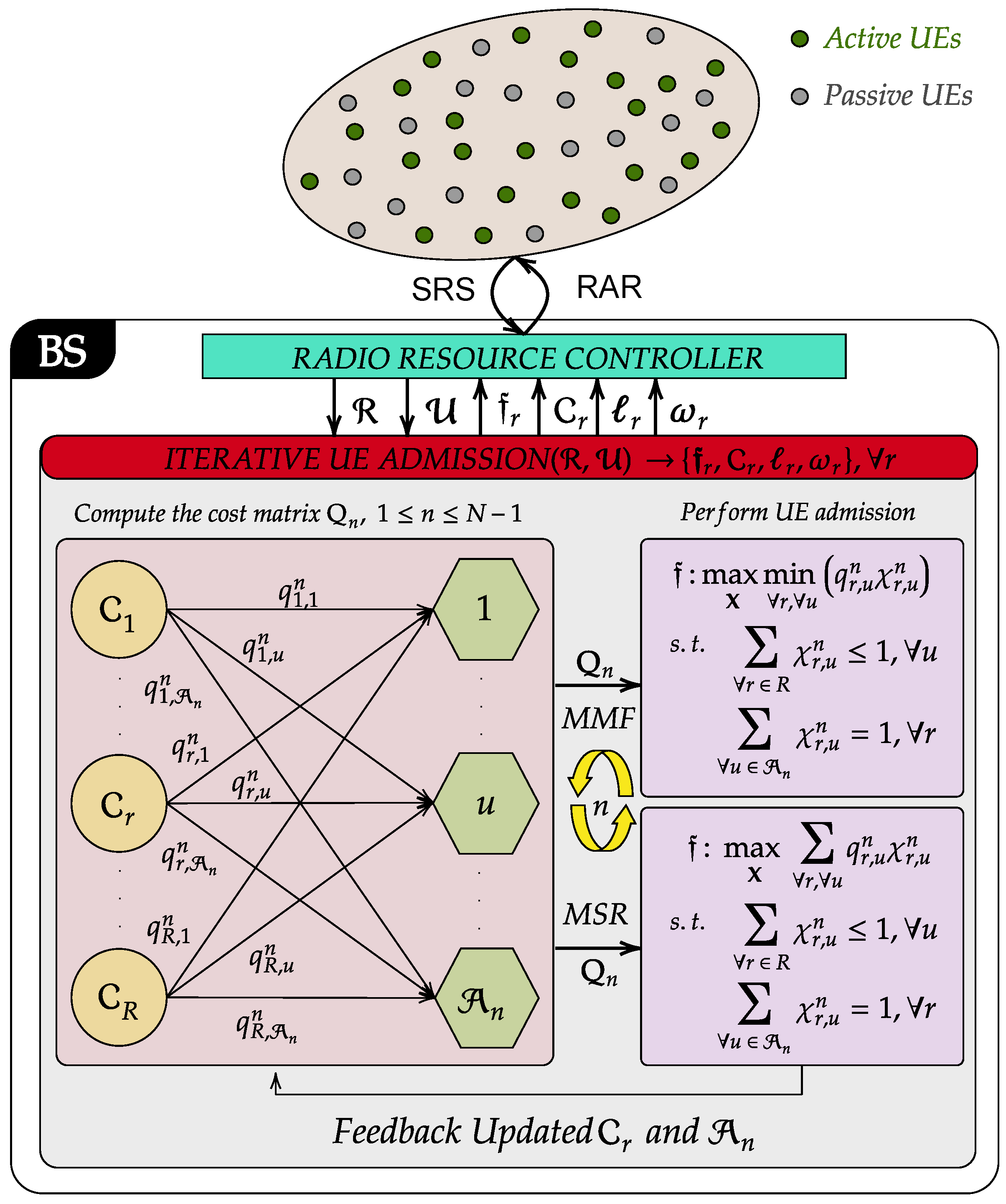
As shown in Figure 2, the proposed GF-NOMA framework operates merely on the received signal strength (RSS) of SRS, which is a Zadoff-Chu sequence transmitted by each UE separately from PUSCH and physical uplink control channel (PUCCH). UEs can transmit SRS on any subcarriers in the last symbol in an uplink subframe regardless of subcarriers assigned to another channel. For the sake of channel reciprocity, we focus on TDD mode, where SRS can also be sent in the last two symbols of the special subframe if the uplink pilot time slot (UpPTS) is configured to be long enough. Based on the RSS, the network controller computes the UL power levels and DL power weights to form a look-up table. Then, the proposed clustering approach iteratively forms clusters based on input parameters , , , and . The iteration starts with creating bi-partite matching weights, i.e., cost matrix entities, between RBs/clusters and the set of UEs awaiting admission . After that, the cost matrix is used to perform UE admission by solving linear sum or linear bottleneck assignments for max–sum rate and max–min rate objectives, respectively. Following the user-cluster assignment, clusters are updated and prepared for the next phase of the UE admission. Once the admissions are finalized, the clustering algorithm returns the cluster sets along with their fitness . Finally, allocated RBs and power levels are encapsulated into RAR messages and broadcast to UEs. Further details of the proposed scheme are provided in the next two sections.
4. A Low-Complexity PD-NOMA
In the DL (UL) NOMA schemes, the BS (UEs) perform successive interference cancellations, where the messages broadcast (transmitted) from the BS (UEs) are decoded in the descending order of signal reception power. It is worth noting that the optimal power allocation strategy is the opposite for UL and DL transmissions. The optimal UL-NOMA scheme ensures the strongest channel gain UE has the highest reception power at the BS such that remaining cluster members have more room to cause interference to improve their SINRs. This is typically achieved by forcing the UE with the strongest channel gain to transmit maximum power. On the contrary, the optimal DL-NOMA ensures the weakest channel gain UE has the highest reception power and experiences interference from the stronger users in the cluster. In this case, the strongest channel gain UE is allocated with the lowest power weight while enjoying substantially reduced interference after the SIC procedure. It is worth noting that a residual interference is possible after the SIC procedure due to hardware imperfections and inaccurate channel estimation [17,18]. Therefore, we numerically evaluate the impact of SIC imperfections in Section VII. In light of the above discussions, this section first formulates the optimal PD-NOMA benchmark. Then, it introduces the low-complexity power control developed explicitly for the proposed GF-NOMA approach.
