

An Automated Skill Assessment Framework Based on Visual Motion Signals and a Deep Neural Network in Robot-Assisted Minimally Invasive Surgery

Abstract
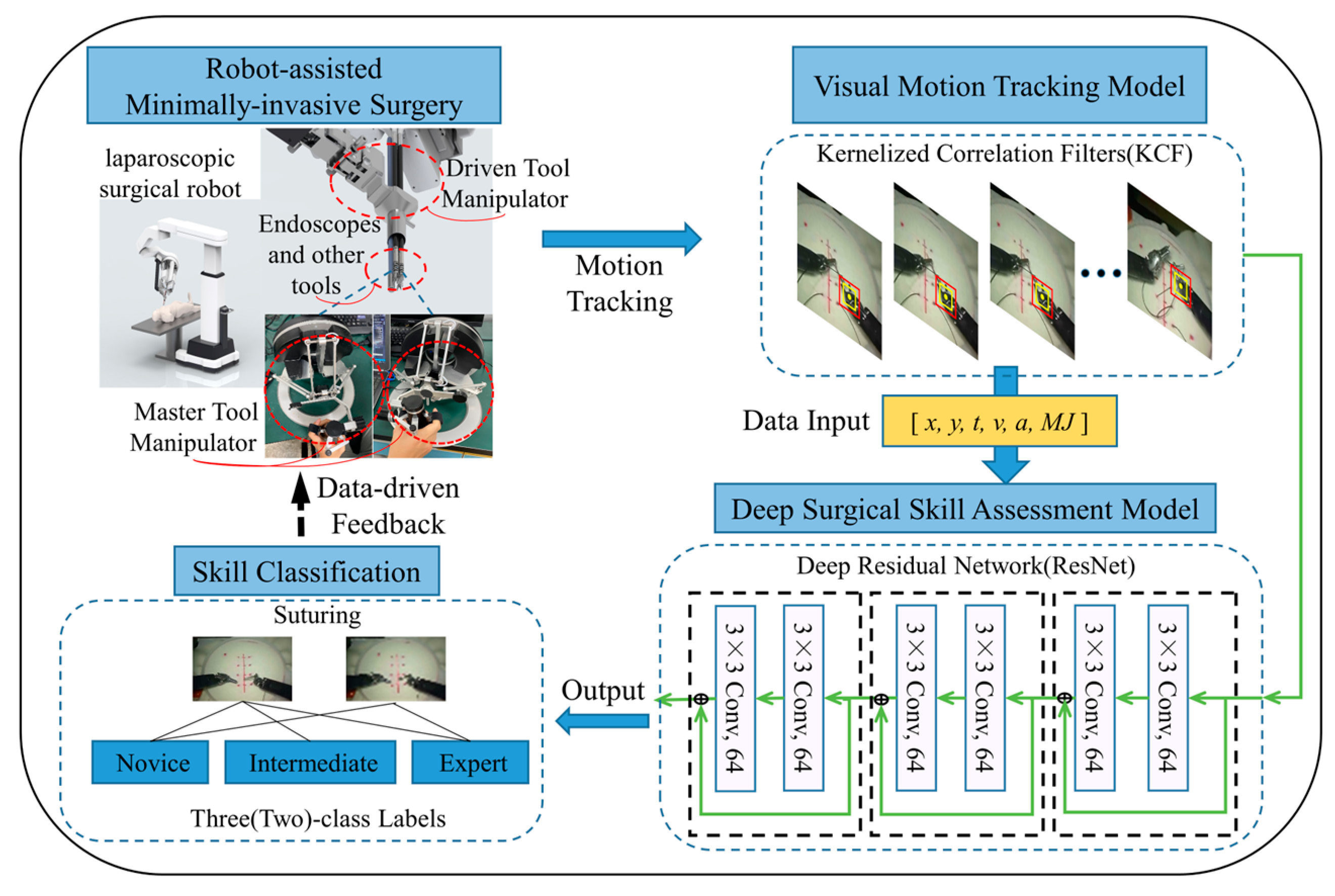
:1. Introduction
- A novel end-to-end analytical framework with visual tracking and deep learning is created for skill assessment based on the high-level analysis of surgical motion.
- Visual technology is used to replace traditional sensors in order to obtain motion signals in RAMIS.
- The proposed model is verified using the JIGSAWS dataset and the exploration of validation schemes applicable to the development of surgical skills assessment in RAMIS.
2. Materials and Methods
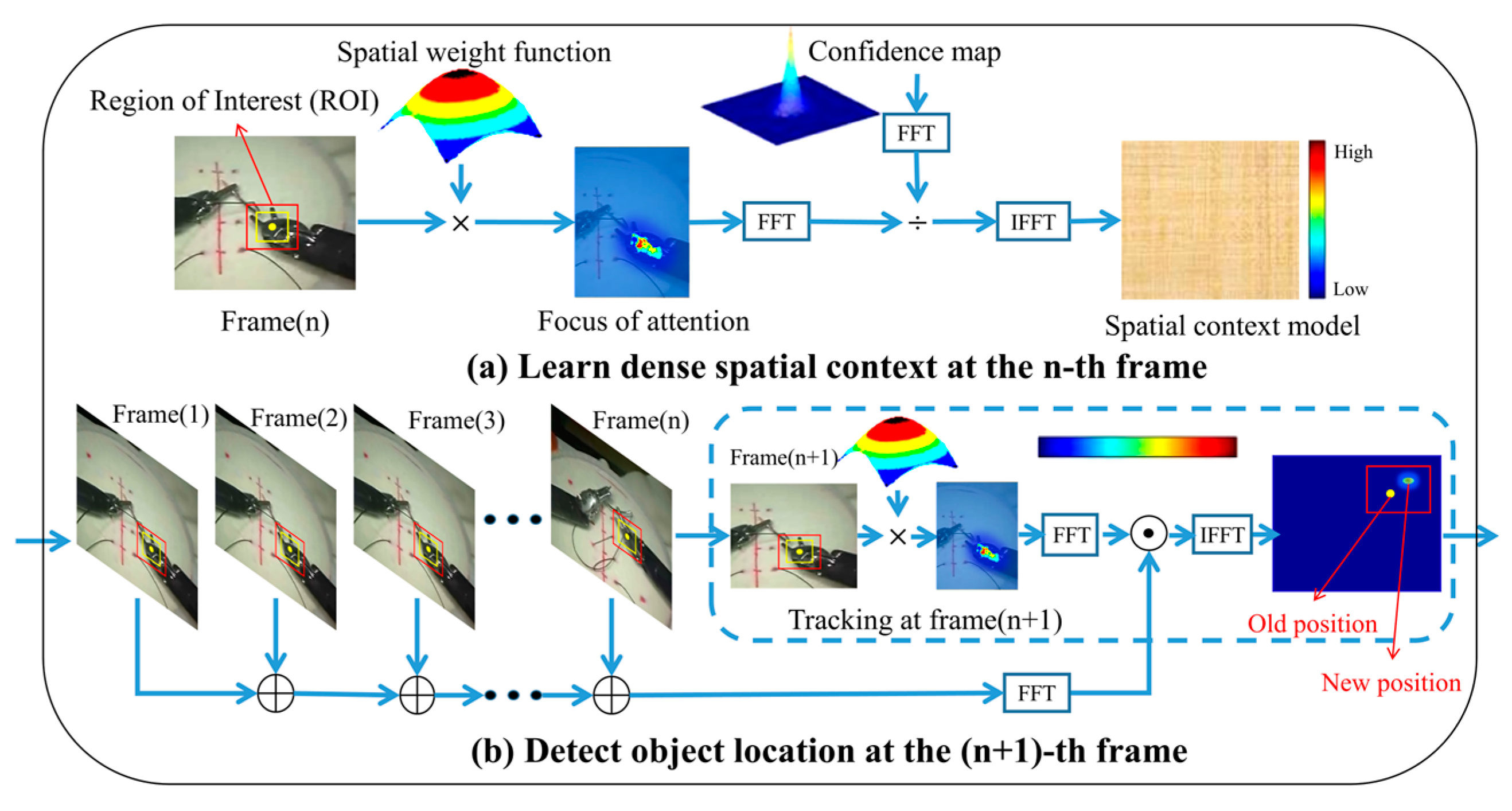
2.1. KCF
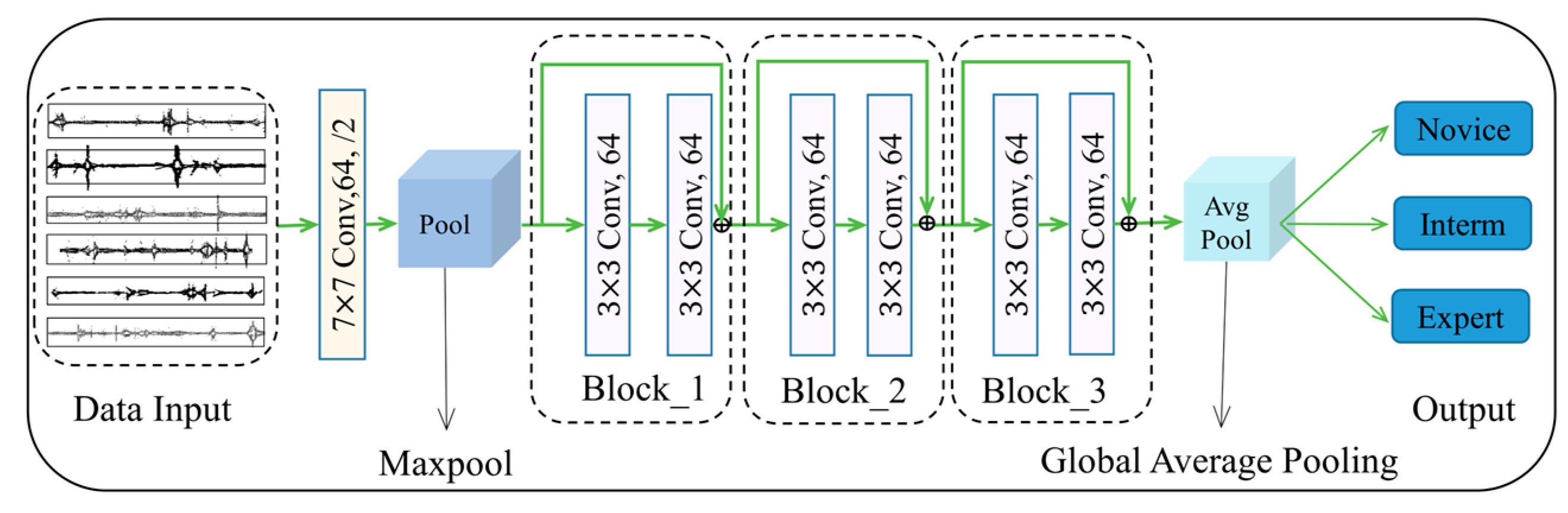
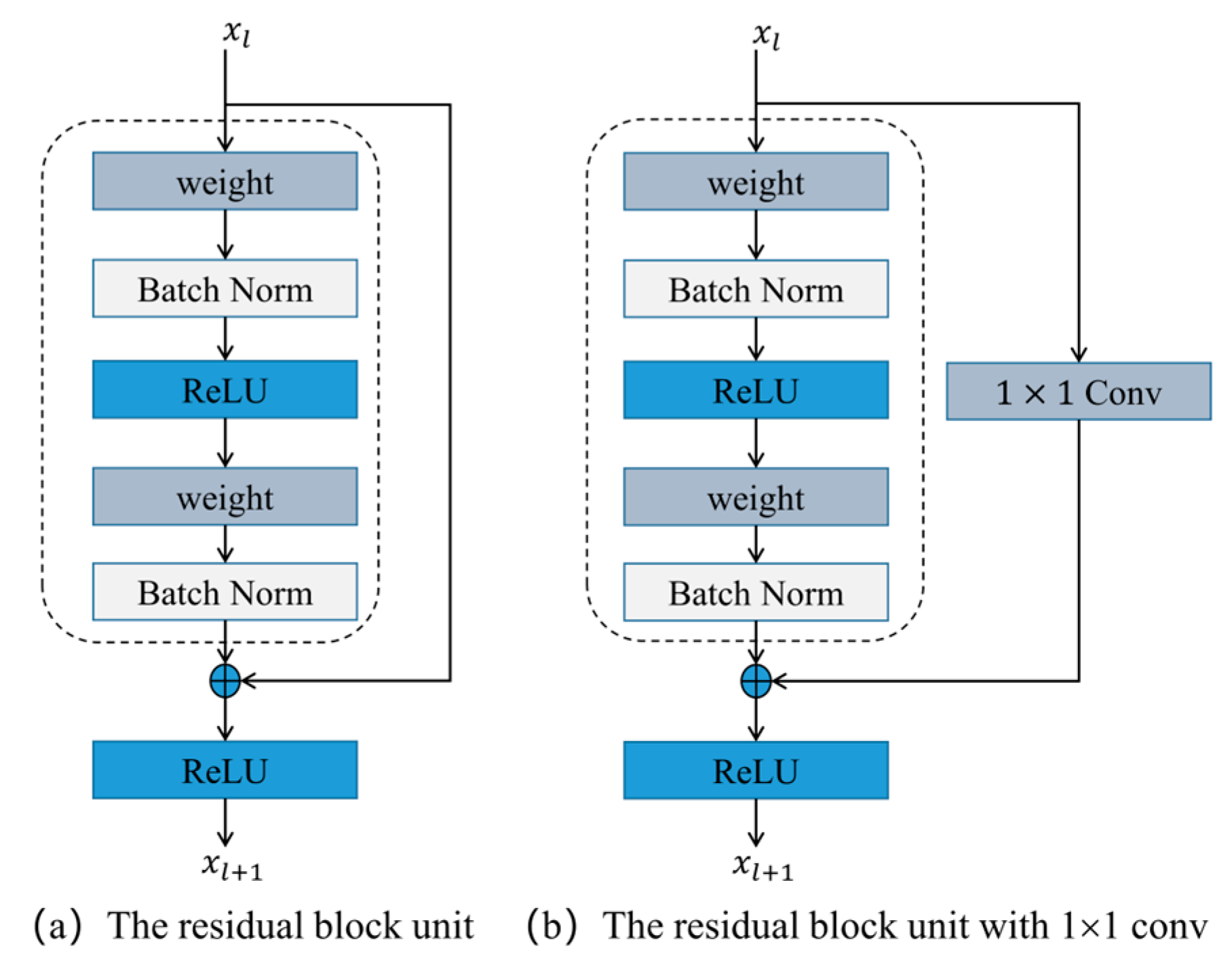
2.2. ResNet
3. Experimental and Results
3.1. Dataset
3.2. Experimental Setup
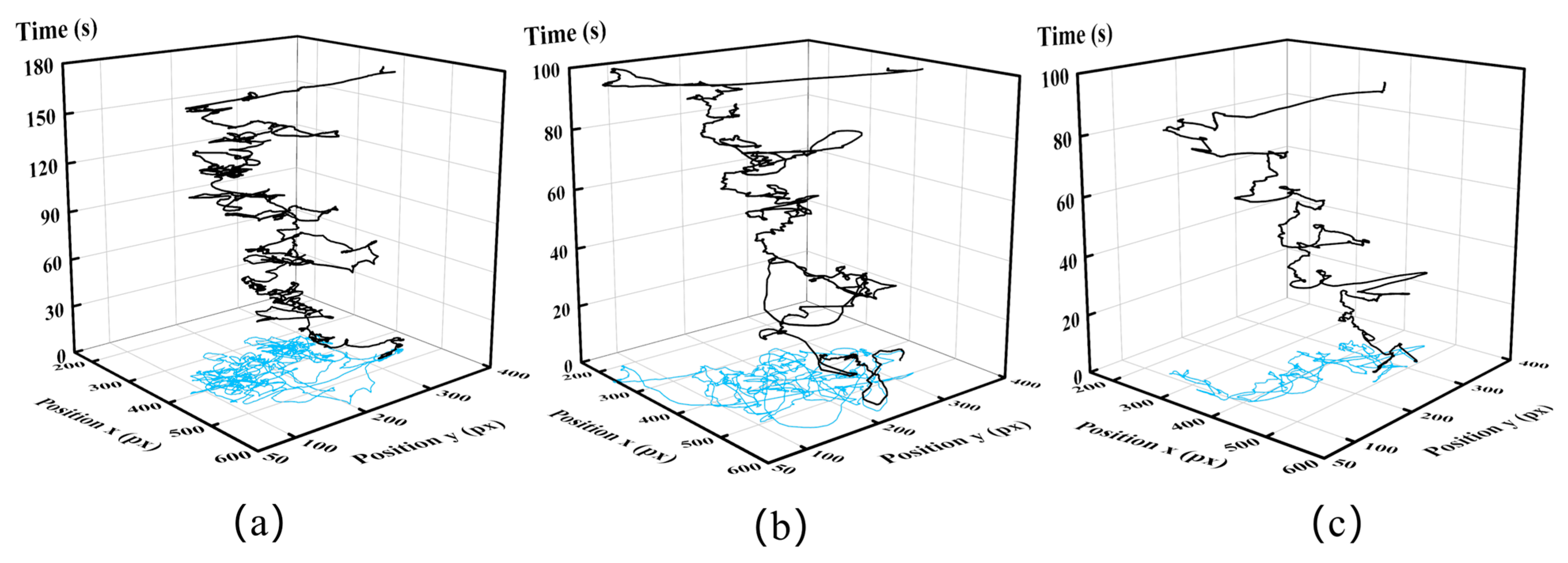
3.2.1. Process of Visual Motion Tracking
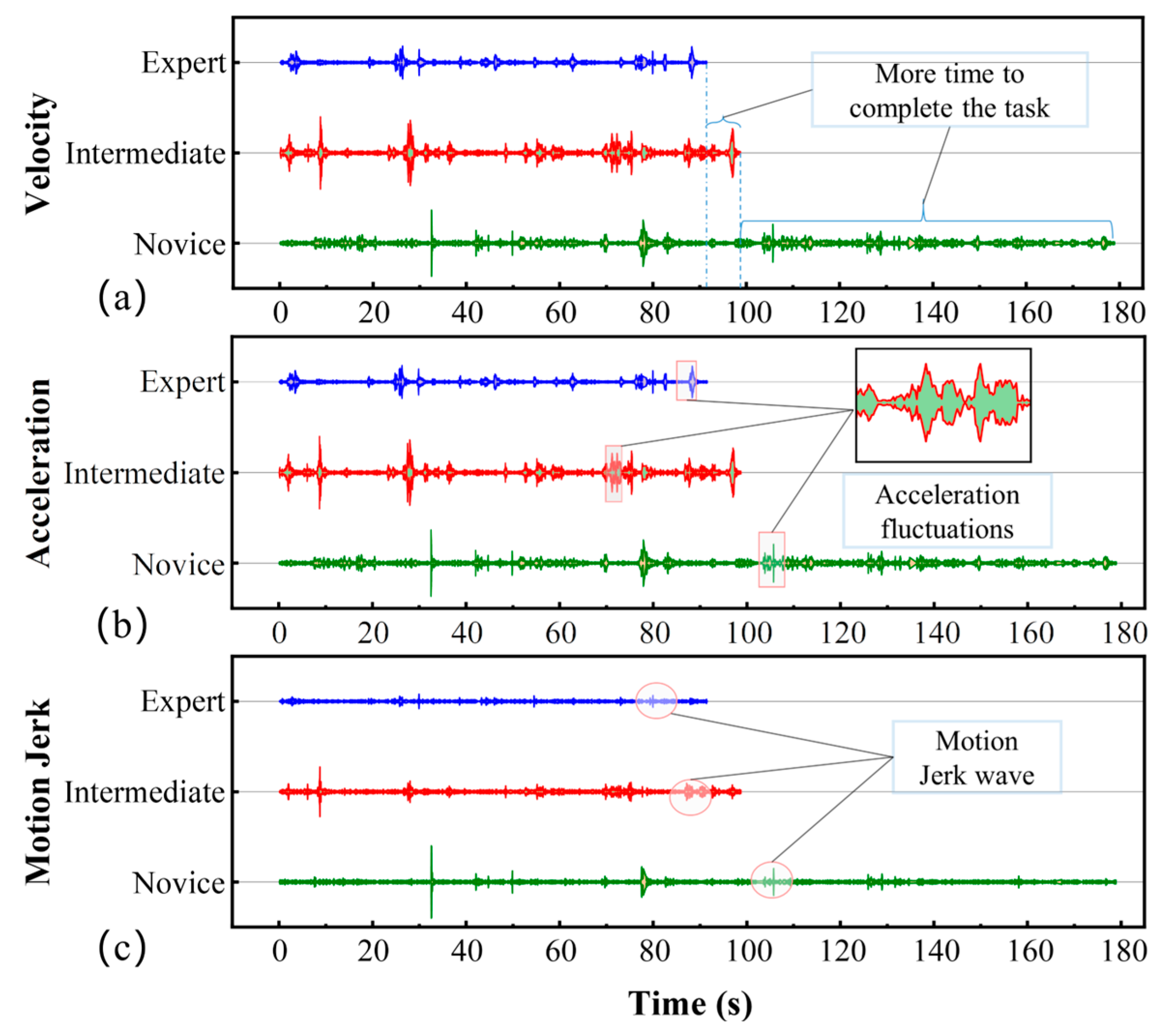
3.2.2. Key Motion Futures
3.2.3. Implementation Details of Classification
3.2.4. Modeling Performance Measures
- accuracy, the ratio between the number of samples correctly classified and the total number of samples;
- precision, the ratio between the correct positive predictions and the total positive results predicted by the classifier;
