
Simulations between Three Types of Networks of Splicing Processors


1
Departamento de Sistemas Informáticos, Universidad Politécnica de Madrid, C/Alan Turing s/n, 28031 Madrid, Spain
2
National Institute for Research and Development of Biological Sciences, Independentei Bd. 296, 060031 Bucharest, Romania
*
Author to whom correspondence should be addressed.
Mathematics 2021, 9(13), 1511; https://doi.org/10.3390/math9131511
Submission received: 4 June 2021
/
Revised: 20 June 2021
/
Accepted: 23 June 2021
/
Published: 28 June 2021
(This article belongs to the Special Issue Bioinspired Computation: Recent Advances in Theory and Applications)
Abstract
:Networks of splicing processors (NSP for short) embody a subcategory among the new computational models inspired by natural phenomena with theoretical potential to handle unsolvable problems efficiently. Current literature considers three variants in the context of networks managed by random-context filters. Despite the divergences on system complexity and control degree over the filters, the three variants were proved to hold the same computational power through the simulations of two computationally complete systems: Turing machines and 2-tag systems. However, the conversion between the three models by means of a Turing machine is unattainable because of the huge computational costs incurred. This research paper addresses this issue with the proposal of direct and efficient simulations between the aforementioned paradigms. The information about the nodes and edges (i.e., splicing rules, random-context filters, and connections between nodes) composing any network of splicing processors belonging to one of the three categories is used to design equivalent networks working under the other two models. We demonstrate that these new networks are able to replicate any computational step performed by the original network in a constant number of computational steps and, consequently, we prove that any outcome achieved by the original architecture can be accomplished by the constructed architectures without worsening the time complexity.
1. Introduction
In recent years, the limitations encountered by our standard computational models have become more apparent, motivating the pursuit of knowledge regarding innovative paradigms capable of overcoming these barriers. Along this line of research, different computational models finding their inspiration on natural phenomena have been proposed in the scientific community. Further research showed their theoretical proficiency for solving intractable problems.
Networks of bio-inspired processors are one of such nature-inspired systems under the parallel and distributed computational framework, boasting a high degree of parallelism (theoretically, unlimited). This model shares numerous characteristics with other known computational paradigms of diverse origins: tissue-like P systems [1], which is a model inspired by the tissue structure introduced in the area of membrane computing [2], a model, called evolutionary systems, that is inspired by the evolution of various cell populations [3], networks of parallel language processors, which is a parallel model for generating languages [4], flow-based programming, which is a particular variant of the data-flow programming [5], connection machine, which is a kind of a parallel non-conventional processing computer [6], distributed computing using mobile programs [7], etc.
A network of bio-inspired processors may be informally described as a set of processors that are placed in the vertices of a graph. Each processor acts over data organized in distinct structures: strings, pictures, graphs, multisets, etc. An early survey may be found in [8] and more recently in [9]. Thus far, the literature differentiates between two subcategories of networks of bio-inspired processors handling string data, namely evolutionary and splicing processors. The first one was proposed in [10] as a logical abstraction of the point mutations taking place in DNA sequences: insertion, deletion or substitution of a single base pair. The second category, introduced in [11] and analyzed for its theoretical application for problem solving in [12], mimics the splicing phenomena in DNA molecules overseen by the various restriction and ligase enzymes [13] from a computational point of view. A more general view of restriction enzymes as sources of inspiration for computing can be seen in [14], which opened a wide area of research.
Under this paradigm, the strings hosted in a splicing processor perform the role of DNA molecules, while the behavioral constraints for the splicing enzymes are abstracted to a set of splicing rules composed by quadruples of strings specifying the cutting positions of the strings in the node. Following a splicing operation, the pieces are recombined as long as they are yielded by the same splicing rule. This model shares common aspects with the test tube distributed splicing systems introduced in [15] and posteriorly examined in [16]. The divergences with this last splicing paradigm and time-varying distributed H systems [17] are discussed in [18].
The computation in the networks of splicing processors follows after a sequence of alternative steps, namely splicing and communication, that continues indefinitely until a predefined halting requirement is met. In the splicing step, the strings in each node are simultaneously cut and recombined into new ones according to the constraints set by all the applicable splicing rules of the processor hosted in that node. Thus, each string of the node has enough replications to allow for the synchronous completion of the relevant rules. Next in line, a communication step redistributes the string data in the network as follows:
(i) The string data in a splicing processor is sent to the connected nodes provided that it meets the established exiting conditions for that node.
(ii) The receiving nodes concurrently accept the incoming data satisfying its input requirements. Any string refused by all these nodes is consequently lost.
This data flow in the network is managed through the introduction of random-context filters deciding upon the entering and exiting requirements of the nodes through semantic or syntactical conditions. Thus, far, there are three variants of the latter category: (i) each node is assigned an input and output filter to manage the incoming and exiting string data, respectively, [19], (ii) these two filters are combined into one unique filter [20] and (iii) the filters of two connected nodes are replaced with ones assigned to the edge between them [21].
A simulation of a model by another one is said to preserve the time complexity if the numbers of computational steps performed by the two models on every input are of the same order. It is obvious that (ii) and (iii) are particular variants of (i). Consequently, they appear to offer less control over the computation; however, several works proved they share the same computational power through efficient simulations of known computationally complete models in [11,22,23].
Nevertheless, the indirect conversion between the previous variants through the intermission of a Turing machine is unattainable because of the enormous spike in the complexity. This paper aims to improve upon this line of research with the proposal of efficient direct simulations between the three discussed variants.
2. Basic Definitions
We describe here the basic definitions and nomenclature used for this research. For the remaining notations related to this work, the reader is encouraged to consult [24].
An alphabet refers to a finite and non-empty set of symbols. We write the cardinality of a given finite set S as . A string over an alphabet V is a finite sequence of symbols belonging to that alphabet V. The set of all strings over the alphabet V is denoted by , the empty string is expressed by , and the length of a string z is written . Moreover, is the smallest set such that holds.
A splicing rule over V is a 4-tuple of strings following the structure , with . Given such a splicing rule and the strings , we define
This definition may be extended as follows. Given a language L over V and a finite set of splicing rules R, we define
Given an alphabet V, two disjoint subsets of V, and a string z over V, we define the following predicates:
In these predicates, the set of permitting contexts P defines the symbols that are required to be present in the current string while the set of forbidding contexts F refers to those symbols that are banned. Both clauses require the nonexistence of symbols in the string z and differ on the flexibility of the conditions related to P. The first one demands for all the symbols in P to exist in z, while the latter statement is met as long as one or more of the symbols in P belong to z.
