
Combined Games with Randomly Delayed Beginnings


Département de Mathématique, Faculté des Sciences, Université Libre de Bruxelles, Campus Plaine, CP 210, B-1050 Brussels, Belgium
Mathematics 2021, 9(5), 534; https://doi.org/10.3390/math9050534
Submission received: 13 January 2021
/
Revised: 24 February 2021
/
Accepted: 27 February 2021
/
Published: 4 March 2021
(This article belongs to the Special Issue Statistical and Probabilistic Methods in the Game Theory)
{kind=link}
Abstract
:This paper presents two-person games involving optimal stopping. As far as we are aware, the type of problems we study are new. We confine our interest to such games in discrete time. Two players are to chose, with randomised choice-priority, between two games and . Each game consists of two parts with well-defined targets. Each part consists of a sequence of random variables which determines when the decisive part of the game will begin. In each game, the horizon is bounded, and if the two parts are not finished within the horizon, the game is lost by definition. Otherwise the decisive part begins, on which each player is entitled to apply their or her strategy to reach the second target. If only one player achieves the two targets, this player is the winner. If both win or both lose, the outcome is seen as “deuce”. We motivate the interest of such problems in the context of real-world problems. A few representative problems are solved in detail. The main objective of this article is to serve as a preliminary manual to guide through possible approaches and to discuss under which circumstances we can obtain solutions, or approximate solutions.
Keywords:
two-person game; optimal stopping; patterns; occurrence time; renewal process; li-algorithm; odds-algorithm; plug-in odds-algorithm; business plans; competitionMSC:
Primary 60G40; Secondary 90A801. Introduction
Two players are to chose, with randomised choice-priority, between two well-defined games and . Priority of choice is decided by a flip of a fair coin, say, and the other player plays the alternative game. Each game and consists of two parts, a first so-called initial part, and a second one which we call the decisive part. After the choice of the games, the players have no influence on their initial parts which determine by well-defined stopping times when the decisive parts begin. Actions must be taken in the respective decisive parts only.
There are clearly many ways in which we can conceive such games, and we will confine our interest to a selection of games which seem interesting to us. Being more restrictive gives us the possibility to discuss examples in sufficient depth. We concentrate on games which are of the following form:
- (i)
- The initial part (called phase 1) of each game and consists of a finite sequence of independent random variables (fixed horizon). Unless stated otherwise, the laws of the random variables are known to both players.
- (ii)
- With , respectively, denoting the filtration generated by the respective variables, we suppose that , and, are well-defined stopping times on these initial parts. These stopping times are truncated by definition by the corresponding horizons of and , say and , that is we confine our interest to the stopping times
- (iii)
- If the event , occurs, then player i cannot enter the second decisive part of the game and loses by definition. We say then that player i fails target 1. Each player i with enters the second part (phase 2) and faces a (possibly new) sequence of independent random variables. The problem is now to stop online in an optimal way on a specified event (target 2). Unless stated otherwise, both player(s) know from the beginning the targets for each game as well as the laws of the random variables.
1.1. General Situation
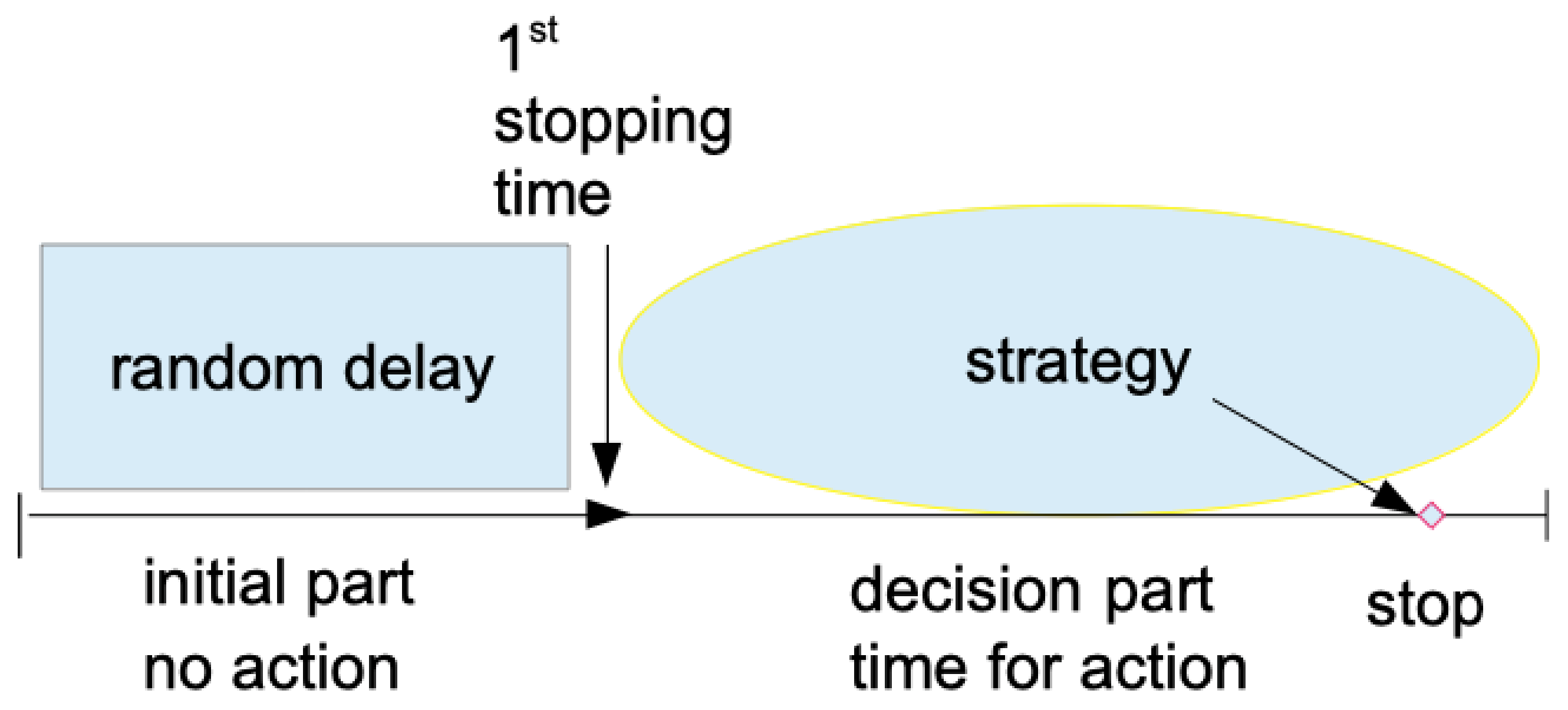
The general type of games we consider is displayed in Figure 1. Unless stated otherwise (as in Problem 4), the two players are only indirectly playing against each other, namely through the choice of their game. The games consist of two parts each, namely a phase 1 (initial part) with a specific target, and a phase 2 (strategic part) with another specific target. The player who has priority must decide which combination of the two parts is more favorable to win the combined game.
