1. Introduction
The development and optimization of biopharmaceutical production processes with cell cultures is cost- and time-consuming, requiring substantial lab work. This necessitates thorough planning of experiments and processes, taking into account existing process knowledge. The need for model-based decision support in biopharmaceutical manufacturing has been emphasized by the US Food and Drug Administration (FDA) [
1,
2], including taking into account available prior know-how and experience within the decision process and uncertainties [
3]. Such methods are still not state-of-the-art for cell culture processes during development or manufacturing [
3,
4], although first approaches have been proposed, for example, in order to optimize the titer of a mammalian cell culture process [
5]. This highlights a need for improved methods and tools for optimal experimental design, optimal and robust process design and process optimization for the purposes of monitoring and controlling during manufacturing.
But also in other engineering fields such as chemical engineering or mechanical engineering, process optimization plays an important role and is the subject of current research. Some application examples rely on dynamic models, an example is the optimization of sustainable algal production processes [
6] or the improvement of the vibration performance of cold orbital forging machines [
7]. Other approaches rely on machine-learning algorithms such as those reported in [
8,
9,
10].
The optimization of one objective criterion (e.g., final titer) is relatively straight forward, i.e., building an objective function with a unique response variable and applying an appropriate optimization algorithm to maximize this function. However, in industry, it is typically desired to optimize several conflicting objectives at a time, leading to suitable trade-offs and compromises. For example, when trying to maximize final titer via viable cell density while minimizing cultivation time. Multi-objective optimization provides a decision-making tool for optimal decisions in the presence of trade-offs between two or more conflicting criteria.
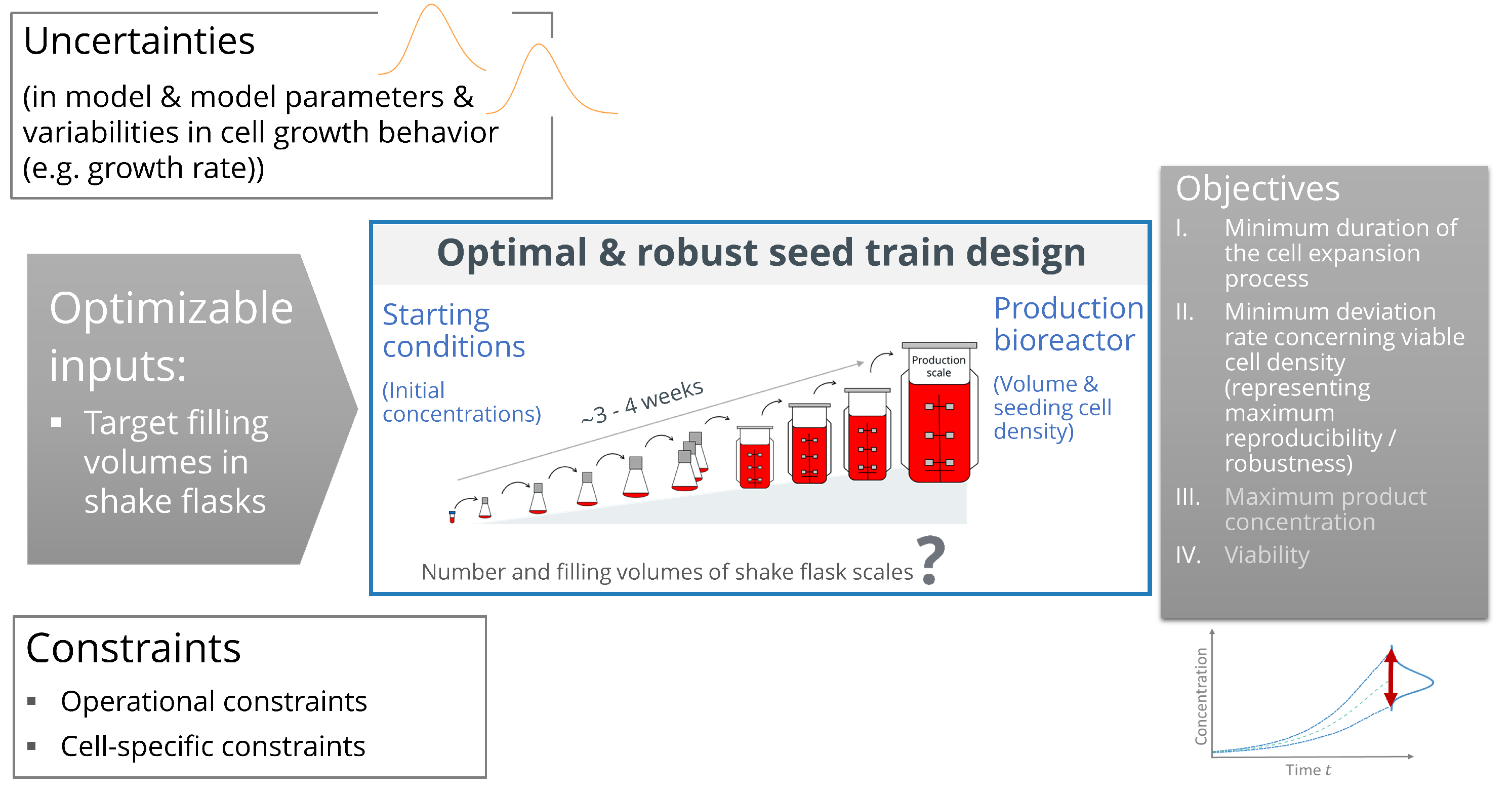
However, multi-objective optimization is more challenging. Its application is still not state-of-the-art in the context of cell culture processes, probably due to a lack of related studies and instructions. Moreover, within the manufacturing life cycle of biopharmaceuticals, some phases are better investigated than others. Still very few investigations are reported concerning the cell expansion process (seed train). It consists of several consecutive cultivation and passaging (transfer) steps, starting with a small amount of cell suspension because cells are frozen in small vials until they are used for a production process. The goal is to expand the number of viable cells in order to reach the required amount to inoculate (start) the production bioreactor (e.g., 10,000 L at industrial scale) while keeping them in a healthy and growing state. A high amount of operational requirements and constraints have to be fulfilled and, as reported in literature [
11,
12], the cell expansion process critically effects product quality and the amount of product at production scale. In [
12] for example, the passage duration, as well as the initial viable cell density for each passage are reported as important parameters with high impact on process time and productivity at production scale. A careful and optimal planning of a seed train is therefore essential. However, this is not a trivial task due to the inherent variability concerning cell growth (cell growth differs from cell line to cell line and also from cultivation run to cultivation run) and uncertainty about the real state of the process due to considerable measurement uncertainties. This requires the design of a reproducible process which is robust regarding viable cell density, meaning that despite (initial) variabilities concerning cell growth, low variations of viable cell density at the end of the seed train are obtained. The goal of this paper is to close the gap between state-of-the-art optimization techniques and modern techniques from machine learning to improve the biopharmaceutical production by allowing easy to use yet powerful multi-objective optimization.
In most multi-objective optimization problems, no single best (unique optimal) solution exists, instead there is a set of optimal solutions (also called Pareto optimal solutions or non-dominated solutions), meaning for each solution that one criterion cannot be improved without degrading at least one of the other criteria. So, the decision maker has to choose from the set of non-dominated solutions according to the most preferred or important objective criterion. A promising approach to optimize objective functions, which are expensive to evaluate, is Bayes optimization. The methodology of Bayes optimization dates back to the work of Harold Kushner in 1964 [
13] and gained impact through the work of Jones et al. in 1998 [
14]. It is a probabilistic global optimization method for finding the maximum of objective functions that are expensive to evaluate or unknown (black-box) objective functions that are approximated using simulations [
15].
In practice, the objective function could be the outcome of interest of a process, for example, process productivity or control metrics to describe the quality of a product. Input parameters can be process parameters needed to be optimized. Bayesian optimization [
16] creates a quick to evaluate model, the so-called surrogate model of the objective function. In order to reduce the objective function evaluations, the surrogate model is iteratively trained and updated on new data. The positions of this new data are chosen by finding a trade-off between exploration (improving the surrogate model) and exploitation (finding optimal points). Typical surrogate models are Gaussian processes.
Gaussian processes (GP’s) are popular machine learning models [
17] because, due to their Bayesian nature, they work well with few data points [
18]. Furthermore, they allow the inclusion of expert knowledge [
19,
20] and can be used in dynamic systems [
6,
21]. GP’s are very flexible non-parametric models, hence, they can approximate any function and do not assume a predefined set of modeling functions.
Bayes optimization is successfully applied in many fields of research and economics [
22]. Moreover, applications of Bayes optimization in the field of bioprocess engineering were published during the last decade [
6,
9,
23,
24]. Furthermore, this methodology was shown to be efficient in solving multi-objective optimization problems [
25] and has also been applied for parameter estimation of kinetic parameters [
26]. However, no applications are reported so far applying model-based multi-objective Bayes optimization within biopharmaceutical process development.
This contribution aims to present the concept of a workflow which couples uncertainty-based upstream simulation and Bayes optimization using Gaussian processes and its application in the form of a simulation case study to illustrate its applicability to a relevant industrial task in process development.
This simulation case study addresses the question if a reference seed train setup comprising five shake flask scales can be optimized through varying shake flask volumes and how many shake flask scales, three, four or five, are recommendable in terms of two objective criteria, seed train duration and deviation rate. Moreover it is investigated how the results change if cells grow with 5% lower or 5% higher maximum cell-specific growth rate.
Afterwards, two more objective criteria, titer (product concentration) and viability after 8 days in the production bioreactor, are added and seed train optimization is performed regarding four objective criteria simultaneously.
Furthermore, the suitability of the proposed method and the required number of iterations is evaluated with respect to the obtained information gain.
2. Methods
The main components of the applied methodology and the corresponding tools are described.
2.1. Upstream Simulation
Upstream simulation comprises a simulation of the cell expansion process (seed train) and simulation of the production scale. The reference upstream process taken as an application example for the here presented simulation case study comprises five consecutive shake flask scales followed by three bioreactor scales and one production scale, similar to the upstream process investigated in [
27]. Further specifications are listed in
Table 1.
A mathematical model is required, describing cell growth and interactions with the main limiting substrates and eventually inhibiting metabolites over time. A cell growth model, a system of ordinary differential equations (ode), already adapted to an industrial cell culture upstream process using a CHO cell line [
27] has been used, which describes the dynamic behavior of viable and total cell density,
and
, concentrations of glucose
, glutamine
, lactate
, ammonia
and product (volumetric titer)
(see
Table A1 in the
Appendix A).
