2. Problems and Motivations
SER is a challenging task due to various reasons. Firstly, (i) emotions are subjective and their expression can vary significantly across individuals. Different people may exhibit varying patterns of speech, tone, and vocal cues to convey the same emotion. (ii) The availability of high-quality, diverse, and standardized datasets is crucial in training and evaluating SER models. (iii) Emotions are often context-dependent, and the same speech utterance can convey different emotions depending on the situational context. These problems are considered the motivations of this study to obtain better SER results. To address the first problem, the proposed model uses MFCCs as input regardless of the patterns of speech and tones. The MFCCs’ spectrograms can serve as a solution to this problem. Data augmentation can be utilized to address the data scarcity problem. We augment the dataset by adding white noise to the speech signals such that the database size is increased. To address the third problem, the model uses a Transformer encoder module to obtain the context-dependent (temporal) features.
Speech emotion recognition systems have gained attention due to the extensive use of deep learning. Prior to deep learning, SER systems were reliant on techniques such as hidden Markov models (HMM) [
2], Gaussian mixture models (GMM) [
3], and support vector machines (SVM) [
4], along with extensive preprocessing and accurate feature engineering. Comprehensive reviews of SER systems are available in [
5,
6]. A benchmark comparison is available in [
7]. However, the development of deep learning tools and processes, and solutions for SER, has also changed. There have been significant studies and research proposing SER techniques to recognize and classify various emotions in speech [
8,
9,
10,
11,
12,
13,
14]. In addition to recent developments in deep learning, there has been a wave of studies on SER using long short-term memory, recurrent neural networks, generative adversarial networks, and autoencoders to solve the above problem [
15,
16,
17,
18,
19,
20,
21,
22].
In the recent past, deep learning has significantly contributed to natural language understanding (NLU). Deep belief network (DBN)-based SER in [
23,
24] showed a substantial improvement over the baseline non-DL models [
25]. Extreme learning machine (ELM)-based SER in [
26,
27] used feature representations from the probability distributions at the segment level, employing a single hidden layer neural network to classify speech emotions at the utterance level. Deep hierarchical models, data augmentation, and regularization-based DNNs for SER are proposed in [
28], whereas deep CNNs using spectrograms are proposed in [
29]. DNNs are trained for SER with the acoustic features extracted from the short intervals of speech using a probabilistic CTC loss function in [
30]. Bidirectional LSTM-based SER in [
31] is trained on feature sequences and achieves better accuracy than DNN-ELM [
26]. Deep CNN+LSTM-based SER in [
32] achieves even better results. The hybrid deep CNN + LSTM improves the SER accuracy but raises the overall computational complexity. Auditory–visual modality (AVM)-based SER in [
33] captures emotional content from different speaking styles. The Tensor Fusion Network (TFN)-based SER in [
34] learns intra- and inter-modality dynamics. Convolutional deep belief network-based SER in [
35] learns multimodal feature representations linked to expressions. The single plain CNN model is weak in classifying the speaker’s emotional state with the required accuracy level because it loses some basic sequential information during the convolutional operation. Therefore, two parallel CNN models can solve the limitation concerning the loss of important information in speech. The study in [
36] shows two parallel CNN models and utilizes them for SER accordingly.
With dominance, pleasure, and excitement, one can nearly define all emotions; however, the implementation of such a deterministic system using DL is very challenging and complex. Therefore, in DL, statistical models and the clustering of samples are used to qualitatively classify emotions such as sadness, happiness, and anger. For the classification and clustering of emotions, features must be extracted from speech, usually relying on different types of prosody, voice quality, and spectral features [
37]. The prosody features usually include the fundamental frequency (F0), intensity, and speaking rate, but they cannot confidently discriminate between angry and happy emotions. The features associated with voice quality are usually the most successful in determining the emotions of the same speaker. However, these features vary from speaker to speaker, making them difficult to use in speaker-independent settings [
38]. On the other hand, spectral features are widely used to determine emotions from speech. These features can confidently distinguish anger from happiness. However, the magnitudes and shifts of the formant frequencies for identical emotions change across different vowels, which increases the complexity of the speech emotion recognition system [
39]. For all the feature types, there are several standard representations of features. Prosody features are typically represented by F0 and measure the speaking rates [
40], whereas spectral features are defined by cepstrum-based feature representations. Mel-frequency cepstral coefficients (MFCC) or linear prediction cepstral coefficients (LPCC) are commonly used spectral features along with formants, and other information can also be used [
41]. Finally, the voice quality features usually include the normalized amplitude quotient, shimmer, and jitter [
42].
