

Left Ventricle Detection from Cardiac Magnetic Resonance Relaxometry Images Using Visual Transformer

 , , , , ,
, , , , ,  and
and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Population
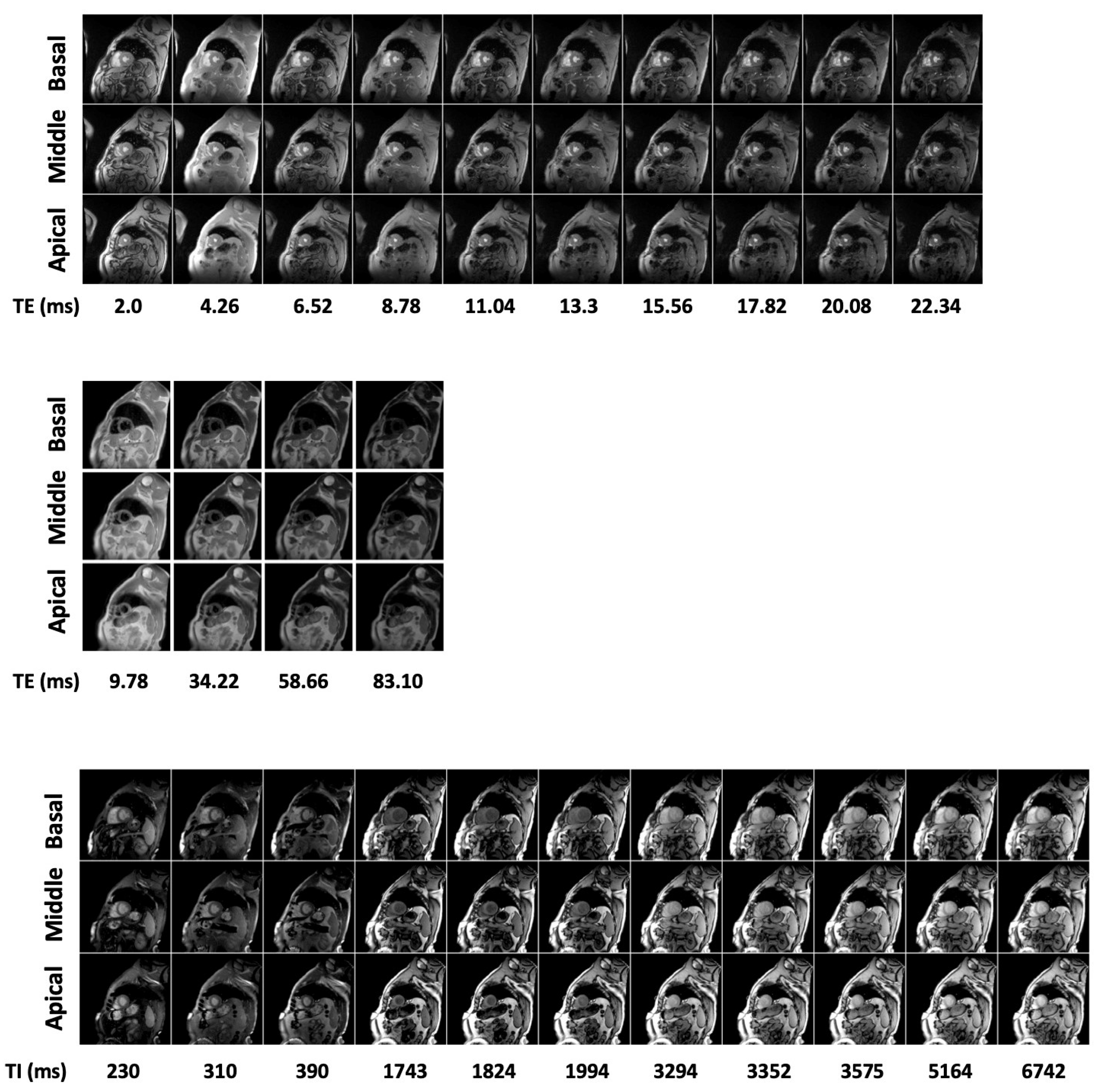
2.2. MR Imaging
2.3. Ground Truth
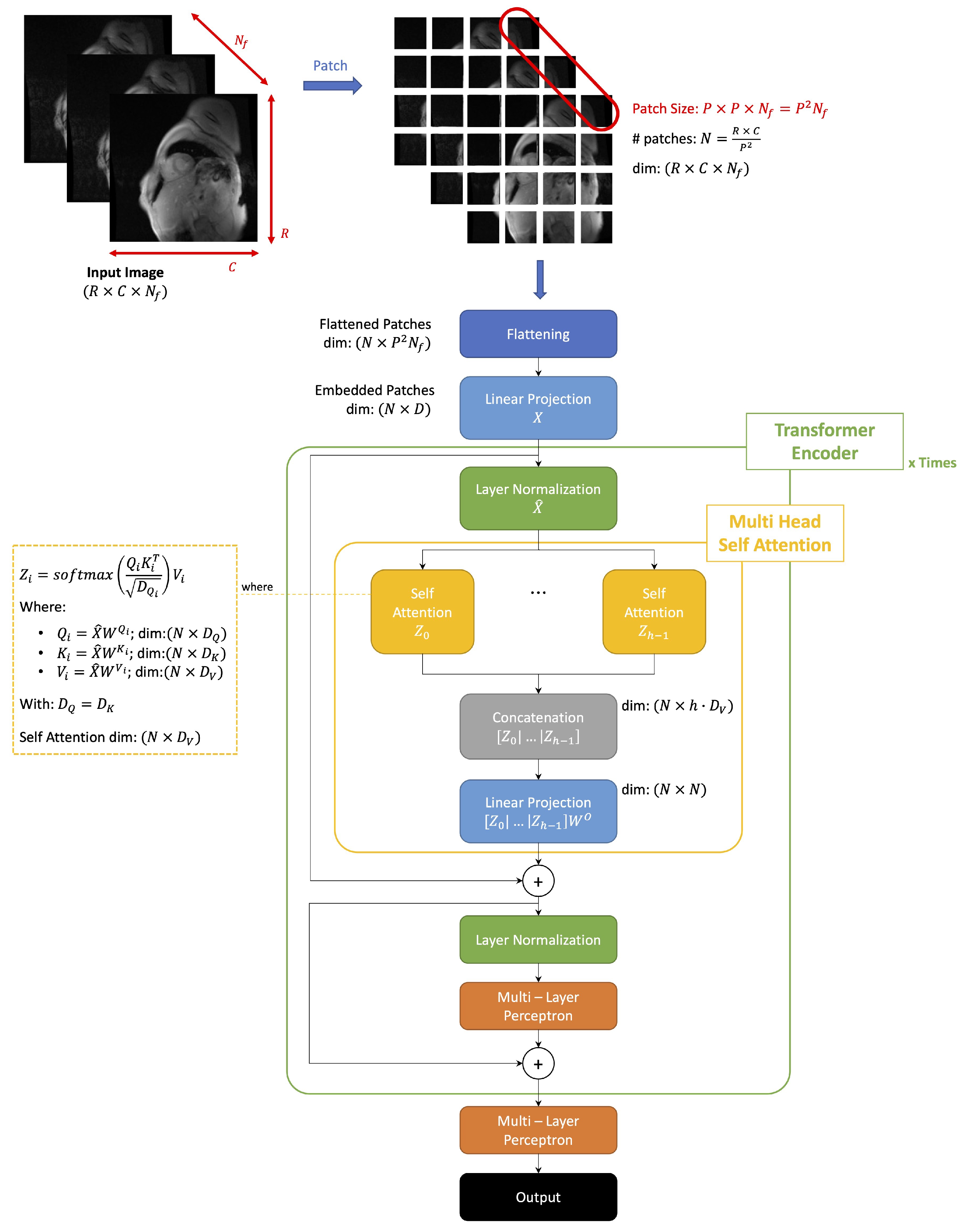
2.4. ViT Architecture
- of the original input image
- : size of a patch
- : resulting number of patches
- : dimension of flattened patch
- Queries:
- -
- Keys:
- -
- Values:
- -
2.5. Model Training and Validation
- Patch size (resulting #patches );
- Dimension of embedded space ;
- #heads in each MHSA layer with dropout ;
- An MLP in each transformer encoder with 2 layers of, respectively, 128 and 64 units and dropout ;
- A final MLP with 5 layers of, respectively, 2048, 1024, 512, 64, and 32 units and dropout .
