
Evaluation of Arabian Vascular Plant Barcodes (rbcL and matK): Precision of Unsupervised and Supervised Learning Methods towards Accurate Identification

 ,
, 
Abstract
:
1. Introduction
2. Results
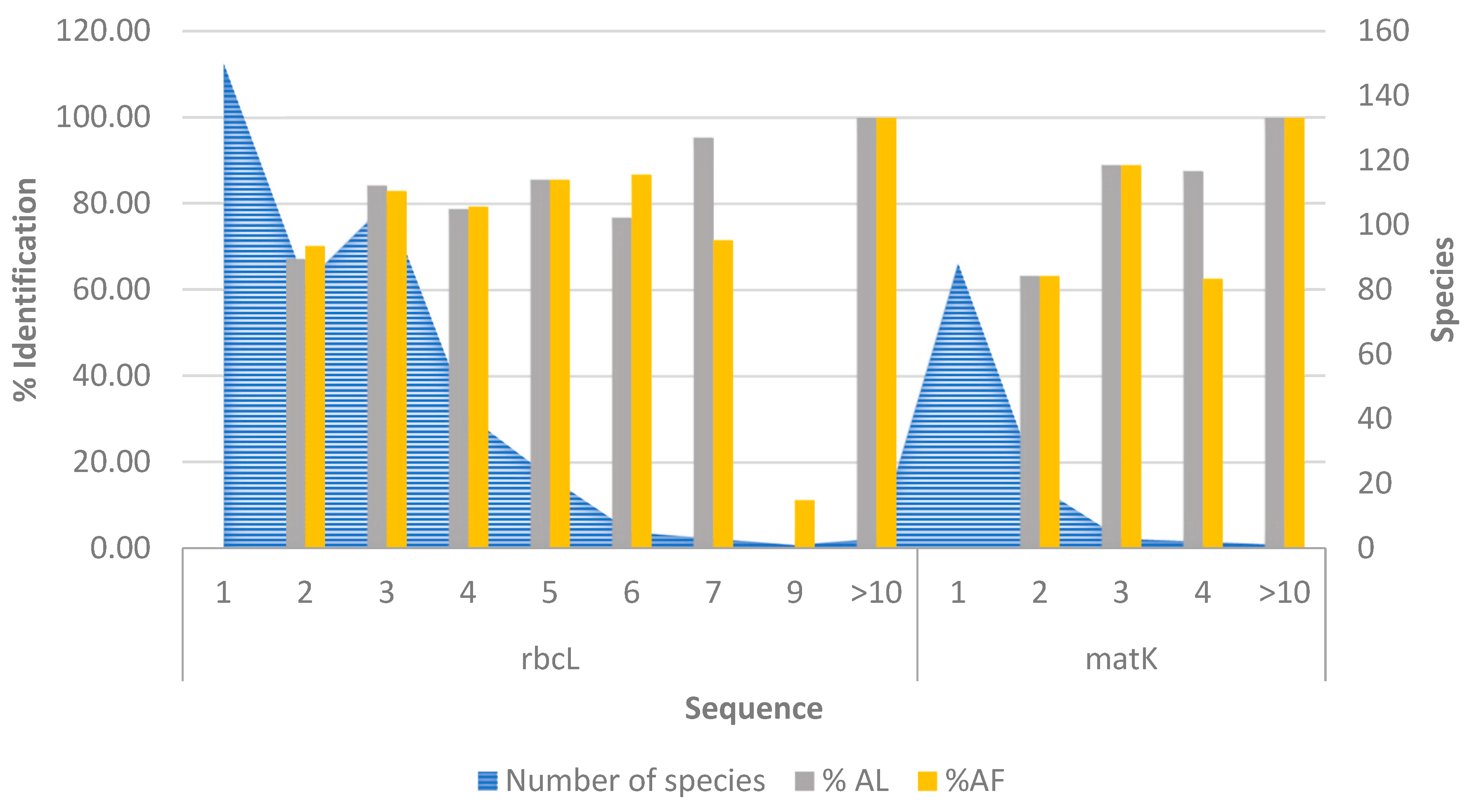
2.1. Data
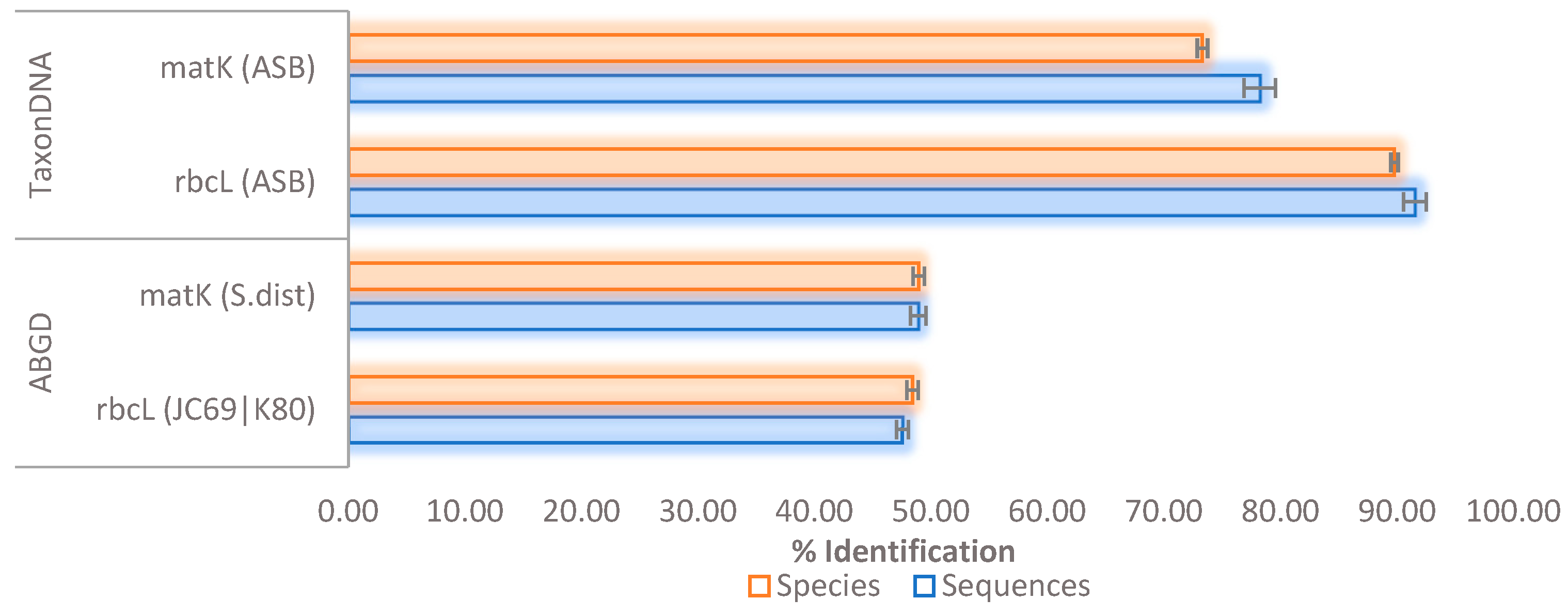
2.2. Unsupervised Species Identification and Barcode Validation
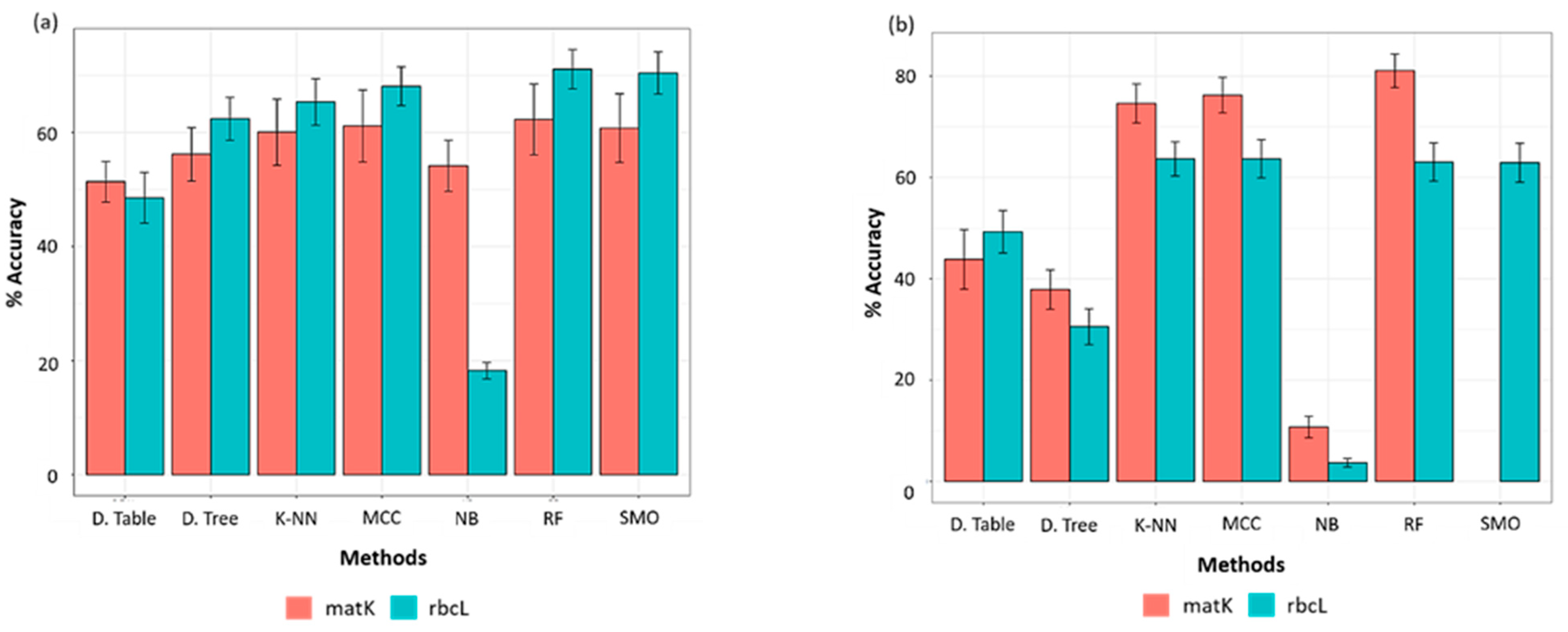
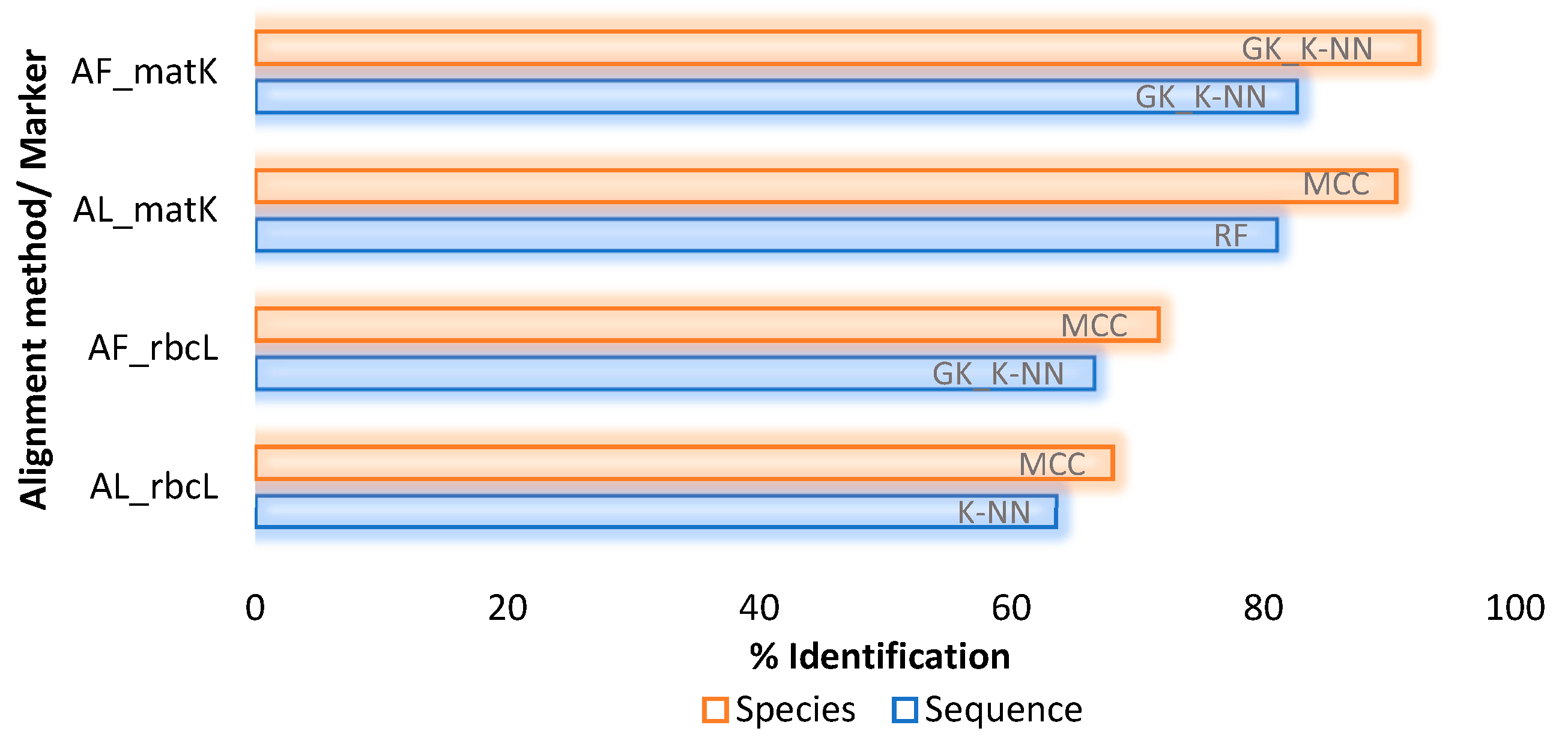
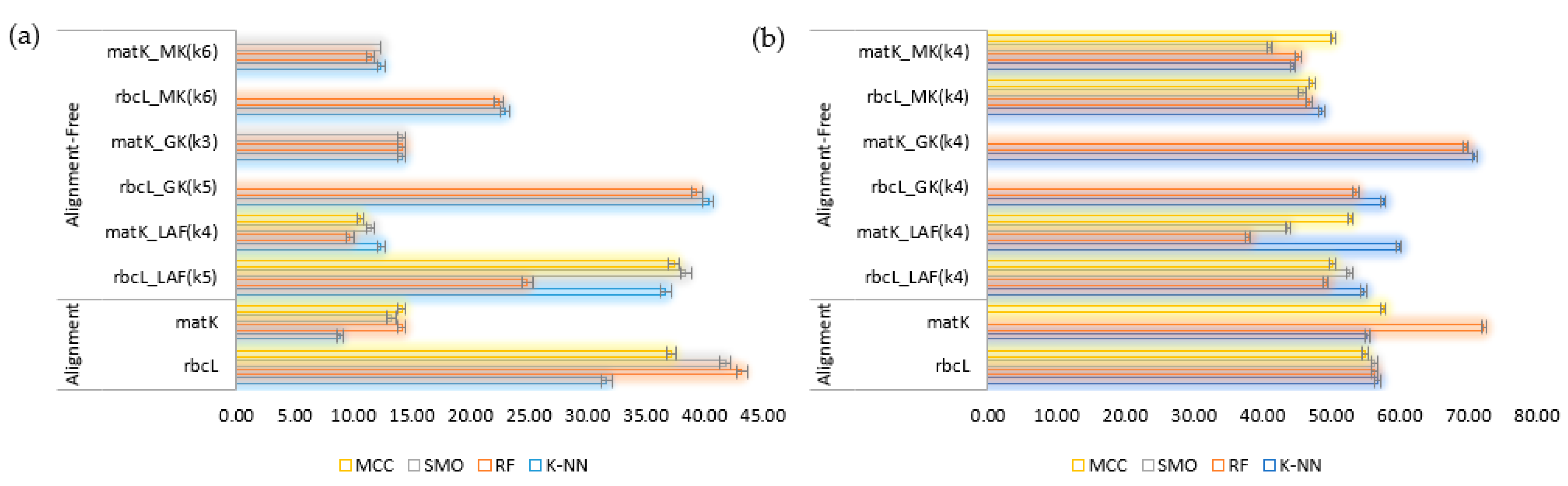
2.3. Supervised Species Identification and Barcode Validation
2.3.1. Evaluation of Classifier(s)
2.3.2. Employing Classifiers for Analysis
