
An Enhanced Food Digestion Algorithm for Mobile Sensor Localization



1
College of Computer Science and Engineering, Shandong University of Science and Technology, Qingdao 266590, China
2
College of Science and Engineering, Flinders University, 1284 South Road, Tonsley, SA 5042, Australia
3
Department of Life Science and Informatics, Maebashi Institute of Technology, Maebashi 371-0816, Japan
4
International WIC Institute, Beijing University of Technology, Beijing 100124, China
5
Beijing International Collaboration Base on Brain Informatics and Wisdom Services, Beijing 100124, China
6
College of Mathematics and Computer Science, Fuzhou University, Fuzhou 350116, China
7
Department of Information Management, Chaoyang University of Technology, Taichung 41349, Taiwan
*
Author to whom correspondence should be addressed.
Sensors 2023, 23(17), 7508; https://doi.org/10.3390/s23177508
Submission received: 19 May 2023
/
Revised: 15 August 2023
/
Accepted: 16 August 2023
/
Published: 29 August 2023
(This article belongs to the Special Issue Algorithms, Systems and Applications of Smart Sensor Networks)
Abstract
:Mobile sensors can extend the range of monitoring and overcome static sensors’ limitations and are increasingly used in real-life applications. Since there can be significant errors in mobile sensor localization using the Monte Carlo Localization (MCL), this paper improves the food digestion algorithm (FDA). This paper applies the improved algorithm to the mobile sensor localization problem to reduce localization errors and improve localization accuracy. Firstly, this paper proposes three inter-group communication strategies to speed up the convergence of the algorithm based on the topology that exists between groups. Finally, the improved algorithm is applied to the mobile sensor localization problem, reducing the localization error and achieving good localization results.
1. Introduction
Metaheuristic algorithms play a huge role in many fields, such as UAV [1,2,3], digital watermarking [4], engineering design [5], unit commitment [6], image processing [7,8,9], intrusion detection systems [10], feature selection [11], multi-robot exploration [12], wireless sensor networks [13,14,15], scheduling problems [16,17], etc.
Although metaheuristics are excellent at solving problems with real-world applications, they are not a panacea, and, as mentioned in the No Free Lunch Theorem [18], each optimization algorithm may be good at solving different problems. Therefore, researchers are constantly exploring new optimization algorithms. For example, Holland proposed the Genetic Algorithm (GA) in 1975 based on Darwinian evolutionary theory [19]. Dorigo et al. proposed the Ant Colony Optimization (ACO) in 1992 [20]. Storn et al. proposed Differential Evolution (DE) in 1995 [21]. Kennedy and Eberhart proposed the Particle Swarm Optimization (PSO) algorithm in 1995 [22]. Karaboga et al. proposed the Artificial Bee Colony algorithm (ABC) in 2005 [23]. Yang et al. proposed the Cuckoo Search (CS) in 2009 [24]. Rashedi et al. proposed the Gravitational Search Algorithm in 2009 [25]. Yang et al. proposed the Bat Algorithm (BA) in 2010 [26]. Mirjalili et al. proposed the Grey Wolf Optimizer (GWO) in 2014 [27]. Mirjalili et al. proposed the Sine Cosine Algorithm (SCA) in 2016 [28]. Abualigah et al. proposed the Aquila Optimizer (AO) in 2021 [29]. Song et al. proposed the Phasmatodea Population Evolution algorithm (PPE) in 2021 [30]. Pan et al. proposed the Gannet Optimization Algorithm (GOA) in 2022 [31].
Numerous researchers have dedicated their efforts to enhancing the performance of metaheuristic algorithms. Among the various approaches, parallel and compact strategies have gained significant attention due to their simplicity and effectiveness. The parallel strategy emphasizes the grouping of populations, facilitating the exchange of information between groups to accelerate the algorithm’s convergence and enhance its ability to discover optimal solutions accurately. On the other hand, the compact strategy involves mapping the population onto a probabilistic model and performing operations on the entire population through manipulations of this model. This approach offers notable benefits such as reduced computational time and memory usage. In this study, we propose a novel approach that combines both parallel and compact strategies to enhance the performance of the food digestion algorithm. We expect that this integrated methodology will effectively enhance the algorithm’s ability to seek optimal solutions in the optimization process, leading to improved outcomes.
Numerous researchers have combined these two strategies to improve metaheuristic algorithms. In reference [32], the authors combine the parallel and compact strategies to enhance DE and utilize the enhanced algorithm for image segmentation, yielding superior outcomes. In reference [33], the authors initially introduce six enhancements to the compact strategy CS, subsequently selecting the algorithm with the most favorable results and incorporating the parallel strategy. Ultimately, the authors apply the improved algorithm to underwater robot path planning, which yields promising results.
Wireless sensor networks (WSNs) are self-organized communication systems consisting of multiple nodes that enable the monitoring of specific areas through multi-hop communication. In a static WSN, the nodes are randomly distributed and their locations remain fixed once determined. However, in practical environments, mobile sensor nodes are in greater demand. For instance, in target tracking applications, real-time positioning of moving targets is essential [34,35]. The mobility of sensor nodes allows for an extended monitoring range, overcoming coverage gaps that may occur due to the failure of static nodes. Furthermore, the movement of nodes enables the network to discover and observe events more effectively, while also enhancing the communication quality among the sensor nodes [36]. Despite the importance of mobile node localization, there is a relative scarcity of research in this area. Most localization methods developed for static sensor nodes are unsuitable for the mobile sensor localization problem, making the study of mobile sensor localization a current research focal point [37]. Additionally, the study of outdoor mobile sensors holds particular significance due to the complex and ever-changing nature of the outdoor environment.
Based on the above reasons, this paper uses parallel and compact strategies to improve the food digestion algorithm and apply it to the outdoor mobile sensor localization problem. Section 2 mainly introduces the food digestion algorithm and mobile sensor localization techniques. Section 3 mainly introduces the implementation of the Parallel Compact Food Digestion Algorithm (PCFDA). Section 4 tests the performance of PCFDA. Section 5 uses PCFDA to optimize the error in mobile sensor localization. Section 6 gives the conclusion of this paper.
2. Related Works
This section mainly introduces the food digestion algorithm and the mobile sensor localization problem.
2.1. Food Digestion Algorithm
The food digestion algorithm mainly covers the process of food digestion in the mouth, stomach, and small intestine. This section describes the modeling processes in these three sites in detail.
2.1.1. Digestion in the Oral Cavity
The digestion of food in the mouth involves both physical and chemical digestion. The process of physical digestion mainly consists of the action of forces, which are represented as follows:
denotes the force on the food in the mouth, denotes the current number of iterations, denotes the maximum number of iterations, and a is used to adjust the size of , which has a value of 1.5574. denotes forces with different sizes and directions, where is a random value in the range [0, 1].
The chemical digestion of food in the mouth is dominated by the digestion of starch by salivary amylase, and, considering the effect of substrate concentration on the enzymatic reaction, the modeling process is as follows:
denotes the enzyme in the oral cavity, randomly setting half of the dimension values to 0 and the other half to 1. denotes that the values of the D dimensions are randomly scrambled. Equation (4) is the Mie equation, which reflects the relationship between substrate concentration and reaction rate [38]. V represents the rate of the enzymatic reaction, represents the maximum reaction rate, and its value is 2. S represents the substrate concentration, and we express it as a sine function, represented by Equation (5), where is a number in the range [0,1]. represents the mathematical constant pi. is a characteristic constant of the enzyme, and in the oral cavity, the value of is 0.8. Therefore, the particle update equation in the oral cavity is as follows:
denotes the ith particle at generation . denotes the kth particle at generation t. k is a randomly selected particle from among N particles. denotes the Rth particle of the tth generation, and R is chosen as shown in Equation (8). b is a constant which has a value of 1.5. denotes the ith particle of the tth generation. represents the global optimal value. and are two random numbers that change with the number of iterations. denotes rounding to positive infinity, and is a random rounding function.
2.1.2. Digestion in the Stomach
The digestion of food in the stomach also involves two processes: physical and chemical digestion. Physical digestion is primarily governed by the forces generated by the contraction and diastole of the stomach as well as peristalsis. The forces are expressed as follows:
represents the force on the food in the stomach. represents a directed force, which takes values in the range [−2, 2]. The chemical digestion modeling process in the stomach is similar to that in the oral cavity. The difference is that different enzymes and different characteristic constants are selected for each iteration. In the stomach, the value of is 0.9. Therefore, the particle update equation in the stomach is as follows:
selects particles according to Equation (13). If the optimal fitness value of the first one-third of the updated particles is less than the global optimum, then we select this particle. Otherwise, we perturb the globally optimal particle and select the perturbed particle. Therefore, its selection condition is . is calculated according to Equation (12).