Given and a language , we write
A splicing processor with random-context filters (SP) over an alphabet V is a 6-tuple , where:
- –
- S is a finite set of splicing rules over V.
- –
- A is a finite set of strings over V. Each string in A is called an auxiliary string.
- –
- (permitting symbols) and (forbidding symbols) are two subsets of V, which both define the input filter of the processor.
- –
- are similar subsets of V that define the output filter of the processor.
We say a splicing processor is uniform if the input and output filters are identical: and . The set of all splicing processors over the alphabet U is denoted by , while denotes the set of all uniform splicing processors over U.
A network of splicing processors (NSP) is a 9-tuple , where:
- are the input and network alphabet, respectively. The working alphabet U contains two special symbols, namely, that do not belong to V.
- is an undirected graph defined by the set of vertices and the set of edges. As the graph does not contain loops, we define an edge by a binary set of vertices. G is called the underlying graph of the network. It is worth mentioning that many papers were dealing with NSP with a complete underlying graph, see, e.g., the survey [9].
- is a function that associates with each vertex the splicing processor .
- is a function that associates with each vertex the type of both its input and output filters. We now define two mappings on the set of all strings over :Informally, (resp. ) decides whether or not the string z can pass the input (resp. output) filter of x. If L is a language, we define by: , that is the set of strings of L that can pass the input filter of x. In an analogous way, we define . Note that though we use the same notation for () and (), there is no confusion because the arguments are different.
- are the input and the halting node of , respectively.
Likewise, a network of splicing processors is considered to be uniform if it is composed by uniform splicing processors. A network of uniform splicing processors (NUSP) is a 9-tuple ,where:
- follow the same specifications as the parameters in NSP.
- is a function that returns the uniform splicing processor associated with the node .
- specifies the strength of the sets P and F associated to node filters.
A network of splicing processors with filtered connections (NSPFC) is a 9-tuple , where:
- follow the same specifications as the parameters in NSP.
- is also an undirected graph such that each node is seen as a splicing processor without filters, with the set of splicing rules and the set of axioms .
- associates with each edge a pair of sets that define the filter on the edge e.
- defines the predicate variant assigned to the edge filters.
The size of a NSP belonging to any of the variants above is defined as the number of nodes in the graph, i.e., . A configuration of is a mapping , which assigns a set of strings to each node , that is the sets of strings that can be found in node x at a given moment. Although for each , is actually a multiset of strings, each string appearing in an arbitrary number of copies, for the sake of simplicity, we work with the support of this multiset. For a string , the initial configuration of on the input string z is and for all .
A configuration can be altered through a splicing step or a communication step. In a splicing step, all the splicing rules belonging to the set applicable to the strings in the set combination of and are realized, causing the change of C to a new configuration . Formally, a configuration C evolves to by a splicing step, denoted as , if and only if the following proposition is true for all :
The communication step is different in NSP (NUSP) and NSPFC. We first define how a communication step works in a NSP (the definition of a communication step in a NUSP is very similar, hence left to the reader). In every node x, all the following tasks are accomplished simultaneously:
- (i)
- The strings that satisfy the output filter condition of x are sent out;
- (ii)
- Copies of the expelled strings from any node y connected to x enter x, provided that they satisfy the input filter condition of x.
We stress that those strings sent out of x that do not satisfy the input filter condition of any node are definitely lost. Formally, a configuration follows a configuration C by a communication step in a NSP (we write if for all
holds.
We now describe how a communication step works in a NSPFC. For every pair of connected nodes , all the strings that satisfy the filter condition associated with the edge are moved from one node to the other. Formally, , if
for all
The computation of a NSP on the input string is defined as a sequence of alternating steps (splicing, communication) that produces the configurations , , , such that and , for all . The computation of NUSP and NSPFC are defined in the same way.
A computation as above halts, if there exists such that the set of strings existing in the output node is non-empty. Then, we say that the string w is admitted by the splicing network in an accepting computation. The language defined/accepted by is the set of all strings w over V such that the computation of on w is an accepting one.
The time complexity of the halting computation , , , of on is denoted by and equals m. The time complexity of is the partial function from to formalized as follows:
Furthermore, for a function and we write
Analogously, one defines as well as .
3. Direct Simulations between NSPs and NUSPs
Obviously, since each NUSP can be immediately transformed into a NSP, we have:
Proposition 1.
for any function .
The converse is also true, namely:
Proposition 2.
for any function .
Proof.
