4.1. Classification Results
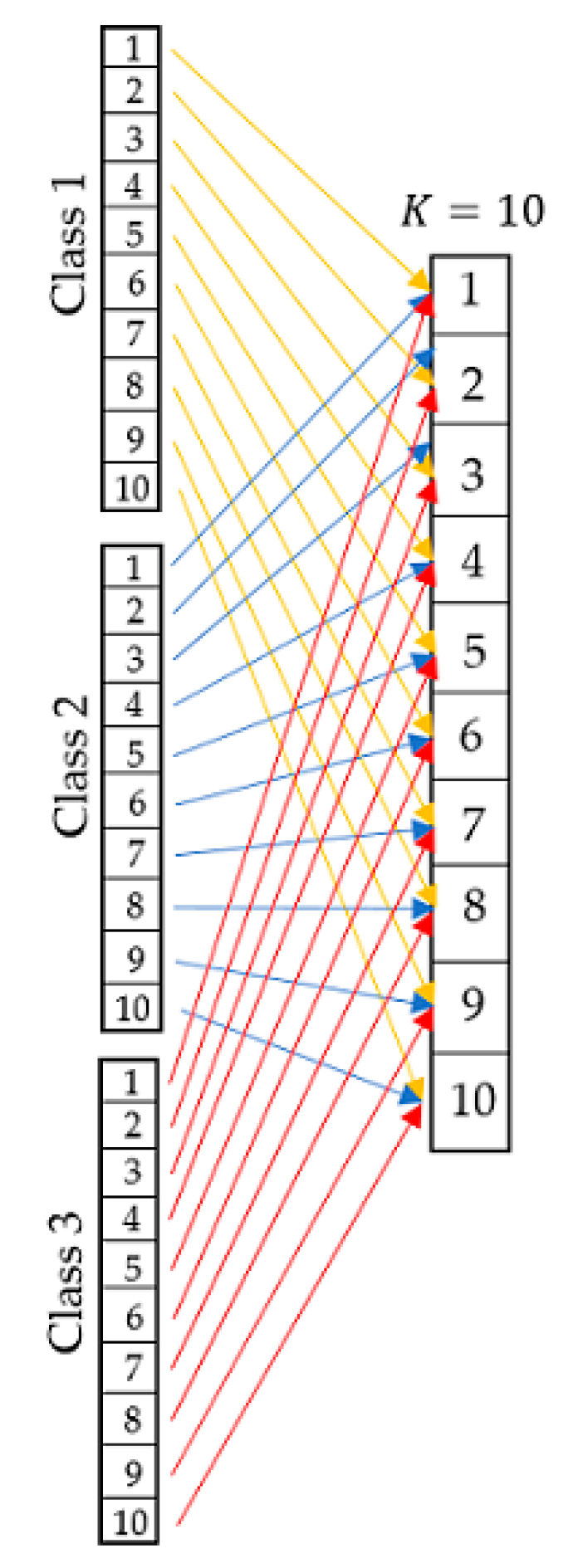
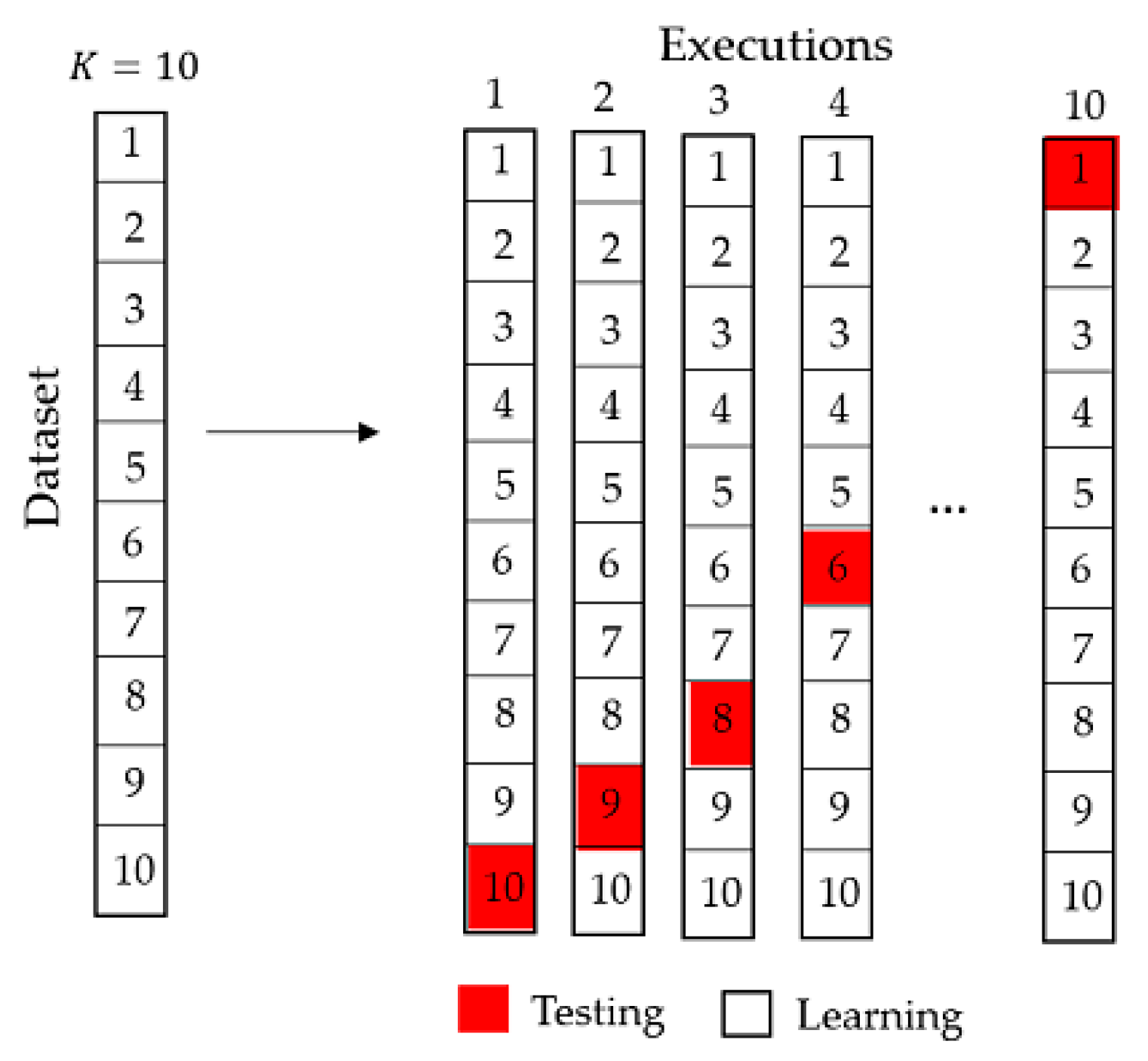
As the datasets were taken from three different repositories, with the exception of the datasets of the Keel repositories that provides the files under the 10-Fold cross validation method, a Python program of the algorithm of the 10-Fold cross validation method was developed as described in
Figure 2 and
Figure 3.
Once learn classes and test classes were generated, the Weka software was applied.
Table 4 shows the behavior of the classifiers according to Balanced Accuracy. Best results are highlighted in bold and indicate that a particular classifier performed better compared to the other classifiers.
As shown in
Table 4, the classifiers with best performance according to Balanced Accuracy measure is Naïve Bayes with seven wins, followed by SVM and Deep Learning, with six and five wins, respectively.
However, the variation in the results is extremely high, ranging from 0.50 to 0.97 for Naïve Bayes, 0.072 to 0.97 for Deep Learning and 0.443 to 0.979 for SVM.
It should be noted at this stage of the research work that this heavy variation supports the need for establishing one of the most important contributions of the present paper: the a priori establishment of the performance of the classifiers, by means of meta-learning procedures.
Table 5 shows the behavior of the classifiers according to Sensitivity.
According to sensitivity (
Table 5), the classifier with best performance is Naïve Bayes, with seven wins, followed by Deep Learning and SVM, with six wins.
However, as for Balanced Accuracy, the variation in the results is extremely high, ranging from 0.493 to 0.975 for Naïve Bayes, 0.51 to 0.979 for SVM, and 0.0743 to 0.979 for Deep Learning.
