
A Residual UNet Denoising Network Based on Multi-Scale Feature Extraction and Attention-Guided Filter


1
School of Mathematics and Statistics, Changchun University of Science and Technology, Changchun 130022, China
2
Laboratory of Remote Sensing Technology and Big Data Analysis, Zhongshan Research Institute, Changchun University of Science and Technology, Zhongshan 528437, China
*
Author to whom correspondence should be addressed.
Sensors 2023, 23(16), 7044; https://doi.org/10.3390/s23167044
Submission received: 13 July 2023
/
Revised: 3 August 2023
/
Accepted: 5 August 2023
/
Published: 9 August 2023
(This article belongs to the Section Sensing and Imaging)
Abstract
:In order to obtain high-quality images, it is very important to remove noise effectively and retain image details reasonably. In this paper, we propose a residual UNet denoising network that adds the attention-guided filter and multi-scale feature extraction blocks. We design a multi-scale feature extraction block as the input block to expand the receiving domain and extract more useful features. We also develop the attention-guided filter block to hold the edge information. Further, we use the global residual network strategy to model residual noise instead of directly modeling clean images. Experimental results show our proposed network performs favorably against several state-of-the-art models. Our proposed model can not only suppress the noise more effectively, but also improve the sharpness of the image.
1. Introduction
As a typical problem in the field of low-level image processing, image denoising aims to recover the clean image from the observed image that is corrupted by some noise. Since both the clean image and the noise are unknown, it is critical to remove the noise while preserving the details of the image.
Traditional image denoising approaches, including filtering-based methods and model-based methods, have always been the main image denoising methods. For example, non-local mean (NLM) [1], block matching and three-dimensional filtering (BM3D) [2], wavelet transform [3,4,5], have become the most advanced image denoising methods. However, these traditional denoising methods tend to blur the image texture and reduce the image visual quality.
Compared with traditional denoising methods, convolutional neural networks (CNNs) have achieved state-of-the-art performances in some representative image denoising tasks. The popularity of CNNs in image denoising can be explained from two aspects. On the one hand, CNN has the advantages of speed, performance, and generalization ability compared with traditional noise removal devices [6,7]. On the other hand, recent research has shown that CNN-based methods can be inserted into model-based optimization methods to solve more complex image restoration tasks [8,9], which can promote the application ability of the CNN models.
By constructing a learnable deep neural network, deep learning denoising methods learn the mapping from damaged images to clean images. Moreover, some classical module methods were inserted to CNNs in order to improve the efficiency of the denoising task efficiently. Feng et al. developed a trainable nonlinear reaction diffusion (TNRD) model to remove the Poisson noise quickly and accurately [10]. The feed-forward denoising convolutional neural networks (DnCNNs) [7] focused on the complementary role of the residual learning and batch normalization in image restoration. Memory blocks were introduced in a persistent memory network (MemNet) for image recovery [11]. The popular attention mechanism was used in an attention-guided denoising convolutional neural network (ADNet) [12]. A convolutional blind denoising network (CBDNet) [13] contains a noise estimation subnet with asymmetric learning to realize the noise level estimation.
Although deep learning-based denoising methods have achieved an excellent denoising effect, it is very difficult to further improve the performance of deep learning-based denoising methods, because they need to increase the depth or width of the network, which will encounter a sharp increase in training parameters. Most deep denoising networks lack the adaptability since these models need to be trained for each noise level, which may induce a poor performance for other noise levels. Therefore, it is worth investigating how to explore and utilize the existing denoising networks, so as to achieve more effective denoising. Multi-scale features are very useful in the field of image quality and visual saliency in computer vision. For example, Varge [14] introduced a no-reference image quality assessment with multi-scale orderless pooling of deep features and Li et al. [15] proposed a visual saliency approach based on multiscale deep features. Beyond that, some enhancement techniques are feasible to improve the recovery quality of deep learning-based denoising methods, such as Tukey’s shrinking strategy [16] and the multi-level wavelet transform [17].
In this paper, we propose a residual-dense neural network (MAGUNet) that incorporates multi-scale feature extraction blocks and attention-guided filter blocks for image denoising. Our proposed model has the ability to compete with the latest denoising methods. Based on the UNet architecture, our model consists of a shrunk subnet and an extended subnet. In the shrink subnetwork, the input block is constructed by the void convolution and multi-scale feature extraction block to extract more useful features from the input noise image. An attention-guided filter block is introduced to restore the image information after each down-sampling operation. Although our model has a larger number of parameters than the conventional methods, our model allows for a smaller number of multiplication operations compared with the models with similar or even higher complexity. Massive experiments have shown that our MAGUNet model outperforms the most advanced denoising methods such as BM3D, FFDNet, RDUNet, and MSAUNet. The contributions of this paper are summarized as follows:
- This paper proposes the MAGUNet model, which extracts more useful features by expanding the acceptance domain, so that our model can achieve a better balance between efficiency and performance.
- The attention-guided filter block is designed to retain the details of the image information after each down-sampling operation.
- The experiment results demonstrate the superiority of the MAGUNet model against the competing methods.
2. Related Work
2.1. CNNs for Image Denoising
At present, there are many methods based on the neural networks to deal with the image denoising problem. Jain and Seung [18] proposed the earliest CNN model for natural image denoising. Burger et al. [19] proposed a multi-layer perceptron (MLP) block that allows the neural network to achieve better results than the BM3D [2] method. Zhang et al. [7] proposed a deep convolutional neural network (DnCNN) for image denoising, which improves the denoising performance by stacking multiple convolution layer blocks.
It is effective to use skip connection operation to enhance the expressiveness of CNN denoising models. By integrating the short-term memory and long-term memory, Tai et al. [11] proposed a deep end-to-end persistent memory network for image restoration, which enhances the influence of the shallow layer through recursion. The fast and flexible denoising CNN(FFDNet) [20] introduced noise feature graphs that deal with non-uniform noise levels to reduce the sampled subimages. A generative adversarial neural network (GAN) is proposed to estimate noise distribution and generate noise samples [21].
