
Cross-Viewpoint Template Matching Based on Heterogeneous Feature Alignment and Pixel-Wise Consensus for Air- and Space-Based Platforms

Abstract
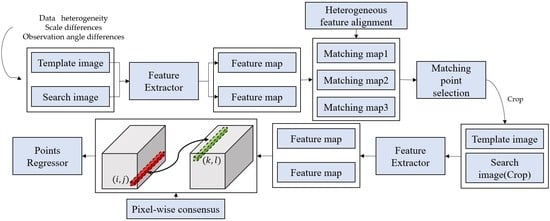
:
1. Introduction
- (1)
- Data heterogeneity between template and search images;
- (2)
- Scale differences between template and search images;
- (3)
- Observation angle differences between template and search images.
- (1)
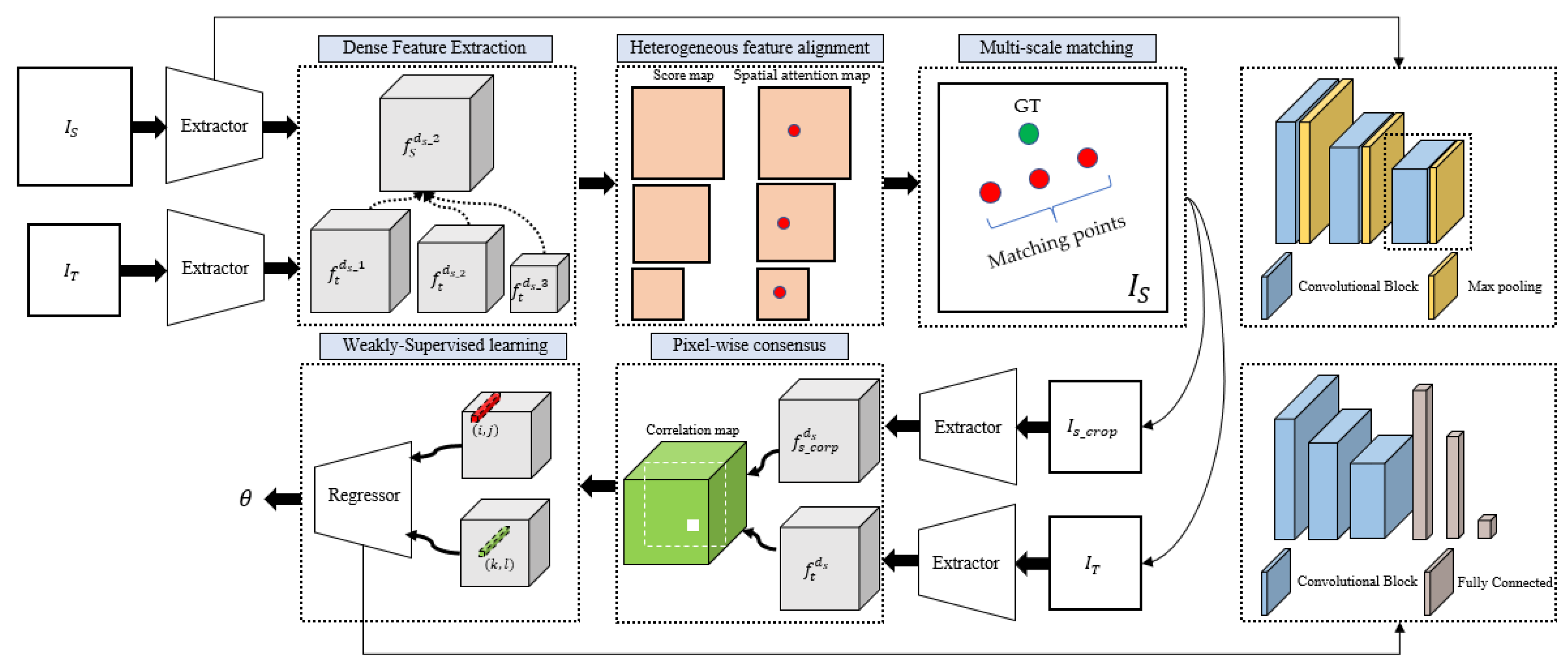
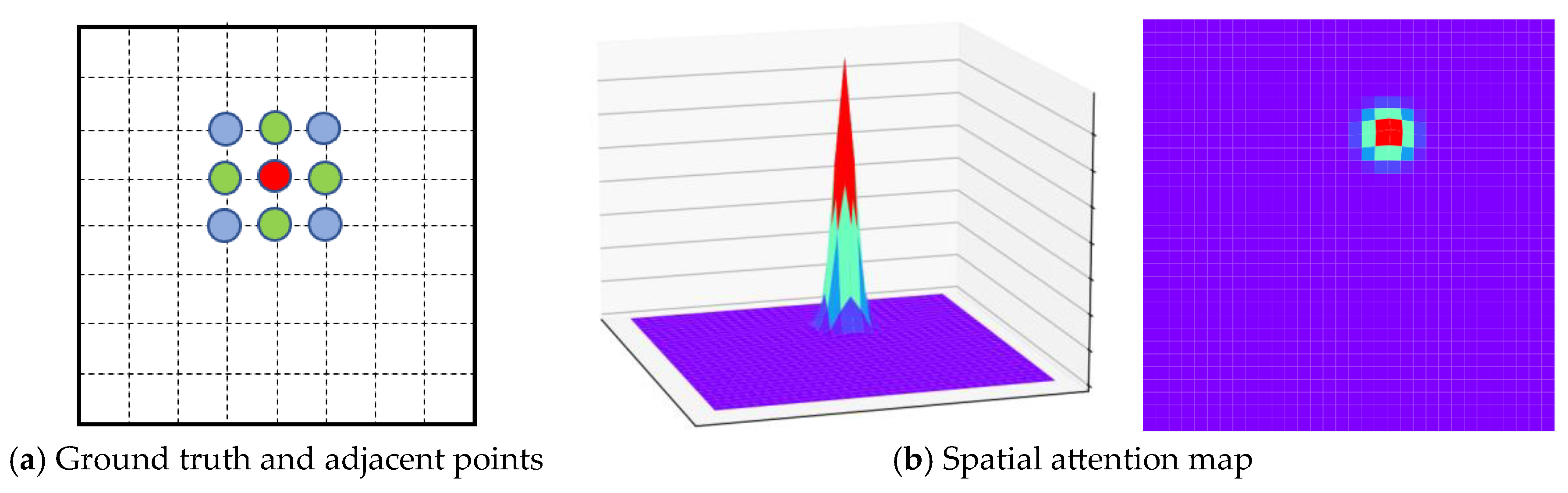
- We propose a heterogeneous feature alignment method, aimed at addressing the problem of data heterogeneity between template and search images caused by sensor distances. Our approach utilizes the Siamese FC [23] as the main model for image matching and addresses domain shift issues by introducing a spatial attention map based on a 2D Gaussian distribution. This method forms an adaptive spatial activation using the 2D Gaussian distribution, which dynamically adjusts the weight of positive and negative samples in the loss function. This allows for convergence during training, reducing the distribution distance between heterogeneous features and enabling the model to better learn regional features for matching template and search images.
