
Inferences of the Multicomponent Stress–Strength Reliability for Burr XII Distributions



1
Department of Mathematical Sciences, University of South Dakota, Vermillion, SD 57069, USA
2
Department of Statistics, Tamkang University, Tamsui District, New Taipei City 25137, Taiwan
3
School of Mathematics, Yunnan Normal University, Kunming 650500, China
4
Department of Mathematics, Universidad de Almería, 04120 Almería, Spain
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Mathematics 2022, 10(14), 2478; https://doi.org/10.3390/math10142478
Submission received: 20 June 2022
/
Revised: 13 July 2022
/
Accepted: 15 July 2022
/
Published: 16 July 2022
(This article belongs to the Special Issue Statistical Simulation and Computation II)
Abstract
:Multicomponent stress–strength reliability (MSR) is explored for the system with Burr XII distributed components under Type-II censoring. When the distributions of strength and stress variables have Burr XII distributions with common or unequal inner shape parameters, the existence and uniqueness of the maximum likelihood estimators are investigated and established. The associated approximate confidence intervals are obtained by using the asymptotic normal distribution theory along with the delta method and parametric bootstrap procedure, respectively. Moreover, alternative generalized pivotal quantities-based point and confidence interval estimators are developed. Additionally, a likelihood ratio test is presented to diagnose the equivalence of both inner shape parameters or not. Conclusively, Monte Carlo simulations and real data analysis are conducted for illustration.
1. Introduction
The stress–strength model, under which a system or unit survives if its strength is greater than the stress imposed, plays a considerable role in lifetime studies, engineering applications, supply and demand applications, and others. The associated stress–strength reliability (SSR), R, is defined to be , where X represents the strength of the system or unit and Y is the associated stress applied on it. Generally, the strength X is defined as the quality characteristics of the main subject and the stress is defined as the quality characteristics Y of the opposite subject in the model. To address the aforementioned stress–strength model, three examples are given for illustration. The first example is about mechanical engineering applications. The strength of the long horizontal part for a crane, denoted by X, is required to exceed the stress of loading weight of the lifting object for operation. We denote the stress of loading weight by Y. The SSR of can be an important measure for assessing the quality of crane. The second example is about civil engineering applications. The allowable bearing capacity of a suspension bridge is an important quality measure. The strength of a pairs of cables for the suspension bridge, denoted by X, should exceed the total amount of car weight passing through. We denote the stress of the total amount of car weight passing through by Y. In this application, a high SSR of is required for the design of the suspension bridge. The third example is about logistics applications. To maintain the quality of a logistics system, the supply capacity can be the strength, denoted by X, and the demand can be the stress, denoted by Y. A high SSR of indicates that the logistics system is reliable. Over the past few years, the stress–strength model has been extensively used in a variety of fields that include economics, hydrology, reliability engineering, seismology and survival analysis, and the inference of SSR had been discussed in numerous works; for example, by Eryilmaz [1], Kundu and Raqad [2], Krishnamoorthy and Lin [3], Mokhlis et al. [4], and Wang et al. [5]. Conventional studies for the SSR inference focus on the system of a sole main component, i.e., a unit. However, many practical systems, which include a series system, parallel system, or a combination of these two systems, are composed of multiple components to achieve their functions. Therefore, the SSR investigation has been extended to a multicomponent system. Generally, aforementioned multicomponent systems consist of k main components that have independent and identically distributed (i.i.d.) strengths subject to an opposite commonly distributed stress, and the system survives if at least main components simultaneously function. In the literature, this system is usually referred to as the s-out-of-k G system.
In reality, there are many examples of a multicomponent system. For a communication system with three transmitters, the average message load may be such that at least two transmitters must be operational at all times; otherwise, critical messages may be lost. Thus, the transmission subsystem functions can be a 2-out-of-3 G system. Another example in the aircraft industry is that the Airbus A-380 has four engines and the airplane can fly if and only if at least two of its four engines are functioning, and this case is referred to as a 2-out-of-4 G system.
