1. Introduction
The Arctic is warming at a faster rate compared with other areas of the Earth [
1]. Environmental changes due to warming promote economic activities which increase anthropogenic emissions, while population growth amplifies the exposure to pollution [
1]. Rising temperatures in the Arctic augment the risk of wildfires [
2], representing a major natural source of atmospheric pollution. In the European Arctic, atmospheric pollution levels and exposure are lower compared with highly populated urban areas at middle latitudes [
3]. Nevertheless, recent studies have raised concerns about the health effects of atmospheric pollution on the local population, generating an issue for public health and policymakers [
1,
4]. A limited number of atmospheric pollution monitoring stations are available in the Arctic to record concentrations at an hourly frequency. One of the most commonly measured parameters at these stations that has a significant impact on human health is the concentration of particulate matter with a diameter equal to 10 µm or less (PM
10). Here, particulate matter (PM) is defined as a mixture of solid particles and liquid droplets present in the air, emitted from anthropogenic and natural sources (US Environmental Protection Agency [
5]). In the Arctic region, PM
10 can originate from local sources, but it can also be transported from midlatitudes by winds [
6]. Looking ahead, the opening of new shipping routes, the expected rise in forest fire frequency, the intensified extraction of resources, and the subsequent expansion of infrastructure are likely to result in increased PM
10 emissions in the Arctic [
1].
PM
10 concentration behavior can be simulated via deterministic or statistical models with varying degrees of reliability [
7]. The Copernicus Atmospheric Monitoring Service (
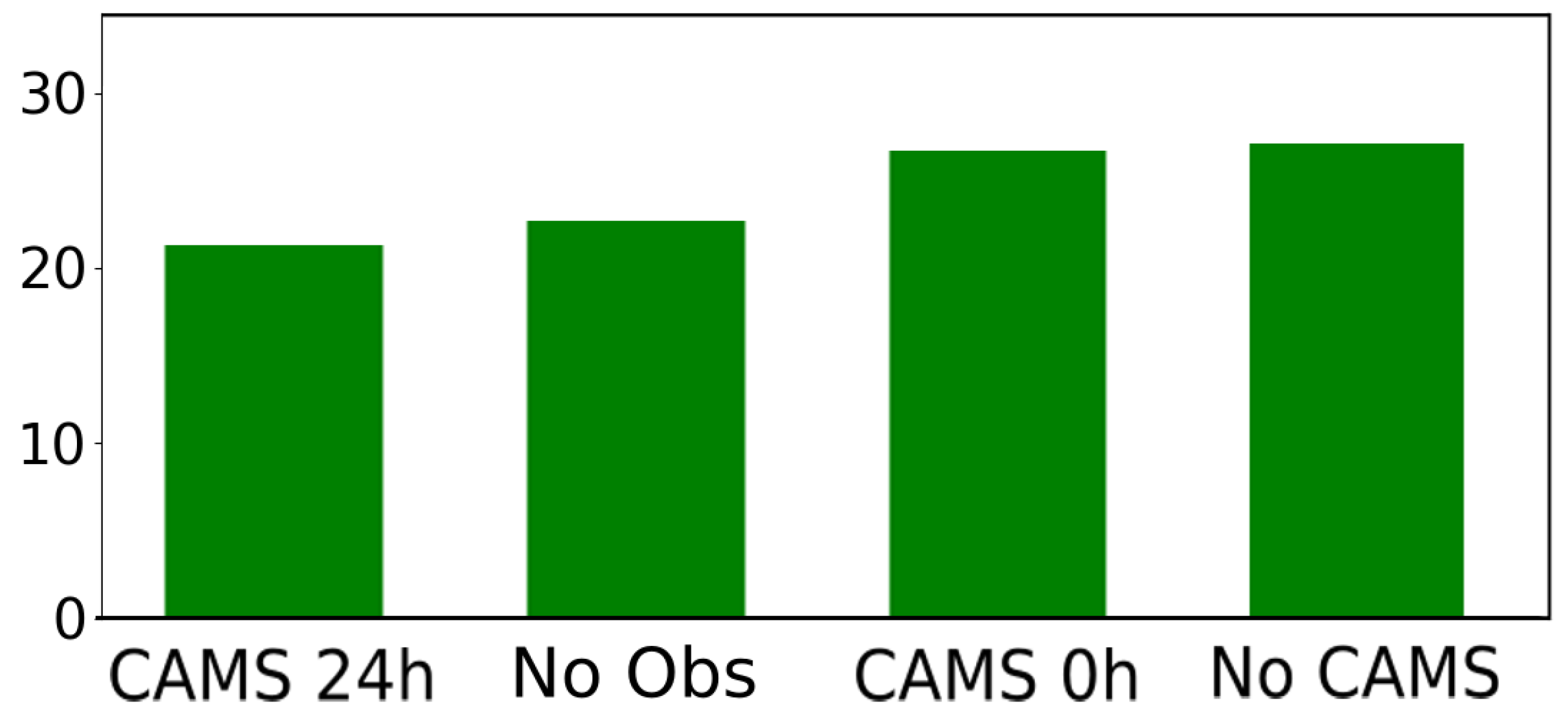
https://atmosphere.copernicus.eu/, (accessed on 24 June 2023)) (CAMS) provides analyses and forecasts of air pollution all over Europe, including the European Arctic, based on an ensemble of deterministic numerical models. In the Arctic, CAMS 24 h PM
10 forecasts align less with in situ measurements (in the remainder of this paper, the terms
measurement and
observation are used interchangeably to refer to the same entity) compared with other European regions [
8]. Forecast errors in deterministic models primarily stem from uncertainties in emissions, meteorological forecasts, model parameters, and initial state estimation [
9].
Several studies demonstrate that statistical models based on Machine Learning algorithms may improve the PM
10 concentration forecasts for a specific geographic point [
9,
10,
11,
12,
13]. In particular, artificial neural networks (ANNs) have proven to be quite efficient in dealing with complex nonlinear interactions; generically speaking, ANNs can have various architectures, from simple multilayer perceptrons [
14,
15,
16] to more sophisticated deep learning structures [
17,
18], or even hybrid solutions [
19,
20,
21,
22]. Among the various macrofamilies of neural networks, recurrent neural networks (RNNs) are particularly well-suited for analyzing time series, such as atmospheric data. RNNs manage to outperform regression models and feed-forward networks by carrying information about previous states and using it to make predictions together with current inputs [
13]. When dealing with long-term dependencies, ANNs such as long short-term memory networks (LSTM) provide effective time series forecasting: LSTMs arise as an enhanced version of recurrent neural networks (RNNs) specifically designed to address the vanishing and exploding gradient problems that can occur during training [
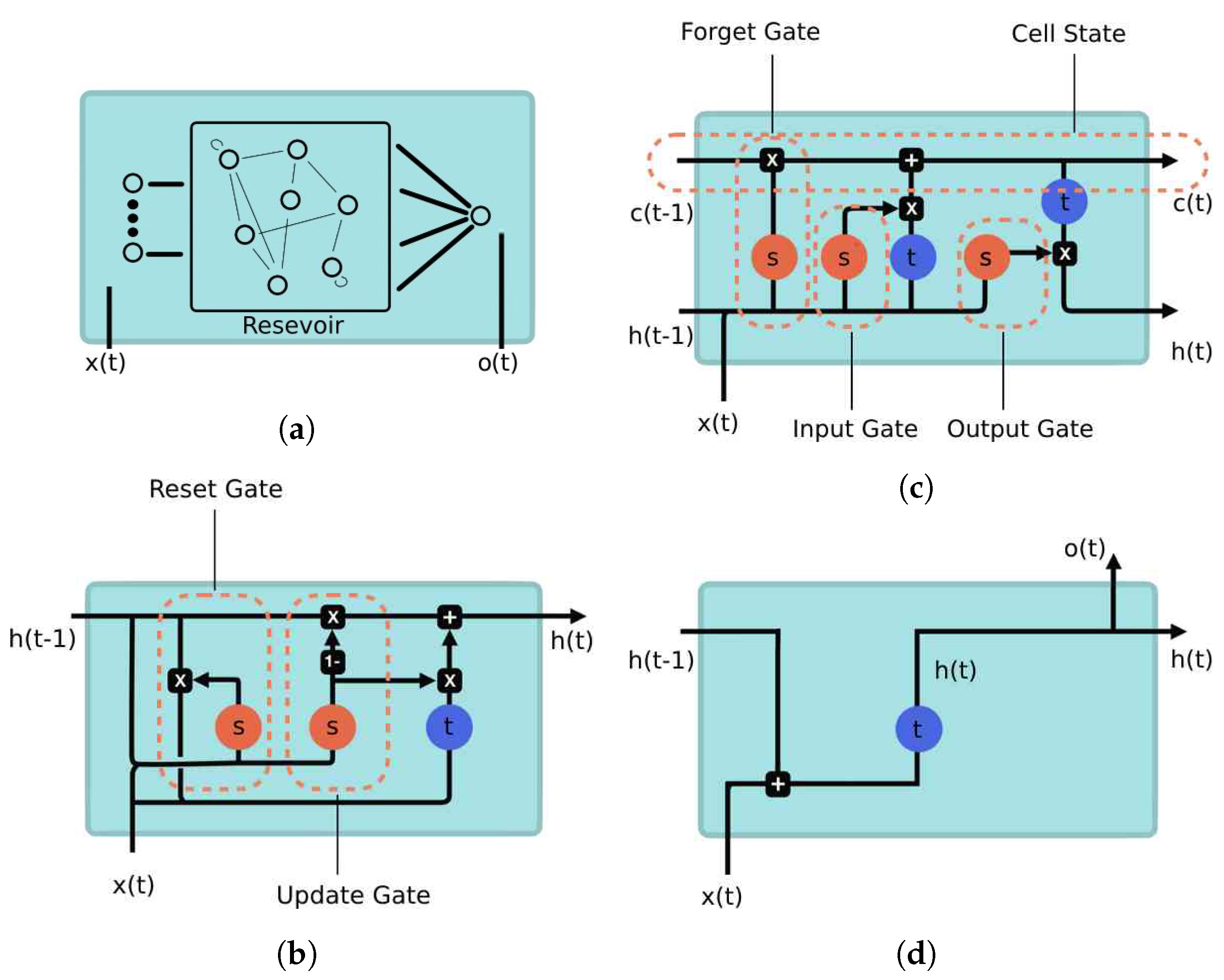
23]. LSTMs incorporate additional processing units, known as memory and forget blocks, which enable the network to selectively retain or discard information over multiple time steps. Gated recurrent unit networks (GRUs) are another variant of recurrent neural networks (RNNs) that offer a simplified structure compared with LSTMs. GRUs aim to address some of the computational complexities of LSTMs while still maintaining the ability to capture long-term dependencies in sequential data.
