A Heuristic-Based Adaptive Iterated Greedy Algorithm for Lot-Streaming Hybrid Flow Shop Scheduling Problem with Consistent and Intermingled Sub-Lots

Abstract
:1. Introduction
- A mixed integer linear programming model is established to highlight the influences of intermingling sub-lots with each other with respect to production efficiency and sequence-dependent setups.
- A heuristic-based adaptive iterated greedy algorithm (HAIG) with three main modifications achieves a more balanced exploration and exploitation. The heuristic-based initialization globally minimizes the maximum completion time by relaxing the sequence-dependent setup time caused by intermingling. Consequently, four special neighborhood structures based on critical paths, and an adaptive strategy, are proposed to enhance the local search capability. Besides, an acceptance criterion of inferior solutions is improved to promote global optimization ability and avoid premature convergence.
2. Literature Review
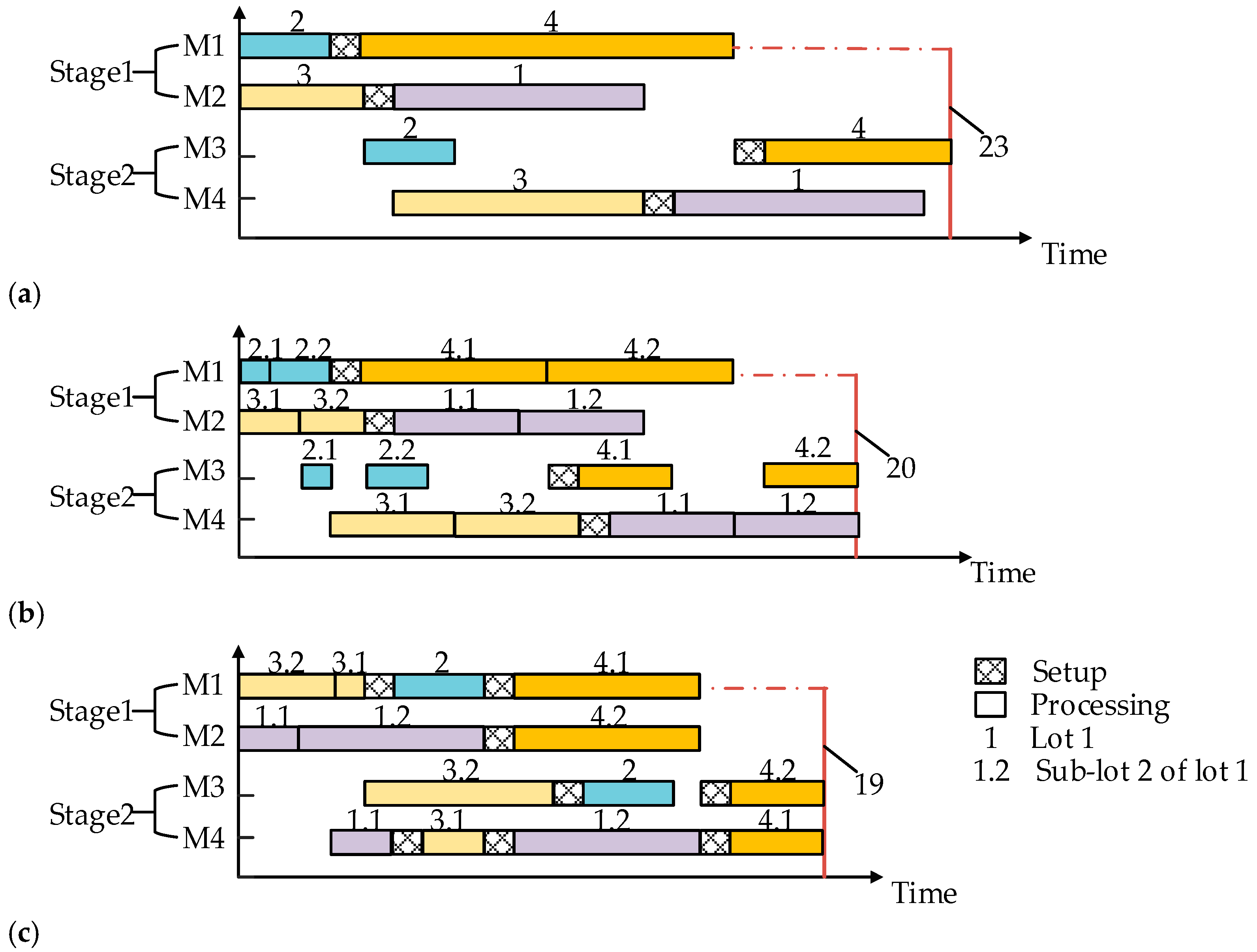
2.1. Flow Shop Scheduling Problem with Consistent and Intermingled Sub-Lots
2.2. Meta-Heuristic Algorithms
3. Results
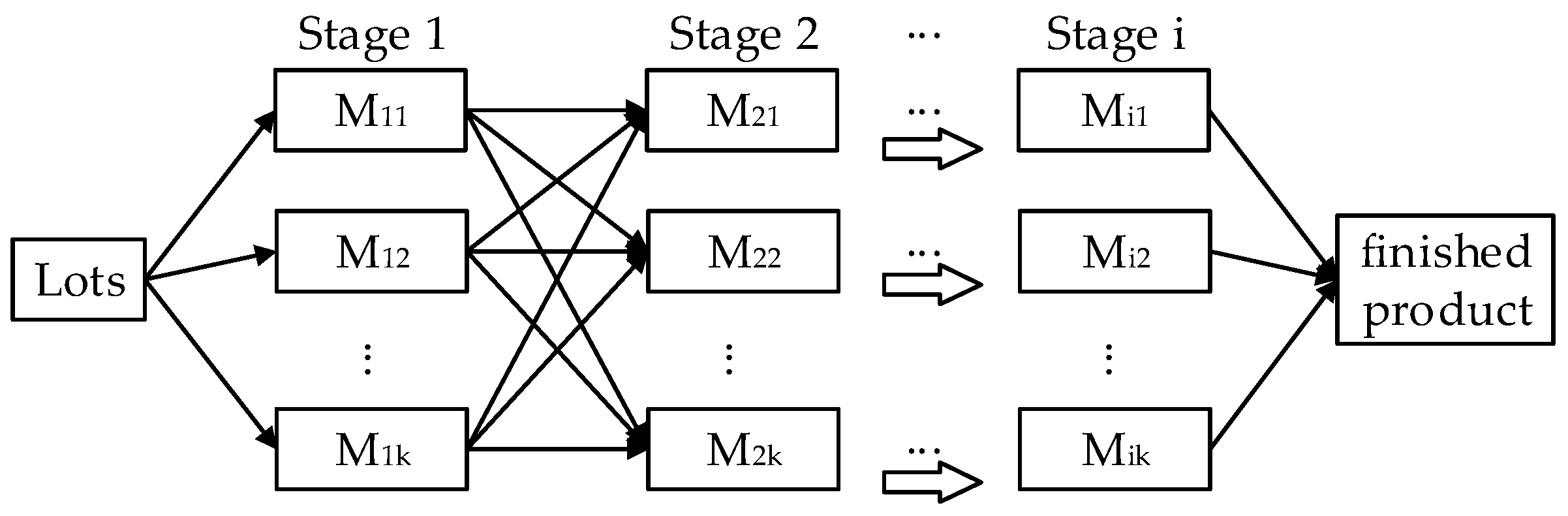
3.1. Problem Formulation
- All items of all lots are available at time zero.
- The number of sub-lots of a lot is limited to its maximum value.
- At each stage, each sub-lot should be allocated to exactly one machine and all sub-lots of a lot may be allocated to more than one machine.
- On each machine, idle times between any two consecutive sub-lots are allowed, and all items in a sub-lot should be processed consecutively and without a break.
- The buffer capacity between the two stages for storing intermediate products is infinite.
- Each sub-lot can be transported to the next stage only after its completion at the current stage.