4.1. Benchmark Optimal PD-NOMA
The benchmark scheme requires UEs’ exact CSI to calculate optimal transmission powers to reach the objective function of interest. For the cluster, , we denote the power weight, composite channel gain, and received power vectors by , , and , respectively. Assuming the reciprocity of DL and UL channels, the optimal received powers in DL and UL transmissions are given by and , respectively. Likewise, the optimal received powers sorted in descending order are represented by with . Accordingly, the signal-to-interference-plus-noise-ratio (SINR) of ordered member of is expressed as
where , is the intra-cluster interference, is the thermal noise power and is the noise power spectral density. When all cluster members are active, i.e., , Equation (6) is specially denoted by . The problem formulations for UL and DL optimal power control for max–min rate and max–sum rate objectives are presented in Table 2, where . These can be reformulated as geometric programming problems as explained in [17,18,43,44] and optimal power control weight vectors can be obtained by using numerical solvers.
4.2. Proposed Low-Complexity PD-NOMA
In the MGF-NOMA, the BS orders UEs as per the RSS obtained from SRSs transmitted by UEs. The ordered UE sets are then partitioned into N distinct groups such that represents the ordered index set of ith highest RSS group of UEs with partition sizes and . The power control range of UEs is divided into N levels such that the dBm scaled maximum and minimum levels are given by and , respectively. Accordingly, the linearly spaced transmit power level set is given by
where [dBm] is the transmission power level of UEs belonging to . By taking the union of transmit power levels for various cluster sizes, i.e., , the BS can form a look-up table, which is known by all UEs in advance. Based on the maximum and minimum UE output power specifications of LTE standards [45], Table 3 shows a power level look-up table for dBm, dBm, and . Based on Table 3, the power level vector of the clusters, , can be decided. For instance, in Figure 1, the highlighted cluster is allocated to RB with power level vector of highlighted cluster is . Thus, the cluster members falling into yellow, green, blue, and purple rings receive RAR messages indicating , , , and ; and transmit with power levels 23 dBm, 2 dBm, −19 dBm, and −40 dBm on RB freely until it receives another RAR, respectively. Accordingly, the SINR of ordered member of is expressed as
where cluster members always transmit at a designated power level regardless of which members are active or passive. The second term of (8), , represents the intra-cluster interference. In the SGF-NOMA, the BS designates an identical power level and broadcasts an RAR message indicating the power level index to all UEs, which can be updated whenever necessary. Since the SGF-NOMA does not need to transmit individual power levels along with the RB indices for each UE, it incurs less signaling overhead than the MGF-NOMA.
Although the DL-NOMA schemes are not limited by signaling overhead, the computational complexity required to calculate the optimal power weights for the massive number of users is still prohibitive. Therefore, we further extend the proposed ultra low-complexity power control scheme to the DL-NOMA by translating the power level set in (7) into the DL power weights as follows
where is obtained by sorting in ascending order since the DL power weights follow opposite power weights as explained at the beginning of this section. Similar to the UL case, the BS can take the union of power weights for various cluster sizes to form a look-up table of weights . For instance, in Figure 1, the BS adjusts the power weight of UEs falling into yellow, green, blue, and purple rings to , , , and , respectively.
5. Iterative UE Admission
This section presents the iterative UE admission approach that integrates proposed power control schemes with RB allocation and UE clustering. Algorithm 1 provides the pseudo-code of the solution methodology pictorially depicted in Figure 2. For the sake of generalization, Algorithm 1 is presented for the MGF-NOMA framework, which can be simply reduced to the SGF-NOMA by considering a single partition and power level. In the remainder, we explain Algorithm 1 in more details:
Following the SRS reception from all UEs in Line 2, the BS determines the number of active UEs, maximum cluster size, and number of clusters in Line 3, Line 4, and Line 5, respectively. Due to the reverse operation characteristics of NOMA in UL and DL direction, Line 7 and Line 9 sort UEs in descending and ascending order of the channel quality for UL and DL iterative UE admission, respectively. Based on the obtained sorted UE index set , Line 11 partitions the UE set into N subsets, i.e., . Then, the clusters are initialized in Line 12, where is initialized with the element of the first partition, .
The iterative UE admission is executed between Line 13 and Line 22 as follows: Line 14 updates the set of UEs awaiting admission. Then, Line 15 calls EvalCostMatrix procedure to compute the cost matrix of nth round of UE admission, , which is explained in the next paragraph. Then, Line 17 and Line 19 determine new admissions that maximizes the sumrate and minimum rate of all clusters by calling Linear Sum Assignment and Linear Bottleneck Assignment procedures, respectively. The assignment problems ensure that all clusters admit a UE if or all UEs are otherwise assigned to a cluster. There exist algorithms that can solve linear assignment problems in polynomial time. For example, the Jonker–Volgenant method has a cubic worst case complexity [46], i.e., where . Burkard et al. proves in Theorem 6.4 in [47] that Linear Bottleneck Assignment can be solved in , where . They also developed a thresholding-based algorithm that uses Linear Sum Assignment and maximum cardinality bipartite matching Algorithm 6.1 in [47]. Based on assignment results, Line 21 updates the clusters for the next round of UE admission. Once the iterative user admission is finalized, power levels and weights of clusters are updated in Line 23 and Line 24, respectively. Finally, Line 25 sends RAR messages to UEs indicating allocated RB and assigned power levels.
The cost matrix is computed by nested for loops between Line 28 and Line 49. At jth inner loop iteration, Line 30 forms a temporary cluster by admitting jth element of into . For the UL transmission, Line 32 determines the power levels as per the MGF-NOMA or SGF-NOMA schemes introduced in the previous section. Based on the objective function of interest, Line 34 and Line 36 compute by evaluating the UL max–sum and max–min rates of temporary cluster , respectively. Similarly, Line 39 determines the DL power weights. Then, Line 41 and Line 43 compute by evaluating the DL max–sum and max–min rates of temporary cluster , respectively. The final cost matrix is then returned for the UE assignment.
| Algorithm 1 Proposed MGF-NOMA and SGF-NOMA |
|
For the max–sum rate objective, the overall time complexity of iterative user admission is given by
where the first and second terms of the left-hand side are the complexity of cost matrix formation and Linear Sum Assignment. Since in practice, the overall complexity can be approximated by the dominant term, which has cubic time complexity. Likewise, the overall time complexity for the max–min rate objective is given by
where the complexity of cost matrix formation is omitted following the same reason above.