Moreover, such an upstream process includes several constraints, operation steps and process parameters (e.g., concerning passaging intervals, substrate/nutrient concentrations, initial viable cell densities and viable cell densities before transferring cells into the next cultivation vessel, as well as the amount of cell suspension and fresh medium), which have to be considered in the simulation workflow. A detailed description of the required components and calculation routines are described in [
28,
29].
Besides these requirements, several passaging strategies can be applied, helping to decide at which point in time cells should be transferred from one cultivation vessel into the next larger one and how to perform these passaging steps (e.g., which amount of cell suspension should be mixed with how much fresh cell culture medium).
For the here presented simulation study, the passaging strategy for robust seed train design was chosen, where robustness refers to the reproducibility of the seed train regarding viable cell density, meaning that despite initial uncertainties and variabilities concerning cell growth, low variations of viable cell density at the end of the seed train are obtained. This strategy grounds on the objective of reaching the previously determined threshold of viable cell density and corresponding probability distributions of viable cell density at different points in time. These distributions are used in combination with a utility function following the mean-variance principle, which grounds on the Markowitz mean-variance portfolio optimization theory [
30,
31]: The utility function
is defined as a function of viable cell density
including the expected value
and the variance
of viable cell density, as well as a risk aversion parameter
which controls the amount of risk (amount of uncertainty) the user is willing to bear. In the here presented example, the risk refers to the probability that viable cell density differs from the expected value (predicted mean). A risk aversion value of
would mean that the expected time profile minus one time the standard deviation of
is considered.
The utility function is defined through:
Based on the simulated time profiles of the current cultivation scale (by solving the corresponding ode system), Equation (
1) is used to calculate the utility function value
per hour and to check if this value reaches or exceeds the required transfer viable cell density
which is necessary to inoculate (start) the next cultivation scale fulfilling the required seeding (initial) viable cell density and the filling volume.
In the next step, it is evaluated whether the calculated point in time lies within the range of practically feasible points in time for cell passaging,
. Thus, the objective is to find the minimum point in time out of the set of practically feasible points in time for passaging,
, which fulfills:
Based on the obtained point in time and the corresponding concentrations of viable cells, total cells, substrates and metabolites at this point in time, starting concentrations (=initial values of the system of ordinary differential equations) of the next cultivation scale are calculated based on the defined configurations and constraints (e.g., working volumes, acceptable range of seeding viable cell density and medium concentrations). This calculation has to be performed for every cultivation scale and passaging step. For more details refer to [
27,
28,
29].
2.2. Bayes Optimization
A typical mathematical optimization problem is the following: Given an objective function over input space , the aim is to find an argument , which optimizes (minimizes or maximizes) f.
The idea behind Bayes Optimization consists of creating a simple, probabilistic and cheap to evaluate model, a so-called surrogate model (substitute model), of the objective function
f [
15,
17,
32]. Bayesian optimization reduces the number of evaluations of the objective
f via the following iterative approach: Before sampling
f at another point, we take into account a trade-off between exploration (i.e., sampling of areas of high uncertainties) and exploitation (sampling from areas which are likely to move towards the optimum), which is encoded in a so-called acquisition function. We can find such points quickly from evaluation of the surrogate model.
Within Bayes optimization the following steps are performed:
- (1)
Generate a set of initial points and evaluate the objective function at these points.
- (2)
Train the surrogate model based on all evaluated points.
- (3)
Optimize the acquisition function, which determines the next candidate point to be evaluated.
- (4)
Compute , the objective function f at the candidate point .
- (5)
Repeat steps 2–4 for N iterations
The key of Bayesian optimization is not to rely on local approximations as many other optimization algorithms and instead to have a global viewpoint of also evaluating the function at unknown positions.
The acquisition function is used to propose the next candidate point to be evaluated based on specific criteria, for example the expected improvement of the optimization criteria, and on the reduction in predictive uncertainty. As in the case of the kernels, there is also a wide variety of possible acquisition functions to choose from. In this study, the Expected Improvement (EI) acquisition function is used [
33,
34].
Gaussian processes (GPs) are well suited surrogate models when making few assumptions [
15]. Just like a Gaussian distribution (a normal probability distribution) is fully described by its mean
m and variance
, a GP is fully described by a mean function
and a covariance function
[
17]. A GP is an extension of a multivariate Gaussian (or normal) distribution to distributions of functions in the sense that if a function
y follows a GP distribution, i.e.,
, then every evaluation of the function follows a Gaussian distribution
. In particular, a GP returns mean and variance of the possible function values (instead of just returning a scalar), and hence also provides information about the uncertainty of a prediction. Moreover, GPs can take into account uncertainty in the form of noise, the class of Gaussian processes is closed under Bayesian updates, and such updates are computationally tractable [
35].
The covariance function describes the assumed characteristics such as smoothness or periodicity of the objective function
f [
16]. They are so-called positive-definite functions, often also called kernels [
17,
36]. It specifies the relationship between two ‘points’ (vector of the input space)
x and
and the corresponding changes in
f at these points. A covariance function is described by a set of parameters, also called hyperparameters, describing a specific behavior. This is how prior information is embedded in the Bayes optimization procedure. Also in this work, the most commonly used covariance function, the Squared Exponential (SE) kernel (often also referred to as Gaussian kernel) is used [
32].
2.3. Problem Definition and Computational Procedure
The goal of the presented application example is to propose a concept and a numerical procedure for optimal robust seed train design, where robustness refers to the reproducibility of the seed train regarding viable cell density, meaning that despite initial uncertainties and variabilities concerning cell growth, low variations of viable cell density at the end of the seed train are obtained.
First, seed train constraints are defined based on a chosen cell line and its characteristics concerning optimal cultivation conditions and based on the operative possibilities (e.g., feasible points in time for cell passaging). Second, the optimizable input parameters and objective criteria (objective response variables) applied in this study are defined (as also illustrated in
Figure 1), followed by the formulation of the mathematical optimization problem. Thereafter, the optimization problem is solved using a workflow which connects seed train simulation and Bayes optimization.
The following objective criteria were chosen to represent an optimal seed train: (I) a minimum duration (
d) (=required cultivation time) of the seed train and (II) a minimum deviation rate (
D) regarding viable cell density, i.e., the probability that the seed train will run outside predefined ranges of viable cell density (for both, seeding viable cell density and transfer viable cell density) (This is important to consider because in the case that specific constraints are not fulfilled, the performance of the cells could decrease. The growth rate could decrease and, furthermore, it has been observed that the violation of constraints could also cause less viability of the cells in the production phase [
12]) (compare to
Figure 1 right gray box). These two attributes shall enable an optimal start of the production scale. Note that, in addition to these criteria, the growth rate is another important parameter affecting an optimal start of the production scale and the growth rate should be high until the end of the seed train. However, in this first optimization study it is not set as optimization criterion because the here defined seed train setup (in terms of medium concentrations and possible cultivation volumes per scale) together with the aim to reduce cultivation time already supports good growth during the entire cultivation. However, for other seed train setups, it might be advisable to include growth rate at the end of the seed train into the optimization problem.
After consideration of the two mentioned objective criteria, a third and fourth objective criterion, the product concentration (titer) and the viability at the end of the cultivation in the production bioreactor (in this simulation study: after 8 days in batch mode, i.e., without addition of nutrient feeds) are added to the optimization problem (see
Figure 1 right gray box (III)). Note: The authors are aware of the fact that cultivation in the production vessel itself, which is often performed in fed-batch mode, is also influenced by several process parameters having an impact on product quantity and quality. Moreover, data of further attributes would be necessary to describe product quality (e.g., of a recombinant therapeutic protein or antibody) but these are not provided and therewith not considered in this study.
The input variables that can be varied to optimize the recently mentioned objective criteria, and thus the optimizable input variables, are the filling volumes in the first five shake flask scales,
(compare to
Figure 1, the part of the seed train between thawing cells from a small vial and inoculation of the first biorector). These target values are important inputs of the seed train simulation process because they are used to calculate points in time for cell passaging. Volumes in the finally proposed seed train protocol (output of the seed train simulation) may vary within allowed working volume ranges and these are also presented in this work.
