1. Introduction
A Brain–Computer Interface (BCI) provides a direct communication pathway between the user’s brain and external devices/software in order to monitor and/or repair sensorimotor and cognitive functions [
1,
2,
3]. The BCI’s input receives brain commands typically via electroencephalograms (EEG), which is a non-invasive, low-cost, high temporal resolution, and portable technique. Many EEG-based BCIs have been developed by using different paradigms, such as P300 event-related potentials [
4,
5], steady-state visual evoked potentials (SSVEP) [
6,
7], and sensorimotor rhythms (SMR) [
8,
9,
10]. Systems using SMR have demonstrated promising results and great potential for training and recovering motor skills through various types of motor imagery tasks. However, the poor EEG signal-to-noise ratio and intra-and inter-subject variability make the MI classification still a challenge.
Deep learning techniques for MI classification have shown better performance than handcrafted feature extraction methods with respect to accuracy [
11,
12,
13,
14,
15,
16,
17,
18,
19]. This success of deep learning also appears in other research areas, such as computer vision, image, and language processing, among others. Nevertheless, these approaches are deterministic architectures, and hence they lack strategies to measure classification trust.
The source of uncertainty in deep learning models may come from data input because of noise and inaccurate measurement (aleatoric uncertainty). Uncertainty from other sources due to lack of knowledge is termed epistemic uncertainty [
20,
21]. For this reason, uncertainty analysis is crucial to providing robust and reliable classification, which is essential in developments that require low error tolerance, such as medical and autonomous navigation systems. For instance, in these systems, classification mistakes may produce poor decisions, and consequently fatal events. In medical applications, uncertainty analysis has been widely used for disease diagnoses, such as COVID-19 [
22], tuberculosis [
23], ataxia [
24], cancer [
25], diabetic retinopathy [
26,
27], and epileptogenic brain malformations [
28]. To the best of our knowledge, strategies for uncertainty analysis have been little explored in MI-based BCIs, excluding a previous study [
29] that applied Monte Carlo dropout techniques with this purpose, considered as an approximate Bayesian inference in deep Gaussian processes [
21]. The current paper follows a different method by applying BNN.
During classification, the output score vector produced by deterministic architectures is often erroneously interpreted as model confidence (as it appears as probabilities due to the Softmax activation function). Various studies have demonstrated that, even when the highest score is large, the score vector can be a poor predictor of uncertainty. For instance, in [
30], the authors perturbed a single pixel in some CIFAR-10 images, and this small change sometimes caused classification mistakes with high output scores, employing well-known models such as VGG [
31] and AlexNet [
32]. This result increased the safety concerns in critical applications.
Approaches using Bayesian modeling have shown good performance during uncertainty analysis of deep learning models. For instance, the Bayesian Neural Network (BNN) models [
33,
34,
35,
36,
37] introduce stochastic components over the network parameters
, simulating various possible models with their probability distribution
. Although these architectures are computationally more expensive than deterministic ones, they offer prediction uncertainty and consequently more reliable outputs.
This work introduces two BNN architectures termed SCBNN and SCBNN-MOPED for MI classification and uncertainty quantification, which were trained here by using the variational inference procedure. In our study, the SCBNN-MOPED architecture uses the MOPED method from [
38] to establish the prior distribution of each weight by employing the weights of the pre-trained equivalent deterministic network. The SCBNN architecture initializes the prior distribution of each weight as a standard Gaussian distribution
, which is established by default in the Python’s TensorFlow Probability package.
As another novelty, an adaptive threshold scheme is also introduced here to implement the MI classification with a reject option. As an advantage, this scheme uses h a closed formula to calculate the threshold, rather than performing an exhaustive search over the space of possible threshold values as performed in previous works [
39,
40,
41]. The datasets 2a and 2b from the BCI Competition IV [
42] were used for evaluation, considering both subject-specific and non-subject-specific strategies for training. As a result, our approach improved the MI classification with/without a reject option. In terms of efficacy, this proposed threshold scheme performed better with respect to other approaches that estimate the best threshold value by using an uncertainty metric.
The main contributions of this current research are listed as follows:
Two BNN architectures by applying the variational inference method for MI classification are proposed, confirming the advantage of using MOPED’s prior distribution for Bayesian models. Additionally, an efficient implementation to reduce computational cost for practical real-world applications is proposed.
An adaptive threshold scheme based on a closed formula for robust MI classification with a reject option is proposed here.
2. Materials and Methods
2.1. Datasets Description
The two popular datasets 2a and 2b from BCI Competition IV were used.
The dataset 2a contains EEG signals with a sampling rate at 250 Hz, recorded during four MI tasks (left hand, right hand, tongue, and foot) from nine healthy subjects over 22 locations (Fz, FC1, FC3, FCz, FC2, FC4, C5, C3, C1, Cz, C2, C4, C6, CP3, CP1, CPz, CP2, CP4, P1, Pz, P2 and POz). Two sessions on different days were collected for each subject, completing a total of 288 trials per session. In our study, the first and second sessions were used for training and testing, respectively, as in [
13,
43,
44,
45,
46,
47].
