

Agreement and Disagreement-Based Co-Learning with Dual Network for Hyperspectral Image Classification with Noisy Labels

Abstract
:1. Introduction
2. Related Work and Contributions
2.1. Label Noise Learning Based on Deep Learning
- (1)
- Robust network architecture: Adding a noise adaptation layer [30] or designing a specific architecture [31] to improve the reliability of estimating label transition probabilities and to mimic the label transition behavior in deep network learning. The goal of the specific architecture is to improve the reliability of estimating label transition probabilities.
- (2)
- Robust loss function: Developing a loss function that is robust to label noise [32,33]. Generally, robust loss functions attempt to achieve a small risk on the training set with label noise. Current studies of robust loss function mainly rely on the basis of mean absolute error loss and cross entropy loss.
- (3)
- Robust regularization: Adding a regularization term into optimization objective to alleviate the overfitting of deep learning on training samples with label noise. Regularization techniques include explicit regularization (such as weight decay [34] and dropout [35]) and implicit regularization (such as mini-batch stochastic gradient descent [36] and data augmentation [37]).
- (4)
- Loss adjustment: Adjusting the loss of all training samples to reduce the effects of label noise. Unlike robust loss functions, loss adjustment adjusts update rules to minimize the negative effects of label noise. Loss adjustment includes loss correction [38], loss reweighting [39], and label refurbishment [40].
- (5)
- Sample selection: Selecting true-labeled samples from the training set with noisy labels. The aim of sample selection is to update deep neural networks for the selected clean samples. Sample selection generally includes multi-network collaborative learning [21,41], multi-round iterative learning [42], and the combination with other learning paradigms [43].
2.2. Deep Neural Network-Based Label Noise Learning in Remote Sensing
- (1)
- Specific network architecture [20,22,23,24,44,45,46,47]. For synthetic aperture radar images, Ref. [44] designed a noise-tolerant network based on layer attention. The developed layer attention module adaptively weights the features of different convolution layers. To handle the noisy label data for building extraction, Ref. [46] proposed a general deep neural network model that is adaptive to label noise, which consists of a base network and an additional probability transition module. To suppress the impact of label noise on the semantic segmentation of RS images, Ref. [47] constructed a general network framework by combining an attention mechanism and a noise robust loss function.
- (2)
- Robust loss function [19,20,25,47,48,49,50]. Ref. [47] added two hyperparameters into the symmetric cross-entropy loss function for label noise learning. Refs. [48,49] proposed two novel loss functions for deep learning, the first being the robust normalized softmax loss used for the characterization of RS images based on deep metric learning, and the second being the noise-tolerant deep neighborhood embedding, which accurately encodes the semantic relationships among RS scenes. Ref. [50] constructed a joint loss consisting of a cross-entropy loss with the updated label and a cross-entropy loss with the original noisy label.
- (3)
- Label correction [45,50,51,52,53,54]. For road extraction from RS images, Ref. [45] introduced label probability sequence into sequence deep learning framework for correcting error labels. Ref. [50] utilized the information entropy to measure the uncertainty of the prediction, which served as a basis for label correction. Ref. [51] adopted unsupervised clustering to recognize the sample’s label, and the network trained on augmented samples with clean labels was used to correct noisy labels further. Similarly, for object detection in aerial images, Ref. [52] designed a new noise filter named probability differential to recognize and correct mislabeled labels. Ref. [53] used the initial pixel-level labels to train an under-trained initial network that was treated as starting training for network updating and initial label correction. In addition, Ref. [54] proposed a novel adaptive multi-feature collaborative representation classifier to correct the labels of uncertain samples.