Let be a NSP with the underlying graph and for some ; and . Let further . We construct the NUSP ; and , where
| , | , |
| , | , |
| , |
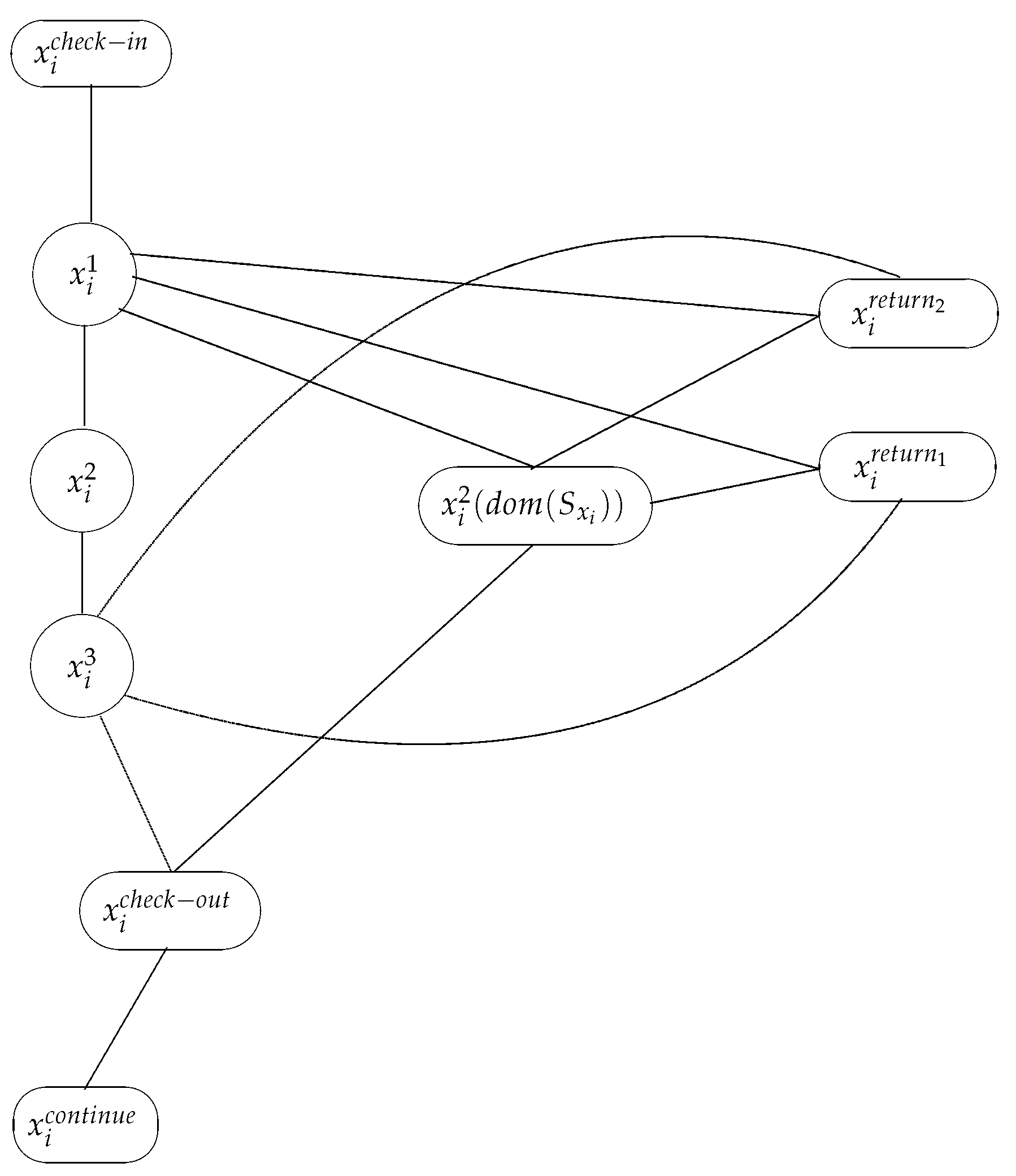
We now define the nodes of by Table 1, Table 2 and Table 3, while the edges of are both listed as well as graphically represented.
and
Let , be a splicing node. If , then the nodes defined in Table 2 belong to .
All the edges
– ,
– ,
– for ,
– , for ,
– , for ,
– for ,
– , ,
for ,
– ,
for ,
– for all , ,
– , for ,
belong to . As we have mentioned above, we present also a graphical representation in Figure 1.
If , then is replaced by nodes of the form , , where , . They are presented in Table 3. Furthermore, if , then is removed. Analogously, if , then is removed. Now, an edge between , and , , on the one hand, and each node , on the other hand, is added to .
The output node is defined as follows: , and , with , . Finally, we add all the edges , to .
We now analyze a computation of on an input string . In the input node , > is replaced with the sequence . Then, enters , where is replaced with the symbols and the resulting string is sent to the node . Thus, the node contains the string associated to the input string placed in the node . More generally, we may assume that a string , for some , is in if contains the corresponding string . Note that any string produced in can return to . However, these strings have the character switched with , which is not accepted by the connected nodes and . Consequently, the node can be disregarded for the rest of the computation.
We now start the simulation of the first splicing step executed by .
Firstly, we analyze the procedure for the case of a splicing node . In , a rule is applied to producing and , if a rule can be applied to in the node . Let be one string obtained after a splicing step from in . Note that if the splicing rule cannot be applied, then may go out from and enter the following nodes:
- , provided that satisfies the condition of the input filter of ,
- and if or each of the nodes if , provided that does not satisfy the condition of the output filter of ,
- .
All cases are to be analyzed. If leaves and enters , the symbol is replaced with , which locks the string in that node. If leaves and enters , then ping-pong processes between these two nodes as well as between and start. We distinguish here the cases of weak and strong filters. If , the string can also enter , starting an identical relationship to the one between and the nodes , . If , the string enters the nodes , provided that does not contain the character , followed by the same ping-pong process between these nodes and , . In this last case, the structure simulates the situation where a string remains in the node because it only contains a proper subset of the characters in .
If leaves and enters , then is replaced by ; the new string is simultaneously sent to all nodes , and . If it enters , then is replaced firstly by (in ) and secondly by some (in ) provided that . The newly obtained string is sent to . Note that this situation simulates exactly the situation when is sent to after staying unchanged for one splicing step in . The case when enters any of the nodes and is considered above.
The only case remaining to be analyzed is when is transformed into (either or ) after applying a splicing rule in . Then, leaves . We follow the route of this string through the network: , where is replaced by , then , where and are replaced by u and v, respectively. We analyze in detail the case for a string with . The application of the first splicing rule on a string yields two strings, namely and . These two strings cannot exit the node, as they contain # and , respectively. In the next splicing step, these two strings can only combine between themselves through the second splicing rule , yielding two new strings: and . The first one cannot be used in the computation anymore, while the latter is the original string with replaced by u. The procedure for a string with is analogous through the application of the other two splicing rules.
After leaving , the new string, say , can enter either or at least one of and . If it enters and consequently , then the following computational step in was simulated in as follows: was obtained from by means of a splicing rule in , then was sent to all neighbors of . The situation when enters one of the nodes and corresponds to the situation when remains in for a new splicing step, as it cannot pass the output filter of .
We now analyze the computational steps required for simulating a computation in . The input node and require 1 splicing step (or 2 computational steps) each. In the worst case, a splicing step in one of the nodes can be simulated in in 7 splicing steps (or 14 computational steps) distributed in the following way:
- 2 steps in .
- 2 steps in .
- 4 steps in .
- 2 steps in .
- 2 steps in .
- 2 steps in .
Note that the simulation only requires 12 computational steps if since is not simulated by a subnetwork and the computation halts once a string enters that node. By all the above considerations, we conclude that and . □
4. Direct Simulations between NSPs and NSPFCs
Proposition 3.
for any function .
Proof.
