1. Introduction
Perception, decision-making, and control are three core modules in autonomous driving(AD) [
1,
2]. Anomalies and uncertainty in perception directly impact how AD systems thoroughly comprehend the world and make driving decisions [
3,
4]. For AD systems to operate safely, the estimation of perceptual uncertainties must be done in real time and with accuracy [
5]. Perception algorithms significantly influence the effectiveness of perception outcomes [
6,
7,
8]. AD perception algorithms have undergone the development stages of the rule model algorithm, machine learning, and Deep Neural Network (DNN) algorithms [
9].
Among these, the perception algorithm based on the rule model performs parameter optimization through feature extraction and manual modeling in a “top-down” manner, which has poor versatility and low efficiency [
10,
11]. DNN algorithms driven by data can handle situations that regular model algorithms cannot handle. Especially when the training data are sufficient, DNN algorithms show better comprehensiveness and accuracy of perception [
12,
13]. With the development of computer hardware computing power, storage, and other technologies, the proportion of DNN algorithms in autonomous driving systems is growing higher and higher. However, DNN algorithms have uncertainty and poor interpretability due to dataset uncertainty, training process uncertainty, and network internal structure factors [
14,
15,
16].
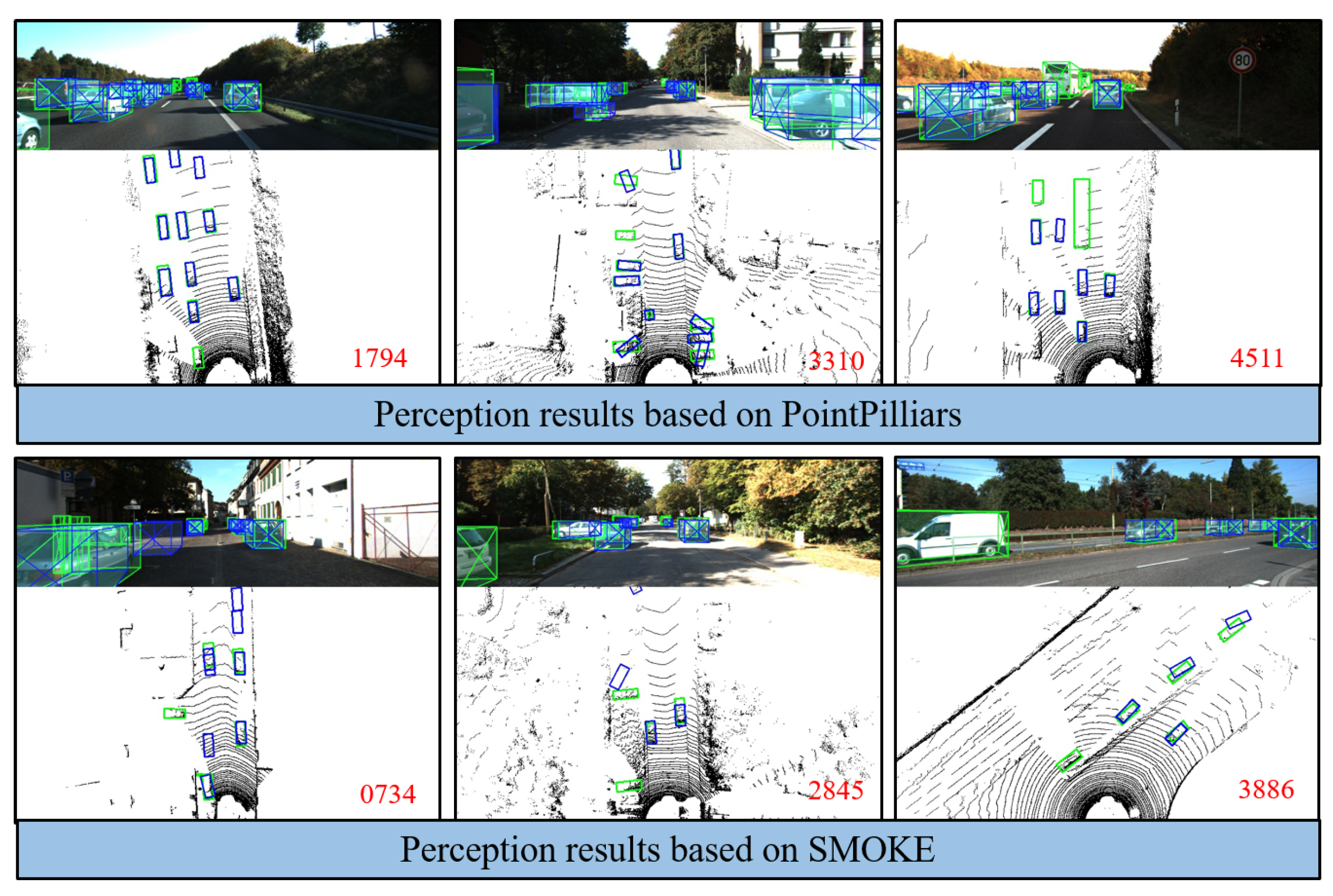
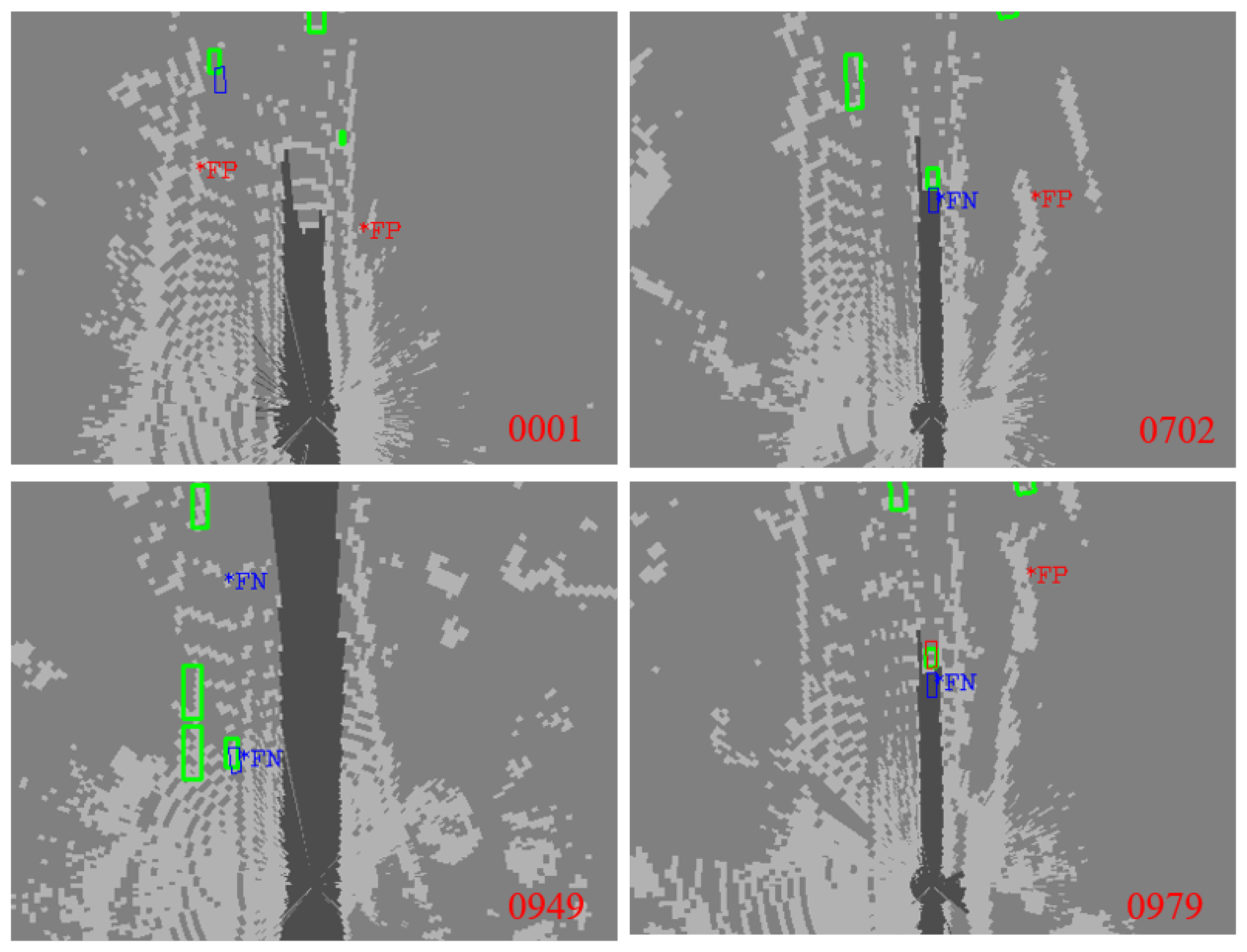
As shown in
Figure 1, perception imperfection can have a crucial influence on AD, especially when missed detection and large spatial uncertainties occur around the vehicle. When the current perception has a serious error, the failure should be detected in real-time for possible emergency response due to safety requirements.
