Dilated Spectral–Spatial Gaussian Transformer Net for Hyperspectral Image Classification


1
State Key Laboratory of Tibetan Plateau Earth System, Resources and Environment (TPESRE), Institute of Tibetan Plateau Research, Chinese Academy of Sciences, Beijing 100101, China
2
Chinese Academy of Surveying & Mapping, Beijing 100036, China
*
Author to whom correspondence should be addressed.
Remote Sens. 2024, 16(2), 287; https://doi.org/10.3390/rs16020287
Submission received: 27 October 2023
/
Revised: 25 December 2023
/
Accepted: 8 January 2024
/
Published: 10 January 2024
(This article belongs to the Section AI Remote Sensing)
Abstract
:In recent years, deep learning-based classification methods for hyperspectral images (HSIs) have gained widespread popularity in fields such as agriculture, environmental monitoring, and geological exploration. This is owing to their ability to automatically extract features and deliver outstanding performance. This study provides a new Dilated Spectral–Spatial Gaussian Transformer Net (DSSGT) model. The DSSGT model incorporates dilated convolutions as shallow feature extraction units, which allows for an expanded receptive field while maintaining computational efficiency. We integrated transformer architecture to effectively capture feature relationships and generate deep fusion features, thereby enhancing classification accuracy. We used consecutive dilated convolutional layers to extract joint low-level spectral–spatial features. We then introduced Gaussian Weighted Pixel Embedding blocks, which leverage Gaussian weight matrices to transform the joint features into pixel-level vectors. By combining the features of each pixel with its neighbouring pixels, we obtained pixel-level representations that are more expressive and context-aware. The transformed vector matrix was fed into the transformer encoder module, enabling the capture of global dependencies within the input data and generating higher-level fusion features with improved expressiveness and discriminability. We evaluated the proposed DSSGT model using five hyperspectral image datasets through comparative experiments. Our results demonstrate the superior performance of our approach compared to those of current state-of-the-art methods, providing compelling evidence of the DSSGT model’s effectiveness.
1. Introduction
Hyperspectral techniques are crucial instruments used to gather and analyse continuous spectrum data on objects in various wavelength ranges. In addition to offering a wide area for the advancement of hyperspectral image (HSI) classification study, the diverse and rich methods of acquiring hyperspectral data also present new problems and opportunities for our comprehension and use of hyperspectral data. HSIs are currently used in several industries, including food safety [1,2], medical diagnostics [3], industrial product quality inspection [4], mineral detection [5], and pest and disease monitoring [6]. A wide range of topics, including noise removal [7], spectrum unmixing [8], data classification and clustering [9], and target identification and recognition [10,11], have been covered by the rich and varied development of HSI processing approaches.
Feature land cover classification algorithms are challenged by the complex spectral properties and high-dimensional features of hyperspectral data. Programs such as Spectral Angle Mapper [12], Support Vector Machines [13,14], Decision Tree [15], and K-Nearest Neighbours [16] identified HSI in the first stage of the process based solely on the similarity or difference between their spectra. In situations when there is a considerable amount of spectral overlap or similarity, techniques that solely consider spectral features have not worked effectively. Therefore, efforts have been made to solve this issue using techniques such as the extended multi-attribute profile (EMAP) [17], the grey scale covariance matrix (GLCM) [18] based on texture features, and the morphological profile (MP) [19] based on shape features. These techniques for logically fusing and representing spectral and spatial characteristics can be used to acquire pixel features that are more thorough and precise. To increase the effectiveness and efficiency of classification, HSIs typically require various dimensionality reduction techniques, such as principal component analysis (PCA) [20,21] and linear discriminant analysis (LDA) [22,23], to maintain important data dimensions and features.
Traditional classification methods often require manual feature selection. The quality and effectiveness of feature extraction rely heavily on human experience and domain knowledge, which may not fully capture the complex and abstract features in images. In comparison, deep learning-based classification methods have stronger feature learning capabilities and automated feature extraction abilities. In this context, they have demonstrated strong performance in the field of image processing tasks. Various HSI classification methods have been proposed based on convolutional neural networks (CNNs) [9,24,25,26,27,28,29,30,31,32,33]. Although CNN-based networks have achieved positive results in visual classification, some areas require optimisation. CNNs typically require a large amount of training data, and smaller datasets may not be sufficient to fully train the CNN model, leading to overfitting. Given the complexity and large number of parameters in CNNs, the training time can be relatively long. The receptive field obtained by CNNs is strongly influenced by the size and variations in the input data. In the context of high-dimensional data such as hyperspectral images, traditional CNN models may require dimensionality reduction or the decomposition of spectral data to adapt to the input requirements of the model.
To address these issues raised regarding CNNs, such as parameter redundancy and a limited ability to handle spatial and scale variations, researchers have introduced various CNN variants to improve the models and enhance the performance and adaptability of CNNs. Wang et al. [34] proposed a model known as the expansion spectral–spatial attention network. It introduces expansion convolution as a dual-branch feature extraction unit, which expands the receptive field of input patches, enhancing the perception of large-scale features. In Ref. [35], kernel-guided deformable convolution was used to dynamically adjust the sampling positions of the convolution kernel, extracting pure spatial–spectral information from the local neighbourhood. Zhao et al. [36] presented a grouped separable convolution model, which combines grouped convolution and separable convolution to reduce the number of parameters and improve computational efficiency. By introducing different convolution operations and sampling mechanisms, these CNN variants effectively increase the receptive field range of the model and more effectively capture spectral, structural, textural, and spatial shape information in images without introducing extra parameters. They also reduce the number of parameters and computational complexity in the network, allowing the model to maintain efficient performance even in resource-constrained environments.
HSI data typically contain many spectral bands, where certain bands are more important for classification tasks and others may contain noise or redundant information. Attention mechanisms [37,38,39,40,41] can assist models to automatically learn and focus on crucial features. The introduction of Vision Transformer [42,43,44,45,46] has opened new avenues for attention-based model design. Visual Transformers use multi-head self-attention mechanisms (MHSAs) and feedforward neural networks for feature extraction instead of CNNs. Through MHSAs, transformers can globally model the relationships within the entire input sequence, enabling more effective capturing of global dependencies in images. Each MHSA head can focus on different correlations, allowing transformers to learn richer and more diverse feature representations. In contrast, relying solely on CNNs for feature representation is limited by fixed convolution kernels and pooling operations. This may fail to capture diverse features within the input. Many researchers have successfully combined transformers with other components of CNNs, achieving state-of-the-art results in image classification tasks [47,48,49,50,51,52].
However, the visual transformer was originally designed for RGB natural images, and applying the transformer to HSI classification tasks still has multiple challenges. Although the transformer has certain advantages in processing images with fewer channels, when dealing with HSIs, which have multiple spectral bands, there may be issues with scattered feature extraction. HSI data have a larger number of spectral bands for each pixel, and the multi-head self-attention (MHSA) in the transformer may establish long-range dependency correlations on a global scale, thereby excluding the local spatial relationships between pixels. This research offers Dilated Spectral–Spatial Gaussian Transformer Net (DSSGT) as a new model framework to enhance transformer performance on HSI classification tasks. The low-level null-spectrum joint characteristics of the input data were extracted using a two-branch cascade of dilated convolutional layers. By using this tactic, the receptive field for global information could be expanded, while the computing burden was decreased. The low-level joint features were then transformed into pixel-level vectors using a Gaussian weight matrix. This was then fed into the transformer encoder block to create high-level long-range fusion features. By using global average pooling to predict the labels of each pixel, we created a classification map.
A summary of the key contributions of this study includes the following:
(1) We proposed a low-level feature extraction module based on dilated convolution. This module stacks multiple dilated convolution layers with different dilation rates to perceive dependencies between features at different scales, thereby enlarging the receptive field and aggregating the obtained features. This allowed us to capture broader spatial–spectral contextual information and global structural correlations while also reducing computational complexity.
(2) We designed a Gaussian Weighted Pixel Embedding block that transforms low-level fusion features into pixel-level vector representations by introducing Gaussian weighted encoding. This transformation method enables the generation of more expressive and context-aware vector matrices, thereby enhancing the representation capability of the features.
(3) By combining a Dilated Convolutional Feature Extraction Unit and a Transformer Architecture Feature Fusion Unit, low, mid, and high semantic HSI features can be extracted effectively and efficiently, and more expressive and discriminative feature representations can be created. Five datasets were the subject of extensive study to verify the efficacy of the suggested model.
2. Methodology
2.1. DSSGT Framework
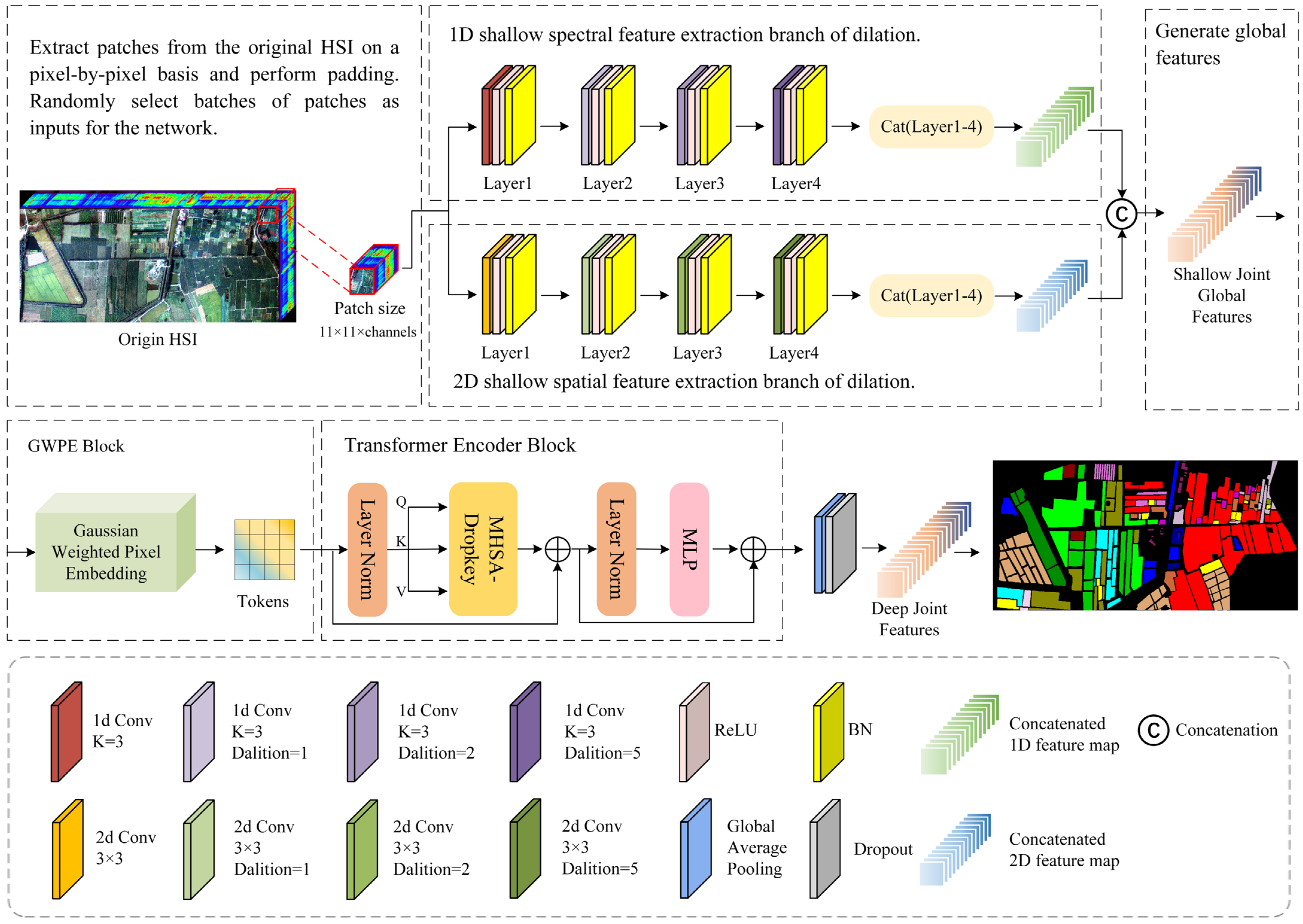
Figure 1 shows the entire framework overview diagram for the DSSGT model. The two model components include a shallow backbone for extracting spatial–spectral features based on dilated convolutional neural networks and a deep backbone for fusing features based on the transformer and GGWPE. Dilation convolution expands the sense field in comparison to regular convolution by introducing fixed-spaced zero-valued items into the convolution kernel. By expanding the convolutional kernel’s effective receptive field, this method can be used to collect a larger variety of spatial–spectral contextual information. The double branches, or the spatial branch and the spectral branch, based on dilated convolutional layers, are used by the shallow spatial–spectral feature extraction backbone of DSSGT to extract HSI features. Among these, the spectral and spatial branches extract effective information in the HSI through one-dimensional and two-dimensional dilatational convolution, respectively. By providing a Gaussian weight function that gives greater weight to the neighbouring points around each feature point in the feature space to more effectively capture the correlation and local structure between features, the GWPE block improves the accuracy of feature representation.
We extracted an image block in both height and width dimensions that was centred on each pixel point in the HSI. We then used a two-branch network to extract the spatial and spectral properties of this image block independently. To ensure that the ensemble features supplied to the deep feature fusion backbone encompassed all the recovered shallow information, we stitched the output feature maps of the four dilated convolutional layers in each branch (Layers 1–4). To produce more representative feature embedding, the Gaussian weighting function in GWPE can be adaptively modified by the distribution of features in the space. For us to generate a suitable embedding representation for the input transformer, we first needed to process the ensemble features through the GWPE block. The deep feature fusion information could only then be extracted through the transformer encoder block. We created the classification graph by mapping characteristics to matching category labels using global average pooling across categories.
We separated the sample data into a training set, a validation set, and a test set, each playing a different role in the study. The training set played a crucial role in model parameter learning and training. By training the model on the training set, we gradually learned and adjusted the weights and parameters of the model to better fit the features and patterns of the training data. The validation set was used for model tuning and hyperparameter selection. The test set was used to evaluate the performance and generalisation ability of the trained model. The proper partitioning and use of these three datasets formed the foundation for ensuring the reliability, generalisation ability, and effectiveness of the model.
2.2. Shallow Feature Extraction Backbone
2.2.1. Convolution of One- and Two-Dimensional Dilation
The size of the region in the input feature map that a convolutional layer concentrates on is determined by the size of the convolutional kernel of the layer below. The performance and expressiveness of the neural network strongly depend on the size of the receptive field, with larger receptive fields capable of capturing a wider range of contextual data. Therefore, a broader receptive field offers a more detailed perspective and aids in a deeper understanding and recognition of the input information while processing images containing large-scale elements. By enlarging the convolution kernel, ordinary convolution often expands the receptive field. However, this increases the number of parameters and the computational complexity, which could cause model overfitting. In practical applications, we need to strike a balance between the size of the receptive field and the constraints of computational resources. To achieve this, additional methods, such as dilation convolution, can be used in combination to widen the receptive field while minimising the number of parameters.
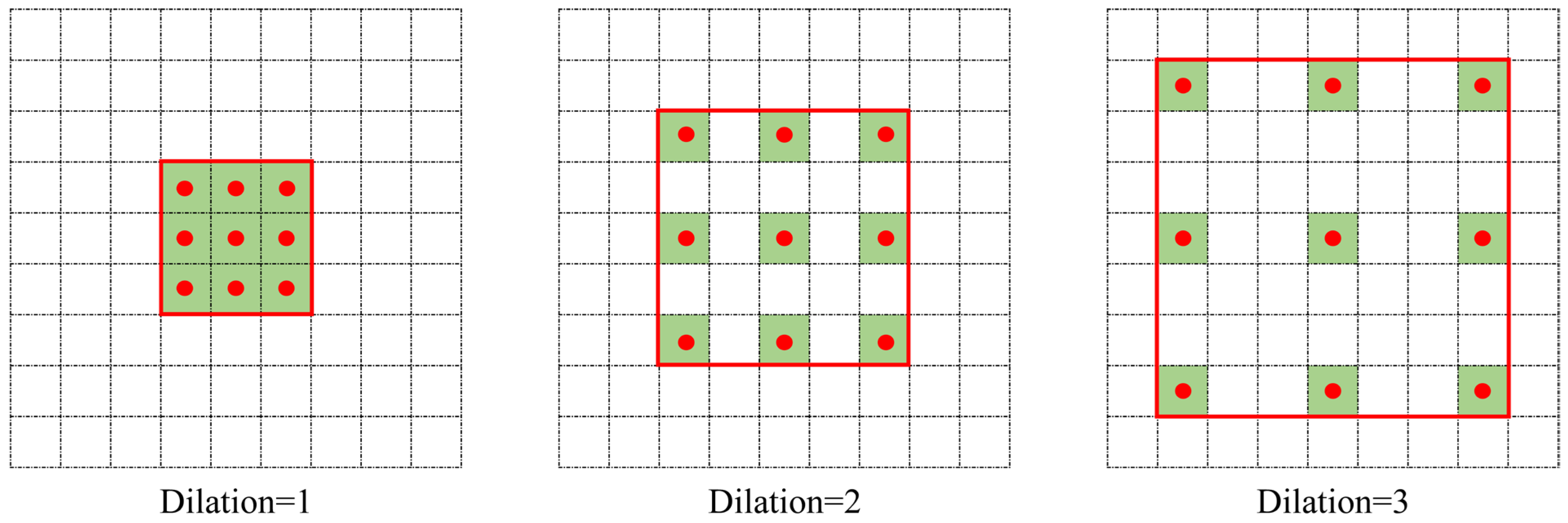
We illustrate the operation of dilated convolution with the example shown in Figure 2. The difference between dilation convolution and conventional convolution is the addition of a hyperparameter termed the dilation rate to the convolution kernel. The size of this controls the number of gaps between sample points in the convolution kernel. In Figure 2, the three images from left to right have dilation rates of 1, 2, and 3, respectively. The comparable convolution kernel size is indicated by the red box area, and the convolution kernel placement is indicated by the red dot. To achieve spacing, a value of 0 is typically entered in the red box blank position. The receptive field remains constant and is the same as the standard convolution when the dilation rate is 1 and the convolution kernel size is 3 × 3 (Figure 2). When the dilation rate is 2, the convolution kernel inserts a row of empty pixels between two nearby locations in the horizontal and vertical directions. This is equivalent to a receptive field with a size of 5 × 5, as in conventional convolution. The receptive field corresponds to a size of 7 × 7 in a typical convolution when the dilation rate is 3. Dilated convolution may successfully capture features at various levels and information at various sizes by expanding the receptive field without growing the convolution kernel by raising the dilation rate. This optimisation maintains computing efficiency while enhancing the model capacity to sense various scales.
The equivalent convolution kernel size and the receptive field size in dilated convolution are represented in Equations (1) and (2), respectively:
where L denotes the equivalent convolution kernel size, l is the size of the original convolution kernel, and the rate is the rate of dilation. Rm+1 is the dilated convolutional layer’s m + 1st receptive field size, and Si denotes the step size of layer i.
When using three or more successive dilated convolutional layers, the design of the dilation rate is especially important. The gridding effect, which is a loss of detailed information and incoherence amongst feature information, can come from improper dilation rate selection and underusing all the data within the corresponding receptive field. Therefore, maintaining detail integrity and feature coherence depends on selecting an appropriate dilation rate. To address the aforementioned issue, hybrid dilated convolution (HDC) [53] is a useful technique. To guarantee optimal performance, HDC uses a sawtooth structure when selecting the expansion factor. The HDC dilation rate size must be designed according to Equation (3)’s specifications.
where di is the Layer I dilation rate. Making Mi ≤ K, where K is the convolution kernel size, is the aim. For instance, the requirement is found to be satisfied for = 2 < K when K = 3 and the dilation rates of the three dilated convolutional layers are d = [1,2,5]. Consequently, in this model, the dilation rates of the dilated convolutional layers in the two branches were set to 1, 2, and 5.
2.2.2. Dilated Spectral–Spatial Feature Extraction
A high spectral index HSI has several spectral bands, and each pixel has rich spectral information. To address the issues of difficulty in feature extraction, redundancy in feature representation, and correlation across categories for HSI data, this model uses a two-branch feature extraction structure. Given that spectral and spatial information are extracted separately in the two branches, they can complementarily represent different aspects of the image. This improves the diversity and differentiation of the features and, thus, improves the classification performance.
To extract shallow spatial features, we used one standard 2D convolutional layer and three consecutive 2D dilated convolutional layers in the spatial branch. Similar to this, we used three successive 1D dilated convolutional layers in the spectral branch and a regular 1D convolutional layer to extract the shallow spectrum characteristics. The space branch operation is next described in detail as an example. A conventional convolutional layer was applied to the patches taken from the HSI to learn low-level edge and texture features that offer rudimentary shape and structural information to gather global information. The resulting feature maps were then input into three successive dilated convolutional layers with dilation rates of 1, 2, and 5. A hierarchical feature learning module was created as a result of this process, which gradually improved the abstraction level and receptive field of feature extraction. We set both branch convolution kernel sizes to 3. The model may retain symmetry when processing images while considering the precise capture of spatial position information and contextual information since this guarantees that the convolution operation has the same receptive field size in each direction. Behind each of the basic convolutional and dilation convolutional layers, we added a batch normalisation layer and an ReLU activation function to increase the network’s nonlinear capacity and to speed up convergence and model generalisation. We performed a splicing operation on the feature maps produced by Layers 1–4 of each branch, drawing inspiration from the ResNet model. represents the spatially spliced feature map and represents the spectrally spliced feature map, and the feature map produced by the two branches is denoted by Equation (4):
where b ∈ {spa, spec} and L ∈ {1,2,3,4}. represents the patch obtained from the HSI. represents the output feature map of the b branch at the L-1 layer. denotes the size of the convolutional kernel, where for two-dimensional convolution and for one-dimensional convolution. ‘’ represents the convolution operation. represents the bias term, and ‘’ denotes the activation function.
Next, we merge and to fuse information from different branches to obtain a richer and integrated feature representation. This fusion enhances the expressiveness and feature diversity of the model. The fusion feature map can be expressed as follows:
where ‘’ denotes merging. The image details, local structure, and global semantic information captured by each convolutional operation are preserved in the fused feature map. This substantially improves the classifier’s ability to perceive and classify feature information at different scales.
2.3. Deep Feature Fusion Backbone
Given that CNNs use a local perceptual field to analyse pictures, each neuron in the network can only perceive a small fraction of the input image. However, when processing HSIs, long-range dependencies need to be recorded because HSI data are strongly connected both geographically and spectrally. In HSIs, a pixel’s class could be connected to its far-off neighbours. In contrast, the transformer plays a significant role in HSI classification tasks given its capacity to handle global contextual information. This enables it to acquire global information about the input image. The transformer was then used as a feature extraction unit in the model presented in this study to extract deep fusion information.
2.3.1. Gaussian Weighted Pixel Embedding
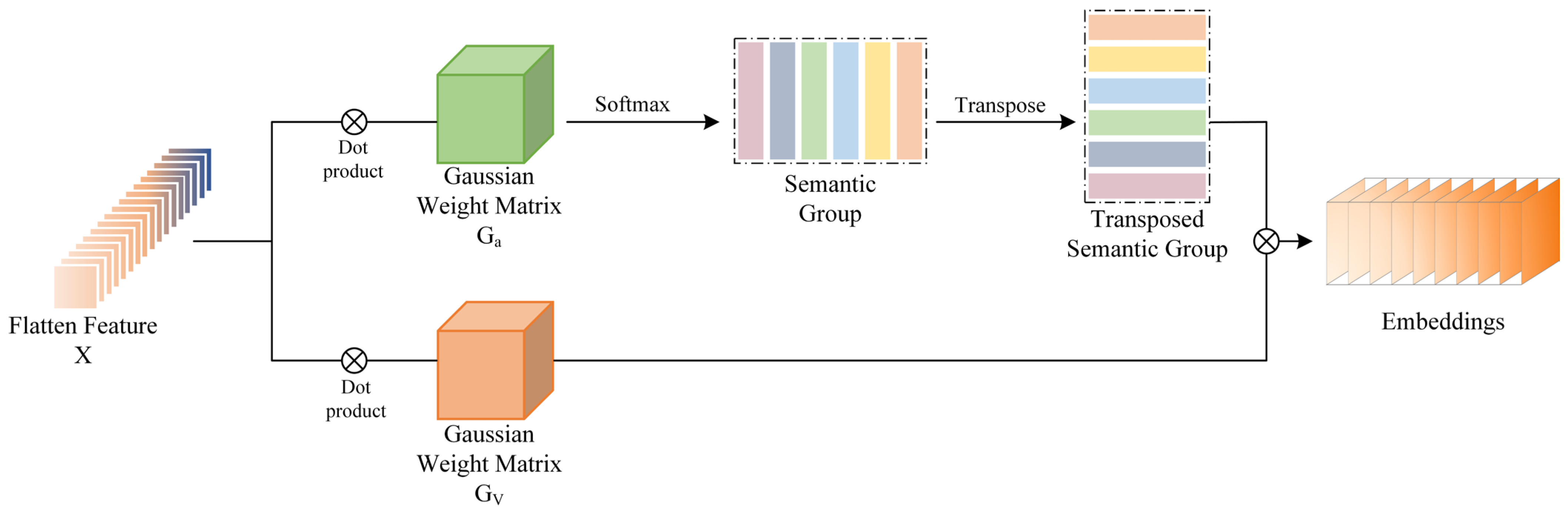
The embedding layer of the Vision Transformer (VIT) model is responsible for converting the incoming picture data into a vector representation that the model can process. The input image is divided by the VIT model into several image blocks, or patches, each of which represents a specific local area of the image. As a result of the embedding layer, each image block is subjected to a linear transformation (often a fully linked layer) to produce a vector representation. However, because this method only considers local parts of the image, the image block representation it produces may make it difficult to model global structures and relationships, especially when working with HSI data that have a lot of context dependencies. The expressive capability of the model may be constrained by the inability of linear transformations employed in embedding, such as fully linked layers, to capture non-linear picture properties and relationships. Given these issues, we suggest an optimisation technique that substitutes pixels for patches in the embedding layer and adds Gaussian weight features. A more detailed description of the details and structure of the image is provided by pixel embedding, which also preserves positional and global information. Pixel embedding collects information about each pixel in an image and maps it separately to a unique vector representation. The capacity to model the overall HSI context is improved by the addition of Gaussian weight features. This allowed us to partially capture the non-linear features and relationships in the image and focus the model more on its main regions and key features.
The GWPE block is shown in Figure 3, and the input to its block is the null-spectrum fusion feature map . and represent Gaussian weight matrices, respectively. denotes the outcome of the features through the embedding layer. This is expressed as shown in the following equation:
Here, denotes the dot product. Mapping to the semantic group SG is conducted by pointwise multiplication of with . Then, the SG is transposed and the softmax function is used to make the transposed SG focus more on important semantic features and suppress unimportant information. SG and are then multiplied with the result after the product to obtain the output feature of the embedding layer.
![Remotesensing 16 00287 g003]()
Figure 3.
Visualisation process of the GWPE block.

