1. Introduction
Change detection (CD) using remote sensing (RS) technology enables the identification and quantitative analysis of changes that occur in a given geographical area by comparing images captured at different times [
1,
2,
3]. With the advent of very high resolution (VHR) aerial and satellite imagery, we can now acquire intricate spatial information and identify subtle alterations, particularly in urban buildings, which are essential elements of cities. Building change detection is essential for numerous applications, including urban planning, disaster assessment, and the identification of illegal construction [
4,
5,
6,
7]. Given the continuous attention it has received, this technology can provide valuable insights into urban expansion and development.
In recent years, there has been a growing trend toward employing neural network techniques and components, typically used for scene segmentation, in change detection tasks. Several prominent methods, such as FC-EF, FC-Siam-conc, and FC-Siam-diff [
8], have been proposed using the U-Net architecture to extract powerful change detection representations, establishing a benchmark in the field. The Siamese network structure has gained popularity as a framework for change detection tasks. To further enhance change detection performance, some studies [
9,
10,
11] have concentrated on improving feature extraction to better describe changes and suppress pseudo-changes. In designing more effective change detection representations, various techniques, such as pyramid models, deep supervision, spatial and channel attention, and others, are often considered. These methods aim to boost the feature extraction efficiency and accuracy by employing multi-scale analysis, attention mechanisms, and advanced training strategies. However, these intricate feature extraction structures or methods increase the complexity of change detection models, which rely on the volume of training data [
12,
13]. Thus, a large, diverse, and class-balanced training dataset can effectively improve the performance of change detection models.
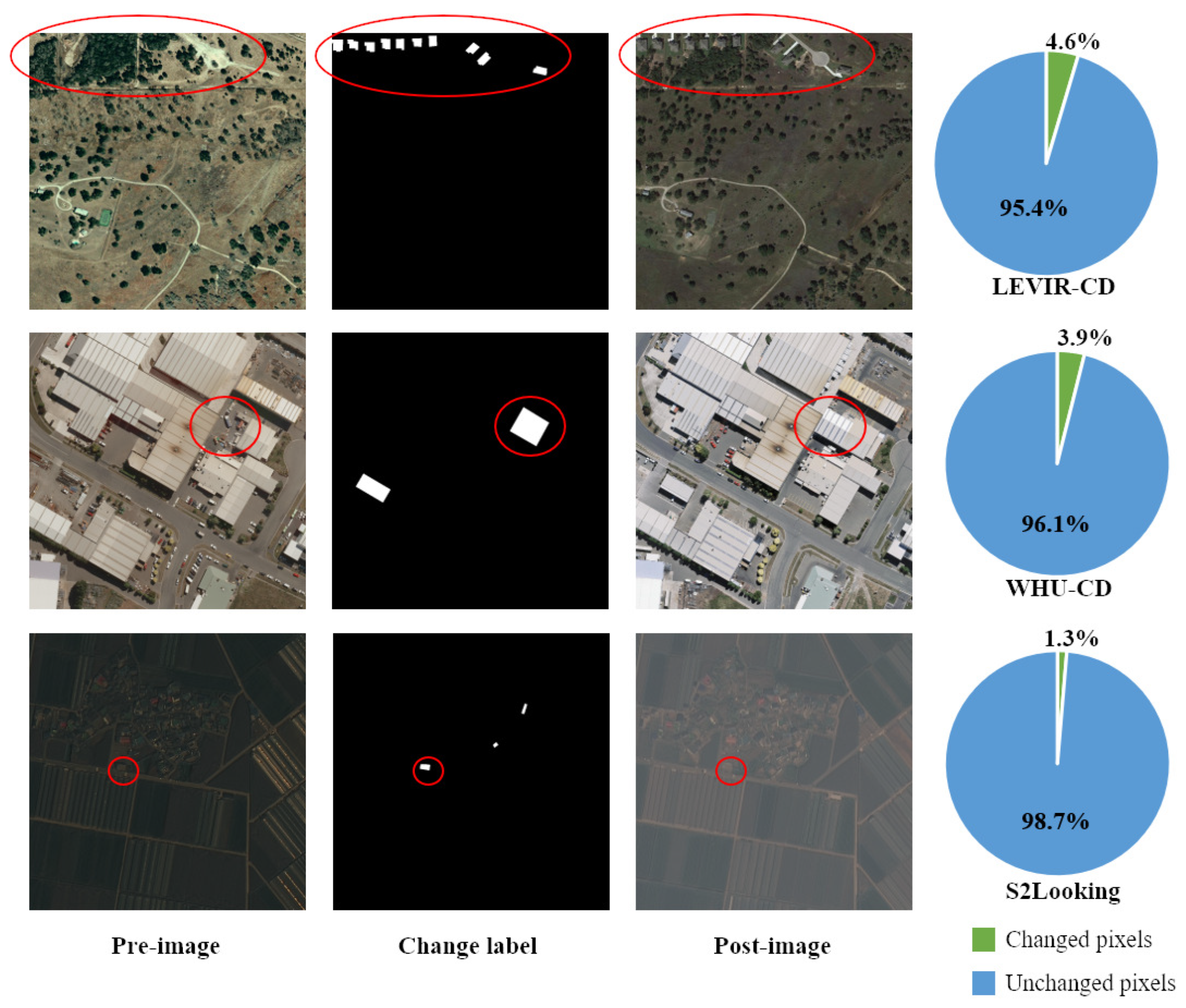
However, obtaining a large dataset of bitemporal remote sensing image pairs containing diverse building changes is challenging. Firstly, it is difficult to collect large-scale bitemporal image pairs due to the inconsistency between the occurrence of building changes and satellite observation periods. Furthermore, high-precision building change detection relies on labor-intensive and time-consuming pixel-level labeling with a limited amount of available data. Secondly, existing change detection datasets typically cover only a small area and limited historical observation time, which result in a lack of diversity in bitemporal image pairs. Thirdly, building changes typically occur at a low frequency. As demonstrated in
