4.2.1. Statistical Analysis
In this section, we discuss the detailed analysis results for the collected dataset in the real-world driving experiment.
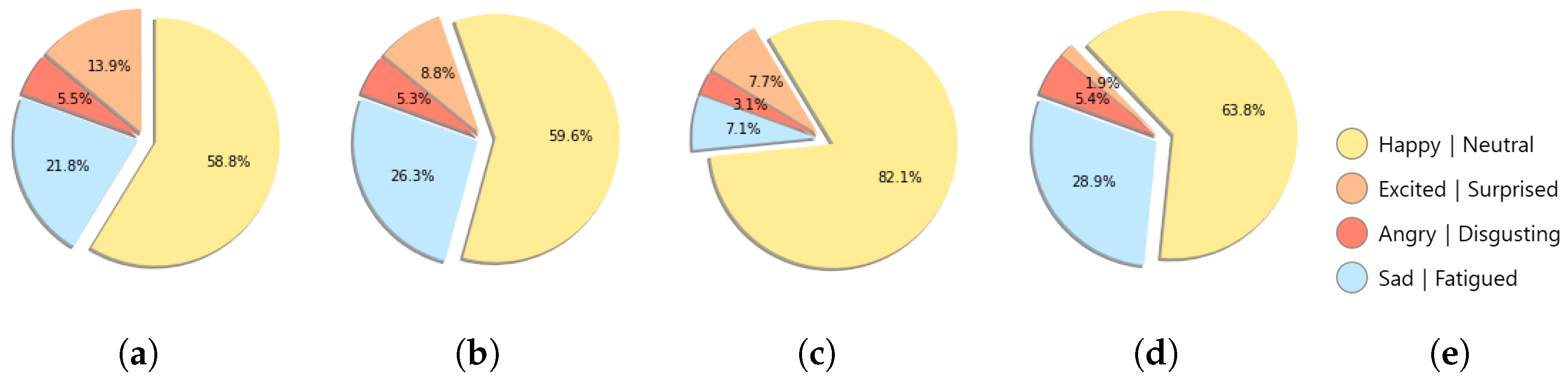
Figure 5 depicts the self-report proportion for each driver as a pie chart. The emotion with the highest proportion was “Happy|Neutral”. More than 50% of the drivers’ self-reported emotion labels are “Happy|Neutral”, and they often account for up to approximately 82%. The proportion of the other three emotions varies by the driver, but it accounts for a small proportion compared to the “Happy|Neutral”.
To confirm the self-reported emotion label tendency of each emotion, the distribution of self-reports and vehicle speed by emotion for all drivers is depicted in
Figure 6 and
Figure 7. In
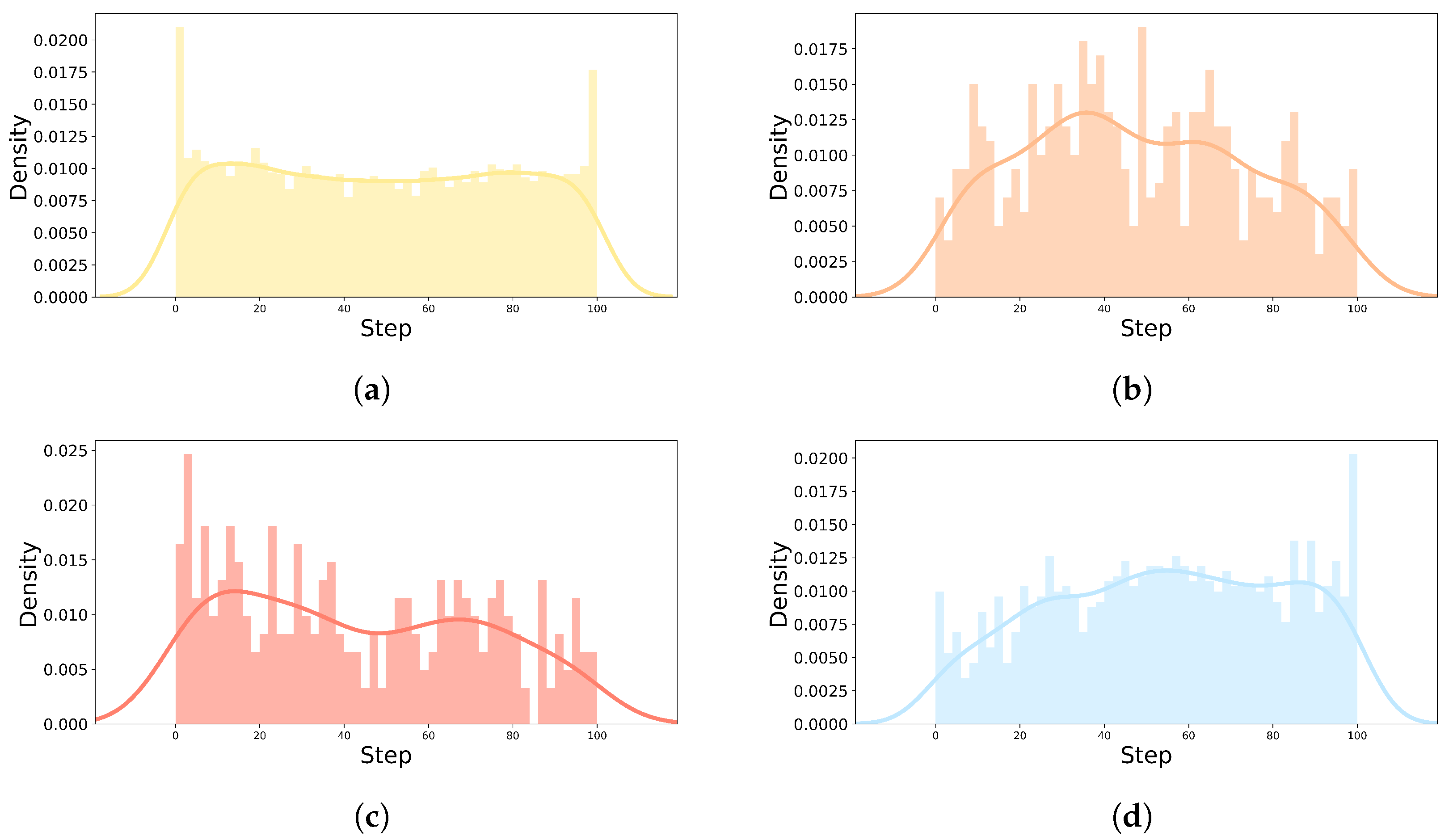
Figure 6, the start and end of all individuals driving were normalized from 0 to 100 steps and divided into 50 sections. The number of self-reported emotion labels for each section is displayed as a histogram and kernel density estimate plot to evaluate the distribution by emotion. “Happy|Neutral” had several distributions at the start and end of the driving, and had an even distribution throughout the driving process, as shown in
Figure 6a. Overall, “Excited|Surprised” and “Angry|Disgusting” had an irregular distribution. “Excited|Surprised” seemed to have a greater variance than “Angry|Disgusting”, as shown in
Figure 6b,c, and it is judged that “Excited|Surprised” was more maintained when the emotion was induced than “Angry|Disgusting”. As shown in
Figure 6d, the distribution of “Sad|Fatigued” emotion increases toward the middle and late stages of driving.
