
Discrimination of Leaves in a Multi-Layered Mediterranean Forest through Machine Learning Algorithms

 , , , , and
, , , , and 
Abstract
:1. Introduction
2. Materials and Methods
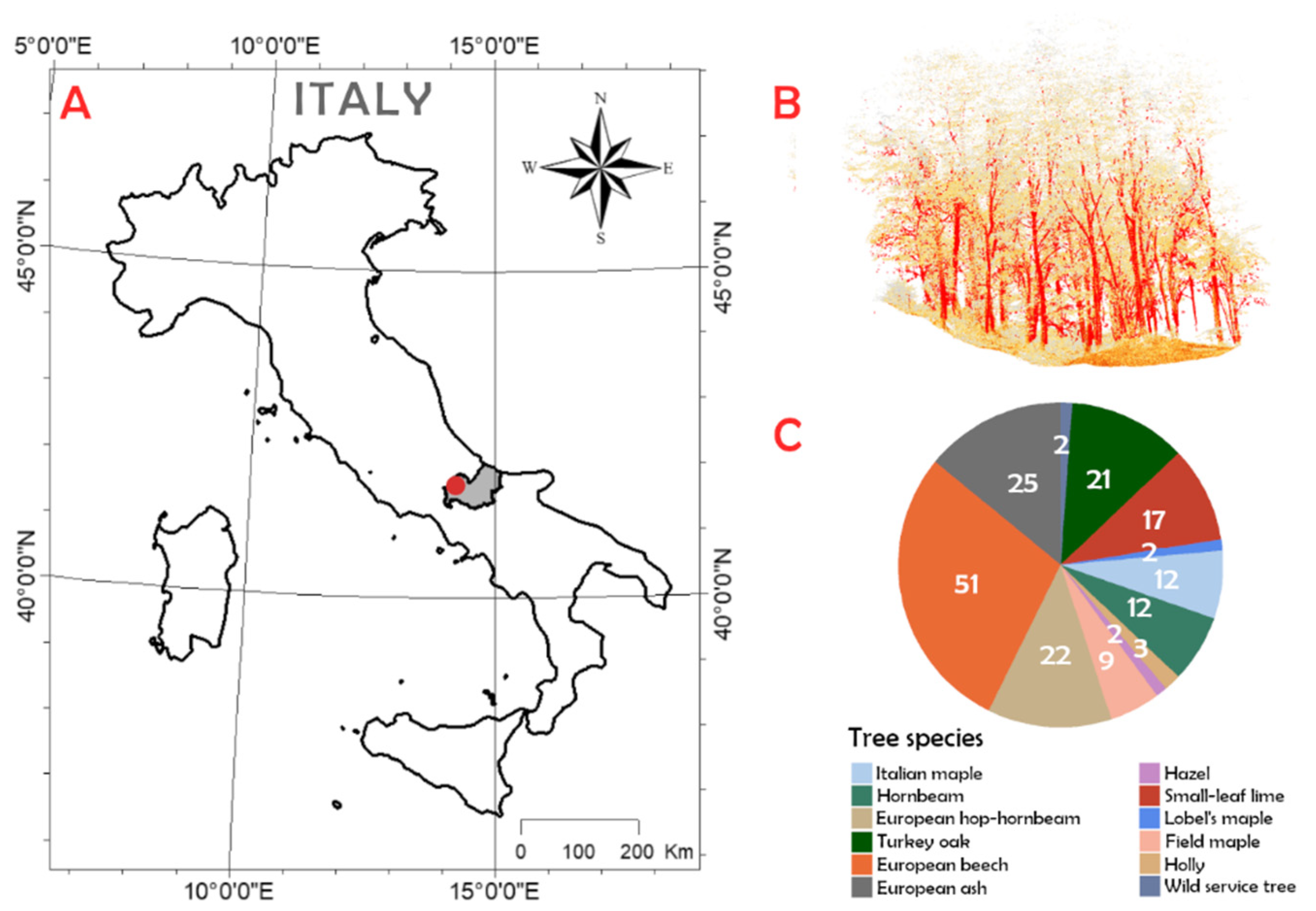
2.1. Study Area
2.2. Data Collection
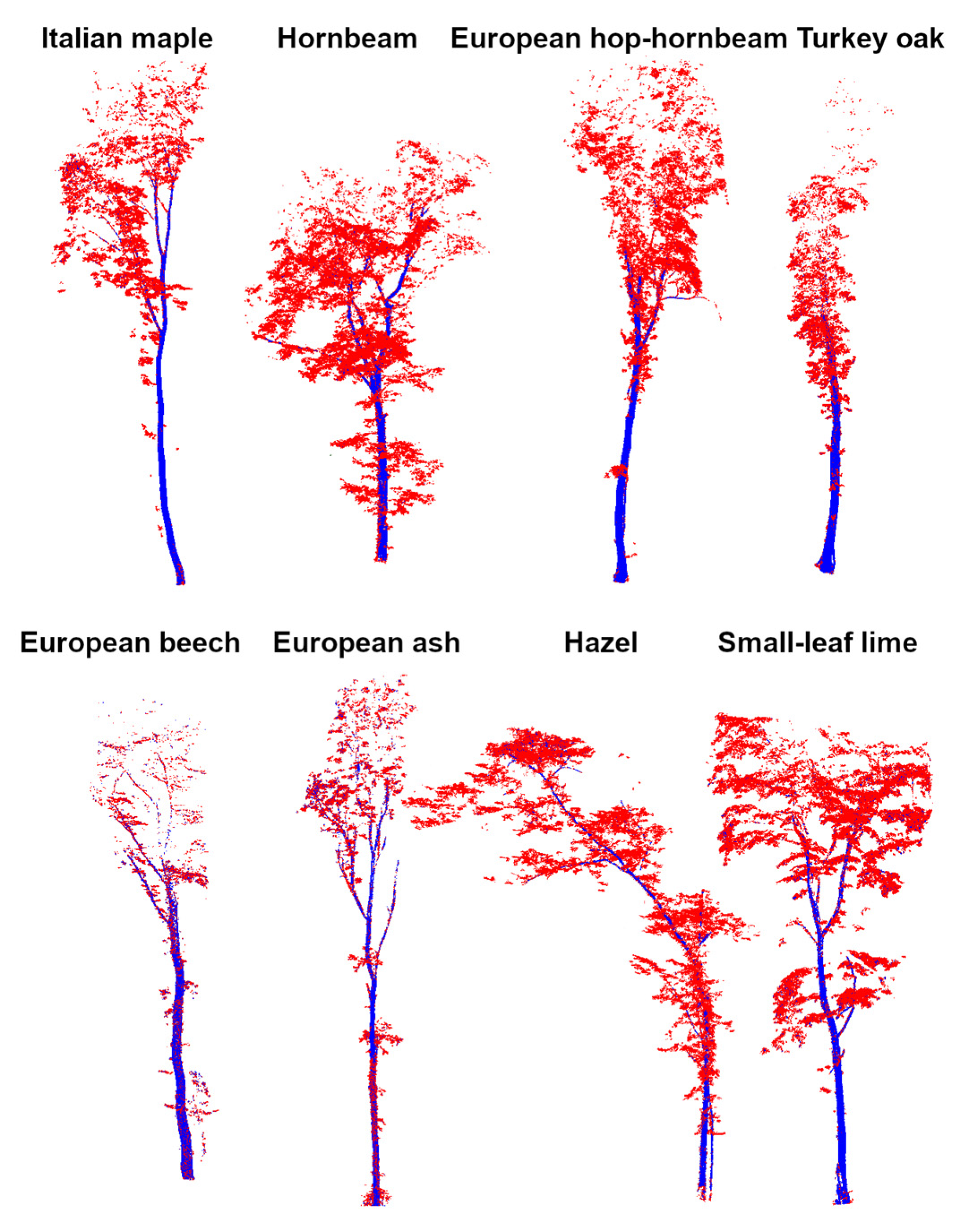
Ground Truth and TLS Data
2.3. Data Analysis
2.3.1. TLS Point Cloud Pre-Processing
2.3.2. Tree Geometry-Based Features
2.3.3. ML Algorithm Implementation
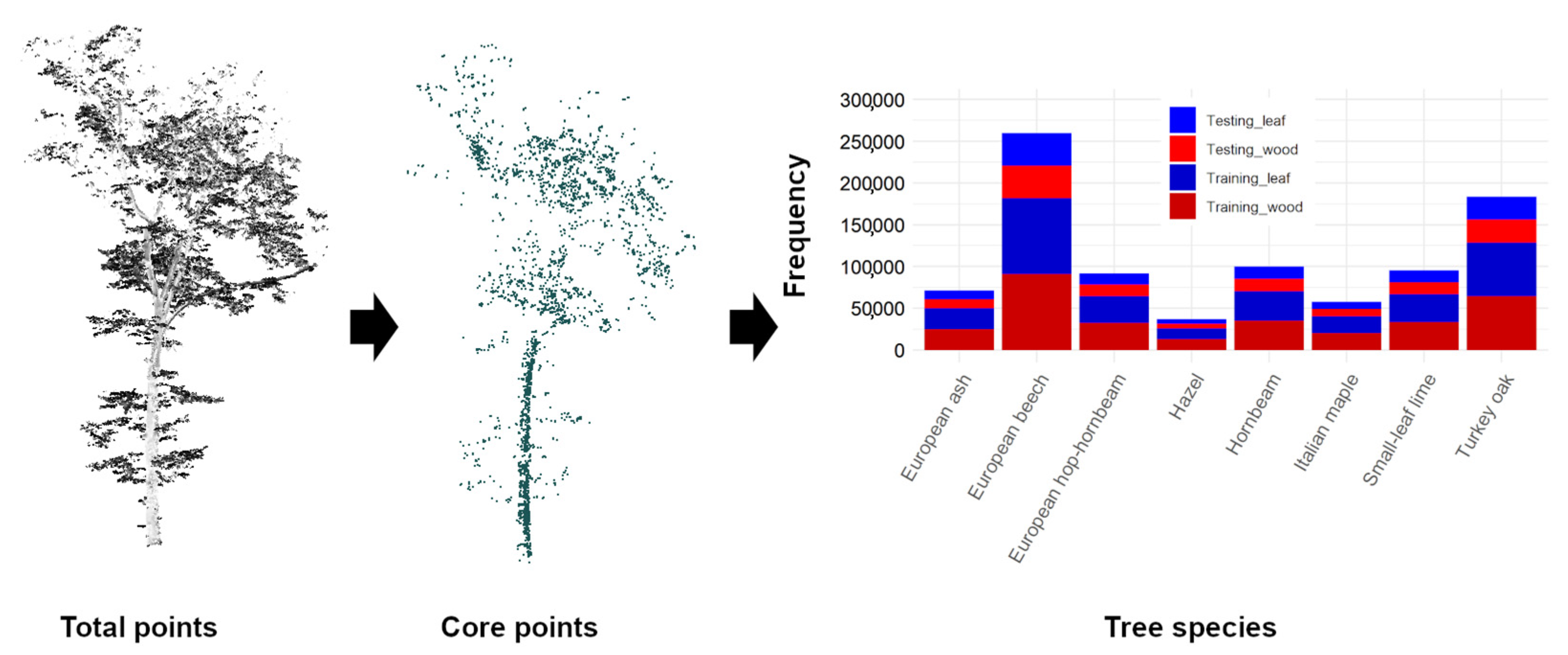
- Dataset partitioning: the point clouds were divided into non-overlapping training (70%) and testing (30%) sets. Each set of data was equally partitioned into leaf and wood components (Appendix A, Figure A1).