The dataset 2b comprises EEG signals collected during the execution of two MI tasks (left hand and right hand) from nine subjects with three bipolar EEG channels (around C3, Cz, and C4), using a sampling rate at 250 Hz. Each subject completed five sessions with a total of 720 trials, comprising 120 trials per session in the first two sessions and 160 trials per session in the remaining three sessions. In our research, the first three sessions were used for training, and the last two sessions for testing, as in [
15,
16,
17,
18,
44,
48].
2.2. Preprocessing and Data Augmentation
Previous studies [
49,
50,
51,
52,
53,
54] reported that real or imagined unilateral movement enhances the mu (8 to 12 Hz) and beta (13 to 30 Hz) rhythms over the primary motor cortex in both contralateral and ipsilateral hemispheres, respectively; phenomena known as event-related desynchronization/synchronization (ERD/ERS) [
55]. Thus, the EEG signals of each trial were band-pass filtered in our study with a frequency range from 4 to 38 Hz through a fourth-order Butterworth filter [
13,
14,
45,
47,
56], aiming to preserve the ERD and ERS potentials, rejecting noise and undesirable physiological and non-physiological artifacts. Afterwards, each filtered EEG trial
x was standardized as
by applying the electrode-wise exponential moving standardization with a decay factor of 0.999, which computes both mean
and variance
values taken at sample
[
45]. The starting values
and
were calculated over periods corresponding to the rest state preceding each trial. In order to rectify outliers, the EEG amplitudes of each trial were first limited to
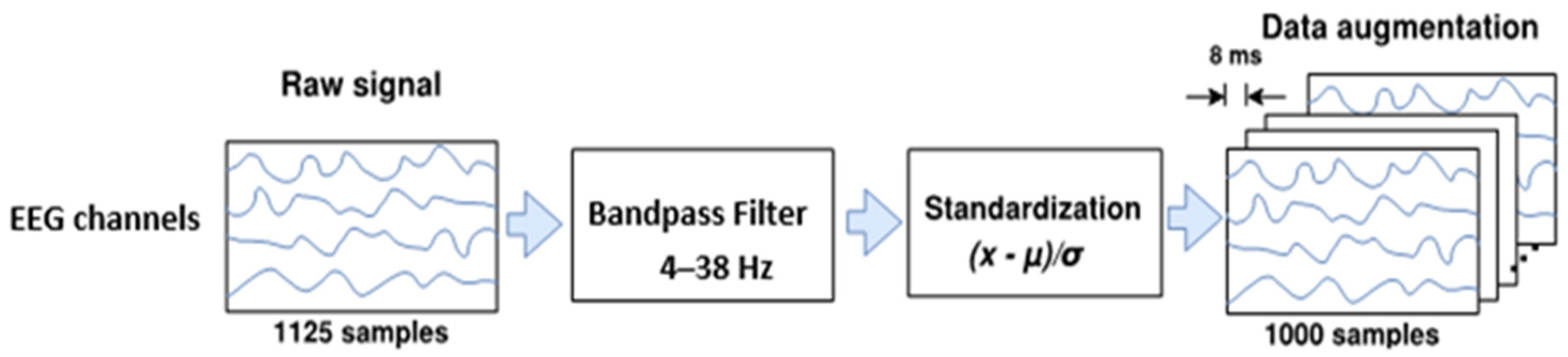
. Finally, the trial crop strategy for data augmentation was employed. For both datasets, crops of 4 s in length each 8 ms from −0.5 to 4 s (cue onset at 0 s) over all trials were extracted in our study.
Figure 1 shows the EEG preprocessing and data augmentation.