- (4)
- Hybrid approach [21,23,26,51,55,56,57,58]. Both [51] and [55] introduced unsupervised method into label noise leaning. In [55], an unsupervised method was combined with domain adaptation for HSI classification. In addition, complementary learning was combined with deep learning for HSI classification [26] and RS scene classification [56]. Recently, Ref. [57] incorporated knowledge distillation with label noise learning to improve building extraction. To obtain datasets containing less noise, Ref. [58] introduced semisupervised learning into the objective learning framework to produce a low-noise dataset.
2.3. Co-Training in Remote Sensing
2.4. Contributions
- (1)
- A new framework incorporating “disagreement” strategy into co-learning, named DCL, is proposed for HSI classification with noisy labels.
- (2)
- A stronger framework that introduces an “agreement” strategy into DCL, termed ADCL, is designed.
- (3)
- A joint loss function is proposed for the dual-network structure.
- (4)
- Extensive experiments on public HSI data sets demonstrate the effectiveness of the proposed method.
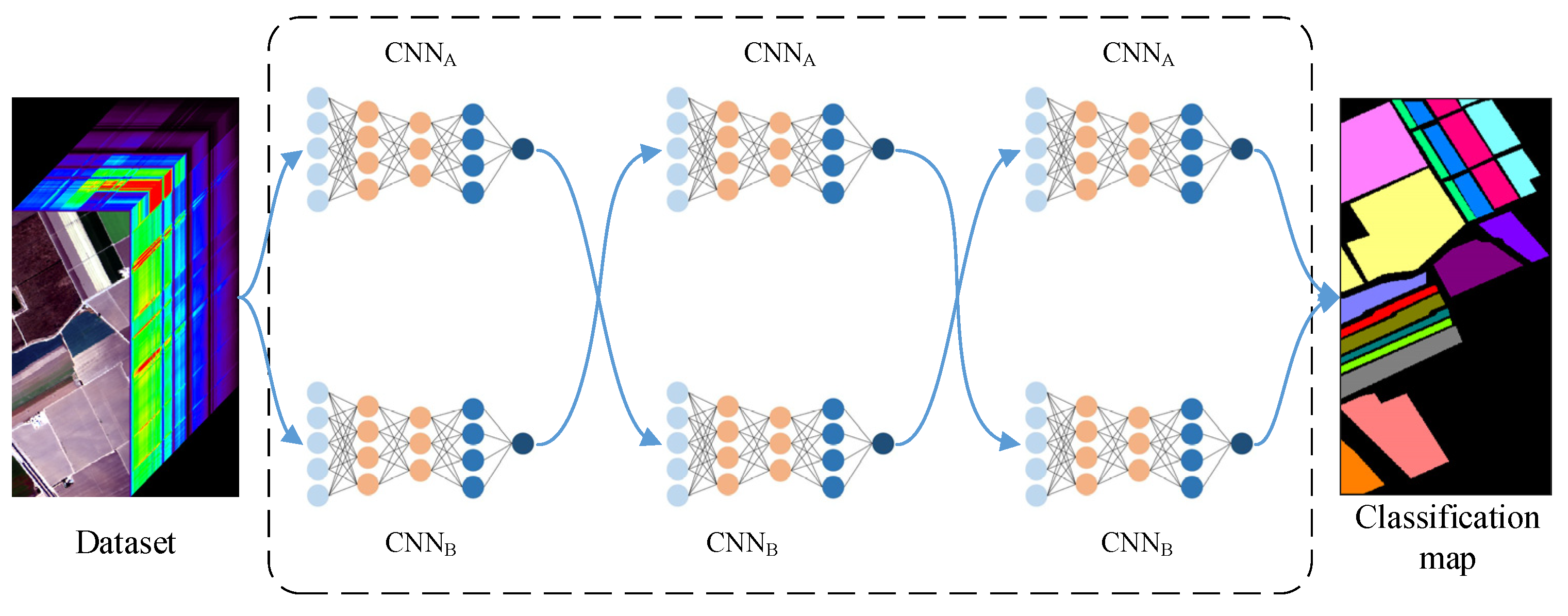
3. Proposed ADCL Method
3.1. Joint Loss
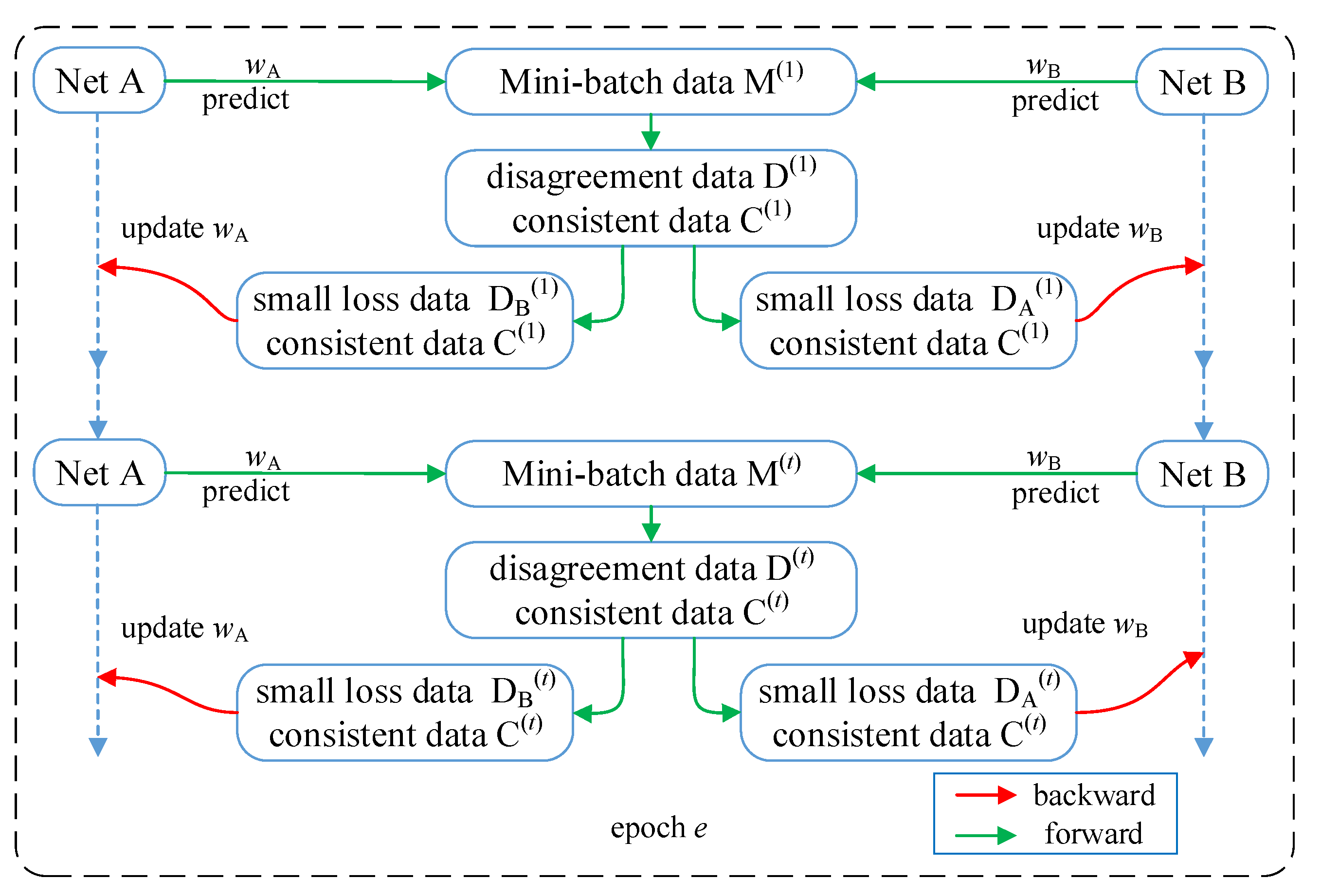
3.2. Agreement and Disagreement-Based Co-Learning Framework
3.3. Formula Analysis
4. Experimental Results and Analysis
4.1. HSI Data Sets
- (1)
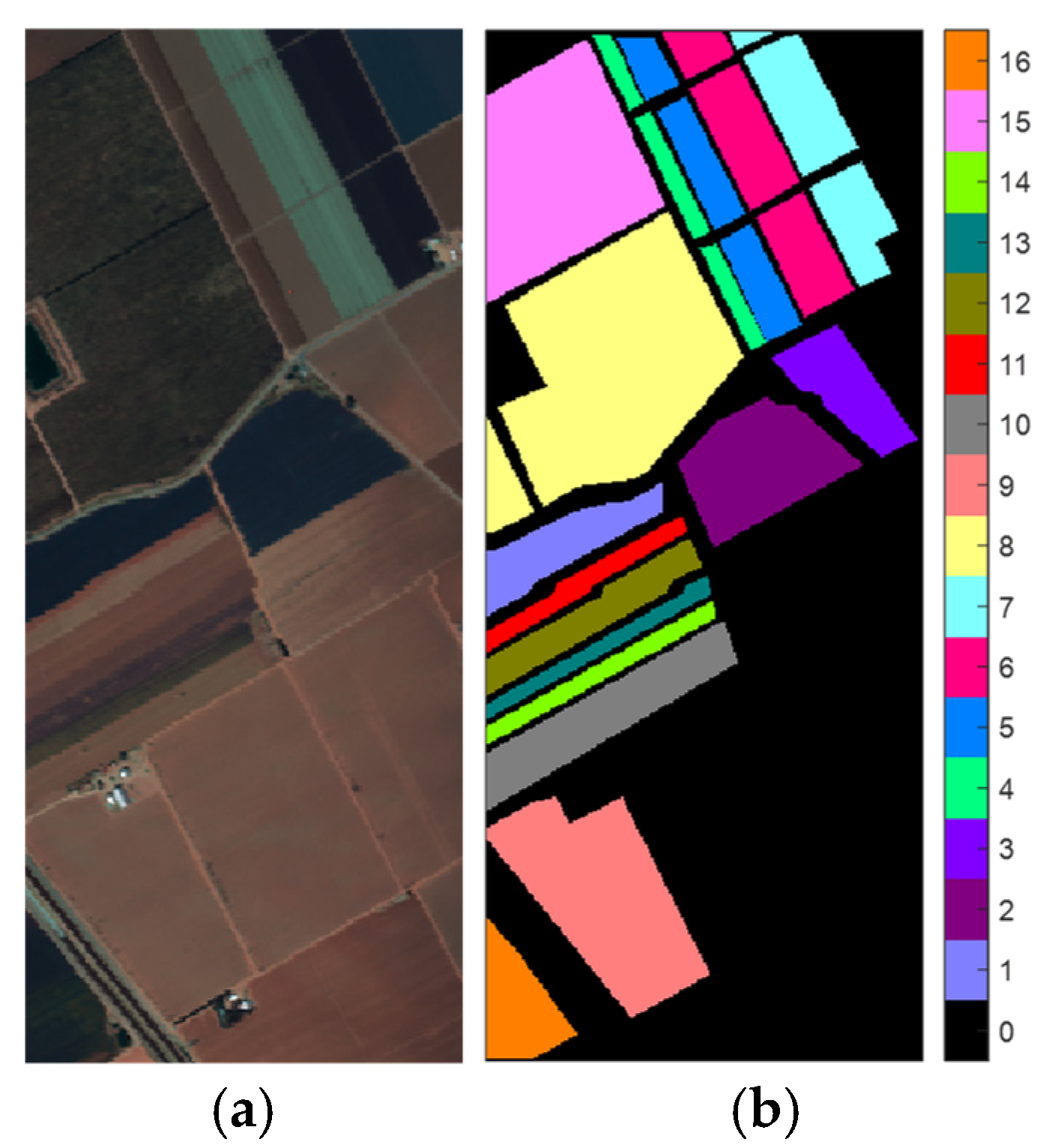
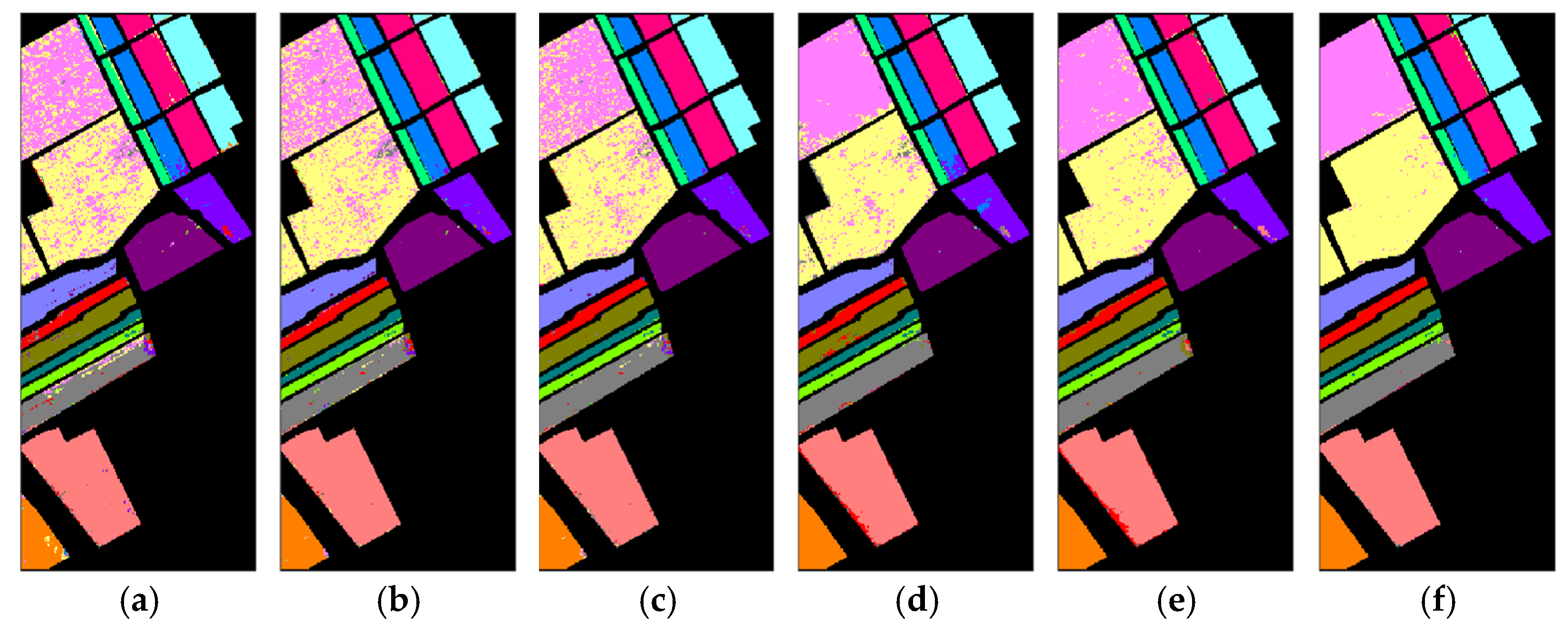
- Salinas Valley (SV) [72]: The SV data set was collected by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor over the agricultural area described as Salinas Valley in California, USA, in 1998. The data set contains 512 × 217 pixels characterized by 224 spectral bands. A total of 204 bands were used for experiments after removing 20 redundant ones. The spatial resolution of SV is 3.7 m per pixel, and the land cover contains 16 classes. The three-band pseudocolor image of the SV and its corresponding reference map are illustrated in Figure 3.
- (2)
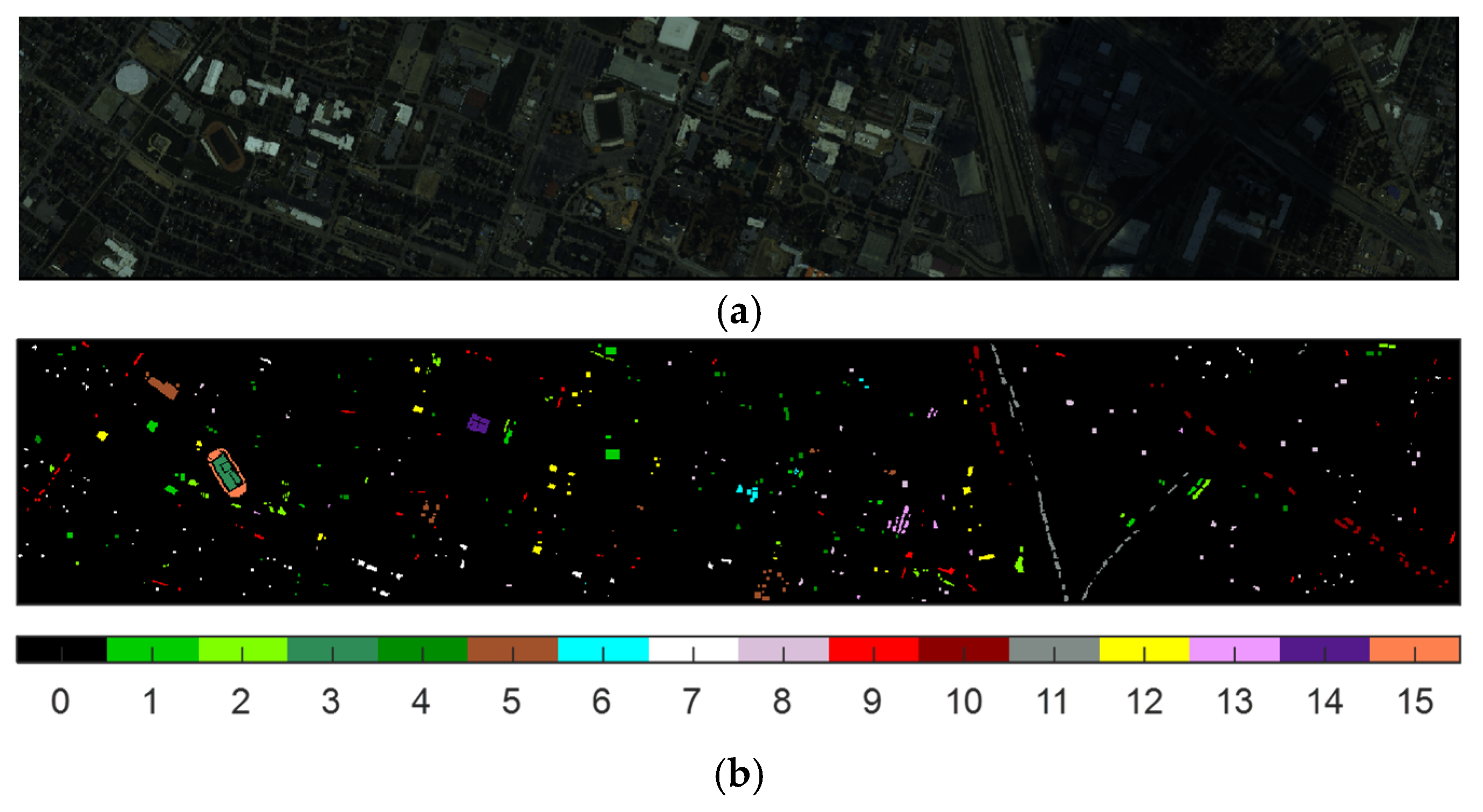
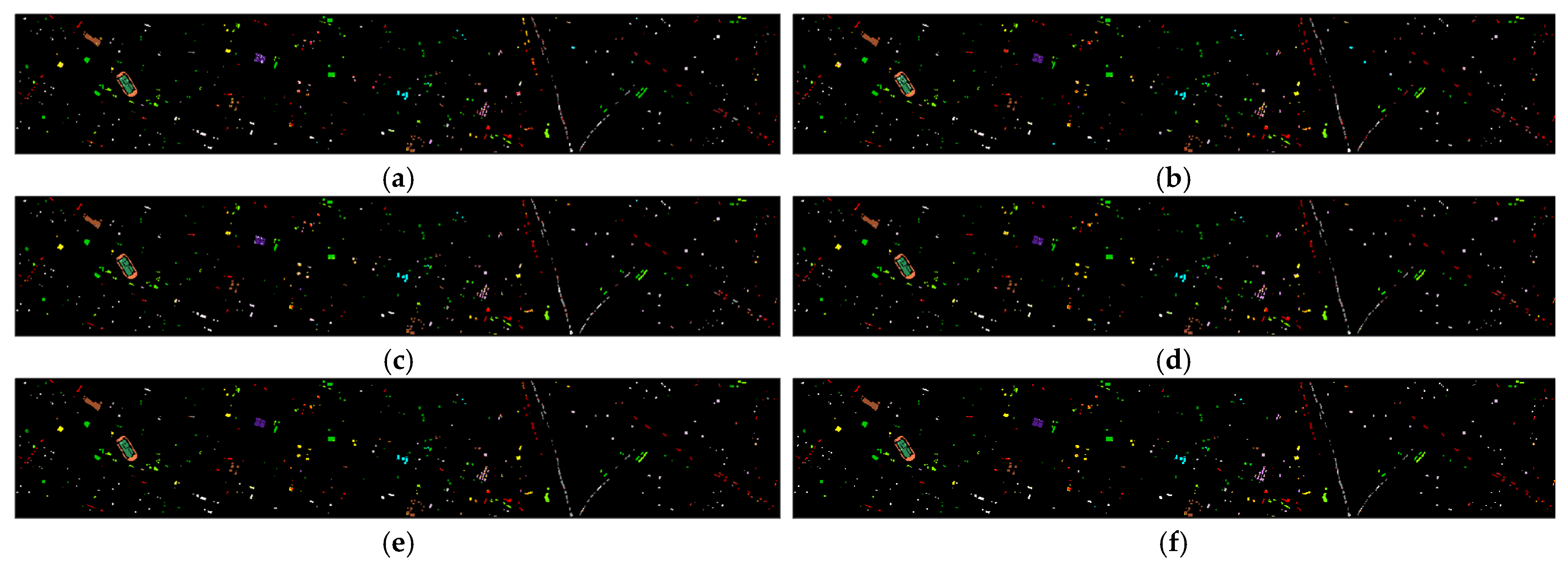
- Houston (HOU) [73]: The HOU data set was obtained by the ITRES CASI-1500 sensor and provided by the 2013 IEEE GRSS Data Fusion Competition. The data set contains 349 × 1905 pixels characterized by 144 spectral bands ranging from 364 to 1046 nm. The spatial resolution of HOU is 2.5 m per pixel, and the land cover includes 15 classes. The three-band pseudocolor image of the HOU and its corresponding reference map are shown in Figure 4.
- (3)
- Kennedy Space Center (KSC) [72]: The KSC data set was acquired by the AVIRIS sensor over the KSC, Florida, on 23 March 1996. The data set contains 512 × 614 pixels characterized by 224 spectral bands. A total of 176 bands were retained for our experiment after removing water absorption bands and low signal-to-noise ratio bands. The spatial resolution of KSC is 3.7 m per pixel, and the land cover includes 13 classes. The three-band pseudocolor image of the KSC and its corresponding reference map are illustrated in Figure 5.
4.2. Experiment Settings
4.3. Evaluation of the Joint Loss Function
4.4. Comparison with State-of-the-Art Methods
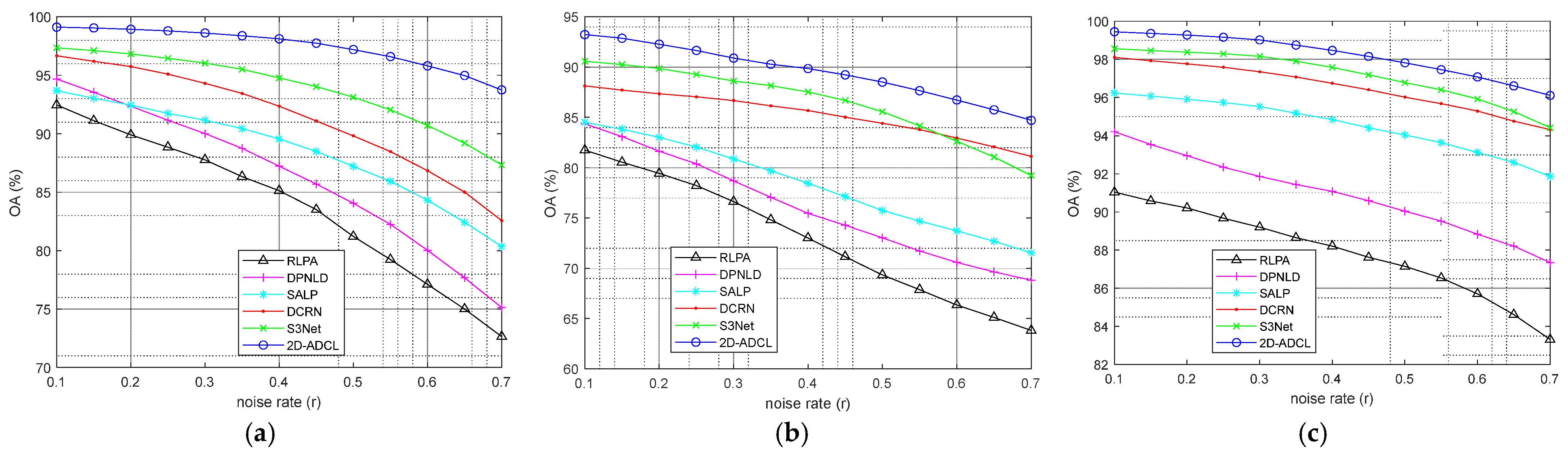
4.5. Performance Evaluation under Different Noise Rates
4.6. Computational Cost
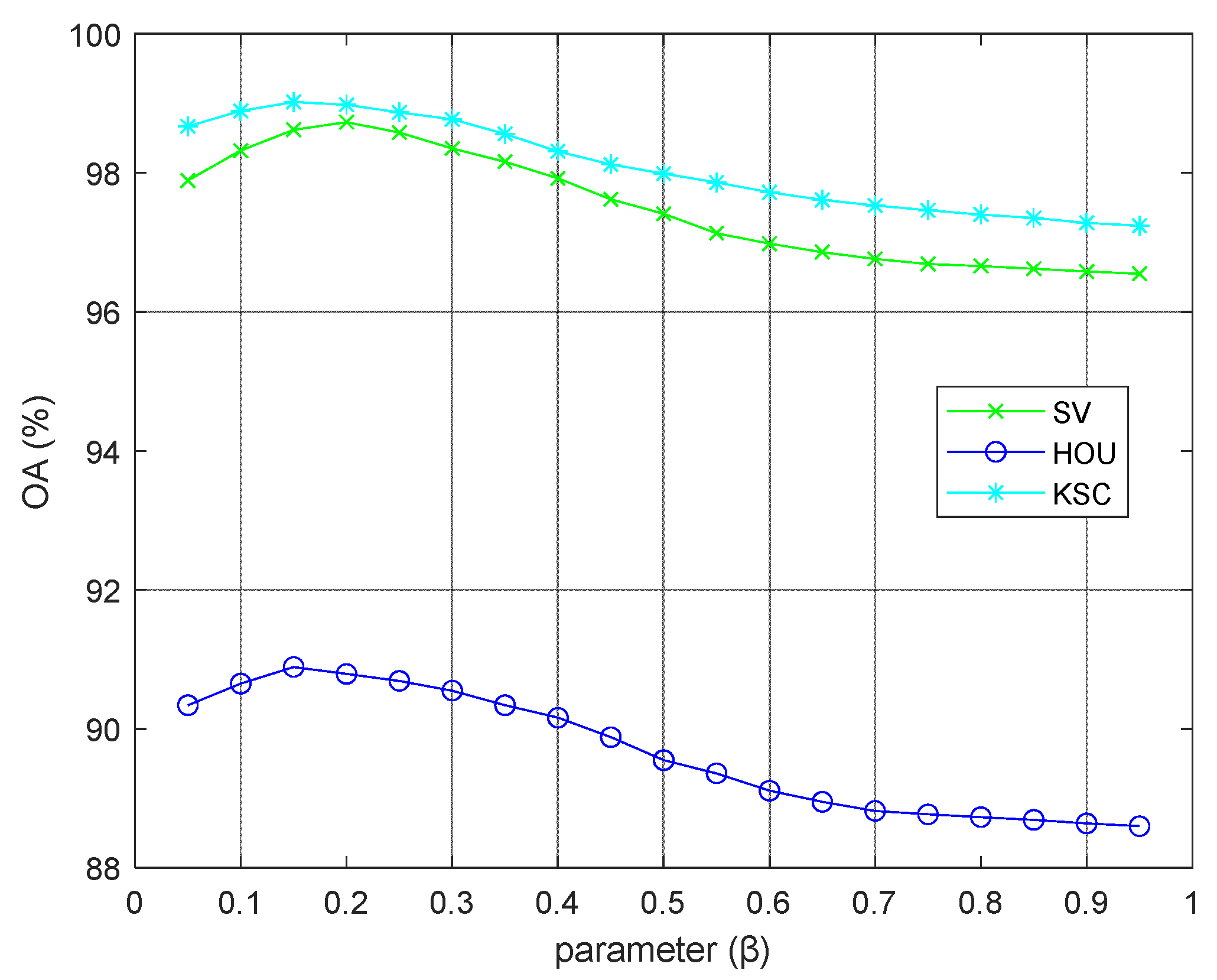
4.7. Further Analysis
5. Discussion
6. Conclusions