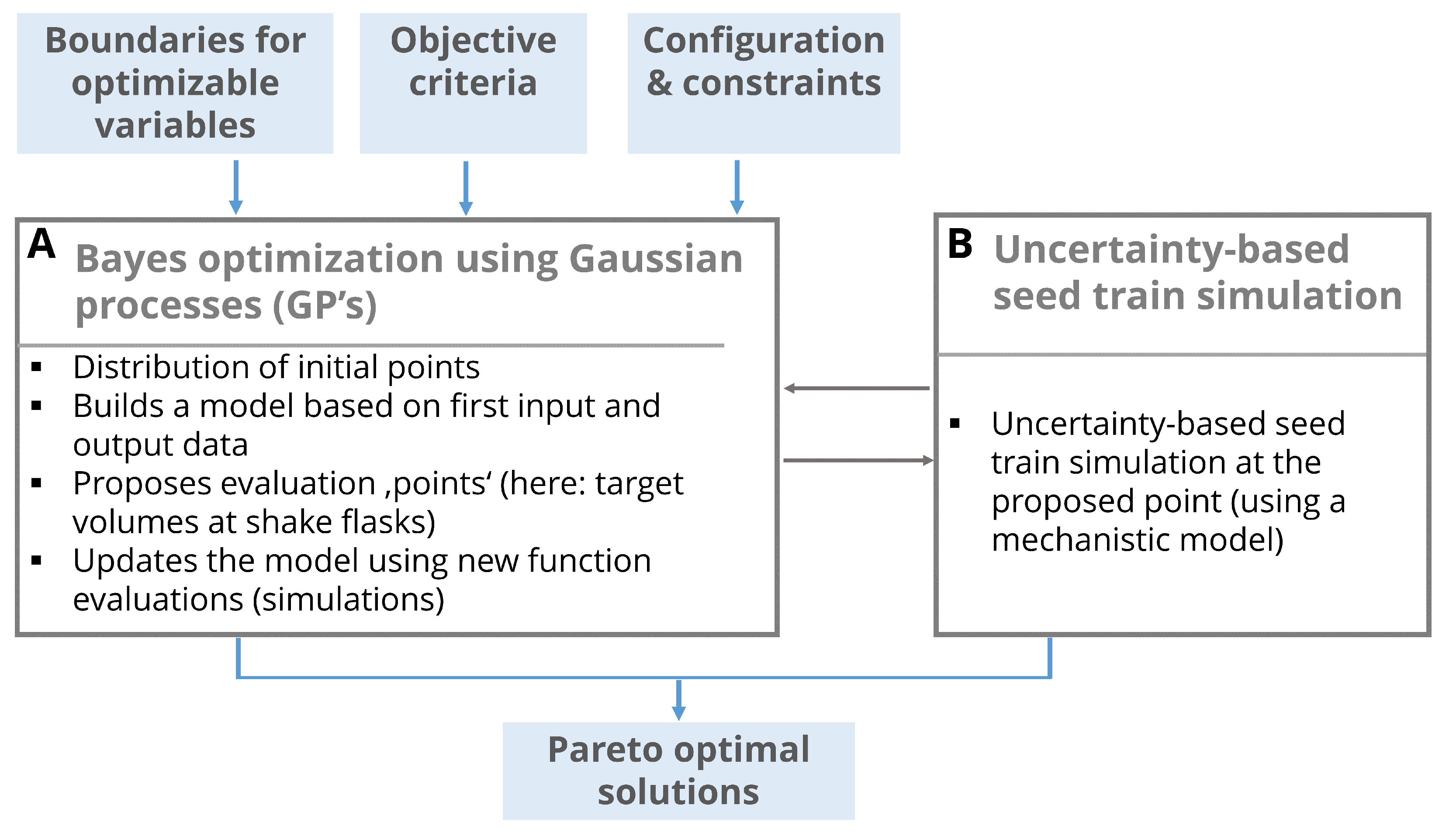
2.4. Connecting Seed Train Simulation and Bayes Optimization
Uncertainty-based seed train simulation as described in
Section 2.1 was coupled with algorithms for Bayes optimization as described in
Section 2.2. The workflow integrating both components is illustrated in
Figure 2. The inputs of the combined framework are the input variables: Boundaries for the optimizable variables (here filling volumes) and objective criteria (here seed train duration, deviation rate and in the second example also product concentration at the end of production scale) given all required seed train configuration settings and constraints (e.g., initial concentrations, practically feasible points in time for cell passaging, acceptable ranges for viable cell density, …).
First points (=combinations of optimizable variables) are determined using a Latin Hypercube design distributing these points within the design space (see
Figure 2, Box A). Seed train simulations are performed at these points in order to obtain the corresponding objective criteria values. Input values together with output values form a data set. An unknown model describing the relationship between inputs and outputs is approximated through a Gaussian process (GP) which has to be trained (see
Figure 2, Box A) based on the given data set. Therefore, the Gaussian process proposes a point that has to be evaluated next (see
Figure 2, Box B).
A robust seed train is simulated, using a mechanistic process model, and the objective criteria are calculated. This output is then returned to the Bayes optimization (Box A) to update the GP. Usually, experiments are performed to return the experimental output. The present approach instead exploits the advantages of the model-based upstream simulation in order to reduce the experimental effort to a minimum.
These steps are repeated various times, e.g., until a previously defined number of maximum iteration steps is reached. The latter depends on the resources (human and financial resources in case of laboratory experiments or computational resources in case of in silico experiments). In every iteration the Gaussian process chooses a new point aiming to move to the optimum and at the same time to reduce model uncertainty.
Results of this optimization framework are the set of Pareto optimal setups (also called Pareto front) and their corresponding response values.
2.5. Numerical Solvers and Tools
The programming language and numeric computing environment MATLAB [
37] was used for the seed train simulations. The code for the optimization workflow was written in Python [
38] using the MATLAB Engine API for Python to call MATLAB as a computational engine from Python code. To perform Bayes optimization within this workflow, the library GPflow [
39] was used.
3. Results and Discussion
3.1. Optimization of Cultivation Vessels Regarding Number of Shake Flask Scales and Filling Volumes for Five, Four and Three Shake Flask Scales
In this section, it is investigated which cultivation filling volumes should be used for the flask scales in order to obtain optimal results in terms of seed train duration and deviation rate, here defined as the probability that the seed train will run outside the predefined acceptable ranges for initial viable cell density (VCD) and transfer VCD (final VCD before transfer into the next cultivation vessel) per scale. The latter is a measure for the robustness of the seed train regarding viable cell density.
For assessment of the optimization results, a conventional reference seed train comprising five shake flask scales was simulated based on a non-optimized design. Therefore, a common passaging interval of 3 days per cultivation scale was fixed and filling volumes were determined following a conservative layout (i.e., choosing not too huge differences between one cultivation scale and the next to ensure that enough viable cells are generated even if they grow a little bit slower than expected).
