1. Introduction
Automatic irrigation systems decrease water consumption [
1,
2]. In these systems, soil moisture is generally obtained using interconnected measuring instruments to determine the water supply. Some works have developed low-cost sensor networks to monitor agronomic and environmental variables; for example, in [
3]. Nonetheless, the implementation complexity and maintenance of a measuring sensor network increase the cost of automatic irrigation systems, which can be an issue, especially in small farms [
4,
5]. An alternative for reducing the physical complexity of measuring networks is estimating soil moisture instead of measuring in situ [
6,
7]. In many applications, combining measurements and estimates is frequent [
8,
9,
10]. In this sense, hybrid systems (measurements and estimations) can be an alternative for reducing the physical complexity of measurement networks to estimate soil moisture instead of measuring it in all relevant points.
Some soil moisture estimation developments are hydrological models [
11,
12,
13,
14,
15]. Likewise, soil water balance calculations [
16,
17,
18], remote sensing using microwaves [
19], artificial neural networks (ANNs) [
20,
21,
22,
23,
24,
25,
26], and supported vector machines (SVMs) [
27,
28,
29,
30] have several advantages. All these models present an accurate estimate of soil moisture but have limitations for implementation in small farms. The input data acquisition for hydrological models is complicated, as are the assumptions made to develop the model. Soil water balance calculations require regular recalibration. In remote sensing, microwave sensors’ implementation on satellites and the resolution scale (~25 to 50 km) are the problem. ANN and SVM training stages require many tests and a large sample data set to estimate soil moisture accurately.
Remote sensing techniques (RSs) have several advantages for evaluating soil properties and moisture, including large-scale coverage, a non-destructive nature, monitoring, multispectral capabilities, and rapid data acquisition. The specific context and objective of the soil measurements can determine the most suitable RS technique [
31]. Other works address the potential of utilizing remotely sensed vegetation and soil moisture observations; likewise, they integrate remote sensing data sets to constrain the uncertainty of irrigation modeling [
32]. Several RS options are available to the agricultural community. However, the farm sector has yet to fully implement RS technologies due to knowledge gaps in their sufficiency, appropriateness, and techno-economic feasibility [
33]. However, RS assists the adaptive evolution of farm practices to face this significant challenge by providing periodic information on crops throughout the season at distinct scales [
34].
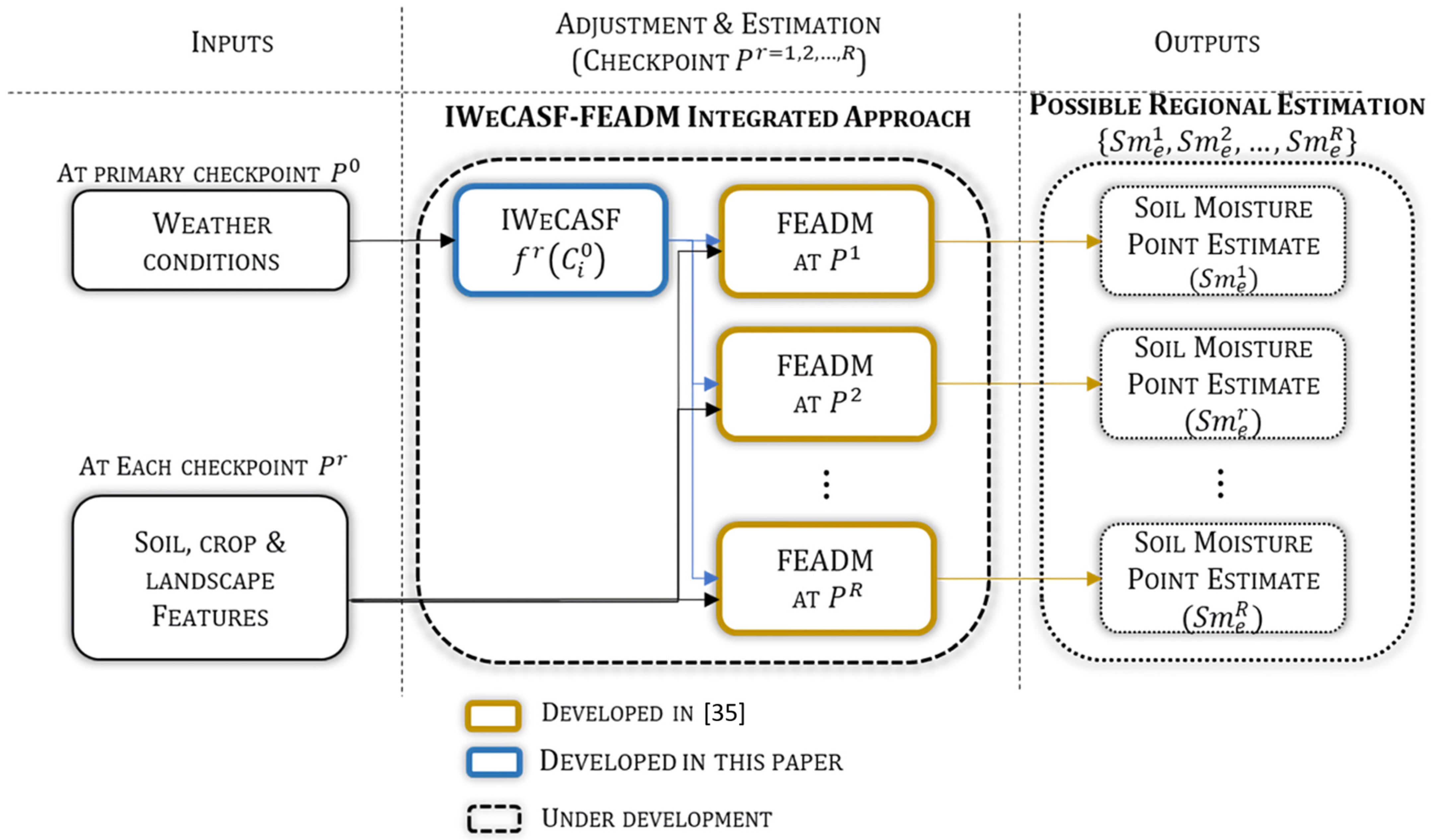
Another estimation approach to soil moisture is the fuzzy estimation approach based on decision making (FEADM) developed in [
35] and called the point estimation model in this paper. The estimate is derived from modeling the interactions among soil moisture, weather conditions, crop, and soil. As shown in [
35], the point estimation model uses a small number of measurement sensors and reduces the necessary calibration tests. However, the point estimation model estimates soil moisture only at one checkpoint (point estimate); if a regional estimation (set of point estimates) is pretended, this model needs to be executed at each checkpoint of the region. The point estimation model alone is not appropriate for a regional estimation because it requires the weather conditions where a point estimate is made. Measuring weather conditions at each checkpoint could be more complicated than deploying a network of soil moisture measuring sensors.
This paper aims to develop a computer model that helps the point estimation model avoid the issues related to the acquisition of weather conditions, as mentioned above. The model developed herein is the intelligent weather conditions adjustment based on spatial features (IWeCASF), called the adjustment model throughout this paper. The adjustment model is not a soil moisture estimation approach but can be part of a regional estimation model described in
Section 2.
Some weather conditions can be considered similar within a region [
22]. Fuzzy logic models for soil moisture content have been used for estimation, and they can contribute to diverse engineering applications such as plantation, crops production, and irrigation [
36]. However, variations are caused by landscape features, the year’s season, and interactions among weather conditions. The adjustment model adapts the weather conditions measured at a primary checkpoint, considering the various factors that affect weather conditions at the other checkpoints. The purpose of the adjustment model (IWeCASF) is to determine the weather conditions at every region’s checkpoint.
The adjustment model performs an automatic and portable extraction of the landscape features from satellite imagery. Then, fuzzy adjustments of weather conditions are conducted based on the interactions of landscape features, checkpoint location, and weather conditions measured at the primary checkpoint. Also, a certainty index of weather condition replication is introduced to contemplate the year’s season’s effects. The result is an adjustment factor for each checkpoint derived from the steady elements (landscape features) and variable elements (season of the year and weather conditions interactions).
This paper is presented in six sections.
Section 2 describes the importance of the adjustment model in a regional estimation based on the point estimation model [
35], which was developed for our research team. In
Section 3, the adjustment model is developed.
Section 4 presents the results and discussion of the weather condition adjustment under several tests. Finally,
Section 5 contains the conclusions.
3. Materials and Methods
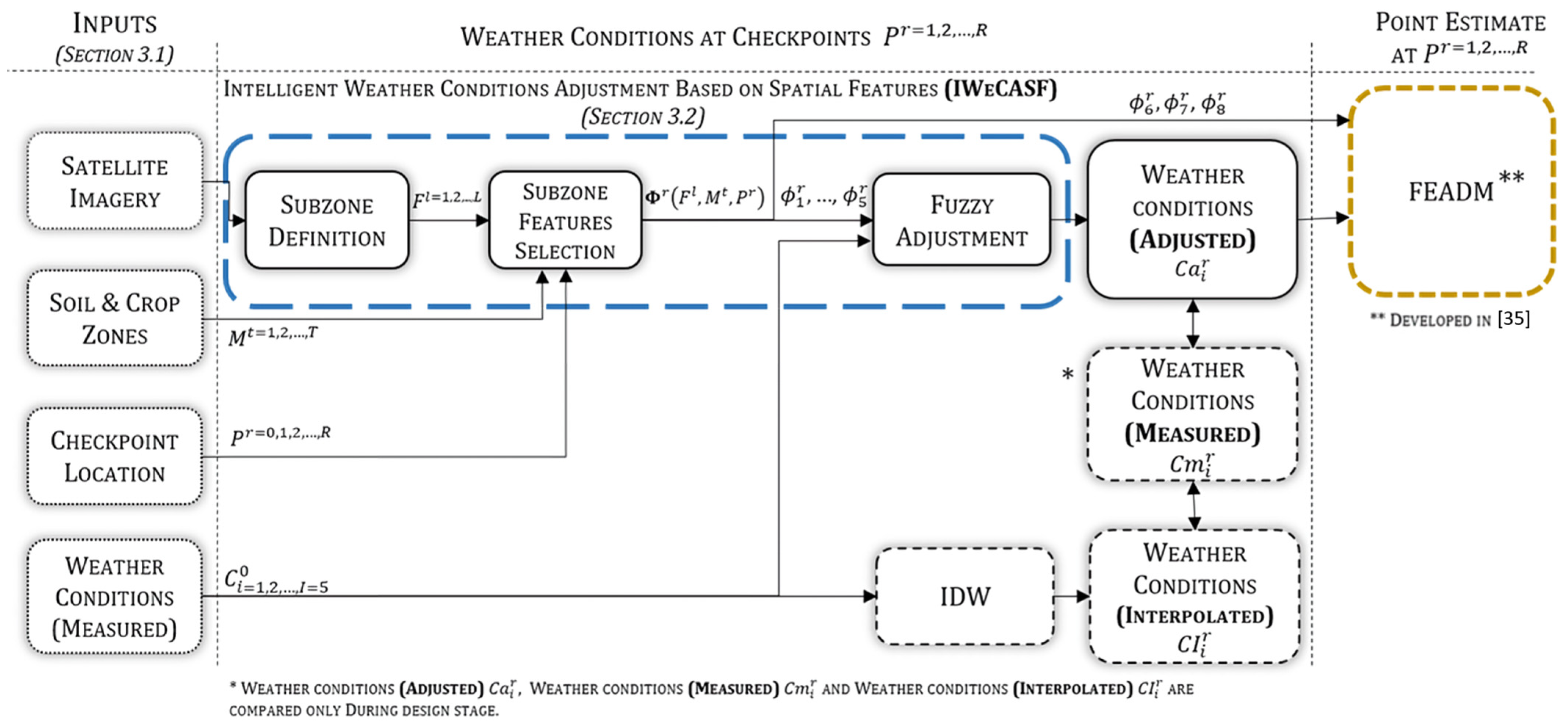
The adjustment model performs three main automatic tasks: landscape feature extraction, selection of particular landscape features, and adjustment of the weather conditions at every region’s checkpoint.