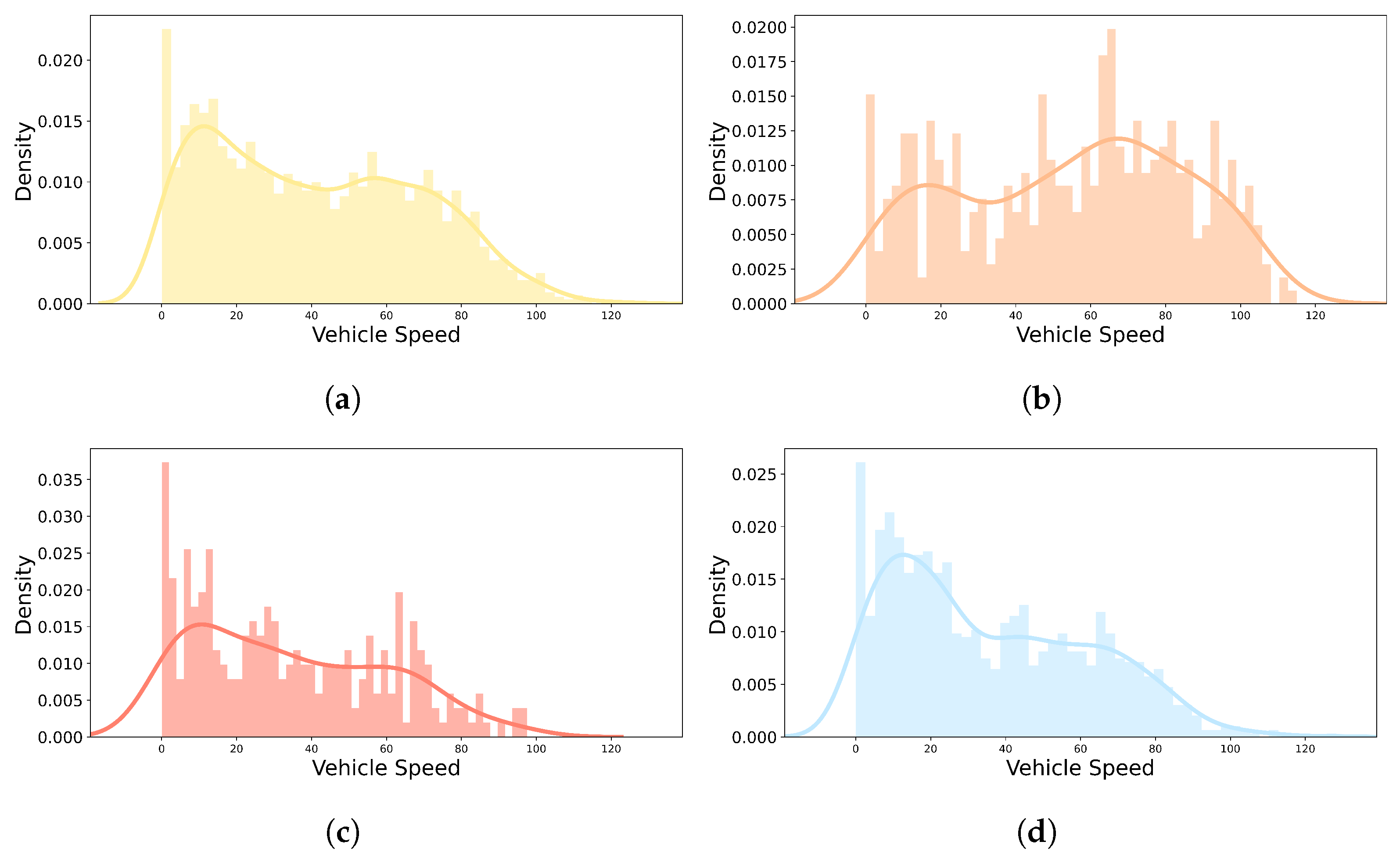
Figure 7 shows the number of self-reported emotion labels at that vehicle speed with a histogram and kernel density estimate plot to evaluate the distribution of vehicle speed by self-reported emotion labels. “Happy|Neutral” had high distributions from 0 to about 15 kph, and an even distribution throughout the driving process, as shown in
Figure 7a. In
Figure 7b,c, the fact that the vehicle speed had a relatively irregular distribution compared to “Happy|Neutral” and “Sad|Fatigued” in “Excited|Surprised” and “Angry|Disgusting” is a common feature with the distribution of self-reported emotion labels in
Figure 6. As shown in
Figure 7d, the distribution of the “Sad|Fatigued” emotion had a particularly high distribution from 0 to about 30 kph. Based on the distribution of self-reports and vehicle speed by emotion (especially in
Figure 6a), “Happy|Neutral” was the default emotion and the others were induced while driving.
In addition to self-reported emotion label data, we used the statistical hypothesis test to analyze the significance of the collected sensor data. We built the null hypothesis (
) that the structured data collected did not differ according to the self-reported emotion label and confirmed the difference by the emotion of each structured data through a Kruskal–Wallis H test [
31,
32]. According to the Kruskal–Wallis H test results, if the significance probability expressed as the
p-value is less than the significance level, 0.05, the null hypothesis (
) can be rejected and the alternative hypothesis (
) can be accepted as true. The statistical significance by self-reported emotion label of each data is described using the
p-value and which hypothesis was accepted as true in
Table 3. If the statistical significance between the four self-reported emotion labels is confirmed by the Kruskal–Wallis H test, it is also necessary to confirm how many of the pairs show statistical significance through the post-hoc test. We confirmed the statistical significance of a total of six self-reported emotion label pairs through the Mann–Whitney U test [
33,
34], a nonparametric statistical hypothesis test, and the total number of the null hypothesis (
) rejection pairs is also listed in
Table 3. As shown in
Table 3, all collected structured data had statistically different distributions for self-reported emotion labels, and three or more pairs out of six pairs were statistically significant.