In a GRU, the simplified structure is achieved by combining the update gate and the reset gate into a single gate, called the “update gate”. This gate controls the flow of information and helps determine how much of the previous hidden state should be updated with the current input [
18].
Several studies have been conducted using the aforementioned neural network algorithms in the context of urban and metropolitan areas. In [
13], for instance, a standard recurrent neural network model is compared with a multiple linear regression and a feed-forward network to predict concentrations of PM
10, showing that the former algorithm provides better performance. As another example, in [
11], the authors compare the performances of a multilayer perceptron with those of a long short-term memory network in predicting concentrations of PM
10 based on data acquired from five monitoring stations in Lima. Results show that both methods are quite accurate in short-term prediction, especially in average meteorological conditions. For more extreme values, on the other hand, the LSTM model results in better forecasts. More evidence can also be found in [
24] and [
12], where convolutional models for LSTM are considered, and in [
25], where different approaches to defining the best hyperparameters for an LSTM are analyzed. Similarly, in [
18], the authors develop architectures based on RNN, LSTM, and GRU, putting together air quality indices from 1498 monitoring stations with meteorological data from the Global Forecasting System to predict concentrations of PM
10; results confirm that the examined networks are effective in handling long-term dependencies. Specifically, the GRU model outperforms both the RNN and LSTM networks. On the other hand, LSTM including spatiotemporal correlations in applications with a dense urban network of measurement stations significantly improves forecast performance [
23] and may be further exploited to forecast air pollution maps [
26].
Another neural methodology used in this study is Echo State Networks (ESNs). The architecture of ESNs follows a recursive structure, where the hidden layer, known as the dynamical reservoir, is composed of a large number of sparsely and recursively connected units. The weights of these units are initialized randomly and remain constant throughout the iterations. The weights for the input and output layers are the ones trained within the learning process. In [