2.3.3. Accuracy of Machine Learning Classifiers
3. Discussion
4. Materials and Methods
4.1. Pre-Processing
4.2. Sequence Analysis
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Almazroui, M.; Islam, M.N.; Athar, H.; Jones, P.; Rahman, M.A. Recent climate change in the Arabian Peninsula: Annual rainfall and temperature analysis of Saudi Arabia for 1978–2009. Int. J. Clim. 2012, 32, 953–966. [Google Scholar] [CrossRef]
- Ghazanfar, S.; Fisher, M. Vegetation of the Arabian Peninsula; Springer: Berlin/Heidelberg, Germany, 1998; ISBN 978-90-481-5020-5. [Google Scholar]
- Ghazanfar, S.A.; McDaniel, T. Floras of the middle east: A quantitative analysis and biogeography of the flora of Iraq. Edinb. J. Bot. 2015, 73, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Al-Hawshabi, O.S.S. Two new records to the flora of the Arabian Peninsula from Yemen. J. Biol. Earth Sci. 2014, 4, B179–B184. [Google Scholar]
- Sawsan, A.O. A list of flowering wild plants in Tafila Province, Jordan. Int. J. Biodivers. Conserv. 2014, 6, 28–40. [Google Scholar] [CrossRef] [Green Version]
- Thomas, J. Flora of Saudi Arabia-Checklist. Available online: http://plantdiversityofsaudiarabia.info/Biodiversity-Saudi-Arabia/Flora/Checklist/Cheklist.htm (accessed on 11 October 2018).