In the first step, the optimal combination of filling volumes for five shake flask scales is investigated and the results are compared to the reference seed train. Afterwards, it is investigated if a reduction in shake flask scales from five to four or three shake flask scales leads to similar or even better results in terms of seed train duration and deviation rate. The number of bioreactor scales was kept fixed. Three bioreactors with filling volumes of 40 L, 320 L and 2100 L were used as pre-stages before inoculation of the production bioreactor with 9600 L. The assumed seed train setup is given in
Table 1.
To find the optimal solution, multi-objective Bayesian optimization coupled with uncertainty-based seed train simulation, as described in
Section 2.1, was applied. First, a Latin hypercube design for
design ‘points’ (combinations of filling volumes, here
) was initiated and seed train simulation was applied to calculate the objective criteria values, here, deviation rate
D and seed train duration
d (replacing the normally required experimental cultivation runs) at each point. Within the Bayes optimization procedure, Gaussian processes were trained based on the simulation outcomes and an acquisition function was calculated in each iteration step in order to propose which point should be evaluated next. The input space for shake flask filling volumes (here the optimizable variables) was defined as described in
Table 2, assuming the possibility of using several shake flasks in parallel for one shake flask scale and also considering their working volumes ranges.
3.1.1. Optimization of Five Shake Flask Scales
The first optimization was performed for a seed train comprising five shake flask scales.
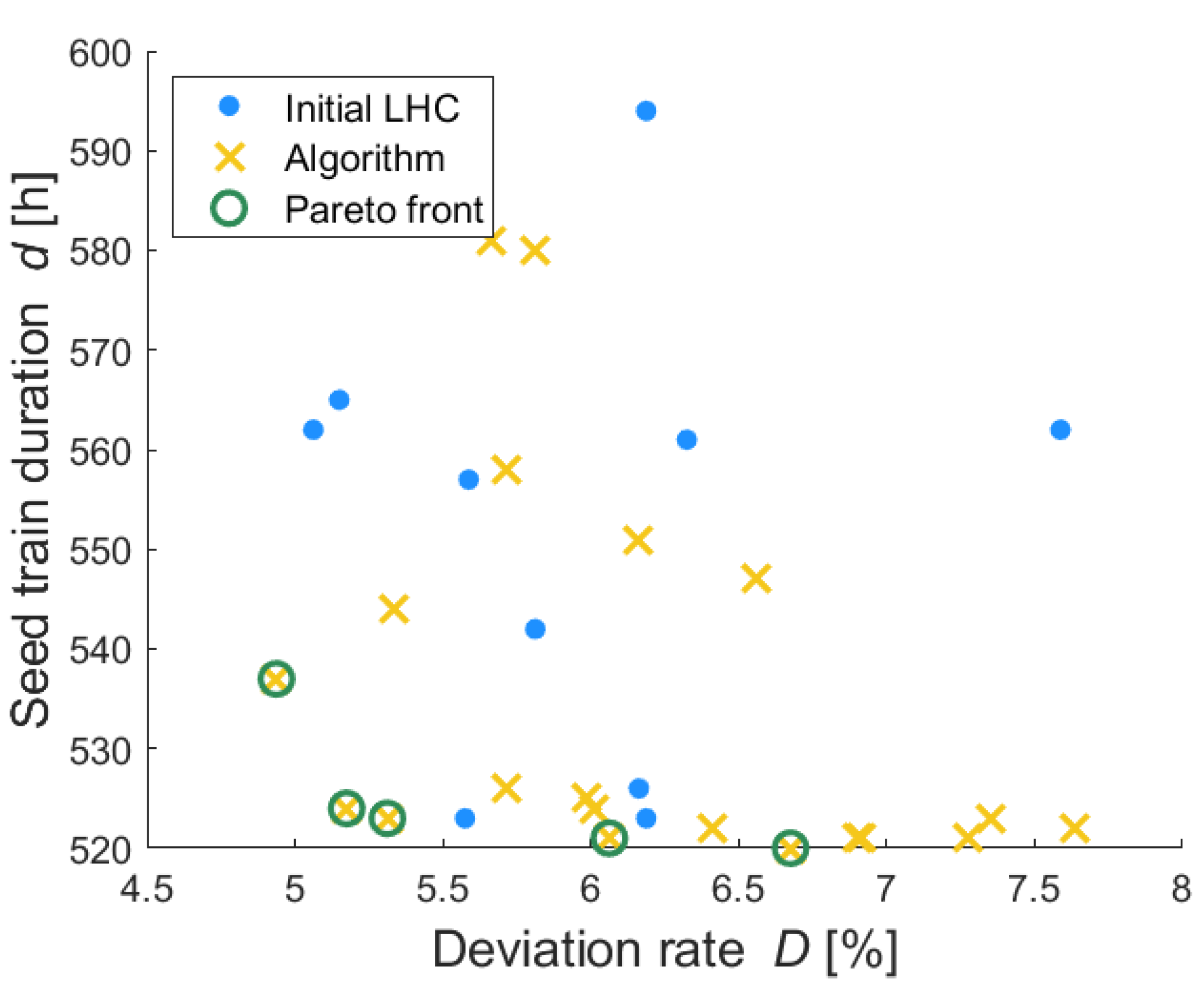
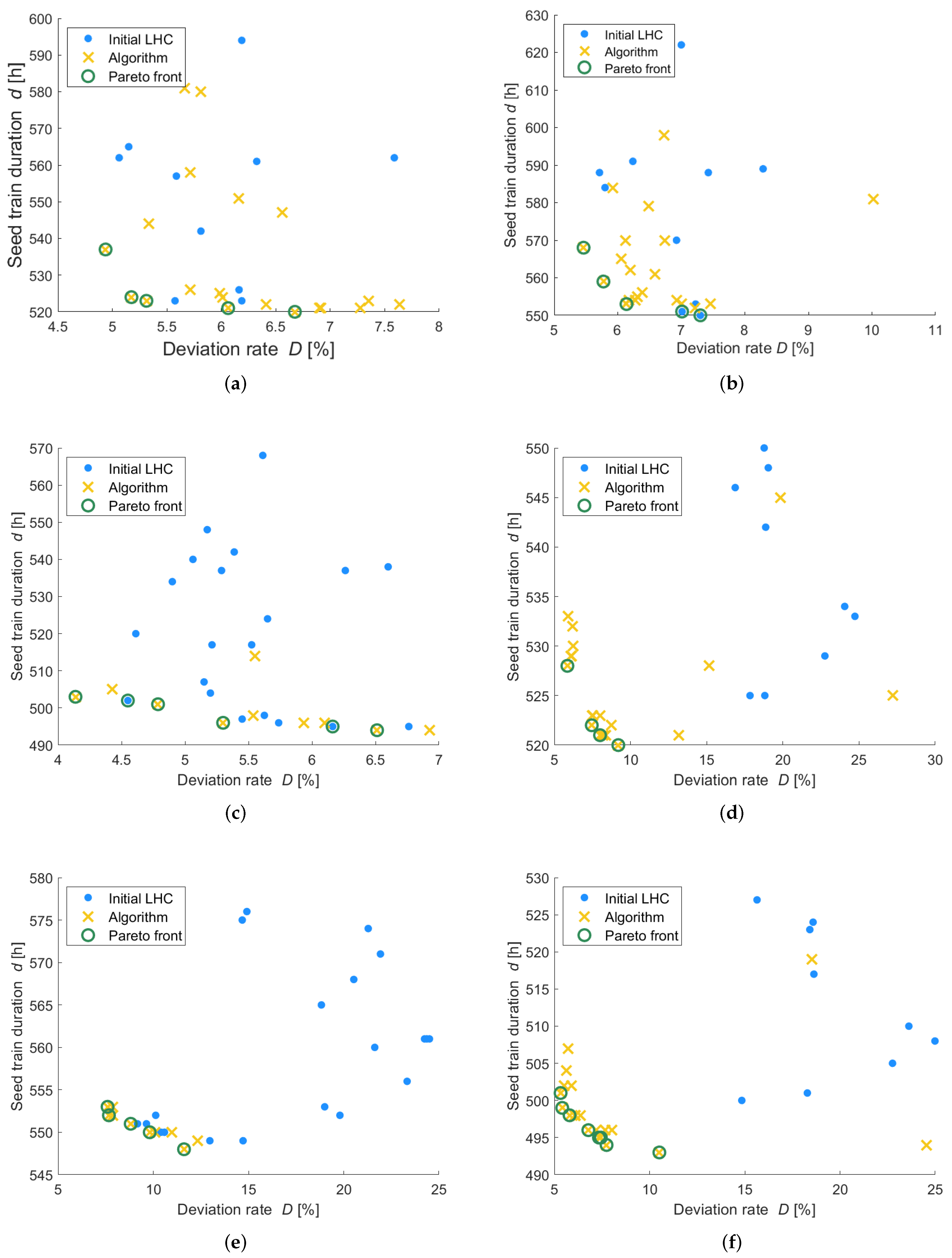
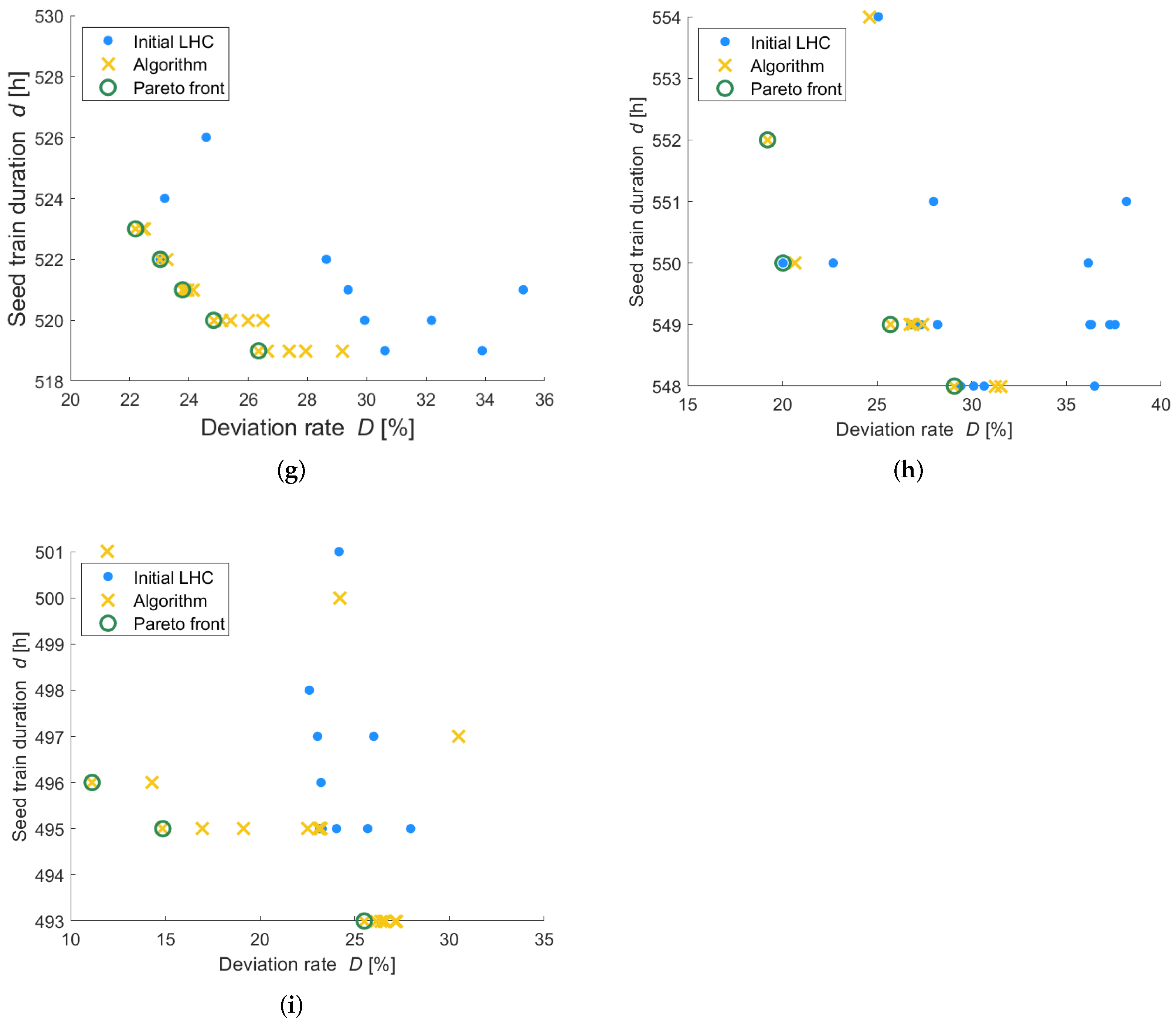
Figure 3 shows the objective criteria values for each evaluated point, whereby the outcomes based on the initial Latin hypercube space are illustrated by blue dots and the outcomes for the proposed points based on the trained Gaussian processes are illustrated through yellow crosses. The optimal solutions are those near to the lower left corner aiming to minimize seed train duration and the deviation rate. The Pareto optimal solutions, also called non-dominated solutions, are illustrated through green circles. A solution (seed train setup/combination of filling volumes) is called non-dominated if no solution exists leading to better (here lower) objective criteria values. As described previously, several Pareto optimal solutions can be obtained because when considering two or more objective criteria then for two different solutions one criterion might have better (here lower) value then the other solution for the same objective, while the other criterion has worse (here higher) values. The set of all Pareto optimal solutions is called Pareto front.
For the investigated scenario (five shake flask scales and the seed train configuration according to
Table 1) five Pareto optimal solutions were obtained (see green circles in
Figure 3). It can be seen that comparing two of these solutions (green circles) each, one solution has a lower (here better) seed train duration value than the other solution and the opposite holds for the deviation rate.
The corresponding values for the optimizable variables, here shake flask filling volumes (
,
,
,
and
), and the corresponding objective criteria values, here deviation rate
D and seed train duration
d, are listed in
Table 3.
The filling volume of the first scale was limited to a very narrow range (14–15 mL) (A higher variation after cell thawing was not expected). Most obtained solutions start with the maximum value of this range (see
Table 3, first column). The filling volume of flask scale 2 varies between 0.065 and 0.115 L, the filling volume of flask scale 3 between 0.340 and 0.904 L, the filling volume of flask scale 4 between 1.582 and 2.355 L and of flask scale 5 between 6.85 and 7.97 L. All five combinations lead to a deviation rate
D of less than 7% and to a seed train duration between 520 to 537 h.