- (2)
- We propose a multi-scale matching method aimed at solving the problem of scale differences between search images and template images caused by observation distances. The template images provided by satellite are usually fixed, while the search images provided by aerial platforms vary with flight trajectories. Therefore, we propose a multi-scale matching method based on multi-level sub-sampling comparison. We extract feature maps of the template images at different sub-sampling levels of the model, respectively match them with the search images, obtain matching points, and determine the optimal matching points by comparing the Euclidean distance between each matching point and the ground truth.
- (3)
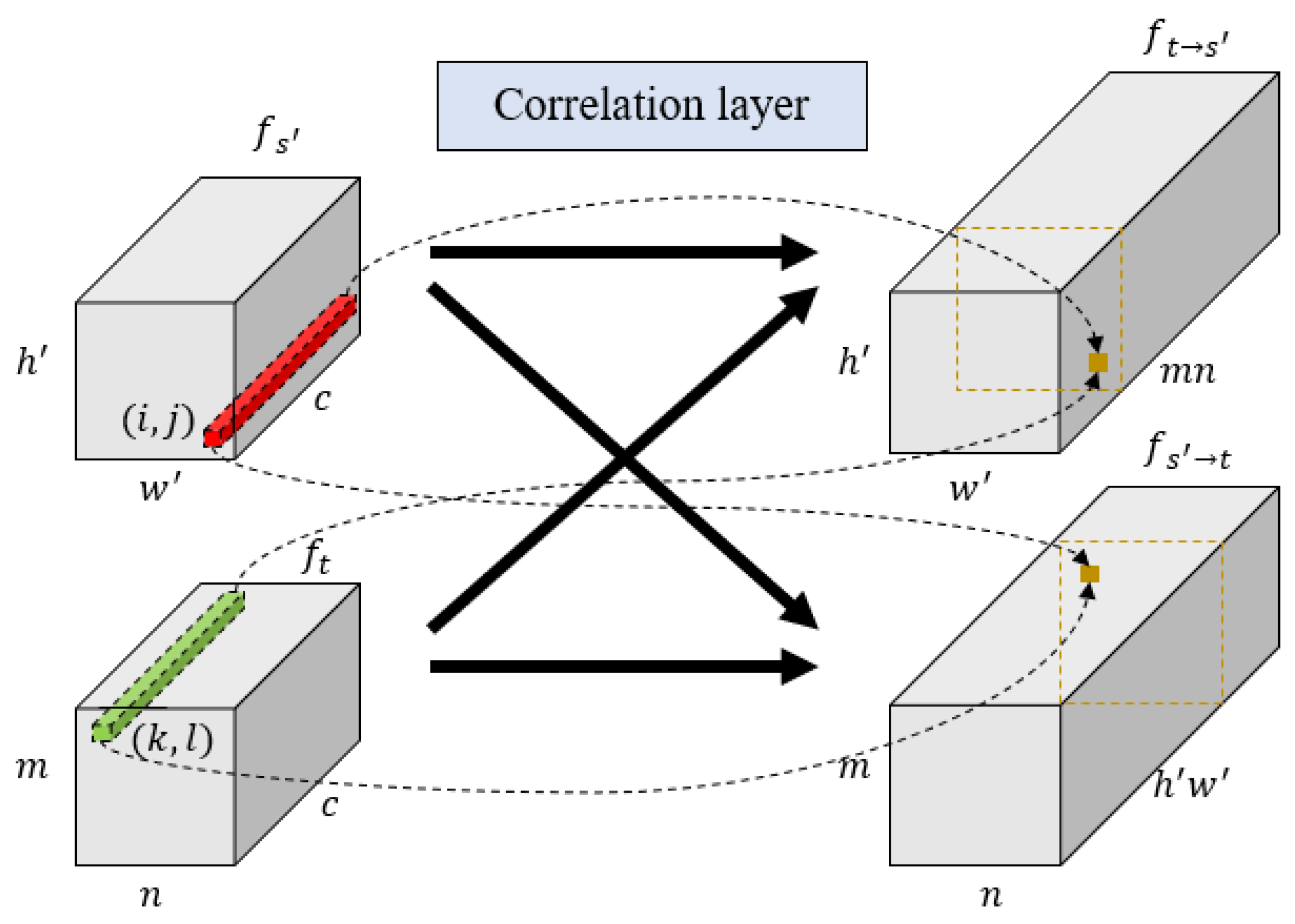
- We proposed a pixel-wise consensus method aimed at addressing the problem of viewpoint differences between template and search images caused by different observation angles. After applying the two aforementioned methods, the model could determine the position of the template image in the search image and achieve image region-level matching. To further achieve image registration at different viewpoints, we proposed a pixel-wise consensus method based on a correlation layer. This method constructs a correlation map between the template feature map and the search feature map, and regresses the matching point pairs by solving for the points with the maximum correlation value.