- recall, the ratio between the positive predictions and the total positive results in the ground truth;
- F1-score, a weighted harmonic average between precision and recall.
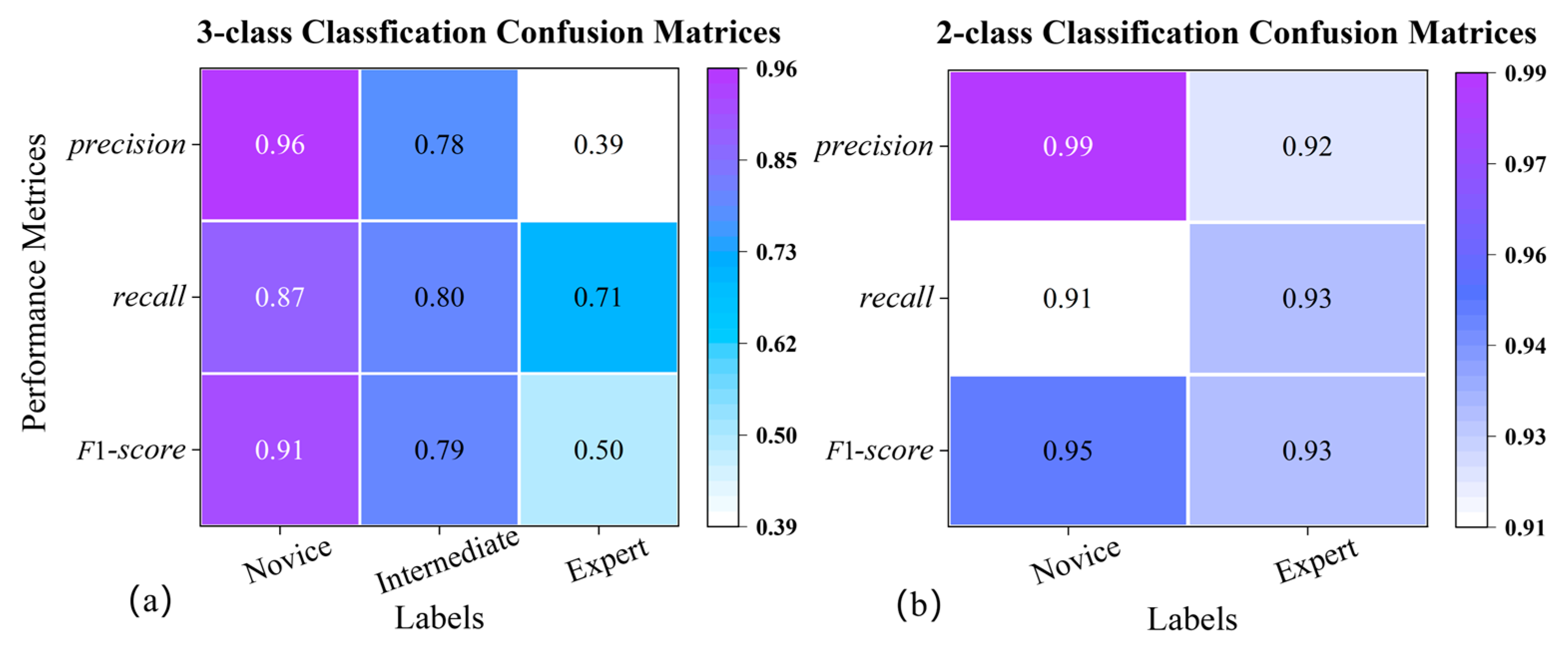
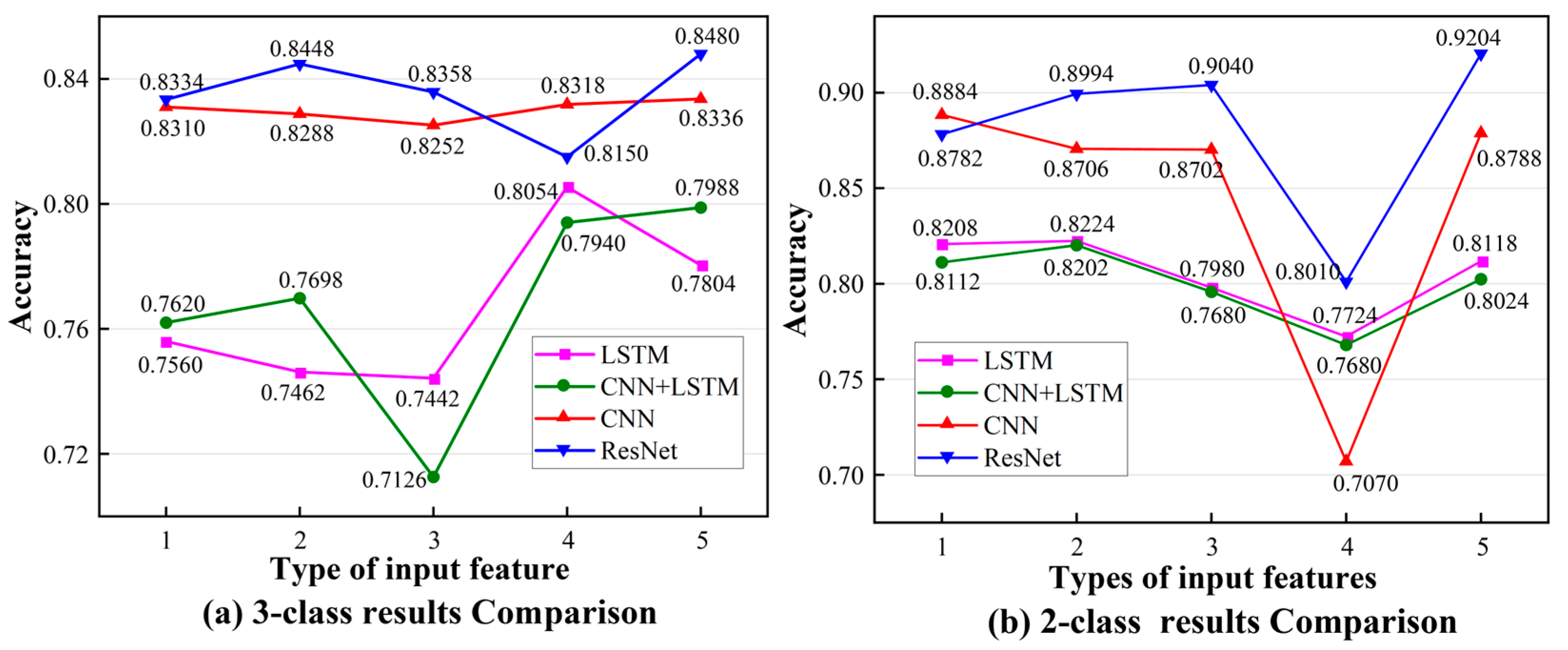
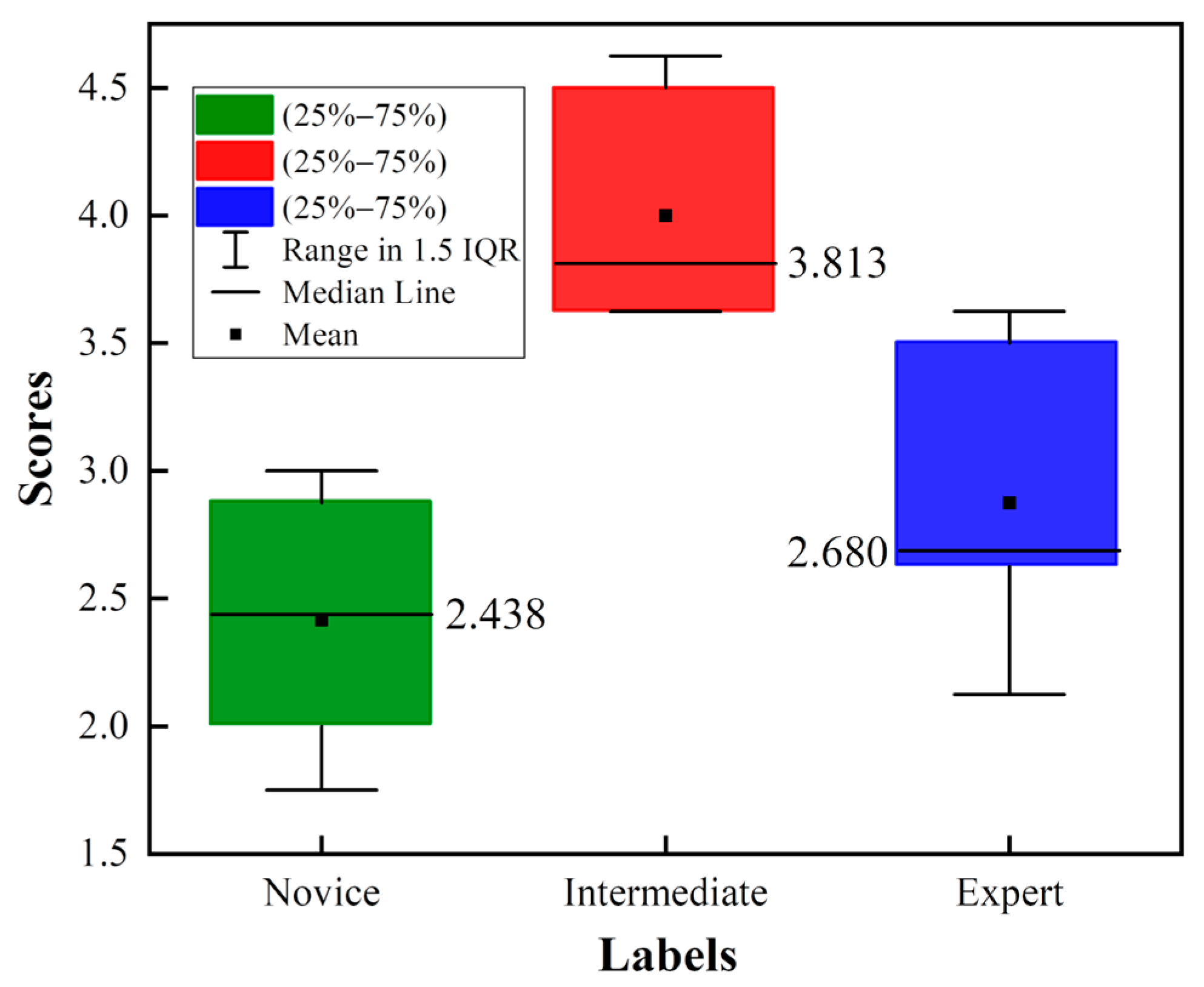
3.3. Results
4. Discussion
4.1. Performance of the Framework
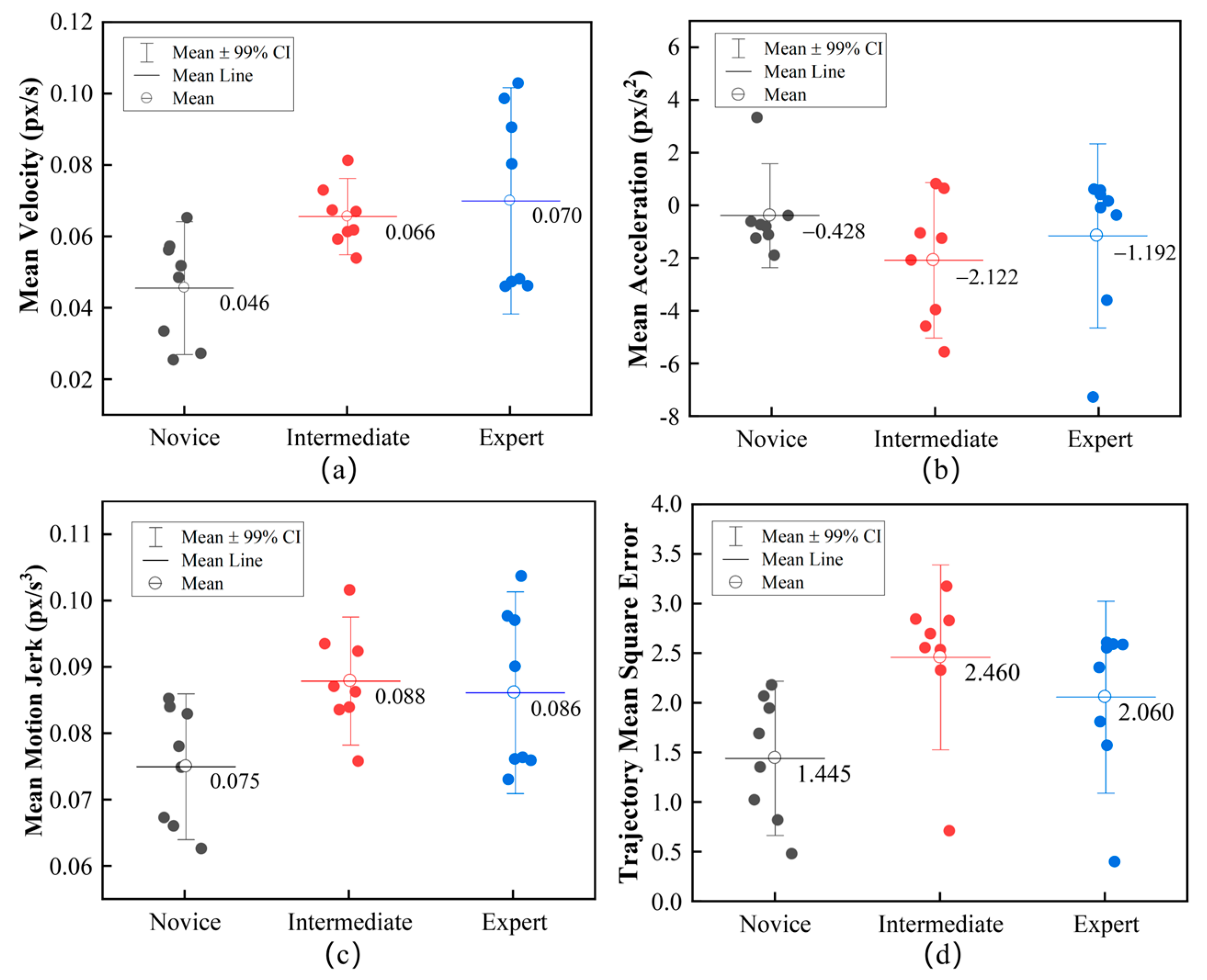
4.2. Motion Features Assessment
4.3. Dataset Assessment
4.4. Limitations and Future Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lane, T. A short history of robotic surgery. Ann. R. Coll. Surg. Engl. 2018, 100, 5–7. [Google Scholar] [CrossRef] [PubMed]
- Nagy, T.a.D.; Haidegger, T.a. A DVRK-based Framework for Surgical. Acta Polytech. Hung. 2019, 16, 68–71. [Google Scholar]
- Reznick, R.K.; MacRae, H. Teaching surgical skills--changes in the wind. N. Engl. J. Med. 2006, 355, 2664–2669. [Google Scholar] [CrossRef]
- Aggarwal, R.; Mytton, O.T.; Derbrew, M.; Hananel, D.; Heydenburg, M.; Issenberg, B.; MacAulay, C.; Mancini, M.E.; Morimoto, T.; Soper, N.; et al. Training and simulation for patient safety. Qual. Saf Health Care 2010, 19 (Suppl. S2), i34–i43. [Google Scholar] [CrossRef]