1.2. Motivation
We note that the type of games we consider in the general situation pictured in Figure 1 is a combined optimal stopping game. A priori, the game character in the usual sense of a two-person game, is missing. If we know the value of game , then we know which game to chose. Furthermore, after the attribution of the games to the players, the latter do not interact with each other except in Problem 4, where players may offer to switch games for a certain price. The main initial decision is to choose the game. It would make no essential difference if we formulated a corresponding problem for games with r of players. However, for convenience and simplicity we always confine to the case
The general setting reflects, as we think, features we see in real world problems, as for instance in business competition. One player sees an opportunity to make money in, or with, a sequence of future events. So does his or her competitor (2nd player). However, both realise that there is not enough room for both to pursue the same goal, and thus alternatives are examined. If there is one, then it will typically be in form of another stream of events, i.e., an alternative game. Each business plan needs preparation, as things may first have to develop to fulfil a certain “pattern” (primary goal = target 1), realised at some stopping time before the environment seems favorable to allow to implement the business plan. is the starting point of phase 2 when the player will optimise his or her strategy. Priority in the real world is typically given by being quick rather than through a flip of coin. Furthermore, in real world both players can be winners (as in our setting), but each would typically like to choose the game with the highest promise of success.
1.3. Related Work
Although this type of problems seems to be new, there exist several studies in the literature which are related, or weakly related. Specific references will be given in the text. Sometimes the link seems weak, but the present paper tries also be a little guide to some connections. Therefore it is adequate to reference at least some of these connections, without trying to go into details.
In the present introduction section we first recall a few general sources.
A wide range of information about the variety of mathematical games and methods of solution can be found for instance in the book by Mazalov [1], or in the recent book by Ferguson [2]. For the theory of Optimal Stopping including free boundary problems we to refer to Peskir and Shiryayev [3]. For a far-going study of approximate solutions of optimal stopping problem, see Rüschendorf [4]. Although we will limit our interest to games in discrete time we also mention that Peskir found an interesting relation between the Nash equilibrium and the value function of an optimal stopping game in continuous time [5].
A closer relation with the present paper is seen in the papers by Ferenstein [6] as well as by Szajowski [7], and Szajowski [8], who study problems of optimal stopping for discrete time Markov processes. As an example, Szajowski solves a generalized best choice problem for two players. See also the review papers by Nowak and Szajowski [9] and Immorlica et al. [10].
2. Framework and Problems
To exemplify the type of games of which we are thinking, we start with an explicit example (Problem 1). This problem will be solved explicitly. We then show in how far a generalisation (Problem 2) would need a different approach to its solution, both from the theoretical and the practical side. The essentials of our approach to Problem 1 will stay valid for Problem 2, and the reader will see this without having to go through computations.
Interesting supplementary modifications of the more general setting of Problem 2 then come also naturally to our mind, and there are two of them (Problems 3 and 4) which we would like to treat in some more detail.
Problem 1.
Let and be positive integers. Two players are informed that a coin will be tossed times. is what we call the horizon for game Tosses are supposed to be independent, each with outcome probability , , where , respectively, , stand for the events “head”, respectively, “tail”. The players know the parameter p and have the option between the following games.
- : If the consecutive pattern is obtained before tosses, the player wants to stop online on the very last T up to toss number
- : If the consecutive pattern is obtained before tosses, the player wants to stop online on the very last H up to toss number
In the case that both players choose the same game, the priority of choice is randomised by the flip of a (fair) coin. If not specified otherwise the second player must then accept to play the remaining game. Thus, the true problem is which game the player having priority should choose.
In Problem 1 we may see as an alphabet, and the h tosses as h independent draws (with replacement) from this alphabet with constant outcome probabilities The stopping times in phase 1 and phase 2 are determined target events. Note that, in each game, the target event of phase 1 is a pattern created by a string of length greater than 1 of elementary events, and that the second target is, in fact, also a composed event.
Problem 2.
The setting of Problem 1 is generalised as follows. Instead of coin tosses we have h independent draws from a finite alphabet and again, as in Problem 1, in each game a target event for phase 1, and another target event for phase 2. No specifications of the target events are given. This opens a whole basket of possibilities, on which we shall comment.
Thinking of games as toy models of the real world, the player who reaches first his or her target in phase 1, has often the possibility to make the competitor withdraw from continuation. In this case, there is at most one winner.