6. Numerical Results
Without loss of generality, we assume that UEs are uniformly distributed over a macrocell area of a radius of 500 m. Unless explicitly stated otherwise, the numerical results are obtained by Matlab using the default parameters summarized in Table 4. The number of available RBs is intentionally selected as to show the proposed GF-NOMA schemes’ capability of supporting mMTC, where many devices share an RB. For benchmarking, we compare the proposed GF-NOMA frameworks with an optimal scheme that exploits CVX’s geometric programming toolbox to solve problems formulated in Table 2. Obtained UL and DL optimal power control weights are then used in the cost matrix formation procedure of Algorithm 1. In the rest of this section, all presented results are obtained by averaging over 1000 network instances. The proposed GF-NOMA frameworks are compared with the optimal benchmark throughout the section. All results are presented in double y-axes plots, where the left and right y-axes with blue and red colors show the max–sum and max–min rates obtained by employing Linear Sum Assignment and Linear Bottleneck Assignment, respectively.
6.1. Benchmark Comparison
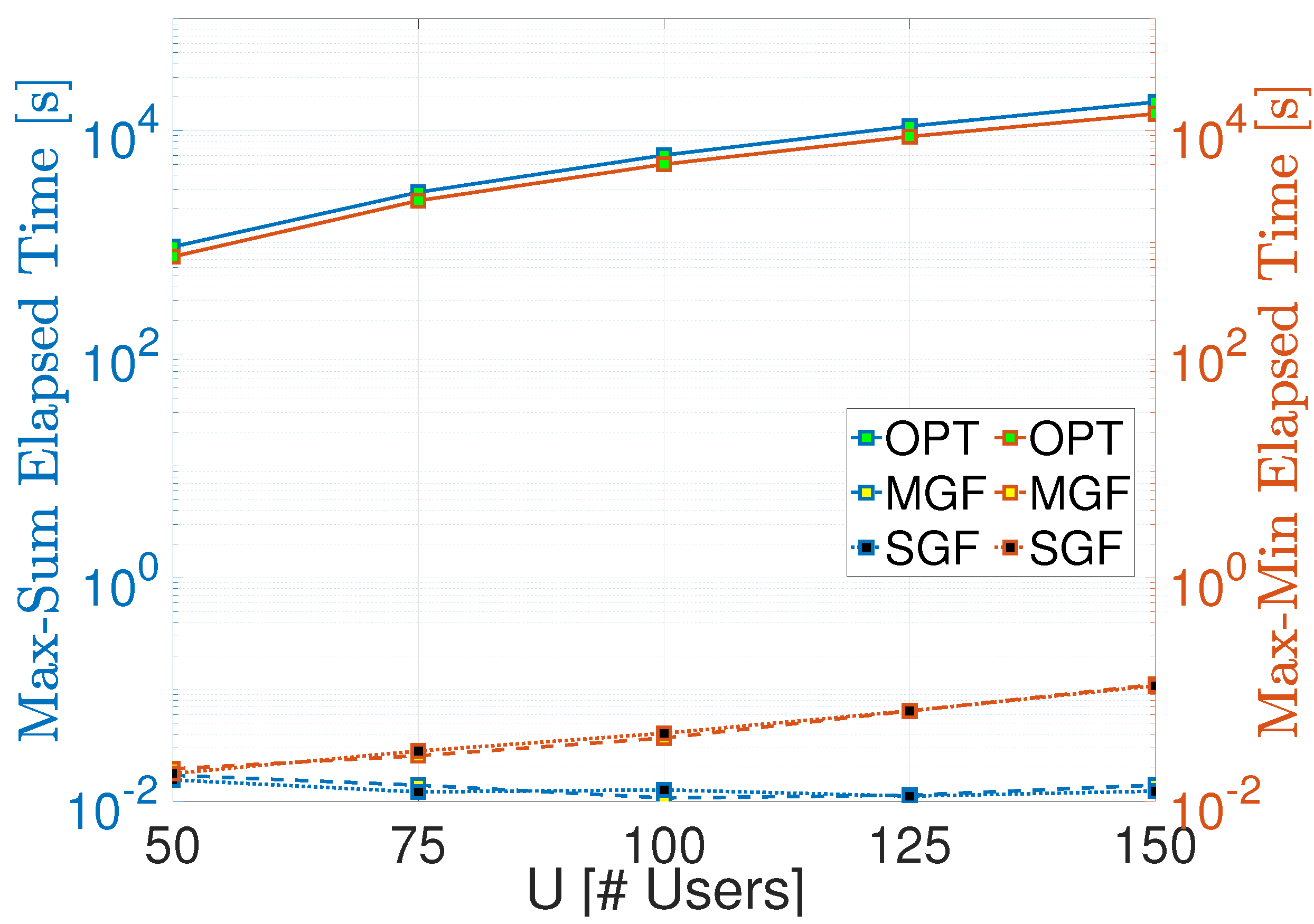
Let us start with the elapsed time comparison of the proposed MGF-NOMA and SGF-NOMA frameworks. Figure 3 shows that the proposed frameworks have similar elapsed time performance, which increases with maximum cluster size such that corresponds to . Although the Linear Sum Assignment takes around 10 ms to finish the entire clustering, Linear Bottleneck Assignment ramps up to 100 ms, which is mainly due to the fact that it calls Linear Sum Assignment and maximum cardinality bipartite matching as sub-procedures. On the other hand, the optimal benchmark takes half an hour to three hours to complete, where the main complexity is due to the cost matrix formation, each element of which is computed using CVX.