- Birkmeyer, J.D.; Finks, J.F.; O’Reilly, A.; Oerline, M.; Carlin, A.M.; Nunn, A.R.; Dimick, J.; Banerjee, M.; Birkmeyer, N.J. Surgical skill and complication rates after bariatric surgery. N. Eng. J. Med. 2013, 369, 1434–1442. [Google Scholar] [CrossRef]
- Sanfey, H. Assessment of surgical training. Surgeon 2014, 12, 350–356. [Google Scholar] [CrossRef]
- Darzi, A.; Mackay, S. Assessment of surgical competence. Qual. Health Care 2001, 10 (Suppl. S2), ii64–ii69. [Google Scholar] [CrossRef]
- Farcas, M.A.; Trudeau, M.O.; Nasr, A.; Gerstle, J.T.; Carrillo, B.; Azzie, G. Analysis of motion in laparoscopy: The deconstruction of an intra-corporeal suturing task. Surg. Endosc. 2017, 31, 3130–3139. [Google Scholar] [CrossRef] [PubMed]
- Shanmugan, S.; Leblanc, F.; Senagore, A.J.; Ellis, C.N.; Stein, S.L.; Khan, S.; Delaney, C.P.; Champagne, B.J. Virtual reality simulator training for laparoscopic colectomy: What metrics have construct validity? Dis. Colon Rectum 2014, 57, 210–214. [Google Scholar] [CrossRef]
- Ebina, K.; Abe, T.; Higuchi, M.; Furumido, J.; Iwahara, N.; Kon, M.; Hotta, K.; Komizunai, S.; Kurashima, Y.; Kikuchi, H.; et al. Motion analysis for better understanding of psychomotor skills in laparoscopy: Objective assessment-based simulation training using animal organs. Surg. Endosc. 2021, 35, 4399–4416. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Xing, Y.; Wang, S.; Liang, K. Evaluation of robotic surgery skills using dynamic time warping. Comput. Methods Programs Biomed. 2017, 152, 71–83. [Google Scholar] [CrossRef] [PubMed]