Recent models, such as DHDN [22], DIDN [23], and RDN [24], have improved the baseline results established by DnCNN and FFDNet models. However, these models significantly increase the number of parameters to achieve the improvement. Presently, UNet model [25] is one of the most widely used in the autoencoder architectures. Liu et al. [17] proposed the MWCNN model, which combines the wavelet transform and convolutional layer in the UNet model instead of simple convolution and maximum polarization. Wang et al. [26] extended the MWCNN model by adding residual-dense blocks to each layer of the model. The DIDN model proposed by Yu et al. [22] utilized several U-Net-based blocks, which may change the image size many times. He et al. [27] proposed the residual U-Net network (ResNets) to solve the problem about network degradation with the increase of the network depth. Dense networks [23] reuse each generated feature map to subsequent convolution within the same convolution block. Additionally, several image denoising methods based on residual learning and dense connectivity have been proposed. Zhang et al. [28] proposed a depth residual network with a linear element layer of parametric rectification for image recovery tasks. A residual dense neural network (RDUNet) for image denoising [29] combines dense concatenated convolutional blocks by feature graphs in the encoding and decoding parts.
2.2. Multi-Scale Feature Extraction
To capture more contextual information in CNNs, increasing the acceptance field size is a common technique. However, this usually requires expanding the depth and width of the network, which produces more parameters in the model. An alternative approach is to use dilated convolution, which can extract multi-scale information while keeping the feature map size constant. The dilated convolution is particularly useful for detection and segmentation tasks, as it can detect large targets and accurately locate them. Shallow layers of neural networks tend to have smaller acceptance domains, but they can learn and transmit image details to deeper layers for feature integration. As the network deepens, there may be a lack of long-term dependencies between features, which can be addressed by broadening the network and extracting richer features [30]. Different networks, such as GoogleNet [31] and CFBI+ [32], have used multi-scale approaches to enhance the expression ability and robustness of the neural network framework. The multi-scale adaptive network proposed by Gou et al. [33] integrates the intra-scale features and cross-scale complementarity into the network design at the same time. Zou et al. designed a dual attention to adaptively reinforce important channels and spatial regions [34]. Li et al. proposed a multi-scale feature fusion network for CT image denoising by combining multiple feature extraction modules [35]. In the multi-scale feature extraction blocks of our proposed MAGUNet model, the residual dilated convolution blocks were utilized to balance the number of parameters and the performance of feature extraction.
2.3. Attentional Mechanisms
As we all know, it is a great challenge to extract suitable features from a given complex background image. Zhu et al. [36] proposed an attention mechanism that combines the training flow and tracking task in a deep learning framework. Karri et al. [37] presented an interpretable multi-module semantically guided attention network including the location attention, channel-wise attention, and edge attention modules, so as to extract the most important spatial-, channel-, and boundary-related features. Fan et al. [38] proposed a new attention ConvNeXt model by introducing a parametrically free attention block. Yan et al. [39] proposed an attention-guided dynamic multi-branch neural network to obtain high-quality underwater images. Wang et al. [40] introduced an attention mechanism into the discriminator to reduce excessive attention and retain more detailed feature information. As an anisotropic filter, a guided filter [41] can preserve edge details efficiently. Wu et al. [42] proposed deep guided filter networks to deal with the problem about limited joint up-sampling capability. In light of the structure of the guide image, Ying et al. [43] generated a set of guide filters to preserve the edge smoothing. By exploring the fusion of the attention mechanism and guided filter, we propose the attention-guided filter block based on the ability of learning important features.
3. Methods
3.1. Network Structure
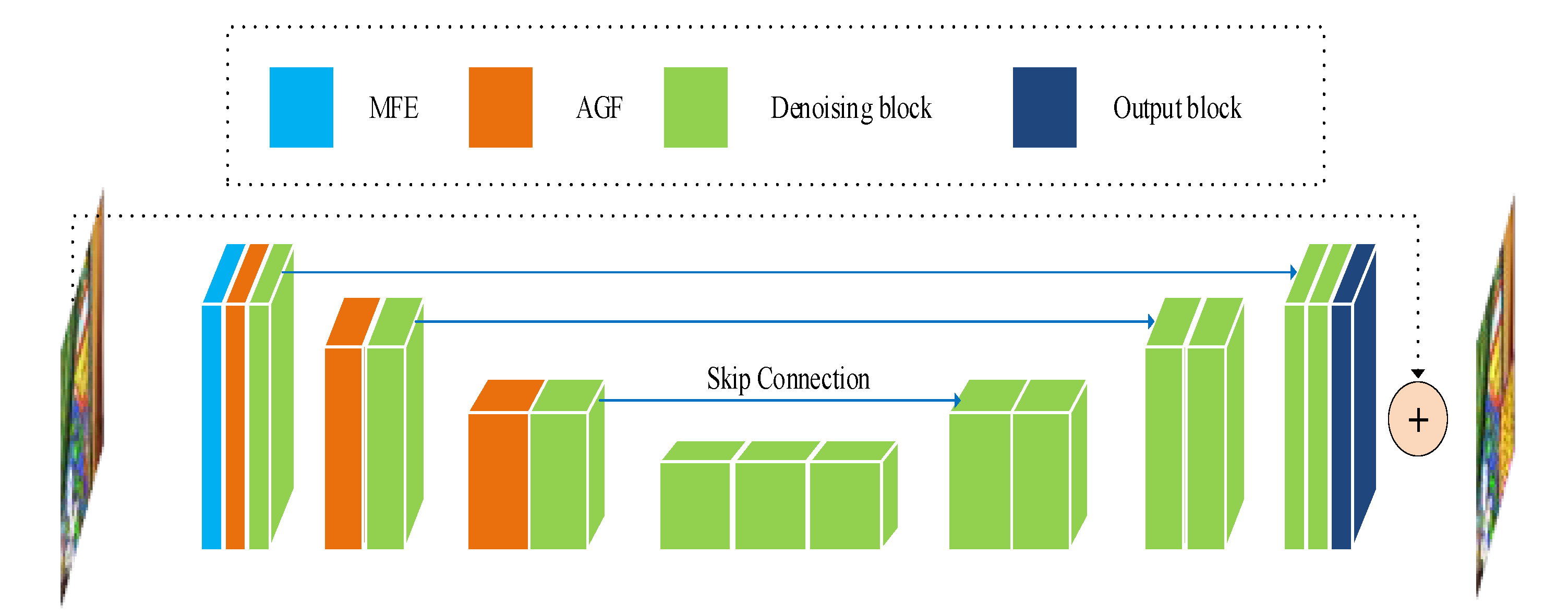
The architecture of our proposed network is shown in Figure 1, which is mainly composed of a multi-scale feature extraction block (MFE), an attention-guided filter block (AGB), and a residual denoising block (RDB).
In this paper, we deal with the noisy image destroyed by the additive white Gaussian noise . The image denoising problem can be formulated as finding the argument function on the trainable parameter vector such that the estimated clean image is computed by
Since the damaged image contains most of the structure of the clean image, it is reasonable to retain the structure information by estimating the noise. To that end, we assume that there exists a parameter mapping such that . Therefore, the denoising parameter model based on residual learning can be written as follows:
Let be the training dataset, where is a noisy image and is the corresponding clean image. For a given balancing factor , the parameter is computed by solving the following optimization problem:
where the first and second terms are, respectively, the fidelity term and the regularization term.
From Figure 1, we can find that the main architecture of the mapping is associated with the MAGUNet model of mapping . The main body of MAGUNet is composed of the encoder and decoder structures. The encoder part is responsible for extracting the low-level features of the image. The decoder part is responsible for recovering high-level features of the image while removing noise. The encoder and decode parts are connected by a series of residual modules. On the basis of the UNet, our MAGUNet model introduces the multi-scale feature extraction blocks as input blocks and attention-guided filter blocks after down-sampling.
In the encoding phase, there is one denoising block and one attention-guided filter block in each layer, and there are two denoising blocks in the decoding phase. The output of each coding layer adopts the down-sampling by means of a convolution kernel of size 2 × 2 and a step of size 2. Each step of down-sampling will double the number of feature maps to reduce the loss of information from one level to another. The up-sampling of the decoding layer is performed by the transposing convolution. The feature fusion between the coding layer and decoding layer is carried out by a skip connection. After each operation of up-sampling and with the skip connection, our model executes the 3 × 3 convolution to reduce the number of features and smooth the up-sampled features, while preserving the most important information of the source image. Our MAGUNet model mostly uses the PReLU activation functions. When the PReLU function is adopted, the number of trainable parameters is the same as the number of feature maps in the corresponding layer, which implies the PReLU function can improve the flexibility of the model without introducing a large number of additional parameters. The sigmoid and GELU activation functions are used only in the attention-guided filter layer. Because the nonlinearity and dropout jointly determine the output of neurons, the use of GELU activation function can make the probability of neuron output higher and reduce over-fitting. The input block used for multi-scale feature extraction is shown in Figure 2. Spatial information can be reasonably used to predict the actual values of the given pixels for the denoising task. In the local area, the current pixel of the predicted image and its adjacent pixels have similar pixel values. A high noise level usually requires a larger patch size to capture the contextual information. One way to obtain more spatial information is to select the convolution kernel of size larger than 3 × 3, which may increase the number of parameters in the spatial dimension. Our MAGUNet model generates 64 feature maps by 3 × 3 and 7 × 7 convolution kernels, so as to increase the receptive field and connect different features. The output block reduces the number of feature maps through two Conv 3 × 3 + PReLU operations to match the size of the input noise image and produce an estimate of residual noise. The corresponding output is used for global residual learning, which adds the corresponding result to the input image, so as to attain the denoised image.
3.2. Main Structure Module
3.2.1. Multi-Scale Feature Extraction Block
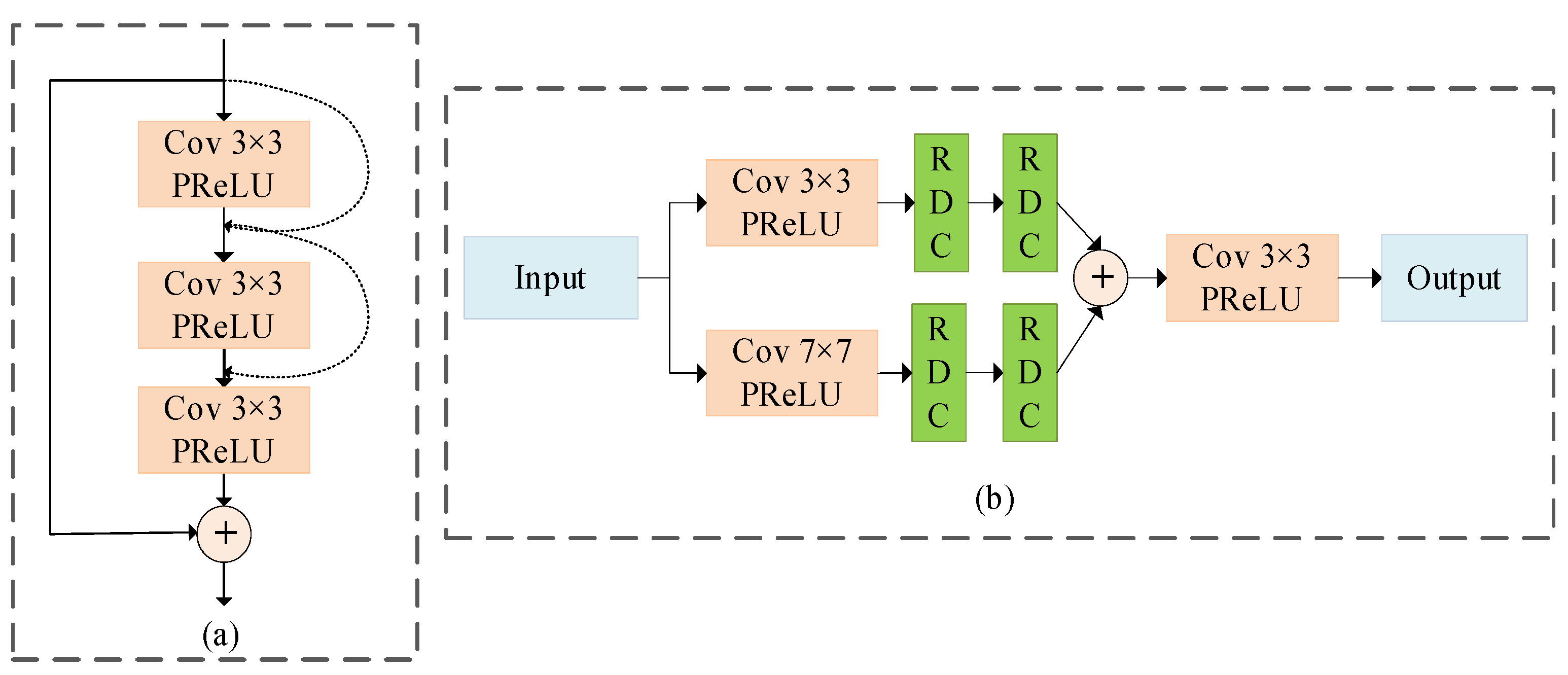