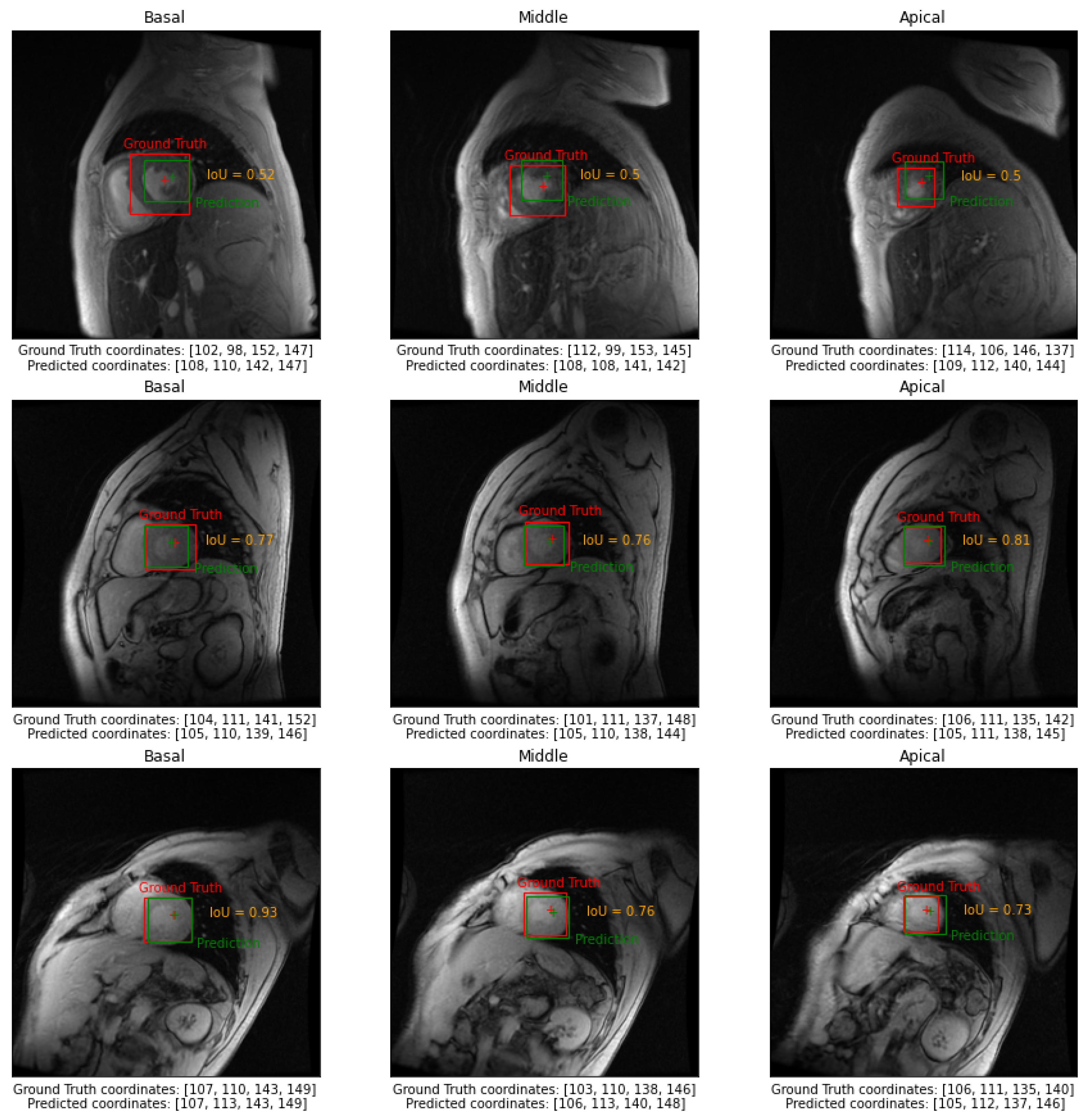
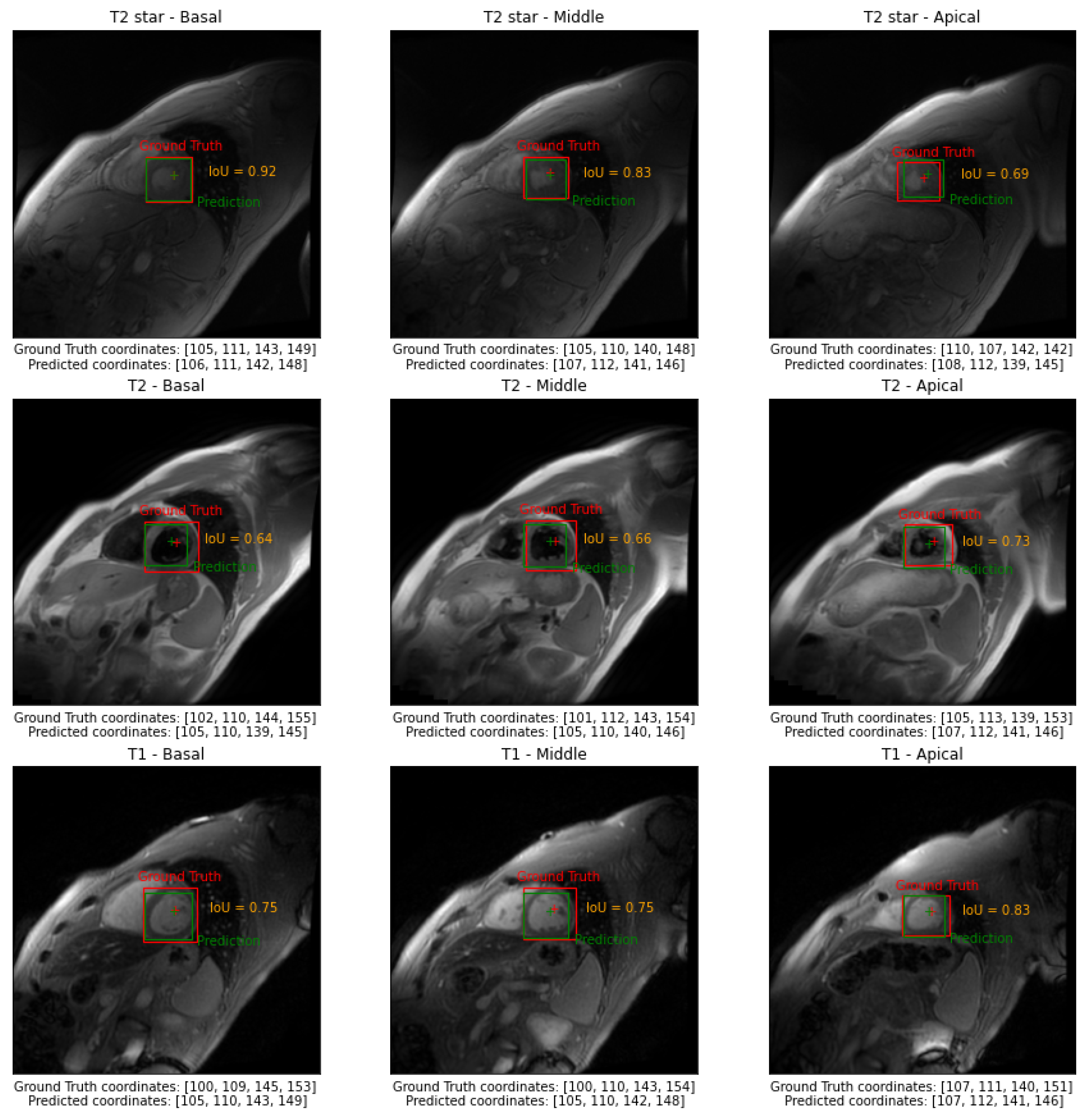
- Intersection over Union () or Jaccard Index:
- Index:where and represent, respectively, the ground truth and predicted bounding boxes.
- Centre Point Absolute Error, : Euclidean distance between the center point of the ground truth and predicted bounding boxes;
- Centre Point Epicardial Fractional Error, : normalized by the radius of a circle having the same area as the epicardial mask;
- Centre Point Endocardial Fractional Error, : normalized by the radius of a circle having the same area as the endocardial mask;
- Correct Identification Rate, : Rate that the Centre Point of the predicted bounding box falls within the endocardial mask on the entire test set.
2.6. Statistical Analysis
2.7. Hardware and Software Specification
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SAV | Short Axis Views |
| LV | Left Ventricle |
| CMR | Cardiac Magnetic Resonance |
| AHA | American Heart Association |
| CV | Computer Vision |
| OD | Object Detection |
| ROI | Region Of Interest |
| DL | Deep Learning |
| AI | Artificial Intelligence |
| ACDC-2017 | Automated Cardiac Diagnosis Challenge |
| FCN | Fully Convolutional Neural network |
| CAP | Cardiac Atlas Project |
| SSAE | deep-stacked sparse auto-encoder |
| R-CNN | Region-based Convolutional Neural Networks |
| YOLO | You Only Look Once |
| SSD | Single Shot Detector |
| SCD | Sunnybrook Cardiac Dataset |
| SSFP | Steady-State Free Precession |
| ViTs | Vision Transformers |
| NLP | Natural Language Processing |
| SA | Self Attention |
| DETR | DEtection TRansformer |
| COTR | COnvolutional and TRansformer layers |
| MIOT | Myocardial Iron Overload in Thalassemia |
| GT | Ground Truth |
| BT | Blood Pool |
| MHSA | Multi Head Self Attention |
| MLP | Multi-Layer Perceptron |
| Intersection over Union | |
| Correct Identification Rate |
References
- Pennell, D.J.; Sechtem, U.P.; Higgins, C.B.; Manning, W.J.; Pohost, G.M.; Rademakers, F.E.; van Rossum, A.C.; Shaw, L.J.; Yucel, E.K. Clinical indications for cardiovascular magnetic resonance (CMR): Consensus Panel report. Eur. Heart J. 2004, 25, 1940–1965. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schulz-Menger, J.; Bluemke, D.A.; Bremerich, J.; Flamm, S.D.; Fogel, M.A.; Friedrich, M.G.; Kim, R.J.; Knobelsdorff-Brenkenhoff, F.V.; Kramer, C.M.; Pennell, D.J.; et al. Standardized image interpretation and post-processing in cardiovascular magnetic resonance—2020 update: Society for Cardiovascular Magnetic Resonance (SCMR): Board of Trustees Task Force on Standardized Post-Processing. J. Cardiovasc. Magn. Reson. 