- A machine can process at most one sub-lot at a time. It can start processing only if it gets ready and the corresponding sub-lot arrives.
- On each machine, setup is compulsory if two consecutive sub-lots are from different lots while it is unnecessary if both of them are from the same lot.
3.2. Mathematical Model
3.3. Complexity Analysis
4. Heuristic-Based Adaptive Iterated Greedy Algorithm
| Algorithm 1 The procedure for the HAIG |
| 1: Define the termination criterion T 2: Initialize the primary solution Heuristic-based Initialization() //initialization 3: //Local search 4: 5: 6: While T is not satisfied do 7: // The destruction-construction (DC) process 8: 9: 10: 11: 12: End While 13: Return |
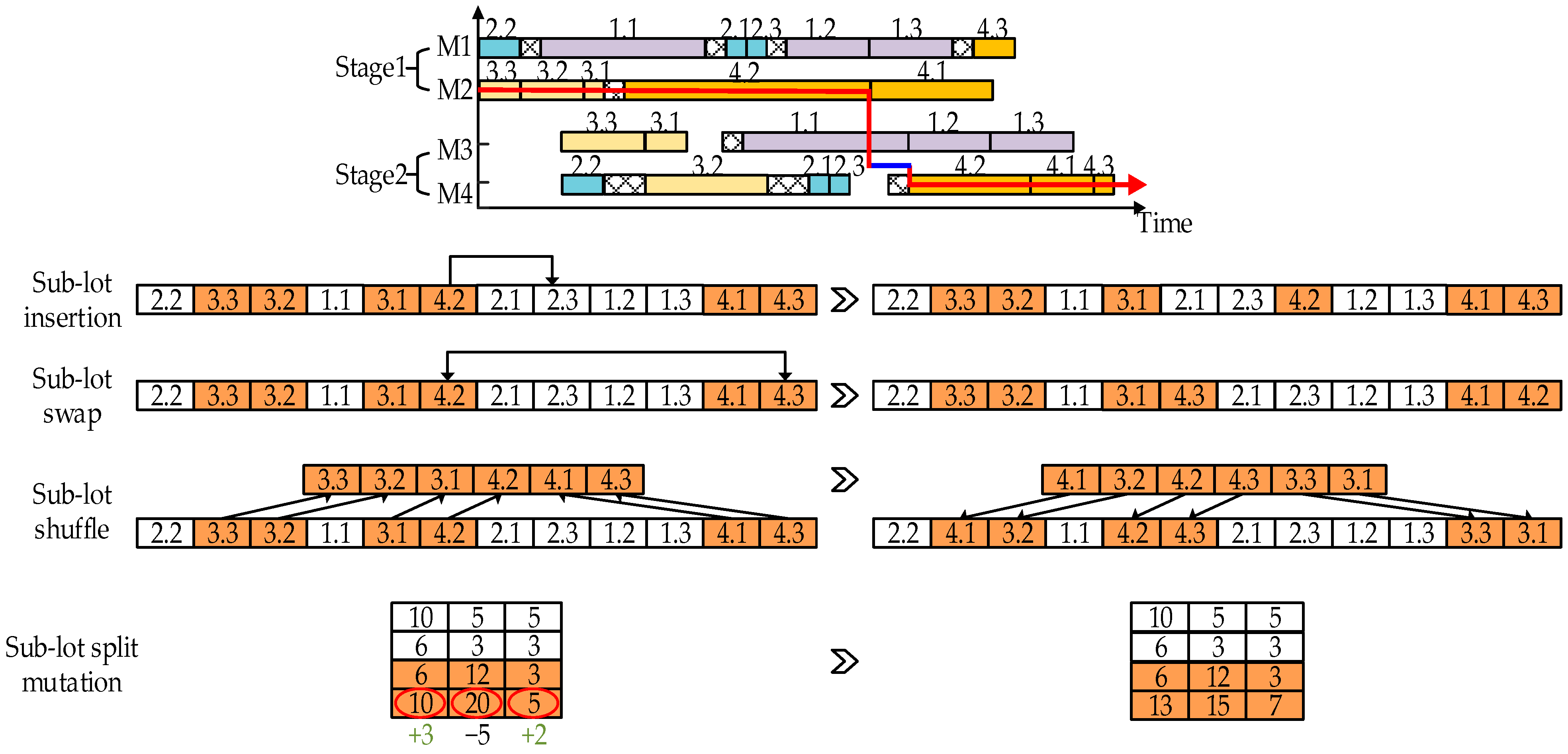
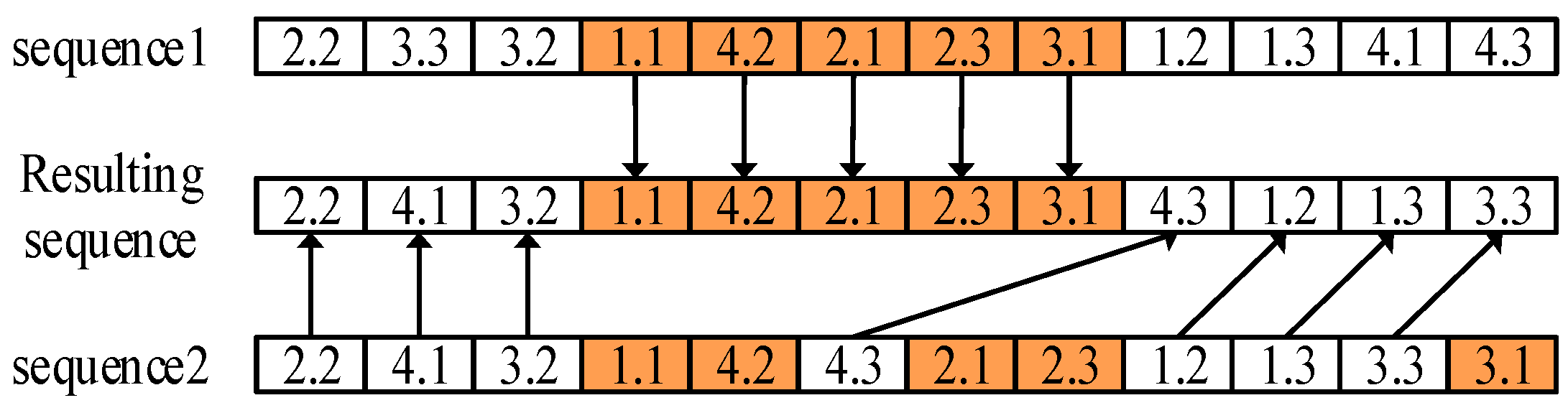
4.1. Encoding with Decoupling Strategy
4.2. Decoding
| Algorithm 2 The procedure for decoding |
| Input:Sub-lot splitting, ; production sequence of sub-lots at the first stage, Output: A schedule. 1: For to do 2: Initialize the time that parallel machines are ready for setup 3: For all sub-lots according to the production sequence do 4: For to do 5: Calculate the available time of machine after transportation and sequence-dependent setup as Equations (12) and (13) 6: End For 7: Assign the sub-lot to the machine with the earliest available time 8: Calculate of according to the earliest available time and processing time 9: End For 10: Update production sequence by completing time ascending 11: End For |
4.3. Heuristic-Based Initialization
| Algorithm 3 The procedure for heuristic-based initialization |
| Input: Losts ; Quantity of items in lots ; Maximum number of sub-lots in each lot Output: an initial solution 1: Define a set that accommodate the unscheduled sub-lots 2: Define a set that accommodate the summation of processing time and sequence-dependent setup time 3: For to do // More-balanced sub-lot splitting 4: For to do 5: 6: End For 7: 8: End For 9: For to do // Improved SPT-based production sequencing 10: 11: For to do 12: For to do 13: 14: 15: End For 16: End For 17: 18: End For |
4.4. Destruction–Construction Phase
| Algorithm 4 The procedure for the destruction-construction (DC) process |
| Input: an initial solution Output: a novel solution 1: For to do // Destruction process 2: Randomly remove sub-lot from 3: 4: End For 5: For to do // Construction process 6: For to do 7: Insert into a random position of 8: Select the best 9: 10: End For 11: End For |
4.5. Adaptive Local Search
4.5.1. Critical Path-Based Neighborhood Operators
4.5.2. Adaptive Strategy
| Algorithm 5 The procedure for local search |
| Input: a solution , , , , , a set of defined neighborhoods Output: the updated solution 1: 2: While do 3: 4: 5: While do 6: 7: If then 8: 9: 10: 11: 12: 13: 14: 15: Else 16: 17: End If 18: End While 19: 20: End While |
4.6. An Improved Acceptance Criterion
| Algorithm 6 The procedure of the improved acceptance criterion |
| Input: the current solution , the updated solution Output: the novel current solution 1: If then // Acceptance criterion 2: 3: 4: 5: Elseif then 6: 7: 8: While do // Optimal operator 9: 10: 11: If then 12: 13: 14: else 15: 16: End If 17: End While 18: End If |