2.3.2. Transformer Encoder Block
The MHSA [54] and the feedforward neural network (MLP) layer make up this module, as shown in Figure 1. By creating correlations between input embedding sequences and offering a context-sensitive representation for each vector, the job of the MHSA is to capture global dependencies. Meanwhile, the MLP functions as a local mapping function that aids in the sequence acquisition of regional patterns and contextual data.
The pixel vector features of the input are mapped into distinct vector subspaces named Q (query), K (key), and V (value) by the MHSA to capture feature relationships in various subspaces. A linear transformation is then used to reduce the dimensionality and keep the useful information by concatenating the outputs of several attention heads and projecting them onto the output space. Equation (8) demonstrates how to calculate the similarity between the query and the key:
where the result obtained by dot-multiplying Q with reflects the similarity between these two vectors. To obtain the normalised attention weights, we applied the softmax function to transform the similarity matrix into an attention-weight matrix. The resulting attention-weight matrix is dot-multiplied with the value vector V to obtain the attention value of the MHSA.
The MLP layer conducts nonlinear transformation of attention values and feature extraction in the transformer, transforming the input into a more expressive feature representation. The MLP layer processes the attention values through a combination of multiple linear transformations and nonlinear activation functions. To add more feature dimensions and capture more information, the attention values are first mapped to a higher dimensional space via a first linear transformation. To extract the most valuable characteristics, the expanded feature space is then compressed and reassembled using a second linear transformation. The nonlinear activation function gives the MLP layer nonlinear characteristics, reducing the impact of noise and unimportant data while emphasising and reiterating characteristics pertinent to the modelling objective. Equation (9) can be used to express the MLP layer output:
where and and and are the weights and biases of the two linear transformations, respectively, and ‘’ is the nonlinear activation function. To mitigate covariate bias and provide a relatively stable gradient signal, a layer normalisation (LN) layer was introduced before the MHSA and MLP layers.
3. Experiment and Analysis
3.1. Data Description
This section introduces the five hyperspectral datasets that were used, and Figure 4, Figure 5, Figure 6, Figure 7 and Figure 8 display the raw HSIs and ground truth labelled images of these datasets.
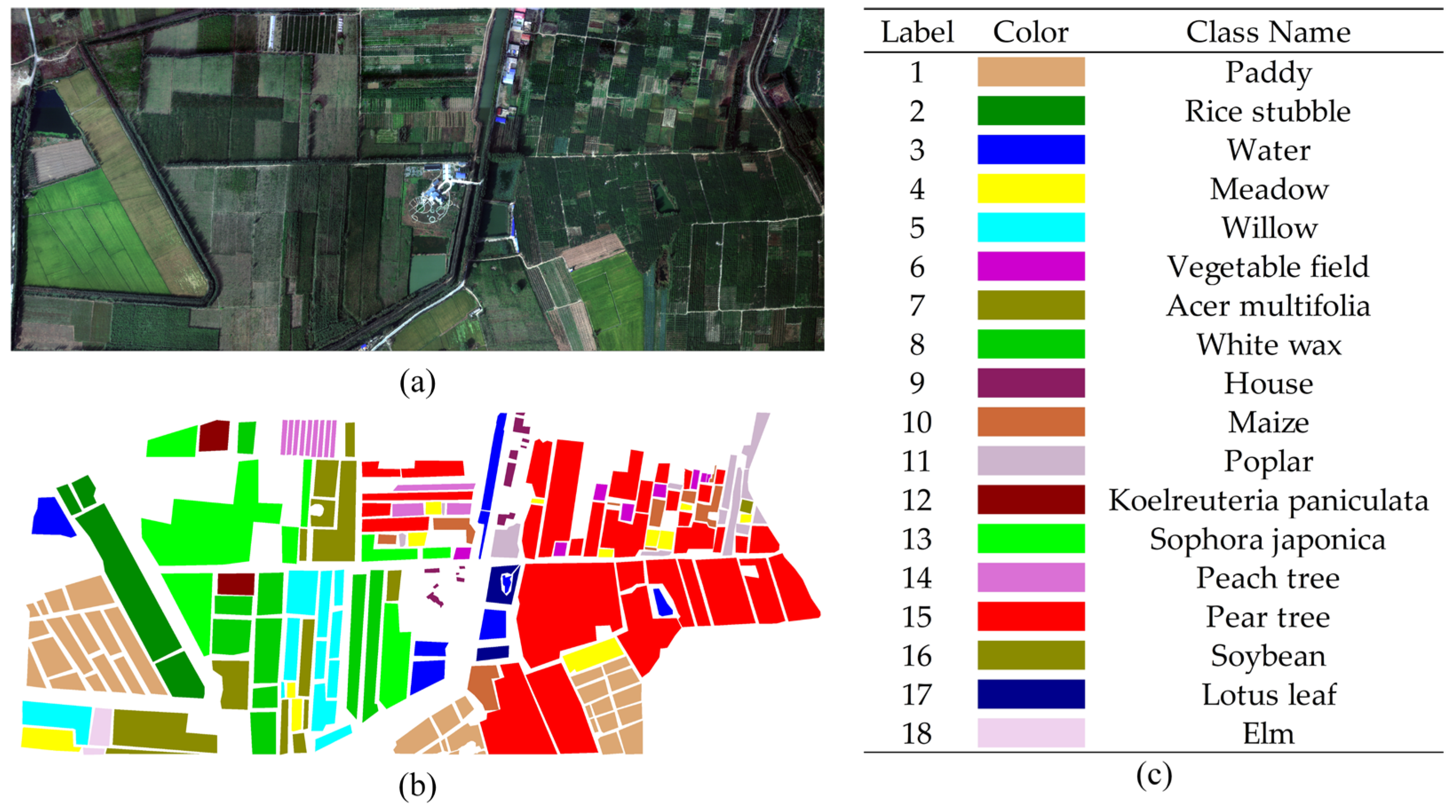
(1) Matiwan Village (MV) dataset: An aerial HSI taken in the Chinese province of Hebei in the village of Matiwan, Xiong’an New Area, Baoding City. With a spectral resolution of 2.1 nm and a range of 400–1000 nm, the dataset consists of 256 bands. The image has a spatial resolution of 0.5 m and 3750 × 1580 image components. Following fieldwork, 18 different varieties of cash crops were chosen as examples for outlining.
![Remotesensing 16 00287 g004]()
Figure 4.
Original HSI and ground truth labels are included in the MV dataset. (a) Original his, (b) ground truth map, and (c) object names and their corresponding colours.
Figure 4.
Original HSI and ground truth labels are included in the MV dataset. (a) Original his, (b) ground truth map, and (c) object names and their corresponding colours.