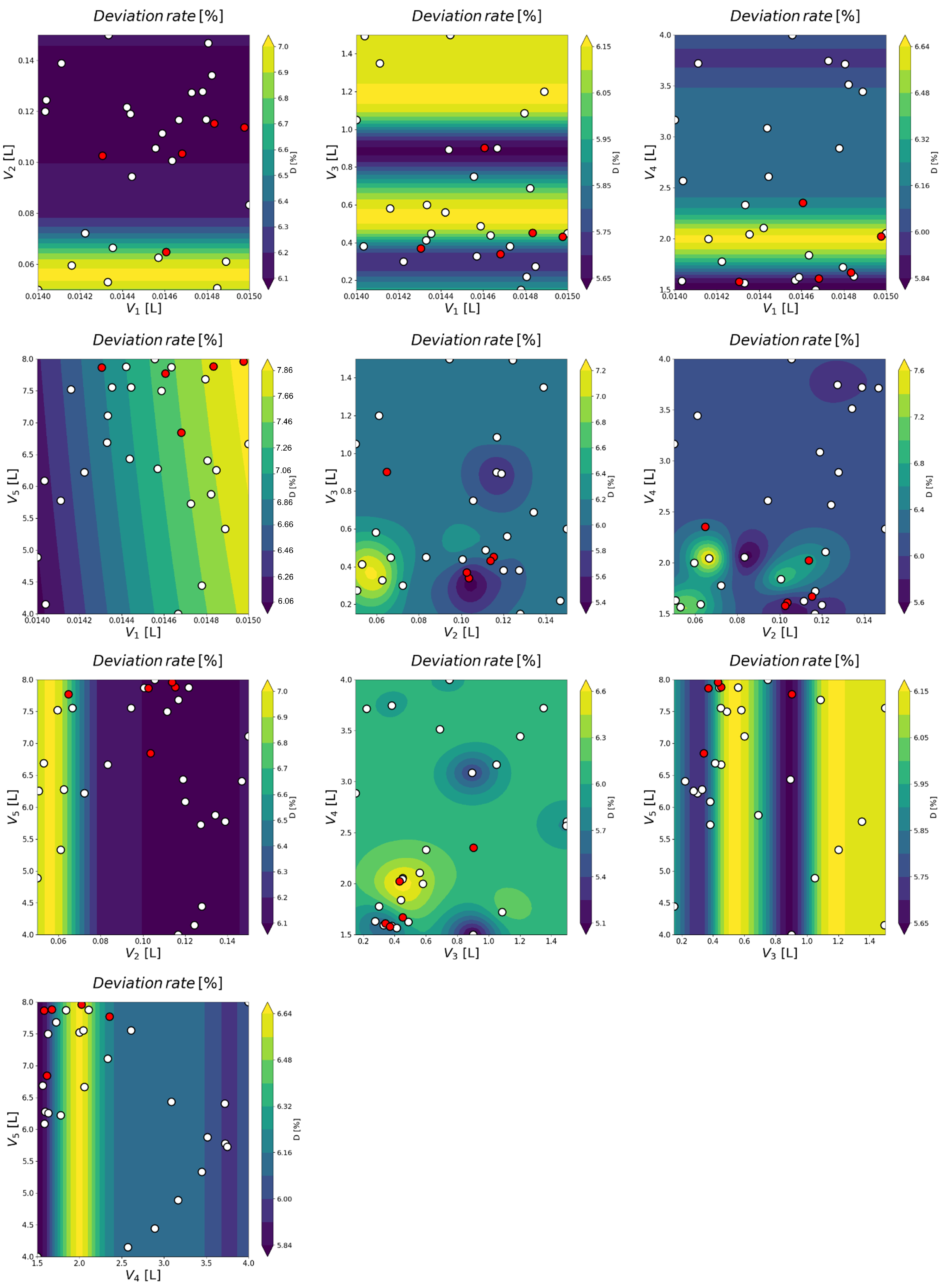
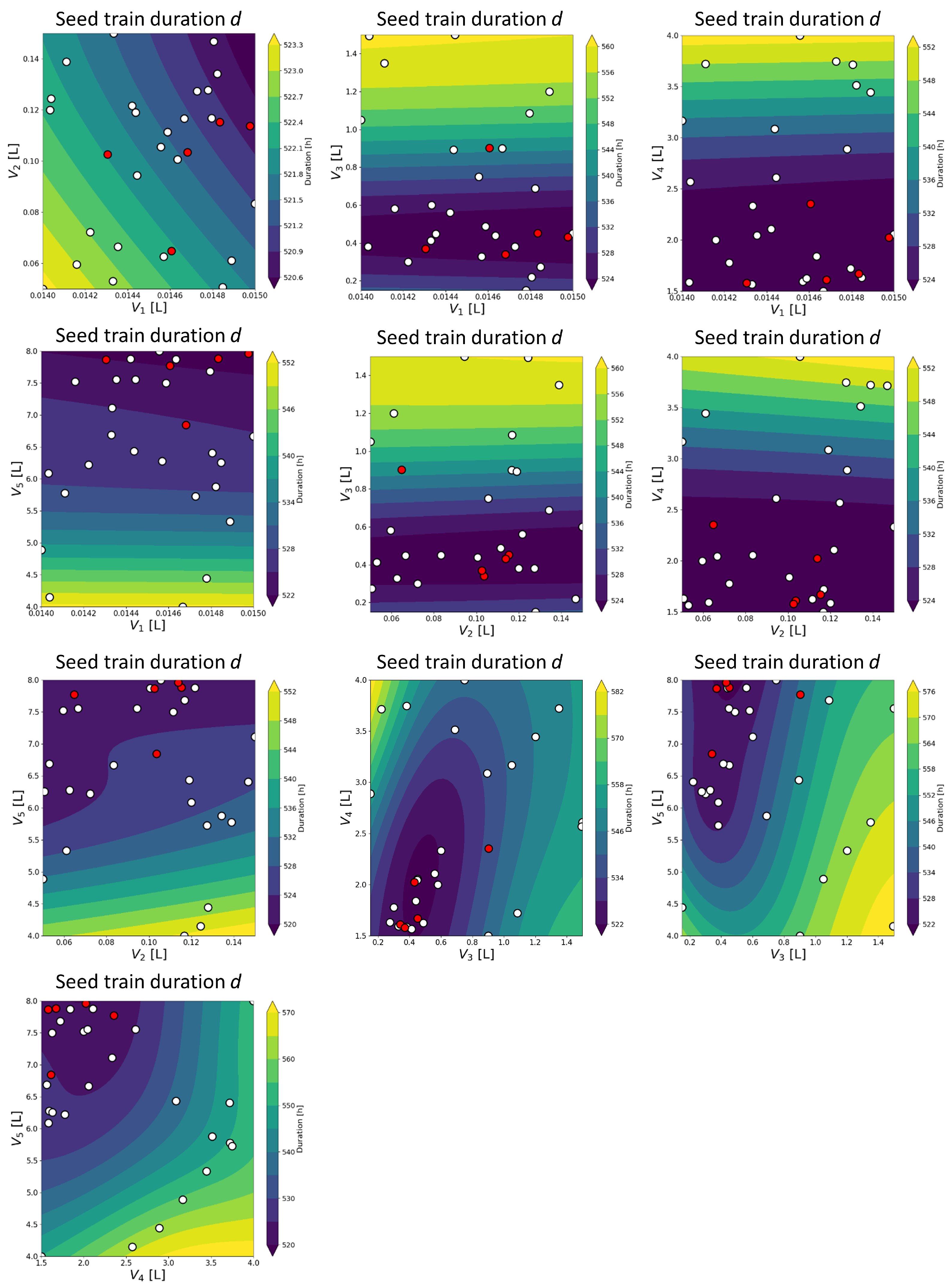
A more detailed illustration of the obtained results is presented in
Figure 4 and
Figure 5. For two optimizable variables and one objective criterion each (deviation rate in
Figure 4 and seed train duration in
Figure 5), a contour plot is shown which illustrates the objective value for each calculated point (combination of the two variables), using the trained Gaussian processes, through colored isolines.
For example, the diagram in the top left of
Figure 4 shows the deviation rate for each combination of
(filling volume in flask scale 1) and
(filling volume in flask scale 2) through colors representing the corresponding values in %, as indicated in the color bar. The results obtained through seed train simulations are shown by dots. The red dots represent the non-dominated (optimal solutions), optimal with respect to the defined multi-objective optimization problem. The dark blue area indicates combinations of
and
leading to a lower deviation rate. It can be seen that values above 0.1 for
combined with any value of
(within the given range) lead to the lowest deviation rates (below 6.2%, see dark blue area). Moreover, the optimal solutions (red dots) are mostly located in the area with higher filling volumes for shake flask 2,
, except one (red dot at
0.065).
For some combinations, a closer delimitation is possible. For example, the middle diagram in the second row (
over
) shows a limited region (dark blue area) and therewith a specific combination of
and
that leads to the lowest deviation rates (<5.6%). These are around 0.3 L for
and around 0.105 L for
. Furthermore, two optimal solutions (red dots) out of the set of Pareto optimal solutions (considering both objective criteria, seed train duration and deviation rate) are located in this region. The remaining red dots are located outside of the dark blue regions (see turquoise regions in the same diagram), meaning that they have higher deviation rates. Analogously,
Figure 5 shows the contour plots for the second objective criterion, seed train duration. The dark blue areas show the combinations with the lowest seed train durations (approximately below 528 h). It can be seen in these diagrams that most red dots are located in the dark blue regions. For some combinations the dark blue areas are wider, distributed over several possible values for one variable, e.g., the diagram in the top center, top left, center, and center right.
Other combinations show narrower regions with low seed train durations as can be seen in the diagram showing over . The lowest seed train duration is obtained for filling volumes between 1.5 and 2.5 L for shake flask 4 in combination with filling volumes between 0.2 and 0.8 L for shake flask 3.
Overall, these diagrams give an overview of the impact of two combined optimizable variables each on a specific objective criterion.
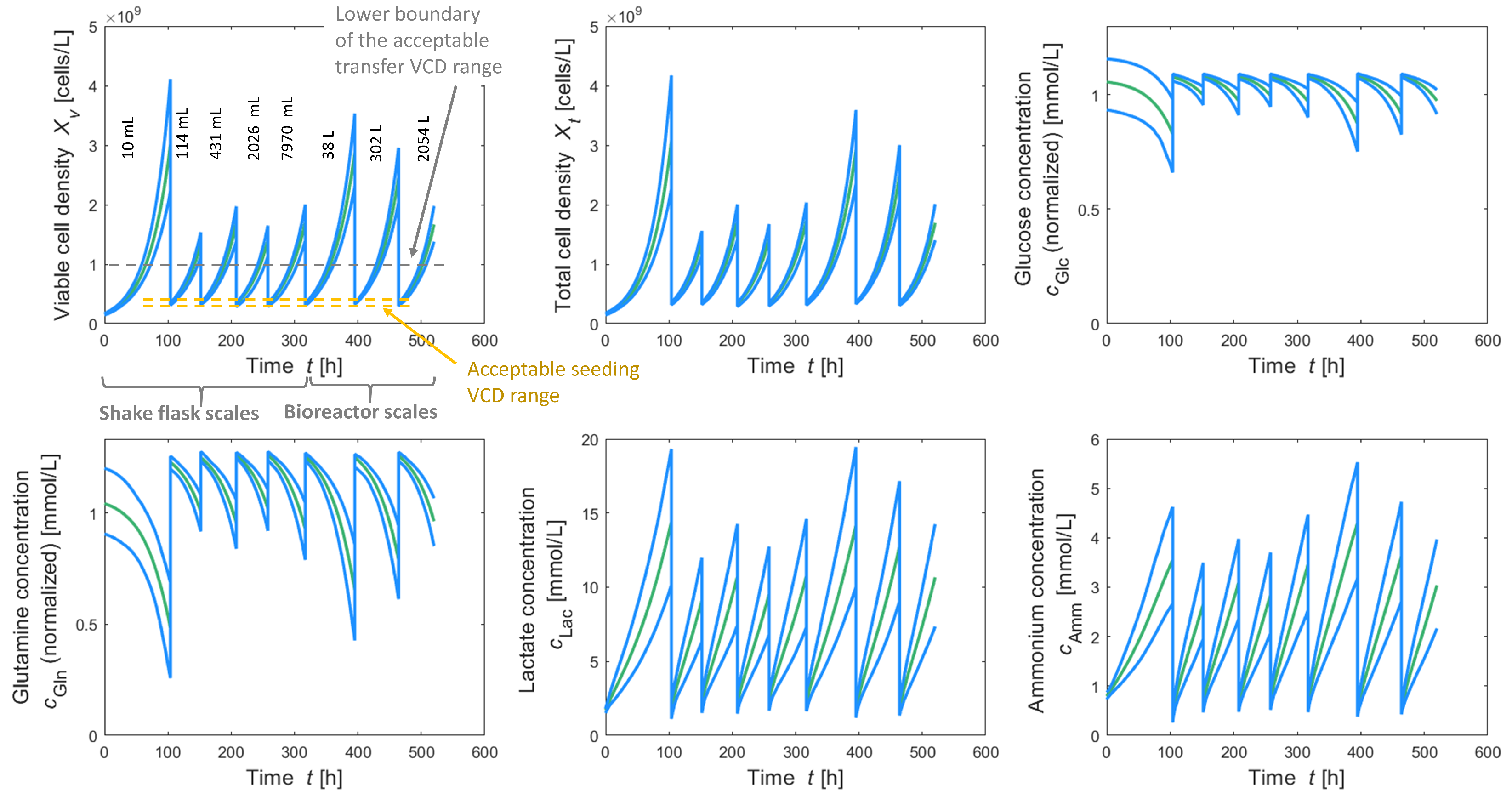
In addition to this information, simulated time profiles (predictive mean in green, 90% prediction bands in blue) of viable and total cell density as well as concentrations of glucose, glutamine, lactate and ammonium (see
Figure 6) can be obtained for each solution, as well as a seed train protocol containing information about the calculated passaging intervals, amount of medium, etc.