5. Experiment Results and Analysis
5.1. Experimental Setting
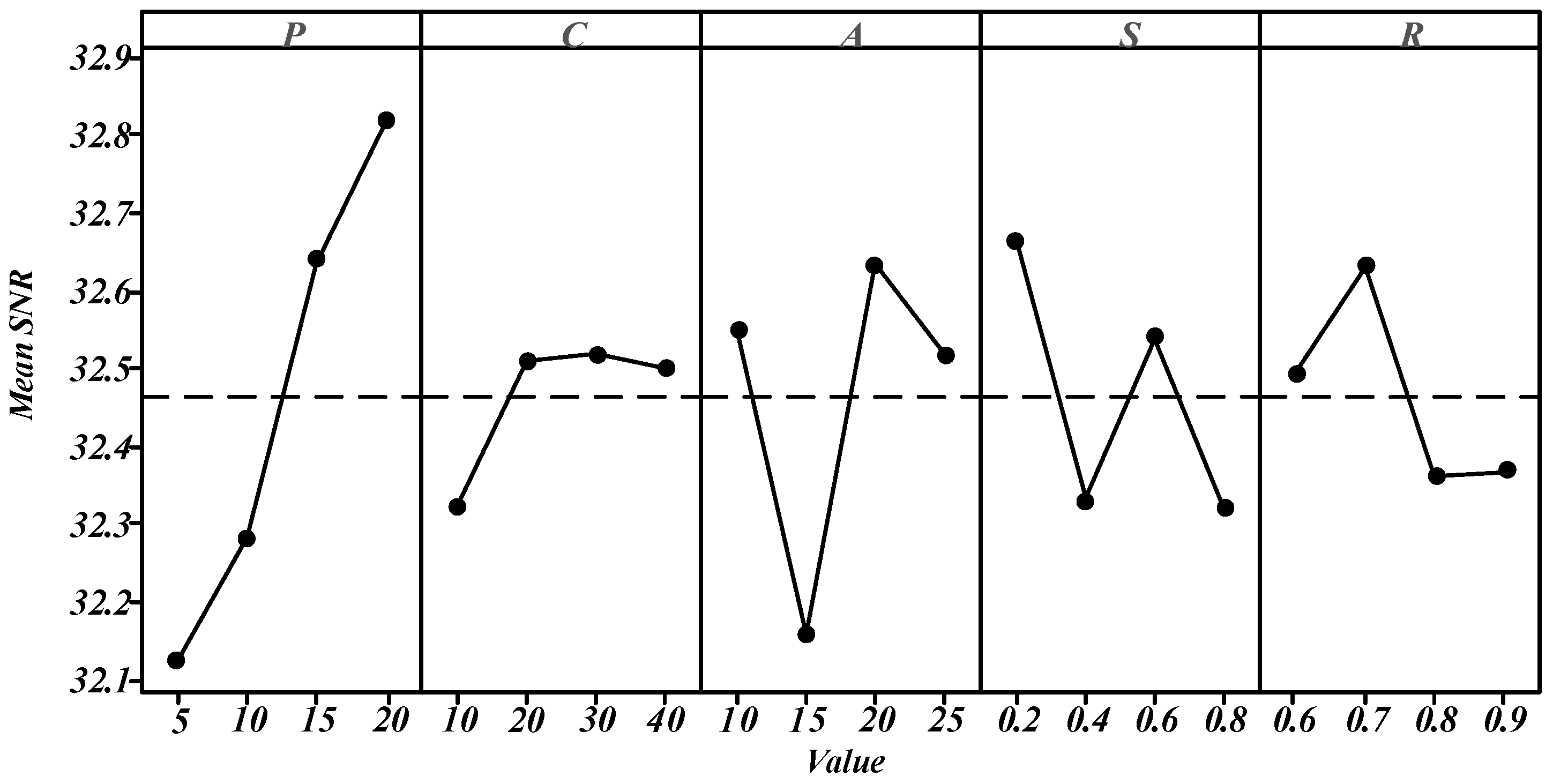
5.2. Parameter Calibration
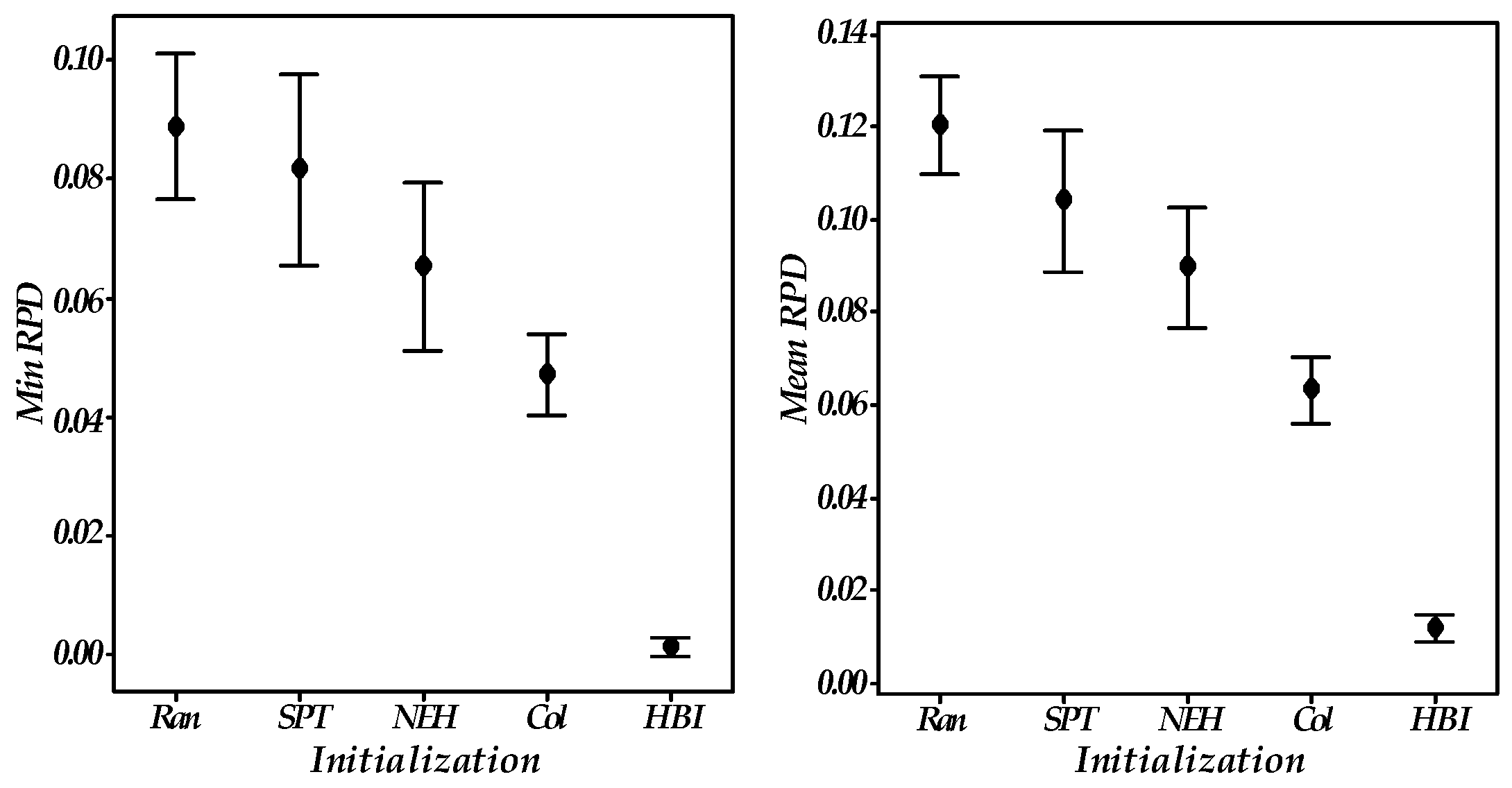
5.3. Effectiveness of Heuristic-Based Initialization
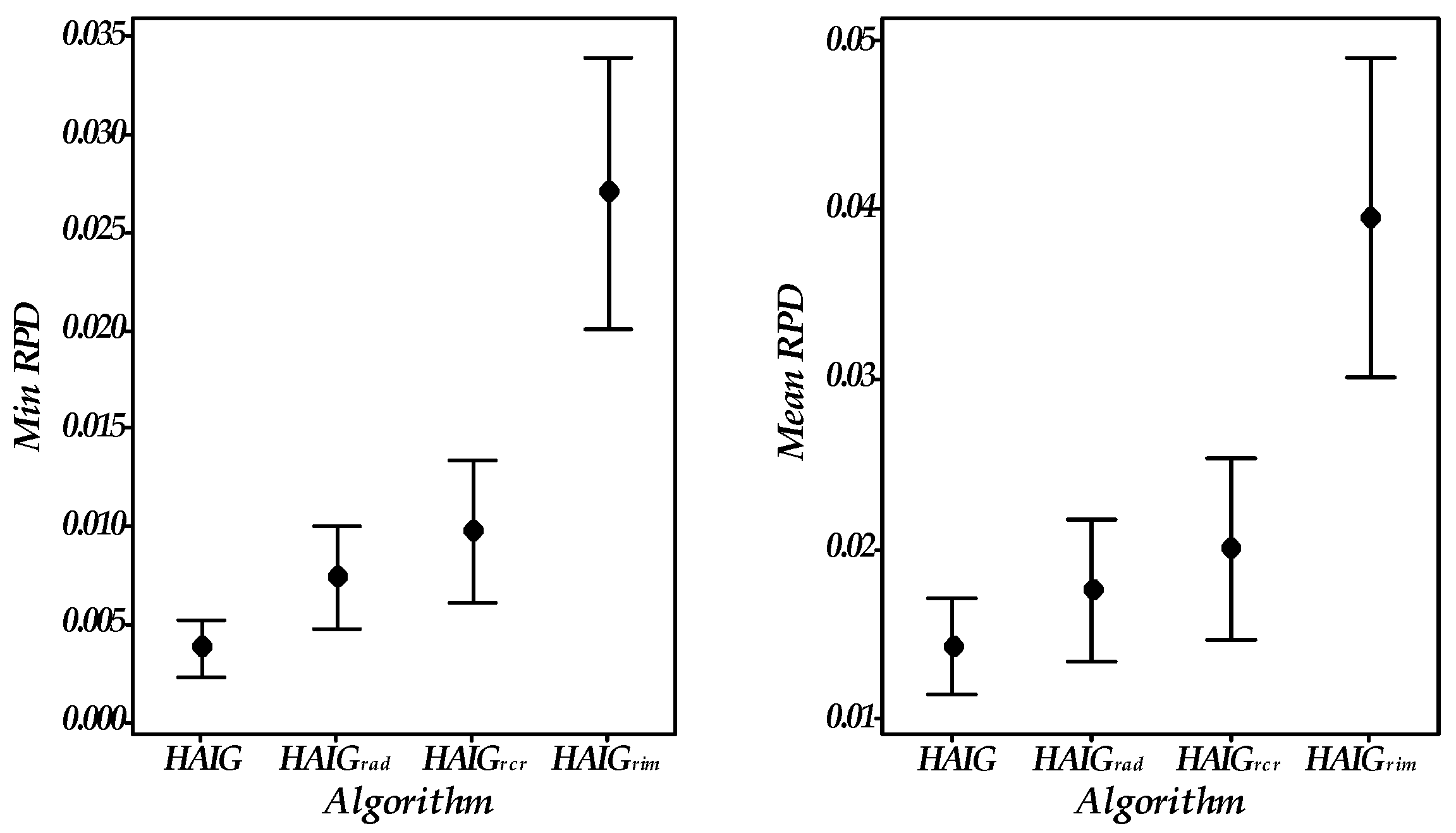
5.4. Effectiveness of Three Improvements
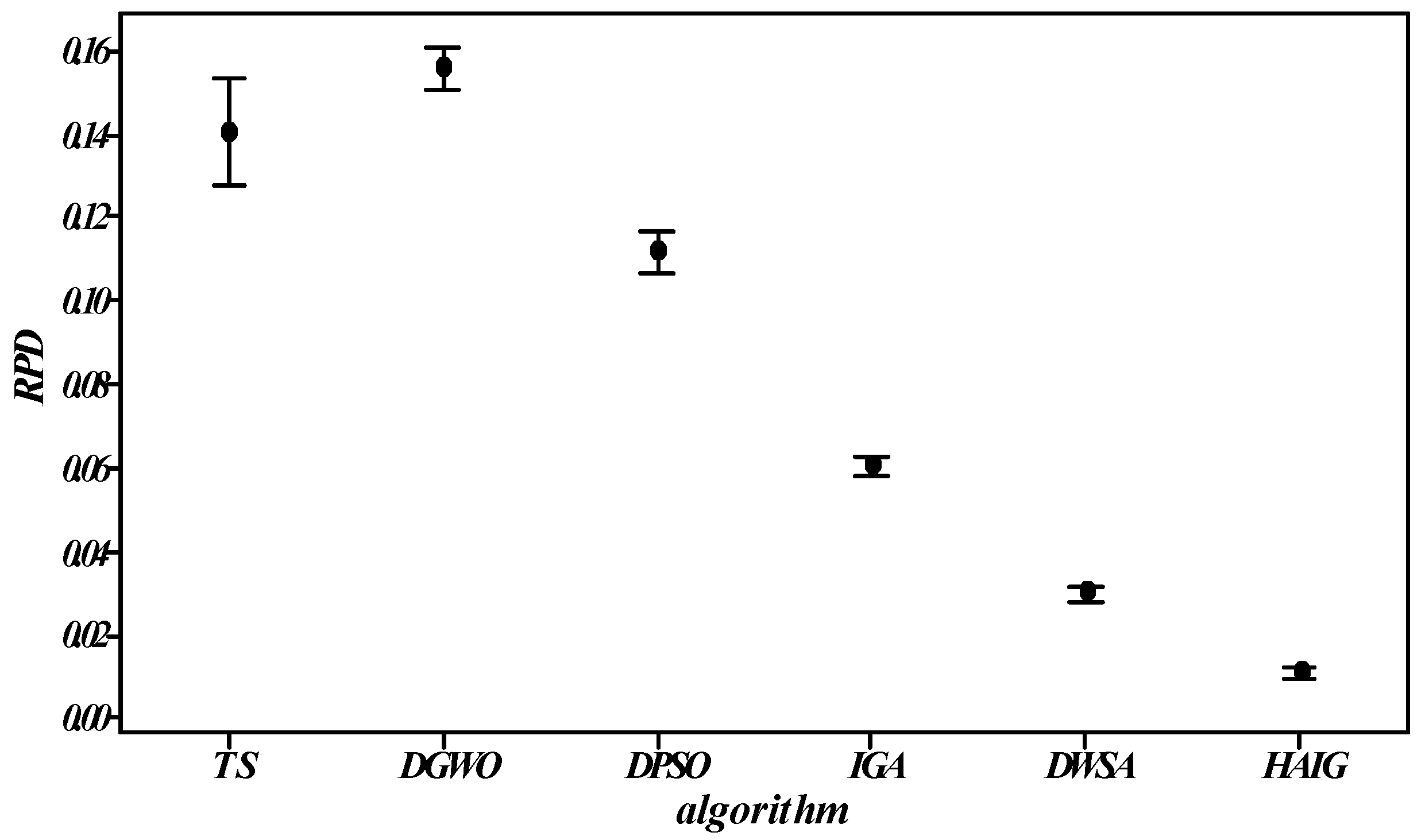
5.5. Effectiveness of the Proposed HAIG
5.6. An Industrial Case
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ruiz, R.; Vázquez-Rodríguez, J.A. The hybrid flow shop scheduling problem. Eur. J. Oper. Res. 2010, 205, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Cheng, M.; Mukherjee, N.; Sarin, S. A review of lot streaming. Int. J. Prod. Res. 2013, 51, 7023–7046. [Google Scholar] [CrossRef]
- Ruiz, R.; Stützle, T. A simple and effective iterated greedy algorithm for the permutation flowshop scheduling problem. Eur. J. Oper. Res. 2007, 177, 2033–2049. [Google Scholar] [CrossRef]
- Dubois-Lacoste, J.; Pagnozzi, F.; Stützle, T. An iterated greedy algorithm with optimization of partial solutions for the makespan permutation flowshop problem. Comput. Oper. Res. 2017, 81, 160–166. [Google Scholar] [CrossRef]
- Ni, F.; Hao, J.; Lu, J.; Tong, X.; Yuan, M.; Duan, J.; Ma, Y.; He, K. A Multi-Graph Attributed Reinforcement Learning based Optimization Algorithm for Large-scale Hybrid Flow Shop Scheduling Problem. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 3441–3451. [Google Scholar] [CrossRef]
- Ercan, M.F. A performance comparison of PSO and GA in scheduling hybrid flow-shops with multiprocessor tasks. In Proceedings of the 2008 ACM Symposium on Applied Computing, Ceará, Brazil, 16–20 March 2008; pp. 1767–1771. [Google Scholar] [CrossRef]
- Salhi, A.; Rodríguez, J.A.V.; Zhang, Q. An estimation of distribution algorithm with guided mutation for a complex flow shop scheduling problem. In Proceedings of the 9th Annual Conference on Genetic and Evolutionary Computation, London, UK, 7–11 July 2007; pp. 570–576. [Google Scholar] [CrossRef] [Green Version]
- Caricato, P.; Grieco, A.; Nucci, F. Simulation and mathematical programming for a multi-objective configuration problem in a hybrid flow shop. In Proceedings of the 2008 Winter Simulation Conference, Miami, FL, USA, 7–10 December 2008; pp. 1820–1828. [Google Scholar] [CrossRef] [Green Version]
- Moslehi, G.; Mirzaee, M.; Vasei, M.; Modarres, M.; Azaron, A. Two-machine flow shop scheduling to minimize the sum of maximum earliness and tardiness. Int. J. Prod. Econ. 2009, 122, 763–773. [Google Scholar] [CrossRef]
- Fernandez-Viagas, V.; Perez-Gonzalez, P.; Framinan, J.M. The distributed permutation flow shop to minimise the total flowtime. Comput. Ind. Eng. 2018, 118, 464–477. [Google Scholar] [CrossRef]
- Pan, Y.; Gao, K.; Li, Z.; Wu, N. Improved Meta-Heuristics for Solving Distributed Lot-Streaming Permutation Flow Shop Scheduling Problems. IEEE Trans. Autom. Sci. Eng. 2022, 20, 361–371. [Google Scholar] [CrossRef]
- Nejati, M.; Mahdavi, I.; Hassanzadeh, R.; Mahdavi-Amiri, N. Lot streaming in a two-stage assembly hybrid flow shop scheduling problem with a work shift constraint. J. Ind. Prod. Eng. 2016, 33, 459–471. [Google Scholar] [CrossRef]