Although the down-sampling can increase the receptive field, the spatial resolution is reduced. The dilated convolution can be used to enlarge the receptive field without decreasing resolution. The dilated convolution has a parameter called the dilation rate, which controls the accepted area of the convolution core. Hence, when the different dilation rates are set, the receptive fields will be different and multi-scale information will be acquired. Indeed, the dilated convolution can arbitrarily expand the receptive field without introducing additional parameters.
Moreover, in order to skip some layers that do not increase the overall accuracy value, the skip connection is added to every two layers. The corresponding architecture is shown in Figure 2a. The specific steps of residual dilated convolution block are as follows. First, we perform the 3 × 3 dilated convolution and PReLU operations on the input image, where the corresponding parameters are padding = 1, dilation = 1. After concatenating the input image, we perform the 3 × 3 dilated convolution and PReLU operations on the concatenated image, where padding = 2 and dilation = 2. Next, we perform convolution and PReLU operations to recover the channel number of the input image. Finally, we add the original input image to attain the final image.
In order to overcome the problem that deep layers may be weakened by shallow layers as the depth increases, we introduce a multi-scale feature extraction (MFE) block in our proposed model. The MFE block increases the field of view by conducting two convolutions of kernel sizes 3 × 3 and 7 × 7, so as to generate 64-deep feature maps which can capture as much information as possible. Then, two residual dilated convolution blocks are used to enlarge the receptive field. The resulting output is merged by the concatenation operation. The architecture of the MFE block is shown in Figure 2b, where denotes the residual dilated convolution function; , and , respectively, denote the functions of PreLU, concatenation operation, and Conv + PreLU; and and , respectively, denote convolutions with kernel sizes of 3 × 3 and 7 × 7. The description of the MFE block can be represented as follows:
3.2.2. Attention-Guided Filter Block
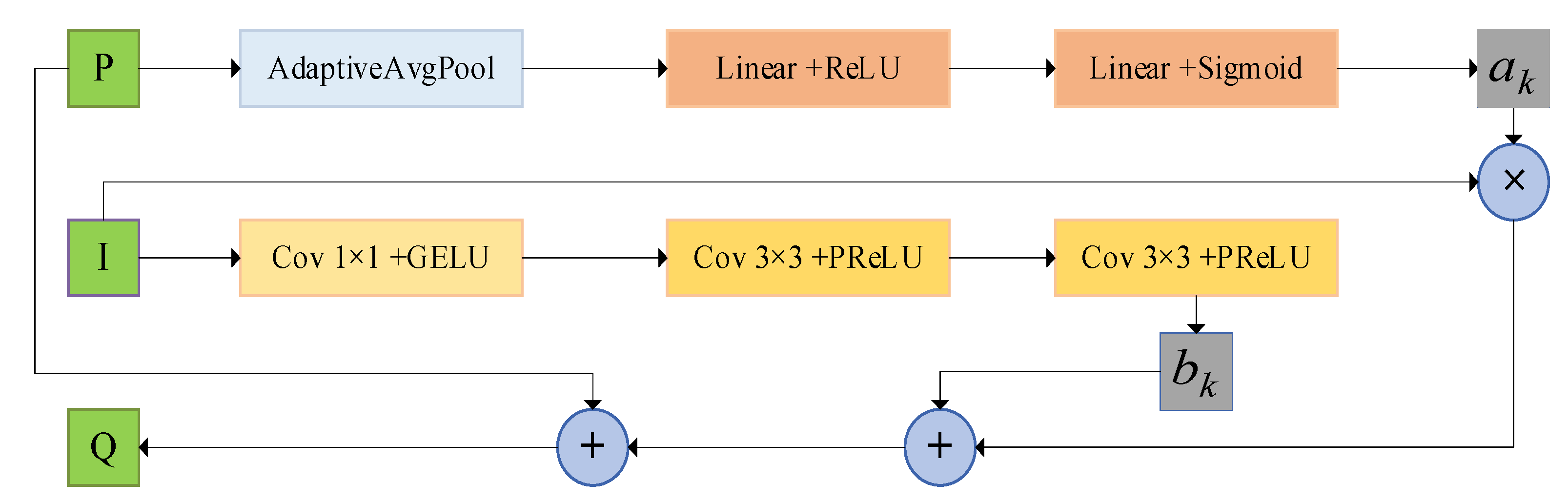
The down-sampling operation of UNet may result in the loss of spatial information. Moreover, this problem cannot be well recovered by skipping connections or up-sampling operations. Therefore, we propose an attention-guided filter block. Specifically, we add a trainable guide filter module after each down-sampling operation to better recover the spatial information loss.
The basic principle of the guided filter is as follows. For input image and the guided image the guided filter is to compute local coefficients , which computes the output image by
where is a local window.
When the input image is the same as the guided image, the guided filter becomes edge-preserving filter. Hence, we choose the case in our model. The specific process is shown in Figure 3. We operate the attention mechanism on the image to improve the sensitivity of the channel features. The coefficient is obtained by performing the AdaptiveAvgPool, Linear + ReLU, and Linear + Sigmoid operations. The coefficient is obtained by performing the Cov + GELU and Cov + PReLU operations on the image .
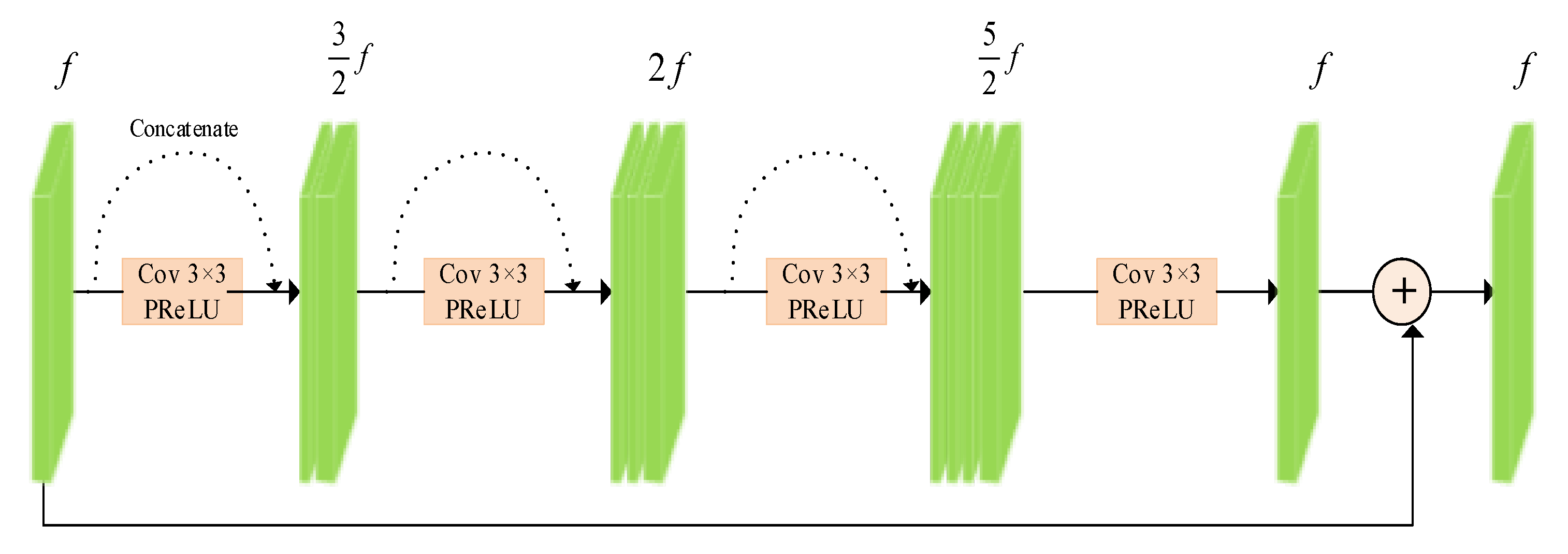
3.2.3. Residual Denoising Block
The residual denoising block is shown in Figure 4, which is composed of the bottleneck blocks and the feature maps on the basis of ResNet50 and the DenseNet model. We first use the 3 × 3 convolution to reduce the number of the feature maps by half. Then, we use two 3 × 3 convolutions to take all the previous feature maps as inputs. Finally, the 3 × 3 convolution is utilized to aggregate all the previous feature maps with the denoising block input. Finally, the last convolution generates the same number of feature maps as the inputs of the denoising block.
4. Results and Discussion
4.1. Experimental Setup
In our experiments, we use the DIV2K dataset [44] and the AID dataset [45] to verify the performance of MAGUNet, respectively. The DIV2K dataset consists of 800 images for training, 100 images for validation, and 100 images for testing. The AID dataset consists of 8000 images for training, 1000 images for validation, and 1000 images for testing. Our model was implemented in Python 3.8 on the basis of PyTorch framework.
To train our proposed model, we split the original training dataset into input and output blocks of size 64 × 64. We trained our model for color images and gray images, respectively. When training our model for grayscale images, we first convert color images to grayscale images, then add Gaussian white noise to clean image block , in order to generate noisy image block . The noise intensity for the training set is in the range . In addition, we apply augmentation techniques, including random vertical, horizontal flips, and 90° rotation, in order to extend the dataset.
We employ Adam optimizer to optimize the network parameters. The regularization parameter appearing in the problem (3) is and the initial learning rate is , which is halved every two iterations throughout the training of the dataset until its value is . The MAGUNet model was trained with a batch size of 16 for 14 epochs.
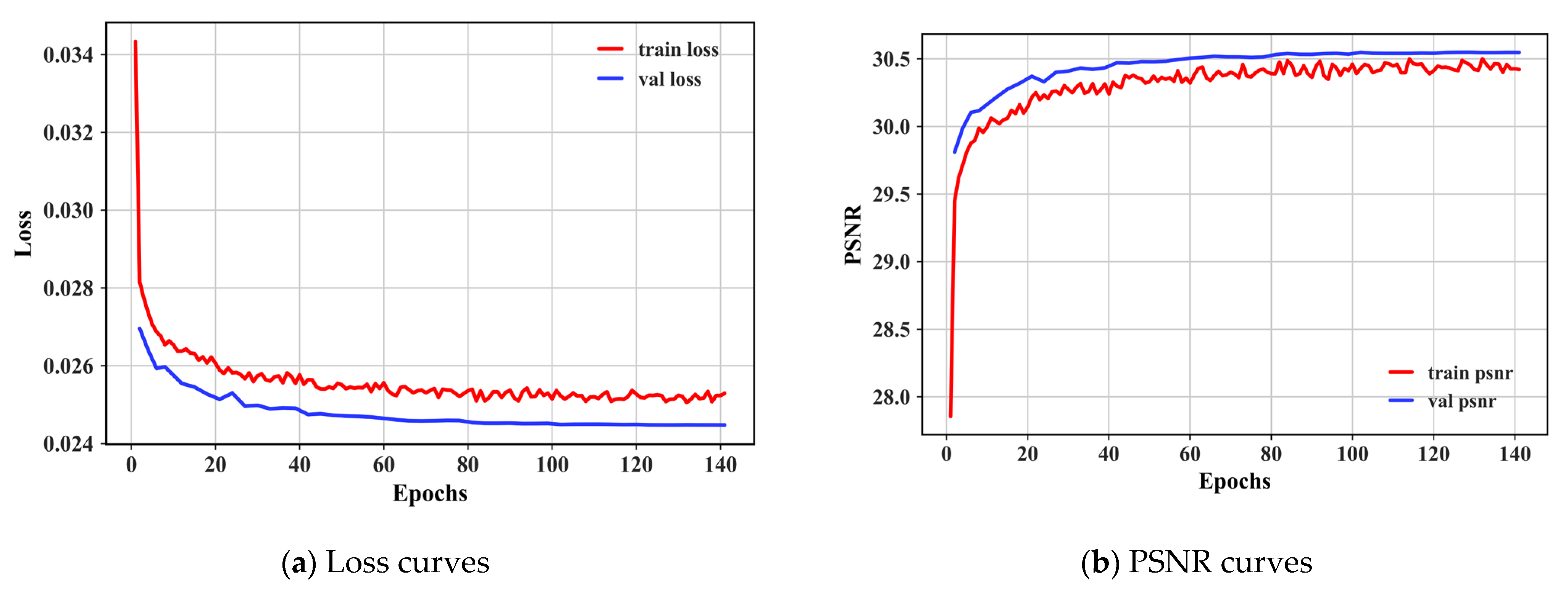
We first report the loss curves and PSNR curves during training. The results show that MAGUNet is well trained and achieves good denoising results on the validation data. It is worth noting that, as shown in Figure 5, here we train for a certain range of noise rather than a specific noise level, and the weight of the noise level increases during training, while the proportion of the noise level remains the same during validation, so it looks like the training results are lower than the validation results.
We first report the Loss curves and PSNR curves during training, and the results show that MAGUNet is well trained and achieves good denoising results on the validation data. It is worth noting that, as shown in Figure 5, here we trained on a certain range of noise rather than a specific noise level, and the weight of 50 noise level was added in the training, but the proportion of 10, 30, and 50 noise levels is the same in the validation, so it seems that the training results are lower than the validation results.
We use Set12 [7], BSD68 [46], Kodak24 [47] datasets for the evaluation of grayscale images, and Set5 [48], LIVE1 [49], McMaster [50] datasets for the evaluation of color images. We compared the MAGUNet model and the enhanced model MAGUNet+ with BM3D [2], IRCNN [9], DnCNN [7], FFDNet [20], ADNet [12], RDUNet [29], and MSANet [33]. The experiment results of all the comparative models are obtained using the respective pre-trained models and the source code tests of the corresponding authors. We select PSNR and SSIM indexes to measure the image denoising effect of different algorithms. We present the results for the noise levels of variance . The best PSNR and SSIM results for each noise level are highlighted in red, and the second-best results are highlighted in blue.
4.2. Grayscale Common Image Denoising
As shown in Table 1, our model achieves satisfactory results. Specifically, our proposed model achieved the best results in the Set12 dataset, outperforming the BM3D algorithm by an average of 1.29 dB, outperforming DnCNN, IRCNN, FFDNet, and ADNet by more than 0.4 dB, and outperforming RDUNet and MSAUNet by an average of 0.04 dB. Additionally, our model has significant advantages over the BSD68 dataset and the Kodak24 dataset. Moreover, the results obtained in the training noise level range of are slightly higher than those obtained by MSAUNet’s separate training of each noise level.
The visual denoising effect of different methods is shown in Figure 6, Figure 7, Figure 8 and Figure 9. The image denoising results of BSD68 dataset 3096 are shown in Figure 6. Our model can recover more detail of the tail letter and reduce artifacts in the letter A. From Figure 7, we can see that the BM3D, DnCNN, IRCNN, FFDNet, ADNet algorithms form a large number of artifacts, and for RDUNet, MSAUNet, our method performs well in detail preservation and smoothing. Furthermore, from Figure 8 and Figure 9, our model outperforms the other models on the tablecloth texture, clearly recovering the detailed texture without excessive smoothing.