As an example, think of an entrepreneur who, by acquiring a technological advantage, can produce certain goods cheaper than the competitor. However, then, to stay successful (phase 2), the entrepreneur must reach sufficient sales numbers of these goods (target 2). In our simplified setting, this gives rise to a third interesting problem type, exemplified by Problem 3 below.
Problem 3.
The basic setting is the same as in Problem 2 except that, if one player reaches target 1 in phase 1 strictly before the other player, then only the first one can continue and win if their or her target 2 is reached before the end of horizon. If both players reach target 1 at the same (discrete) time, both are allowed to continue.
Note that in none of the problems we speak of rewards for winning a game. Hence, by our definition, players succeeding to get their two targets win their game. Consequently there can be two winners, or just one, or none at all, and some real-world problems may convince, that this setting has some advantages.
If, however, we want to modify this setting by attributing different (positive) rewards for winning a game, then this is no problem. We would then naturally agree to call the “real” winner the player who receives the higher reward.
As said before, we will examine the impact of possible modifications of the preceding problems, and show, or discuss, how to deal with them without solving them completely. One more natural modification merits to be understood as a problem of its own.
Problem 4.
After attributing the randomised priority, obtained by player A, say, player B either accepts to play the other game or else B offers to A an amount of money for obtaining priority. The problem is now not only which game to choose, but also what would be a fair offer for obtaining priority? Moreover, what would be a faire price for switching at an arbitrary time during a game?
Problems 1–4 are the framework of our discussion. Problem 1 is defined in detail, and will be solved by classical methods. Problems 2 and 3 may take many different forms according to the chosen type of targets in the respective phases. We make suggestions, how to tackle the different forms. Depending on the nature of the specific targets, suggestions may turn out to be rather modest. Problem 4 is again of a different kind, and so is our Section 5 dealing with games under weak information.
2.1. Consecutive Steps to Solutions
We begin with the first step to the solution of Problem 1.
First part of the solution of Problem 1.
Since the probability of succeeding in phase 2 depends on how many draws will be available after the desired pattern in phase 1 has appeared, we compute the distribution of the first occurrence time. The latter can be obtained from a well-known renewal-type argument.
Look first at the desired pattern for We denote patterns by the generic letter and the subscript will refer to the game. Hence Let
Partitioning according to the non-occurrence of the pattern in the first four tosses we obtain by independence for the recursion that is, with evident initial conditions and
After having computed these we obtain the desired distribution, as follows. The first occurrence of occurs in k if has not appeared until step and will be realised at steps and Note that, in order to assure that this will be the first time that the pattern appears up until toss , we need to see a T at step . Hence, again by the independence of tosses, we get
The value of game say, provided an optimal continuation exists, is thus just the absolute win probability under optimal play for the player playing , that is
With (1)–(3), a part of Problem 1 is solved since, passing through (1) and (2) correspondingly for the pattern we can obtain in (3) the corresponding expression for the value for game Clearly, we can compute these values explicitly, and thus compare them, as soon as we know the optimal behaviour in both cases in phase 2 after the occurrence of the respective target pattern and of phase 1.
Intuitively, there should exist for each player in phase 2 an optimal threshold time from which onward one should stop on a tail in , respectively, on a head in This intuition turns out correct in the present example. Actually, it stays correct under more general conditions than requiring complete independence, as we shall later prove in Theorem 1. After the proof of this theorem, we will complete the solution of Problem 1.
However, we now want first to discuss the interest of such problems in more generality.
In the following we think about the true strategic part of such games, i.e., phase 2. We shall argue, that the objective of being successful is actually often an objective to obtain a so-called last success. Problem 1, where target 2 is simply a last , respectively, a last H exemplifies this objective.
2.2. Last Success Problems
Last-success problems seem to attract general interest, and this independently of the context of games. One reason is that the notion of a last success is very flexible, because success can be defined as an event which is of interest for the decision maker.
So for example, in the secretary problem, we may consider each candidate who is better than all preceding ones as a record (the very first one is a record by definition). If we succeed in stopping online on the last record then we obtain the best candidate. In the same vein, if a candidate is an offer we receive for an asset we sell, stopping on the last record means selling best. Similarly we can define lower records in order to solve the problem for buying an asset for the cheapest price. See also Gnedin [11]. Among newer examples, and methods of solutions, we cite the work of Goldenshluger et al. [12] which includes several such problems in a surprisingly unified form. We also like to mention a paper with a single specific objective function, namely the paper by Grau Ribas [13]. It shows us that, for certain generalisations of a last success objective, the classical dynamic programming approach may have clear advantages.
See also Grau Ribas [14].
More should be said on flexibility. A last success need not be a record, not even be of interest itself in any sense. It may become distinguished simply by being the last one to complete a specified set. This is exemplified in a study of planning medical treatments (Bruss [15]) where a convincing way to comply with ethical constraints is to pursue a last success. Additional flexibility can also be obtained to some extent by adapting the notion of a last success to more than one selection, by focussing on the best-or-second best, as in Ano and Ando [16], Ano et al. [17], and Bayón et al. [18], looking at multiple stopping versions as in Tamaki [19] and Kurushima and Ano [20], and also by allowing for missing observations, as in the work of Ramsey [21].
Another reason for the interest in last-success problems is that the resulting optimization is often much more “robust” than one would intuitively expect, as exemplified by the -law of Bruss [22]. The latter concerns the case of an unknown number of candidates, but this holds also for other important modifications as shown in Szajowski [23] and Ferguson (2016) as well as in the study of bounds for multiple stopping problems (Matsui and Ano [24,25]). Hence last success settings are versatile. Since we must limit our interest the general model somewhere, we propose to concentrate on these for phase 2.