It can be seen in the top left of
Figure 6 that based on the given filling volumes in addition to the flexibility to choose individual points in time for cell passaging in each scale, it is possible to set the seeding viable cell density at the beginning of each cultivation scale on the desired value with low variability, allowing to stay within the corresponding acceptable ranges for seeding VCD (see yellow dashed lines). Moreover, transfer VCDs lie within the corresponding acceptable range with high probability (see lower boundary, gray dashed line). Moreover, it can be seen that substrate concentrations are not depleted and according to [
27], values of 20 mmol/L lactate and 5 mmol/L ammonium are not yet inhibiting concentrations for this cell line.
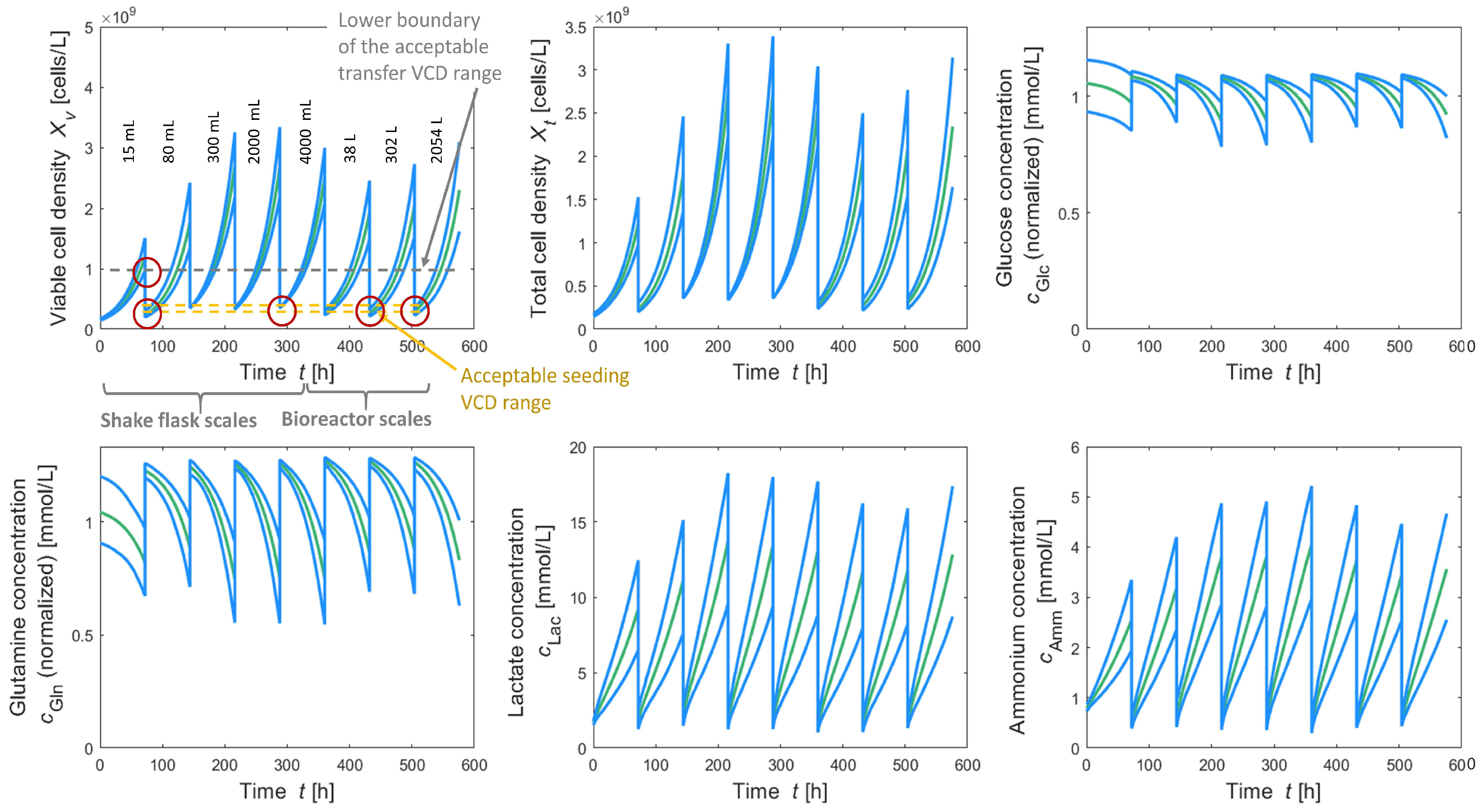
For a better assessment, the obtained results are compared to the reference seed train which is also defined in this work for five shake flask scales and illustrated in
Figure 7. It grounds on a (non-optimized) configuration setup for five shake flask scales using fixed passaging intervals of 72 h each (common practice) and filling volumes of 15 mL (flask scale 1), 80 mL (flask scale 2), 300 mL (flask scale 3), 2000 mL (flask scale 4) and 4000 mL (flask scale 5). This choice grounds on a rather conservative approach aiming to avoid the risk of reaching too low transfer cell densities at the end of a cultivation scale but without the inclusion of probabilistic simulations.
The proposed method instead includes risk calculations and a passaging strategy aiming to minimize this risk but at the same time identifying a seed train configuration which is optimal regarding further objectives such as seed train duration in the present case.
A comparison of the seed train solutions obtained after optimization and the reference seed train shows that deviation rate is much lower after optimization (4.9–6.7% instead of 41.7%) and seed train duration could be reduced by 56 h from 576 h to 520 h.
Figure 7, diagram top left shows where seeding or transfer viable cell density do not lie fully within the acceptable ranges (see red circles). This is different for the optimized solutions, e.g., solution 5, as illustrated in
Figure 6, where seeding VCD lies within the acceptable range and also transfer VCD lies above the lower bound of the acceptable range for transfer VCD. This significant reduction in time (≈2 days per seed train) would contribute to a meaningful acceleration of the production process.
3.1.2. Optimization of Three and Four Shake Flask Scales
In the next step, the number of shake flask scales was reduced from five to four and then to three shake flask scales and the same optimization procedure was applied. The aim was to investigate if less cultivation vessels would lead to comparable results and if so, which target and filling volumes should be chosen. This is of interest because less operations (such as transferring cells from one scale into another one) signify less risk of failure and deviations.
Figure 8 shows the obtained values for the objective criteria deviation rate and seed train duration for different combinations of filling volumes for three (left) and for four shake flask scales (right). Furthermore, here, the solutions based on the initial Latin hypercube design are shown by blue dots and Pareto optimal solutions are highlighted through green circles.
It can be seen that for both scenarios, combinations of filling volumes could be found leading to an overall seed train cultivation time between 519 and 530 h. However, the scenario of using four shake flask scales, leads to lower deviation rates () compared to the scenario of using three shake flask scales ().
The corresponding filling volumes and the obtained filling volumes (based on the underlying passaging strategy) of the Pareto optimal solutions are listed in
Table 4 together with the results for five shake flask scales from
Table 3. The results are sorted as discovered by the optimization algorithm. The obtained filling volumes for four shake flask scales are very similar, except for shake flask scale 4 (
= 15 mL,
= 158–200 mL,
= 1.51–1.60 L and
= 4.81–7.58 L). Some of the obtained solutions would be seen or treated as equal in practice, because the differences are rather small. For example it would not be distinguished between 0.190 and 0.195 L. Probably 200 mL would be used instead. However, the applied optimization algorithm works on a continuous input space and differentiates between the solutions listed in the
Table 4, even though the differences are very low. The obtained optimal filling volumes for three shake flask scales also look similar, but with a bit more variation for shake flask 3 (4.45–5.58 L).
Comparing the results for the three scenarios (three, four and five shake flask scales) endorses a decision against the three flask scales-scenario due to the higher deviation rates (>20%), which stands for less process robustness. Between the other two scenarios (four or five shake flask scales) only little differences with respect to deviation rates are observed for the determined optimal solutions (4.9–6.7% for five shake flasks, 5.9–9.2% for four shake flasks). Using five shake flask scales would lead to more or less similar cultivations times (520–537 h) but one operational step more would be required.
This information, together with the corresponding seed train protocol, provides a solid basis to take a decision for one of the proposed optimal seed trains designs, taking into account seed train duration, robustness (expressed through deviation rates) and operational steps.