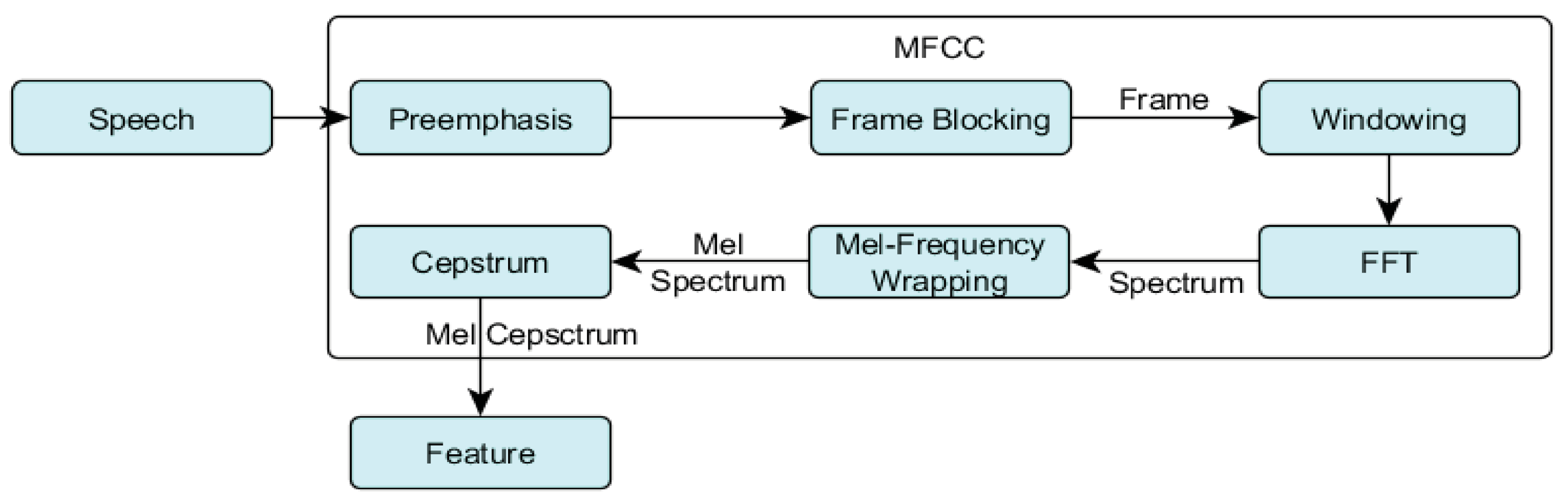
Feature extraction is a crucial step in many machine learning tasks, including speech recognition, computer vision, and natural language processing. The goal of feature extraction is to transform raw data into a representation that captures the most salient information for the task at hand. In speech recognition, features are typically extracted from the acoustic signal using techniques such as mel-frequency cepstral coefficients (MFCCs), which have been widely used in the literature due to their effectiveness in capturing the spectral envelope of a signal. Other popular techniques include perceptual linear predictive (PLP) features, gamma tone features, and filterbank energies. In computer vision, features are extracted from images using techniques such as SIFT, SURF, and HOG, which are effective in capturing local visual patterns. In natural language processing, features are extracted from text using techniques such as bag-of-words, n-grams, and word embeddings, which capture the syntactic and semantic information in the text [
43,
44,
45,
46,
47,
48]. This study uses MFCCs as input features for several reasons. First, (i) the MFCCs are used as a grayscale image as a simultaneous input to the parallel CNNs and Transformer modules for spectral and temporal feature extraction. (ii) MFCCs can capture the spectral envelopes of speech signals, which is crucial in characterizing different emotional states. MFCCs are less sensitive to variations in speaker characteristics, background noise, and channel distortions, making them more robust for emotion recognition tasks. (iii) MFCCs are derived based on the human auditory system’s