
Credit Risk Theoretical Model on the Base of DCC-GARCH in Time-Varying Parameters Framework

 ,
,  ,
, 
Abstract
:1. Introduction
2. Literature Review
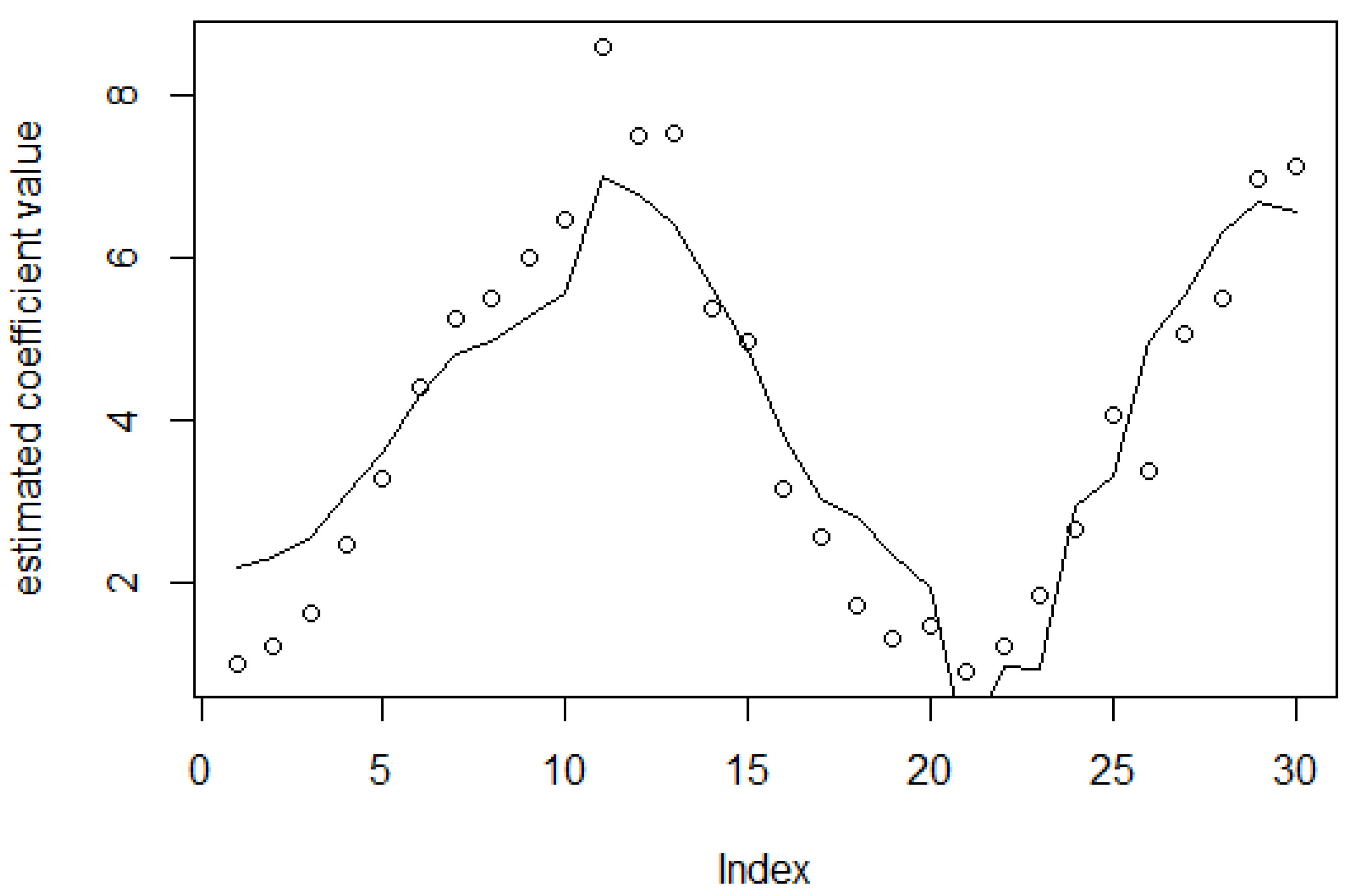
3. Materials and Methods
4. Empirical Reasoning for the Method
5. Simulation Experiment
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Bansal, G.; Sinha, A.P.; Zhao, H. Tuning data mining methods for cost-sensitive regression: A study in loan charge-off forecasting. J. Manag. Inf. Syst. 2008, 25, 315–336. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Legro, R.S.; Zhang, J.; Zhang, L.; Chen, X.; Huang, H.; Casson, P.R.; Schlaff, W.D.; Diamond, M.P.; Krawetz, S.A.; et al. Decision trees for identifying predictors of treatment effectiveness in clinical trials and its application to ovulation in a study of women with polycystic ovary syndrome. Hum. Reprod. 2010, 25, 2612–2621. [Google Scholar] [CrossRef] [Green Version]
- Smith, L.D.; Lawrence, E.C. Forecasting losses on a liquidating long-term loan portfolio. J. Bank. Financ. 1995, 19, 959–985. [Google Scholar] [CrossRef]
- Greenidge, K.; Grosvenor, T. Forecasting non-performing loans in Barbados. J. Bus. Financ. Econ. Emerg. Econ. 2010, 5, 80–108. [Google Scholar]
- Abdou, H.A.; Pointon, J. Credit scoring, statistical techniques and evaluation criteria: A review of the literature. Intell. Syst. Acc. Financ. Manag. 2011, 18, 59–88. [Google Scholar] [CrossRef] [Green Version]
- Darroch, J.N.; Ratcliff, D. Generalized iterative scaling for log-linear models. Ann. Math. Stat. 1972, 43, 1470–1480. [Google Scholar] [CrossRef]
- Eddy, Y.L.; Engku Abu Bakar, E.M.N. Credit scoring models: Techniques and issues. J. Adv. Res. Bus. Manag. Stud. 2017, 7, 29–41. [Google Scholar]
- Eletter, S.F.; Yaseen, S.G.; Elrefae, G.A. Neuro-based artificial intelligence model for loan decisions. Am. J. Econ. Bus. Adm. 2010, 2, 27. [Google Scholar] [CrossRef]
- Khashman, A. Neural networks for credit risk evaluation: Investigation of different neural models and learning schemes. Expert Syst. Appl. 2010, 37, 6233–6239. [Google Scholar] [CrossRef]
- Finlay, S. Are we modelling the right thing? The impact of incorrect problem specification in credit scoring. Expert Syst. Appl. 2009, 36, 9065–9071. [Google Scholar] [CrossRef]
- Kamalloo, E.; Saniee Abadeh, M. Credit risk prediction using fuzzy immune learning. Adv. Fuzzy Syst. 2014, 2014, 7. [Google Scholar] [CrossRef] [Green Version]
- Durand, D. Risk Elements in Consumer Installment Financing; National Bureau of Economic Research: New York, NY, USA, 1941. [Google Scholar]
- Makowski, P. Credit scoring branches out. Credit World 1985, 75, 30–37. [Google Scholar]
- Angelini, E.; Di Tollo, G.; Roli, A. A neural network approach for credit risk evaluation. Q. Rev. Econ. Financ. 2008, 48, 733–755. [Google Scholar] [CrossRef]
- Henley, W.; Hand, D.J. AK-Nearest-Neighbour Classifier for Assessing Consumer Credit Risk. J. R. Stat. Soc. Ser. D Stat. 1996, 45, 77–95. [Google Scholar]
