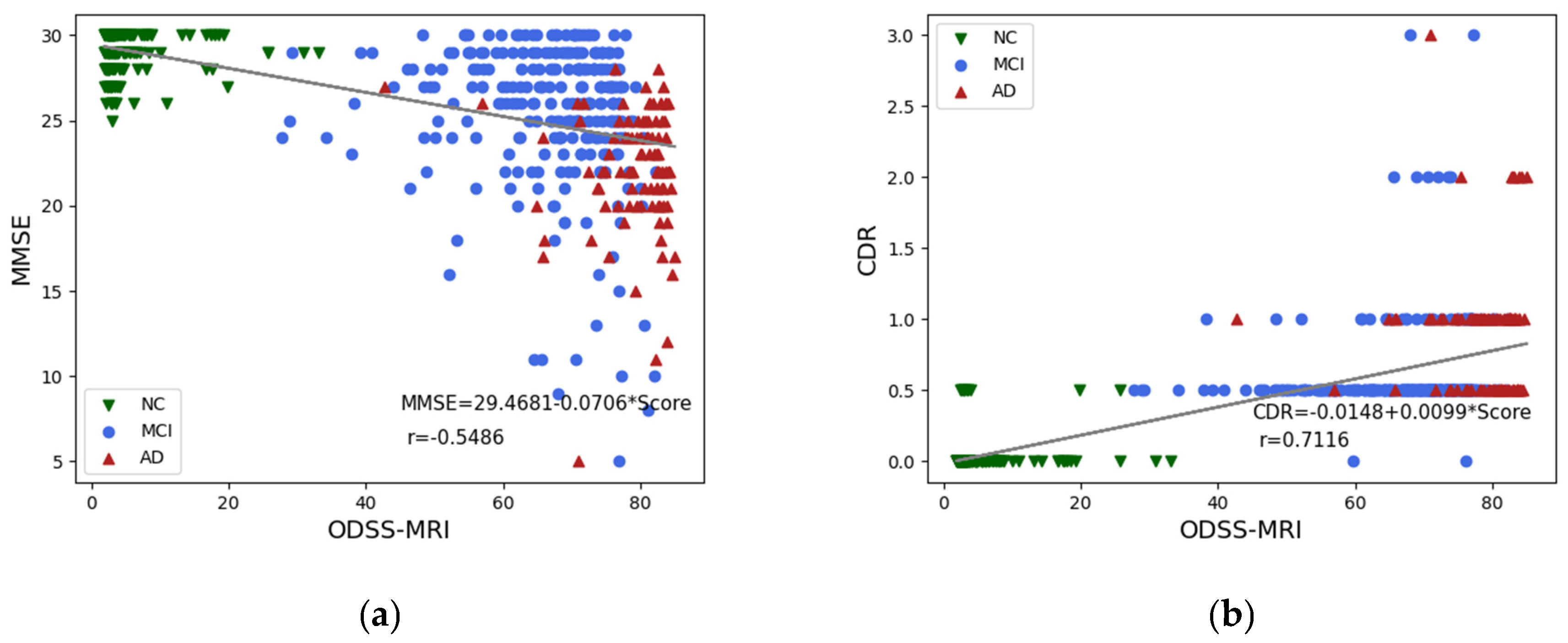
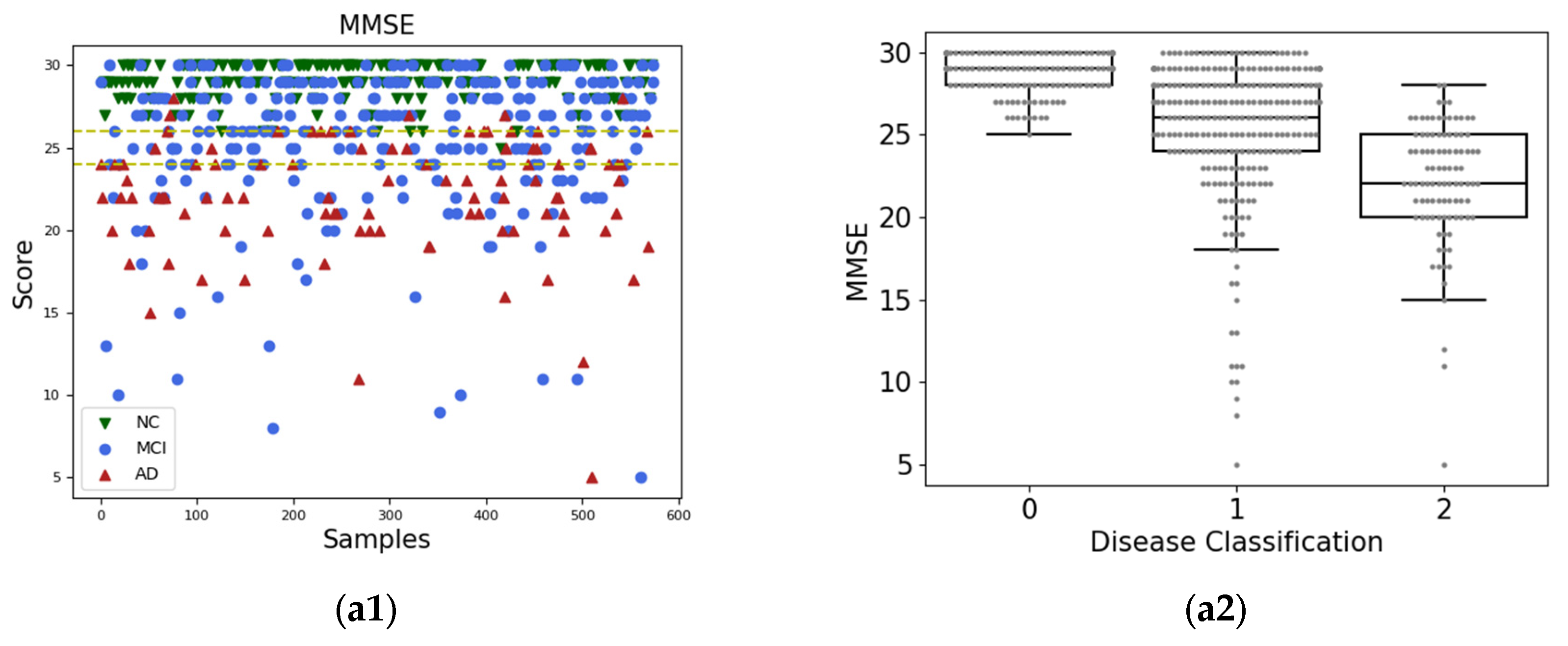
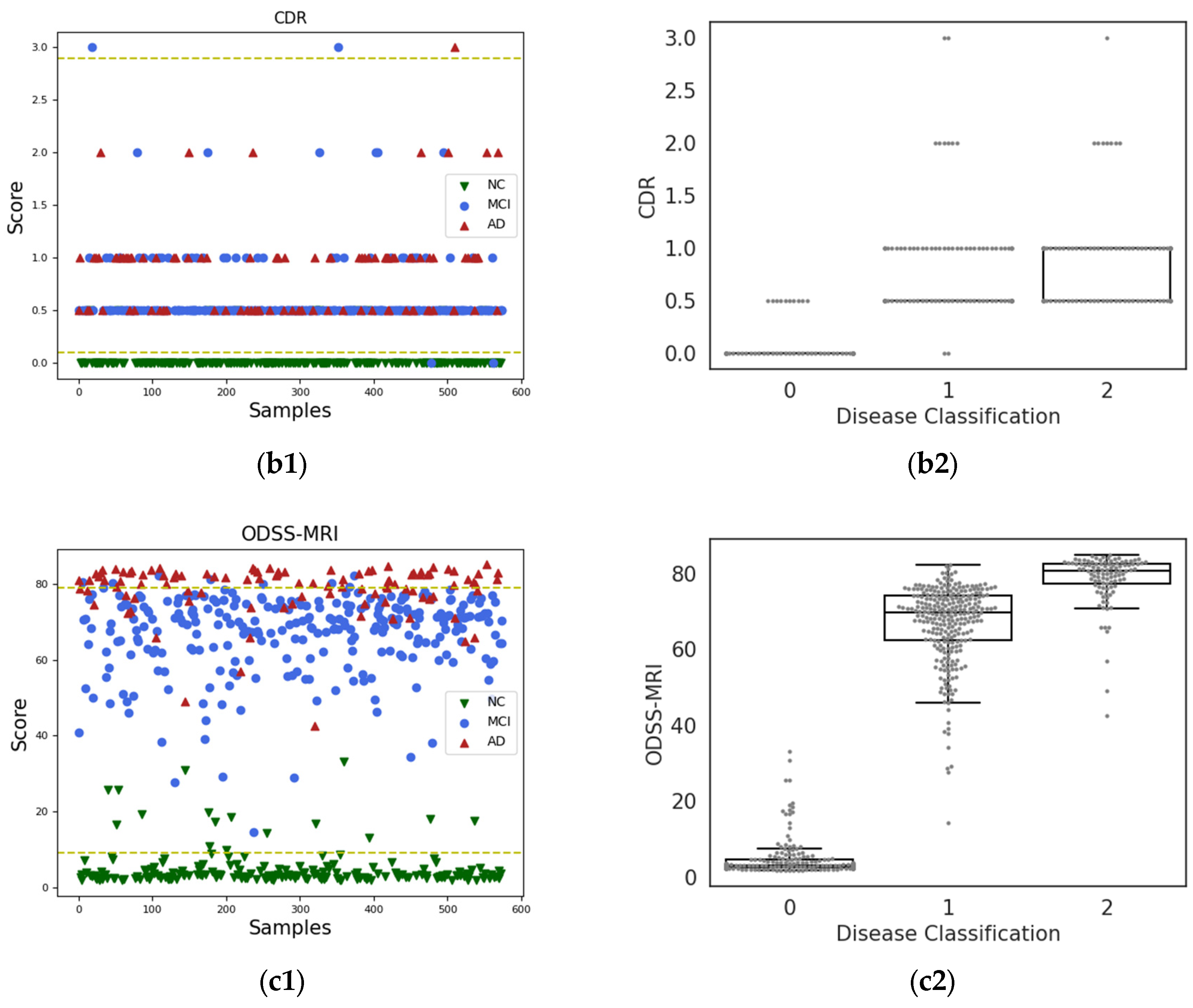
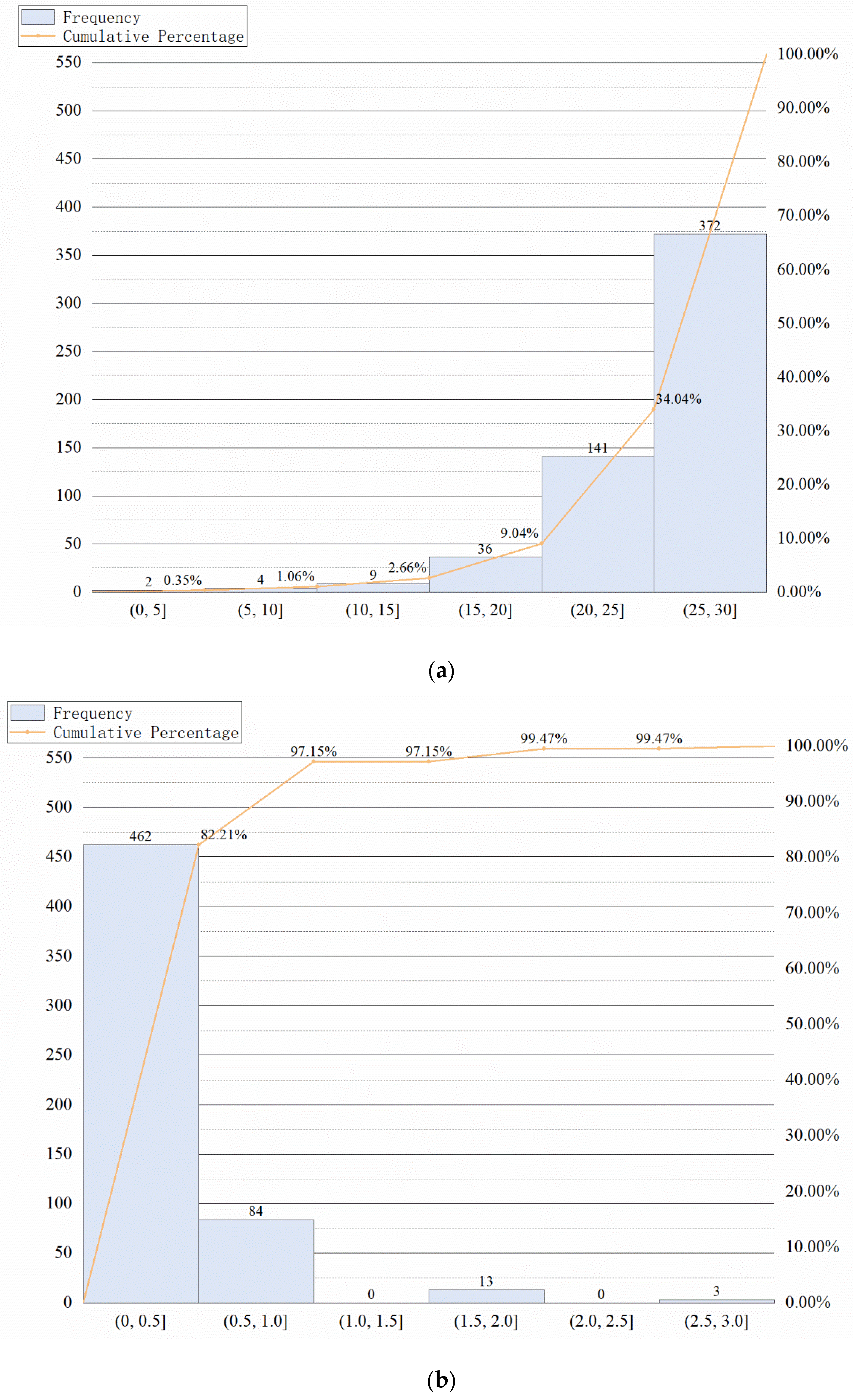
3.1. Materials
3.1.1. Participants
The sMRI data used in this experiment were obtained from the ADNI program (adni.loni.usc.edu, accessed on 24 June 2022), which was established in 2003 and led by Principal Investigator Michael W. Weiner, MD. ADNI is a longitudinal multicenter study aimed at developing clinical, imaging, genetic, and biochemical biomarkers for the early detection and follow-up of AD. This program provides researchers with a variety of neuroimaging data, such as magnetic resonance imaging, functional magnetic resonance imaging, magnetic resonance diffusion tensor imagery, and positron emission scanning images, which is currently the most widely used public