- (4)
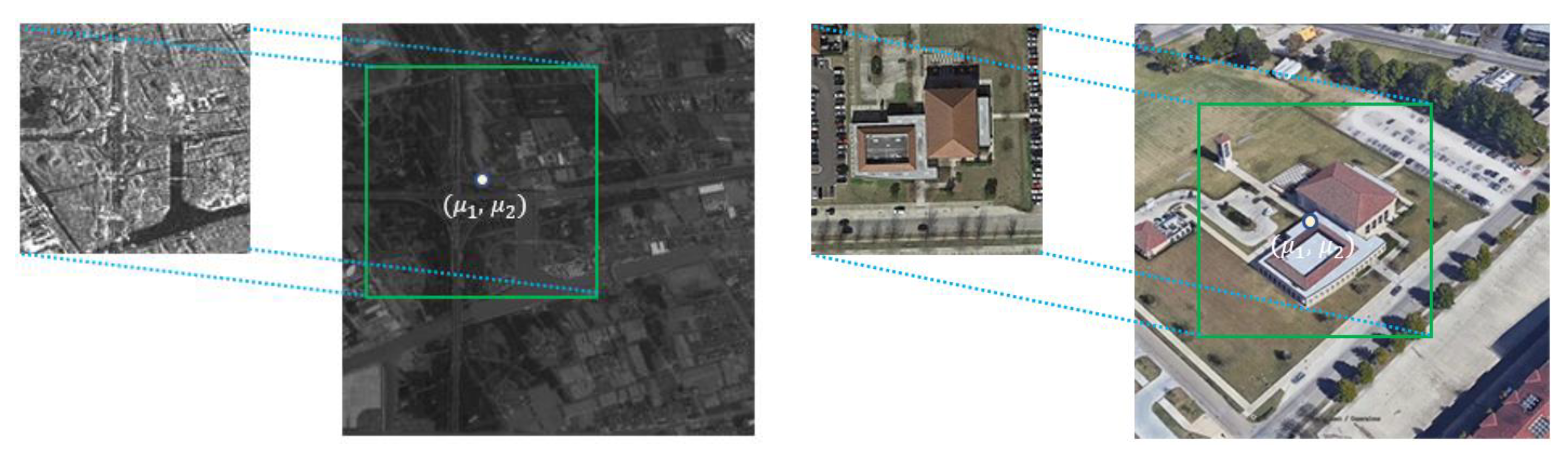
- The annotation of labels for image matching is a labor-intensive and time-consuming task. Therefore, the weakly supervised learning method was proposed to reduce the labeling workload. In this method, we only labeled one point, which was the centroid of the template image, and indicated its position in the search image. The model could learn the local features during training and predict the location of the template image in the search image. We compared the distance between the ground truth and the prediction to determine the positive and negative samples, labeled as 1 and −1, respectively. Then, we implemented the regression process on the correlation map to produce pairs of matching points.
- (5)
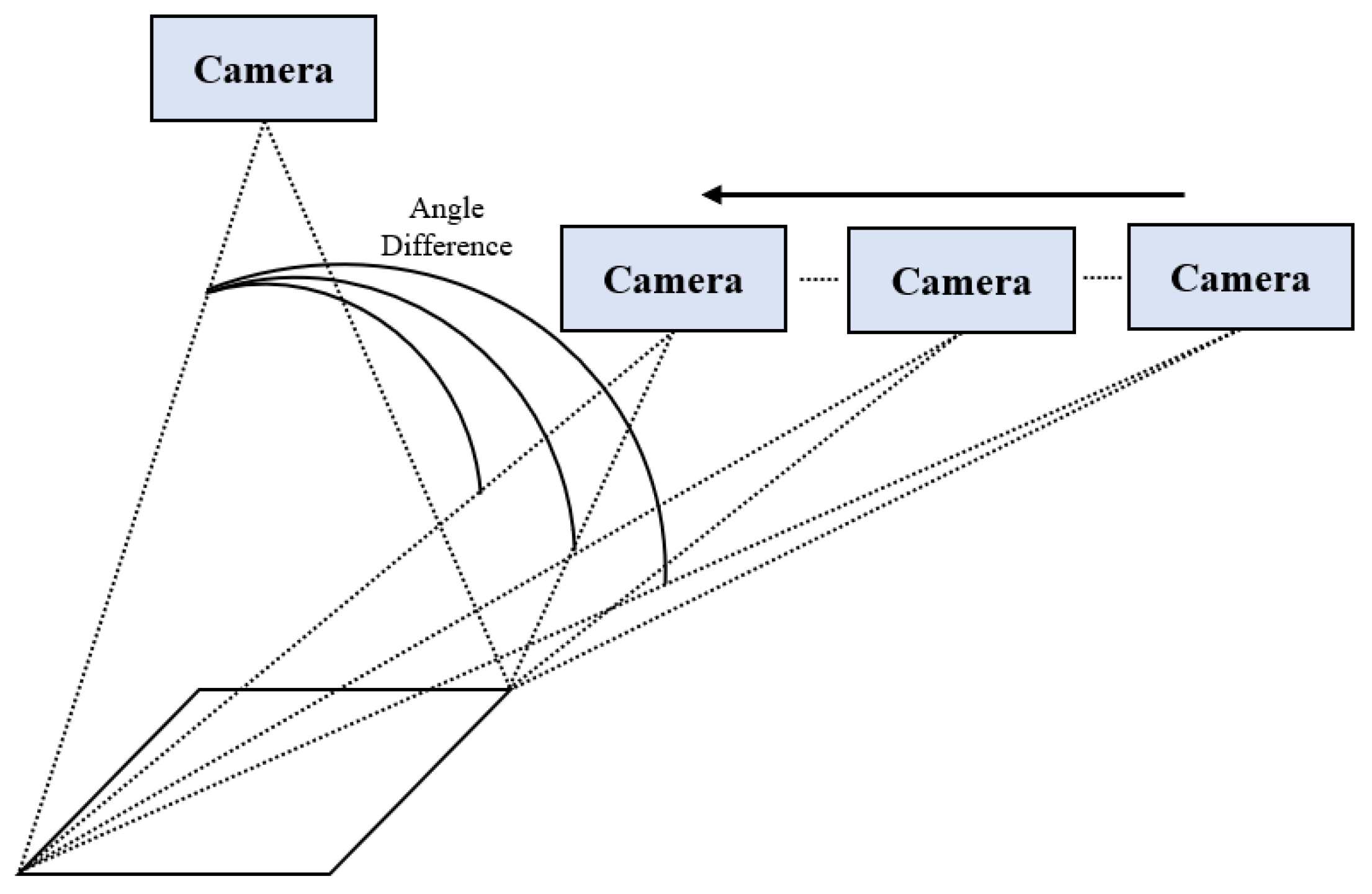
- We conducted three types of matching experiments, including SAR to RGB, infrared to RGB, and RGB to RGB, each with viewpoint differences. Furthermore, to demonstrate the robustness of our method in the context of viewpoint changes, we conducted simulations at several exact angles. Additionally, we compared all of the experiments using different methods, including handcrafted and deep-learning-based methods, to verify the effectiveness of the proposed method and demonstrate its feasibility.