Let denote the strength variables of k components in an s-out-of-k G system and follow a common cumulative distribution function (CDF), . Each component is subject to a stress, denoted by Y, which follows the CDF . Bhattacharyya and Johnson [6] provided the multicomponent stress–strength reliability (MSR), , as follows:
The s-out-of-k G system has attracted extensive attention and inference has been broadly investigated by numerous studies. These include multicomponent strength–stress models for Kumaraswamy distribution by Dey et al. [7], based on Chen distribution by Kayal [8], based on general class of inverse exponentiated distribution and proportional reversed hazard rate distribution by Kizilaslan [9,10], based on bivariate Kumaraswamy distribution by Kizilaslan and Nadar [11], based on Marshall-Olkin bivariate Weibull distribution by Nadar and Kizilaslan [12], based on Rayleigh stress–strength model by Rao [13], based on Burr XII distribution by Rao et al. [14], based on progressively Type-II censored samples from generalized Pareto distribution by Sauer et al. [15], and based on Rayleigh stress–strength model by Wang et al. [16].
The Burr XII distribution has gained much attention regarding the applications of modeling in reliability studies in recent decades. Let T be the Burr XII distributed random variable. Then, the CDF and probability density function (PDF) of T are respectively given as
where is the inner shape parameter and is the outer shape parameter. For easy reference, the Burr XII distribution with parameters and will be denoted by BurrXII, hereafter. The BurrXII was initially introduced by Burr [17]. Due to two shape parameters, the BurrXII is a very important and flexible probability model for any positive random variable. Tadikamalla [18] provided the link of BurrXII to some widely used lifetime distributions such as Weibull, chi-square, Rice, and extreme value models. Since then, many authors have investigated the inference methods with different applications of the Bur XII model. Kumar [19] studied the mathematical properties for the moment-generating function, conditional moments, mean residual time and mean past time, the mean deviation about mean and median, stochastic ordering, and SSR estimates for the Burr XII distribution. Lio and Tsai [20] investigated the SSR estimates using progressively first-failure-censored samples of strength and stress that are Burr XII distributed. Wingo [21,22] explored the existence and uniqueness of the maximum likelihood estimators of the Burr XII distribution parameters based on multiple censored datasets. An example of the failure times of a certain electronic component was used for illustration. Wu et al. [23] studied the failure-censored sampling plan for the Burr XII distribution and used the proposed sampling for quality control applications, and Zimmer et al. [24] used Burr XII distribution to characterize several real lifetime datasets for reliability analysis, including the breakdown of an insulting fluid between electrodes at a voltage of 34 kilovolts in minutes and the first-failure time of small electric carts.
In statistical inference, the sample size often has a strong impact on the validity of results. Because modern products always feature high reliability and a long life-cycle, complete failure times for all test units do not often obtain possibly in practice, except censored failure times. The goal of this investigation is to develop an alternative novelty inferential methodology for when strength and stress variables follow the Burr XII distributions under Type-II censoring on strength data. Three contributions of current work are addressed as follows: the MSR model has been formulated under a censored data scenario to save sample resource; the existence and uniqueness properties of the maximum likelihood estimators of the model parameters and the associated estimates for are established to guarantee the maximum likelihood estimation method under Type-II censoring; moreover, the proposed alternative novelty generalized estimates of the model parameters and the associated estimates of using pivotal quantities are shown uniquely existence under Type-II censoring and the simulation study shows the proposed generalized estimates of to be competitive with the maximum likelihood ones. To our best knowledge, the procedures developed in the current study have not appeared in the literature for the Burr XII distribution.
The rest of this paper is organized as follows. In Section 2, the Type-II censored strength and the associated stress samples for each s-out-of-k G system and the likelihood function based on n systems are briefly described. Section 3 presents maximum likelihood-based inferential approaches to estimate when the latent strength and stress variables follow Burr XII distributions. Theoretical results are provided to support the existence and uniqueness of estimators. Meanwhile, asymptotic confidence intervals (ACIs) are also developed based on delta method and bootstrap percentile procedure. Section 4 provides inferences based on pivotal quantities and numerous theoretical results to support the existence and uniqueness of estimators. To compare the equivalence of strength and stress Burr XII inner shape parameters, a likelihood ratio test is presented in Section 5. Simulation studies and a real data example are provided in Section 6 for illustration. Finally, some concluding remarks are addressed in Section 7.