- The proposed framework, based on a dual-network structure, proved to be robust to label noise, and it can achieve good classification performance even in the case of a high noise rate.
- The designed joint loss function, composed of the supervision loss and relative loss, demonstrated good robustness to label noise. This is because when there is label noise, the self-supervised information of each network may not be completely accurate, but the mutual supervised information from both networks will help to correct and improve the accuracy of the predictions.
- In terms of time efficiency, the proposed method is acceptable because we do not use a complex network except for a dual-network structure.
- The “agreement” strategy plays an important role in improving the classification accuracy, as it helps mitigate the problem of difficult convergence of neural networks when there is a high ratio of label noise.
Author Contributions
Funding
Conflicts of Interest
References
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent advances of hyperspectral imaging technology and applications in agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Huang, H.; Liu, L.; Ngadi, M.O. Recent developments in hyperspectral imaging for assessment of food quality and safety. Sensors 2014, 14, 7248–7276. [Google Scholar] [CrossRef] [PubMed]
- Cruz-Ramos, C.; Garcia-Salgado, B.P.; Reyes-Reyes, R.; Ponomaryov, V.; Sadovnychiy, S. Gabor features extraction and land-cover classification of urban hyperspectral images for remote sensing applications. Remote Sens. 2021, 13, 2914. [Google Scholar] [CrossRef]
- Ye, C.; Li, Y.; Cui, P.; Liang, L.; Pirasteh, S.; Marcato, J.; Goncalves, W.N.; Li, J. Landslide detection of hyperspectral remote sensing data based on deep learning with constrains. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5047–5060. [Google Scholar] [CrossRef]
- Wang, F.; Gao, J.; Zha, Y. Hyperspectral sensing of heavy metals in soil and vegetation: Feasibility and challenges. ISPRS J. Photogramm. Remote Sens. 2018, 136, 73–84. [Google Scholar] [CrossRef]
- Okwuashi, O.; Ndehedehe, C.E. Deep support vector machine for hyperspectral image classification. Pattern Recognit. 2020, 103, 107298. [Google Scholar] [CrossRef]
- Zhang, Y.; Cao, G.; Li, X.; Wang, B.; Fu, P. Active semi-supervised random forest for hyperspectral image classification. Remote Sens. 2019, 11, 2974. [Google Scholar] [CrossRef]
- Yu, X.; Feng, Y.; Gao, Y.; Jia, Y.; Mei, S. Dual-weighted kernel extreme learning machine for hyperspectral imagery classification. Remote Sens. 2021, 13, 508. [Google Scholar] [CrossRef]
- Peng, J.; Sun, W.; Li, H.; Li, W.; Meng, X.; Ge, C.; Du, Q. Low-rank and sparse representation for hyperspectral image processing: A review. IEEE Geosci. Remote Sens. Mag. 2022, 10, 10–43. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Vali, A.; Comai, S.; Matteucci, M. Deep learning for land use and land cover classification based on hyperspectral and multispectral earth observation data: A review. Remote Sens. 2020, 12, 2495. [Google Scholar] [CrossRef]
- Tu, B.; Zhang, X.; Kang, X.; Zhang, G.; Li, S. Density peak-based noisy label detection for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1573–1584. [Google Scholar] [CrossRef]
- Tu, B.; Zhang, X.; Kang, X.; Wang, J.; Benediktsson, J.A. Spatial density peak clustering for hyperspectral image classification with noisy labels. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5085–5097. [Google Scholar] [CrossRef]
- Tu, B.; Zhou, C.; He, D.; Huang, S.; Plaza, A. Hyperspectral classification with noisy label detection via superpixel-to-pixel weighting distance. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4116–4131. [Google Scholar] [CrossRef]
- Jiang, J.; Ma, J.; Wang, Z.; Chen, C.; Liu, X. Hyperspectral image classification in the presence of noisy labels. IEEE Trans. Geosci. Remote Sens. 2019, 57, 851–865. [Google Scholar] [CrossRef]