- Oquendo, Y.A.; Riddle, E.W.; Hiller, D.; Blinman, T.A.; Kuchenbecker, K.J. Automatically rating trainee skill at a pediatric laparoscopic suturing task. Surg. Endosc. 2018, 32, 1840–1857. [Google Scholar] [CrossRef] [PubMed]
- Sbernini, L.; Quitadamo, L.R.; Riillo, F.; Lorenzo, N.D.; Gaspari, A.L.; Saggio, G. Sensory-Glove-Based Open Surgery Skill Evaluation. IEEE Trans. Hum. Mach. Syst. 2018, 48, 213–218. [Google Scholar] [CrossRef]
- Beulens, A.J.W.; Namba, H.F.; Brinkman, W.M.; Meijer, R.P.; Koldewijn, E.L.; Hendrikx, A.J.M.; van Basten, J.P.; van Merrienboer, J.J.G.; Van der Poel, H.G.; Bangma, C.; et al. Analysis of the video motion tracking system “Kinovea” to assess surgical movements during robot-assisted radical prostatectomy. Int. J. Med. Robot. 2020, 16, e2090. [Google Scholar] [CrossRef] [PubMed]
- Ganni, S.; Botden, S.; Chmarra, M.; Goossens, R.H.M.; Jakimowicz, J.J. A software-based tool for video motion tracking in the surgical skills assessment landscape. Surg. Endosc. 2018, 32, 2994–2999. [Google Scholar] [CrossRef]
- Rivas-Blanco, I.; P’erez-del-Pulgar, C.J.; Mariani, A.; Quaglia, C.; Tortora, G.; Menciassi, A.; Muñoz, V.F. A surgical dataset from the da Vinci Research Kit for task automation and recognition. arXiv 2021, arXiv:2102.03643. [Google Scholar]