Although the statistical hypothesis test results can explain the significance of the emotion recognition of the collected sensor data, another aspect that requires analysis is whether there is a significant distribution difference according to the driver. Therefore, the same statistical hypothesis test as above was repeated by separating the data for each driver, and the results are shown in
Table 4. EDA and steering wheel angle are the only structured data with the same results for all drivers. Not only were the post-hoc results different, but also the results of determining whether to reject the null hypothesis were different for each driver. That means the collected data significantly vary from driver to driver. This may be because each driver has a different way of expressing their emotions while driving. Therefore, different data will be required to recognize each driver’s emotion. In other words, emotion recognition research requires personalization.
4.2.2. Driver Face Detection
One of the most common approaches to recognizing a driver’s emotional state is using face images. Studies adopting this approach generally use a well-known face detector to crop only the face image from the driver’s frontal image and use it as input data. The most popular face detectors have proven their performance only on in-the-wild datasets such as FDDB [
35] or WIDER FACE [
36]. Thus, we evaluate the performance of five popular face detectors, Haar [
37], Dlib [
38], OpenCV [
39], MMOD [
40], and MTCNN [
40], on detecting the driver’s front image in the collected real-world driving dataset. First, the detection results of the five detectors for the collected IR-front images were output and qualitatively compared.
Figure 8 is an example of the detection results of the five detectors. According to the results, Haar has a high false positive rate, i.e., nonfaces are detected, and Dlib has a high false negative rate, i.e., faces are not detected. In contrast to Haar and Dlib, other detectors are capable of detecting the driver’s face to a similar degree.