2.3. Baseline Architecture
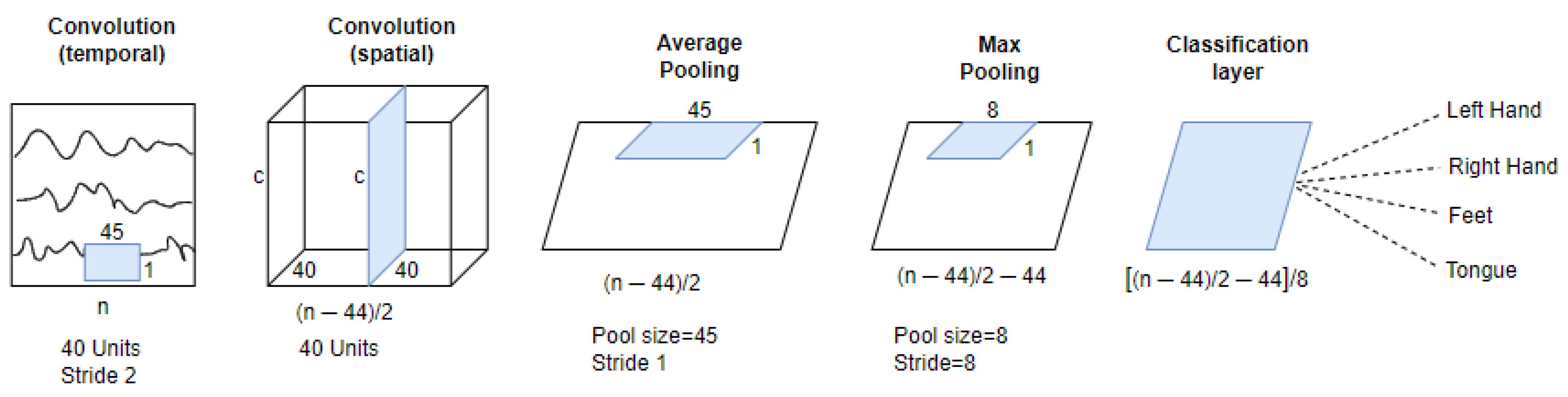
A shallow architecture based on a Convolutional Neural Network (SCNN) [
57] was used in our work as a baseline deterministic network, as shown in
Figure 2. This architecture contains two convolutional layers and a dense classification layer. The first convolution has an input tensor of
, where
c is the number of EEG channels. The first convolution applies a temporal convolution with a
filter and 40 channels, giving an output tensor of
after performing a down-sampling with a stride of 2. The second convolutional layer realizes a spatial convolution composed of 40 channels and a
filter, which performs a convolution amongst all EEG channels. Following the spatial convolution, the model executes a sequence of transformations as follows: a batch normalization layer, an activation function with square non-linearity, an average pooling layer with
sliding windows, and a max-pooling layer with
pool size,
stride, and a logarithmic activation function. Lastly, the classification layer composed of a dense layer using the Softmax activation function receives 2160 features, which are translated into a
prediction vector,
being the number of classes.
Although dropout layers and the “MaxNorm” regularization have been previously used in the baseline architecture [
57] to avoid overfitting, we did not use them in BNN models that are already more robust and less prone to overfitting. Furthermore, the “Early Stopping” and the decay of learning rate techniques were used. Additionally, the Adam optimizer and the Categorical Cross-Entropy as a cost function were employed.
2.4. Bayesian Neural Networks
BNNs [
58] provide a probabilistic interpretation of deep learning models by placing distributions over their weights. In BNNs, the weights are no longer considered as fixed values, but rather as random variables sampled according to a distribution whose parameters are learned in the training stage. This makes each prediction different for the same input, and for many forward passes, the average behavior produces relevant results. Notably, the variability of these predictions also allows assessment of the model’s confidence.
Let be a training set with inputs and expected outputs or targets , where and , being the number of classes. The Bayesian modeling aims to approximate the posterior distribution of weights that generated the output vector . Following this approach, the prior distribution that represents the initial beliefs about the weights has to be established.
If
is known, then for a given input
, the predictive distribution
can be determined from the outputs
corresponding to a specific set of weights
as follows:
The integral in (1) can be estimated by using the Monte Carlo method. For this, it is necessary to perform
evaluations of the neural network on the same input
and weights
sampled from the posterior distribution
. As a result, instead of a single output, we obtain
outputs from the model
. According to [
21],
is a good balance in terms of complexity and accuracy. The set
can be interpreted as a sample of the predictive distribution. The final prediction of BNN on the input
is seen as the sample mean of the predictive distribution:
In neural networks, the uncertainty measures how reliable a model is when making predictions. The statistical dispersion of the predictive distribution is one indicator of uncertainty. A “large” dispersion in means that the neural network produces less confident results. In contrast, a “small” dispersion indicates that the network always provides similar results independently of the sampled weights .
To summarize, if the posterior distribution is known, it is possible to obtain, for each input
an approximation of the predictive distribution
. This then allows us to estimate the BNN prediction and an uncertainty measure. However, finding and sampling the posterior distribution for complex models, such as neural networks, is a computationally intractable problem because of their high dimensionality and non-convexity. To address this issue, two popular approaches have been introduced previously in other studies, such as (1) variational inference [
33] and (2) Monte Carlo dropout [
21]. The next section only describes the former method, which was used in our approach.
2.5. Variational Inference
In variational inference, rather than sampling from the exact posterior distribution
, a variational distribution
) is used, parametrized by a vector
. The
values are then learned in such a way that
) is close as possible to
in a Kullback–Leibler (KL) divergence sense. It is known that minimizing the KL divergence between
) and
is equivalent to maximizing the evidence lower bound (ELBO) function, denoted as
, which serves as the objective function to train the model.
Maximizing the first term in (3) encourages to explain the data well, while minimizing the second term encourages to be close to .
Although in general guessing
is complex, to adopt an independent Gaussian distribution
for each weight is a simple and common approach that often works. Additionally, with respect to the prior distribution, a standard normal distribution
is commonly used. In contrast, the MOPED method [
38] proposes to specify prior distributions
from deterministic weights
derived from a pretrained DNN with the same architecture.