27], an ESN predicts values of PM
2.5 concentration based on the correlation between average daily concentrations and night-time light images from the National Geophysical Data Center. Hybrid models can also be considered to improve the performance of an ESN model, as in [
28], where an integration with particle swarm optimization is performed, and in [
29], where the authors manage to further optimize computational speed.
In conclusion, neural networks appear to be a viable approach for obtaining reliable forecasts of pollutant concentrations. However, the performance of the network often depends on architectural features, as well as the quality of the acquired data. One of the shortcomings in existing works that we have addressed is the reliance on traditional time series forecasting methods that consider only historical measurements up to a specific time point [
12,
30] or deterministic model forecasts [
9,
31]. In contrast, our new architecture leverages the availability of observational and model data at different times, allowing for a more comprehensive and dynamic analysis of the underlying patterns and trends, as shown in
Section 2.3. In our comparative study, we show that the proposed approach allows us to more accurately capture the temporal dynamics of the data and improve the performance of our forecasts.
Paper Plan
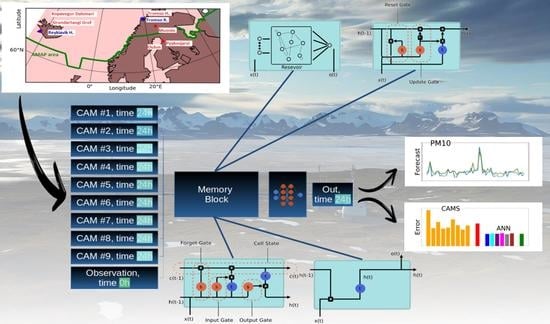
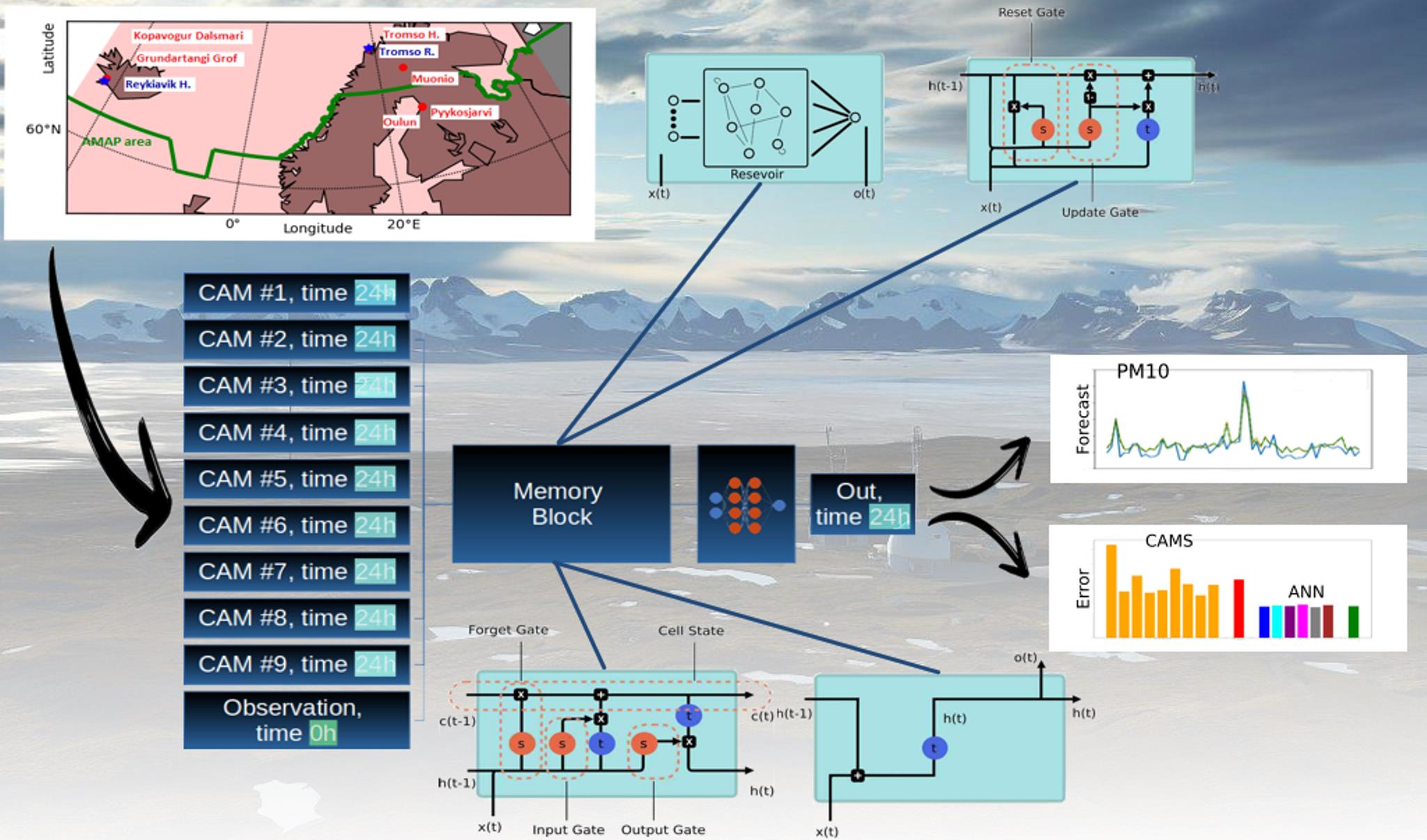
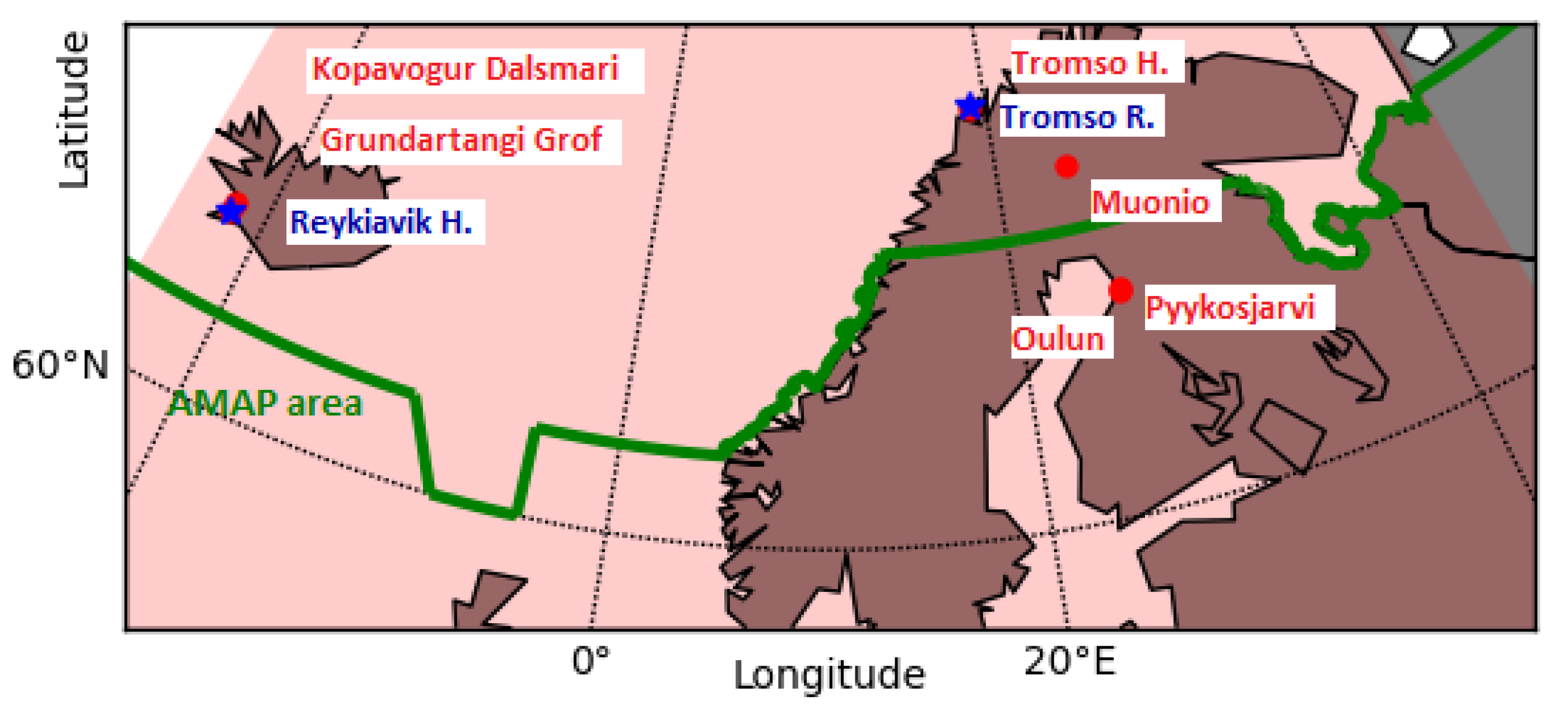
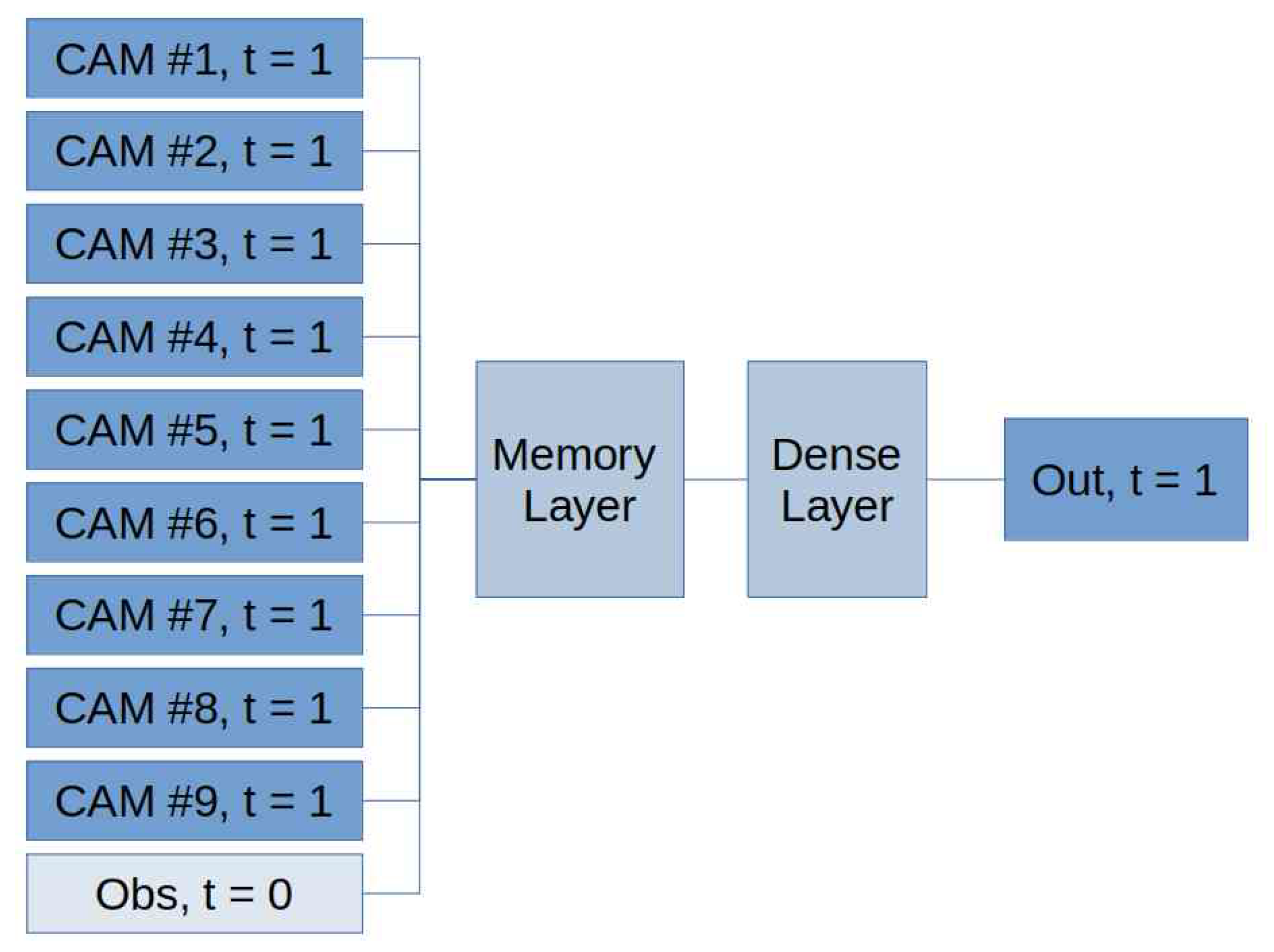
In the upcoming sections, we evaluate the performance of six distinct memory cells. Our study utilizes two components as input time series: (i) measurements of PM10 concentration recorded at 00:00 UTC from six stations situated in the Arctic polar region within the AMAP area and (ii) PM10 forecasts generated by CAMS models at 00:00 UTC for the next day.
In
Section 2, we provide an overview of data acquisition and processing, describe the structure underlying the architecture, including details of each ANN design, and outline the technical aspects of implementation.
In
Section 3, we present the results and compare the performance of the aforementioned architectures.
In
Section 4, we present our discussion and draw our conclusions.