Table 6 shows the behavior of the classifiers according to Specificity.
According to specificity (
Table 6), the classifier with best performance is SVM (six wins), followed by Naïve Bayes (five wins). It is interesting that Deep Learning showed poor behavior regarding specificity, with only two wins.
Again, the variation in the results is extremely high, ranging from 0.304 to 0.979 for SVM.
4.2. Statistical Analysis
Despite the previous results, which support the idea that the best performed classifiers are Naïve Bayes and Support Vector Machines, there is a need to establish if the differences in performance among the classifiers are significant or not. To do so, several authors suggest the use of non-parametric statistical tests [
56].
For statistical analysis, we used the Friedman test for the comparison of multiple related samples [
57] and the Holm test for post hoc analysis [
58]. The application of the Friedman test implies the creation of a block for each of the samples analyzed in such a way that each block contains an observation from the application of each of the different contrasts or treatments. In terms of matrices, the blocks correspond to rows and the treatments to columns.
The null hypothesis establishes that the performances obtained by different treatments are equivalent, while the alternative hypothesis proposes that there is a difference between these performances, which would imply differences in the central tendency.
If
k is defined as the number of treatments, then for each block a range between 1 and
k is assigned to each input, 1 to the best result and
k to the worst. In case of ties, the average rank is assigned. Next, the variable
Rj (
j = 1,…,
k) is assigned the value of the sum of the ranges corresponding to each treatment. If the performances obtained from the different treatments are equivalent, then
Rj =
Rj for all
i ≠
j. Thus, from this procedure it is possible to determine when an observed disparity between the
Rj is sufficient to reject the null hypothesis. Let
n be the number of blocks, and
k be the number of treatments, then the Friedman statistic (
S) is given by:
For values of n ≥ 10 and k ≥ 4, the S statistic approximates a chi-square random variable with k − 1 degrees of freedom. The critical region of size is the right tail of the distribution of said variable. The null hypothesis is rejected when the value of S is greater than the critical value.
In the case that the Friedman test determines the existence of significant differences in the performance of the algorithms, it is recommended to use a post hoc test to determine between which of the algorithms compared in the Friedman test there are such differences. Holm’s post hoc test is designed to reduce type I errors when analyzing phenomena that include several hypotheses, and consists of adjusting the rejection criterion for each one of them.
The procedure begins with the ascending ordering of the probability values of each hypothesis. Once ordered, each of these values is compared with the quotient obtained by dividing the level of significance by the total number of hypotheses whose p-value has not been compared. When finding some p-value that exceeds this quotient, all the null hypotheses associated with the p-values that have already been compared are rejected.
Let be a group of k hypotheses and the corresponding probability values. By ordering these p-values in ascending order, a new nomenclature is established: for the ordered p-values and for the hypothesis associated with each of them. If is the level of significance and j is the minimum index for which it is satisfied that then the null hypotheses are rejected.
For both Friedman and Holm test, a significance level = 0.05 was established, for 95% confidence. We begin by establishing the following hypotheses:
H0: There are no significant differences in the performance of the algorithms.
H1: There are significant differences in the performance of the algorithms.
The Friedman test obtained a significance values of 0.01758, 0.017996 and 0.152972, for Balanced Accuracy, Sensitivity and Specificity measures, respectively. Therefore, the null hypothesis for both Balanced Accuracy and Sensitivity measures are rejected, showing that there are significant differences in the performance of the compared algorithms.
Table 7 shows the ranking obtained by the Friedman test.
As can be seen in
Table 7, the first algorithm in the ranking for Balanced Accuracy was Naïve Bayes, for Sensitivity this was SVM, and for Specificity the best algorithm was Logistic. Holm’s test compares the performance of the best ranked algorithm with the remaining ones.
Table 8 shows the results of the Holm’s test for Balanced Accuracy.
Table 9 shows the results of the Holm’s test for Sensitivity.
For Balanced Accuracy, Holm’s procedure rejects the hypotheses that have an unadjusted p-value ≤ 0.01. The results of the Holm test show that there are no significant differences in the performance of the Naïve Bayes algorithm with respect to the compared algorithms apart from 3-NN, which showed a significantly worse behavior according to Balanced Accuracy.