- Patzelt, A. Synopsis of the flora and vegetation of Oman, with special emphasis on patterns of plant endemism. Abh. Braunschw. Wiss. Ges. 2014, 282, 317. [Google Scholar]
- Sakkir, S. Medicinal plants diversity and their conservation status in the United Arab Emirates (UAE). J. Med. Plants Res. 2012, 6, 1304–1322. [Google Scholar] [CrossRef]
- Abdullah, M.T. Conserving the Biodiversity of Kuwait through DNA Barcoding the Flora; The University of Edinburgh: Edinburgh, UK, 2017. [Google Scholar]
- Norton, J.; Abdul Majid, S.; Allan, D.; Al Safran, M.; Böer, B.; Richer, R.; Renee, A. An Illustrated Checklist of the Flora of Qatar; Browndown Publications: Gosport, UK, 2009; ISBN 9780956396105. [Google Scholar]
- Abbas, J.A. Plant communities bordering the sabkhat of Bharain island. In Sabkha Ecosystems; Barth, H.J., Böer, B., Eds.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2002; pp. 51–62. [Google Scholar]
- Hebert, P.D.N.; Gregory, T.R. The promise of DNA barcoding for taxonomy. Syst. Biol. 2005, 54, 852–859. [Google Scholar] [CrossRef]
- Kress, W.J.; Erickson, D.L. DNA barcodes: Genes, genomics, and bioinformatics. Proc. Natl. Acad. Sci. USA 2008, 105, 2761–2762. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mosa, K.A.; Gairola, S.; Jamdade, R.; El-Keblawy, A.; Al Shaer, K.I.; Al Harthi, E.K.; Shabana, H.A.; Mahmoud, T. The promise of molecular and genomic techniques for biodiversity research and DNA barcoding of the Arabian Peninsula flora. Front. Plant Sci. 2019, 9, 1929. [Google Scholar] [CrossRef]
- Jamdade, R.; Mahmoud, T.; Gairola, S. Prospects of genomic resources available at the global databases for the flora of United Arab Emirates. 3 Biotech 2019, 9, 333. [Google Scholar] [CrossRef]
- CBOL Plant Working Group; Hollingsworth, P.M.; Forrest, L.L.; Spouge, J.L.; Hajibabaei, M.; Ratnasingham, S.; van der Bank, M.; Chase, M.W.; Cowan, R.S.; Erickson, D.L.; et al. A DNA barcode for land plants. Proc. Natl. Acad. Sci. USA 2009, 106, 12794–12797. [Google Scholar] [CrossRef] [Green Version]
- Li, F.-W.; Kuo, L.-Y.; Rothfels, C.; Ebihara, A.; Chiou, W.-L.; Windham, M.D.; Pryer, K.M. rbcL and matK earn two thumbs up as the core DNA barcode for ferns. PLoS ONE 2011, 6, e26597. [Google Scholar] [CrossRef]
- De Vere, N.; Rich, T.C.G.; Ford, C.R.; Trinder, S.; Long, C.; Moore, C.W.; Satterthwaite, D.; Davies, H.S.; Allainguillaume, J.; Ronca, S.; et al. DNA barcoding the native flowering plants and conifers of Wales. PLoS ONE 2012, 7, e37945. [Google Scholar] [CrossRef] [Green Version]
- Saarela, J.M.; Sokoloff, P.; Gillespie, L.J.; Consaul, L.L.; Bull, R.D. DNA Barcoding the Canadian arctic flora: Core plastid barcodes (rbcL + matK) for 490 vascular plant species. PLoS ONE 2013, 8, e77982. [Google Scholar] [CrossRef] [Green Version]
- Braukmann, T.W.A.; Kuzmina, M.; Sills, J.; Zakharov, E.V.; Hebert, P.D.N. Testing the efficacy of DNA barcodes for identifying the vascular plants of Canada. PLoS ONE 2017, 12, e0169515. [Google Scholar] [CrossRef]
- Parveen, I.; Singh, H.K.; Malik, S.; Raghuvanshi, S.; Babbar, S.B. Evaluating five different loci (rbcL, rpoB, rpoC1, matK, and ITS) for DNA barcoding of Indian orchids. Genome 2017, 60, 665–671. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Elansary, H.O.; Ashfaq, M.; Ali, H.M.; Yessoufou, K. The first initiative of DNA barcoding of ornamental plants from Egypt and potential applications in horticulture industry. PLoS ONE 2017, 12, e0172170. [Google Scholar] [CrossRef] [PubMed]
- Bafeel, S.; Arif, I.; Bakir, M.; Khan, H.; Al Farhan, A.; Al Homaidan, A.; Ahamed, A.; Thomas, J. Comparative evaluation of PCR success with universal primers of maturase K (matK) and ribulose-1, 5-bisphosphate carboxylase oxygenase large subunit (rbcL) for barcoding of some arid plants. Plant Omics 2011, 4, 195–198. [Google Scholar]
- Bafeel, S.O.; Arif, I.A.; Al-Homaidan, A.A.; Khan, H.A.; Ahamed, A.; Bakir, M.A. Assessment of DNA barcoding for the identification of Chenopodium murale L. (Chenopodiaceae). Int. J. Biol. 2012, 4, 66–74. [Google Scholar] [CrossRef] [Green Version]