Figure 3 presents the adjustment model overview. The inputs processed are geographic data such as satellite imagery, soil and crop features (
), checkpoint location (
, and measurements of the weather conditions (
). Then, landscape matrices (
) are extracted from the satellite imagery in the subzone definition.
Afterwards, particular features (), i.e., the checkpoint’s features (grasslands, tree-covered areas, buildings areas, elevation, spatial configuration, soil type, crop type, and crop stage), are selected in subzone features selection. Particular features are utilized in the fuzzy adjustment to achieve the weather conditions adjusted (. A set of integrated sensor suite was installed at several checkpoints to compare the weather conditions adjusted ( with weather conditions measured and weather conditions interpolated ( derived from IDW, a model from the literature. This comparison is performed only during the design stage to validate the results, and it is not necessary for the adjustment model operation.
3.1. Inputs
3.1.1. Satellite Imagery
The satellite imagery was acquired using the USGS National Map Viewer, downloaded from Landsat in March 2017. It is processed using the QGIS [
41]. The scale is 1:10,000. The region used to develop the adjustment model corresponds to a basin that stretches for almost 2 km. There are buildings, roads, grassy areas, and tree-covered areas. The landscape characteristics of this region are more complex than those of purely agricultural lands. A more complex region such as the one utilized allows for testing the adjustment model with different landscape features under controlled conditions.
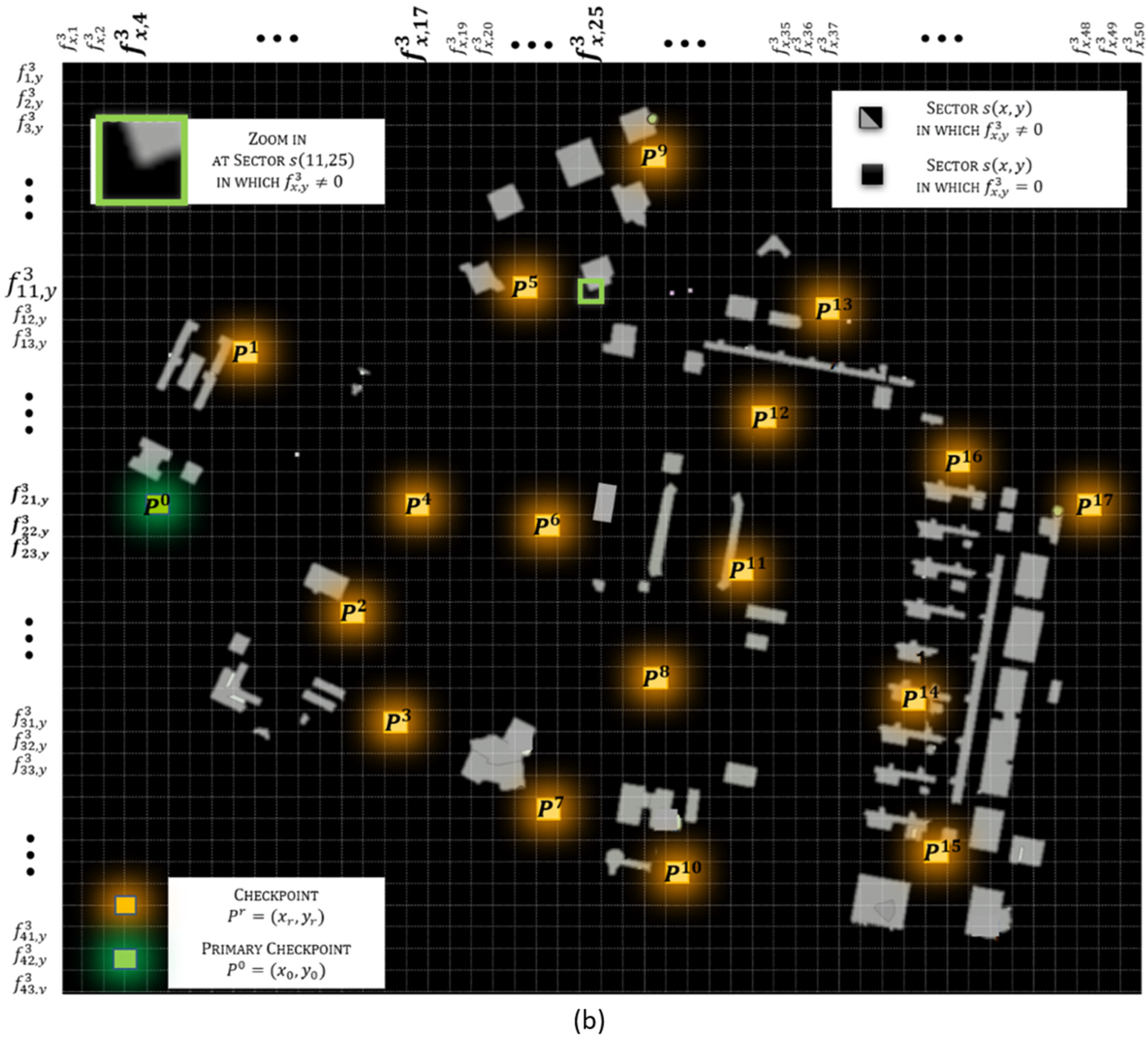
Each satellite image is divided into
sectors, giving a result of pairwise sectors (
), where
,
is the image width divided into
sectors, and
is the image height divided into
sectors. A sector
is a small area of the region; its size is defined by the maximum extent to which, in all sectors, one landscape feature prevails. Preliminary tests were conducted to obtain an appropriate size and resolution of the image; these tests avoid uncertainties in the feature selection stage and error propagation. For instance, the satellite image of the region is shown in
Figure 4. The size of each sector is
; the image is divided into
S = 2150 sectors. The image resolution is 145
pixels, i.e., one pixel represents approximately 1.8
.
3.1.2. Soil and Crop Features
The soil and crop features are geographic data (
soil type, crop type, and crop stage). Soil and crop features are not entirely related to the weather conditions adjustment; however, the adjustment model processes them to the point estimation model in which
soil and crop features are wholly utilized.
Soil and crop features are defined and classified according to the point estimation model [
35]. Other soil parameters involved in soil moisture estimation, such as the vertical distribution of water and the root depths, are not considered in
soil and crop features because these parameters are determined internally in the point estimation model.
Two databases compound soil and crop features. The first contains geo-information of the region divided into zones according to field capacity and available water content. These properties define the soil type because they are highly interrelated, e.g., when soil moisture exceeds field capacity, it drains through lower soil levels due to reduced available water content [
42].
Table 1 shows the soil type classification.
The second database is geo-information of crop properties such as crop type or development stage. Depending on crop type and stage, the crop can withstand different soil moisture levels [
43]. Specific crops, such as rice, require a high water supply; meanwhile, other crops such as beans can grow under a lower water supply. In addition, the crop can be more sensitive to water during flowering or grain-filling stages. The crop types and stages are defined according to the Food and Agriculture Organization (FAO) Indicative Crop Classification (ICC) of the agricultural consensus [
44].
Both geographic databases are used to develop the feature matrices , where is the total of features (soil type, crop type, and crop stage). The feature matrices are the following:
contains soil type data.
contains crop type data.
contains crop stage data.
Feature matrices are the same size (
) as satellite image matrices. Each element
of the feature matrices represents the feature
at the sector
, e.g., element
denotes that, at sector
, there are 100 pixels of soil type
as defined in
Table 1.
For example, the feature matrix
(soil type data) used in all tests performed is shown in
Figure 4. According to the number of sectors in the region, the size of the feature matrices is
and
. In
Figure 4, all the elements
) of soil type matrix (
) are type
. The databases used for determining feature matrices of this region are well defined due to previous academic work. The region shown in
Figure 4 is not farmland; therefore, the crop type matrix (
) only refers to the type of vegetation that prevails in each sector of the region.
