1. Introduction and Background
Over the past decade, Internet of Things (IoT) traffic has increased exponentially. As more devices transfer data across networks in different sectors such as healthcare, agriculture, logistics, etc., network traffic is expected to increase exponentially, and it is predicted that by 2023, there will be at least 43 billion devices [
1]. Hence, being able to monitor and recognize malicious activity and cyberattacks has become imperative. In this work, Zeek, an open-source network-monitoring tool that provides the raw network data needed to tackle today’s toughest networking challenges in the enterprise, cloud, and industrial computing environments, was used to collect data [
2]. This one-of-a-kind new modern dataset,
UWF-ZeekData22 [
3], was labeled using the MITRE Adversarial Tactics, Techniques, and Common Knowledge (ATT&CK) framework. The MITRE ATT&CK framework is a globally accessible knowledge base of adversary tactics and techniques used to accomplish specific objectives [
4]. This work, specifically using Zeek’s Connection (Conn) Log files from the
UWF-ZeekData22 dataset [
3], tries to identify connections that lead to the two adversary tactics, reconnaissance (TA0043) and discovery (TA0007). Users of the reconnaissance tactic gather information about vulnerabilities, which can be used for future attacks [
5], and users of the discovery tactic try to better understand the internal network [
6]. Zeek’s Conn log files track the protocols and associated information such as IP addresses, durations, transferred (two way) bytes, states, packets, and tunnel information. In short, Zeek’s Conn files provide all the data regarding the connection between two points [
7].
Due to the volume of data involved, the Hadoop Distributed File System (HDFS) was used to store the data. HDFS is a scalable, fault-tolerant system that allows processing of big data by making it available across a cluster of computers [
8]. An open-source framework for big data analytics that sits on top of the Hadoop framework, Apache Spark, was used for machine learning (ML). Spark’s machine learning algorithms, specifically decision tree (DT), gradient boosted trees (GBT), logistic regression (LR), naïve Bayes (NB), random forest (RF), and support vector machines (SVM), were used for binary classification in the big data framework. New binning methods were introduced to bin the raw network data, and feature reduction was performed using information gain. In addition to statistical metrics and execution timings obtained from the machine learning algorithms, an analysis was also performed to determine the ideal Spark parameter configurations for classifying a raw network dataset in the big data framework.
The uniqueness of this paper can be highlighted as follows: (i) this analysis is performed on a modern, one-of-a-kind, newly created Zeek MITRE ATT&CK framework labelled dataset,
UWF-ZeekData22, which is available at
datasets.uwf.edu (accessed on 20 August 2022) [
3]; (ii) this is the first work to date that analyzes Zeek network connections that lead to the classification of the reconnaissance and discovery tactics as defined by the MITRE ATT&CK framework; and (iii) new binning methods are presented to bin a raw network dataset.
The rest of this paper is divided into the following sections.
Section 2 presents the related works;
Section 3 briefly explains how this new dataset was generated and the characteristics of this dataset;
Section 4 explains the pre-processing in detail;
Section 5 presents the machine learning algorithms and the Spark parameters used;
Section 6 presents and discusses the results obtained;
Section 7 presents the conclusion, and
Section 8 presents the future works.
2. Related Works
Analysis of network data for the purpose of supporting an anomaly-based IDS has been a topic of interest for some time [
9,
10,
11,
12,
13,
14,
15,
16,
17]. The first widely studied network dataset was the KDD99Cup dataset, analyzed in [
10,
12,
15]. Reference [
12] used a decision tree classifier to support anomaly-based intrusion detection in network data. They found that a particle swarm optimization algorithm can be used to prune trees and significantly improve model performance. Reference [
15] showed that SVM, using principal component analysis for feature reduction, is effective for anomaly detection in a fog computing environment. Reference [
10] used multiple learning algorithms (logistic regression, SVM, random forest, gradient boosting tree, and naïve Bayes) to test the performance differences that occur as the number of features are changed. They found that the accuracy of these learners is minimally affected by reducing the number of features, but training and testing time can be significantly reduced.
The next big dataset, NSL-KDD, is a smaller subset of the KDD99Cup dataset, with a significant number of duplicate records removed. It was analyzed by [
10,
13]. Reference [
10] used both NSL-KDD and KDD99Cup and found that the larger, more redundant KDD99Cup dataset produced slower models as compared to the models developed using the smaller NSL-KDD dataset. Reference [
13] combined different decision tree models and found that models perform best when combined with a sum-rule scheme.
The UNSW-NB15 dataset was created in 2015 by the University of New South Wales and features nine different attack types along with significantly more modern network traffic as compared to the KDD datasets. Reference [
9] analyzed this dataset using the SVM, naïve Bayes, decision tree, and random forest classifiers on the Apache Spark framework and found that the random forest classifier performed the best in terms of both accuracy and execution time. Reference [
18] analyzed this dataset on the Apache Spark framework using binary and multiclass random forest classifiers with principal component analysis and information gain as feature selection methods. They found that PCA made model training slower, and in some cases, accuracy was the same or worse than models trained without PCA. They also found that the binary classifier produces more accurate models than the multiclass classifier. Reference [
19] analyzed UNSW-NB15 using both binary and multiclass random forest algorithms using information gain and principal component analysis as feature reduction methods and Apache Spark as the framework. They found that binary random forest outperforms multiclass random forest in terms of accuracy and that information gain outperforms principal component analysis in terms of both accuracy and speed.
Reference [
17] analyzed CICIDS2017, and this work addresses issues with traffic diversity and volume, lack of metadata, outdated attack payloads, and anonymized packets found in other datasets. Reference [
17] implemented k-nearest neighbor, random forest, decision tree, gradient boosting tree, multilayer perceptron, naïve Bayes, and quadratic discriminant analysis classifiers and reported their performance, stressing the importance of generating and analyzing updated IDS datasets to keep up with current network traffic/network attacks.
CSE-CIC-IDS2018, an update to CICIDS2017, followed a set of guidelines to create a systematic update to keep the IDS dataset up to date with current network trends. It was analyzed by [
16], who applied gradient boosting tree, decision tree, random forest, naïve Bayes, and logistic regression classifiers to this dataset to determine the impact of feature selection and specifically the use of the Destination_Port feature. Reference [
16] found that the Destination_Port feature was generally useful in terms of model accuracy and should be included when analyzing IDS data. This feature affected the performance of the machine learning algorithms. They found that feature selection algorithms produce models that perform as well as or better than models created without using feature selection algorithms while consuming fewer computing resources.
In addition to large, general-purpose IDS datasets, some studies have produced their own data tailored to their specific use cases. Reference [
11] created and analyzed datasets of varying sizes labeled SYNDOS10K-SYNDOS2MIL, which were generated by making SYN DoS attacks on a network consisting of three PCs and nine IoT devices. They analyzed these datasets with logistic regression, decision tree, random forest, gradient boosting tree, and linear SVM and found that random forest performed best in terms of both accuracy and execution time on this type of data.
Other studies, such as [
14], used data that are not made publicly available. They applied a multilayer SVM to their data to support a block lowest common ancestor algorithm to cluster network intrusion features. They found that this approach produces better clustering detection times when compared to similar methods.
There are very few works to date on the MITRE ATT&CK framework with respect to identifying attacks using machine learning. Reference [
20] used two hidden layer feed-forward neural networks to impute missing values in a 2018/2019 ENISA dataset [
21] based on ATT&CK descriptions of the intrusions. They found that this is a valid approach for filling out intrusion datasets with missing values. Reference [
22] used hierarchical clustering on a small (270 records) intrusion dataset from MITRE to predict likely future attacks based on other recent attacks. They found that 75% of the ATT&CK techniques can be highly predicted based on earlier attacks by the same advanced persistent threat. Thus, though there are some works on the MITRE ATT&CK framework, there are no works that map a large, raw network dataset with attacks labeled according to the ATT&CK framework, which is then analyzed using machine learning.
4. Preprocessing
Preprocessing is broken down into two parts. The first part presents a way to preprocess raw network data using binning, and the second part uses information gain for feature selection.