database of AD. We obtained 2997 sMRI images from 633 subjects in the ADNI dataset, including 149 AD, 263 mild cognitive impairment (MCI), and 221 NC subjects.
Table 1 shows the demographic information of the subjects included in our dataset, including the category, number of subjects, sex (male/female), age (average), and the number of sMRI images.
3.1.2. Data Pre-Processing
Data pre-processing was performed to ensure that the model was capable of effectively learning pattern information in the dataset. In the data-preprocessing stage, we obtained the image from the ADNI website after gradient nonlinear correction, non-uniform correction, and histogram sharpening. To quickly process a large amount of sMRI data, we used the Matlab-based CAT12 toolbox for batch processing of the data. First, we performed an anterior commissure-posterior commissure (AC-PC) correction of the image data and obtained standard brain atlas images using the AC-PC line as the baseline. Subsequently, we de-skulled and removed invalid areas of the images, preserving only the brain locations, after which we aligned the images with the Montreal Neurological Institute (MNI) standard template. Finally, we modulated the images to ensure spatial consistency and preserve variability.
After the pre-processing stage, we can obtain whole brain images with a size of 113 × 137 × 113. Subsequently, we sliced the 3D image. Considering that the middle part of the image contains richer brain information, we sliced the middle layer (69/137) of the 3D whole brain image along the coronal plane. Finally, we obtained the 2D slice dataset for this study and divided the dataset into the training dataset (80%) and the test