
TD3-Based Optimization Framework for RSMA-Enhanced UAV-Aided Downlink Communications in Remote Areas
by
 , , and
, , and
Tri-Hai Nguyen
1 ,
,
Luong Vuong Nguyen
2 ,
,
L. Minh Dang
3,4,
Vinh Truong Hoang
5 and
Laihyuk Park
1,* 1
Department of Computer Science and Engineering, Seoul National University of Science and Technology, Seoul 01811, Republic of Korea
2
Department of Artificial Intelligence, FPT University, Da Nang 550000, Vietnam
3
Institute of Research and Development, Duy Tan University, Da Nang 550000, Vietnam
4
Faculty of Information Technology, Duy Tan University, Da Nang 550000, Vietnam
5
Faculty of Computer Science, Ho Chi Minh City Open University, Ho Chi Minh City 700000, Vietnam
*
Author to whom correspondence should be addressed.
Remote Sens. 2023, 15(22), 5284; https://doi.org/10.3390/rs15225284
Submission received: 26 September 2023
/
Revised: 30 October 2023
/
Accepted: 7 November 2023
/
Published: 8 November 2023
(This article belongs to the Special Issue The Convergence of Remote Sensing, Communication, and Computing for 6G Space-Air-Ground Integrated Networks)
Abstract
:The need for reliable wireless communication in remote areas has led to the adoption of unmanned aerial vehicles (UAVs) as flying base stations (FlyBSs). FlyBSs hover over a designated area to ensure continuous communication coverage for mobile users on the ground. Moreover, rate-splitting multiple access (RSMA) has emerged as a promising interference management scheme in multi-user communication systems. In this paper, we investigate an RSMA-enhanced FlyBS downlink communication system and formulate an optimization problem to maximize the sum-rate of users, taking into account the three-dimensional FlyBS trajectory and RSMA parameters. To address this continuous non-convex optimization problem, we propose a TD3-RFBS optimization framework based on the twin-delayed deep deterministic policy gradient (TD3). This framework overcomes the limitations associated with the overestimation issue encountered in the deep deterministic policy gradient (DDPG), a well-known deep reinforcement learning method. Our simulation results demonstrate that TD3-RFBS outperforms existing solutions for FlyBS downlink communication systems, indicating its potential as a solution for future wireless networks.
1. Introduction
In recent years, the increasing demand for wireless communication networks has been driven by the widespread use of mobile devices, Internet of Things (IoT) applications, and smart cities. To meet this demand, the next generation of wireless technology (6G) is being developed to be even faster, more efficient, and more capable than its predecessors [1,2,3,4]. This advanced technology could enable innovative applications and services that were previously unthinkable. However, IoT devices can be installed in remote and isolated locations such as rural areas, mountains, and deserts. Establishing direct communication between IoT devices can be challenging in these areas due to their considerable distance. Additionally, ground base stations (BSs) are often absent in these remote areas due to the high economic costs. To address these challenges, aerial access networks and space–air–ground integrated networks have been developed [1,2,3,4,5]. Notably, due to exceptional merits such as high mobility, maneuverability, and flexibility, unmanned aerial vehicles (UAVs) can be deployed as flying base stations (FlyBSs or UAV-BSs), which enables rapid deployment in remote locations, disaster-stricken zones, or temporary events [4,5]. In addition, UAVs can also serve as wireless power transmitters, enabling energy delivery to ground users via wireless power transfer technology [6].
Concurrently, as the number of mobile users continues to grow, the available spectrum resources have diminished significantly. In light of this, multiple access techniques have become increasingly essential [7]. Recently, rate-splitting multiple access (RSMA) has been proposed as a novel multiple access scheme to improve the efficiency of multi-user communication systems [8,9]. Previous research has shown that RSMA outperforms other advanced multiple access techniques, i.e., non-orthogonal multiple access (NOMA) [10,11]. Specifically, NOMA requires a single user to decode the messages of other co-scheduled users to obtain its intended message [7], which reduces the communication performance. In contrast, RSMA divides each user’s message into two parts: common and private. All users can decode the common part, while the intended recipients only decode the private parts. Then, the original message can be reconstructed from the common part and the private part via a successive interference cancellation (SIC) technique [12]. RSMA can be used with multi-antenna transmission to achieve an optimal performance with high coverage. Several research efforts have been devoted to RSMA [10,11,13,14,15,16,17,18]. However, they have been limited to terrestrial BSs. On the other hand, FlyBSs offer greater freedom in system design, enabling new and innovative applications. For example, high-altitude UAVs with RSMA have assisted in computation offloading from IoT devices and smart vehicles [19,20]. However, these platforms are typically stationary in one stratosphere location, limiting their mobility and flexibility. Additionally, they can be more expensive to build and maintain than low-altitude UAVs and require a longer deployment time. Prior work on RSMA-based FlyBS downlink communication systems has focused on developing optimization techniques to improve the performance, but none of these studies have considered time-varying environments [21,22,23,24]. In [25], multiple UAVs assist a BS in providing RSMA communication services to ground users; however, they are deployed in fixed locations. In [26], a FlyBS downlink communication system with RSMA is proposed; however, it is limited to two-dimensional (2D) space, which restricts the system’s performance. To fully exploit the FlyBS’s high mobility and flexibility, it should be operated in three-dimensional (3D) space. In addition, optimizing RSMA-enabled FlyBS communications poses challenges due to the complex interactions between the parameters of RSMA, FlyBS, and mobile users. Traditional optimization methods may not solve these problems efficiently, especially in dynamic environments where the channel conditions and user mobility change frequently. Therefore, the optimization aspect of RSMA-enabled FlyBS systems with 3D trajectory continues to be an open area of research.
Recent advances in machine learning have led to the emergence of deep reinforcement learning (DRL) [27], a powerful technique that combines reinforcement learning and deep learning to solve a wide range of optimization problems [28,29,30,31,32]. Deep Q-network (DQN) is the first DRL algorithm [27]. DQN approximates the Q-function using a deep neural network (DNN), which estimates the expected cumulative reward for taking a specific action in a particular state and following a certain policy. The Q-function is then used to select the action with the highest expected reward. However, DQN can be unstable to train and slow to learn in complex environments. Additionally, when using DQN to solve optimization problems, the action space must be discretized, which can reduce the optimization performance. In contrast to DQN, the deep deterministic policy gradient (DDPG) is specifically designed for scenarios involving high-dimensional continuous action spaces [33]. DDPG employs an actor–critic architecture consisting of two DNNs: an actor network and a critic network. The actor network is responsible for taking the optimal action in a given state, while the critic network evaluates the quality of action chosen by the actor network. At present, many studies have applied the DDPG algorithm to wireless communication systems [19,20,26,34,35]. However, one shortcoming of DDPG is that the learned Q-function often overestimates the Q-values, resulting in significant errors in the policy. To address this issue, the twin-delayed deep deterministic policy gradient (TD3) algorithm, a more recent DRL approach, has been introduced [36]. It uses three critical modifications to DDPG: clipped double Q-learning, target policy smoothing, and delayed policy updates. TD3 is more stable and robust than DDPG and it can perform better than other DRL techniques in various tasks [36]. However, to the best of our knowledge, there is no existing research on applying TD3 to optimize RSMA-enabled FlyBS systems with 3D trajectories.
Motivated by the above discussion, this paper proposes a TD3-based optimization framework, TD3-RFBS, to optimize an RSMA-enhanced FlyBS system with a 3D trajectory. The system has potential practical implications, such as facilitating emergency communication services in disaster zones, connecting rural communities to the Internet, and enabling remote monitoring and control of critical infrastructure. The key contributions of this work can be summarized as follows:
- We introduce an RSMA-enhanced FlyBS system, where the FlyBS equipped with a multi-antenna array serves mobile ground users in hard-to-reach areas. At the same time, the communication channel is improved by RSMA technology. To maximize the downlink sum rate, we formulate an optimization problem that considers the 3D FlyBS trajectory and RSMA parameters, i.e., the precoding matrix and common rate vector, while considering the mobility of ground users.
- We transform the problem into a Markov decision process (MDP) by carefully defining the state space, action space, and reward function. To solve the MDP model, we develop the TD3-RFBS optimization framework, which stands for Twin-Delayed Deep Deterministic policy gradient for Rate-splitting multiple access-enhanced Flying Base Station. The TD3 algorithm is used to overcome the overestimation bias issue present in the well-known DDPG algorithm. In the framework, the FlyBS engages, monitors, and acquires knowledge of channel patterns without any pre-existing channel state information (CSI) to optimize its actions.
- We conduct extensive simulations to evaluate the performance of the TD3-RFBS framework. The results confirm that the framework outperforms baseline solutions, including DDPG and local search-based counterparts regarding the learning convergence and total achievable rate.
Structure: The rest of this paper is organized as follows. Section 2 reviews the background and related work. Section 3 presents the system model and problem formulation. Section 4 describes the MDP model and introduces our proposed framework based on the TD3 algorithm. The simulation results and performance analysis are presented in Section 5. Finally, we conclude the paper in Section 6.
Notations: Matrices and vectors are represented by boldface uppercase and lowercase symbols, respectively. The transpose, Hermitian transpose, and trace of a matrix are denoted by , , and , respectively. A complex number’s real and imaginary parts are represented by and . denotes the expectation operator, ⊗ denotes the Kronecker product, denotes the Euclidean norm, denotes the absolute value, and denotes the identity matrix.
2. Related Work
Recently, rate-splitting multiple access (RSMA) technology has emerged as a promising approach for advancing next-generation mobile networks [8,9]. Table 1 presents a comprehensive comparison of studies closely related to our work on downlink RSMA-based communication systems. According to the principles of RSMA, each message intended for a user is partitioned into two parts: a common part and a private part. The common parts are merged into a single common signal, and the private part is encoded into a private signal for each user individually. By decoding interference partially and treating the remainder as noise, RSMA enables effective interference management. This allows RSMA to enhance various aspects of communication systems, such as reliability, energy efficiency, spectrum efficiency, and quality of service (QoS). RSMA outperforms other multiple access techniques by offering greater flexibility and powerful interference management capabilities [10]. In downlink RSMA, numerous studies have focused on optimizing the transmission power and precoding vectors for both the common and private signals to achieve various objectives, such as sum-rate maximization [10,13,14,15], max–min rate fairness [16,17], and energy efficiency maximization [11,18].