4.1. Preprocessing Using Binning
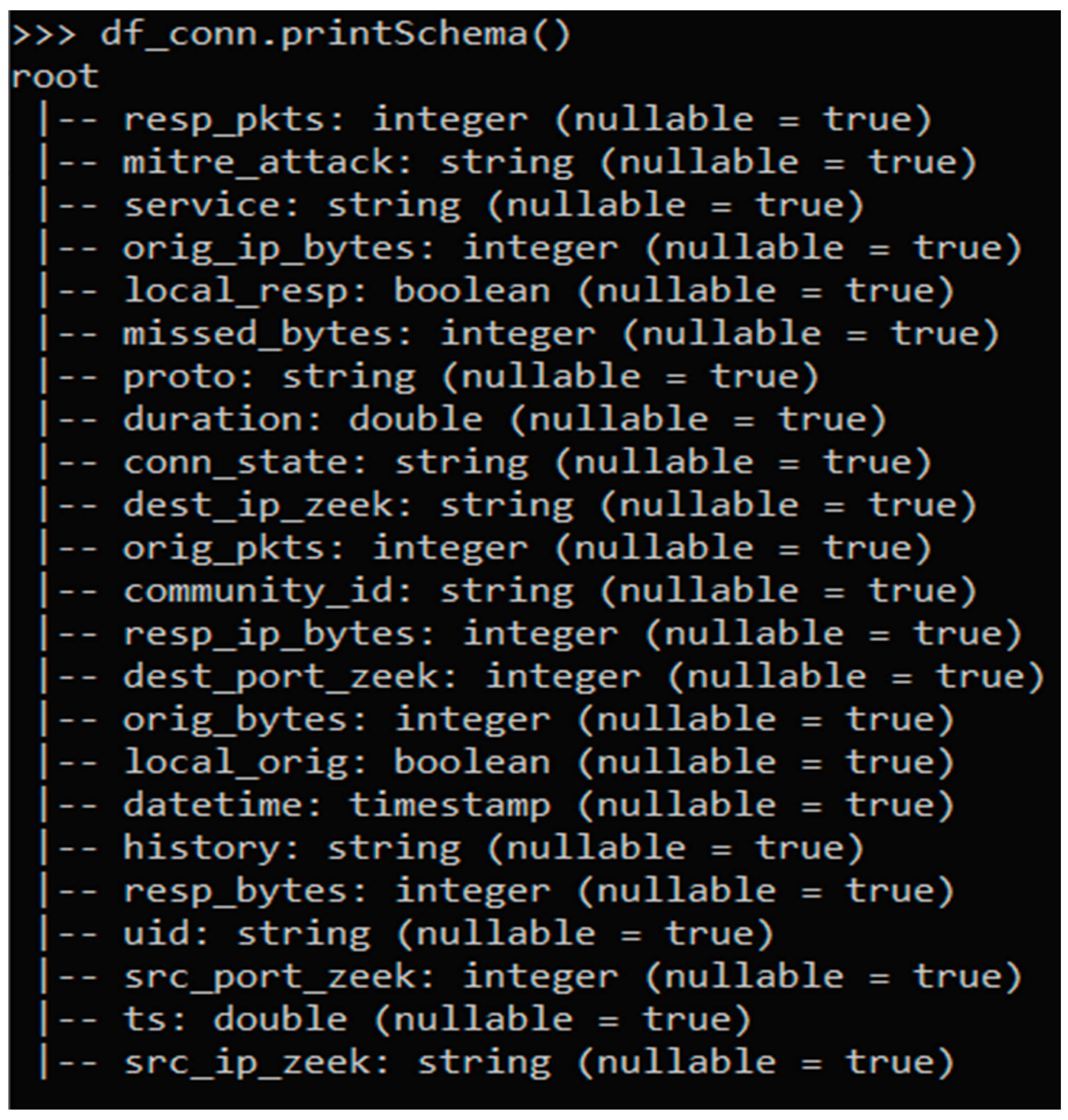
The Zeek Conn logs contain continuous valued attributes, nominal attributes, IP addresses, and port numbers. For processing in Spark’s machine learning environment, preprocessing was required. The following sections cover how each type of column in the dataset (i.e., continuous value, nominal, IP number, and port) was preprocessed and binned.
4.1.1. Binning Continuous Valued Columns
To establish the set of bin ranges for the continuous valued columns in this dataset, the trimmed mean and standard deviation was calculated for each column. To calculate the trimmed mean, first, null values as well as extreme outliers were removed. Several columns in this dataset (for example, duration) exhibit skewed data distributions, often forming long tails skewing to the right. To address the skewness caused by lengthy and low-lying tails, a 10% trim on the data was used to generate the bins. This resulted in 80% of these data being used for mean and standard deviation calculations, with 10% of the lowest-ranking and highest-ranking values being removed. The binning can be outlined with the following edges:
edge0 = float(‘−inf’)
edge1 = mean_val − stddev_val × 2
edge2 = mean_val − stddev_val
edge3 = mean_val
edge4 = mean_val + stddev_val
edge5 = mean_val + stddev_val × 2
edge6 = float(‘inf’)
edges = [edge0, edge1, edge2, edge3, edge4, edge5, edge6]
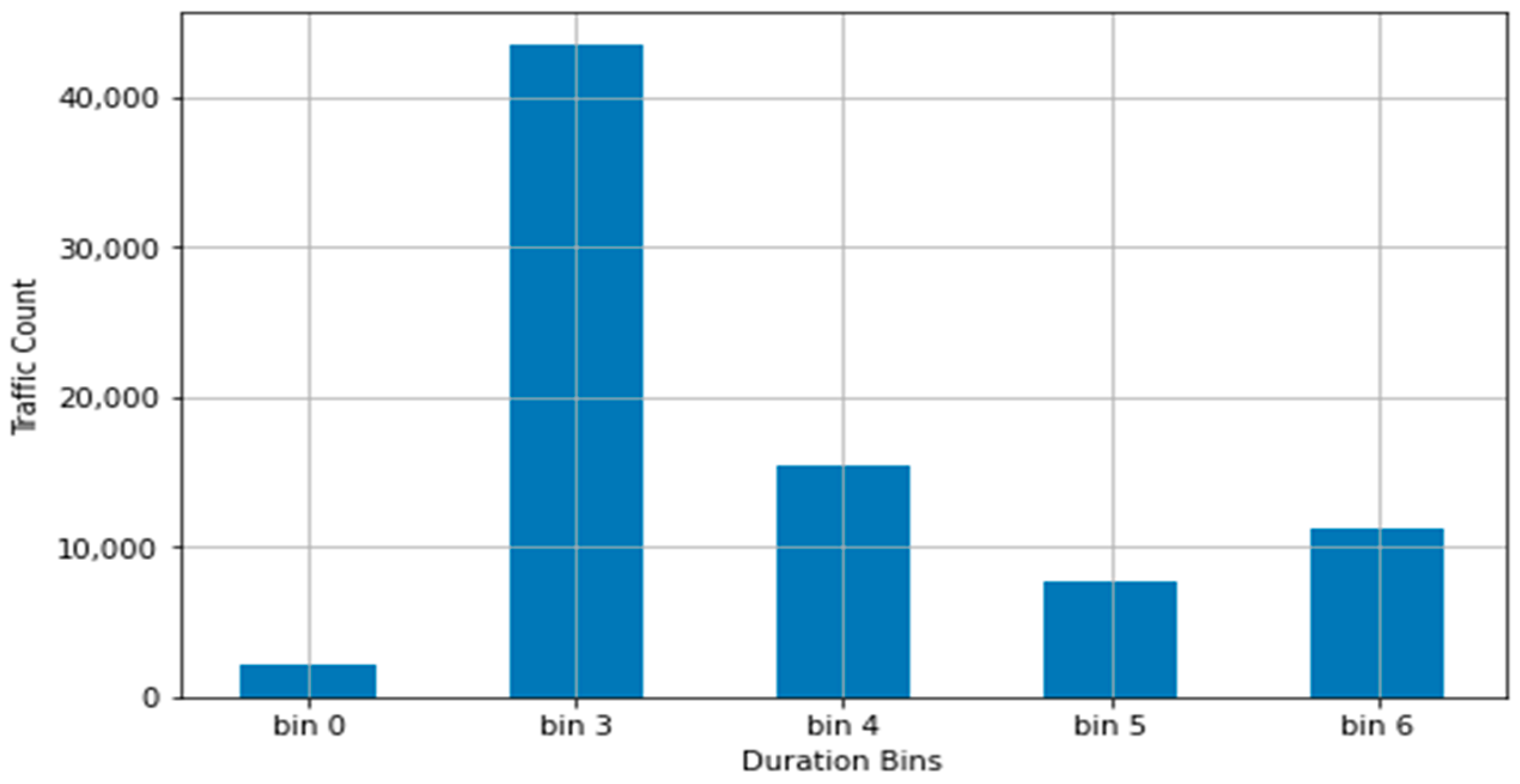
The bin ranges were used in conjunction with the PySpark ML Bucketizer function to convert the respective columns into a limited range of integer values. The resulting bins and distribution for the duration column, using the above binning outline, are presented in
Table 3 and
Figure 2.