dataset (20%) based on the subjects and added the image from the first patient participation test to the test dataset as historical data to the training dataset.
3.2. Methods
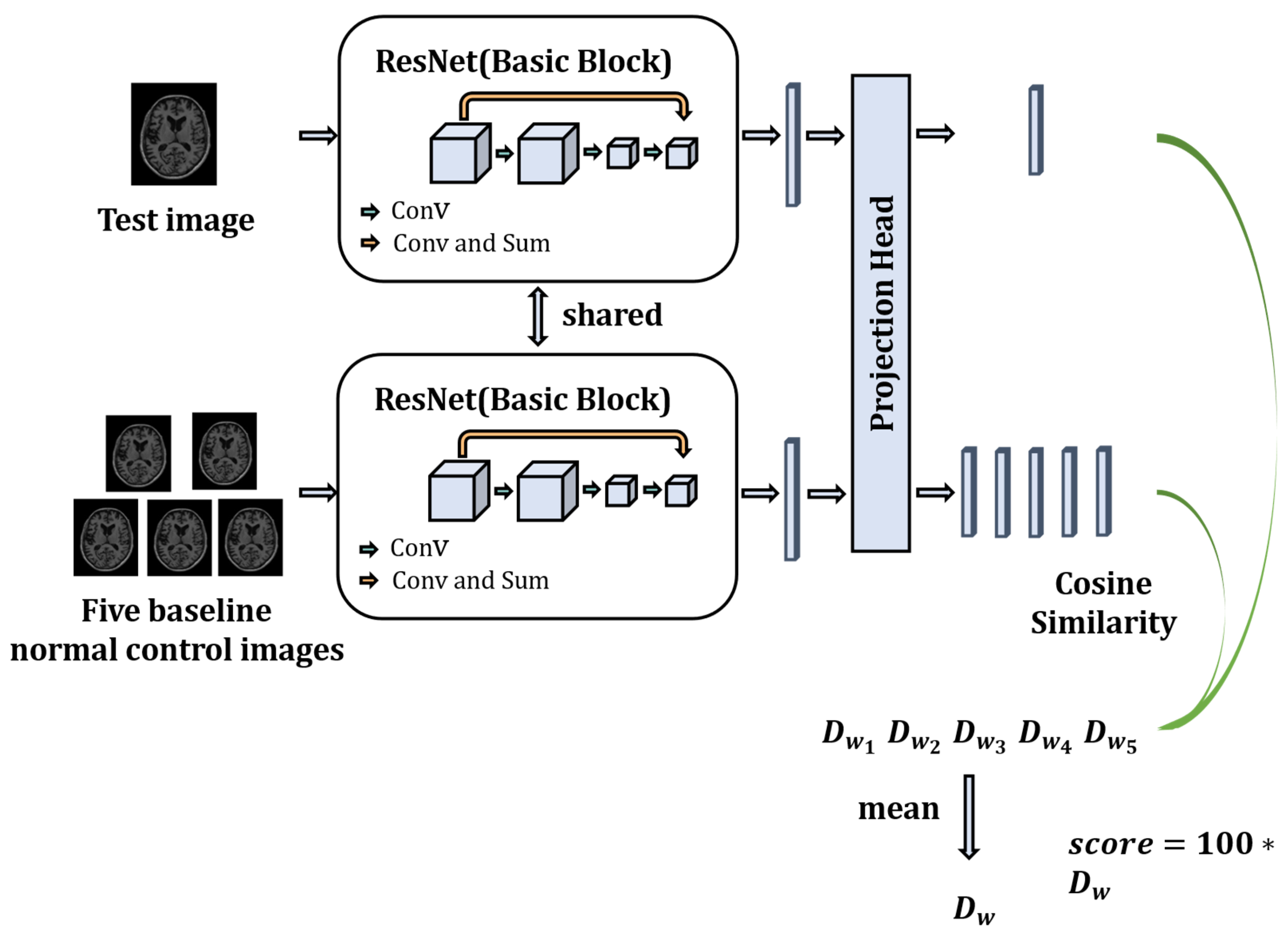
In this section, we propose an objective dementia severity scale based on MRI using a contrastive learning strategy for AD neurological evaluation problems. The proposed evaluation model is driven by MRI and uses a contrastive learning framework to evaluate the neurological function of patients with AD. The model comprehensively considers the neurological functional information of the patient’s whole brain and does not require any additional knowledge of neurology and pathology, effectively ensuring that the obtained functional scores are not influenced by biased subjective factors of the physician and the patient. The model structure is shown in
Figure 1. The model utilizes a two-channel structure, in which the test sample is to be evaluated. The MRI images of the healthy person were randomly selected as the baseline sample. They are utilized as input of two channels, and then the samples are entered into a Residual Networks (ResNet) model with shared weights to obtain the high-dimensional feature vectors of the sample to be evaluated and the baseline healthy person sample. We then map the high-dimensional feature vectors into a low-dimensional feature space using a Projection Head. Finally, the cosine similarity is used to calculate the similarity between the low-dimensional feature vectors of the sample to be evaluated and the baseline healthy subjects. The similarity is expanded by a hundredfold to obtain the final neurological function evaluation score.
