
Sustainable Resource Allocation and Reduce Latency Based on Federated-Learning-Enabled Digital Twin in IoT Devices
 , , , , and
, , , , and 
Abstract
:1. Introduction
1.1. Related Works
1.2. Motivation and Contributions
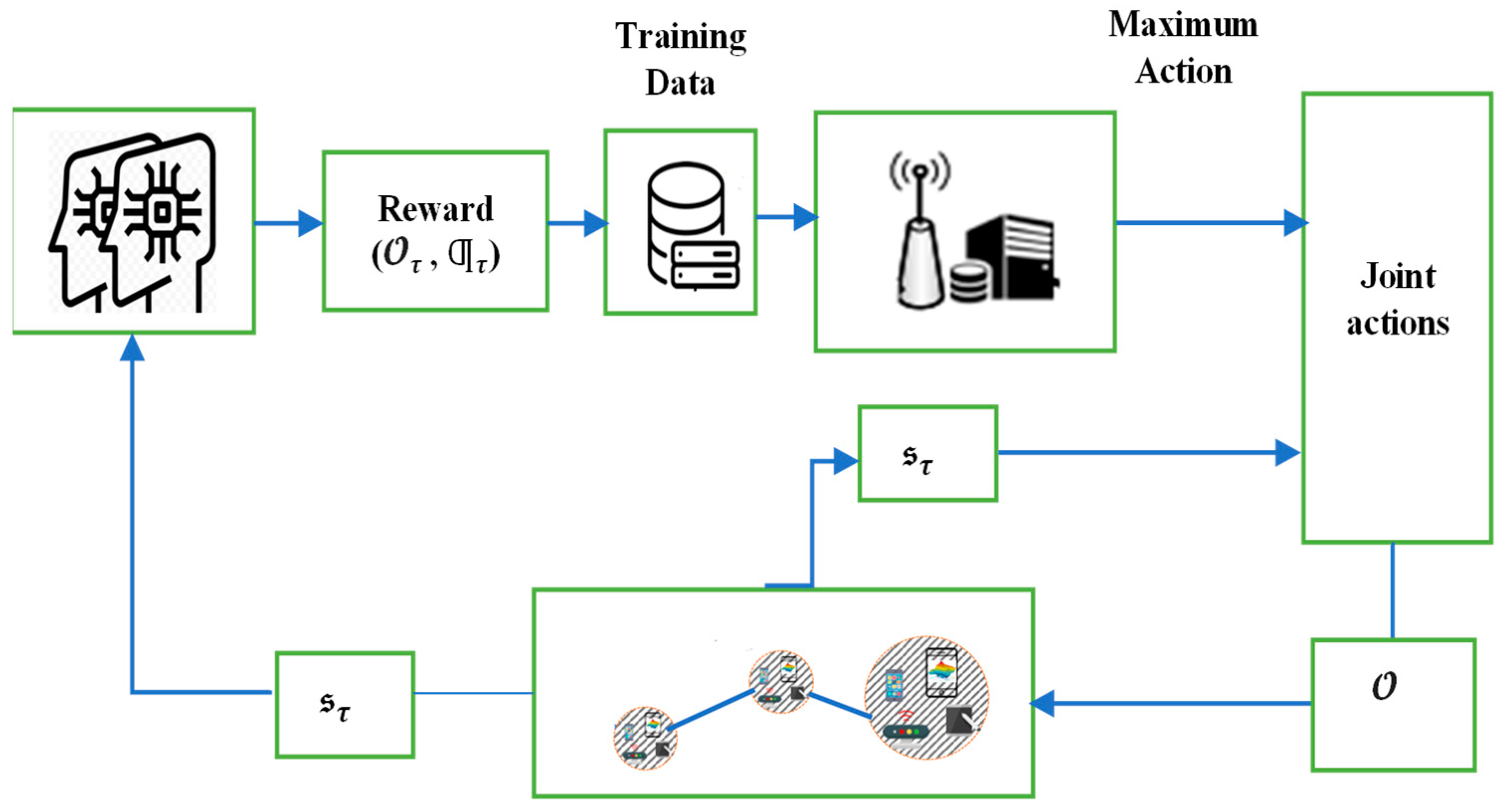
- To effectively and appropriately optimize IoT networks, we proposed a DT-empowered IoT framework that maps a data-driven DT device’s real-time operation using blockchain technology.
- We use the FL framework to build the DT edge network models by employing a gradient descent approach that can lower the overhead of data transfer and safeguard data privacy. Furthermore, we use asynchronous model aggregation to increase communication efficiency, which depends on enhancing the target of local computing by decreasing wait times and keeping track of the training process achievement at edge servers to reduce redundant user delays.