- Model optimization: the training dataset was processed to efficiently determine the optimal combination of hyperparameters using fewer predictors [23]. The hyperparameter tuning procedure used a 10-fold cross-validation framework, while selecting predictors was conducted through a variable importance assessment. Both of these steps were executed using the ‘h2o.grid’ and ‘h2o.varimp’ functions within the ‘h2o’ package ‘h2o’ [54], ‘caret’ [55], ‘naivebayes’ [56], and ‘foreach’ [57]. Optimal hyperparameters were derived from the best model reporting the highest ‘logloss’ values (from 0% to 100%; the binary-class classification logloss equation was 1) and the ‘h2o.getGrid’ function. The logloss algorithm quantifies the cross-entropy loss of models, comparing their observed and predicted results [58].
- 4.
- Model evaluation: the top-performing models were validated through various evaluation criteria, such as statistical metrics, computation time, and predictor count. A detailed explanation of the validation approach is specified in the subsequent step (Section 2.3.4).
2.3.4. Model Validation
3. Results
3.1. Hyperparameters Selected for Best Model Results
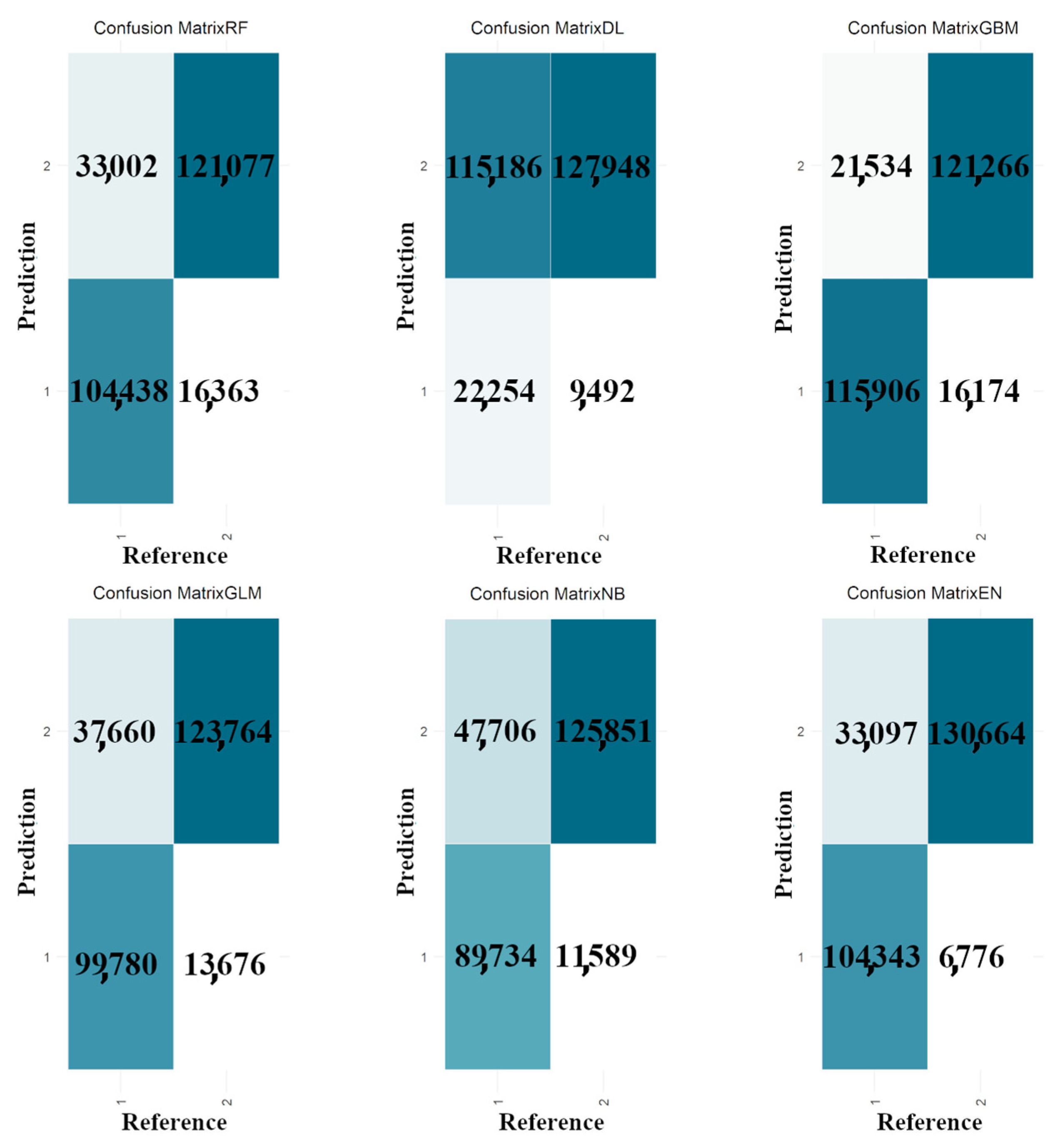
3.2. Binary-Class Classification Results for Individual Tree Species
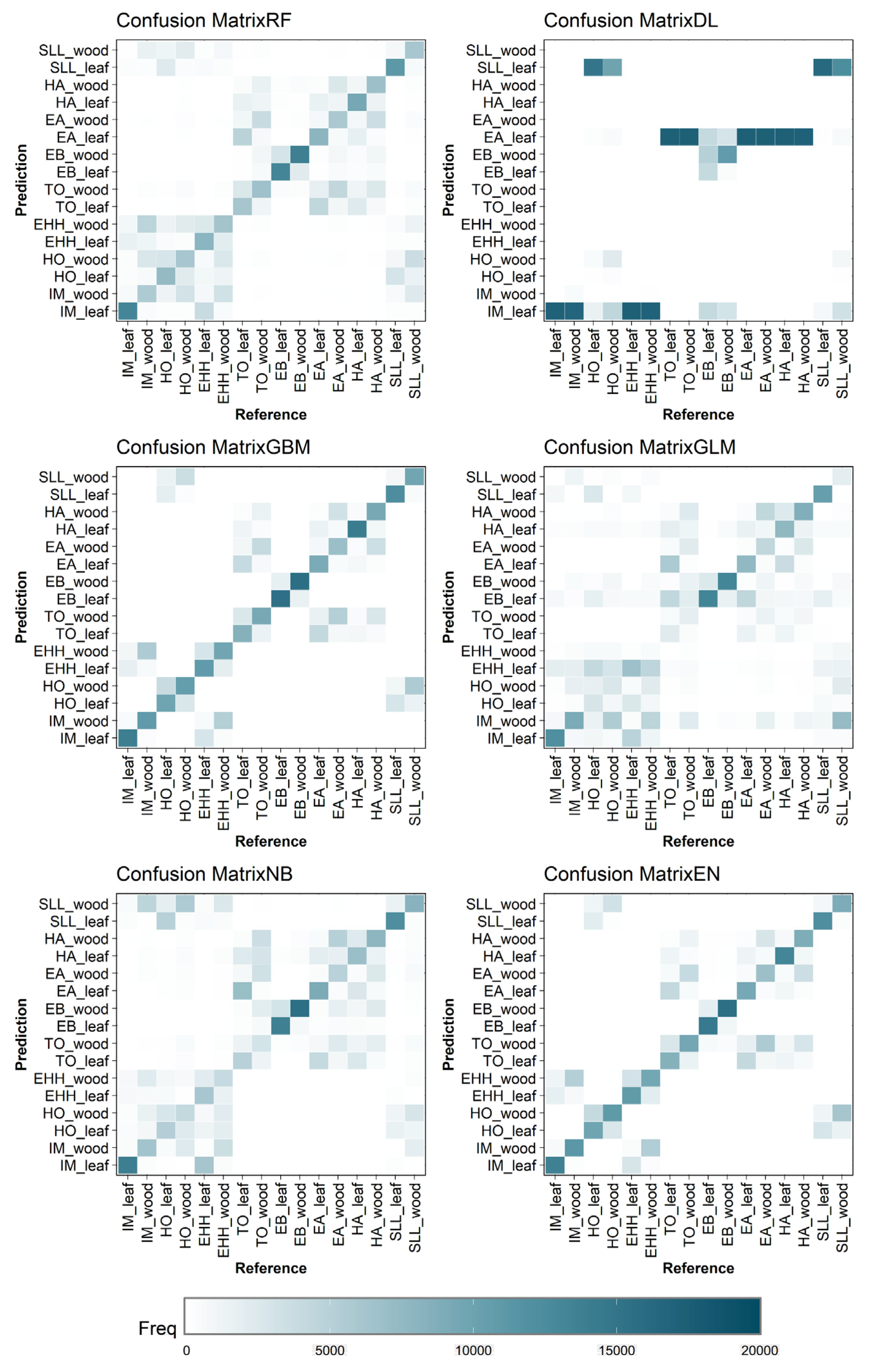
3.3. Binary-Class and Multi-Class Classification Results for Combined Tree Species Datasets
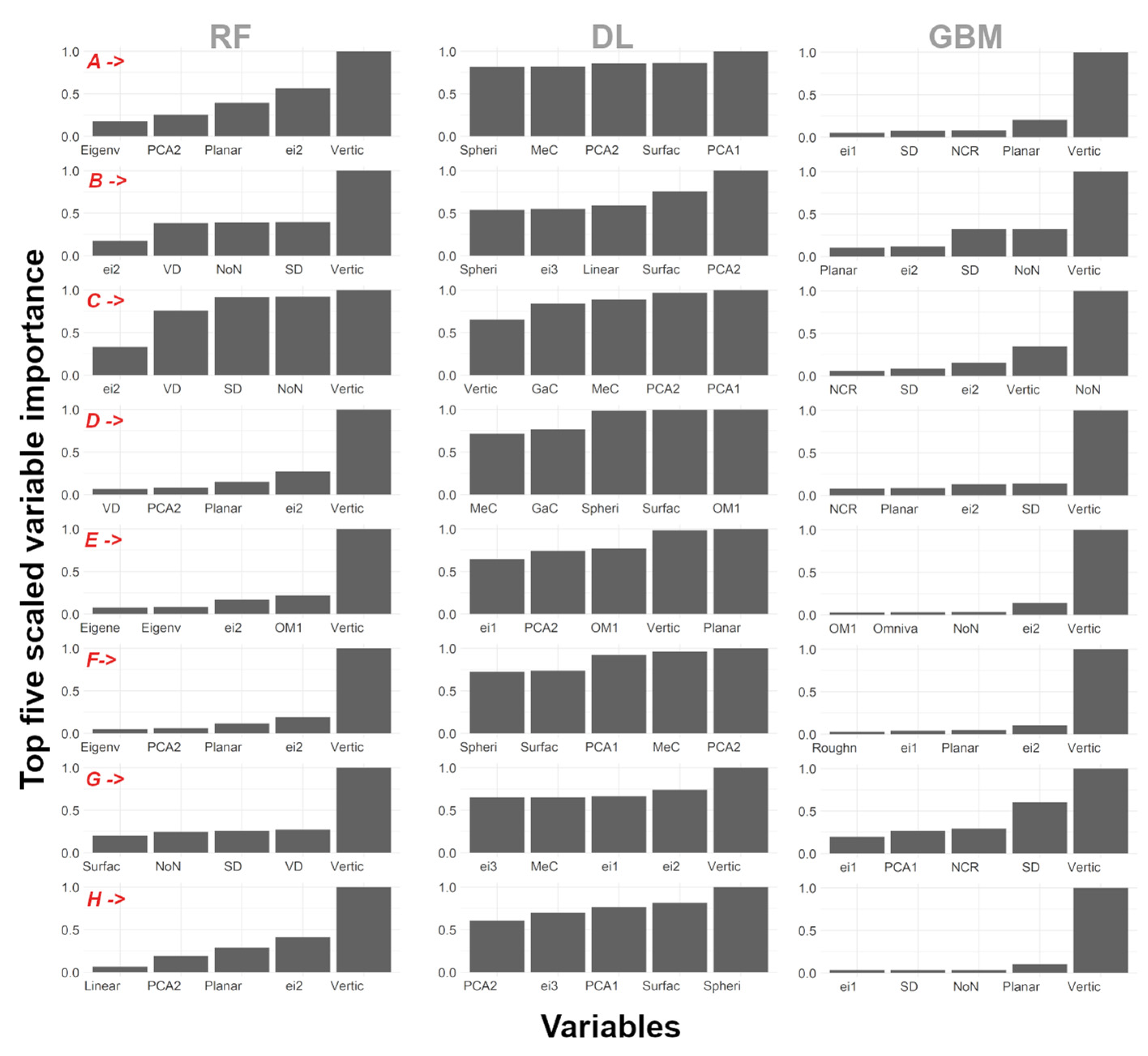
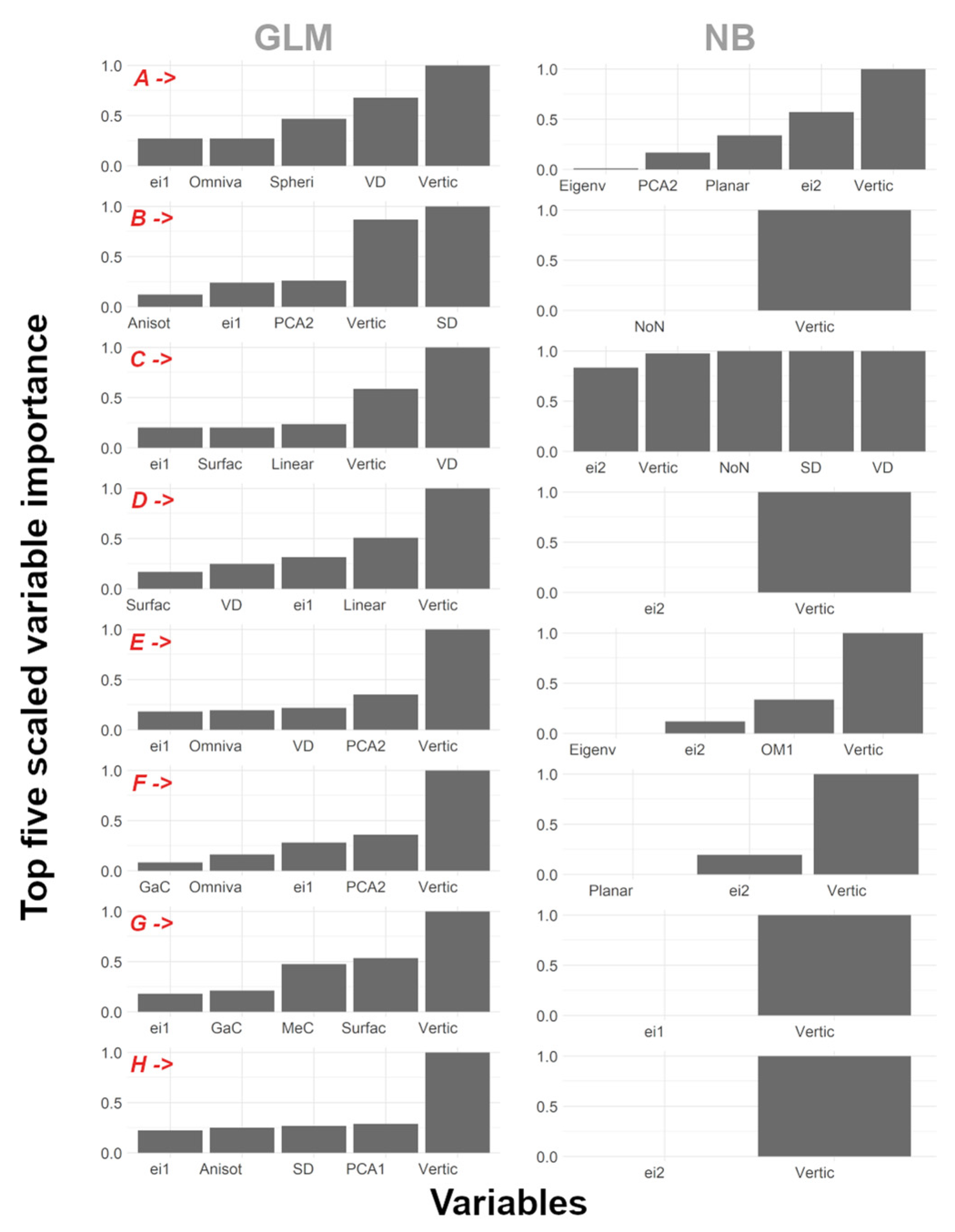
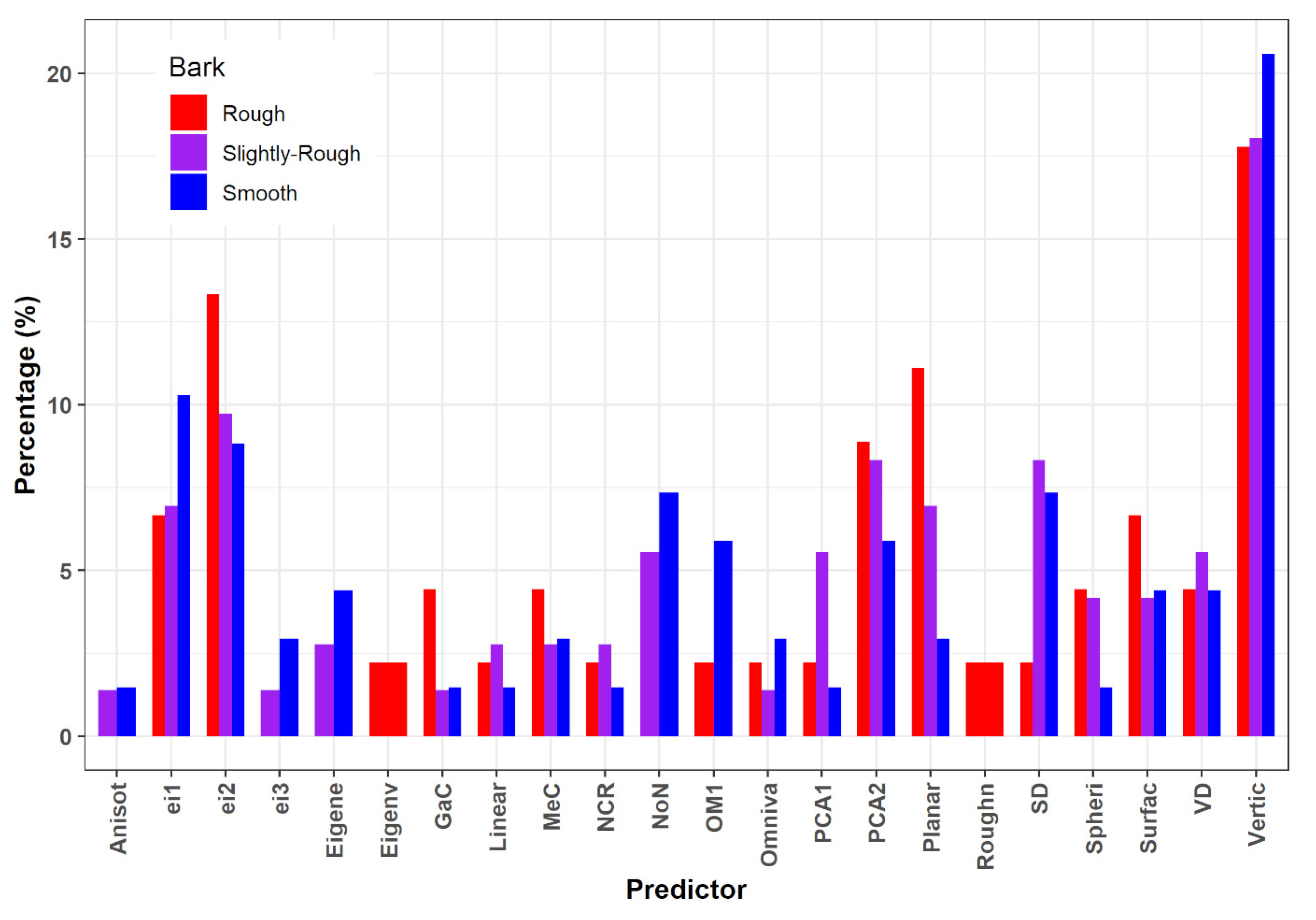
3.4. Predictor Ranking Contribution to Timber–Leaf Discrimination
3.5. Computing Time for Model Optimization and Best Model Implementation
4. Discussion
4.1. Algorithms, Datasets, and Binary- and Multi-Class Classification Factors Influencing Timber–Leaf Discrimination
4.2. Key Factors Hindering Accurate Binary-Class Classifications
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Millennium Ecosystem Assessment. In Ecosystems and Human Well-Being: Synthesis; Island Press: Washington, DC, USA, 2005.
- Chirici, G.; Barbati, A.; Maselli, F. Modelling of Italian forest net primary productivity by the integration of remotely sensed and GIS data. For. Ecol. Manag. 2007, 246, 285–295. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Tomppo, E.O. Remote sensing support for national forest inventories. Remote Sens. Environ. 2007, 110, 412–419. [Google Scholar] [CrossRef]
- Dassot, M.; Constant, T.; Fournier, M. The use of terrestrial LiDAR technology in forest science: Application fields, benefits and Challenges The use of terrestrial LiDAR technology in forest science: Application fields benefits and challenges. Ann. For. Sci. 2011, 68, 959–974. [Google Scholar] [CrossRef]
- Liang, X.; Wang, Y.; Pyörälä, J.; Lehtomäki, M.; Yu, X.; Kaartinen, H.; Kukko, A.; Honkavaara, E.; Issaoui, A.E.I.; Nevalainen, O.; et al. Forest in situ observations using unmanned aerial vehicle as an alternative of terrestrial measurements. For. Ecosyst. 2019, 6, 20. [Google Scholar] [CrossRef]
- Saarinen, N.; Kankare, V.; Vastaranta, M.; Luoma, V.; Pyörälä, J.; Tanhuanpää, T.; Liang, X.; Kaartinen, H.; Kukko, A.; Jaakkola, A.; et al. Feasibility of Terrestrial laser scanning for collecting stem volume information from single trees. ISPRS J. Photogramm. Remote Sens. 2017, 123, 140–158. [Google Scholar] [CrossRef]