2. Methods
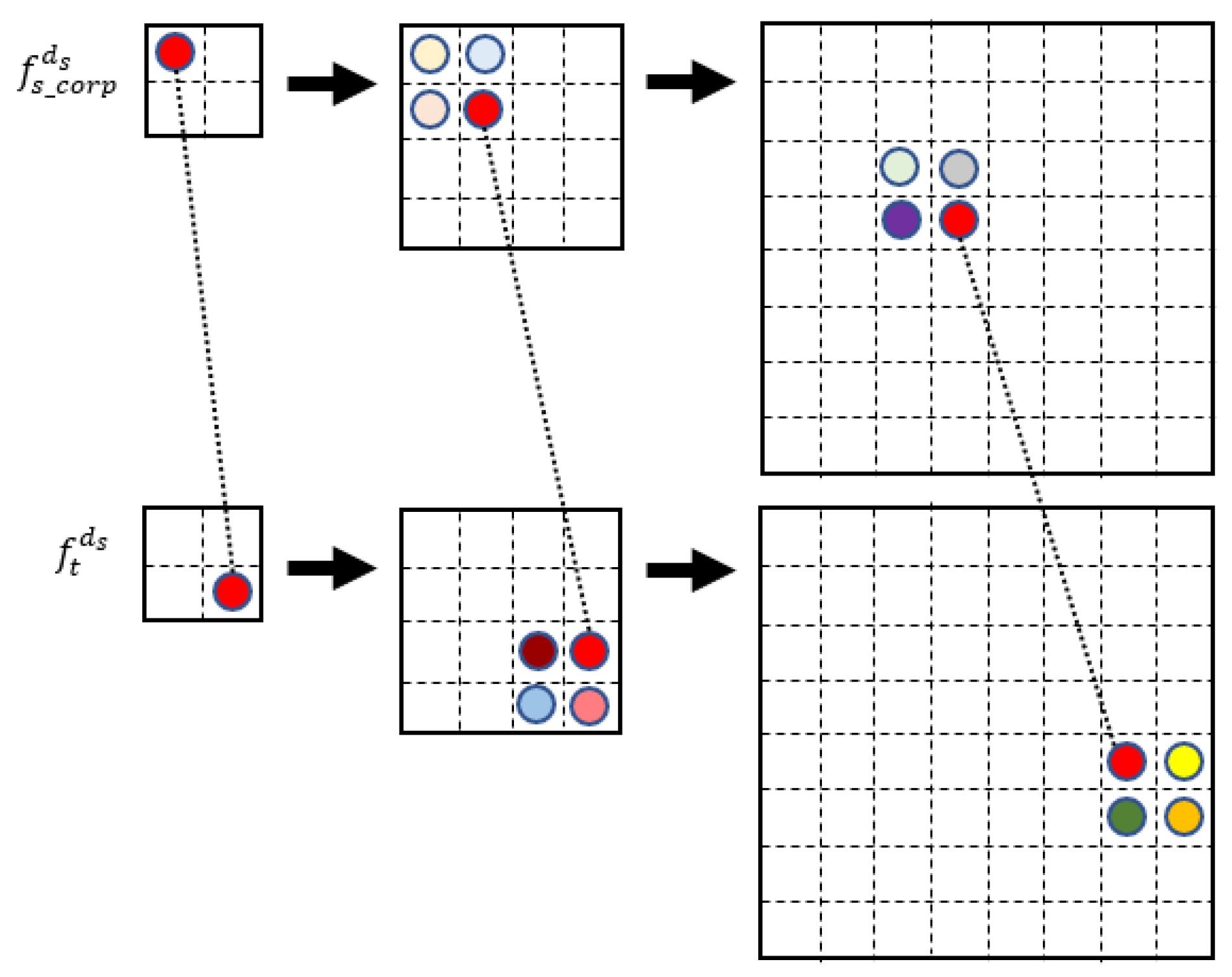
2.1. Dense Feature Extraction
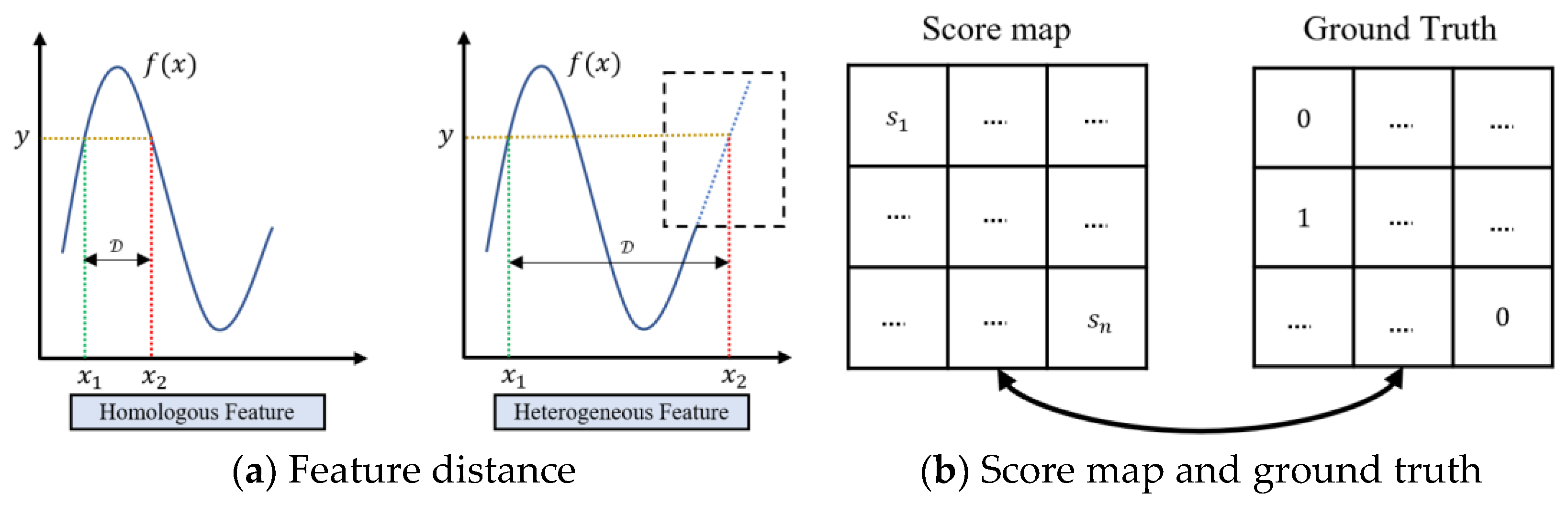
2.2. Heterogeneous Feature Alignment
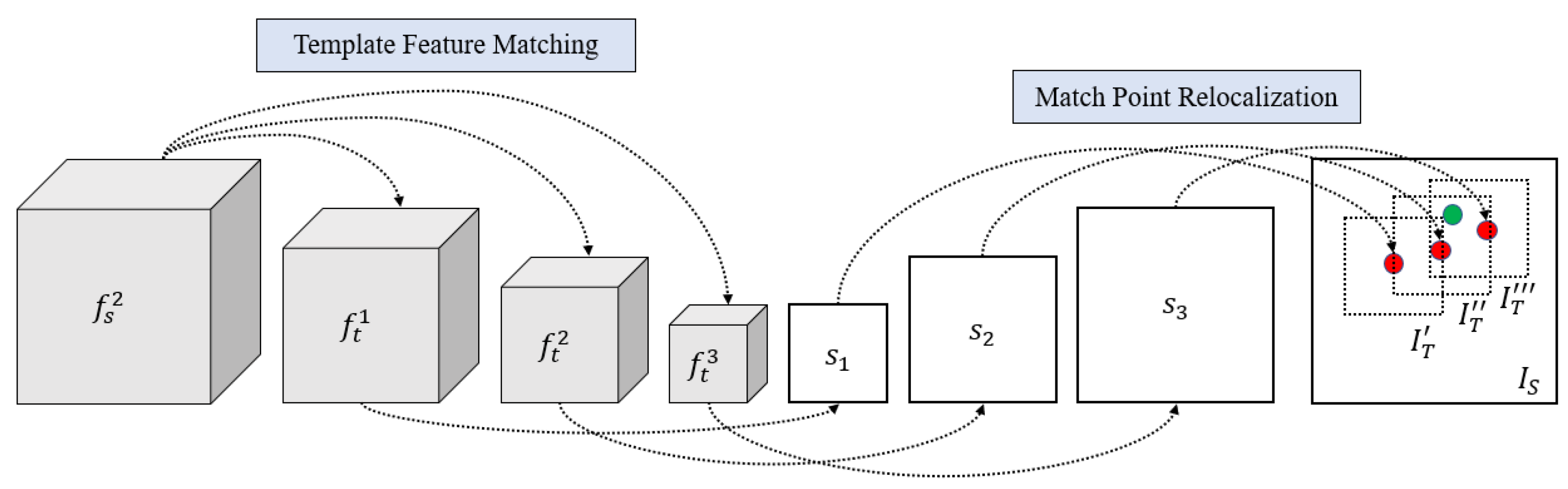
2.3. Multi-Scale Matching
2.4. Pixel-Wise Consensus
2.5. Weakly Supervised Learning
2.6. Match Point Re-Localization
3. Experiments
3.1. Experimental Datasets
- (1)
- SAR to RGB: The SEN1-2 Dataset [30] was used for this part of the experiments. The dataset contained SAR images from Sentinel-1 satellites and multispectral images from Sentinel-2 satellites. The dataset included 32 cities and terrain such as mountains, forests, lakes, rivers, wastelands, buildings, etc., spanning a wide range of categories and thus being challenging for heterogeneous