- Hurley, M.; Adebayo, J. Credit scoring in the era of big data. Yale J. Law Tech. 2016, 18, 148. [Google Scholar]
- DAVIS, R.H.; Edelman, D.B.; Gammerman, A.J. Machine-learning algorithms for credit-card applications. IMA J. Manag. Math. 1992, 4, 43–51. [Google Scholar] [CrossRef]
- Frydman, H.; Altman, E.I.; Kao, D.L. Introducing recursive partitioning for financial classification: The case of financial distress. J. Financ. 1985, 40, 269–291. [Google Scholar] [CrossRef]
- Zhou, S.R.; Zhang, D.Y. A nearly neutral model of biodiversity. Ecology 2008, 89, 248–258. [Google Scholar] [CrossRef] [Green Version]
- Jensen, H.L. Using neural networks for credit scoring. Manag. Financ. 1992, 18, 15–26. [Google Scholar] [CrossRef]
- West, D. Neural network credit scoring models. Comput. Oper. Res. 2000, 27, 1131–1152. [Google Scholar] [CrossRef]
- West, D.; Dellana, S.; Qian, J. Neural network ensemble strategies for financial decision applications. Comput. Oper. Res. 2005, 32, 2543–2559. [Google Scholar] [CrossRef]
- Dietterich, T.G. Machine-learning research. AI Mag. 1997, 18, 97. [Google Scholar]
- Huang, Z.; Chen, H.; Hsu, C.J.; Chen, W.H.; Wu, S. Credit rating analysis with support vector machines and neural networks: A market comparative study. Decis. Support Syst. 2004, 37, 543–558. [Google Scholar] [CrossRef]
- Zhu, Y.; Xie, C.; Wang, G.J.; Yan, X.G. Comparison of individual, ensemble and integrated ensemble machine learning methods to predict China’s SME credit risk in supply chain finance. Neural Comput. Appl. 2017, 28, 41–50. [Google Scholar] [CrossRef]
- Opitz, D.; Maclin, R. Popular ensemble methods: An empirical study. J. Artif. Intell. Res. 1999, 11, 169–198. [Google Scholar] [CrossRef]
- Bitto, A.; Frühwirth-Schnatter, S. Achieving shrinkage in a time-varying parameter model framework. J. Econ. 2019, 210, 75–97. [Google Scholar] [CrossRef]
- Chan, J.C.; Eisenstat, E. Bayesian model comparison for time-varying parameter VARs with stochastic volatility. J. Appl. Econ. 2018, 33, 509–532. [Google Scholar] [CrossRef]
- Kalli, M.; Griffin, J.E. Time-varying sparsity in dynamic regression models. J. Econ. 2014, 178, 779–793. [Google Scholar] [CrossRef] [Green Version]
- Orlando, G.; Pelosi, R. Non-performing loans for Italian companies: When time matters: An empirical research on estimating probability to default and loss given default. Int. J. Financ. Stud. 2020, 8, 68. [Google Scholar] [CrossRef]
- Aslan, A.; Poppe, L.; Posch, P. Are sustainable companies more likely to default? Evidence from the dynamics between credit and ESG ratings. Sustainability 2021, 13, 8568. [Google Scholar] [CrossRef]
- Orlova, E.V. Methodology and models for individuals’ creditworthiness management using digital footprint data and machine learning methods. Mathematics 2021, 9, 1820. [Google Scholar] [CrossRef]