2.1.3. Digestion in the Small Intestine
The digestion of food in the small intestine also involves two processes: physical and chemical digestion. Physical digestion is primarily governed by forces generated by peristalsis of the small intestine, which is expressed as follows:
represents the force on the food in the small intestine. a is a constant that has a value of 1.5574. is used to regulate the magnitude of the force, which has a value of 1. represents a directed force, which is a random value in the range [−2, 2]. Thus, the equation for particles updated in the small intestine is as in Equation (16).
The judgment condition for is , which is calculated from Equation (17). denotes Lévy flight, which is calculated as follows:
and are random numbers in the range [0, 1], and is a constant whose value is 1.5.
The food digestion algorithm simulates the process of food digestion in the three main digestive sites in the human body to construct the particle optimization process. In the oral cavity, particles always follow a random particle to update their positions, which promotes the diversity of particles. As the number of iterations increases, particles gradually select particles with better fitness values to update their positions. This selection enhances population diversity in the early iterations and facilitates rapid convergence in later stages.
In the stomach, particles follow the optimal particles from the previous site or particles after perturbation to update their positions. This accelerates the convergence process. Additionally, particles follow the average particles to update their positions, promoting particle diversity and preventing them from getting trapped in local optima.
In the small intestine, particles update their positions after the global optimum, enabling quick convergence. Furthermore, particles update their positions using the Lévy flight strategy, which helps avoid falling into local optima.
Algorithm 1 provides a detailed description of the FDA.
| Algorithm 1 Food Digestion Algorithm |
| Output: Population size N; Dimension D; Maximum number of iterations ; Lower boundary ; Upper boundary ; |
| Input: Global optimal position , Global optimal fitness value ; |
|
2.2. Mobile Sensor Localization Problem
This section introduces a localization method called Monte Carlo Localization (MCL) for mobile sensor networks, as described in references [39,40]. In wireless sensor networks, Monte Carlo localization methods typically involve fixed anchor nodes. These anchor nodes serve as reference points in the localization algorithm, and their positions are known in advance and remain unchanged over time. During the localization process, anchor nodes send signals to the mobile node and receive signals back from it, aiding in determining the mobile node’s position.
The Monte Carlo localization method is a probabilistic and statistical-based algorithm used to estimate the location of a mobile node through multiple random simulations. It calculates the position of the mobile node using measurements such as received signal strength, arrival time, or other relevant data. The algorithm relies on important parameters, among which the pre-known position of the anchor node plays a crucial role.
In Monte Carlo localization methods, the use of multiple fixed anchor nodes enables the provision of additional measurements for estimating the position of the mobile node. This, in turn, improves the accuracy of the localization process. The fixed positions of the anchor nodes, along with reliable measurement data, form the foundation for the effectiveness of the Monte Carlo localization method in achieving accurate localization.
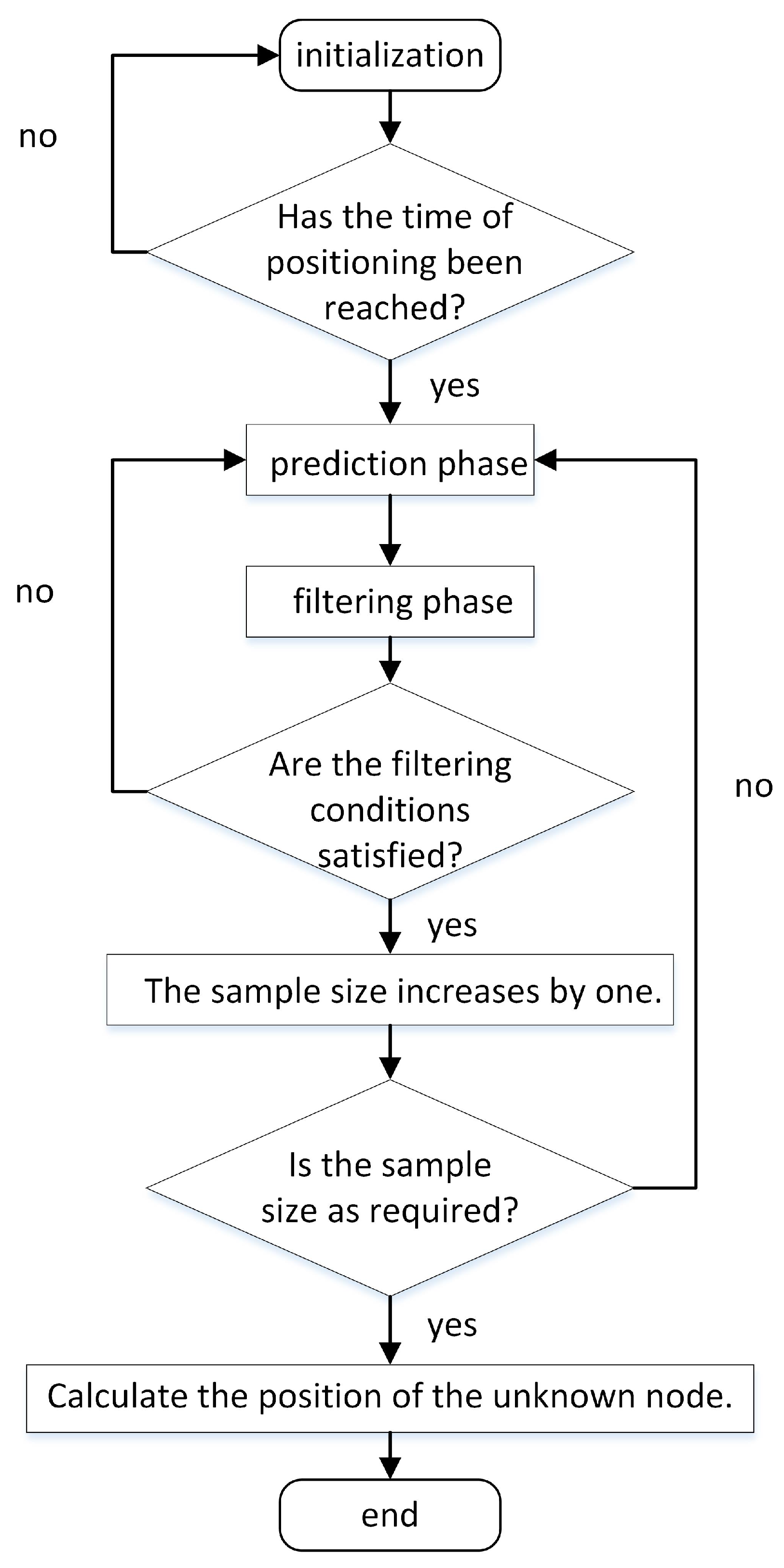
The MCL (Monte Carlo Localization) method consists of three main phases: initialization, prediction, and filtering [41]. In the initialization phase, each node is assigned motion regions and maximum motion speeds. During the prediction phase, a preliminary estimate of the mobile node’s location is calculated. This estimate corresponds to a circular region, where the last known position of the node serves as the center, and the product of the velocity and positioning interval time determines the radius. Figure 1 illustrates the execution flow of the MCL algorithm.