3.1.3. Checkpoint Location
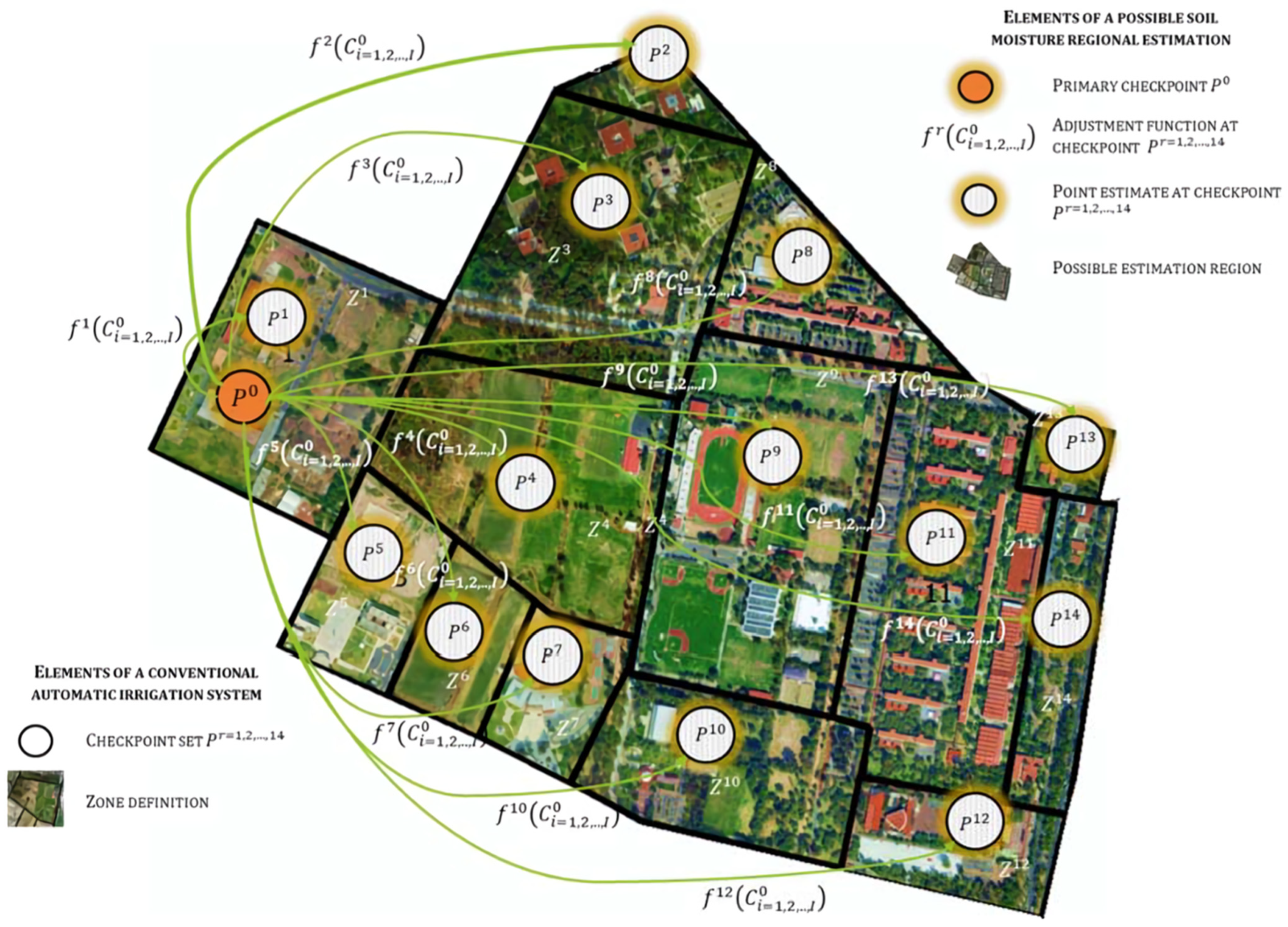
The location
of every checkpoint (
) is used to identify the particular features of the sector where the checkpoint is located. The locations of the checkpoints shown in the region depicted in
Figure 4 are included in
Appendix A. During the model design stage, the next conditions define the checkpoint set: each landscape feature must predominate in at least one checkpoint, and checkpoints must allow for testing of the adjustment model at different lengths from the primary checkpoint
. During this model’s operation stage, every sector of the region is intended to be a checkpoint.
3.1.4. Weather Conditions Measured
The weather conditions measured (
correspond to (
environmental variables measured at the primary checkpoint
These weather conditions are necessary to estimate soil moisture with the point estimation model [
35,
45,
46].
Temperature, rain, solar radiation, and
wind speed are measured with an integrated sensor suite (ISS), and the integrated sensor suite calculates potential evapotranspiration. The values
presented in
Table 2 correspond to measurements of a single day at primary checkpoint. Values corresponding to
temperature (
),
solar radiation (
), and
wind speed (
) are the average records of the day, whereas values
of
rain (
) and
potential evapotranspiration (
) are the cumulative measurements of the day.
3.2. Subzone Definition
In this stage, the landscape features (grassland, tree-covered areas, buildings areas, elevation, and spatial configuration) are identified through image processing of the
satellite imagery. First, a space color conversion is executed from red, green, and blue (RGB) to the International Commission of Lighting (CIE L*a*b). Afterwards, a decorrelation is made as in [
47]. For further information on image processing, refer to
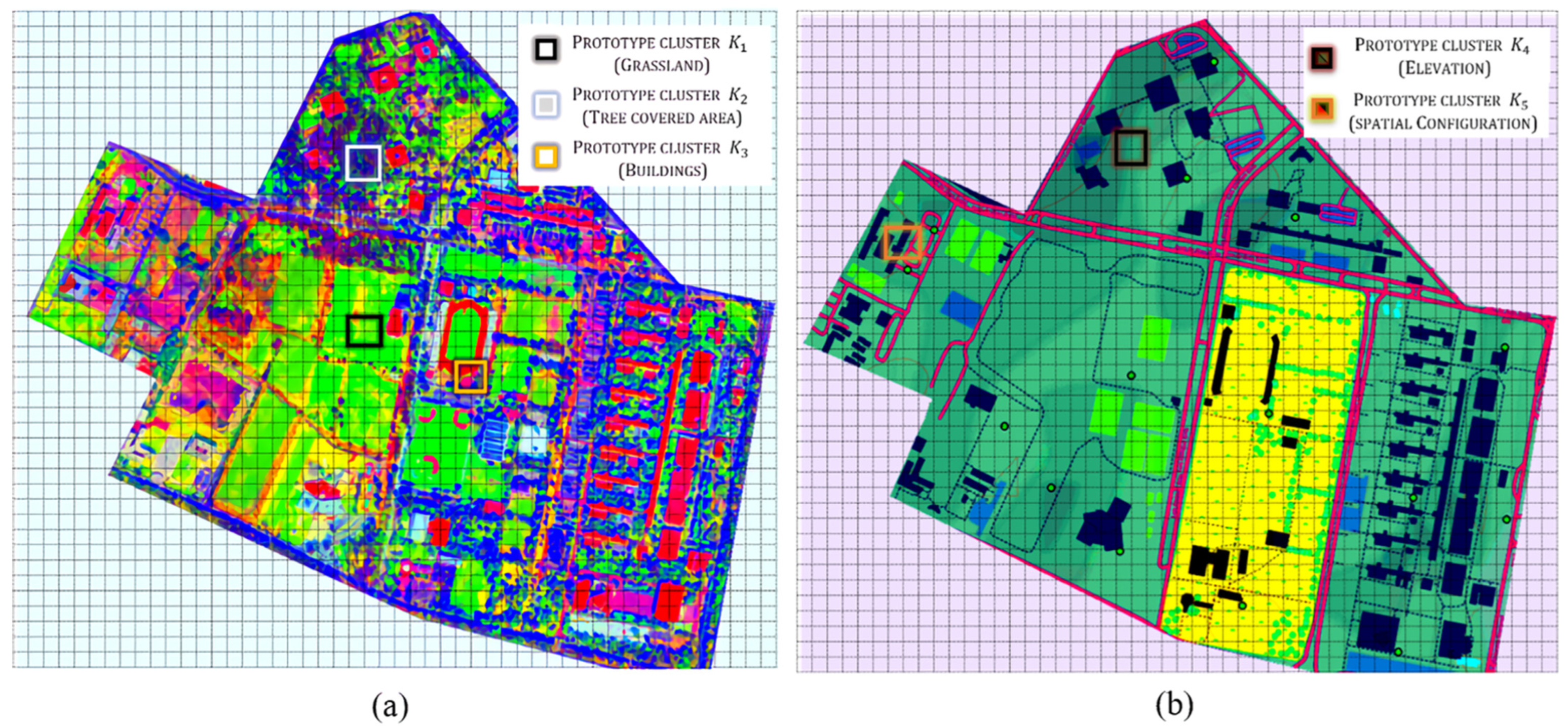
Appendix B. The image processing highlights the colors and shapes of the region so that a color segmentation of satellite images can be performed. In this paper, the two images from
Figure 5a,b are processed images used to identify the landscape features. Grassland, tree-covered areas, and buildings are extracted from
Figure 5a.
Figure 5b is utilized to identify elevation and spatial configuration.
In color segmentation, a cluster (
) is determined for each color band identified. Each cluster is associated with a landscape feature. In this work, the merging method is used for color segmentation. This method assumes that the features of all pixels are unlike at the beginning. Then, the algorithm K-means merges pixels according to the similarity criterion (Equation (1)) until no pixels remain merged [
48]. Afterwards, the merged pixels are assigned to a cluster. Some pixels may not be assigned to a cluster, and a deficient color segmentation could mislead the weather conditions adjustment. When there is a high percentage of pixels not assigned (
), it is necessary to use an image with better resolution. In this paper, a
is utilized based on the preliminary experimental analysis as described in
Section 4.
So far, the image is segmented pixel by pixel into clusters. Nonetheless, in the same way as the satellite image, the segmented images must be divided into sectors
) to obtain landscape matrices (
). In feature matrices, the size of each landscape matrix is
. For matrices
, each element (
) represents the number of pixels in a sector that belong to the cluster
as shown in
Figure 6a,b. The landscape matrices defined are the following:
Matrix corresponds to grasslands.
Matrix corresponds to tree-covered areas.
Matrix corresponds to building areas.
Matrix corresponds to elevation.
Matrix corresponds to spatial configuration.
Figure 6.
(a) Landscape matrix (grassland). (b) Landscape matrix (buildings).
Figure 6.
(a) Landscape matrix (grassland). (b) Landscape matrix (buildings).
For instance, landscape matrices
(
grassland) and
(
buildings) are depicted in
Figure 6a,b, respectively. In this paper, each sector contains
pixels. The value of the element
corresponding to sector
is
because there are 596 pixels that belong to cluster
(
grassland).
Furthermore, landscape matrix (elevation) is a particular case because its value not only refers to the number of pixels but also contains the elevation level of these pixels, e.g., element defines that, at sector , there are 550 pixels that belong to elevation level . Elevation levels are named as , according to the region elevation model.