Nonetheless, the studies above have predominantly focused on terrestrial-fixed BSs. In contrast, UAV-aided communication systems offer greater cost-effectiveness and potential for improved QoS due to their high mobility, on-demand coverage, and ability to establish line-of-sight (LoS) links compared to their terrestrial counterparts. In [21], the authors explored the simultaneous optimization of the UAV position and RSMA variables to maximize the downlink weighted sum-rate in a UAV-aided communication system. However, their objective was to find the optimal placement for UAV deployment, not the UAV trajectory. Similarly, several studies [22,23,24] investigated the performance of downlink communication in a UAV-BS setting utilizing RSMA to serve multiple users. These works adopted alternating optimization, sub-problem decomposition, and iterative approaches, which are problem-specific, challenging to extend to general cases, and do not consider the time-varying environment [21,22,23,24]. On another front, DRL has been widely used to solve non-convex optimization problems in wireless communication systems [13,19,20,25,26,34,35,37]. The work [25] proposed a multi-UAV-assisted BS system to deliver communication services to ground users with both downlink and uplink RSMA transmissions. It used proximal policy optimization (PPO) to solve the sum-rate maximization problem in the system. However, PPO can be slow to converge, especially in complex environments, and it requires a large amount of data to train effectively, which can be a challenge in some applications. In [34], the authors utilized a UAV with an intelligent reflecting surface as a relay to assist downlink communications from a terrestrial BS to ground users. In [19,20,37], RSMA-based high-altitude UAVs assisted IoT devices or connected vehicles with computation offloading. In [26], the authors investigated a UAV-supported downlink communication system with RSMA. However, these studies limit the UAV flying trajectory to a 2D space or deploy the UAVs in a fixed position, which restricts the mobility and flexibility of the UAVs [19,20,25,26]. In addition, the well-known DDPG algorithm, which is used in [19,20,26,34,37], suffers from the overestimation problem, which can degrade the performance of wireless communication systems. The TD3 algorithm can address this issue through three improved techniques: clipped double Q-learning, target policy smoothing, and delayed policy updates. TD3 has proven more efficient than DDPG, PPO, and other DRL approaches in various learning tasks [36].
Different from the previous studies, we focus on a multi-antenna FlyBS with RSMA that can fly along a 3D trajectory while providing communication services to mobile ground users. The multi-antenna technology has been extensively employed in ground-based BSs [10,11,13,14,15,16,17,18]. By leveraging the benefits of increased signal strength, expanded coverage, reduced interference, and beamforming capabilities, multi-antenna arrays can provide reliable and high-quality wireless services. With recent technological advancements such as miniaturized antennas, low-power electronics, and improved signal processing techniques, the integration of multi-antenna arrays into FlyBSs holds immense potential for enhancing communication capabilities in remote and underserved areas [21,24,25,26]. Lastly, we leverage the TD3 algorithm to solve the optimization problem rather than the well-known DDPG algorithm, which suffers from an overestimation bias.
3. System Model and Problem Formulation
This section begins with an introduction to the system model for a FlyBS system enhanced by RSMA, including mobility, channel, and signal models. Following this, the problem of maximizing the sum-rate is formulated.
3.1. System Model
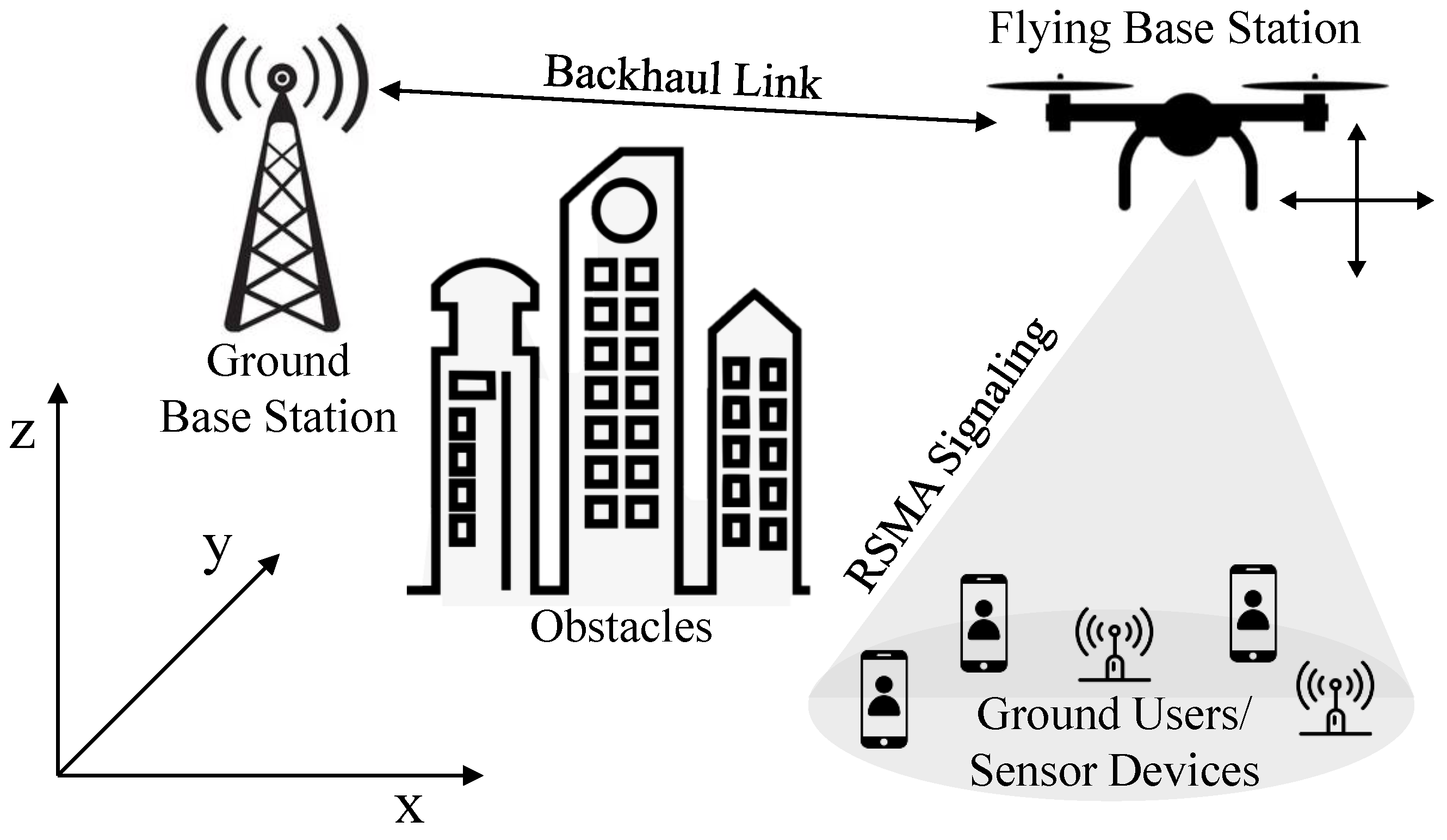
We investigate the RSMA-enhanced FlyBS model depicted in Figure 1. The system comprises a UAV-BS or FlyBS equipped with a uniform rectangular array containing antennas and K single-antenna ground users (GUs or sensors devices installed in remote areas). Due to obstacles such as high buildings, mountains, or long distances, a direct link between the ground BS and the GUs is unavailable. Therefore, the FlyBS is used to transmit data to GUs. The group of K GUs is denoted by . Similar to [4,20,34], the operation time is divided into T equal time slots, each with a duration of , which is sufficiently small to assume that the network topology remains constant within each time slot. The collection of time slots is represented as .
3.1.1. Mobility Model
The location of the FlyBS and GU k are denoted by and , respectively, in a 3D Cartesian coordinate system. Accordingly, the distance between the FlyBS and GU k can be calculated by
During time slot t with duration , the FlyBS can fly towards an azimuth angle of and an elevation angle of with a velocity of (m/s), where denotes the maximum velocity of FlyBS. Hence, its mobility at time slot can be expressed by [34]
We assume that each GU k moves randomly within the considered area with a velocity (m/s), where denotes the maximum velocity of the GU k. In addition, the operation of FlyBS is limited in a region of with a height between . Thus, we have
3.1.2. Channel Model
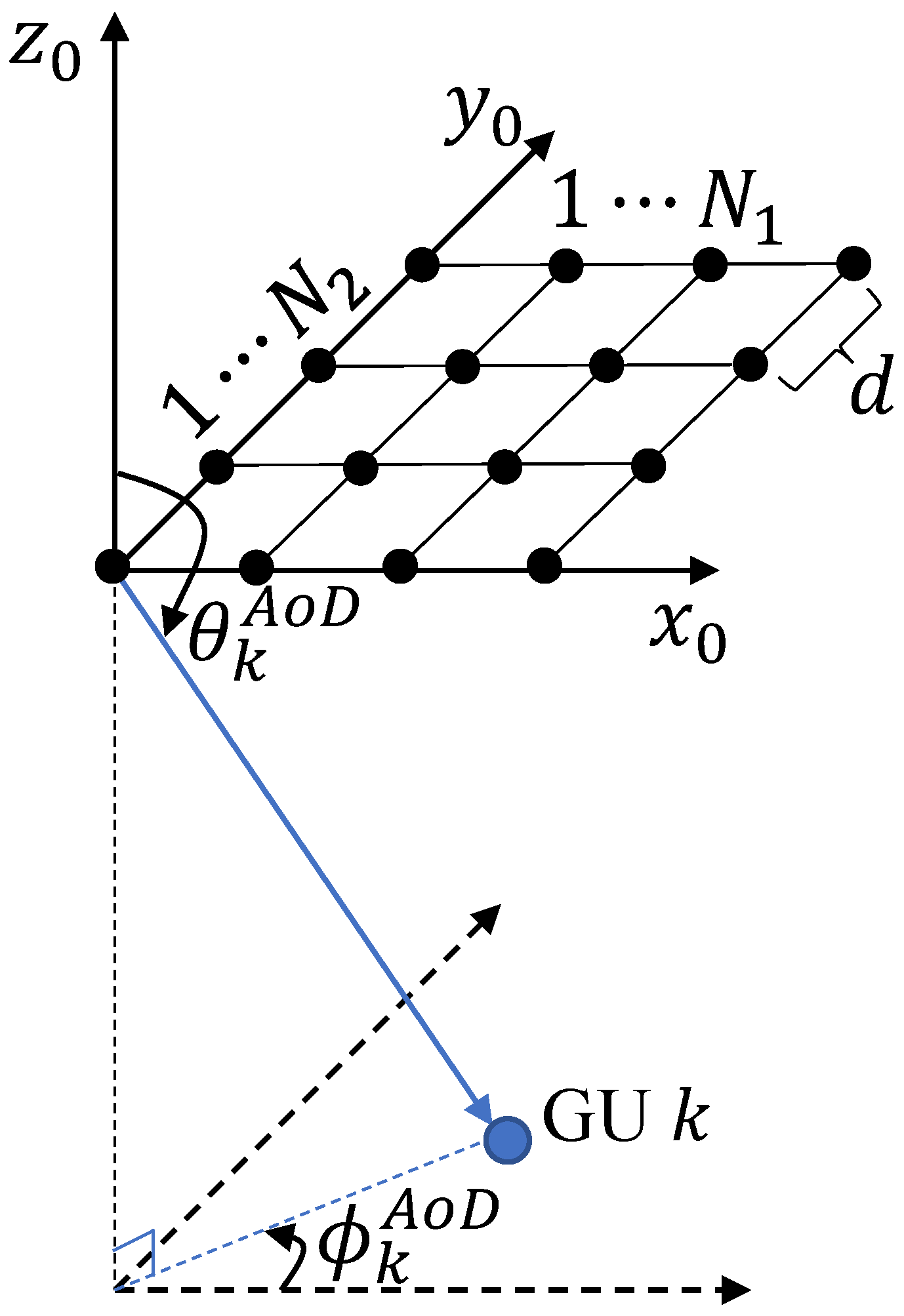
In multi-antenna technology, a uniform rectangular array (URA) offers the advantage of higher gain while maintaining a compact size compared to a traditional uniform linear array [38]. By employing radiation beam patterns in both elevation and azimuth planes, URAs provide additional degrees of freedom that enhance interference suppression, wireless network coverage, and system capacity. Therefore, we consider equipping the FlyBS with the URA of dimensions , as illustrated in Figure 2.