For accurate performance comparison of the similar three face detectors, we selected 200 different images and labeled face bounding boxes. If the intersection over union (IoU) value between the labeled bounding box and the detection bounding box is greater than or equal to the threshold, it is considered true positive (TP); if the IoU value is less than the threshold, it is considered false positive (FP).
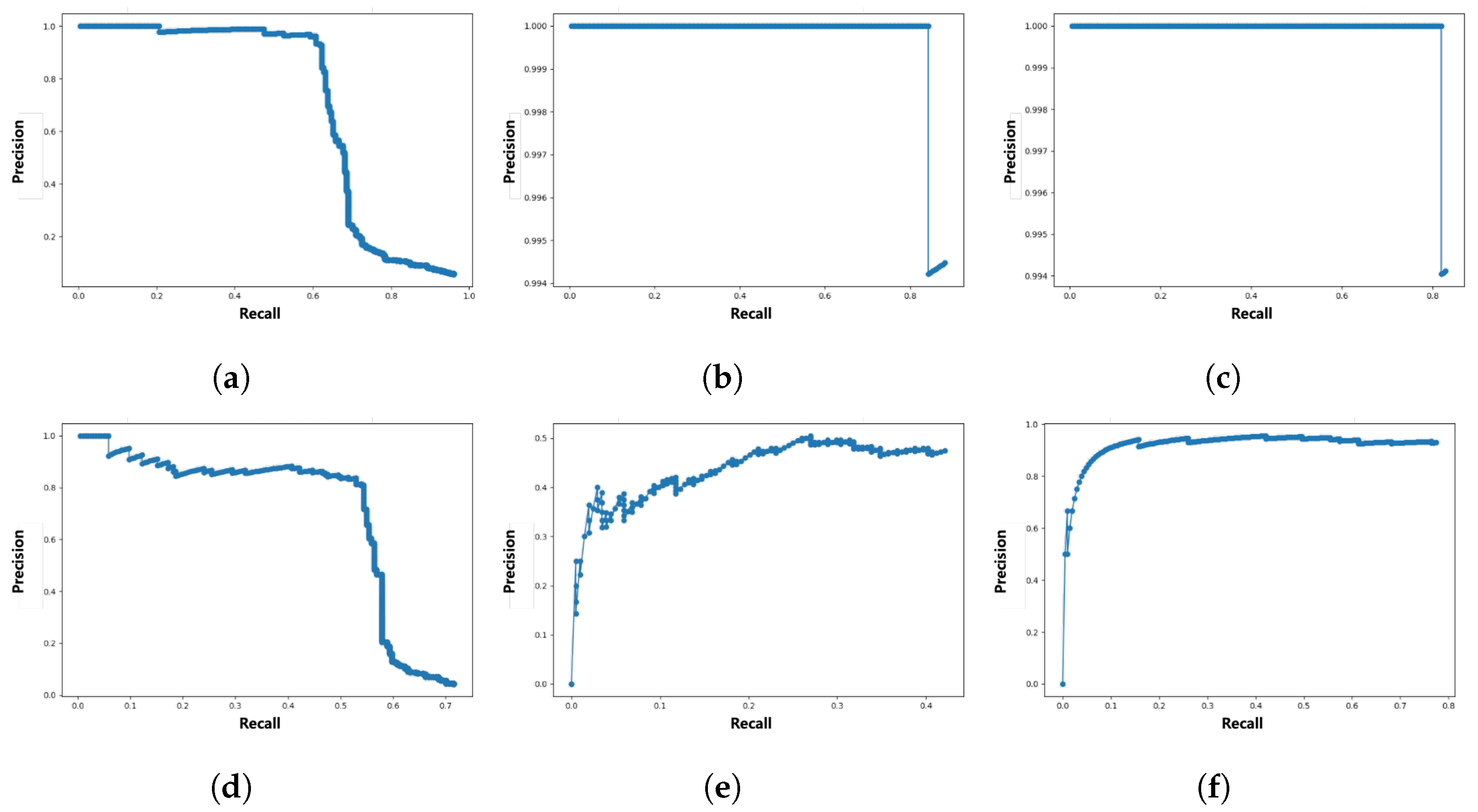
Figure 9 shows the precision–recall (PR) curve drawn using the considered TP and FP. Quantitative performance comparison of face detectors can be made with the average precision (AP) value calculated by the area under the PR curve. Depending on whether the threshold is 0.5, 0.75, or 0.95, AP performance is expressed as AP50, AP75, or AP95, respectively. Refer to
Table 5 for detailed comparison results. Since the inference speed of the face detector is as important as detection accuracy,
Table 5 describes the inference speed and the GPU specifications.
OpenCV has the fastest inference speed, but its detection performance is low. For MMOD and MTCNN, AP50 is at a similar level, but at AP75, the detection performance of MMOD decreases rapidly. Although the AP75 performance of MTCNN is inferior to AP50, it is insignificant. Conversely, in the case of inference speed performance, MMOD significantly outperforms MTCNN. Since the inference speed of MTCNN is also insufficient, it seems appropriate to use a suitable face detector as the driver face detector depending on the purpose or computational sources. In terms of AP95, the performance of all detectors is 0.0. This is due to the small area occupied by the driver’s face in the driver’s front image, and the IoU value may not exceed the threshold value of 0.95 due to differences in determining whether only the eyes and nose are included, or including the forehead or chin when the bounding box is labeled.
Figure 10 shows an example image of the detected and labeled driver face bounding boxes with an IoU value of 0.68, it detects the driver’s facial expression sufficiently. In face detection for driver emotion recognition, the threshold should not be as high as 0.5 or 0.95. Therefore, we crop the face image using the MMOD face detector, which achieved the highest detection performance in AP50 for driver emotion recognition, as discussed in
Section 4.2.3.