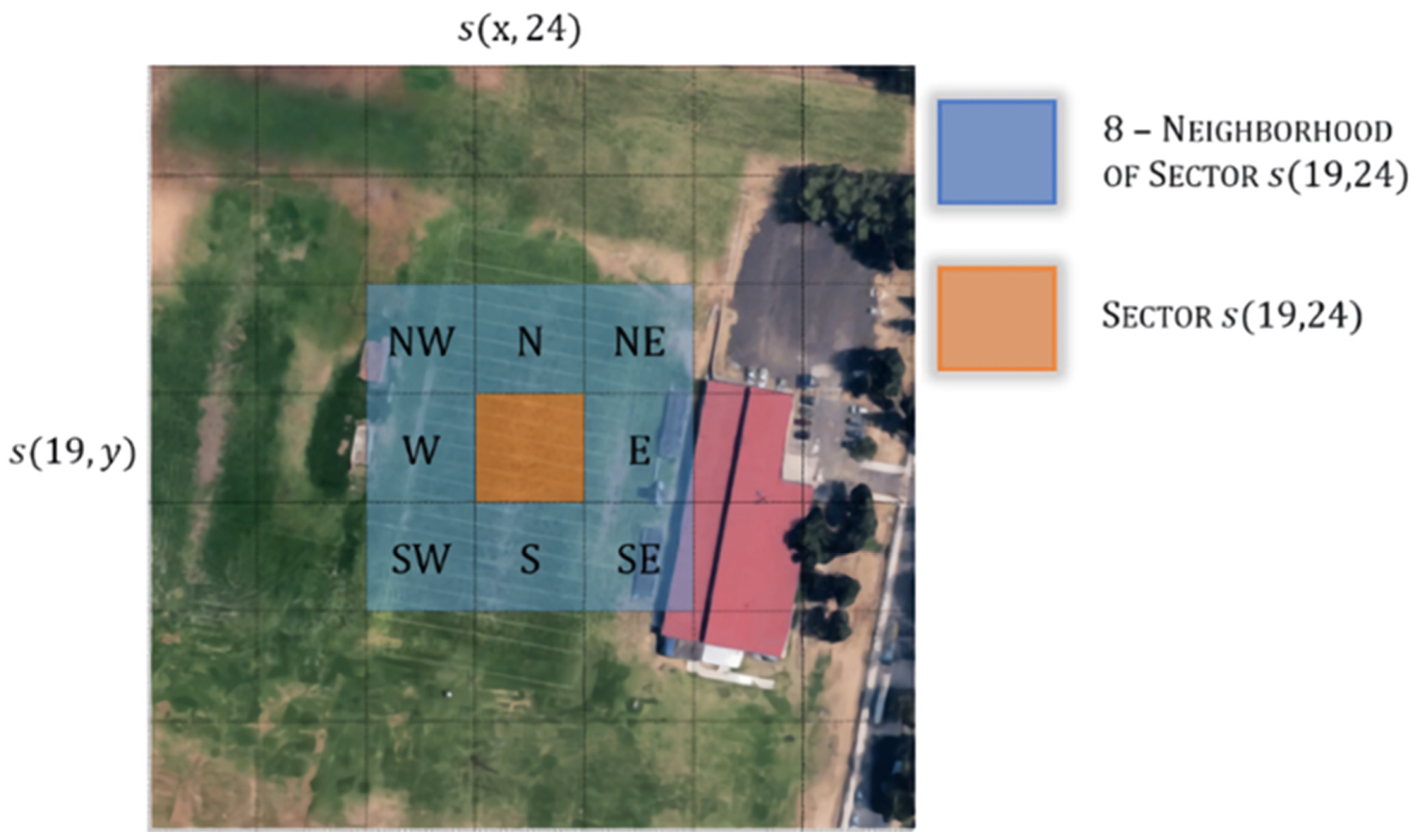
Moreover, for landscape matrix
(
spatial configuration), elements
contain the number of pixels corresponding to the surrounding sectors’ buildings, roads, or natural barriers. A landscape feature analysis of the 8 neighborhoods of sector
is performed, e.g., sector
of the satellite image given in
Figure 4 is shown in
Figure 7, and the features of 8-neighborhood sectors (
) are analyzed. Neighbor sectors
present no buildings, roads, or natural barriers; meanwhile, neighbor sectors
denote the existence of buildings. The value of
spatial configuration at sector
is the addition of all pixels that belong to
tree-covered areas (
) and
buildings (
) in the neighbor sectors
. The
spatial configuration is used by the adjustment model for modeling the interactions between the 8 neighborhoods and sector
.
The weather conditions of a sector are not only influenced by its particular features but also by the particular features of the surrounding sectors ().
3.3. Subzone Features Selection
The subzone features selection stage receives the landscape matrices (), the feature matrices (), and the checkpoint locations . The data about landscape features () and soil and crop features () at the checkpoint location are selected from the matrices mentioned before.
These elements (grasslands, tree-covered areas, buildings areas, elevation, spatial configuration, soil type, crop type, and crop stage) compound the particular features (
of the checkpoint (
as shown in Equation (2).
The following calculation example uses checkpoint
with location
according to
Figure 4 and
Table A1. The particular features
of this test checkpoint, shown in Equation (3), are selected as defined in Equation (2), and their values are described in Equation (4). There are 818 pixels corresponding to
(
grassland) at checkpoint
, 17 pixels corresponding to
(tree-covered areas), and so on.
Notation
shown in Equation (5) is used to denote particular features expressed as a percentage so that the level of each feature can be identified more easily.
For instance, in Equation (6), the particular features from Equation (4) are expressed as a percentage, as defined in Equation (5). Equation (6) indicates that, at the test checkpoint,
of the pixels correspond to grassland,
correspond to tree covered areas, and so on.
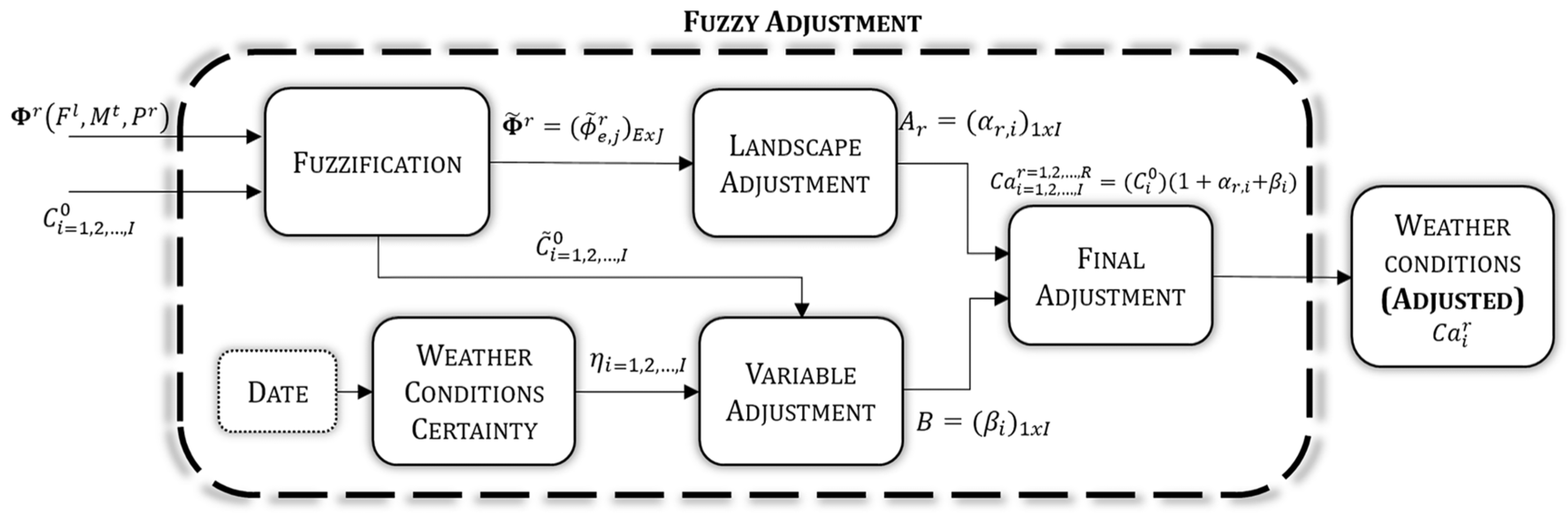
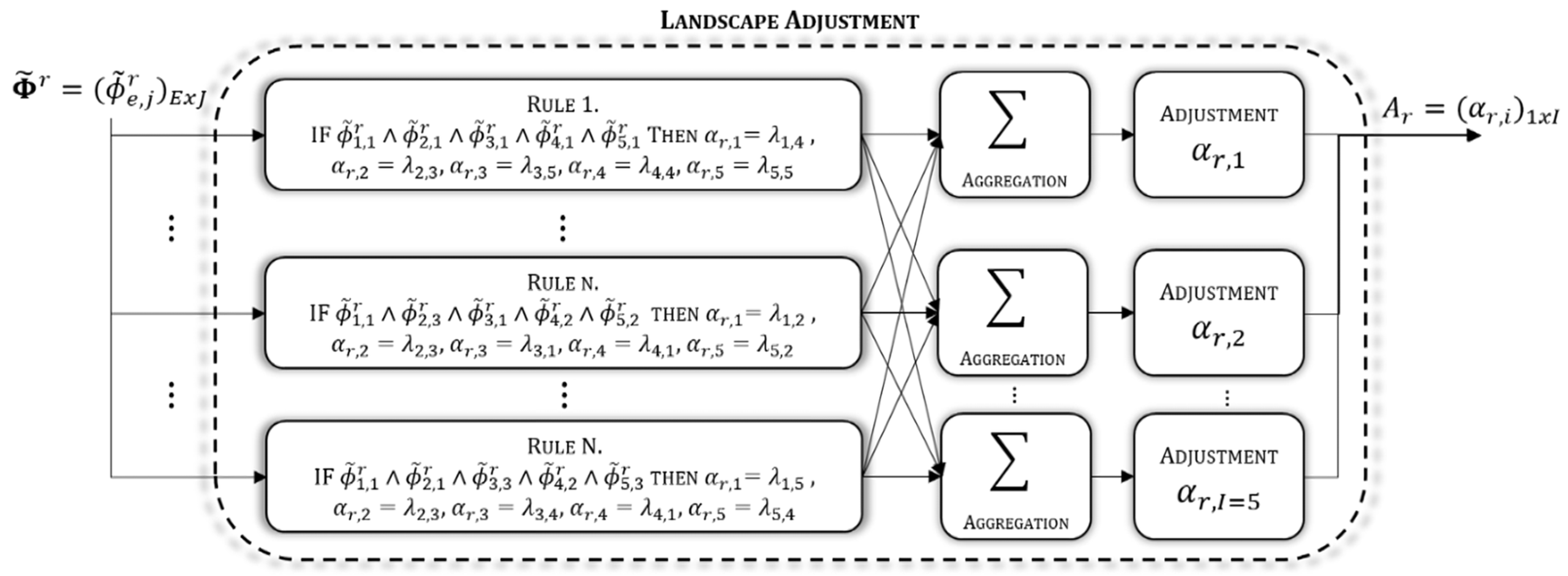
3.4. Fuzzy Adjustment
The
fuzzy adjustment stage is depicted in
Figure 8. This stage receives the particular features (from the previous stage) and the weather conditions measured (from inputs), and both are fuzzified.