Figure 1, compared to the unchanged regions, the changed regions generally comprise a significantly smaller number of pixels, resulting in a severe class imbalance between the changed and unchanged classes. Sliding-window-based detectors often encounter a substantial class imbalance between the background and target building changes. In some instances, the number of background windows can be up to
times higher than the number of target windows [
14]. For LEVIR-CD [
10], which is commonly used for building change detection, the building change samples are sparsely distributed. After the original images are cut into
patches, it contains 7120 bitemporal image pairs, but only 3167 of them contain change information, and the others are all unchanged images. Moreover, in the 3167 changed bitemporal image pairs, the proportion of changed pixels in the total image pixels is mostly less than
. Such a class imbalance phenomenon will lead to the convergence process of the change detection model being biased toward unchanged samples, resulting in false alarms and missed detections, thereby degrading the performance of change detection.
The challenges of limited training sample pairs and class-imbalanced data are significant obstacles for building change detection models. Directly training a change detection model on such datasets may result in overfitting to specific types of changes and limit the model’s generalization capabilities. Furthermore, the class-imbalance issue renders accuracy an unreliable performance metric, as high training metrics for change detection models may not be applicable to images with different building appearances or image conditions in new geographical areas. One approach to address these issues is to develop a method for generating data that focuses on the fundamental problem: the dataset itself. This method posits that generating additional data may enable the extraction of more information from the original dataset and help mitigate overfitting. Expanding the training data and rebalancing the classes would provide a larger and more diverse set of examples for the model to learn from. This would aid the model in better comprehending the spectrum of potential inputs it may encounter during testing, ultimately resulting in enhanced performance when faced with novel, previously unseen data. In essence, by making the training set more comprehensive, we can reduce the gap between the training set and future testing sets, leading to the improved generalization performance of the model.