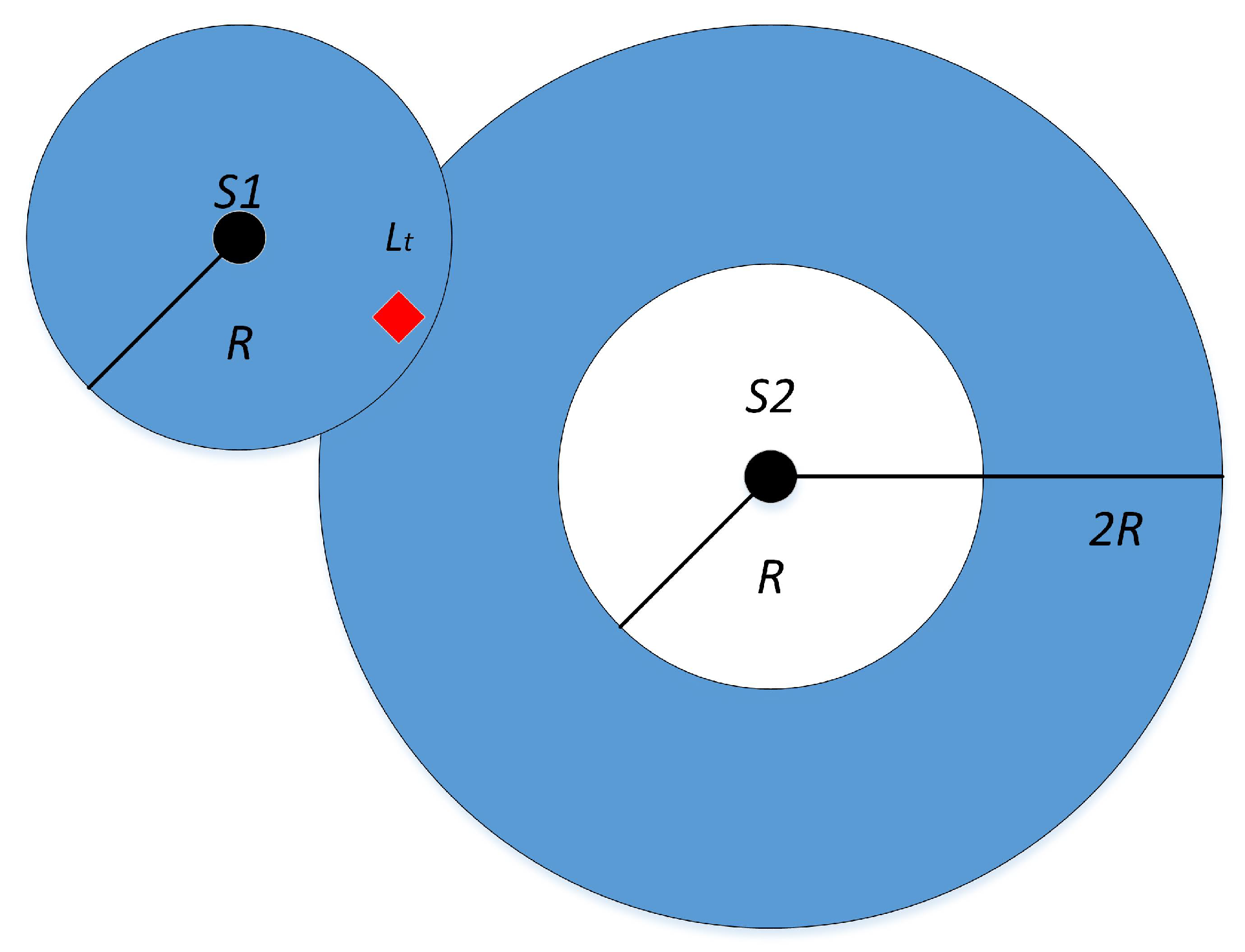
The filtering phase plays a crucial role in MCL. Initially, MCL calculates the set of single-hop beacon nodes, denoted as , and the set of two-hop beacon nodes, denoted as , based on their distances to other nodes. Subsequently, MCL randomly selects points within the feasible region and checks if they belong to the set of unknown nodes by verifying if they fall within the range of either single-hop or two-hop beacon nodes. Specifically, a selected point is classified as an unknown node if its nearest anchor is within the range of , or if both its closest and next closest anchors fall within the range of . Points that fail to satisfy these criteria are filtered out. The filtering condition is expressed in Equation (20).
As shown in Figure 2, the unknown node L senses the information of the surrounding anchor nodes at the moment t, where is its one-hop anchor node and is its two-hop anchor node, and the estimated coordinate sample of the unknown node L is a valid sample only if it satisfies the filter condition that the distance from is less than R and the distance from is between R and , Lt in the figure meets the filter condition, and is retained as a reasonable sample particle.
After the filtering phase, numerous sample particles’ coordinates are eliminated, resulting in an insufficient number of sample sets. Hence, the prediction and filtering phases are iteratively executed until an adequately high number of samples remain in the sample set. Eventually, the arithmetic mean of the sample coordinates is calculated, serving as an estimation for the final node coordinates, thereby concluding the localization at the current moment. Equation (21) was employed to estimate the locations of the unknown nodes based on the filtered reference points.
3. Enhanced Food Digestion Algorithm
This section introduces three intergroup communication strategies and proposes a concise approach to enhance the food digestion algorithm.
3.1. Design of Parallel Strategies
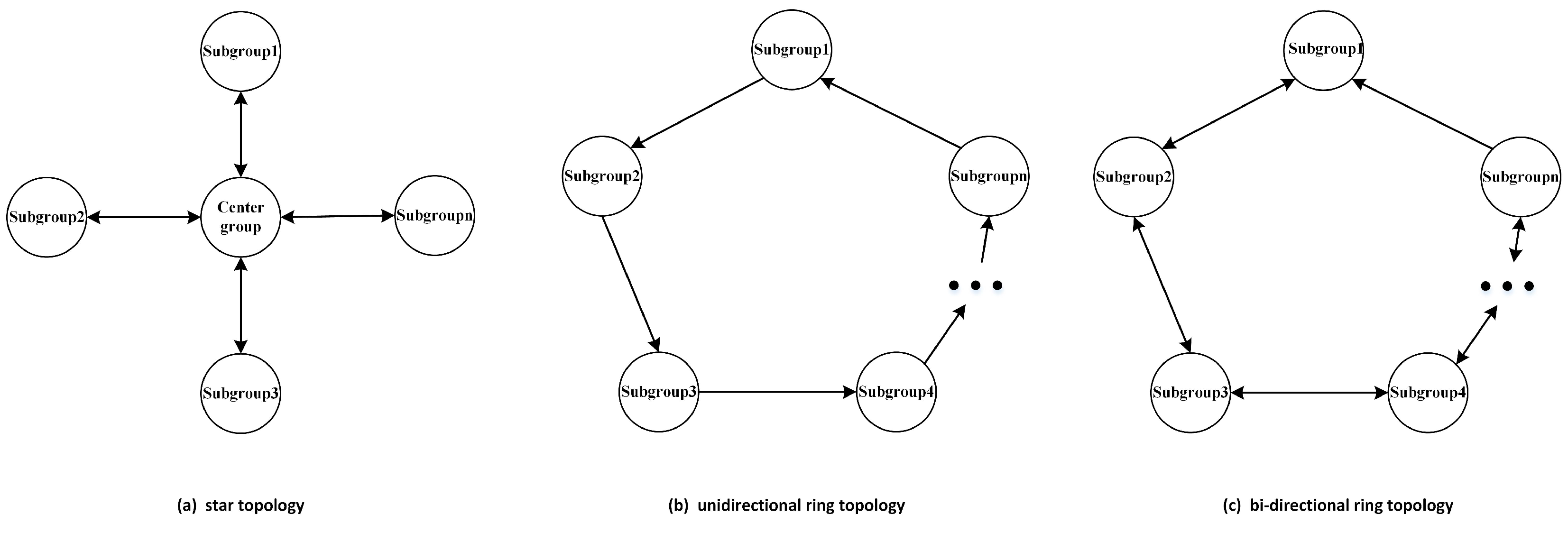
This section proposes three parallel strategies to speed up the convergence of the algorithm and to improve the algorithm’s optimization finding accuracy. These three parallel strategies use different topologies. Their topologies are shown in Figure 3.
The first parallelization strategy uses a star topology. First, we choose one group as the central group and the others as subgroups. Particles in the central group exchange information with particles in the subgroups, and there is no communication between subgroups. The pseudo-code for the algorithm is shown in Algorithm 2.
The second parallel strategy uses a unidirectional ring topology. The structure allows only subgroups to communicate with their neighboring side, and the side that each group chooses to communicate with is in the same direction in the ring structure. Algorithm 3 shows the details of the communication strategy.
| Algorithm 2 Parallel strategy for star topology |
|
| Algorithm 3 Parallel strategy for unidirectional ring topology |
|
The third parallel strategy uses a bi-directional ring topology. The structure allows subgroups to exchange information with their neighboring groups, and in a ring structure, subgroups exchange information in a specific direction. Implementation details are given in Algorithm 4.
| Algorithm 4 Parallel strategy for bi-directional ring topology |
|
3.2. Design of Compact Strategy
This section describes the principles of the compact mechanism and the detailed process for improving the food digestion algorithm using the compact mechanism.
3.2.1. Principles of the Compact Mechanism
The Distribution Estimation Algorithm (EDA) is a method based on probabilistic models [42]. It maps the population into a probability model and realizes the operation of the population by operating the probability model [43]. Compact algorithms are a type of EDA. It dramatically reduces the use of memory space and speeds up the algorithm’s operation by using a probabilistic model to characterize the distribution of the entire population. The compact algorithm uses a virtual population instead of the actual population. This virtual population is encoded in a vector. It is an N × 2 matrix in compact differential evolution (CDE) [43] and real-valued compact genetic algorithms (RCGAs) [44].
and denote the mean and standard deviation of the , respectively, and t denotes the current number of iterations. Each pair of mean and standard deviation in corresponds to the corresponding Probability Density Function (), which is truncated at [−1, 1] and normalizes the amplitude area to 1 [45]. The calculation of is given by Equation (23).
is the error function. By constructing Chebyshev polynomials, can correspond to a Cumulative Distribution Function () with values ranging from 0 to 1 [46,47]. is calculated as shown in Equation (24):
In Equation (24), x takes values in the range [−1, 1]. The function can be expressed as Equation (25):
returns the value in the range [0, 1].
The process of sampling the design variable from the vector is to first generate a random number R from a uniform distribution and then calculate its corresponding inverse function of to obtain a new value. This newly generated value is compared with another value, with the one with the better fitness value being the winner and the one with the worse fitness value being the loser, both of which are retained for updating the vector. The updated equations of mean and standard deviation are shown in Equations (26) and (27).
denotes the size of the virtual population, which is a typical parameter of compact algorithms, and the size of this parameter is usually several times the size of the actual population [44].