3.2. Application to Further Cell Lines with Potentially Different Growth Rates
The optimization examples presented in the previous subsection were applied to a specific CHO cell line with growth characteristics described by a set of model parameters derived from an industrial cell culture process which was investigated in [
27]. If a different cell line or a clonal cell population with potentially differing growth behavior is used, then the optimization has to be performed for this specific cell line. In the following simulation study, a cell line having a 5% lower and a cell line having a 5% higher maximum cell-specific growth rate compared to the reference maximum growth rate (
= 0.028 h
for the first bioreactor scale and
= 0.029 h
for the remaining seed train scales) are assumed and the optimization is applied for both scenarios.
The results for the obtained/proposed filling volumes, as well as the corresponding seed train duration and deviation rate are listed in
Table 5.
As expected, cells which grow faster (higher maximum growth rate
) would require less time until reaching a specific target cell density. This can be seen in the right column of
Table 5. Using five flask scales, the optimal required seed train duration would lie between 494 and 503 h for a cell line with a 5% higher growth rate compared to the reference cell line which would need 520–537 h (see
Table 3). Correspondingly, cells with a 5% lower growth rate would need more time (550–568 h). The same is observed when using four or three shake flasks.
With respect to the deviation rates which represent the robustness of the seed train design regarding variability of viable cells, it can be seen that low deviation rates of between 4.1% and 11.6% can be reached when using five or four flask scales, even if the maximum growth rate varies ±5%. A critical limit was identified for the combination of using three shake flask scales for a slower growing cell line. The corresponding optimal solution shows a comparatively higher deviation rate (19.2–29.1%) together with a high seed train duration (548–552 h).
3.3. Optimization Regarding Four Objectives Including Product Concentration
To show the applicability of the proposed method to more than two objectives, a third and a fourth objective criterion, titer concentration and viability at the end of the production vessel (after 8 days) was added. Whereas the first two objective criteria (seed train duration and deviation rate) are related to the seed train itself, the third and fourth criterion refer to the generated product in the production vessel and to the viability of the cells in the production vessel. Product concentration, as well as product quality can be influenced by many factors (seeding cell density, substrate concentrations and nutrient feeds, metabolite production, temperature, pH, dissolved oxygen and carbon dioxide concentration, osmolality and more) and also by the amount and the state of the cells at the end of the seed train. Since no data describing product quality are available, product concentration and viability are considered in this study. A further simplification that was made is the assumption that the production vessel is performed in batch-mode (meaning without any addition of nutrient feeds or medium renewals). The reason for this simplification is to avoid confounding effects. The authors are aware of the fact that many factors affect product concentration and product quality and when data of other critical process parameters or quality attributes are available, these could also be considered in the same manner. The main purpose of the present simulation example is to demonstrate how the proposed method can be applied to more than two objectives and how the corresponding results can be illustrated and interpreted.
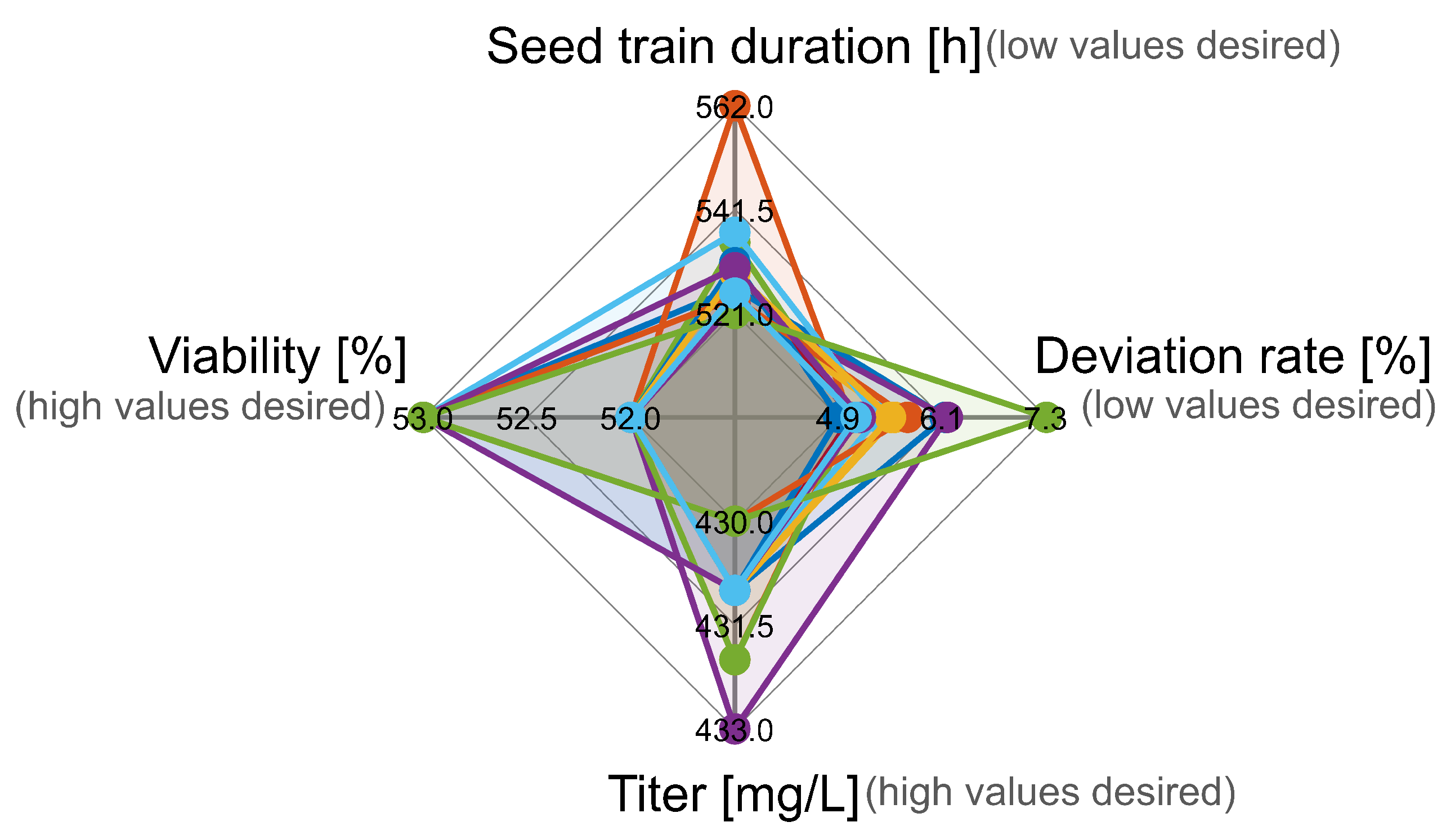
To obtain a visual overview for multiple objective criteria in one figure, a so-called spider plot (or net plot) can be used, which is shown in
Figure 9.
The horizontal axis shows the values of the deviation rate (on the right) and of the viability (on the left). The vertical axis shows the values of the seed train duration (above) and of the titer (below). The aim of the optimization was to minimize seed train duration and deviation rate and to maximize viability and titer. Each color (hyperplane) represents one of the Pareto optimal seed train configurations (based on the optimal combinations of filling volumes in shake flask scales). Since seed train duration and deviation rate should be minimal and titer and viability should be maximal, hyperplanes covering the lower left area would be desired. However, no such solution (hyperplane) was obtained. The reason is that the optimization problem contains conflicting objective criteria, meaning that an improvement of one criterion leads to a degradation of another criterion. The here presented solutions are all non-dominated (see the green circles in the figures for two objective criteria). For all shown solutions, the deviation rate is rather low (4.9–7.3%), the seed train duration lies between 521 and 562 h and a titer of approximately 430–433 mg/L (assuming here a cell-specific production rate of
mg cell
h
, as reported in [
40]) and a viability of 52–53% is reached after 8 days in the production vessel (here via batch-mode). Of course, the obtained values depend a lot on the real process conditions (production bioreactor probably performed in fed-batch model) and the model parameter values obtained after model validation. However, the presented simulation example shall illustrate how the proposed approach can be applied for risk-based decision making under consideration of several criteria that should be optimal.