- Jiang, J.; Ma, J.; Liu, X. Multilayer spectral-spatial graphs for label noisy robust hyperspectral image classification. IEEE Trans. Neural Networks Learn. Syst. 2022, 33, 839–852. [Google Scholar] [CrossRef] [PubMed]
- Leng, Q.; Yang, H.; Jiang, J. Label noise cleansing with sparse graph for hyperspectral image classification. Remote Sens. 2019, 11, 1116. [Google Scholar] [CrossRef]
- Maas, A.E.; Rottensteiner, F.; Heipke, C. A label noise tolerant random forest for the classification of remote sensing data based on outdated maps for training. Comput. Vis. Image Underst. 2019, 188, 102782. [Google Scholar] [CrossRef]
- Damodaran, B.B.; Flamary, R.; Seguy, V.; Courty, N. An entropic optimal transport loss for learning deep neural networks under label noise in remote sensing images. Comput. Vis. Image Underst. 2020, 191, 102863. [Google Scholar] [CrossRef]
- Xu, Y.; Li, Z.; Li, W.; Du, Q.; Liu, C.; Fang, Z.; Zhai, L. Dual-channel residual network for hyperspectral image classification with noisy labels. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5502511. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, H.; Zhang, L. A superpixel guided sample selection neural network for handling noisy labels in hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9486–9503. [Google Scholar] [CrossRef]
- Roy, S.K.; Hong, D.; Kar, P.; Wu, X.; Liu, X.; Zhao, D. Lightweight heterogeneous kernel convolution for hyperspectral image classification with noisy labels. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5509705. [Google Scholar] [CrossRef]
- Wei, W.; Xu, S.; Zhang, L.; Zhang, J.; Zhang, Y. Boosting hyperspectral image classification with unsupervised feature learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5502315. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, L.; Wei, W.; Zhang, Y. Toward effective hyperspectral image classification using dual-level deep spatial manifold representation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5505614. [Google Scholar] [CrossRef]
- Ghafari, S.; Ghobadi Tarnik, M.; Sadoghi Yazdi, H. Robustness of convolutional neural network models in hyperspectral noisy datasets with loss functions. Comput. Electr. Eng. 2021, 90, 107009. [Google Scholar] [CrossRef]
- Huang, L.; Chen, Y.; He, X. Weakly supervised classification of hyperspectral image based on complementary learning. Remote Sens. 2021, 13, 5009. [Google Scholar] [CrossRef]
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.G. Learning from noisy labels with deep neural networks: A survey. IEEE Trans. Neural Networks Learn. Syst. 2022; in press. [Google Scholar] [CrossRef]
- Algan, G.; Ulusoy, I. Image classification with deep learning in the presence of noisy labels: A survey. Knowledge-Based Syst. 2021, 215, 106771. [Google Scholar] [CrossRef]
- Karimi, D.; Dou, H.; Warfield, S.K.; Gholipour, A. Deep learning with noisy labels: Exploring techniques and remedies in medical image analysis. Med. Image Anal. 2020, 65, 101759. [Google Scholar] [CrossRef]
- Goldberger, J.; Ben-Reuven, E. Training deep neural-networks using a noise adaptation layer. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017; pp. 1–9. [Google Scholar]
- Yao, J.; Wang, J.; Tsang, I.W.; Zhang, Y.; Sun, J.; Zhang, C.; Zhang, R. Deep learning from noisy image labels with quality embedding. IEEE Trans. Image Process. 2019, 28, 1909–1922. [Google Scholar] [CrossRef]
- Ghosh, A.; Kumar, H.; Sastry, P.S. Robust loss functions under label noise for deep neural networks. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 1919–1925. [Google Scholar]
- Englesson, E.; Azizpour, H. Generalized jensen-shannon divergence loss for learning with noisy labels. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Virtual, Online, 6–14 December 2021; pp. 30284–30297. [Google Scholar]
- Gupta, A.; Lam, S.M. Weight decay backpropagation for noisy data. Neural Networks 1998, 11, 1127–1138. [Google Scholar] [CrossRef] [PubMed]