Existing research focuses on the quantitative evaluation methods, influencing factors, trigger mechanisms, and processing methods of DNN uncertainties [
7,
12,
17]. However, most of these references focus on uncertainty analysis with only one DNN; there are few references on mutual inspection based on multiple neural networks. It is difficult for a single neural network to avoid missed detection, which is a typical long-tail scenario in perception. Many approaches have emerged for false detection [
18], perception anomalies [
19], and perception risk assessment [
5,
20,
21]. Most of these methods are judged based on the continuity of the perception data stream and the confidence index of the object output. These methods lack matching and verification with other data, meaning that the accuracy must be demonstrated. In addition, there are research methods for studying the perception uncertainty from the perspective of the safety of the intended functionality (SOTIF) [
6,
22,
23]. These studies focus more on capturing uncertainty and researching the trigger mechanisms of uncertainty. The utilization of uncertain results can be applied in decision-making and the adjustment of the internal structure of the network [
24,
25,
26]. Even if certain references extract uncertainty and process the uncertainty inside the network or through a decision-making algorithm, there is no quantitative demonstration of the correctness of the extracted uncertainty. In addition, many methods cannot be implemented in real-time.
A complete and accurate uncertainty assessment must face three core issues. How can we extract uncertainty completely to deal with long-tail scenarios under missed detection conditions in real time? How can the extracted uncertainty be verified without the ground truth of the dataset? What are the factors influencing neural network uncertainty?
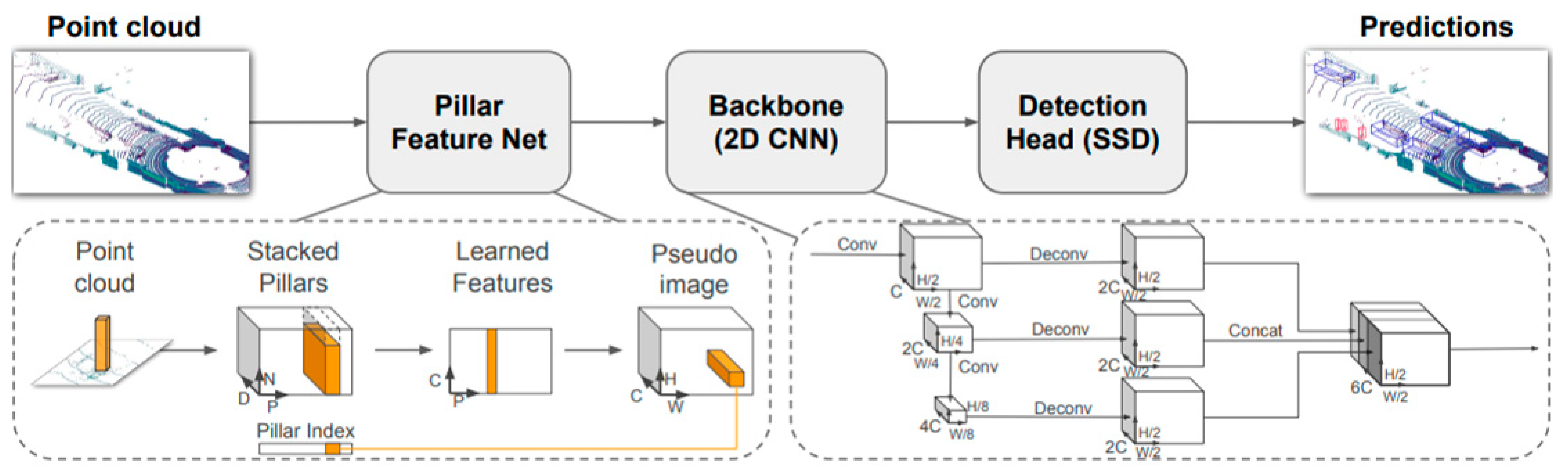
Therefore, how to judge the effectiveness and uncertainty of perception results based on the matching of multi-source perception results in real-time needs further research. This work proposes a novel real-time evaluation method for AD perception. We select two kinds of objects detection DNN algorithms as our basic perception methods: Pointpillars, based on LiDAR [
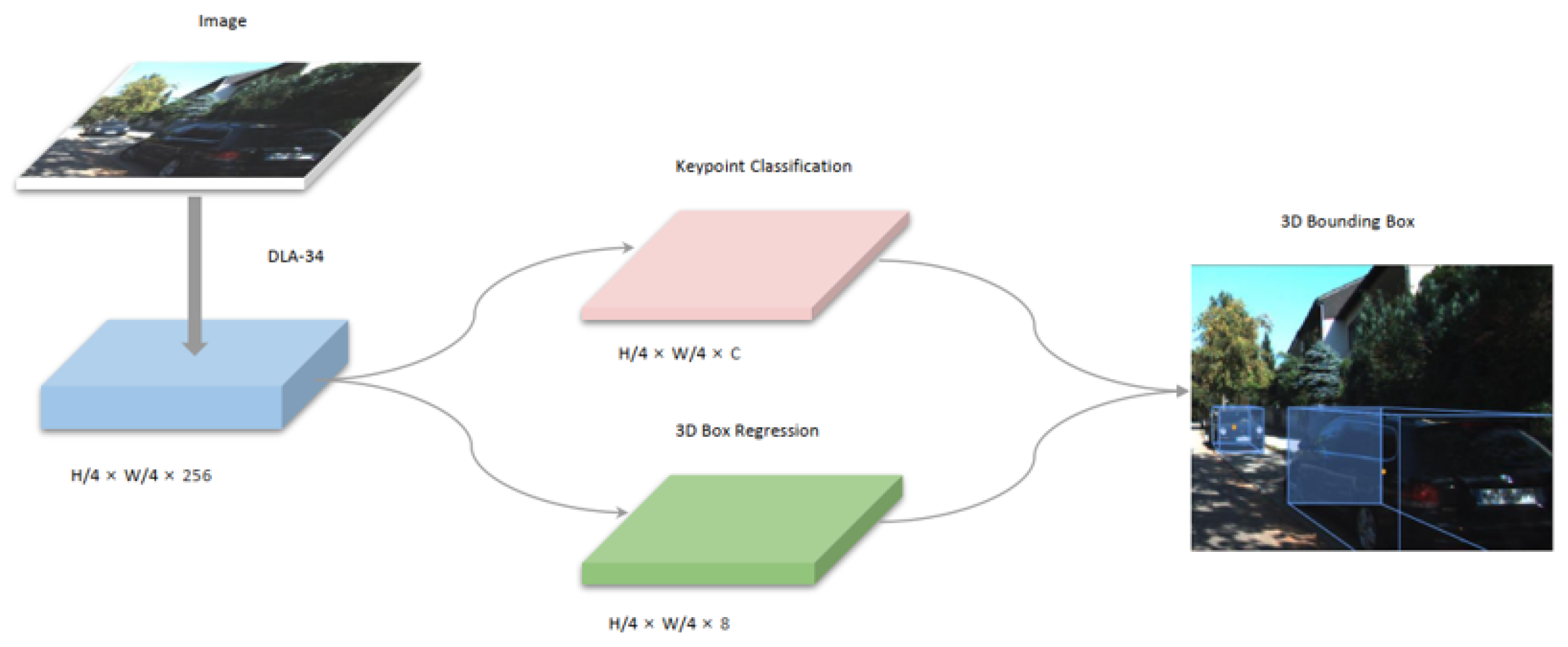
27], and SMOKE (Single-Stage Monocular 3D Object Detection via Keypoint Estimation camera), based on camera [
28]. Then, we analyze the uncertainty results to evaluate the effectiveness of the perception results in real-time. Furthermore, quantitative analysis is carried out on the spatial uncertainty of the detected objects. Finally, the uncertainty results analyzed are verified based on the ground truth. In addition, the factors influencing DNN uncertainty are demonstrated quantitatively.