For simplicity of presentation, we omit the time slot index in the following discussion. Let represent the air-to-ground channel from the FlyBS to GU k. The channel is assumed to follow a widely recognized Rician fading model [26,34,35]. Consequently, the channel connecting the FlyBs and GU k can be expressed as
where is the deterministic LoS component, is the non-line-of-sight (NLoS) component, is the Rician factor, and is the distance-dependent large-scale path loss. According to [26,34,38], since the FlyBS equipped the URA, the LoS component of the channel is computed by
where and represent the azimuth and elevation angle-of-departure (AoD) at the FlyBS to GU k, respectively, and represents the antenna array response between the FlyBS and GU k. Furthermore, and can be calculated as
where represents the carrier wavelength, d represents the distance between the antennas, , and .
3.1.3. Signal Model
Following the one-layer RSMA principle [8,10], the FlyBS divides the intended message for each GU k into common and private parts. Next, the common part messages of all GUs are encoded using a shared codebook into a common signal , designed to reduce interference. All GUs subsequently decode the common signal . On the other hand, the private part of the message for each GU is encoded using an independent codebook into a dedicated private signal , which can only be decoded by the corresponding GU. It is important to emphasize that the shared codebook for the common signal is accessible to all GUs, while the codebooks for the private signals are exclusively known by their corresponding GUs. This distinction enables each GU to differentiate between its private signal and the private signals of other GUs [8]. Accordingly, the vector comprising the signals for transmission is represented as , with . A precoding matrix is used to precode the signals. Here, is the linear precoder corresponding to the signal . Thus, the received signal at GU k can be expressed as
where represents the additive white Gaussian noise at GU k with noise power . The transmission power of FlyBS is limited by , where represents the maximum transmit power [11,21].
The decoding process at GU k is as follows. Initially, GU k decodes the common signal by considering all private signals as noise. Once is completely decoded, it is eliminated from the obtained signals using the SIC technique, enabling the extraction of private signals [12]. Afterward, GU k decodes its desired private signal by considering the private signals of other GUs as noise. By combining the common part and the private part from the decoded signals, GU k can retrieve its message. The signal-to-interference-plus-noise ratio (SINR) for the common signal and private signal at GU k can be respectively determined by
Accordingly, the achievable rate of decoding and at GU k is denoted as , where B is the bandwidth. Furthermore, the attainable rate of the common signal is defined as to guarantee the successful decoding of the common signal by all GUs. Let denote the part of the common rate allocated to GU k, such that . Thus, the overall achievable rate (in bits/second/Hertz, or bit/s/Hz) of GU k can be given as
3.2. Problem Formulation
This paper focuses on the joint optimization of the precoding matrix , the common rate vector , and the 3D trajectory of the FlyBS (taking into account the azimuth angle , elevation angle , and velocity ) to maximize the sum-rate of all GUs across all time slots. The optimization problem can be formulated as
where (10b) ensures that every GU can successfully decode the common signal, (10c) ensures that each GU’s portion of the common rate is a positive value, (10d) guarantees the QoS for the GUs by a minimum required rate , and (10e), (10f), and (10g) ensure that the FlyBS’s parameters, such as the transmit power, directional angles, velocity, and location, are within the accessible ranges. It can be observed that the defined problem is non-convex and difficult to be addressed by conventional optimization approaches. DRL shows its advantages in solving problems in highly dynamic environments [19,20,26,34,35]. The next section presents a DRL-inspired optimization framework to address the optimization problem.
4. TD3-RFBS Optimization Framework for RSMA-Enhanced FlyBS System
To tackle the challenges posed by the high complexity and dynamic nature of the optimization problem, we reformulate it as an MDP model. Subsequently, we propose a DRL-based algorithm under the TD3 framework to solve the MDP model.
4.1. Markov Decision Process Transformation
An MDP is a mathematical framework for modeling sequential decision-making problems. We transform the original problem into an MDP model, expressed as a tuple . Here, denotes the state space, denotes the action space, denotes the reward function, and denotes the discount factor. In this setup, the FlyBS acts as the agent, while the entire communication system is considered the environment. At each time step t, the agent observes its present state . Based on this observation, the agent selects an action . After executing the action , the agent moves to a new state and receives an immediate reward . The agent aims to discover an optimum policy that maximizes the total reward, considering the discount factor . The discount factor determines how much the agent values future rewards relative to immediate rewards. When is set to 0, the agent only cares about immediate rewards. As increases, the agent places more weight on future rewards. Each component of the MDP model is explained in more detail below.
- State: At every time interval, the state comprises the present location information of both the FlyBS and K GUs. By utilizing these observed locations, it is possible to estimate the CSI between the FlyBS and the respective GUs [34]. The state is represented as
- Action: At each state , the agent makes decisions on the joint action , which encompasses the optimization variables of the precoding matrix , the common rate vector , and the parameters of the FlyBS (i.e., the azimuth angle , elevation angle , and velocity ). It is formally given aswhere is the complex-valued linear precoder for the signal and . It is worth noting that the action defined in the above equation contains both discrete, continuous, and complex-valued variables which are not directly accessible to the DRL-based learning algorithms. To address this issue, we redefine the precoding matrix as , where is reformed as and [35]. Hence, the original value of can be computed bywhere . In addition, by applying the softmax function to the element of , we define as the normalized vector of , where the is calculated asFurthermore, we define as normalized variables of , , and , respectively, to eliminate the effect of diversity of the variables. Thus, we haveAs a result, all the action variables are normalized in the range of . The action can be rewritten by
- Reward: The agent is given an immediate reward upon performing action . This study aims to maximize the system sum-rate. Therefore, the reward is determined by the combined achievable rate of all GUs, which is represented asThe agent aims to maximize the discounted cumulative reward, expressed as
4.2. TD3-RFBS Optimization Framework
Since the action space is continuous and high-dimensional, the existing works use the DDPG algorithm as a DRL method for decision making [19,20,26,34,35]. However, DDPG is sensitive to the hyperparameters and DNN size and it often overestimates the Q-value, leading to suboptimal or unstable policies. Recently, the TD3 algorithm was proposed to tackle the above issues with three key techniques [36]:
- Clipped double Q-learning: TD3 uses two critic networks instead of one, as in DDPG. By using the minimum Q-value from the target networks, TD3 improves the accuracy of value estimates and reduces the overestimation bias.
- Target policy smoothing: TD3 adds noise to the target action when updating the policy. This makes the policy more robust to Q-value estimation errors.
- Delayed policy updates: TD3 updates the policy and target networks less frequently than the critic networks. This prevents the policy from exploiting the overestimated Q-values.