- Bafeel, S.; Arif, I.; Bakir, M.; Al Homaidan, A.; Al Farhan, A.; Khan, H. DNA barcoding of arid wild plants using rbcL gene sequences. Genet. Mol. Res. 2012, 11, 1934–1941. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.; Al-Qurainy, F.; Nadeem, M.; Tarroum, M. Development of genetic markers for Ochradenus arabicus (Resedaceae), an endemic medicinal plant of Saudi Arabia. Genet. Mol. Res. 2012, 11, 1300–1308. [Google Scholar] [CrossRef]
- Khan, S.; Al-qurainy, F.; Nadeem, M.; Tarroum, M. Selection of Chloroplast DNA markers for the development of DNA barcode and reconstruction of phylogeny of senecio asirensis boulos and j.r.i. wood. Pak. J. Bot. 2013, 45, 703–710. [Google Scholar]
- Enan, M.; Ahamed, A. DNA barcoding based on plastid matK and RNA polymerase for assessing the genetic identity of date (Phoenix dactylifera L.) cultivars. Genet. Mol. Res. 2014, 13, 3527–3536. [Google Scholar] [CrossRef]
- Enan, M.; Ahmed, A. Cultivar-level phylogeny using chloroplast DNA barcode psbK-psbI spacers for identification of Emirati date palm (Phoenix dactylifera L.) varieties. Genet. Mol. Res. 2016, 15, gmr.15038470. [Google Scholar] [CrossRef] [PubMed]
- Enan, M.R.; Palakkott, A.R.; Ksiksi, T.S. DNA barcoding of selected UAE medicinal plant species: A comparative assessment of herbarium and fresh samples. Physiol. Mol. Biol. Plants 2017, 23, 221–227. [Google Scholar] [CrossRef] [Green Version]
- Maloukh, L.; Kumarappan, A.; Jarrar, M.; Salehi, J.; El-Wakil, H.; Lakshmi, T.V.R. Discriminatory power of rbcL barcode locus for authentication of some of United Arab Emirates (UAE) native plants. 3 Biotech 2017, 7, 144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meyer, C.P.; Paulay, G. DNA barcoding: Error rates based on comprehensive sampling. PLoS Biol. 2005, 3, e422. [Google Scholar] [CrossRef] [Green Version]
- Check, E. Cowrie study strikes a blow for traditional taxonomy. Nat. Cell Biol. 2005, 438, 722–723. [Google Scholar] [CrossRef]
- Cognato, A.I.; Caesar, R.M.; Blaxter, M.; Vogler, A.P. Will DNA barcoding advance efforts to conserve biodiversity more efficiently than traditional taxonomic methods? Front. Ecol. Environ. 2006, 4, 268–273. [Google Scholar]
- DasMahapatra, K.K.; Mallet, J. Taxonomy: DNA barcodes: Recent successes and future prospects. Heredity 2006, 97, 254–255. [Google Scholar] [CrossRef]
- Cognato, A.I. Standard percent DNA sequence difference for insects does not predict species boundaries. J. Econ. Entomol. 2006, 99, 1037–1045. [Google Scholar] [CrossRef]
- Meier, R.; Shiyang, K.; Vaidya, G.; Ng, P.K.L. DNA barcoding and taxonomy in diptera: A tale of high intraspecific variability and low identification success. Syst. Biol. 2006, 55, 715–728. [Google Scholar] [CrossRef] [Green Version]
- Meier, R.; Zhang, G.; Ali, F. The use of mean instead of smallest interspecific distances exaggerates the size of the “barcoding gap” and leads to misidentification. Syst. Biol. 2008, 57, 809–813. [Google Scholar] [CrossRef]
- Moritz, C.; Cicero, C. DNA barcoding: Promise and pitfalls. PLoS Biol. 2004, 2, e354. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Puillandre, N.; Lambert, A.; Brouillet, S.; Achaz, G. ABGD, automatic barcode gap discovery for primary species delimitation. Mol. Ecol. 2011, 21, 1864–1877. [Google Scholar] [CrossRef] [PubMed]
- Weitschek, E.; Fiscon, G.; Felici, G. Supervised DNA Barcodes species classification: Analysis, comparisons and results. BioData Min. 2014, 7, 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, A.-B.; Feng, J.; Ward, R.D.; Wan, P.; Gao, Q.; Wu, J.; Zhao, W.-Z. A new method for species identification via. protein-coding and non-coding DNA barcodes by combining machine learning with bioinformatic methods. PLoS ONE 2012, 7, e30986. [Google Scholar] [CrossRef] [Green Version]
- Weitschek, E.; Cunial, F.; Felici, G. LAF: Logic alignment free and its application to bacterial genomes classification. BioData Min. 2015, 8, 39. [Google Scholar] [CrossRef] [Green Version]
- Schaffer, C. Selecting a classification method by cross-validation. Mach. Learn. 1993, 13, 135–143. [Google Scholar] [CrossRef]