4. Discussion and Conclusions
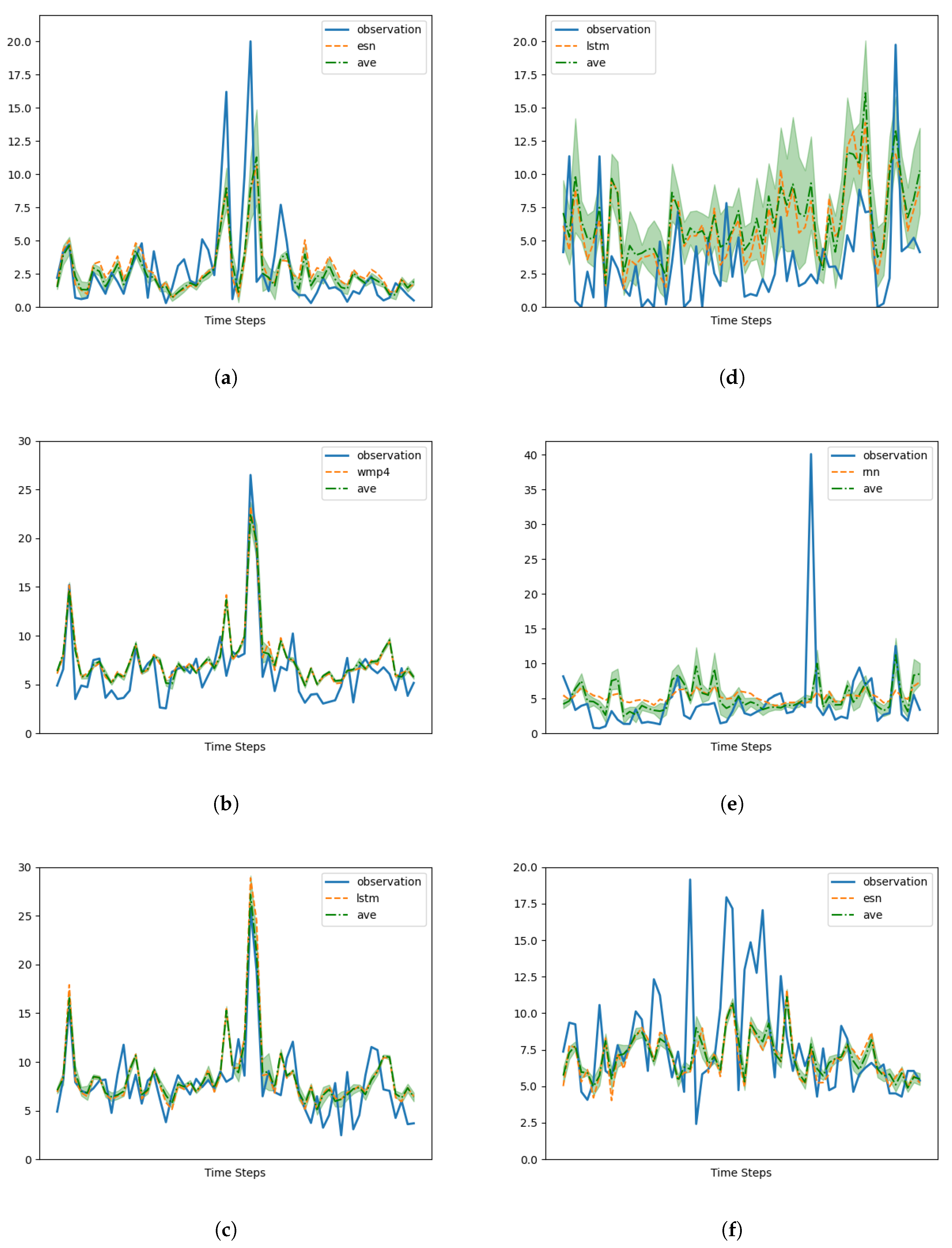
In this study, we conduct an in-depth analysis of a 24 h forecasting design for PM10 concentrations that leverages both in situ measurements and forecasts generated by deterministic models. This utilization of input data consisting of measurements and model forecasts at different times introduces a novel perspective to the task at hand, enhancing the predictive capabilities of the algorithms employed. Furthermore, it offers a valuable contribution to the existing literature by demonstrating the potential of incorporating multitemporal data in time series forecasting.
Central to the design are the memory cells, which serve as alternative options for modeling the data and improving forecasting accuracy. Specifically, we explore the utilization