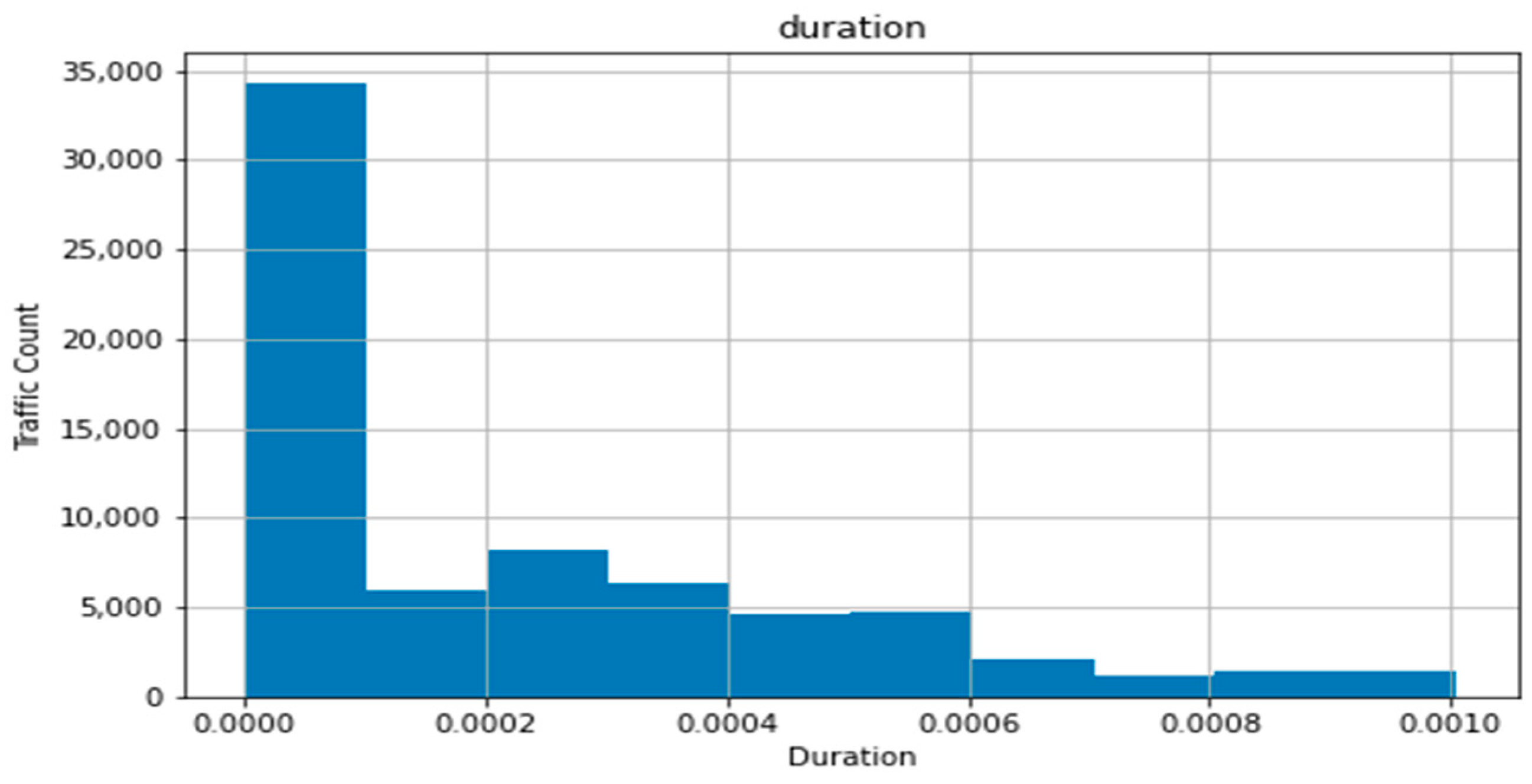
The resulting distribution for duration, with bin1 and bin2 ending in a negative value for their high end and having a 0 count of values, was caused by the slant of the dataset, resulting in two standard deviations left of the dataset’s mean pushing over the 0 value. This difference with a normal distribution, where the application of the standard deviation is ideal, can be seen in
Figure 3, generated using the maximum value of the trimmed dataset, which clearly shows a heavily leftwards distribution.
Using the Moving-Mean to Bin Continuous Valued Columns
To maintain the desired number of bins in spite of the skewness of the data and to avoid redundant bin ranges, a moving-mean logic was inserted during the establishment of the edges (where the minimum value of an attribute never drops below 0):
This moving-mean logic would insert itself in the binning method such that the bins established through a set number of standard deviations within the mean value of the trimmed dataset would shift rightwards with the moving-mean value until the first two bins no longer encompassed a redundant range of data.
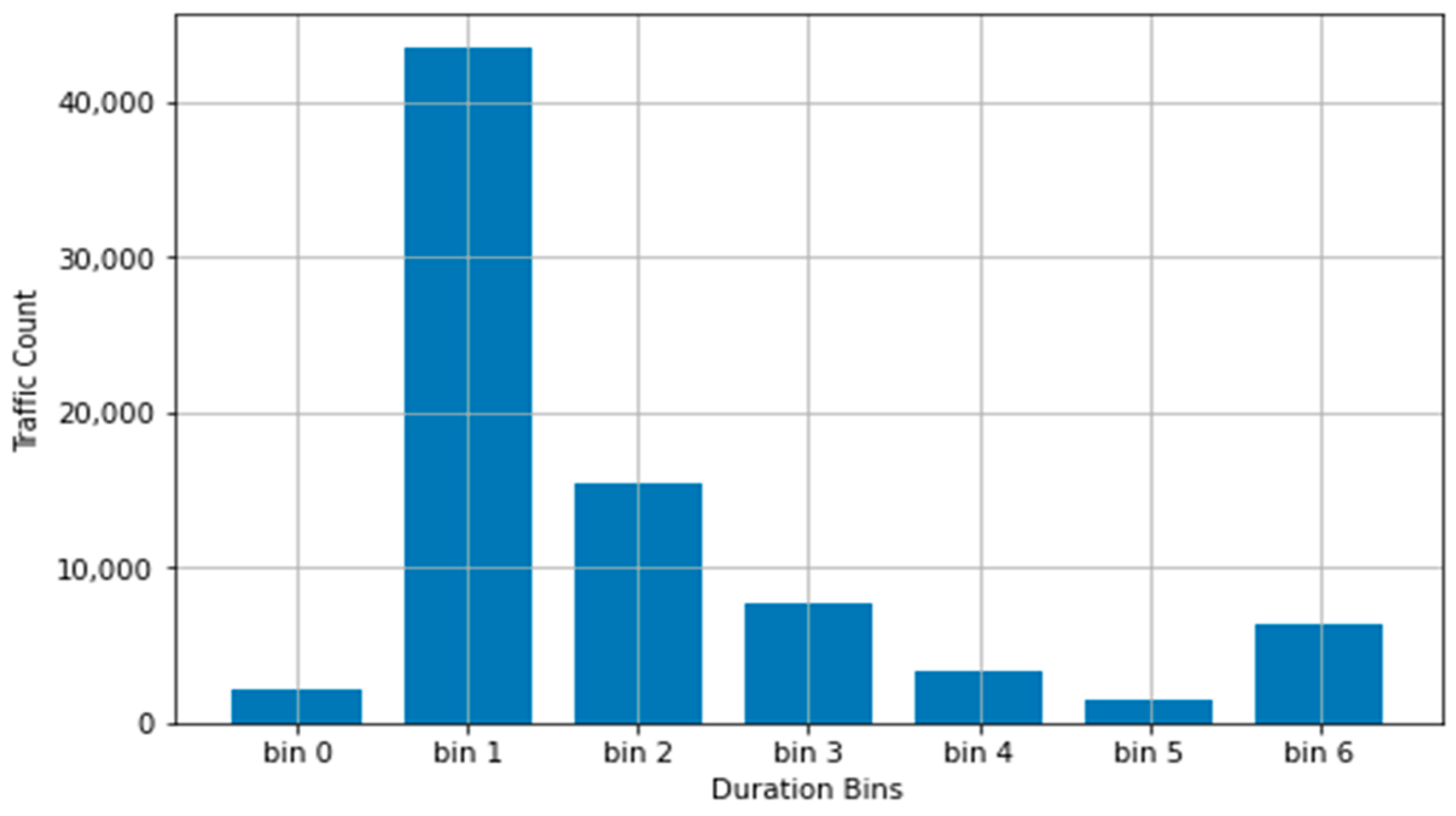
Table 4 presents the distribution with this process performed on the duration column.