- Gao, Y.; Vedula, S.S.; Reiley, C.E.; Ahmidi, N.; Varadarajan, B.; Lin, H.C.; Tao, L.; Zappella, L.; Béjar, B.; Yuh, D.D.; et al. JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS): A Surgical Activity Dataset for Human Motion Modeling. 2014. Available online: https://cirl.lcsr.jhu.edu/wp-content/uploads/2015/11/JIGSAWS.pdf (accessed on 22 September 2022).
- Kitaguchi, D.; Takeshita, N.; Matsuzaki, H.; Takano, H.; Owada, Y.; Enomoto, T.; Oda, T.; Miura, H.; Yamanashi, T.; Watanabe, M.; et al. Real-time automatic surgical phase recognition in laparoscopic sigmoidectomy using the convolutional neural network-based deep learning approach. Surg. Endosc. 2019, 34, 4924–4931. [Google Scholar] [CrossRef]
- Anh, N.X.; Nataraja, R.M.; Chauhan, S. Towards near real-time assessment of surgical skills: A comparison of feature extraction techniques. Comput. Methods Programs Biomed 2020, 187, 105234. [Google Scholar] [CrossRef]
- Zhang, J.; Nie, Y.; Lyu, Y.; Yang, X.; Chang, J.; Zhang, J.J. SD-Net: Joint surgical gesture recognition and skill assessment. Int. J. Comput. Assist. Radiol. Surg. 2021, 16, 1675–1682. [Google Scholar] [CrossRef]