image matching. We cropped the SAR image as the template image and the RGB image as the search image. The total number of image pairs was 1200.
- (2)
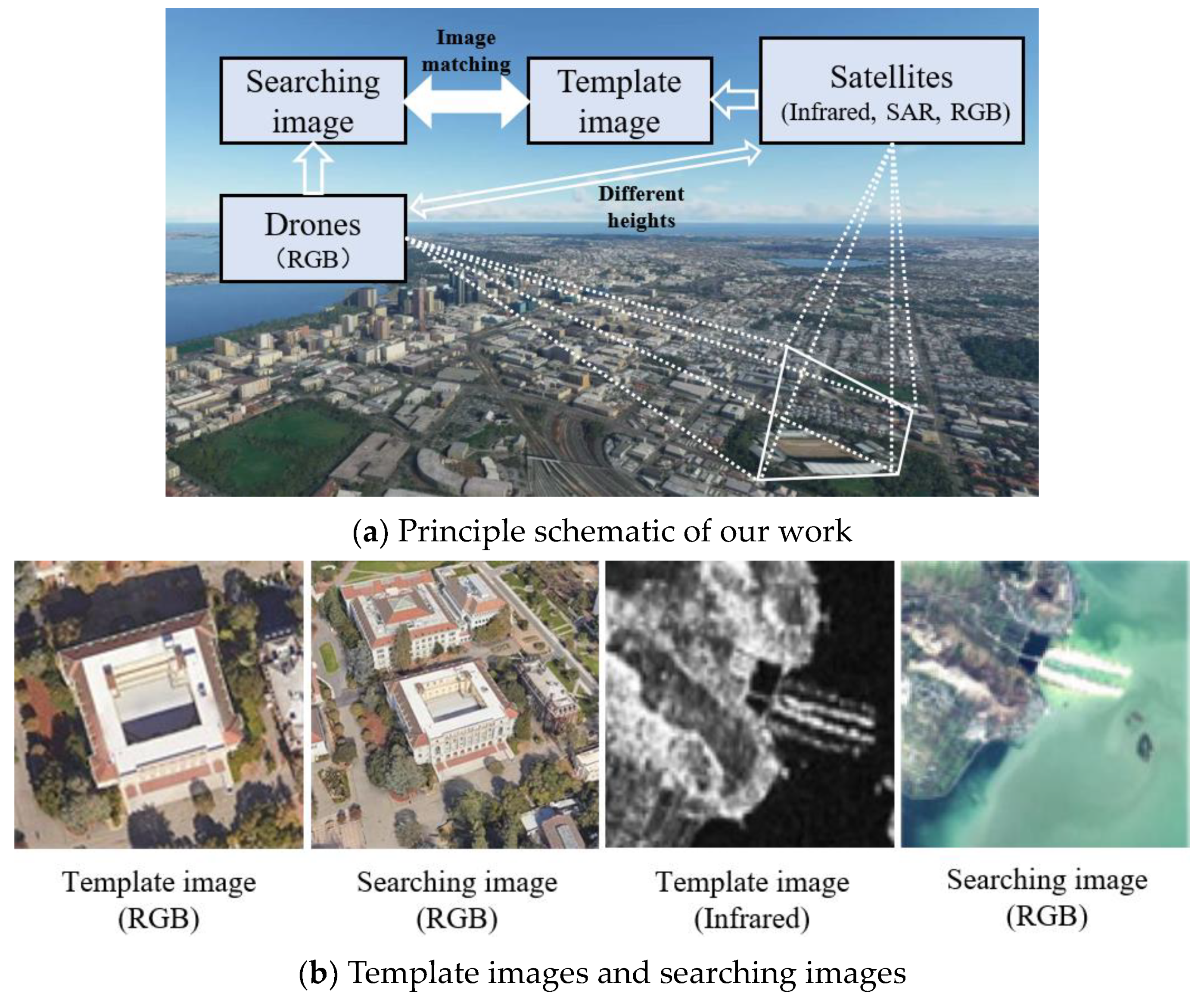
- Infrared to RGB: The Drone-view, which is our self-built dataset, was used in this part of the experiments. We used the drone’s infrared and visible sensors to photograph the ground at 200 m and 500 m altitudes, respectively, as shown in Figure 9. The dataset contained a variety of scenarios, such as lakes, roads, mountains, etc. The images acquired at the 500 m altitude were template images, and the images acquired at the 200 m altitude were considered as search images. The total number of image pairs to conduct the experiment in this part was 3482.