As can be seen in
Figure 4, the moving-mean generated two additional bins, taking away from the previously established bin6. Previously representing a bin range of duration values more than three standard deviations away from the true mean of the trimmed dataset, this would now (after the emergence of two additional bins) encompass values more than five standard deviations from the true mean.
The parity of box6 in both sets of results, as well as the obvious positive skewness leftward, is contradictory to the nature of normal distributions. This, however, must be taken with the general level of abstraction inherent in any binning methodology.
Table 5 shows the bin counts for each attribute when this binning method is applied to the continuous attributes in the Zeek Conn file. The moving-mean bins were also calculated. An additional bin was generated for null values with a bin designation of 0.
4.1.2. Binning Nominal Valued Columns
Nominal values within this dataset are columns containing non-numeric data. They may contain names of things, categories, states, or sequences. They often contain non-numeric characters although that is not always the case. One of the difficulties in their consideration in algorithms is that such data can contain many unique values, whose naming conventions do not necessarily indicate an intrinsic value difference. For this analysis, non-numeric values were converted into numbers. Spark provides a convenient means of performing such conversions through the StringIndexer method from MLib [
6], which is Apache Spark’s scalable machine learning library. This method was set up to keep all invalid or empty values, converting those as well to separate integer values for binning purposes. This method was applied to the columns presented in
Table 6, with the resulting bin counts.
Though the IP addresses and port numbers would also fall under this category, they were handled as explained in the next couple sections.
4.1.3. Binning IP Address Columns
For binning IP addresses of traffic source and destination, the commonly recognized network classifications of A, B, C, D, and E were used, each of which pertain to specific ranges of the first octet in the IP address [
24]. These different octet ranges correlate to different default subnet masks, with ascending classifications reserving more bits for the network address and fewer for the host address. Class A is best-suited for serving incredibly large networks, while Class C would normally be assigned to very small networks. Classes D and E are normally relegated to experimental use cases, such as for multicasting, research, and development [
24].
Below are the established octet ranges (inclusive) for each classification [
24]:
Class A: First octet value 0–126;
Class B: First octet value 128–191;
Class C: First octet value 192–223;
Class D: First octet value 224–239;
Class E: First octet value 240–254.
Using these ranges, the data in these attributes were binned into seven categories, as shown in
Table 7. The “Other” classification was used to capture values that may exceed these boundaries, and a category was used for null or non-applicable values. An example of this classification method was applied to the dest_ip column of the Zeek Conn data, as shown in
Table 7. This column represents the IP address of a packet destination on the network, and it totaled 312 unique addresses within the scope of the sample dataset.
Based on
Table 5, Classes A and B IP addresses were the most plentiful in this data. This is to be expected given that Classes A, B, and C are considered the most commonly occurring IP types in most network traffic [
24]. The remaining bins represent a small fraction of the total dataset.
Applied to both of the IP columns in the Zeek Conn data,
Table 8 shows the changes in unique values before and after binning.
4.1.4. Binning Port Numbers
Port numbers can range widely in value, with the Internet Assigned Numbers Authority (IANA) administering ports 0 through 65,535 [
25]. This spectrum can be divided into three ranges covering well-known ports, registered ports, and dynamic/private ports. Well-known ports range from 0 to 1023 and are protected, with operating systems restricting access to these ports to only processes with appropriate privileges. Registered ports range from 1024 to 49,151, and their use should only be with IANA registration. All other ports up to 65,353 can be used more freely for all manner of purposes.
Based on this classification system,
Table 9 shows the bin ranges that were generated to represent the three port ranges, with a bin value of 0 representing null values. With the bin ranges applied in
Table 9, the results for dest_port and src_port are as shown in
Table 10.
The difference between the two port types (src_port and dest_port) within this dataset is also more clearly defined, with most of the source network traffic originating from registered and dynamic ports and the destination ports largely made up of the well-known ports, as can be observed in
Table 11.
4.2. Information Gain
After binning, information gain was used to assess the relevance of the 18 features. Information gain is the difference between a class’s entropy and the entropy of the class and a selected feature split, with entropy measuring the extent of randomness in the dataset [
27]. It is an assessment of the usefulness of a feature in classification.
The following calculations [
28] were performed on each feature to produce information gain values for ranking purposes:
where
Given that
Info(D) is the average amount of information needed to identify the class level of a tuple in D;
InfoA(D) is the expected information required to classify a tuple from D based on partitioning from A;
pi is the nonzero probability that an arbitrary tuple belongs to a class;
|Dj|/|D| is the weight of the partition.
The information gain values for the features (attributes) in the Zeek Conn logs are presented in
Table 12.
The higher the attribute on the list, the more relevant it is in the classification process. Based on these results, the top 6, top 9, top 12, and top 18 attributes were used to run the machine learning algorithms.