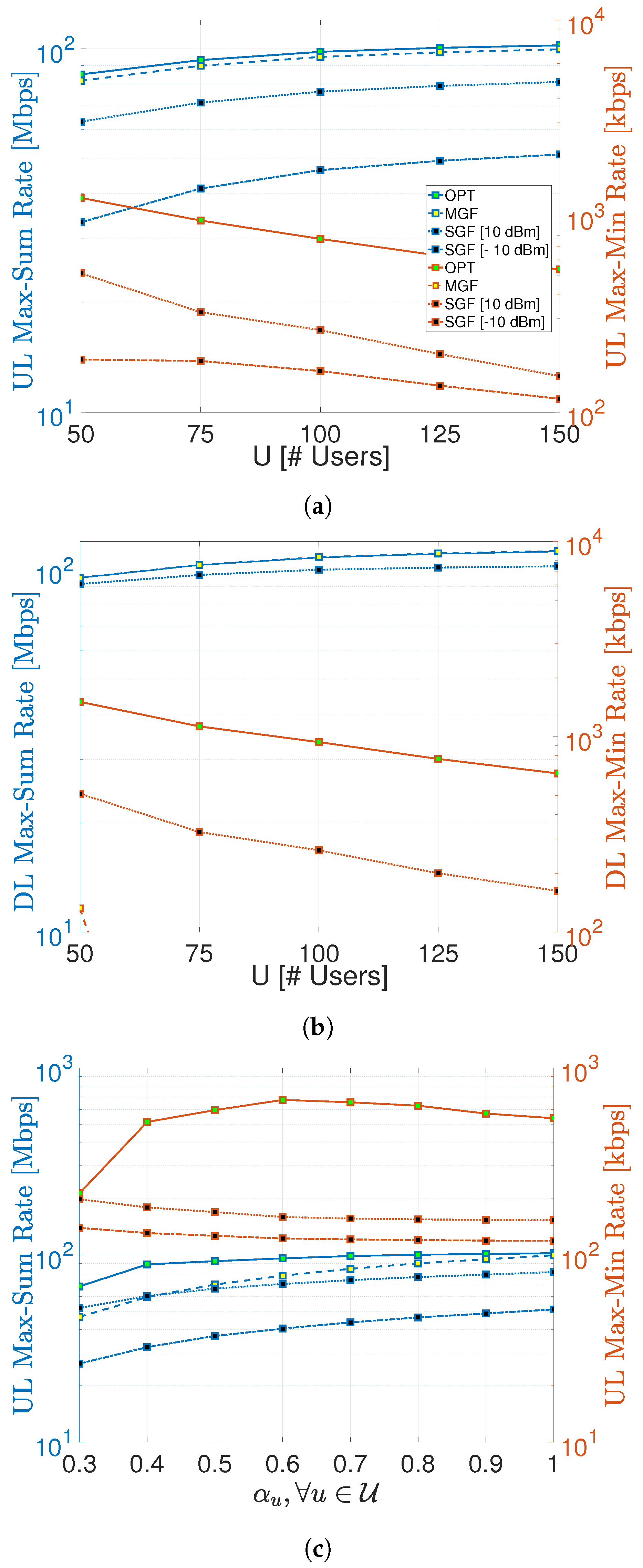
The max–sum and max–min rates of proposed GF-NOMA schemes are benchmarked against the optimal NOMA scheme in Figure 4, where left and right y-axes are scaled to Mbps and kbps for the sake of better visibility. Figure 4a shows that the MGF-NOMA scheme can reach 96–98% of the UL optimal max–sum rate. It is important to note that this slight difference is mainly caused by the power consumption difference, as explained in the next section. On the other hand, the SGF-NOMA scheme can reach 40–50% and 75–80% of the optimal UL max–sum rate for dBm and dBm, respectively. Therefore, significantly impacts the SGF-NOMA performance, as the next section shows that the SGF-NOMA can reach above 90 % of the optimal UL max–sum rate under the same power consumption.
Although the MGF-NOMA provides a max–sum rate performance very close to the optimal benchmark, it delivers extremely poor max–min rate performance, which is 20 kbps at and sharply reduces to 0.25 kbps for . Such a huge performance degradation is due to the fact that leveled power control does not comply with the max–min rate power control’s main goal of having all nodes reach the same transmission rate. On the other hand, the SGF-NOMA can reach 15–22% and 29–41% of the optimal UL max–min rate for dBm and dBm, respectively. Similar to the case in the max–sum rate, the substantially impacts the max–min rate performance, which is investigated more in detail in the next section.
Likewise, Figure 4b compares the DL max–sum and max–min rates of the proposed GF-NOMA frameworks with the optimal benchmark. Figure 4b shows that the MGF-NOMA and SGF-NOMA frameworks can reach 96–99.9% and 96–91% of the DL optimal max–sum rate, respectively. The drop from 96% to 91% is due to the fact that the SGF-NOMA equally shares the available DL transmission power among UEs, and it reduces as U increases. However, the max–min rate performance of the SGF-NOMA is not as good as the max–sum rate; it reaches 25–33% of the optimal max–min rate. Similar to the UL scenario, the MGF-NOMA also delivers the worst max–min rate performance, which starts with 132 kbps at and sharply reduces to 212 kbps for .
A common trend in Figure 4a,b is that the max–sum rate improves as U increases, mainly because an RB is more efficiently utilized as cluster size increases. On the contrary, the max–min rate degrades as cluster size increases since admitting more UEs into the same RB has a detrimental impact on the UEs performing worst. Notice that power control cannot simply eliminate this behavior, which all schemes share, including optimal benchmark.
Finally, Figure 4c shows the impact of the probability of being active on max–sum and max–min rates. It is worth reminding that only the MGF-NOMA scheme requires the number of active UEs to determine the proper power levels for UE partitions. The MGF curve in Figure 4c shows the performance at various UE activity scenarios when power levels are set, assuming all UEs are active. Therefore, the MGF curve converges to the optimal benchmark as reaches unity. At this point, it is obvious that having a coarse estimate of U with accuracy can still turn into a desirable performance compared to the optimal benchmark.
6.2. Date Rate, Power Consumption, and Energy-Efficiency Comparison
As mentioned above, the substantially impacts the performance of SGF-NOMA, which is investigated more in depth in this section. Figure 5a shows the average power consumption per UEs with respect to . The optimal benchmark consumes 50% more power than the MGF-NOMA to deliver around 2% higher max–sum rate as depicted in Figure 5b. On the other hand, the optimal max–min rate benchmark consumes 27.5% less than the optimal max–sum rate benchmark. It is obvious from Figure 5a that the SGF-NOMA consumes the same power consumption as the MGF-NOMA and optimal benchmark when reaches 15 and 16.5 dBm, respectively. At the same power consumption levels, the SGF-NOMA can reach 87% and 88% of the optimal benchmark and MGF-NOMA max–sum rate, respectively. On the other hand, the SGF-NOMA can reach a 25% max–min rate of the optimal benchmark starting from dBm, which is around 100 times less power consumption than the optimal benchmark. However, increasing does not improve the max–min rate beyond dBm.
At this point, it is crucial to compare these approaches from an energy-efficiency point of view since most IoT nodes are designed as low-power devices to increase their cost and lifetime [48]. As shown in Figure 5c, the optimal benchmark always has better energy efficiency than the MGF-NOMA, i.e., the aforementioned 2% max–sum rate enhancement in return for 50% more consumption yields a significant energy-efficiency improvement for the optimal benchmark. Even though the SGF-NOMA delivers a lower max–sum rate up to around dBm, Figure 5c shows it has the highest energy efficiency in this region. For the max–min rate case, the optimal benchmark, and the MGF-NOMA always deliver the highest and the lowest energy-efficiency performance, respectively. The SGF-NOMA turns relatively better energy efficiency, which constantly reduces after dBm. Finally, we summarize the best value of for various performance metrics under max–sum rate and max–min rate operational regimes in Table 5.