4.2.3. Personalized Driver Emotion Recognition
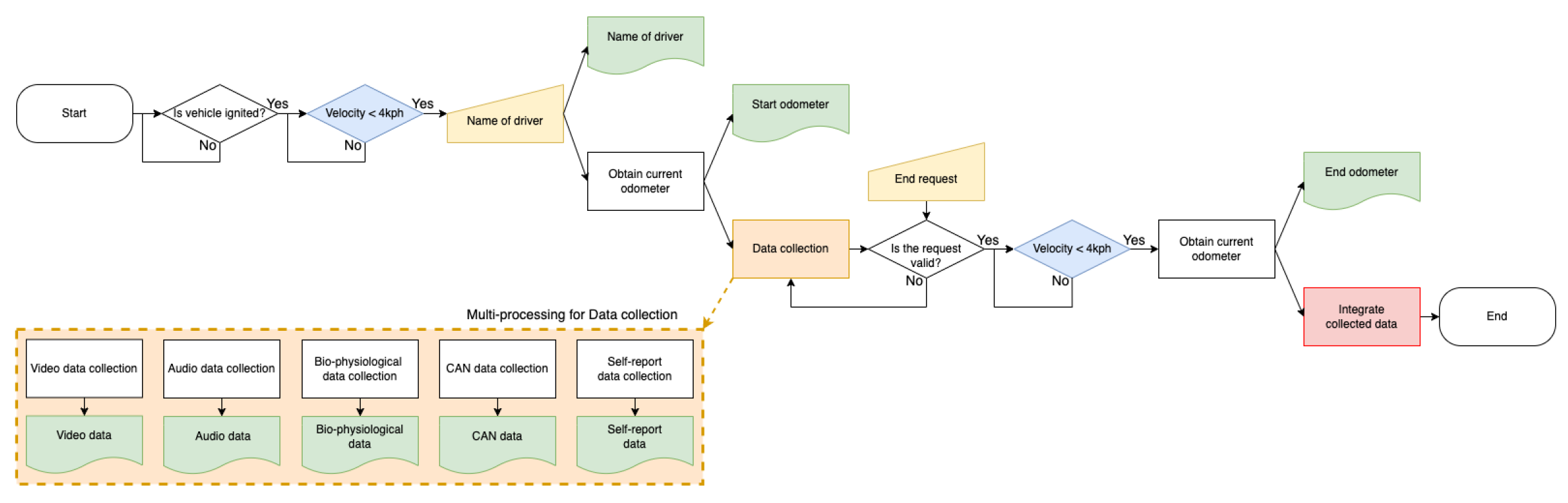
This section discusses the results of personalized driver emotion recognition utilizing single or multimodal data. Since individual driver data are required for personalized driver emotion recognition training, the data required to complete the training should be as small as possible, and the performance of the trained recognition model should be preserved for as long as possible. Therefore, the collected data are sorted in ascending order of mileage, and the mileage for completing the collection of training data, K, is determined. The data collected during K km driving from the initial mileage for each individual are used as training data, and the data from thereafter to the last data are used as test data. We set the completing mileage for the training data, K, to 500 km, and to obtain more test data than training data, we experimented with drivers A and B, who collected data over 1000 km.
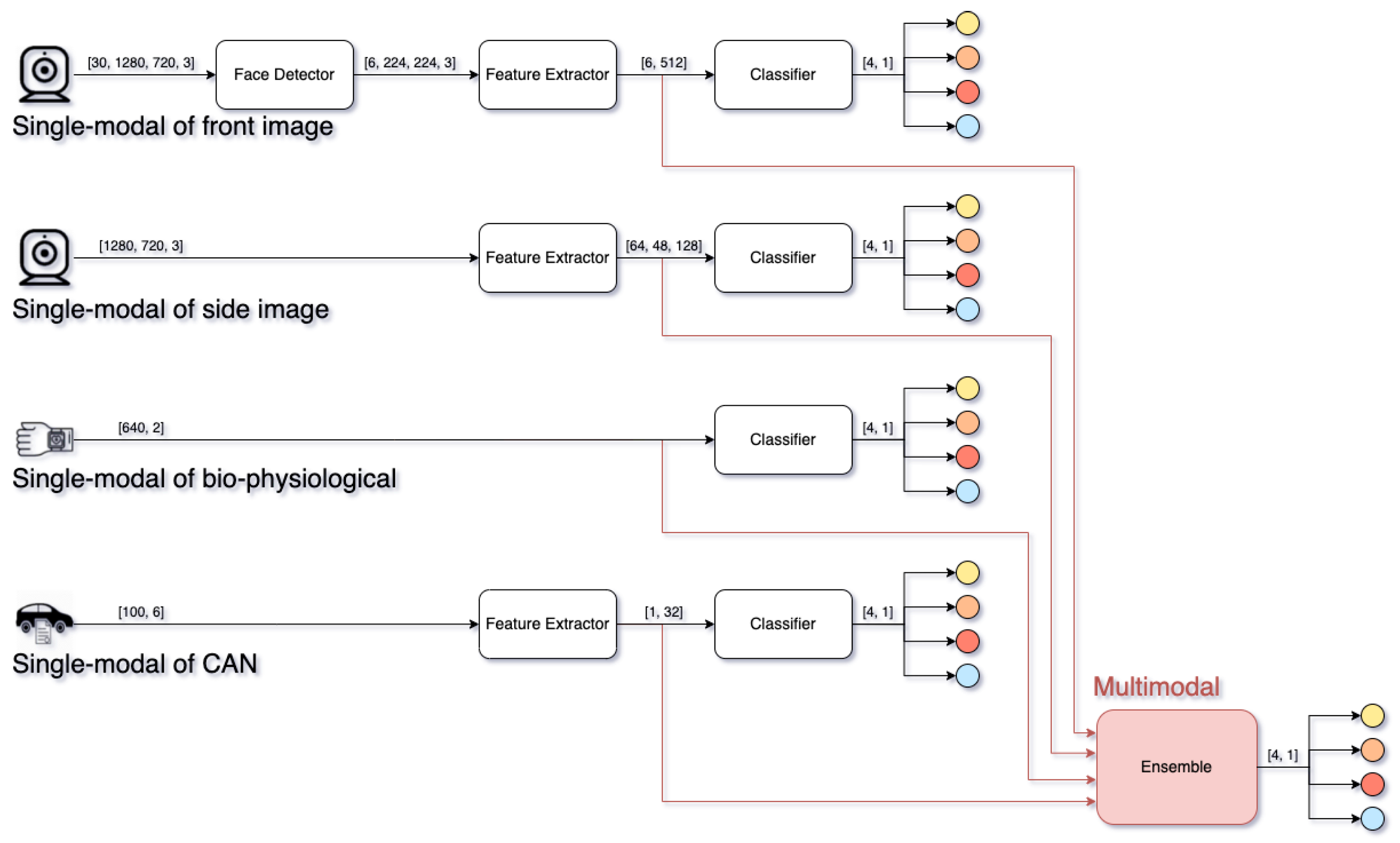
We proposed a personalized driver emotion recognition model based on deep learning networks that recognize a driver’s emotional state using four multimodal inputs: front and side image, biophysiological, and CAN data. The proposed model is trained and verified using only individual data, and, as shown in
Figure 11, each multimodal input performs single-modal emotion recognition and multimodal emotion recognition through an ensemble model. Each single-modal model and multimodal recognition model are described as follows.
Single-modal of front image (
): The single-modal recognition model of the front image uses front IR images for 2 s from 4 s to 2 s before the driver’s self-reporting. Because RGB images are vulnerable to changes in illuminance, IR images that can always capture a stable image are used as input. From 2 s before self-reporting, it shows uniform motion for