- Liang, X.; Hyyppä, J.; Kaartinen, H.; Lehtomäki, M.; Pyörälä, J.; Pfeifer, N.; Holopainen, M.; Brolly, G.; Francesco, P.; Hackenberg, J.; et al. International benchmarking of terrestrial laser scanning approaches for forest inventories. ISPRS J. Photogramm. Remote Sens. 2018, 144, 137–179. [Google Scholar] [CrossRef]
- Torresan, C.; Berton, A.; Carotenuto, F.; Di Gennaro, S.F.; Gioli, B.; Matese, A.; Miglietta, F.; Vagnoli, C.; Zaldei, A.; Wallace, L. Forestry applications of UAVs in Europe: A review. Int. J. Remote Sens. 2017, 38, 2427–2447. [Google Scholar] [CrossRef]
- Næsset, E. Predicting forest stand characteristics with airborne scanning laser using a practical two-stage procedure and field data. Remote Sens. Environ. 2001, 80, 88–99. [Google Scholar] [CrossRef]
- Pfeifer, N.; Gorte, B.; Winterhalder, D. Automatic reconstruction of single trees from terrestrial laser scanner data. In Proceedings of the 20th ISPRS Congress, Istanbul, Turkey, 12–23 July 2004; Volume 35, pp. 114–119. [Google Scholar]
- Alvites, C.; Marchetti, M.; Lasserre, B.; Santopuoli, G. LiDAR as a Tool for Assessing Timber Assortments: A Systematic Literature Review. Remote Sens. 2022, 14, 4466. [Google Scholar] [CrossRef]
- Alvites, C.; Santopuoli, G.; Hollaus, M.; Pfeifer, N.; Maesano, M.; Moresi, F.V.; Marchetti, M.; Lasserre, B. Terrestrial laser scanning for quantifying timber assortments from standing trees in a mixed and multi-layered mediterranean forest. Remote Sens. 2021, 13, 4265. [Google Scholar] [CrossRef]
- Calders, K.; Adams, J.; Armston, J.; Bartholomeus, H.; Bauwens, S.; Bentley, L.P.; Chave, J.; Danson, F.M.; Demol, M.; Disney, M.; et al. Terrestrial laser scanning in forest ecology: Expanding the horizon. Remote Sens. Environ. 2020, 251, 112102. [Google Scholar] [CrossRef]
- Wang, D.; Hollaus, M.; Pfeifer, N. Feasibility of machine learning methods for separating wood and leaf points from terrestrial laser scanning data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 157–164. [Google Scholar] [CrossRef]
- Hackenberg, J.; Spiecker, H.; Calders, K.; Disney, M.; Raumonen, P. SimpleTree—An efficient open source tool to build tree models from TLS clouds. Forests 2015, 6, 4245–4294. [Google Scholar] [CrossRef]
- Montoya, O.; Icasio-Hernández, O.; Salas, J. TreeTool: A tool for detecting trees and estimating their DBH using forest point clouds. SoftwareX 2021, 16, 100889. [Google Scholar] [CrossRef]
- Molina-Valero, J.A.; Martínez-Calvo, A.; Ginzo Villamayor, M.J.; Novo Pérez, M.A.; Álvarez-González, J.G.; Montes, F.; Pé-rez-Cruzado, C. Operationalizing the use of TLS in forest inventories: The R package FORTLS. Environ. Model. Softw. 2022, 150, 105337. [Google Scholar] [CrossRef]
- Terryn, L.; Calders, K.; Åkerblom, M.; Bartholomeus, H.; Disney, M.; Levick, S.; Origo, N.; Raumonen, P.; Verbeeck, H. An-alysing individual 3D tree structure using the R package ITSMe. Methods Ecol. Evol. 2022, 2022, 231–241. [Google Scholar] [CrossRef]
- Yun, T.; An, F.; Li, W.; Sun, Y.; Cao, L.; Xue, L. A novel approach for retrieving tree leaf area from ground-based LiDAR. Remote Sens. 2016, 8, 942. [Google Scholar] [CrossRef]