Two fuzzy inference systems (landscape adjustment and variable adjustment) are performed to obtain the adjustment factors: steady and variable . Both adjustment factors determine the weather conditions adjusted ().
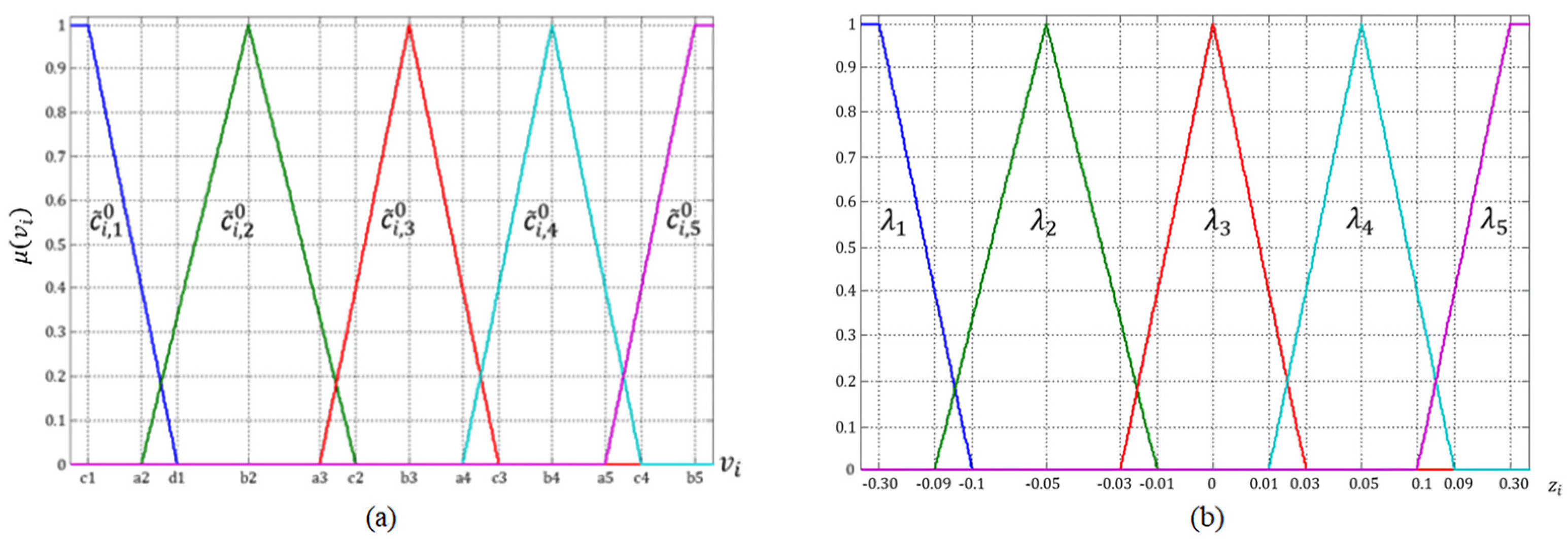
3.4.1. Fuzzification
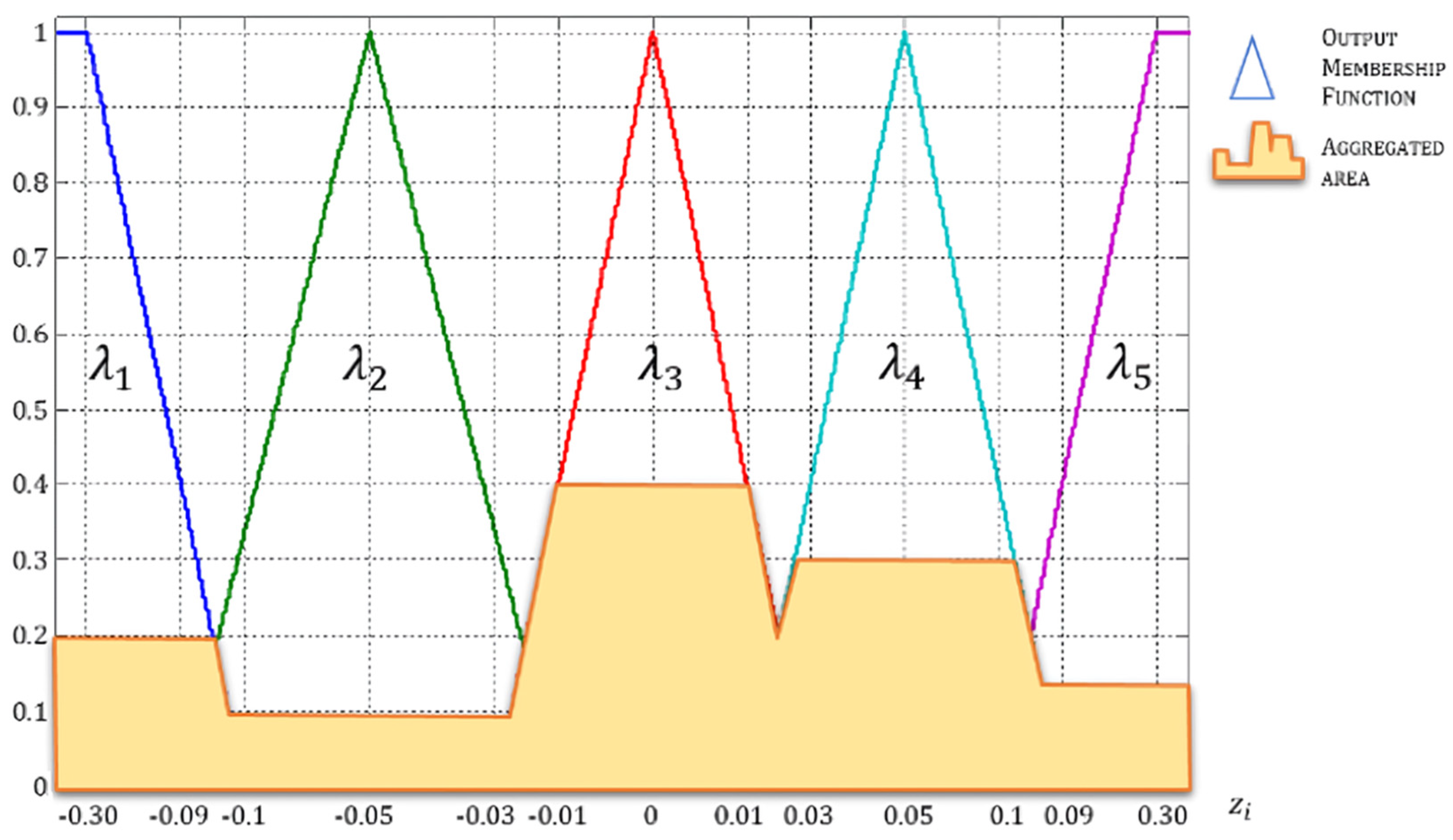
The particular features and weather conditions measured are fuzzified using membership functions with the
triangle form defined in Equation (7),
L form defined in Equation (8), and
gamma form defined in Equation (9) [
49].
Each measured weather condition is fuzzified with five linguistic values (
lower, low, medium, high, and higher) so that, by the time fuzzification is applied, each weather condition (
temperature, rain, solar radiation, wind speed, and evapotranspiration) turns into a fuzzy weather condition vector
, where
.
is the value of the weather condition
and
is the universe of discourse defined in
Table 3. Each fuzzy weather condition vector is composed of five elements (
) as defined in Equations (10)–(14).
Elements of the fuzzy weather condition vector are associated with a linguistic variable . The linguistic labels used are the following:
Lower level of weather condition .
Low level of weather condition .
Medium level of weather condition .
High level of weather condition .
Higher level of weather condition .
In the same way, each element is related to a membership function of the form defined in Equations (7)–(9). Element
comes from the
gamma shape membership function, whereas element
is
L shape membership function. Elements
are triangle membership functions. The linguistic values and the membership functions are set based on the experimental analysis’s best results during the adjustment model’s development stage. The parameters determined for the region shown in
Figure 4 are described in
Table 4 and depicted in
Figure A1a. Suppose that the adjustment model is implemented in another region; in that case, the entire process followed in the experiments developed in this paper must be replicated to obtain the parameters of the new region. However, the membership functions and linguistic labels’ type and number remain the same. The membership functions’ parameters presented in this document can be utilized, but they must be modified according to the best results of the new experimental analysis.
For example, the weather conditions measured from
Table 2 and their parameters (
Table 4) are utilized to obtain the values of fuzzy weather condition vectors of Equations (15)–(19).
Moreover, to fuzzify particular features defined in Equation (5), it is necessary to compare the differences between specific features at the primary checkpoint
and particular features at each checkpoint
. This comparison allows one to determine the variations in the weather conditions derived from landscape influence. For example, according to the checkpoint set from
Figure 4 and
Table A1, and comparing the tree-covered area (a particular feature
, the primary checkpoint is not a tree-covered area, while checkpoint
is. So,
temperature (
) measured at the primary checkpoint can be higher than
temperature (
) at
because trees reduce sun exposure (
solar radiation ) and cool air temperature (
). However, despite this fact, if there are high winds (
wind speed ) at primary checkpoint, air temperature (
) can be reduced because of the wind chill factor; meanwhile, at
trees block high winds (
) and no wind chill is present at this location. As a consequence, the
temperature measured (
) can be the same as
temperature (
) at
.
The comparison (
between particular features is a difference as shown in Equation (20).
For instance, the particular features at the primary checkpoint are shown in Equation (21) and particular features at the test checkpoint in Equation (6). The comparison (
is executed using Equation (20); the result is shown in Equations (22) and (23).
The comparison of particular features is fuzzified with a similar process as that followed to fuzzify the weather conditions measured. The comparison denotes whether each particular feature ( at the primary checkpoint is lower, equal, or higher than the particular feature ( at any checkpoint ( Hence, the linguistic labels used to fuzzify the particular features comparison are the following:
is lower than .
is equal to .
is higher than .