6.3. Impact of SIC Imperfections on System Performance
In real life, a perfect SIC operation is not always possible due to the imperfections caused by CSI acquisition errors and hardware impairments.
- Decoding Errors: The success of SIC largely depends on the accurate decoding of the strongest signal. If there is an error in the decoding of the strongest user, this error becomes propagated when subtracting it from the combined signal, affecting the decoding of the next user.
- Receiver Non-linearities: Even with perfect decoding, there might be residual interference after subtraction due to non-linearities in the receiver, which can degrade the performance of the subsequent user’s signal decoding.
- Channel Estimation Errors: For the subtraction to be perfect, the receiver must accurately estimate the channel conditions. Any error in channel estimation will lead to imperfect cancellation.
- Out-of-Order Decoding: The assumption that users can be perfectly ordered according to their channel conditions may not always hold, especially in dynamic environments. Decoding a user out of order can degrade the performance of SIC.
One way of showing detrimental impacts of imperfect SIC operation is quantifying the residual error after each SIC operation using an SIC error factor [17,18,43,44], which can be incorporated into the SINR expression in (10) as follows
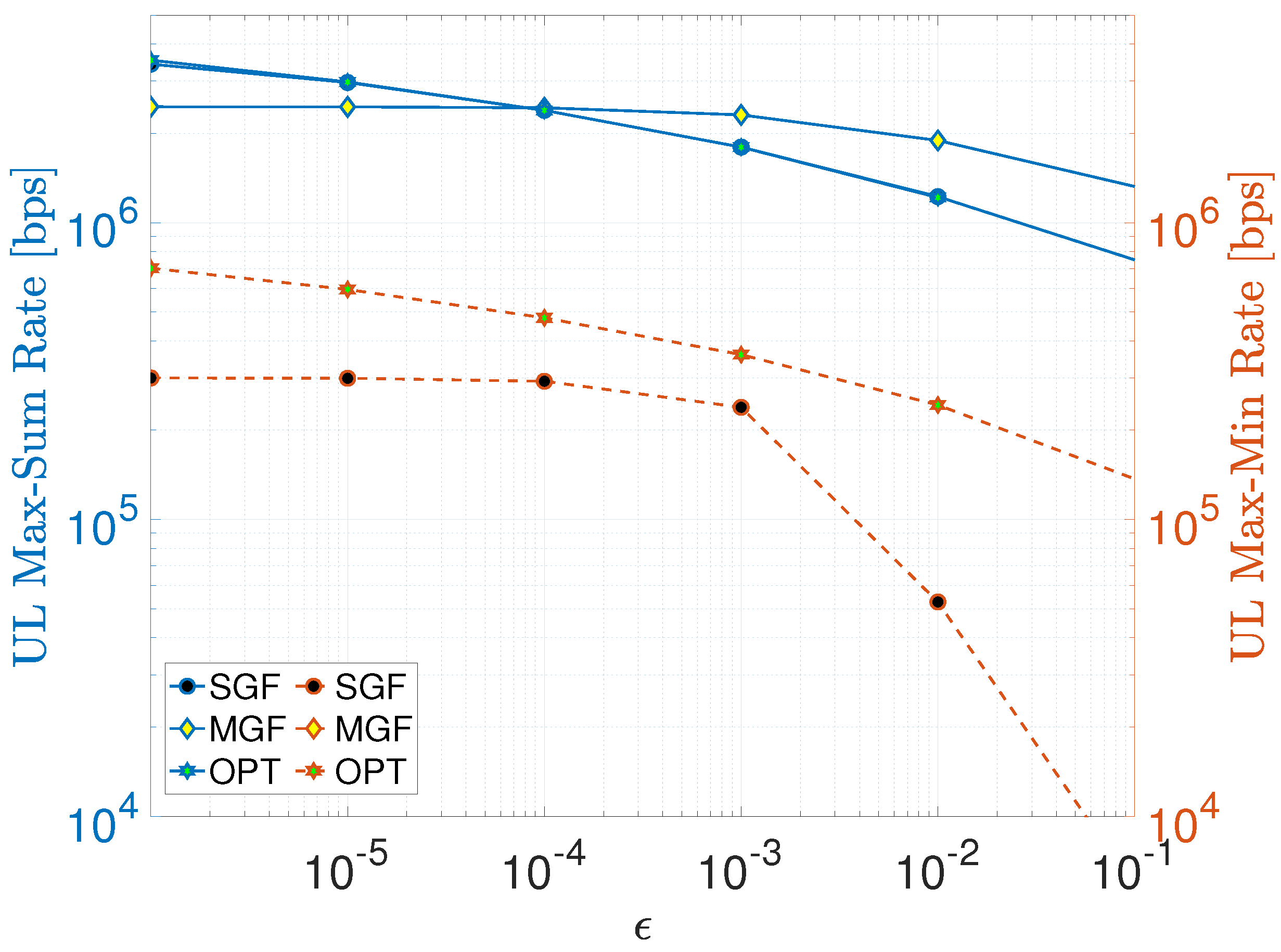
where the first term in the denominator represents the total residual interference after SIC due to the aforementioned imperfections, whereas the second term is non-cancellable intra-cluster interference. To investigate the impact of residual interference on max–sum and max–min rates, let us content ourselves with the UL scenario and set the identical transmit power of SGF-NOMA to the mean power consumption of MGF-NOMA (i.e., dBm) for a fair comparison. Figure 6 compares the impact of increasing the SIC error factor on SGF-NOMA, MGF-NOMA, and OPT-NOMA schemes on the average cluster sum and max–min rate. For the max–sum rate, SGF-NOMA provided a performance close to OPT-NOMA that exploits the CVX solver to optimize power levels by taking into account. Even if the proposed schemes are not designed to account for SIC imperfection factor , their performance is noteworthy as they deliver a performance comparable to the optimal scheme that adjusts power weights to mitigate the impact of residual interference. This was possible due to the implicit power control through the proposed clustering approach. On the other hand, MGF-NOMA provides better immunity against SIC imperfections starting from . Nonetheless, all schemes suffer from increasing residual interference regardless of underlying the power control and clustering approach. The influence of optimal power control is more significant in the case of max–min fairness, where OPT-NOMA outperforms SGF-NOMA, especially for . Notice that MGF-NOMA is not shown in Figure 6 as it delivers around 50 bps max–min rate performance, which is much less than bps.
Figure 5.
Data rate, power consumption, and energy-efficiency comparisons. []. (a) Average power consumption comparisons. (b) Max–sum rate and max–min rate comparisons. (c) Energy-efficiency comparisons.