For Sensitivity, in addition to 3-NN, which maintained a significantly worse behavior, the Multilayer Perceptron algorithm was also significantly worse than the SVM classifier.
4.3. Meta-Learning
After obtaining the results for the compared classifiers, we discretized the performance values into three categories of performance: Good, Regular and Poor. Then, for each classifier, we obtained a new dataset, having as conditional attributes the values of the 12 complexity measures of
Table 2, and as decision (class) attribute the discretized performance.
We used the Balanced Accuracy measure as decision attribute, due to the fact that it integrates the results of both sensitivity and specificity.
With such information, we were able to train a decision tree to a priori determine the performance of the classifiers. The decision tree is shown in
Figure 4.
In the following, we show the performance results of our proposed meta-learning decision tree (in the form of a confusion matrix), as well as the obtained tree, for each classifier. In the decision trees, G stands for Good, P for Poor and R for Regular.
For the MLP classifier, the proposed meta-learning algorithm had only two errors: a dataset with Regular performance and a dataset with Poor performance, both classified as having Good performance, for a Balanced Accuracy of 0.9144.
The corresponding confusion matrix is shown in
Table 10.
The resulting decision tree (
Figure 4a) has only six leaves, with size = 11. The decision tree only considers complexity measures L1, N2, N4 and T2 to make the decision.
As for the MLP classifier, the proposed meta-learning algorithm had only two errors (
Table 11): a dataset with Regular performance and a dataset with Poor performance, both classified as having Good performance, for a Balanced Accuracy of 0.6410.
The dataset with Poor performance, assigned to have a Good performance, was the BCWD2, in which the classifier obtained the last place, with 0.9261 Balanced Accuracy, which was not a bad result per se.
The resulting decision tree (
Figure 4b) has only seven leaves, with size = 13. The decision tree only considers complexity measures F2, L3, N1, N3 and T1 to make the decision.
For the 3-NN classifier, the proposed meta-learning algorithm had again only two errors: a dataset with Regular performance predicted as having Poor performance and a dataset with Poor performance classified as having Regular performance, for a Balanced Accuracy of 0.8929, as shown in
Table 12.
The resulting decision tree (
Figure 4c) has only seven leaves, with size = 13. The decision tree only considers complexity measures F2, L1, L2, N1, and T1 to make the decision. For the C4.5 classifier, the proposed meta-learning algorithm had only one error (
Table 13): a dataset with Good performance predicted as having Poor performance, for a Balanced Accuracy of 0.9333.
The resulting decision tree (
Figure 4d) has only six leaves, with size = 11. The decision tree only considers complexity measures F1, F3, N1, and N2 to make the decision.
For the Logistic classifier, the proposed meta-learning algorithm did not have good results. It misclassified the two datasets with Poor performance, assigning them into Regular and Good classes.
In addition, it misclassified a dataset with Good performance, and predicted it as Regular (
Table 14); such results correspond to a Balanced Accuracy of 0.5744. The resulting decision tree (
Figure 4e) again has six leaves, for a tree size of 11, and includes only the measures N2, N3, F3 and T1 of data complexity.
For the Deep Learning classifier, the proposed meta-learning algorithm misclassified the three datasets (two of them with Good performance, assigned into Regular and Bad classes, and another of Poor performance, assigned into Regular class).
The corresponding confusion matrix is shown in
Table 15, with a Balanced Accuracy of 0.8561.
The resulting decision tree (
Figure 4f) is quite small, with only five leaves for a tree size of nine, and it includes only the measures L1, L2, N2 and N4 of data complexity.
Last but not least, for the Support Vector Machine classifier (one of the best-performing algorithms for medical datasets), the proposed meta-learning decision tree was the best, with all datasets correctly classified, for a perfect Balanced Accuracy of 1.0. Such results were obtained with a very small decision tree (
Figure 4g), of five leaves and tree size of nine, using only three complexity measures: L1, F2 and T2.
In our opinion, such results represent a breakthrough for medical datasets classification, because they allow determination a priori of the expected performance of the seven analyzed classifiers, six of them with Balanced Accuracy over 0.85, which is very promising.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}