self-reporting, so it is excluded from the input data. The input images are evenly time-divided into six equal parts and input to a face detector; the MMOD-based face detector outputs one cropped face image with the highest confidence value for each input. The cropped images are resized to the input shape of the feature extractor and sequentially fed into a feature extractor and a classifier based on CAPNet [
41]. Because the classification form is different from that of CAPNet, only the number of units in the top layer of the classifier is modified to the number of representative driver emotional states. The last activation function is softmax and outputs the probability of each representative driver emotional state.
Single-modal of side image (
): The single-modal recognition model of the side image uses the side IR image captured 2 s before self-reporting. The reason for using the image from 2 s ago is the same as that for using the front image. The input image is fed into a feature extractor based on AlphaPose [
42]. The feature extractor consists of layers up to just before outputting feature points in the form of histograms in AlphaPose. The classifier consists of a global max pooling layer and fully connected layers. The top layer of the classifier is the same as other classifiers to output the probability of each representative driver emotional states.
Single-modal of biophysiological (): The single-modal recognition model of biophysiological data uses the PPG and EDA data for 10 s before the driver’s self-reporting. Since PPG and EDA have different sample rates, up-sampling using linear interpolation is applied to the EDA data to match the input shape. The biophysiological input is directly fed into the classifier without a feature extractor to output the probability of each representative driver emotional state. The classifier is composed of the fully connected and batch normalization layers.
