1. Introduction
Machine learning (ML) algorithms grow increasingly popular in various, industrial applications. Using the right ML method in different processes with varying complexity can significantly improve overall performance and solve key problems. At the same time, finding the right set of data to appropriately train selected algorithms can pose some issues. One of the key elements in this process is choosing the appropriate method to extract features to be used.
The wood industry, in general, and furniture manufacturing, specifically, is one of many areas in which the nature of the production environment poses a series of problems. It is especially the case with the tool condition monitoring aspect of the industry [
1], where both identification of the best signals, and reducing total downtime are important factors. The most commonly used material, according to various researchers, is laminated chipboard panels [
2,
3,
4,
5]. While it is relatively cheap, this wood product also has some serious issues, apparent in the production process in the form of various wear signs and defects [
3,
4,
5,
6,
7]. Additionally, its structure is difficult to predict. Depending on glue density and occurrence of air pockets, it can contain harder and softer spaces. In the case of the drilling process used with such material, pinpointing the exact moment when the drill needs to be exchanged is an important problem, with significant need for automation [
8,
9,
10].
The topic of tool condition monitoring in the case of wood based industries, including furniture manufacturing, is not a new one. There are numerous solutions already available [
11,
12,
13,
14,
15,
16,
17,
18,
19]. A significant amount of them use large arrays of sensors, measuring parameters such as acoustic emission, noise, vibrations, cutting torque, feed force, or other, similar ones [
20,
21,
22,
23,
24]. There are also quite a few approaches based on ML algorithms, ranging from ones focusing mainly on monitoring the overall machining process [
25,
26], to approaches meant to recognize various species of wood. One of the key advantages of ML algorithms is that they can be adjusted to deal with various problems [
27]. At the same time, all such solutions require a well-matched set of features to be incorporated in the training process.
Another interesting set of approaches moves away from large sets of sensors in favor of using simplified input in the form of images. Especially, transfer and deep learning methodologies were proven to be accurate in such applications [
28,
29]. Additional improvements were made with data augmentation and classifier ensemble approaches [
30,
31]. The type of used classifiers also significantly influenced the overall solution quality [
32,
33,
34,
35].
One common element for all the ML-based solutions is the need to extract the set of features to be used in the algorithm training. Drill wear recognition is a process, where various possible parameters can be taken into account. It is especially the case when images of drilled holes are considered, since apart from easily calculated parameters, other ones can be derived from image structure. There is a need for a solidified and systematic approach for choosing the best feature extraction methodology, pointing out potential gains that different methods can provide.
In this work, an evaluation of various feature extraction methodologies is presented. The problem used as a base for evaluation is a well-defined one. Various works present working solutions with good accuracy [
8,
9,
20,
24,
28,
29,
30,
31,
33,
34,
35,
36,
37,
38], including both image- and sensor-based approaches. Similarly, as in most of them, three wear classes were defined to describe the drill bit state. A total of five classifiers were trained using a feature set obtained with different extraction methodologies. The influence of those methods over the model quality was then evaluated. Additional tests focused on checking the influence that the chosen voting approach introduces to ensemble classifiers. Each instance of the classifier was tested in terms of overall accuracy, general solution parameters and number of critical errors performed (mistakes between border classes).
The rest of this work includes the detailed description of the used data set and methods in
Section 2, presentation of obtained results and related discussion in
Section 3 as well as overall conclusions in
Section 4.
3. Results and Discussion
The general approach used in this work trained classifiers on different sets of features in order to evaluate extraction methodologies, and general characteristics of feature sets obtained from them. Each model was evaluated in terms of accuracy, overall parameters and number of performed misclassifications between different classes.