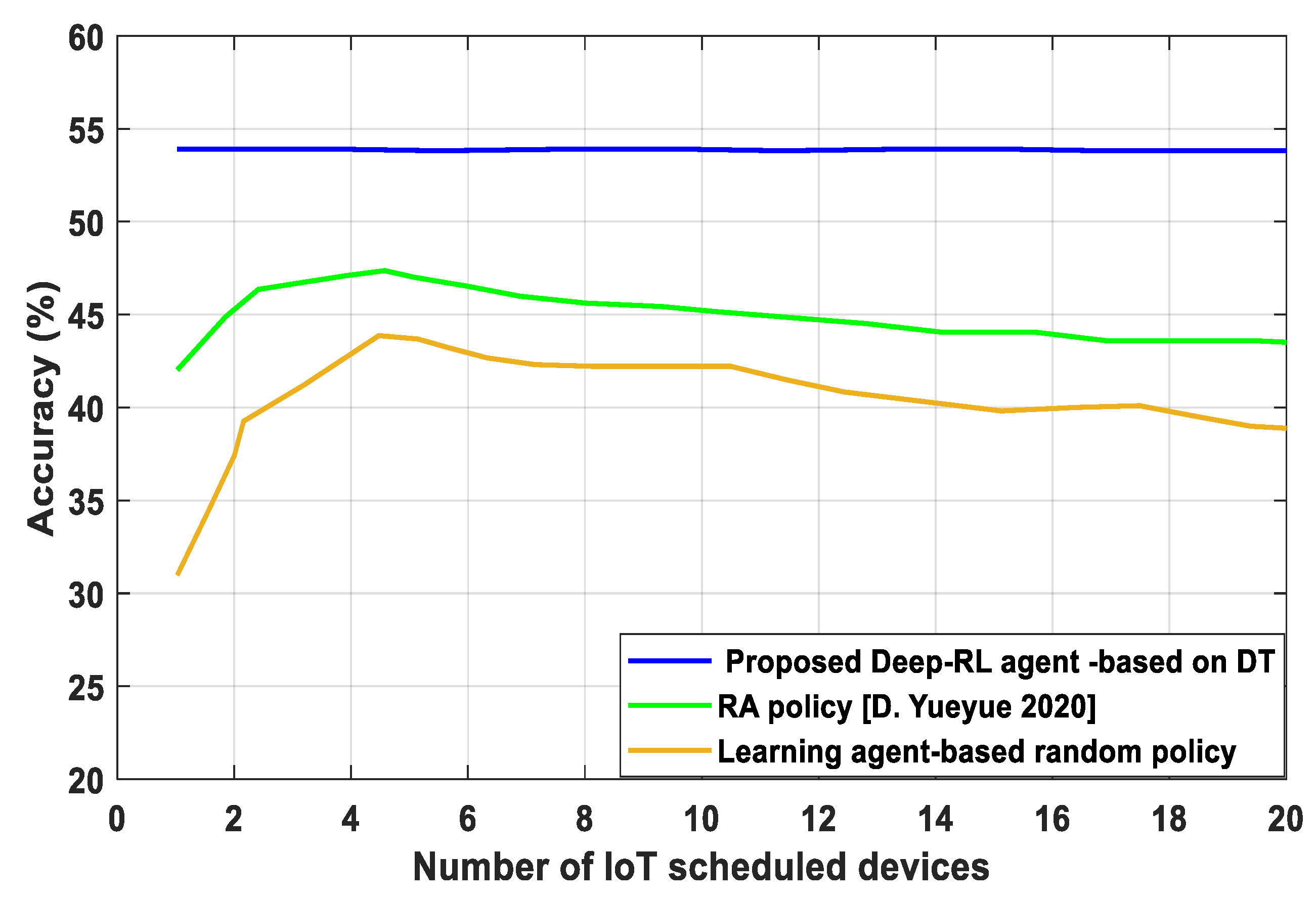
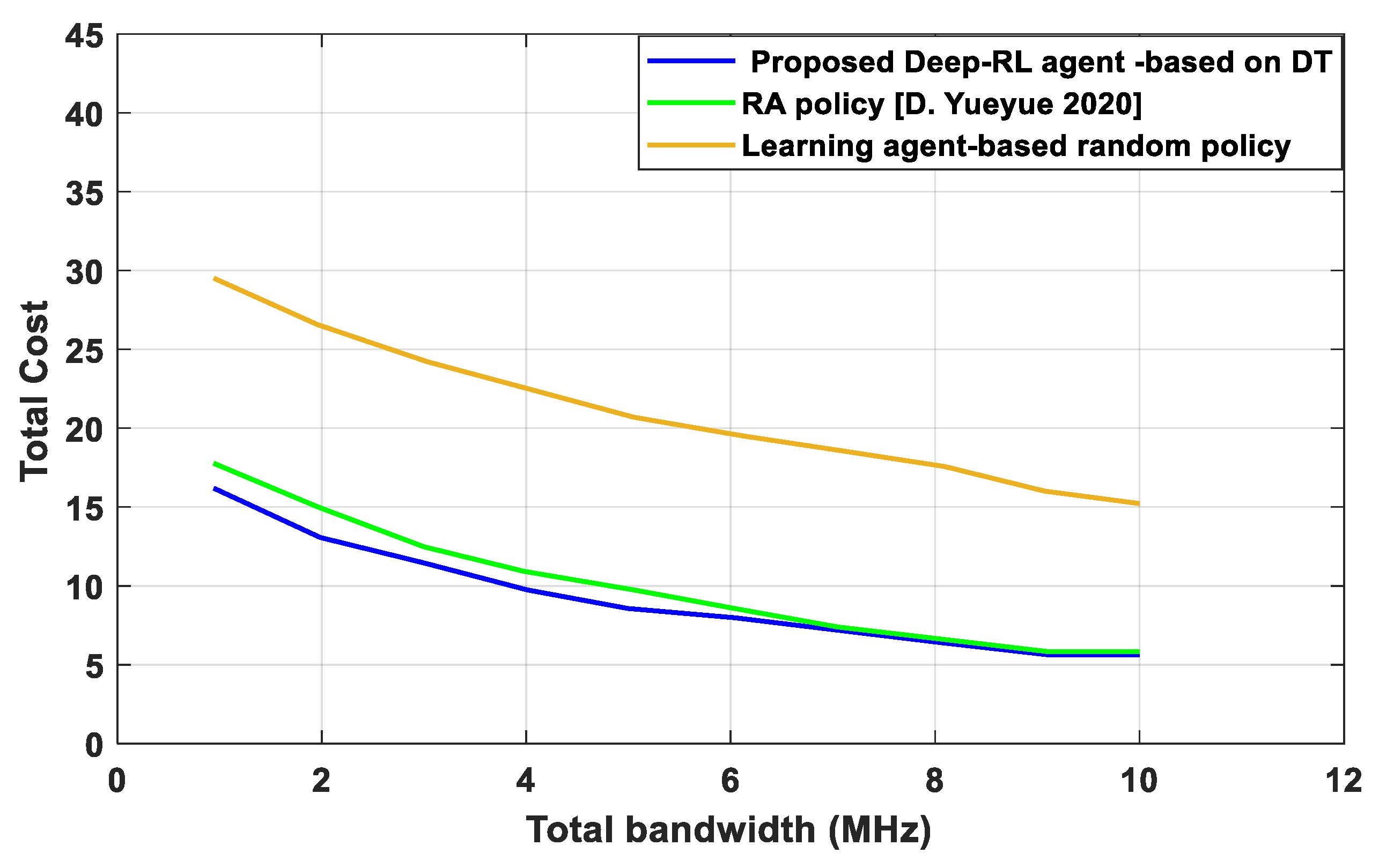
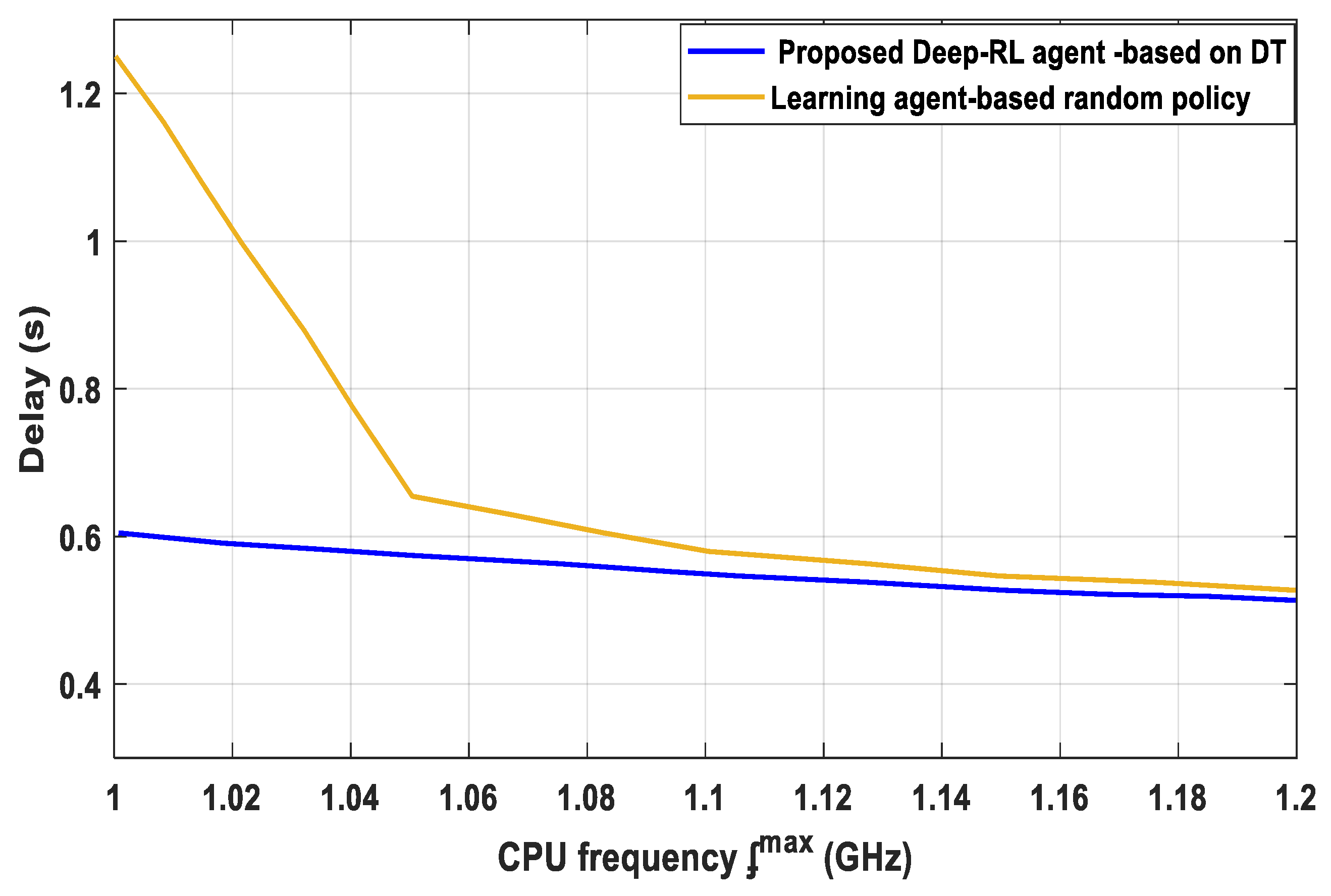
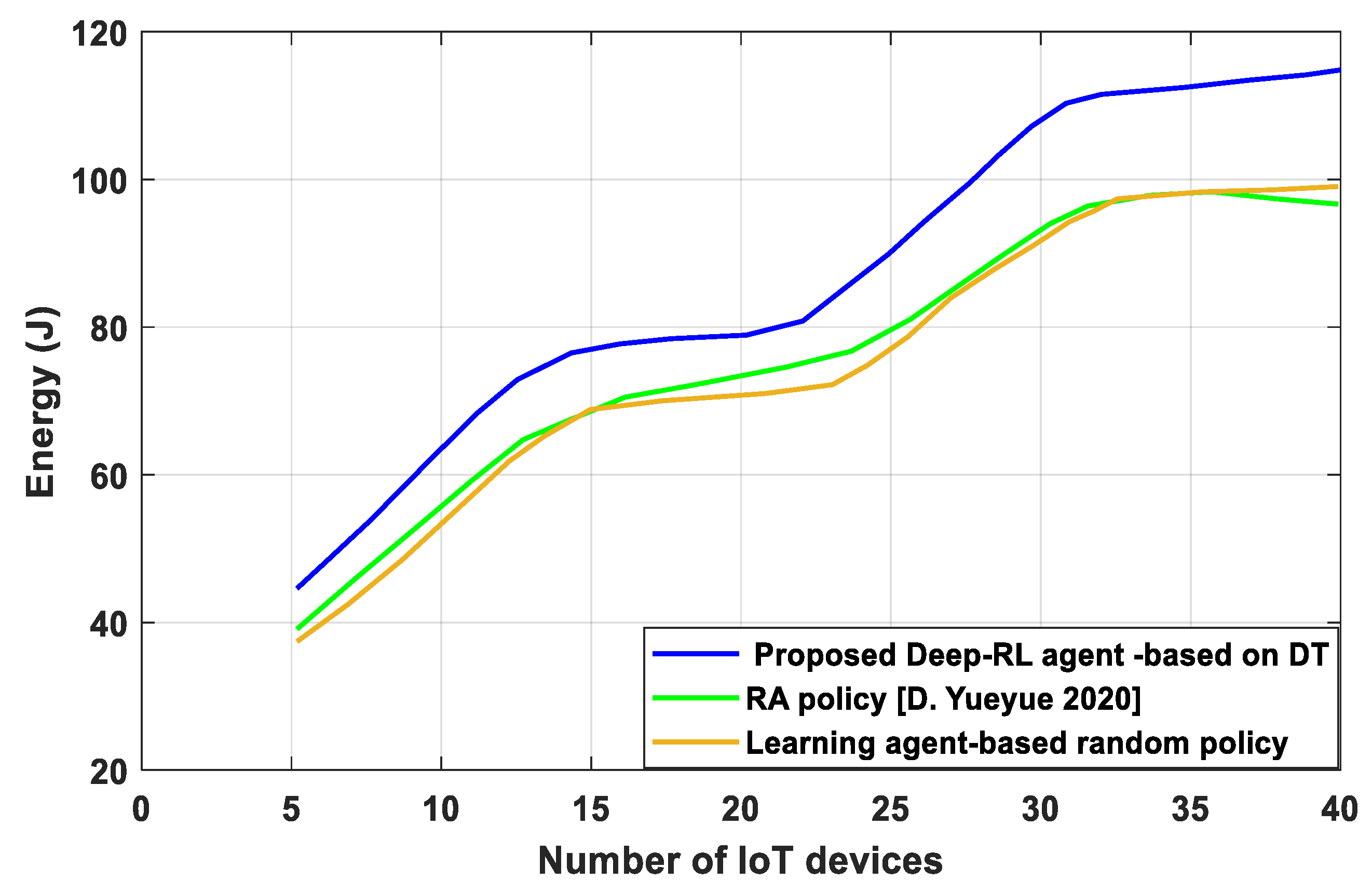
- We present a unique blockchain-supported DT-IoT framework to reduce the system delay and EC and provide secure and reliable computing in DNN, as well as new insight into the impact of the training process achievement requirements on the RA efficiency. The proposed Deep-RL agent based on DT evaluates the performance action based on RA for the user scheduling and bandwidth allocation in IoT devices in order to increase system stability, develop a balance in learning accuracy, and guarantee the learning accuracy of IoT devices.