Figure 5.
Data rate, power consumption, and energy-efficiency comparisons. []. (a) Average power consumption comparisons. (b) Max–sum rate and max–min rate comparisons. (c) Energy-efficiency comparisons.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 5.
The best value of for various performance metric under different regimes.
| Performance Metrics | |||
|---|---|---|---|
| Operational Regime | Power Consumption | Data Rate | Energy Efficiency |
| Max–Sum Rate | 14.50 [dBm] | 23.00 [dBm] | −40.00 [dBm] |
| Max–Min Rate | 15.25 [dBm] | 23.0 [dBm] | 2.00 [dBm] |
7. Conclusions and Future Research Directions
This paper introduces a synchronous GF-NOMA framework that seamlessly integrates straightforward yet highly efficient power control techniques with UE clustering and RB allocation strategies. The results obtained from these methods demonstrate the remarkable capability to form clusters within milliseconds and achieve max–sum rates that closely approach the optimal benchmark. However, it is worth noting that the proposed frameworks exhibit relatively lower performance when compared to the optimal benchmark in terms of max–min fairness. Therefore, future research endeavors should be directed towards the development of low-complexity power control schemes aimed at further enhancing the max–min rate performance.
In addition, an intriguing avenue for exploration lies in extending the proposed frameworks to MIMO systems. Hybridizing spatial NOMA schemes with the proposed approach in MIMO configurations holds the potential to yield fascinating insights and performance improvements. Furthermore, there is considerable promise in leveraging deep-learning methodologies for tasks such as user activity detection and dynamic power level determination based on underlying network parameters. These machine-learning techniques can potentially enhance the adaptability and optimization of GF-NOMA systems.
Another vital area ripe for future research is the security aspects of GF-NOMA. This includes a comprehensive exploration of vulnerability analysis, the development of robust encryption techniques, and the creation of innovative methods to safeguard against eavesdropping attacks, which become particularly challenging in grant-free operations where traditional user authentication mechanisms through grant acquisition are absent.
Funding
This work is supported by the Office of Sponsored Research (OSR) of King Abdullah University of Science and Technology (KAUST).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- ITU-R. IMT Vision—Framework and Overall Objectives of the Future Development of IMT for 2020 and Beyond; ITU-R: Geneva, Switzerland, 2015. [Google Scholar]
- Khan, B.S.; Jangsher, S.; Ahmed, A.; Al-Dweik, A. URLLC and eMBB in 5G Industrial IoT: A Survey. IEEE Open J. Commun. Soc. 2022, 3, 1134–1163. [Google Scholar] [CrossRef]
- Chithaluru, P.; Singh, A.; Dhatterwal, J.S.; Sodhro, A.H.; Albahar, M.A.; Jurcut, A.; Alkhayyat, A. An Optimized Privacy Information Exchange Schema for Explainable AI Empowered WiMAX-based IoT networks. Future Gener. Comput. Syst. 2023, 148, 225–239. [Google Scholar] [CrossRef]
- Lin, Z.; Lin, M.; Cola, T.; Wang, J.; Zhu, W.; Cheng, J. Supporting IoT With Rate-Splitting Multiple Access in Satellite and Aerial-Integrated Networks. IEEE Internet Things J. 2021, 14, 11123–11134. [Google Scholar] [CrossRef]
- Ali, R.; Zikria, Y.B.; Bashir, A.K.; Garg, S.; Kim, H.S. URLLC for 5G and Beyond: Requirements, Enabling Incumbent Technologies and Network Intelligence. IEEE Access 2021, 9, 67064–67095. [Google Scholar] [CrossRef]
- Dahlman, E.; Parkvall, S.; Skold, J.; Beming, P. 3G Evolution: HSPA and LTE for Mobile Broadband; Academic Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Sesia, S.; Toufik, I.; Baker, M. LTE-the UMTS Long Term Evolution: From Theory to Practice; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Shirvanimoghaddam, M.; Li, Y.; Dohler, M.; Vucetic, B.; Feng, S. Probabilistic rateless multiple access for machine-to-machine communication. IEEE Trans. Wirel. Commun. 2015, 14, 6815–6826. [Google Scholar] [CrossRef]
- Saito, Y.; Kishiyama, Y.; Benjebbour, A.; Nakamura, T.; Li, A.; Higuchi, K. Non-Orthogonal Multiple Access (NOMA) for Cellular Future Radio Access. In Proceedings of the 2013 IEEE 77th Vehicular Technology Conference (VTC Spring), Dresden, Germany, 2–5 June 2013; pp. 1–5. [Google Scholar]
- Makki, B.; Chitti, K.; Behravan, A.; Alouini, M.-S. A Survey of NOMA: Current Status and Open Research Challenges. IEEE Open J. Commun. Soc. 2020, 1, 179–189. [Google Scholar] [CrossRef]
- Ding, Z.; Schober, R.; Poor, H.V. Unveiling the Importance of SIC in NOMA Systems—Part 1: State of the Art and Recent Findings. IEEE Commun. Lett. 2020, 24, 2373–2377. [Google Scholar] [CrossRef]
- Kang, A.; Lin, M.; Ouyang, J.; Zhu, W.-P. Secure Transmission in Cognitive Satellite Terrestrial Networks. IEEE J. Sel. Areas Commun. 2016, 34, 3025–3037. [Google Scholar]
- Nikopour, H.; Baligh, H. Sparse code multiple access. In Proceedings of the IEEE 24th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications (PIMRC), London, UK, 8–11 September 2013; pp. 332–336. [Google Scholar]
- Yuan, Z.; Yu, G.; Li, W.; Yuan, Y.; Wang, X.; Xu, J. Multi-User Shared Access for Internet of Things. In Proceedings of the 2016 IEEE 83rd Vehicular Technology Conference (VTC Spring), Nanjing, China, 15–18 May 2016; pp. 1–5. [Google Scholar]