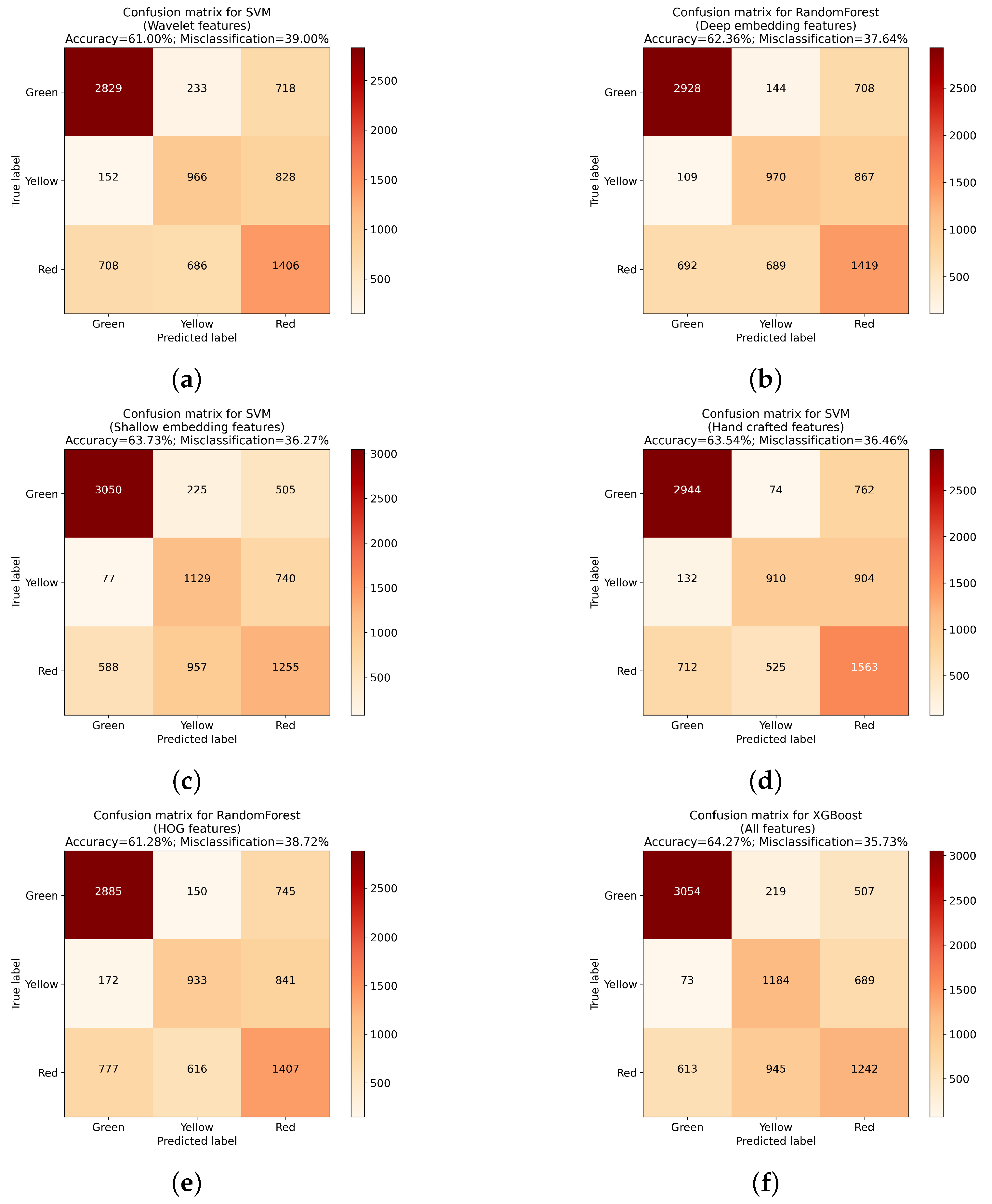
Table 3 contains the general outline for the performance of each individual model.
After preparing the initial feature sets and training five selected classifiers using those sets, it can be seen that the type of extraction method used can have high influence over algorithm performance. When evaluating each classifier, it can be seen that the difference between the worst and best instances of the model were quite significant. It can also be seen that not all classifiers performed the best using the same sets of features, although instances trained on all available features achieved best results for three out of five classifiers (LGBM, RF and XGBoost). When it comes to the remaining models, KNN performed best with features extracted using the deep embedding approach, while for SVM, the shallow embedding methodology returned higher results. What is more, for all algorithms, the difference between the best and worst instances of the classifiers was higher than 3%, with the largest difference occurring for the KNN algorithm (5.24%). Confusion matrices presenting detailed results for the best instance of each classifier are presented at
Figure 5a–e and
Figure 6a.