Typically, data generation methods can be categorized into two primary approaches: traditional transformation-based techniques [
15,
16,
17] and GAN-based methods [
18,
19,
20,
21]. Traditional transformation-based methods include rotation, mirror image, horizontal flipping, random cropping, and the addition of noise to existing training samples [
15,
16]. This strategy is usually used to perform inpainting and copy and paste on a single temporal image to generate a new, changed temporal image, resulting in a pair of new bitemporal images [
17]. Nonetheless, these approaches merely reorganize the original datasets without effectively enhancing their richness. Moreover, various GAN-based methods have been proposed to generate changed samples, such as buildings or cars, within the original image pairs. One approach is to use GAN-generated image patches, as seen in work by Kumdakci et al. [
18]. Another method involves unsupervised CycleGAN for style transfer, as demonstrated by Jiang et al. [
19]. To address the shortcomings of existing datasets, Rui et al. [
20] developed mask-guided image generation models by employing GANs to create disaster remote sensing images featuring various disaster types and distinct building damages. Furthermore, Chen et al. [
21] introduced an instance-level image generation model, termed instance-level change augmentation (IAug), capable of generating bitemporal images with numerous building changes. Although there are some methods for change detection data generation, these approaches have some limitations. Some involve several independent steps and require significant human intervention, making them less intelligent. Other methods rely solely on style transfer, and the generated sample pairs contain no new building instances, so they cannot address the issue of class imbalance mentioned before. Although some methods can generate entirely new building-instance-level changes, they may not produce building instances that look like real enough, or they may not reflect the actual distribution of buildings in the real world, which can be considered another type of unreality. Furthermore, most methods do not consider the importance of background pseudo-change generation for improving the data diversity.
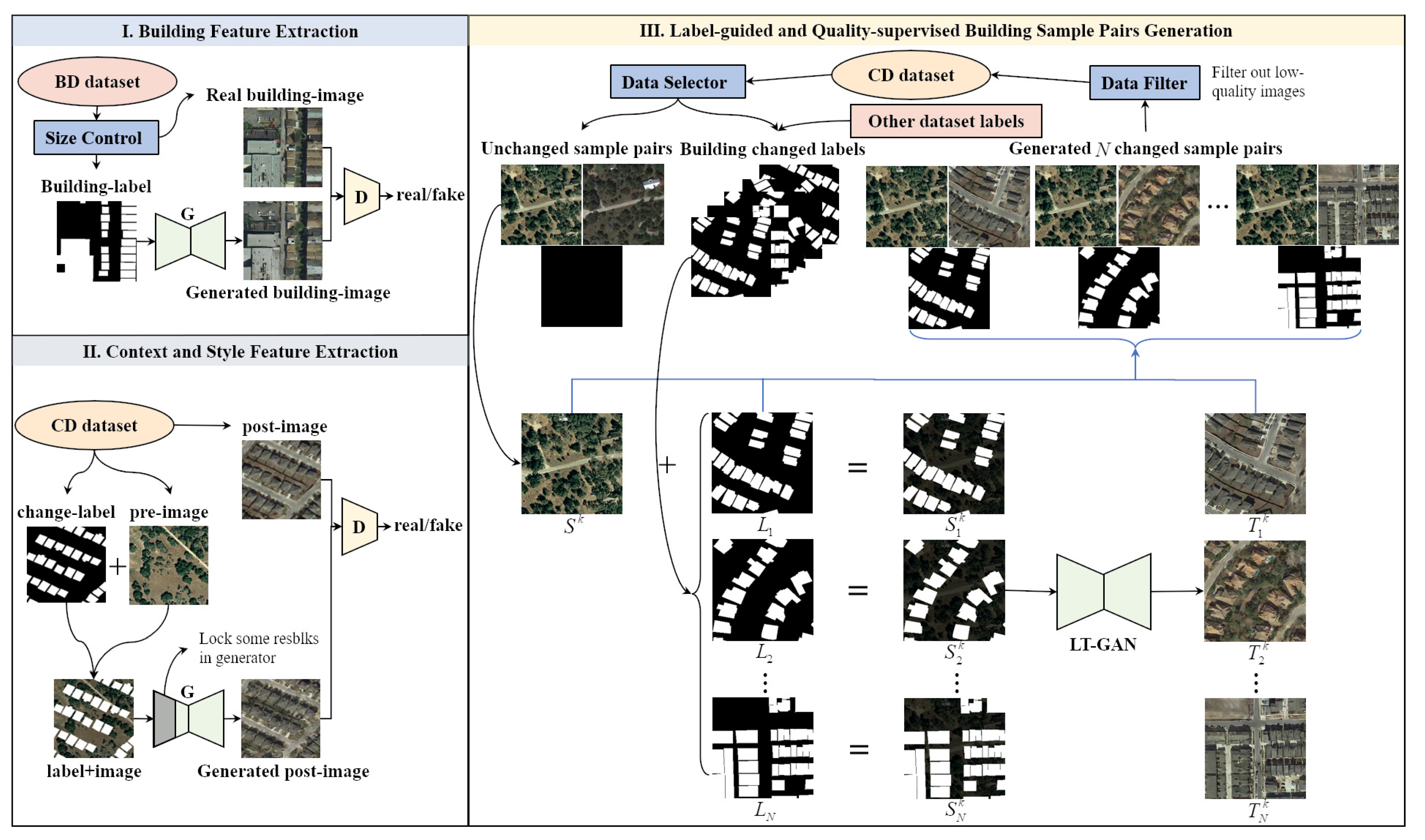
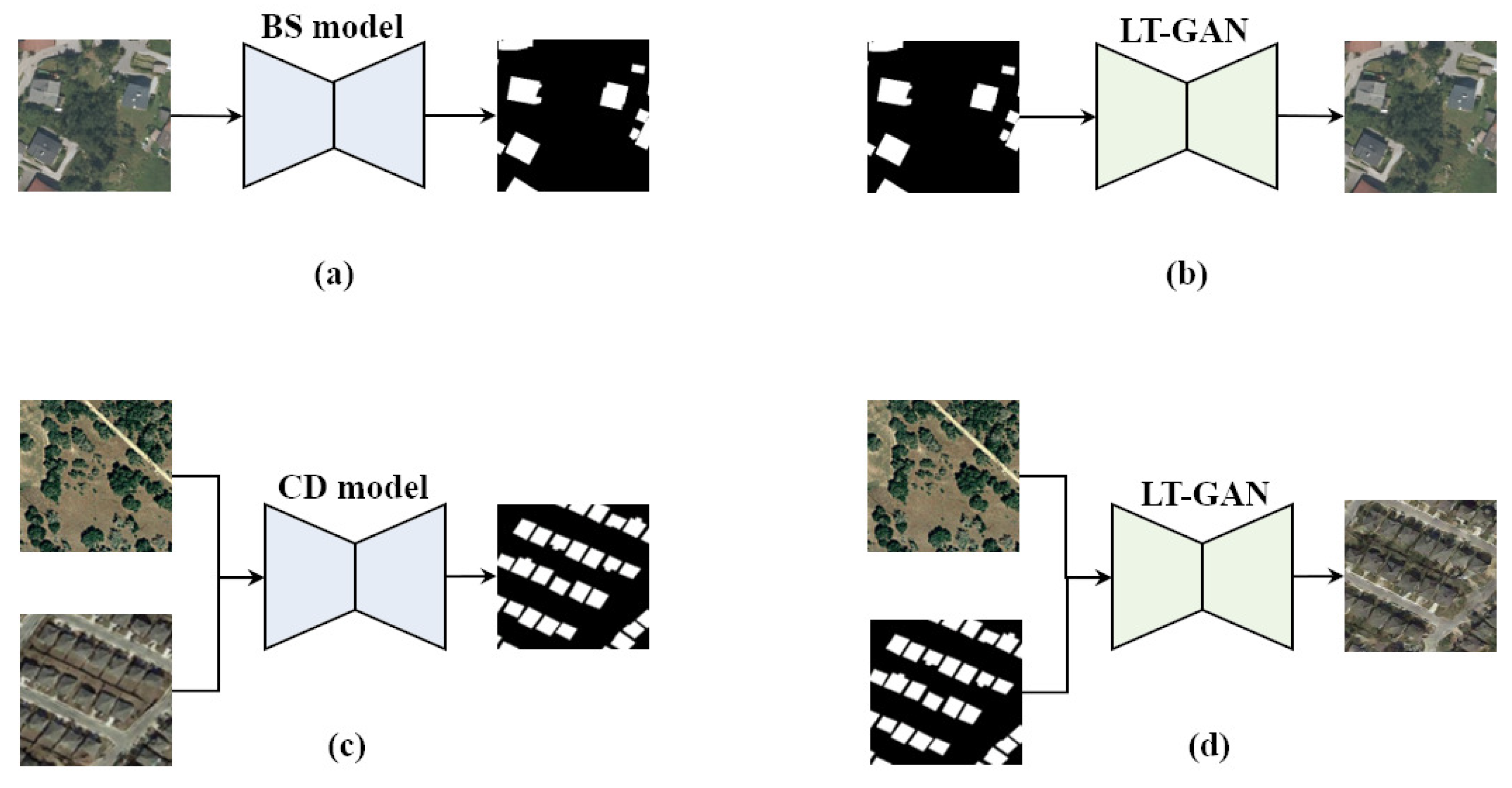
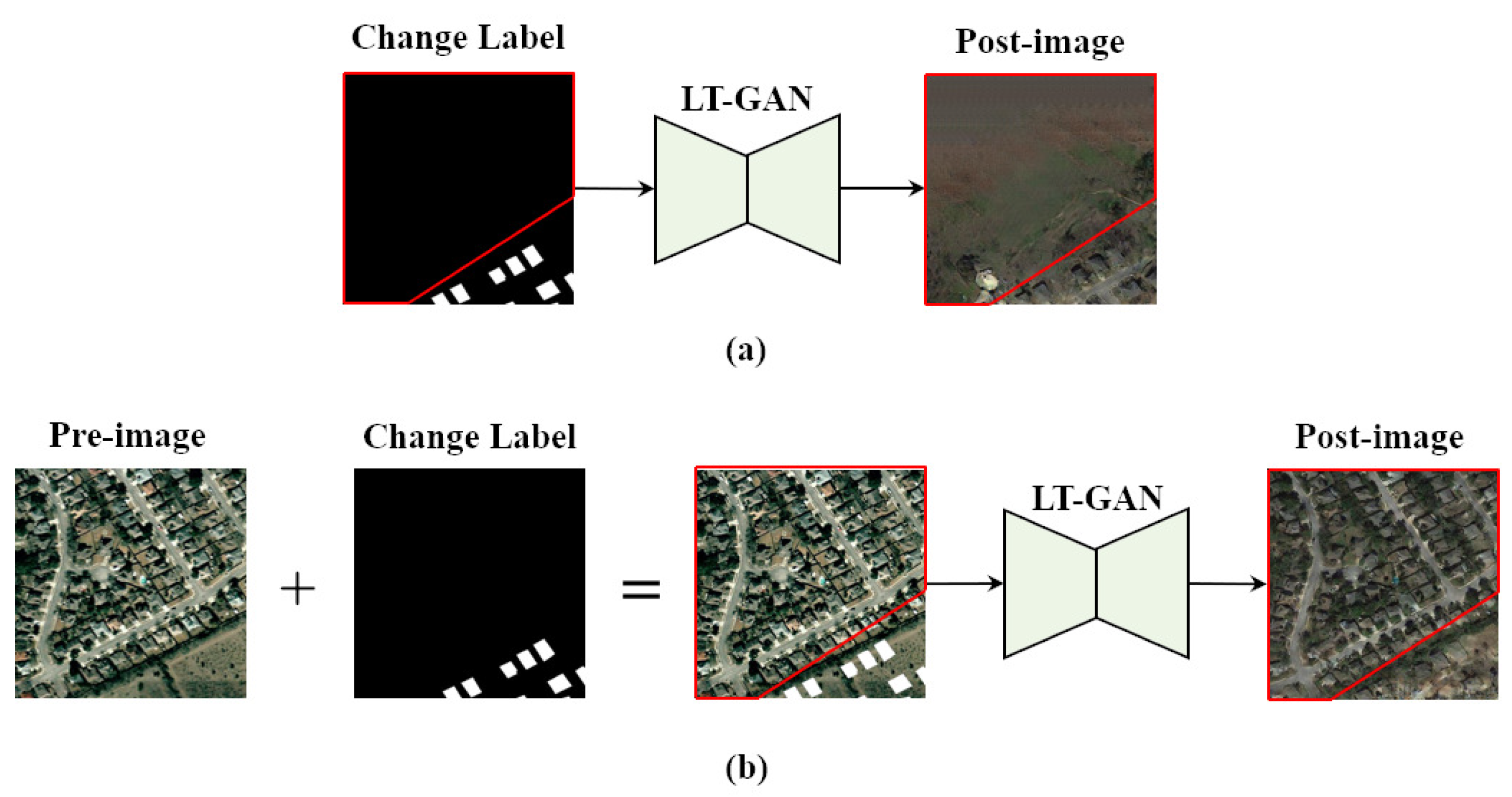
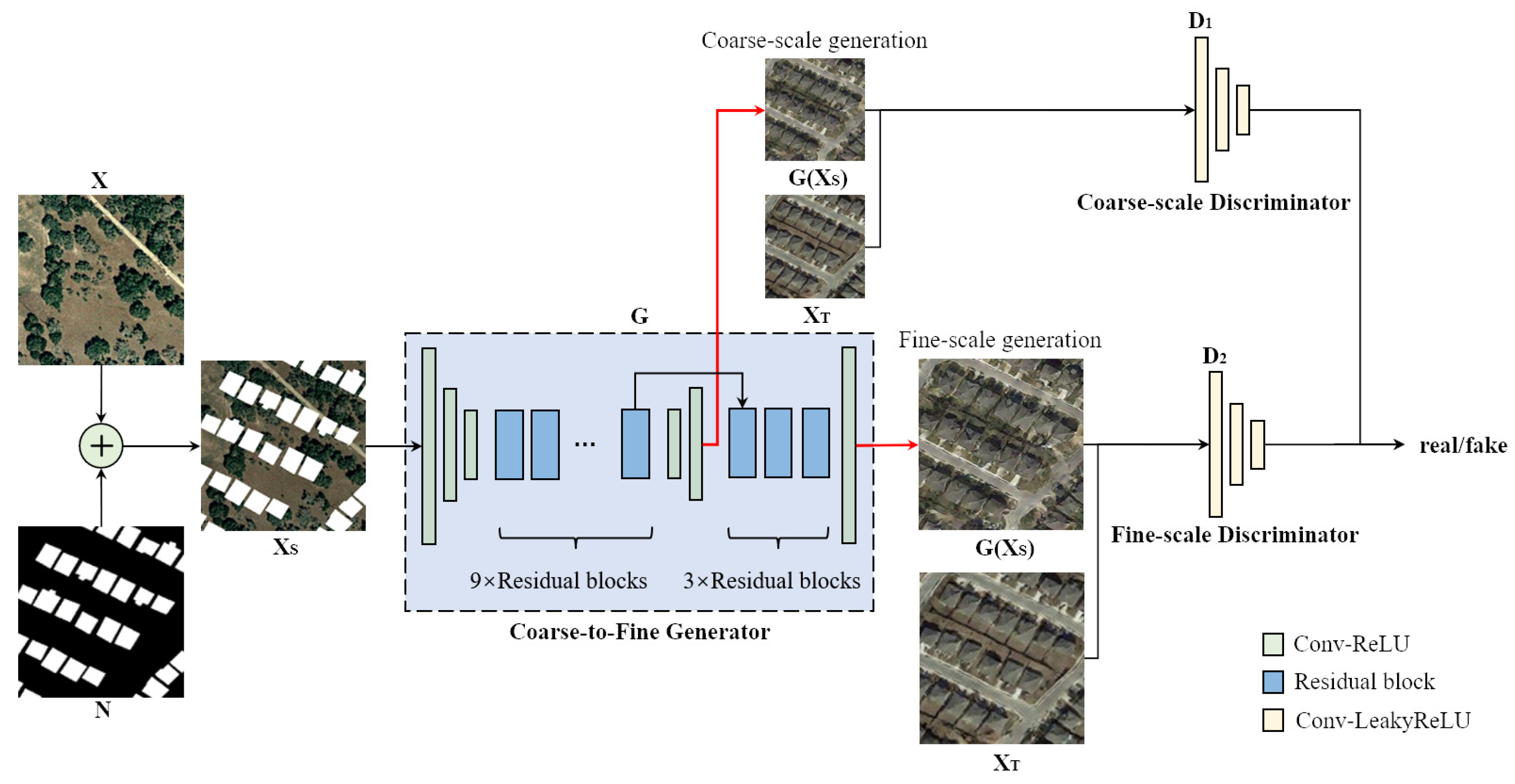
In this paper, we introduce a novel multi-temporal sample pair generation technique called Image-level Sample Pair Generation (ISPG) to enhance the building change detection performance. Our approach focuses on generating bitemporal sample pairs that include new types of building