We take a NSP with the underlying graph with the set of nodes for some ; and . We construct the NSPFC ; and , where
| , | , |
| , | , |
| , |
We now define the parameters of . First, for each pair of nodes of with , we have the following nodes in
and the following edges (the nodes and are to be defined below):
| : | , | , |
| : | , | , |
| : | , | , | , |
| : | , | , | , |
| : | , | , | . |
The specifications for the input node and the output node are as follows:
and the edge:
| : | , | , |
| : | , | . |
| : | , | , | . |
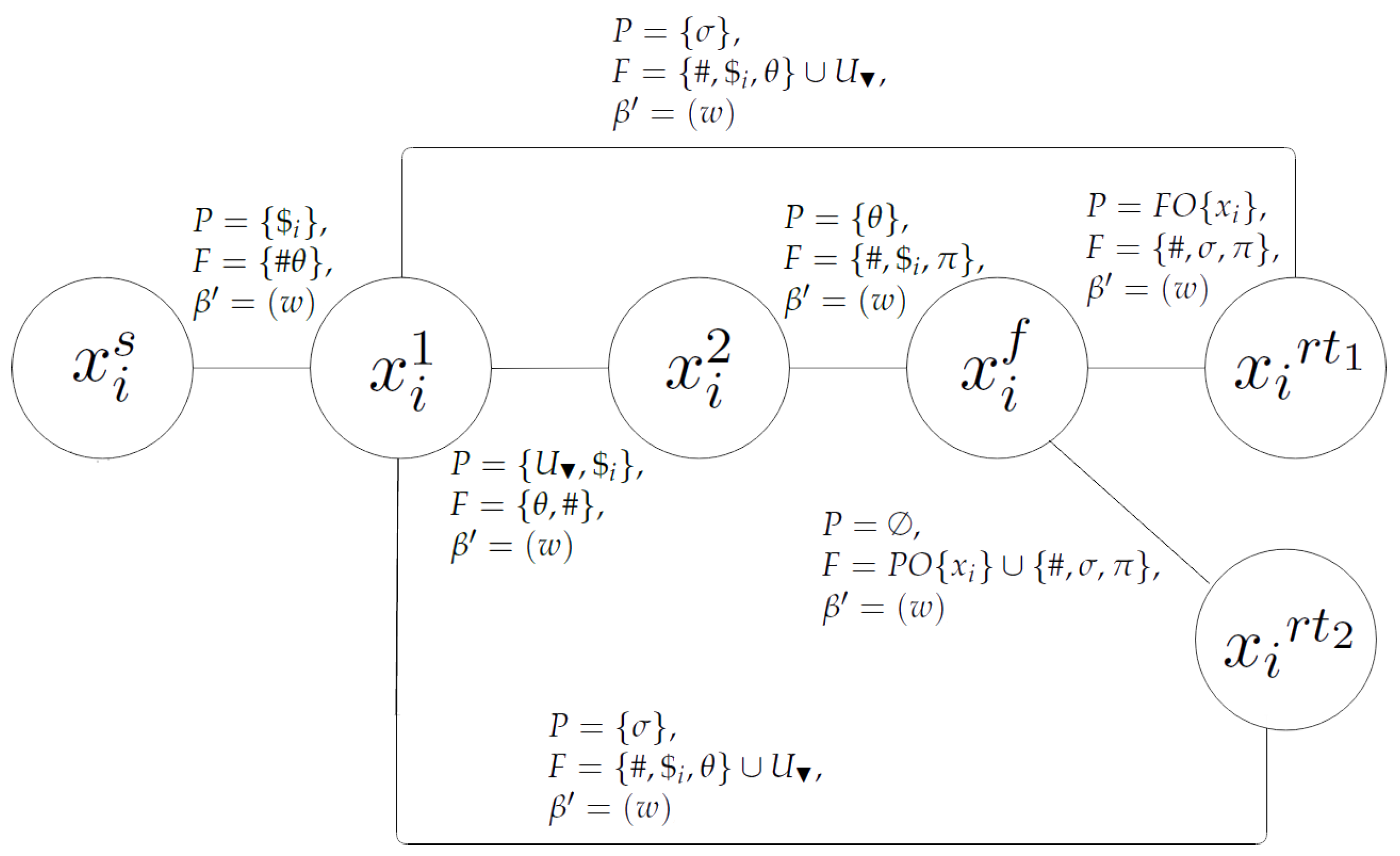
For each node in , we add a subnetwork (Figure 2).to according to the cases considered in the sequel.
Case 1. If is a splicing node with , the subnetwork is defined as follows:
The edges between them are:
| : | , | , | , |
| : | , | , | , |
| : | , | , | , |
| : | , | , | , |
| : | , | , | , |
| : | , | , | , |
| : | , | , | , |
Case 2. If is a splicing node with strong filters, we replace the node with nodes of the form , , where , . These new nodes are defined as follows:
and the edges between and the nodes and are replaced with edges of the form
In both cases, if , then the nodes and are removed. Analogously, if , then is removed.
We now analyze a computation of on the input string . In the input node , the symbol is attached at the end of the string. Next, it enters and the simulation of a computation in starts. We assume that lies in while the string w is found in , the input node of . Inductively, we may assume that a string w is found in some , a node of , as well as in from .
Let be a splicing node, where a rule is applied to w producing and , if or w otherwise. In , the string is processed as follows. First becomes in , then it can enter only. Here, it may become or , if , or it is left unchanged.
Further, a string of the form produced in this node can go back to , where is changed to , sealing that string in the node. On the other hand, the strings can also enter . In , the symbols and are replaced by , closing the route back to . Note that the other produced strings , and remain locked in the node.
Finally, the strings enter where each symbol or , if present, is rewritten into the associated symbol c, replacing with u and with v. Thoroughly, the string is split into the strings and . Both strings cannot leave the node because of the characters and #. In the next splicing step, the only rule that can be applied to these strings is . At the same time, this rule can only be applied to these two new strings. The rule yields and . The former contains the string generated by the original node , , completing the simulation of the splicing step. On the other hand, the latter cannot exit the node or be modified by any rule, so it remains locked for the rest of the computation. The logic is analogous for the other string generated by the splicing rule. Thus, in node , we have obtained the strings and , if .
In conclusion, if is a string in the nodes of and in of , then we can obtain in one splicing step of if and only if we can obtain the associated string in the node of in 4 splicing steps (or 8 computational steps). At this point, we note that can leave and enter in if and only if the string can leave and enter via the nodes and . If it can leave , but cannot enter in , then it is trapped in in . Furthermore, a string entering has the character replaced with , and consequently, it cannot return back to . Finally, if the string cannot leave the node , then it is sent by to and (in the case of weak filters) or to the nodes and , for all (in the case of strong filters). In these nodes, the character is replaced with , and the resulting string is sent to . If the string is not split in the following splicing step, it returns to the nodes and in the case of weak filters or to the nodes and in the case of strong filters, starting a ping-pong process between them, which continues until the string yields new ones by means of another splicing step in . In this last case, the new strings can only enter because it contains characters and the process described above is repeated.