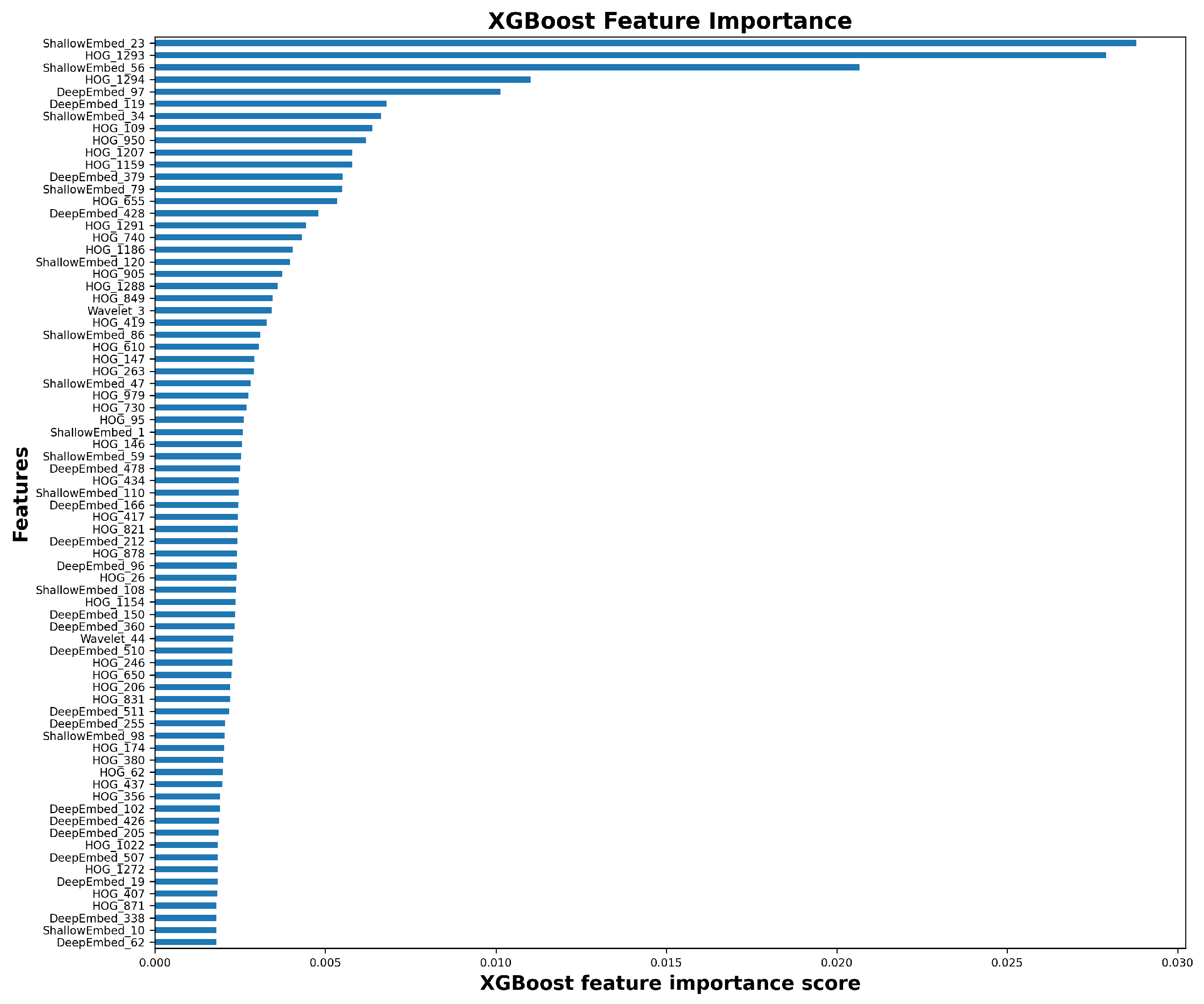
Since for most cases, the best results were obtained using set containing all extracted features, the following classifiers were tested using those results. The first of them was XGBoost, also used to evaluate importance of features from initial sets. Out of a total 1998 features, the XGBoost feature selection method chose 1109.
Table 4 outlines the importance of the remaining features from each initial feature set. As can be seen, two of the most important sets with over 80% set share were obtained using deep embedding and HOG feature extraction approaches. The ranking of 75 of the most important features for the XGBoost algorithm is presented in
Figure 7, while the confusion matrix is shown at
Figure 5f. At
Figure 7, it can be noticed that the main importance groups of features are deep embedding, shallow embedding and HOG. There is a significantly larger number of HOG features in comparison to the rest of the group. However, analyzing
Table 4, it is clear that features having the greatest share and impact are the ones automatically extracted by the state-of-the-art deep learning algorithms.