TD3 is a more stable and robust algorithm with these three improvements than DDPG. To address the defined MDP model, we propose the TD3-RFBS optimization framework, which leverages the advantages of TD3 over DDPG. TD3 contains three main DNNs: one actor network and two critic networks. The actor network selects actions based on the existing state, whereas the critic networks assess the actions produced by the actor network. Using two critic networks is intended to address the issue of overestimating the Q-values. Each main network is accompanied by a target network for stabilizing the training process. Accordingly, TD3 consists of six DNNs: an actor network with parameter , two critic networks and with parameter and , respectively, a target actor network with parameter , and two target critic networks and with parameter and , respectively. During the training procedure, the actor network is used to generate action as
where represents a noise following the Gaussian process. When the agent takes action , the environment changes from state to state . The agent is given a reward corresponding to the state–action pair . This sample is saved in the experience replay buffer , which is utilized for updating the network parameters. A randomly sampled mini-batch of S transition tuples is extracted from to update the actor and critic networks. The critic networks are updated by minimizing the loss function , given by
where represents a smoothing noise and c is the binding of noise. TD3 employs delayed policy updates and utilizes the deterministic policy gradient to update the actor network parameters every f iterations, as
Lastly, TD3 employs a soft update approach to update the target network parameters. This is performed at a rate of every f iterations and can be expressed as
Algorithm 1 describes the training process for the TD3-RFBS optimization framework. An actor network and two critic networks are initialized with random parameters, and corresponding target networks are created by copying the parameters from the original networks (lines 1–2). An experience replay buffer is established to store the experience samples (line 3), with a predetermined capability that replaces the earliest sample with a new one upon reaching its limit. During each episode, an action is generated from the current policy and noise given the current state , resulting in an immediate reward and a next state (lines 6–8). The sample is then stored in the buffer (line 9). To train the networks, a mini-batch of S transitions is randomly sampled from the buffer (line 10). The parameters of the critic networks are updated using the loss function (lines 11–12). The actor network is updated using a delayed update strategy with deterministic gradient descent, and the target networks are updated using a soft update constant (lines 14–15). After the specified number of episodes, the training phase terminates, yielding a proficiently trained actor network (line 19). The trained actor network can then generate actions in real-time execution.
| Algorithm 1 Training process for the TD3-RFBS optimization framework. |
|
4.3. Computational Complexity
In the following, the computational complexity of the TD3-RFBS framework is analyzed. According to [20,39], the computational complexity for a DNN is based on the number of multiplications as , where L is the number of layers and is the number of neurons of the l-th layer. In training mode, the TD3-RFBS algorithm uses a finite number of DNNs and requires iterations to complete the training phase, with S being the mini-batch size, M being the total count of episodes, and T being the number of steps per episode. As a result, the overall computational complexity can be estimated as .
In execution mode, the critic networks do not contribute to decision making. Instead, the FlyBS algorithm solely relies on the trained actor network to perform real-time decisions in a dynamic environment. The computational complexity associated with this process is approximately .
5. Performance Evaluation and Discussion
In this section, we present comprehensive simulation results to demonstrate the effectiveness of our optimization framework. First, we describe the simulation settings. Then, we conduct a convergence analysis and compare the performance of our framework against several baseline methods.
5.1. Simulation Setup
We developed the RSMA-enhanced FlyBS communication system using Python (Version 3.10) and trained it using PyTorch (Version 1.12.1). We consider a FlyBS equipped with URA of N antennas. The FlyBS serves K single-antenna GUs randomly distributed in a flat area. The initial FlyBS coordinate is set to m and the height range is limited to m. The maximum speed of FlyBS and GUs are set to 20 and 5 m/s, respectively. The current simulation setup is limited in capturing the complexities of real-world environments, such as mountainous terrains. As an alternative, the Rician factor value is employed to control the communication channel quality, enabling a network performance assessment under varying channel conditions [26,34,35]. Unless otherwise specified, other parameters are set to their default values as shown in Table 2.
To demonstrate the efficacy of the proposed framework, we compare it to several baseline algorithms, which are defined as follows.
- TD3-RFBS: Our proposed optimization framework is based on the TD3 algorithm with a normalized action space. It optimizes the precoding matrix, common rate vector, and 3D trajectory for the RSMA-enabled FlyBS to maximize the system sum-rate.
- TD3 algorithm for NOMA-based FlyBS (TD3-NFBS): TD3-NFBS uses the NOMA scheme for the communication channel between the FlyBS and GUs, as opposed to the RSMA scheme in TD3-RFBS. In NOMA, the user with the stronger signal must decode all other users’ messages before accessing its own [7]. The TD3 algorithm optimizes the precoding matrix and 3D trajectory to maximize the system sum-rate.
To assess the effectiveness of the methods, we use the sum-rate metric, which represents the total achievable rate of all users. A higher sum-rate indicates better performance. We run ten simulations for each method and compute the average values to ensure reliability.
5.2. Convergence Analysis
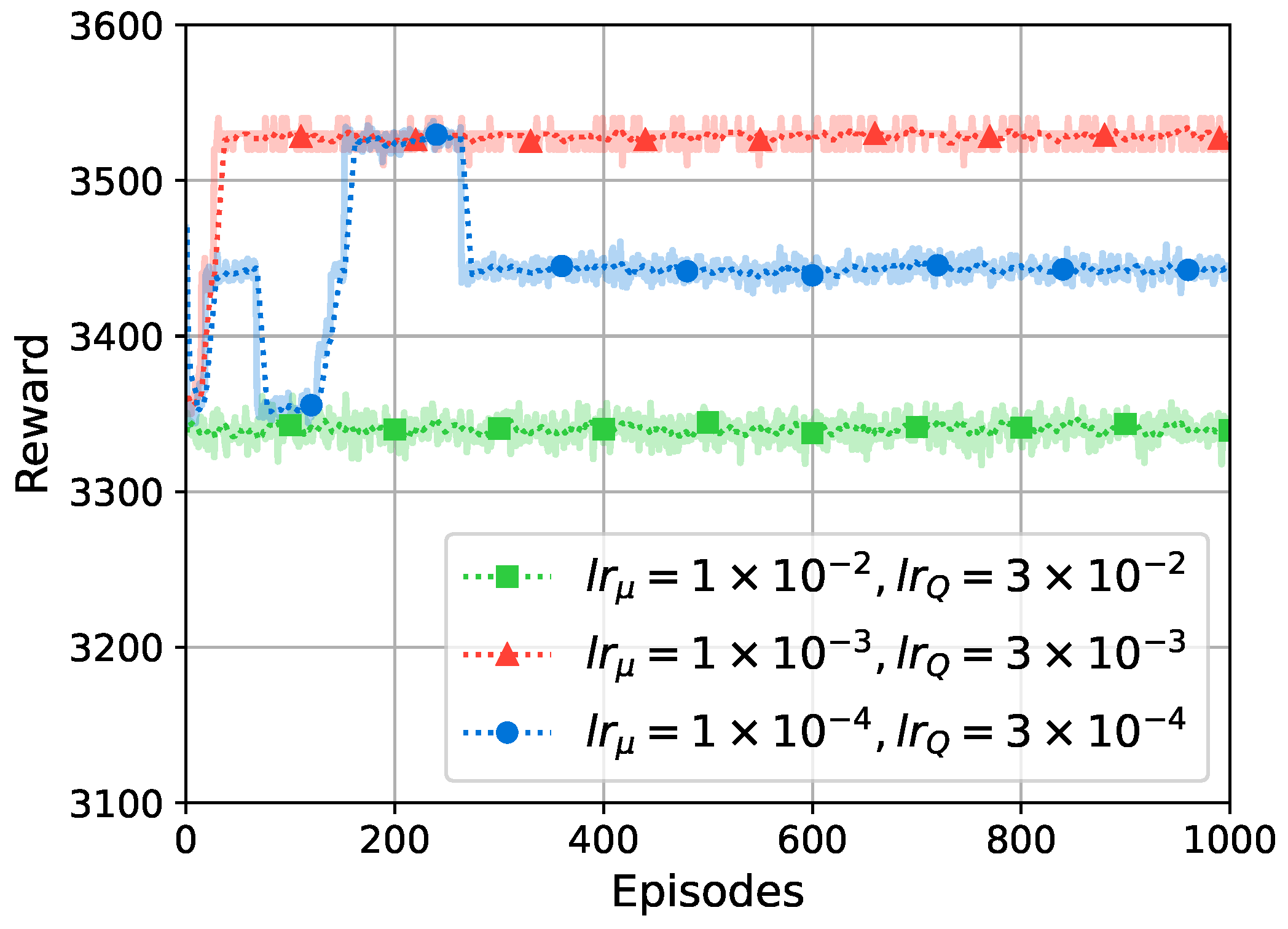
To assess the convergence of TD3-RFBS, we compare its convergence patterns of reward values using different learning rates. The learning rate is a critical parameter that significantly impacts the learning performance. We consider three sets of learning rates: , where and represent the learning rates of the actor and critic networks, respectively. All other hyperparameters are set to their default values. Figure 3 illustrates the convergence outcomes for the three sets of learning rates. Among them, the set demonstrates the most favorable training performance in terms of higher rewards and stability. Consequently, this particular set of learning rates is chosen for the rest of the simulations.