- Zhou, J.; Wei, H.; Zhou, G.; Song, L. Separating leaf andwood points in terrestrial laser scanning data using multiple optimal scales. Sensors 2019, 19, 1852. [Google Scholar] [CrossRef]
- Weinmann, M.; Urban, S.; Hinz, S.; Jutzi, B.; Mallet, C. Distinctive 2D and 3D features for automated large-scale scene analysis in urban areas. Comput. Graph. 2015, 49, 47–57. [Google Scholar] [CrossRef]
- Ferrara, R.; Virdis, S.G.P.; Ventura, A.; Ghisu, T.; Duce, P.; Pellizzaro, G. An automated approach for wood-leaf separation from terrestrial LIDAR point clouds using the density based clustering algorithm DBSCAN. Agric. For. Meteorol. 2018, 262, 434–444. [Google Scholar] [CrossRef]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Wang, D.; Momo Takoudjou, S.; Casella, E. LeWoS: A universal leaf-wood classification method to facilitate the 3D modelling of large tropical trees using terrestrial LiDAR. Methods Ecol. Evol. 2020, 11, 376–389. [Google Scholar] [CrossRef]
- Stovall, A.E.L.; Masters, B.; Fatoyinbo, L.; Yang, X. TLSLeAF: Automatic leaf angle estimates from single-scan terrestrial laser scanning. New Phytol. 2021, 232, 1876–1892. [Google Scholar] [CrossRef]
- Vicari, M.B.; Disney, M.; Wilkes, P.; Burt, A.; Calders, K.; Woodgate, W. Leaf and wood classification framework for terrestrial LiDAR point clouds. Methods Ecol. Evol. 2019, 10, 680–694. [Google Scholar] [CrossRef]
- Moorthy, S.M.K.; Calders, K.; Vicari, M.B.; Verbeeck, H. Improved Supervised Learning-Based Approach for Leaf and Wood Classification from LiDAR Point Clouds of Forests. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3057–3070. [Google Scholar] [CrossRef]
- Tan, K.; Zhang, W.; Dong, Z.; Cheng, X.; Cheng, X. Leaf and Wood Separation for Individual Trees Using the Intensity and Density Data of Terrestrial Laser Scanners. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7038–7050. [Google Scholar] [CrossRef]
- Wang, D.; Brunner, J.; Ma, Z.; Lu, H.; Hollaus, M.; Pang, Y.; Pfeifer, N. Separating tree photosynthetic and non-photosynthetic components from point cloud data using Dynamic Segment Merging. Forests 2018, 9, 252. [Google Scholar] [CrossRef]
- Sun, J.; Wang, P.; Gao, Z.; Liu, Z.; Li, Y.; Gan, X.; Liu, Z. Wood–leaf classification of tree point cloud based on intensity and geometric information. Remote Sens. 2021, 13, 4050. [Google Scholar] [CrossRef]
- Tan, K.; Ke, T.; Tao, P.; Liu, K.; Duan, Y.; Zhang, W.; Wu, S. Discriminating Forest Leaf and Wood Components in TLS Point Clouds at Single-Scan Level Using Derived Geometric Quantities. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5701517. [Google Scholar] [CrossRef]
- Xi, Z.; Hopkinson, C.; Rood, S.B.; Peddle, D.R. See the forest and the trees: Effective machine and deep learning algorithms for wood filtering and tree species classification from terrestrial laser scanning. ISPRS J. Photogramm. Remote Sens. 2020, 168, 1–16. [Google Scholar] [CrossRef]
- Wang, L.; Meng, W.; Xi, R.; Zhang, Y.; Ma, C.; Lu, L.; Zhang, X. 3D point cloud analysis and classification in large-scale scene based on deep learning. IEEE Access 2019, 7, 55649–55658. [Google Scholar] [CrossRef]
- Hackel, T.; Wegner, J.D.; Schindler, K. Fast Semantic Segmentation of 3D Point Clouds with Strongly Varying Density. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 177–184. [Google Scholar] [CrossRef]