(2) WHU-LongKou dataset: This dataset consists of a hyperspectral unmanned aerial vehicle image that was taken in Longkou Town, Hubei Province, China, on 17 July 2018. There were no clouds or rain clouds in the sky during data collection. The dataset has a spatial resolution of approximately 0.463 m and a spatial dimension of 400 × 550 pixels. There are 270 bands in a spectral range of 400–1000 nm. Agriculture constitutes most of the research region and six of the nine elements that were defined are related to agriculture.
![Remotesensing 16 00287 g005]()
Figure 5.
Original HSI and ground truth labels are included in the WHU-LongKou dataset. (a) Original his, (b) ground truth map, and (c) object names and their corresponding colours.
Figure 5.
Original HSI and ground truth labels are included in the WHU-LongKou dataset. (a) Original his, (b) ground truth map, and (c) object names and their corresponding colours.

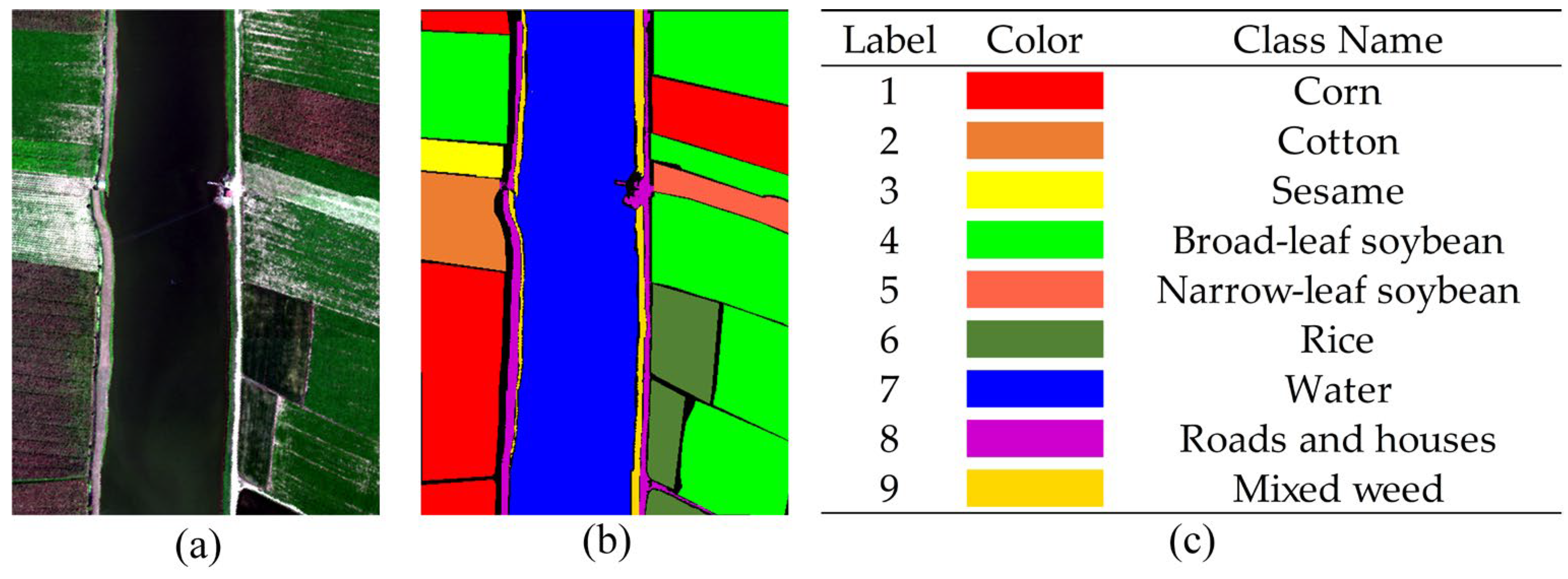
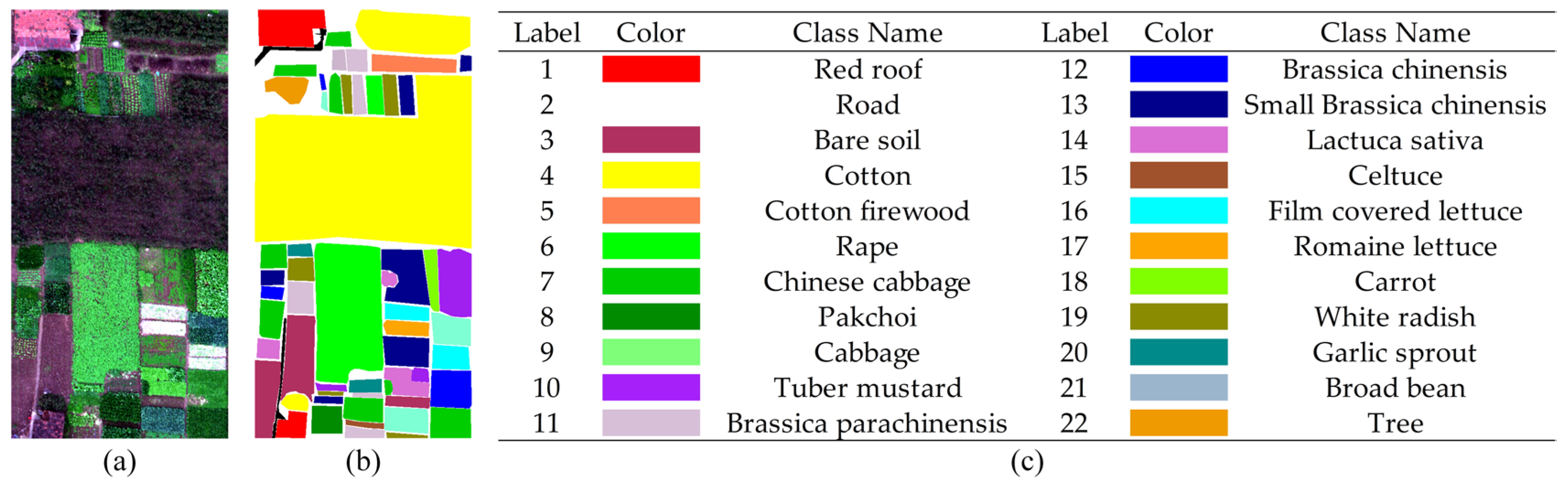
(3) WHU-HongHu dataset: This dataset was collected on 20 November 2017 in Honghu City, Hubei Province, China. During the collection process, the UAV data were obscured by a small amount of cloud cover. The dataset has a spatial extent of 940 × 475 pixels, a spatial resolution of 0.043 m, and contains a total of 270 bands. The dataset mainly covers a wide range of complex crop types, and has a high degree of similarity between specific feature classes, such as Chinese cabbage/cabbage and Brassica chinensis/small Brassica chinensis. In total, 22 feature types were outlined.
![Remotesensing 16 00287 g006]()
Figure 6.
Original HSI and ground truth labels are included in the WHU-HongHu dataset. (a) Original his, (b) ground truth map, and (c) object names and their corresponding colours.
Figure 6.
Original HSI and ground truth labels are included in the WHU-HongHu dataset. (a) Original his, (b) ground truth map, and (c) object names and their corresponding colours.

(4) Houston dataset: This dataset was provided by the GRSS Data Fusion Contest 2013, and its scope was the University of Houston and its neighbouring cities. The dataset has a spatial extent of 1905 × 349 with a spatial resolution of 2.5 m and a total of 144 bands. The dataset contains 15 different feature classes such as roofs, streets, gravelled roads, grass, trees, water, and shadows.
![Remotesensing 16 00287 g007]()
Figure 7.
Original HSI and ground truth labels are included in the Houston dataset. (a) Original his, (b) ground truth map, and (c) object names and their corresponding colours.
Figure 7.
Original HSI and ground truth labels are included in the Houston dataset. (a) Original his, (b) ground truth map, and (c) object names and their corresponding colours.

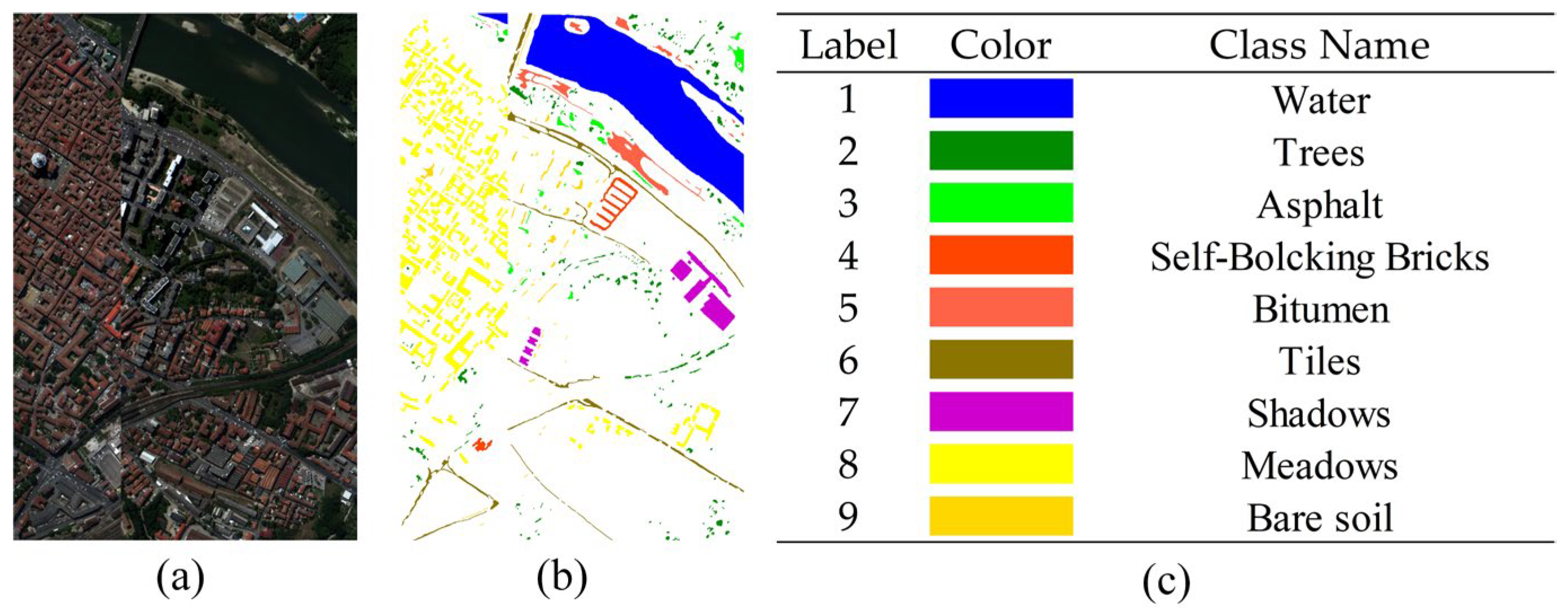
(5) Pavia Centre (PC) dataset: The northern Italian city of Pavia was the collection point for the PC dataset. The dataset has 102 bands with an image size of 1096 by 715 pixels, spanning the spectral range from 380 nm to 1050 nm. Nine distinct feature classes, including roads, trees, grass, water, and buildings, are present in the dataset.
![Remotesensing 16 00287 g008]()
Figure 8.
Original HSI and ground truth labels are included in the PC dataset. (a) Original his, (b) ground truth map, and (c) object names and their corresponding colours.
Figure 8.
Original HSI and ground truth labels are included in the PC dataset. (a) Original his, (b) ground truth map, and (c) object names and their corresponding colours.