- (3)
- RGB to RGB: The University-1652 [31] was used in this part of the experiments. This dataset contained maps of 1652 colleges and universities derived from three platforms: drones, satellites and ground cameras. We used the data of the drones and satellites, and the differences in viewpoints between the two was obvious. The images of the satellite were considered as direct template images, and the images of drones were regarded as search images. The total number of image pairs in this part of the evaluation was 701.
3.2. Experimental Details and Metrics
- TP: Matching error ≤ 3 pixels.
- FN: Matching pairs ignored by the model.
- FP: Matching error > 3 pixels.
- TN: Remaining pixel pairs.
3.3. Experimental Results of SAR to RGB
3.4. Experimental Results of Infrared to RGB
3.5. Experimental Results for RGB to RGB
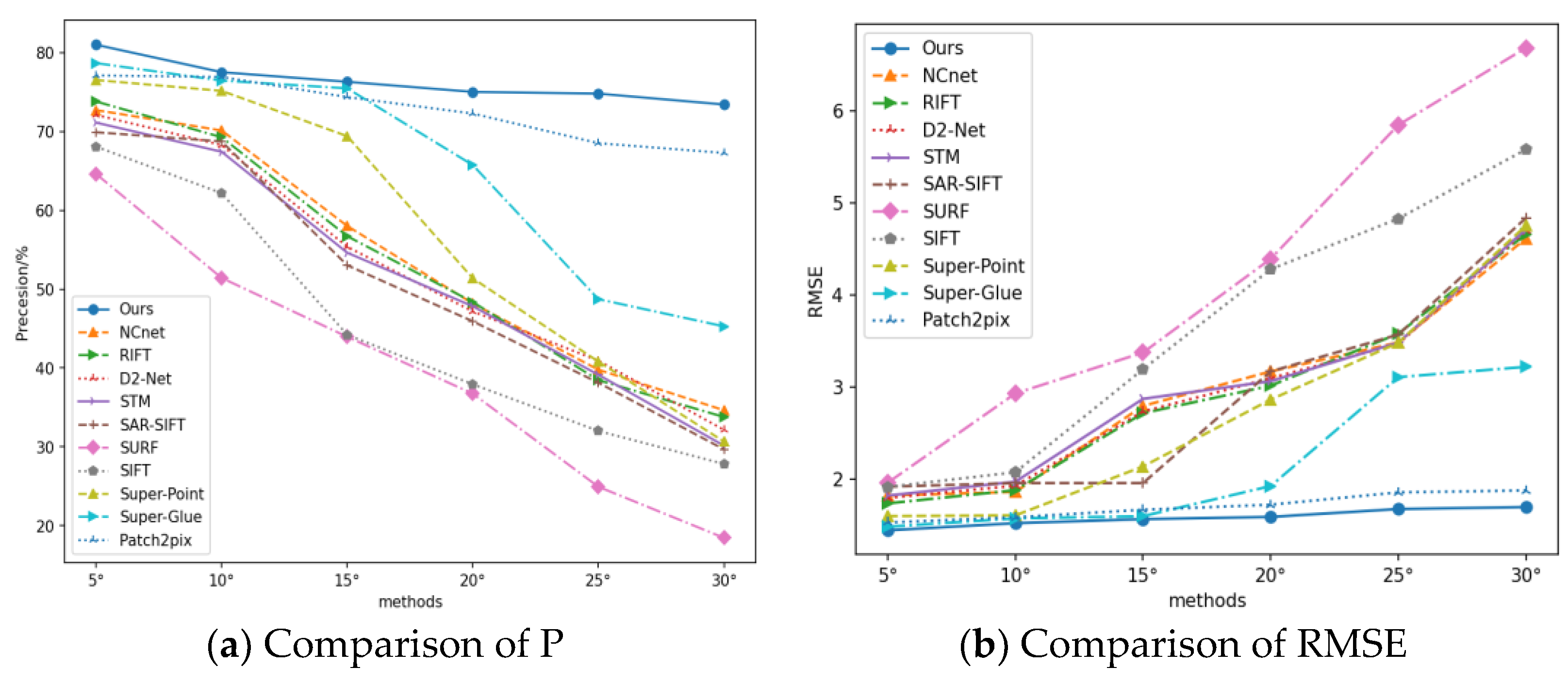
3.6. Experimental Results for Different Viewpoints
4. Conclusions
- (1)
- To address the first challenge of the heterogeneous images produced by different sensors, we proposed a method called the heterogeneous feature alignment method based on the spatial attention map. In this approach, we added a two-dimensional Gaussian distribution to the loss function to minimize the distance between the distributed heterogeneous features. By doing so, we can effectively match the features of the template image with those of the search image, allowing them to correspond to each other.
- (2)
- To address the second challenge of the scale variation caused by different heights, we proposed a multi-scale matching method based on multi-layer sampling point regression. With this approach, we perform regression on the matching points at different down-sampling scales to preserve the result with the smallest distance error. By doing so, we can effectively match the template and search images at different scales, overcoming the challenge of scale variation caused by different heights.