Our contributions can be summarized as follows:
(1) A real-time perception effectiveness estimation algorithm is proposed combining multi-source perception fusion and a deep learning ensemble. The model can judge the effectiveness of perception results and capture the spatial uncertainties of detected objects. This model can handle missed detections that are not intractable for a single network.
(2) While judging the perception effectiveness in real-time, the model can extract the spatial uncertainty of detected objects in real-time. Our study of the correlation of the ground truth with the uncertainty and error verifies the proposed model’s effectiveness.
(3) The perception effectiveness and spatial uncertainty obtained based on this model are verified on the KITTI dataset, demonstrating the correctness and accuracy of the model. The influencing factors of perception uncertainty are analyzed and verified.
The research in this paper can provide theoretical and practical guidance for real-time judgment of the effectiveness of AD perception results.
The remainder of the paper is structured as follows:
Section 2 summarizes related works about perception uncertainties.
Section 3 introduces the methodology used to evaluate uncertainty in this paper.
Section 4 discusses the experimental results and demonstrates the relationship between the extracted uncertainties and the ground truth error. Finally,
Section 5 summarizes our conclusions and describes possible future work.
2. Related Works
Significant studies have been devoted to capturing the perception uncertainty of DNN algorithms and to judging and monitoring perception anomalies.
Concept uncertainty, dataset uncertainty, network training, and migration uncertainty influence the uncertainty of perception based on DNN algorithms [
29,
30,
31]. The Uncertainty Classification can be summarized into epistemic uncertainty and aleatoric uncertainty. Perception uncertainty theories include Bayesian theory, sampling-based methods, Gaussian theory, evidence theory, and propagation mechanisms [
6,
32,
33]. For specific research methods, the Bayesian model can effectively capture uncertainty, although the computation cost is high.
Subsequently, Laplace Approximation (LA), Variational Inference (VI), and Markov Chain Monte Carlo (MCMC) have optimized the Bayesian model. For epistemic uncertainty, the Monte Carlo Dropout (MCD) [
30] method and Deep Ensemble (DE) sampling [
34] have been proposed. Compared with the MCD method, DE has higher calculation accuracy and meets real-time requirements.
Regarding uncertainty evaluation metrics, Di Feng [
30] summarized the precision, recall, and F1-Score, along with the mean average precision, Shannon entropy, mutual information, calibration plot, error curve, etc. Zining Wang [
35] proposed a new evaluation metric, Jaccard IoU (JIoU), that incorporates label uncertainty. Stefano Gasperini [
36] provided separate uncertainties for each output signal: objectness, class, location, and size, and proposed a new metric to evaluate location and size uncertainty.
In terms of uncertainty influencing factors, Di Feng [
37] proved that uncertainty is related to multiple factors, such as the detection distance, occlusion, softmax score, and orientation. Hujie Pan [
38] found that the corner uncertainty distribution agrees with the point cloud distribution in the bounding box, meaning that the corner with denser observed points has lower uncertainty.
Evaluated perception uncertainty can be applied in the following aspects: improving perception performance, optimizing decision-making control algorithms, and providing warning and monitoring for AD systems. Gregory P. Meyer [
13] estimated the uncertainty in detection by predicting a probability distribution over object bounding boxes, and proposed a method to improve the ability to learn the probability distribution by considering the potential noise in the ground-truth labeled data. Di Feng [
37] leveraged heteroscedastic aleatoric uncertainty to improve its detection performance significantly. Q.M Rahman [
5] studied run-time monitoring of machine learning for robotic perceptions based on perception uncertainty. In addition, from the perspective of SOTIF, Liang Peng [
6,
23] proposed a trigger mechanism for perception uncertainty and optimized the decision based on the uncertainty extracted.
In all, the mentioned references have greatly contributed to the evaluation methods and applications of perception uncertainty. However, the research object is usually one single detection network. In this situation, although the spatial uncertainty can be studied, it is difficult to deal with false detection and missed detection. This calls for mutual inspection of multiple perception algorithms. Moreover, perception failure needs to be detected in real-time to ensure safety. However, this is seldom studied in existing research. Therefore, it is important to judge the effectiveness of the current perception results. Finally, the analyzed perception uncertainty is a learning-based guess as to the relation of the error to the ground truth. Therefore, studying the relationship between real-time uncertainty evaluation, the error, and the ground truth is important. Thus, we have made an effort to contribute to these three problems, as stated in the Introduction.
3. Methodology
This section first introduces the theory of the DE method for uncertainty assessment, the clustering algorithm for multi-network results, and the principle of the matching algorithm for multi-source perception results. These three algorithms are the basis for the judgment of perception effectiveness and spatial uncertainty. Then, the perception effectiveness judgment algorithm and evaluation metrics for spatial uncertainty are discussed.
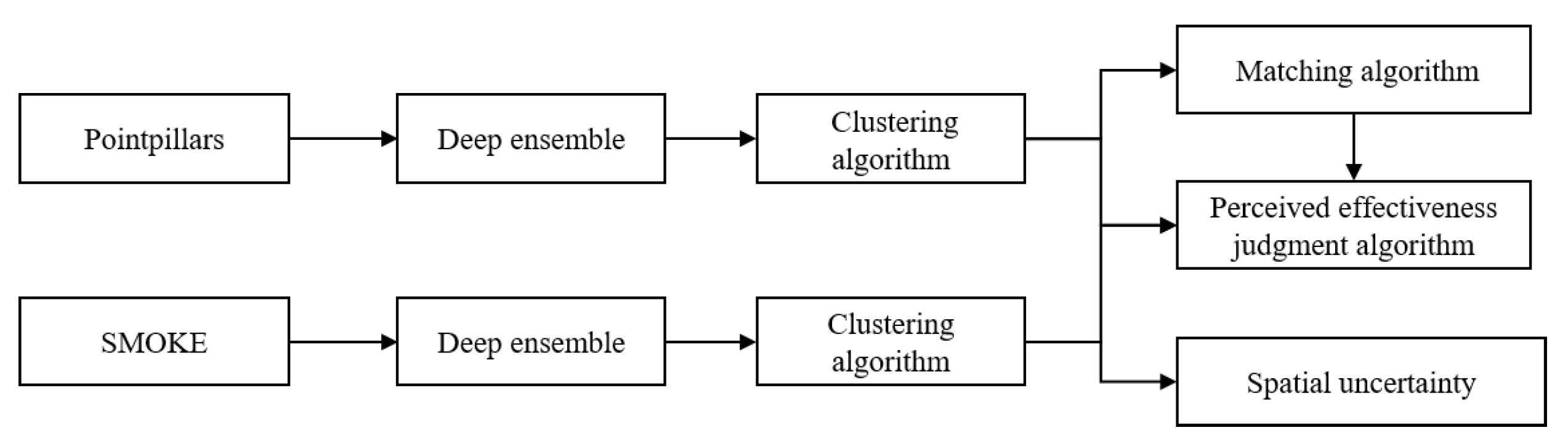
The logic flow between different algorithms is shown in
Figure 2. PointPillars and SMOKE, shown in
Figure 2, are two DNN algorithms for object detection, and represent two sources of perception. The DNN algorithm can detect objects using multiple neural networks after DE processing. The objects detected by different networks can be classified into different objects after being processed by the clustering algorithm. After the matching algorithm matches the objects from the two perception sources, the effectiveness of the current perception scene can be judged in real-time and combined with the remaining clustering results. Based on the clustering results, the spatial uncertainty of the detected objects can be solved directly.