3.2. Experimental Setup
(1) Configuration of the workstations: To maintain equity, we conducted the trials using workstations outfitted with Intel(R) Xeon(R) Gold 5218R CPUs, NVIDIA GeForce RTX 3080 GPUs, and 128 GB of RAM, running Windows 10. Using the PyTorch deep learning framework, all the models underwent training. We implemented an early terminating training technique and limited the number of training epochs to 300. This indicated that we would terminate training and store the best model if the loss function stopped decreasing, that is, approached saturation, for 30 consecutive epochs. The early halting method speeds up training while assisting in preventing the overfitting of the model. The experiment results are more reliable because we repeated each experiment ten times and used the mean treatment.
(2) Input settings: We experimented on five datasets, progressively increasing the patch size from 5 × 5 to 15 × 15, to establish the ideal patch size. Considerations were the model computing expense, the accuracy of the experiments, and the capacity of the image to capture rich contextual information and minute features. Ultimately, we decided that the patch input size for this experiment would be 11 × 11.
(3) Sample proportion setting: For the training, validation, and test sets of the five HSI datasets, different sample proportions were used in this experiment. For the MV dataset, 1% of the total data were chosen at random to serve as the training and validation sets, and the other 98% were the test set. From the WHU-LongKou dataset, 99.8% of the labelled data were used for testing, 0.1% for validation, and 0.1% for training. From the WHU-HongHu dataset, 0.5%, 0.5%, and 99% of the samples were chosen for testing, validation, and training, respectively. From the Houston dataset, the percentage of labelled samples used for testing, validation, and training was 90%, 5%, and 5%, respectively. The percentages for the PC dataset were 1%, 1%, and 98%.
(4) Learning rate setting: For this, we experimented with five different learning rates (1E-3, 1E-4, 5E-4, 1E-5, and 5E-5) and tested the model against five datasets. After conducting numerous rounds of trials, we ascertained that 1E-4 represents the ideal learning rate size. The model performance and the outcomes of the experiment were carefully considered before making this decision.
(5) Evaluation Criteria: The overall accuracy (OA), average accuracy (AA), and kappa coefficient were important metrics for evaluating the goodness of the classification results. OA provides an intuitive measure of the overall classification accuracy, AA considers the evaluation in the case of category imbalance, and the kappa coefficient measures the consistency of the model classification results with the randomised classification. Their calculation formulas are as follows:
where represents the overall accuracy of each class, C represents the confusion matrix, and K represents the number of land cover classes in the dataset. Thus, . For any given pixel, represents the number of samples where the jth class is classified as the ith class, represents the number of true labels for the ith class, and represents the number of predicted labels for the ith class. M represents the total number of samples.
3.3. Experimental Results
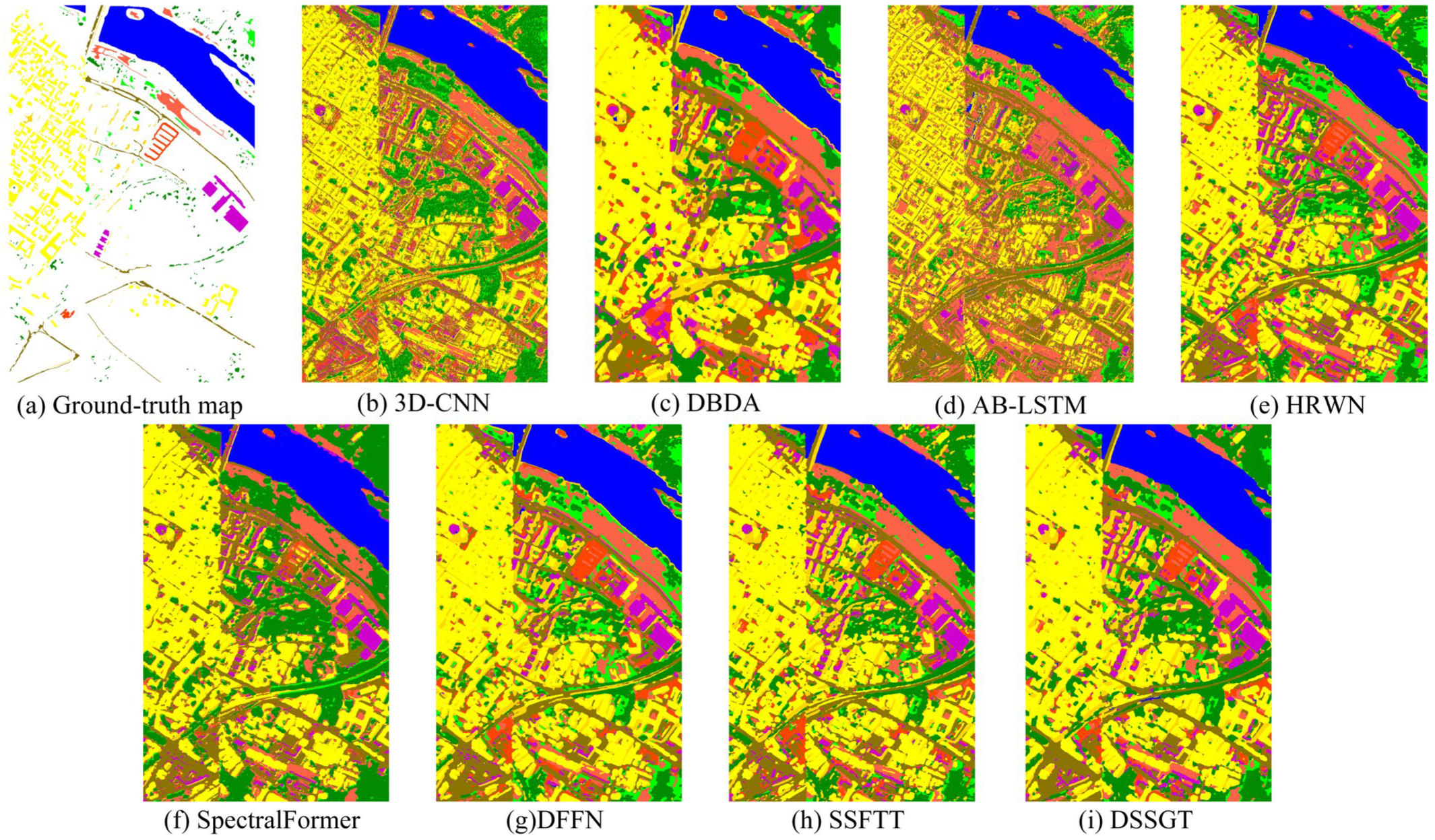
We compared the proposed method with seven classical and novel deep learning HSI classification models, including 3D-CNN [55], DBDA [40], AB-LSTM [56], HRWN [57], SpectralFormer [58], DFFN [31], and SSFTT [47]. Three convolutional layers and two pooling layers comprise a 3D-CNN. Convolutional layers, spatial attention modules, and channel attention modules are used by DBDA to extract features. Based on a recurrent neural network, the AB-LSTM is a bidirectional long- and short-term memory HSI classification network. An effective hierarchical random walk joint classification network is the hierarchical random walk network. Based on the transformer architecture, SpectralFormer is an HSI classification model that excels at processing high-dimensional, multi-channel data. It extracts features and classifies them using a multilayer perceptron and self-attention mechanism. Recursive learning is used by DFFN, a deep feature fusion network, to streamline the training procedure. High-level semantic characteristics and null-spectrum features are captured using the transformer-based HSI classification model SSFTT.
(1) Experimental Results for the MV Dataset: In Table 1 and Figure 9, we show the classification effectiveness of this dataset among eight methods. In Table 1, ‘Train’ represents the number of pixels used for training, while ‘Test’ represents the number of pixels used for testing. The proposed method demonstrated the highest OA, AA, and kappa coefficient on the MV dataset. While DSSGT achieved the highest average precision among the 13 classes, it struggled to accurately classify the ’Maize (label 10)’ and ‘Soybean (label 16)’ land cover types, as observed in Figure 9. Insufficient training samples for these two classes limited the ability of all methods to learn their specific features, resulting in subpar classification performance. However, the GWPE-based transformer module excelled at learning long-range global features from small sample sizes, enabling it to achieve reasonable results even with limited training data. DSSGT boasted an average training time of 7.72 s per epoch, providing a 2.18 s advantage over SSFTT. Although HRWN had the fastest training speed, its classification accuracy fell short. DSSGT tackled this issue by using dilated convolutions as feature extraction units, effectively expanding the receptive field while improving training efficiency. This demonstrated an effective balance between performance and efficiency. The MV dataset primarily consists of land cover types associated with economic crops including maize, soybean, and trees, which share similar spectral characteristics. However, Figure 9 shows that the DSSGT model performed effectively on the MV dataset, yielding the highest similarity between the generated land cover classification map and the ground truth map. This highlights the advantages of DSSGT in capturing subtle spectral differences and spatial contextual information, enabling superior differentiation among these visually similar categories.
(2) Experimental Results for the WHU-LongKou Dataset: Table 2 and Figure 10 contain an accuracy evaluation table and classification effect graphs for this dataset. We only chose 0.1% of the labelled samples as the training set and there were five categories in this training set with less than 10 pixels of training samples. The DSSGT method demonstrated the highest OA of 91.96%, while the DFFN method achieved the highest kappa coefficient (96.51%). All methods exhibited relatively low AA, which suggests a potential impact of data imbalance. The significant disparity in the number of training and testing samples may have adversely affected the performance of the classifiers. To mitigate this issue, the GWPE approach introduced a Gaussian weighted matrix, assigning higher weights to minority classes to give them more attention. Consequently, the DSSGT method achieved the highest AA (66.55%). Figure 10 shows that all methods incorrectly classified ‘Sesame (Label 3)’ as ‘Broad-leaf soybean (Label 4)’. This misclassification can be attributed to the high similarity between these two classes in terms of spectral features, making them challenging to differentiate. However, our proposed method excelled in distinguishing between these two categories by simultaneously extracting spectral, spatial, and texture features from the input data.
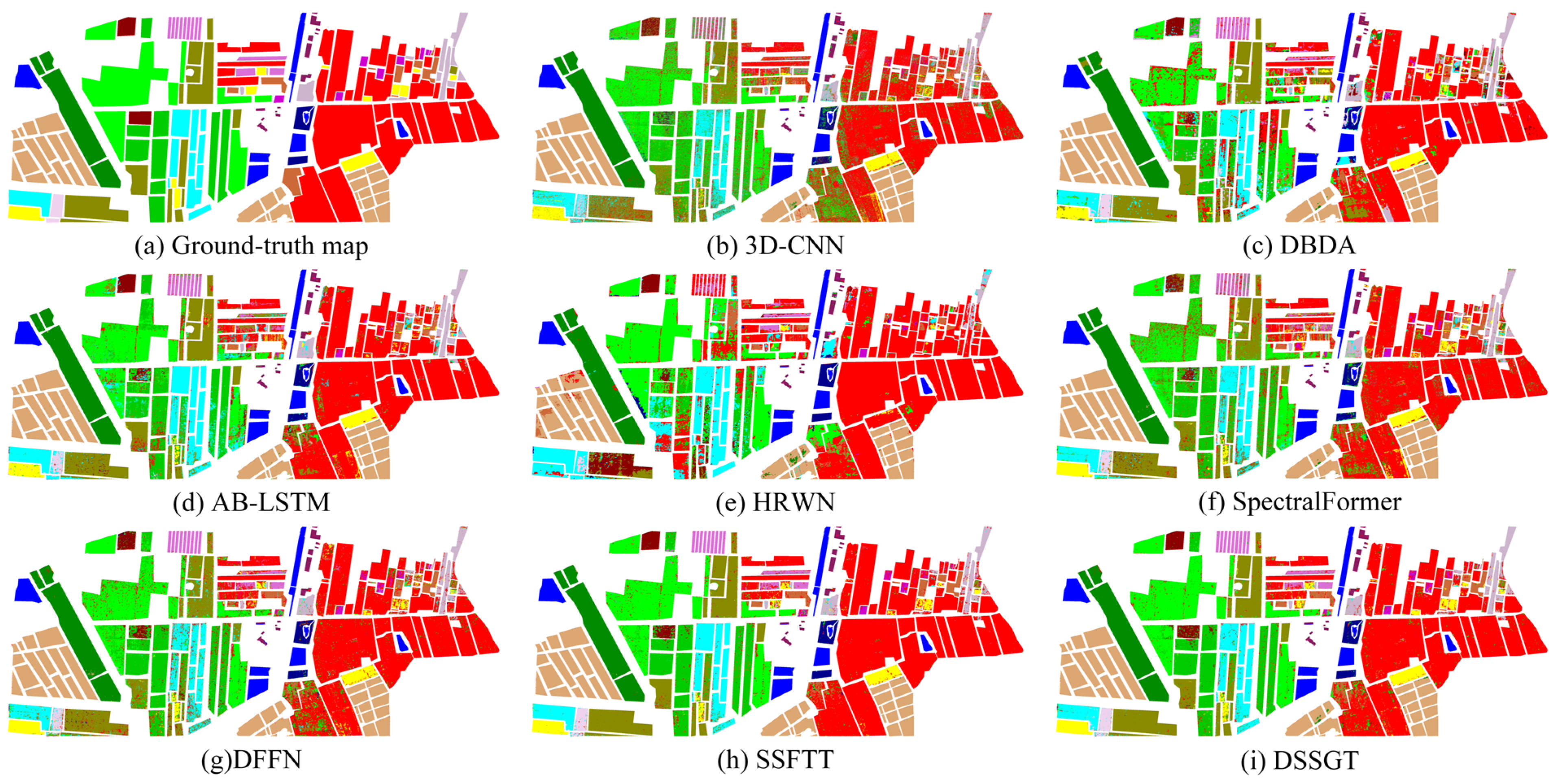
(3) Experimental results for the WHU-HongHu Dataset: Table 3 and Figure 11 illustrate the quantitative evaluation results of the WHU-HongHu dataset. DBDA and SSFTT achieved accuracy results on par with DSSGT, indicating their effective use of spatial–spectral attention mechanisms. By leveraging these mechanisms, they could more effectively capture the interdependencies and contextual information among land cover categories. This enhanced capability allowed the models to accurately discern the spatial distribution patterns of land features, thereby improving the overall classification accuracy. However, while DSSGT excelled in achieving the highest classification accuracy in 11 out of the 22 land cover classes, it accounted for only half of the total classes. This discrepancy may be attributed to the greater similarity among the remaining 11 land cover classes, posing challenges for the classifier to accurately differentiate them. Consequently, future model optimisation efforts should focus on using more refined and sophisticated feature extraction techniques and classifier designs to effectively tackle classes with similar features.
(4) Experimental Results for the Houston Dataset: Figure 12 shows the corresponding feature classification maps, while Table 4 displays the classification outcomes for DSSGT and the other seven classifiers. The classification model appears to have a high level of accuracy overall and across categories and a high level of consistency with the random selection. This is because DSSGT produced the best classification results and the three evaluation factors were relatively close. Given the limited training samples and the variety of data sources, the current dataset DBDA representation is relatively weak. This made it difficult for the conventional two-channel attentional mechanism to effectively capture useful characteristics. Meanwhile, SSFTT and DSSGT based on MHSA can better understand the long-distance connections between features, which enhances the classification outcomes. The classification maps generated using 3D-CNN exhibit numerous isolated noise points and discontinuous pixels, indicating a considerable issue with salt-and-pepper noise. This could be attributed to the limited robustness of 3D-CNN in handling noise and variations in details during land cover classification. Meanwhile, DBDA struggles to differentiate subtle variations between different species, incorrectly categorising large patches as the same category and disregarding inter-species differences. In contrast, the classification maps produced by DFFN, SSFTT, and DSSGT show significant improvements. These models demonstrated enhanced accuracy in identifying subtle variations and differences between species, effectively eliminating the salt-and-pepper noise phenomenon, and improving image quality.
(5) Experimental Results for the PC Dataset: The findings of the quantitative evaluation metrics and classification plots for the PC dataset are shown in Table 5 and Figure 13. In this dataset, DSSGT outperformed other methods in terms of evaluation metrics such as OA, AA, and the kappa coefficient. This highlights its effectiveness in capturing complex spatial relationships between land cover categories. This indicates that DSSGT exhibits stronger capabilities in modelling dependencies and contextual information among different land features, resulting in more accurate and consistent classification results. The observed discontinuities and patchy patterns in the classification maps generated by 3D-CNN and AB-LSTM raise concerns about their ability to capture fine-grained details and handle spatial variations. This can lead to misclassifications and inconsistencies in land cover recognition. In contrast, the classification maps generated by DSSGT are smooth and accurate, demonstrating its ability to effectively eliminate patchy structures and produce visually coherent results. This is attributed to the attention mechanisms and the model’s ability to capture long-range dependencies, enabling it to better capture spatial context and generate more refined classification boundaries.
3.4. Discussion
3.4.1. Ablation Experiments
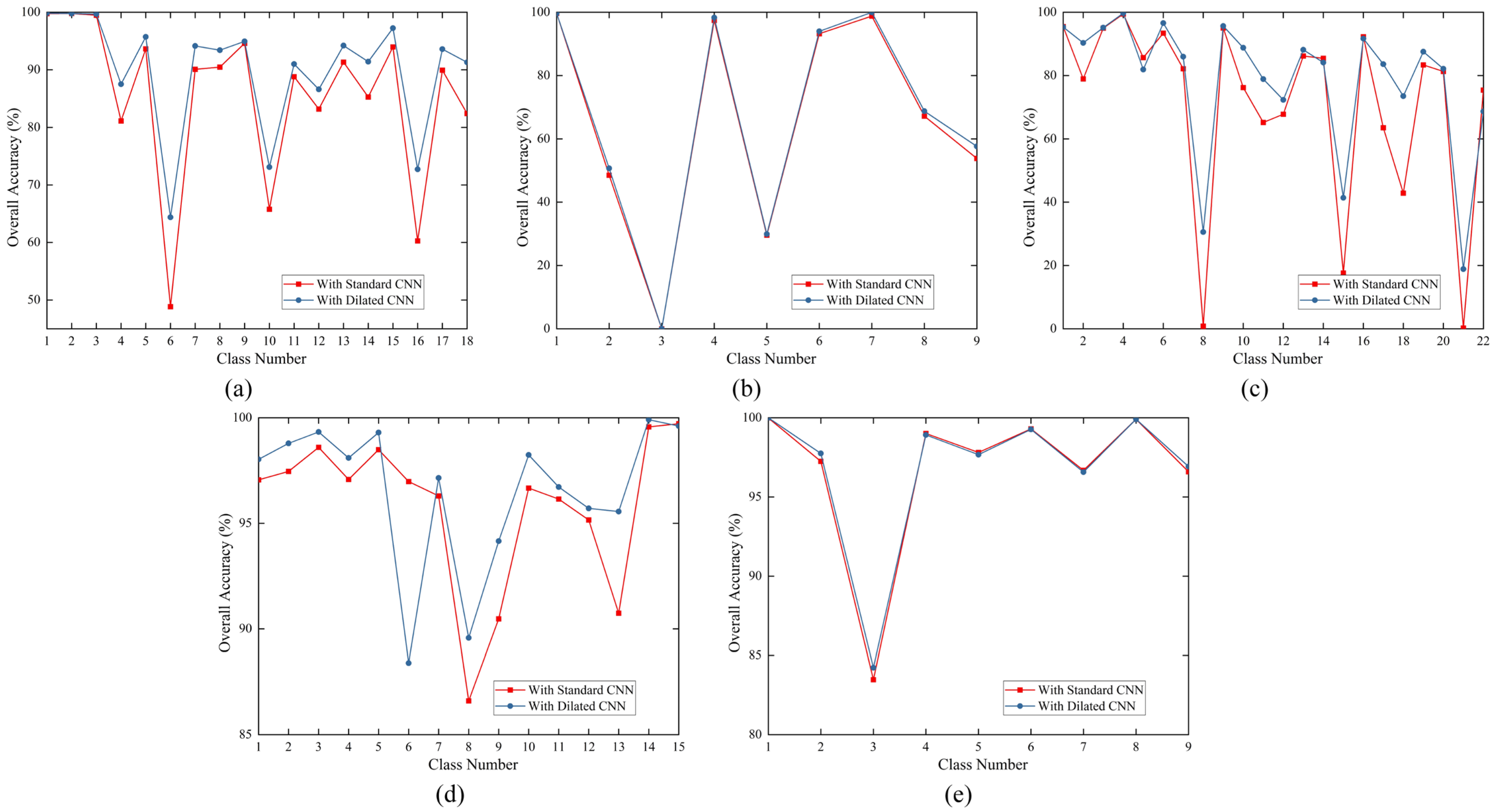
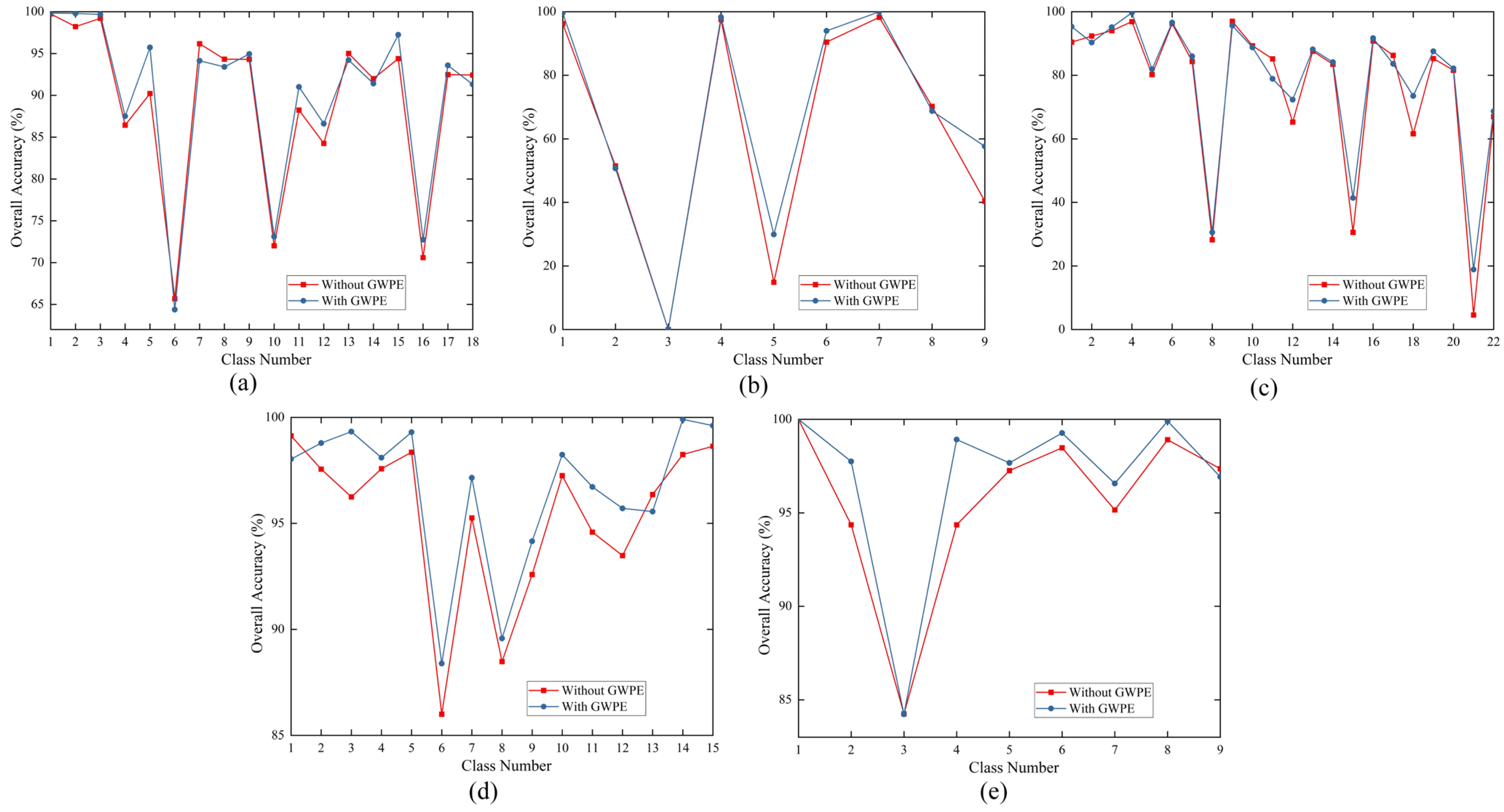
We performed ablation tests on five datasets to validate the efficacy of the novel component of our suggested technique. The effectiveness of the dilated convolution in comparison to that of the standard convolution was assessed in the first section of the ablation experiments, and the effectiveness of the GWPE block was assessed in the second section. The experimental results are presented in Table 6, where each dataset’s first row represents the usage of standard convolution with GWPE. The second row corresponds to the usage of dilated convolution without GWPE, and the third row represents the usage of dilated convolution with GWPE.
(1) Impact of dilated convolutions: Table 6 shows the results from adjusting the variables using the GWPE scenario, using standard and dilated convolution, respectively, in the first and third rows of each dataset. In all five datasets, utilising dilated convolution resulted in greater OA, AA, and kappa coefficients than doing so with normal convolution. This is because our model’s input patch size was 11. The range of the receptive field included the global data of the input patches when we used three consecutive dilated convolutional layers with dilation rates of one, two, and five. This architecture enhanced the model’s performance on the dataset by enabling it to capture the contextual and general aspects of the input data more effectively. Figure 14 uses standard and dilated convolution for each category to illustrate the effects of DSSGT on five datasets. The graphed results show that the accuracy of feature categorisation is not significantly affected by the type of convolution used, for both the WHU-LongKou and PC datasets. The usage of dilated convolution performs better in several of the poorly categorised feature classes, as shown by the other three datasets. Specific categories that benefited from the use of dilation convolution include ‘vegetable field (Label 6)’ in the MV dataset, ‘Pakchoi (Label 8)’ in the WHU-HongHu dataset, and ‘commercial (Label 8)’ in the Houston dataset. This shows that dilation convolution has an advantage over typical standard convolution in capturing feature categories whose features are concealed or inconspicuous and can do so more effectively.
(2) Impact of GWPE: GWPE is the most critical component of the DSSGT module. It enhances the classification performance by introducing Gaussian weights to emphasise important parts of the input features. In Table 6, the second and third rows for each dataset represent the classification results with and without the GWPE module, respectively. Figure 15 shows the influence of GWPE on each category. The framework with GWPE achieved an OA improvement of 3.7% compared to the regular framework on the MV dataset. Similar results were observed with the WHU-LongKou and WHU-HongHu datasets, with an OA increase of approximately 1% in both cases. However, given the already high initial OA values in the Houston and PC datasets, the improvement brought by GWPE is not significant. Nevertheless, the annotations in Figure 15 indicate that GWPE has a positive impact on all land cover classification tasks in the Houston and PC datasets. The introduction of GWPE enables the model to more effectively capture the distinctions between land cover categories and the correlations among features, significantly enhancing the classification accuracy and performance.
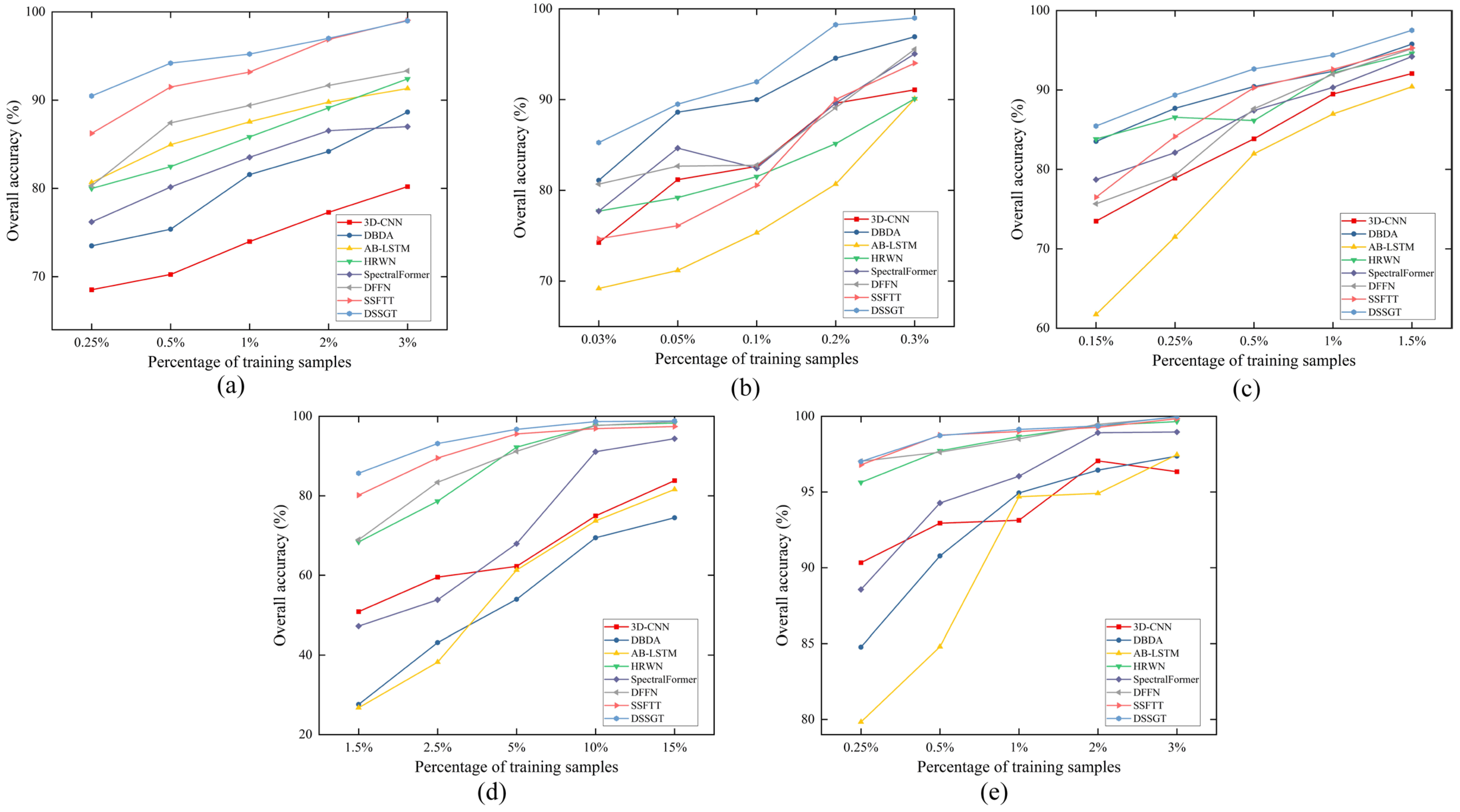
3.4.2. Robustness Evaluation
