Metabolic Flux Analysis—Linking Isotope Labeling and Metabolic Fluxes


1
Department of Medicine, Rutgers-Robert Wood Johnson Medical School, New Brunswick, NJ 08901, USA
2
Metabolomics Shared Resource, Rutgers Cancer Institute of New Jersey, New Brunswick, NJ 08903, USA
3
Division of Biostatistics, College of Public Health, The Ohio State University, Columbus, OH 43210, USA
4
Department of Mathematics, University of Central Florida, Orlando, FL 32816, USA
*
Author to whom correspondence should be addressed.
Metabolites 2020, 10(11), 447; https://doi.org/10.3390/metabo10110447
Submission received: 14 September 2020
/
Revised: 3 November 2020
/
Accepted: 4 November 2020
/
Published: 6 November 2020
(This article belongs to the Special Issue Stable Isotope Guided Metabolomics)
Abstract
:Metabolic flux analysis (MFA) is an increasingly important tool to study metabolism quantitatively. Unlike the concentrations of metabolites, the fluxes, which are the rates at which intracellular metabolites interconvert, are not directly measurable. MFA uses stable isotope labeled tracers to reveal information related to the fluxes. The conceptual idea of MFA is that in tracer experiments the isotope labeling patterns of intracellular metabolites are determined by the fluxes, therefore by measuring the labeling patterns we can infer the fluxes in the network. In this review, we will discuss the basic concept of MFA using a simplified upper glycolysis network as an example. We will show how the fluxes are reflected in the isotope labeling patterns. The central idea we wish to deliver is that under metabolic and isotopic steady-state the labeling pattern of a metabolite is the flux-weighted average of the substrates’ labeling patterns. As a result, MFA can tell the relative contributions of converging metabolic pathways only when these pathways make substrates in different labeling patterns for the shared product. This is the fundamental principle guiding the design of isotope labeling experiment for MFA including tracer selection. In addition, we will also discuss the basic biochemical assumptions of MFA, and we will show the flux-solving procedure and result evaluation. Finally, we will highlight the link between isotopically stationary and nonstationary flux analysis.
1. Introduction
Metabolism involves a set of chemical reactions that convert nutrients to energy and macromolecules to sustain cellular survival and growth. Many enzymes are thought to work on production lines: the product coming from the first enzyme is the substrate for the second enzyme. Together, these enzymes form metabolic pathways that fulfill certain metabolic tasks. The catabolic pathways, for example, break down large molecules such as proteins and lipids to make ATP and other small molecule metabolites. The anabolic pathways use biochemical energy stored in ATP to synthesize macromolecules. Interestingly, the catabolism and anabolism are overlapped rather than exclusive. Some enzymes, such as the fructose-bisphosphate aldolase, are shared between the catabolic glycolysis pathway and the anabolic gluconeogenesis pathway. Meanwhile, co-factors such as ATP, acetyl-CoA and NAD(PH) are shared among many enzymatic reactions [1]. These features demonstrate the fact that these biochemical reactions are highly interconnected and essentially form a network. The elucidation of the metabolic network was a huge scientific achievement in the 20th century [2]. Despite the vast knowledge on the structure of the metabolic network, the dynamic partition of metabolic material through different pathways under various physiological and pathological conditions remains incompletely characterized.
In the past two decades, metabolic research has been rapidly expanded due to the huge improvement on technologies for metabolite measurements. These technological advances include nuclear magnetic resonance (NMR) and mass spectrometry (MS) [3,4,5,6,7,8,9]. The large-scale analysis of the metabolite pool sizes, namely metabolomics, has been widely deployed in clinical research and pharmacology [10]. Metabolites can serve as biomarkers for diagnosis. For example, elevated spermine level and decreased citrate level in the prostate fluid has been shown to be a distinct metabolomics profile in prostate cancer patients [11,12]. Although these discoveries are highly valuable for diagnosis, the measurement of metabolite pool size alone reveals little information regarding the biochemical events behind such changes [13,14]. The increased pool size of a metabolite can be the result of either enhanced production or diminished consumption. For example, sildenafil is an inhibitor of phosphodiesterase type 5, which breaks down cyclic guanosine monophosphate (cGMP). Usage of sildenafil increases the pool size of cGMP but the flux through this metabolite is decreased [15]. This example demonstrates that changes in metabolite pool size do not directly translate into flux changes. An analogy for the relationship between the metabolite pool size and metabolic flux is the car traffic. The metabolite pool size represents the density of cars on the road while the flux represents the flow of traffic. Although the density of cars can be measured by taking a static picture of the road, such a measurement alone is insufficient to tell how fast the flow of traffic is.
Unlike the pool size of metabolites that can be directly measured by NMR and MS, the metabolic fluxes are usually unmeasurable. Although the extracellular fluxes such as nutrient uptake rates can be calculated based on the concentration changes over time, the intracellular fluxes cannot be measured this way. Instead, they have to be solved by the approach named flux analysis [16,17,18,19]. Flux analysis is a powerful technique and has been applied in multiple fields of research such as pharmaceutical production, drug design and cancer biology [20,21,22]. For example, about one century ago, Warburg et al. [23] discovered cancer cells generate more lactate than healthy cells under aerobic conditions, a phenomenon now well known as the Warburg effect [24]. However, it remains unclear for many decades how cancer cells could make use of lactate to support its own growth. Recently, with the help of metabolic flux analysis, it became clear that lactate is an important carbon source for citric acid cycle in both healthy and cancer cells [25,26].
Depending on what experimental data are available, the flux analysis can be carried out in different ways. However, all flux analysis methods must resolve one basic problem: the total number of unknown fluxes often exceed the total number of measurement (i.e., the network is undetermined). One way to resolve this issue is by simplifying the flux network and using stoichiometry balance of the intracellular metabolites to reduce the total number of unknown fluxes. This approach is known as stoichiometric flux analysis (SFA) [16,27,28,29]. On the other hand, if a detailed flux network has to be used, one could also resolve this issue by assuming a cellular objective function (e.g., maximum cell growth or ATP production). This approach is known as the flux balance analysis (FBA) [17,30,31,32,33,34]. In addition to satisfying the stoichiometric constraints, the intracellular fluxes must also maximize the objective function.
Despite the popular application of FBA and SFA in system biology and metabolic engineering, these methods have some apparent limitations: (1) it is hard to estimate the fluxes through parallel pathways, cyclic pathways or bidirectional reversible reactions [17,35,36]. (2) The objective function for mammalian cell metabolism is hard to define. Mammalian cells, unlike bacteria in a batch culture, can exhibit different metabolic phenotypes during proliferation, differentiation and senescence [37]. These practical limitations largely come from the limited amount of measurements that are utilized in FBA and SFA. In contrast, metabolic flux analysis (MFA) uses stable isotope tracers and takes labeling patterns of intracellular metabolites as additional input information. While more commonly referred to as 13C-MFA, the framework of MFA is not limited to 13C labeling. In fact, MFA has been applied to analyze labeling from 15N, 2H and other tracers [14,38]. As a result, MFA is much more powerful than FBA and SFA in overcoming the two limitations mentioned above [17]. Table 1 has listed some most commonly used software tools for MFA. In this review, we will demonstrate how MFA is carried out, and we will discuss the principles of using MFA to solve metabolic fluxes.
2. Example on Upper Glycolysis
Without using isotope tracers, we have a very limited insight on how metabolites interconvert in the metabolic network. Taking upper glycolysis pathway as an example. If glucose is consumed at the rate of 100 nmol/h, glyceraldehyde-3-phosphate (GAP) goes to lower glycolysis at the rate of 200 nmol/h (Figure 1A). No more information on the metabolic fluxes can be drawn from this unlabeled experiment. In comparison, when 1,2-13C2-Glucose (Glucose where C-1 and C-2 are labeled with 13C) tracer is used (Figure 1B), we can observe the reversibility of upper glycolysis reactions. The fructose 1,6-bisphosphate (FBP) will be labeled in three forms, M+0 (no 13C labeling), M+2 (2 carbon atoms are labeled with 13C) and M+4 (4 carbon atoms are labeled with 13C) (Figure 1B). FBP can be made from the glucose tracer through the intermediates glucose-6-phopshate (Glc6P) and fructose-6-phopshate (Fruc6P). Both intermediates would have the same labeling (M+2) as the glucose tracer since their production only involves phosphorylation and isomerization without breaking the C-C bonds. Therefore, the M+2 FBP represents its synthesis flux mostly directly from Fruc6P (f1; Figure 1B). The observation of M+0 and M+4 FBP, however, suggests the presence of additional synthesis route for FBP, which involves recombination of the carbon backbones. Indeed, the aldolase reaction that breaks down FBP into dihydroxyacetone phosphate (DHAP) and GAP is reversible (f2 and f3; Figure 1B). The observed M+4 FBP has to be generated from M+2 DHAP and M+2 GAP through the reverse reaction of aldolase (f3; Figure 1B). Similarly, M+0 FBP has to be generated from M+0 DHAP and M+0 GAP. However, since the DHAP derived from Glucose C1–C3 (Glc[1-3]) must be M+2 labeled, there has to be an alternative way to generate M+0 DHAP. In fact, the triose phosphate isomerase (TPI) reaction is also reversible (f4 and f5; Figure 1B) converting M+0 DHAP from M+0 GAP. Thus, using isotopic tracers, we have established a qualitative link between the labeling pattern of FBP and the reversibility of the aldolase and TPI reactions. The lower the observed FBP M+2, the higher the reverse flux of aldolase (f3) is; the higher the observed FBP M+0, the higher the reverse flux of TPI (f5) is. Such reversibility of aldolase and TPI would not have been measurable without using an isotope labeled glucose tracer.
Although the real metabolic network might be more complicated than we illustrated (e.g., the existence of pentose phosphate pathway), this simple example illustrates the gist of MFA. When we use the suitable isotope labeled tracer, the labeling patterns of intercellular metabolites reflect the fluxes. The goal of MFA is to infer the metabolic fluxes from these isotope labeling patterns. Before we move to the solving process of MFA, we need to examine quantitatively how the labeling patterns are determined by the fluxes and what information is encoded in the labeling patterns.
When the cells are at metabolic steady state, the production rate of an intercellular metabolite equals the consumption rates of it. Furthermore, when the cells are under isotopic steady state, the production rate of a specific labeling fraction equals the consumption rates of it. For FBP, such mass balances on the labeled fractions are described by the following equation.
In Equation (1), we use DHAP⊕GAP to represent the combination of GAP and DHAP. In such a condensation reaction, the substrates are combined independently in terms of their labeling patterns. Therefore, we have the following equations.