- Arplt, D.; Jastrzȩbskl, S.; Bailas, N.; Krueger, D.; Bengio, E.; Kanwal, M.S.; Maharaj, T.; Fischer, A.; Courville, A.; Bengio, Y.; et al. A closer look at memorization in deep networks. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, NSW, Australia, 6–11 August 2017; pp. 233–242. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. In Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–13. [Google Scholar]
- Nishi, K.; Ding, Y.; Rich, A.; Höllerer, T. Augmentation strategies for learning with noisy labels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, Online, 19–25 June 2021; pp. 8022–8031. [Google Scholar]
- Patrini, G.; Rozza, A.; Menon, A.K.; Nock, R.; Qu, L. Making deep neural networks robust to label noise: A loss correction approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1944–1952. [Google Scholar]
- Liu, T.; Tao, D. Classification with noisy labels by importance reweighting. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 447–461. [Google Scholar] [CrossRef] [PubMed]
- Song, H.; Kim, M.; Lee, J.G. SELFIE: Refurbishing unclean samples for robust deep learning. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 10–15 June 2019; pp. 5907–5915. [Google Scholar]
- Ye, M.; Li, H.; Du, B.; Shen, J.; Shao, L.; Hoi, S.C.H. Collaborative refining for person re-identification with label noise. IEEE Trans. Image Process. 2022, 31, 379–391. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Sanghavi, S. Learning with bad training data via iterative trimmed loss minimization. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 10–15 June 2019; pp. 5739–5748. [Google Scholar]
- Yi, R.; Huang, Y.; Guan, Q.; Pu, M.; Zhang, R. Learning from pixel-level label noise: A new perspective for semi-supervised semantic segmentation. IEEE Trans. Image Process. 2022, 31, 623–635. [Google Scholar] [CrossRef] [PubMed]
- Meng, D.; Gao, F.; Dong, J.; Du, Q.; Li, H.C. Synthetic aperture radar image change detection via layer attention-based noise-tolerant network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4026505. [Google Scholar] [CrossRef]
- Li, P.; He, X.; Qiao, M.; Cheng, X.; Li, J.; Guo, X.; Zhou, T.; Song, D.; Chen, M.; Miao, D.; et al. Exploring label probability sequence to robustly learn deep convolutional neural networks for road extraction with noisy datasets. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614018. [Google Scholar] [CrossRef]
- Zhang, Z.; Guo, W.; Li, M.; Yu, W. GIS-supervised building extraction with label noise-adaptive fully convolutional neural network. IEEE Geosci. Remote Sens. Lett. 2020, 17, 2135–2139. [Google Scholar] [CrossRef]
- Xi, M.; Li, J.; He, Z.; Yu, M.; Qin, F. NRN-RSSEG: A deep neural network model for combating label noise in semantic segmentation of remote sensing images. Remote Sens. 2023, 15, 108. [Google Scholar] [CrossRef]
- Kang, J.; Fernandez-Beltran, R.; Kang, X.; Ni, J.; Plaza, A. Noise-tolerant deep neighborhood embedding for remotely sensed images with label noise. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 4, 2551–2562. [Google Scholar] [CrossRef]
- Kang, J.; Fernandez-Beltran, R.; Duan, P.; Kang, X.; Plaza, A.J. Robust normalized softmax loss for deep metric learning-based characterization of remote sensing images with label noise. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8798–8811. [Google Scholar] [CrossRef]
- Dong, R.; Fang, W.; Fu, H.; Gan, L.; Wang, J.; Gong, P. High-resolution land cover mapping through learning with noise correction. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4402013. [Google Scholar] [CrossRef]
- Wang, C.; Shi, J.; Zhou, Y.; Li, L.; Yang, X.; Zhang, T.; Wei, S.; Zhang, X.; Tao, C. Label noise modeling and correction via loss curve fitting for SAR ATR. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5216210. [Google Scholar] [CrossRef]