of echo state networks (ESNs), long short-term memory (LSTM), GRUs (gated recurrent units), and recurrent neural networks (RNNs), as well as four-step and one-step temporally windowed multilayer perceptron.
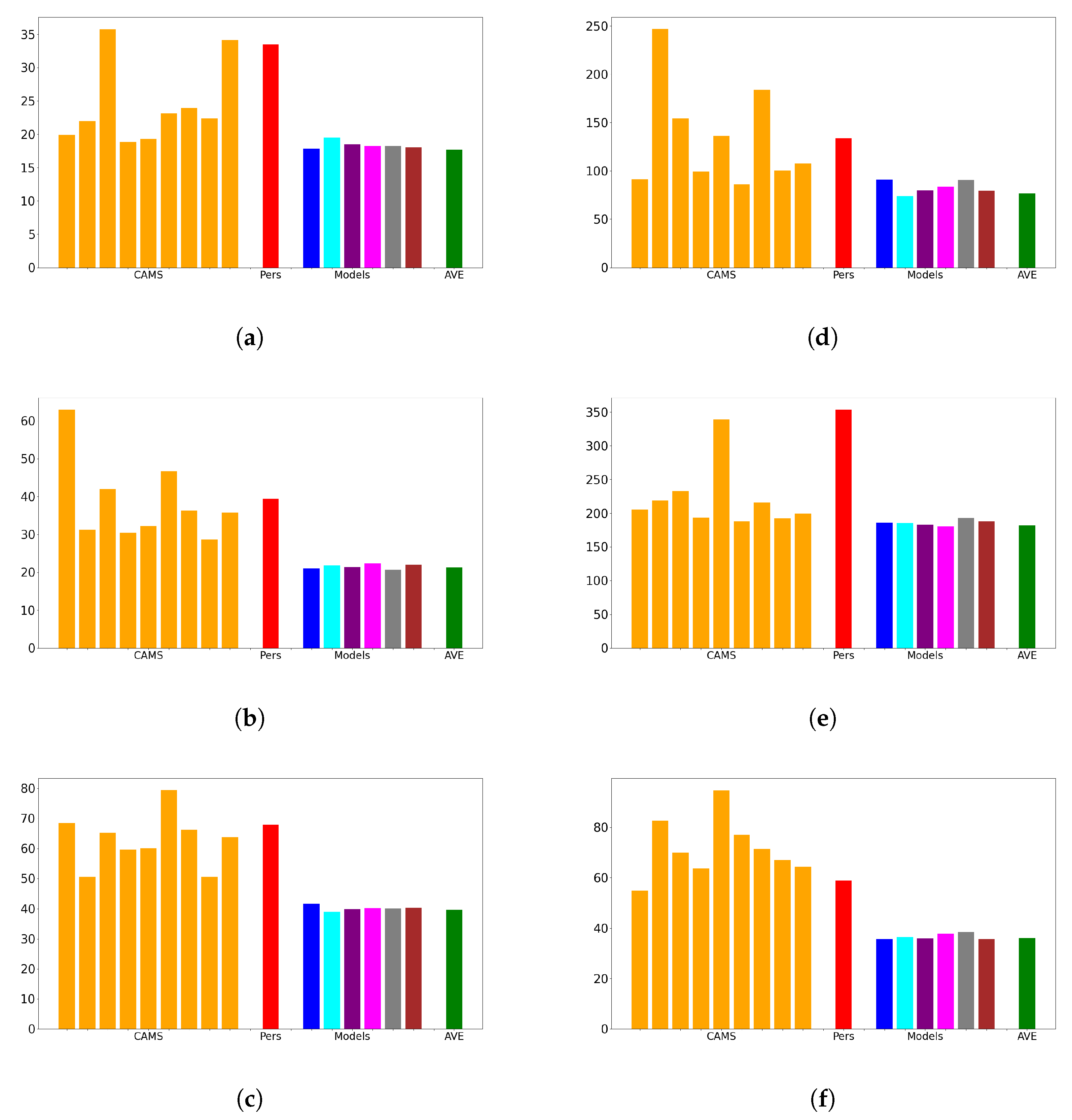
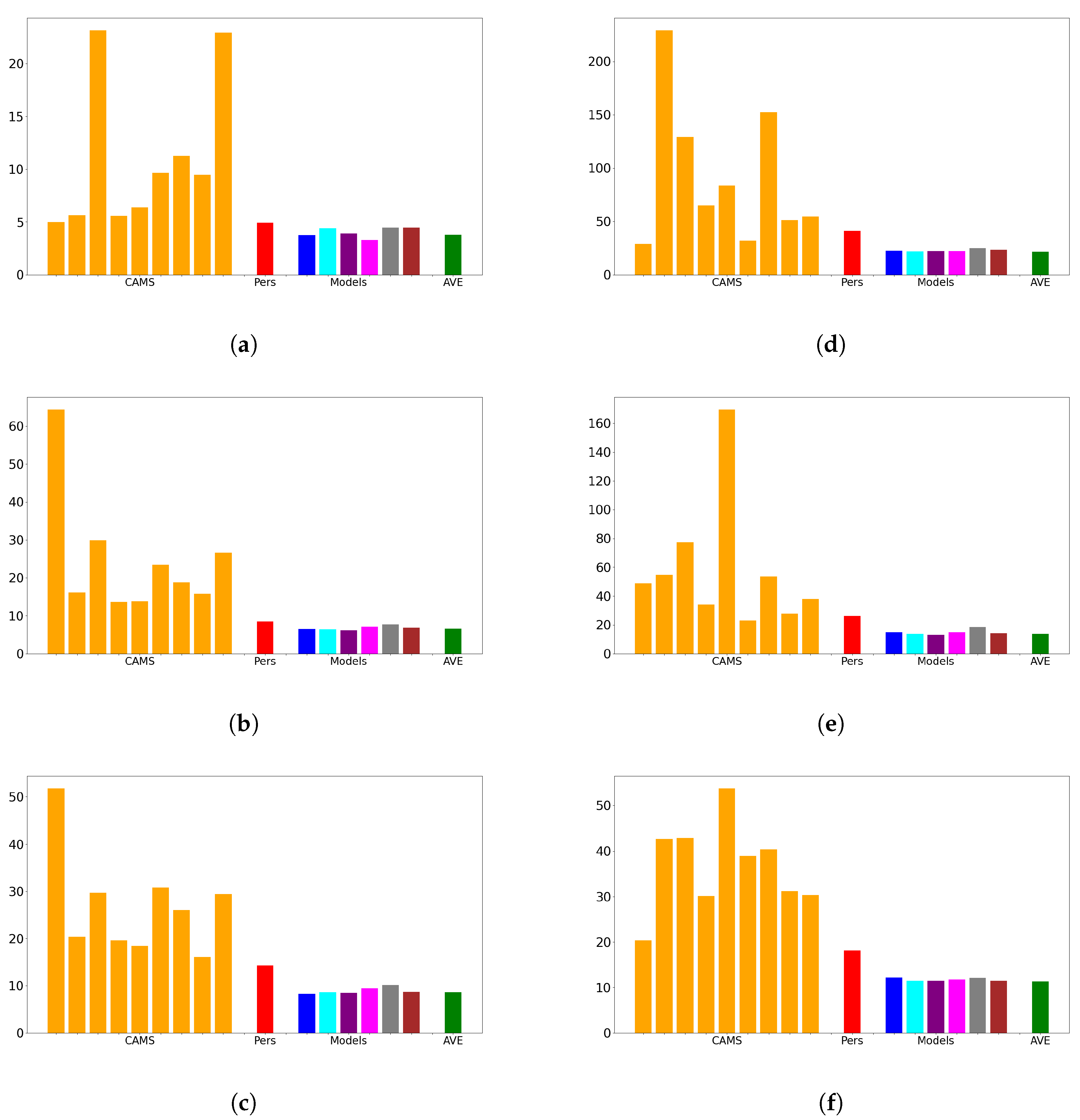
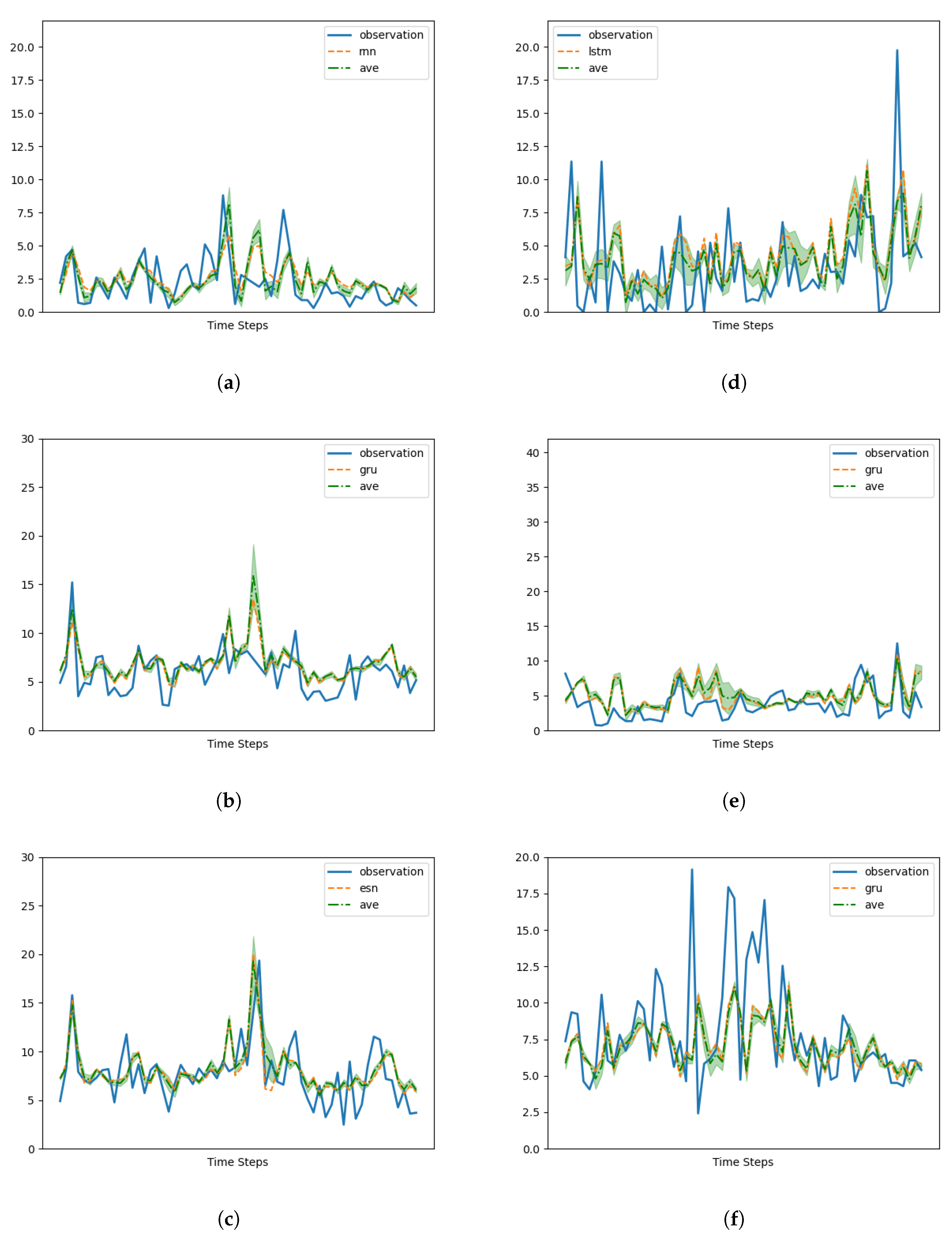
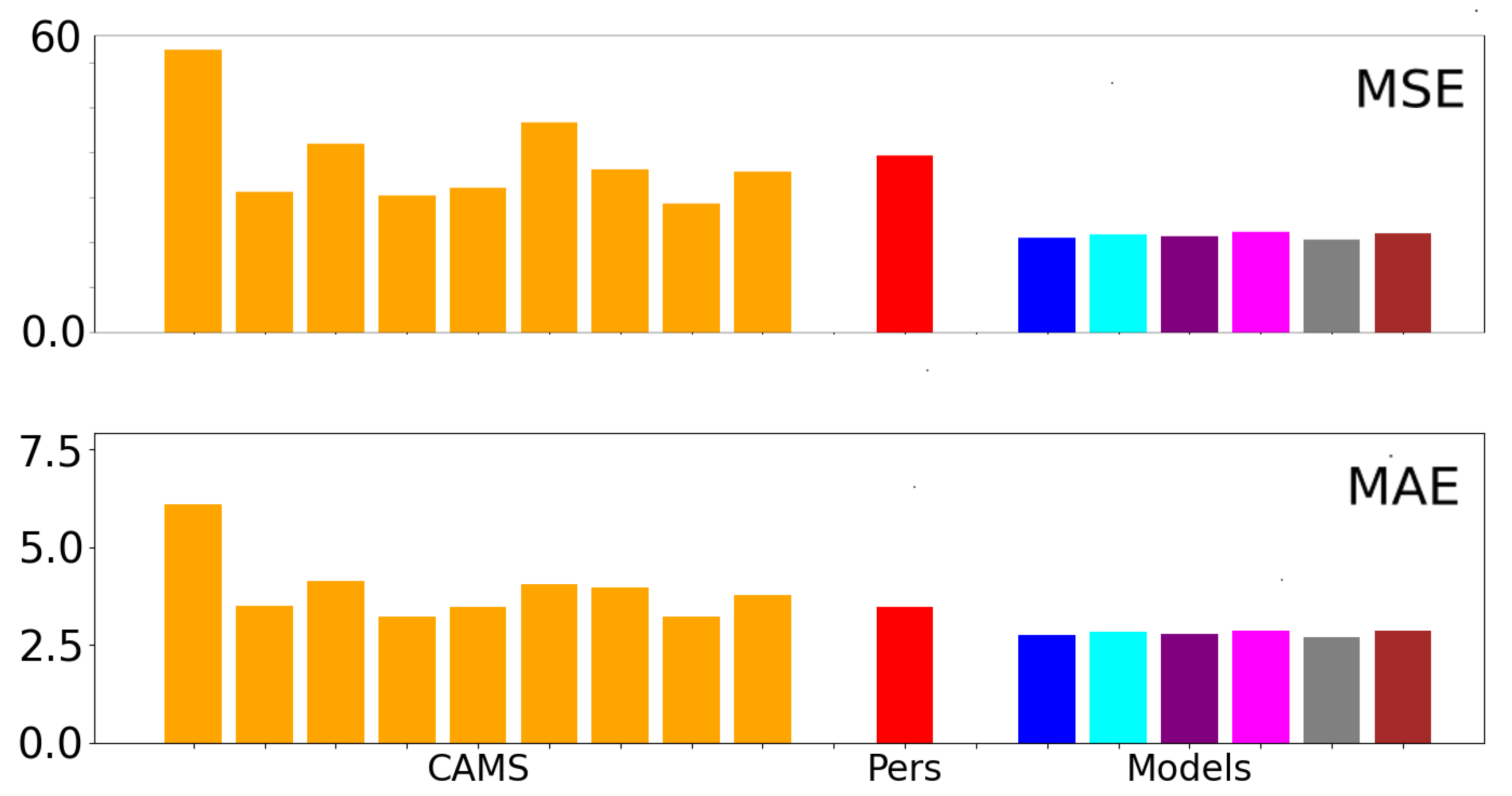
Our architecture exhibits remarkable performance by effectively capturing the strengths of either the CAMS or measurements, regardless of the specific memory cell employed. It consistently outperforms the CAMS, resulting in significant average improvements ranging from 25% to 40% in terms of mean squared error (MSE). This demonstrates the effectiveness of the design in harnessing the predictive capabilities of the alternative memory cells.