- Jia, M.; Gao, Q.; Guo, Q.; Gu, X. Energy-Efficiency Power Allocation Design for UAV-Assisted Spatial NOMA. IEEE Internet Things J. 2021, 8, 15205–15215. [Google Scholar] [CrossRef]
- Celik, A.; Chaaban, A.; Shihada, B.; Alouini, M.-S. Topology Optimization for 6G Networks: A Network Information-Theoretic Approach. IEEE Veh. Technol. Mag. 2020, 15, 83–92. [Google Scholar] [CrossRef]
- Celik, A.; Tsai, M.; Radaydeh, R.M.; Al-Qahtani, F.S.; Alouini, M. Distributed cluster formation and power-bandwidth allocation for imperfect NOMA in dl-hetnets. IEEE Trans. Commun. 2019, 67, 1677–1692. [Google Scholar] [CrossRef]
- Celik, A.; Tsai, M.; Radaydeh, R.M.; Al-Qahtani, F.S.; Alouini, M. Distributed user clustering and resource allocation for imperfect NOMA in heterogeneous networks. IEEE Trans. Commun. 2019, 67, 7211–7227. [Google Scholar] [CrossRef]
- Wang, B.; Dai, L.; Zhang, Y.; Mir, T.; Li, J. Dynamic Compressive Sensing-Based Multi-User Detection for Uplink Grant-Free NOMA. IEEE Commun. Lett. 2016, 20, 2320–2323. [Google Scholar] [CrossRef]
- Cirik, A.C.; Balasubramanya, N.M.; Lampe, L.; Vos, G.; Bennett, S. Toward the Standardization of Grant-Free Operation and the Associated NOMA Strategies in 3GPP. IEEE Commun. Stand. Mag. 2019, 3, 60–66. [Google Scholar] [CrossRef]
- Tran, D.-D.; Sharma, S.K.; Ha, V.N.; Chatzinotas, S.; Woungang, I. Multi-Agent DRL Approach for Energy-Efficient Resource Allocation in URLLC-Enabled Grant-Free NOMA Systems. IEEE Open J. Commun. Soc. 2023, 4, 1470–1486. [Google Scholar] [CrossRef]
- Shahab, M.B.; Abbas, R.; Shirvanimoghaddam, M.; Johnson, S.J. Grant-free non-orthogonal multiple access for IoT: A survey. IEEE Commun. Surv. Tutor. 2020, 22, 1805–1838. [Google Scholar] [CrossRef]
- Balevi, E.; Rabee, F.T.A.; Gitlin, R.D. Aloha-NOMA for massive machine-to-machine iot communication. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–5. [Google Scholar]
- Choi, J. NOMA-based random access with multichannel aloha. IEEE J. Sel. Areas Commun. 2017, 35, 2736–2743. [Google Scholar] [CrossRef]
- Elkourdi, M.; Mazin, A.; Balevi, E.; Gitlin, R.D. Enabling slotted aloha-NOMA for massive m2m communication in iot networks. In Proceedings of the 2018 IEEE 19th Wireless and Microwave Technology Conference (WAMICON), Sand Key, FL, USA, 9–10 April 2018; pp. 1–4. [Google Scholar]
- Zhang, C.; Liu, Y.; Ding, Z. Semi-grant-free NOMA: A stochastic geometry model. IEEE Trans. Wirel. Commun. 2022, 21, 1197–1213. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, Y.; Yi, W.; Qin, Z.; Ding, Z. Semi-grant-free NOMA: Ergodic rates analysis with random deployed users. IEEE Wirel. Commun. Lett. 2021, 10, 692–695. [Google Scholar] [CrossRef]
- Liu, J.; Wu, G.; Zhang, X.; Fang, S.; Li, S. Modeling, analysis, and optimization of grant-free NOMA in massive mtc via stochastic geometry. IEEE Internet Things J. 2021, 8, 4389–4402. [Google Scholar] [CrossRef]
- Fayaz, M.; Yi, W.; Liu, Y.; Nallanathan, A. Transmit power pool design for grant-free NOMA-iot networks via deep reinforcement learning. IEEE Trans. Wirel. Commun. 2021, 20, 7626–7641. [Google Scholar] [CrossRef]
- Abbas, R.; Shirvanimoghaddam, M.; Li, Y.; Vucetic, B. A novel analytical framework for massive grant-free NOMA. IEEE Trans. Commun. 2019, 67, 2436–2449. [Google Scholar] [CrossRef]
- Doğan, S.; Tusha, A.; Arslan, H. NOMA with index modulation for uplink URLLC through grant-free access. IEEE J. Sel. Top. Signal Process. 2019, 13, 1249–1257. [Google Scholar] [CrossRef]
- Liu, Y.; Deng, Y.; Elkashlan, M.; Nallanathan, A.; Karagiannidis, G.K. Optimization of grant-free NOMA with multiple configured-grants for mURLLC. IEEE J. Sel. Areas Commun. 2022, 40, 1222–1236. [Google Scholar] [CrossRef]
- Liu, Y.; Deng, Y.; Zhou, H.; Elkashlan, M.; Nallanathan, A. Deep reinforcement learning-based grant-free NOMA optimization for mURLLC. IEEE Trans. Commun. 2023, 71, 1475–1490. [Google Scholar]
- Zhang, X.; Fan, P.; Hao, L.; Quan, X. Generalized approximate message passing based bayesian learning detectors for uplink grant-free NOMA. IEEE Trans. Veh. Technol. 2023, in press. [Google Scholar] [CrossRef]
- Zhang, X.; Fan, P.; Liu, J.; Hao, L. Bayesian learning-based multiuser detection for grant-free NOMA systems. IEEE Trans. Wirel. Commun. 2022, 21, 6317–6328. [Google Scholar] [CrossRef]
- Yu, H.; Fei, Z.; Zheng, Z.; Ye, N.; Han, Z. Deep learning-based user activity detection and channel estimation in grant-free NOMA. IEEE Trans. Wirel. Commun. 2023, 22, 2202–2214. [Google Scholar] [CrossRef]
- Khan, M.U.; Paolini, E.; Chiani, M. Enumeration and identification of active users for grant-free NOMA using deep neural networks. IEEE Access 2022, 10, 125616–125625. [Google Scholar] [CrossRef]
- Cao, K.; Ding, H.; Wang, B.; Lv, L.; Tian, J.; Wei, Q.; Gong, F. Enhancing physical-layer security for iot with nonorthogonal multiple access assisted semi-grant-free transmission. IEEE Internet Things J. 2022, 9, 24669–24681. [Google Scholar] [CrossRef]
- Lin, Z.; Niu, H.; An, K.; Wang, Y.; Zheng, G.; Chatzinotas, S.; Hu, Y. Refracting RIS-Aided Hybrid Satellite-Terrestrial Relay Networks: Joint Beamforming Design and Optimization. Trans. Aerosp. Electron. Syst. 2022, 58, 3717–3724. [Google Scholar] [CrossRef]