2. Materials and Methods
2.1. Sustainable Blockchain Model for Secure Communication
2.2. Learning Accuracy for DT-IoT -FL
2.3. IoT Device for EC
3. Formulation of the Communication Effectiveness Problem for DT-IoT Using FL
3.1. DNN-Train-Based Resource Scheduling Algorithm in DT-IoT
3.2. Deep-RL Agent for RA
| Algorithm 1: Deep-RL Agent for RA Scheduling Algorithm in DT-IoT |
|
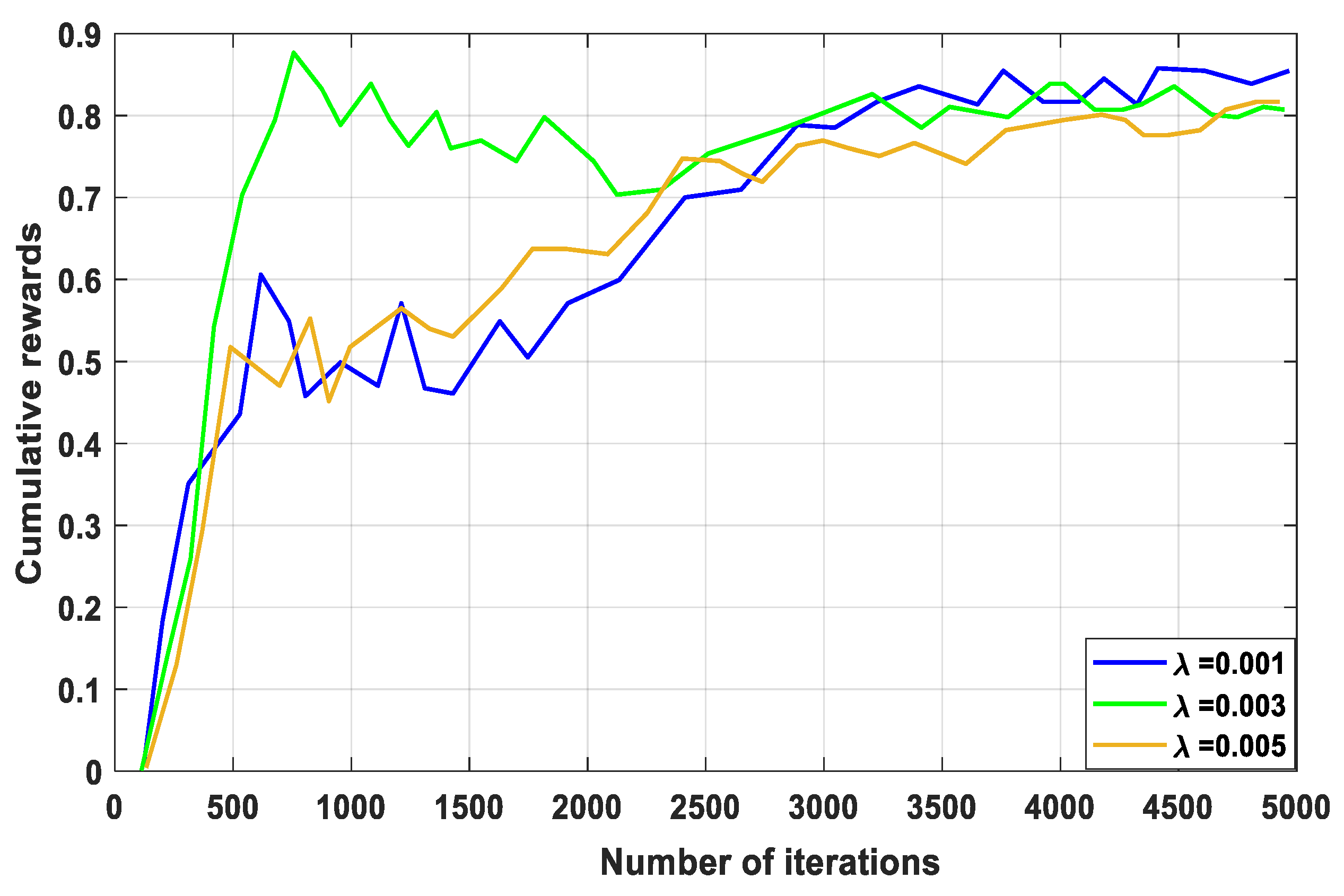
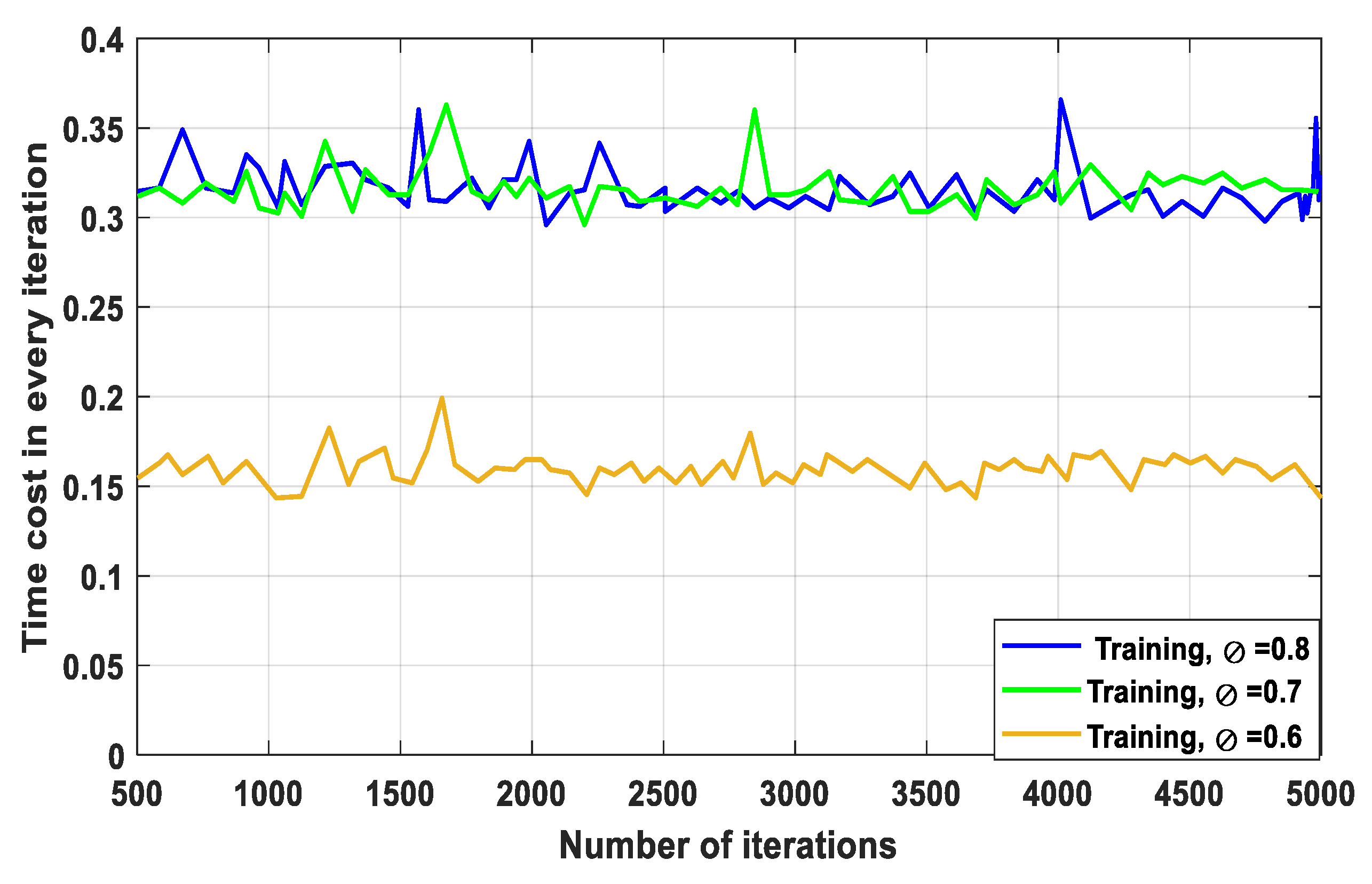
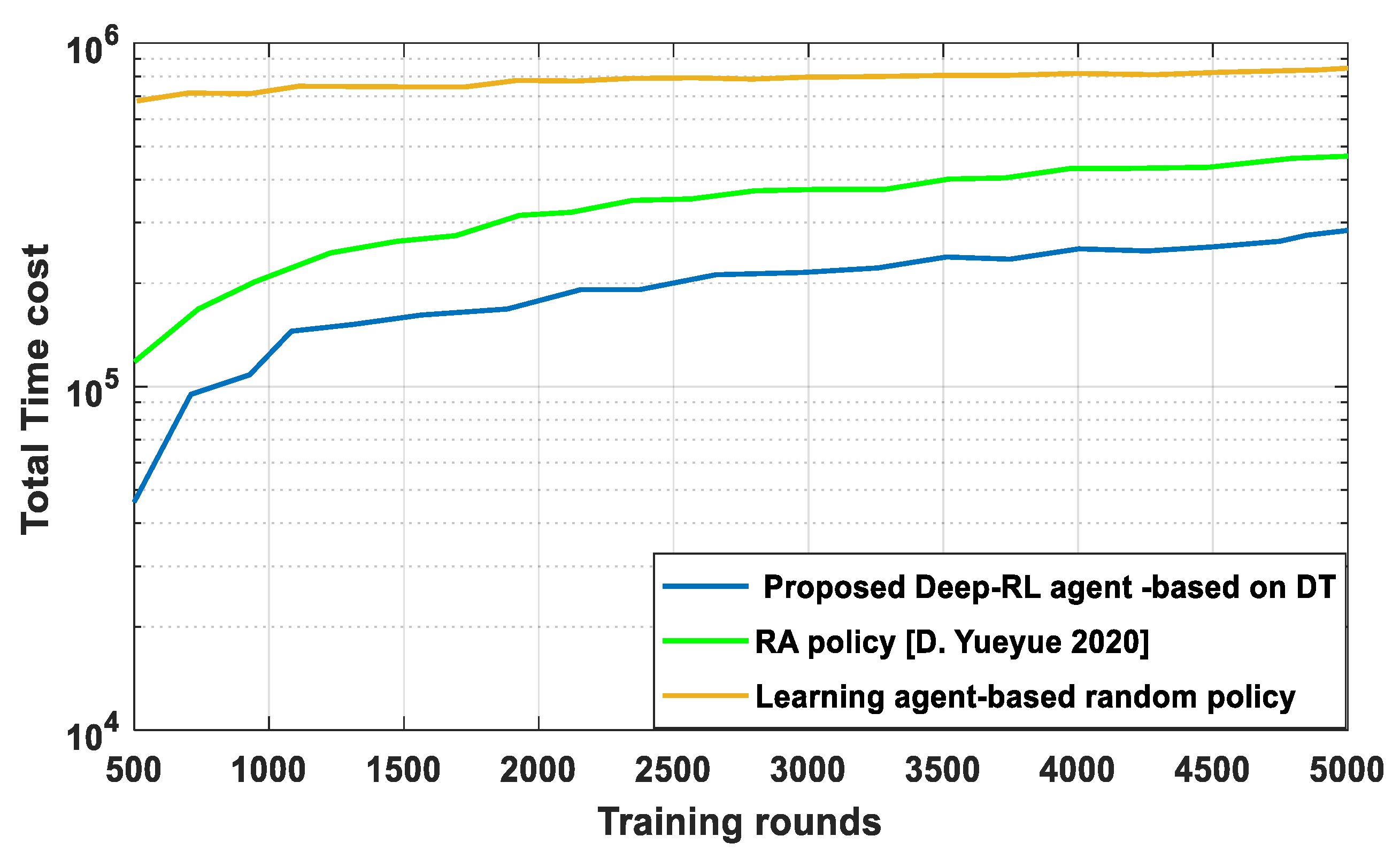
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, W.; Xiang, W.; Yang, Y.; Cheng, P. Optimizing federated learning with deep reinforcement learning for digital twin empowered industrial IoT. IEEE Trans. Ind. Inform. 2022, 19, 1884–1893. [Google Scholar] [CrossRef]
- Salh, A.; Audah, L.; Shah, N.S.; Alhammadi, A.; Abdullah, Q.; Kim, Y.H.; Al-Gailani, S.A.; Hamzah, S.A.; Esmail, B.A.; Almohammedi, A.A. A survey on deep learning for ultra-reliable and low-latency communications challenges on 6G wireless systems. IEEE Access 2021, 9, 55098–55131. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, K.; Zhang, Y. Digital twin networks: A survey. IEEE Internet Things J. 2021, 8, 13789–13804. [Google Scholar] [CrossRef]
- Schluse, M.; Priggemeyer, M.; Atorf, L.; Rossmann, J. Experimentable digital twins—Streamlining simulation-based systems engineering for industry 4.0. IEEE Trans. Ind. Inform. 2018, 14, 1722–1731. [Google Scholar] [CrossRef]
- Zhang, K.; Zhu, Y.; Maharjan, S.; Zhang, Y. Edge intelligence and blockchain empowered 5G beyond for the industrial Internet of Things. IEEE Netw. 2019, 33, 12–19. [Google Scholar] [CrossRef]
- Wang, P.; Xu, N.; Sun, W.; Wang, G.; Zhang, Y. Distributed incentives and digital twin for resource allocation in air-assisted internet of vehicles. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar]
- Dai, Y.; Xu, D.; Zhang, K.; Maharjan, S.; Zhang, Y. Deep reinforcement learning and permissioned blockchain for content caching in vehicular edge computing and networks. IEEE Trans. Veh. Technol. 2020, 69, 4312–4324. [Google Scholar] [CrossRef]