However, it is important to note that the choice of the memory cell has a substantial impact on the forecasting capability of the design when dealing with data series characterized by intricate behavior.
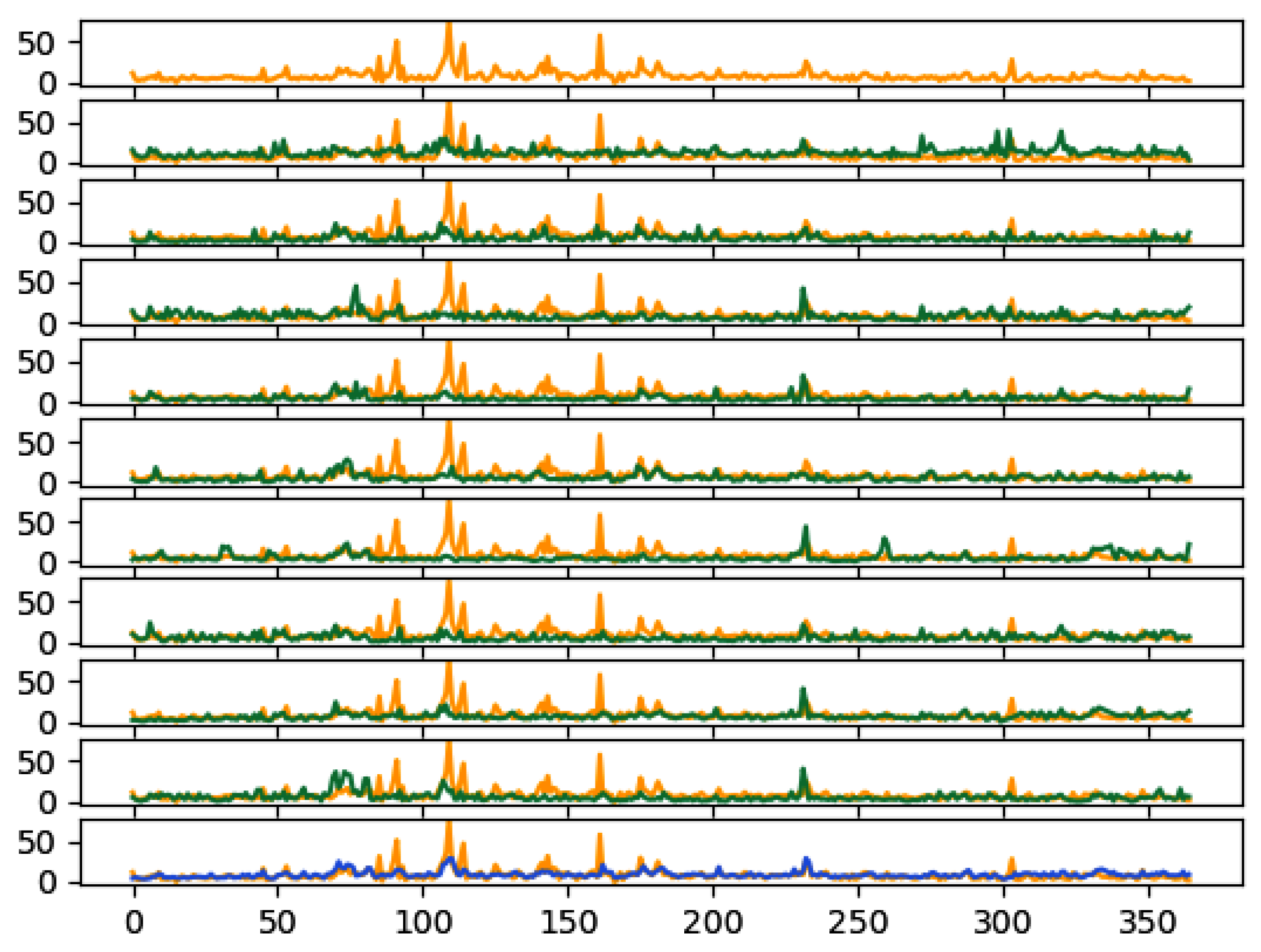
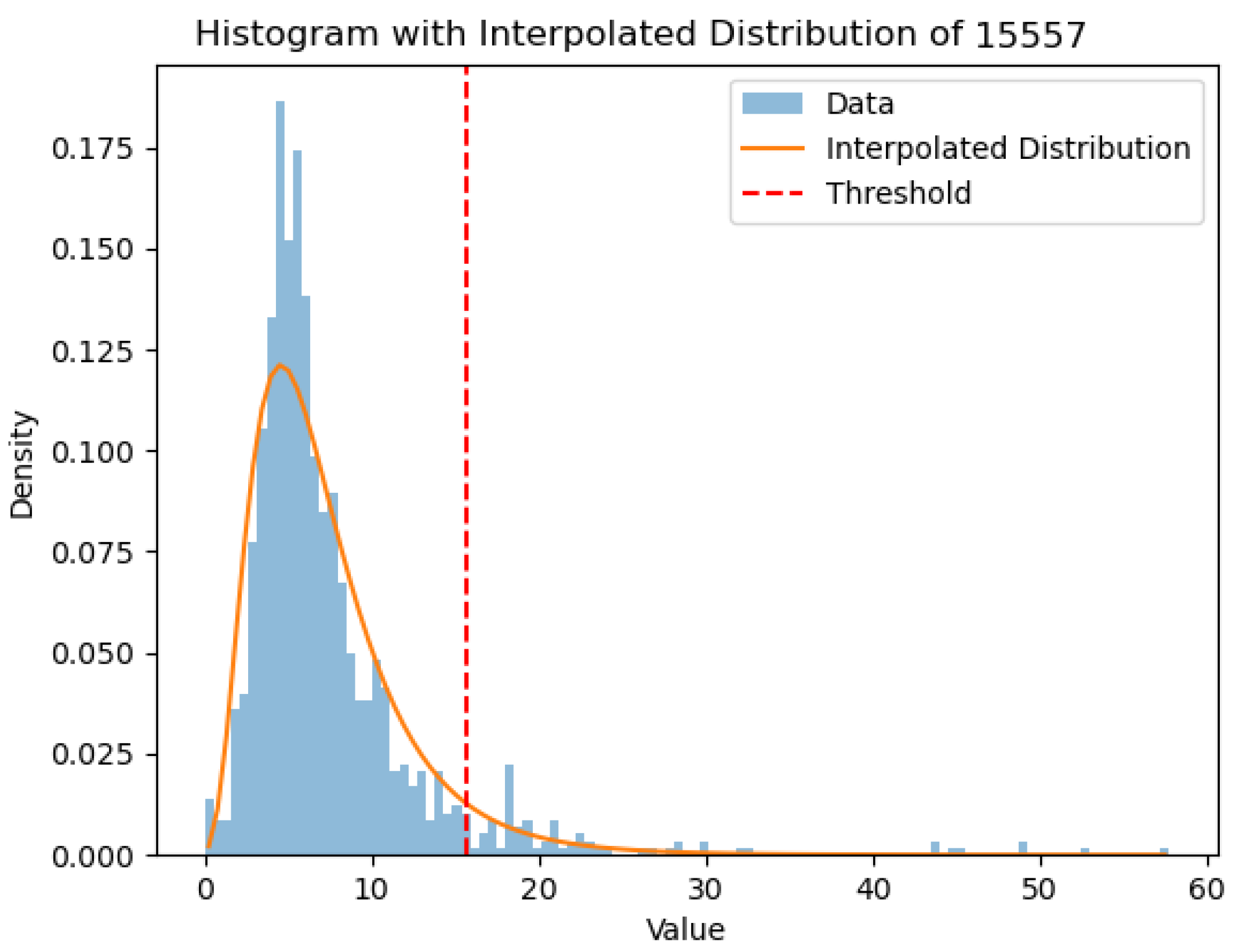
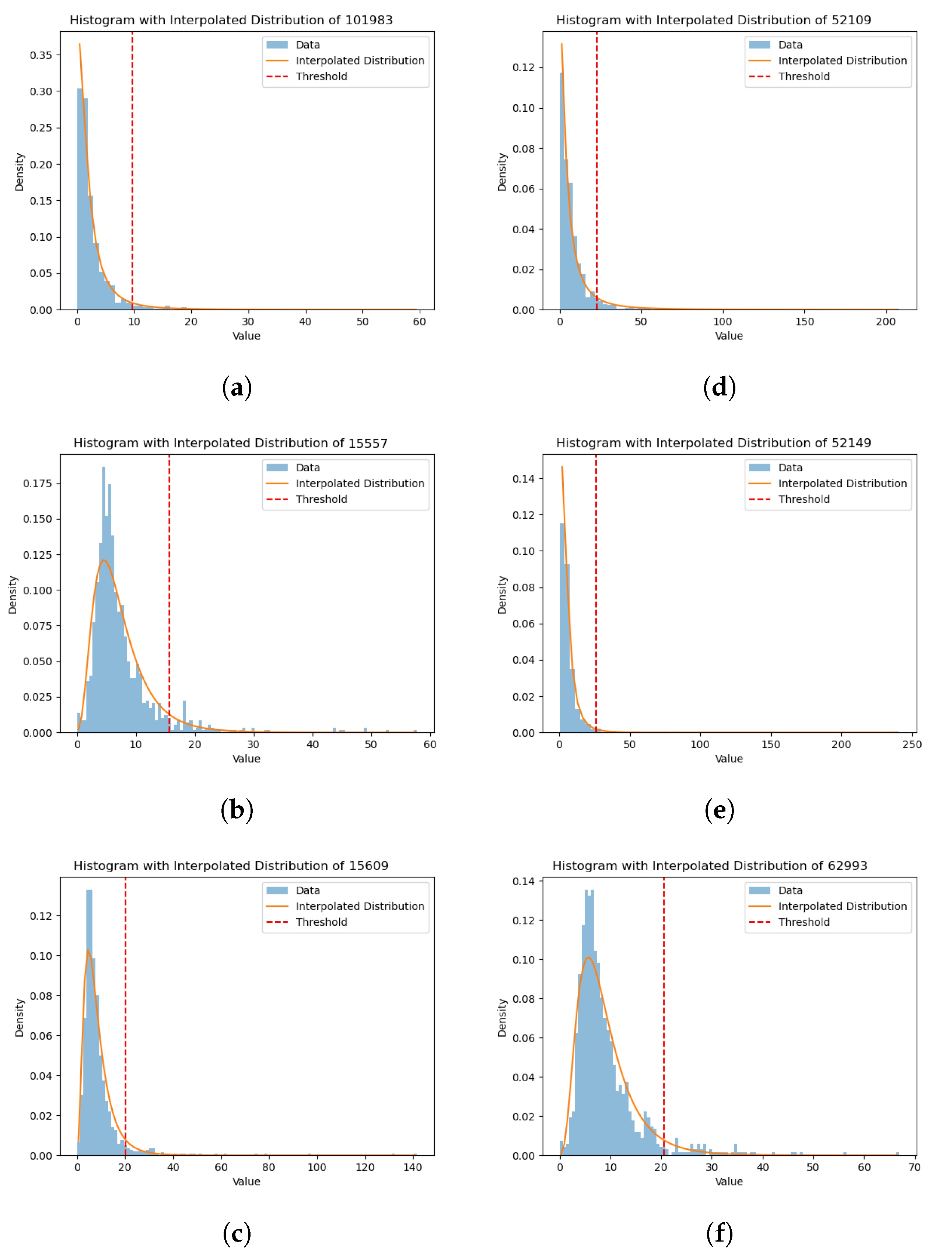
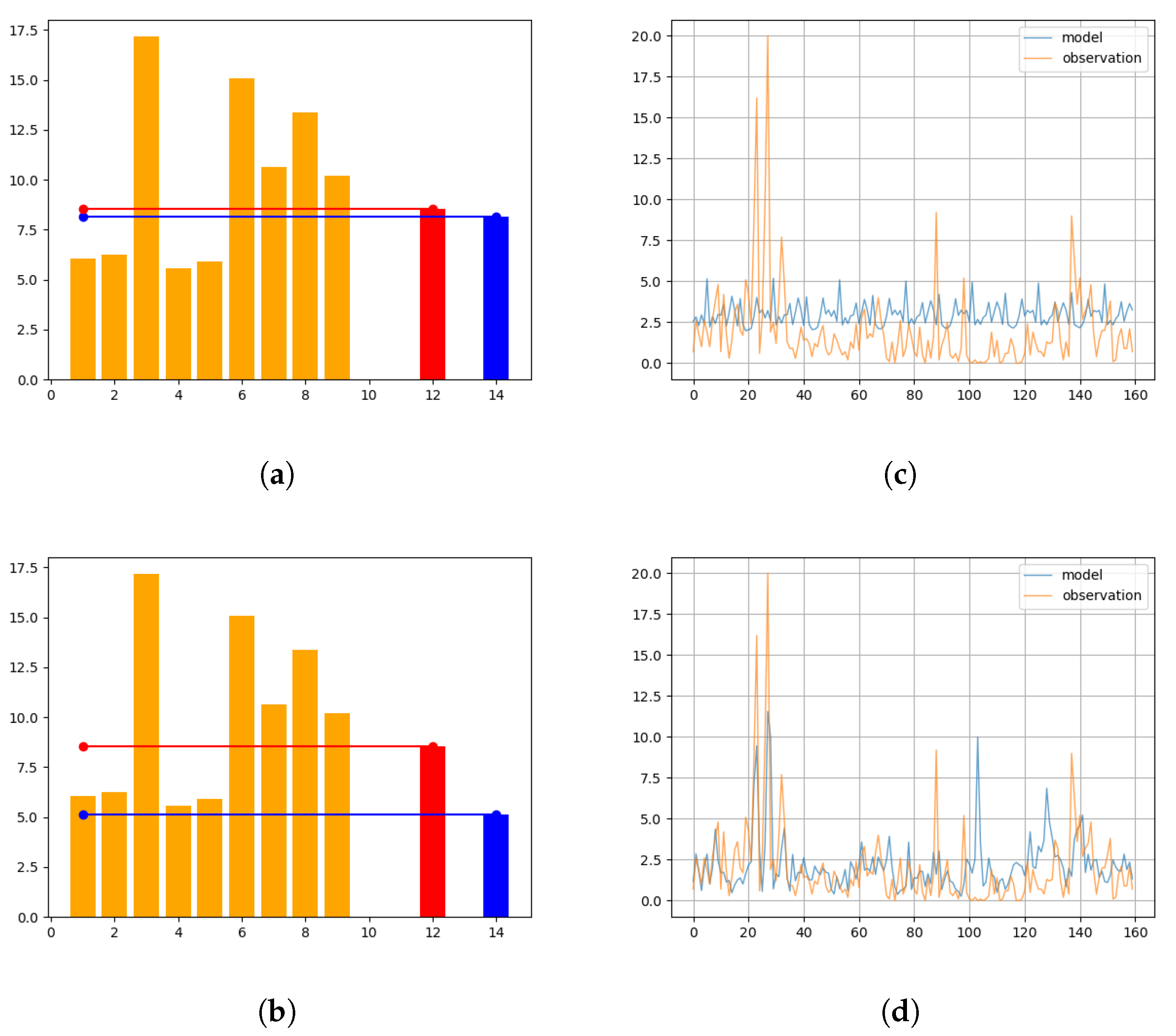
Furthermore, we investigated the impact of outliers as a potential source of error and assessed how their removal significantly affects the forecasting capability of our model.
While our proposed approach has shown effectiveness in our tests, there are limitations that should be acknowledged. These include the simplistic method of combining memory cell contributions (simple average) and the limited input data considering only PM10 observations without accounting for the relationship between pollutant concentrations and chemical constituents.
Therefore, future research endeavors can explore the integration and fusion of the distinct strengths exhibited by different memory cells, going beyond the conventional approach of simply averaging their results. By developing an ensemble design that selectively leverages the best options based on the specific characteristics of the data series to be forecast, we can further enhance the overall forecasting performance and reliability of the system. Additionally, an interesting avenue for exploration in future studies could involve redesigning the ANN model to incorporate spatiotemporal correlations among nearby monitoring stations (for instance inserting graph neural networks [
49] or graph networks [
50] at the beginning of the forecasting pipeline) and the PM
10 chemistry composition, potentially providing valuable insights into the relationship between pollutant concentrations and chemical constituents. Such investigations have the potential to enhance our understanding of air quality dynamics and improve the accuracy of PM
10 forecasts.