2020, 22, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Cerqueira, M.D.; Weissman, N.J.; Dilsizian, V.; Jacobs, A.K.; Kaul, S.; Laskey, W.K.; Pennell, D.J.; Rumberger, J.A.; Ryan, T.; Verani, M.S. Standardized Myocardial Segmentation and Nomenclature for Tomographic Imaging of the Heart. Circulation 2002, 105, 539–542. [Google Scholar] [CrossRef] [PubMed]
- Pednekar, A.S.; Muthupillai, R.; Lenge, V.V.; Kakadiaris, I.A.; Flamm, S.D. Automatic identification of the left ventricle in cardiac cine-MR images: Dual-contrast cluster analysis and scout-geometry approaches. J. Magn. Reson. Imaging 2006, 23, 641–651. [Google Scholar] [CrossRef] [PubMed]
- Kurkure, U.; Pednekar, A.; Muthupillai, R.; Flamm, S.D.; Kakadiaris, I.A. Localization and segmentation of left ventricle in cardiac cine-MR images. IEEE Trans. Biomed. Eng. 2009, 56, 1360–1370. [Google Scholar] [CrossRef] [PubMed]
- Tan, L.K.; Liew, Y.M.; Lim, E.; Aziz, Y.F.A.; Chee, K.H.; McLaughlin, R.A. Automatic localization of the left ventricular blood pool centroid in short axis cardiac cine MR images. Med. Biol. Eng. Comput. 2018, 56, 1053–1062. [Google Scholar] [CrossRef] [PubMed]
- Attar, R.; Pereañez, M.; Gooya, A.; Albà, X.; Zhang, L.; de Vila, M.H.; Lee, A.M.; Aung, N.; Lukaschuk, E.; Sanghvi, M.M.; et al. Quantitative CMR population imaging on 20,000 subjects of the UK Biobank imaging study: LV/RV quantification pipeline and its evaluation. Med. Image Anal. 2019, 56, 26–42. [Google Scholar] [CrossRef]
- Shaaf, Z.F.; Jamil, M.M.A.; Ambar, R.; Alattab, A.A.; Yahya, A.A.; Asiri, Y. Detection of Left Ventricular Cavity from Cardiac MRI Images Using Faster R-CNN. Comput. Mater. Contin. 2023, 74, 1819–1835. [Google Scholar] [CrossRef]
- Papetti, D.M.; Van Abeelen, K.; Davies, R.; Menè, R.; Heilbron, F.; Perelli, F.P.; Artico, J.; Seraphim, A.; Moon, J.C.; Parati, G.; et al. An accurate and time-efficient deep learning-based system for automated segmentation and reporting of cardiac magnetic resonance-detected ischemic scar. Comput. Methods Programs Biomed. 2023, 229, 107321. [Google Scholar] [CrossRef]
- Xue, H.; Brown, L.A.; Nielles-Vallespin, S.; Plein, S.; Kellman, P. Automatic in-line quantitative myocardial perfusion mapping: Processing algorithm and implementation. Magn. Reson. Med. 2020, 83, 712–730. [Google Scholar] [CrossRef] [Green Version]
- Bhatt, N.; Ramanan, V.; Gunraj, H.; Guo, F.; Biswas, L.; Qi, X.; Roifman, I.; Wright, G.A.; Ghugre, N.R. Technical Note: Fully automatic segmental relaxometry (FASTR) for cardiac magnetic resonance T1 mapping. Med. Phys. 2021, 48, 1815–1822. [Google Scholar] [CrossRef] [PubMed]