We conducted tests on five datasets to examine the impact of various ratios on the outcomes by reducing or increasing the number of their training samples by two or three times, respectively. This was performed to ensure the stability of the suggested strategy. For instance, we selected the 0.25%, 0.5%, 2%, and 3% labelled samples as the training set for the MV dataset. Figure 16 shows the quantitative results of different classifiers, which demonstrate that DSSGT outperformed the other methods. However, the improvement in DSSGT compared to other methods is not significant for datasets such as WHU-LongKou, Houston, and PC, which have a large proportion of training samples. Meanwhile, when faced with extremely limited sample sizes, the advantage of DSSGT becomes more pronounced. This indicates that the proposed method not only performs well with an ample amount of sample data but also demonstrates superior results in scenarios with limited sample data. In contrast, AB-LSTM performs poorly in small-sample scenarios, emphasising the superiority and stability of DSSGT in addressing data scarcity issues.
4. Conclusions
In this study, we proposed a novel HSI classification model called DSSGT. Our model incorporates several key components aimed at improving performance and enhancing contextual understanding of the classification task. We introduced a feature extraction module based on dilated convolutions to effectively capture shallow spectral features within input image patches. By stacking multiple dilated convolutional layers with varying dilation rates but the same kernel size, we expanded the receptive field. This design enabled us to capture a wider range of contextual information while preserving local details. Through the progressive stacking of dilated convolutional layers, we gradually extended the feature extraction range, enabling the model to more effectively comprehend the global structure and relationships within the input data. Next, we fed the extracted shallow features from the feature extraction module into the GWPE module, transforming them into pixel-level vector representations. This module combines the features of each pixel with its surrounding pixels in a Gaussian weighted manner, thereby generating more expressive and context-aware pixel-level representations. We then input the obtained pixel-level vector matrix into the transformer encoder blocks to generate deep long-range fused features. By stacking MLP and MHSA layers, we could effectively capture global dependencies within the input data and generate more expressive and discriminative feature representations. We performed global average pooling on the deep long-range fused features to generate a classification probability map. This map provided category probability information for each pixel in the HSI. We conducted comparative experiments on five datasets, comparing DSSGT with seven state-of-the-art methods. The consistent experimental results have demonstrated the substantial advantages of DSSGT across all datasets, validating the effectiveness of our proposed approach.
Author Contributions
Conceptualization, Z.Z. and S.W.; methodology, Z.Z.; software, S.W.; validation, Z.Z., W.Z. and S.W.; formal analysis, Z.Z.; investigation, Z.Z.; resources, S.W.; data curation, S.W.; writing—original draft preparation, Z.Z.; writing—review and editing, Z.Z.; visualization, S.W.; supervision, W.Z.; project administration, S.W.; funding acquisition, W.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was co-supported by the National Natural Science Foundation of China (Grant 41672358), the Second Tibetan Plateau Scientific Expedition and Research (2019QZKK0707), and the Basic Science Centre for Tibetan Plateau Earth System (CTPES, Grant 41988101-01).
Data Availability Statement
The MV dataset used in this study is available at http://www.hrs-cas.com/a/share/shujuchanpin/2019/0501/1049.html, accessed on 15 August 2023; the WHU-HongHu and WHU-LongKou dataset used in this study are available at http://rsidea.whu.edu.cn/resource_WHUHi_sharing.htm, accessed on 15 August 2023; the Houston dataset used in this study is available at https://hyperspectral.ee.uh.edu/?page_id=1075, accessed on 15 August 2023; the PC dataset is available from https://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes, accessed on 15 August 2023.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Liu, M.; Zhao, J.; Zheng, J.; Wu, R. Review of Hyperspectral Imaging in Quality and Safety Inspections of Agricultural and Poultry Products. Trans. Chin. Soc. Agric. Mach. 2005, 36, 139–143. [Google Scholar]
- Wu, D.; Sun, D.-W. Advanced applications of hyperspectral imaging technology for food quality and safety analysis and assessment: A review—Part I: Fundamentals. Innov. Food Sci. Emerg. Technol. 2013, 19, 1–14. [Google Scholar] [CrossRef]
- Cui, R.; Yu, H.; Xu, T.; Xing, X.; Cao, X.; Yan, K.; Chen, J. Deep Learning in Medical Hyperspectral Images: A Review. Sensors 2022, 22, 9790. [Google Scholar] [CrossRef]
- Gerdes, N.; Hoff, C.; Hermsdorf, J.; Kaierle, S.; Overmeyer, L. Hyperspectral imaging for prediction of surface roughness in laser powder bed fusion. Int. J. Adv. Manuf. Technol. 2021, 115, 1249–1258. [Google Scholar] [CrossRef]
- Dong, X.; Yan, B.; Gan, F.; Li, N. Progress and prospectives on engineering application of hyperspectral remote sensing for geology and mineral resources. In Proceedings of the Fifth Symposium on Novel Optoelectronic Detection Technology and Application, Xi’an, China, 24–26 October 2018; SPIE: Bellingham, WA, USA, 2019. [Google Scholar]
- Luo, H.; Kan, Y.; Wang, L.; Fang, J.; Dai, S. Hyperspectral remote sensing for crop diseases and pest dectection. Guandong Agric. Sci. 2012, 39, 76–80. [Google Scholar]
- Sun, L.; He, C.; Zheng, Y.; Tang, S. SLRL4D: Joint Restoration of Subspace Low-Rank Learning and Non-Local 4-D Transform Filtering for Hyperspectral Image. Remote Sens. 2020, 12, 2979. [Google Scholar] [CrossRef]
- Wang, R.; Li, H.-C.; Liao, W.; Huang, X.; Philips, W. Centralized Collaborative Sparse Unmixing for Hyperspectral Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1949–1962. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef]
- Ge, H.; Tang, Y.; Bi, Z.; Zhan, T.; Xu, Y.; Song, A. MMSRC: A Multidirection Multiscale Spectral-Spatial Residual Network for Hyperspectral Multiclass Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9254–9265. [Google Scholar] [CrossRef]
- Hou, Z.; Li, W.; Li, L.; Tao, R.; Du, Q. Hyperspectral Change Detection Based on Multiple Morphological Profiles. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5507312. [Google Scholar] [CrossRef]
- Chen, H.; Du, X.; Liu, Z.; Cheng, X.; Zhou, Y.; Zhou, B. Target Recognition Algorithm for Fused Hyperspectral Image by Using Combined Spectra. Spectrosc. Lett. 2015, 48, 251–258. [Google Scholar] [CrossRef]
- Haitao, L.I.; Haiyan, G.U.; Bing, Z.; Lianru, G.A.O. Research on Hyperspectral Remote Sensing Image Classification Based on MNF and SVM. Remote Sens. Inf. 2007, 12–15, 25. [Google Scholar]
- Ma, X.; Yan, W.; Bian, H.; Sun, B.; Wang, P. Hyperspectral Remote Sensing Classification Based on SVM with End-member Extraction. In Proceedings of the MIPPR 2013: Remote Sensing Image Processing, Geographic Information Systems, and Other Applications, Wuhan, China, 26–27 October 2013; SPIE: Bellingham, WA, USA, 2013. [Google Scholar]
- Li, Y.; Wang, H.; Lv, X. The Comparison of Several Classification Algorithms and Case Analysis. In Proceedings of the International Conference on Graphic and Image Processing (ICGIP 2012), Singapore, 5–7 October 2012; SPIE: Bellingham, WA, USA, 2013. [Google Scholar]
- Zeng, Y.; Yang, Y.; Zhao, L. Nonparametric classification based on local mean and class statistics. Expert Syst. Appl. 2009, 36, 8443–8448. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Villa, A.; Benediktsson, J.A.; Chanussot, J.; Bruzzone, L. Classification of Hyperspectral Images by Using Extended Morphological Attribute Profiles and Independent Component Analysis. IEEE Geosci. Remote Sens. Lett. 2011, 8, 542–546. [Google Scholar] [CrossRef]
- Su, H.; Sheng, Y.; Du, P.; Chen, C.; Liu, K. Hyperspectral image classification based on volumetric texture and dimensionality reduction. Front. Earth Sci. 2015, 9, 225–236. [Google Scholar] [CrossRef]
- Wang, Z.; Du, B.; Zhang, L.; Zhang, L. Based on Texture Feature and Extend Morphological Profile Fusion for Hyperspectral Image Classification. Acta Photonica Sin. 2014, 43, 0810002. [Google Scholar] [CrossRef]
- Licciardi, G.; Marpu, P.R.; Chanussot, J.; Benediktsson, J.A. Linear Versus Nonlinear PCA for the Classification of Hyperspectral Data Based on the Extended Morphological Profiles. IEEE Geosci. Remote Sens. Lett. 2012, 9, 447–451. [Google Scholar] [CrossRef]
- Ren, Y.; Liao, L.; Maybank, S.J.; Zhang, Y.; Liu, X. Hyperspectral Image Spectral-Spatial Feature Extraction via Tensor Principal Component Analysis. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1431–1435. [Google Scholar] [CrossRef]
- Liu, J. Hyperspectral Remote Sensing Image Terrain Classification Based on Direct LDA. Comput. Sci. 2011, 38, 274–277. [Google Scholar]
- Yang, M.; Fan, Y.; Li, B. Research on dimensionality reduction and classification of hyperspectral images based on LDA and ELM. J. Electron. Meas. Instrum. 2020, 34, 190–196. [Google Scholar]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, X.; Ye, Y.; Lau, R.Y.K.; Lu, S.; Li, X.; Huang, X. Synergistic 2D/3D Convolutional Neural Network for Hyperspectral Image Classification. Remote Sens. 2020, 12, 2033. [Google Scholar] [CrossRef]
- Shi, C.; Liao, D.; Zhang, T.; Wang, L. Hyperspectral Image Classification Based on Expansion Convolution Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5528316. [Google Scholar] [CrossRef]
- Li, J.; Zhao, X.; Li, Y.; Du, Q.; Xi, B.; Hu, J. Classification of Hyperspectral Imagery Using a New Fully Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 292–296. [Google Scholar] [CrossRef]
- He, N.; Paoletti, M.E.; Mario Haut, J.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Feature Extraction with Multiscale Covariance Maps for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 755–769. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 770–778. [Google Scholar]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral Image Classification with Deep Feature Fusion Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Feng, F.; Zhang, Y.; Zhang, J.; Liu, B. Small Sample Hyperspectral Image Classification Based on Cascade Fusion of Mixed Spatial-Spectral Features and Second-Order Pooling. Remote Sens. 2022, 14, 505. [Google Scholar] [CrossRef]
- Meng, Z.; Zhao, F.; Liang, M.; Xie, W. Deep Residual Involution Network for Hyperspectral Image Classification. Remote Sens. 2021, 13, 3055. [Google Scholar] [CrossRef]
- Wang, S.; Liu, Z.; Chen, Y.; Hou, C.; Liu, A.; Zhang, Z. Expansion Spectral-Spatial Attention Network for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 6411–6427. [Google Scholar] [CrossRef]
- Zhao, C.; Zhu, W.; Feng, S. Hyperspectral Image Classification Based on Kernel-Guided Deformable Convolution and Double-Window Joint Bilateral Filter. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5506505. [Google Scholar] [CrossRef]
- Zhao, Z.; Xu, X.; Li, J.; Li, S.; Plaza, A. Gabor-Modulated Grouped Separable Convolutional Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5518817. [Google Scholar] [CrossRef]
- Xu, F.; Zhang, G.; Song, C.; Wang, H.; Mei, S. Multiscale and Cross-Level Attention Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5501615. [Google Scholar] [CrossRef]
- Wang, X.; Tan, K.; Du, P.; Pan, C.; Ding, J. A Unified Multiscale Learning Framework for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4508319. [Google Scholar] [CrossRef]
- Wang, L.; Zhu, T.; Kumar, N.; Li, Z.; Wu, C.; Zhang, P. Attentive-Adaptive Network for Hyperspectral Images Classification with Noisy Labels. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5505514. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Yang, Y.; Wang, X. Classification of Hyperspectral Image Based on Double-Branch Dual-Attention Mechanism Network. Remote Sens. 2020, 12, 582. [Google Scholar] [CrossRef]
- Cai, W.; Ning, X.; Zhou, G.; Bai, X.; Jiang, Y.; Li, W.; Qian, P. A Novel Hyperspectral Image Classification Model Using Bole Convolution with Three-Direction Attention Mechanism: Small Sample and Unbalanced Learning. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5500917. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Gao, F.; Huang, H.; Yue, Z.; Li, D.; Ge, S.S.; Lee, T.H.; Zhou, H. Cross-Modality Features Fusion for Synthetic Aperture Radar Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5214814. [Google Scholar] [CrossRef]
- Zhong, H.-F.; Sun, Q.; Sun, H.-M.; Jia, R.-S. NT-Net: A Semantic Segmentation Network for Extracting Lake Water Bodies from Optical Remote Sensing Images Based on Transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5627513. [Google Scholar] [CrossRef]
- Zhang, C.; Su, J.; Ju, Y.; Lam, K.-M.; Wang, Q. Efficient Inductive Vision Transformer for Oriented Object Detection in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5616320. [Google Scholar] [CrossRef]
- Zhou, Y.; Chen, S.; Zhao, J.; Yao, R.; Xue, Y.; El Saddik, A. CLT-Det: Correlation Learning Based on Transformer for Detecting Dense Objects in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4708915. [Google Scholar] [CrossRef]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral–Spatial Feature Tokenization Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5522214. [Google Scholar] [CrossRef]
- Zhang, J.; Meng, Z.; Zhao, F.; Liu, H.; Chang, Z. Convolution Transformer Mixer for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6014205. [Google Scholar] [CrossRef]
- Cao, X.; Lin, H.; Guo, S.; Xiong, T.; Jiao, L. Transformer-Based Masked Autoencoder with Contrastive Loss for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5524312. [Google Scholar] [CrossRef]
- Li, B.; Wang, Q.-W.; Liang, J.-H.; Zhu, E.-Z.; Zhou, R.-Q. SquconvNet: Deep Sequencer Convolutional Network for Hyperspectral Image Classification. Remote Sens. 2023, 15, 983. [Google Scholar] [CrossRef]
- Qiu, Z.; Xu, J.; Peng, J.; Sun, W. Cross-Channel Dynamic Spatial-Spectral Fusion Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5528112. [Google Scholar] [CrossRef]
- Zhao, Z.; Hu, D.; Wang, H.; Yu, X. Convolutional Transformer Network for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6009005. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV 2018), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: New York, NY, USA, 2018; pp. 1451–1460. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ben Hamida, A.; Benoit, A.; Lambert, P.; Ben Amar, C. 3-D Deep Learning Approach for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef]
- Mei, S.; Li, X.; Liu, X.; Cai, H.; Du, Q. Hyperspectral Image Classification Using Attention-Based Bidirectional Long Short-Term Memory Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5509612. [Google Scholar] [CrossRef]
- Zhao, X.; Tao, R.; Li, W.; Li, H.-C.; Du, Q.; Liao, W.; Philips, W. Joint Classification of Hyperspectral and LiDAR Data Using Hierarchical Random Walk and Deep CNN Architecture. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7355–7370. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking Hyperspectral Image Classification with Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5518615. [Google Scholar] [CrossRef]
Figure 1.
Detailed flowchart of the DSSGT model.