Our first observation is that Equation (1) is a set of linear equations. We can re-write them as
The second observation is, due to the mass balance of FBP, the sum of the production fluxes equals the consumption flux
Therefore, we can replace the consumption flux of FBP with the sum of the production fluxes, and Equation (3) can be written as
Equation (5) shows that the labeling of FBP is the flux-weighted average of its substrates’ labeling (i.e., the higher the ratio of f1/f3, the similar the labeling pattern of FBP to that of Glc). If we move the FBP labeling vector to the left side of the equation, we have:
If we know DHAP⊕GAP, Glc and FBP, we can plug these values into Equation (6) and solve for the ratio between f1 and f3. In fact, all three equations of M+0, M+2 and M+4 fractions will give the same f1/f3 value. It should be noted that it is not the absolute value of f1 and f3 but the ratio of them affects the equation. In fact, f1 can take any value to fulfill Equation (6) as long as the ratio of f1/f3 remains unchanged. This observation brings up the essence of labeling balance equations. The labeling balance equations describe the ratio of converging fluxes.
Similar to the FBP labeling equations, based on the labeling balance of DHAP and GAP we have the following equations
In the above equations, FBP[1-3] and FBP[4-6] denote the labeling patterns of the first and the last three carbon atoms of FBP, which are converted to DHAP and GAP, respectively, by the aldolase reaction. It is noteworthy that FBP[1-3] and FBP[4-6] are used only to calculate DHAP and GAP. The labeling of FBP[1-6] is not the convolution of FBP[1-3] and FBP[4-6]. The labeling balance of DHAP provides us the ratio between f2 and f5, which are the two fluxes making DHAP. The labeling balance of GAP provides us with the ratio between f2 and f4, which are the two fluxes making GAP. Equations (6)–(8) can be combined as
Note that Equation (9) is a set of homogeneous linear equations. All fluxes are unitless and can be scaled up or down without violating the equation. Only when the absolute value of f1 is measured by other experiments, these fluxes can be expressed in absolute values as well.
The general form of the labeling balance equation should be apparent by now. Suppose we have n fluxes making the same metabolite, which has the labeling pattern of . If each substrate i has the labeling pattern of and is contributing to the product through flux fi, then
Equation (10) illustrates several fundamental principles of MFA. First, the use of isotope labeling is required to solve fluxes. While this statement seems obvious, it naturally emerges from Equation (10). If no tracer is used, then the labeling pattern of all substrates () equals to that of the product
(). Therefore, the matrix contains only zero vectors and can take any value to satisfy the equation. For the same reason, if the two substrates of one metabolite are identically labeled (e.g., when the U-13C glucose tracer is used, all metabolites would be fully labelled with 13C), the fluxes from these substrates still cannot be solved. This is the principle guiding the tracer selection in MFA, which will be discussed later in more detail. Second, at the isotope labeling steady state, the labeling pattern of a metabolite is determined only by its production fluxes and is independent of its consumption fluxes. The consumption flux of one metabolite shows up in the labeling balance equations only when it becomes the production flux of another metabolite. Third, metabolite concentration is not in this equation, meaning that under isotopic steady state the fluxes are independent of the metabolite pool size. This is the concept we discussed in the introduction. It is also a natural consequence of the steady-state labeling balance equation. We will show later that under the isotopic non-steady state condition the metabolite pool size is related with fluxes.
3. Generalization of the Labeling Balance Equations
In order to calculate the labeling of DHAP and GAP, we introduced the terms FBP[1-3] and FBP[4-6] in Equations (7) and (8), which are parts of the FBP molecule. These terms are commonly referred to as elementary metabolite units (EMU). EMU is defined as a moiety comprising any distinct subset of a compound’s atoms [66]. The use of EMU is a natural choice when calculating the labeling pattern of metabolites synthesized by combining the carbon backbones. EMU significantly simplifies the flux calculation. Taking FBP as an example, there are totally 26 = 64 different forms in which FBP can be 13C-labeled. Using the EMU approach, we are only concerned with three EMUs for FBP: FBP[1-3], FBP[4-6] and FBP[1-6]. Without this simplification process, the calculation of fluxes would become much more difficult. For example, if all the possible EMU should be described, Equation (3) would have to use 128 unknown parameters to describe the labeling of DHAP⊕GAP and FBP, and 64 known parameters to describe the labeling of glucose tracer. The overall workload becomes unnecessarily large.
EMU should also account for the molecular symmetry in the metabolites. In citric acid cycle, for example, succinate is a symmetric molecule. The first and fourth carbon of succinate (Suc [1] and Suc [4]) should always have the same labeling pattern. A sufficiently large “flipping” flux that interconverts Suc [1234] and Suc [4321] can be introduced to the flux model to account for such symmetry. It is also noteworthy that such flipping flux should not be applied to pro-chiral metabolites. Prochirality of a metabolite is often overlooked. In fact, prochirality is easy to identify in the isotope labeling experiment. A molecule is pro-chiral if isotope labeling can convert it from achiral to chiral. Citrate, for example, has two -CH2COOH groups, one derived from acetyl-CoA and the other one from oxaloacetate. If the acetyl-CoA is 13C-labeled, the 13C2-citrate becomes a chiral molecule. This suggests that citrate is a pro-chiral molecule. Therefore, even though the two -CH2COOH groups are symmetric with respect to a mirror plane, they are not interconvertible.
EMU is the natural choice to describe the labeling pattern of metabolites when they are measured in the forms of mass isotopomer distributions (MIDs) by mass spectrometry. However, if NMR instead of MS is used, the labeling pattern would be described more easily in the form of positional labeling. One such approach is known as cumomers [67]. The cumomer approach is only concerned with the percentage that FBP and other metabolites that are labeled at specific carbon atoms, regardless of the labeling at other positions. In this case, we can rewrite Equations (6)–(8), which describes the labeling balance in EMU terms, using the cumomer approach as the following.
In these equations, we are concerned with FBP labeling on C-2 and C-5 position, which is FBP $010000 and FBP $000010 in the cumomer terms. This example demonstrates that EMUs and cumomers follow exactly the same labeling balance equations. They are only different in how the labeling patterns are expressed.
Another way to express the isotope labeling is by enrichment. Enrichment is defined as the percentage of labeling on average atom level. The enrichment of FBP (EFBP) can be calculated from its labeling pattern.
The good property of enrichment is that the enrichment of the product in a combination reaction is the carbon number-weighted average of the enrichment of the substrates.
Isotopic enrichment is commonly used for radioactive tracers. For stable isotope tracers, this is also a convenient term because the labeling vector is converted to a single number. Nonetheless, the labeling balance follows Equation (10) when using the enrichment to represent the labeling patterns.
4. Basic Assumptions in MFA
Having shown that the labeling balance Equation (10) is the basis for many different versions of MFA, it is time to examine the basic assumptions behind Equation (10) and MFA. The first assumption that we have adopted in this equation is that the fluxes are linear with respect to all the labeled fractions. This means the enzymes and transporters do not discriminate between unlabeled and labeled substrates. In another word, there is no kinetic isotope effect (KIE) [68,69,70,71,72]. As Liuni et al. [69] has shown, 12C/13C KIE is typically < 1.1 so this assumption is largely valid in carbon labeling experiments. In deuterium (2H)-labeling experiments, however, strong KIE (>2–4) may come in play. The KIE makes the subtraction of a 2H atom slower than the subtraction of a 1H atom. This rate difference can be measured using isolated enzymes and substrates in a test tube. However, the cellular homeostatic mechanisms may result in a smaller impact on the isotope labelling patterns in cells [73]. One possibility is that the total metabolic fluxes are maintained even when the heavy isotope tracers are used. This is likely the case when the enzyme has remaining capacity at the physiological flux level. Another possibility is that the pathway flux is decreased by the same magnitude that the enzyme reaction in vitro is slowed down due to the heavy-labeled substrate. The actual flux change due to KIE is likely somewhere in between and should be evaluated on a case-by-case basis. To introduce KIE to the labeling balance equation of MFA, the flux coefficients (; Equation (10)) should be replaced by row vectors of fluxes specific to each labeled fraction.
The second assumption adopted in Equation (10) is that all the metabolites are well-mixed. We are assuming that each metabolite is labeled homogenously so that its labeling pattern can be expressed in a single vector. This simple assumption has different meanings and implications on different levels in the biological system. On the molecular level, the intermediates in a metabolic pathway can be passed from one enzyme to the next without equilibration with the cellular pool [74]. This process is known as substrate channeling [75,76,77]. The assumption that the metabolites are well-mixed means there is no substrate channeling. On the cellular level, a metabolite can be distributed in different cellular compartments, such as cytosol and mitochondrion [78,79,80]. The well-mixed assumption means either the metabolite is exclusively in one cellular compartment, or there is fast exchange among the compartments so that the labeling patterns are averaged out. On the organ level, we have a mixture of different types of cells. We are assuming these cells share the same labeling patterns of metabolites, or there is fast exchange among cells. When these well-mixed assumptions are violated, separate pools of metabolites should be considered when designing MFA models to address the compartmentalization or substrate channeling issues.
5. Predicting Labeling Patterns and Solving Metabolic Fluxes
Now we are ready to solve the fluxes for our example of upper glycolysis pathway. Since the value of f1 is measured as 100 nmol/h, our goal is to find a set of fluxes f2–f6 that generates a labeling pattern of FBP that best matches the observation. Even though the labeling patterns of DHAP and GAP are not measurable, their labeling patterns can still be predicted along with that of FBP when a set of fluxes are given. Based on the mass balance on each of the labeled fractions of DHAP, GAP and FBP, we have the following equations.
Due to the mass balance of FBP, DHAP and GAP, we have another set of equations.
Since f1 = 100. There are only two free fluxes f3 and f5. All other fluxes can be calculated from these two free fluxes because of the mass balance.
Take Equation (18) into Equation (16), we have the following equation.
Equation (19) illustrates how we can calculate labeling patterns from the free fluxes. For example, if we take the values of f3 = 50 and f5 = 150, the four unknowns of FBP[1-3], FBP[4-6], DHAP and GAP become solvable through Equation (20). Since we used the tracer of 1,2-13C2-glucose, and are 1. All other forms of Glc[1-3] and Glc[4-6] are 0.
To solve the FBP[1-3], FBP[4-6], DHAP and GAP, we simply need to take the inverse of the left matrix containing the fluxes and multiply it with the other two matrices on the right.
Therefore, we can calculate FBP labeling from Equation (3).