- (3)
- To address the third challenge of feature distortion caused by different viewing angles, we proposed a pixel-wise consensus method based on the correlation layer. With this method, we use a correlation layer to extract the pixel points with the highest correlation between the feature maps of the search image and the template image, thus obtaining the matching feature points. By doing so, we can effectively overcome the feature distortion caused by different viewing angles and achieve accurate template matching.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sattler, T.; Maddern, W.; Toft, C.; Torii, A.; Hammarstrand, L.; Stenborg, E.; Safari, D.; Okutomi, M.; Pollefeys, M.; Sivic, J.; et al. Benchmarking 6DOF Outdoor Visual Localization in Changing Conditions. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8601–8610. [Google Scholar] [CrossRef]
- Taira, H.; Okutomi, M.; Sattler, T.; Cimpoi, M.; Pollefeys, M.; Sivic, J.; Pajdla, T.; Torii, A. InLoc: Indoor Visual Localization with Dense Matching and View Synthesis. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1293–1307. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar] [CrossRef]
- Ham, B.; Cho, M.; Schmid, C.; Ponce, J. Proposal Flow. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3475–3484. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Zhao, Z.; Jiao, L.; Zhao, J.; Gu, J.; Zhao, J. Discriminant deep belief network for high-resolution SAR image classification. Pattern Recognit. 2017, 61, 686–701. [Google Scholar] [CrossRef]
- Alali, F.M.; Tarakji, B.; Alqahtani, A.S.; Alqhtani, N.R.; Nabhan, A.B.; Alenzi, A.; Alrafedah, A.; Robaian, A.; Noushad, M.; Kujan, O.; et al. SAR Image segmentation based on convolutional-wavelet neural network and markov random field. Pattern Recognit. 2017, 64, 255–267. [Google Scholar] [CrossRef]
- Zhao, W.; Jiao, L.; Ma, W.; Zhao, J.; Zhao, J.; Liu, H.; Cao, X.; Yang, S. Superpixel-Based Multiple Local CNN for Panchromatic and Multispectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4141–4156. [Google Scholar] [CrossRef]
- Altwaijry, H.; Trulls, E.; Hays, J.; Fua, P.; Belongie, S. Learning to Match Aerial Images with Deep Attentive Architectures. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3539–3547. [Google Scholar] [CrossRef]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. Matchnet: Unifying feature and metric learning for patch-based matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3279–3286. [Google Scholar] [CrossRef]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-Net: A Trainable CNN for Joint Description and Detection of Local Features. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8084–8093. [Google Scholar] [CrossRef]
- Cui, S.; Ma, A.; Wan, Y.; Zhong, Y.; Luo, B.; Xu, M. Cross-Modality Image Matching Network with Modality-Invariant Feature Representation for Airborne-Ground Thermal Infrared and Visible Datasets. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Zhu, H.; Jiao, L.; Ma, W.; Liu, F.; Zhao, W. A Novel Neural Network for Remote Sensing Image Matching. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2853–2865. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Ni, W.; Yan, W.; Xiang, D.; Wu, J.; Yang, X.; Bian, H. Registration of Multi-modal Remote Sensing Image Based on Deep Fully Convolutional Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3028–3042. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, H.; Huang, Y. A Rotation-Invariant Optical and SAR Image Registration Algorithm Based on Deep and Gaussian Features. Remote Sens. 2021, 13, 2628. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T. Van Gool, LSurf: Speeded up robust features. In Computer Vision—ECCV 2006, Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar] [CrossRef]
- Rocco, I.; Arandjelovic, R.; Sivic, J. Convolutional Neural Network Architecture for Geometric Matching. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 39–48. [Google Scholar] [CrossRef]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 337–350. [Google Scholar] [CrossRef]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperGlue: Learning Feature Matching with Graph Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4937–4946. [Google Scholar] [CrossRef]
- Rocco, I.; Cimpoi, M.; Arandjelović, R.; Torii, A.; Pajdla, T.; Sivic, J. NCNet: Neighbourhood Consensus Networks for Estimating Image Correspondences. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1020–1034. [Google Scholar] [CrossRef]
- Zhou, Q.; Sattler, T.; Leal-Taixé, L. Patch2Pix: Epipolar-Guided Pixel-Level Correspondences. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4667–4676. [Google Scholar] [CrossRef]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. In Computer Vision—ECCV 2016 Workshops. ECCV 2016; Springer: Cham, Switzerland, 2016; pp. 850–865. [Google Scholar] [CrossRef]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar] [CrossRef]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4277–4286. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. 2014. Available online: https://arxiv.org/abs/1409.1556 (accessed on 1 October 2021).
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. FlowNet: Learning Optical Flow with Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar] [CrossRef]
- Schmitt, M.; Hughes, L.H.; Zhu, X. The SEN1-2 Dataset for Deep Learning in SAR-RGB Data Fusion. arXiv 2018, arXiv:1807.01569. [Google Scholar]
- Zheng, Z.; Wei, Y.; Yang, Y. University-1652: A Multi-view Multi-source Benchmark for Drone-based Geo-localization. arXiv 2020, arXiv:2002.12186. [Google Scholar]