Figure 2.
Working principle of 2D dilated convolution.

Figure 9.
Classification map derived from eight methods on the MV dataset using 1% of the samples for training. (a) Ground truth map, (b) 3D-CNN (OA = 73.98%), (c) DBDA (OA = 81.57%), (d) AB-LSTM (OA = 87.55%), (e) HRWN (OA = 85.84%), (f) SpectralFormer (OA = 83.53%), (g) DFFN (OA = 89.40%), (h) SSFTT (OA = 93.19%), (i) DSSGT (OA = 95.22%).
Figure 9.
Classification map derived from eight methods on the MV dataset using 1% of the samples for training. (a) Ground truth map, (b) 3D-CNN (OA = 73.98%), (c) DBDA (OA = 81.57%), (d) AB-LSTM (OA = 87.55%), (e) HRWN (OA = 85.84%), (f) SpectralFormer (OA = 83.53%), (g) DFFN (OA = 89.40%), (h) SSFTT (OA = 93.19%), (i) DSSGT (OA = 95.22%).

Figure 10.
Classification map derived from eight methods on the WHU-LongKou dataset using 0.1% of the samples for training. (a) Ground truth map, (b) 3DCNN (OA = 82.64%), (c) DBDA (OA = 89.99%), (d) AB-LSTM (OA = 75.32%), (e) HRWN (OA = 81.51%), (f) SpectralFormer (OA = 82.44%), (g) DFFN (OA = 82.77%), (h) SSFTT (OA = 80.55%), (i) DSSGT (OA = 91.96%).
Figure 10.
Classification map derived from eight methods on the WHU-LongKou dataset using 0.1% of the samples for training. (a) Ground truth map, (b) 3DCNN (OA = 82.64%), (c) DBDA (OA = 89.99%), (d) AB-LSTM (OA = 75.32%), (e) HRWN (OA = 81.51%), (f) SpectralFormer (OA = 82.44%), (g) DFFN (OA = 82.77%), (h) SSFTT (OA = 80.55%), (i) DSSGT (OA = 91.96%).

Figure 11.
Classification map derived from eight methods on the WHU-HongHu dataset using 0.5% of the samples for training. (a) Ground truth map, (b) 3DCNN (OA = 83.85%), (c) DBDA (OA = 90.42%), (d) AB-LSTM (OA = 81.96%), (e) HRWN (OA = 86.15%), (f) SpectralFormer (OA = 87.41%), (g) DFFN (OA = 87.63%), (h) SSFTT (OA = 90.28%), (i) DSSGT (OA = 92.64%).
Figure 11.
Classification map derived from eight methods on the WHU-HongHu dataset using 0.5% of the samples for training. (a) Ground truth map, (b) 3DCNN (OA = 83.85%), (c) DBDA (OA = 90.42%), (d) AB-LSTM (OA = 81.96%), (e) HRWN (OA = 86.15%), (f) SpectralFormer (OA = 87.41%), (g) DFFN (OA = 87.63%), (h) SSFTT (OA = 90.28%), (i) DSSGT (OA = 92.64%).

Figure 12.
Classification map derived from eight methods on the Houston dataset using 5% of the samples for training. (a) Ground truth map, (b) 3D-CNN (OA = 62.23%), (c) DBDA (OA = 53.96%), (d) AB-LSTM (OA = 61.31%), (e) HRWN (OA = 92.21%), (f) SpectralFormer (OA = 67.94%), (g) DFFN (OA = 91.17%), (h) SSFTT (OA = 95.57%), (i) DSSGT (OA = 96.72%).
Figure 12.
Classification map derived from eight methods on the Houston dataset using 5% of the samples for training. (a) Ground truth map, (b) 3D-CNN (OA = 62.23%), (c) DBDA (OA = 53.96%), (d) AB-LSTM (OA = 61.31%), (e) HRWN (OA = 92.21%), (f) SpectralFormer (OA = 67.94%), (g) DFFN (OA = 91.17%), (h) SSFTT (OA = 95.57%), (i) DSSGT (OA = 96.72%).