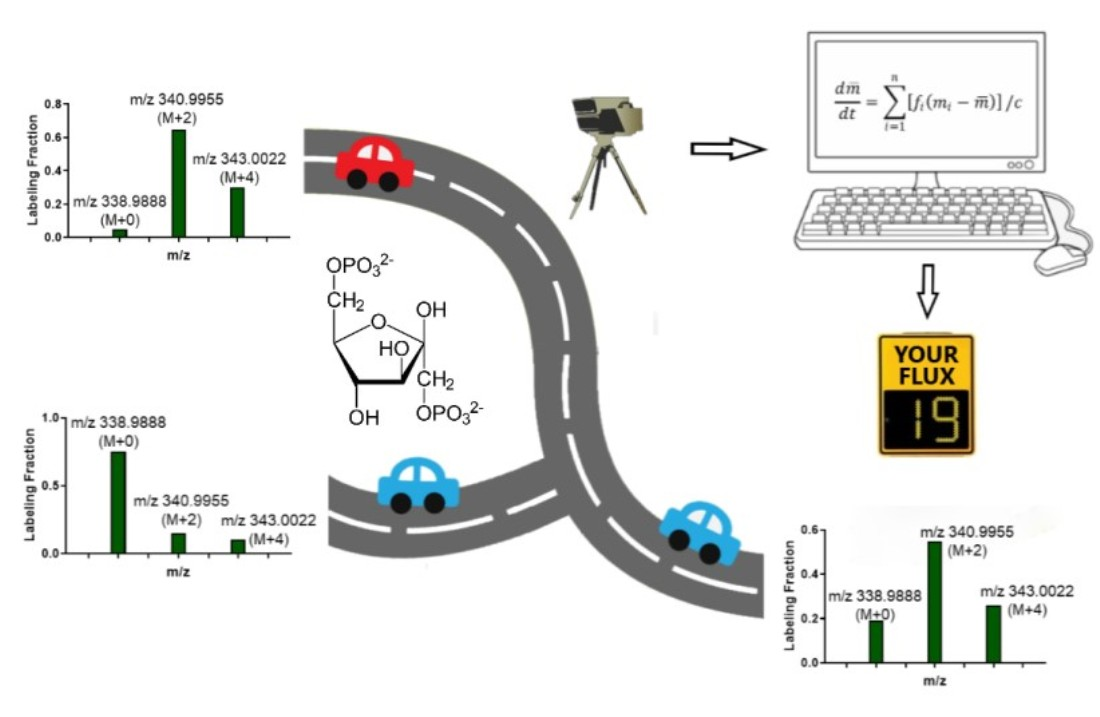
Therefore, by given the values of two free fluxes f3 = 50 and f5 = 150, the labeling pattern of FBP can be predicted as 5.00% M+0, 83.33% M+2 and 11.67% M+4. The real MFA process, however, is the reverse of this question (Figure 2A): if the actual labeling pattern of FBP is given, can we find the value of f3 and f5 that best fit this observation? Since in most cases there is no direct way to calculate the free fluxes by simply plugging in the numbers, the best-fit fluxes are often solved as an optimization problem. The flux-solving process is essentially a “guessing game”, which is iterative and consists of two steps: (1) calculate the labeling patterns of FBP based on the “guessed flux”, and (2) update the “guessed flux” to reduce the discrepancy between the predicted FBP labeling pattern and the observation. The discrepancy (R) can be defined as the sum of squared residuals (SSR), and it is often inversely weighted by the experimental standard deviations expressed as the measurement covariance matrix with measurement variances located on the diagonal (ΣMeasured) [81].
Once the discrepancy is sufficiently small or no better guesses can be made, the optimized flux combination is our best estimation. Figure 2B–D demonstrated such a process. By starting from a random flux combination, the gradient descent algorithm can find the direction to minimize the discrepancy between the labeling measurements and the model prediction. When the discrepancy cannot be further minimized, the optimization completes, and the optimal flux combination is the solution.
From this example, we can see that the calculation of the labeling patterns is the most important part in the flux determination. The labeling calculation gives us the landscape, such as shown in Figure 2B, which describes the difference between the model prediction and the experimental measurements when the flux combination takes different values. The goal of the optimization is to find the path on the landscape to reach the lowest point. There are many generic algorithms that can work for such a purpose, including gradient descent, differential evolution and particle swarm optimization algorithms.
6. Evaluation of MFA Result and Tracer Selection
In the example of upper glycolysis, if we start from the FBP measurement of 5.00% M+0, 83.33% M+2 and 11.67% M+4, we can land on the flux combination of f3 = 50 and f5 = 150. This solution is both unique and precise. No other flux combination can generate exactly the same FBP labeling pattern. However, in the real experiments, because of the existence of measurement errors, we may not have a flux combination that perfectly fit the measurements. The optimization algorithms can help us to achieve a locally best solution. However, it is hard to know whether this is the best situation globally. One workaround is to run the optimization algorithm multiple times with a random starting point in each round. If the solutions converge to one flux combination, we have confidence that this is the globally best solution (Figure 2B). If multiple solutions are reported, we can compare the results and choose the best one.
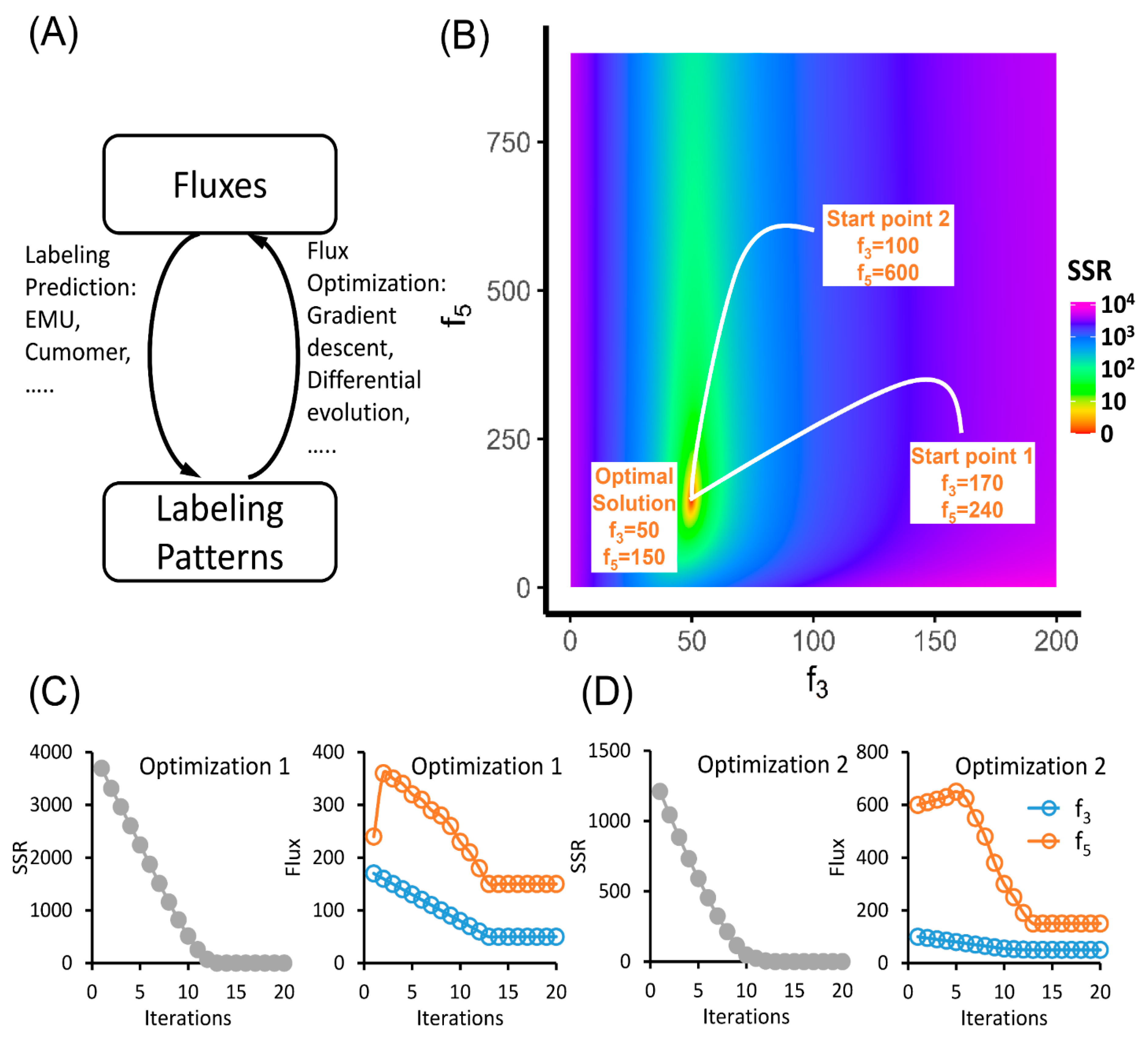
In addition to the best flux combination, we want to know the uncertainty in each flux to fully evaluate the results. The flux uncertainty is commonly represented as the confidence intervals of individual fluxes. When the flux takes a sub-optimal value within the confidence interval, the SSR goes up but is still within the statistically acceptable range. For example, if we assume the measurement of the MID of FBP has 1% error, then the combination of f3 = 48 and f5 = 210 would also be an acceptable solution since its SSR (χ2 = 1.33) was lower than the threshold assuming 1% error on all labeled fractions (χ2(α = 0.95,df = 1) = 3.84) [81]. In fact, if we plot all the acceptable solutions in the coordinate system of f3 and f5, an area of confidence interval is generated (Figure 3A). In this case, the area of confidence is in an oval shape ranging from 43.5 to 57.5 and from 75 to 330 on the x and y axis, respectively. These ranges are also the confidence intervals for f3 and f5. A narrow confidence interval on a flux indicates that the SSR is sensitive to the change of this flux. Therefore, this flux can be determined more precisely. On the other hand, a wide confidence interval suggests the SSR is insensitive to the change of this flux and the flux is poorly determined. It should be noted that the range of the confidence interval is determined by the precision of the MID measurements and the sensitivity of the SSR to the fluxes. The flux sensitivity is a local property. When the optimal flux fit changes, the flux confidence interval should be re-evaluated.
By drawing the area of confidence intervals, we can also evaluate the tracer selection for MFA. The choice of the tracer has tremendous impact on the effectiveness of MFA. For example, 1,2-13C2 glucose is an effective tracer to determine the free fluxes f3 and f5 in the upper glycolysis network (Figure 3A). In contrast, if we use 50% U-13C- glucose + 50% unlabeled glucose, we can only determine f3 but not f5 (Figure 3B). This observation motivates us to investigate the principle behind tracer selection to achieve the best effectiveness of MFA.