4.3. Color Common Image Denoising
Table 2 presents the denoising results of color images with different methods on Set5, LIVE1, and McMaster datasets with Gaussian white noise of variances of 10, 30, and 50. We can see that our model also greatly outperforms other competing methods on color images, having a slightly higher effect than MSAUNet. It should be noticed that MSAUNet is trained separately at each noise level. From Figure 10, Figure 11, Figure 12 and Figure 13, we compared our model with the visual denoising effects of CBM3D, DnCNN, IRCNN, FFDNet, ADNet, RDUNet, and MSAUNet. From Figure 10, our method has no artifacts on the lamp post, unlike other methods. Consequently, our model has an advantage in detail retention. As shown in Figure 11, the image obtained by our method is smoother in the uniform region and the edge region compared with other methods. Additionally, it can be seen from Figure 12 and Figure 13 that our method is richer in color and details.
4.4. Remote Sensing Image Denoising
Table 3 lists the color image denoising results of different methods on selected test datasets with noise levels of 10, 30, and 50. It can be seen that our model outperforms the other competing methods. Figure 14 and Figure 15 show the denoising results of different methods for images with a noise level of 50. Our model is compared with BM3D, DnCNN, IRCNN, FFDNet, ADNet, and RDUNet for image denoising. Figure 14 shows that the denoised image obtained by the proposed method is smoother in the uniform region and sharper in the edge region, as compared to other methods. In Figure 15, the image handled by our method has richer and clearer color and detail content compared to the state-of-the-art denoising methods DnCNN, ADNet, and BM3D.
4.5. Ablation Study
To further verify the effectiveness of our proposed model, we conducted the following ablation experiments to show the effects of the denoising block, guided filter layer, as well as the MFE block. Case 0 denotes our proposed model. Case 1 represents our MAGUNet without the MFE block. Case 2 represents MAGUNet without the attention-guided block. Case 3 indicates MAGUNet model with only RDB blocks. Case 4 represents adding a normal guided filter for training to the MAGUNet model with RDB blocks. Table 4 shows the denoising results for different cases on the McMaster dataset with a Gaussian noise of the variance 50.
For the effectiveness of multi-scale feature extraction blocks, the results about Case 0, 2, and 3 show that the multi-scale features extracted by adding extra MFE blocks can improve the network performance.
For the effectiveness of attention-guided filter blocks, by comparing Cases 0, 1, and 3, the effectiveness of the attention-guided filter can be observed. In the absence of attention guidance in the denoising network, learning the global average directly yields that Case 3 cannot fully focus on structural information during the denoising process. Attention guidance can supplement the down-sampled feature information and provide guidance for the extraction of structural information. In addition, Cases 3 and 4 have similar network structures, but Case 4 adds trainable guided filters. Experimental results show that the performance of attention-guided filter blocks is better than that of traditional guided filters.
Note that as the model complexity increases, so does its computational cost and performance.
5. Discussion
Deep learning-based image denoising methods are becoming increasingly popular among researchers due to their ease of implementation and fast processing. In this paper, we analyzed the limitations of down-sampling in U-shaped networks and propose an attention-directed filtering to overcome these limitations. We conducted comparative experiments between the proposed method and other methods. The experiment results showed that our model significantly improves the denoising performance. Also, we foresee the potential of combining traditional denoising techniques with deep learning models for more effective noise reduction strategies.
The MFE and AGF blocks in MAGUNet are designed to address the limitations of the down-sampling problem. Specifically, the MFE block is trained to increase the receptive domain and connect different features for extracting more image information, while the AGF block can preserve the information of image edges after each down-sampling operation, relying on its edge retention capabilities. We performed the corresponding ablation experiments to elucidate the function of the MFE and AGF blocks. Indeed, removing either MFE or AGF leads to the reduction of PSNR and SSIM, which proves the importance of these two blocks in the process of image denoising.
However, our work still has some limitations. It lacks the disadvantage of real-time applications due to its high computational complexity. In this paper, we have only used Gaussian noise to train the dataset and failed to train on various types of noise. And failing to be tested and evaluated in the real world, the proposed model may only be generally applicable to certain image denoising tasks, which may require additional optimization for specific use cases. In addition, while the model performs well in terms of PSNR and SSIM, there are other metrics that may help optimize and evaluate the model. These issues will also be further explored in future research.
6. Conclusions
In this paper, we propose a residual UNet model that introduces an attention-guided filter and multi-scale feature extraction. Instead of using a standard input block, we use a multi-scale feature extraction block as the input block. Our MFE blocks placed in the shallow layer of the network are designed to increase the acceptance domain and connect different features. In addition, we develop the attention-guided filter to keep the edge, which has good detail retention ability after each down-sampling operation. We use a global residual network strategy to model residual noise, which does not require the information about the noise level in the noisy image. Experiment results show that our proposed method is competitive with the state-of-the-art methods.
Author Contributions
Conceptualization, Z.L. and H.L.; methodology, Z.L. and H.L.; software, S.L. and H.L.; validation, H.L., Z.L., and S.L.; formal analysis, Z.L.; investigation, H.L.; resources, Z.L.; data curation, H.L.; writing—original draft preparation, H.L.; writing—review and editing, Z.L. and H.L.; visualization, H.L.; supervision, Z.L.; project administration, Z.L. and L.C.; funding acquisition, Z.L. and L.C. All authors have read and agreed to the published version of the manuscript.
Funding
This paper is supported by the National Nature Science Foundation of China under Grant (No.12171054) and the fund of the Department of Education of Jilin Province (JJKH20230788KJ).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Datasets used in this paper are open access and are available from: DIV2K is openly available in “NTIRE 2017 challenge on single image super-resolution: Dataset and study”, reference number [45]; Set12 is openly available in “Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising”, reference number [8]; BSD68 is openly available in “Fields of Experts: a framework for learning image priors”, reference number [46]; Kodak24 is openly available in “Kodak lossless true color image suite: PhotoCD PCD0992” at url: http://r0k.us/graphics/kodak.182(accessed on 14 July 2023), reference number [47]. Set5 is openly available in “Accurate Image Super-Resolution Using Very Deep Convolutional Networks”, reference number [48]; LIVE1 is openly available in “A Statistical Evaluation of Recent Full Reference Image Quality Assessment Algorithms”, reference number [49]; McMaster is openly available in “Color demosaicking by local directional interpolation and nonlocal adaptive thresholding”, reference number [50].
Acknowledgments
The authors would like to acknowledge the contributions of all the reviewers and thank them for their insightful comments on the early drafts of this article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Buades, A.; Coll, B.; Morel, J.-M. A non-local algorithm for image denoising. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [PubMed]