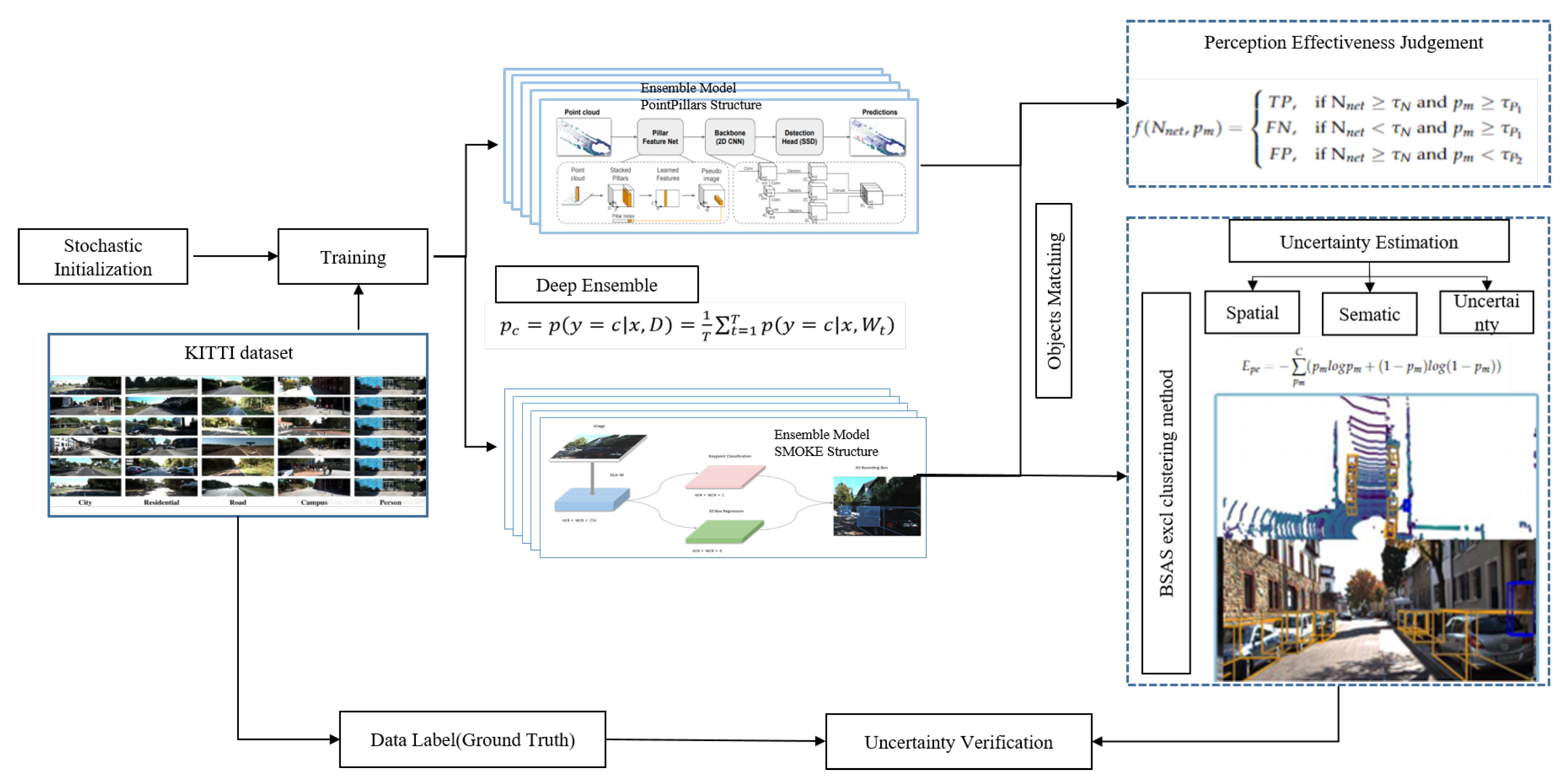
The schematic sequence of the perception effectiveness and spatial uncertainty evaluation is shown in
Figure 3. As shown in
Figure 3, the uncertainty of detection results is primarily collected with Deep Ensemble. With multiple perception inputs, mutual inspection is carried out to analyze missed/false detection. Then, through a statistical study, the perception effectiveness is judged. If the result is judged to be effective, the spatial uncertainty of the outputs is estimated. Finally, with the ground truth of the objects from the dataset, the effectiveness judgment and the spatial uncertainty estimation result can be verified.
3.1. Deep Ensemble
The ensembles consist of two kinds of methods: randomization–based approaches and boosting-based approaches [
34].
Bayesian neural networks provide a natural explanation for uncertainty estimation in deep learning [
39]. The posterior distribution parameters in the Bayesian formula are related to the network parameters. Randomization–based sampling of the network parameters is required to simulate the output distribution. The Monte Carlo method can be used to sample the neural network parameters randomly, then the statistics can simulate this distribution [
40]. The deep ensemble method based on randomization-based approaches is a simplified method. The deep ensemble can achieve random fine-tuning network parameters within a certain range. This pre-parameter sampling method does not increase the amount of calculation used in reasoning. Different sampling networks’ operation processes are the same, and can be calculated in parallel [
41,
42].
Therefore, the present study focuses on the randomization–based approach, as this approach is better suited for distributionand parallel computation. We use the DE approach to capture the real-time uncertainty of classification and regression outputs. The pseudo-code of the approach training procedure is summarized in Algorithm 1.
| Algorithm 1 Deep Ensemble |
| Input:
Neural networks and number of networks .
|
| Output:
Associated classification probability , location of detected objects , rotation , and dimension . |
- 1:
Construction and selection of neural networks. - 2:
Parameter initialization of neural networks - 3:
for to N do - 4:
Randomize the data loading mode for each network - 5:
Train different networks on the same dataset - 6:
Obtain classification and regression results - 7:
end for - 8:
return , , , .
|
In the training of neural networks, deep ensemble requires random initialization of the neural network parameters, along with randomized shuffling of data points, which is sufficient to obtain good training effects in practice.
3.2. Clustering Algorithm
The number and order of detected objects by different networks in the same frame scene are inconsistent; thus, the accurate matching of objects is an important guarantee of the accuracy and uncertainty of perception results. The objects merging strategy for sampling-based uncertainty used in this study is the basic sequential algorithmic scheme with intra-sample exclusivity (BSAS_excl) [
17]. The approach training procedure is summarized in Algorithm 2.
| Algorithm 2 Basic sequential algorithmic scheme with intra-sample exclusivity |
| Input:
A set of predictions . |
| Output:
A set of clusters . |
- 1:
Create a cluster for each for each object box in . - 2:
for to do - 3:
Set = , is the number of clusters - 4:
for in , for in do - 5:
if affinity( and then - 6:
Put - 7:
else - 8:
Create a new cluster, n = n + 1 - 9:
end if - 10:
end for - 11:
end for - 12:
return .