When fuzzified, the comparison of features turns into the fuzzy particular feature matrix (
, defined in Equation (24). This matrix is the fuzzified comparison of features at the primary checkpoint and any other checkpoint. As the comparison of features is executed individually, a fuzzy particular feature matrix is obtained for each checkpoint. The matrix rows represent each element of the comparison vector, and the columns contain the fuzzy values (
obtained with the membership (
).
The universe of discourse is the same for all elements of the comparison, and it is expressed in a percentage as . Meanwhile, the membership functions are also those defined in Equations (7)–(9).
Elements come from gamma shape membership function, elements are L shape membership functions, and elements are triangle shape membership functions.
The linguistic values and membership functions are set based on the experimental analysis’s best result during the adjustment model’s development stage. The parameters of a particular feature
(grassland) obtained for this region are shown in
Table 5; they are the same for all particular features.
For example, according to Equation (24), the fuzzy particular feature matrix of the test checkpoint (Equation (25)) is derived from fuzzifying the comparison of Equation (23) using the membership functions described in
Table 5. The fuzzy particular feature matrix of Equation (25) highlights that particular features of the primary checkpoint and the test checkpoint are alike, so weather conditions are expected to be similar at both locations.
3.4.2. Landscape Adjustment
In the adjustment model, there is a stage that models the influence of particular features over the weather conditions. It is called the
landscape adjustment and is depicted in
Figure 9. As the particular features of each checkpoint can be different, a
landscape adjustment is performed at each checkpoint. A fuzzy inference system is implemented in all the
landscape adjustments. The results of every landscape adjustment are the steady factors; these are considered steady because they do not change while the particular features of the checkpoint remain the same. So, this adjustment does not need to be implemented each time a weather condition adjustment is made.
The input of the fuzzy inference system is the fuzzy particular features matrix of the checkpoint, and the outputs are the steady factors. Each steady factor (
, where
is the total of weather conditions) is divided into output sets (
where
). The membership functions used for the output sets are of the form defined in Equations (7)–(9). The universe of discourse is
,
. Each output membership represents a percentage of adjustment in each weather condition, as shown in
Table 6.
is an
L shape function,
are triangle functions, and
is a
gamma shape function. The membership functions used for all steady factors
) are defined in
Table 6 and depicted in
Figure A1b.
All rules are generated manually based on observation and expert knowledge. Adjusting membership functions and rule generation using automatic methods are outside this work’s scope. Rules
, where
, are established and processed for modeling steady factors, as shown in
Figure 9. The rules are established based on the effects of particular features on the weather conditions. Each rule inter-relates the fuzzy particular features (
) using the premise IF THEN. Furthermore, the rules remain the same for all the checkpoints. The rules are of the form: IF
THEN
,
, , , , e.g., the previous rule corresponds to rule
applied at the test checkpoint, and it can be interpreted as follows:
IF grassland is Higher () and tree-covered area is Equal () and building area is Equal and elevation is Equal and spatial configuration is Equal () THEN adjustment factor for temperature ) is Barely High (), adjustment factor for rain ) is Null (), adjustment factor for solar radiation ) is High (), adjustment factor for wind speed ) is Null (); meanwhile, adjustment factor for evapotranspiration ) is Barely High ().
The rule definition matrices
, where elements
) determine the fuzzy particular features utilized for assessing each rule
of checkpoint
as described in Equation (26). The rows refer to the number of rules and the columns to the fuzzy particular feature.
Moreover,
is the output definition matrix for
landscape adjustment of checkpoint
. Elements
denote which output membership function (
low, barely low, null, barely high, high) represents the output
according to rule
. The rows refer to the number of rules and the columns to the output membership functions of the steady factor. The implication of the rule
is denoted by the word “
and”, defined as the function
min. The result of the assessment
is obtained as defined in Equation (27).
Afterwards, the results of the assessments are sent to the
aggregation process. The aggregation delimits the output functions (
and aggregates them in a single area, as shown in
Figure A2. The method used for aggregation is the
maximum defined in Equation (28), where
is the aggregated function for output
.
For instance, using Equation (27), the rule definition matrix (
), and the output definition matrix (
), the rule
for the steady factor of
temperature (
) is assessed as in Equation (29). The result of rule (
) is assigned to the output membership function
barely high (
). The same process is applicable for the
rules as well as for the
outputs.
Afterwards, the aggregated function (
is defuzzfied to obtain the steady factor
) of each weather condition
. The defuzzification method used in this paper is the centroid method defined in Equation (30).
All the steady factors (
) defuzzfied conform the steady factors vector presented in Equation (31). The steady factors vector (
adjusts each weather condition measured according to the particular features of checkpoint
.
For example, the steady factors vector (
for the test checkpoint is obtained according to Equation (31) and is shown in Equation (32). In this case, the steady factor for
temperature (
indicates that, according to the features at the test checkpoint, the
temperature must be modified to
, i.e., the adjustment is about
of its value.
3.4.3. Weather Conditions Certainty
Sometimes, weather conditions can vary in two near locations within a region, i.e., sometimes, it can be raining at the initial location where the observer is, but when the observer moves from the initial location to another a few meters ahead, it cannot be raining. This situation is caused by different events [
50]. However, one of the most relevant is the season of the year, which increases the certainty that a weather condition is similar in most locations within a region of interest, e.g., it is more conceivable that, in the rainy season, it is raining in the whole region. Therefore, a certainty distribution function, which depends on the date, can describe the certainty of the weather condition replication in a region. Moreover, not all the weather conditions considered in this work present the uncertainties described above, e.g., temperature, which remains homogeneous in a specific region if the variations due to landscape features are not considered.
Consequently, in the
variable adjustment, the date and a certainty distribution function are utilized to determine the weather conditions certainty
.
Rain ,
solar radiation ,
wind speed , and
evapotranspiration are expected to be affected by the date (season of the year), and their distribution function is defined in Equation (33). Weather conditions certainty of
temperature is not considered to be influenced by the date (season of the year).
In Equation (33), is the month, and are the function parameters: indicates rainy season deviation expressed in months, and defines the month of peak rainy season. This certainty distribution function corresponds to a Gaussian bell, which increases the certainty during the rainy season. The certainty distribution function parameters for certainties (rain, solar radiation, and evapotranspiration) are ; meanwhile, for certainty (wind speed), the parameters are . The weather conditions were measured at different checkpoints during the development stage of the adjustment model. The measurement records allow for the definition of parameters that best describe the certainty distribution function. If the adjustment model is applied in another region, the parameters presented in this paper can be utilized, although they can be modified to adapt appropriately to the features of the new region.
For example, certainty
(
temperature) is always considered as
. Certainties
are calculated with Equation (33) using the parameters
above defined for each weather condition. The certainties
during August
, a rainy season month, are shown in Equations (34) and (35).
3.4.4. Variable Adjustment
The
variable adjustment models the interactions among weather conditions. The
variable adjustment also implements a fuzzy inference system. The result is the variable factor (
). In this adjustment, first, the weather condition certainty (
is used to weigh the fuzzy weather conditions (
) obtained in
Section 3.4.3. If the certainty
is high, then it is more likely that the weather condition is similar in the whole region. Therefore, it is more important to model its interactions
. For example, if the
rain certainty is
, it is more feasible that the
rain value measured at the primary checkpoint is similar at the other checkpoints, with a high certainty value; if it is raining at the primary checkpoint, it is more likely that it is raining throughout the region. Consequently, rainfall value should be considered more relevant for modeling the variations in weather conditions caused by the rain effects over the other weather conditions, such as the decrease in temperature or solar radiation. Weather conditions are weighed by a product of fuzzy weather conditions and their certainty of replication.
The variable factor vector (
) is formed of individual variable factors (
). The output membership functions
, where
) of the variable factors are also associated with linguistic labels, which refer to the required adjustment in a percentage of the weather conditions measured. Also, output functions
are
shape functions as defined in Equation (7),
are
triangle shape functions as defined in Equation (8), and
are
gamma shapes as in Equation (9). The output membership functions are defined for
, where
is the universe of discourse. The output membership functions for all variable factors are described in
Table 7; meanwhile,
Figure A1b can be used to depict the shape of the output membership functions due to the similarity of both output membership function sets.
A similar procedure to that developed in
Section 3.4.2 is followed in this adjustment. However, the variable adjustment does not depend on the particular features of a checkpoint, so this adjustment is the same for any checkpoint; the same variable factor vector is utilized. Nonetheless, this adjustment is executed each time a weather conditions adjustment is made. There are
rules (
) set by experts to model the interactions among weather conditions.
The
rules model the interactions among weather conditions. These rules are of the form
IF THEN, as in the fuzzy inference system described in
Section 3.4.2.
For instance, two rules are shown next:
: IF THEN , , , , .
: IF THEN , , , , .
It can be interpreted as:
: IF Rain is High and Solar Radiation is Low and Wind Speed is High , THEN Temperature decreases, and the rest of the weather conditions remain the same; that is to say, the variable adjustment is Low and are Equal ().
: IF Temperature is Medium and Rain is Lower and Solar Radiation is Higher , THEN output , are Barely High , , are Equal ().
The rules are processed through the implication shown in Equation (37). There are certain rules in which a variable in the proposition does not modify the consequence of the rule, e.g., no fuzzy value of temperature was used in the proposition of the rule shown in (a).
In the same way as in
landscape adjustment, a rules definition matrix
) defined in Equation (36) contains the rules set for
variable adjustment.
Also, an output definition matrix (
) is defined for
variable adjustment. Elements
determine the output membership function (
) chosen for assessing each variable factor. Equation (37) shows a generalized implication in which all weather conditions are considered.
where
is the result of rule
for each output
.
For example, according to Equation (37) and using the rule of row
of the rule definition matrix (
) and the output definition matrix (
), the result of the assessment (
) for the variable factor of
temperature (
) is described in Equations (38) and (39).
Afterwards, the aggregation is performed through the operator max as in Equation (40).
is the resulting function of the aggregation. In Equation (41), the variable factor
is obtained after performing the centroid method.
The variable factors vector is defined in Equation (42) as the set of variable factors (
). The variable factors vector is the same for all checkpoints.
For example, the variable factors are obtained using Equations (40) and (41) and, according to Equation (42), the variable factors vector
derived from the previous examples is shown in Equation (43). In this case, for
temperature, the variable factor is
; that is to say, there is an adjustment of
derived from the interactions of the current values of the weather conditions.