frequency resolution, which aligns well with how humans perceive and differentiate sounds. By focusing on perceptually relevant information, MFCCs can effectively capture the distinctive features related to emotions conveyed through speech. (iv) MFCCs provide a compact representation of speech signals by summarizing the spectral information into a smaller number of coefficients. This dimensionality reduction helps to reduce the computational complexity and memory requirements of SER models while still preserving the essential information needed for emotion classification. (v) By computing MFCCs over short time frames and applying temporal analysis techniques such as delta and delta–delta features, the dynamic changes in speech can be captured. Emotions often manifest as temporal patterns in speech, and MFCCs enable the modeling of these dynamics, enhancing the discriminative power of SER models.
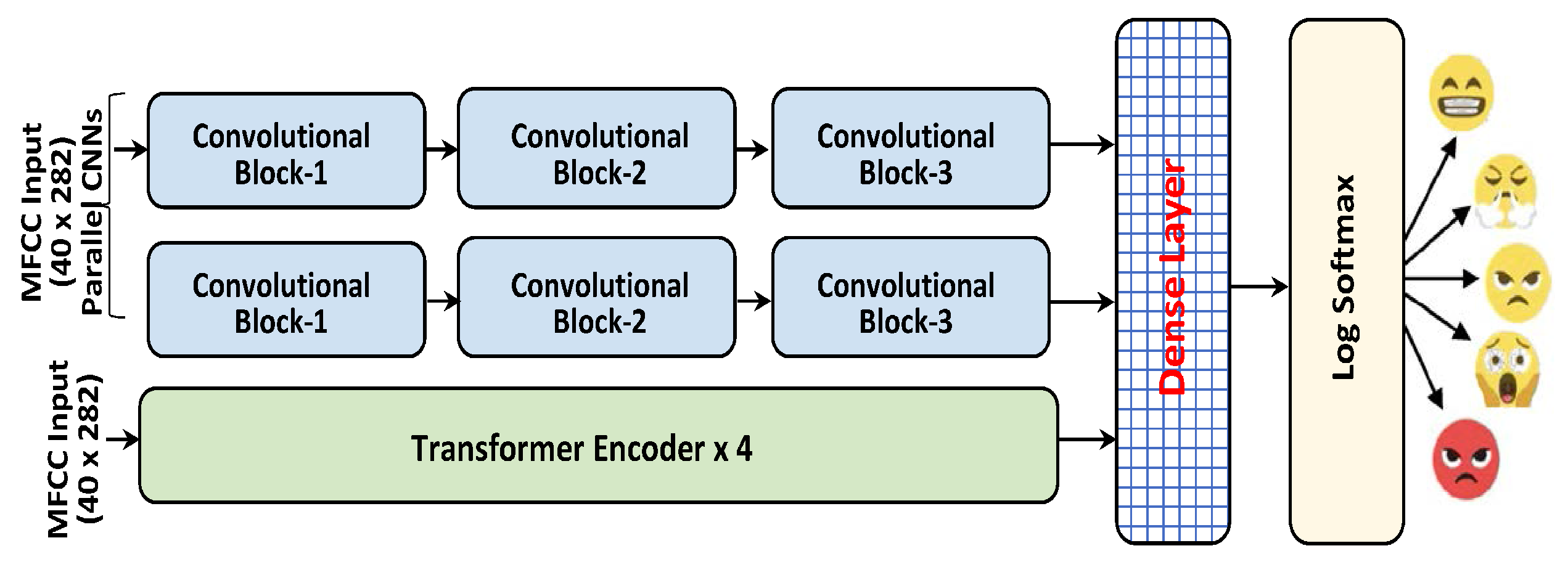
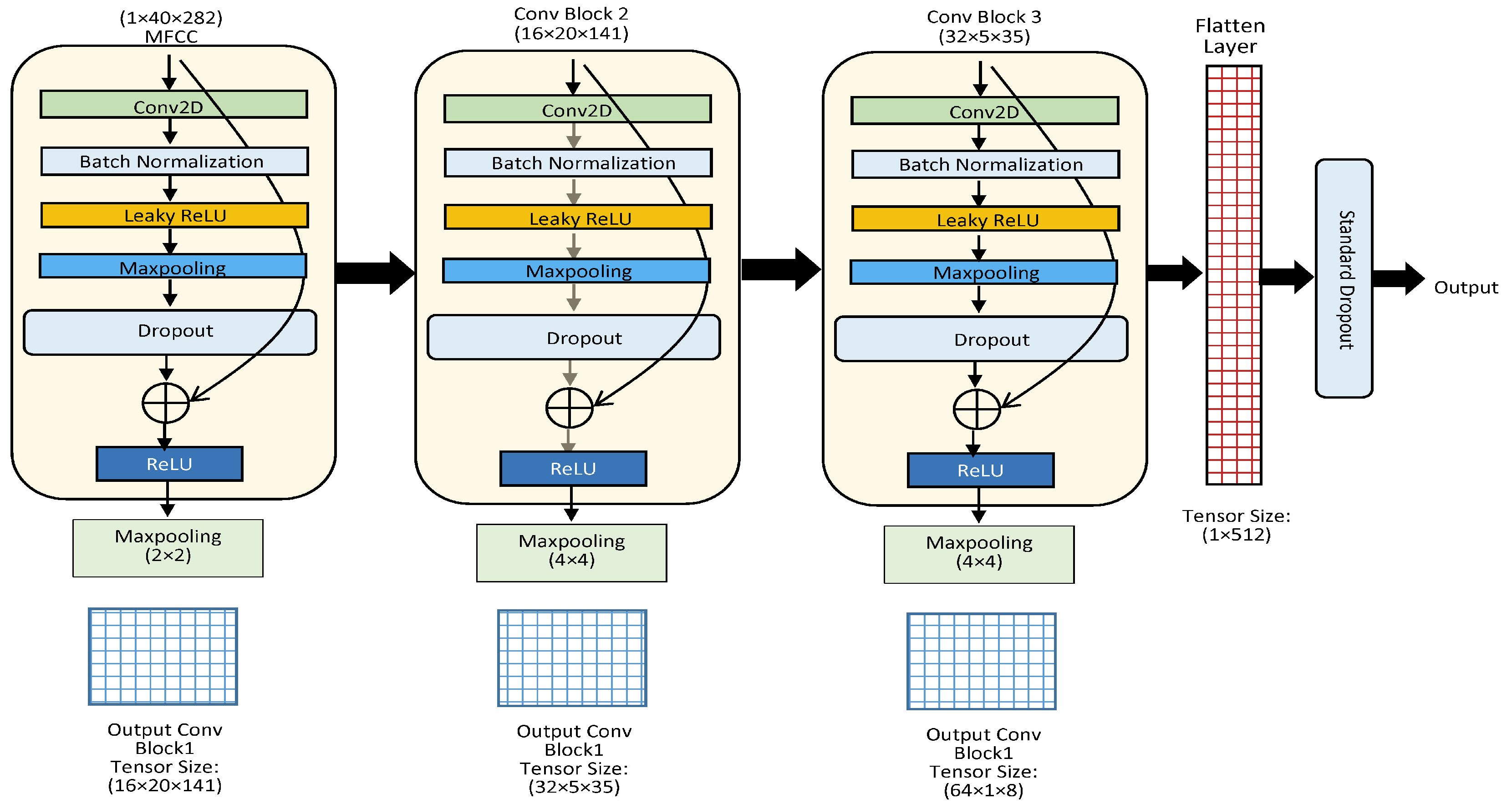
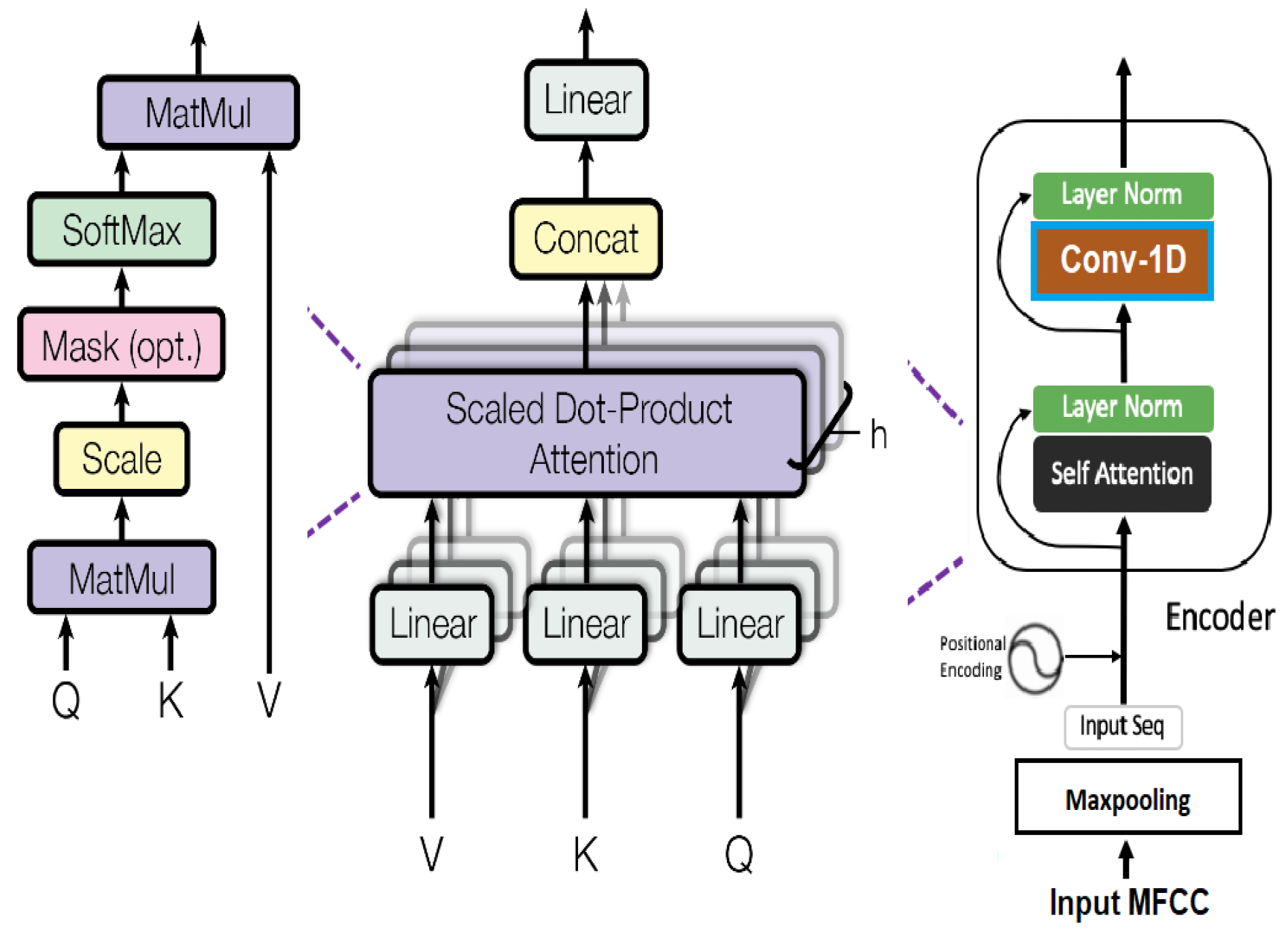
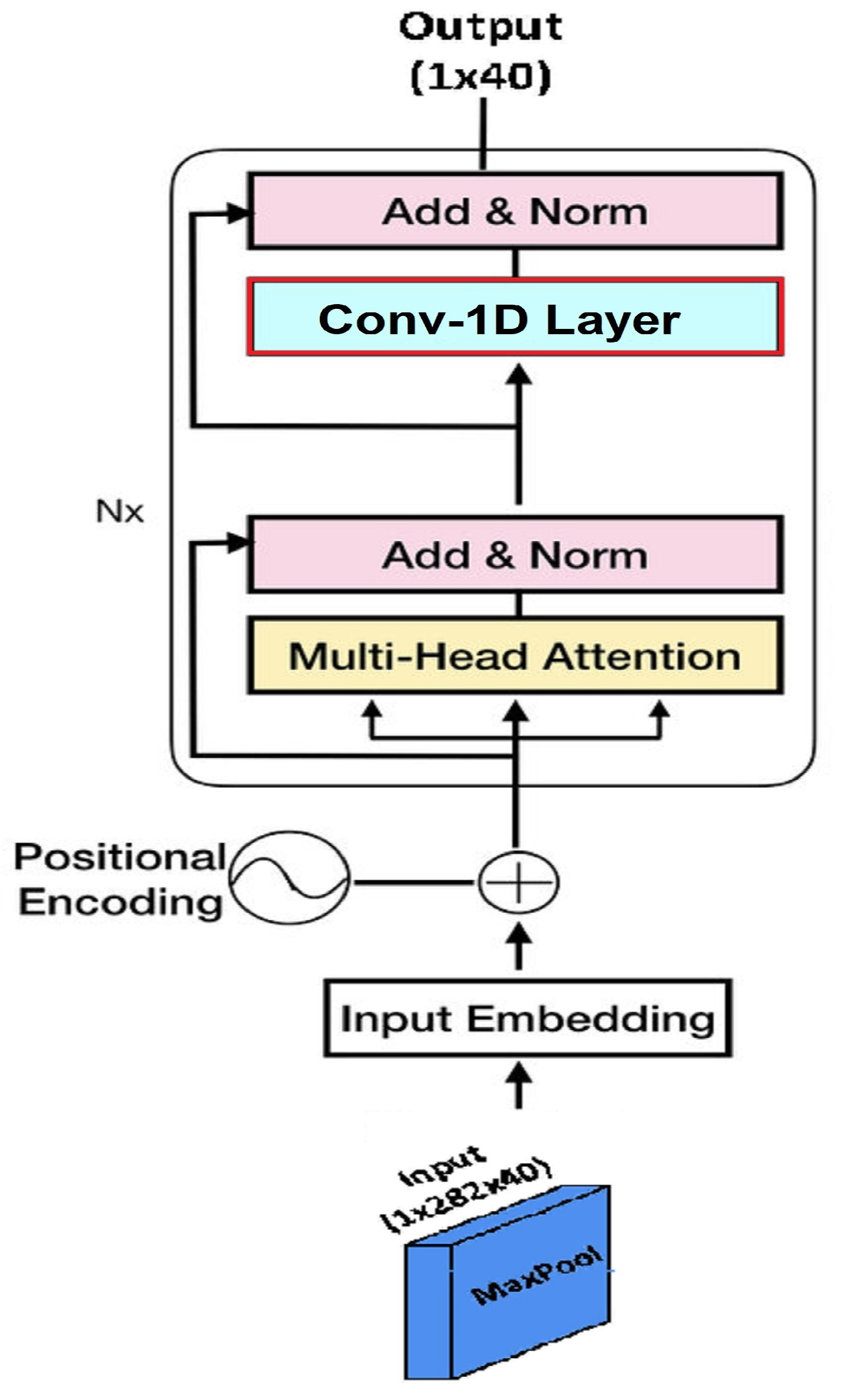
We have studied and examined the recent speech processing literature and observed that speech signals follow a hybrid structure, such as temporal features and spatial features, where both feature representations contain essential cues for SER. The majority of the existing SER systems lack parallel neural architectures to process speech signals and acquire information about high-level deep spatiotemporal features. As a result of this limitation, we have proposed a fusion of spatial and temporal feature representations of speech emotions by parallelizing CNNs and a Transformer encoder for SER, named CTENet. We have stacked