- Wang, D. Unsupervised semantic and instance segmentation of forest point clouds. ISPRS J. Photogramm. Remote Sens. 2020, 165, 86–97. [Google Scholar] [CrossRef]
- Barbati, A.; Marchetti, M.; Chirici, G.; Corona, P. European Forest Types and Forest Europe SFM indicators: Tools for monitoring progress on forest biodiversity conservation. For. Ecol. Manag. 2014, 321, 145–157. [Google Scholar] [CrossRef]
- Santopuoli, G.; Di Cristofaro, M.; Kraus, D.; Schuck, A.; Lasserre, B.; Marchetti, M. Biodiversity conservation and wood pro-duction in a Natura 2000 Mediterranean forest. A trade-off evaluation focused on the occurrence of microhabitats. iForest Biogeosci. For. 2019, 12, 76–84. [Google Scholar] [CrossRef]
- Alvites, C.; Santopuoli, G.; Maesano, M.; Chirici, G.; Moresi, F.V.; Tognetti, R.; Marchetti, M.; Lasserre, B. Unsupervised al-gorithms to detect single trees in a mixed-species and multi-layered Mediterranean forest using LiDAR data. Can. J. For. Res. 2021, 51, 1766–1780. [Google Scholar] [CrossRef]
- Hackel, T.; Wegner, J.D.; Schindler, K. Contour detection in unstructured 3D point clouds. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1610–1618. [Google Scholar] [CrossRef]
- Wu, B.; Zheng, G.; Chen, Y. An improved convolution neural network-based model for classifying foliage and woody components from terrestrial laser scanning data. Remote Sens. 2020, 12, 1010. [Google Scholar] [CrossRef]
- Abed, S.H.; Al-Waisy, A.S.; Mohammed, H.J.; Al-Fahdawi, S. A modern deep learning framework in robot vision for automated bean leaves diseases detection. Int. J. Intell. Robot. Appl. 2021, 5, 235–251. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Suzuki, K.; Suzuki, K. Artificial Neural Networks: Methodological Advances and Biomedical Applications; BoD–Books on Demand; Suzuki: Hamamatsu, Japan, 2011; ISBN 9789533072432. [Google Scholar]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.E.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [PubMed]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef]
- Nelder, J.A.; Wedderburn, R.W.M. Generalized linear models. J. Royral Stat. Soc. 1972, 135, 370–384. [Google Scholar] [CrossRef]
- McCullagh, P. Generalized Linear Models; Routledge: Abingdon, UK, 2019. [Google Scholar]
- Rish, I. An empirical study of the naive bayes classifier. In Proceedings of the IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence, Seattle, WA, USA, 4–6 August 2001; Volume 3, pp. 41–46. [Google Scholar] [CrossRef]
- Marcot, B.G.; Steventon, J.D.; Sutherland, G.D.; McCann, R.K. Guidelines for developing and updating Bayesian belief net-works applied to ecological modeling and conservation. Can. J. For. Res. 2006, 36, 3063–3074. [Google Scholar] [CrossRef]
- Breiman, L. Stacked regressions. Mach. Learn. 1996, 24, 49–64. [Google Scholar] [CrossRef]
- Roussel, J.R.; Auty, D.; Coops, N.C.; Tompalski, P.; Goodbody, T.R.H.; Meador, A.S.; Bourdon, J.F.; de Boissieu, F.; Achim, A. lidR: An R package for analysis of Airborne Laser Scanning (ALS) data. Remote Sens. Environ. 2020, 251, 112061. [Google Scholar] [CrossRef]
- Wickham, H.; Francois, R.; Lionel, H.; Müller, K.; Vaughan, D.; Software, P. Dplyr: A Grammar of Data Manipulation. R Package Version 1.1.2. 2023. Available online: https://github.com/tidyverse/dplyr (accessed on 10 June 2023).