- Li, J.; Hu, Q.; Ai, M. RIFT: Multi-Modal Image Matching Based on Radiation-Variation Insensitive Feature Transform. IEEE Trans. Image Process. 2020, 29, 3296–3310. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Han, L.; Ding, M.; Cao, H.; Hu, H. A deep learning semantic template matching framework for remote sensing image registration. J. Photogramm. Remote Sens. 2021, 181, 205–217. [Google Scholar] [CrossRef]
- Dellinger, F.; Delon, J.; Gousseau, Y.; Michel, J.; Tupin, F. SAR-SIFT: A SIFT-Like Algorithm for SAR Images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 453–466. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | The SEN1-2 Dataset [30] (Contains Mountains, Cities, Lakes, Rivers, etc.) | The Drone-View (Contains Roads, Lakes, Rivers, etc.) | The University-1652 [31] (Contains Cities, Buildings, etc.) | ||||
|---|---|---|---|---|---|---|---|
| Types | Training | Testing | Training | Testing | Training | Testing | |
| SAR to RGB | 960 | 240 | N/A | N/A | N/A | N/A | |
| Infrared to RGB | N/A | N/A | 2786 | 696 | N/A | N/A | |
| RGB to RGB | N/A | N/A | N/A | N/A | 561 | 140 | |
| Methods | P | R | RMSE | Time |
|---|---|---|---|---|
| SIFT [16] | 32.43% | 31.28% | 3.795 | 7.63 s |
| SURF [17] | 33.47% | 31.57% | 3.783 | 2.40 s |
| SAR-SIFT [34] | 39.73% | 38.26% | 3.658 | 4.48 s |
| STM [33] | 43.77% | 42.16% | 3.364 | 0.95 s |
| D2Net [11] | 62.16% | 63.39% | 2.393 | 1.62 s |
| RIFT [32] | 64.81% | 64.14% | 2.327 | 5.32 s |
| NCnet [21] | 74.02% | 72.39% | 1.824 | 0.82 s |
| SuperPoint [19] | 72.48% | 71.16% | 1.867 | 0.12 s |
| SuperGlue [20] | 76.14% | 75.26% | 1.761 | 0.14 s |
| Patch2pix [22] | 78.68% | 77.12% | 1.603 | 0.76 s |
| Ours | 81.49% | 80.04% | 1.528 | 0.09 s |
| Methods | P | R | RMSE | Time |
|---|---|---|---|---|
| SIFT [16] | 44.79% | 43.28% | 3.228 | 7.71 s |
| SURF [17] | 42.16% | 42.03% | 3.297 | 2.37 s |
| SAR-SIFT [34] | 45.31% | 46.21% | 3.101 | 4.54 s |
| STM [33] | 52.61% | 51.47% | 2.851 | 0.97 s |
| D2Net [11] | 53.34% | 52.71% | 2.814 | 1.61 s |
| RIFT [32] | 57.62% | 55.18% | 2.723 | 5.35 s |
| NCnet [21] | 58.03% | 57.83% | 2.678 | 0.80 s |
| SuperPoint [19] | 59.31% | 59.12% | 2.573 | 0.11 s |
| SuperGlue [20] | 66.17% | 65.44% | 2.215 | 0.14 s |
| Patch2pix [22] | 75.13% | 74.67% | 1.783 | 0.77 s |
| Ours | 78.33% | 77.14% | 1.614 | 0.08 s |
| Methods | P | R | RMSE | Time |
|---|---|---|---|---|
| SIFT [16] | 64.16% | 65.43% | 1.924 | 7.36 s |
| SURF [17] | 61.47% | 60.18% | 2.416 | 2.32 s |
| SAR-SIFT [34] | 67.42% | 68.79% | 1.902 | 4.52 s |
| STM [33] | 72.02% | 71.68% | 1.887 | 0.96 s |
| D2Net [11] | 73.67% | 73.28% | 1.761 | 1.58 s |
| RIFT [32] | 74.48% | 74.16% | 1.748 | 5.32 s |
| NCnet [21] | 75.93% | 76.17% | 1.682 | 0.78 s |
| SuperPoint [19] | 78.41% | 77.84% | 1.603 | 0.13 s |
| SuperGlue [20] | 81.29% | 80.16% | 1.519 | 0.13 s |
| Patch2pix [22] | 83.48% | 83.73% | 1.451 | 0.76 s |
| Ours | 85.16% | 86.32% | 1.397 | 0.09 s |
| Methods | SIFT [16] | SURF [17] | SAR-SIFT [34] | STM [33] | D2-Net [11] | RIFT [32] | NCnet [21] | SuperPoint [19] | SuperGlue [20] | Patch2pix [22] | Ours | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Angle/Metrics | ||||||||||||
| 5° | P | 68.08% | 64.62% | 69.91% | 71.13% | 72.11% | 73.81% | 72.72% | 76.53% | 78.68% | 77.12% | 81.01% |
| R | 67.52% | 63.18% | 68.82% | 70.16% | 71.68% | 72.93% | 71.67% | 75.83% | 77.15% | 76.88% | 80.57% | |
| RMSE | 1.911 | 1.957 | 1.914 | 1.817 | 1.792 | 1.732 | 1.818 | 1.594 | 1.478 | 1.524 | 1.439 | |
| 10° | P | 62.17% | 51.42% | 68.74% | 67.43% | 68.28% | 69.27% | 70.13% | 75.16% | 76.46% | 76.92% | 77.53% |
| R | 61.72% | 50.73% | 67.93% | 66.81% | 67.65% | 68.12% | 69.65% | 74.83% | 75.93% | 75.36% | 76.57% | |
| RMSE | 2.071 | 2.928 | 1.953 | 1.968 | 1.924 | 1.876 | 1.857 | 1.602 | 1.569 | 1.581 | 1.517 | |
| 15° | P | 44.21% | 43.96% | 53.03% | 54.62% | 55.38% | 56.72% | 58.02% | 69.41% | 75.48% | 74.37% | 76.31% |
| R | 43.82% | 43.15% | 53.67% | 53.73% | 54.91% | 56.87% | 57.68% | 68.16% | 74.37% | 73.68% | 75.29% | |
| RMSE | 3.191 | 3.372 | 2.984 | 2.869 | 2.731 | 2.713 | 2.792 | 2.134 | 1.593 | 1.663 | 1.561 | |
| 20° | P | 37.93% | 36.74% | 45.92% | 47.83% | 47.17% | 48.36% | 48.18% | 51.37% | 65.74% | 72.28% | 75.03% |
| R | 36.58% | 35.73% | 44.78% | 46.37% | 46.82% | 49.21% | 47.62% | 50.19% | 64.43% | 71.37% | 74.62% | |
| RMSE | 4.278 | 4.391 | 3.167 | 3.061 | 3.093 | 3.012 | 3.167 | 2.861 | 1.921 | 1.718 | 1.585 | |
| 25° | P | 32.01% | 24.93% | 38.13% | 39.14% | 40.93% | 38.46% | 39.78% | 40.81% | 48.73% | 68.52% | 74.81% |
| R | 32.14% | 23.69% | 37.82% | 38.76% | 39.63% | 37.53% | 38.64% | 39.73% | 47.92% | 67.68% | 73.64% | |
| RMSE | 4.829 | 5.847 | 3.568 | 3.481 | 3.468 | 3.578 | 3.483 | 3.479 | 3.105 | 1.852 | 1.671 | |
| 30° | P | 27.82% | 18.45% | 29.68% | 30.15% | 32.15% | 33.78% | 34.64% | 30.67% | 45.28% | 67.28% | 73.43% |
| R | 26.82% | 17.67% | 28.52% | 29.27% | 31.76% | 32.41% | 33.71% | 29.68% | 44.62% | 66.69% | 72.57% | |
| RMSE | 5.581 | 6.686 | 4.836 | 4.712 | 4.696 | 4.659 | 4.613 | 4.752 | 3.217 | 1.873 | 1.692 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hui, T.; Xu, Y.; Zhou, Q.; Yuan, C.; Rasol, J. Cross-Viewpoint Template Matching Based on Heterogeneous Feature Alignment and Pixel-Wise Consensus for Air- and Space-Based Platforms. Remote Sens. 2023, 15, 2426. https://doi.org/10.3390/rs15092426
Hui T, Xu Y, Zhou Q, Yuan C, Rasol J. Cross-Viewpoint Template Matching Based on Heterogeneous Feature Alignment and Pixel-Wise Consensus for Air- and Space-Based Platforms. Remote Sensing. 2023; 15(9):2426. https://doi.org/10.3390/rs15092426
Chicago/Turabian StyleHui, Tian, Yuelei Xu, Qing Zhou, Chaofeng Yuan, and Jarhinbek Rasol. 2023. "Cross-Viewpoint Template Matching Based on Heterogeneous Feature Alignment and Pixel-Wise Consensus for Air- and Space-Based Platforms" Remote Sensing 15, no. 9: 2426. https://doi.org/10.3390/rs15092426