two parallel CNNs for the spatial feature representation, which is paired with multi-head self-attention layers from the Transformer encoder for the temporal feature representation to classify the speech emotions. By increasing the filter channel dimensions and decreasing the feature maps of CNNs, better feature representations can be achieved at a low computational cost. The Transformer encoder is utilized such that the SER model can learn to anticipate the frequency distributions of various speech emotions. The MFCC plot of a speech utterance is treated as a grayscale image where the width of the MFCC is treated as a time scale and the height is treated as a frequency scale, respectively. The pixel values in the MFCC plots are the speech signal intensities at the mel-frequency range and time steps. Since the input data are sequential, the Transformer accurately establishes the temporal relations between the pitch transitions in various emotions. We augment and intensify the variations in the RAVDESS dataset with AWGN to minimize model overfitting. With the CNN for the spatial feature representations and the Transformer for the sequential encoding, the proposed CTENet for SER achieves 82.31% accuracy when classifying eight speech emotions. The main contributions of this study are summarized below.
Stacked parallel CNNs with multi-head self-attention layers are implemented. The channel dimensions of filters and feature maps are reduced, allowing an expressive representation of features at a lower computational cost. With multi-head self-attention, the network learns to predict the frequency distributions of speech emotions in accordance with the overall MFCC structure.