- An, J.; Mikhaylov, A.; Jung, S.-U. A Linear Programming Approach for Robust Network Revenue Management in the Airline Industry. J. Air Transp. Manag. 2021, 91, 101979. [Google Scholar] [CrossRef]
- Mikhaylov, A. Development of Friedrich von Hayek’s theory of private money and economic implications for digital currencies. Terra Econ. 2021, 19, 53–62. [Google Scholar] [CrossRef]
- An, J.; Mikhaylov, A.; Richter, U.H. Trade War Effects: Evidence from Sectors of Energy and Resources in Africa. Heliyon 2020, 6, e05693. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Zhou, L.; Xie, C.; Wang, G.-J.; Nguyen, T.V. Forecasting SMEs’ credit risk in supply chain finance with an enhanced hybrid ensemble machine learning approach. Int. J. Prod. Econ. 2019, 211, 22–33. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subsample Number | Time Range | Closed Credit Sum | Number of Payments to Loan Term Ratio | |||
|---|---|---|---|---|---|---|
| From | To | Coef | p-Value | Coef | p-Value | |
| 1 | 12.01.2015 | 29.06.2015 | −0.767 | 0.039 | −0.147 | 0.718 |
| 2 | 01.07.2015 | 30.12.2015 | −0.449 | 0.061 | −0.432 | 0.126 |
| 3 | 11.01.2016 | 30.06.2016 | −0.200 | 0.479 | −0.375 | 0.225 |
| 4 | 01.07.2016 | 31.12.2016 | −0.569 | 0.002 | −0.505 | 0.011 |
| 5 | 01.01.2017 | 30.06.2017 | −0.522 | 0.003 | −0.403 | 0.038 |
| 6 | 01.07.2017 | 31.12.2017 | −0.729 | 0.000 | −0.521 | 0.001 |
| 7 | 01.01.2018 | 30.06.2018 | −0.687 | 0.000 | −0.462 | 0.000 |
| 8 | 01.07.2018 | 31.12.2018 | −0.427 | 0.000 | −0.386 | 0.000 |
| 9 | 01.01.2019 | 30.06.2019 | −0.306 | 0.000 | −0.304 | 0.000 |
| 10 | 01.07.2019 | 31.12.2019 | −0.254 | 0.000 | −0.188 | 0.000 |
| Method | Profit Received | Number of Issued Loans | Number of Defaulted Loans | Percent of Defaulted Loans | Mean Squared Forecast Error | Mean Absolute Error |
|---|---|---|---|---|---|---|
| Generic logit | 19,414 | 301,291 | 9741 | 3.23% | 0.030 | 0.035 |
| Random Forest | 19,627 | 301,232 | 9542 | 3.17% | 0.030 | 0.035 |
| Gradient boosting | 19,735 | 301,168 | 9438 | 3.13% | 0.030 | 0.035 |
| ARIMA | 24,537.6 | 300,904 | 5048 | 1.68% | 0.024 | 0.029 |
| State space DCC-GARCH | 28,531.8 | 300,831 | 1405 | 0.47% | 0.016 | 0.021 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moiseev, N.; Sorokin, A.; Zvezdina, N.; Mikhaylov, A.; Khomyakova, L.; Danish, M.S.S. Credit Risk Theoretical Model on the Base of DCC-GARCH in Time-Varying Parameters Framework. Mathematics 2021, 9, 2423. https://doi.org/10.3390/math9192423
Moiseev N, Sorokin A, Zvezdina N, Mikhaylov A, Khomyakova L, Danish MSS. Credit Risk Theoretical Model on the Base of DCC-GARCH in Time-Varying Parameters Framework. Mathematics. 2021; 9(19):2423. https://doi.org/10.3390/math9192423
Chicago/Turabian StyleMoiseev, Nikita, Aleksander Sorokin, Natalya Zvezdina, Alexey Mikhaylov, Lyubov Khomyakova, and Mir Sayed Shah Danish. 2021. "Credit Risk Theoretical Model on the Base of DCC-GARCH in Time-Varying Parameters Framework" Mathematics 9, no. 19: 2423. https://doi.org/10.3390/math9192423