- Rasheed, A.; San, O.; Kvamsdal, T. Digital twin: Values, challenges and enablers from a modeling perspective. IEEE Access 2020, 8, 21980–22012. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, G.; Yan, Q. Dynamic resource allocation optimization for digital twin-driven smart shopfloor. In Proceedings of the 2018 IEEE 15th International Conference on Networking, Sensing and Control (ICNSC), Zhuhai, China, 27–29 March 2018; pp. 1–5. [Google Scholar]
- Sun, W.; Wang, P.; Xu, N.; Wang, G.; Zhang, Y. Dynamic digital twin and distributed incentives for resource allocation in aerial-assisted internet of vehicles. IEEE Internet Things J. 2021, 9, 5839–5852. [Google Scholar] [CrossRef]
- Zhang, K.; Cao, J.; Maharjan, S.; Zhang, Y. Digital twin empowered content caching in social-aware vehicular edge networks. IEEE Trans. Comput. Soc. Syst. 2021, 9, 239–251. [Google Scholar] [CrossRef]
- Razzaq, S.; Shah, B.; Iqbal, F.; Ilyas, M.; Maqbool, F.; Rocha, A. Deep ClassRooms: A deep learning based digital twin framework for on-campus class rooms. Neural Comput. Appl. 2023, 35, 8017–8026. [Google Scholar] [CrossRef]
- Dai, Y.; Xu, D.; Maharjan, S.; Chen, Z.; He, Q.; Zhang, Y. Blockchain and deep reinforcement learning empowered intelligent 5G beyond. IEEE Netw. 2019, 33, 10–17. [Google Scholar] [CrossRef]
- Shen, M.; Tang, X.; Zhu, L.; Du, X.; Guizani, M. Privacy-preserving support vector machine training over blockchain-based encrypted IoT data in smart cities. IEEE Internet Things J. 2019, 6, 7702–7712. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Blockchain and federated learning for 5G beyond. IEEE Netw. 2020, 35, 219–225. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated learning in mobile edge networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Communication-efficient federated learning and permissioned blockchain for digital twin edge networks. IEEE Internet Things J. 2020, 8, 2276–2288. [Google Scholar] [CrossRef]