Essentially, the principle for tracer selection is illustrated in Equation (10). The role of the tracer in MFA is to make the metabolite labeling patterns reflective of the fluxes. More specifically, if one metabolite can be made by two or more reactions, the labeling pattern of this metabolite is the flux-weighted average of the labeling of the substrates. This allows us to determine the ratio of the converging fluxes. However, if the fluxes of two reactions utilize substrates with the same labeling pattern, the product can be only made in the same labeling pattern, and no flux ratio can be determined. In the example of upper glycolysis, when 50% U-13C glucose and 50% unlabeled glucose was used as the tracer, the labeling patterns of FBP[1-3] and GAP became identical (50% M+0; 50% M+3). Therefore, no matter how f5 changes, the labeling pattern of DHAP would remain the same. In another word, the labeling pattern of DHAP can no longer reflect the ratio between f3 and f5. Thus, the confidence region of the free fluxes is a vertical belt (Figure 3B). In contrast, the value of f3 can still be determined. This is because the labeling patterns of the two substrates glucose and DHAP⊕GAP are still different. On the network level, we can assess tracer effectiveness by calculating the sensitivity. The good tracer makes the labeling patterns sensitive to the changes of the flux inputs. Multiple studies have been conducted to evaluate the performance of different tracers on evaluating fluxes in glycolysis [82,83], the pentose phosphate pathway [83,84,85] and the TCA cycle [83,86].
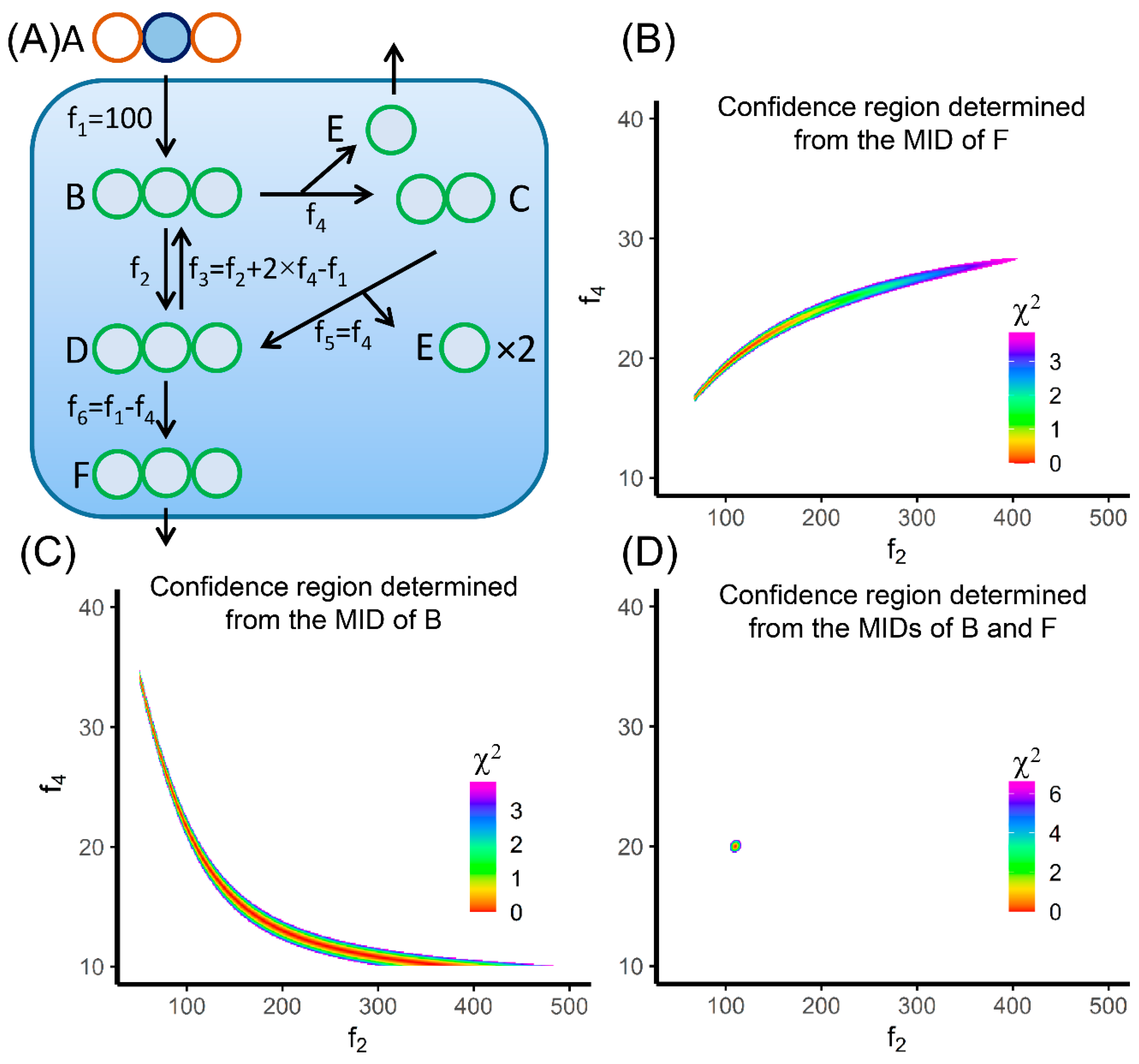
It should be noted that the confidence interval of each flux is not independent from others in the more general cases. In Figure 4, we are demonstrating the flux confidence intervals for the metabolic network presented in the EMU paper [66]. f2 and f4 are the two free fluxes in this model (Figure 4A). We are using 2-13C1-A as the tracer, and the MID measurement is made on metabolite F. If we allow 0.3% error on each of the labeled fractions, the confidence intervals of f2 and f4 are 16.4-28.3 and 67–405, respectively. The overall confidence region plotted on the f2–f4 plane is a belt from lower left to the upper right (Figure 4B). The direction of the belt means when f2 gets larger, f4 needs to go larger to minimize the increase of the SSR. The confidence intervals of these two free fluxes are highly correlated. The wide confidence intervals of f2 and f4 suggest the fluxes are poorly determined when given the MID measurement of F. This result is seemingly odd because we only have two free fluxes to determine, yet four numbers were measured (M+0–M+3) from the MID of F. The reason that these fluxes are still poorly determined is because the four measurements from the MID of F are not totally independent. Similarly, if we only measure the MID of B in this metabolic network, we also have wide confidence intervals on f2 and f4 (Figure 4C). In this case, these two fluxes are anti-correlated. When f2 gets larger, f4 needs to go smaller to minimize the increase of the SSR. This observation suggests that we need to measure the MIDs of both B and F to achieve best precision of MFA (Figure 4D). This example demonstrates that the identifiability of flux should be assessed seriously. Simply having more fractional numbers in the MIDs than the number of free fluxes does not guarantee identifiability [87].
Figure 4B,C also show that the confidence region is non-linear and non-convex. Therefore, the calculation of confidence intervals is not quite straightforward, especially in large metabolic network with a large number of free fluxes. The method to accurately calculate confidence intervals has been proposed by Antoniewicz et al. [81]. In brief, the confidence intervals were calculated by (1) moving one target flux away from the best-fit value by a small step; (2) choosing a combination of the other fluxes that minimize the increase of SSR; and (3) calculating the new SSR and repeating step (1) to (3) until the new SSR reached the cutoff for 95% confidence interval. An alternative is the Markov Chain Monte Carlo (MCMC) method. We could sample in the flux space and allow the MID and other measurements to have Gaussian error terms. The distribution of the flux values from the perturbed measurements is used to approximate the flux confidence intervals. The advantage of MCMC method is that it can generate a comprehensive probability distribution of fluxes [88,89].
7. Kinetic Flux Profiling and Isotopically Non-Stationary MFA
So far, all the MFA we have discussed are based on the assumptions of steady states. Essentially, the assumptions are (1) the metabolic steady state is the condition that the metabolite pool sizes and fluxes do not change over time and (2) isotopic steady state is the condition that the labeling patterns of metabolites do not change with time [90]. Experimentally, the isotopic steady state is achieved by incubating or infusing the tracer for sufficiently long time so that the labeling patterns of the metabolites do not change anymore. Under this condition, the ratio of the converging fluxes can be determined if the substrates are labeled in different patterns. Moreover, the size of metabolite pools does not affect the labeling patterns. One limitation of isotopically stationary MFA is that it does not work on pathways where no differential labeling can be observed. For example, CO2 is the sole carbon source of the photosynthetic product in autotrophic tissues of plant. At isotopic steady state, all the photosynthetic intermediates and products would have exactly the same labeling as CO2. Consequently, no flux information can be derived [91]. One solution to such a problem is kinetic flux profiling (KFP) [92]. In KFP experiments, we can switch the carbon source from unlabeled to the labeled one and examine the labeling patterns of intermediates and products at different time points. The key idea in KFP is that turnover rate of the metabolite pool is determined by the synthesizing flux and the pool size of metabolite. In fact, KFP is the extension of MFA in isotopic non-steady state case. In the final part of this review paper, we wish to highlight the link between steady state MFA and KFP in isotopic non-steady state [92,93,94,95], and further extend it to the general non-steady state case.
For an intracellular metabolite under isotopic non-steady state, the total pool labeling change with regard to all the labeled fractions can be expressed as
represents the net change in a metabolite from t = 0 to t = T. can be the amount of a specific labeled fraction, or a vector to describe all labeled fractions. represents the production flux from the i-th substrate. represents the sum of the consumption fluxes. These fluxes are normalized to cell volume V. represents the labeling pattern of the i-th substrate and represents the labeling pattern of the product. When expressed in vector forms, the , and describe the same set of labeled fractions.
Under metabolic steady state, where fluxes and the cell volume are constant over time, and the consumption flux equals the sum of the production fluxes, we have
Furthermore, under metabolic steady state, the intracellular metabolite pool size does not change. With a constant metabolite concentration, we also have
In Equation (26), c is the intracellular concentration of the metabolite and V is the cell volume.
Combining Equations (25) and (26), we have
We can also take derivative of Equation (27), which gives
Equation (28) is the equation describing the labeling change with respect to time for KFP. It is also the isotopic non-steady state generalization of Equation (6). When the isotopic steady state is reached, = 0, and Equation (28) degenerates to Equation (10). This means the isotopic non-steady state and steady state cases are closely related.