2.6. Bayesian Neural Models for Uncertainty Estimation and MI Classification
In this work, two BNN architectures (SCBNN and SCBNN-MOPED) derived from the SCNN baseline are proposed. They only differ in the way the prior distribution of the weights is established. The former initializes the prior distribution of weights as a standard Gaussian distribution , whereas the second uses the MOPED method. For SCBNN-MOPED, the prior distribution of each weight is initialized as an independent Gaussian distribution with the mean taken from the pretrained weights of the SCNN architecture and a scale
Both models were obtained by starting from a deterministic network SCNN and translating it onto a Bayesian network by using the Flipout estimator [
59] from TensorFlow. We preferred the Flipout estimator instead of using reparameterization [
60] because it offers a significant low variance, albeit it uses roughly twice that of floating point operations.
Table 1 shows the main differences between SCNN and the two proposed Bayesian neural architectures, following the terminology used in the “TensorFlow probability” library of Python for better comparison [
33].
2.7. Uncertainty Measures
Several uncertainty measures can be used to quantify the model uncertainty [
33,
39,
40,
61]. For better understanding, three well-known metrics—predictive entropy
, mutual information
, and margin of confidence
—were first presented as follows.
Let be the total number of classes and the model output for a given input in a stochastic forward pass . Let be the average of predictions .
Predictive Entropy . This metric captures through Equation (4) the average on the amount of information contained in the predictive distribution, reaching its maximum value
when all classes have equal uniform probability (maximum uncertainty, in other words). In contrast, it reaches zero value (the minimum) when a unique class has probability equal to
, confirming a certain prediction.
To facilitate the comparison across various datasets, the predictive entropy was normalized as follows: , .
Mutual Information . This measures the epistemic uncertainty by capturing the model’s confidence from its output.
Margin of Confidence . Let
be the predicted class. The most intuitive form of measuring uncertainty is through analyzing the difference between two predictions of highest confidence. For this, in each forward pass
, the difference
between the output
(predicted class) and the other output of highest score value
is calculated. These differences are then averaged as follows:
2.8. Classification with a Reject Option
The uncertainty values, calculated by using any of the aforementioned measures, provide to classifiers the ability to accept or reject inputs. For instance, a high uncertainty means that the classifier may be performing random predictions; therefore, the associated input should be rejected. This type of classification is known as classification with a reject option [
36,
62], which is of great importance for applications that require low error tolerance. Classification with a reject option generalizes the decision problem of class predictions, and also determines whether the prediction is reliable (accept) or unreliable (reject).
The process of refraining from providing a response or discarding an input when the system does not have enough confidence in its prediction is a topic of interest that has been addressed over the last 60 years [
63]. Recent methods [
39,
40,
41] have implemented the classification of rejection from an established threshold
by using any uncertainty metric, rejecting inputs that present an uncertainty value above
.
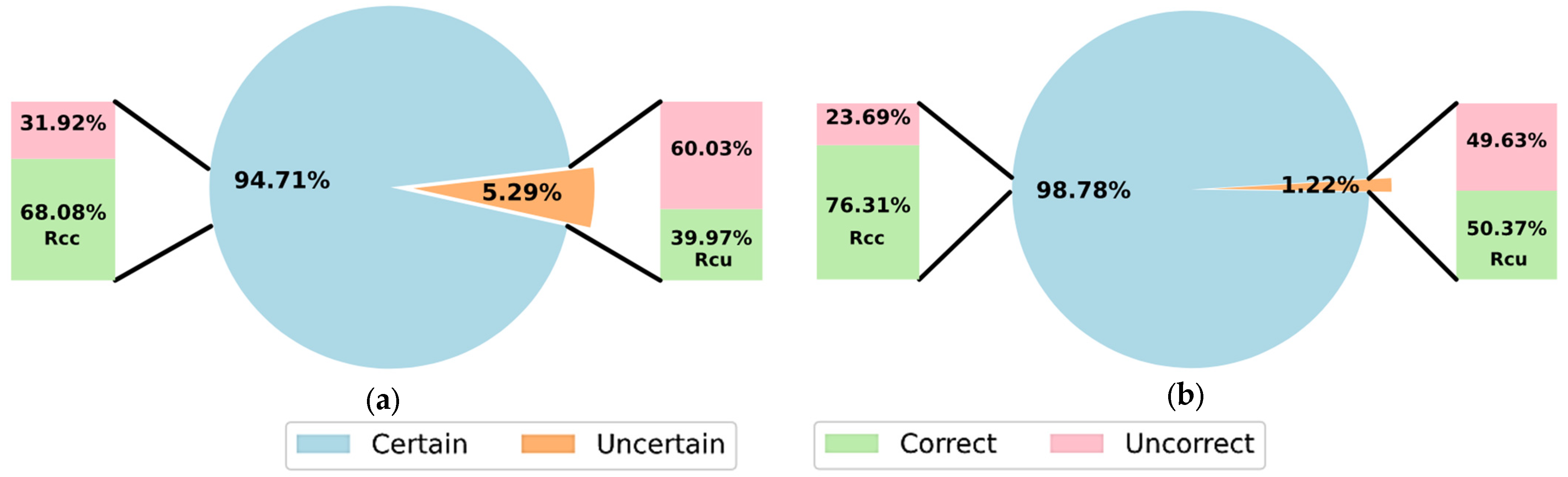
The criteria used in [
39] incorporate the ground-truth label, model prediction, and uncertainty value to evaluate the selected threshold. In this approach, the map of
correct and
incorrect values is computed by matching the ground truth labels with the model’s predictions. Then, given a threshold
, the predictions are classified as
certain and
uncertain, providing four combinations to predict an input as follows: incorrect–uncertain (iu), correct–uncertain (cu), correct–certain (cc), and incorrect–certain (ic).