- Wang, D.; Li, B.; Song, B.; Liu, Y.; Muhammad, K.; Zhou, X. Dual-driven resource management for sustainable computing in the blockchain-supported digital twin IoT. IEEE Internet Things J. 2022, 10, 6549–6560. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Communication-efficient federated learning for digital twin edge networks in industrial IoT. IEEE Trans. Ind. Inform. 2020, 17, 5709–5718. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Low-latency federated learning and blockchain for edge association in digital twin empowered 6G networks. IEEE Trans. Ind. Inform. 2020, 17, 5098–5107. [Google Scholar] [CrossRef]
- Wang, Z.; Song, M.; Zhang, Z.; Song, Y.; Wang, Q.; Qi, H. Beyond inferring class representatives: User-level privacy leakage from federated learning. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 2512–2520. [Google Scholar]
- Triastcyn, A.; Faltings, B. Federated learning with bayesian differential privacy. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 2587–2596. [Google Scholar]
- Dai, Y.; Zhang, K.; Maharjan, S.; Zhang, Y. Deep reinforcement learning for stochastic computation offloading in digital twin networks. IEEE Trans. Ind. Inform. 2020, 17, 4968–4977. [Google Scholar] [CrossRef]
- Tran, N.H.; Bao, W.; Zomaya, A.; Nguyen, M.N.; Hong, C.S. Federated learning over wireless networks: Optimization model design and analysis. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1387–1395. [Google Scholar]
- Salh, A.; Ngah, R.; Audah, L.; Kim, K.S.; Abdullah, Q.; Al-Moliki, Y.M.; Aljaloud, K.A.; Talib, H.N. Energy-Efficient Federated Learning with Resource Allocation for Green IoT Edge Intelligence in B5G. IEEE Access 2023, 11, 16353–16367. [Google Scholar] [CrossRef]
- Wang, H.; Sievert, S.; Liu, S.; Charles, Z.; Papailiopoulos, D.; Wright, S. Atomo: Communication-efficient learning via atomic sparsification. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Caldas, S.; Konečny, J.; McMahan, H.B.; Talwalkar, A. Expanding the reach of federated learning by reducing client resource requirements. arXiv 2018, arXiv:1812.07210. [Google Scholar]