Next, we assume neither isotopic steady state nor metabolic steady state. Starting from Equation (24), considering that the sum of the consumption fluxes can be replaced by the sum of production fluxes minus the net production flux, we can re-write Equation (24) to
Taking the derivative of Equation (29), we have
Without assuming constant metabolite concentration or cell volume, the overall change of the labeling of metabolite pool is
Taking the derivative of it, we have
The metabolite pool size is only affected by the net production flux
Taking Equation (33) into Equation (32), we have
Combining Equation (34) and Equation (30), we have
Divide both sides with cV, we have
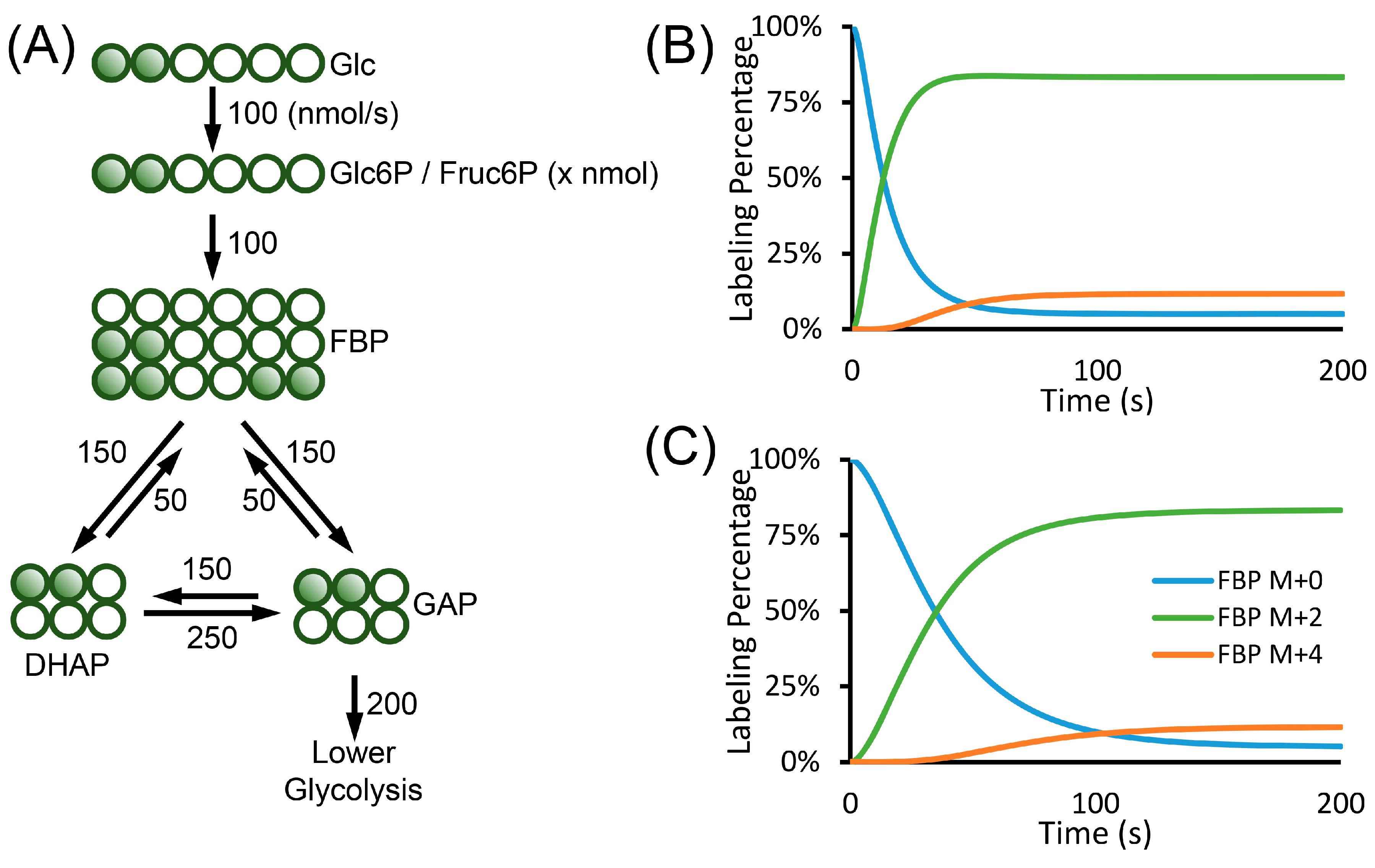
Equation (36) has the same form as Equation (28). The term c in Equation (36) is a function of time, whereas it is a constant in Equation (28). Equation (36) is the general equation describing the flux and the change in the labeling patterns. It applies to biological systems with changing cell numbers and intracellular metabolite concentrations. Similar to the metabolic and isotopic steady state case in Equation (10), the changes in the labeling patterns are largely affected by the input fluxes. The consumption fluxes are not included in the equation. They can only affect the concentration term c to impact the labeling changes. Comparing Equations (10) and (36), we also see that the metabolite concentration under isotopic steady state is not related to the flux and the labeling patterns. However, the concentration term determines how fast the labeling can change under non-steady state condition. The change of pool size in one metabolite will also result in the changes in the labeling kinetics of other metabolites. For example, when the Glc6P pool expands, the FBP labeling also becomes slower. However, when the isotopic steady state is reached, the pool size of Glc6P does not affect the labeling pattern of FBP (Figure 5).
To solve the fluxes under isotopic non-steady state, we also take the simulation-optimization approach. Given a set of fluxes and the metabolite concentrations, we can predict the labeling patterns at different time points of sampling. The model predictions are compared to the experimental measurements. The flux combinations that generate the labeling kinetics that match the measurements the best are the optimal solution for the isotopic non-steady state MFA.
8. Conclusions
In conclusion, MFA uses stable isotope labeling to solve metabolic fluxes. MFA commonly adopts two assumptions: the metabolites are well-mixed, and the kinetic isotope effect is negligible. Under isotopic steady state, one metabolite’s labeling pattern represents the flux-weighted average of the substrates. Under non-steady state, the rate of change of the labeling pattern is determined by the substrate and product labeling patterns, the production fluxes of this metabolite and the concentration of the metabolite.
Author Contributions
Y.W. and X.S. wrote the main draft. F.E.W., C.S. and T.Z. revised the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported, in part, by NIH grants P30CA072720-5923 (XS).
Conflicts of Interest
The authors declare no conflict of interest.
Code Availability
All the code used to generate graphs can be accessed at https://github.com/XiaoyangSu/MFA-Demo.
References
- Boyle, J. Lehninger Principles of Biochemistry (4th ed.): Nelson, D., and Cox, M. Biochem. Mol. Biol. Educ. 2005, 33, 74–75. [Google Scholar] [CrossRef]
- Caspi, R.; Altman, T.; Billington, R.; Dreher, K.; Foerster, H.; Fulcher, C.A.; Holland, T.A.; Keseler, I.M.; Kothari, A.; Kubo, A.; et al. The MetaCyc database of metabolic pathways and enzymes and the BioCyc collection of Pathway/Genome Databases. Nucleic Acids Res. 2014, D1, D459–D471. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fiehn, O. The link between genotypes and phenotypes. Plant Mol. Biol. 2002, 48, 155–171. [Google Scholar] [CrossRef] [PubMed]
- Beckonert, O.; Keun, H.C.; Ebbels, T.M.D.; Bundy, J.; Holmes, E.; Lindon, J.C.; Nicholson, J.K. Metabolic profiling, metabolomic and metabonomic procedures for NMR spectroscopy of urine, plasma, serum and tissue extracts. Nat. Protoc. 2007, 2, 2692–2703. [Google Scholar] [CrossRef]
- Hollywood, K.; Brison, D.R.; Goodacre, R. Metabolomics: Current technologies and future trends. Proteomics 2006, 6, 4716–4723. [Google Scholar] [CrossRef]
- Nicholson, J.K.; Lindon, J.C. Systems biology: Metabonomics. Nature 2008, 455, 1054–1056. [Google Scholar] [CrossRef]
- Holmes, E.; Antti, H. Chemometric contributions to the evolution of metabonomics: Mathematical solutions to characterising and interpreting complex biological NMR spectra. Analyst 2002, 127, 1549–1557. [Google Scholar] [CrossRef]
- Hoult, D.I.; Busby, S.J.W.; Gadian, D.G.; Radda, G.K.; Richards, R.E.; Seeley, P.J. Observation of tissue metabolites using nuclear magnetic resonance. Nature 1974, 252, 285–287. [Google Scholar] [CrossRef] [PubMed]
- Griffiths, W.J.; Wang, Y. Mass spectrometry: From proteomics to metabolomics and lipidomics. Chem. Soc. Rev. 2009, 38, 1882–1896. [Google Scholar] [CrossRef] [PubMed]
- Gomez-Casati, D.F.; Zanor, M.I.; Busi, M.V. Metabolomics in plants and humans: Applications in the prevention and diagnosis of diseases. Biomed Res. Int. 2013, 2013. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Swanson, M.G.; Zektzer, A.S.; Tabatabai, Z.L.; Simko, J.; Jarso, S.; Keshari, K.R.; Schmitt, L.; Carroll, P.R.; Shinohara, K.; Vigneron, D.B.; et al. Quantitative analysis of prostate metabolites using 1H HR-MAS spectroscopy. Magn. Reson. Med. 2006, 55, 1257–1264. [Google Scholar] [CrossRef] [PubMed]
- Kline, E.E.; Treat, E.G.; Averna, T.A.; Davis, M.S.; Smith, A.Y.; Sillerud, L.O. Citrate Concentrations in Human Seminal Fluid and Expressed Prostatic Fluid Determined via 1H Nuclear Magnetic Resonance Spectroscopy Outperform Prostate Specific Antigen in Prostate Cancer Detection. J. Urol. 2006, 176, 2274–2279. [Google Scholar] [CrossRef]
- Sauer, U. Metabolic networks in motion: 13C-based flux analysis. Mol. Syst. Biol. 2006, 2, 62. [Google Scholar] [CrossRef] [Green Version]
- Jang, C.; Chen, L.; Rabinowitz, J.D. Metabolomics and Isotope Tracing. Cell 2018, 173, 822–837. [Google Scholar] [CrossRef] [PubMed]
- Jeremy, J.Y.; Ballard, S.A.; Naylor, A.M.; Miller, M.A.W.; Angelini, G.D. Effects of sildenafil, a type-5 cGMP phosphodiesterase inhibitor, and papaverine on cyclic GMP and cyclic AMP levels in the rabbit corpus cavernosum in vitro. Br. J. Urol. 1997, 79, 958–963. [Google Scholar] [CrossRef]
- Wiechert, W. 13C metabolic flux analysis. Metab. Eng. 2001, 3, 195–206. [Google Scholar] [CrossRef] [PubMed]
- Antoniewicz, M.R. Methods and advances in metabolic flux analysis: A mini-review. J. Ind. Microbiol. Biotechnol. 2015, 42, 317–325. [Google Scholar] [CrossRef]
- Dai, Z.; Locasale, J.W. Understanding metabolism with flux analysis: From theory to application. Metab. Eng. 2017, 43, 94–102. [Google Scholar] [CrossRef] [PubMed]
- Zamboni, N. 13C metabolic flux analysis in complex systems. Curr. Opin. Biotechnol. 2011, 22, 103–108. [Google Scholar] [CrossRef]
- Cascante, M.; Selivanov, V.; Ramos-Montoya, A. Application of tracer-based metabolomics and flux analysis in targeted cancer drug design. Methods Pharmacol. Toxicol. 2012, 299–320. [Google Scholar] [CrossRef]
- Antoniewicz, M.R. A guide to 13C metabolic flux analysis for the cancer biologist. Exp. Mol. Med. 2018, 50, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boghigian, B.A.; Seth, G.; Kiss, R.; Pfeifer, B.A. Metabolic flux analysis and pharmaceutical production. Metab. Eng. 2010, 12, 81–95. [Google Scholar] [CrossRef]
- Warburg, O.; Posener, K.; Negelein, E. The metabolism of cancer cells. Biochem. Z 1924, 152, 319–344. [Google Scholar]
- Vander Heiden, M.G.; Cantley, L.C.; Thompson, C.B. Understanding the Warburg effect: The metabolic requirements of cell proliferation. Science 2009, 324, 1029–1033. [Google Scholar] [CrossRef] [Green Version]
- Faubert, B.; Li, K.Y.; Cai, L.; Hensley, C.T.; Kim, J.; Zacharias, L.G.; Yang, C.; Do, Q.N.; Doucette, S.; Burguete, D.; et al. Lactate Metabolism in Human Lung Tumors. Cell 2017, 171, 358–371. [Google Scholar] [CrossRef] [Green Version]