- Hu, Z.; Gao, K.; Zhang, X.; Wang, J.; Wang, H.; Han, J. Probability differential-based class label noise purification for object detection in aerial images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6509705. [Google Scholar] [CrossRef]
- Cao, Y.; Huang, X. A coarse-to-fine weakly supervised learning method for green plastic cover segmentation using high-resolution remote sensing images. ISPRS J. Photogramm. Remote Sens. 2022, 188, 157–176. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Zhu, Z. Error-tolerant deep Learning for remote sensing image scene classification. IEEE Trans. Cybern. 2021, 51, 1756–1768. [Google Scholar] [CrossRef]
- Wei, W.; Li, W.; Zhang, L.; Wang, C.; Zhang, P.; Zhang, Y. Robust hyperspectral image domain adaptation with noisy labels. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1135–1139. [Google Scholar] [CrossRef]
- Li, Q.; Chen, Y.; Ghamisi, P. Complementary learning-based scene classification of remote sensing images with noisy labels. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8021105. [Google Scholar] [CrossRef]
- Xu, G.; Deng, M.; Sun, G.; Guo, Y.; Chen, J. Improving building extraction by using knowledge distillation to reduce the impact of label noise. Remote Sens. 2022, 14, 5645. [Google Scholar] [CrossRef]
- Xu, G.; Fang, Y.; Deng, M.; Sun, G.; Chen, J. Remote sensing mapping of build-up land with noisy label via fault-tolerant learning. Remote Sens. 2022, 14, 2263. [Google Scholar] [CrossRef]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Annual Conference on Computational Learning Theory (COLT), Madison, WI, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Malach, E.; Shalev-Shwartz, S. Decoupling “when to update” from “how to update”. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 961–971. [Google Scholar]
- Han, B.; Yao, Q.; Yu, X.; Niu, G.; Xu, M.; Hu, W.; Tsang, I.W.; Sugiyama, M. Co-teaching: Robust training of deep neural networks with extremely noisy labels. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montréal, QC, Canada, 3–8 December 2018; pp. 8536–8546. [Google Scholar]
- Yu, X.; Han, B.; Yao, J.; Niu, G.; Tsang, I.W.; Sugiyama, M. How does disagreement help generalization against label corruption? In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 10–15 June 2019; pp. 7164–7173. [Google Scholar]
- Wei, H.; Feng, L.; Chen, X.; An, B. Combating noisy labels by agreement: A joint training method with co-regularization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–18 June 2020; pp. 13726–13735. [Google Scholar]
- Zhang, X.; Song, Q.; Liu, R.; Wang, W.; Jiao, L. Modified co-training with spectral and spatial views for semisupervised hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2044–2055. [Google Scholar] [CrossRef]
- Romaszewski, M.; Głomb, P.; Cholewa, M. Semi-supervised hyperspectral classification from a small number of training samples using a co-training approach. ISPRS J. Photogramm. Remote Sens. 2016, 121, 60–76. [Google Scholar] [CrossRef]
- Zhou, S.; Xue, Z.; Du, P. Semisupervised stacked autoencoder with cotraining for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3813–3826. [Google Scholar] [CrossRef]
- Fang, B.; Chen, G.; Chen, J.; Ouyang, G.; Kou, R.; Wang, L. CCT: Conditional co-training for truly unsupervised remote sensing image segmentation in coastal areas. Remote Sens. 2021, 13, 3521. [Google Scholar] [CrossRef]
- Hu, T.; Huang, X.; Li, J.; Zhang, L. A novel co-training approach for urban land cover mapping with unclear landsat time series imagery. Remote Sens. Environ. 2018, 217, 144–157. [Google Scholar] [CrossRef]
- Jia, D.; Gao, P.; Cheng, C.; Ye, S. Multiple-feature-driven co-training method for crop mapping based on remote sensing time series imagery. Int. J. Remote Sens. 2020, 41, 8096–8120. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, X.; Chen, Z.; Luo, Y.; Yi, J.; Bailey, J. Symmetric cross entropy for robust learning with noisy labels. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 322–330. [Google Scholar]