- Kilinc, F.; Tasci, R.A.; Celik, A.; Abdallah, A.; Eltawil, A.M.; Basar, E. RIS-Assisted Grant-Free NOMA: User Pairing, RIS Assignment, and Phase Shift Alignment. IEEE Trans. Cogn. Commun. Netw. 2023. early access. [Google Scholar] [CrossRef]
- Makin, M.; Arzykulov, S.; Celik, A.; Eltawil, A.; Nauryzbayev, G. Optimal RIS Partitioning and Power Control for Bidirectional NOMA Networks. IEEE Trans. Wirel. Commun. 2023. early access. [Google Scholar] [CrossRef]
- Al-Hourani, A.; Kandeepan, S.; Lardner, S. Optimal lap altitude for maximum coverage. IEEE Wirel. Commun. Lett. 2014, 3, 569–572. [Google Scholar] [CrossRef]
- Arzykulov, S.; Celik, A.; Nauryzbayev, G.; Eltawil, A.M. UAV-assisted cooperative & cognitive NOMA: Deployment, clustering, and resource allocation. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 263–281. [Google Scholar]
- Arzykulov, S.; Nauryzbayev, G.; Celik, A.; Eltawil, A.M. Hardware and interference limited cooperative CR-NOMA networks under imperfect SIC and CSI. IEEE Open J. Commun. Soc. 2021, 2, 1473–1485. [Google Scholar] [CrossRef]
- 3GPP. LTE; Evolved Universal Terrestrial Radio Access (E-UTRA); User Equipment (UE) Radio Transmission and Reception; Technical Report TS 136 101 V10.24.1; ETSI: Valbonne, France, 2017. [Google Scholar]
- Jonker, R.; Volgenant, A. A shortest augmenting path algorithm for dense and sparse linear assignment problems. Computing 1987, 38, 325–340. [Google Scholar] [CrossRef]
- Burkard, R.; Dell’Amico, M.; Martello, S. Assignment Problems: Revised Reprint; SIAM: Philadelphia, PA, USA, 2012. [Google Scholar]
- Lin, Z.; Lin, M.; Champagne, B.; Zhu, W.; Al-Dhahir, N. Secrecy-Energy Efficient Hybrid Beamforming for Satellite-Terrestrial Integrated Networks. IEEE Trans. Commun. 2021, 69, 6345–6360. [Google Scholar] [CrossRef]
Figure 1.
Illustration of UE partitioning for , , and .

Figure 2.
Schematic illustration of the solution methodology.

Figure 3.
Time complexity compari1son.

Figure 4.
UL and DL max–sum rate and max–min rate comparison of proposed schemes. (a) UL max–sum rate and max–min rate. []. (b) DL max–sum rate and max–min rate. []. (c) UL max–sum rate and max–min rate. [].
Figure 4.
UL and DL max–sum rate and max–min rate comparison of proposed schemes. (a) UL max–sum rate and max–min rate. []. (b) DL max–sum rate and max–min rate. []. (c) UL max–sum rate and max–min rate. [].

Figure 6.
Impact on residual SIC interference.

Table 1.
Table of Notations.
| Nots. | Description |
|---|---|
| Set of U users | |
| Set of R RBs | |
| N | Cluster size, |
| B | RB bandwidth |
| Access probability of UE | |
| Clustering binary indicator if UE is assigned to RB, 0 otherwise | |
| Cluster set of users belonging to RB | |
| Set of active members of | |
| Maximum transmit power of UE | |
| Minimum transmit power of UE | |
| Composite channel gain between generic nodes i and j | |
| SINR of UE at RB | |
| QoS requirement of UE | |
| Power allocation vector for | |
| Linearly spaced N power transmit levels, | |
| N levels of DL transmit power, | |
| Number of users awaiting cluster admission | |
| cost matrix of user admission iteration |
Table 2.
Problem formulations for optimal max–min fair and max–sum rate PD-NOMA schemes.
| Uplink PD-NOMA | Downlink PD-NOMA | |
|---|---|---|
| Max–Min | ||
| Max–Sum |
Table 3.
Power level look-up table for dBm, dBm, and .
| Level Indices | Powers [dBl | N (Cluster Size) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| 23 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| 16 | – | – | – | – | – | – | – | – | ✓ | |
| 15.125 | – | – | – | – | – | – | – | ✓ | – | |
| 14 | – | – | – | – | – | – | ✓ | – | – | |
| 12.5 | – | – | – | – | – | ✓ | – | – | – | |
| 10.4 | – | – | – | – | ✓ | – | – | – | – | |
| 9 | – | – | – | – | – | – | – | – | ✓ | |
| 7.25 | – | – | – | ✓ | – | – | – | ✓ | – | |
| 5 | – | – | – | – | – | – | ✓ | – | – | |
| 2 | – | – | ✓ | – | – | ✓ | – | – | ✓ | |
| −0.625 | – | – | – | – | – | – | – | ✓ | – | |
| −2.2 | – | – | – | – | ✓ | – | – | – | – | |
| −4 | – | – | – | – | – | – | ✓ | – | – | |
| −5 | – | – | – | – | – | – | – | – | ✓ | |
| −8.5 | – | ✓ | – | ✓ | – | ✓ | – | ✓ | – | |
| −12 | – | – | – | – | – | – | – | – | ✓ | |
| −13 | – | – | – | – | – | – | ✓ | – | – | |
| −14.8 | – | – | – | – | ✓ | – | – | – | – | |
| −16.375 | – | – | – | – | – | – | – | ✓ | – | |
| −19 | – | – | ✓ | – | – | ✓ | – | – | ✓ | |
| −21 | ✓ | – | – | – | – | – | – | – | – | |
| −22 | – | – | – | – | – | – | ✓ | – | – | |
| −24.25 | – | – | – | ✓ | – | – | – | ✓ | – | |
| −26 | – | – | – | – | – | – | – | – | ✓ | |
| −27.4 | – | – | – | – | ✓ | – | – | – | – | |
| −29.5 | – | – | – | – | – | ✓ | – | – | – | |
| −31 | – | – | – | – | – | – | ✓ | – | – | |
| −32.125 | – | – | – | – | – | – | – | ✓ | – | |
| −33 | – | – | – | – | – | – | – | – | ✓ | |
| −40 | – | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Celik, A. Grant-Free NOMA: A Low-Complexity Power Control through User Clustering. Sensors 2023, 23, 8245. https://doi.org/10.3390/s23198245
AMA Style
Celik A. Grant-Free NOMA: A Low-Complexity Power Control through User Clustering. Sensors. 2023; 23(19):8245. https://doi.org/10.3390/s23198245
Chicago/Turabian StyleCelik, Abdulkadir. 2023. "Grant-Free NOMA: A Low-Complexity Power Control through User Clustering" Sensors 23, no. 19: 8245. https://doi.org/10.3390/s23198245
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.