5. Experimentation
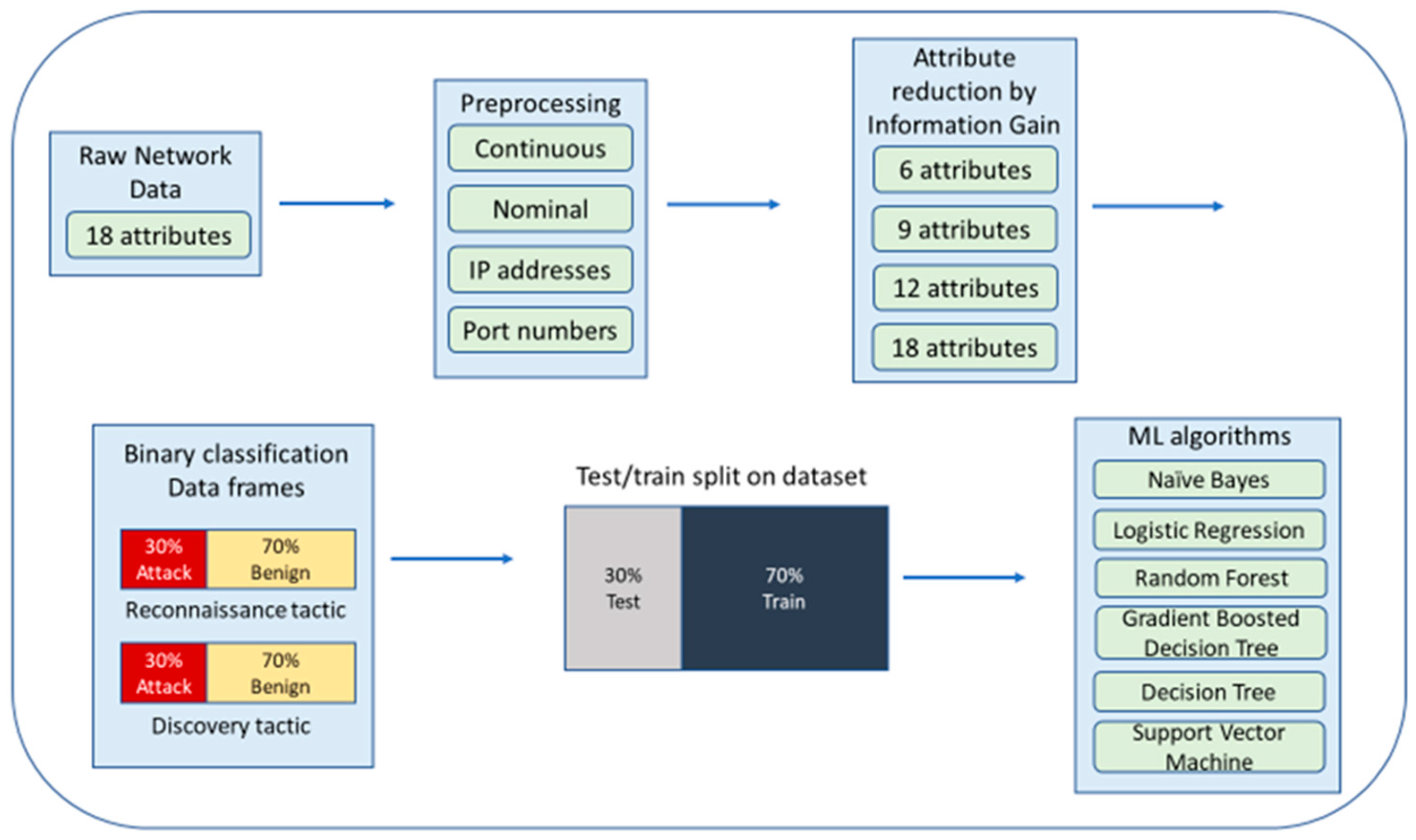
Figure 5 presents the experimentation process. First, after binning the raw network data, information gain was calculated. Then, the two tactics, reconnaissance and discovery, were isolated and segregated into separate dataframes for binary classification. The ratio of attack to benign data was maintained at 30%:70% in each dataframe. The dataset was split into 70:30 for training and testing the machine learning classifiers. For each machine learning algorithm, four sets of attributes were tested: 6, 9, 12, and 18.
5.1. Computing Environment
The University of West Florida’s Hadoop cluster was used. This cluster consists of six Dell PowerEdge R730XD servers and three Dell PowerEdge R730 servers, each of which has dual Intel Xeon E5-2650v3 CPUs with 10 cores and 20 threads per CPU (40 cores) and 128 GB of DDR4 RDIMM RAM. The cluster has six worker nodes that execute the machine learning algorithms. Spark 3.2.1 and Hadoop 3.3.1 were used for the environment. Spark provides a rich set of APIs that were used to implement and run the various machine learning algorithms [
29].
5.2. Machine Learning Algorithms Used
Six different classifiers were compared: logistic regression, naïve Bayes, random forest, gradient boosted tree, decision tree, and support vector machines. Spark’s Machine learning libraries were used to run the various classifiers, and the BinaryClassificationMetrics was used to generate various statistical results such as accuracy, precision, recall, F-measure, area under the curve, and false-positive rate.
5.2.1. Logistic Regression
Logistic regression (LR) applies a linear discriminant rule and is a widely used machine learning algorithm used for classification of data [
11]. Logistic regression considers each feature by associating a specific weight to it to generate a probability of being classified to a specific class. Larger weights represent more variation in a feature and have a larger impact on the algorithm. Binary responses can be predicted by making use of binary logistic regression. Spark 3.2.1′s
pyspark.ml.classification.LogisticRegression implementation was used in this study, and the parameters are specified in
Table 13.
5.2.2. Naïve Bayes
Naïve Bayes (NB) is a popular machine learning algorithm that uses the Bayes rule of classification and assumes independence of features [
10]. The model is easy to build and intuitive [
10], and studies have shown that it works with high accuracy for smaller datasets. Spark 3.2.1′s
pyspark.ml.classification.NaiveBayes implementation was used in this study, and all parameters used are default values, as shown in
Table 13.
5.2.3. Random Forest
Random forest (RF) is an ensemble method; multiple decision trees are constructed, with each tree being built from a limited number of the available features. The classification is performed by polling the collection of trees, and a majority vote is used for this. Spark 3.2.1′s
pyspark.ml.classification.RandomForestClassifier was used in this study, with the default settings shown in
Table 13.
5.2.4. Gradient Boosted Tree
Gradient boosted tree (GBT) is another class of ensemble methods with many popular implementations. Gradient boosted tree is based on constructing multiple decision trees in sequence, with each decision tree being made in such a way as to minimize the classification error rate of the previous tree(s). Spark 3.2.1′s
pyspark.ml.classification.GBTClassifier implementation was used in this study (this is an implementation of stochastic gradient boosting [
30]), and the default parameters were used, as shown in
Table 13.
5.2.5. Decision Tree
A decision tree (DT) is a set of nodes that partitions the data and returns a binary decision (yes or no) given the node’s condition. Based on the decision made, the corresponding child node is given the input vector. This continues until a leaf node is reached, and the final decision is made. The Spark implementation supports decision trees for binary and multi classification and for regression. The creation of the Spark’s decision tree is based on information gain and works through a greedy algorithm that performs recursive binary partitioning.
Spark 3.2.1′s
pyspark.ml.classification.DecisionTreeClassifier implementation was used in this study. Most default parameters were used, as presented in
Table 13, except for maxBins and MaxDepth. Due to the binning methods used, none of the features used in the training and test phases contained more than 60 unique values. A max bin value was set for 100, just in case any of the nominal attributes had significantly more in larger datasets. To further account for this possibility, the potential depth of the resulting classifier tree was increased from 5 to 100, at the expense of performance, to ensure a large degree of granularity.
5.2.6. Support Vector Machines
Support vector machines (SVM) is a supervised machine learning algorithm used for regression and classification. The goal of the SVM algorithm is to find an optimal hyperplane (also known as a classification vector) in a multi-dimensional space, which allows for the classification of data points relative to their position to the hyperplane. Linear SVM in Spark machine learning supports binary classification. Internally, it optimizes the hinge loss using the OWLQN optimizer. Spark 3.2.1′s
pyspark.ml.classification.LinearSVM implementation was used in this study, and the default settings were used, as shown in
Table 13.
7. Conclusions
The objective of this paper was to see if the reconnaissance and discovery tactics, labelled using the MITRE ATT&CK framework, could be identified from the Zeek Conn logs using a newly created dataset,
UWF-ZeekData22 [
3]. In addition to looking at the performance of these classifiers using Spark, scalability and response time were also analyzed.