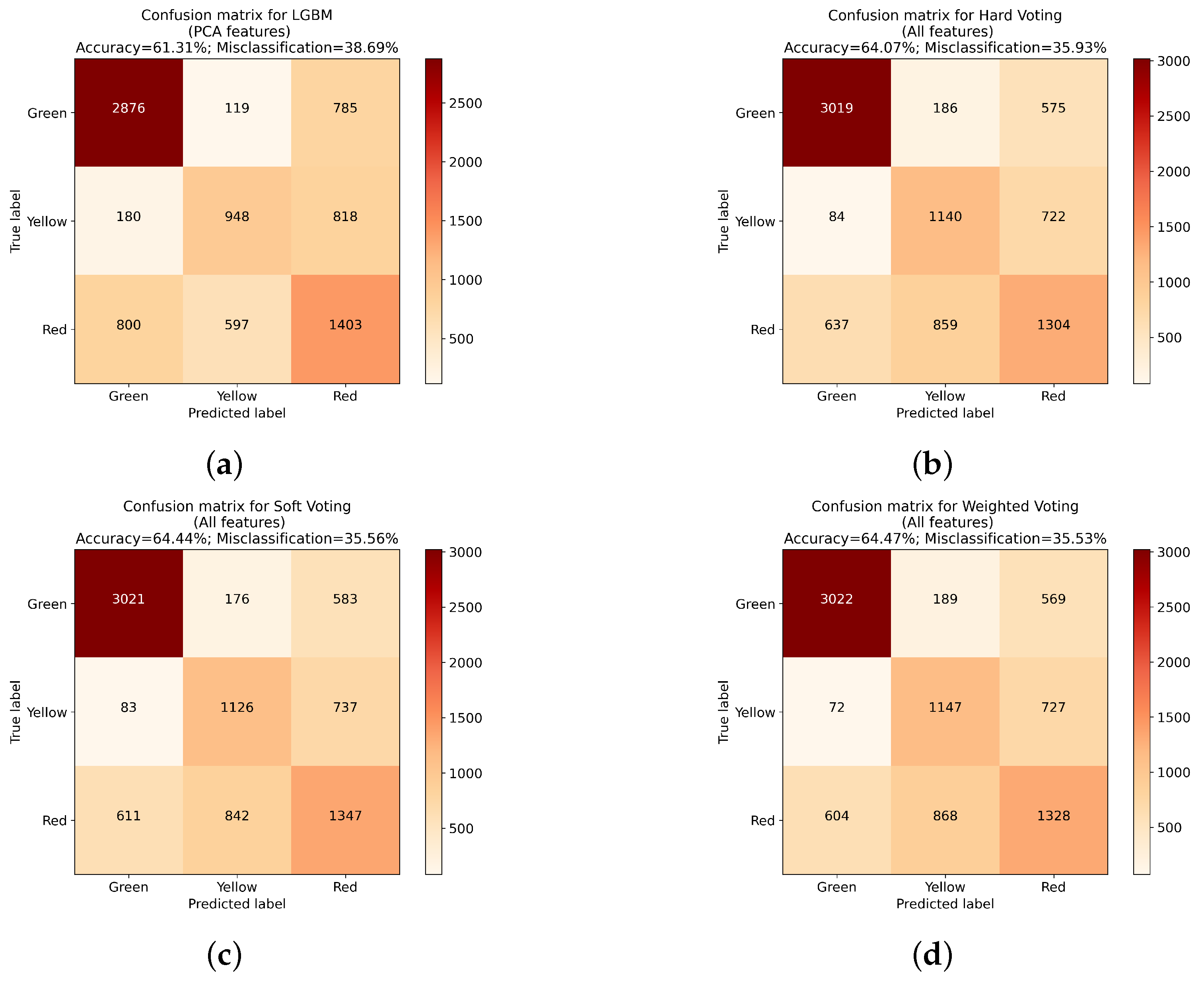
Both in the case of classifiers using different feature sets, as well as with PCA and XGBoost where subsets of features with highest influence are chosen, the improvement in overall accuracy can be seen. Further evaluation focused on checking the influence of voting type used for classifier ensembles. Three types of voting were used in presented approach. The first, called hard voting, used a standard majority voting approach, without any regard to individual classifier performance. The second, denoted as soft voting, used highest average probability. The final approach, called weighted voting, used modified soft voting with an additional modifier. This parameter took into account how the individual classifier performed with different feature sets, and assigned points according to the place it took in that aspect (ranging from 1 to 5). The individual classifier scores and resulting weights are presented in
Table 5.
All three voting approaches achieved similar results, with the highest score achieved by the weighted voting approach (
Table 6). All classifiers were trained using the same features set, containing all available features. At the same time, the difference between best and worst approach reaches only 0.4%, which is not as significant as in the case of differences between feature extraction methodologies.
While accuracy is a good parameter for evaluating the overall algorithm performance, in the presented case another important factor is the types of errors made (
Table 7). From the manufacturer point of view, the worst type of misclassifications are instances where Red class will be classified as Green. In those cases, denoted as critical errors, a product with notable imperfections will be created, which can result in financial loss, since such elements need to be discarded. Similarly, as with overall accuracy, in the case of the number of Red–Green errors, a classifier trained on all features achieved the best results. In the case of voting classifiers, the hard voting approach was the best performing one. As with overall accuracy, the difference here is minimal, nevertheless the best approach improves the error score by 24 Red–Green misclassifications.