- Tabe-Bordbar, S.; Emad, A.; Zhao, S.D.; Sinha, S. A closer look at cross-validation for assessing the accuracy of gene regulatory networks and models. Sci. Rep. 2018, 8, 6620. [Google Scholar] [CrossRef] [Green Version]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; pp. 1137–1143. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Elsevier: San Francisco, CA, USA, 2011. [Google Scholar] [CrossRef] [Green Version]
- Leslie, C.S.; Eskin, E.; Cohen, A.; Weston, J.; Noble, W.S. Mismatch string kernels for discriminative protein classification. Bioinformatics 2004, 20, 467–476. [Google Scholar] [CrossRef]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Keerthi, S.S.; Shevade, S.K.; Bhattacharyya, C.; Murthy, K.R.K. Improvements to Platt’s SMO algorithm for SVM classifier design. Neural Comput. 2001, 13, 637–649. [Google Scholar] [CrossRef]
- Platt, J.C. Fast training of support vector machines using sequential minimal optimization. In Advances in Kernel Methods: Support Vector Learning; MIT Press: Cambridge, MA, USA, 1999; pp. 185–208. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Hebert, P.D.N.; Cywinska, A.; Ball, S.L.; Dewaard, J.R. Biological identifications through DNA barcodes. Proc. R. Soc. B Boil. Sci. 2003, 270, 313–321. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fazekas, A.J.; Kesanakurti, P.R.; Burgess, K.S.; Percy, D.M.; Graham, S.W.; Barrett, S.C.H.; Newmaster, S.G.; Hajibabaei, M.; Husband, B.C. Are plant species inherently harder to discriminate than animal species using DNA barcoding markers? Mol. Ecol. Resour. 2009, 9, 130–139. [Google Scholar] [CrossRef] [PubMed]
- Collins, R.A.; Cruickshank, R.H. The seven deadly sins of DNA barcoding. Mol. Ecol. Resour. 2012, 13, 969–975. [Google Scholar] [CrossRef] [PubMed]
- Hovmöller, R.; Knowles, L.L.; Kubatko, L.S. Effects of missing data on species tree estimation under the coalescent. Mol. Phylogen. Evol. 2013, 69, 1057–1062. [Google Scholar] [CrossRef] [PubMed]
- Smith, B.T.; Mauck, W.M.; Benz, B.W.; Andersen, M.J. Uneven missing data skew phylogenomic relationships within the lories and lorikeets. Genome Biol. Evol. 2020, 12, 1131–1147. [Google Scholar] [CrossRef] [PubMed]
- Santos, C.; Pereira, F. Identification of plant species using variable length chloroplast DNA sequences. Forensic Sci. Int. Genet. 2018, 36, 1–12. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5 Programs for Machine Learning; Morgan Kaufmann: Burlington, MA, USA, 1993; Volume 5, p. 302. [Google Scholar]
- Wyler, S.C.; Naciri, Y. Evolutionary histories determine DNA barcoding success in vascular plants: Seven case studies using intraspecific broad sampling of closely related species. BMC Evol. Biol. 2016, 16, 103. [Google Scholar] [CrossRef] [Green Version]
- Fiannaca, A.; La Rosa, M.; Rizzo, R.; Urso, A. A k-mer-based barcode DNA classification methodology based on spectral representation and a neural gas network. Artif. Intell. Med. 2015, 64, 173–184. [Google Scholar] [CrossRef]
- Tan, J.; Lim, P.-E.; Phang, S.-M.; Hong, D.D.; Sunarpi, H.; Hurtado, A.Q. Assessment of four molecular markers as potential DNA barcodes for red Algae kappaphycus doty and Eucheuma J. agardh (Solieriaceae, Rhodophyta). PLoS ONE 2012, 7, e52905. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.-Q.; Dong, Y.-R.; Gu, Z.-J.; Liang, N.; Yang, J.B. A preliminary assessment of matK, rbcL and trnH—psbA as DNA barcodes for calamus (Arecaceae) species in China with a note on ITS. Ann. Bot. Fenn. 2012, 49, 319–330. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, X.; Chen, J.; Li, Z. DNA barcoding and phylogenetic relationships in Omphalogramma (Primulaceae) from the Hengduan Mountain region of China. Phytotaxa 2019, 402, 97–106. [Google Scholar] [CrossRef]
- Ashfaq, M.; Asif, M.; Anjum, Z.I.; Zafar, Y. Evaluating the capacity of plant DNA barcodes to discriminate species of cotton (G. ossypium: M. alvaceae). Mol. Ecol. Resour. 2013, 13, 573–582. [Google Scholar] [CrossRef]