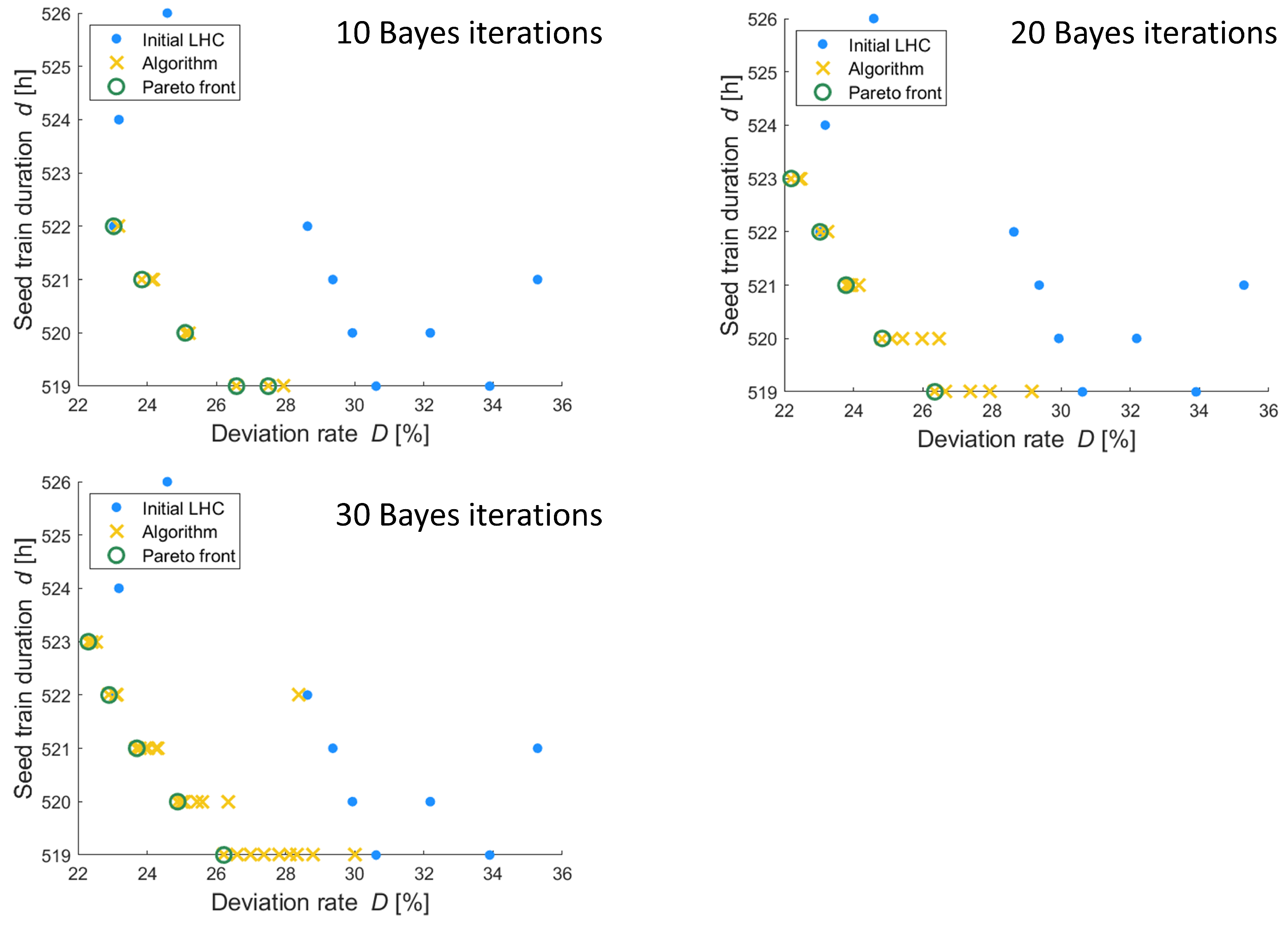
3.4. Impact of Performed Iterations during Bayes Optimization
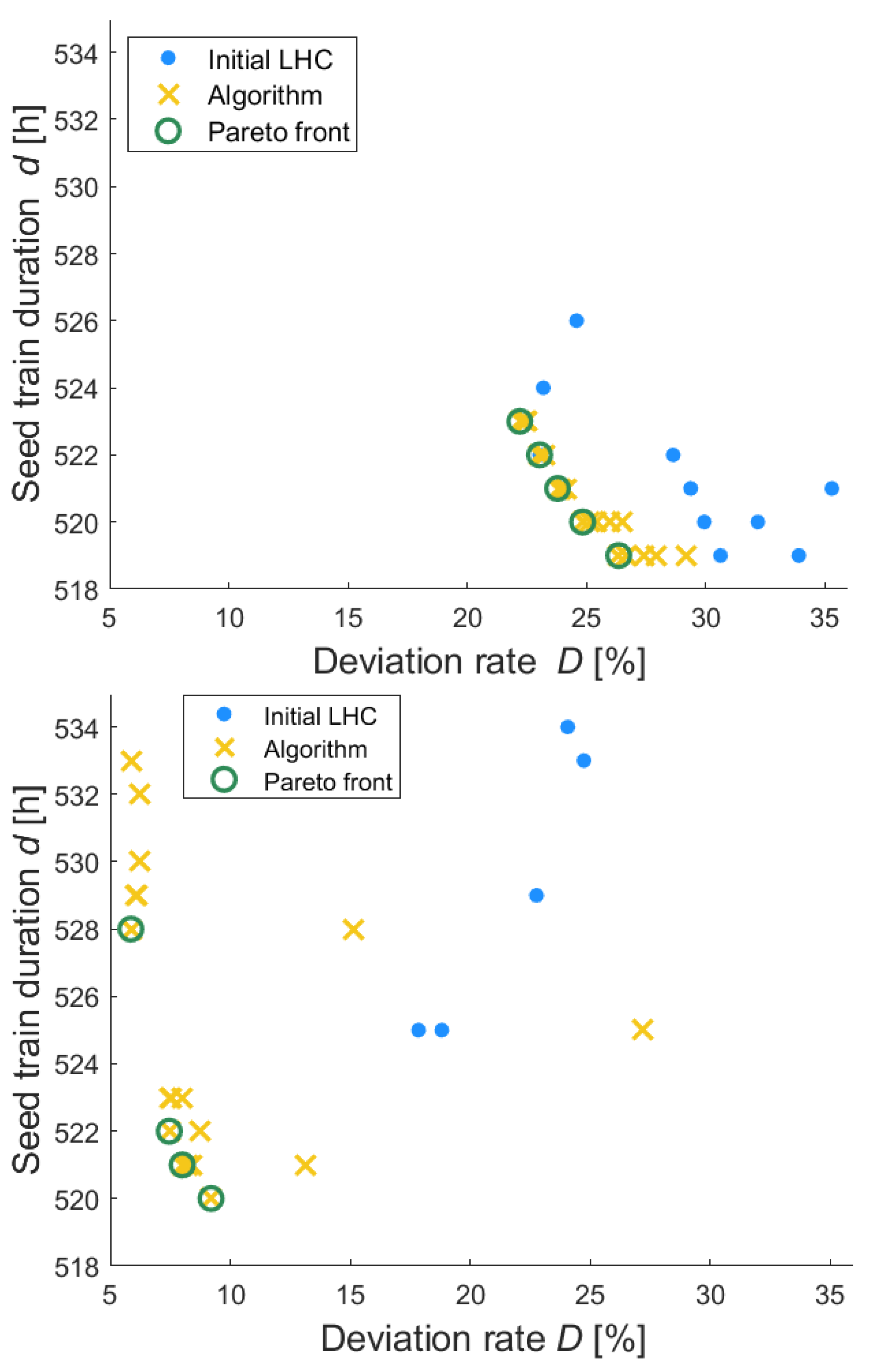
For the example of three shake flask scales, (followed by three bioreactor scales) and optimizing filling volumes for all shake flask scales with respect to the two objective criteria: seed train duration and deviation rate, the number of performed iterations during the optimization procedure was varied. First, 10 initial points (combinations of filling volumes) distributed based on a Latin hypercube design were evaluated, followed by 10 Bayes iterations, which means that 10 times the algorithm updates the black box model (the Gaussian process), calculates the acquisition function and proposes the next point based on the outcome of this calculation. Then, the optimization was performed again for the same seed train setup but using 20 and then 30 Bayes iterations. The obtained solutions are illustrated in
Figure 10.
Increasing the number of iterations from 10 to 20 helped to identify one solution that has not been discovered when running only 10 iterations. This can be seen when comparing the green circles in the diagram top left and the green circles in the diagram top right. The solution with 22 and d = 523 cannot been found in the diagram top left.
Increasing the number of iterations from 20 to 30 did not lead to an improved optimum as can be seen when comparing the green circles in the
Figure 10 top right diagram and bottom left diagram. This underlines the efficiency of the Bayes optimization. In the present example, only 10 initial points (distributed randomly according to a Latin hypercube design) and 20 Bayes optimization iteration steps were required to obtain the results which were confirmed when applying 30 iteration steps.
3.5. Summary
The objective of the first optimization problem was to design a robust seed train (cell expansion process), which means a seed train layout (including the number of cultivation scales, filling volumes and passaging intervals) leading to a reproducible seed train with low variability regarding viable cell density and with a minimum seed train duration. The obtained solutions were compared to a non-optimized reference seed train and a comparison showed that the deviation rate is much lower after optimization (<10% instead of 41.7%) and seed train duration could be reduced by 56 h from 576 h to 520 h, which means a significant reduction of more than 2 days.
Addressing the question of if variation of the number of shake flask scales (and therewith the number of passaging steps) would lead to similar results in terms of deviation rates and seed train duration, it turned out that a reduction to three shake flask scales, would mean an increase in deviation rate and is therefore not recommended, at least under the assumed working volume ranges.
In industrial practice, typically more than one cell line is in use (different cell lines may be used to produce different molecules/products). Since growth rates of different cell lines differ, it was investigated how optimal seed train designs would differ for cell lines with 5% higher or lower growth rates. It turned out that the same optimization procedure could be easily adapted (by modification of the model parameter maximum growth rate) and applied to the modified setup revealing critical limits, e.g., for the combination of using three shake flask scales for a slower growing cell line. The latter shows comparatively high deviation rates (19.2–29.1%) together with high seed train durations (548–552 h instead of 519–523 h for the reference growth rate).
To show the applicability of the proposed method to more than two objective criteria, a third and fourth objective criterion, product concentration (titer) and viability after 8 days in the production phase, were added and the optimization was performed regarding four objective criteria in total. These are seed train duration, deviation rate (i.e., the probability that the seed train will run outside the predefined criteria), titer and viability at the end of the production phase.
Moreover, it was investigated for one seed train configuration (three shake flask scales and two objectives using the reference cell growth rate) if increasing the number of Bayes iterations would identify different optima. A number of 20 Bayes iterations turned out to be sufficient, because running 20 or 30 Bayes iterations showed similar results, which underlines the efficiency of the Bayes optimization approach.
In the present case study, the volumes are considered as fixed after optimization. If the production process allows for more flexibility in terms of adapting the volume within a specific range in the case that cells grow slower than the expected mean, then a reduction in the deviation rate can be achieved because varying the volumes allows for regulation of the inoculum viable cell density. However, this flexibility is not always given due to regulatory requirements and therefore not considered in the present study.
4. Conclusions
A concept has been developed to use process models in combination with algorithms for Bayes optimization using Gaussian processes to solve multi-objective optimization problems in the context of biopharmaceutical production processes. To illustrate this approach, a relevant exemplary optimization problem was chosen and solved using the proposed method.
The goal was to find optimal combinations of filling volumes for the shake flask scales of a seed train leading to a minimum deviation rate regarding viable cell densities and a minimum process duration. Compared to a non-optimized reference seed train, the optimized process showed much lower deviation rates regarding viable cell densities (<10% instead of 41.7%) using five or four shake flask scales and seed train duration could be reduced by 56 h from 576 h to 520 h.
Overall, it is shown that applying Bayes optimization to a multi-objective optimization function with several optimizable input variables and under a considerable amount of constraints, lead to revealing results with a low computational effort. This approach provides the potential to be used in form of a decision tool, e.g., for the choice of an optimal and robust seed train design but also to further optimization tasks within process development.
It should be noted that Bayes optimization and the corresponding computational modules could also be applied, even if no mechanistic process model is available, following a slightly different workflow. Instead of performing model-based in silico experiments (process simulations), real lab experiments would be performed and fed back to update the black box model (here the Gaussian process). This adaptive procedure (also called Bayesian experimental design or experimental design with Bayesian optimization [
41]) or further related optimization methods might be promising tools to support experimental planning, process characterization, process transfer or optimization of cell culture processes but they still require further research and being embedded in software solutions that are easy to use for operators.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