3.2.2. Compact Food Digestion Algorithm
Compact algorithms reduce memory space usage and speed up algorithms, but they reduce population diversity and tend to fall into local optima. A solution is generated by sampling from the probabilistic model during each iteration to solve this problem. Then three solutions are generated using the sampled solutions in conjunction with the characteristics of the FDA algorithm. These three solutions are generated using the particle update formulae in the oral cavity, stomach, and small intestine. Since the extent of the sampling space is not the same as the actual space, it is essential to map the generated solution to the actual computational space once it has been sampled in the probabilistic model, and we use Equation (28) to complete this process.
and are the maximum and minimum bounds on the actual space, respectively. The updated equation for the three solutions is given by Equations (29)–(31).
is the particle generated using the particle update equation in the oral cavity, where is the particle generated by sampling from the probabilistic model, is the optimal global particle, and is the optimal particle of the gth group. is the particle generated using the particle update equation in the stomach, and is the particle obtained by averaging and . is the particle generated using the particle update equation in the small intestine. The meaning of the other variables in these three equations is the same as in the FDA in Section 2. The pseudo-code of the FDA algorithm for the parallel compact strategy is shown in Algorithm 5.
| Algorithm 5 Parallel Compact Food Digestion Algorithm |
| Output: Population size ; Dimension D; Maximum number of iterations ; Lower boundary ; Upper boundary ; |
| Input: Global optimal position , Global optimal fitness value ; |
|
4. Numerical Experimental Results and Analysis
This section not only compares the PCFDA with the original FDA but also compares it with the PCSCA [28]. In reference [28], the authors propose three strategies for parallel communication, which apply to solving single-peak, multi-peak, and mixed-function problems. This section verifies the effectiveness of PCFDA by comparing it with them.
4.1. Parameter Settings
In this section, experiments are conducted using a Lenovo computer manufactured in Shanghai, China, equipped with an Intel(R) Core(TM) i3-8100 CPU at 3.60 GHz, 24 GB of RAM, a 64-bit Windows 10 operating system, and MATLAB2018a.
This section uses the CEC2013 test set for test experiments. The test set consists of 28 test functions, including five unimodal, fifteen multimodal, and eight mixed functions. Unimodal functions have only one global optimal solution and are used to test the ability of the algorithm to develop. Multimodal functions have multiple local optimal solutions and are mainly used to test the ability of the algorithm to escape from local optimal solutions. Mixed functions are extremely complex, they have the characteristics of both single-peak and multi-peak functions, and can test both the development ability of the algorithm and the ability of the algorithm to escape from the local optimal solution, which is the function that can best reflect the ability of the algorithm to solve complex problems. Using these three types of function tests to test the metaheuristic algorithm can effectively assess the performance and reliability of the algorithm and improve the practical application value of the algorithm.
To ensure the experiments’ fairness and reduce the effect of algorithmic instability, we let all algorithms run ten times on 28 test functions for 1000 iterations. Finally, the mean and standard deviation of their runs on each function are compared. The dimension of each particle is set to 30, and the range of the particle search is in the range [−100, 100]. The number of groups in the algorithm is set to 4, and the initial mean and standard deviation values are set to 0 and 10. The number of particles in the FDA is set to 20. has three different values that indicate the three characteristic constant values of the algorithm in the oral cavity, stomach, and small intestine, which have values of 0.8, 0.9, and 1, respectively. The parameter settings of PCSCA follow the original paper, and its three algorithms are denoted by PCSCAS1, PCSCAS2, and PCSCAS3, respectively. For the experiments in this section, we use PCFDA1, PCFDA2, and PCFDA3 to represent the enhanced FDA using Algorithms 2–4.
4.2. Comparison with the Original FDA
In this section, we use PCFDA to compare with the original FDA, mainly comparing the mean and standard deviation of their runs on each function as well as the time cost and memory usage of their runs to determine the performance of PCFDA. The mean and standard deviation comparison results are shown in Table 1 and Table 2.
In Table 1 and Table 2, the data in the last row indicate the number of PCFDAs better than the FDA. On the Unimodal functions f1–f5, PCFDA1 has a better searching ability on the first three functions and is more stable on f2 and f3. On the Multimodal functions f6–f20, all the algorithms have good searchability and stability on f8 and f20. PCFDA3’s search ability is poor on Multimodal functions. FDA and PCFDA2, and PCFDA3 outperformed on different Multimodal functions with comparable performance. On the Mixed functions f21–f28, PCFDA2 has better searchability and stability on four functions, while PCFDA3 only performs better on f26. Overall, PCFDA1 and PCFDA2 are comparable to the original FDA regarding merit-seeking ability but are more stable than the FDA. PCFDA3 has improved performance on a few functions, but overall performance is not as good as the FDA.
In order to statistically verify the effectiveness of the improved algorithm, this paper uses the Wilkerson rank sum test to verify the significant difference between the improved algorithm and the original algorithm. The significance level alpha is set to 0.05. Table 3 displays the p-values for the comparison results. The data with p-values less than 0.05 are highlighted in red. From the data in the table, it can be observed that the improved algorithm holds a significant advantage.
Improving the algorithms using compact strategies is more concerned with the time cost and the memory footprint size. Table 4 shows the time loss and memory usage for each algorithm.
In Table 4, the average running time indicates the average time to run each algorithm 10 times on 28 functions, the memory usage indicates the memory space occupied by each particle in each algorithm, the * is used as a multiplication sign, and D indicates the particle dimension. denotes the memory occupied by the 20 particles in the FDA and one globally optimal particle. In the last three columns of Table 4, denotes the memory occupied by and in the four groups. The following two 4s represent the memory occupied by the four particles obtained from each update (including one sampled particle and three generated particles) and the optimal particle in the four groups, respectively. The last 1 denotes the memory occupied by a temporary particle needed in the communication strategy. Combining the results of each algorithm in Table 1 and Table 2 leads to the conclusion that the improved algorithms are improved in terms of both time cost and memory space.
4.3. Comparison with PCSCA
This section compares the improved FDA with PCSCA. Both algorithms use parallel and compact strategies for improvement, so we only compare their searchability and stability here. Table 5 and Table 6 show the mean and standard deviation comparison results.
The red font in Table 5 and Table 6 indicates the mean and standard deviation of the optimum found by each algorithm on each function. As seen from the tables, on the f20, all algorithms show good searching ability and stability. On the f8, all algorithms have the same search ability, but PCSCAS3 is more stable. On the other functions, the PCFDA outperformed the PCSCA regarding searching superiority.
In this section, the Wilcoxon rank sum test was also used for the significance analysis of the proposed algorithm in this paper. We conducted significance analysis of the three algorithms proposed in this paper with the parallel compact SCA algorithm. Table 7, Table 8 and Table 9 display the comparison results, with red font indicating data with p-values greater than 0.05. From the data in the table, it can be observed that the proposed algorithm in this paper outperforms the parallel compact SCA algorithm in most functions.