changes and pseudo-changes in the background. This addresses the challenges of limited data volume and severe class-imbalance issues. In order to simplify image generation and make it smarter, we did not design any color transfer or context-blending steps for properly pasting building instances into the original images but chose to design a Label Translation GAN (LT-GAN), which is a kind of Semantic Image Synthesis (SIS) technology, to realize the complete image-to-image translation between the building change labels and one of the bitemporal image pairs.
Since building change detection datasets suffer from limited data volume and class imbalance, these issues also affect the LT-GAN training process. Furthermore, LT-GAN is a data-hungry model that requires more paired data for training, making it unsuitable for direct training on change detection datasets. Fortunately, building segmentation datasets exhibit better class balance compared to building change detection datasets. This is because building changes necessitate time-period accumulation and are relatively low-probability events, whereas all existing buildings are labeled in building segmentation datasets. We can leverage this aspect to pretrain the encoder–decoder of LT-GAN and perform image-to-image translation with a greater number of building instances. With our sample pair generation strategy, LT-GAN extracts not only building detail features but also semantically related context features on other building segmentation datasets and then uses the change detection dataset to generate new sample pairs with abundant and diverse building changes with related pseudo-changes. To be specific, we use building change labels selected from the original dataset with any one of unchanged bitemporal sample pairs in the original dataset to generate other temporal images. On the other hand, LT-GAN can also generate semantically related instance-level pseudo-changes, such as roads and concrete floors, and style-level pseudo-changes, which help to improve the diversity of the generated data. Then, the generated images with more building changes form a series of class-balanced sample pairs. It is worth noting that different combinations of building change labels and unchanged sample pairs in the original dataset result in different new sample pairs with diverse and abundant building changes and pseudo-changes, so ISPG would greatly enrich the number and diversity of the original dataset and reduce the impact of the class-imbalance issue.
Compared with natural-scene images, remote sensing images are more complex, with various shapes and types of objects, different sizes, and various distributions. Therefore, building changes may appear at any scale and in any background. In order to generate various buildings and pseudo-changes and to ensure that the differently scaled objects generated have sufficient details to look realistic, LT-GAN adopts a coarse-to-fine generator with two discriminators at different supervision scales, which are the coarse scale and fine scale, to supervise remote sensing image generation. The coarse-scale discriminator with the largest receptive field would have better control over the global image generated, while the fine-scale discriminator with a smaller receptive field has better control over the image details. Different from the traditional GAN with one pair of a generator and discriminator, we use multi-scale adversarial loss (MAL) to train one generator with two discriminators at two scales of images. Conversely, to stabilize the adversarial generation training process for intricate and detailed building changes and pseudo-changes, we also employ feature matching loss (FML). This loss function helps suppress mode collapse during adversarial training and further enhances the quality of the generated sample pairs. Specifically, we extract feature representations from different layers for the two discriminators and calculate the loss function by comparing the feature differences between generated images and real images.