- Hui, S.; Ghergurovich, J.M.; Morscher, R.J.; Jang, C.; Teng, X.; Lu, W.; Esparza, L.A.; Reya, T.; Zhan, L.; Yanxiang Guo, J.; et al. Glucose feeds the TCA cycle via circulating lactate. Nature 2017, 551, 115–118. [Google Scholar] [CrossRef] [Green Version]
- Van Gulik, W.M.; Antoniewicz, M.R.; deLaat, W.T.A.M.; Vinke, J.L.; Heijnen, J.J. Energetics of growth and penicillin production in a high-producing strain of Penicillium chrysogenum. Biotechnol. Bioeng. 2001, 72, 185–193. [Google Scholar] [CrossRef]
- Orman, M.A.; Berthiaume, F.; Androulakis, I.P.; Ierapetritou, M.G. Advanced stoichiometric analysis of metabolic networks of mammalian systems. Crit. Rev. Biomed. Eng. 2011, 39, 511–534. [Google Scholar] [CrossRef]
- Carinhas, N.; Bernal, V.; Teixeira, A.P.; Carrondo, M.J.; Alves, P.M.; Oliveira, R. Hybrid metabolic flux analysis: Combining stoichiometric and statistical constraints to model the formation of complex recombinant products. BMC Syst. Biol. 2011, 5, 34. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feist, A.M.; Palsson, B.O. The biomass objective function. Curr. Opin. Microbiol. 2010, 13, 344–349. [Google Scholar] [CrossRef] [Green Version]
- Orth, J.D.; Thiele, I.; Palsson, B.O. What is flux balance analysis? Nat. Biotechnol. 2010, 28, 245–248. [Google Scholar] [CrossRef]
- Ranganathan, S.; Suthers, P.F.; Maranas, C.D. OptForce: An optimization procedure for identifying all genetic manipulations leading to targeted overproductions. PLoS Comput. Biol. 2010, 6, e1000744. [Google Scholar] [CrossRef]
- Raghunathan, A.; Shin, S.; Daefler, S. Systems approach to investigating host-pathogen interactions in infections with the biothreat agent Francisella. Constraints-based model of Francisella tularensis. BMC Syst. Biol. 2010, 4, 118. [Google Scholar] [CrossRef] [Green Version]
- Harcombe, W.R.; Delaney, N.F.; Leiby, N.; Klitgord, N.; Marx, C.J. The ability of flux balance analysis to predict evolution of central metabolism scales with the initial distance to the optimum. PLoS Comput. Biol. 2013, 9, e1003091. [Google Scholar] [CrossRef] [Green Version]
- Bonarius, H.P.J.; Timmerarends, B.; De Gooijer, C.D.; Tramper, J. Metabolite-balancing techniques vs. 13C tracer experiments to determine metabolic fluxes in hybridoma cells. Biotechnol. Bioeng. 1998, 58, 258–262. [Google Scholar] [CrossRef]
- Schmidt, K.; Marx, A.; De Graaf, A.A.; Wiechert, W.; Sahm, H.; Nielsen, J.; Villadsen, J. 13C tracer experiments and metabolite balancing for metabolic flux analysis: Comparing two approaches. Biotechnol. Bioeng. 1998, 58, 254–257. [Google Scholar] [CrossRef]
- Çalik, P.; Akbay, A. Mass flux balance-based model and metabolic flux analysis for collagen synthesis in the fibrogenesis process of human liver. Med. Hypotheses 2000, 55, 5–14. [Google Scholar] [CrossRef]
- Reisz, J.A.; D’Alessandro, A. Measurement of metabolic fluxes using stable isotope tracers in whole animals and human patients. Curr. Opin. Clin. Nutr. Metab. Care 2017, 20, 366. [Google Scholar] [CrossRef]
- Weitzel, M.; Nöh, K.; Dalman, T.; Niedenführ, S.; Stute, B.; Wiechert, W. 13CFLUX2—High-performance software suite for 13C-metabolic flux analysis. Bioinformatics 2013, 29, 143–145. [Google Scholar] [CrossRef]
- Beste, D.J.V.; Nöh, K.; Niedenführ, S.; Mendum, T.A.; Hawkins, N.D.; Ward, J.L.; Beale, M.H.; Wiechert, W.; McFadden, J. 13C-flux spectral analysis of host-pathogen metabolism reveals a mixed diet for intracellular mycobacterium tuberculosis. Chem. Biol. 2013, 20, 1012–1021. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Z.; Bommareddy, R.R.; Frank, D.; Rappert, S.; Zeng, A.P. Deregulation of feedback inhibition of phosphoenolpyruvate carboxylase for improved lysine production in Corynebacterium glutamicum. Appl. Environ. Microbiol. 2014, 4, 1388–1393. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Shah, S.; Fan, J.; Park, J.O.; Wellen, K.E.; Rabinowitz, J.D. Malic enzyme tracers reveal hypoxia-induced switch in adipocyte NADPH pathway usage. Nat. Chem. Biol. 2016, 12, 345–352. [Google Scholar] [CrossRef] [Green Version]
- Zamboni, N.; Fischer, E.; Sauer, U. FiatFlux—A software for metabolic flux analysis from 13C-glucose experiments. BMC Bioinform. 2005, 6, 209. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Q.; Zhang, Y.; Yang, C.; Xiong, H.; Lin, Y.; Yao, J.; Li, H.; Xie, L.; Zhao, W.; Yao, Y.; et al. Acetylation of metabolic enzymes coordinates carbon source utilization and metabolic flux. Science 2010, 5968, 1004–1007. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Del Castillo, T.; Ramos, J.L.; Rodríguez-Herva, J.J.; Fuhrer, T.; Sauer, U.; Duque, E. Convergent peripheral pathways catalyze initial glucose catabolism in Pseudomonas putida: Genomic and flux analysis. J. Bacteriol. 2007, 189, 5142–5152. [Google Scholar] [CrossRef] [Green Version]
- Fong, S.S.; Nanchen, A.; Palsson, B.O.; Sauer, U. Latent pathway activation and increased pathway capacity enable Escherichia coli adaptation to loss of key metabolic enzymes. J. Biol. Chem. 2006, 281, 8024–8033. [Google Scholar] [CrossRef] [Green Version]
- Young, J.D. INCA: A computational platform for isotopically non-stationary metabolic flux analysis. Bioinformatics 2014, 30, 1333–1335. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lewis, C.A.; Parker, S.J.; Fiske, B.P.; McCloskey, D.; Gui, D.Y.; Green, C.R.; Vokes, N.I.; Feist, A.M.; Vander Heiden, M.G.; Metallo, C.M. Tracing Compartmentalized NADPH Metabolism in the Cytosol and Mitochondria of Mammalian Cells. Mol. Cell 2014, 55, 253–263. [Google Scholar] [CrossRef] [Green Version]
- Jiang, L.; Shestov, A.A.; Swain, P.; Yang, C.; Parker, S.J.; Wang, Q.A.; Terada, L.S.; Adams, N.D.; McCabe, M.T.; Pietrak, B.; et al. Reductive carboxylation supports redox homeostasis during anchorage-independent growth. Nature 2016, 532, 255–258. [Google Scholar] [CrossRef]
- Vacanti, N.M.; Divakaruni, A.S.; Green, C.R.; Parker, S.J.; Henry, R.R.; Ciaraldi, T.P.; Murphy, A.N.; Metallo, C.M. Regulation of substrate utilization by the mitochondrial pyruvate carrier. Mol. Cell 2014, 56, 425–435. [Google Scholar] [CrossRef] [Green Version]
- Green, C.R.; Wallace, M.; Divakaruni, A.S.; Phillips, S.A.; Murphy, A.N.; Ciaraldi, T.P.; Metallo, C.M. Branched-chain amino acid catabolism fuels adipocyte differentiation and lipogenesis. Nat. Chem. Biol. 2016, 12, 15–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yoo, H.; Antoniewicz, M.R.; Stephanopoulos, G.; Kelleher, J.K. Quantifying reductive carboxylation flux of glutamine to lipid in a brown adipocyte cell line. J. Biol. Chem. 2008, 283, 20621–20627. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Metallo, C.M.; Gameiro, P.A.; Bell, E.L.; Mattaini, K.R.; Yang, J.; Hiller, K.; Jewell, C.M.; Johnson, Z.R.; Irvine, D.J.; Guarente, L.; et al. Reductive glutamine metabolism by IDH1 mediates lipogenesis under hypoxia. Nature 2012, 481, 380–384. [Google Scholar] [CrossRef] [Green Version]
- Noguchi, Y.; Young, J.D.; Aleman, J.O.; Hansen, M.E.; Kelleher, J.K.; Stephanopoulos, G. Effect of anaplerotic fluxes and amino acid availability on hepatic lipoapoptosis. J. Biol. Chem. 2009, 48, 33425–33436. [Google Scholar] [CrossRef] [Green Version]
- Sriram, G.; Fulton, D.B.; Iyer, V.V.; Peterson, J.M.; Zhou, R.; Westgate, M.E.; Spalding, M.H.; Shanks, J.V. Quantification of compartmented metabolic fluxes in developing soybean embryos by employing biosynthetically directed fractional 13C labeling, two-dimensional [13C, 1H] nuclear magnetic resonance, and comprehensive isotopomer balancing. Plant Physiol. 2004, 136, 3043–3057. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Murarka, A.; Clomburg, J.M.; Moran, S.; Shanks, J.V.; Gonzalez, R. Metabolic analysis of wild-type Escherichia coli and a Pyruvate Dehydrogenase Complex (PDHC)-deficient derivative reveals the role of PDHC in the fermentative metabolism of glucose. J. Biol. Chem. 2010, 285, 31548–31558. [Google Scholar] [CrossRef] [Green Version]
- Fu, Y.; Yoon, J.M.; Jarboe, L.; Shanks, J.V. Metabolic flux analysis of Escherichia coli MG1655 under octanoic acid (C8) stress. Appl. Microbiol. Biotechnol. 2015, 99, 4397–4408. [Google Scholar] [CrossRef]
- Iyer, V.V.; Sriram, G.; Fulton, D.B.; Zhou, R.; Westgate, M.E.; Shanks, J.V. Metabolic flux maps comparing the effect of temperature on protein and oil biosynthesis in developing soybean cotyledons. Plant Cell Environ. 2008, 31, 506–517. [Google Scholar] [CrossRef]