- Nguyen, X.A.; Ljuhar, D.; Pacilli, M.; Nataraja, R.M.; Chauhan, S. Surgical skill levels: Classification and analysis using deep neural network model and motion signals. Comput. Methods Programs Biomed. 2019, 177, 1–8. [Google Scholar] [CrossRef]
- Wang, Z.; Majewicz Fey, A. Deep learning with convolutional neural network for objective skill evaluation in robot-assisted surgery. Int. J. Comput. Assist. Radiol. Surg. 2018, 13, 1959–1970. [Google Scholar] [CrossRef] [PubMed]
- Yanik, E.; Intes, X.; Kruger, U.; Yan, P.; Diller, D.; Voorst, B.; Makled, B.; Norfleet, J.; De, S. Deep neural networks for the assessment of surgical skills: A systematic review. J. Def. Model. Simul. 2022, 19, 159–171. [Google Scholar] [CrossRef]
- Lee, D.; Yu, H.W.; Kwon, H.; Kong, H.-J.; Lee, K.E.; Kim, H.C. Evaluation of Surgical Skills during Robotic Surgery by Deep Learning-Based Multiple Surgical Instrument Tracking in Training and Actual Operations. J. Clin. Med. 2020, 9, 1964. [Google Scholar] [CrossRef] [PubMed]
- Funke, I.; Mees, S.T.; Weitz, J.; Speidel, S. Video-based surgical skill assessment using 3D convolutional neural networks. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 1217–1225. [Google Scholar] [CrossRef]
- Ming, Y.; Cheng, Y.; Jing, Y.; Liangzhe, L.; Pengcheng, Y.; Guang, Z.; Feng, C. Surgical skills assessment from robot assisted surgery video data. In Proceedings of the 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA), Shenyang, China, 22–24 January 2021; pp. 392–396. [Google Scholar]