4.4. Convergence Analysis
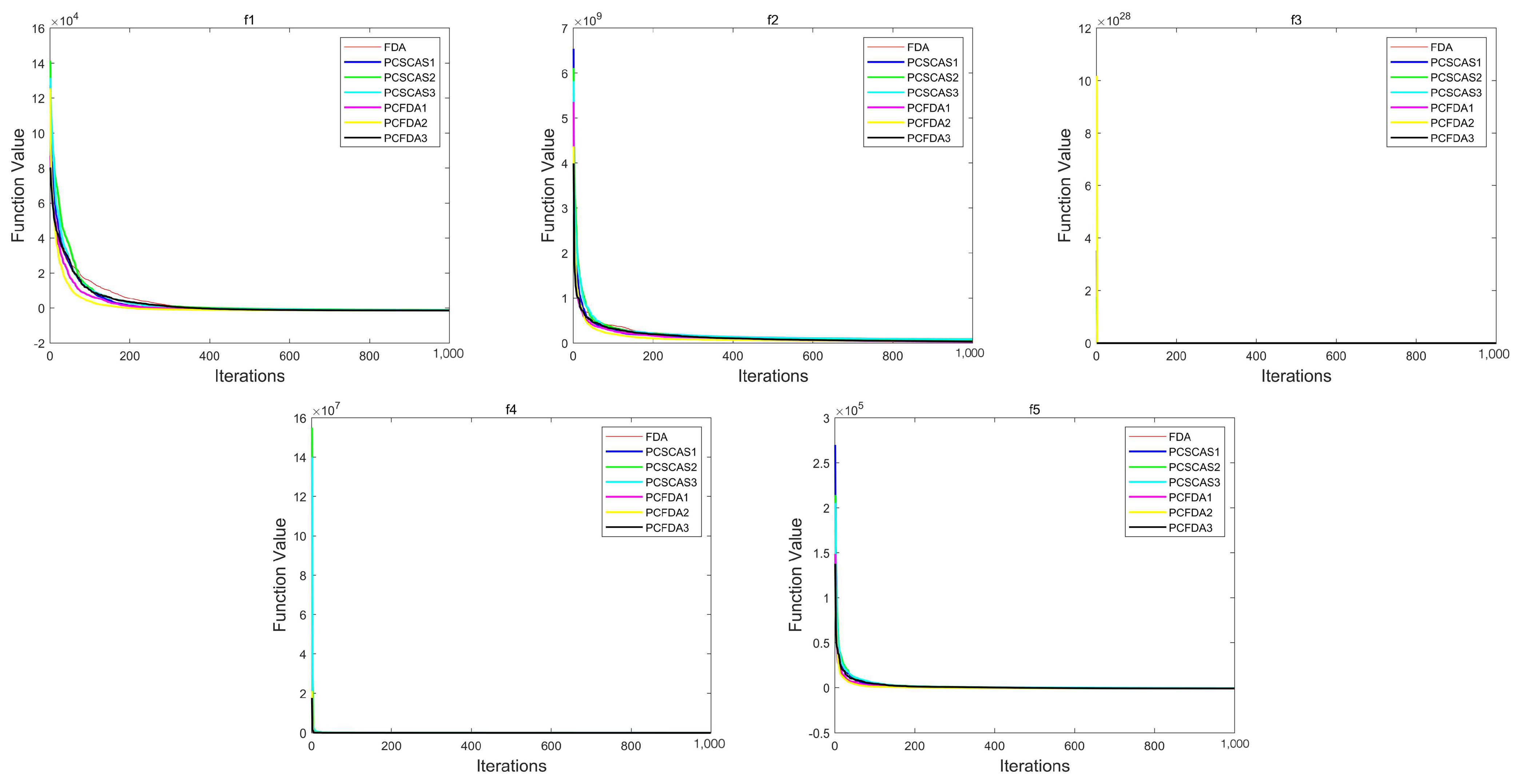
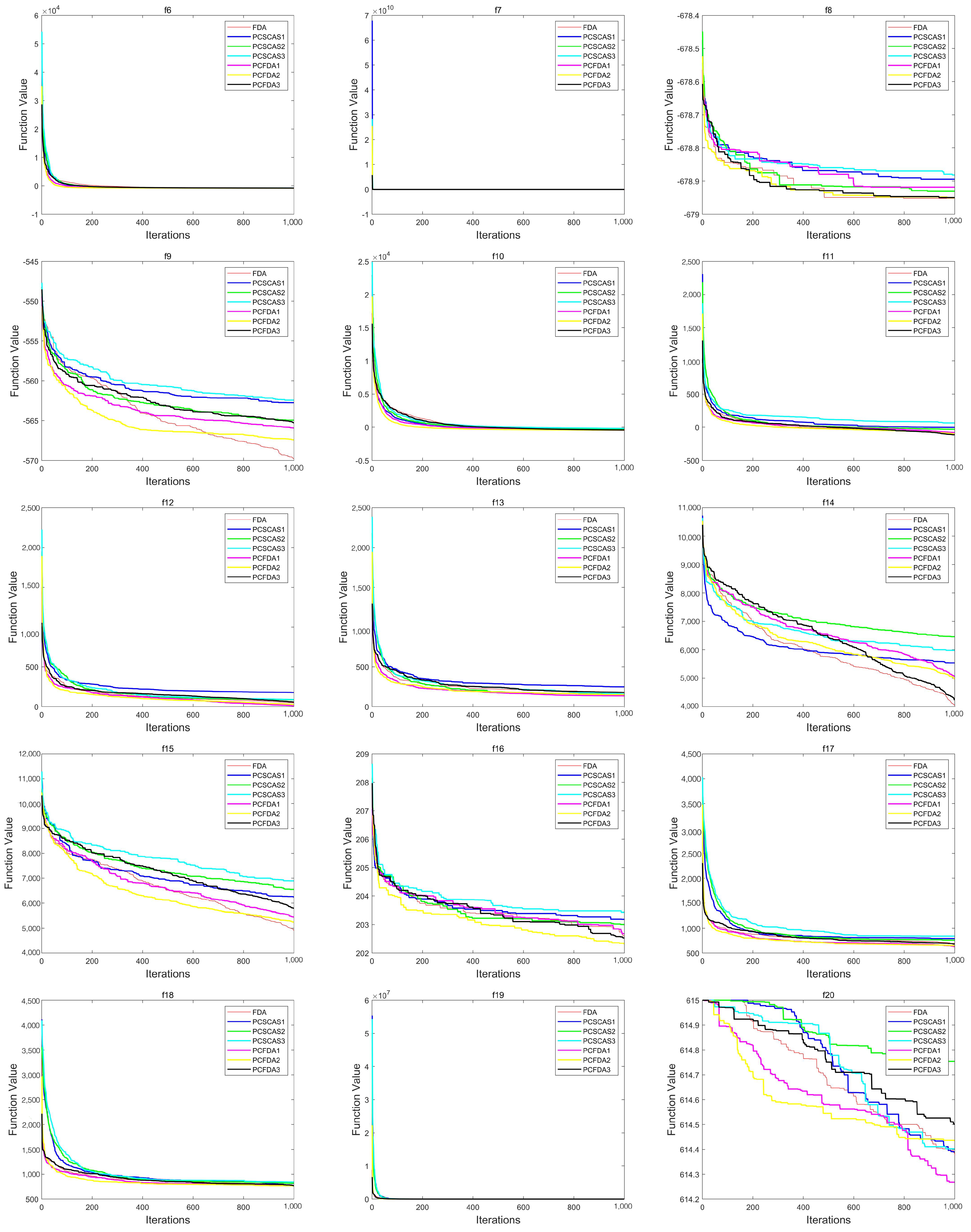
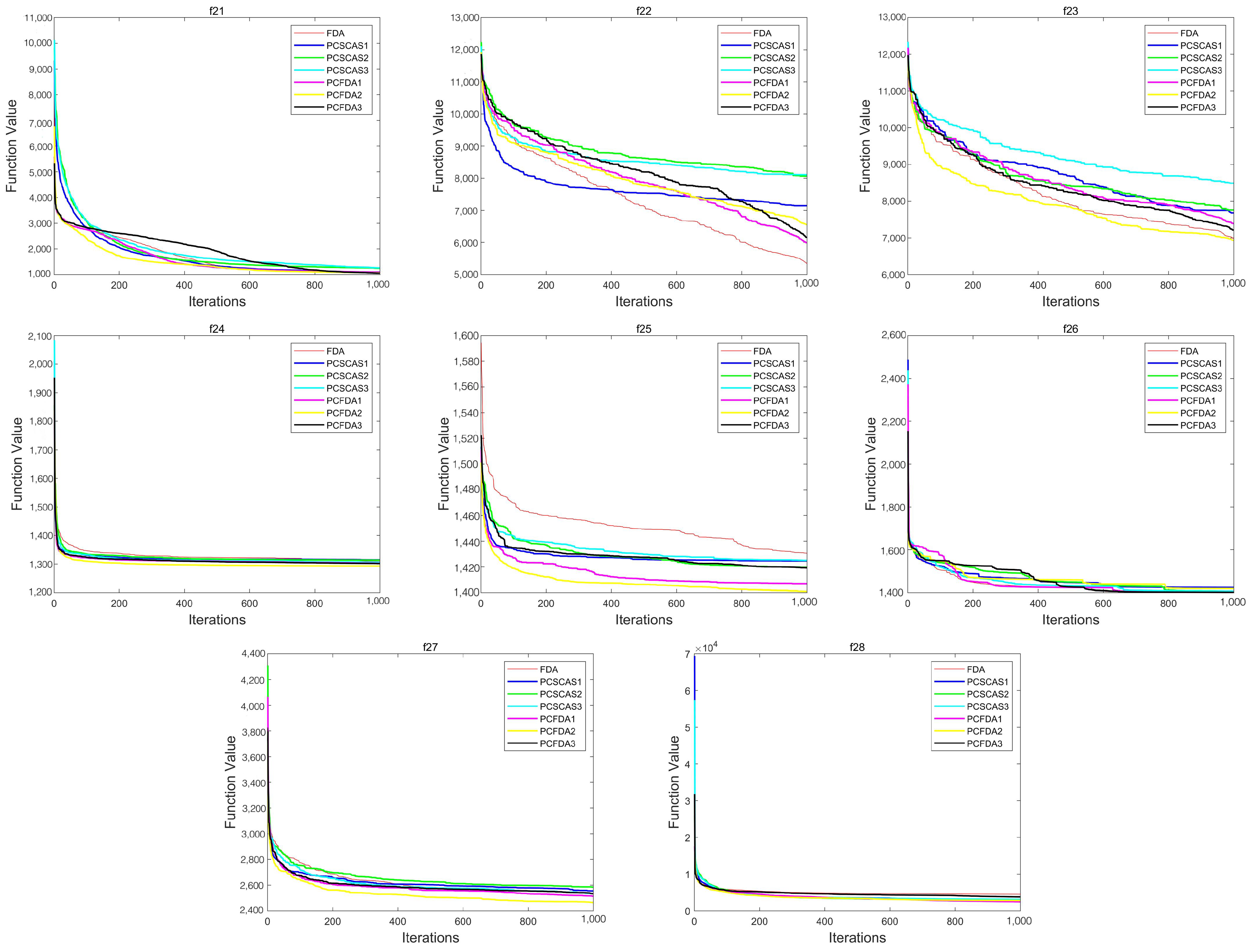
This section evaluates the performance of the algorithms by comparing the convergence curves of the PCFDA and PCSCA algorithms on three classes of functions. Figure 4, Figure 5 and Figure 6 show the corresponding experimental results.