|
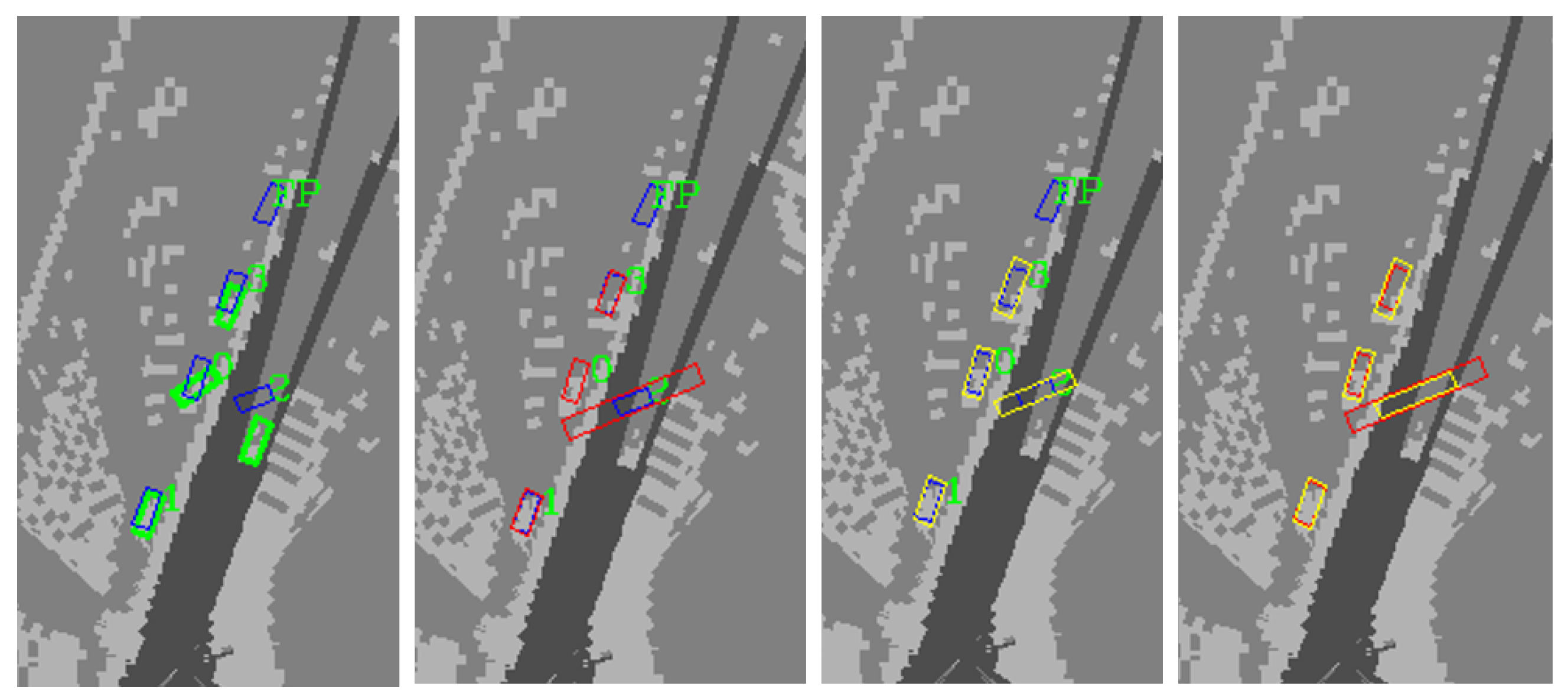
3.3. Object-Matching Algorithm
If there are multiple sources of perception, the perception results from different sources can be matched for further mutual inspection. Multi-source perception mutual inspection is an important method to improve perception performance. The object-matching algorithm is the basis of multi-source mutual inspection. This paper uses an algorithm based on triangle similarity [
43,
44] matching, which can effectively deal with the matching errors caused by object position errors.
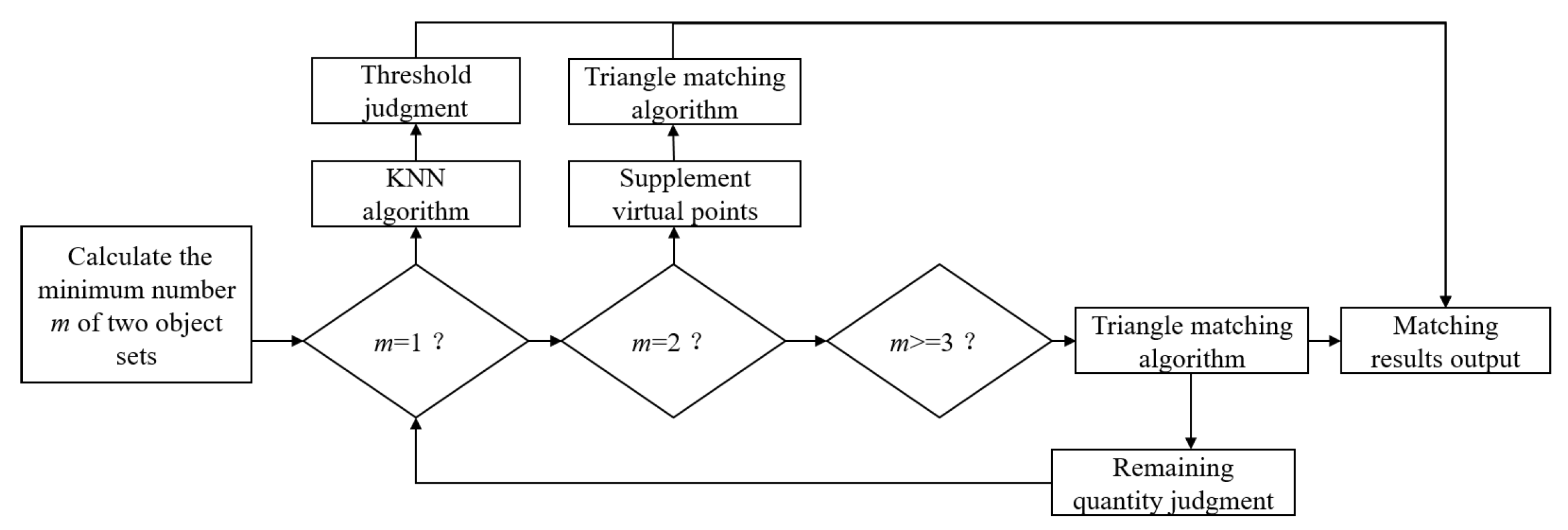
The scheme flow of objects matching algorithm is shown in
Figure 4. The steps of object matching can be summarized from step(1) to step(7)
- (1)
Set object sets and object sets . Calculate the number of object sets and the number of object sets .
- (2)
Calculate the minimum value of elements in the object sets .
- (3)
If
, use the K-Nearest Neighbor (KNN) method to calculate the distance of all of the points in
to all of the points in
. The distance between point A and point B can be calculated in Equation (
1).
where
represents the 3D space distance between two points with set distance threshold
. If
, this shows that the two points can be matched. Otherwise, the two points cannot be matched, indicating that the identified object may be a false negative or false positive.
- (4)
If , it is necessary to add a point at a distance to form a triangle, and both object sets need to add a point. The detection range is set to be 50 m. In order to achieve a better matching effect, the coordinates of the object points selected in this study can be (500,500) and (499,499). Points farther than 50 m away are added to form triangles for matching. These points do not belong to the objects within the perceived range and will not be output. It should be noted that the two points cannot be the same, but the distance between them cannot be too large. After adding points, triangle matching method can be used, which is shown below.
- (5)
If
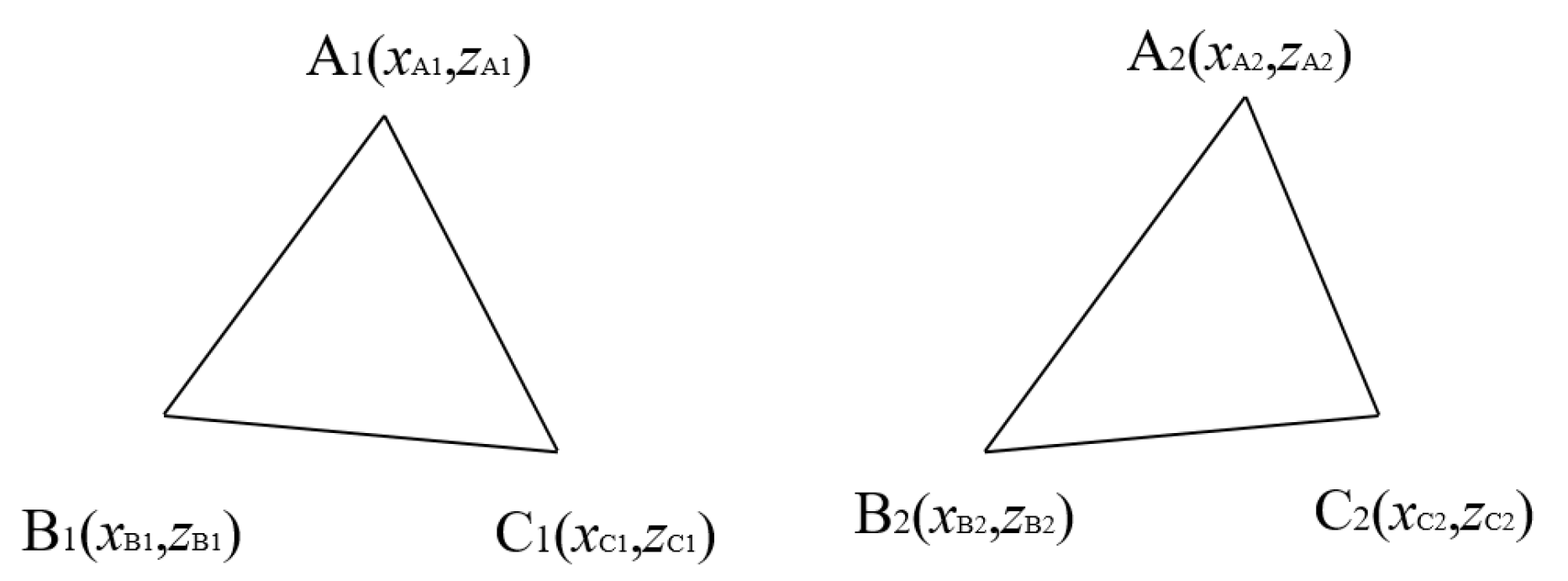
, the triangle matching method can be used. The diagram of the triangle matching algorithm is shown in
Figure 5.