- Aiello, S.; Eckstrand, E.; Fu, A.; Landry, M.; Aboyoun, P. Machine Learning with R and H2O. 2016. Available online: https://h2o-release.s3.amazonaws.com/h2o/master/3283/docs-website/h2o-docs/booklets/R_Vignette.pdf (accessed on 20 August 2023).
- Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Majka, A.M.; Majka, M.M. Package ‘Naivebayes’. 2020. Available online: https://cloud.r-project.org/web/packages/naivebayes/naivebayes.pdf (accessed on 10 June 2023).
- Weston, S.; Calaway, R.; Ooi, H.; Daniel, F. Package ‘Foreach’. Version 1.5.2. Available online: https://github.com/RevolutionAnalytics/foreach (accessed on 10 June 2023).
- Shpakovych, M. Optimization and Machine Learning Algorithms Applied to the Phase Control of an Array of Laser Beams Maksym Shpakovych to Cite This Version: HAL Id: Tel-03941758 e des Sciences et Techniques These Optimization and Machine Learning Algorithms Applied. 2023. Optimization and Control [math.OC]. Université de Limoges, 2022. English. NNT: 2022LIMO0120. Available online: https://theses.hal.science/ (accessed on 9 September 2023).
- Berrar, D. Bayes’ theorem and naive bayes classifier. Encycl. Bioinform. Comput. Biol. ABC Bioinform. 2018, 403, 412. [Google Scholar] [CrossRef]
- Zuur, A.F.; Ieno, E.N.; Elphick, C.S. A protocol for data exploration to avoid common statistical problems. Methods Ecol. Evol. 2010, 1, 3–14. [Google Scholar] [CrossRef]
- Ripley, B.; Venables, W.; Ripley, M.B. Package ‘Nnet’. R Package Version. 2016. Available online: https://staff.fmi.uvt.ro/~daniela.zaharie/dm2019/RO/lab/lab3/biblio/nnet.pdf (accessed on 9 September 2023).
- Zhu, X.; Skidmore, A.K.; Darvishzadeh, R.; Niemann, K.O.; Liu, J.; Shi, Y.; Wang, T. Foliar and woody materials discriminated using terrestrial LiDAR in a mixed natural forest. Int. J. Appl. Earth Obs. Geoinf. 2018, 64, 43–50. [Google Scholar] [CrossRef]
- Hui, Z.; Xia, Y.; Nie, Y.; Chang, Y.; Hu, H.; Li, N.; He, Y. Fractal Dimension Based Supervised Learning for Wood and Leaf Classification from Terrestrial Lidar Point Clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 5, 95–99. [Google Scholar] [CrossRef]
- Hui, Z.; Jin, S.; Xia, Y.; Wang, L.; Yevenyo Ziggah, Y.; Cheng, P. Wood and leaf separation from terrestrial LiDAR point clouds based on mode points evolution. ISPRS J. Photogramm. Remote Sens. 2021, 178, 219–239. [Google Scholar] [CrossRef]
- Robin, X.A.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.-C.; Muller, M.J. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011, 12, 77. [Google Scholar] [CrossRef] [PubMed]
- Wickham, H.; Vaughan, D.; Girlich, M.; Ushey, K.; PBC, Posit. Package ‘Tidyr’. Version 1.3.0. Available online: https://tidyr.tidyverse.org (accessed on 10 June 2023).
- Sun, S. Meta-analysis of Cohen’s kappa. Health Serv. Outcomes Res. Methodol. 2011, 11, 145–163. [Google Scholar] [CrossRef]
- Wei, H.; Zhou, G.; Zhou, J. Comparison of single and multi-scale method for leaf and wood points classi-fication from terrestrial laser scanning data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4, 217–223. [Google Scholar] [CrossRef]
- Martinez-Gil, J. A comprehensive review of stacking methods for semantic similarity measurement. Mach. Learn. Appl. 2022, 10, 100423. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Decision trees: A recent overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Ojha, V.K.; Abraham, A.; Sná, V. Metaheuristic design of feedforward neural networks: A review of two decades of research. Eng. Appl. Artif. Intell. 2017, 60, 97–116. [Google Scholar]
- Rehush, N.; Abegg, M.; Waser, L.T.; Brändli, U. Identifying Tree-Related Microhabitats in TLS Point Clouds Using Machine Learning. Remote Sens. 2018, 10, 1735. [Google Scholar] [CrossRef]
- Kane, M.J.; Emerson, J.W.; Weston, S. Scalable strategies for computing with massive data. J. Stat. Softw. 2013, 55, 1–19. [Google Scholar] [CrossRef]
- Wen, H.; Zhou, X.; Zhang, C.; Liao, M.; Xiao, J. Different-Classification-Scheme-Based Machine Learning Model of Building Seismic Resilience Assessment in a Mountainous Region. Remote Sens. 2023, 15, 2226. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Point Cloud (pts) | Time (s or min) | Hardware Specifications | Reference |
|---|---|---|---|---|
| 1 | 1 × 106 | 90 s | PC 64-bit Windows 10 PC, Intel® CoreTM i7-8850H, 32 GB RAM | [24] |
| 2 | 1 × 105 | 60 s | Not specified | [26] |
| 3 | 5 × 105 | 500 s | PC with Core i7 CPU 920 2.67 GHz, 3G RAM, NVIDIA GeForce GTX | [33] |
| 4 | 3 × 108 | 90 min | PC with Intel® Xeon E5-1650 CPU, 64 GB RAM | [34] |
| 5 | 1 × 106 | 30–90 s | PC 64-bit Windows 7 with an Intel® Xeon(R) E5-2609 v4 1.7 GHz processor and 32 GB RAM | [20] |
| 6 | 1 × 106 | 64 s | PC 64-bit Windows 10, Intel® CoreTM i7-8850H and 32 GB RAM | [35] |
| Machine Learning Algorithms Used for the Binary Classification | ||
|---|---|---|
| Algorithm | Description | Reference |
| Random forests | An ensemble algorithm composed of a pool of tree-structured classifiers, where every tree grows based on the training data and randomly and identically distributed random vectors, and allows a vote for the most popular input data class. RF supports both regression and classification analyses. | [42] |
| Deep learning | A mathematical model computing a set of data in a similar way to how the human brain processes information, and it is based on a multi-layer feedforward artificial neural network. | [43,44] |
| Gradient boosting machines | An ensemble machine learning algorithm developed by Friedman. The learning approach of this algorithm is based on the construction of a robust predictive model that, in turn, is trained by a sequential weak predictive model. | [45,46] |
| Generalized linear model | Encompasses conventional regression models analyzing continuous and/or categorical predictor values characterized by a normal (i.e., Gaussian) or non-normal (i.e., Poisson, binomial, and gamma) distribution. | [47,48] |