3. Odds-Theorem for Delayed Stopping
In the following we need the terminology of the Odds-theorem (Bruss [26] (Th.1)) which we recall for convenience. Let be an integer, and let be independent Bernoulli random variables with success parameters The objective is to maximise the probability of stopping online on the last success, i.e., on the last The optimal strategy to achieve this goal is obtained as follows. For , let
and let the integer (called threshold index) be defined by
The strategy to stop on the first index k with and , if such a k exists, maximises the probability of stopping on the last success. If no such k exists, then we have to stop at time n and lose by definition. The corresponding optimal win probability is easy to compute by the odds-algorithm (Bruss [26] (Th.1)) and equals
3.1. Randomly Delayed Stopping
To be rigorous in our conclusions for the Problems 1–4, we need however more. Consider the case of a delay imposed by a random time W with values in Stopping is not allowed before time W. As before, we want to maximise the probability of stopping on the very last success.
Does it suffice to replace simply the threshold s defined in (5) by to obtain an optimal strategy? This seems trivial (and is true) if W is deterministic. In general this is not true, of course, even not true if W is a stopping time on .
The following is possibly the most adequate formulation of minimum requirements needed for applying a type of an Odds-Theorem.
Theorem 1.
Let be Bernoulli random variables on a filtered probability space where denotes the σ-field generated by Suppose there exists a random time W for on the same probability space such that the with are independent random variables satisfying
Then, putting it is optimal to stop at the random time
Here it is understood that, if we stop at time n and lose by definition.
Proof.
Our proof will profit from the proof of the Odds-Theorem (Bruss [26]) if we rewrite the threshold index (5) in an equivalent form.
Recall the definition of in (4).
If we define, as usual, an empty sum as zero, then s defined in (5) can be alternatively written as
which is straightforward to verify.
Recall as defined in Theorem 1, and let for
This means from the assumptions concerning W that are independent random variables with laws only dependent on the event If we think of w as being fixed, then we can and do define for all and use the same notation as before defined in (4) with the corresponding odds Accordingly, we have for from (4) the simple monotonicity property
It is easy to check that this monotonicity property is equivalent to the uni-modality property proved in Bruss [26] (p. 1386, lines 3–12), reference [27]. The latter implies that the optimal rule is a monotone rule in the sense that, once it is optimal to stop on a success at index then it is also optimal to stop on a success after index (For a convenient criterion for a stopping rule in the discrete setting being monotone, see also Ferguson [28] (p. 49)).
Note that, whatever , the odds are deterministic functions of the , and so the future odds after the (random) time W are also known and will not change. The only restriction we have to keep in mind for the simplified notation is that the index k here satisfies on the set However, then the monotonicity property of is also not affected, that is
Since the latter implies the uni-modality property of the resulting win probability on , the monotone rule property is again maintained for the optimal rule after the random time exactly as in the proof of the Odds–Theorem [26] (Th. 1, p. 1385). Therefore the optimal strategy is to stop on the first success (provided it exists) from time onwards where satisfies
This is the threshold index of Theorem 1 defined in (7) as well as the same stopping time. Hence the proof. □
Remark 1.
Note that the statement of Theorem 1 is intuitive. Its applicability may nevertheless be delicate. It depends on the ’s being predictable for all Often this is not the case. For instance, we may have (conditionally) independent random variables, but, if we collect information about the from observations then the distributions of the future values of typically depend on on which the event may be allowed to depend!
Completing the Solution of Problem 1.
In Problem 1 we have i.i.d. draws, i.e. the conditions for Theorem 1 are clearly satisfied. Hence the optimal rule is determined by the threshold index (8). This one is here particularly simple, namely the odds are homogeneous in time with for , and for game Hence we have
where denotes the floor of x. Recall that it is understood, that a player who chooses a game with a required pattern looses by definition if the pattern does not occur until time , respectively, If it does, then the player can apply his or her strategy to stop online on a second required event, and wins the game if they succeed to do so.
Suppose that player 1 (= Alice, say) has chosen . Thus, player 2 (=Bernard, say) plays We note that there are now for A and B three possibilities. We state them for A; for B it would be analogous:
- (i)
- A sees the first target realised before the optimal threshold index for continuation, which means for her before the threshold index To play optimally she must therefore wait until and stop, if possible, at the first realisation of her target 2. This yields a first part of her absolute win probability, i.e., from (3) and (4)
- (ii)
- A sees the first target realised at a time t with From the uni-modality property she knows that, to play optimally to get the last success, she should stop as soon as possible, i.e., at the first realisation of target 2. This yields the second part of her absolute win probability
- (iii)
- Finally, if her target 1 does not occur strictly before , she can no longer win, and the contribution equals 0.
The same arguments hold, correspondingly, for player B.
Since the horizons and are fixed and known to the players, the only interest for the players is to know for which values of p one has or else the contrary. The graphs and as a function of p would give the answer for any and The solution of Problem 1 is thus complete. □
Remark 2.
In this solution of Problem 1 we have not used the fact that H and T are complementary draws, which would have shortened our solution essentially, since implies that In this case the odds-algorithm shows that the optimal strategy in phase 2 is trivial for one of the games. Namely, it is to wait for the last toss, yielding success probability .
What we just said does not hold for more general alphabets, of course. This is one among several reasons for posing Problem 2.
3.2. Analysis of Problem 2
We briefly analyze when our approach to solve Problem 1 is valid to solve Problem 2, and when it is not. Here it is understood that the first target is supposed to be an arbitrary pattern and the second target some other arbitrary pattern. However, since we confined our study to last-success problems, the latter must appear as the last of its type before the end of the horizon.
First, with independent draws from more general alphabets we can, as before, use again the same renewal type arguments (see (1) to (2)) to establish the recursive equations for the occurrence time distribution of the first target. These may now become more complicated because the draw probabilities of the relevant letters of the alphabet figuring in the pattern might all be different. However, the reasoning does not change, and there is no important difference to report here.