- (6)
The principle of the triangle matching method can be described from step (1) to step (7). Taking the object in the BEV perspective as an example, this paper only considers the index elements in x and z directions in the KITTI dataset camera coordinate system.
- (1)
Numbering data to all of the points in and .
- (2)
Calculate the coordinate difference values
,
,
,
between the maximum and minimum values in
x and
z directions in object sets
and object sets
by using Equations (
2) and (
3).
- (3)
Sort the points in object sets and object sets . Calculate the maximum value of the coordinate difference values. If the maximum value is in the x direction, the object sets and object sets are sorted by the value of x. Otherwise, object sets and object sets are sorted by the value of z.
- (4)
Randomly select three points to form a triangle in object sets and object sets , and return the index of the point location.
- (5)
The formed triangles in object sets and object sets are normalized. The side length of each triangle is divided by the shortest side length. This setting can ensure the setting of a uniform threshold for successful matching.
- (6)
Calculate the error sum of the edges and points for each triangle in object sets
with all triangles in object sets
. Take any two points in a triangle as an example. As shown in
Figure 5, Point
and point
are corresponding points. The error of point A can be expressed in Equation (
4).
The error of edge AB can be expressed in Equation (
5).
The total error (TE) of two triangles can be expressed in Equation (
6).
- (7)
Calculate the minimum value of all trianglestriangle. If is less than the triangle error threshold , the two triangles are matched, and the corresponding points of the triangle sorted by (3) are the matching objects.
- (7)
Judge the remaining points, and repeat steps (3), (4), and (5) until all points are matched.
3.4. Perception Effectiveness Judgment
Each perception source will have missed and false detection; thus, it is necessary to judge the effectiveness of the current frame perception information in real time. If the perception results are invalid, it is necessary to make an early warning, or perception switching can be performed directly. If the perception results are valid, the spatial uncertainty of the detected objects is calculated to carry out further trajectory planning and the construction of the drivable space.
Therefore, here comes three key questions: (1) What are the criteria for judging the effectiveness of perception results? (2) How can we judge the effectiveness of current perception results in real time? (3) How can we verify the judgment results?
First of all, for the real-time perception effectiveness judgment, the precision, recall, and F1-score of the perception results of the current frame are applied as the criteria. The judgment threshold is based on the statistical results of the KITTI full data set. Second, for the method of perception effectiveness judgment, this paper adopts a fusion model based on multi-source perception and deep ensemble to judge the effectiveness of current perception results in real time. Third, to verify the judgment results, this paper matches the perception results with the ground truth of the dataset. And calculate the precision, recall, and F1 score of each frame information to judge the effectiveness of the perception results. Compare the validity results of the real-time judgment with the validity of the ground truth matching results to verify the validity of the judgment results. Finally, calculate the anomaly diagnosis rate.
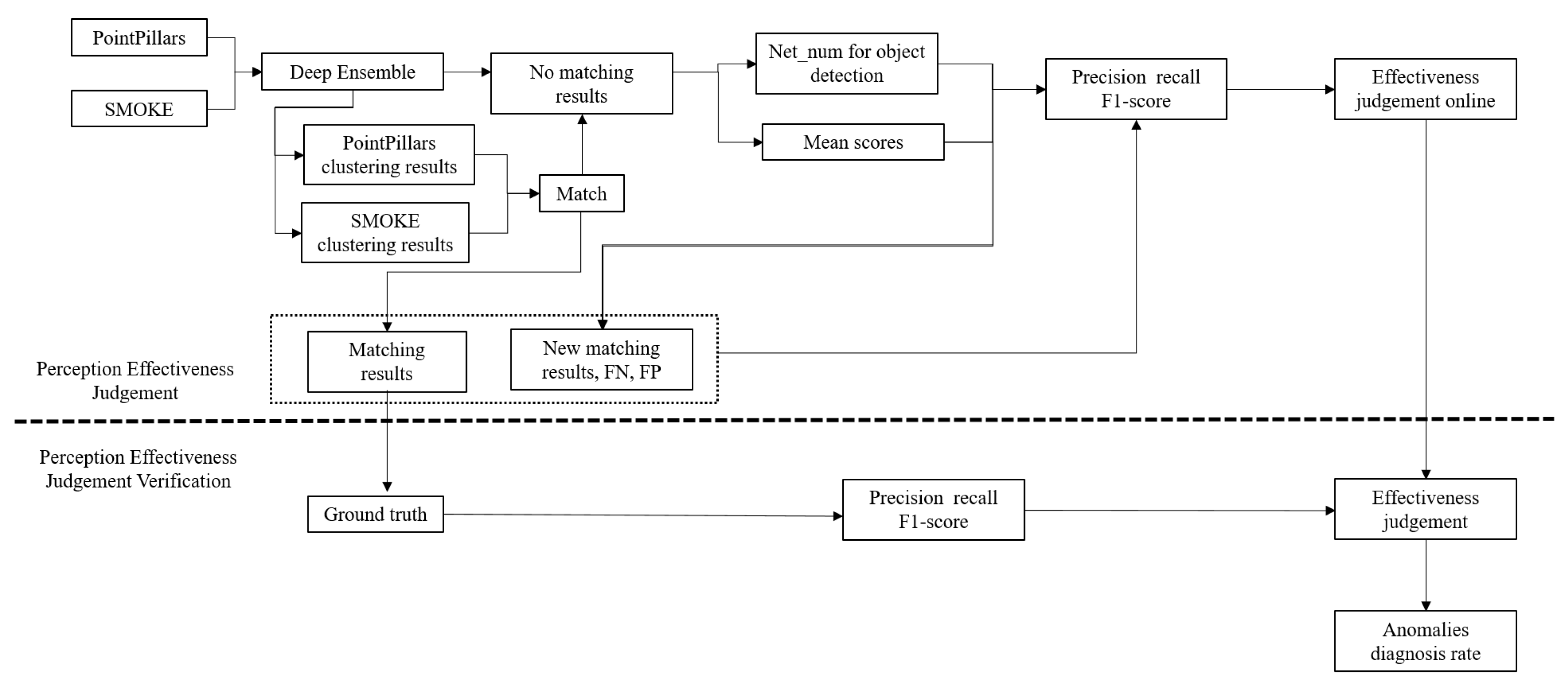
The flowchart of perception effectiveness judgment is shown in
Figure 6. The DE method is used to study the uncertainty of object occupation. The normal detection (True Positive, TP), missed detection (False Negative, FN), and virtual detection(false positive, FP) of the perception results are studied. If there is only one perception source, it can evaluate the object occupation uncertainty according to the number of networks
and the average confidence
. If there are multiple perception sources, this paper uses the method combining deep ensemble and multi-source perception mutual acceptance to research occupancy uncertainty.
First, the steps of uncertainty research for one perception source are as follows.
- (1)
The perception results are processed in the DE method. After clustering and statistics, the number of networks detecting the object
and the average confidence level
of the detected object are calculated in Equation (
7), respectively.
where
c represents the classification of detected objects.
D represents the dataset to evaluate the detected objects and
represents the weights of the network.
- (2)
Set detection network number threshold and average confidence and .
- (3)
Judge the uncertainty by using Equation (
8).
If there are multiple sources of perception, the matching of different perception results is carried out first. Then the uncertainty research is carried out by using the DE method.
- (1)
First, the triangle matching method is used for object matching of multi-source perception results. Objects that are successfully matched are considered to be real objects.
- (2)
For the results that cannot be matched in each perception source, the DE method is used for judgment.
- (3)
The final processing results are fused.
In addition, for the uncertainty of classification and occupation of each detected object, the prediction entropy
is selected in this study as the uncertainty evaluation index, which is calculated in Equation (
9). During the calculation of prediction entropy, the confidence levels of different networks are averaged, and then the prediction entropy is calculated
Because there is missed detection in the calculation process, it is necessary to punish the object detected to calculate the detected object’s uncertainty more objectively, which is calculated in Equation (
10).
where
p represents the penalty coefficient.