- Gong, D.; Han, Y.; Sun, J. A novel hybrid multi-objective artificial bee colony algorithm for blocking lot-streaming flow shop scheduling problems. Knowl.-Based Syst. 2018, 148, 115–130. [Google Scholar] [CrossRef]
- Zhang, B.; Pan, Q.-K.; Meng, L.-L.; Zhang, X.-L.; Ren, Y.-P.; Li, J.-Q.; Jiang, X.-C. A collaborative variable neighborhood descent algorithm for the hybrid flowshop scheduling problem with consistent sublots. Appl. Soft Comput. 2021, 106, 107305. [Google Scholar] [CrossRef]
- Fattahi, P.; Hosseini, S.M.H.; Jolai, F.; Tavakkoli-Moghaddam, R. A branch and bound algorithm for hybrid flow shop scheduling problem with setup time and assembly operations. Appl. Math. Model. 2014, 38, 119–134. [Google Scholar] [CrossRef]
- Feldmann, M.; Biskup, D. Lot streaming in a multiple product permutation flow shop with intermingling. Int. J. Prod. Res. 2007, 46, 197–216. [Google Scholar] [CrossRef]
- Mortezaei, N.; Norzima, Z.; Tang, S.; Rosnah, M.Y. Lot Streaming and Preventive Maintenance in a Multiple Product Permutation Flow Shop with Intermingling. Appl. Mech. Mater. 2014, 564, 689–693. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, L.; Wang, S.-Y. A discrete fruit fly optimization algorithm for flow shop scheduling problem with intermingling equal sublots. In Proceedings of the 33rd Chinese Control Conference, Nanjing, China, 28–30 July 2014; pp. 7466–7471. [Google Scholar] [CrossRef]
- Meng, L.; Zhang, C.; Shao, X.; Ren, Y.; Ren, C. Mathematical modelling and optimisation of energy-conscious hybrid flow shop scheduling problem with unrelated parallel machines. Int. J. Prod. Res. 2018, 57, 1119–1145. [Google Scholar] [CrossRef] [Green Version]
- Meng, L.; Gao, K.; Ren, Y.; Zhang, B.; Sang, H.; Chaoyong, Z. Novel MILP and CP models for distributed hybrid flowshop scheduling problem with sequence-dependent setup times. Swarm Evol. Comput. 2022, 71, 101058. [Google Scholar] [CrossRef]
- Meng, L.; Zhang, C.; Shao, X.; Ren, Y. MILP models for energy-aware flexible job shop scheduling problem. J. Clean. Prod. 2018, 210, 710–723. [Google Scholar] [CrossRef]
- Meng, L.; Zhang, C.; Ren, Y.; Zhang, B.; Lv, C. Mixed-integer linear programming and constraint programming formulations for solving distributed flexible job shop scheduling problem. Comput. Ind. Eng. 2020, 142, 106347. [Google Scholar] [CrossRef]
- Öztop, H.; Tasgetiren, M.F.; Eliiyi, D.T.; Pan, Q.-K. Iterated greedy algorithms for the hybrid flowshop scheduling with total flow time minimization. In Proceedings of the Genetic and Evolutionary Computation Conference, Kyoto, Japan, 15–19 July 2018; pp. 379–385. [Google Scholar] [CrossRef]
- Zhang, H.; Li, J.; Hong, M.; Man, Y. Artificial intelligence algorithm-based multi-objective optimization model of flexible flow shop smart scheduling. In Applications of Artificial Intelligence in Process Systems Engineering; Elsevier: Amsterdam, The Netherlands, 2021; pp. 447–472. [Google Scholar] [CrossRef]
- Tsubone, H.; Ohba, M.; Uetake, T. The impact of lot sizing and sequencing on manufacturing performance in a two-stage hybrid flow shop. Int. J. Prod. Res. 1996, 34, 3037–3053. [Google Scholar] [CrossRef]