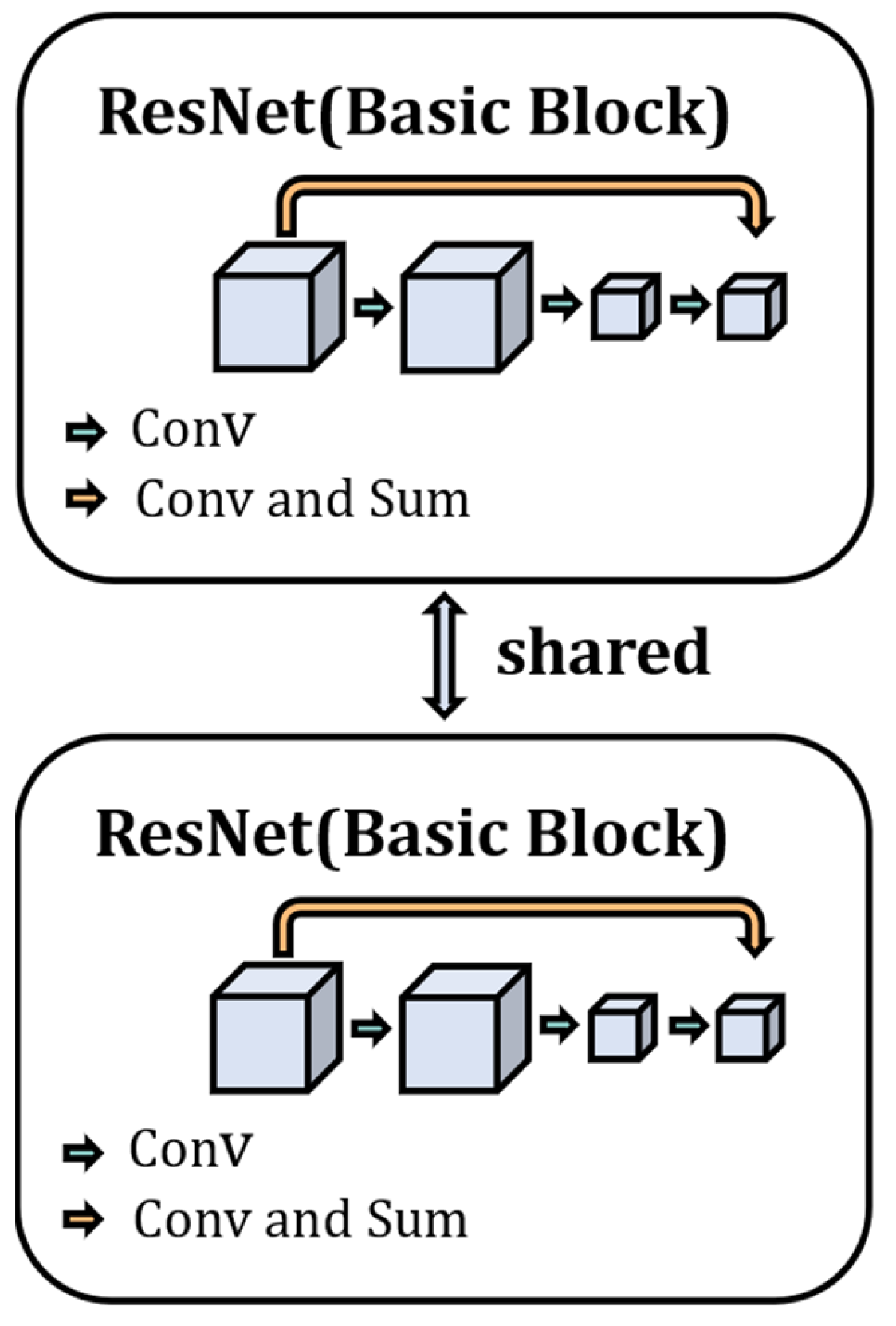
The two-channel structure of the ODSS-MRI model is a weight-sharing residual neural network, as shown in
Figure 2. First, the network simultaneously mines potentially valid pattern information from the data in both input channels and performs weight sharing during optimization to ensure that the samples in the two channels are mapped into the same feature space. Second, the model adapts the residual neural network as the feature encoder, which utilizes a skip connection, as shown in
Figure 2, so that gradient diffusion does not occur when the depth of the network increases. At the same time, the network parameters are easier to optimize, and the gradient information propagates more easily during the back-propagation stage.
- 2.
Model Training
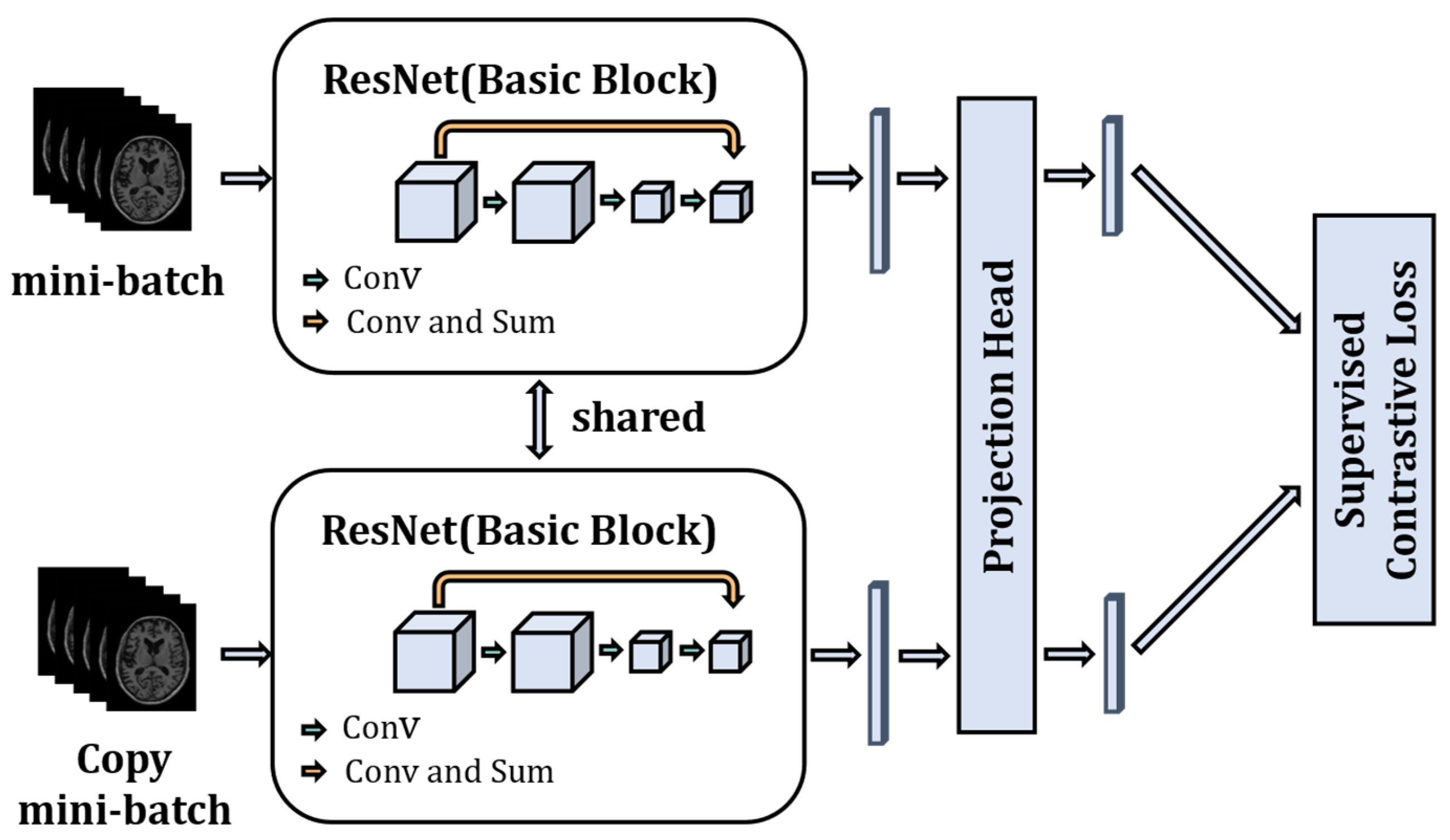
The model is trained using the supervised contrastive strategy. As shown in
Figure 3, there are two channels, and each batch of images is copied once and fed into the two channels. Then the ResNet model is used as a feature encoder to extract features from the input images. ResNet uses the network structure of skip connection to significantly increase the depth of the network, which can extract semantically informative features from images. The fully connected layer is removed from ResNet and only the 1024-dimensional feature vector output obtained from the average pooling layer is used. A Projection Head is added after the encoder, which maps the 1024-dimensional feature vector space to a 128-dimensional feature vector space, and then we normalize the 128-dimensional feature vectors to keep them on a unit hypersphere. The essence of the projection head is a multi-layer perceptron consisting of linear fully connected layers and the ReLU function to add nonlinearity, and the number of fully connected layers of the projection head is set to one in the model. The study [
24] (SimCLR) has shown that the addition of a learnable nonlinear transformation between the feature representation of the image and the contrastive loss can significantly improve the quality of the learned representation feature vector of the images. Finally, the supervised contrastive loss is used to train the model to fully utilize the image and label information of the data.
- 3.
Supervised contrastive learning loss function
In the contrastive learning domain, the purpose of the loss function is to allow the model learning to cluster similar samples in the feature space and mutually exclude dissimilar samples so that similar samples are aggregated together in the feature space. Most contrastive loss functions do not use the label information, but supervised contrastive learning adds label information to the loss function based on contrastive learning, as shown in Equations (1) and (2), where
N represents the amount of image data in a mini-batch,
y represents the label of the image,
z represents the feature vector, and
τ represents the temperature parameter.
The supervised contrastive loss function is a generalization of the contrastive loss function. Supervised contrastive loss treats data with the same label as positive pairs, and those with different labels as negative samples. This expands the number of positive pairs while maintaining a sufficient number of negative pairs. The loss function calculates the similarity for all positive pairs and then performs a weighted average, which contrasts with a large number of negative pairs. In addition, by increasing the number of positive samples, the network can better characterize intra-class similarities.
- 4.