With the classification and spatial feature representation of CNNs, the MFCCs are used as grayscale images, where the widths and heights of the MFCC are the time and frequency scales, respectively. The pixel values in the MFCC indicate the speech signal intensities at the mel-frequency range and time steps.
The dataset is augmented with AWGN. Creating new, real samples is a very difficult task. Thus, white noise is added to the speech signals to mask the random effect of noise existing in the training dataset. Moreover, this generates pseudo-new training samples and counterbalances the noise impact inherent in the dataset.
The rest of this paper is organized as follows. The related SER literature is presented in
Section 2. An in-depth explanation of the proposed SER with parallel CNNs using skips and a Transformer encoder is given in
Section 3. The experiments and setups are explained in
Section 4.
Section 5 gives the results and discussion. Finally,
Section 6 concludes this research.
3. Related SER Literature
Speech emotion recognition is an attractive research field and numerous novel techniques have been proposed to learn optimal SER solutions. The SER method contains two modules, namely feature representation and emotion classification. Optimal feature representation and superior classification for a robust SER system are difficult tasks [
9]. The MFCC feature-based SER in [
49] classifies various emotions using the logistic model tree (LMT) classifier. An ensemble model using 20 SVMs with a Gaussian kernel in [
50] is proposed for SER and achieves 75.79% accuracy. The 2D-CNN-based SER method in [
51] recognizes emotions by extracting deep discriminative cues from spectrograms. Pre-trained CNN architectures—for example, AlexNet and VGG—are used to construct the SER framework via transfer learning to classify emotions from spectrograms in [
52]. A trained CNN model in [
53] is utilized for the extraction of features from spectrograms, and speech emotions are classified using SVM. Moreover, 1D-CNN + FCN-based SER in [
54] use prosodic and spectral features from MFCCs to classify various speech emotions. The LSTM and RNNs are used to classify the long-term sequences in the speech signals for SER [
55]. The DNN-LSTM-based SER method in [
56] uses a hybrid approach to learn spatiotemporal cues from raw speech data.
The CNN-BLSTM-based SER method in [
57] learns the spatial features and temporal cues of speech symbols and increases the accuracy of the existing model. The SER extracts spatial features and feeds them to the BLSTM in order to learn temporal cues for the recognition of the emotional state. A DNN in [
26] is used to compute the probability distributions for various emotions given all segments. The DNN identifies emotions from utterance-level feature representations, and, with the given features, ELM is used to classify speech emotions. The CNN in [
58] successfully detects emotions with 66.1% accuracy when compared to the feature-based SVM. Meanwhile, the 1D-CNN in [
59] reports 96.60% classification accuracy for negative emotions. The CNN-based SER in [
60] learns deep features and employs a plain rectangular filter with a new pooling scheme to achieve more effective emotion discrimination. A novel attention-based SER is proposed utilizing a long attention process to link mel-spectrogram and interspeech-09 features to generate the attention weights for a CNN. A deep CNN-based SER is constructed in [
61] for the ImageNet LSVRC-2010 challenge. The AlexNet trained with 1.2 million images and fine-tuned with samples from the EMO-DB is used to recognize angry, sad, and happy emotions. An end-to-end context-aware SER system in [
62] classifies speech emotions using CNNs followed by LSTM.
The difference compared to other deep learning SER frameworks lies in not using the preselected features before network training and introducing raw input to the SER system. The ConvLSTM-based SER in [
63] adopted convolutional LSTM layers for the state transitions so as to extract spatial cues. Four LFLBs are used for the extraction of the spatiotemporal cues in the hierarchical correlational form of speech signals utilizing a residual learning strategy. The BLSTM + CNN stacking-based SER in [
64] matches the input formats and recognizes emotions by using logistic regression. BC-LSTM relies on context-aware utterance-level representations of features. This model captures the contextual cues from utterances using a BLSTM layer. The SVM-DBN-based SER in [
65] improves emotion recognition via diverse feature representation. Gender-dependent and -independent results show 80.11% accuracy. The deep-stride CNN-based SER in [
66] uses raw spectrograms and learns discriminative features from speech spectrograms. After learning the features, the Softmax classifier is employed to classify speech emotions.
Attention mechanism-based deep learning for SER is another notable approach that has achieved vast success; a complete review can be found in [
67]. In classical DL-based SER, all features in a given utterance receive the same attention. Nevertheless, emotions are not consistently distributed over all localities in the speech samples. In attention-based DL, attention is paid by the classifier to the given specific localities of the samples using attention weights assigned to a particular locality of data. The SER system based on multi-layer perceptron (MLP) and a dilated CNN in [
68] uses channel and spatial attention to extract cues from input tensors. Bidirectional LSTM with the weighted-polling scheme in [
69] learns more illustrative feature representations concerning speech emotions. The model focuses more on the main emotional aspects of an utterance, whereas it ignores other aspects of the utterance. The self-attention and multitasking learning CNN-BLSTM in [
70] improves the SER accuracy by 7.7% in comparison with the multi-channel CNN [
71] when applied to the IEMOCAP dataset. With speech spectrograms as input, gender classification has been considered as a secondary task. The LSTM in [
18] for SER demonstrates reduced computational complexity by replacing the LSTM forget gate with an attention gate, where attention is applied on the time and feature dimensions. The attention LSTM-based time-delay SER in [
72] extracts high-level feature representations from raw speech waveforms to classify emotions.
The deep RNN-based SER in [
73] learns emotionally related acoustic features and aggregates them temporally into a compact representation at the utterance level. Another deep CNN [
74] is proposed for SER. In addition, a feature pooling strategy over time is proposed, using local attention to focus on specific localities of a speech utterance that are emotionally prominent. A self-attention mechanism utilizes a CNN via sequential learning to generate the attention weights. Another attention-based SER is proposed that uses a fully connected neural network (FCNN). Frame- and utterance-level features are used for emotion classification by applying MLP and attention processes to classify emotions. A multi-hop attention model for SER in [
75] uses two BLSTM streams to extract the hidden cues from speech utterances. The multi-hop attention model is applied for the generation of final weights for the classification of emotions. Other important research related to SER includes fake news and sentiment analysis, as emotions can also be found in fake news, negative sentiments, and hate speech [
76,
77,
78,
79,
80,
81]. A short summary of the related literature is given in
Table 1. Accuracy holds significant importance in the speech emotion recognition (SER) system, where the primary goal is to predict emotions in speech utterances with a high level of precision. Consequently, researchers in the field strive to enhance this particular aspect. By examining
Table 1, which is extracted from the aforementioned literature, it becomes evident that models have made advancements in terms of accuracy. However, there is still substantial room for further improvement. Simultaneously, the depth of the model (its computational complexity) remains a crucial consideration for real-time applications. Hence, our objective is to propose an SER model that achieves both high accuracy and a compact size. To accomplish this, we present a novel approach distinct from the models presented in the table, where CNNs combined with RNNs are predominantly employed for SER. Instead, we incorporate Transformer encoders to obtain robust features for network training, as they exhibit strong capabilities in capturing temporal features.