Figure 13.
Classification map derived from eight methods on the PC dataset, using 1% of the samples for training. (a) Ground truth map, (b) 3D-CNN (OA = 93.13%), (c) DBDA (OA = 94.94%), (d) AB-LSTM (OA = 94.69%), (e) HRWN (OA = 98.66%), (f) SpectralFormer (OA = 96.04%), (g) DFFN (OA = 98.50%), (h) SSFTT (OA = 98.99%), and (i) DSSGT (OA = 99.13%).
Figure 13.
Classification map derived from eight methods on the PC dataset, using 1% of the samples for training. (a) Ground truth map, (b) 3D-CNN (OA = 93.13%), (c) DBDA (OA = 94.94%), (d) AB-LSTM (OA = 94.69%), (e) HRWN (OA = 98.66%), (f) SpectralFormer (OA = 96.04%), (g) DFFN (OA = 98.50%), (h) SSFTT (OA = 98.99%), and (i) DSSGT (OA = 99.13%).

Figure 14.
Impact of DSSGT on the classification results of each class in five datasets using either standard convolution or dilated convolution. (a) MV, (b)WHU-LongKou, (c) WHU-HongHu, (d) Houston, and (e) PC.
Figure 14.
Impact of DSSGT on the classification results of each class in five datasets using either standard convolution or dilated convolution. (a) MV, (b)WHU-LongKou, (c) WHU-HongHu, (d) Houston, and (e) PC.

Figure 15.
Impact of applying GWPE in DSSGT on the classification results in each class for five datasets. (a) MV, (b) WHU-LongKou, (c) WHU-HongHu, (d) Houston, and (e) PC.
Figure 15.
Impact of applying GWPE in DSSGT on the classification results in each class for five datasets. (a) MV, (b) WHU-LongKou, (c) WHU-HongHu, (d) Houston, and (e) PC.