Neurological function scoring
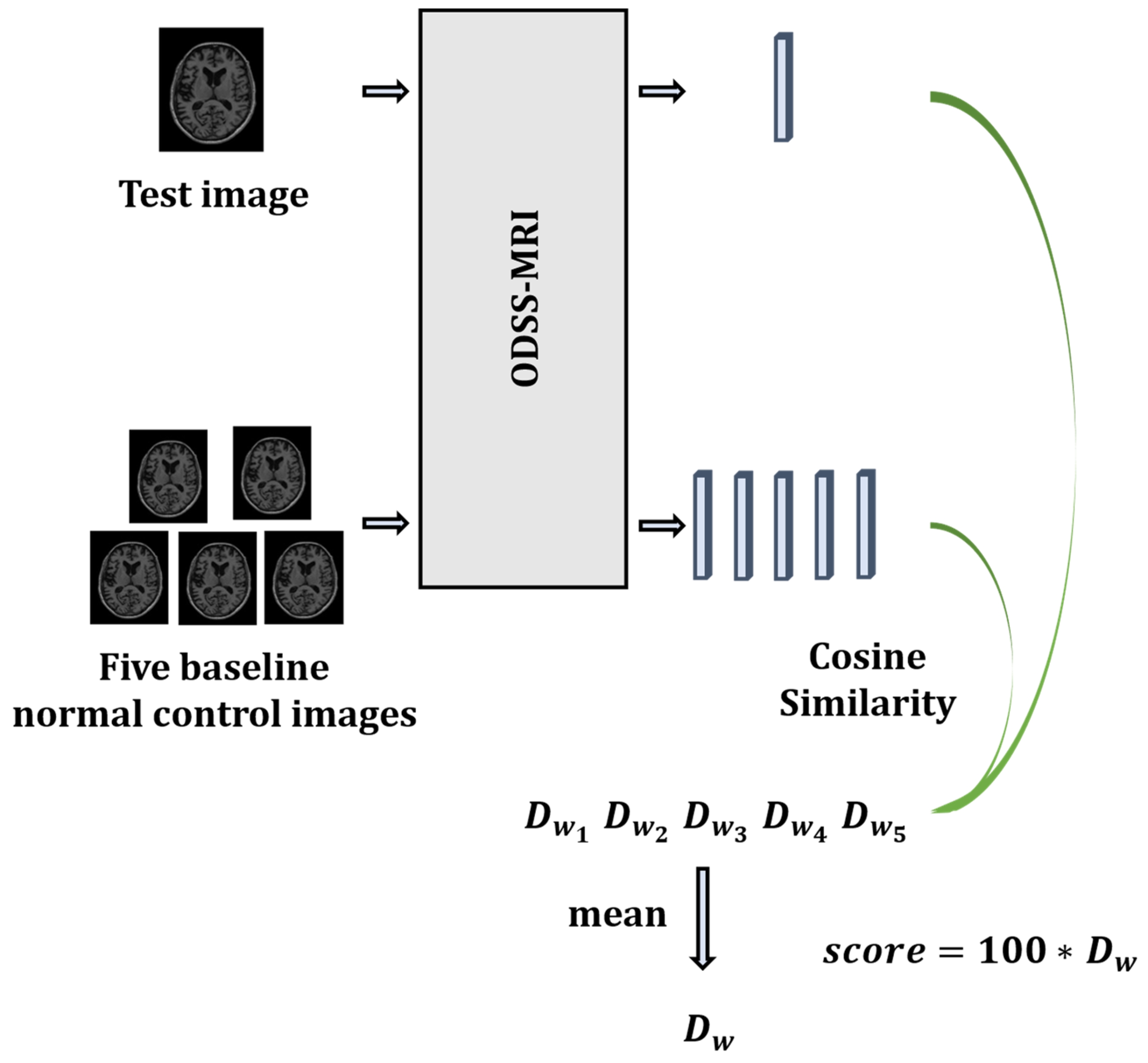
After training the model, a distance metric function needs to be chosen to calculate the distance between the two output vectors, in order to transform the output feature vectors into neurological function scores. There are many distance metric functions, such as Euclidean distance and Mahalanobis Distance. However, the more similar the images in this framework, the higher the similarity of the two vectors corresponding to the output, and the smaller the distance between the images. Therefore, this framework utilizes the cosine distance to measure the distance between the two vectors. The neurological function score is calculated using Equation (3):
Figure 4 shows the specific process of neurological function scoring. We randomly select five baseline healthy individuals from the training dataset as the baseline for comparison with the test dataset. This approach assumes that healthy individuals exhibit a relatively consistent level of neurological function. However, given that subtle differences may exist between healthy individuals’ nervous systems, they are eliminated by averaging the five scores obtained.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}