We now analyze the computational steps required for simulating a computation in . The input node and the node require 1 splicing step (or 2 computational steps) each. In the worst case, a splicing step in one of the nodes can be simulated in in 7 splicing steps (or 14 computational steps) distributed in the following way:
- 2 steps in .
- 2 steps in .
- 4 steps in .
- 2 steps in .
- 2 steps in .
- 2 steps in .
Note that the simulation only requires 12 computational steps if since the computation halts when a string enters . We conclude that and . □
The converse of the previous proposition holds.
Proposition 4.
for any function .
Proof.
Let be a NSPFC with , having n nodes ; and . We construct the NSP , , ; and , where
| , | , |
| , | , |
| , | |
We now define the parameters of . First, we add a main subnetwork composed by the input node , the nodes , the nodes and the nodes .
- node :,– , , , ,– .
- nodes , :,,– , , , ,– .
- node :,,– , , , ,– .
- nodes , :,,– , , , ,– .
- nodes , :,,– , , , ,– .
- nodes , :,,– , , , ,– .
The edges between them are:
Next, for each node in , we add a subnetwork to according to the cases considered in the sequel.
Case 1. Let be the number of nodes connected to the node of the form , we add the corresponding nodes to the subnetwork. Note that is also equal to the number of edges between the node and the nodes in the network . If the edges have , the subnetwork is defined as follows:
- nodes , :,,– , , , ,– .
- nodes , :,,– , , , ,– .
The edges between them are:
Case 2. If the k edge has , we replace each of the nodes for nodes of the form , , where , . The parameters S, A and of these new nodes remain the same, while the input and output filters are defined as follows:
and the edges involving are replaced with p edges involving each of the nodes .
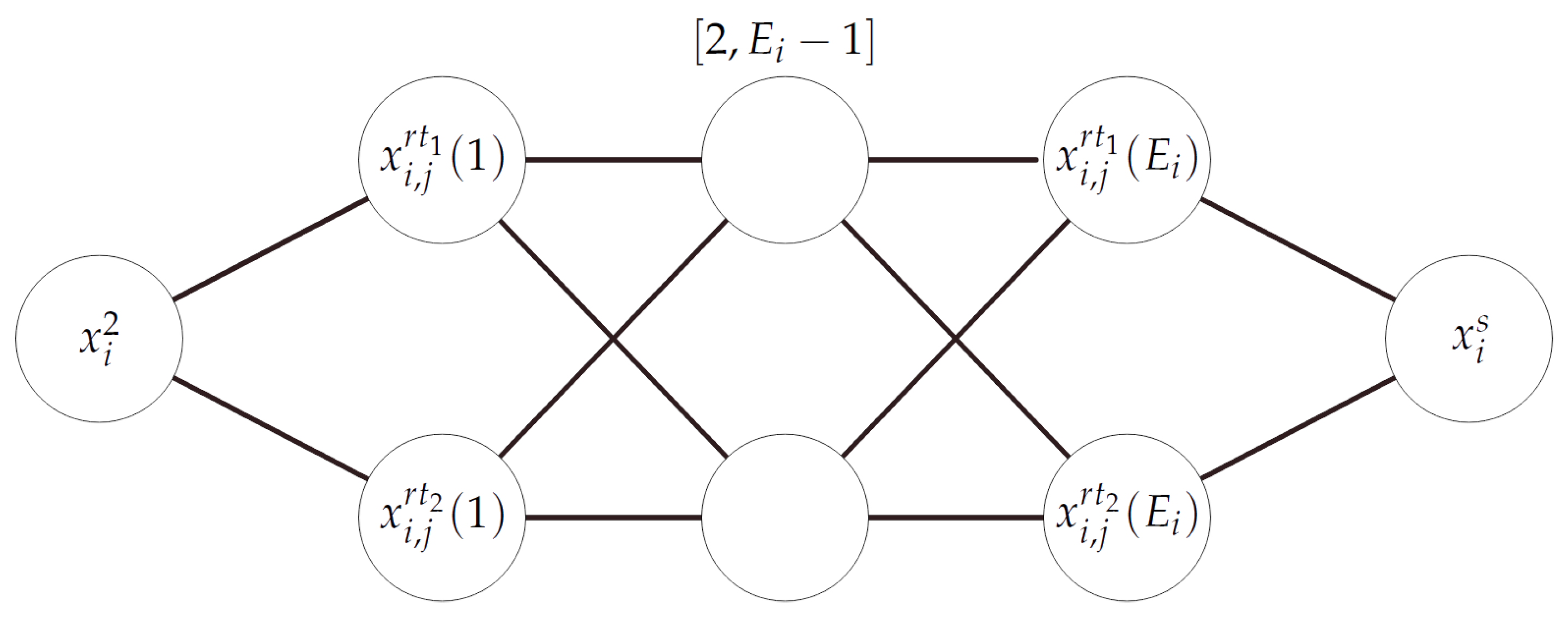
In both cases, if the k edge has , then the nodes and are removed. Analogously, if , then is removed. Furthermore, if and , the whole subnetwork given in Figure 3 is removed because a string is always able to leave the node through the edge k.
Let us assume the string to be the input string in . In the input node of , the symbol is attached to the string and then sent to the node . Thus, the node contains the string while lies in the analogous node . In a more general setting, we assume that a string , , enters at a given step of the computation of on w if and only if the string y enters at a given step of the computation of on w.
Let y be transformed into and in node and and/or can pass the filter on the edge between and . In , the string is transformed into and in the node . If the string is of the form , it is transformed into and . The strings enter where the characters and are replaced with . Thus, we get the same strings with either or . Then, it continues into , where the symbols in and , if present, are replaced with the original counterpart u and v. In detail, the string is split into the strings and . Both strings cannot leave the node because of the characters and #. In the next splicing step, the rule is applied to the two strings, yielding and . The former constitutes the string where is the string yielded by , completing the simulation of the application of a splicing rule of . On the other hand, the latter cannot exit the node or be modified by any rule, so it remains locked for the rest of the computation. The logic is analogous for the other string generated by the splicing rule. The new string is sent to the nodes associated to the edges in the original network. Since the input filters of these nodes are identical to the edge filters in , the string can enter a node if and only if the string can pass the filter between and in . Note that the converse is also true. Subsequently, the symbol is replaced with and the new string is sent to where a similar procedure starts. Alternatively, if the string y is not split in , the same event happens in . If the string is of the form , it remains locked in that node until a splicing rule can be applied on it while a string of the form still enters the node because of the symbol and the same computational process described above starts.