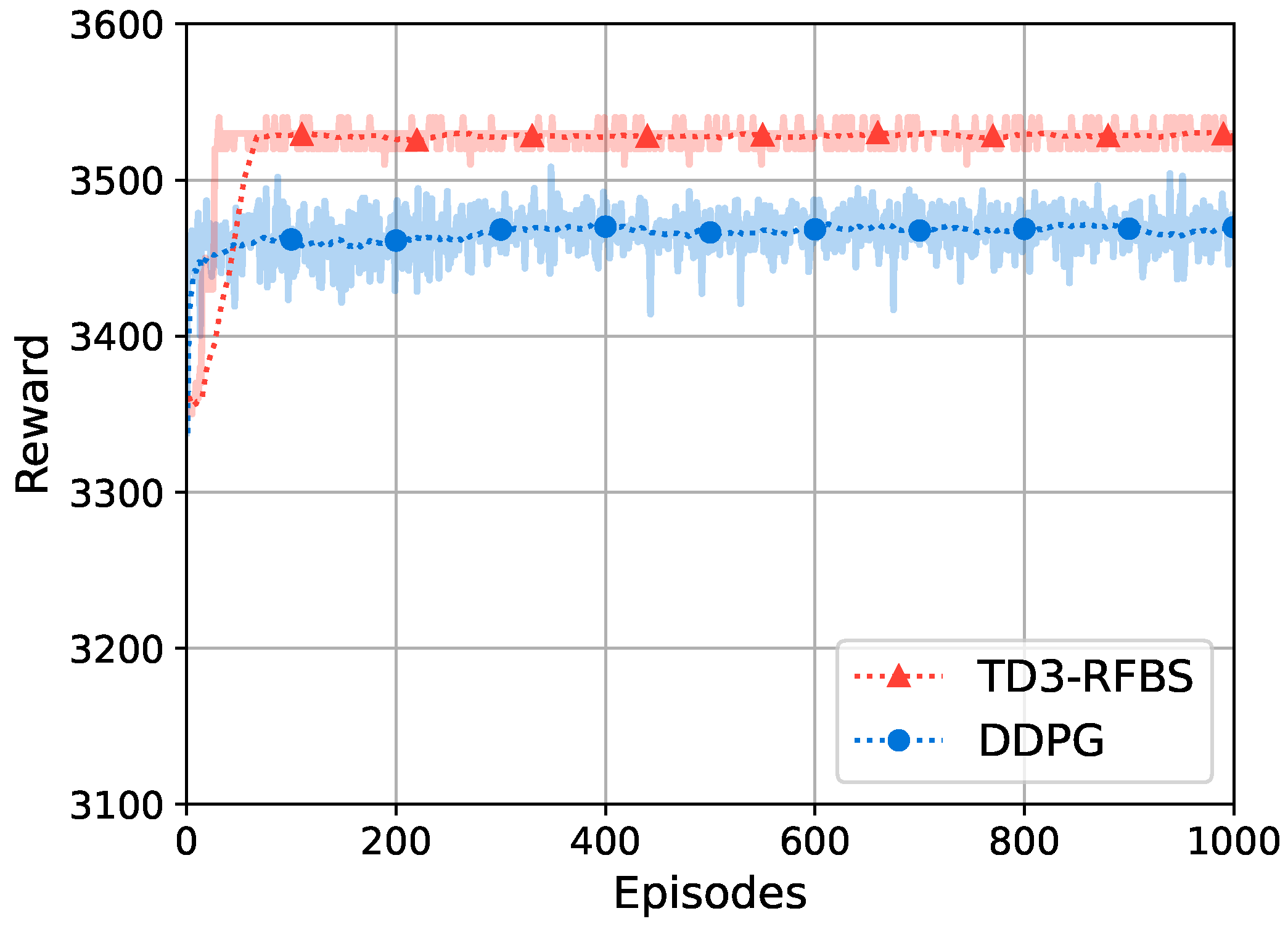
A comparative analysis is performed to evaluate the convergence of TD3-RFBS and DDPG, as illustrated in Figure 4. To ensure a fair comparison, the same hyperparameters are used for both methods, except those specific to TD3-RFBS. While TD3-RFBS and DDPG exhibit similar reward values at the initial stages, TD3-RFBS demonstrates superior convergence, achieving a higher and more stable reward after approximately 100 episodes. This is because DDPG is susceptible to overestimating value functions, which can lead to suboptimal policies. To mitigate this issue, TD3-RFBS employs two critic networks to generate two Q-value functions and uses the minimum Q-value during policy updates. It helps to reduce overestimation bias and improve the performance of TD3-RFBS.
5.3. Performance Analysis
In the following, to demonstrate the effectiveness of RSMA over NOMA, we assess the performance of TD3-RFBS and TD3-NFBS. We also investigate the impact of 3D and 2D FlyBS trajectories on performance. Finally, we compare the performance of TD3-RFBS, DDPG, and Local Search in the RSMA-enabled FlyBS system with a 3D trajectory by varying the transmission power and Rician factor.
5.3.1. Comparison of Multiple Access Schemes
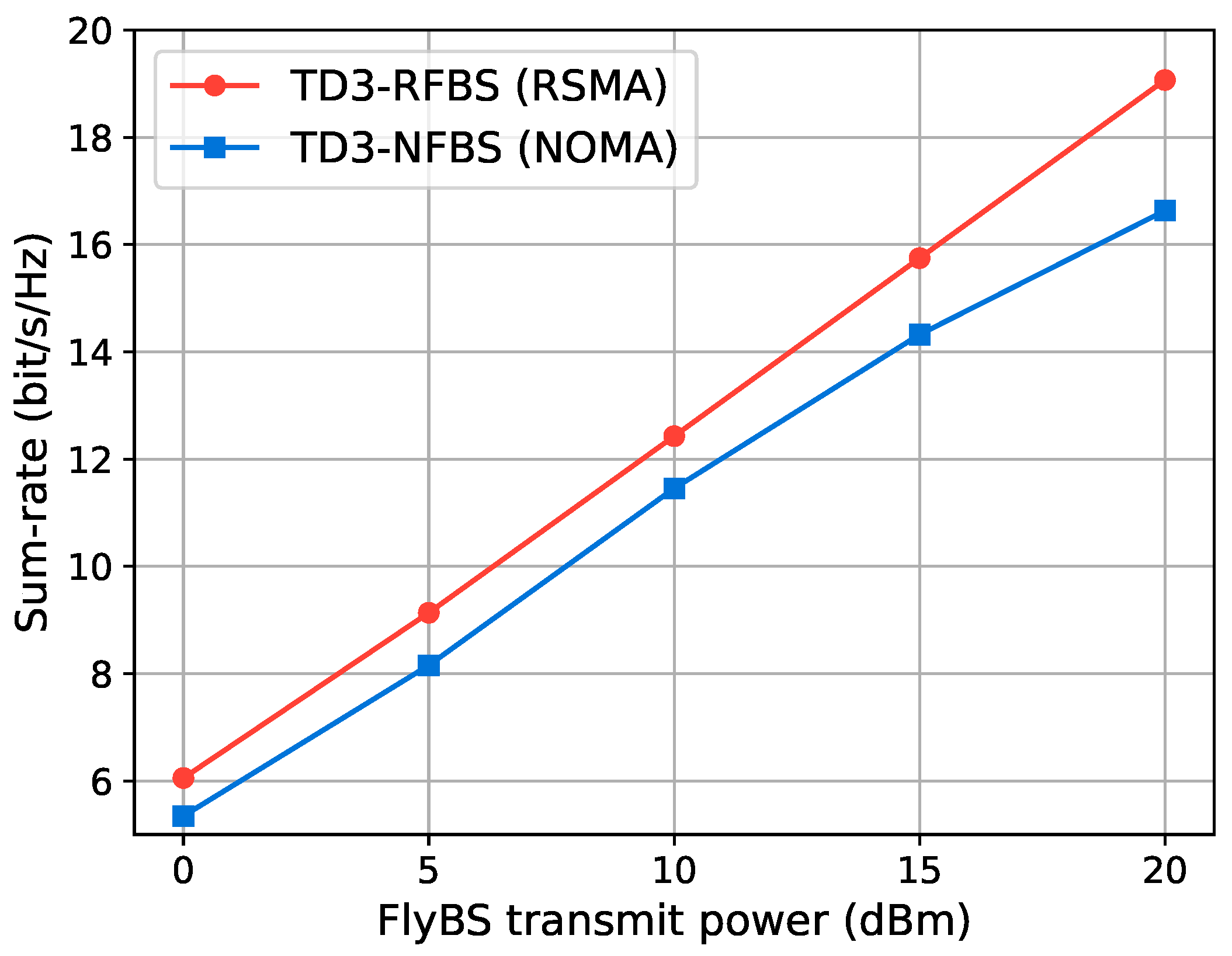
Figure 5 compares the achievable sum-rate of the FlyBS system optimized by the TD3 algorithm using RSMA signaling (TD3-RFBS) and NOMA signaling (TD3-NFBS). As transmit power increases, both schemes exhibit an improved performance. However, RSMA performs better than NOMA due to rate-splitting and effective interference management. With NOMA, increased transmit power also increases interference, limiting the performance gains. Additionally, NOMA is complex due to the requirement for the user with the stronger signal to decode the messages of all other users, necessitating multi-layer SIC [10]. In contrast, RSMA achieves a superior performance to NOMA with a one-layer SIC, substantially reducing the complexity of the receiver. These results suggest that RSMA is a more effective signaling scheme for optimizing the system sum-rate in the FlyBS network.
5.3.2. Comparison of 3D and 2D FlyBS Trajectories
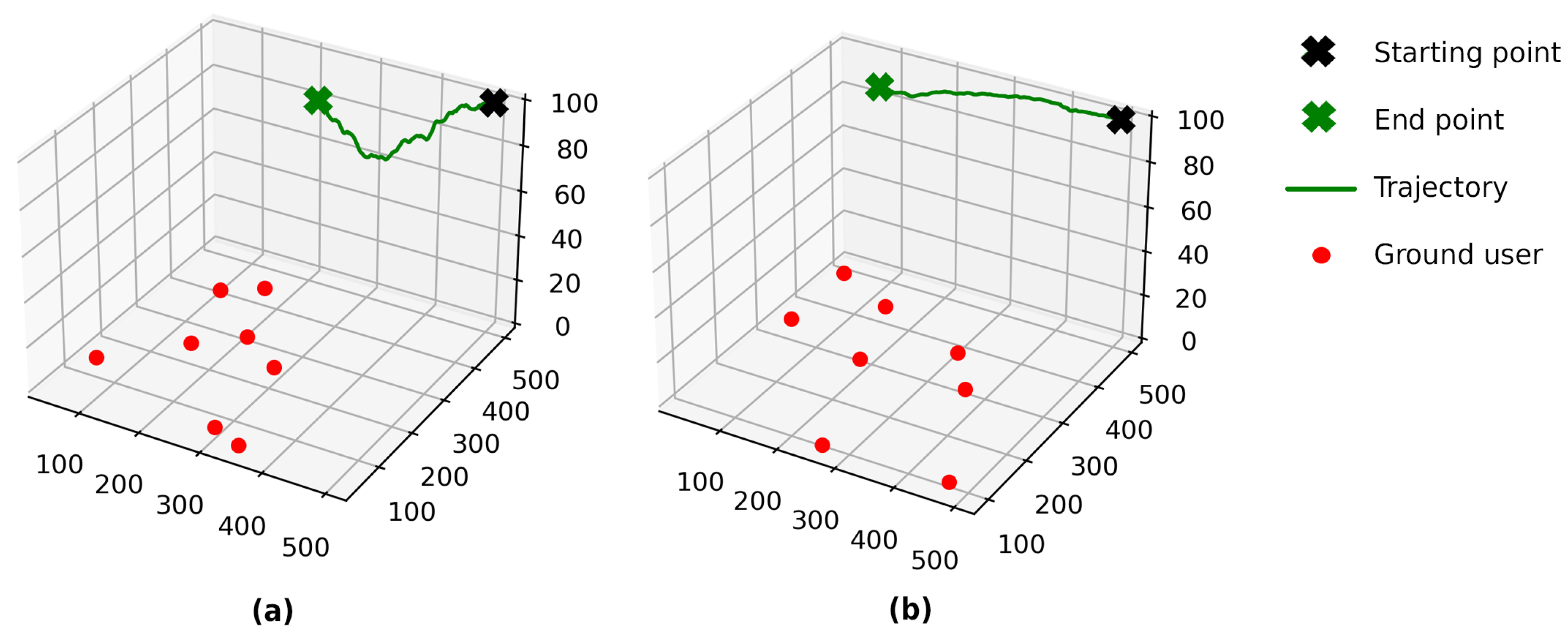
In TD3-RFBS with 2D space (TD3-RFBS 2D), the FlyBS maintains a fixed altitude of 100 m, while in TD3-RFBS with 3D space (TD3-RFBS 3D), the FlyBS can fly at altitudes ranging from 50 to 200 m. The starting position of the FlyBS is set to m. Figure 6 illustrates an example of the FlyBS trajectories obtained by TD3-RFBS 3D and TD3-RFBS 2D. We can see that the FlyBS trajectory obtained by TD3-RFBS 3D is more complex than the FlyBS trajectory obtained by TD3-RFBS 2D. This is because TD3-RFBS 3D has the freedom to fly at different altitudes, which allows it to improve the channel quality. As a result, TD3-RFBS 3D is expected to outperform TD3-RFBS 2D regarding coverage, capacity, and reliability.