The primary contributions of this study can be summarized as follows:
- (1)
We propose Image-level Sample Pair Generation (ISPG), which is applicable to building change detection datasets. To address the class-imbalance problem and expand the dataset, we leverage other labels with numerous building changes to introduce changes to the abundant unchanged sample pairs. Utilizing LT-GAN, we achieve image-to-image translation between labels and remote sensing images, thereby mitigating the impact of class imbalance.
- (2)
We designed a GAN, namely, Label Translation GAN (LT-GAN), to efficiently synthesize new remote sensing images that contain changes involving numerous and diverse building changes and instance-level or style-level pseudo-changes in the background, which can improve the data diversity. Based on MAL and FML, it can generate complete and detailed remote sensing images end-to-end without manually editing or blending buildings into the background.
- (3)
The method introduced in this paper offers a simple yet effective solution to the data scarcity problem in change detection. Our method and several existing CD methods were used for data augmentation on LEVIR-CD [
10] and WHU-CD [
22], obtaining better performance than the original dataset. Even the simplest change detection model with less raw data can achieve a performance better than or equal to state-of-the-art (SOTA) models. This plug-and-play solution has the potential to accelerate the development of the field of change detection by allowing researchers to work with smaller datasets and still achieve high accuracy.
5. Discussion
Based on LEVIR-CD [
10] and WHU-CD [
22], we constructed several synthesized training sets with varying imbalance ratios by using different hyperparameters
N in ISPG. We define the imbalance ratio as the proportion of the number of pixels belonging to the unchanged class to the number of pixels in the changed class. The imbalance ratios of the original training sets and the corresponding synthesized training sets in LEVIR-CD [
10] and WHU-CD [
22] are listed in
Table 6.
The quantitative results of different hyperparameters
N in LEVIR-CD [
10] are listed in
Table 7, and those in WHU-CD [
22] are listed in
Table 8. The change detection model used is FC-Siam-Conc [
8]. Visual comparisons of LEVIR-CD’s [
10] and WHU-CD’s [
22] change detection results after using different hyperparameters
N of ISPG are shown in
Figure 13 and
Figure 14, respectively.
From
Table 7 and
Table 8, it can be seen that by increasing the value of the hyperparameter
N in the ISPG method, the imbalance ratio of the training set gradually decreases and the performance of the change detection model improves as the amount of data used varies (5%, 20%, and 100%) in different datasets (LEVIR-CD [
10] and WHU-CD [
22]). This indicates that ISPG can effectively reduce class imbalance in the dataset and that class imbalance in the dataset greatly affects the performance of the change detection model. When using 5% and 20% of the data, there are fewer imbalanced sample pairs in the dataset, so using ISPG with
or
leads to similar performance improvements. However, when using 100% of the data, there is a severe class-imbalance issue, so using ISPG with
results in a more significant performance improvement compared to using
. This further demonstrates the effectiveness of ISPG in addressing the problem of imbalanced building change detection datasets.
It should also be noted that when the dataset is very limited, such as when only 5% of the original data are used, the performance of ISPG with the hyperparameter is lower than that with or . This may be due to the limited building change labels used in ISPG, resulting in too many identical distributions of buildings being generated. To further improve the diversity of data augmentation using ISPG in extremely limited datasets, it is suggested to consider introducing change labels from other datasets to generate different distributions of building instances.
Conversely, when the dataset is more sufficient, such as when 100% of the original data are used, the hyperparameter N in ISPG can be increased to fully unleash its data augmentation performance. At this time, the different ways of combining change labels and unchanged image pairs in the third step of ISPG will increase exponentially, and more effective generated image pairs can be obtained to improve the model performance.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}