- Jing, X.-L.; Pan, Q.-K.; Gao, L.; Wang, Y.-L. An effective Iterated Greedy algorithm for the distributed permutation flowshop scheduling with due windows. Appl. Soft Comput. 2020, 96, 106629. [Google Scholar] [CrossRef]
- Li, J.-Q.; Du, Y.; Gao, K.-Z.; Duan, P.-Y.; Gong, D.-W.; Pan, Q.-K.; Suganthan, P.N. A Hybrid Iterated Greedy Algorithm for a Crane Transportation Flexible Job Shop Problem. IEEE Trans. Autom. Sci. Eng. 2021, 19, 2153–2170. [Google Scholar] [CrossRef]
- Riahi, V.; Chiong, R.; Zhang, Y. A new iterated greedy algorithm for no-idle permutation flowshop scheduling with the total tardiness criterion. Comput. Oper. Res. 2019, 117, 104839. [Google Scholar] [CrossRef]
- Huang, J.-P.; Pan, Q.-K.; Gao, L. An effective iterated greedy method for the distributed permutation flowshop scheduling problem with sequence-dependent setup times. Swarm Evol. Comput. 2020, 59, 100742. [Google Scholar] [CrossRef]
- Du, K.-L.; Swamy, M.N.S. Tabu Search and Scatter Search. In Search and Optimization by Metaheuristics; Birkhäuser: Cham, Switzerland, 2016; pp. 327–336. [Google Scholar] [CrossRef]
- Kaminsky, P.; Simchi-Levi, D. The Asymptotic Optimality of the SPT Rule for the Flow Shop Mean Completion Time Problem. Oper. Res. 2001, 49, 293–304. [Google Scholar] [CrossRef] [Green Version]
- Duarte, A.; Sánchez-Oro, J.; Mladenović, N.; Todosijević, R. Variable Neighborhood Descent. In Handbook of Heuristics; Springer: Cham, Switzerland, 2018; pp. 341–367. [Google Scholar] [CrossRef]
- Öztop, H.; Tasgetiren, M.F.; Eliiyi, D.T.; Pan, Q.-K. Metaheuristic algorithms for the hybrid flowshop scheduling problem. Comput. Oper. Res. 2019, 111, 177–196. [Google Scholar] [CrossRef]
- Zhang, B.; Pan, Q.-K.; Gao, L.; Zhang, X.-L.; Chen, Q.-D. A hybrid variable neighborhood search algorithm for the hot rolling batch scheduling problem in compact strip production. Comput. Ind. Eng. 2018, 116, 22–36. [Google Scholar] [CrossRef]
- Ballantyne, K.; van Oorschot, R.; Mitchell, R. Reduce optimisation time and effort: Taguchi experimental design methods. Forensic Sci. Int. Genet. Suppl. Ser. 2008, 1, 7–8. [Google Scholar] [CrossRef]
- Nawaz, M.; Enscore, E.E.; Ham, I. A heuristic algorithm for the m-machine, n-job flow-shop sequencing problem. Omega 1983, 11, 91–95. [Google Scholar] [CrossRef]
- Yu, C.; Semeraro, Q.; Matta, A. A genetic algorithm for the hybrid flow shop scheduling with unrelated machines and machine eligibility. Comput. Oper. Res. 2018, 100, 211–229. [Google Scholar] [CrossRef]
- Anjana, V.; Sridharan, R.; Kumar, P.N.R. Development and Analysis of a Discrete Particle Swarm Optimisation for Bi-criteria Scheduling of a Flow Shop with Sequence-Dependent Setup Time. In Advances in Simulation, Product Design and Development; Proceedings of AIMTDR 2018; Springer: Singapore, 2020; pp. 267–284. [Google Scholar] [CrossRef]
- Zhang, C.; Tan, J.; Peng, K.; Gao, L.; Shen, W.; Lian, K. A discrete whale swarm algorithm for hybrid flow-shop scheduling problem with limited buffers. Robot. Comput. Manuf. 2020, 68, 102081. [Google Scholar] [CrossRef]
- Panwar, K.; Deep, K. Discrete Grey Wolf Optimizer for symmetric travelling salesman problem. Appl. Soft Comput. 2021, 105, 107298. [Google Scholar] [CrossRef]