- Positano, V.; Meloni, A.; Santarelli, M.F.; Gerardi, C.; Bitti, P.P.; Cirotto, C.; De Marchi, D.; Salvatori, C.; Landini, L.; Pepe, A. Fast generation of T2* maps in the entire range of clinical interest: Application to thalassemia major patients. Comput. Biol. Med. 2015, 56, 200–210. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.; Hadid, A.; Pang, Y.; Granger, E.; Feng, X. Deep Learning in Object Detection and Recognition; Springer: Singapore, 2019; pp. 1–224. [Google Scholar] [CrossRef]
- Awad, A.I.; Hassaballah, M. Studies in Computational Intelligence 630 Image Feature Detectors and Descriptors Foundations and Applications; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Lin, X.; Cowan, B.R.; Young, A.A. Automated Detection of Left Ventricle in 4D MR Images: Experience from a Large Study. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2006, Copenhagen, Denmark, 1–6 October 2006; Larsen, R., Nielsen, M., Sporring, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 728–735. [Google Scholar]
- Jolly, M.P. Automatic Recovery of the Left Ventricular Blood Pool in Cardiac Cine MR Images. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2008, New York, NY, USA, 6–10 September 2008; Metaxas, D., Axel, L., Fichtinger, G., Székely, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 110–118. [Google Scholar]
- Zhong, L.; Zhang, J.M.; Zhao, X.; Tan, R.S.; Wan, M. Automatic localization of the left ventricle from cardiac cine magnetic resonance imaging: A new spectrum-based computer-aided tool. PLoS ONE 2014, 9, e0092382. [Google Scholar] [CrossRef] [PubMed]
- Abdeltawab, H.; Khalifa, F.; Taher, F.; Alghamdi, N.S.; Ghazal, M.; Beache, G.; Mohamed, T.; Keynton, R.; El-Baz, A. A deep learning-based approach for automatic segmentation and quantification of the left ventricle from cardiac cine MR images. Comput. Med. Imaging Graph. 2020, 81, 101717. [Google Scholar] [CrossRef]
- Niu, Y.; Qin, L.; Wang, X. Myocardium detection by deep SSAE feature and within-class neighborhood preserved support vector classifier and regressor. Sensors 2019, 19, 1766. [Google Scholar] [CrossRef] [Green Version]
- Yang, R.; Yu, Y. Artificial Convolutional Neural Network in Object Detection and Semantic Segmentation for Medical Imaging Analysis. Front. Oncol. 2021, 11, 638182. [Google Scholar] [CrossRef]