- Gogoi, B.; Bhau, B.S. DNA barcoding of the genus Nepenthes (Pitcher plant): A preliminary assessment towards its identification. BMC Plant Biol. 2018, 18, 153. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; ZhiYong, Z.; LeJing, L.; BenKe, K.; YuLong, D.; TianTian, D. Implications of nrDNA and cpDNA region in Acer (Aceraceae): DNA barcoding and phylogeny. Inter. J. Agri. Biol. 2019, 21, 1073–1082. [Google Scholar] [CrossRef]
- Gadek, P.A.; Alpers, D.L.; Heslewood, M.M.; Quinn, C.J. Relationships within Cupressaceae sensu lato: A combined morphological and molecular approach. Am. J. Bot. 2000, 87, 1044–1057. [Google Scholar] [CrossRef]
- Chen, Q.; Wu, X.; Zhang, D. Comparison of the abilities of universal, super, and specific DNA barcodes to discriminate among the original species of Fritillariae cirrhosae bulbus and its adulterants. PLoS ONE 2020, 15, e0229181. [Google Scholar] [CrossRef]
- Müller, K.F.; Borsch, T.; Hilu, K.W. Phylogenetic utility of rapidly evolving DNA at high taxonomical levels: Contrasting matK, trnT-F, and rbcL in basal angiosperms. Mol. Phylogen. Evol. 2006, 41, 99–117. [Google Scholar] [CrossRef]
- Moura, C.C.D.M.; Brambach, F.; Bado, K.J.H.; Krutovsky, K.V.; Kreft, H.; Tjitrosoedirdjo, S.S.; Siregar, I.Z.; Gailing, O. Integrating DNA barcoding and traditional taxonomy for the identification of dipterocarps in remnant lowland forests of Sumatra. Plants 2019, 8, 461. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuksa, P.; Pavlovic, V. Efficient alignment-free DNA barcode analytics. BMC Bioinform. 2009, 10, S9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amancio, D.R.; Comin, C.; Casanova, D.; Travieso, G.; Bruno, O.; Rodrigues, F.; Costa, L.D.F. A systematic comparison of supervised classifiers. PLoS ONE 2014, 9, e94137. [Google Scholar] [CrossRef] [PubMed]
- Meyer, D.; Leisch, F.; Hornik, K. The support vector machine under test. Neurocomputing 2003, 55, 169–186. [Google Scholar] [CrossRef]
- Patil, T.S.; Jamdade, R.; Patil, S.M.; Govindwar, S.P.; Muley, D.V. DNA barcode based delineation of freshwater fishes from northern Western Ghats of India, one of the world’s biodiversity hotspots. Biodivers. Conserv. 2018, 27, 3349–3371. [Google Scholar] [CrossRef]
- John, G.H.; Langley, P. Estimating continuous distributions in bayesian classifiers. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–20 August 1995; Morgan Kaufmann: San Mateo, CA, USA, 1995; pp. 338–345. [Google Scholar]
- Kohavi, R. The power of decision tables. In Proceedings of the 8th European Conference on Machine Learning, Crete, Greece, 25–27 April 1995; pp. 174–189. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Identification | rbcL | matK | |||||
|---|---|---|---|---|---|---|---|
| BM | BCM | ASB | BM | BCM | ASB | ||
| Sequences (rbcL = 1118; matK = 277) | Correct | 54.83 | 54.74 | 58.68 | 61.37 | 61.37 | 52.35 |
| Incorrect | 14.31 | 12.79 | 6.80 | 31.04 | 18.05 | 2.89 | |
| Ambiguous | 30.86 | 30.68 | 32.74 | 7.59 | 6.14 | 30.32 | |
| No match (@3% Threshold) | NA | 1.79 | 1.79 | NA | 14.44 | 14.44 | |
| Species (rbcL = 414; matK = 113) | Correct | 41.06 | NA | 35.99 | 15.04 | NA | 4.42 |
| True species | 28.50 | NA | 34.54 | 7.08 | NA | 3.54 | |
| Barcode Marker | Distance Method | Partitions | Partition at Prior Maximal Distance (P) | Groups | Correct | Incorrect | Ambiguous | Singleton | True Species |
|---|---|---|---|---|---|---|---|---|---|
| rbcL (species = 414; sequences = 1118) | Jukes-Cantor (JC69) | 9 | 0.002783 | 411 | 43.29 | 25.04 | 22.90 | 8.77 | 29.47 |
| Kimura (K80) | 4 | 0.002783 | 411 | 43.29 | 25.04 | 22.90 | 8.77 | 29.47 | |
| Simple distance | 9 | 0.002783 | 248 | 31.93 | 53.22 | 9.12 | 5.72 | 18.36 | |
| matK (Species = 113; sequences = 277) | Jukes-Cantor (JC69) | 10 | 0.0359 | 52 | 50.90 | 34.66 | 4.69 | 9.75 | 3.54 |
| Kimura (K80) | 10 | 0.0359 | 52 | 50.90 | 34.66 | 4.69 | 9.75 | 3.54 | |
| Simple distance | 10 | 0.0359 | 52 | 50.90 | 34.66 | 4.69 | 9.75 | 3.54 |
| Method | k = 2 | k = 3 | k = 4 | k = 5 | k = 6 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| rbcL | matK | rbcL | matK | rbcL | matK | rbcL | matK | rbcL | matK | |
| 1-NN | ||||||||||
| LAF | 49.19 | 51.98 | 52.14 | 57.76 | 66.99 | 60.64 | 68.15 | 59.92 | 67.26 | 58.84 |