- Harbaoui, H.; Khalfallah, S. Tabu-search optimization approach for no-wait hybrid flow-shop scheduling with dedicated machines. Procedia Comput. Sci. 2020, 176, 706–712. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
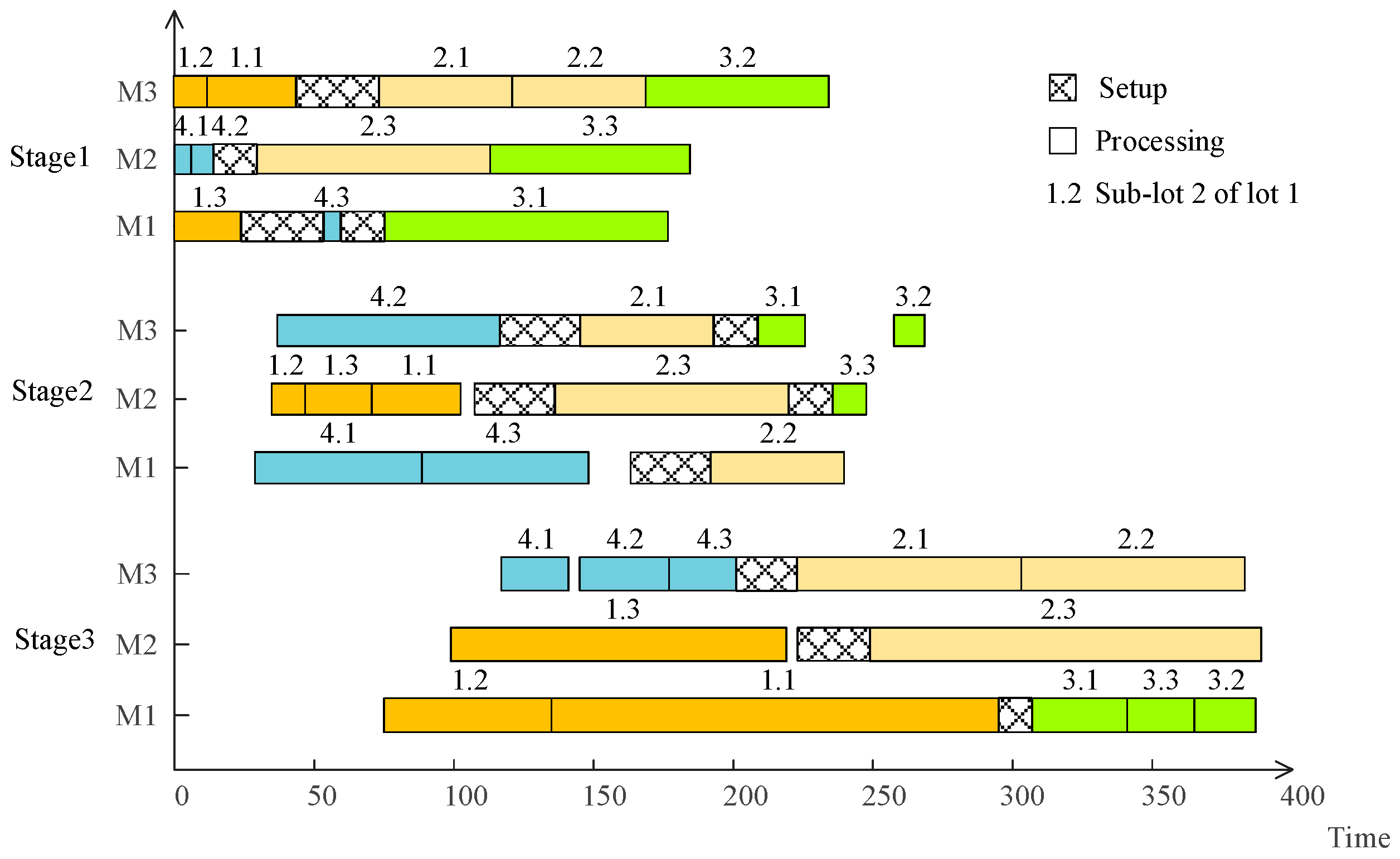{kind=link}
| Parameters and Sets: | |
| The maximum number of sub-lots from each lot. | |
| f | The number of stages |
| v | The number of lots |
| r | The number of machines |
| Set of stages and . | |
| Set of lots and . | |
| Sets of sub-lots, and . | |
| Set of machines and . | |
| Set of machines at stage . | |
| The quantity of the items in lot . | |
| Processing time per item of lot by machine at stage . | |
| Setup time between lots and on a machine at stage . | |
| Transportation time from stage to the next stage. | |
| A positive large number. | |
| Discrete variables: | |
| Integer variable, the quantity of the items in sub-lot from lot . | |
| Binary variable. It takes the value of 1 when the quantity of items in sub-lot from lot is larger than 1 and 0 otherwise. | |
| Binary variable. It takes the value of 1 when sub-lot of lot is allocated to machine at stage and 0 otherwise. | |
| Binary variable. It takes the value of 1 when on machine at stage sub-lot of lot is performed immediately before sub-lot from lot and 0 otherwise. | |
| Continuous variables: | |
| Beginning time of sub-lot of lot at stage i. | |
| Finishing time of sub-lot of lot j at stage i. | |
| Maximum completion time. | |
| Algorithm | Parameter |
|---|---|
| Problem | Min RPD | Mean RPD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Ran | SPT | NEH | Col | HBI | Ran | SPT | NEH | Col | HBI | |
| 0.0325 | 0.04 | 0.018 | 0.005 | 0 | 0.092 | 0.095 | 0.074 | 0.014 | 0.023 | |
| 0.0347 | 0.003 | 0.034 | 0.032 | 0 | 0.079 | 0.014 | 0.153 | 0.088 | 0.004 | |
| 0.0053 | 0.009 | 0 | 0.002 | 0.002 | 0.067 | 0.032 | 0.045 | 0.028 | 0.02 | |
| 0.038 | 0.167 | 0.005 | 0.014 | 0 | 0.104 | 0.167 | 0.12 | 0.055 | 0.004 | |
| 0.06 | 0 | 0.018 | 0.053 | 0.026 | 0.087 | 0.025 | 0.069 | 0.104 | 0.039 | |
| 0.1 | 0.121 | 0.128 | 0.057 | 0 | 0.157 | 0.155 | 0.142 | 0.064 | 0.022 | |
| 0.087 | 0.003 | 0.012 | 0.037 | 0 | 0.144 | 0.038 | 0.03 | 0.092 | 0.01 | |
| 0.136 | 0.083 | 0.089 | 0.087 | 0 | 0.175 | 0.112 | 0.138 | 0.114 | 0.012 | |
| 0.059 | 0.025 | 0 | 0.037 | 0.004 | 0.095 | 0.046 | 0.036 | 0.06 | 0.019 | |
| 0.123 | 0.12 | 0.115 | 0.042 | 0 | 0.145 | 0.16 | 0.13 | 0.055 | 0.008 | |
| 0.091 | 0.043 | 0.024 | 0.019 | 0 | 0.141 | 0.107 | 0.043 | 0.082 | 0.012 | |
| 0.126 | 0.12 | 0.098 | 0.08 | 0 | 0.148 | 0.15 | 0.123 | 0.093 | 0.014 | |
| 0.038 | 0.024 | 0.027 | 0.029 | 0 | 0.077 | 0.044 | 0.045 | 0.045 | 0.016 | |
| 0.107 | 0.142 | 0.09 | 0.055 | 0 | 0.146 | 0.162 | 0.106 | 0.057 | 0.006 | |
| 0.067 | 0.053 | 0.017 | 0.069 | 0 | 0.115 | 0.073 | 0.026 | 0.093 | 0.027 | |
| 0.137 | 0.119 | 0.089 | 0.071 | 0 | 0.159 | 0.14 | 0.115 | 0.075 | 0.006 | |
| 0.048 | 0.036 | 0.025 | 0.04 | 0 | 0.07 | 0.061 | 0.036 | 0.05 | 0.014 | |
| 0.121 | 0.149 | 0.107 | 0.06 | 0 | 0.151 | 0.17 | 0.119 | 0.06 | 0.004 | |
| 0.056 | 0.058 | 0 | 0.027 | 0.015 | 0.089 | 0.072 | 0.018 | 0.044 | 0.027 | |
| 0.122 | 0.114 | 0.109 | 0.067 | 0 | 0.15 | 0.133 | 0.127 | 0.067 | 0.008 | |
| 0.096 | 0.096 | 0.074 | 0.064 | 0 | 0.125 | 0.114 | 0.088 | 0.08 | 0.006 | |