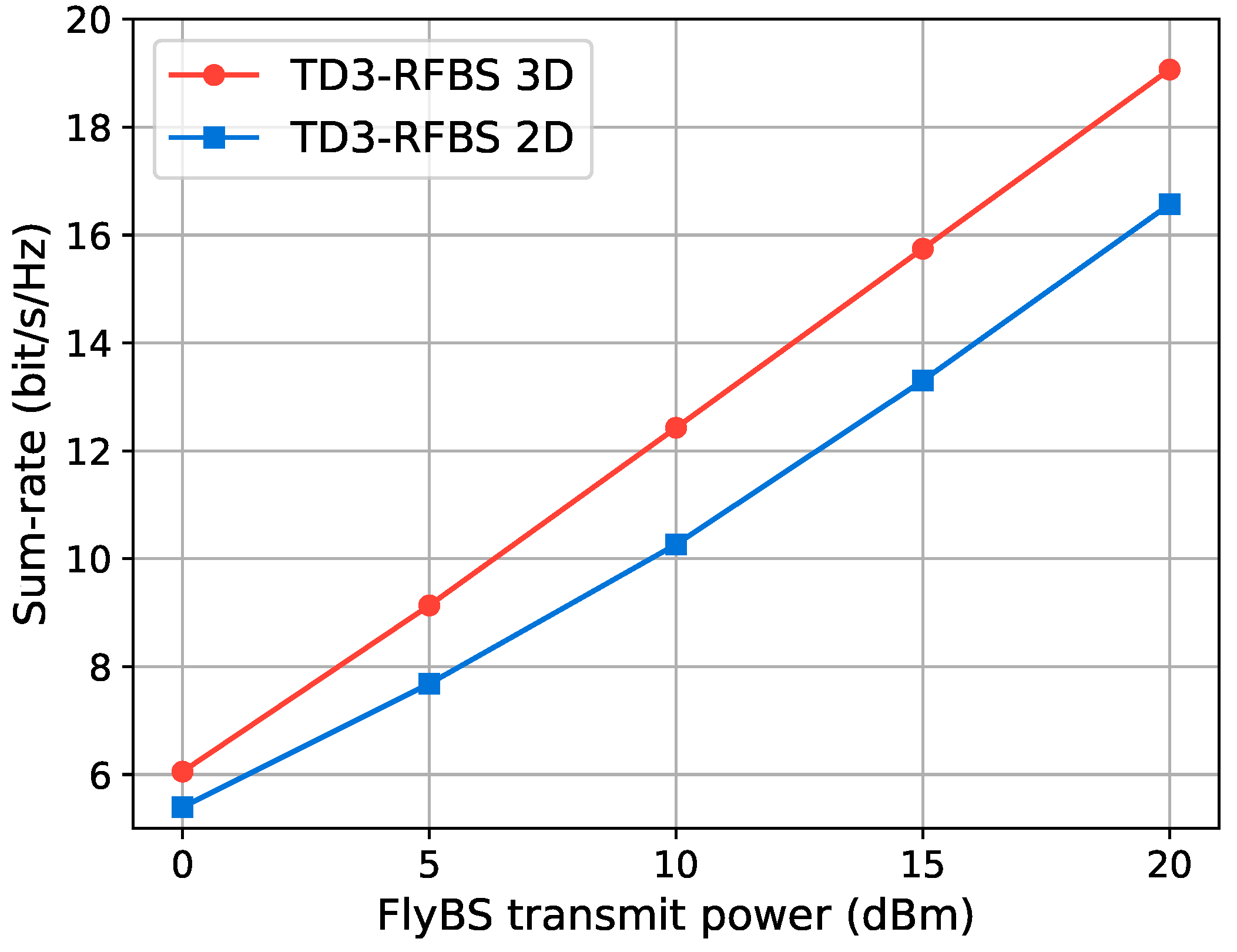
Figure 7 shows the sum-rate achieved by TD3-RFBS 3D and TD3-RFBS 2D for different transmit power levels. As the transmission power increases, the system sum-rate increases proportionally. Notably, controlling the FlyBS altitude improves the system sum-rate. For instance, at a transmit power of 20 dBm, the sum-rate for TD3-RFBS 3D is 19.07 bit/s/Hz, which is a 15.09% improvement over the sum-rate of 16.57 bit/s/Hz for TD3-RFBS 2D. The key to TD3-RFBS 3D’s superior performance is its ability to control the FlyBS altitude. Positioning the FlyBS at a suitable altitude can reduce interference and improve the LoS links to the GUs. In contrast, with a 2D trajectory as in TD3-RFBS 2D, the FlyBS cannot change its altitude in any channel conditions, which limits its performance.
5.3.3. Comparison of Algorithms
We assess the effectiveness of TD3-RFBS against DDPG and Local Search algorithms across varying parameters in the network environment with the RSMA-enabled communications and 3D trajectory of the FlyBS. Figure 8 plots the downlink sum-rate achieved by TD3-RFBS, DDPG, and Local Search versus the transmit power of the FlyBS. As the FlyBS’s transmission power escalates, the sum-rate of all methods also increases linearly. Compared to Local Search, DRL-based approaches consistently achieve a higher sum-rate. Local Search starts with an initial solution and iteratively improves it by making small changes; however, it can become stuck in the local optima and may not find the global optimum. One advantage of DRL approaches, TD3-RFBS, and DDPG over Local Search is their ability to learn from experience and improve their performance over time. Of the two compared DRL approaches, TD3-RFBS achieves better results than DDPG since TD3-RFBS overcomes the overestimation issue of DDPG in policy learning. At a transmit power of 20 dBm, TD3-RFBS obtains a sum-rate of 19.07 bit/s/Hz, which is 8.66% and 17.57% higher than the sum-rate values achieved by DDPG and Local Search, which are 17.55 and 16.22 bit/s/Hz, respectively.
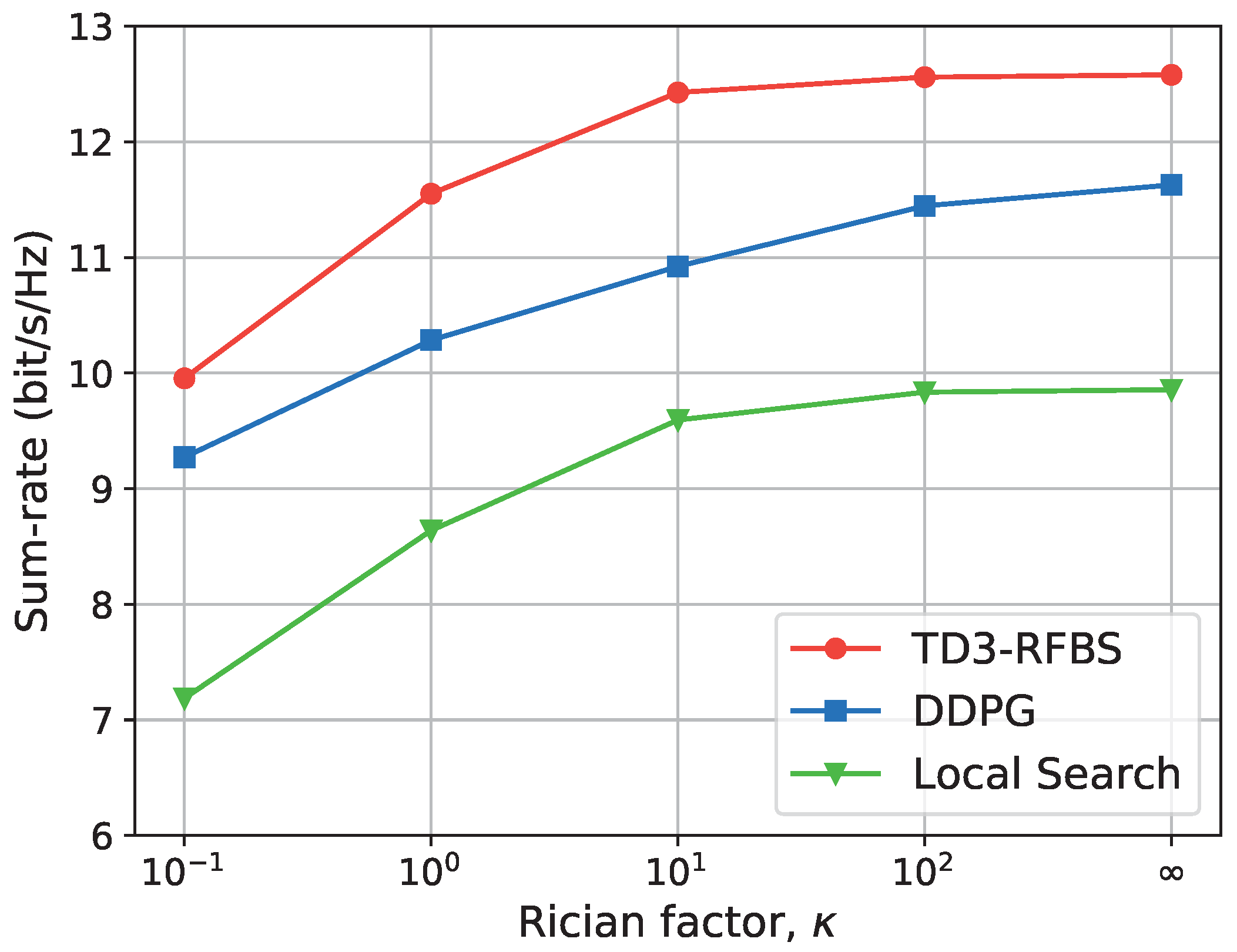
Finally, the proposed framework and baseline schemes are evaluated in fading channels with various Rician factor values. Fading channels are suitable models for emulating realistic channel conditions in wireless communications, such as multipath scattering, temporal dispersion, and Doppler shifts that arise from the relative movement between the transmitter and receiver [26,34,35]. Figure 9 shows the achievable sum-rate results for five values of the Rician factor, . As the Rician factor diminishes in value, the NLoS element within the communication channel experiences an increase, rising uncertainty in the channel condition. In particular, when the Rician factor is ∞, it represents an ideal scenario without any chaotic signal, resulting in an optimal performance for all methods. We can observe that TD3-RFBS performs well in an environment with a Rician factor of , where the obtained sum-rate value is close to that of the ideal scenario. In contrast, DDPG and Local Search can only achieve results near the ideal situation when the Rician factor is up to . Overall, the sum-rate increases with the Rician factor value and our proposed framework, TD3-RFBS, outperforms the comparison schemes.