Single-modal of CAN (): The single-modal recognition model of CAN data uses all collected signals for 10 s before the driver’s self-reporting. The input data are down-sampled by a tenth before being fed into the feature extractor. The feature extractor is an encoder of long short-term memory-based autoencoder that extracts the feature vector for driving propensity. The classifier consists of fully connected layers and a dropout and outputs the probability of each representative driver emotional states by receiving the feature vector.
Multimodal (M): The multimodal recognition model uses the input vectors of each classifier of single-modal as input vectors. The model is a deep learning-based ensemble model that outputs the probability of each representative driver emotional states by fusing all input vectors. The feature vectors of the front image, CAN, and side image are flattened using flatten and pooling layers. The flattened vectors are concatenated using the concatenate layer. The concatenated vector undergoes the normalization, fully connected layers, and softmax activation function to become the final output. The input modalities to fuse can be chosen, and the modals are denoted by a subscript, e.g., is the ensemble model that fuses the front image and biophysiological data. We evaluated three or more input modal combinations for multimodal models.
It is necessary to define a loss function when training the proposed models. Because the self-reported emotion label has data imbalance, as described in
Section 4.2.1, high performance cannot be expected if a typical loss function is used such as cross entropy. We overcome the data imbalance problem by making the precision and recall differentiable by computing the likelihood values of TP, FP, and false negative (FN) using probabilities. The loss function we used is shown as follows:
where
and
represent a one-hot vector of the self-reported emotion and predicted emotion, respectively, where the first element of each vector represents the default emotion, “Happy|Neutral”.
,
, and
are the likelihood values of TP, FP, and FN, respectively, where ∘ is an element-wise product.
Equation (
1) is a loss function for increasing the precision of default emotion and for increasing the recall of induced emotions, where
N represents the total number of representative emotions, and
represents a very small value that prevents the precision or recall values from going to infinity. This loss function,
, can be used for backpropagation by probabilistically expressing the precision and recall for each prediction class. It increases precision for the majority class, the default emotional state, and increases recall for minority class, inducible emotional states.
The evaluation results with test data are in terms of F1 score, precision, and recall, and are described for each driver. As mentioned in
Section 4.2.1, since the representative driver emotional states are divided into default and inducible emotions, the recognition performance of inducible emotions is evaluated first.
Table 6 and
Table 7 summarize the performance of inducible emotion recognition between default and inducible emotions for each driver. The highest recognition performance is the F1 score 0.698 of
for Driver A and 0.667 of
for Driver B. As expected in
Section 4.2.1, the input modals with the best performance for each driver differed. Driver A achieved the best performance in a single front image, and Driver B achieved the best in a side image, biophysiological, CAN data combination. However, their performance was similar. Driver B had similar performance between all evaluated models from 0.562 to 0.667. For Driver A, models without CAN data had a similar performance from 0.613 to 0.696, but models with CAN data such as
,
,
,
, and
had a significantly lower performance from 0.228 to 0.469. Driver B can interpret that when inducible emotions are induced while driving, emotions are expressed overall in the front and side images and biophysiological, and CAN data, whereas driver A can interpret that the induction of emotion is not expressed in CAN data. These results may support the fact that driver emotion recognition necessitates personalization.
The performance of driver emotion recognition among the inducible emotions for each driver is also summarized. The recognition performance for each of the three inducible emotions and the average of three F1 scores are described in
Table 8 and
Table 9. Comparing the recognition performance using the F1 scores of each emotion and average value, none of the input models with the best performance matched among the drivers. The common results, regardless of the driver, were that “Sad|Fatigued” emotion had the best recognition performance and “Angry|Disgusting” emotion had the worst recognition performance. “Sad|Fatigued” emotion recognition performance was 0.835 and 0.859 and “Excited|Surprised” emotion recognition performance was 0.653 and 0.583 for Drivers A and B, respectively. Both of which are similar performances. However, in the case of “Angry|Disgusting” emotion, recognition performance differed, 0.571 and 0.373 for each driver. Notably, there was very little performance difference between all evaluated models. The difference between the highest and lowest average F1 score was 0.163 and 0.061 for Drivers A and B, respectively. This can be a fail-safe method of the driver emotion recognition model, and each input modal will ensure each other’s redundancy.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