- Liang, X.; Wu, L.; Li, J.; Wang, Y.; Meng, Q.; Qin, T.; Chen, W.; Zhang, M.; Liu, T.Y. R-Drop: Regularized dropout for neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Virtual, Online, 6–14 December 2021; pp. 10890–10905. [Google Scholar]
- Grupo de Inteligencia Computacional (GIC). Available online: https://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes (accessed on 28 February 2020).
- 2013 IEEE GRSS Data Fusion Contestest. Available online: https://hyperspectral.ee.uh.edu/?page_id=459 (accessed on 31 May 2013).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class No. | Class Name | Train | Test | Total |
|---|---|---|---|---|
| 1 | Brocoli_green_weeds_1 | 201 | 1808 | 2009 |
| 2 | Brocoli_green_weeds_2 | 373 | 3353 | 3726 |
| 3 | Fallow | 198 | 1778 | 1976 |
| 4 | Fallow_rough_plow | 139 | 1255 | 1394 |
| 5 | Fallow_smooth | 268 | 2410 | 2678 |
| 6 | Stubble | 396 | 3563 | 3959 |
| 7 | Celery | 358 | 3221 | 3579 |
| 8 | Grapes_untrained | 1127 | 10144 | 11271 |
| 9 | Soil_vinyard_develop | 620 | 5583 | 6203 |
| 10 | Corn_senesced_green_weeds | 328 | 2950 | 3278 |
| 11 | Lettuce_romaine_4wk | 107 | 961 | 1068 |
| 12 | Lettuce_romaine_5wk | 193 | 1734 | 1927 |
| 13 | Lettuce_romaine_6wk | 92 | 824 | 916 |
| 14 | Lettuce_romaine_7wk | 107 | 963 | 1070 |
| 15 | Vinyard_untrained | 727 | 6541 | 7268 |
| 16 | Vinyard_vertical_trellis | 181 | 1626 | 1807 |
| Class No. | Class Name | Train | Test | Total |
|---|---|---|---|---|
| 1 | Healthy grass | 125 | 1126 | 1251 |
| 2 | Stressed grass | 125 | 1129 | 1254 |
| 3 | Stressed grass | 70 | 627 | 697 |
| 4 | Trees | 124 | 1120 | 1244 |
| 5 | Soil | 124 | 1118 | 1242 |
| 6 | Water | 33 | 292 | 325 |
| 7 | Residential | 127 | 1141 | 1268 |
| 8 | Commercial | 124 | 1120 | 1244 |
| 9 | Road | 125 | 1127 | 1252 |
| 10 | Highway | 123 | 1104 | 1227 |
| 11 | Railway | 124 | 1111 | 1235 |
| 12 | Parking Lot 1 | 123 | 1110 | 1233 |
| 13 | Parking Lot 2 | 47 | 422 | 469 |
| 14 | Tennis Court | 43 | 385 | 428 |
| 15 | Running Track | 66 | 594 | 660 |
| Class No. | Class Name | Train | Test | Total |
|---|---|---|---|---|
| 1 | Scrub | 76 | 685 | 761 |
| 2 | Willow swamp | 24 | 219 | 243 |
| 3 | Cabbage palm hammock | 26 | 230 | 256 |
| 4 | Cabbage palm/oak hammock | 25 | 227 | 252 |
| 5 | Slash pine | 16 | 145 | 161 |
| 6 | Oak/broadleafhammock | 23 | 206 | 229 |
| 7 | Hardwood swamp | 11 | 94 | 105 |
| 8 | Graminoid marsh | 43 | 388 | 431 |
| 9 | Spartina marsh | 52 | 468 | 520 |
| 10 | Cattail marsh | 40 | 364 | 404 |
| 11 | Salt marsh | 42 | 377 | 419 |
| 12 | Mud flats | 50 | 453 | 503 |
| 13 | Water | 93 | 834 | 927 |
| Data Sets | SV | HOU | KSC | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Loss | CE | SCE | R-Drop | Proposed | CE | SCE | R-Drop | Proposed | CE | SCE | R-Drop | Proposed |
| OA | 93.21 | 95.26 | 95.38 | 98.62 | 84.75 | 86.35 | 87.11 | 90.89 | 95.58 | 97.28 | 97.45 | 99.02 |
| AA | 92.35 | 95.14 | 95.78 | 98.73 | 84.54 | 85.92 | 86.87 | 90.94 | 95.43 | 96.87 | 97.14 | 98.50 |
| k × 100 | 91.95 | 95.08 | 95.46 | 98.47 | 84.39 | 86.11 | 86.94 | 90.11 | 95.17 | 97.05 | 97.23 | 98.91 |
| Class | RLPA [15] | DPNLD [12] | SALP [17] | DCRN [20] | S3Net [21] | 2D-ADCL |
|---|---|---|---|---|---|---|
| 1 | 97.75 | 98.48 | 99.83 | 99.70 | 99.50 | 99.99 |
| 2 | 99.14 | 99.75 | 99.80 | 99.78 | 99.35 | 99.86 |
| 3 | 96.56 | 97.07 | 99.55 | 92.73 | 98.31 | 99.78 |
| 4 | 89.88 | 99.69 | 99.53 | 99.64 | 99.64 | 98.86 |
| 5 | 94.28 | 96.84 | 96.61 | 88.23 | 96.73 | 97.18 |
| 6 | 97.47 | 98.74 | 97.83 | 98.94 | 94.54 | 97.19 |
| 7 | 98.11 | 99.20 | 99.44 | 99.78 | 99.80 | 99.80 |
| 8 | 72.88 | 79.39 | 78.50 | 88.45 | 94.06 | 98.20 |
| 9 | 97.35 | 99.02 | 98.79 | 95.32 | 94.28 | 99.43 |
| 10 | 78.91 | 87.22 | 92.60 | 96.33 | 93.28 | 97.19 |
| 11 | 90.94 | 91.84 | 96.81 | 96.03 | 95.35 | 98.34 |