| Naive Bayes | A classifier algorithm belonging to a group of probabilistic classifiers based on the Bayes theorem. Its learning approach assumes that each feature of a set of data is independent and that such a feature belongs to a class according to the Bayesian probability. | [49,50] |
| Stacked ensemble models | A supervised algorithm proposing a better combination of ensemble algorithms. EN encompasses all five previous machine/deep learning algorithms through a stacked ensemble approach to generate an improved model based on their principles. The lowest cross-validation error rate selects a better combination of algorithms. | [51] |
| ID | Algorithm | Hyperparameters |
|---|---|---|
| 1 | RF | Nfolds:10 |
| 2 | Ntrees: From 50 to 500, by 50 | |
| 3 | Max_depth: From 10 to 30, by 2 | |
| 4 | Nbins: From 20 to 30, by 10 | |
| 5 | Sample_rate: From 0.55 to 0.80, by 0.05 | |
| 6 | Mtries: From 2 to 6, by 1 | |
| 7 | DL | Nfolds:10 |
| 8 | Activation (type1): Rectifier and Maxout | |
| 9 | Hidden (type1): list(c(5, 5, 5, 5, 5), c(10, 10, 10, 10), c(50, 50, 50), c(100, 100, 100)) | |
| 10 | Epochs (type1): From 50 to 200, by 10 | |
| 11 | L1 (type1): c(0, 0.00001, 0.0001) | |
| 12 | L2 (type1): c(0, 0.00001, 0.0001) | |
| 13 | GBM | Nfolds:10 |
| 14 | Ntree: From 50 to 500, by 50 | |
| 15 | Max_depth: From 10 to 30, by 2 | |
| 16 | Sample_rate: From 0.55 to 0.80, by 0.05 | |
| 17 | NB | Nfolds: 10 |
| 18 | Laplace: From 0 to 5, by 0.5 |
| Tree TLS and Field Data | ||||||
|---|---|---|---|---|---|---|
| Tree Species | Total Points | Core Points | APD | APS | TH | DBH |
| (pts) | (pts) | (pts m−2) | (mm) | (m; Mean and SD) | ||
| Italian maple | 597,799 | 59,780 | 5486 | 1.36 | 24.35 (±2.95) | 0.27 (±0.05) |
| Hornbeam | 1,008,280 | 100,828 | 6535 | 1.26 | 17.93 (±6.14) | 0.35 (±0.22) |
| European hop-hornbeam | 918,532 | 91,853 | 6603 | 1.23 | 21.85 (±3.49) | 0.42 (±0.26) |
| Turkey oak | 1,837,063 | 183,706 | 19,512 | 0.8 | 24.3 (±4.93) | 0.5 (±0.11) |
| European beech | 2,759,658 | 275,966 | 29,175 | 0.77 | 25.04 (±5) | 0.38 (±0.09) |
| European ash | 715,930 | 71,593 | 18,040 | 0.77 | 19.76 (±8.18) | 0.26 (±0.21) |
| Hazel | 370,675 | 37,068 | 13,391 | 0.9 | 7.68 (±2.30) | 0.08 (±0.01) |
| Small-leaved lime | 954,630 | 95,463 | 15,595 | 0.83 | 22.49 (±5.99) | 0.23 (±0.02) |
| Combined tree species | 114,532 | |||||
| ID | Algorithm | Hyperparameter | Tree Species Results | All_CTS | All_ITS | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IM | HO | TO | EHH | EB | EA | HA | SLL | |||||
| 1 | RF | nfolds | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 |
| 2 | ntrees | 300 | 350 | 500 | 100 | 250 | 500 | 350 | 500 | 50 | 50 | |
| 3 | max_depth | 22 | 10 | 10 | 26 | 14 | 10 | 26 | 10 | 20 | 18 | |
| 4 | nbins | 20 | 30 | 30 | 20 | 30 | 20 | 30 | 30 | 30 | 30 | |
| 5 | mtries | 5 | 5 | 6 | 6 | 5 | 6 | 6 | 6 | 3 | 3 | |
| 6 | sample_rate | 0.75 | 0.55 | 0.55 | 0.55 | 0.55 | 0.55 | 0.75 | 0.75 | 0.55 | 0.55 | |
| 7 | DL | nfolds | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 |
| 8 | activation | MAX | MAX | MAX | MAX | REC | MAX | MAX | MAX | REC | MAX | |
| 9 | epochs | 100 | 50 | 100 | 100 | 50 | 200 | 200 | 200 | 60 | 50 | |
| 10 | hidden | 100 | 100 | 50 | 100 | 5 | 50 | 5 | 10 | 10 | 5 | |
| 11 | l1 | 10−4 | 10−5 | 10−5 | 0 | 10−4 | 10−4 | 10−5 | 10−4 | 0 | 0 | |
| 12 | l2 | 0 | 0 | 10−4 | 10−4 | 0 | 0 | 0 | 0 | 0 | 10−5 | |
| 13 | GBM | nfolds | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 |
| 14 | ntrees | 150 | 200 | 350 | 150 | 450 | 150 | 71 | 200 | 50 | 100 | |
| 15 | max_depth | 10 | 10 | 10 | 10 | 10 | 10 | 25 | 10 | 25 | 25 | |
| 16 | sample_rate | 0.75 | 0.8 | 0.7 | 0.75 | 0.7 | 0.7 | 0.7 | 0.75 | 0.75 | 0.8 | |
| 17 | NB | nfolds | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 |
| 18 | laplace | 2.5 | 4.5 | 0.5 | 1 | 0.5 | 2.5 | 2.5 | 0.5 | 0.5 | 5 | |
| Timber–Leaf Discrimination Results | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Algorithm | Statistics | IT | HO | EHH | TO | EB | EA | HA | SLL | Mean (±SD) |
| RF | OA | 0.95 | 0.82 | 0.87 | 0.85 | 0.94 | 0.89 | 0.95 | 0.93 | 0.90 (±0.05) |
| Kappa | 0.90 | 0.58 | 0.70 | 0.70 | 0.85 | 0.78 | 0.68 | 0.84 | 0.75 (±0.11) | |
| AUC | 0.98 | 0.86 | 0.92 | 0.93 | 0.98 | 0.96 | 0.95 | 0.97 | 0.94 (±0.04) | |
| Precision | 0.94 | 0.80 | 0.85 | 0.82 | 0.96 | 0.87 | 0.95 | 0.91 | 0.89 (±0.06) | |
| Recall | 0.98 | 0.96 | 0.96 | 0.95 | 0.95 | 0.93 | 0.99 | 0.98 | 0.96 (±0.02) | |
| F1_score | 0.96 | 0.87 | 0.90 | 0.88 | 0.95 | 0.90 | 0.97 | 0.94 | 0.92 (±0.04) | |
| DL | OA | 0.95 | 0.82 | 0.87 | 0.86 | 0.94 | 0.89 | 0.94 | 0.93 | 0.90 (±0.05) |
| Kappa | 0.89 | 0.57 | 0.69 | 0.71 | 0.84 | 0.77 | 0.64 | 0.84 | 0.74 (±0.11) | |
| AUC | 0.98 | 0.86 | 0.92 | 0.92 | 0.97 | 0.95 | 0.93 | 0.97 | 0.94 (±0.04) | |
| Precision | 0.94 | 0.80 | 0.85 | 0.82 | 0.95 | 0.87 | 0.95 | 0.91 | 0.89 (±0.06) | |
| Recall | 0.96 | 0.93 | 0.95 | 0.95 | 0.94 | 0.91 | 0.98 | 0.97 | 0.95 (±0.02) | |
| F1_score | 0.95 | 0.86 | 0.89 | 0.88 | 0.95 | 0.89 | 0.97 | 0.94 | 0.92 (±0.04) | |
| GBM | OA | 0.95 | 0.82 | 0.87 | 0.86 | 0.94 | 0.90 | 0.94 | 0.93 | 0.90 (±0.05) |
| Kappa | 0.90 | 0.57 | 0.72 | 0.71 | 0.85 | 0.79 | 0.66 | 0.85 | 0.76 (±0.1) | |
| AUC | 0.98 | 0.86 | 0.93 | 0.93 | 0.98 | 0.96 | 0.94 | 0.97 | 0.94 (±0.04) | |
| Precision | 0.95 | 0.83 | 0.88 | 0.85 | 0.97 | 0.89 | 0.96 | 0.93 | 0.91 (±0.05) | |
| Recall | 0.96 | 0.87 | 0.91 | 0.89 | 0.93 | 0.89 | 0.98 | 0.95 | 0.92 (±0.04) | |
| F1_score | 0.96 | 0.85 | 0.90 | 0.87 | 0.95 | 0.89 | 0.97 | 0.94 | 0.92 (±0.04) | |
| GLM | OA | 0.94 | 0.81 | 0.86 | 0.84 | 0.91 | 0.87 | 0.91 | 0.91 | 0.88 (±0.04) |
| Kappa | 0.87 | 0.55 | 0.68 | 0.68 | 0.80 | 0.74 | 0.37 | 0.80 | 0.69 (±0.16) | |
| AUC | 0.98 | 0.85 | 0.91 | 0.91 | 0.95 | 0.94 | 0.88 | 0.94 | 0.92 (±0.04) | |
| Precision | 0.93 | 0.79 | 0.85 | 0.81 | 0.95 | 0.86 | 0.92 | 0.90 | 0.88 (±0.06) | |