From the convergence curves of the three types of functions, on the unimodal function, the convergence speed of each algorithm is not much different. Only on f1 do the PCFDA1 and PCFDA2 algorithms converge faster in the early stage. On the multimodal functions f8 and f20, although the convergence speeds of the algorithms are quite different, they have similar optimization capabilities based on the data in Table 1 and Table 5. On f6, f7, f10, and f19, the convergence speed of each algorithm is similar. Due to the instability of each algorithm’s search on other multimodal functions, the convergence speed and accuracy are different. On the mixed functions f23, f24, f25, and f27, PCFDA2 converges faster and has the best optimization accuracy. On the function f22, the FDA has better convergence speed and accuracy than other algorithms.
5. Application of PCFDA in Mobile Sensor Localization Problem
This section discusses the PCFDA algorithm for mobile sensor localization and compares it with the original MCL algorithm under different numbers of anchor nodes and communication radii. Locations with large errors are first obtained by the MCL localization technique, and then the PCFDA algorithm is applied for further optimization around the obtained locations to reduce the localization error. The error function is defined as Equation (32):
Z represents the total number of unknown nodes, and N represents the total number of anchor nodes. denotes the estimated location of the unknown node l, and denotes the location of the anchor node. represents the distance between unknown node l and anchor node k. This section assumes that anchor node k can obtain the distance between anchor node k and unknown node l through the signal strength received from unknown node l. The smaller the error value, the higher the positioning accuracy.
5.1. Experimental Analysis of Different Numbers of Anchor Nodes
In this section, the total number of nodes is set to 300, randomly distributed within the space range of 300 × 300. The number of anchor nodes is set to 10, 20, 30, 40, and 50, and the communication radius is set to 50. Experiments were performed using the MCL localization algorithm, FDA, and PCFDA. To avoid randomness, this section runs each algorithm 10 times and takes the average of 10 runs as the final result. The experimental results are shown in Table 10.
In Table 10, Ave and Std represent the mean and standard deviation of the run results, respectively. It can be seen from Table 10 that under the condition of a fixed communication radius, the more the number of anchor nodes, the smaller the positioning error and the more accurate the positioning. Compared with the MCL positioning algorithm, the positioning accuracy of the FDA has improved a lot, but the FDA is extremely unstable. The cAPSO [48] algorithm has comparable localization accuracy to the FDA algorithm, but it is more stable than the FDA algorithm. Under the same experimental conditions, the performance of the PCFDA is remarkable, both in positioning accuracy and algorithm stability are better than the FDA, and the positioning accuracy is much better than the MCL algorithm.
5.2. Experimental Analysis of Different Communication Radius
This section also uses 300 nodes for experiments and distributes them in the space of 300 × 300. The number of anchor nodes is set to 50, and the communication radius is set to 20, 40, 60, and 80, respectively. Each algorithm is run 10 times in this section, and the mean and standard deviation of 10 runs are taken for experimental analysis. The experimental results are shown in Table 11.
Table 11 shows that when the number of anchor nodes is fixed, the larger the communication radius, the smaller the positioning error, and the more accurate the positioning. The positioning accuracy of the FDA is better than the MCL positioning algorithm, but the stability is poor. The cAPSO algorithm is comparable to the FDA algorithm in terms of localization accuracy, but with better stability. The performance improvement of PCFDA is more significant and has good results in positioning accuracy and operational stability.
6. Conclusions
This paper proposes three intergroup communication strategies to improve the food digestion algorithm. These three strategies use different topologies, which significantly demonstrate the efficiency of particle communication and speed up the algorithm’s convergence. This paper also uses a compact strategy to improve the food digestion algorithm, reducing the algorithm’s running time and saving memory space. Then, this paper tested the PCFDA algorithm on the CEC2013 test set and achieved good results. Finally, this paper uses the improved algorithm to solve the problem of mobile sensor localization, which reduces the error of positioning and improves the accuracy of positioning.
In the future, we can use other inter-group communication strategies to further improve the FDA’s search accuracy. In the meantime, we will consider using the improved algorithm for other localization problems in wireless sensor networks. The design process of the algorithm does not take into account issues such as communication barriers of mobile sensors in real environments, so these factors can be considered to be added in future research.
Author Contributions
Conceptualization, S.-C.C. and Z.-Y.S.; Methodology, J.-S.P.; Software, N.Z. and G.-G.L.; Validation, Z.-Y.S.; Data curation, J.-S.P.; Writing—original draft preparation, Z.-Y.S.; Writing—review and editing, J.-S.P. and S.-C.C.; Supervision, N.Z.; Project administration, G.-G.L. and J.-S.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Shao, Z.Y.; Pan, J.S.; Hu, P.; Chu, S.C. Equilibrium optimizer of interswarm interactive learning strategy. Enterp. Inf. Syst. 2023, 17, 1949636. [Google Scholar] [CrossRef]
- Wu, T.; Guo, X.; Chen, Y.; Kumari, S.; Chen, C. Amassing the security: An enhanced authentication protocol for drone communications over 5G networks. Drones 2022, 6, 10. [Google Scholar] [CrossRef]
- Zhang, Z.K.; Li, P.Q.; Zeng, J.J.; Liu, X.K. Capacity Optimization of Hybrid Energy Storage System Based on Improved Golden Eagle Optimization. J. Netw. Intell. 2022, 7, 4. [Google Scholar]
- Pan, J.S.; Sun, X.X.; Chu, S.C.; Abraham, A.; Yan, B. Digital watermarking with improved SMS applied for QR code. Eng. Appl. Artif. Intell. 2021, 97, 104049. [Google Scholar] [CrossRef]
- Mantere, T.; Alander, J.T. Evolutionary software engineering, a review. Appl. Soft Comput. 2005, 5, 315–331. [Google Scholar] [CrossRef]
- Pan, J.S.; Hu, P.; Chu, S.C. Binary fish migration optimization for solving unit commitment. Energy 2021, 226, 120329. [Google Scholar] [CrossRef]
- Sarkar, S.; Das, S.; Chaudhuri, S.S. A multilevel color image thresholding scheme based on minimum cross entropy and differential evolution. Pattern Recognit. Lett. 2015, 54, 27–35. [Google Scholar] [CrossRef]
- Rodríguez-Esparza, E.; Zanella-Calzada, L.A.; Oliva, D.; Heidari, A.A.; Zaldivar, D.; Pérez-Cisneros, M.; Foong, L.K. An efficient Harris hawks-inspired image segmentation method. Expert Syst. Appl. 2020, 155, 113428. [Google Scholar] [CrossRef]
- Pan, J.S.; Nguyen, T.L.P.; Ngo, T.G.; Dao, T.K.; Nguyen, T.T.T.; Nguyen, T.T. An Optimizing Cross-Entropy Thresholding for Image Segmentation based on Improved Cockroach Colony Optimization. J. Inf. Hiding Multim. Signal Process. 2020, 11, 162–171. [Google Scholar]
- Fatani, A.; Dahou, A.; Abd Elaziz, M.; Al-qaness, M.A.; Lu, S.; Alfadhli, S.A.; Alresheedi, S.S. Enhancing Intrusion Detection Systems for IoT and Cloud Environments Using a Growth Optimizer Algorithm and Conventional Neural Networks. Sensors 2023, 23, 4430. [Google Scholar] [CrossRef]