- Rabbouch, H.; Saâdaoui, F.; Vasilakos, A. A wavelet assisted subband denoising for tomographic image reconstruction. J. Vis. Commun. Image Represent. 2018, 55, 115–130. [Google Scholar]
- Kaur, G.; Kaur, R. Image de-noising using wavelet transform and various filters. Int. J. Res. Comput. Sci. 2012, 2, 15–21. [Google Scholar]
- Song, Q.; Ma, L.; Cao, J.; Han, X. Image denoising based on mean filter and wavelet transform. In Proceedings of the 2015 4th International Conference on Advanced Information Technology and Sensor Application (AITS), Harbin, China, 21–23 August 2015; pp. 21–23. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar]
- Romano, Y.; Elad, M.; Milanfar, P. The little engine that could: Regularization by denoising (red). SIAM J. Imaging Sci. 2017, 10, 1–50. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Feng, W.; Qiao, P.; Chen, Y. Fast and accurate poisson denoising with trainable nonlinear diffusion. IEEE Trans. Cybern. 2018, 48, 1708–1719. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. MemNet: A persistent memory network for image restoration. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4549–4557. [Google Scholar]
- Tian, C.; Xu, Y.; Li, Z.; Zuo, W.; Fei, L.; Liu, H. Attention-guided CNN for image denoising. Neural Netw. 2020, 124, 117–129. [Google Scholar]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward convolutional blind denoising of real photographs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1712–1722. [Google Scholar]
- Varga, D. No-Reference Image Quality Assessment with Multi-Scale Orderless Pooling of Deep Features. J. Imaging 2021, 7, 112. [Google Scholar] [CrossRef]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the 2015 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar] [CrossRef] [Green Version]
- Bühlmann, P.; Yu, B. Boosting with the L2 loss: Regression and classification. J. Am. Stat. Assoc. 2003, 98, 324–339. [Google Scholar]
- Liu, P.; Zhang, H.; Zhang, K.; Lin, L.; Zuo, W. Multi-level wavelet-CNN for image restoration. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake, UT, USA, 18–22 June 2018; pp. 773–782. [Google Scholar]
- Jain, V.; Seung, S. Natural image denoising with convolutional networks. In Proceedings of the 21st International Conference on Neural Information Processing Systems (NIPS’08), Vancouver, BC, Canada, 8–11 December 2008; Curran Associates Inc.: Red Hook, NY, USA; pp. 769–776. [Google Scholar]
- Burger, H.C.; Schuler, C.J.; Harmeling, S. Image denoising: Can plain neural networks compete with BM3D? In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2392–2399. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar]
- Chen, J.; Chen, J.; Chao, H.; Yang, M. Image blind denoising with generative adversarial network-based noise modeling. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3155–3164. [Google Scholar]
- Park, B.; Yu, S.; Jeong, J. Densely connected hierarchical network for image denoising. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 2104–2113. [Google Scholar] [CrossRef]
- Yu, S.; Park, B.; Jeong, J. Deep iterative down-up CNN for image denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 2095–2103. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2480–2495. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Broxz, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Wang, S.-F.; Yu, W.-K.; Li, Y.-X. Multi-wavelet residual dense convolutional neural network for image denoising. IEEE Access 2020, 8, 214413–214424. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, Y.; Sun, L.; Yan, C.; Ji, X.; Dai, Q. Adaptive residual networks for high-quality image restoration. IEEE Trans. Image Process. 2018, 27, 3150–3163. [Google Scholar]
- Gurrola-Ramos, J.; Dalmau, O.; Alarcón, T.E. A residual dense U-Net neural network for image denoising. IEEE Access 2021, 9, 31742–31754. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A.; Liu, W.; et al. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Wei, Y.; Yang, Y. Collaborative video object segmentation by multi-scale foreground-background integration. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4701–4712. [Google Scholar] [CrossRef]
- Gou, Y.; Hu, P.; Lv, J.; Peng, X. Multi-scale adaptive network for single image denoising. Adv. Neural Inf. Process. Syst. 2022, 35, 14099–14112. [Google Scholar]
- Zou, P.; Teng, Y.; Niu, T. Multi scale feature extraction and fusion for online knowledge distillation. In Proceedings of the International Conference on Artificial Neural Networks, Bristol, UK, 6–9 September 2022; Springer: Cham, Switzerland, 2022; Volume 13532. [Google Scholar] [CrossRef]
- Li, Z.; Liu, Y.; Shu, H.; Lu, J.; Kang, J.; Chen, Y.; Gui, Z. Multi-scale feature fusion network for low-dose CT denoising. J. Digit Imaging 2023, 36, 1808–1825. [Google Scholar] [CrossRef]
- Zhu, Z.; Wu, W.; Zou, W.; Yan, J. End-to-end flow correlation tracking with spatial-temporal attention. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 548–557. [Google Scholar] [CrossRef] [Green Version]
- Karri, M.; Annavarapu, C.S.R.; Acharya, U.R. Explainable multi-module semantic guided attention-based network for medical image segmentation. Comput. Biol. Med. 2022, 151, 106231. [Google Scholar] [CrossRef]
- Fan, S.; Liang, W.; Ding, D.; Yu, H. LACN: A lightweight attention-guided ConvNeXt network for low-light image enhancement. Eng. Appl. Artif. Intell. 2023, 117, 105632. [Google Scholar]
- Yan, X.; Qin, W.; Wang, Y.; Wang, G.; Fu, X. Attention-guided dynamic multi-branch neural network for underwater image enhancement. Knowl.-Based Syst. 2022, 258, 110041. [Google Scholar]
- Wang, J.; Yu, L.; Tian, S.; Wu, W.; Zhang, D. AMFNet: An attention-guided generative adversarial network for multi-model image fusion. Biomed. Signal Process. Control 2022, 78, 103990. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 6, 1397–1409. [Google Scholar]
- Wu, H.; Zheng, S.; Zhang, J.; Huang, K. Fast end-to-end trainable guided filter. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1838–1847. [Google Scholar] [CrossRef] [Green Version]
- Yin, H.; Gong, Y.; Qiu, G. Guided filter bank. In Intelligent Computing: Proceedings of the 2021 Computing Conference; Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2021; Volume 1, pp. 783–792. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Roth, S.; Black, M. Fields of Experts: A framework for learning image priors. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 860–867. [Google Scholar]
- Franzen, R. Kodak Lossless True Color Image Suite: PhotoCD PCD0992. Available online: http://r0k.us/graphics/kodak (accessed on 14 July 2023).
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Sheikh, H.; Sabir, M.; Bovik, A. A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Trans. Image Process. 2006, 15, 3440–3451. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, X.; Buades, A.; Li, X. Color demosaicking by local directional interpolation and nonlocal adaptive thresholding. J. Electron. Imaging 2011, 20, 023016. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
The structures of the encoder and decoder are the main body of the proposed MAGUNet, which contains four main blocks, namely, MFE block, AGF block, denoising block, and output block. The encoder and decoder parts are connected by a multi-scale feature extraction block, attention-guided filter blocks, and residual modules. The main task of the encoder part is to extract the low-level features of the image. The decoder part is responsible for recovering the high-level features of the image while removing the noise.
Figure 1.
The structures of the encoder and decoder are the main body of the proposed MAGUNet, which contains four main blocks, namely, MFE block, AGF block, denoising block, and output block. The encoder and decoder parts are connected by a multi-scale feature extraction block, attention-guided filter blocks, and residual modules. The main task of the encoder part is to extract the low-level features of the image. The decoder part is responsible for recovering the high-level features of the image while removing the noise.