| 0.105 | 0.122 | 0.089 | 0.038 | 0 | 0.13 | 0.143 | 0.099 | 0.04 | 0.003 | |
| 0.08 | 0.075 | 0.052 | 0.037 | 0 | 0.114 | 0.104 | 0.062 | 0.058 | 0.012 | |
| 0.115 | 0.119 | 0.096 | 0.039 | 0 | 0.133 | 0.13 | 0.104 | 0.044 | 0.007 | |
| 0.077 | 0.06 | 0.073 | 0.049 | 0 | 0.08818 | 0.069 | 0.082 | 0.061 | 0.013 | |
| 0.121 | 0.129 | 0.106 | 0.052 | 0 | 0.147 | 0.152 | 0.124 | 0.053 | 0.002 | |
| 0.052 | 0.042 | 0.035 | 0.037 | 0 | 0.079 | 0.06 | 0.042 | 0.049 | 0.018 | |
| 0.122 | 0.123 | 0.111 | 0.051 | 0 | 0.148 | 0.135 | 0.12 | 0.051 | 0.003 | |
| 0.08 | 0.0576 | 0.069 | 0.07 | 0 | 0.099 | 0.081 | 0.08 | 0.078 | 0.007 | |
| 0.124 | 0.139 | 0.115 | 0.053 | 0 | 0.145 | 0.155 | 0.119 | 0.054 | 0.001 | |
| 0.058 | 0.051 | 0.048 | 0.04 | 0 | 0.081 | 0.08 | 0.069 | 0.055 | 0.017 | |
| 0.139 | 0.112 | 0.11 | 0.054 | 0 | 0.148 | 0.124 | 0.124 | 0.058 | 0.003 | |
| 0.092 | 0.09 | 0.093 | 0.081 | 0 | 0.109 | 0.101 | 0.107 | 0.089 | 0.012 | |
| 0.132 | 0.12 | 0.116 | 0.056 | 0 | 0.151 | 0.138 | 0.126 | 0.056 | 0.003 | |
| 0.084 | 0.051 | 0.051 | 0.042 | 0 | 0.094 | 0.072 | 0.07 | 0.059 | 0.019 | |
| 0.135 | 0.127 | 0.112 | 0.053 | 0 | 0.148 | 0.133 | 0.122 | 0.053 | 0.001 | |
| Problem | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 452 | 535.1 | 437 | 468 | 447 | 473 | 416 | 423.6 | 416 | 420.6 | 400 | 409.2 | |
| 711 | 748.1 | 664 | 726.9 | 701 | 728.6 | 660 | 665.1 | 644 | 658.2 | 634 | 636.4 | |
| 640 | 852.1 | 641 | 671.8 | 631 | 642.1 | 589 | 603.7 | 571 | 576.6 | 567 | 577.6 | |
| 845 | 1038.4 | 811 | 902.8 | 955 | 963.2 | 810 | 813.3 | 794 | 804.3 | 760 | 763 | |
| 1051 | 1112.9 | 1098 | 1122.3 | 1054 | 1085.1 | 1023 | 1049.7 | 1030 | 1037.5 | 1004 | 1017.2 | |
| 2157 | 2214.5 | 2300 | 2377.2 | 2204 | 2234.1 | 2045 | 2067.5 | 1975 | 2021.1 | 1928 | 1970.6 | |
| 1325 | 1502.5 | 1315 | 1374.1 | 1211 | 1243.8 | 1183 | 1235.3 | 1173 | 1188 | 1167 | 1178.5 | |
| 2229 | 2389.7 | 2443 | 2554.2 | 2320 | 2383.5 | 2180 | 2264.1 | 2138 | 2170.5 | 2054 | 2078 | |
| 1714 | 1855.6 | 1741 | 1802.1 | 1673 | 1712.6 | 1648 | 1674.7 | 1642 | 1671.1 | 1609 | 1632.4 | |
| 3932 | 4106.1 | 4383 | 4470.7 | 4236 | 4318.6 | 3935 | 3981.6 | 3849 | 3879.8 | 3753 | 3782.8 | |
| 2026 | 2303.3 | 1949 | 2083.9 | 1910 | 1922.3 | 1886 | 1971.8 | 1811 | 1847.5 | 1789 | 1811 | |
| 4159 | 4221.5 | 4501 | 4601.6 | 4364 | 4473 | 4134 | 4165.1 | 4010 | 4066.6 | 3874 | 3930.1 | |
| 2923 | 3022.1 | 2953 | 3008.9 | 2885 | 2915.1 | 2821 | 2864.6 | 2839 | 2860.4 | 2736 | 2779.5 | |
| 7234 | 7305.3 | 7802 | 7912.8 | 7237 | 7291.7 | 6968 | 7005.1 | 6690 | 6701.6 | 6586 | 6627.1 | |
| 3268 | 3510.8 | 3327 | 3429.2 | 3128 | 3172.1 | 3233 | 3319.8 | 3145 | 3185.1 | 3047 | 3129.6 | |
| 7140 | 7328.7 | 7824 | 8003.5 | 7561 | 7640.1 | 7110 | 7190.7 | 6784 | 6883.9 | 6696 | 6738.7 | |
| 3996 | 4058 | 3868 | 3960 | 3810 | 3846 | 3743 | 3791 | 3735 | 3790 | 3633 | 3684.9 | |
| 9683 | 9861.2 | 10,412 | 10,570.2 | 9820 | 9895.8 | 9326 | 9361.2 | 8925 | 8939.4 | 8811 | 8844.4 | |
| 4091 | 4339.9 | 4292 | 4332.3 | 4066 | 4094.2 | 4013 | 4053.9 | 4011 | 4056.5 | 3996 | 4043 | |
| 9504 | 9696.4 | 10,463 | 10,615.2 | 9994 | 10,123.3 | 9507 | 9536.4 | 9131 | 9158 | 8933 | 9000.1 | |