3.4.5. Final Adjustment
The final adjustment stage is implemented to achieve the weather conditions adjusted
), which are calculated with Equation (44). The weather conditions adjusted are given by the product of the crisp value of weather conditions measured
contained in
Table 2, and the addition of the steady and variable adjustment factors (
) of vectors
defined in Equations (31) and (42), respectively. The final adjustment collects the weather condition variations derived from the particular feature’s effects and the weather conditions’ interactions.
For instance, with the previous examples, the weather conditions adjusted
at the test checkpoint, it can be calculated with Equations (45)–(49). According to
Table 2, the measured value of
temperature is
, and its adjustment factors are
and
contained in
from Equation (32) and
from Equation (43). In this case,
is modified in a combined adjustment of
, which can be interpreted as an increase of
of the measured value. Therefore, the adjusted value of
temperature is
as shown in Equation (45). This can be applied similarly to the rain (Equation (46)), solar radiation (Equation (47)), wind speed (Equation (48)), and evapotranspiration (Equation (49)). Checkpoint 4
is used as an example because it is a place that is very similar to a crop field. Additional meteorological stations were installed at checkpoints 4 and 6.
At this point, the adjustment model concludes with a comparison of the weather conditions adjusted at the test checkpoint derived from the examples developed as depicted in the work overview from
Figure 3, and the weather conditions measured at the same checkpoint are given in
Table 8. This comparison is only performed during the development stage of the adjustment model to validate the results, and it is not required during the adjustment model operation. A further analysis of the results of weather conditions adjustment in other checkpoints of the region is presented in the next section.
4. Results and Discussion
A weather conditions data set was utilized to test the adjustment. A total of 40% of the data set was used to validate the results, consolidating the recognition of the environmental interactions (weather conditions–particular features; weather conditions–weather conditions)—the remaining 60% was used for optimizing the model.
Daily measurements of weather conditions in the region formed the data set; the measurements were carried out over a year. The data are equally distributed so that validation and optimization sets contain records from each year’s season, so that the adjustment model can be tested under a wide range of environmental conditions. The results in this section correspond to the tests performed with the data set mentioned before.
The region shown in
Figure 4 is used in this work to adjust the weather conditions and is described in
Section 3.1.1. It is expected that particular features of farmland remain alike throughout the region. The region used to validate the adjustment model is not farmland; its particular features considerably change. Changing particular features is needed to validate the model on a wide variety of features. Regions with landscape features such as water bodies, e.g., rivers or lakes, are not considered in the adjustment model but can be included in further enhancement.
A preliminary experimental analysis is performed to determine the initial parameters of the adjustment model. This analysis assesses the adjustment model performance under every combination derived from keeping fixed an initial parameter and varying the rest of the proposals. The initial parameters of the adjustment model are the size of sector
, the image resolution, percentage of not assigned pixels, and distribution function of the weather conditions certainty. The proposals of initial parameters and the best performance for each initial parameter are shown in
Table 9. The normalized root mean square error (
) is used to assess the performance of the adjustment model.
According to
Table 9, the sector size with the better performance is
(
); therefore, this size is utilized in this paper. Sizes of sector
less than
, such as
or
, do not significantly decrease the error (
), but they do increase the adjustment model computational cost. The number of sectors increased from 2150 using
to 15,295 using
. With sizes of sector
greater than
, such as
, there is not a predominant landscape feature in each sector and, as a consequence, a significant increase in the error (
) occurs. This increase can be due to the complexity of modeling weather conditions’ interactions being magnified when it is unclear which landscape features affect weather conditions the most.
Additionally, the image resolution can strongly affect the landscape features extraction; the resolution utilized in this paper, , i.e., , which entails an error . The adjustment model can support bigger resolutions such as , i.e., , with an error but acquiring the region’s image may require more complex methods than those used in this paper. More significant resolutions are recommended when a more detailed analysis of the regional landscape features is needed. The adjustment model works with a minimum resolution of 8 pixels, i.e., , with an error . Lower image resolutions can trigger a significant error .
The percentage of pixels not assigned to a color band is directly related to an inaccurate landscape features extraction and, consequently, a misleading weather conditions adjustment. As shown in
Table 9, when the percentage of not assigned pixels is
the adjustment model performs better (
) than with greater percentages, such as those shown in
Table 9. The error increases (
,
,
) as the percentage increases. It is possible to achieve a
but, in certain cases, this
required processing an image with a resolution bigger than
, which leads to the aforementioned issues. Any error derived from the landscape extraction (size of sector
, satellite image resolution, or color segmentation) must be diminished during the preliminary experimental analysis. Additionally, the fuzzy parameters of the model developed herein are set according to the best performance in a similar way to the process used to obtain the initial parameters during the preliminary tests.
A set of integrated sensors suite (ISS) was deployed within the region so that weather conditions can be measured at different checkpoints, such as
. The ISS set is only deployed during the design stage to perform a calibration of the adjustment model. The measurements obtained with the ISS are also utilized to execute a spatial interpolation, the results of which are compared with those of the adjustment model. As shown in
Figure 3, inverse distance weighting (IDW) and a spatial interpolation method from the literature [
37,
38], as well as the weather condition measurements from ISS, were employed to validate adjustment model results, the
weather conditions adjusted . When the adjustment model is in operation, it only needs measurement devices at one checkpoint, such as the ISS installed at the primary checkpoint of the region utilized in this paper. The normalized root mean square error (
) is also used for assessing the performance the interpolation.
Table 10,
Table 11,
Table 12,
Table 13 and
Table 14 depict a comparison of results at checkpoint
.
Weather conditions adjusted (
), weather conditions measurements (
), and
weather conditions interpolated are compared. Checkpoint
is one of the test checkpoints utilized; it is located at a distance relatively close to the primary checkpoint, and its landscape features are similar to those of farmland. In the case of
temperature, shown in
Table 10,
presents an
which is almost equal to
corresponding to the interpolation
. More accurate results are presented when temperatures over 18
are adjusted with an
, which is even smaller than the interpolation error. The error
of both
and
is not a problem for estimating point soil moisture with the point estimation model.
Referring to
rain, according to
Table 11, the weather conditions adjusted
with an
are more accurate than the
weather conditions interpolated with an
.
The best adjustments were performed with rains lower than 1 mm. Nevertheless, the resolution of the rain gauge adds uncertainties to determine if the adjustment model or IDW performs better in tests A, D, E, I, and J, where the error of both approaches is less than the rain meter resolution (0.2 mm).
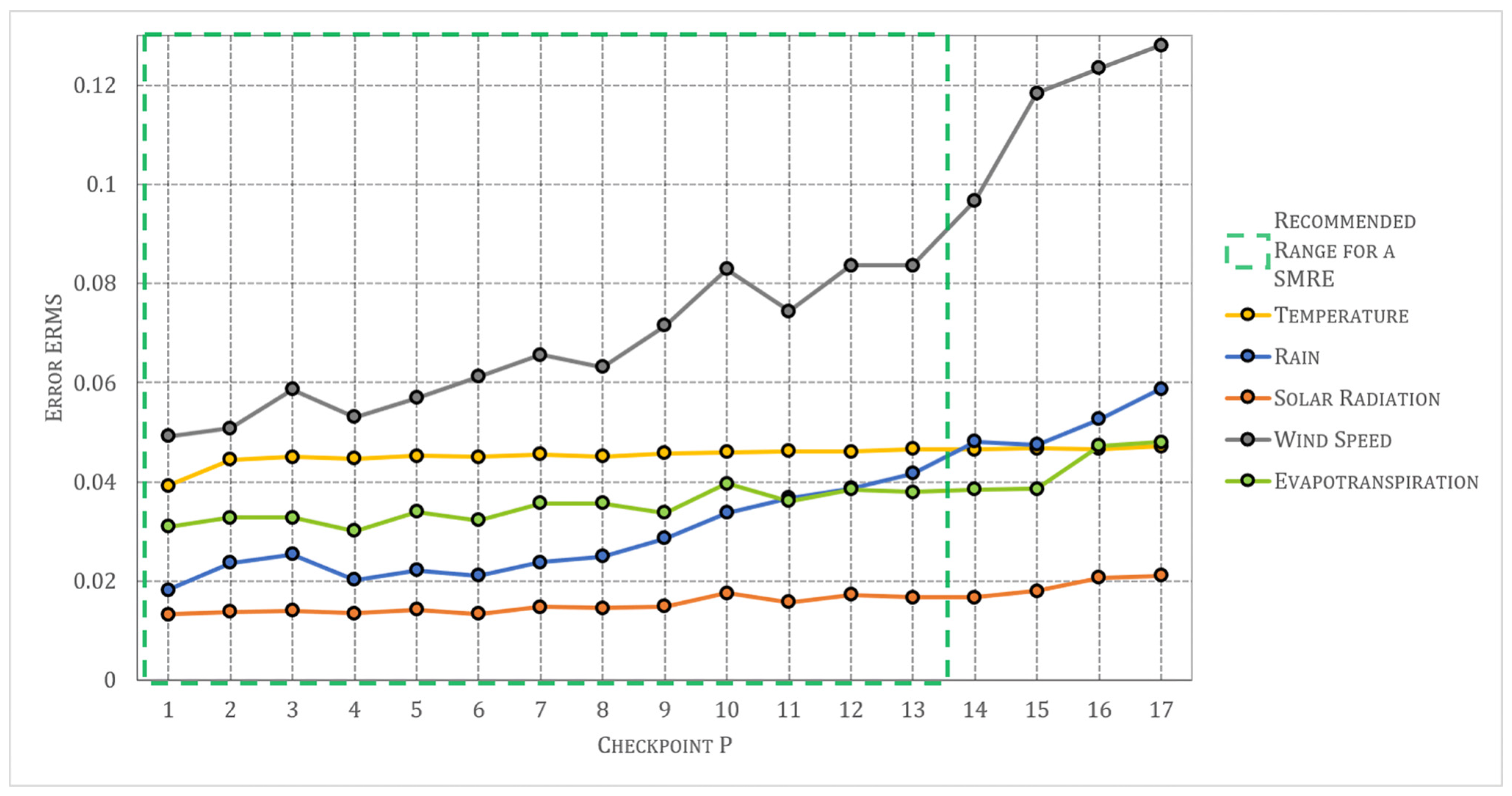
Moreover,
Figure 10 depicts the performance of adjustments for
at checkpoints
and
considering the weather conditions certainty
as well as the performance without considering
.