On the other hand, a copy of the string is also sent to the subnetwork illustrated in Figure 3, where the case of a string not passing the filters of any edge between the node and the connected nodes in the original network is handled. We distinguish here between the cases of strong and weak filters. For each edge k with , , the node checks if the string cannot enter the corresponding node because of containing forbidden symbols, while the node verifies if the string contains the characters required by the filter of the node . Thoroughly, the string exits and enters the first pair of nodes and granted that the associated string z could not pass the filters of the first edge in the network . In that node, is replaced with ensuring that the new string could only enter the next pair of nodes and associated to the second edge. Subsequently, is replaced by the next character in the remaining pair of nodes and , forcing the string to continue through them in sequence. If the string can enter one of the connected nodes through an edge in , it will be lost at some point of this subnetwork as it will be refused by the input filters of the nodes corresponding to that edge. Otherwise, it will reach the last pair of nodes where the symbol will be changed to , yielding a string of the form which will be returned to . Because of the character , this string cannot leave the node ensuring it remains there until it can be used in a new splicing step. Thus, the following computational step in was simulated in : z could not leave the node and it remained in that node for new splicing steps. In the case of an edge k with strong filters, the computation follows the same procedure described above with the difference that the node is replaced with nodes of the form , , where , . A node refuses any string z containing the character . Thus, the string can only continue through this network by means of a node for some if it only contains a proper subset of .
We analyze now the case where a string enters from a node , for some . In that node, is replaced with and the resulting string enters , ending the computation. Note that by the considerations above, a string enters if and only if a string from was able to pass the filter on the edge between and in .
We now analyze the computational steps required for simulating a computation in . The input node requires 1 splicing step (or 2 computational steps). In the worst case, a splicing step in one of the nodes can be simulated in the associated subnetwork in splicing steps (or computational steps) distributed in the following way:
- 2 steps in .
- 2 steps in .
- 4 steps in .
- 2 steps in if the string z yielded by the splicing step in the node could pass any of the edge filters between and in ; .
- steps if z could not pass any of the edge filters in .
Since is bounded by , where n is the number of nodes in , a NSPFC can be simulated by NSP in time. As a result of this analysis, we conclude that and . □
5. Direct Simulations between NUSPs and NSPFCs
Proposition 5.
for any function .
Proof.
This proposition can be proved through a NSPFC simulation of NUSP identical to the proposed simulation for NSP in the previous section, with the only difference being the replacement of the filters with P and with F in the specifications.
Therefore, the input node and the node require 1 splicing step (or 2 computational steps) each. In the worst case, a splicing step in one of the nodes can be simulated in in 7 splicing steps (or 14 computational steps) distributed in the following way:
- 2 steps in .
- 2 steps in .
- 4 steps in .
- 2 steps in .
- 2 steps in .
- 2 steps in .
Similarly, we conclude that and . □
The converse of the previous proposition holds.
Proposition 6.
for any function .
Proof.
Let be a NSPFC with , having n nodes ; and . We construct the NUSP , , ; and , where
| , | , |
| , | , |
| , | |
We now define the parameters of . First, we add a main subnetwork composed by the input node , the nodes , the nodes and the nodes .
- node :,– , ,– .
- node :,– , ,– .
- nodes , :,,– , ,– .
- nodes :,,– , ,– .
- nodes , :,,– , ,– .
- nodes , :,,– , ,– .
- nodes , :,,– , ,– .
The edges between them are:
Next, for each node in , we add a subnetwork to according to the cases considered in the sequel.
Case 1. Let be the number of nodes connected to the node of the form , we add the corresponding nodes to the subnetwork. Note that is also equal to the number of edges between the node and the nodes in the network . If the edges have , the subnetwork is defined as follows:
- nodes , :,– , ,– .
- nodes , :,– , ,– .
The edges between them are:
Case 2. If the k edge has , we replace each of the nodes for nodes of the form , , where , .The parameters S, A and of these new nodes remain the same, while the input and output filters are defined as follows:
and the edges involving are replaced with p edges involving each of the nodes .
In both cases, if the k edge has , then the nodes and are removed. Analogously, if , then is removed. Furthermore, if and , the whole subnetwork given in in Figure 3 is removed because a string is always able to leave the node through the edge k.
Let us assume the string to be the input string in . In the input node of , the symbol is attached to the string and then sent to the node , where it is replaced with . Then, the new string is sent to and the simulation process starts. Thus, the node contains the string while lies in the analogous node . In a more general setting, we assume that a string , , enters at a given step of the computation of on w if and only if the string y enters at a given step of the computation of on w. Note that any string entering from will have the character replaced with #, which will result in that string being locked in that node. Therefore, the two nodes and do not interfere with the computation anymore.
Let y be transformed into and in node and and/or can pass the filter on the edge between and . In , the string , with , is transformed into and . The strings enter , where the characters and are replaced with . Thus, we get the same strings with any . Then, it continues into , where the symbols in and , if present, are replaced with the original counterpart u and v. In detail, the string is split into the strings and . Both strings cannot leave the node because of the characters and #. In the next splicing step, the rule is applied to the two strings, yielding and . The former constitutes the string where is the string yielded by , completing the simulation of the splicing step. On the other hand, the latter cannot exit the node or be modified by any rule, so it remains locked for the rest of the computation. The logic is analogous for the other string generated by the splicing rule. The new string is sent to the nodes associated to the edges in the original network. Since the filters of these nodes are identical to the edge filters in , the string can enter a node if and only if the string can pass the filter between and in . Note that the converse is also true. Subsequently, the symbol is replaced with and the new string is sent to where a similar procedure starts. Note that if the string returns to the previous node in this sequence, it is ultimately blocked or lost. In , the strings entering from are split into two strings containing the forbidden symbol # and consequently they remain locked in that node. The same situation happens if a string enters from a node . On the other hand, if a string enters a node from for a given j, the string is split into two strings containing the symbol #. In the next communication step, these two strings are ejected from the network because they are not accepted by any node connected to . Alternatively, if the string y remains unchanged in , the same event happens in . If the string is of the form , it starts a ping-pong process with the nodes and (or the nodes if the edge has strong filters) until a splicing rule can be applied on it. On the other hand, if the string is of the form , it still enters the node because of the symbol , starting the same computational process described above.