- Lajkó, G.; Nagyné Elek, R.; Haidegger, T. Endoscopic Image-Based Skill Assessment in Robot-Assisted Minimally Invasive Surgery. Sensors 2021, 21, 5412. [Google Scholar] [CrossRef]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zheng, K.; Zhang, Z.; Qiu, C. A Fast Adaptive Multi-Scale Kernel Correlation Filter Tracker for Rigid Object. Sensors 2022, 22, 7812. [Google Scholar] [CrossRef]
- Rifkin, R.; Yeo, G.; Poggio, T. Regularized Least-Squares Classification. In Advances in Learning Theory: Methods, Model and Applications, NATO Science Series III: Computer and Systems Sciences; IOS Press: Amsterdam, The Netherlands, 2003; Volume 190. [Google Scholar]
- Zhang, K.; Zhang, L.; Liu, Q.; Zhang, D.; Yang, M.-H. Fast Visual Tracking via Dense Spatio-temporal Context Learning. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 127–141. [Google Scholar]
- Lefor, A.K.; Harada, K.; Dosis, A.; Mitsuishi, M. Motion analysis of the JHU-ISI Gesture and Skill Assessment Working Set using Robotics Video and Motion Assessment Software. Int. J. Comput. Assist. Radiol. Surg. 2020, 15, 2017–2025. [Google Scholar] [CrossRef]
- da Vinci Surgical System, Intuitive Surgical, Inc. Available online: https://www.davincisurgery.com/ (accessed on 29 September 2022).