- Wang, X.; Wang, F.; Niu, Y. A convolutional neural network combining discriminative dictionary learning and sequence tracking for left ventricular detection. Sensors 2021, 21, 3693. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Shamshad, F.; Khan, S.; Zamir, S.W.; Khan, M.H.; Hayat, M.; Khan, F.S.; Fu, H. Transformers in Medical Imaging: A Survey. arXiv 2022, arXiv:2201.09873. [Google Scholar]
- Pachetti, E.; Colantonio, S.; Pascali, M.A. On the Effectiveness of 3D Vision Transformers for the Prediction of Prostate Cancer Aggressiveness. In Proceedings of the Image Analysis and Processing, ICIAP 2022 Workshops, Lecce, Italy, 23–27 May 2022; Mazzeo, P.L., Frontoni, E., Sclaroff, S., Distante, C., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 317–328. [Google Scholar]
- Willemink, M.J.; Roth, H.; Sandfort, V. Toward Foundational Deep Learning Models for Medical Imaging in the New Era of Transformer Networks. Radiol. Artif. Intell. 2022, 4, e210284. [Google Scholar] [CrossRef]
- Pepe, A.; Pistoia, L.; Gamberini, M.R.; Cuccia, L.; Lisi, R.; Cecinati, V.; Maggio, A.; Sorrentino, F.; Filosa, A.; Rosso, R.; et al. National networking in rare diseases and reduction of cardiac burden in thalassemia major. Eur. Heart J. 2021, 43, 2482–2492. [Google Scholar] [CrossRef] [PubMed]
- Meloni, A.; Ramazzotti, A.; Positano, V.; Salvatori, C.; Mangione, M.; Marcheschi, P.; Favilli, B.; De Marchi, D.; Prato, S.; Pepe, A.; et al. Evaluation of a web-based network for reproducible T2* MRI assessment of iron overload in thalassemia. Int. J. Med. Inform. 2009, 78, 503–512. [Google Scholar] [CrossRef] [PubMed]
- Positano, V.; Pepe, A.; Santarelli, M.F.; Scattini, B.; De Marchi, D.; Ramazzotti, A.; Forni, G.; Borgna-Pignatti, C.; Lai, M.E.; Midiri, M.; et al. Standardized T2* map of normal human heart in vivo to correct T2* segmental artefacts. NMR Biomed. 2007, 20, 578–590. [Google Scholar] [CrossRef]
- Meloni, A.; Nicola, M.; Positano, V.; D’Angelo, G.; Barison, A.; Todiere, G.; Grigoratos, C.; Keilberg, P.; Pistoia, L.; Gargani, L.; et al. Myocardial T2 values at 1.5 T by a segmental approach with healthy aging and gender. Eur. Radiol. 2022, 32, 2962–2975. [Google Scholar] [CrossRef] [PubMed]
- Meloni, A.; Martini, N.; Positano, V.; D’Angelo, G.; Barison, A.; Todiere, G.; Grigoratos, C.; Barra, V.; Pistoia, L.; Gargani, L.; et al. Myocardial T1 Values at 1.5 T: Normal Values for General Electric Scanners and Sex-Related Differences. J. Magn. Reson. Imaging 2021, 54, 1486–1500. [Google Scholar] [CrossRef]
- Object Detection with Vision Transformers. Available online: https://github.com/keras-team/keras-io/blob/master/examples/vision/object_detection_using_vision_transformer.py (accessed on 1 October 2022).