Let
,
and
be the total number of each type of predictions in each subset, where
is the total number of predictions, and
is the proportion of certain predictions with respect to the total number of predictions:
Then, the following criteria measure the effectiveness of an uncertainty estimator and a threshold selector [
39]:
The correct–certain ratio
measures the ability of a classifier to accurately classify non-rejected samples:
The overall accuracy of the uncertainty estimation can be measured through the Uncertainty Accuracy
, which indicates the ability of a classifier to accurately classify non-rejected samples, and reject misclassified samples:
penalizes both the incorrect–certain and correct–uncertain predictions, and its highest values suggest better thresholds. Thus, this criterion can be also used to compare between different threshold values, in order to increase the reliability, effectivity, and feasibility for practical applications.
In this study, the correct–uncertain ratio
was proposed to calculate the accuracy of rejected predictions, as shown in Equation (10). This criterion was incorporated with the objective of evaluating how close the accuracy on rejected predictions was with respect to the hypothetical accuracy that would be obtained if the classifier provided random predictions.
2.9. Adaptive Uncertainty Threshold
To select the cut-off threshold, recent works [
39,
40,
41] propose to evaluate all threshold values for a given uncertainty measure, such as predictive entropy. For this purpose, this study measured the performance by using each threshold, taking into account a criterion of quality as
, consequently keeping the best threshold. This strategy has high computational cost because of its expensive and exhaustive search. As a contribution, we introduced a low-computational-cost novel threshold scheme based on a closed formula, rather than an exhaustive search.
Our threshold scheme uses Equation (6) to compute the margin of confidence
, which takes values close to zero when the prediction has high uncertainty. It is worth mentioning that if
is not significantly higher than zero, there will be no significant difference between the two highest confidence predictions of the model. Therefore, we reduced the labeling problem on the prediction of an input
as uncertain to a hypothesis test for the mean
, where
denotes all possible differences
that could be obtained from the forward passes associated with the input
. As a result, if the prediction is certain, the null hypothesis
:
must be rejected, whereas the alternative hypothesis
:
must be accepted. The test statistic is:
where
is the standard deviation of the sample
, and
is the number of forward passes over each input
. It is worth remarking that the rejection region for the null hypothesis is the right tail of the distribution.
is a sample mean of
random values
, making
follow a normal distribution with variance
. Therefore, we assume that the random variable
follows a standard normal distribution. The quantile
is used as the critical value of the test, where
is the cumulative distribution function (CDF) of the standard normal distribution, and
is the confidence level. The null hypothesis is rejected for
. Thus, if the prediction is certain,
must be greater than
. This way, the proposed adaptive threshold can be calculated as follows:
As a highlight, our adaptive threshold scheme highlights four observations. First, the threshold scheme is statistically based on a closed formula. Second, the threshold is not fixed; it varies depending on the sample variance of . In other words, this novel threshold is adaptive to the predictive distribution characteristics of each input . Third, our scheme is conservative, as it does not classify as uncertain those inputs in which the predictions for each forward pass are consistent (). However, increasing the confidence level , the threshold scheme behaves less conservatively. Fourth, our threshold scheme can be considered as universal, as it does not require prior knowledge about the data, depending exclusively on the predictive distribution.
2.10. Experiments
The proposed methods were evaluated with three experiments, using subject-specific and non-subject-specific classification strategies.
The first experiment analyzed the accuracy of the Bayesian Neural Network models SCBNN and SCBNN-MOPED for MI classification, compared with their deterministic counterpart SCNN [
57].
The second experiment assessed the quality using the proposed adaptive threshold scheme within the SCBNN-MOPED model. The quality was measured by looking into accepted and rejected partitions of the testing set, measuring how well each partition could be classified. Ideally, the rejected partition should be hard to classify, with significantly better accuracy than random guessing.