6. Results and Discussion
In this section, the results of the CTENet model in terms of various measures are first presented. Then, we compare the CTENet model with other SOTA models for SER using the RAVDESS and IEMOCAP corpora.
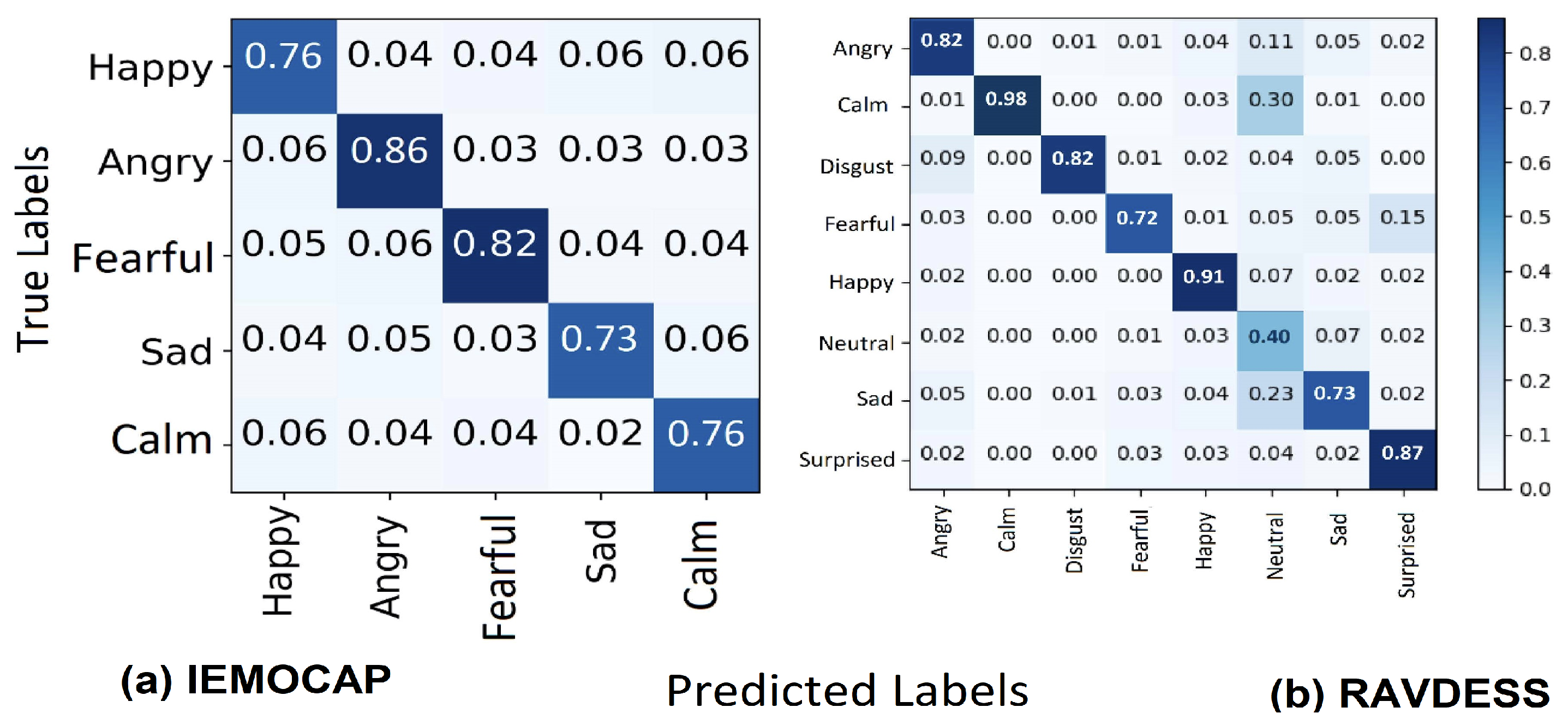
We examined the emotion recognition performance of the suggested CTENet model and utilized various measures to evaluate the model, such as recognition accuracy, precision, F1 scores, and recall. The confusion matrix plots of the model visualized the model performance in terms of actual and predicted labels for each emotion class. In addition, we conducted an ablation study for different emotions and achieved results with different models. The results of CTENet for the RAVDESS and IEMOCAP datasets are illustrated in
Table 5 with regard to recognition rates for each emotion class. We present the recognition accuracy of CTENet for each speech emotion from the RAVDESS and IEMOCAP datasets (W.Acc indicates weighted accuracy, whereas UW. Acc denotes unweighted accuracy). In addition, the confusion matrices visualize the testing sets in
Figure 8. For RAVDESS (8-way), the simulation results in
Table 5 show that CTENet obtains improved recognition accuracy in individual speech emotion recognition tasks at most times, exclusively for the happy, calm, surprised, and angry emotions. Meanwhile, we find that CTENet confuses the calm and angry emotions with the neutral and disgust emotions in a few cases (as demonstrated in
Figure 8a). Consequently, the CTENet model requires us to learn more about anger and disgust. The lowest recognition accuracy is obtained for the neutral emotion, since the neutral emotion is under-represented in the RAVDESS dataset (6.67% of the dataset). For the IEMOCAP (5-way) dataset, improvements in recognition performance can be seen for most emotion classes, as shown in
Table 5. Specifically, anger and fear outscore other speech emotions, including happiness, sadness, and calm. This can be attributed to the better ability of the CTENet model to classify features that are important for emotional discrimination. Meanwhile, we find that a few emotions are confused with others in some cases (as shown in
Figure 8b).