- Varoquaux, G.; Cheplygina, V. Machine learning for medical imaging: Methodological failures and recommendations for the future. NPJ Digit. Med. 2022, 5, 48. [Google Scholar] [CrossRef]
- Amel, L.; Ammar, M.; El Habib Daho, M.; Mahmoudi, S. Toward an automatic detection of cardiac structures in short and long axis views. Biomed. Signal Process. Control. 2023, 79, 104187. [Google Scholar] [CrossRef]
- Fadil, H.; Totman, J.J.; Hausenloy, D.J.; Ho, H.H.; Joseph, P.; Low, A.F.H.; Richards, A.M.; Chan, M.Y.; Marchesseau, S. A deep learning pipeline for automatic analysis of multi-scan cardiovascular magnetic resonance. J. Cardiovasc. Magn. Reson. 2021, 23, 1–13. [Google Scholar] [CrossRef]
- Martini, N.; Meloni, A.; Positano, V.; Latta, D.D.; Keilberg, P.; Pistoia, L.; Spasiano, A.; Casini, T.; Barone, A.; Massa, A.; et al. Fully Automated Regional Analysis of Myocardial T2* Values for Iron Quantification Using Deep Learning. Electronics 2022, 11, 2749. [Google Scholar] [CrossRef]
- Howard, J.P.; Chow, K.; Chacko, L.; Fontana, M.; Cole, G.D.; Kellman, P.; Xue, H. Automated Inline Myocardial Segmentation of Joint T1 and T2 Mapping Using Deep Learning. Radiol. Artif. Intell. 2023, 5, e220050. [Google Scholar] [CrossRef]
- He, T.; Gatehouse, P.D.; Kirk, P.; Tanner, M.A.; Smith, G.C.; Keegan, J.; Mohiaddin, R.H.; Pennell, D.J.; Firmin, D.N. Black-blood T2* technique for myocardial iron measurement in thalassemia. J. Magn. Reson. Imaging 2007, 25, 1205–1209. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Slice | ||||||
|---|---|---|---|---|---|---|
| Basal | 0.69 ± 0.03 | 0.81 ± 0.02 | 7.12 ± 0.97 | 0.27 ± 0.03 | 0.31 ± 0.04 | 1.00 ± 0.00 |
| Middle | 0.71 ± 0.02 | 0.82 ± 0.02 | 6.52 ± 0.81 | 0.26 ± 0.03 | 0.31 ± 0.04 | 0.99 ± 0.00 |
| Apical | 0.63 ± 0.01 | 0.77 ± 0.01 | 6.68 ± 0.77 | 0.33 ± 0.04 | 0.42 ± 0.05 | 0.97 ± 0.01 |
| Global | 0.68 ± 0.02 | 0.80 ± 0.02 | 6.77 ± 0.81 | 0.29 ± 0.03 | 0.35 ± 0.04 | 0.99 ± 0.00 |
| Slice | ||||||
|---|---|---|---|---|---|---|
| T2* test set | ||||||
| Basal | 0.74 ± 0.10 | 0.84 ± 0.07 | 5.44 ± 2.89 | 0.21 ± 0.11 | 0.24 ± 0.13 | 1.00 |
| Middle | 0.74 ± 0.10 | 0.85 ± 0.07 | 5.24 ±2.89 | 0.21 ± 0.12 | 0.25 ± 0.15 | 0.99 |
| Apical | 0.65 ± 0.13 | 0.78 ± 0.11 | 5.65 ± 3.45 | 0.29 ± 0.19 | 0.36 ± 0.24 | 0.97 |
| Global | 0.71 ± 0.12 | 0.82 ± 0.09 | 5.44 ± 3.10 | 0.23 ± 0.15 | 0.29 ± 0.19 | 0.99 |
| T2* independent test set | ||||||
| Basal | 0.70 ± 0.15 | 0.81 ± 0.12 | 7.59 ± 6.33 | 0.25 ± 0.20 | 0.30 ± 0.23 | 1.00 |
| Middle | 0.69 ± 0.14 | 0.81 ± 0.12 | 7.42 ± 6.47 | 0.26 ± 0.21 | 0.30 ± 0.24 | 0.95 |
| Apical | 0.63 ± 0.21 | 0.76 ± 0.17 | 8.44 ± 7.08 | 0.36 ± 0.31 | 0.45 ± 0.38 | 0.86 |
| Global | 0.68 ± 0.17 | 0.79 ± 0.14 | 7.82 ± 6.54 | 0.29 ± 0.24 | 0.35 ± 0.30 | 0.94 |
| T2 independent test set | ||||||
| Basal | 0.62 ± 0.12 | 0.75 ± 0.10 | 8.56 ± 5.67 | 0.29 ± 0.18 | 0.34 ± 0.21 | 1.00 |
| Middle | 0.62 ± 0.13 | 0.76 ± 0.10 | 9.32 ± 6.16 | 0.33 ± 0.21 | 0.39 ± 0.24 | 0.95 |
| Apical | 0.63 ± 0.14 | 0.76 ± 0.11 | 8.90 ± 6.02 | 0.38 ± 0.30 | 0.47 ± 0.38 | 0.90 |
| Global | 0.62 ± 0.13 | 0.76 ± 0.10 | 8.93 ± 5.86 | 0.33 ± 0.24 | 0.40 ± 0.29 | 0.95 |