For phase 2, things may be different. All depends on the type of the last-success which is required. For instance, if a string of the form is a success if it is an event of the form
i.e., we speak of a success only if the pattern is finished at a time which is a multiple 3. Then successes are independent since the draw indices do not overlap and the draws themselves are independent. The same would thus also hold for more complicated patterns (including permitting holes) as long as the index-ranges would not overlap. If strings may overlap, the odds-algorithm cannot be applied. In general it becomes then much harder to find the optimal strategy.
Now, having said this, the possible drawback of trying to use the odds-algorithm to find the optimal strategy in phase 2 contrasts another advantage the odds- algorithm offers. Indeed, it often fits more complicated cases:
Corollary 1.
For fixed target patterns to be independent of each other in non-overlapping sections of indices (allowing to apply the odds-algorithm) it suffices that the elementary draws constituting these patterns are independent of each other. Alphabets and drawing probabilities are allowed to vary in time.
Proof.
The Odds-Theorem and the corresponding Odds-algorithm (see [26]) hold for arbitrary success probabilities, that is, drawing probabilities are allowed to be inhomogeneous in time. Consequently the alphabet(s) from which the draws are made in order to form the desired pattern may also depend on time. All what is needed is that the draws themselves stay independent. □
Remark 3.
As an addendum to Corollary 1 we should add that, again under the condition of independent draws, we can also deal with other types of last-success objectives. For example, the paper by Bruss and Paindaveine [29] solves by an extended odds-algorithm the problem of maximising the probability of collecting online the last k successes in observations, where k is a fixed positive integer.
3.3. Analysis of Problem 3
Problem 3 specifies that, if, by coincidence, target 1 is reached at the same in both games and then both players can continue. We fist note that such coincidences are possible since we did not specify the type of targets we allow in phase 1. They need not be specified strings. If for instance requires that target 1 is fulfilled as soon as the specific pattern appears, whereas requires only numbers a’s so far is at least three, then it is clearly possible that both targets are reached at the same time. In such a case we are by definition in the situation of Problem 2.
A little reflection shows that both players should first concentrate on phase 1.
Theorem 2.
Let be the first time of the realisation of target 1 in game Further let be the absolute win probability if is played.
- (i) If , then choose , and if then choose
- (ii) If none of the conditions of (i) is satisfied, i.e., , then the conditional win probability must be computed for each game. The choice of the game then follows from the comparison of and .
Proof.
- (i)
- We note that, if a player cannot reach target 1, then they cannot win the combined game, simply because target 1 is a necessary condition for being allowed to enter phase 2. The probabilities to succeed in phase 2 for possible outcomes of and need not be compared since, having a positive expected payoff, this is always better than obtaining zero. Consequently, if one of the conditions of (i) is satisfied, then the resulting choice is optimal.
- (ii)
- If none of the conditions in (i) holds, we have of course and thus we are with positive probability in the situation of Problem 2. Without additional information it is thus, for a comparison, necessary to compare the For these we need the conditional distributions
□
The conclusion we can draw from Theorem 2 is that, as we saw in (ii) of the proof, the solution of Problem 3 may need much less work as for Problem 2. Moreover, in many specific problems it is likely that we can see without much work that, in fact, one of the conditions of (i) holds, and then all is already done. In the next section we briefly discuss tools which allow to replace precise computations for comparisons by rather reliable estimates.
Before this, we should still deal with Problem 4.
3.4. Comments on Problem 4
Problem 4 raises two additional questions. First, if after attributing the priority of choice to A, say, and B would like to buy priority, what would be a fair price? Secondly, more generally, if players can offer to switch games, and this at any stage, what would be a fair price for a switch?
Clearly, in both questions the notion of a fair price is only meaningful, if both games come with a well-defined reward for winning the game. Let us suppose that winning game brings a monetary reward
where the are fixed positive numbers. If the games are defined without unknown parameters, as it is the case in all our problems discussed so far, then the first question is straightforward to answer, namely the fair price is
The second question needs in general more to be answered. Note that the horizons and intervene everywhere, and switching games at arbitrary times means one has to study the respective win probabilities for the updated remaining horizons. If we look at those times k only, in which none of the targets of phase 1 is realised, not even a beginning of them, then we just have to read off the new horizons and plug them in (instead of and ) into the computations. However, if not, then a partially realised target pattern is a “conditional” target pattern, and then the computation of the fair price must take into account two possibilities. Either a partial pattern is completed in the minimum number of steps, or else, the problem is again the same as before but with shortened horizons.
Note that in the second case the situation is partially similar to the famous “problem of points” of Blaise Pascal. The difference is that, in the latter, exactly one player comes always one step closer to the target number of points whereas in our problem it is only the horizon which surely decreases by 1.
If one is satisfied with a rough guess of a fair price, then things would be much easier, and we can imagine many situations where a rough guess would do. Indeed, in our next section we briefly deal with questions why certain situations may persuade decision makers to be satisfied with estimates (or even simple guesses) and what are the tools which come to our mind. We will mainly think of time constraints rather than some technical constraints. For example, when the game is seen by spectators, time constraints are important.
4. Deciding under Time Constraints
Whether we want to have a precise answer, or at least an approximate answer for the value of a game, this depends in practice on constraints. For example, are we allowed to use a computer, or only paper and pencil, or even nothing at all?
As we have seen in Problem 3, for instance, we need not always compute the precise values of the games to make an optimal choice. If our adversary is not keen either on making precise computations, we may simply try with estimates which come to our mind. In Problem 4, for instance, why not making a spontaneous offer for switching games, and then see what happens? Since the present article tries to be a little guide for making choices between games, we want to briefly touch also such questions.