| 4910 | 5112.9 | 5157 | 5235.7 | 4906 | 4993.2 | 4787 | 4856.6 | 4718 | 4769.4 | 4563 | 4590.3 | |
| 13,783 | 13,894.1 | 14,823 | 14,936 | 13,932 | 14,050.6 | 13,281 | 13,330.6 | 12,913 | 12,924.1 | 12,768 | 12,810.8 | |
| 5289 | 5455.8 | 5385 | 5538.3 | 5233 | 5268.9 | 5056 | 5130.6 | 5046 | 5077 | 4919 | 4977.5 | |
| 13,673 | 13,877.1 | 14,899 | 14,987 | 14,241 | 14,335 | 13,497 | 13,538.9 | 13,013 | 13,151.7 | 12,902 | 12,998.3 | |
| 5797 | 5949.7 | 6028 | 6154.3 | 6039 | 6112.7 | 5879 | 5917.5 | 5751 | 5808.6 | 5592 | 5666.2 | |
| 16,159 | 16,440.5 | 17,489 | 17,678.5 | 16,722 | 16,862 | 15,679 | 15,694.9 | 14,932 | 15,016.7 | 14,887 | 14,913.7 | |
| 6283 | 6428.4 | 6378 | 6528.1 | 6276 | 6323.1 | 6194 | 6301.3 | 6014 | 6109 | 6003 | 6112.8 | |
| 16,235 | 16,632.6 | 17,399 | 17,603.4 | 16,729 | 16,982.2 | 15,853 | 15,878 | 15,203 | 15,247.8 | 15,038 | 15,080 | |
| 7481 | 7746.1 | 7738 | 7872.6 | 7725 | 7765.2 | 7536 | 7639.7 | 7264 | 7302 | 7118 | 7166.7 | |
| 21,266 | 21,692.5 | 22,867 | 23,039 | 21,824 | 21,953.9 | 20,624 | 20,661.6 | 19,641 | 19,650.8 | 19,543 | 19,571 | |
| 7744 | 7941.9 | 8035 | 8241.3 | 8019 | 8073.8 | 7792 | 7884.3 | 7645 | 7720 | 7505 | 7631.1 | |
| 21,320 | 21,646.7 | 22,717 | 22,931 | 22,107 | 22,247 | 20,776 | 20,880.8 | 19,869 | 19,879.4 | 19,699 | 19,756.7 | |
| 8626 | 8841.8 | 8962 | 9091.3 | 8929 | 9012.6 | 8669 | 8756.2 | 8398 | 8437 | 8097 | 8191 | |
| 24,610 | 25,354.8 | 26,619 | 26,776.3 | 25,513 | 25,597.9 | 23,816 | 23,817.8 | 22,648 | 22,678 | 22,522 | 22,583 | |
| 8929 | 9009.1 | 9278 | 9414.2 | 9323 | 9438.1 | 8881 | 8984.5 | 8827 | 8924.1 | 8658 | 8824.6 | |
| 24,622 | 24,974.2 | 26,417 | 26,619 | 25,630 | 25,722.4 | 23,935 | 23,972 | 22,875 | 22,914.6 | 22,712 | 22,738.9 | |
| (a) | ||||||||
| Lot | Stage 1 | Stage 2 | Stage 3 | Unit | Sequence-Dependent Setup Time/Stages | |||
| Lot1 | Lot2 | Lot3 | Lot4 | |||||
| lot1 | A1 | B1 | RF9 | 34 | 0, 0, 0 | 30, 30, 26 | 30, 30, 12 | 30, 19, 21 |
| lot2 | A2 | B2 | WB4 | 30 | 30, 30, 26 | 0, 0, 0 | 0, 16, 19 | 16, 29, 22 |
| lot3 | A2 | B3 | WB1 | 40 | 30, 30, 12 | 0, 16, 19 | 0, 0, 0 | 16, 21, 21 |
| lot4 | A3 | B4 | WB5 | 20 | 30, 19, 21 | 16, 29, 22 | 16, 21, 21 | 0, 0, 0 |
| (b) | ||||||||
| Stage | Transportation Time | Unit Time per Item/Lots | ||||||
| Stage 1 | 23 | 2, 6, 6, 1 | ||||||
| Stage 2 | 28 | 2, 6, 1, 10 | ||||||
| Stage 3 | - | 10, 10, 2, 4 | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Y.; Tang, Q.; Pan, Q.; Zhao, L.; Zhu, Y. A Heuristic-Based Adaptive Iterated Greedy Algorithm for Lot-Streaming Hybrid Flow Shop Scheduling Problem with Consistent and Intermingled Sub-Lots. Sensors 2023, 23, 2808. https://doi.org/10.3390/s23052808
Lu Y, Tang Q, Pan Q, Zhao L, Zhu Y. A Heuristic-Based Adaptive Iterated Greedy Algorithm for Lot-Streaming Hybrid Flow Shop Scheduling Problem with Consistent and Intermingled Sub-Lots. Sensors. 2023; 23(5):2808. https://doi.org/10.3390/s23052808
Chicago/Turabian StyleLu, Yiling, Qiuhua Tang, Quanke Pan, Lianpeng Zhao, and Yingying Zhu. 2023. "A Heuristic-Based Adaptive Iterated Greedy Algorithm for Lot-Streaming Hybrid Flow Shop Scheduling Problem with Consistent and Intermingled Sub-Lots" Sensors 23, no. 5: 2808. https://doi.org/10.3390/s23052808