Table 6 and
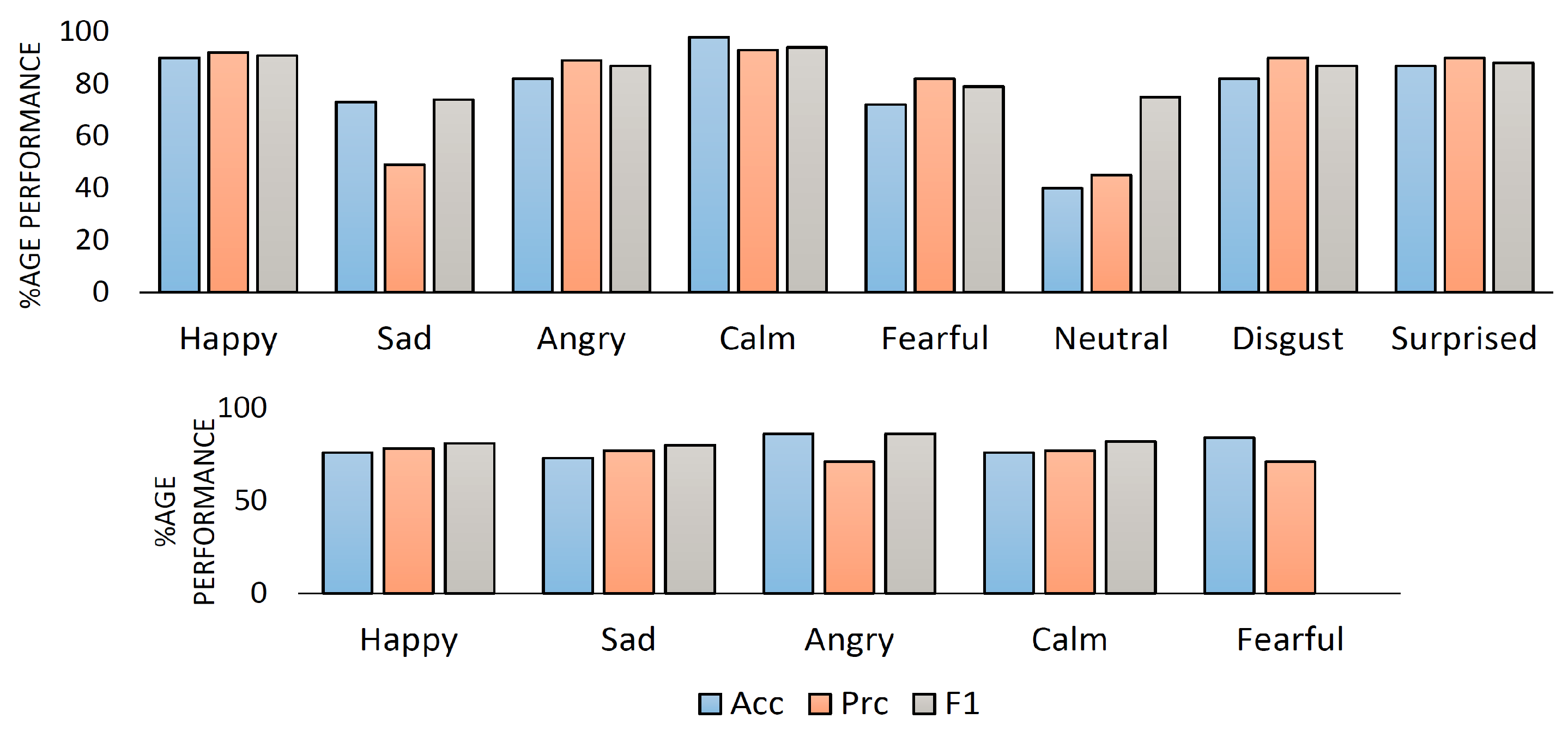
Table 7 describe the experimental results of CTENet model prediction in terms of overall model precision and the F1-score for the RAVDESS and IEMOCAP datasets. The experimental results show that CTENet obtains improved F1 accuracy and precision in the individual speech emotion recognition tasks for most instances, exclusively for the happy and calm emotions, for both the RAVDESS (8-way) and IEMOCAP (5-way) datasets. We confirmed the robustness of CTENet over the two standard datasets, and it achieved 78.75% precision for RAVDESS and 74.80% precision for IEMOCAP. Furthermore, CTENet achieved 84.38% F1 for RAVDESS and 82.20% F1 for IEMOCAP, respectively. The CTENet accuracy for the two datasets was 82.31% and 79.42%, respectively.
Figure 9 visualizes the complete performance of CTENet for both datasets in terms of precision, accuracy, and F1 scores, respectively.
To show the importance of the multi-head attention Transformer (MHAT) encoder in CTENet, we present
Table 8, which demonstrates the accuracy, precision, and F1 scores for speech emotions achieved with CTENet without MHAT and with the MHAT encoder, respectively. The experimental outcomes indicate the significance of MHAT inclusion in CTENet, where the recognition results are enhanced considerably. On average, the accuracy, precision, and F1 scores are improved by 7.29%, 5.13%, and 3.26%, respectively, with MHAT. The accuracy is improved from 70.32% with the RAVDESS dataset to 78.0%, and from 70.32% to 79.0% with the IEMOCAP dataset. In addition, the F1 score is improved from 80.40% with the RAVDESS dataset to 84.37%, whereas it changes from 79.65% to 82.20% with the IEMOCAP dataset.
The proposed CTENet model demonstrated improved generalization during the experiments and evaluations for both datasets, and it obtained better emotion recognition accuracy with a low computational cost. In brief, we can assume that the proposed CTENet model for SER is accurate and computationally less complex. Consequently, it is able to examine human behaviors and emotions. Moreover, with the lightweight framework, this model is appropriate for real-time applications since it requires less training time.
Table 9 gives the training time and model size (in Mb). We compared the training time and model size with those of other SER frameworks, including DS-CNN [
51], CB-SER [
57], and AttNet [
68], for comparison. The experiments proved that the CTENet model is lightweight (compact model size of 4.54 Mb), generalizable, and computationally less expensive, and it requires less processing time to recognize emotions, which indicates the appropriateness of the model for real-world applications. The processing time is significantly minimized as the simultaneously expanded filter depth and feature map reduction provide an expressive hierarchical feature representation at the minimum computational cost. The total trainable parameters are 222,248 for the CTENet model.