- Yuan, N.; He, W.; Shen, J.; Qiu, X.; Guo, S.; Li, W. Delay-aware NFV resource allocation with deep reinforcement learning. In Proceedings of the NOMS 2020–2020 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 20–24 April 2020; pp. 1–7. [Google Scholar]
- Dinh, C.T.; Tran, N.H.; Nguyen, M.N.; Hong, C.S.; Bao, W.; Zomaya, A.Y.; Gramoli, V. Federated learning over wireless networks: Convergence analysis and resource allocation. IEEE/ACM Trans. Netw. 2020, 29, 398–409. [Google Scholar] [CrossRef]
- Wang, D.; Zhao, N.; Song, B.; Lin, P.; Yu, F.R. Resource management for secure computation offloading in softwarized cyber–physical systems. IEEE Internet Things J. 2021, 8, 9294–9304. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Communication bandwidth | 30 MHz |
| Transmit power | 20 dBm |
| Adjusting the target weight [1,6,12] | 0.8 |
| CPU clock speed mobile edge server [17,19] | Hz |
| Discount factor [25,26,27] | 0.5 |
| Time slot duration [1,3,10] | 0.05 |
| Noise figure | 5 dB |
| The data size of each IoT device [25,28] | [0 MB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alhartomi, M.A.; Salh, A.; Audah, L.; Alzahrani, S.; Alzahmi, A.; Altimania, M.R.; Alotaibi, A.; Alsulami, R.; Al-Hartomy, O. Sustainable Resource Allocation and Reduce Latency Based on Federated-Learning-Enabled Digital Twin in IoT Devices. Sensors 2023, 23, 7262. https://doi.org/10.3390/s23167262
Alhartomi MA, Salh A, Audah L, Alzahrani S, Alzahmi A, Altimania MR, Alotaibi A, Alsulami R, Al-Hartomy O. Sustainable Resource Allocation and Reduce Latency Based on Federated-Learning-Enabled Digital Twin in IoT Devices. Sensors. 2023; 23(16):7262. https://doi.org/10.3390/s23167262
Chicago/Turabian StyleAlhartomi, Mohammed A., Adeeb Salh, Lukman Audah, Saeed Alzahrani, Ahmed Alzahmi, Mohammad R. Altimania, Abdulaziz Alotaibi, Ruwaybih Alsulami, and Omar Al-Hartomy. 2023. "Sustainable Resource Allocation and Reduce Latency Based on Federated-Learning-Enabled Digital Twin in IoT Devices" Sensors 23, no. 16: 7262. https://doi.org/10.3390/s23167262