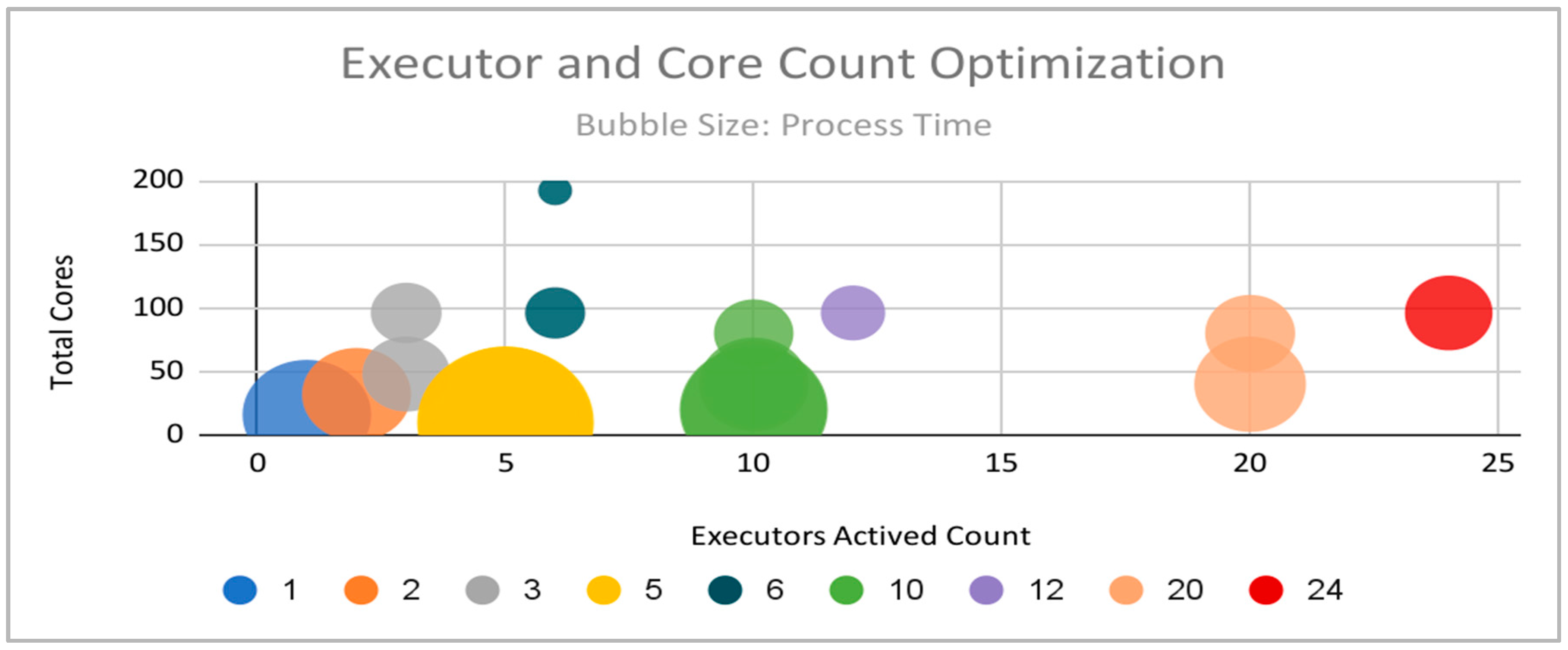
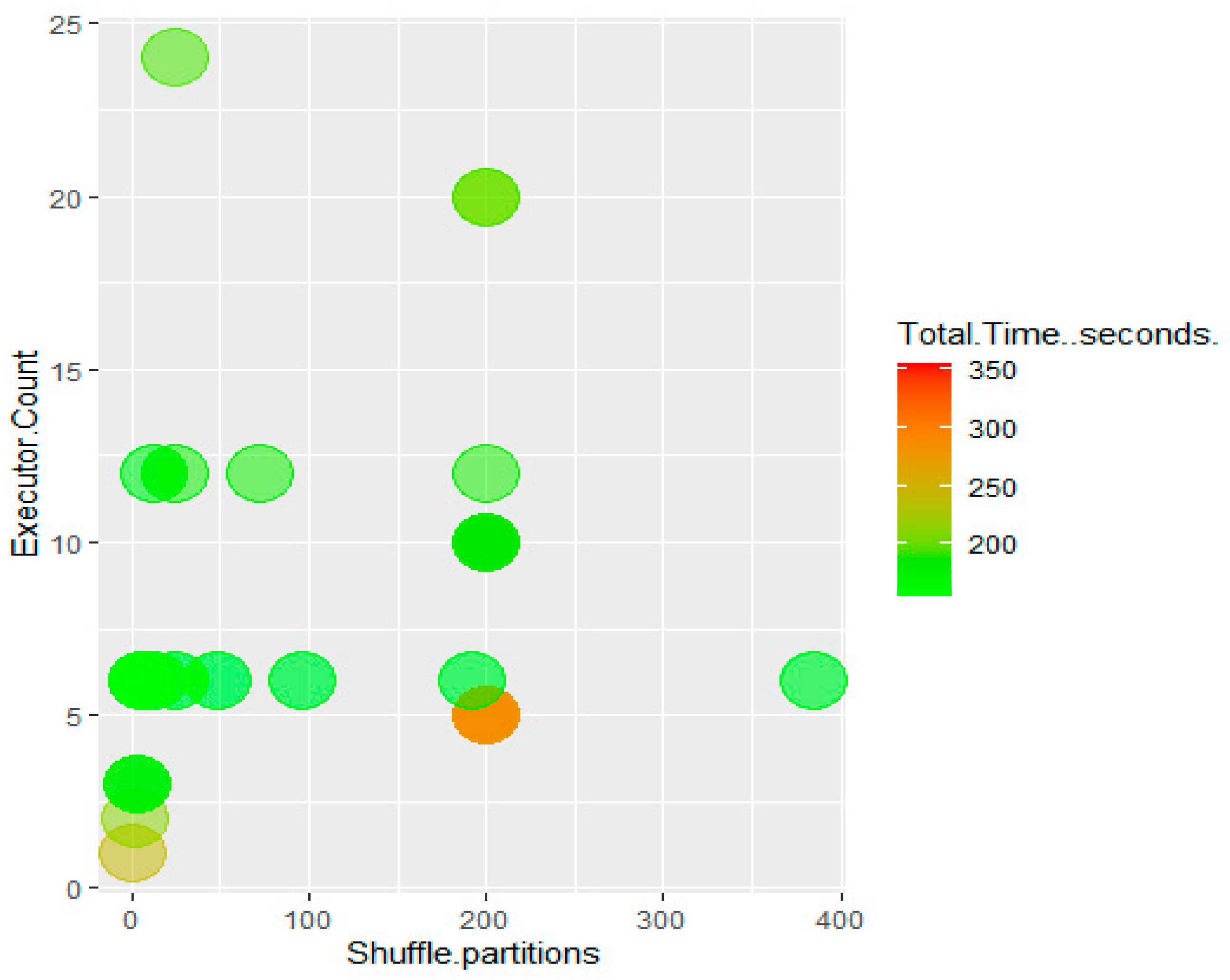
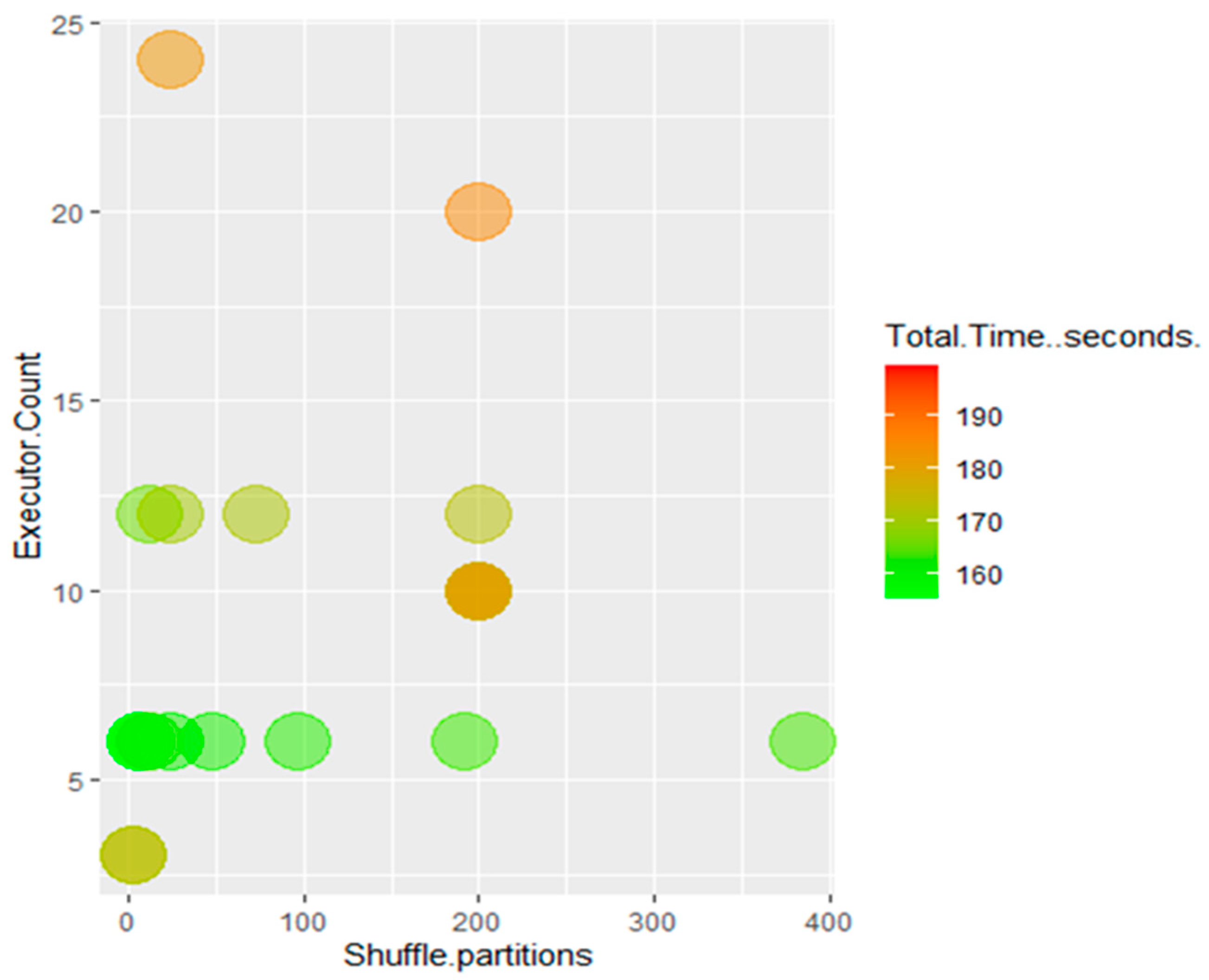
In terms of optimizing classifier performance on the Spark cluster, we found that more total cores provided to the Spark application make machine learning algorithms run faster but with diminishing returns. It can be noted that classifiers run fastest when the number of shuffle partitions is the same as the total number of executors. There was no significant correlation between runtimes and the total amount of memory allocated (though allocating too little memory can cause executors to crash).
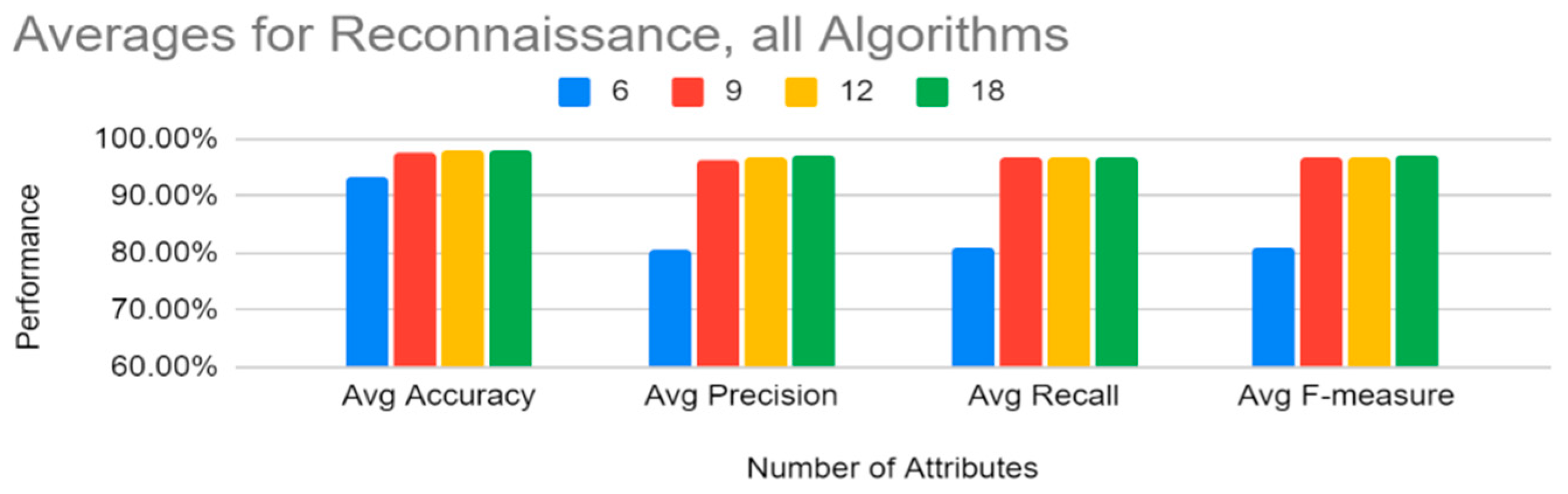
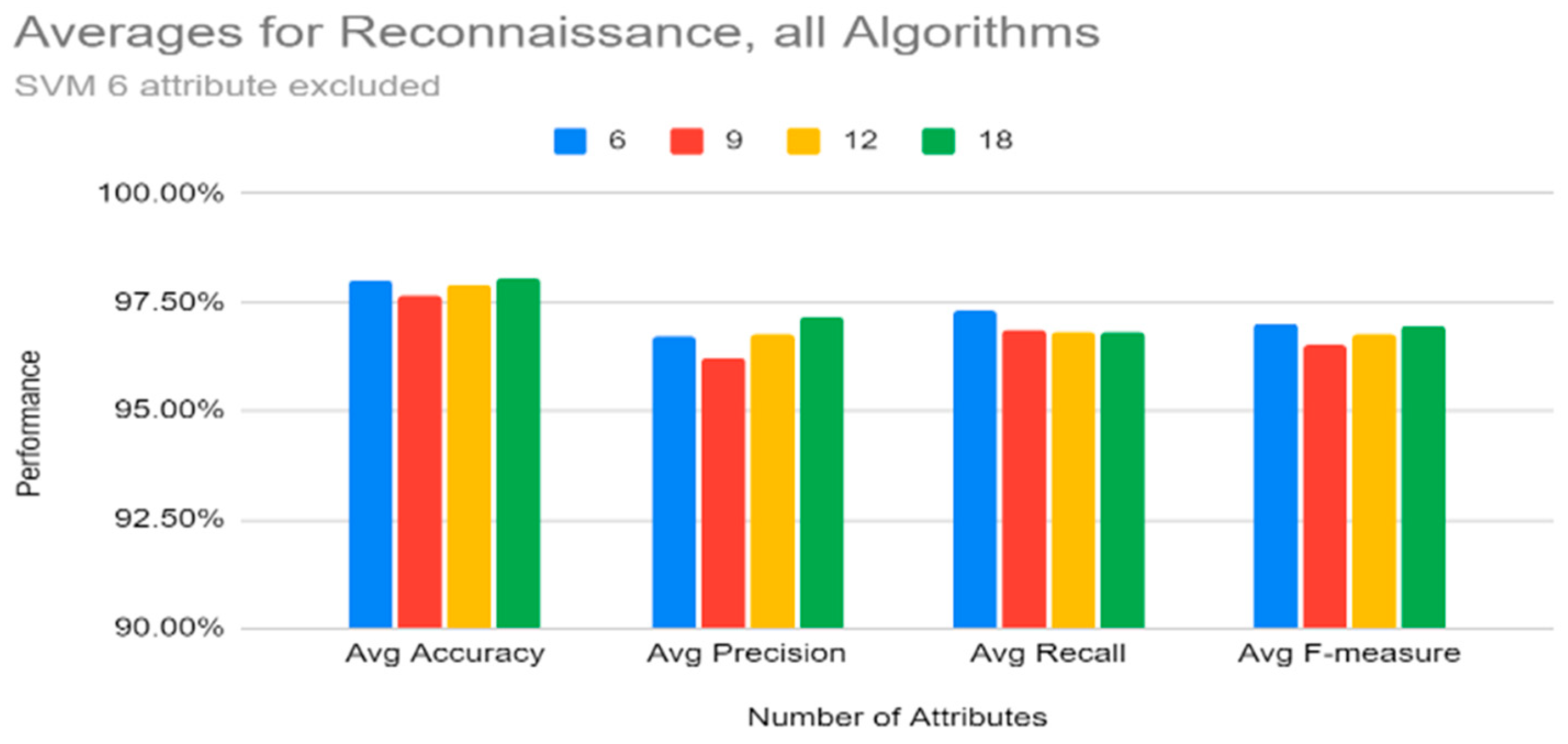
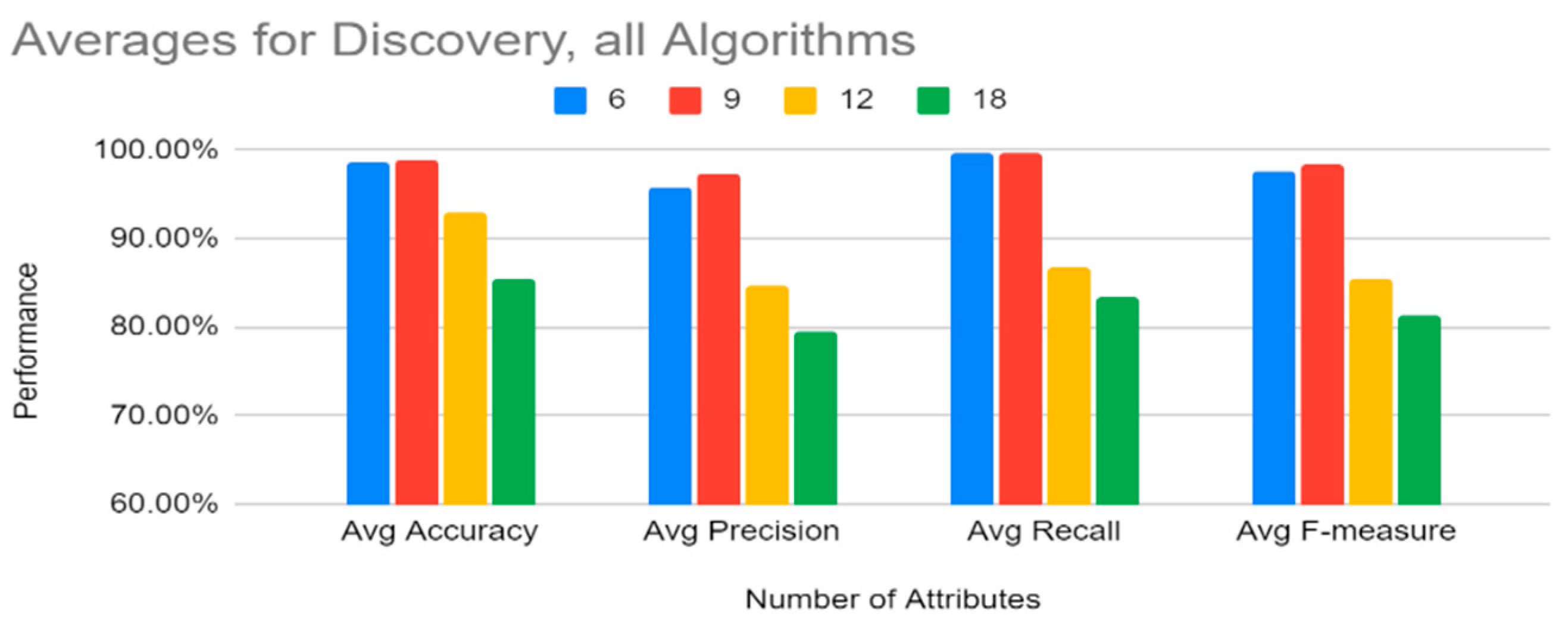