- Quek, L.E.; Wittmann, C.; Nielsen, L.K.; Krömer, J.O. OpenFLUX: Efficient modelling software for 13C-based metabolic flux analysis. Microb. Cell Fact. 2009, 8, 25. [Google Scholar] [CrossRef] [Green Version]
- Nocon, J.; Steiger, M.G.; Pfeffer, M.; Sohn, S.B.; Kim, T.Y.; Maurer, M.; Rußmayer, H.; Pflügl, S.; Ask, M.; Haberhauer-Troyer, C.; et al. Model based engineering of Pichia pastoris central metabolism enhances recombinant protein production. Metab. Eng. 2014, 24, 129–138. [Google Scholar] [CrossRef]
- Bommareddy, R.R.; Chen, Z.; Rappert, S.; Zeng, A.P. A de novo NADPH generation pathway for improving lysine production of Corynebacterium glutamicum by rational design of the coenzyme specificity of glyceraldehyde 3-phosphate dehydrogenase. Metab. Eng. 2014, 25, 30–37. [Google Scholar] [CrossRef]
- Buschke, N.; Becker, J.; Schäfer, R.; Kiefer, P.; Biedendieck, R.; Wittmann, C. Systems metabolic engineering of xylose-utilizing Corynebacterium glutamicum for production of 1,5-diaminopentane. Biotechnol. J. 2013, 8, 557–570. [Google Scholar] [CrossRef]
- Kajihata, S.; Furusawa, C.; Matsuda, F.; Shimizu, H. OpenMebius: An Open Source Software for Isotopically Nonstationary 13C-Based Metabolic Flux Analysis. Biomed Res. Int. 2014, 2014, 627014. [Google Scholar] [CrossRef] [Green Version]
- Miyazawa, H.; Yamaguchi, Y.; Sugiura, Y.; Honda, K.; Kondo, K.; Matsuda, F.; Yamamoto, T.; Suematsu, M.; Miura, M. Rewiring of embryonic glucose metabolism via suppression of PFK-1 and aldolase during mouse chorioallantoic branching. Development 2017, 144, 63–73. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wada, K.; Toya, Y.; Banno, S.; Yoshikawa, K.; Matsuda, F.; Shimizu, H. 13C-metabolic flux analysis for mevalonate-producing strain of Escherichia coli. J. Biosci. Bioeng. 2017, 123, 177–182. [Google Scholar] [CrossRef]
- Antoniewicz, M.R.; Kelleher, J.K.; Stephanopoulos, G. Elementary metabolite units (EMU): A novel framework for modeling isotopic distributions. Metab. Eng. 2007, 9, 68–86. [Google Scholar] [CrossRef] [Green Version]
- Wiechert, W.; Möllney, M.; Isermann, N.; Wurzel, M.; De Graaf, A.A. Bidirectional reaction steps in metabolic networks: III. Explicit solution and analysis of isotopomer labeling systems. Biotechnol. Bioeng. 1999, 66, 69–85. [Google Scholar] [CrossRef]
- Simmons, E.M.; Hartwig, J.F. On the interpretation of deuterium kinetic isotope effects in C-H bond functionalizations by transition-metal complexes. Angew. Chemie. Int. Ed. 2012, 51, 3066–3072. [Google Scholar] [CrossRef] [PubMed]
- Liuni, P.; Olkhov-Mitsel, E.; Orellana, A.; Wilson, D.J. Measuring kinetic isotope effects in enzyme reactions using time-resolved electrospray mass spectrometry. Anal. Chem. 2013, 85, 3758–3764. [Google Scholar] [CrossRef]
- Tea, I.; Tcherkez, G. Natural Isotope Abundance in Metabolites: Techniques and Kinetic Isotope Effect Measurement in Plant, Animal, and Human Tissues. In Methods in Enzymology; Acacdemic Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Roth, J.P.; Klinman, J.P. Kinetic Isotope Effects. In Encyclopedia of Biological Chemistry, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2013; ISBN 9780123786319. [Google Scholar]
- Westheimer, F.H. The magnitude of the primary kinetic isotope effect for compounds of hydrogen and deuterium. Chem. Rev. 1961, 61, 265–273. [Google Scholar] [CrossRef]
- Fan, J.; Ye, J.; Kamphorst, J.J.; Shlomi, T.; Thompson, C.B.; Rabinowitz, J.D. Quantitative flux analysis reveals folate-dependent NADPH production. Nature 2014, 510, 298–302. [Google Scholar] [CrossRef] [Green Version]
- Williams, T.C.R.; Sweetlove, L.J.; George Ratcliffe, R. Capturing metabolite channeling in metabolic flux phenotypes. Plant Physiol. 2011, 157, 981–984. [Google Scholar] [CrossRef] [Green Version]
- Spivey, H.O.; Ovádi, J. Substrate channeling. Methods A Companion Methods Enzymol. 1999, 19, 306–321. [Google Scholar] [CrossRef] [PubMed]
- Miles, E.W.; Rhee, S.; Davies, D.R. The molecular basis of substrate channeling. J. Biol. Chem. 1999, 274, 12193–12196. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.H.P. Substrate channeling and enzyme complexes for biotechnological applications. Biotechnol. Adv. 2011, 29, 715–725. [Google Scholar] [CrossRef]
- Wahrheit, J.; Nicolae, A.; Heinzle, E. Eukaryotic metabolism: Measuring compartment fluxes. Biotechnol. J. 2011, 6, 1071–1085. [Google Scholar] [CrossRef] [PubMed]
- Allen, D.K.; Shachar-Hill, Y.; Ohlrogge, J.B. Compartment-specific labeling information in 13C metabolic flux analysis of plants. Phytochemistry 2007, 68, 2197–2210. [Google Scholar] [CrossRef]
- Toledano, M.B.; Delaunay-Moisan, A.; Outten, C.E.; Igbaria, A. Functions and cellular compartmentation of the thioredoxin and glutathione pathways in yeast. Antioxid. Redox Signal. 2013, 18, 1699–1711. [Google Scholar] [CrossRef] [Green Version]
- Antoniewicz, M.R.; Kelleher, J.K.; Stephanopoulos, G. Determination of confidence intervals of metabolic fluxes estimated from stable isotope measurements. Metab. Eng. 2006, 8, 324–337. [Google Scholar] [CrossRef]
- Metallo, C.M.; Walther, J.L.; Stephanopoulos, G. Evaluation of 13C isotopic tracers for metabolic flux analysis in mammalian cells. J. Biotechnol. 2009, 144, 167–174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Crown, S.B.; Long, C.P.; Antoniewicz, M.R. Optimal tracers for parallel labeling experiments and 13C metabolic flux analysis: A new precision and synergy scoring system. Metab. Eng. 2016, 38, 10–18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nargund, S.; Sriram, G. Designer labels for plant metabolism: Statistical design of isotope labeling experiments for improved quantification of flux in complex plant metabolic networks. Mol. Biosyst. 2013, 9, 99–112. [Google Scholar] [CrossRef] [PubMed]
- Crown, S.B.; Ahn, W.S.; Antoniewicz, M.R. Rational design of 13C-labeling experiments for metabolic flux analysis in mammalian cells. BMC Syst. Biol. 2012, 6, 43. [Google Scholar] [CrossRef] [Green Version]
- Millard, P.; Sokol, S.; Letisse, F.; Portais, J.C. IsoDesign: A software for optimizing the design of 13C-metabolic flux analysis experiments. Biotechnol. Bioeng. 2014, 111, 202–208. [Google Scholar] [CrossRef]
- Isermann, N.; Wiechert, W. Metabolic isotopomer labeling systems. Part II: Structural flux identifiability analysis. Math. Biosci. 2003, 183, 175–214. [Google Scholar] [CrossRef]
- Kadirkamanathan, V.; Yang, J.; Billings, S.A.; Wright, P.C. Markov Chain Monte Carlo Algorithm based metabolic flux distribution analysis on Corynebacterium glutamicum. Bioinformatics 2006, 22, 2681–2687. [Google Scholar] [CrossRef]
- Yang, J.; Wongsa, S.; Kadirkamanathan, V.; Billings, S.A.; Wright, P.C. Metabolic flux distribution analysis by13C-tracer experiments using the Markov chain-Monte Carlo method. Biochem. Soc. Trans. 2005, 33, 1421–1422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Buescher, J.M.; Antoniewicz, M.R.; Boros, L.G.; Burgess, S.C.; Brunengraber, H.; Clish, C.B.; DeBerardinis, R.J.; Feron, O.; Frezza, C.; Ghesquiere, B.; et al. A roadmap for interpreting 13C metabolite labeling patterns from cells. Curr. Opin. Biotechnol. 2015, 34, 189–201. [Google Scholar] [CrossRef]
- Ma, F.; Jazmin, L.J.; Young, J.D.; Allen, D.K. Isotopically nonstationary 13C flux analysis of changes in Arabidopsis thaliana leaf metabolism due to high light acclimation. Proc. Natl. Acad. Sci. USA 2014, 111, 16967–16972. [Google Scholar] [CrossRef] [Green Version]
- Yuan, J.; Bennett, B.D.; Rabinowitz, J.D. Kinetic flux profiling for quantitation of cellular metabolic fluxes. Nat. Protoc. 2008, 3, 1328. [Google Scholar] [CrossRef] [Green Version]
- Noack, S.; Nöh, K.; Moch, M.; Oldiges, M.; Wiechert, W. Stationary versus non-stationary 13C-MFA: A comparison using a consistent dataset. J. Biotechnol. 2011, 154, 179–190. [Google Scholar] [CrossRef]
- Nöh, K.; Wiechert, W. Experimental design principles for isotopically instationary 13C labeling experiments. Biotechnol. Bioeng. 2006, 94, 234–251. [Google Scholar] [CrossRef]
- Nöh, K.; Grönke, K.; Luo, B.; Takors, R.; Oldiges, M.; Wiechert, W. Metabolic flux analysis at ultra short time scale: Isotopically non-stationary 13C labeling experiments. J. Biotechnol. 2007, 129, 249–267. [Google Scholar] [CrossRef]
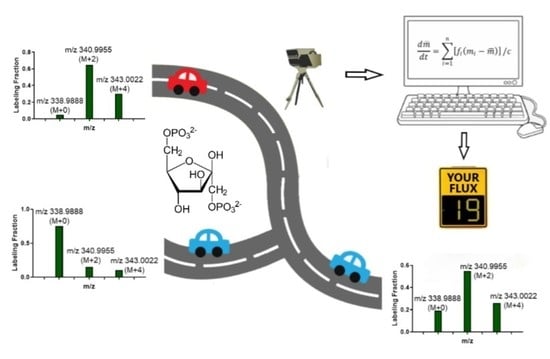
Figure 1.