- Martin, J.A.; Regehr, G.; Reznick, R.; Macrae, H.; Murnaghan, J.; Hutchison, C.; Brown, M. Objective structured assessment of technical skill (OSATS) for surgical residents. Br. J. Surg. 2005, 84, 273–278. [Google Scholar] [CrossRef]
- Azari, D.P.; Frasier, L.L.; Quamme, S.R.P.; Greenberg, C.C.; Pugh, C.M.; Greenberg, J.A.; Radwin, R.G. Modeling Surgical Technical Skill Using Expert Assessment for Automated Computer Rating. Ann. Surg. 2019, 269, 574–581. [Google Scholar] [CrossRef]
- Frasier, L.L.; Azari, D.P.; Ma, Y.; Pavuluri Quamme, S.R.; Radwin, R.G.; Pugh, C.M.; Yen, T.Y.; Chen, C.H.; Greenberg, C.C. A marker-less technique for measuring kinematics in the operating room. Surgery 2016, 160, 1400–1413. [Google Scholar] [CrossRef] [PubMed]
- Liang, K.; Xing, Y.; Li, J.; Wang, S.; Li, A.; Li, J. Motion control skill assessment based on kinematic analysis of robotic end-effector movements. Int. J. Med. Robot. 2018, 14, e1845. [Google Scholar] [CrossRef] [PubMed]
- Ahmidi, N.; Tao, L.; Sefati, S.; Gao, Y.; Lea, C.; Haro, B.B.; Zappella, L.; Khudanpur, S.; Vidal, R.; Hager, G.D. A Dataset and Benchmarks for Segmentation and Recognition of Gestures in Robotic Surgery. IEEE Trans. Biomed. Eng. 2017, 64, 2025–2041. [Google Scholar] [CrossRef]
- Kumar, R.; Jog, A.; Malpani, A.; Vagvolgyi, B.; Yuh, D.; Nguyen, H.; Hager, G.; Chen, C.C. Assessing system operation skills in robotic surgery trainees. Int. J. Med. Robot. 2012, 8, 118–124. [Google Scholar] [CrossRef]
- Vedula, S.S.; Ishii, M.; Hager, G.D. Objective Assessment of Surgical Technical Skill and Competency in the Operating Room. Annu. Rev. Biomed. Eng. 2017, 19, 301–325. [Google Scholar] [CrossRef]
- Hasan, M.K.; Calvet, L.; Rabbani, N.; Bartoli, A. Detection, segmentation, and 3D pose estimation of surgical tools using convolutional neural networks and algebraic geometry. Med. Image Anal. 2021, 70, 101994. [Google Scholar] [CrossRef] [PubMed]
- Dockter, R.L.; Lendvay, T.S.; Sweet, R.M.; Kowalewski, T.M. The minimally acceptable classification criterion for surgical skill: Intent vectors and separability of raw motion data. Int. J. Comput. Assist. Radiol. Surg. 2017, 12, 1151–1159. [Google Scholar] [CrossRef]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Self-Proclaimed Skill Labels | Name | Number of Videos | Time (s) | The GRS |
|---|---|---|---|---|
| Novice | B, G, H, I | 8 | 172.5 ± 58.3 | 14.5 ± 2.9 |
| Intermediate | C, F | 8 | 90.8 ± 15.1 | 24.0 ± 3.8 |
| Expert | D, E | 8 | 83 ± 13.3 | 17.3 ± 2.5 |
| Symbol | Description | Formula |
|---|---|---|
| The time recorded at frame n | / | |
| Position x coordinate at frame n | / | |
| Position y coordinate at frame n | / | |
| Distance moved between consecutive frames | ||
| The mean velocity of the ROI in consecutive frames | ||
| Mean acceleration of the ROI in consecutive frames | ||
| MJ | A parameter based on the cubic derivative of displacement with time, which refers to the change in the motion acceleration of the ROI used to study motion smoothness |
| Author (Year) | Method | Suture |
|---|---|---|
| Ming et al. (2021) [26] | STIP | 79.29% |
| Ming et al. (2021) [26] | IDT | 76.79% |
| Lajkó G et al. (2021) [27] | CNN | 80.72% |
| Lajkó G et al. (2021) [27] | CNN + LSTM | 81.58% |
| Lajkó G et al. (2021) [27] | ResNet | 81.89% |
| Current Study | KCF + ResNet | 84.80% |
| Number | Input Features |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 |
| Input Features | Method | Time |
|---|---|---|
| CNN | 1~3 s | |
| ResNet | 3~5 s | |
| CNN + LSTM | 24~48 s | |
| LSTM | 16~68 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, M.; Wang, S.; Li, J.; Li, J.; Yang, X.; Liang, K. An Automated Skill Assessment Framework Based on Visual Motion Signals and a Deep Neural Network in Robot-Assisted Minimally Invasive Surgery. Sensors 2023, 23, 4496. https://doi.org/10.3390/s23094496
Pan M, Wang S, Li J, Li J, Yang X, Liang K. An Automated Skill Assessment Framework Based on Visual Motion Signals and a Deep Neural Network in Robot-Assisted Minimally Invasive Surgery. Sensors. 2023; 23(9):4496. https://doi.org/10.3390/s23094496
Chicago/Turabian StylePan, Mingzhang, Shuo Wang, Jingao Li, Jing Li, Xiuze Yang, and Ke Liang. 2023. "An Automated Skill Assessment Framework Based on Visual Motion Signals and a Deep Neural Network in Robot-Assisted Minimally Invasive Surgery" Sensors 23, no. 9: 4496. https://doi.org/10.3390/s23094496