| (0.0436) | (0.0812) | (0.0424) | (0.0767) | (0.0359) | (0.0744) | (0.0353) | (0.0751) | (0.0357) | (0.0759) | |
| Gappy kernel | 69.14 | 61.37 | 70.84 | 61.73 | 71.19 | 61.37 | 71.55 | 61.37 | NA | 61.37 |
| (0.0351) | (0.0739) | (0.0343) | (0.0736) | (0.0341) | (0.0738) | (0.0339) | (0.0738) | (0.0737) | ||
| Mismatch kernel | 47.04 | 55.59 | 54.38 | 59.2 | 57.6 | 60.28 | 58.85 | 59.56 | 59.74 | 61.01 |
| (0.0445) | (0.0769) | (0.0416) | (0.0737) | (0.0402) | (0.0731) | (0.0397) | (0.0735) | (0.0393) | (0.0725) | |
| 3-NN | ||||||||||
| LAF | 34.25 | 51.26 | 41.05 | 53.79 | 56.08 | 55.23 | 59.21 | 55.59 | 55.72 | 54.15 |
| (0.0446) | (0.0756) | (0.0427) | (0.0725) | (0.0377) | (0.0714) | (0.0372) | (0.072) | (0.0381) | (0.0725) | |
| Gappy kernel | 58.76 | 55.95 | 61.71 | 55.23 | 61.44 | 54.87 | 61.53 | 54.51 | NA | 54.51 |
| (0.0373) | (0.0713) | (0.0365) | (0.0714) | (0.0364) | (0.0714) | (0.0364) | (0.0715) | (0.0717) | ||
| Mismatch kernel | 37.74 | 51.98 | 40.51 | 55.23 | 43.2 | 57.4 | 45.08 | 55.23 | 45.52 | 55.95 |
| (0.0447) | (0.0739) | (0.0425) | (0.0715) | (0.0418) | (0.0708) | (0.0414) | (0.0714) | (0.0412) | (0.0708) | |
| 5-NN | ||||||||||
| LAF | 29.78 | 50.9 | 36.4 | 51.98 | 46.6 | 55.95 | 46.6 | 54.51 | 43.55 | 53.79 |
| (0.0451) | (0.0742) | (0.0432) | (0.0716) | (0.04) | (0.0701) | (0.0399) | (0.0704) | (0.0405) | (0.0714) | |
| Gappy kernel | 47.76 | 54.15 | 48.56 | 55.95 | 48.39 | 54.87 | 48.3 | 54.15 | NA | 54.15 |
| (0.0399) | (0.0704) | (0.0395) | (0.0701) | (0.0395) | (0.0704) | (0.0394) | (0.0706) | (0.0711) | ||
| Mismatch kernel | 30.41 | 52.34 | 34.43 | 53.79 | 36.49 | 55.95 | 38.46 | 53.79 | 38.72 | 54.87 |
| (0.045) | (0.0733) | (0.0436) | (0.0707) | (0.0431) | (0.0700) | (0.0428) | (0.0707) | (0.0426) | (0.0699) | |
| Method | Alignment (%) | Alignment-Free (%) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Logical Alignment Free (LAF) | Gappy Kernel (GK) | Mismatch Kernel (MK) | |||||||
| rbcL | matK | rbcL (k = 5) | matK (k = 4) | rbcL (k = 5) | matK (k = 3) | rbcL (k = 6) | matK (k = 6) | ||
| K-nearest Neighbor (IBK) | Sequences | 65.03 | 59.93 | 68.15 | 60.65 | 71.55 | 61.73 | 59.74 | 61.01 |
| (0.0357) | (0.0727) | (0.0353) | (0.0744) | (0.0339) | (0.0736) | (0.0393) | (0.0725) | ||
| Species | 53.38 | 15.93 | 55.80 | 15.04 | 57.25 | 15.93 | 50.24 | 15.93 | |
| Random Forest | Sequences | 71.11 | 62.45 | 60.91 | 59.21 | 71.19 | 61.37 | 59.12 | 60.64 |
| (0.0316) | (0.0643) | (0.0366) | (0.0655) | (0.0321) | (0.064) | (0.0364) | (0.0646) | ||
| Species | 54.35 | 15.93 | 52.17 | 14.16 | 58.21 | 15.04 | 50.24 | 15.93 | |
| Support Vector Machine (SMO) | Sequences | 70.30 | 61.01 | 69.76 | 61.01 | NA | 61.37 | NA | 61.01 |
| (0.049) | (0.0935) | (0.049) | (0.0935) | (NA) | (0.0935) | (NA) | (0.0935) | ||
| Species | 54.11 | 15.04 | 54.35 | 15.04 | NA | 15.04 | NA | 15.93 | |
| Multi-Class Classifier | Sequences | 68.34 | 61.37 | 69.49 | 58.84 | NA | NA | NA | NA |
| (0.0349) | (0.0773) | (0.0359) | (0.0781) | ||||||
| Species | 54.83 | 15.04 | 56.52 | 13.27 | NA | NA | NA | NA | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jamdade, R.; Upadhyay, M.; Al Shaer, K.; Al Harthi, E.; Al Sallani, M.; Al Jasmi, M.; Al Ketbi, A. Evaluation of Arabian Vascular Plant Barcodes (rbcL and matK): Precision of Unsupervised and Supervised Learning Methods towards Accurate Identification. Plants 2021, 10, 2741. https://doi.org/10.3390/plants10122741
Jamdade R, Upadhyay M, Al Shaer K, Al Harthi E, Al Sallani M, Al Jasmi M, Al Ketbi A. Evaluation of Arabian Vascular Plant Barcodes (rbcL and matK): Precision of Unsupervised and Supervised Learning Methods towards Accurate Identification. Plants. 2021; 10(12):2741. https://doi.org/10.3390/plants10122741
Chicago/Turabian StyleJamdade, Rahul, Maulik Upadhyay, Khawla Al Shaer, Eman Al Harthi, Mariam Al Sallani, Mariam Al Jasmi, and Asma Al Ketbi. 2021. "Evaluation of Arabian Vascular Plant Barcodes (rbcL and matK): Precision of Unsupervised and Supervised Learning Methods towards Accurate Identification" Plants 10, no. 12: 2741. https://doi.org/10.3390/plants10122741