Comparison of stoichiometric flux analysis (SFA) and metabolic flux analysis (MFA). (A) For SFA, no isotope tracer is used. In the upper glycolysis network, the consumption rate of glucose and the production rate of GAP is 100 nmol/h and 200 nmol/h, respectively. The atoms of FBP, DHAP and GAP are numbered to illustrate the atom transition. (B) For MFA, 1,2-13C2-glucose is used as the tracer. As the result, FBP is labeled as M+0, M+2 and M+4. This labeling pattern indicates that the aldolase and triose phosphate isomerase have reverse fluxes, which are f3 and f5, respectively. The abbreviations used in the figure are: Glc, glucose; Glc6P, glucose-6-phosphate; Fruc6P, fructose-6-phosphate; FBP, fructose 1,6-bisphosphate; DHAP, dihydroxyacetone phosphate and GAP, glyceraldehyde-3-phosphate. The fluxes are in the unit of nmol/h.
Figure 1.
Comparison of stoichiometric flux analysis (SFA) and metabolic flux analysis (MFA). (A) For SFA, no isotope tracer is used. In the upper glycolysis network, the consumption rate of glucose and the production rate of GAP is 100 nmol/h and 200 nmol/h, respectively. The atoms of FBP, DHAP and GAP are numbered to illustrate the atom transition. (B) For MFA, 1,2-13C2-glucose is used as the tracer. As the result, FBP is labeled as M+0, M+2 and M+4. This labeling pattern indicates that the aldolase and triose phosphate isomerase have reverse fluxes, which are f3 and f5, respectively. The abbreviations used in the figure are: Glc, glucose; Glc6P, glucose-6-phosphate; Fruc6P, fructose-6-phosphate; FBP, fructose 1,6-bisphosphate; DHAP, dihydroxyacetone phosphate and GAP, glyceraldehyde-3-phosphate. The fluxes are in the unit of nmol/h.

Figure 2.
The solving process of MFA. (A) The relationship between fluxes and labeling patterns. The choice of tracer and fluxes can determine the labeling patterns, which can be calculated by elementary metabolite units (EMU), cumomer or other methods. The flux-solving process is the inverse problem of the labeling prediction, which involves iterative fitting between the labeling pattern predicted from “guessed” fluxes and the observed labeling pattern. (B–D) Iterative paths of optimization from two different start points ending with the same solution. (B) The landscape plot of sum of squared residuals (SSR) on the plane of free fluxes. Each dot on this plane represents a combination of fluxes, which gives a prediction on the labeling pattern of FBP. This predicted labeling pattern is compared to the measurement and the discrepancy between them is defined as the SSR and is plotted with different colors on the plane. For flux calculation, we can start from a random point and perform gradient descent or other optimization algorithms to minimize the SSR. The iterative paths starting from two randomly chosen points are shown. (C,D) Change of SSR and fluxes from start point 1 (C) and 2 (D) to the optimal solution.
Figure 2.
The solving process of MFA. (A) The relationship between fluxes and labeling patterns. The choice of tracer and fluxes can determine the labeling patterns, which can be calculated by elementary metabolite units (EMU), cumomer or other methods. The flux-solving process is the inverse problem of the labeling prediction, which involves iterative fitting between the labeling pattern predicted from “guessed” fluxes and the observed labeling pattern. (B–D) Iterative paths of optimization from two different start points ending with the same solution. (B) The landscape plot of sum of squared residuals (SSR) on the plane of free fluxes. Each dot on this plane represents a combination of fluxes, which gives a prediction on the labeling pattern of FBP. This predicted labeling pattern is compared to the measurement and the discrepancy between them is defined as the SSR and is plotted with different colors on the plane. For flux calculation, we can start from a random point and perform gradient descent or other optimization algorithms to minimize the SSR. The iterative paths starting from two randomly chosen points are shown. (C,D) Change of SSR and fluxes from start point 1 (C) and 2 (D) to the optimal solution.

Figure 3.
Evaluation on the tracer selection for MFA. (A) The colored region is showing the 95% confidence region of f3 and f5 using 1,2-13C2 glucose as tracer, assuming 1% error on all labeled fractions of FBP. Both f3 and f5 can be relatively well-determined. (B) The colored region is showing the 95% confidence region of f3 and f5 using 50% U-13C- glucose + 50% unlabeled glucose as the tracer. Only f3 can be determined.
Figure 3.
Evaluation on the tracer selection for MFA. (A) The colored region is showing the 95% confidence region of f3 and f5 using 1,2-13C2 glucose as tracer, assuming 1% error on all labeled fractions of FBP. Both f3 and f5 can be relatively well-determined. (B) The colored region is showing the 95% confidence region of f3 and f5 using 50% U-13C- glucose + 50% unlabeled glucose as the tracer. Only f3 can be determined.

Figure 4.
Plotting flux confidence region for the network from Antoniewicz et al. [66]. (A) The network structure. f2 and f4 are two free fluxes in this model network. 2-13C1 A is used as a tracer. (B) The colored region is showing the 95% confidence region determined by measuring the labeling pattern of F only. (C) The colored region is showing the 95% confidence region determined by measuring the labeling pattern of B only. (D) The colored region is showing the 99% confidence region, in order to enlarge the region to be more visible, determined by measuring the labeling patterns of both B and F. The discrepancy between predicted labeling pattern and the measurement is converted to the χ2-statistic assuming 0.3% error on the labeled fractions.
Figure 4.
Plotting flux confidence region for the network from Antoniewicz et al. [66]. (A) The network structure. f2 and f4 are two free fluxes in this model network. 2-13C1 A is used as a tracer. (B) The colored region is showing the 95% confidence region determined by measuring the labeling pattern of F only. (C) The colored region is showing the 95% confidence region determined by measuring the labeling pattern of B only. (D) The colored region is showing the 99% confidence region, in order to enlarge the region to be more visible, determined by measuring the labeling patterns of both B and F. The discrepancy between predicted labeling pattern and the measurement is converted to the χ2-statistic assuming 0.3% error on the labeled fractions.

Figure 5.
Example of isotopically non-stationary MFA. (A) Upper glycolysis network, the carbon sources were switched from non-labeled glucose to 1,2-13C2-glucose to measure the kinetics of metabolite labeling. The numbers next to the arrows are fluxes in the unit of nmol/s. (B,C) In isotopically non-stationary MFA, the labeling patterns of metabolite is affected by the pool size of the metabolites. FBP, DHAP and GAP all have the pool size of 1 µmol. The pool size of Glc6P is assumed to be 400 nmols (B) or 3000 nmols (C). (B) FBP in the network with small Glc6P pool size reaches steady state faster. (C) FBP in the network with large Glc6P pool size reaches steady state slower. The abbreviations used in the figure are: Glc, glucose; Glc6P, glucose-6-phosphate; Fruc6P, fructose-6-phosphate; FBP, fructose 1,6-bisphosphate; DHAP, dihydroxyacetone phosphate and GAP, glyceraldehyde-3-phosphate.
Figure 5.
Example of isotopically non-stationary MFA. (A) Upper glycolysis network, the carbon sources were switched from non-labeled glucose to 1,2-13C2-glucose to measure the kinetics of metabolite labeling. The numbers next to the arrows are fluxes in the unit of nmol/s. (B,C) In isotopically non-stationary MFA, the labeling patterns of metabolite is affected by the pool size of the metabolites. FBP, DHAP and GAP all have the pool size of 1 µmol. The pool size of Glc6P is assumed to be 400 nmols (B) or 3000 nmols (C). (B) FBP in the network with small Glc6P pool size reaches steady state faster. (C) FBP in the network with large Glc6P pool size reaches steady state slower. The abbreviations used in the figure are: Glc, glucose; Glc6P, glucose-6-phosphate; Fruc6P, fructose-6-phosphate; FBP, fructose 1,6-bisphosphate; DHAP, dihydroxyacetone phosphate and GAP, glyceraldehyde-3-phosphate.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Commonly used software tools for metabolic flux analysis (MFA).
| Name | Data Source | Main Features | Number of Citations | Reference and Most Cited Applications |
|---|---|---|---|---|
| 13CFLUX2 | MS and NMR | Compatible to multi-platform | 107 | [39,40,41,42] |
| FiatFlux | GC-MS | 13C Glucose tracer, flux ratio | 160 | [43,44,45,46] |
| INCA | MS and NMR | Isotopically non-stationary MFA | 147 | [47,48,49,50,51] |
| METRAN | MS | Intuitive graphical user interface, confidence interval calculation | 183 | [52,53,54] |
| NMR2Flux+ | NMR | NMR data, plant network | 124 | [55,56,57,58] |
| OpenFLUX | MS | Steady-state 13C MFA, experimental design | 154 | [59,60,61,62] |
| OpenMebius | MS | Isotopically non-stationary MFA | 47 | [63,64,65] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wang, Y.; Wondisford, F.E.; Song, C.; Zhang, T.; Su, X. Metabolic Flux Analysis—Linking Isotope Labeling and Metabolic Fluxes. Metabolites 2020, 10, 447. https://doi.org/10.3390/metabo10110447
AMA Style
Wang Y, Wondisford FE, Song C, Zhang T, Su X. Metabolic Flux Analysis—Linking Isotope Labeling and Metabolic Fluxes. Metabolites. 2020; 10(11):447. https://doi.org/10.3390/metabo10110447
Chicago/Turabian StyleWang, Yujue, Fredric E. Wondisford, Chi Song, Teng Zhang, and Xiaoyang Su. 2020. "Metabolic Flux Analysis—Linking Isotope Labeling and Metabolic Fluxes" Metabolites 10, no. 11: 447. https://doi.org/10.3390/metabo10110447
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.