| Recall | 0.97 | 0.95 | 0.94 | 0.92 | 0.94 | 0.91 | 0.98 | 0.97 | 0.95 (±0.03) | |
| F1_score | 0.95 | 0.86 | 0.89 | 0.86 | 0.95 | 0.88 | 0.95 | 0.93 | 0.91 (±0.04) | |
| NB | OA | 0.93 | 0.78 | 0.84 | 0.84 | 0.93 | 0.87 | 0.90 | 0.91 | 0.87 (±0.05) |
| Kappa | 0.85 | 0.45 | 0.64 | 0.67 | 0.83 | 0.74 | 0.37 | 0.79 | 0.67 (±0.18) | |
| AUC | 0.95 | 0.82 | 0.88 | 0.91 | 0.95 | 0.93 | 0.87 | 0.95 | 0.91 (±0.05) | |
| Precision | 0.91 | 0.76 | 0.83 | 0.81 | 0.95 | 0.85 | 0.90 | 0.89 | 0.86 (±0.06) | |
| Recall | 0.98 | 0.96 | 0.95 | 0.91 | 0.94 | 0.91 | 1.00 | 0.97 | 0.95 (±0.03) | |
| F1_score | 0.94 | 0.85 | 0.88 | 0.86 | 0.95 | 0.88 | 0.94 | 0.93 | 0.90 (±0.04) | |
| EN | OA | 0.93 | 0.96 | 0.94 | 0.89 | 0.87 | 0.83 | 0.96 | 0.85 | 0.90 (±0.05) |
| Kappa | 0.84 | 0.73 | 0.86 | 0.78 | 0.71 | 0.60 | 0.91 | 0.70 | 0.77 (±0.10) | |
| AUC | 0.97 | 0.96 | 0.98 | 0.96 | 0.93 | 0.87 | 0.99 | 0.93 | 0.95 (±0.04) | |
| Precision | 0.95 | 0.80 | 0.86 | 0.83 | 0.96 | 0.87 | 0.96 | 0.91 | 0.89 (±0.06) | |
| Recall | 0.97 | 0.96 | 0.94 | 0.93 | 0.95 | 0.94 | 0.99 | 0.99 | 0.96 (±0.02) | |
| F1_score | 0.96 | 0.87 | 0.90 | 0.88 | 0.95 | 0.90 | 0.97 | 0.94 | 0.92 (±0.04) | |
| Mean (±SD) | OA | 0.94 (±0.01) | 0.83 (±0.06) | 0.88 (±0.03) | 0.86 (±0.02) | 0.92 (±0.03) | 0.87 (±0.03) | 0.93 (±0.02) | 0.91 (±0.03) | 0.89 (±0.04) |
| Mean (±SD) | Kappa | 0.88 (±0.02) | 0.58 (±0.09) | 0.71 (±0.08) | 0.71 (±0.04) | 0.81 (±0.05) | 0.74 (±0.07) | 0.60 (±0.21) | 0.80 (±0.06) | 0.73 (±0.1) |
| Mean (±SD) | AUC | 0.97 (±0.01) | 0.87 (±0.05) | 0.92 (±0.03) | 0.93 (±0.02) | 0.96 (±0.02) | 0.94 (±0.03) | 0.93 (±0.04) | 0.95 (±0.02) | 0.93 (±0.03) |
| Mean (±SD) | Precision | 0.94 (±0.02) | 0.80 (±0.02) | 0.85 (±0.02) | 0.82 (±0.02) | 0.96 (±0.01) | 0.87 (±0.01) | 0.94 (±0.03) | 0.91 (±0.01) | 0.89 (±0.06) |
| Mean (±SD) | Recall | 0.97 (±0.01) | 0.94 (±0.03) | 0.94 (±0.02) | 0.92 (±0.02) | 0.94 (±0.01) | 0.92 (±0.02) | 0.98 (±0.01) | 0.97 (±0.01) | 0.95 (±0.02) |
| Mean (±SD) | F1_score | 0.95 (±0.01) | 0.86 (±0.01) | 0.90 (±0.01) | 0.87 (±0.01) | 0.95 (±0) | 0.89 (±0.01) | 0.96 (±0.01) | 0.94 (±0.01) | 0.92 (±0.04) |
| Type of Classification | Statistics | Results by Algorithm | ||||||
|---|---|---|---|---|---|---|---|---|
| RF | DL | GBM | GLM | NB | EN | Mean (±SD) | ||
| Binary-class classification 1 | OA | 0.82 | 0.55 | 0.86 | 0.81 | 0.78 | 0.85 | 0.78 (±0.12) |
| Kappa | 0.64 | 0.09 | 0.73 | 0.63 | 0.57 | 0.71 | 0.56 (±0.24) | |
| AUC | 0.86 | 0.58 | 0.94 | 0.89 | 0.87 | 0.94 | 0.85 (±0.13) | |
| Precision | 0.79 | 0.53 | 0.85 | 0.77 | 0.73 | 0.80 | 0.74 (±0.11) | |
| Recall | 0.88 | 0.93 | 0.88 | 0.90 | 0.92 | 0.95 | 0.91 (±0.03) | |
| F1_score | 0.83 | 0.67 | 0.87 | 0.83 | 0.81 | 0.87 | 0.81 (±0.07) | |
| Multi-class classification 2 | OA | 0.51 | 0.31 | 0.64 | 0.40 | 0.46 | 0.64 | 0.49 (±0.13) |
| Kappa | 0.47 | 0.27 | 0.62 | 0.36 | 0.42 | 0.62 | 0.46 (±0.14) | |
| Precision | 0.90 | 0.97 | 0.95 | 0.93 | 0.95 | 0.95 | 0.94 (±0.03) | |
| Recall | 0.91 | 0.49 | 0.98 | 0.93 | 0.95 | 0.99 | 0.87 (±0.19) | |
| F1_score | 0.91 | 0.65 | 0.96 | 0.93 | 0.95 | 0.97 | 0.89 (±0.12) | |
| Number of Predictors Used by Each Algorithm | |||||
|---|---|---|---|---|---|
| Tree Species | Algorithms | ||||
| NB | DL | GBM | GLM | RF | |
| European ash | 3 | 22 | 16 | 7 | 17 |
| European beech | 4 | 19 | 20 | 9 | 17 |
| European hop-hornbeam | 14 | 22 | 21 | 7 | 15 |
| Hazel | 2 | 20 | 7 | 8 | 17 |
| Hornbeam | 2 | 17 | 22 | 9 | 18 |
| Italian maple | 6 | 22 | 6 | 9 | 18 |
| Small-leaf lime | 2 | 22 | 14 | 8 | 16 |
| Turkey oak | 2 | 14 | 12 | 9 | 16 |
| Minimum | 2 | 14 | 6 | 7 | 15 |
| Maximum | 14 | 22 | 22 | 9 | 18 |
| Mean | 4 | 20 | 15 | 8 | 17 |
| Number of Predictors for Each Algorithm | |||||
|---|---|---|---|---|---|
| Type of Classification | Algorithms | ||||
| NB | DL | GBM | GLM | RF | |
| Binary-class classification 1 | 7 | 9 | 21 | 11 | 22 |
| Multi-class classification 2 | 6 | 22 | 16 | 11 | 22 |
| Computing Time for Model Optimization and Implementation | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Procedure | Individual Tree Species Datasets 1 (s) | Combined Tree Species Datasets 2 (s) | |||||||||
| Algorithm | EA | EB | EHH | HA | HO | IM | SLL | TO | All_ITS | All_CTS | |
| Model optimization | DL | 424 | 908 | 453 | 272 | 532 | 383 | 376 | 699 | 934 | 921 |
| EN | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| GBM | 902 | 904 | 904 | 903 | 903 | 903 | 903 | 903 | 905 | 937 | |
| GLM | 2 | 3 | 3 | 4 | 1 | 2 | 4 | 2 | 52 | 548 | |
| NB | 5 | 5 | 5 | 3 | 5 | 5 | 5 | 3 | 23 | 23 | |
| RF | 607 | 903 | 864 | 546 | 902 | 541 | 750 | 904 | 901 | 929 | |
| Best model implementation | DL | 67 | 6 | 183 | 9 | 200 | 132 | 26 | 79 | 325 | 400 |
| EN | 12 | 13 | 11 | 12 | 12 | 12 | 12 | 14 | 1 | 2801 | |
| GBM | 42 | 283 | 53 | 7 | 72 | 19 | 60 | 128 | 121 | 402 | |
| GLM | 2 | 3 | 3 | 2 | 1 | 2 | 4 | 2 | 4 | 6 | |
| NB | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 5 | |
| RF | 146 | 267 | 92 | 170 | 115 | 139 | 182 | 265 | 4 | 69 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alvites, C.; Maesano, M.; Molina-Valero, J.A.; Lasserre, B.; Marchetti, M.; Santopuoli, G. Discrimination of Leaves in a Multi-Layered Mediterranean Forest through Machine Learning Algorithms. Remote Sens. 2023, 15, 4450. https://doi.org/10.3390/rs15184450
Alvites C, Maesano M, Molina-Valero JA, Lasserre B, Marchetti M, Santopuoli G. Discrimination of Leaves in a Multi-Layered Mediterranean Forest through Machine Learning Algorithms. Remote Sensing. 2023; 15(18):4450. https://doi.org/10.3390/rs15184450
Chicago/Turabian StyleAlvites, Cesar, Mauro Maesano, Juan Alberto Molina-Valero, Bruno Lasserre, Marco Marchetti, and Giovanni Santopuoli. 2023. "Discrimination of Leaves in a Multi-Layered Mediterranean Forest through Machine Learning Algorithms" Remote Sensing 15, no. 18: 4450. https://doi.org/10.3390/rs15184450