Based on our results in
Section 3.4.2, we interpret that the PM
10 Arctic observations exhibit predominantly Markovian behavior, where the future evolution of the underlying dynamic system depends primarily on the present state. However,
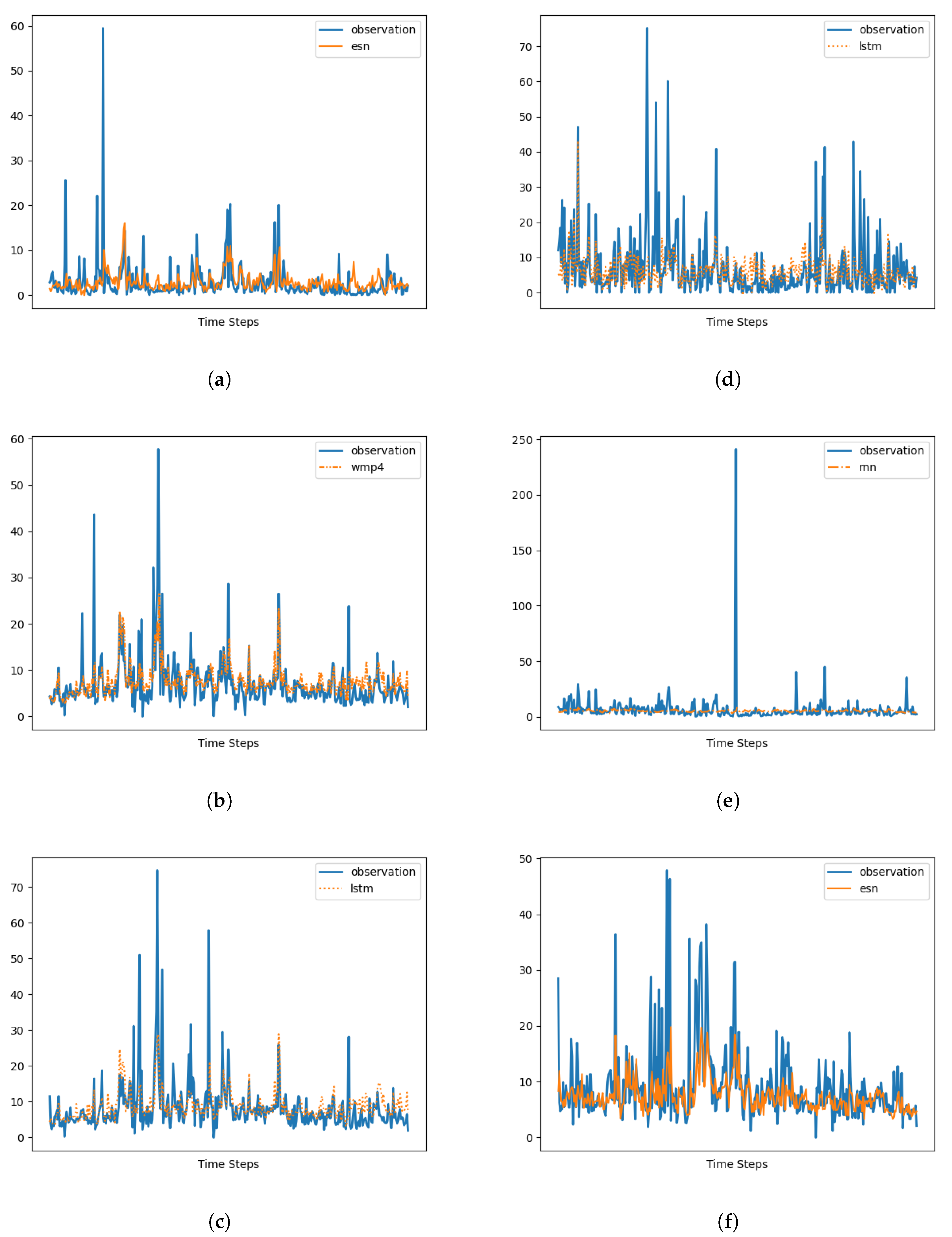
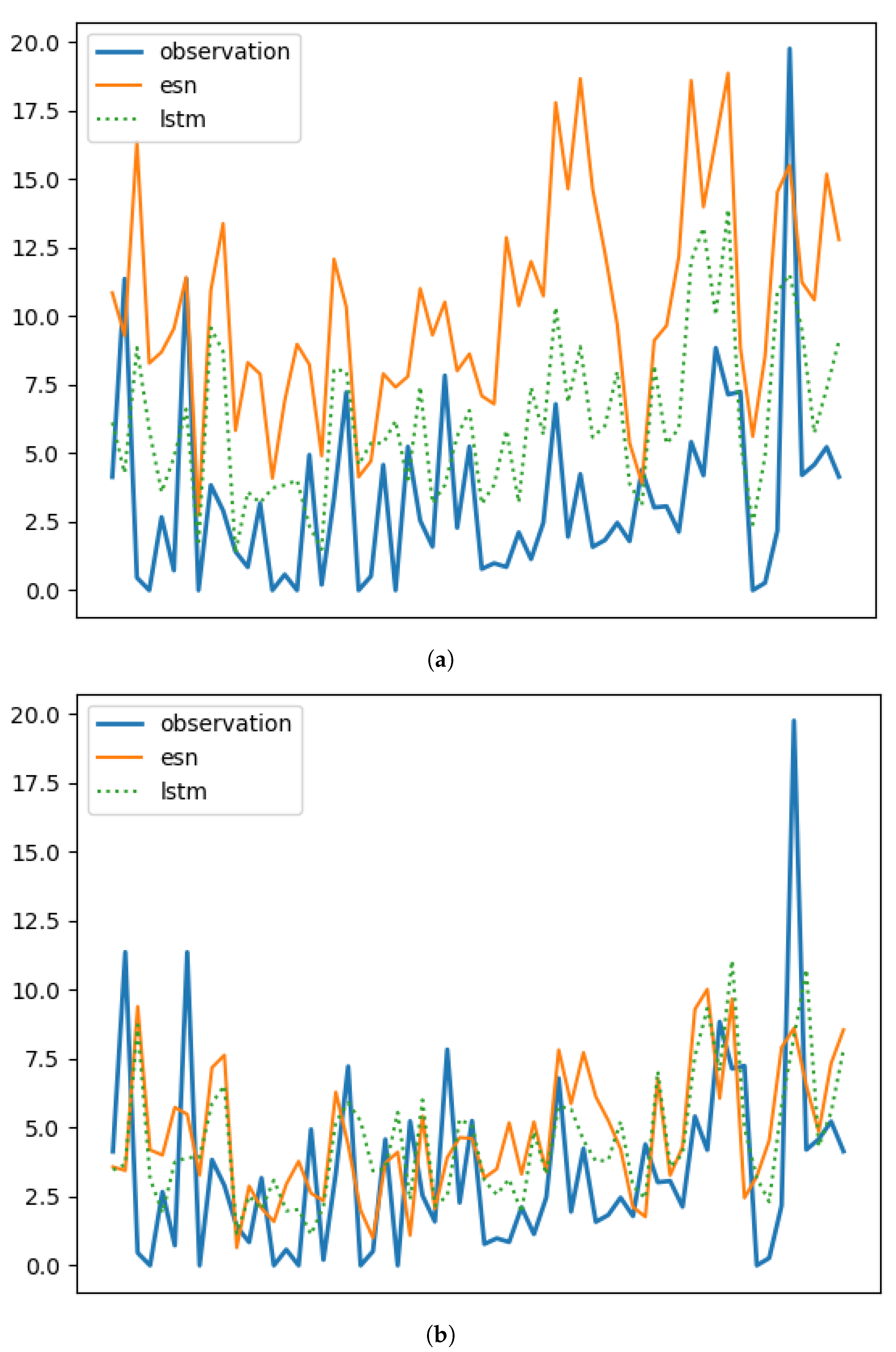
Figure 11 demonstrates that two non-Markovian memory cells, namely LSTM and ESN, react differently to outliers. Specifically, ESN shows poorer performance in the presence of outliers, while LSTM performs best among all the memory cells.
Figure 11 also illustrates that the performances of the two cells are comparable only when the outliers (i.e., values deviating from the log-normal distribution) are filtered out. Although we did not make hypotheses about the cause of these outliers, these results suggest that outliers introduce higher-order non-Markovian contents that pose challenges for the ESN cell but can be effectively utilized by the LSTM cell. Therefore, as another interesting topic for future research, it would be valuable to investigate the presence of outliers in the data, their nature, and their impact on the non-Markovian nature of the underlying dynamics. This research could potentially lead to improved modeling techniques that can effectively handle outliers and prevent large or catastrophic events.


 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}