Overall, the above analysis shows, that approach used for feature extraction can have significant impact on the training process. The difference between the best and worst performing instances of the classifiers reached 5.24% in the case of a single classifier trained on different feature sets. This gap was even higher when different classifiers and feature sets were considered, especially with the introduction of voting approaches. Final improvement reached 11.14%, between overall worst classifier (KNN using Wavelet feature set) and the best one from the initial set (XGBoost trained on all features). Introduction of different voting approaches further improved the accuracy, with weighted soft voting having 0.20% better accuracy.
An additional problem that needs to be considered is the trade-off between the approach complexity and achieved accuracy. In the case of results obtained by classifiers trained on different feature sets (see
Table 3), the highest accuracy was obtained by solutions trained on all available features. At the same time, the difference in terms of accuracy between this approach (XGBoost) and the best performing classifier using one of the feature sets (SVM, using shallow embedding features) is only 0.54% (accuracy equal to 64.27% vs 63.73%). At the same time the difference in complexity is significant (1998 features in contrast to only 128). This is even more visible with the hand crafted feature set for the same, SVM algorithm, with accuracy equal to 63.54% (total difference of 0.73%) with only 9 features used. Depending on the problem, such drastic improvement in solution complexity with only minimal gain may not be considered as a acceptable trade-off. Those differences are also a good indication that choosing appropriate feature extraction methodology, or a subset of features altogether, is a very important problem, that needs to be seriously considered and evaluated.
The results for the critical errors performed are not as clear, with best approaches diverging from the accuracy score. Nevertheless, using different feature sets resulted in significant difference in those errors as well. In the case of Red–Green errors, the total difference reached 321 (best instance of hand crafted features which performed 1563 errors, and the same for all features with 1242 errors). Further research might be needed to exactly point out the best features for excluding chosen error types.
The main focus of the presented research was to evaluate the influence the different feature extraction methods had on overall algorithm performance. The differences between chosen sets, and further influence of voting approaches in the case of ensemble approaches is clearly present. Further research could focus either on evaluating additional feature extraction methods, and incorporating different classifiers for testing purposes.
4. Conclusions
In this paper, a new approach to evaluating feature extraction methodologies is presented. In the case of ML algorithms, obtaining the appropriate set of features to be used in the training process is one of the key problems, significantly influencing the final solution performance.
The presented approach used five classifiers (KNN, XGBoost, Random Forest, LGBM and SVM), trained on different feature sets. The first five feature sets were obtained using different extraction methodologies: wavelet image scattering, deep and shallow embedding features from a pretrained ResNet-18 network, hand crafted features and HOG approach. An additional feature set containing all parameters in the initial sets, and ones taken from this range using the PCA method, were added. To further evaluate the influence of the classifier, three voting approaches were incorporated. A total of 38 classifier instances were trained.
It can be clearly seen that the type of features obtained using different extraction methodologies has a significant impact on the final model accuracy. The difference between best and worst solution instances reached 11.14%. The same goes for the Red–Green misclassifications. The difference between best and worst classifiers reached a total of 321 errors (between approaches based on hand-crafted and all features).
While the accuracy score presents clear results, there are also additional factors to consider. While the best classifier (XGBoost, trained on all 1998 features) achieved an accuracy equal to 64.27%, the best solution based on a significantly smaller set of parameters (SVM using 128 features obtained using shallow embedding methodology) was less accurate only by 0.54%. Additionally, nine hand-crafted features (also using SVM) achieved 63.54% accuracy and were only 0.73% worse from the best solution in that set. When feature extraction methods are considered, the problem of trade-off between solution complexity and overall solution accuracy is also an important factor. As can be seen, the impact of appropriate extraction methodology is even more visible in that case.
In addition to algorithm performance, the influence of the used voting methodology was checked. The same set of five classifiers was tested, using three approaches: hard, soft and weighted soft voting. While the differences between those classifiers are still visible, they are far less impactful than the changes caused by using different feature sets. Additionally, a classifier with a hard voting approach performed best in terms of critical errors, while one with weighted soft voting achieved best accuracy.
Overall, it can be noted that extracted features can significantly impact the solution quality. Pointing out the best performing set is not always straightforward. Additionally, the above evaluation clearly shows that choosing the appropriate feature extraction method can be a key element influencing the overall solution quality and complexity. Depending on the type of problem and general specifications, different approaches need to be considered.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}