4.1. Shortcuts
Since we have confined our interest for the players being already in phase 2 to last-success targets, we now look in particular at phase 1.
As soon as the pattern, for which a player has to wait in the first phase of a game are more complicated, the recurrence equations leading to the distribution of the waiting time become usually more involved. This is typically the case if patterns are based on independent draws from a larger alphabet, say, and/or if sub-patterns may serve as the new beginning of the desired pattern. So, for instance, the occurrence of the pattern fails to produce the desired pattern However, its last sub-pattern constitutes a new beginning of the desired pattern. The renewal-type recursive equations “split” accordingly, and this may take more time. Under time constraints, it may be thus be useful to have the option of a time-saving approximate approach.
What about replacing the distribution of the waiting time of the desired pattern (target 1) by its expected occurrence time? This will in general lead to a sub-optimal decision for the whole game, but if the respective horizon h is reasonably large, the actual loss of the value is often small.
The expected waiting time in a renewal process can be computed (precisely) by a linear recursion equation, which is in general easier. Still, if players do not have the right to use a computer, or not much time, what would be acceptable alternatives?
4.1.1. Li-Algorithm
The arguably quickest way to compute the expected occurrence time of a pattern precisely is to use what we want to call the Li-algorithm (see Li [30]). It is based on the concept of a stopping time of a martingale obtained by a fair betting scheme. The idea is to imagine one bettor for each draw, each having one Euro, to make a fair bet on a draw, and to use the occurrence time of the completion of the desired pattern as the relevant stopping time. Since a stopped martingale is a martingale, the expected value of all losses and gains of all players to a casino at the stopping time must equal its expected value at the beginning, that is zero. With the trick of having one bettor for each draw, we see at the stopping time those bettors who have lost their Euro, and those who are still in the game with winnings. The balance of expected gains and losses yields then a simple equation showing the expected occurrence time.
This algorithm can also be applied to compute the probability of one desired pattern to occur before another one (see, e.g., Ross [31]). Remember that this option is very helpful for certain problem types as exemplified in Problem 3.
4.1.2. Delayed Renewal Rate
If time constraints are even very harsh, a simple estimate of the occurrence time is preferable. Classical renewal theory is here also helpful.
If draws are all independent with a homogeneous outcome distribution, our process of drawing until a given pattern appears, is a delayed renewal process. The easiest way to estimate the expected occurrence time is then to take its asymptotic rate (as the horizon ) as the true rate of a renewal process. This means we use
as an estimate for the expected occurrence time where ℓ runs (with repetition, if any) through all letters of the pattern This is doable by head-computation.
With the quick estimate of the expected value we have a simple bound for deviations, namely from Markov’s inequality for Clearly, having a good estimate of would allow us to use Chebychev’s inequality and thus better estimates of the deviation from the mean. However, depending on the target form, a good estimate of the variance may take time. In conclusion, if players have less than a minute (say) to decide, they are probably well advised to rely on the asymptotic renewal rate (11) for the mean, and the audacious hypothesis
Remark 4.
What we have said here specifically applies to targets expressed in terms of patterns, and their induced stopping time (first occurrence time). Of course, in principle it also holds for other targets, i.e. the expected occurrence time will maintain its interest. However, it seems hard to propose generally useful shortcuts to deal then best with time constraints under which one has to estimate it.
5. Unknown Draw Probabilities
Imagine for a moment that Problem 1 were modified in the sense that the players are not informed what the parameter is. Does this modified Problem 1 then make sense?
A priori, it seems it makes no sense at all. First, p and may then both be zero or one, in which case no player can win. If the players know at least for sure that then the problem makes slightly more sense, but not much more. The author would not know better than others, and may decide to randomize his choice. Having said this, on second thoughts, he may try to persuade you to choose game simply since its first target pattern T, T, T, is shorter than H, H, H, H in The idea is that we hope for the best that p is not too close to zero, where “too close” must be seen in relation with the value which is known.
On the one hand, we all do agree, that the problem is not a well-posed problem. (For a detailed discussion of criteria for a problem being well-posed see the subsection Hadamard’s criteria in Bruss and Yor [32].) On the other hand we also agree, that the situation is different, when the players are informed that the parameter p has been chosen by randomisation according to a known discrete or absolute continuous distribution. Then, even before any observation, the expectation of the random parameter p provides already an essential information.
We may further think of intermediate cases of information. For example, no distribution of p is provided, but a lower bound and an upper bound for p is provided, with The players’ feeling is now, that phase 1 should give them the opportunity to collect information about and that the best they can do is to stop somewhere, and then, in phase 2, pursue the goal of obtaining online the last head, respectively, the last tail.
How could these tasks be combined in a reasonable way under such a weak information? Since the choice of a game must be taken before the game starts, the choice remains a question of good luck (unless the bounds and are both below , or both above 1/2.) We therefore only address the problem of how to continue in an approximatively optimal way in phase 2.
Plug-In Odds Algorithm
The plug-in odds algorithm is a method to provide answers to last success problems when the probability of success is not known but must be learned from preceding observations. As far as we are aware, its use was first suggested in a talk of Bruss, and later in the paper of Bruss and Louchard [33]. The method was defined in Bruss [15] as the algorithm which uses at step k estimated posterior success probabilities,
where denotes the history of observations up to time t. Both Bayesian and non-Bayesian updating procedures for the posterior distribution can be used conveniently.