Figure 2.
Details of the multi-scale feature extraction block. (a) Residual dilated convolution block (RDC), (b) multi-scale feature extraction block structure. The practical application of different convolutional kernels is to extend the receptive field for multi-scale feature extraction.
Figure 2.
Details of the multi-scale feature extraction block. (a) Residual dilated convolution block (RDC), (b) multi-scale feature extraction block structure. The practical application of different convolutional kernels is to extend the receptive field for multi-scale feature extraction.

Figure 3.
Attention-guided filter block. The coefficients are computed by performing the channel attention mechanism on the input image P, and the coefficient is computed by convolving the guided image I. Separately, the output image Q is obtained from the residual structure.
Figure 3.
Attention-guided filter block. The coefficients are computed by performing the channel attention mechanism on the input image P, and the coefficient is computed by convolving the guided image I. Separately, the output image Q is obtained from the residual structure.

Figure 4.
Residual denoising block. Reuse of feature maps by using densely connected denoising blocks.
Figure 4.
Residual denoising block. Reuse of feature maps by using densely connected denoising blocks.

Figure 5.
Loss and PSNR curves for training MAGUNet in AWGN denoising. The training dataset is the DIV2K training set, and the PSNR results are computed on the DIV2K dataset at a noise level .
Figure 5.
Loss and PSNR curves for training MAGUNet in AWGN denoising. The training dataset is the DIV2K training set, and the PSNR results are computed on the DIV2K dataset at a noise level .