On the other hand, a copy of the string is also sent to the subnetwork illustrated in Figure 3, where the case of a string not passing the filters of any edge between the node and the connected nodes in the original network is handled. We distinguish here between the cases of strong and weak filters. For each edge k with , , the node checks if the string cannot enter the corresponding node because of containing forbidden symbols, while the node verifies if the string contains the characters required by the P filter of the node . Thoroughly, the string exits and enters the first pair of nodes and granted that the associated string z could not pass the filters of the first edge in the network . In that node, is replaced with , ensuring that the new string could only enter the next pair of nodes and associated to the second edge. Subsequently, is replaced by the next character in the remaining pair of nodes and , forcing the string to continue through them in sequence. If the string can enter one of the connected nodes through an edge in , it will be lost at some point of this subnetwork as it will be refused by the input filters of the nodes corresponding to that edge. Otherwise, it will reach the last pair of nodes where the symbol will be changed to yielding a string of the form which will be returned to . Now, the string can either be used for another splicing step in which case the resulting strings will exit the node and enter as it will contain a character or a ping-pong process will start between this node and the nodes and that may continue forever or until a splicing rule may be applied to the string. Thus, the following computational step in was simulated in : z could not leave the node , and it remained in that node for new splicing steps. In the case of an edge k with strong filters, the computation follows the same procedure described above with the difference that the node is replaced with nodes of the form , , where , . A node refuses any string z containing the character . Thus, the string can only continue through this network by means of a node for some if it only contains a proper subset of . Note that a string can also enter the previous nodes and granted that , but that string is split into two new strings with the forbidden symbol # through the application of the rule and, consequently, they will remain locked in that node.
We analyze now the case where a string enters from a node , for some . In that node, is replaced with and the resulting string enters , ending the computation. Note that by the considerations above, a string enters if and only if a string from was able to pass the filter on the edge between and in .
We analyze now the computational steps required for simulating a computation in . The input node requires 1 splicing step (or 2 computational steps). In the worst case, a splicing step in one of the nodes can be simulated in the associated subnetwork in splicing steps (or computational steps) distributed in the following way:
- 2 steps in .
- 2 steps in .
- 4 steps in .
- 2 steps in if the string z yielded by the splicing step in the node could pass any of the edge filters between and in ; .
- steps if z could not pass any of the edge filters in .
Since is bounded by where n is the number of nodes in , a NSPFC can be simulated by NUSP in time. As a result of this analysis, we conclude that and . □
In virtue of the results obtained in the proposed simulations, we are now able to state the main conclusion of this research:
Theorem 1.
for any function .
6. Conclusions and Further Work
As being a theoretical piece of work, the methodology used in this paper is the standard one: identifying the problem, discussing the theoretical implications and possible practical applications, stating the results, proving the statements, and discussing different aspects of the results.
We demonstrate here an efficient method to simulate different variants of NSP with random-context filters with each other. We describe a methodology to translate any network belonging to one of the three variants into an equivalent on of the other two models. The definitions of the former regarding splicing rules, auxiliary strings, random-context filters and connections between nodes are used to determine the corresponding ones for the new network. Later on, they are assigned to the nodes and edges according to an established procedure. Although the constructed networks may appear to be more complex and to have a significantly bigger size than the original network, the time complexity remains unchanged. This statement is proven true by the capability of these new networks to simulate any computational step in the original architecture in a constant number of computational steps. This method is theoretically important and attractive, as it allows direct and time efficient conversions of one variant of NSP into another one, avoiding intermediate computational models. Efficient simulations between different bio-inspired computational models are essential in the theoretical and practical studies in this field. It is common for these paradigms to be used as problem solvers, and simulations between two models would allow the scientific community to translate a solution proposed for one of the models to the other, avoiding the time and effort required otherwise. Furthermore, research about this topic could also have important practical applications in architecture design, such as the hypothetical establishment of systems, composed of a mix of different bio-inspired architectures, in an effort towards improving the efficiency of a given task.
As one can see, the underlying graph of the simulating network might be different than that of the original network. An attractive line for further research, which may be considered not only for the variants considered here, would be to impose some conditions on the topology of the underlying graph (to be the same as the original one, to have a predefined form, etc.).
Author Contributions
Conceptualization, V.M. and J.A.S.M.; formal analysis, V.M. and M.P.; investigation, J.R.S.C. and V.M.; writing—original draft preparation, J.A.S.M.; writing—review and editing, V.M.; supervision, V.M.; funding acquisition, M.P. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially supported by a grant of the Romanian Ministry of Education and Research, CCCDI-UEFISCDI, Project No. PN-III-P2-2.1-PED-2019-2391, within PNCDI III.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
This work was partially supported by the Comunidad de Madrid under Convenio Plurianual with the Universidad Politécnica de Madrid in the actuation line of Programa de Excelencia para el Profesorado Universitario.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Martín-Vide, C.; Pazos, J.; Păun, G.; Rodrxixguez-Patón, A. A new class of symbolic abstract neural nets: Tissue P systems. Lect. Notes Comput. Sci. 2002, 2387, 290–299. [Google Scholar]