5.4. Practical System Implication
Throughout the evaluations, TD3-RFBS efficiently optimizes the FlyBS trajectory and RSMA parameters for various configurations in the RSMA-enabled FlyBS system. This work has significant practical implications for future wireless networks, as it can improve the performance and reliability of aerial communication systems. This could benefit diverse applications such as disaster management, remote sensing, search and rescue, smart agriculture, and intelligent transportation systems [1,5,19,20,21]. Examples are as follows.
- Disaster management: FlyBSs can provide communication coverage in areas where terrestrial BSs have been damaged or destroyed by natural disasters, such as hurricanes and earthquakes. The TD3-RFBS optimization framework can improve the performance of these systems, leading to more reliable and efficient communications in disaster areas, which can be critical for search and rescue efforts.
- Remote sensing: FlyBSs can collect data on remote areas, such as forests, mountains, and oceans, for various applications, including environmental monitoring and remote control of critical infrastructure. The TD3-RFBS optimization framework can increase the spectral efficiency of these systems, leading to more timely and accurate data collection.
While the practical implementation of the proposed framework may face challenges such as hardware and software requirements, regulatory issues, and cost considerations, we believe that these challenges can be overcome through further research and development.
6. Conclusions
This paper investigated a sum-rate maximization problem in an RSMA-enhanced FlyBS system. Since the problem is non-convex and the TD3 algorithm is superior to the DDPG algorithm, we reformulated the problem as an MDP. We developed an optimization framework that utilizes TD3, namely TD3-RFBS, to solve the MDP model. This framework jointly optimizes the 3D FlyBS trajectory, precoding matrix, and common rate allocation without requiring prior knowledge of CSI. Simulation results showed that the TD3-based algorithm outperformed the DDPG-based algorithm in terms of reward and convergence. Moreover, the proposed framework achieved significant rate improvements compared to other baseline solutions in various scenarios with time-varying channel conditions.
In future work, the system model could be extended to include a multi-FlyBS environment, paving the way for developing multi-agent DRL methods to tackle the optimization challenge. To enhance the realism of the simulation environment, future work could focus on incorporating detailed terrain models that capture the impact of geographical features on communication channels. Additionally, exploring new communication technologies, such as reconfigurable intelligent surfaces and terahertz communications, could further enhance the system sum-rate. Finally, further research and development in practical systems are necessary to fully realize the potential of the proposed optimization framework.
Author Contributions
Conceptualization, T.-H.N. and L.P.; methodology, T.-H.N., L.V.N., L.M.D. and V.T.H.; software, T.-H.N. and L.V.N.; validation, T.-H.N. and L.V.N.; formal analysis, T.-H.N., L.M.D. and V.T.H.; investigation, T.-H.N. and L.P.; resources, L.P.; data curation, T.-H.N. and V.T.H.; writing—original draft preparation, T.-H.N.; writing—review and editing, L.V.N., L.M.D., V.T.H. and L.P.; visualization, T.-H.N. and L.V.N.; supervision, L.P.; project administration, L.P.; funding acquisition, T.-H.N. and L.P. All authors have read and agreed to the published version of the manuscript.
Funding
This study was financially supported by Seoul National University of Science and Technology.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| 2D | Two-dimensional |
| 3D | Three-dimensional |
| BS | Base station |
| CSI | Channel state information |
| DDPG | Deep deterministic policy gradient |
| DNN | Deep neural network |
| DRL | Deep reinforcement learning |
| FlyBS | Flying base station |
| GU | Ground user |
| IoT | Internet of Things |
| LoS | Line-of-sight |
| MDP | Markov decision process |
| NLoS | Non-line-of-sight |
| NOMA | Non-orthogonal multiple access |
| QoS | Quality of service |
| RSMA | Rate-splitting multiple access |
| SIC | Successive interference cancellation |
| TD3 | Twin-delayed deep deterministic policy gradient |
| UAV | Unmanned aerial vehicle |
| URA | Uniform rectangular array |
References
- Dao, N.N.; Pham, Q.V.; Tu, N.H.; Thanh, T.T.; Bao, V.N.Q.; Lakew, D.S.; Cho, S. Survey on Aerial Radio Access Networks: Toward a Comprehensive 6G Access Infrastructure. IEEE Commun. Surv. Tutor. 2021, 23, 1193–1225. [Google Scholar] [CrossRef]
- Zhao, M.; Chen, C.; Liu, L.; Lan, D.; Wan, S. Orbital collaborative learning in 6G space-air-ground integrated networks. Neurocomputing 2022, 497, 94–109. [Google Scholar] [CrossRef]
- Dong, F.; Song, J.; Zhang, Y.; Wang, Y.; Huang, T. DRL-Based Load-Balancing Routing Scheme for 6G Space–Air–Ground Integrated Networks. Remote Sens. 2023, 15, 2801. [Google Scholar] [CrossRef]
- Lakew, D.S.; Tran, A.T.; Dao, N.N.; Cho, S. Intelligent Offloading and Resource Allocation in Heterogeneous Aerial Access IoT Networks. IEEE Internet Things J. 2023, 10, 5704–5718. [Google Scholar] [CrossRef]
- Geraci, G.; Garcia-Rodriguez, A.; Azari, M.M.; Lozano, A.; Mezzavilla, M.; Chatzinotas, S.; Chen, Y.; Rangan, S.; Renzo, M.D. What Will the Future of UAV Cellular Communications Be? A Flight From 5G to 6G. IEEE Commun. Surv. Tutor. 2022, 24, 1304–1335. [Google Scholar] [CrossRef]
- Shi, J.; Cong, P.; Zhao, L.; Wang, X.; Wan, S.; Guizani, M. A Two-Stage Strategy for UAV-enabled Wireless Power Transfer in Unknown Environments. IEEE Trans. Mob. Comput. 2023, in press. [Google Scholar] [CrossRef]
- Dai, L.; Wang, B.; Yuan, Y.; Han, S.; Chih-lin, I.; Wang, Z. Non-orthogonal multiple access for 5G: Solutions, challenges, opportunities, and future research trends. IEEE Commun. Mag. 2015, 53, 74–81. [Google Scholar] [CrossRef]
- Mao, Y.; Dizdar, O.; Clerckx, B.; Schober, R.; Popovski, P.; Poor, H.V. Rate-Splitting Multiple Access: Fundamentals, Survey, and Future Research Trends. IEEE Commun. Surv. Tutor. 2022, 24, 2073–2126. [Google Scholar] [CrossRef]
- Clerckx, B.; Mao, Y.; Jorswieck, E.A.; Yuan, J.; Love, D.J.; Erkip, E.; Niyato, D. A Primer on Rate-Splitting Multiple Access: Tutorial, Myths, and Frequently Asked Questions. IEEE J. Sel. Areas Commun. 2023, 41, 1265–1308. [Google Scholar] [CrossRef]
- Mao, Y.; Clerckx, B.; Li, V.O. Rate-splitting multiple access for downlink communication systems: Bridging, generalizing, and outperforming SDMA and NOMA. EURASIP J. Wirel. Commun. Netw. 2018, 2018, 133. [Google Scholar] [CrossRef]
- Mao, Y.; Clerckx, B.; Li, V.O.K. Rate-Splitting for Multi-Antenna Non-Orthogonal Unicast and Multicast Transmission: Spectral and Energy Efficiency Analysis. IEEE Trans. Commun. 2019, 67, 8754–8770. [Google Scholar] [CrossRef]
- Sen, S.; Santhapuri, N.; Choudhury, R.R.; Nelakuditi, S. Successive Interference Cancellation: Carving Out MAC Layer Opportunities. IEEE Trans. Mob. Comput. 2013, 12, 346–357. [Google Scholar] [CrossRef]
- Hieu, N.Q.; Hoang, D.T.; Niyato, D.; Kim, D.I. Optimal Power Allocation for Rate Splitting Communications with Deep Reinforcement Learning. IEEE Wirel. Commun. Lett. 2021, 10, 2820–2823. [Google Scholar] [CrossRef]
- Xu, Y.; Mao, Y.; Dizdar, O.; Clerckx, B. Rate-Splitting Multiple Access with Finite Blocklength for Short-Packet and Low-Latency Downlink Communications. IEEE Trans. Veh. Technol. 2022, 71, 12333–12337. [Google Scholar] [CrossRef]
- Van, N.T.T.; Luong, N.C.; Feng, S.; Nguyen, V.D.; Kim, D.I. Evolutionary Games for Dynamic Network Resource Selection in RSMA-Enabled 6G Networks. IEEE J. Sel. Areas Commun. 2023, 41, 1320–1335. [Google Scholar] [CrossRef]
- Yu, D.; Kim, J.; Park, S.H. An Efficient Rate-Splitting Multiple Access Scheme for the Downlink of C-RAN Systems. IEEE Wirel. Commun. Lett. 2019, 8, 1555–1558. [Google Scholar] [CrossRef]
- Xu, Y.; Mao, Y.; Dizdar, O.; Clerckx, B. Max-Min Fairness of Rate-Splitting Multiple Access with Finite Blocklength Communications. IEEE Trans. Veh. Technol. 2023, 72, 6816–6821. [Google Scholar] [CrossRef]
- Zhou, G.; Mao, Y.; Clerckx, B. Rate-Splitting Multiple Access for Multi-Antenna Downlink Communication Systems: Spectral and Energy Efficiency Tradeoff. IEEE Trans. Wirel. Commun. 2022, 21, 4816–4828. [Google Scholar] [CrossRef]