| 12 | 97.43 | 99.62 | 99.02 | 94.62 | 91.53 | 99.89 |
| 13 | 97.32 | 97.43 | 98.33 | 97.46 | 98.88 | 98.52 |
| 14 | 93.17 | 94.95 | 94.17 | 93.30 | 96.11 | 97.36 |
| 15 | 74.99 | 69.92 | 77.71 | 91.76 | 96.69 | 98.03 |
| 16 | 94.15 | 98.30 | 98.59 | 99.98 | 99.39 | 100 |
| OA | 87.77 | 90.01 | 91.16 | 94.31 | 96.04 | 98.62 |
| AA | 91.90 | 94.22 | 94.58 | 95.76 | 96.72 | 98.73 |
| k × 100 | 86.41 | 88.87 | 90.17 | 93.68 | 95.59 | 98.47 |
| Class | RLPA [15] | DPNLD [12] | SALP [17] | DCRN [20] | S3Net [21] | 2D-ADCL |
|---|---|---|---|---|---|---|
| 1 | 90.21 | 93.47 | 90.66 | 95.09 | 95.16 | 98.05 |
| 2 | 96.99 | 98.53 | 91.78 | 98.54 | 97.68 | 98.83 |
| 3 | 92.67 | 88.42 | 97.77 | 98.02 | 97.24 | 97.69 |
| 4 | 91.72 | 92.46 | 91.80 | 96.27 | 96.85 | 97.16 |
| 5 | 93.76 | 95.80 | 95.40 | 96.53 | 98.09 | 98.12 |
| 6 | 83.65 | 94.44 | 92.47 | 95.29 | 91.59 | 98.59 |
| 7 | 82.92 | 76.63 | 80.75 | 84.47 | 85.50 | 92.22 |
| 8 | 68.36 | 63.92 | 68.68 | 78.68 | 82.20 | 86.47 |
| 9 | 73.19 | 79.95 | 77.81 | 77.19 | 84.87 | 83.25 |
| 10 | 71.76 | 78.33 | 74.35 | 87.71 | 85.29 | 89.84 |
| 11 | 68.79 | 58.30 | 70.19 | 78.18 | 84.74 | 81.70 |
| 12 | 27.79 | 45.45 | 58.08 | 71.90 | 81.59 | 79.11 |
| 13 | 25.88 | 23.16 | 38.30 | 44.73 | 36.57 | 66.27 |
| 14 | 92.05 | 96.10 | 89.37 | 97.62 | 98.13 | 98.35 |
| 15 | 82.76 | 95.16 | 97.60 | 96.85 | 95.55 | 98.32 |
| OA | 76.63 | 78.69 | 80.86 | 86.67 | 88.62 | 90.89 |
| AA | 76.17 | 78.68 | 81.00 | 86.47 | 87.40 | 90.94 |
| k × 100 | 74.74 | 76.95 | 79.30 | 85.56 | 87.69 | 90.11 |
| Class | RLPA [15] | DPNLD [12] | SALP [17] | DCRN [20] | S3Net [21] | 2D-ADCL |
|---|---|---|---|---|---|---|
| 1 | 97.50 | 96.98 | 97.90 | 98.82 | 99.47 | 99.21 |
| 2 | 84.77 | 91.77 | 93.42 | 95.47 | 97.94 | 97.94 |
| 3 | 90.33 | 90.23 | 94.14 | 96.88 | 97.66 | 100 |
| 4 | 70.24 | 76.98 | 87.30 | 88.10 | 94.44 | 97.62 |
| 5 | 59.63 | 65.22 | 77.02 | 86.90 | 91.30 | 93.79 |
| 6 | 51.97 | 64.63 | 80.35 | 95.24 | 88.65 | 94.76 |
| 7 | 92.38 | 74.29 | 95.24 | 99.07 | 100 | 100 |
| 8 | 84.69 | 90.22 | 95.13 | 98.85 | 98.61 | 98.84 |
| 9 | 91.92 | 93.46 | 97.50 | 99.01 | 99.04 | 99.81 |
| 10 | 86.14 | 95.43 | 96.78 | 98.97 | 97.77 | 99.01 |
| 11 | 97.18 | 98.57 | 99.28 | 99.05 | 99.69 | 99.76 |
| 12 | 90.66 | 93.84 | 96.82 | 98.41 | 99.81 | 99.80 |
| 13 | 99.75 | 99.76 | 99.89 | 99.89 | 100 | 100 |
| OA | 89.20 | 91.86 | 95.53 | 97.35 | 98.16 | 99.02 |
| AA | 84.40 | 87.01 | 93.14 | 95.73 | 97.19 | 98.50 |
| k × 100 | 87.95 | 90.93 | 95.02 | 97.05 | 97.95 | 98.91 |
| Time (s) | SV | HOU | KSC |
|---|---|---|---|
| RLPA [15] | 85.8 | 55.3 | 19.5 |
| DPNLD [12] | 65.5 | 41.3 | 26.5 |
| SALP [17] | 113.6 | 46.5 | 28.5 |
| DCRN [20] | 148.8 | 91.4 | 45.3 |
| S3Net [21] | 161.7 | 116.8 | 48.7 |
| 2D-ADCL | 178.1 | 130.4 | 55.4 |
| Data Sets | SV | HOU | KSC | |||
|---|---|---|---|---|---|---|
| Method | 2D-DCL | 2D-ADCL | 2D-DCL | 2D-ADCL | 2D-DCL | 2D-ADCL |
| OA | 95.64 | 97.20 | 86.15 | 88.51 | 96.25 | 97.82 |
| AA | 95.82 | 97.34 | 86.44 | 88.43 | 95.74 | 97.14 |
| k × 100 | 95.23 | 97.11 | 86.29 | 88.31 | 95.82 | 97.25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Sun, J.; Shi, H.; Ge, Z.; Yu, Q.; Cao, G.; Li, X. Agreement and Disagreement-Based Co-Learning with Dual Network for Hyperspectral Image Classification with Noisy Labels. Remote Sens. 2023, 15, 2543. https://doi.org/10.3390/rs15102543
Zhang Y, Sun J, Shi H, Ge Z, Yu Q, Cao G, Li X. Agreement and Disagreement-Based Co-Learning with Dual Network for Hyperspectral Image Classification with Noisy Labels. Remote Sensing. 2023; 15(10):2543. https://doi.org/10.3390/rs15102543
Chicago/Turabian StyleZhang, Youqiang, Jin Sun, Hao Shi, Zixian Ge, Qiqiong Yu, Guo Cao, and Xuesong Li. 2023. "Agreement and Disagreement-Based Co-Learning with Dual Network for Hyperspectral Image Classification with Noisy Labels" Remote Sensing 15, no. 10: 2543. https://doi.org/10.3390/rs15102543