Figure 16.
Comparison of OAs for eight methods under various training ratios. (a) MV, (b) WHU-LongKou, (c) WHU-HongHu, (d) Houston, and (e) PC.
Figure 16.
Comparison of OAs for eight methods under various training ratios. (a) MV, (b) WHU-LongKou, (c) WHU-HongHu, (d) Houston, and (e) PC.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Quantitative evaluation was performed on the MV dataset using eight methods (%).
| Label | Train | Test | Methods | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3D-CNN | DBDA | AB-LSTM | HRWN | SpectralFormer | DFFN | SSFTT | DSSGT | |||
| 1 | 3117 | 305,486 | 99.03 ± 0.15 | 99.33 ± 0.23 | 99.86 ± 0.06 | 97.62 ± 3.20 | 99.63 ± 0.09 | 99.24 ± 0.54 | 99.65 ± 0.19 | 99.84 ± 0.06 |
| 2 | 1580 | 154,928 | 97.44 ± 1.65 | 98.67 ± 0.67 | 99.88 ± 0.10 | 99.51 ± 0.67 | 99.72 ± 0.05 | 99.43 ± 0.33 | 99.69 ± 0.19 | 99.79 ± 0.09 |
| 3 | 990 | 97,089 | 96.50 ± 2.19 | 99.48 ± 0.12 | 99.59 ± 0.15 | 99.70 ± 0.12 | 99.28 ± 0.19 | 99.83 ± 0.06 | 99.67 ± 0.14 | 99.68 ± 0.06 |
| 4 | 797 | 78,165 | 62.00 ± 7.55 | 60.77 ± 6.65 | 66.92 ± 8.63 | 57.99 ± 37.07 | 68.59 ± 5.37 | 80.49 ± 0.82 | 84.35 ± 2.61 | 87.51 ± 2.85 |
| 5 | 1541 | 151,047 | 75.33 ± 6.60 | 85.92 ± 3.21 | 91.78 ± 2.95 | 94.64 ± 3.96 | 79.88 ± 6.51 | 85.22 ± 4.11 | 93.02 ± 0.43 | 95.72 ± 1.34 |
| 6 | 221 | 21,746 | 21.20 ± 3.30 | 27.31 ± 8.92 | 14.56 ± 10.44 | 40.90 ± 16.76 | 28.18 ± 11.87 | 48.78 ± 3.28 | 52.91 ± 4.94 | 64.38 ± 5.38 |
| 7 | 2391 | 234,377 | 58.81 ± 3.77 | 83.61 ± 2.46 | 88.22 ± 4.39 | 61.40 ± 35.94 | 81.80 ± 3.46 | 85.68 ± 4.52 | 93.32 ± 0.86 | 94.14 ± 1.31 |
| 8 | 2171 | 212,807 | 45.65 ± 11.14 | 69.88 ± 6.46 | 80.01 ± 1.30 | 69.38 ± 21.58 | 74.96 ± 1.31 | 86.93 ± 1.93 | 92.70 ± 1.62 | 93.41 ± 0.72 |
| 9 | 180 | 17,640 | 87.70 ± 2.88 | 88.81 ± 2.07 | 92.91 ± 1.76 | 92.76 ± 5.84 | 80.93 ± 7.02 | 93.31 ± 0.90 | 94.98 ± 0.99 | 94.94 ± 1.10 |
| 10 | 583 | 57,163 | 27.42 ± 1.36 | 34.81 ± 3.05 | 43.05 ± 7.87 | 45.35 ± 15.32 | 30.46 ± 10.73 | 60.96 ± 5.11 | 64.42 ± 8.42 | 73.11 ± 4.00 |
| 11 | 666 | 65,346 | 65.97 ± 5.00 | 76.82 ± 9.22 | 85.84 ± 2.79 | 70.29 ± 32.02 | 80.31 ± 2.22 | 86.79 ± 3.56 | 88.26 ± 1.87 | 91.01 ± 4.65 |
| 12 | 344 | 33,761 | 49.42 ± 7.55 | 45.92 ± 14.36 | 60.83 ± 11.57 | 76.59 ± 9.04 | 53.05 ± 1.69 | 74.16 ± 4.67 | 81.90 ± 5.44 | 86.61 ± 2.37 |
| 13 | 3340 | 327,389 | 67.50 ± 8.79 | 71.19 ± 7.07 | 82.56 ± 7.19 | 86.24 ± 4.39 | 77.05 ± 2.56 | 86.28 ± 2.39 | 91.52 ± 2.20 | 94.22 ± 1.08 |
| 14 | 534 | 52,410 | 34.84 ± 9.53 | 60.05 ± 13.57 | 67.78 ± 8.28 | 71.52 ± 22.07 | 49.36 ± 8.40 | 80.96 ± 1.84 | 88.42 ± 0.75 | 91.42 ± 0.12 |
| 15 | 9130 | 894,799 | 82.29 ± 1.37 | 85.83 ± 1.42 | 92.37 ± 0.64 | 95.53 ± 1.85 | 89.20 ± 1.40 | 91.59 ± 0.54 | 94.62 ± 0.97 | 97.24 ± 0.57 |
| 16 | 28 | 2802.8 | 6.41 ± 2.97 | 13.29 ± 10.33 | 0.00 ± 0.00 | 45.69 ± 33.02 | 8.86 ± 11.31 | 69.58 ± 2.54 | 67.95 ± 12.14 | 72.73 ± 6.43 |
| 17 | 251 | 24,598 | 50.42 ± 15.44 | 72.87 ± 13.58 | 80.46 ± 8.41 | 92.39 ± 7.39 | 75.74 ± 5.86 | 88.47 ± 2.89 | 92.54 ± 0.76 | 93.59 ± 0.34 |
| 18 | 174 | 17,140 | 31.18 ± 13.48 | 52.79 ± 37.44 | 53.57 ± 25.98 | 51.69 ± 25.02 | 68.97 ± 5.88 | 80.79 ± 10.65 | 91.50 ± 0.68 | 91.31 ± 1.67 |
| OA | 73.98 ± 1.83 | 81.57 ± 1.38 | 87.55 ± 1.87 | 85.84 ± 7.88 | 83.53 ± 0.85 | 89.40 ± 1.27 | 93.19 ± 0.40 | 95.22 ± 0.26 | ||
| AA | 58.84 ± 2.87 | 68.19 ± 2.26 | 72.23 ± 4.88 | 74.95 ± 12.9 | 69.22 ± 2.90 | 83.25 ± 1.83 | 87.30 ± 0.82 | 90.04 ± 1.41 | ||
| K × 100 | 68.91 ± 2.36 | 78.15 ± 1.66 | 85.18 ± 2.27 | 82.92 ± 9.67 | 80.32 ± 0.97 | 87.41 ± 1.53 | 91.91 ± 0.49 | 94.31 ± 0.32 | ||
| Train Times (s)/epoch | 36.73 | 56.14 | 8.12 | 6.40 | 35.52 | 8.89 | 9.90 | 7.72 | ||
Table 2.
Quantitative evaluation was performed on the WHU-LongKou dataset using eight methods (%).
| Label | Train | Test | Methods | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3D-CNN | DBDA | AB-LSTM | HRWN | SpectralFormer | DFFN | SSFTT | DSSGT | |||
| 1 | 34 | 34,166 | 90.43 ± 2.37 | 99.01 ± 0.20 | 73.74 ± 7.27 | 85.80 ± 3.66 | 89.09 ± 1.84 | 93.68 ± 5.26 | 88.63 ± 7.88 | 99.65 ± 0.37 |
| 2 | 8 | 8290 | 53.79 ± 7.42 | 52.87 ± 12.63 | 0.00 ± 0.00 | 43.82 ± 2.77 | 55.94 ± 9.10 | 41.14 ± 5.16 | 34.12 ± 18.57 | 50.72 ± 4.52 |
| 3 | 3 | 3002 | 1.25 ± 1.61 | 13.07 ± 26.14 | 0.00 ± 0.00 | 0.00 ± 0.00 | 0.03 ± 0.07 | 0.00 ± 0.00 | 0.00 ± 0.00 | 0.00 ± 0.00 |
| 4 | 63 | 62,580 | 90.05 ± 4.48 | 98.22 ± 0.27 | 98.07 ± 3.43 | 93.60 ± 1.25 | 92.60 ± 2.75 | 98.20 ± 0.39 | 94.61 ± 3.12 | 98.31 ± 0.37 |
| 5 | 4 | 4109 | 8.02 ± 5.31 | 31.98 ± 19.53 | 0.00 ± 0.00 | 25.33 ± 5.98 | 0.87 ± 1.49 | 34.29 ± 5.54 | 0.00 ± 0.00 | 29.9 ± 17.78 |
| 6 | 11 | 11,735 | 29.11 ± 10.25 | 85.10 ± 7.55 | 0.00 ± 0.00 | 12.79 ± 3.03 | 15.00 ± 5.51 | 3.99 ± 3.22 | 13.10 ± 13.04 | 93.97 ± 3.22 |
| 7 | 67 | 66,386 | 98.09 ± 0.78 | 97.86 ± 0.49 | 99.32 ± 0.96 | 98.39 ± 0.22 | 99.27 ± 0.36 | 99.76 ± 0.22 | 99.54 ± 0.46 | 99.96 ± 0.05 |
| 8 | 7 | 7053 | 56.11 ± 10.58 | 71.83 ± 4.33 | 0.00 ± 0.00 | 46.22 ± 2.04 | 54.49 ± 3.25 | 25.21 ± 2.53 | 44.72 ± 25.29 | 68.76 ± 9.47 |
| 9 | 5 | 5177 | 53.61 ± 9.24 | 15.83 ± 4.63 | 0.00 ± 0.00 | 46.60 ± 2.59 | 45.49 ± 12.00 | 16.48 ± 7.48 | 0.10 ± 0.15 | 57.65 ± 5.63 |
| OA | 82.64 ± 2.00 | 89.99 ± 0.70 | 75.32 ± 6.01 | 81.51 ± 0.48 | 82.44 ± 0.93 | 82.77 ± 0.91 | 80.55 ± 3.48 | 91.96 ± 0.55 | ||
| AA | 53.58 ± 1.29 | 62.86 ± 4.09 | 30.13 ± 4.03 | 50.28 ± 1.24 | 50.31 ± 1.61 | 45.86 ± 1.46 | 41.65 ± 4.38 | 66.55 ± 2.13 | ||
| K × 100 | 76.78 ± 2.54 | 89.69 ± 0.97 | 64.95 ± 9.33 | 75.09 ± 0.77 | 76.33 ± 1.21 | 96.51 ± 1.31 | 73.39 ± 4.82 | 89.25 ± 0.74 | ||
| Train Times (s)/epoch | 0.25 | 0.51 | 0.07 | 0.05 | 0.32 | 0.07 | 0.08 | 0.07 | ||
Table 3.
Quantitative evaluation was performed on the WHU-HongHu dataset using eight methods (%).
| Label | Train | Test | Methods | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3D-CNN | DBDA | AB-LSTM | HRWN | SpectralFormer | DFFN | SSFTT | DSSGT | |||
| 1 | 70 | 13,900 | 86.84 ± 1.06 | 94.17 ± 0.66 | 91.21 ± 2.29 | 95.51 ± 0.61 | 94.79 ± 1.58 | 95.56 ± 1.03 | 96.11 ± 0.86 | 95.31 ± 1.09 |
| 2 | 17 | 3475 | 57.75 ± 5.14 | 78.26 ± 3.97 | 32.05 ± 19.05 | 88.21 ± 2.77 | 56.13 ± 5.12 | 82.25 ± 4.27 | 67.35 ± 14.61 | 90.31 ± 2.13 |
| 3 | 109 | 21,602 | 94.08 ± 0.31 | 94.71 ± 1.27 | 94.26 ± 1.60 | 93.3 ± 1.09 | 94.12 ± 1.22 | 93.79 ± 1.53 | 96.08 ± 0.78 | 95.12 ± 0.50 |
| 4 | 816 | 161,652 | 99.80 ± 0.04 | 99.47 ± 0.07 | 99.35 ± 0.23 | 99.34 ± 0.21 | 99.60 ± 0.12 | 99.13 ± 0.11 | 99.44 ± 0.38 | 99.70 ± 0.09 |
| 5 | 31 | 6153 | 46.47 ± 5.76 | 75.14 ± 2.63 | 46.02 ± 12.04 | 74.66 ± 4.27 | 71.52 ± 5.60 | 83.17 ± 11.05 | 75.99 ± 11.37 | 81.93 ± 1.99 |
| 6 | 222 | 44,109 | 93.54 ± 0.57 | 95.21 ± 1.44 | 90.11 ± 2.60 | 91.79 ± 2.30 | 91.81 ± 1.03 | 91.26 ± 2.14 | 94.93 ± 1.55 | 96.58 ± 1.37 |
| 7 | 120 | 23,859 | 74.48 ± 4.40 | 87.44 ± 3.14 | 81.54 ± 5.91 | 77.2 ± 10.38 | 80.44 ± 5.27 | 82.02 ± 5.37 | 86.49 ± 4.41 | 85.98 ± 3.35 |
| 8 | 20 | 4010 | 11.38 ± 1.63 | 16.77 ± 12.62 | 0.35 ± 0.42 | 7.60 ± 4.26 | 0.20 ± 0.34 | 8.44 ± 6.64 | 0.59 ± 0.94 | 30.57 ± 13.8 |
| 9 | 54 | 10,707 | 84.84 ± 1.49 | 92.70 ± 2.37 | 82.46 ± 10.84 | 93.16 ± 3.02 | 94.34 ± 0.89 | 92.27 ± 2.39 | 94.91 ± 1.04 | 95.66 ± 1.45 |
| 10 | 61 | 12,266 | 68.35 ± 2.42 | 80.25 ± 6.11 | 59.85 ± 12.37 | 73.20 ± 5.60 | 73.50 ± 4.49 | 65.70 ± 2.76 | 83.33 ± 1.39 | 88.78 ± 2.22 |
| 11 | 55 | 10,905 | 45.78 ± 10.93 | 78.05 ± 6.31 | 31.08 ± 19.63 | 39.64 ± 10.53 | 66.85 ± 9.02 | 46.66 ± 6.26 | 62.98 ± 6.56 | 78.89 ± 10.69 |
| 12 | 44 | 8861 | 51.02 ± 3.86 | 62.95 ± 4.41 | 41.78 ± 8.44 | 49.59 ± 5.85 | 47.77 ± 8.72 | 65.72 ± 3.68 | 65.45 ± 1.42 | 72.34 ± 3.99 |
| 13 | 112 | 22,280 | 79.16 ± 1.64 | 78.29 ± 2.42 | 73.51 ± 4.92 | 67.54 ± 11.02 | 81.39 ± 3.60 | 77.13 ± 6.06 | 85.4 ± 1.91 | 88.15 ± 3.63 |
| 14 | 36 | 7281 | 46.30 ± 4.10 | 77.31 ± 4.30 | 48.99 ± 5.09 | 60.61 ± 5.65 | 59.99 ± 8.02 | 69.57 ± 11.73 | 85.15 ± 2.34 | 84.13 ± 3.15 |
| 15 | 5 | 990 | 4.70 ± 0.81 | 40.3 ± 22.16 | 0.00 ± 0.00 | 9.60 ± 4.83 | 1.40 ± 2.80 | 7.90 ± 10.63 | 6.50 ± 8.37 | 41.40 ± 24.84 |
| 16 | 36 | 7187 | 82.60 ± 2.96 | 87.08 ± 1.44 | 85.88 ± 9.47 | 93.02 ± 2.57 | 97.12 ± 1.47 | 85.91 ± 7.96 | 93.42 ± 3.88 | 91.67 ± 4.18 |
| 17 | 15 | 2980 | 58.47 ± 2.89 | 86.98 ± 3.53 | 18.01 ± 22.10 | 52.76 ± 10.86 | 2.16 ± 3.16 | 73.16 ± 20.10 | 55.61 ± 26.61 | 83.62 ± 3.91 |
| 18 | 16 | 3183 | 19.32 ± 2.90 | 64.70 ± 8.12 | 11.51 ± 11.11 | 29.95 ± 15.45 | 31.14 ± 20.37 | 43.55 ± 18.07 | 26.35 ± 21.47 | 73.50 ± 8.27 |
| 19 | 43 | 8623 | 63.74 ± 3.59 | 79.06 ± 5.70 | 58.48 ± 17.28 | 80.83 ± 4.85 | 85.05 ± 6.20 | 79.89 ± 2.13 | 84.71 ± 3.52 | 87.53 ± 3.83 |
| 20 | 17 | 3450 | 19.51 ± 6.24 | 76.79 ± 15.34 | 8.35 ± 14.71 | 74.26 ± 7.18 | 67.86 ± 16.71 | 75.04 ± 4.64 | 89.47 ± 3.41 | 82.15 ± 4.88 |
| 21 | 6 | 1312 | 2.49 ± 0.70 | 0.53 ± 1.06 | 0.00 ± 0.00 | 20.08 ± 10.8 | 0.00 ± 0.00 | 10.11 ± 5.10 | 0.00 ± 0.00 | 18.87 ± 9.70 |
| 22 | 20 | 4000 | 9.23 ± 2.45 | 79.53 ± 5.27 | 32.92 ± 27.25 | 66.51 ± 5.29 | 79.33 ± 5.98 | 74.63 ± 6.62 | 80.30 ± 2.54 | 68.66 ± 12.83 |
| OA | 83.85 ± 0.58 | 90.42 ± 0.31 | 81.96 ± 0.91 | 86.15 ± 0.52 | 87.41 ± 0.79 | 87.63 ± 0.71 | 90.28 ± 0.44 | 92.64 ± 0.92 | ||
| AA | 54.54 ± 1.51 | 73.89 ± 2.44 | 49.44 ± 2.94 | 65.38 ± 1.46 | 62.57 ± 2.50 | 68.31 ± 7.74 | 69.57 ± 1.74 | 78.68 ± 3.33 | ||
| K × 100 | 79.27 ± 0.77 | 87.85 ± 0.41 | 77.02 ± 1.19 | 82.45 ± 0.65 | 84.34 ± 0.99 | 84.34±0.91 | 87.68 ± 0.55 | 90.67 ± 1.18 | ||
| Train Times (s)/epoch | 2.55 | 5.21 | 0.63 | 0.51 | 3.05 | 0.61 | 0.73 | 0.48 | ||
Table 4.
Quantitative evaluation was performed on the Houston dataset using eight methods (%).
| Label | Train | Test | Methods | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3D-CNN | DBDA | AB-LSTM | HRWN | SpectralFormer | DFFN | SSFTT | DSSGT | |||
| 1 | 68 | 1236 | 80.79 ± 4.83 | 70.97 ± 5.35 | 93.16 ± 0.28 | 95.61 ± 1.04 | 90.63 ± 3.50 | 95.42 ± 2.35 | 97.48 ± 0.52 | 98.03 ± 0.45 |
| 2 | 72 | 1308 | 78.47 ± 4.66 | 75.54 ± 3.25 | 86.70 ± 1.61 | 97.45 ± 0.97 | 74.28 ± 4.65 | 95.05 ± 3.15 | 97.51 ± 1.01 | 98.79 ± 0.67 |
| 3 | 39 | 715 | 59.38 ± 10.55 | 28.39 ± 15.0 | 58.60 ± 27.27 | 99.50 ± 0.42 | 78.07 ± 4.05 | 98.43 ± 0.74 | 99.19 ± 0.65 | 99.33 ± 0.70 |
| 4 | 63 | 1137 | 76.48 ± 4.77 | 66.03 ± 13.97 | 91.47 ± 2.02 | 94.18 ± 1.09 | 71.36 ± 7.95 | 89.27 ± 2.92 | 97.61 ± 0.70 | 98.10 ± 1.53 |
| 5 | 64 | 1168 | 68.46 ± 9.23 | 86.66 ± 6.28 | 91.82 ± 4.07 | 96.85 ± 0.70 | 94.86 ± 1.85 | 96.80 ± 1.54 | 98.63 ± 0.85 | 99.30 ± 0.41 |
| 6 | 16 | 305 | 42.23 ± 7.85 | 21.05 ± 21.0 | 45.25 ± 22.62 | 55.54 ± 2.88 | 5.31 ± 3.58 | 81.57 ± 12.51 | 98.03 ± 3.14 | 88.39 ± 3.67 |
| 7 | 73 | 1328 | 71.67 ± 5.37 | 47.98 ± 13.72 | 88.06 ± 2.75 | 94.67 ± 0.56 | 82.95 ± 3.23 | 92.56 ± 2.61 | 96.07 ± 2.21 | 97.15 ± 1.21 |
| 8 | 67 | 1218 | 48.88 ± 9.99 | 43.73 ± 7.75 | 25.70 ± 9.85 | 85.17 ± 2.53 | 54.58 ± 3.22 | 83.12 ± 2.34 | 88.83 ± 1.96 | 89.57 ± 1.51 |
| 9 | 77 | 1398 | 59.38 ± 5.28 | 55.35 ± 9.22 | 63.91 ± 12.27 | 84.88 ± 1.73 | 73.03 ± 4.92 | 86.31 ± 3.86 | 89.54 ± 2.94 | 94.16 ± 1.40 |
| 10 | 71 | 1281 | 50.88 ± 12.04 | 45.84 ± 31.09 | 28.45 ± 0.90 | 94.80 ± 1.98 | 71.74 ± 7.90 | 84.82 ± 10.57 | 98.10 ± 0.92 | 98.24 ± 0.64 |
| 11 | 78 | 1409 | 48.30 ± 5.96 | 21.82 ± 12.40 | 53.41 ± 23.53 | 89.96 ± 1.59 | 46.25 ± 12.74 | 92.08 ± 2.60 | 95.71 ± 1.16 | 96.72 ± 1.85 |
| 12 | 71 | 1286 | 45.79 ± 10.97 | 47.99 ± 18.36 | 22.67 ± 18.39 | 91.23 ± 1.90 | 45.63 ± 16.34 | 89.41 ± 5.49 | 92.53 ± 3.70 | 95.71 ± 1.46 |
| 13 | 31 | 568 | 62.57 ± 10.6 | 32.82 ± 21.04 | 23.50 ± 4.67 | 87.57 ± 2.82 | 10.35 ± 2.02 | 86.90 ± 3.02 | 93.56 ± 2.74 | 95.56 ± 2.39 |
| 14 | 25 | 461 | 51.50 ± 10.72 | 50.80 ± 14.14 | 3.80 ± 3.80 | 96.92 ± 0.56 | 60.78 ± 10.49 | 97.83 ± 2.25 | 99.26 ± 0.38 | 99.91 ± 0.17 |
| 15 | 39 | 718 | 73.70 ± 12.53 | 85.21 ± 8.91 | 88.37 ± 7.87 | 98.41 ± 0.34 | 95.60 ± 1.57 | 99.86 ± 0.22 | 98.11 ± 1.42 | 99.61 ± 0.64 |
| OA | 62.23 ± 5.73 | 53.96 ± 5.79 | 61.31 ± 0.80 | 92.21 ± 0.29 | 67.94 ± 1.03 | 91.17 ± 1.11 | 95.57 ± 0.70 | 96.72 ± 0.46 | ||
| AA | 61.23 ± 5.36 | 52.01 ± 5.17 | 57.66 ± 2.42 | 90.85 ± 0.43 | 63.7 ± 1.31 | 91.30 ± 1.34 | 96.01 ± 0.82 | 96.57 ± 0.55 | ||
| K × 100 | 59.14 ± 6.19 | 50.24 ± 6.22 | 58.06 ± 0.92 | 91.58 ± 0.31 | 65.25 ± 1.12 | 90.46 ± 1.21 | 95.21 ± 0.76 | 96.46 ± 0.49 | ||
| Train Times (s)/epoch | 0.56 | 3.95 | 0.18 | 0.18 | 0.54 | 0.25 | 0.22 | 0.18 | ||
Table 5.
Quantitative evaluation was performed on the PC dataset using eight methods (%).
| Label | Train | Test | Methods | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3D-CNN | DBDA | AB-LSTM | HRWN | SpectralFormer | DFFN | SSFTT | DSSGT | |||
| 1 | 659 | 64,651 | 99.47 ± 0.18 | 99.65 ± 0.28 | 99.68 ± 0.13 | 99.89 ± 0.04 | 99.88 ± 0.05 | 99.90 ± 0.05 | 100 ± 0.00 | 100 ± 0.00 |
| 2 | 75 | 7446 | 92.37 ± 0.96 | 89.45 ± 3.07 | 90.59 ± 7.33 | 96.59 ± 0.52 | 99.23 ± 0.73 | 94.75 ± 2.06 | 97.86 ± 1.25 | 97.75 ± 1.11 |
| 3 | 20 | 3028 | 66.44 ± 10.87 | 56.57 ± 22.45 | 52.85 ± 12.84 | 86.18 ± 2.11 | 17.75 ± 17.52 | 85.69 ± 3.73 | 82.89 ± 4.06 | 84.23 ± 5.60 |
| 4 | 26 | 2631 | 45.63 ± 9.64 | 84.35 ± 13.10 | 22.87 ± 20.74 | 96.34 ± 1.33 | 64.92 ± 17.86 | 98.60 ± 1.47 | 93.55 ± 3.39 | 98.92 ± 0.93 |
| 5 | 65 | 6452 | 82.47 ± 5.52 | 86.37 ± 5.28 | 91.36 ± 5.80 | 94.87 ± 1.13 | 93.57 ± 1.12 | 93.24 ± 2.09 | 97.47 ± 0.44 | 97.67 ± 0.48 |
| 6 | 92 | 9063 | 74.06 ± 5.89 | 83.93 ± 9.07 | 97.76 ± 0.89 | 96.84 ± 0.67 | 92.82 ± 3.41 | 98.34 ± 0.99 | 98.42 ± 0.76 | 99.27 ± 0.04 |
| 7 | 72 | 7141 | 79.44 ± 2.66 | 84.80 ± 4.34 | 75.43 ± 7.02 | 94.58 ± 0.52 | 91.91 ± 2.08 | 92.77 ± 0.83 | 96.40 ± 0.72 | 96.57 ± 0.34 |
| 8 | 428 | 41,969 | 97.08 ± 1.29 | 99.00 ± 0.34 | 98.67 ± 1.09 | 99.86 ± 0.02 | 99.70 ± 0.20 | 99.84 ± 0.02 | 99.91 ± 0.04 | 99.91 ± 0.03 |
| 9 | 28 | 2805 | 84.06 ± 3.27 | 72.92 ± 16.28 | 90.15 ± 4.80 | 98.70 ± 0.22 | 84.73 ± 6.56 | 97.08 ± 1.44 | 99.22 ± 0.60 | 96.92 ± 1.10 |
| OA | 93.13 ± 1.23 | 94.94 ± 0.96 | 94.69 ± 1.10 | 98.66 ± 0.07 | 96.04 ± 0.49 | 98.50 ± 0.18 | 98.99 ± 0.17 | 99.13 ± 0.05 | ||
| AA | 80.11 ± 2.97 | 84.12 ± 4.67 | 79.93 ± 2.84 | 95.98 ± 0.28 | 82.72 ± 3.03 | 95.58 ± 0.54 | 96.19 ± 0.64 | 96.80 ± 0.37 | ||
| K × 100 | 90.27 ± 1.73 | 92.83 ± 1.37 | 92.47 ± 1.55 | 98.11 ± 0.11 | 94.68 ± 1.71 | 97.87 ± 0.25 | 98.57 ± 0.24 | 98.77 ± 0.07 | ||
| Train Times (s)/epoch | 0.70 | 4.53 | 0.21 | 0.27 | 0.67 | 0.40 | 0.28 | 0.24 | ||
Table 6.
Ablation experiments on five datasets using the proposed model.
| Component | Indicators | |||||
|---|---|---|---|---|---|---|
| Standard CNN | Dilated CNN | GWPE | OA (%) | AA (%) | K × 100 | |
| MV | √ | ✕ | √ | 93.89 | 86.49 | 91.99 |
| ✕ | √ | ✕ | 92.15 | 84.59 | 89.20 | |
| ✕ | √ | √ | 95.22 | 90.04 | 94.31 | |
| WHU-LongKou | √ | ✕ | √ | 91.64 | 66.13 | 88.84 |
| ✕ | √ | ✕ | 90.21 | 66.12 | 88.08 | |
| ✕ | √ | √ | 91.96 | 66.55 | 89.25 | |
| WHU-HongHu | √ | ✕ | √ | 90.20 | 71.93 | 87.61 |
| ✕ | √ | ✕ | 91.20 | 78.89 | 89.95 | |
| ✕ | √ | √ | 92.64 | 78.68 | 90.67 | |
| Houston | √ | ✕ | √ | 95.49 | 95.80 | 95.13 |
| ✕ | √ | ✕ | 96.12 | 95.90 | 96.46 | |
| ✕ | √ | √ | 96.72 | 96.57 | 96.46 | |
| PC | √ | ✕ | √ | 99.10 | 96.67 | 98.72 |
| ✕ | √ | ✕ | 99.01 | 96.60 | 98.22 | |
| ✕ | √ | √ | 99.13 | 96.80 | 98.77 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhang, Z.; Wang, S.; Zhang, W. Dilated Spectral–Spatial Gaussian Transformer Net for Hyperspectral Image Classification. Remote Sens. 2024, 16, 287. https://doi.org/10.3390/rs16020287
AMA Style
Zhang Z, Wang S, Zhang W. Dilated Spectral–Spatial Gaussian Transformer Net for Hyperspectral Image Classification. Remote Sensing. 2024; 16(2):287. https://doi.org/10.3390/rs16020287
Chicago/Turabian StyleZhang, Zhenbei, Shuo Wang, and Weilin Zhang. 2024. "Dilated Spectral–Spatial Gaussian Transformer Net for Hyperspectral Image Classification" Remote Sensing 16, no. 2: 287. https://doi.org/10.3390/rs16020287
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.