The last experiment evaluated the proposed threshold scheme with respect to [
39] as a benchmark, as it seeks the optimum threshold via exhaustive search. The aim was to demonstrate that our proposed adaptive threshold may achieve the state-of-the-art performance without brute force.
All experiments were designed to meet the requirements for the BCI Competition IV dataset, never using the testing sets during training or validation.
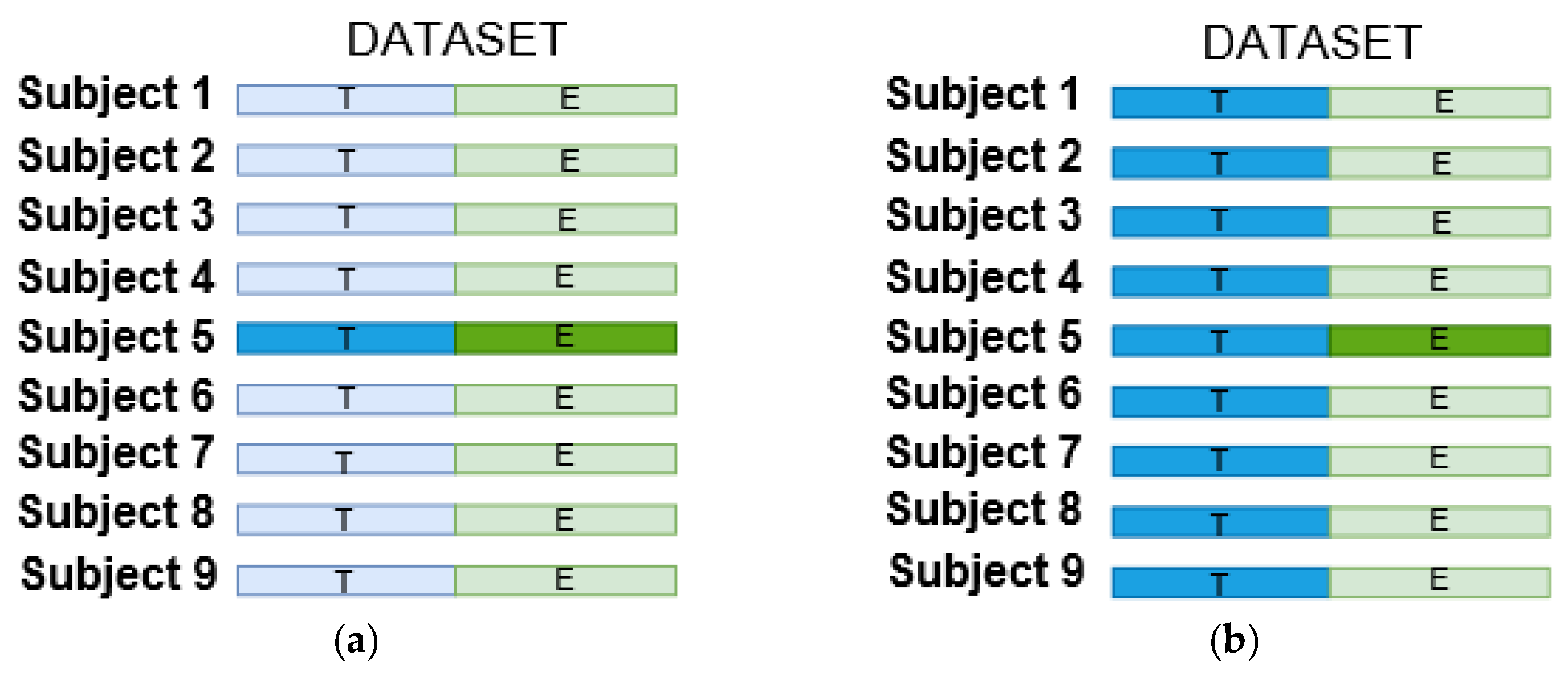
Figure 3 shows the difference between both subject-specific and non-subject-specific strategies, respectively, where the former restricts itself to the training data of each subject (see
Figure 3a), whereas the latter calibrates the classifier by using the training data from all subjects (see
Figure 3b).
In all experiments, a repeated holdout validation over the same testing set was carried out, considering both subject-specific and non-subject-specific classification strategies. For each repetition, a subset of the training set was randomly picked, guaranteeing identical class ratios in with respect to the class ratios in . The subset was used for validation purposes, which is necessary to build deep learning models. For training purposes, the remaining set was used. Once the model was trained for each pair and , it was evaluated on the testing set . To reduce the influence of random factors, this process was repeated 16 times for each model, reporting the average of some metrics, such as accuracy, , among others.
Specifically, the accuracy was used for evaluation in the first experiment, whereas the criteria
,
and
(see Equations (7), (8) and (10)) were used in the second experiment, assessing the quality of accepted and rejected partitions on the testing set. As in [
39], we used
(Equation (9)) as an evaluation criterion in the third experiment.