- Zafar, A.; Hussain, S.J.; Ali, M.U.; Lee, S.W. Metaheuristic Optimization-Based Feature Selection for Imagery and Arithmetic Tasks: An fNIRS Study. Sensors 2023, 23, 3714. [Google Scholar] [CrossRef] [PubMed]
- Romeh, A.E.; Mirjalili, S. Multi-Robot Exploration of Unknown Space Using Combined Meta-Heuristic Salp Swarm Algorithm and Deterministic Coordinated Multi-Robot Exploration. Sensors 2023, 23, 2156. [Google Scholar] [CrossRef]
- Wu, J.; Xu, M.; Liu, F.F.; Huang, M.; Ma, L.; Lu, Z.M. Solar Wireless Sensor Network Routing Algorithm Based on Multi-Objective Particle Swarm Optimization. J. Inf. Hiding Multim. Signal Process. 2021, 12, 1. [Google Scholar]
- He, J.Y.; Hu, X.Y.; Hu, C.C.; Wu, M.X.; Zhang, M. Three-dimensional Localization Algorithm for WSN Nodes Based on Hybrid RSSI and DV-Hop. J. Netw. Intell. 2022, 7, 3. [Google Scholar]
- Li, X.; Liu, S.; Kumari, S.; Chen, C.M. PSAP-WSN: A Provably Secure Authentication Protocol for 5G-Based Wireless Sensor Networks. CMES—Comput. Model. Eng. Sci. 2023, 135, 711–732. [Google Scholar] [CrossRef]
- Wang, G.G.; Gao, D.; Pedrycz, W. Solving multiobjective fuzzy job-shop scheduling problem by a hybrid adaptive differential evolution algorithm. IEEE Trans. Ind. Inform. 2022, 18, 8519–8528. [Google Scholar] [CrossRef]
- Li, M.; Wang, G.G.; Yu, H. Sorting-based discrete artificial bee colony algorithm for solving fuzzy hybrid flow shop green scheduling problem. Mathematics 2021, 9, 2250. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–67. [Google Scholar] [CrossRef]
- Dorigo, M.; Maniezzo, V.; Colorni, A. Ant system: Optimization by a colony of cooperating agents. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 1996, 26, 29–41. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential evolution-a simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; IEEE: New York, NY, USA, 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Glob. Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Yang, X.S.; Deb, S. Cuckoo search via Lévy flights. In Proceedings of the 2009 World congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; IEEE: New York, NY, USA, 2009; pp. 210–214. [Google Scholar]
- Rashedi, E.; Nezamabadi-Pour, H.; Saryazdi, S. GSA: A gravitational search algorithm. Inf. Sci. 2009, 179, 2232–2248. [Google Scholar] [CrossRef]
- Yang, X.S.; Hossein Gandomi, A. Bat algorithm: A novel approach for global engineering optimization. Eng. Comput. 2012, 29, 464–483. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Abualigah, L.; Yousri, D.; Abd Elaziz, M.; Ewees, A.A.; Al-Qaness, M.A.; Gandomi, A.H. Aquila optimizer: A novel meta-heuristic optimization algorithm. Comput. Ind. Eng. 2021, 157, 107250. [Google Scholar] [CrossRef]
- Song, P.C.; Chu, S.C.; Pan, J.S.; Yang, H. Simplified Phasmatodea population evolution algorithm for optimization. Complex Intell. Syst. 2022, 8, 2749–2767. [Google Scholar] [CrossRef]
- Pan, J.S.; Zhang, L.G.; Wang, R.B.; Snášel, V.; Chu, S.C. Gannet optimization algorithm: A new metaheuristic algorithm for solving engineering optimization problems. Math. Comput. Simul. 2022, 202, 343–373. [Google Scholar] [CrossRef]
- Sui, X.; Chu, S.C.; Pan, J.S.; Luo, H. Parallel compact differential evolution for optimization applied to image segmentation. Appl. Sci. 2020, 10, 2195. [Google Scholar] [CrossRef]
- Song, P.C.; Pan, J.S.; Chu, S.C. A parallel compact cuckoo search algorithm for three-dimensional path planning. Appl. Soft Comput. 2020, 94, 106443. [Google Scholar] [CrossRef]
- Sheu, J.P.; Hu, W.K.; Lin, J.C. Distributed localization scheme for mobile sensor networks. IEEE Trans. Mob. Comput. 2009, 9, 516–526. [Google Scholar] [CrossRef]
- Amundson, I.; Koutsoukos, X.D. A survey on localization for mobile wireless sensor networks. In Proceedings of the Mobile Entity Localization and Tracking in GPS-less Environnments: Second International Workshop, MELT 2009, Orlando, FL, USA, 30 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 235–254. [Google Scholar]
- Singh, M.; Sethi, M.; Lal, N.; Poonia, S. A tree based routing protocol for mobile sensor networks (MSNs). Int. J. Comput. Sci. Eng. 2010, 2, 55–60. [Google Scholar]
- Sekhar, P.; Lydia, E.L.; Elhoseny, M.; Al-Akaidi, M.; Selim, M.M.; Shankar, K. An effective metaheuristic based node localization technique for wireless sensor networks enabled indoor communication. Phys. Commun. 2021, 48, 101411. [Google Scholar] [CrossRef]
- Michaelis, L.; Menten, M.L. Die kinetik der invertinwirkung. Biochem. Z. 1913, 49, 352. [Google Scholar]
- Eriksson, J.; Girod, L.; Hull, B.; Newton, R.; Madden, S.; Balakrishnan, H. The pothole patrol: Using a mobile sensor network for road surface monitoring. In Proceedings of the 6th International Conference on Mobile Systems, Applications, and Services, Breckenridge, CO, USA, 17–20 June 2008; pp. 29–39. [Google Scholar]
- Heo, N.; Varshney, P.K. Energy-efficient deployment of intelligent mobile sensor networks. IEEE Trans. Syst. Man Cybern.—Part A Syst. Hum. 2004, 35, 78–92. [Google Scholar] [CrossRef]
- Hu, L.; Evans, D. Localization for mobile sensor networks. In Proceedings of the 10th Annual International Conference on Mobile Computing and Networking, Philadelphia, PA, USA, 26 September–1 October 2004; pp. 45–57. [Google Scholar]
- Pelikan, M.; Hauschild, M.W.; Lobo, F.G. Estimation of distribution algorithms. In Springer Handbook of Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2015; pp. 899–928. [Google Scholar]
- Mininno, E.; Neri, F.; Cupertino, F.; Naso, D. Compact differential evolution. IEEE Trans. Evol. Comput. 2010, 15, 32–54. [Google Scholar] [CrossRef]
- Mininno, E.; Cupertino, F.; Naso, D. Real-valued compact genetic algorithms for embedded microcontroller optimization. IEEE Trans. Evol. Comput. 2008, 12, 203–219. [Google Scholar] [CrossRef]
- Bronshtein, I.N.; Semendyayev, K.A. Handbook of Mathematics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Rivlin, T.J. Chebyshev Polynomials; Courier Dover Publications: Mineola, NY, USA, 2020. [Google Scholar]
- Cody, W.J. Rational Chebyshev approximations for the error function. Math. Comput. 1969, 23, 631–637. [Google Scholar] [CrossRef]
- Zheng, W.M.; Liu, N.; Chai, Q.W.; Chu, S.C. A compact adaptive particle swarm optimization algorithm in the application of the mobile sensor localization. Wirel. Commun. Mob. Comput. 2021, 2021, 1676879. [Google Scholar] [CrossRef]
Figure 1.
Flowchart of the MCL algorithm.

Figure 2.
Filtering stage.

Figure 3.
Three topologies.

Figure 4.
Convergence curves on the unimodal functions.

Figure 5.
Convergence curves on multimodal functions.

Figure 6.
Convergence curves on mixed functions.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The average of the running results of the improved FDA and the original FDA.
| Functions | FDA | PCFDA1 | PCFDA2 | PCFDA3 |
|---|---|---|---|---|
| f1 | − | − | − | − |
| f2 | ||||
| f3 | ||||
| f4 | ||||
| f5 | − | − | − | − |
| f6 | − | − | − | − |
| f7 | − | − | − | − |
| f8 | − | − | − | − |
| f9 | − | − | − | − |
| f10 | − | − | − | − |
| f11 | − | − | − | − |
| f12 | ||||
| f13 | ||||
| f14 | ||||
| f15 | ||||
| f16 | ||||
| f17 | ||||
| f18 | ||||
| f19 | ||||
| f20 | ||||
| f21 | ||||
| f22 | ||||
| f23 | ||||
| f24 | ||||
| f25 | ||||
| f26 | ||||
| f27 | ||||
| f28 | ||||
| win | 14 | 16 | 12 |
Table 2.
The standard deviation of the running results of the improved FDA and the original FDA.
| Functions | FDA | PCFDA1 | PCFDA2 | PCFDA3 |
|---|---|---|---|---|
| f1 | ||||
| f2 | ||||
| f3 | ||||
| f4 | ||||
| f5 | ||||
| f6 | ||||
| f7 | ||||
| f8 | ||||
| f9 | ||||
| f10 | ||||
| f11 | ||||
| f12 | ||||
| f13 | ||||
| f14 | ||||
| f15 | ||||
| f16 | ||||
| f17 | ||||
| F18 | ||||
| f19 | ||||
| f20 | ||||
| f21 | ||||
| f22 | ||||
| f23 | ||||
| f24 | ||||
| f25 | ||||
| f26 | ||||
| f27 | ||||
| f28 | ||||
| win | 18 | 18 | 14 |
Table 3.