To stay with an example fitting in the class of our general problem, suppose the first target was reached at time with As said before, we confine our interest in phase 2 to a last success problem. In analogy to (4) we then define for
and propose to stop, if possible, at
Here again it is understood that the game is lost by definition if
Using this algorithm, the conditional estimated probability of winning after target 1 realized at time t is thus, based on (4)–(6), and now according to (13) and (14), the value
Note that we can see as a conditional win probability only under the condition that the updating of probabilities in (11), and used in (12), is considered as “frozen” from the stopping time on. By this we mean more precisely that the current estimate of p is no longer considered as history-driven, but, from index k onward, as the true parameter This allows us (recall Remark 1) to consider the conditions of Theorem 1 as being satisfied, and thus apply the odds-algorithm.
However, we are well aware that by freezing the update at some step, the future part of the history-dependence of success probabilities is not taken into account. Theorem 1 is applied formally but the conclusion is now weaker. No optimality of the suggested solution can be claimed as for the solution of the Odds-Theorem. This is the price one has to pay for plugging in at each step what one knows so far about but not really knowing
However, it is true that the latter performs in general well if the horizon is large enough for the estimates to have time to converge into a sufficiently close neighbourhood of This holds also if we have no prior distribution for In this case we propose in (12) to use the estimator
and the corresponding definitions (13), since (15) is a both simple and unbiased estimator of p.
For larger alphabets and more complicated forms of successes, this procedure is in principle equally feasible, if the probabilities of the independent draws stay homogeneous in time, as it is the case in the preceding modification of Problem 1. Clearly, complicated forms of successes often go with small success probabilities, so that typically the horizon must be large to maintain the interest of the plug-in odds-algorithm as a suitable approach.
Furthermore, remembering that the odds-algorithm (see (4) to (6)) can cope straightforwardly with inhomogeneous draw probabilities, one may wonder what this means for applying the plug-in odds-algorithm in such a case. The answer is that the algorithm would work all the same but that it becomes difficult to propose convincing estimators , as e.g., (15) in the homogeneous case. The concept of learning would have to be extended essentially, at least if more than one parameter should be estimated at the same time.
With this last example we want to conclude. Clearly our attempt to approach solutions for real-life problems of this type cannot be more than a first step.
6. Conclusions
There are many situations in real life where a first event, or even just an expected event, stimulates the interest for a second event, because the latter, given the first, seems then likely to happen. Trying to profit from such expectations is probably a rather typical feature in real-world business life. What comes with it is that competitors may have similar ideas.
This paper tries to “toy-model” such situations as two-legged games between competitors (players). We confine our interest to two players but the essence of the problems we consider does not change for more players. There is a first target event in leg 1 (phase 1) on which the player has no (or, in practical situations, not much) influence, and then a second target event which the player aims to obtain by applying his or her strategy (Section 1). The framework for such problems and a selection of four representative problems are given in Section 2. In these problems we confine the target in phase 2 to so-called last-success objectives. In Section 3, we state and prove our major theoretical tool, namely Theorem 1, which puts optimal stopping on a last success after a random beginning time on a rigorous basis. Being able to decide sufficiently quickly under time constraints and/or weak information are also typical features of real-world situations, and the related questions are discussed in Section 4 and Section 5, respectively.
The present paper, with its few selected problems and solutions, cannot be more than a first step into the direction of linking real-world decision problems with games involving optimal stopping, and its limitations are clear. However, for the scientific community in the domains of games and optimal stopping, the motivation we give may entice interest, and will possibly stimulate the research for more general results.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Acknowledgments
The author would like to thank the Academic Editor Krzysztof Szajowski for his invitation to contribute to the present Special Volume. His warm thanks go also to the three reviewers for their careful reading and helpful comments.
Conflicts of Interest
The author declares no conflict of interest.
References
- Mazalov, V. Mathematical Game Theory and Applications; John Wiley & Sons, Ltd.: Chichester, UK, 2014; pp. xiv+414. [Google Scholar]
- Ferguson, T.S. A Course in Game Theory; World Scientific: Hackensack, NJ, USA, 2020; pp. xviii + 390. [Google Scholar] [CrossRef]
- Peskir, G.; Shiryaev, A. Optimal Stopping and Free-Boundary Problems; Lectures in Mathematics; ETH Zürich Birkhäuser: Basel, Switzerland, 2006; pp. xxii; 500p. [Google Scholar]
- Rüschendorf, L. Approximative solutions of optimal stopping and selection problems. Math. Appl. 2016, 44, 17–44. [Google Scholar] [CrossRef]
- Peskir, G. Optimal Stopping Games and Nash Equilibrium. Theory Probab. Appl. 2009, 53, 558–571. [Google Scholar] [CrossRef] [Green Version]