Figure 6.
Comparison of the visual quality of different algorithms for a 3096 image from the BSD68 dataset with Gaussian noise of variance 50.
Figure 6.
Comparison of the visual quality of different algorithms for a 3096 image from the BSD68 dataset with Gaussian noise of variance 50.

Figure 7.
Comparison of the visual quality of different algorithms for a 302008 image from the BSD68 dataset with Gaussian noise of variance 50.
Figure 7.
Comparison of the visual quality of different algorithms for a 302008 image from the BSD68 dataset with Gaussian noise of variance 50.

Figure 8.
Comparison of the visual quality of different algorithms for a starfish image from the Set12 dataset with Gaussian noise of variance 50.
Figure 8.
Comparison of the visual quality of different algorithms for a starfish image from the Set12 dataset with Gaussian noise of variance 50.

Figure 9.
Comparison of the visual quality of different algorithms for a Barbara image from the Set12 dataset with Gaussian noise of variance 50.
Figure 9.
Comparison of the visual quality of different algorithms for a Barbara image from the Set12 dataset with Gaussian noise of variance 50.

Figure 10.
Comparison of the visual quality of different algorithms for 4 images from the McMaster dataset with a noise level of 50.
Figure 10.
Comparison of the visual quality of different algorithms for 4 images from the McMaster dataset with a noise level of 50.

Figure 11.
Comparison of the visual quality of different algorithms for butterfly images from the Set5 dataset with a noise level of 50.
Figure 11.
Comparison of the visual quality of different algorithms for butterfly images from the Set5 dataset with a noise level of 50.

Figure 12.
Comparison of the visual quality of different algorithms for 1 image from the McMaster dataset with a noise level of 50.
Figure 12.
Comparison of the visual quality of different algorithms for 1 image from the McMaster dataset with a noise level of 50.

Figure 13.
Comparison of the visual quality of different algorithms for 2 images from the McMaster dataset with a noise level of 50.
Figure 13.
Comparison of the visual quality of different algorithms for 2 images from the McMaster dataset with a noise level of 50.

Figure 14.
Comparison of the visual quality of different algorithms for a farmland image from the testing dataset with a noise level of 50.
Figure 14.
Comparison of the visual quality of different algorithms for a farmland image from the testing dataset with a noise level of 50.