For the third experiment, the method in [
39] was replicated by using the SCBNN-MOPED architecture and the normalized predictive entropy
as the uncertainty measure. As in [
39,
40,
41], the optimum threshold was obtained by making the uncertainty threshold
vary over the interval [0.05, 1] and calculating
over the validation set
for each
. Once the optimal threshold was found, its performance was evaluated with respect to the criterion
by using the testing set
Similar to the other experiments, 16 validation sets (
) were used to compute the overall assessment of the method in [
39].
An HPC using a Dell PowerEdge R720 server with four 2.40 GHz Intel Xeon processors and 48 GB was used for all experiments. An NVIDIA GM107L Tesla M10 GPU with 32 GB memory was used to train and test the Bayesian models by using the Python TensorFlow 2.3.0 framework.
4. Considerations for Reducing Computational Cost
All evaluations considering the classification accuracy and uncertainty analysis throughout this current work were carried out by using data augmentation, as shown in
Figure 1. The accuracy was obtained as a ratio between correct classified crops and the total crops, as proposed in the CAgross method [
19]. Others studies followed different strategies. For instance, a single prediction for each trial was obtained in the CAST method [
19] by using majority voting, whereas in [
45] the authors averaged the predictions over all crops. This analysis of the crops requires an extra computational cost, which increases even more with the use of Bayesian architectures, as it realizes
T forward passes to obtain the prediction over the same input.
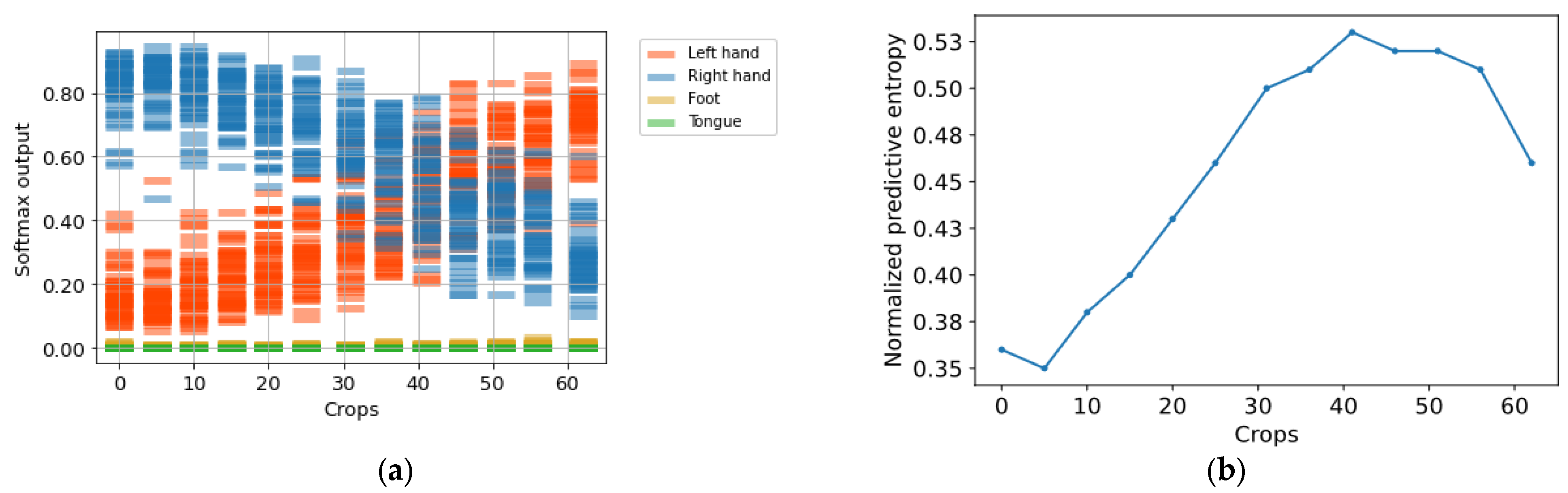
Given the nature of the problem that is addressed in our study, the EEG variability of patterns associated with MI tasks, and the large intra- and inter-subject differences can be observed through the ERD/ERS potentials throughout. As a result, in certain crops, the aforementioned phenomena were not detected appropriately by the model, producing incorrect predictions.
Figure 6a shows the predictive distribution histograms of crops over a specific trial on Subject A01 from dataset 2a, where the initial crops were classified correctly as left-hand MI, but after approximately crop number 45, they were incorrectly predicted as right-hand MI.
Figure 6b shows that this change correlated with the increase of uncertainty. Observing this behavior, we believe that, when considering the predictions over all crops predicting the MI of each trial, it is not the most appropriate strategy, since all crops do not have the same certainty. Therefore, it is preferable to consider the crops with less uncertainty.
We hypothesize that if the predictions with less uncertainty are determined over the same time interval for all trials on the validation set, similar behavior may be also obtained in the testing set. This allows us to choose only crops contained in that interval for classification with/without a reject option, reducing the computational cost with high accuracy.