Machine learning results indicate that the tree-based methods (decision tree, gradient boosting tree, and random forest) performed better on most metrics than the other three algorithms in classifying this dataset for both the reconnaissance and discovery tactics. These three algorithms all showed 99% + accuracy for both attack tactics, with similarly higher scores in precision, recall, f-measure, and AUROC. Of the tree-based methods, gradient boosting tree and random forest performed a little better than decision tree in terms of recall for both the tactics, but in terms of the false-positive rate, decision tree had the lowest false-positive rates for both reconnaissance and discovery (in fact, it was at 0% for discovery). Gradient boosting tree and random forest also performed well in terms of false-positive rate for discovery, but for reconnaissance, gradient boosting tree performed a little better than random forest. Based on these results, it should also be mentioned that the binning methods used in this study were also effective in the classification process.
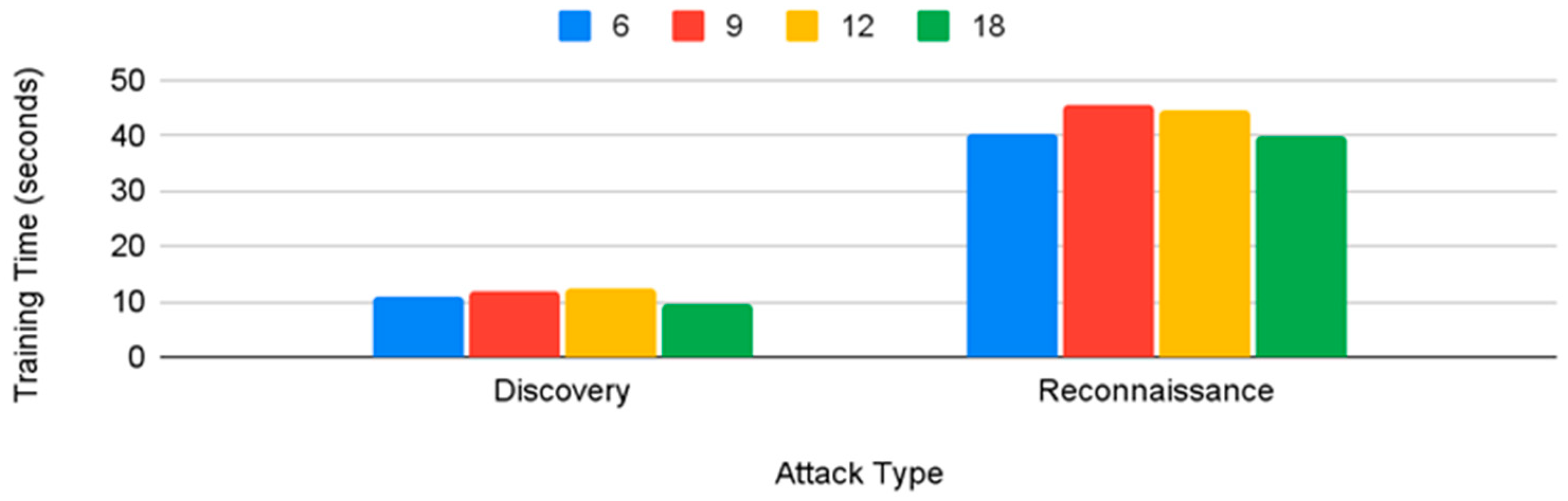
With respect to the training times of the tree-based classifiers, random forest performed the best for the reconnaissance tactic, followed by decision tree, and for the discovery tactic, decision tree performed the best.
With respect to the number of attributes to be used, the top six attributes from information gain (history, protocol, service, orig_bytes, dest_ip, and orig_pkts) can be considered enough to provide the best classification results for both the reconnaissance and discovery tactics for all the machine learning classifiers (except SVM with respect to reconnaissance), and the training time of the top six attributes was also lower.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