Figure 15.
Comparison of the visual quality of different algorithms for a harbor image from the testing dataset with a noise level of 50.
Figure 15.
Comparison of the visual quality of different algorithms for a harbor image from the testing dataset with a noise level of 50.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
PSNR (dB) and SSIM results of different denoising methods on Set12, BSD86 and Kodak24 grayscale datasets with different noise levels.
Table 1.
PSNR (dB) and SSIM results of different denoising methods on Set12, BSD86 and Kodak24 grayscale datasets with different noise levels.
| Method\Gray | Set12 | BSD68 | Kodak24 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10.00 | 30.00 | 50.00 | 10.00 | 30.00 | 50.00 | 10.00 | 30.00 | 50.00 | ||||||||||
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| BM3D | 34.08 | 0.9204 | 28.69 | 0.8199 | 26.18 | 0.7411 | 33.16 | 0.9160 | 27.59 | 0.7671 | 25.41 | 0.6722 | 34.07 | 0.9113 | 28.68 | 0.7779 | 26.42 | 0.6918 |
| DnCNN | 34.52 | 0.9241 | 29.52 | 0.8422 | 27.18 | 0.7816 | 33.73 | 0.9241 | 28.35 | 0.7982 | 26.23 | 0.7164 | 34.68 | 0.9207 | 29.52 | 0.8082 | 27.39 | 0.7364 |
| IRCNN | 34.71 | 0.9272 | 29.45 | 0.8393 | 27.12 | 0.7804 | 33.75 | 0.9263 | 28.27 | 0.7993 | 26.19 | 0.7169 | 34.67 | 0.9212 | 29.42 | 0.8064 | 27.33 | 0.7354 |
| FFDnet | 34.64 | 0.9270 | 29.60 | 0.8464 | 27.30 | 0.7899 | 33.77 | 0.9266 | 28.39 | 0.8031 | 26.29 | 0.7239 | 34.72 | 0.9223 | 29.58 | 0.8122 | 27.49 | 0.7434 |
| ADNet | 34.63 | 0.9247 | 29.62 | 0.8449 | 27.29 | 0.7874 | 33.65 | 0.9216 | 28.32 | 0.7949 | 26.22 | 0.7148 | 34.67 | 0.9200 | 29.51 | 0.8066 | 27.4 | 0.7367 |
| RDUNet | 34.99 | 0.9315 | 29.96 | 0.8552 | 27.72 | 0.8044 | 33.97 | 0.9297 | 28.58 | 0.8099 | 26.48 | 0.7346 | 35.00 | 0.9262 | 29.86 | 0.8228 | 27.78 | 0.7577 |
| MSANet | \ | \ | 30.00 | 0.8366 | 27.72 | 0.7864 | \ | \ | 28.62 | 0.7939 | 26.52 | 0.7229 | \ | \ | 29.91 | 0.8112 | 27.82 | 0.7516 |
| Ours | 35.03 | 0.9320 | 29.96 | 0.8548 | 27.70 | 0.8044 | 33.99 | 0.9298 | 28.56 | 0.8081 | 26.45 | 0.7318 | 35.04 | 0.9263 | 29.86 | 0.8222 | 27.75 | 0.7559 |
| Ours+ | 35.07 | 0.9324 | 30.01 | 0.8556 | 27.76 | 0.8057 | 34.02 | 0.9301 | 28.59 | 0.8090 | 26.48 | 0.7329 | 35.08 | 0.9267 | 29.91 | 0.8233 | 27.81 | 0.7574 |
Table 2.
PSNR (dB) and SSIM results of different denoising methods on Set5, LIVE1, and McMaster color datasets with different noise levels.
Table 2.
PSNR (dB) and SSIM results of different denoising methods on Set5, LIVE1, and McMaster color datasets with different noise levels.
| Method\Color | Set5 | LIVE1 | McMaster | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 30 | 50 | 10 | 30 | 50 | 10 | 30 | 50 | ||||||||||
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| BM3D | 36.02 | 0.9392 | 30.93 | 0.8592 | 28.69 | 0.8092 | 35.82 | 0.9484 | 30.08 | 0.8542 | 27.66 | 0.7816 | 35.91 | 0.9336 | 30.84 | 0.8512 | 28.54 | 0.79 |
| DnCNN | 35.74 | 0.9321 | 31.15 | 0.864 | 28.96 | 0.8146 | 35.69 | 0.9485 | 30.35 | 0.864 | 27.95 | 0.7951 | 34.79 | 0.9226 | 30.79 | 0.854 | 28.62 | 0.7986 |
| IRCNN | 36.13 | 0.9392 | 31.17 | 0.8655 | 29.00 | 0.8172 | 36.00 | 0.9497 | 30.36 | 0.8648 | 27.97 | 0.7979 | 36.45 | 0.9406 | 31.31 | 0.8642 | 28.93 | 0.8069 |
| FFDNet | 36.16 | 0.9397 | 31.35 | 0.8689 | 29.24 | 0.8252 | 36.07 | 0.9508 | 30.49 | 0.8663 | 28.10 | 0.7988 | 36.45 | 0.9414 | 31.53 | 0.8701 | 29.19 | 0.8149 |
| ADNet | 35.97 | 0.9355 | 31.21 | 0.8664 | 28.99 | 0.8158 | 35.97 | 0.9501 | 30.37 | 0.8639 | 27.93 | 0.792 | 36.27 | 0.939 | 31.33 | 0.8658 | 29.03 | 0.936 |
| RDUNet | 36.54 | 0.9422 | 31.83 | 0.8797 | 29.69 | 0.8398 | 36.51 | 0.9546 | 31.00 | 0.8789 | 28.64 | 0.8195 | 36.95 | 0.9469 | 32.09 | 0.885 | 29.79 | 0.8378 |
| MSANet | \ | \ | 31.83 | 0.8865 | 29.69 | 0.8437 | \ | \ | 30.96 | 0.8816 | 28.64 | 0.8224 | \ | \ | 32.10 | 0.8884 | 29.82 | 0.8409 |
| Ours | 36.57 | 0.9426 | 31.84 | 0.8786 | 29.72 | 0.8387 | 36.54 | 0.9546 | 31.01 | 0.8782 | 28.64 | 0.8181 | 37.05 | 0.9477 | 32.13 | 0.8851 | 29.82 | 0.8373 |
| Ours+ | 36.61 | 0.9429 | 31.89 | 0.8795 | 29.76 | 0.8396 | 36.58 | 0.9549 | 31.06 | 0.8790 | 28.70 | 0.8192 | 37.11 | 0.9483 | 32.20 | 0.8864 | 29.90 | 0.8393 |
Table 3.
PSNR (dB) and SSIM results of different denoising methods on testing datasets with different noise levels.
Table 3.
PSNR (dB) and SSIM results of different denoising methods on testing datasets with different noise levels.
| Method | 10 | 30 | 50 | |||
|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| BM3D | 36.81 | 0.9416 | 31.51 | 0.8349 | 29.30 | 0.7579 |
| DnCNN | 36.71 | 0.9401 | 31.49 | 0.8336 | 29.32 | 0.7588 |
| IRCNN | 36.75 | 0.9408 | 31.43 | 0.8333 | 29.31 | 0.7607 |
| FFDNet | 36.81 | 0.9415 | 31.58 | 0.8348 | 29.43 | 0.7600 |
| ADNet | 36.76 | 0.9408 | 31.49 | 0.8325 | 29.31 | 0.7553 |
| RDUNet | 37.06 | 0.9446 | 31.96 | 0.8482 | 29.87 | 0.7814 |
| Ours | 37.25 | 0.9462 | 32.04 | 0.8500 | 29.90 | 0.7822 |
| Ours+ | 37.28 | 0.9466 | 32.07 | 0.8509 | 29.95 | 0.7838 |
Table 4.
Ablation investigation for MAGUNet. Average PSNR (dB) and SSIM values on McMaster for a noise of level 50.
Table 4.
Ablation investigation for MAGUNet. Average PSNR (dB) and SSIM values on McMaster for a noise of level 50.
| Case 0 | Case 1 | Case 2 | Case 3 | Case 4 | |
|---|---|---|---|---|---|
| MFE | √ | × | √ | × | × |
| RDB | √ | √ | √ | √ | √ |
| AGF | √ | √ | × | × | × |
| PSNR | 29.8235 | 29.8107 | 29.7970 | 29.7907 | 29.7895 |
| SSIM | 0.8373 | 0.8360 | 0.8347 | 0.8328 | 0.8327 |
| Complexity | 2.61 GMac | 2.26 GMac | 2.55 GMac | 2.20 GMac | 2.48 GMac |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, H.; Li, Z.; Lin, S.; Cheng, L. A Residual UNet Denoising Network Based on Multi-Scale Feature Extraction and Attention-Guided Filter. Sensors 2023, 23, 7044. https://doi.org/10.3390/s23167044
AMA Style
Liu H, Li Z, Lin S, Cheng L. A Residual UNet Denoising Network Based on Multi-Scale Feature Extraction and Attention-Guided Filter. Sensors. 2023; 23(16):7044. https://doi.org/10.3390/s23167044
Chicago/Turabian StyleLiu, Hualin, Zhe Li, Shijie Lin, and Libo Cheng. 2023. "A Residual UNet Denoising Network Based on Multi-Scale Feature Extraction and Attention-Guided Filter" Sensors 23, no. 16: 7044. https://doi.org/10.3390/s23167044
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.