| T1 independent test set | ||||||
| Basal | 0.66 ± 0.09 | 0.79 ± 0.07 | 6.51 ± 2.90 | 0.22 ± 0.11 | 0.26 ± 0.12 | 1.00 |
| Middle | 0.69 ± 0.10 | 0.81 ± 0.07 | 6.38 ± 3.37 | 0.24 ± 0.16 | 0.28 ± 0.19 | 1.00 |
| Apical | 0.67 ± 0.13 | 0.80 ± 0.09 | 7.02 ± 4.57 | 0.31 ± 0.27 | 0.38 ± 0.34 | 0.95 |
| Global | 0.67 ± 0.11 | 0.80 ± 0.08 | 6.64 ± 3.63 | 0.26 ± 0.19 | 0.31 ± 0.24 | 0.98 |
| Author | Dataset | LV OD Approach | Performances |
|---|---|---|---|
| Pednekar et al. [4] | Vector Cardiographic Gating (VCG)-gated cine Steady-State Free-Precession SSFP cardiac MR images (locally acquired dataset) | Two different algorithms:
| Best results obtained with SG algorithm. |
| Kurkure et al. [5] | Vector Cardiographic Gating VCG-gated cine SSFP cardiac MR images (locally acquired dataset) | Scout-view geometry, blood-to-myocardial tissue contrast, and geometrical continuity constraint | |
| Zhong et al. [17] | Cardiac cine MR images (locally acquired dataset), algorithm tested on 10 volunteers | Fourier Transform followed by anisotropic weighted circular Hough transform | By visual inspection, the cropped ROI of all cases contains the LV Average Cropping Ratio = 0.165 |
| Tan et al. [6] | Cardiac cine MRI data:
| Fourier transform over time to highlight regions of significant motion | from 0.67 to 0.88 from 2.8 to 4.7 mm from 12 to |
| Niu et al. [19] | Cardiac cine MR images from Cardiac Atlas Project (CAP) dataset 27 subjects test set | Region proposal + Deep-Stacked Sparse Auto-Encoder (SSAE) + Soft margin support vector (C-SVC) classifier and multiple-output support vector (-SVR) regressor | True positive rate, Positive predicted value |
| Abdeltawab et al. [18] | Cardiac cine MR images:
| Fully Convolutional Neural network (FCN) | = 1.41 ± 1.65 |
| Wang et al. [21] | Cardiac cine MR images collected from CAP dataset | Two stage R-CNN based on VGG-16 backbone | Three different R-CNN version:
|
| Shaaf et al., 2023 [8] | Cardiac cine MR images collected from SCD MICCAI workshop 2009 | Faster R-CNN | = 0.83 Accuracy = 0.91 Recall = 0.95 Precision = 0.94 F1 = 0.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
De Santi, L.A.; Meloni, A.; Santarelli, M.F.; Pistoia, L.; Spasiano, A.; Casini, T.; Putti, M.C.; Cuccia, L.; Cademartiri, F.; Positano, V. Left Ventricle Detection from Cardiac Magnetic Resonance Relaxometry Images Using Visual Transformer. Sensors 2023, 23, 3321. https://doi.org/10.3390/s23063321
De Santi LA, Meloni A, Santarelli MF, Pistoia L, Spasiano A, Casini T, Putti MC, Cuccia L, Cademartiri F, Positano V. Left Ventricle Detection from Cardiac Magnetic Resonance Relaxometry Images Using Visual Transformer. Sensors. 2023; 23(6):3321. https://doi.org/10.3390/s23063321
Chicago/Turabian StyleDe Santi, Lisa Anita, Antonella Meloni, Maria Filomena Santarelli, Laura Pistoia, Anna Spasiano, Tommaso Casini, Maria Caterina Putti, Liana Cuccia, Filippo Cademartiri, and Vincenzo Positano. 2023. "Left Ventricle Detection from Cardiac Magnetic Resonance Relaxometry Images Using Visual Transformer" Sensors 23, no. 6: 3321. https://doi.org/10.3390/s23063321