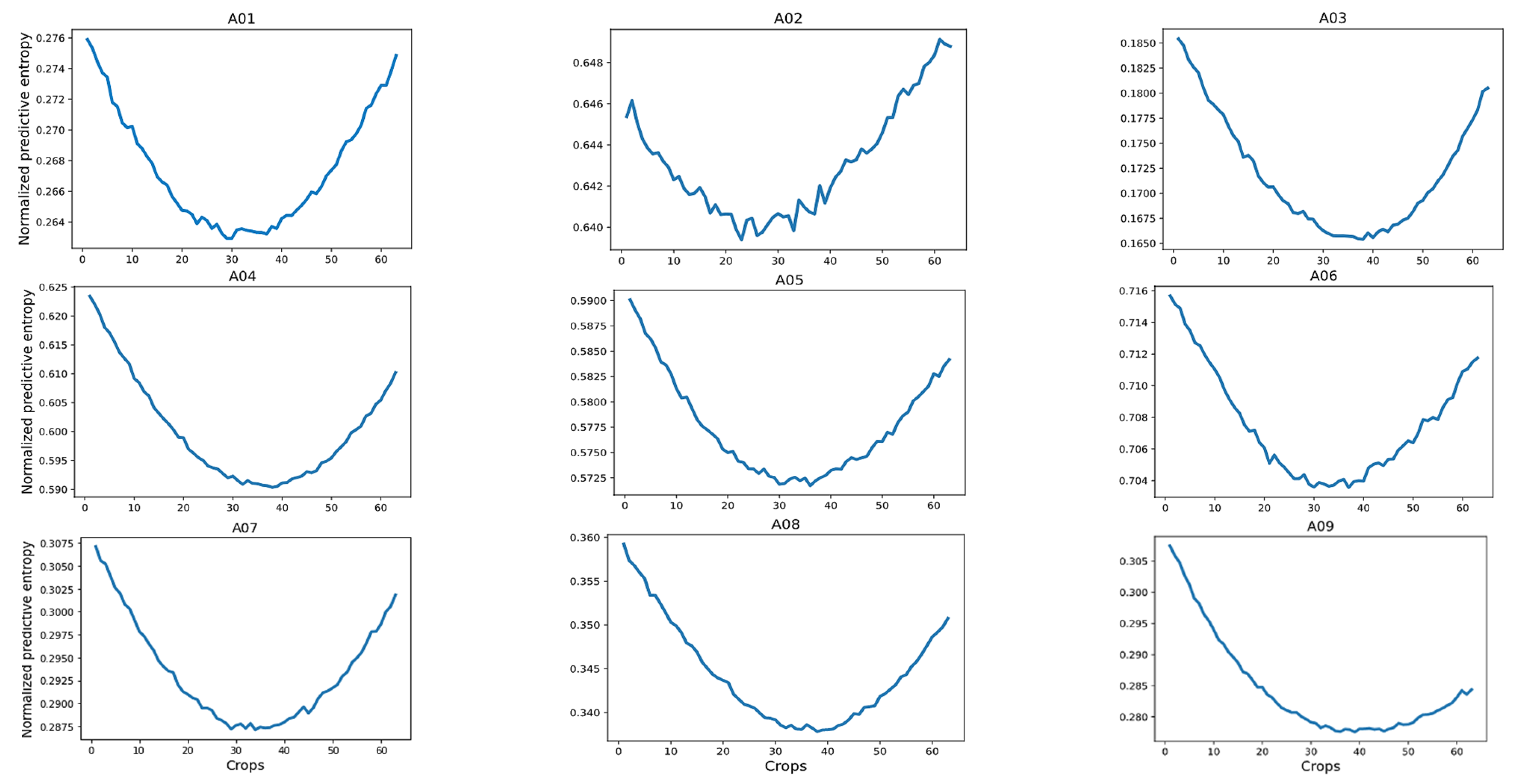
Figure 7 shows the normalized predictive entropy on a validation set from database 2a. We observed that the central crops covering a time interval from 1.724 to 5.756 s regularly presented the lowest uncertainty with respect to the crops located at the extremes. It is worth mentioning that this finding was also observed in dataset 2b.
From our findings, we selected the five central crops of each trial, aiming to reduce computational cost during the evaluation step. Then, we averaged the predictions of these five central crops to rank each trial.
Table 8 shows the classification accuracy without/with a reject option achieved on the selected crops of each trial (from the testing set), using SCBNN-MOPED architecture and subject-specific strategy with each database. For a better assessment of the established criterion, we also added the achieved results from
Table 2 and
Table 3, using all the crops.
The results show that the established criterion to reduce the computational cost by using the five central crops provides advantages during MI classification without/with a reject option. This proposal increases the possibilities of real implementations using Bayesian classifiers for MI tasks. However, for practical implementation, other criteria must be considered, since neural network models require large hardware resources. This analysis is outside the scope of this current work.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}