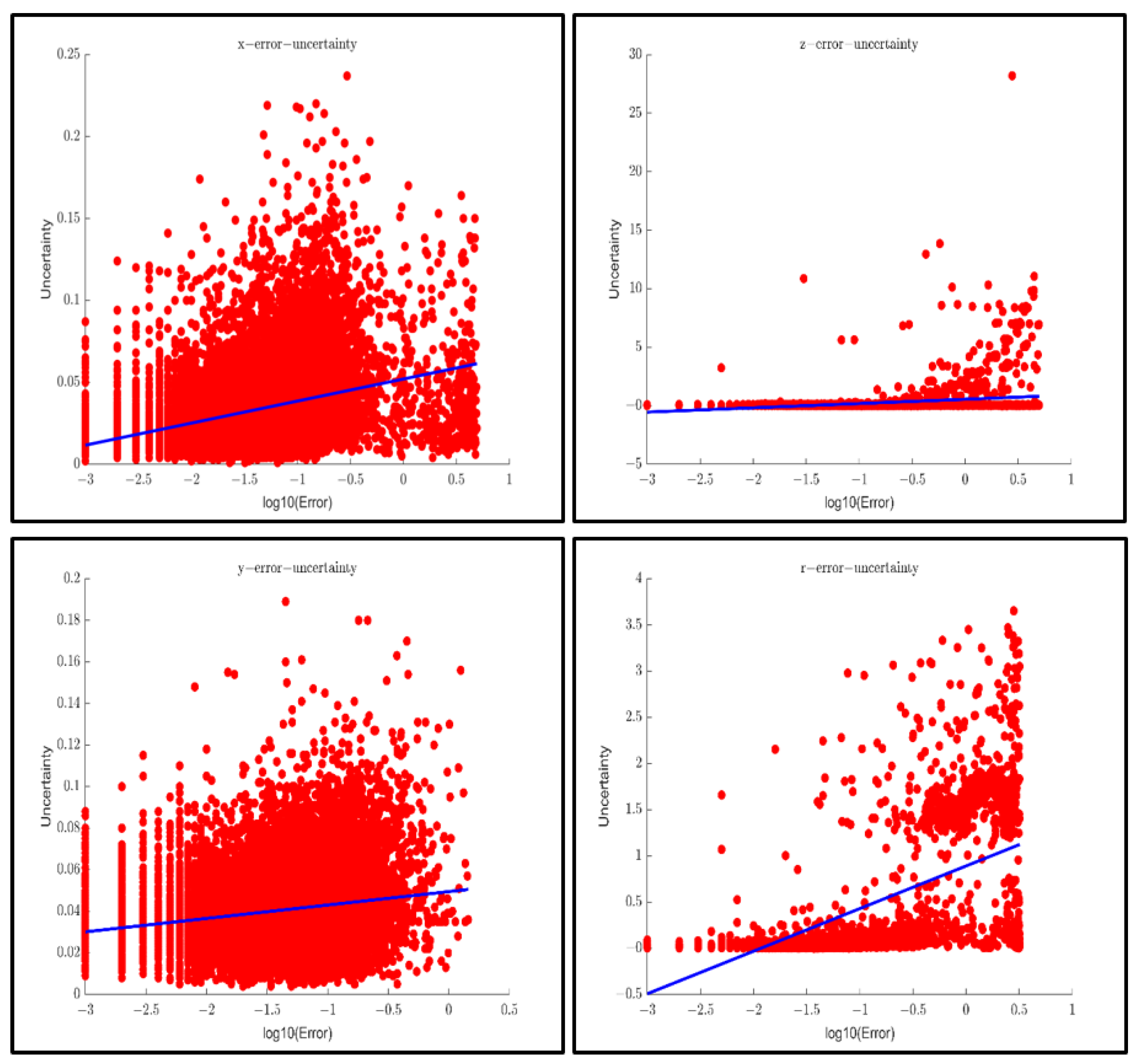
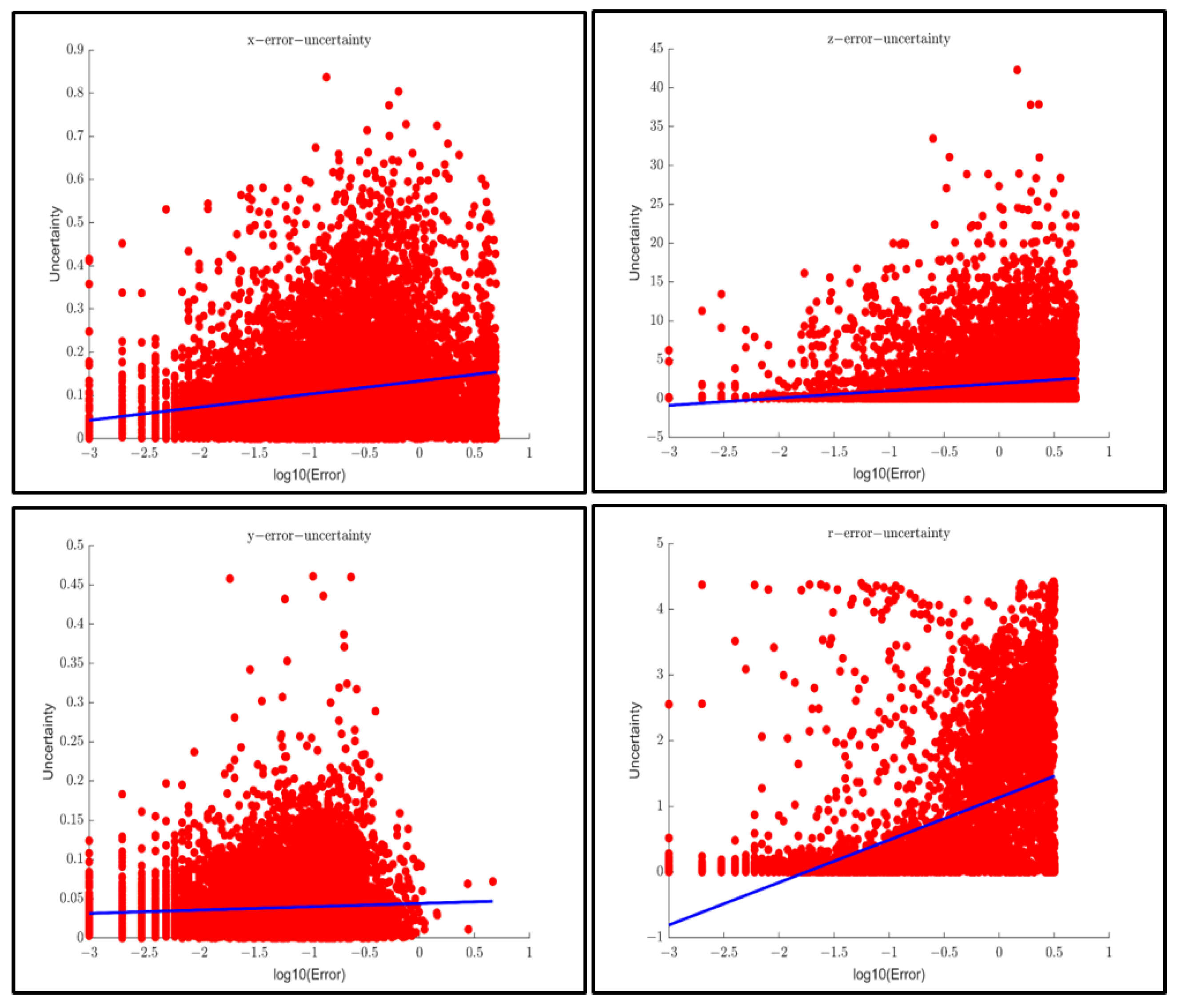
3.5. Spatial Uncertainty
The spatial information in the regression of the neural network algorithm includes the horizontal position (x), vertical position (z), and vertical position (y) of the detected object, the length (l), width (w), and height (h) of the detected object, and the orientation (r) of the detected object. The corresponding uncertainty evaluation indicators can be represented by variance and total variance (TV).