- Truong, T.P.; Dao, N.N.; Cho, S. HAMEC-RSMA: Enhanced Aerial Computing Systems with Rate Splitting Multiple Access. IEEE Access 2022, 10, 52398–52409. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Park, L. HAP-Assisted RSMA-Enabled Vehicular Edge Computing: A DRL-Based Optimization Framework. Mathematics 2023, 11, 2376. [Google Scholar] [CrossRef]
- Jaafar, W.; Naser, S.; Muhaidat, S.; Sofotasios, P.C.; Yanikomeroglu, H. On the Downlink Performance of RSMA-Based UAV Communications. IEEE Trans. Veh. Technol. 2020, 69, 16258–16263. [Google Scholar] [CrossRef]
- Singh, S.K.; Agrawal, K.; Singh, K.; Li, C.P. Ergodic Capacity and Placement Optimization for RSMA-Enabled UAV-Assisted Communication. IEEE Syst. J. 2023, 17, 2586–2589. [Google Scholar] [CrossRef]
- Singh, S.K.; Agrawal, K.; Singh, K.; Chen, Y.M.; Li, C.P. Performance Analysis and Optimization of RSMA Enabled UAV-Aided IBL and FBL Communication with Imperfect SIC and CSI. IEEE Trans. Wirel. Commun. 2023, 22, 3714–3732. [Google Scholar] [CrossRef]
- Xiao, M.; Cui, H.; Huang, D.; Zhao, Z.; Cao, X.; Wu, D.O. Traffic-Aware Energy-Efficient Resource Allocation for RSMA Based UAV Communications. IEEE Trans. Netw. Sci. Eng. 2023, in press. [Google Scholar] [CrossRef]
- Ji, J.; Cai, L.; Zhu, K.; Niyato, D. Decoupled Association with Rate Splitting Multiple Access in UAV-assisted Cellular Networks Using Multi-agent Deep Reinforcement Learning. IEEE Trans. Mob. Comput. 2023, in press. [Google Scholar] [CrossRef]
- Hua, D.T.; Do, Q.T.; Dao, N.N.; Cho, S. On sum-rate maximization in downlink UAV-aided RSMA systems. ICT Express 2023, in press. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Sánchez, J.A.H.; Casilimas, K.; Rendon, O.M.C. Deep Reinforcement Learning for Resource Management on Network Slicing: A Survey. Sensors 2022, 22, 3031. [Google Scholar] [CrossRef]
- Wang, Z.; Pan, W.; Li, H.; Wang, X.; Zuo, Q. Review of Deep Reinforcement Learning Approaches for Conflict Resolution in Air Traffic Control. Aerospace 2022, 9, 294. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Park, L. A Survey on Deep Reinforcement Learning-driven Task Offloading in Aerial Access Networks. In Proceedings of the 2022 13th International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 19–21 October 2022; pp. 822–827. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Park, H.; Park, L. Recent Studies on Deep Reinforcement Learning in RIS-UAV Communication Networks. In Proceedings of the 2023 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Bali, Indonesia, 20–23 February 2023; pp. 378–381. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Park, H.; Seol, K.; So, S.; Park, L. Applications of Deep Learning and Deep Reinforcement Learning in 6G Networks. In Proceedings of the 2023 Fourteenth International Conference on Ubiquitous and Future Networks (ICUFN), Paris, France, 4–7 July 2023; pp. 427–432. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the 4th International Conference on Learning Representations (ICLR 2016), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Truong, T.P.; Tuong, V.D.; Dao, N.N.; Cho, S. FlyReflect: Joint Flying IRS Trajectory and Phase Shift Design Using Deep Reinforcement Learning. IEEE Internet Things J. 2023, 10, 4605–4620. [Google Scholar] [CrossRef]
- Hua, D.T.; Do, Q.T.; Dao, N.N.; Nguyen, T.V.; Lakew, D.S.; Cho, S. Learning-based Reconfigurable Intelligent Surface-aided Rate-Splitting Multiple Access Networks. IEEE Internet Things J. 2023, 10, 17603–17619. [Google Scholar] [CrossRef]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1587–1596. [Google Scholar]
- Nguyen, T.H.; Truong, T.P.; Dao, N.N.; Na, W.; Park, H.; Park, L. Deep Reinforcement Learning-based Partial Task Offloading in High Altitude Platform-aided Vehicular Networks. In Proceedings of the 2022 13th International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 19–21 October 2022; pp. 1341–1346. [Google Scholar] [CrossRef]
- Yong, S.K.; Thompson, J. Three-dimensional spatial fading correlation models for compact MIMO receivers. IEEE Trans. Wirel. Commun. 2005, 4, 2856–2869. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 15 July 2023).
Figure 1.
RSMA-enhanced FlyBS system.

Figure 2.
Geometry of URA with antennas.

Figure 3.
Convergence behavior of TD3-RFBS with three different learning rate configurations.

Figure 4.
Convergence behavior of TD3-RFBS in comparison with DDPG.

Figure 5.
Sum-rate performance of the TD3-RFBS with its counterpart, TD3-NFBS, for different transmit power levels.
Figure 5.
Sum-rate performance of the TD3-RFBS with its counterpart, TD3-NFBS, for different transmit power levels.

Figure 6.
FlyBS trajectories obtained by TD3-RFBS. (a) 3D trajectory; (b) 2D trajectory.

Figure 7.
Sum-rate versus transmit power for 3D and 2D FlyBS trajectories using TD3-RFBS.

Figure 8.
Sum-rate achieved by three compared methods for various transmit power levels of FlyBS.

Figure 9.
Sum-rate performance of three methods with varying Rician factor values.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
A comparison with existing studies on downlink RSMA-based communication systems.
| References | Optimization Objective | Optimization Method | FlyBS | FlyBS Trajectory | Time-Varying Environment |
|---|---|---|---|---|---|
| [10] | Sum-rate maximization | Alternating optimization | ✗ | Not applicable | ✗ |
| [11] | Energy efficiency | Successive convex approximation | ✗ | Not applicable | ✗ |
| [13] | Sum-rate maximization | DRL (i.e., PPO) | ✗ | Not applicable | ✓ |
| [14] | Sum-rate maximization | Successive convex approximation | ✗ | Not applicable | ✗ |
| [15] | Sum-rate maximization | Evolutionary game | ✗ | Not applicable | ✓ |
| [16] | Max–min rate fairness | Iterative algorithm | ✗ | Not applicable | ✗ |
| [17] | Max–min rate fairness | Successive convex approximation | ✗ | Not applicable | ✗ |
| [18] | Energy efficiency | Successive convex approximation | ✗ | Not applicable | ✗ |
| [21] | Sum-rate maximization | Alternating optimization | ✓ | Optimal position | ✗ |
| [22] | Sum-rate maximization | Alternating optimization | ✓ | Optimal position | ✗ |
| [23] | Sum-rate maximization | Alternating optimization | ✓ | Optimal position | ✗ |
| [24] | Energy efficiency | Sub-problem decomposition | ✓ | Optimal position | ✗ |
| [25] | Sum-rate maximization | DRL (i.e., PPO) | ✓ | Fixed position | ✓ |
| [26] | Sum-rate maximization | DRL (i.e., DDPG) | ✓ | 2D trajectory | ✓ |
| Our work | Sum-rate maximization | DRL (i.e., TD3) | ✓ | 3D trajectory | ✓ |
The symbol ✓ is used to denote that an aspect is included in the study, while ✗ indicates that it is not.
Table 2.
Parameter setup.
| Parameter | Value |
|---|---|
| System | |
| Number of GUs, K | 8 |
| Channel bandwidth, B | 1 MHz |
| Noise power, | −174 dBm/Hz |
| GUs’ maximum velocity | 5 m/s |
| FlyBS’s maximum velocity | 20 m/s |
| FlyBS’s maximum transmit power, | 10 dBm |
| Number of antennas, N | 16 |
| Rician factor, | 10 |
| Large-scale path loss, | dB |
| Time slot duration, | 0.1 s |
| Algorithm | |
| Optimizer | Adam |
| Discount factor, | 0.95 |
| Size of replay buffer | |
| Size of mini-batch, S | 64 |
| Actor learning rate, | |
| Critic learning rate, | |
| Frequency of policy updates, f | 2 |
| Policy noise variance, | 0.2 |
| Noise clip, c | 0.2 |
| Soft update rate, | |
| Number of training episodes | 2000 |
| Number of testing episodes | 100 |
| Number of time slots in each episode | 300 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Nguyen, T.-H.; Nguyen, L.V.; Dang, L.M.; Hoang, V.T.; Park, L. TD3-Based Optimization Framework for RSMA-Enhanced UAV-Aided Downlink Communications in Remote Areas. Remote Sens. 2023, 15, 5284. https://doi.org/10.3390/rs15225284
AMA Style
Nguyen T-H, Nguyen LV, Dang LM, Hoang VT, Park L. TD3-Based Optimization Framework for RSMA-Enhanced UAV-Aided Downlink Communications in Remote Areas. Remote Sensing. 2023; 15(22):5284. https://doi.org/10.3390/rs15225284
Chicago/Turabian StyleNguyen, Tri-Hai, Luong Vuong Nguyen, L. Minh Dang, Vinh Truong Hoang, and Laihyuk Park. 2023. "TD3-Based Optimization Framework for RSMA-Enhanced UAV-Aided Downlink Communications in Remote Areas" Remote Sensing 15, no. 22: 5284. https://doi.org/10.3390/rs15225284
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.