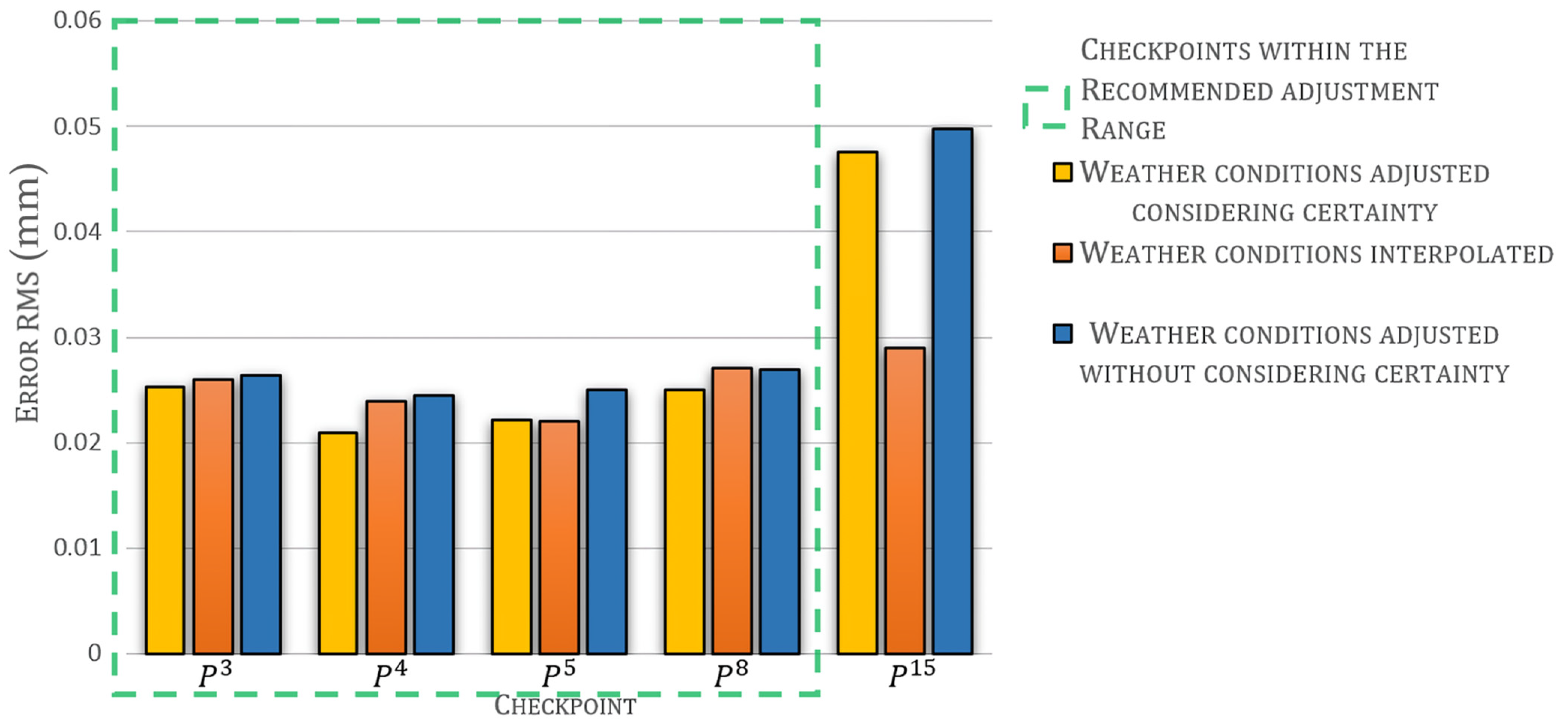
The performance of the interpolation method is also included, e.g., at checkpoint , the error without certainty is , which is similar to the error obtained from the interpolation method (), whereas the error considering the certainty ) is less than both.
Although the certainty of weather conditions replication can be improved further by enhancing the adjustment model, its performance is better than IDW when the certainty distribution function is used. The benefits of including the weather conditions certainty are more evident in the case of rain.
In
Table 12, the
solar radiation adjusted
presents an
; meanwhile, the
solar radiation interpolated has an
. Both errors are remarkably alike because
solar radiation denotes less dependency on weather conditions variability in a narrow region as expected for a future soil moisture regional estimation.
Table 13 contains the comparison of
wind speed results. The error from
is
and the error from
is
. In this case, the adjustment model performs better than IDW because of the spatial analysis of the region.
Wind speed adjustment is highly complex due to its changing conditions and the presence of natural or non-natural barriers that block the wind. This is usually not considered with some interpolation models, which can affect the soil moisture point estimate.
The adjustment model performs a more detailed modeling of
potential evapotranspiration , as well as of
rain . These two weather conditions are the most significant for the point estimation model because
denotes the amount of water that outflows from the soil, whereas
determine the water that is provided to the soil. According to
Table 14, the adjustment model results
present an error
; meanwhile, the interpolation results
present an error
.
All these errors are acceptable for the second objective of the adjustment model, i.e., the weather conditions applied to the point estimation model. The existing differences between
weather condition measurements (
) and
weather conditions adjusted (
) do not compromise the accuracy of the soil moisture estimation. In fact, there are some uncertainties or instrumental errors in some tests, such as
from
Table 10. An
can be considered because the deviation between the adjustment model result
and the
weather condition measured
is lower than the accuracy of the integrated sensor suite shown, e.g., in test
from
Table 10, the deviation between
and
is:
meanwhile, the accuracy of the ISS for temperature is
.
Furthermore, despite similar results from the adjustment model and inverse distance weighing (IDW), or even better IDW results, such as for
temperature and
solar radiation , the adjustment model presents two advantages over the spatial interpolation IDW for developing the application proposed in
Section 2 of this paper. The first advantage is a better performance when adjusting an inconsistent variable such as rain. The weather conditions certainty
is responsible for this result. The second is that the adjustment model does not require deploying more than one measuring station when it is operating, unlike interpolation methods, which need more than one measuring point to perform the interpolation.
The adjustment model was also tested at other checkpoints, such as checkpoint
.
Figure 11 depicts the error of
weather conditions adjusted
at checkpoint
. Checkpoint
is located out of the recommended adjustment range. The distance from checkpoint
and the different landscape features reverberate in the accuracy of the results. The normalized errors
at checkpoint
are the following:
for temperature.
for rain.
for solar radiation.
for wind speed.
for evapotranspiration.
Figure 11.
Errors of weather conditions adjusted at checkpoint .
Figure 11.
Errors of weather conditions adjusted at checkpoint .
In the case of (temperature, solar radiation, and evapotranspiration), the errors remain remarkably similar to those obtained at checkpoint due to the maximum increase in the errors is 0.0085. For (rain), the error increase is 0.0266. Both error increases show that the distance between the primary checkpoint influences weather condition adjustments and the checkpoint where the adjustment is performed . The case of (wind speed) shows a remarkable increase of 0.0646 in the error. This error increase is caused not only by the distance issue but also by the changing wind behavior conditions in a region with a substantial amount of natural or non-natural barriers. Nevertheless, in farmland, it is not usual to find barriers scattered along the region of interest.
Figure 12 depicts the error
of the adjusted weather conditions compared with those measured at every checkpoint. In this paper, the recommended adjusting range of the adjustment model is 1.4 km, measured from
. Considering the location of checkpoints from
Table A.1., the recommended adjusting range includes checkpoints
to
. This range is defined based on the error of weather conditions adjusted. Not all weather conditions adjustments beyond this distance present a significant error. For example, the error of
(
temperature) is
at checkpoint
(
km from
); however, if a weather condition with an important error (
) is supplied to the point estimation model, e.g., the error of
(
wind speed) is
at checkpoint
, an erroneous point estimate could be obtained. The recommended adjusting range depends on the features of the region where the adjustment is performed. A more homogeneous region can increase the range. An adjustment region like the one presented in this paper can be considered a small-scale region. This kind of region presents limited variations in weather conditions but can strongly affect soil moisture. However, the adjustment model is intended to be part of a soil moisture regional estimation where an accurate modeling of the small variations in weather conditions is required.
The integrated suite sensor utilized by the adjustment model to measure at the primary checkpoint transmits the data to a console, which must be indoors; thus, the location of must be at least 300 m from this console, which is the transmitting range of the integrated sensor suite. Signal repeaters can be used if a more extensive transmitting range is needed. The transmission is made via radio frequency; the adjustment model needs no other connection (telephony or Internet). In addition, the primary checkpoint is recommended to be located at a centric sector , which accomplishes the condition abovementioned. A proper location of checkpoint directly affects the recommended adjusting range. In this paper, a set of checkpoints is defined to validate the adjustment model; however, the aim is that any sector can be a checkpoint when the adjustment model is implemented.
At 1.4 km from checkpoint , the model is most effective for an intelligent adjustment of weather conditions based on spatial features; however, changes that will be highlighted in the following paragraphs can be made. Using only one integrated sensor suite in a range of 1.4 km, the almost null maintenance needed by the measurement devices and the non-use of measurement devices in situ throughout the region can help small farmlands reduce the complexity (physical and financial) of measuring soil moisture. Additionally, as the adjustment range is 1.4 km, a group of small farmlands can join to implement this method.
The appropriate size of the estimation region is related to the complexity of the ground conditions. The more heterogeneous the region is, the less precise the estimation is, which can be improved with the installation of another meteorological station that would create a new estimation region adjacent to the existing one, and it can even be carried out in the future by including remote sensing to increase the precision of the estimate and the extent of the region if required. However, this can be seen as the collaboration of two estimation regions. When the ground conditions change abruptly concerning those of checkpoint , it is advisable to carry out the above. That is why it is essential to choose as a checkpoint a place representative of the terrain conditions that predominate in the study region.
The model can be complemented with remote measurements of meteorological variables. This would increase the estimate’s precision in the study region; however, it would also increase the operational complexity, i.e., the model would be more exposed to a failure or erroneous estimation if the remote measurement units break down or are vandalized. Remote sensing is recommended if the study region is complex enough (heterogeneity in terrain conditions), and it is necessary to improve the estimate’s precision and accept the increase in operational complexity.
During one year, our team verified that the integrated sensor suite ensures the reliable measurement of data of meteorological variables; likewise, other portable measurement devices were used for verification. However, unreliable data from the primary checkpoint could be due to heterogeneity in terrain conditions; in this case, it is advisable to evaluate if checkpoint is a place adequately representative of the terrain conditions that predominate in the study region. In addition, remote sensing or the collaboration of two adjacent estimation regions can be recommended.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