The variance of each indicator can be expressed in Equation (
11)
Similarly, the variance of other indicators is calculated using the same equation. Each object has a location and dimension, and the TV of location and dimension can be calculated in Equations (
12) and (
13).
5. Conclusions
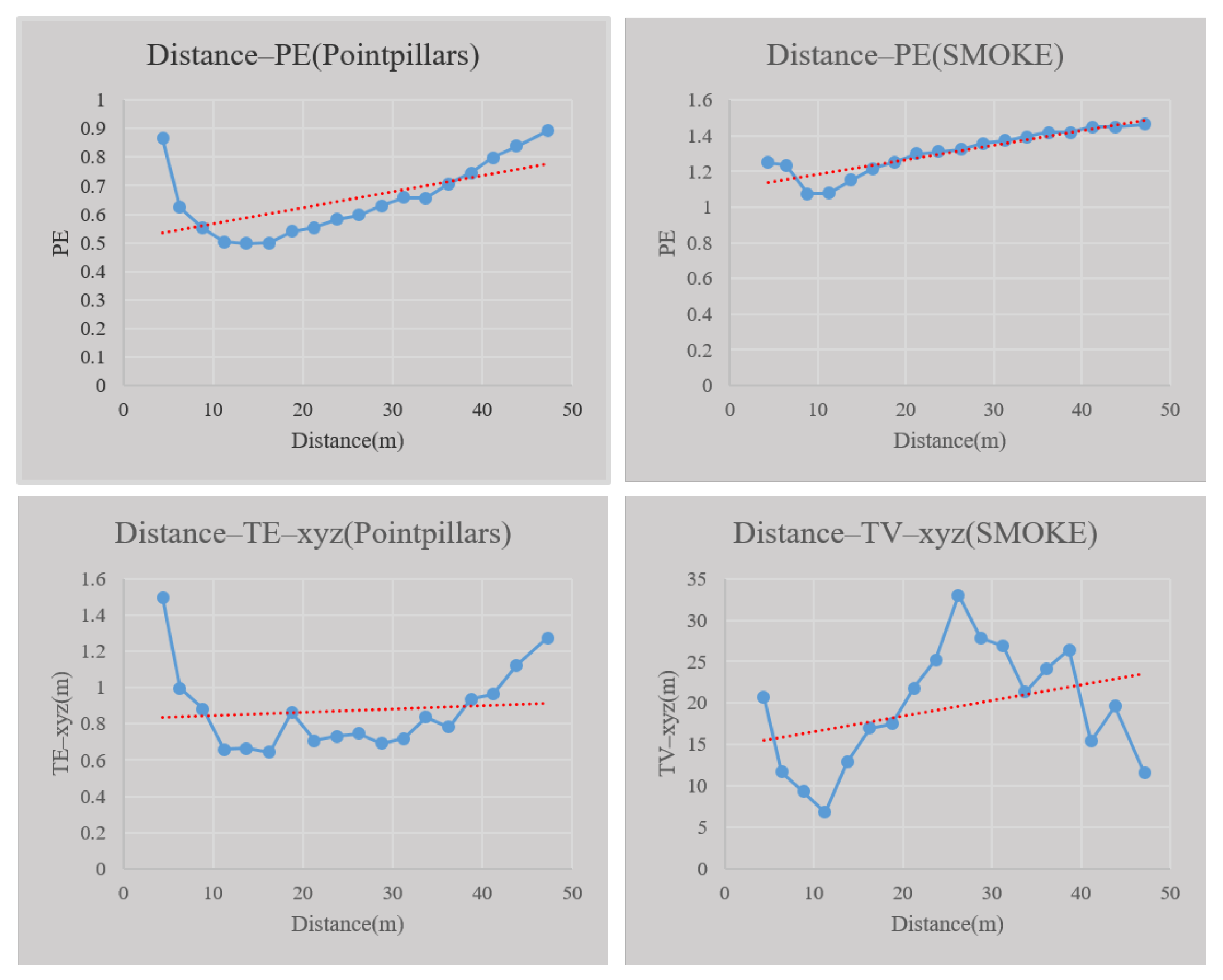
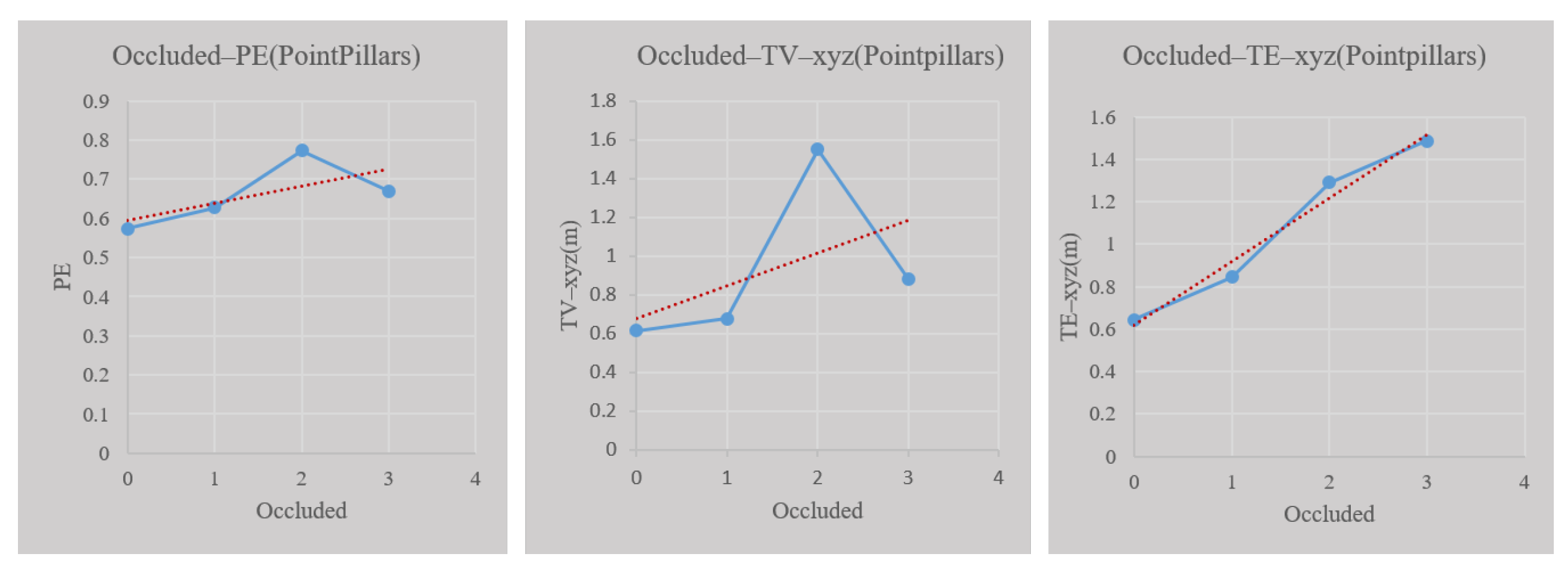
This paper proposes a fusion model based on multi-source perception and Deep Ensemble to judge the effectiveness of perceptual results in each frame and evaluate the spatial uncertainty of the objects detected simultaneously. Based on the KITTI dataset, the research results of this paper show that the accuracy of judging the effectiveness of perception based on the multi-source perception inspection and Deep Ensemble fusion model can reach 92%. In addition, a positive correlation is found between perception spatial uncertainty and error between perception results and ground truth. The results grant the uncertainty evaluation a physical meaning anchored to the objective error. In addition, this study found that perception uncertainty is related to the distance and the degree of occlusion of the detected objects.
Compared with the previous research, the research in this paper can effectively and real-time deal with the missed detection in the long tail scenario and judge the perception effectiveness, which is very important for the safe operation of autonomous driving. The research in this paper can effectively improve the accuracy of perception and further improve the safety of autonomous driving. Suppose a perception failure is found in real-time. In such a case, it can be replaced with other perception sources to realize real-time judgment and switching of autonomous driving perception sources and ensure the safety of autonomous driving. Although we have achieved good results, we only studied the uncertainty of perception occupancy, which needs to be verified on real vehicles. In the future, we hope to further study the uncertainty of semantics and motion of perception results to improve AD’s perception performance and safety. The model proposed in this article is incredibly important for assessing perception uncertainty in real-time, and could benefit autonomous driving safety even more.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}