The comparison results between PCFDA1, PCFDA2, and PCFDA3 with FDA.
| Functions | PCFDA1 | PCFDA2 | PCFDA3 |
|---|---|---|---|
| f1 | |||
| f2 | |||
| f3 | |||
| f4 | |||
| f5 | |||
| f6 | |||
| f7 | |||
| f8 | |||
| f9 | |||
| f10 | |||
| f11 | |||
| f12 | |||
| f13 | |||
| f14 | |||
| f15 | |||
| f16 | |||
| f17 | |||
| f18 | |||
| f19 | |||
| f20 | |||
| f21 | |||
| f22 | |||
| f23 | |||
| f24 | |||
| f25 | |||
| f26 | |||
| f27 | |||
| f28 |
Table 4.
The average running time and memory usage of each algorithm.
| Evaluation Indicators | FDA | PCFDA1 | PCFDA2 | PCFDA3 |
|---|---|---|---|---|
| Average running time | 36.34 | 33.22 | 30.37 | 35.46 |
| Memory usage |
Table 5.
The running results of the average value of each algorithm.
| Functions | PCSCAS1 | PCSCAS2 | PCSCAS3 | PCFDA1 | PCFDA2 | PCFDA3 |
|---|---|---|---|---|---|---|
| f1 | − | − | − | − | − | − |
| f2 | ||||||
| f3 | ||||||
| f4 | ||||||
| f5 | − | − | − | − | − | − |
| f6 | − | −2.52 | − | − | − | − |
| f7 | − | − | − | − | − | − |
| f8 | − | − | − | − | − | − |
| f9 | − | − | − | − | − | − |
| f10 | − | − | − | − | − | − |
| f11 | −1.35 | − | − | − | − | |
| f12 | 3.38 | 9.36 | ||||
| f13 | ||||||
| f14 | ||||||
| f15 | ||||||
| f16 | ||||||
| f17 | ||||||
| f18 | ||||||
| f19 | ||||||
| f20 | ||||||
| f21 | ||||||
| f22 | ||||||
| f23 | ||||||
| f24 | ||||||
| f25 | ||||||
| f26 | ||||||
| f27 | ||||||
| f28 |
Table 6.
The running results of the standard deviation of each algorithm.
| Functions | PCSCAS1 | PCSCAS2 | PCSCAS3 | PCFDA1 | PCFDA2 | PCFDA3 |
|---|---|---|---|---|---|---|
| f1 | ||||||
| f2 | ||||||
| f3 | ||||||
| f4 | ||||||
| f5 | ||||||
| f6 | ||||||
| f7 | ||||||
| f8 | ||||||
| f9 | ||||||
| f10 | ||||||
| f11 | ||||||
| f12 | ||||||
| f13 | ||||||
| f14 | ||||||
| f15 | ||||||
| f16 | ||||||
| f17 | ||||||
| f18 | ||||||
| f19 | ||||||
| f20 | ||||||
| f21 | ||||||
| f22 | ||||||
| f23 | ||||||
| f24 | ||||||
| f25 | ||||||
| f26 | ||||||
| f27 | ||||||
| f28 |
Table 7.
The comparison results between PCFDA1 with three improved SCA algorithms.
| Functions | PCSCAS1 | PCSCAS2 | PCSCAS3 |
|---|---|---|---|
| f1 | |||
| f2 | |||
| f3 | |||
| f4 | |||
| f5 | |||
| f6 | |||
| f7 | |||
| f8 | |||
| f9 | |||
| f10 | |||
| f11 | |||
| f12 | |||
| f13 | |||
| f14 | |||
| f15 | |||
| f16 | |||
| f17 | |||
| f18 | |||
| f19 | |||
| f20 | |||
| f21 | |||
| f22 | |||
| f23 | |||
| f24 | |||
| f25 | |||
| f26 | |||
| f27 | |||
| f28 |
Table 8.
The comparison results between PCFDA2 with three improved SCA algorithms.
| Functions | PCSCAS1 | PCSCAS2 | PCSCAS3 |
|---|---|---|---|
| f1 | |||
| f2 | |||
| f3 | |||
| f4 | |||
| f5 | |||
| f6 | |||
| f7 | |||
| f8 | |||
| f9 | |||
| f10 | |||
| f11 | |||
| f12 | |||
| f13 | |||
| f14 | |||
| f15 | |||
| f16 | |||
| f17 | |||
| f18 | |||
| f19 | |||
| f20 | |||
| f21 | |||
| f22 | |||
| f23 | |||
| f24 | |||
| f25 | |||
| f26 | |||
| f27 | |||
| f28 |
Table 9.
The comparison results between PCFDA3 with three improved SCA algorithms.
| Functions | PCSCAS1 | PCSCAS2 | PCSCAS3 |
|---|---|---|---|
| f1 | |||
| f2 | |||
| f3 | |||
| f4 | |||
| f5 | |||
| f6 | |||
| f7 | |||
| f8 | |||
| f9 | |||
| f10 | |||
| f11 | |||
| f12 | |||
| f13 | |||
| f14 | |||
| f15 | |||
| f16 | |||
| f17 | |||
| f18 | |||
| f19 | |||
| f20 | |||
| f21 | |||
| f22 | |||
| f23 | |||
| f24 | |||
| f25 | |||
| f26 | |||
| f27 | |||
| f28 |
Table 10.
Experimental results of the localization error of different anchor nodes.
| Algorithms | Evaluation Indicators | 10 | 20 | 30 | 40 | 50 |
|---|---|---|---|---|---|---|
| MCL | Ave | 23.6269 | 16.3017 | 11.8374 | 9.7348 | 8.8307 |
| Std | 2.8153 | 0.8655 | 0.5684 | 0.5097 | 0.7238 | |
| FDA | Ave | 20.8774 | 15.1468 | 7.5836 | 5.5885 | 6.2892 |
| Std | 4.5022 | 11.0386 | 4.8461 | 5.5609 | 3.6356 | |
| cAPSO | Ave | 20.2842 | 15.1823 | 9.3829 | 7.2389 | 5.8412 |
| Std | 2.7114 | 1.0986 | 0.8491 | 0.4829 | 0.2983 | |
| PCFDA1 | Ave | 19.2934 | 15.3938 | 6.2677 | 5.4326 | 3.2778 |
| Std | 2.1672 | 1.0578 | 0.5648 | 0.4364 | 0.5363 | |
| PCFDA2 | Ave | 19.3737 | 14.3896 | 6.3897 | 5.2874 | 3.9473 |
| Std | 2.6438 | 1.1724 | 0.6573 | 0.5483 | 0.6372 | |
| PCFDA3 | Ave | 19.2478 | 15.3851 | 6.0837 | 5.3573 | 3.3732 |
| Std | 2.6327 | 1.2563 | 0.5885 | 0.8356 | 0.6334 |
Table 11.
Experimental results of the localization error of different communication radius.
| Algorithms | Evaluation Indicators | 20 | 40 | 60 | 80 |
|---|---|---|---|---|---|
| MCL | Ave | 16.8253 | 11.1635 | 7.5723 | 6.6517 |
| Std | 2.2746 | 0.8523 | 0.2663 | 0.4111 | |
| FDA | Ave | 14.0564 | 8.5623 | 4.7753 | 1.3562 |
| Std | 9.2742 | 10.6584 | 4.2358 | 5.2645 | |
| cAPSO | Ave | 14.3829 | 8.5933 | 4.8321 | 1.8932 |
| Std | 1.3922 | 1.0529 | 0.4721 | 0.2292 | |
| PCFDA1 | Ave | 7.0317 | 3.3189 | 1.5642 | 0.6523 |
| Std | 1.7834 | 0.9748 | 0.5943 | 0.2984 | |
| PCFDA2 | Ave | 6.9851 | 3.3451 | 1.1567 | 0.6586 |
| Std | 1.8375 | 0.9732 | 0.5382 | 0.4928 | |
| PCFDA3 | Ave | 6.9856 | 3.7652 | 1.3654 | 0.8562 |
| Std | 1.9382 | 0.9375 | 0.4878 | 0.7362 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Chu, S.-C.; Shao, Z.-Y.; Zhong, N.; Liu, G.-G.; Pan, J.-S. An Enhanced Food Digestion Algorithm for Mobile Sensor Localization. Sensors 2023, 23, 7508. https://doi.org/10.3390/s23177508
AMA Style
Chu S-C, Shao Z-Y, Zhong N, Liu G-G, Pan J-S. An Enhanced Food Digestion Algorithm for Mobile Sensor Localization. Sensors. 2023; 23(17):7508. https://doi.org/10.3390/s23177508
Chicago/Turabian StyleChu, Shu-Chuan, Zhi-Yuan Shao, Ning Zhong, Geng-Geng Liu, and Jeng-Shyang Pan. 2023. "An Enhanced Food Digestion Algorithm for Mobile Sensor Localization" Sensors 23, no. 17: 7508. https://doi.org/10.3390/s23177508
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.