- Păun, G. Membrane Computing. An Introduction; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Csuhaj-Varjú, E.; Mitrana, V. Evolutionary systems: A language generating device inspired by evolving communities of cells. Acta Inform. 2000, 36, 913–926. [Google Scholar] [CrossRef]
- Csuhaj-Varjú, E.; Salomaa, A. Networks of parallel language processors. Lect. Notes Comput. Sci. (LNCS) 1997, 1218, 299–318. [Google Scholar]
- Morrison, J. Flow-Based Programming: A New Approach to Application Development; CreateSpace: Scotts Valley, CA, USA, 2010. [Google Scholar]
- Hillis, D. The Connection Machine; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Gray, R.; Kotz, D.; Nog, S.; Rus, D.; Cybenko, G. Mobile agents: The next generation in distributed computing. In Proceedings of the IEEE International Symposium on Parallel Algorithms Architecture Synthesis, Aizu-Wakamatsu, Japan, 17–21 March 1997; pp. 8–24. [Google Scholar]
- Manea, F.; Martín-Vide, C.; Mitrana, V. Accepting networks of evolutionary word and picture processors: A survey. Sci. Appl. Lang. Methods 2010, 2, 525–560. [Google Scholar]
- Arroyo, F.; Castellanos, J.; Mitrana, V.; Santos, E.; Sempere, J.M. Networks of bio-inspired processors. Triangle Lang. Lit. Comput. 2012, 7, 4–22. [Google Scholar]
- Castellanos, J.; Martín-Vide, C.; Mitrana, V.; Sempere, J.M. Networks of evolutionary processors. Acta Inform. 2003, 39, 517–529. [Google Scholar] [CrossRef]
- Manea, F.; Martín-Vide, C.; Mitrana, V. Accepting networks of splicing processors. In New Computational Paradigms, First Conference on Computability in Europe, CiE 2005, Amsterdam, The Netherlands, 8–12 June 2005; Barry Cooper, S., Löwe, B., Torenvliet, L., Eds.; Volume 3526 of Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; pp. 300–309. [Google Scholar]
- Manea, F.; Martín-Vide, C.; Mitrana, V. All NP-problems can be solved in polynomial time by accepting networks of splicing processors of constant size. In DNA Computing, 12th International Meeting on DNA Computing, DNA12, Seoul, Korea, 5–9 June 2006, Revised Selected Papers; Chengde, M., Takashi, Y., Eds.; Volume 4287 of Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; pp. 47–57. [Google Scholar]
- Head, T.; Păun, G.; Pixton, D. Language theory and molecular genetics: Generative mechanisms suggested by DNA recombination. In Handbook of Formal Languages, Volume 2. Linear Modeling: Background and Application; Grzegorz, R., Arto, S., Eds.; Springer: Berlin/Heidelberg, Germany, 1997; pp. 295–360. [Google Scholar]
- Head, T. Restriction Enzymes in Language Generation and Plasmid Computing. In Biomolecular Information Processing: From Logic Systems to Smart Sensors and Actuators; Wiley: Hoboken, NJ, USA, 2012; pp. 245–263. [Google Scholar]
- Csuhaj-Varjú, E.; Kari, L.; Păun, G. Test tube distributed systems based on splicing. Comput. Artif. Intell. 1996, 15, 211–232. [Google Scholar]
- Păun, G. Distributed architectures in DNA computing based on splicing: Limiting the size of components. In Proceedings of the 1st International Conference on Unconventional Models of Computation, Auckland, New Zealand, 5–9 January 1998; pp. 323–335. [Google Scholar]
- Păun, G. DNA computing; Distributed splicing systems. Lect. Notes Comput. Sci. 2005, 1261, 353–370. [Google Scholar]
- Manea, F.; Martín-Vide, C.; Mitrana, V. Accepting networks of splicing processors: Complexity results. Theor. Comput. Sci. 2007, 371, 72–82. [Google Scholar] [CrossRef] [Green Version]
- Margenstern, M.; Mitrana, V.; Pérez-Jiménez, M.J. Accepting hybrid networks of evolutionary processors. In DNA Computing, 10th International Workshop on DNA Computing, DNA 10, Milan, Italy, 7–10 June 2004, Revised Selected Papers; Claudio, F., Giancarlo, M., Claudio, Z., Eds.; Volume 3384 of Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2004; pp. 235–246. [Google Scholar]
- Bottoni, P.; Labella, A.; Manea, F.; Mitrana, V.; Petre, I.; Sempere, J.M. Complexity-preserving simulations among three variants of accepting networks of evolutionary processors. Nat. Comput. 2011, 10, 429–445. [Google Scholar] [CrossRef]
- Dragoi, C.; Manea, F.; Mitrana, V. Accepting networks of evolutionary processors with filtered connections. J. Univers. Comput. Sci. 2007, 13, 1598–1614. [Google Scholar]
- Castellanos, J.; Manea, F.; de Mingo López, L.F.; Mitrana, V. Accepting networks of splicing processors with filtered connections. In Machines, Computations, and Universality; Jérôme, D.-L., Maurice, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 218–229. [Google Scholar]
- Gómez-Canaval, S.; Mitrana, V.; Pŭn, M.; Sanchez Martín, J.A.; Sánchez Couso, J.R. Networks of uniform splicing processors: Computational power and simulation. Mathematics 2020, 8, 1217. [Google Scholar] [CrossRef]
- Rozenberg, G.; Salomaa, A. Handbook of Formal Languages; Springer: Berlin, Germany, 1997. [Google Scholar]
- Arroyo, F.; Gómez-Canaval, S.; Mitrana, V.; Păun, M.; Sánchez Couso, J.R. Towards probabilistic networks of polarized evolutionary processors. In Proceedings of the 2018 International Conference on High Performance Computing & Simulation (HPCS), Orléans, France, 16–20 July 2018; pp. 764–771. [Google Scholar]
- Gómez-Canaval, S.; Mitrana, V.; Păun, M.; Vararuk, S. High performance and scalable simulations of a bio-inspired computational model. In Proceedings of the 2019 International Conference on High Performance Computing & Simulation (HPCS), Dublin, Ireland, 15–19 July 2019; pp. 543–550. [Google Scholar]
- Sánchez, J.A.; Arroyo, F. Simulating probabilistic networks of polarized evolutionary processors. Procedia Comput. Sci. 2019, 159, 1421–1430. [Google Scholar] [CrossRef]
Figure 1.
A graphical representation of the network.

Figure 2.
Subnetwork for splicing step.

Figure 3.
Subnetwork to handle strings that cannot exit the node .


{kind=link}
{kind=link}
{kind=link}
Table 1.
Description of the initial nodes.
| Node | S | P | F | A | |
|---|---|---|---|---|---|
Table 2.
Description of the intermediate nodes.
| Node | S | P | F | A | |
|---|---|---|---|---|---|
| ∅ | |||||
| ∅ | |||||
Table 3.
Description of the returning nodes.
| Node | S | P | F | A | |
|---|---|---|---|---|---|
| ∅ | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Sánchez Couso, J.R.; Sanchez Martín, J.A.; Mitrana, V.; Păun, M. Simulations between Three Types of Networks of Splicing Processors. Mathematics 2021, 9, 1511. https://doi.org/10.3390/math9131511
AMA Style
Sánchez Couso JR, Sanchez Martín JA, Mitrana V, Păun M. Simulations between Three Types of Networks of Splicing Processors. Mathematics. 2021; 9(13):1511. https://doi.org/10.3390/math9131511
Chicago/Turabian StyleSánchez Couso, José Ramón, José Angel Sanchez Martín, Victor Mitrana, and Mihaela Păun. 2021. "Simulations between Three Types of Networks of Splicing Processors" Mathematics 9, no. 13: 1511. https://doi.org/10.3390/math9131511
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.