Comparison with Existing Models
To confirm the effectiveness of the presented method, we compared CTENet with SOTA baseline benchmarks on the RAVDESS (8-way) and IEMOCAP (5-way) datasets. The SOTA baseline benchmarks included Att-Net, ensemble SVMs, 1D-CNN, BC-LSTM, ConvLSTM, and DeepNet. This section first compares CTENet with the SOTA baseline benchmarks in terms of the overall performance using accuracy, precision, and F1. After this, we compare the recognition accuracy, precision, and F1 for individual emotions.
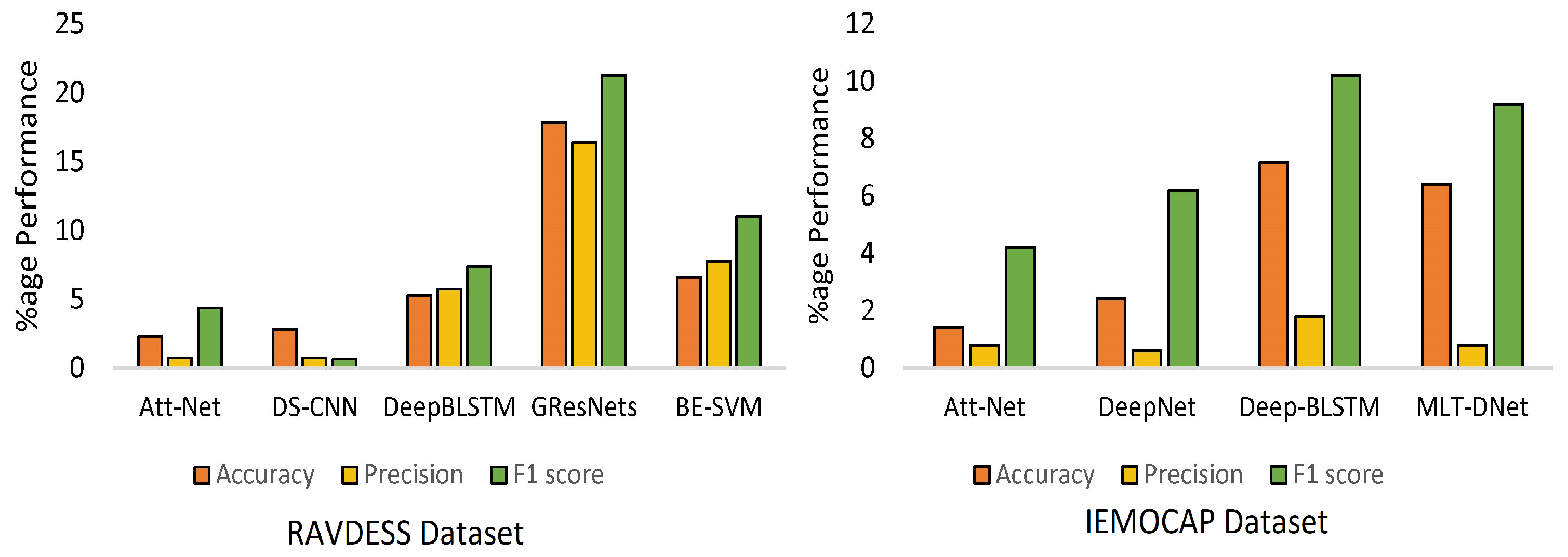
Table 10 shows a comparison of CTENet with the SOTA baseline benchmarks on the RAVDESS and IEMOCAP datasets. The experimental results show the effectiveness of CTENet. For the RAVDESS dataset, CTENet achieves 82.31% accuracy, which indicates an improvement of 2.31% over Att-Net, 2.81% over DS-CNN, and improvements other SOTA models given in
Table 10. In addition, for the IEMOCAP dataset, the CTENet achieves 79.42% accuracy, indicating an absolute improvement of 6.92% over Deep-BLSTM, 2.42% over DeepNet, and improvements over other SOTA models with reasonable margins. CTENet surpasses BE-SVM, GResNets, and Deep-BLSTM and improves the precision by 7.75%, 16.43%, and 5.75% on an absolute scale for the RAVDESS dataset. For the IEMOCAP dataset, CTENet outperforms the SOTA models, except for DS-CNN, which improves the precision by 12%. In terms of the F1 score, CTENet consistently achieves the highest percentage improvements. The overall F1 for CTENet is 82.20%, which is 6.0%, 10.0%, and 5.0% higher than that of DeepNet, Deep-BLSTM, and MLT-DNet for the IEMOCAP dataset. On the other hand, for the RAVDESS dataset, the CTENet achieves an 84.37% F1 score, which is 7.37% higher than that of Deep-BLSTM and 21.26% higher than GResNets.
Figure 10 shows the detailed performance of CTENet over the SOTA models [
87].
7. Conclusions and Recommendations
In this paper, we describe the combination of spatial and temporal feature representations of speech emotions by parallelizing CNNs and a Transformer encoder for SER. We extract the spatial and temporal features with parallel CNNs and the Transformer encoder from the MFCC spectrum. In the CTENet model, MFCCs are used as grayscale images, where the width is the time scale and height is the frequency scale. The experimental results on two popular benchmark datasets, RAVDESS and IEMOCAP, validate the usefulness of the CTENet model for SER. Our model achieves better experimental results over state-of-the-art models for speech emotion recognition, with overall accuracy of 82.31% and 79.80% for the benchmark datasets. Furthermore, the experimental results for different speech emotion classes show the effectiveness of the spatial and temporal feature fusion. The experimental results show the importance of MHAT inclusion in CTENet, where the emotion recognition results are improved significantly. The experimental results also prove that CTENet is compact (4.54 Mb) and computationally less costly, and requires less processing time to recognize different emotions, indicating the appropriateness of CTENet for real-world applications. With few entries in the datasets, the model sometimes overfits; however, we can fine-tune the model to avoid overfitting, such as by applying dropout regularization. It is also recommended to increase the database entries for better results and optimized model parameters.
The present study provides acceptable accuracy; however, a further improvement in accuracy can be achieved if the model architecture is further refined, e.g., a more effective feature extractor can be adopted. Different feature sets can be combined for more robust training features. Further, besides temporal and spatial features, we aim to add modalities to further increase the recognition accuracy using modality cues. In addition, we will apply recently introduced models to achieve state-of-the-art SER results.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}