- Ferenstein, E.Z. Two-person non-zero-sum games with priorities. In Strategies for Sequential Search and Selection in Real Time: Proceedings of the AMS-IMS-SIAM Join Summer Research Conferences held June 21–27, 1990; Bruss, F.T., Ferguson, T.S., Samuels, S.M., Eds.; Contemporary Mathematics; American Mathematical Society: Providence, RI, USA, 1992; Volume 125, pp. 119–133. [Google Scholar]
- Szajowski, K. Markov stopping games with random priority. Z. Oper. Res. 1994, 39, 69–84. [Google Scholar] [CrossRef]
- Szajowski, K. Optimal stopping of a discrete Markov process by two decision makers. SIAM J. Control Optim. 1995, 33, 1392–1410. [Google Scholar] [CrossRef]
- Nowak, A.S.; Szajowski, K. Nonzero-Sum Stochastic Games. In Stochastic and Differential Games: Theory and Numerical Methods; Bardi, M., Raghavan, T.E.S., Parthasarathy, T., Eds.; Birkhäuser Boston: Boston, MA, USA, 1999; pp. 297–342. [Google Scholar] [CrossRef] [Green Version]
- Immorlica, N.; Kleinberg, R.; Mahdian, M. Secretary Problems with Competing Employers. In Internet and Network Economics; Spirakis, P., Mavronicolas, M., Kontogiannis, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 389–400. [Google Scholar] [CrossRef] [Green Version]
- Gnedin, A. Recognising the last record of sequence. Stochastics 2007, 79, 199–209. [Google Scholar] [CrossRef]
- Goldenshluger, A.; Malinovsky, Y.; Zeevi, A. A unified approach for solving sequential selection problems. Probab. Surv. 2020, 17, 214–256. [Google Scholar] [CrossRef]
- Ribas, J.M.G. An extension of the last-success-problem. Statist. Probab. Lett. 2020, 156, 108591. [Google Scholar] [CrossRef]
- Ribas, J.M.G. A Turn-Based Game Related to the Last-Success-Problem. Dyn. Games Appl. 2020, 10, 836–844. [Google Scholar] [CrossRef]
- Bruss, F.T. A mathematical approach to comply with ethical constraints in compassionate use treatments. Math. Sci. 2018, 43, 10–22. [Google Scholar]
- Ano, K.; Ando, M. A note on Bruss’ stopping problem with random availability. In Game Theory, Optimal Stopping, Probability and Statistics; IMS Lecture Notes Monogr. Ser. Institute of Mathematical Statistics: Beachwood, OH, USA, 2000; Volume 35, pp. 71–82. [Google Scholar] [CrossRef]
- Ano, K.; Kakinuma, H.; Miyoshi, N. Odds theorem with multiple selection chances. J. Appl. Probab. 2010, 47, 1093–1104. [Google Scholar] [CrossRef]
- Bayón, L.; Fortuny Ayuso, P.; Grau, J.M.; Oller-Marcén, A.M.; Ruiz, M.M. The Best-or-Worst and the Postdoc problems. J. Comb. Optim. 2018, 35, 703–723. [Google Scholar] [CrossRef] [Green Version]
- Tamaki, M. Sum the multiplicative odds to one and stop. J. Appl. Probab. 2010, 47, 761–777. [Google Scholar] [CrossRef] [Green Version]
- Kurushima, A.; Ano, K. Multiple stopping odds problem in Bernoulli trials with random number of observations. Math. Appl. 2016, 44, 209–220. [Google Scholar] [CrossRef]
- Ramsey, D.M. A secretary problem with missing observations. Math. Appl. 2016, 44, 149–165. [Google Scholar] [CrossRef]
- Bruss, F.T. A unified approach to a class of best choice problems with an unknown number of options. Ann. Probab. 1984, 12, 882–889. [Google Scholar] [CrossRef]
- Szajowski, K. A game version of the Cowan-Zabczyk-Bruss’ problem. Statist. Probab. Lett. 2007, 77, 1683–1689. [Google Scholar] [CrossRef] [Green Version]
- Matsui, T.; Ano, K. A note on a lower bound for the multiplicative odds theorem of optimal stopping. J. Appl. Probab. 2014, 51, 885–889. [Google Scholar] [CrossRef]
- Matsui, T.; Ano, K. Lower bounds for Bruss’ odds problem with multiple stoppings. Math. Oper. Res. 2016, 41, 700–714. [Google Scholar] [CrossRef] [Green Version]
- Bruss, F.T. Sum the odds to one and stop. Ann. Probab. 2000, 28, 1384–1391. [Google Scholar] [CrossRef]
- Bruss, F.T. Odds-theorem and monotonicity. Math. Appl. 2019, 47, 25–43. [Google Scholar] [CrossRef]
- Ferguson, T.S. The sum-the-odds theorem with application to a stopping game of Sakaguchi. Math. Appl. 2016, 44, 45–61. [Google Scholar] [CrossRef]
- Bruss, F.T.; Paindaveine, D. Selecting a sequence of last successes in independent trials. J. Appl. Probab. 2000, 37, 389–399. [Google Scholar] [CrossRef] [Green Version]
- Li, S.Y.R. A martingale approach to the study of occurrence of sequence patterns in repeated experiments. Ann. Probab. 1980, 8, 1171–1176. [Google Scholar] [CrossRef]
- Ross, S.M. Stochastic Processes; Wiley Series in Probability and Mathematical Statistics: Probability and Mathematical Statistics; Lectures in Mathematics, 14; John Wiley & Sons, Inc.: New York, NY, USA, 1983; pp. vii+309. [Google Scholar]
- Bruss, F.T.; Yor, M. Stochastic processes with proportional increments and the last-arrival problem. Stoch. Process. Appl. 2012, 122, 3239–3261. [Google Scholar] [CrossRef]
- Bruss, F.T.; Louchard, G. Optimal stopping on patterns in strings generated by independent random variables. J. Appl. Probab. 2003, 40, 49–72. [Google Scholar] [CrossRef]
Figure 1.
Displays the form of each game. In phase 1 each player waits for the occurrence of a special event. Then, in phase 2, they can apply a strategy to maximise the probability to obtain the 2nd target event. The problem is to choose a game as the package of its parts.
Figure 1.
Displays the form of each game. In phase 1 each player waits for the occurrence of a special event. Then, in phase 2, they can apply a strategy to maximise the probability to obtain the 2nd target event. The problem is to choose a game as the package of its parts.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Bruss, F.T. Combined Games with Randomly Delayed Beginnings. Mathematics 2021, 9, 534. https://doi.org/10.3390/math9050534
AMA Style
Bruss FT. Combined Games with Randomly Delayed Beginnings. Mathematics. 2021; 9(5):534. https://doi.org/10.3390/math9050534
Chicago/Turabian StyleBruss, F. Thomas. 2021. "Combined Games with Randomly Delayed Beginnings" Mathematics 9, no. 5: 534. https://doi.org/10.3390/math9050534
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.