2. The G System Model and Likelihood Function
Let ns-out-of-k G systems be put on a life-testing experiment, where each system contains k i.i.d. strength components subject to a commonly distributed stress. Under the failure mechanism of the system, the samples of strength and stress can be, respectively, presented as follows:
where are the first s strength samples with for under Type-II censoring and is the associated common stress variable for the ith system, . Let the lifetimes of the i.i.d. system components follow the CDF with the PDF and the associated stress variables follow the CDF with the PDF is . The joint likelihood function of samples described by (3) can be given as
The likelihood function of (4) is a general form. When , it presents the likelihood function for the conventional series system; although , it is the likelihood function for the parallel system.
3. The Maximum Likelihood Estimation of
In this section, estimation is developed for based on the maximum likelihood method when the strength and stress variables have Burr XII distributions with various parameter assumptions.
In general, let the observed strength sample, and associated stress sample, for of (3) be from BurrXII and BurrXII, respectively. Using Equations (2), the likelihood function (4) of based on samples of (3) can be represented as
and the log-likelihood function without constant term can be obtained by
3.1. Case 1: Common Inner Shape Parameter
Let . Equation (1) can be represented as follows:
and the likelihood function of (5) based on observed samples of (3) will be reduced to the following one for ,
and the associated log-likelihood function without constant term is given by
3.1.1. Point Estimator for
The partial derivatives of with respective to , and can be given as
The MLE of is the solution to the normal equation , where
is the gradient of with respect to . The MLEs can be established through Theorems 1 and 2. It is worth mentioning that no literature has provided the following theories, yet.
Theorem 1.
Given a positive value of and a positive value of , if and only if either one of strength or stress contains at least one observation different from unity then the MLE () of λ is uniquely defined as the solution to the following equation,
Proof.
See Appendix A. □
Theorem 2.
Let and . Suppose that at least two observations from the strength and stress are different. Then, the MLEs of , and λ are uniquely defined if and only if at least one observation from strength and stress less than 1.
Proof.
See Appendix B. □
Because the MLE does not have an analytic form in the nonlinear Equation (A4), it can be obtained using an iterative procedure such as the Newton–Raphson method with an initial guess can be a random generated value from uniform distribution over (0, 2) or uniroot function with an arbitrary interval and option extendInt = “yes” in R. In this work, uniroot function will be used. Then, the MLEs of and can be obtained from Equation (A3) and expressed by
and
respectively. Therefore, the MLE of can be obtained from (7) and expressed by
3.1.2. Asymptotic Confidence Interval for
Because it is difficult to derive the exact sampling distribution of , the exact confidence interval cannot be available. In this subsection, two ACIs of are constructed by using the asymptotic normal distribution along with the delta method and the bootstrap sampling technique, respectively.
The observed Fisher information matrix of is given by
where the second derivatives can be acquired directly. The detailed expressions of the second derivatives are omitted here for concision. An ACI can be obtained using delta method based on Theorems 3 and 4.
Theorem 3.
When , , where is the associated MLE of and ‘’ stands for ‘converges in law’.
Proof.
Using the asymptotic properties of MLEs and multivariate central limit theorem, the result can be proven. □
Based on Theorem 3, the following result is provided.
Theorem 4.
Proof.
See Appendix C. □
Substituting by its MLE, and given arbitrary , a ACI of can be formed by Theorem 4 as,
where and
The ACI obtained by the procedure mentioned above may have a negative lower bound. To remove this drawback, the logarithmic transformation and delta methods can be applied to develop the asymptotic normal distribution of as follows:
The ACI of can alternatively be derived as,
where by delta method via Taylor’s expansion.
For complementary and comparison purposes, a bootstrap confidence interval (BCI) for is further established using the parametric bootstrap procedure and the details are provided in Algorithm 1. For more detail information about the parametric bootstrap procedure, one may refer to Efron [25] and Hall [26].
| Algorithm 1: Parametric Bootstrap Percentile for the Case of |
|
3.2. Case 2: Unequal Inner Shape Parameters
Let the strength variable follow BurrXII and the associated stress variable follow BurrXII, where and . Under this condition, can be expressed by
It is worth mentioning that no existing study has published the MSR parameter based on Burr XII distributions under unequal parameters based on our best knowledge.
3.2.1. Point Estimator for
The partial derivatives of with respective to , , and can be given as
The MLE of is the solution to the normal equation , where
is the gradient of with respect to . The existence and uniqueness of MLE, , can be verified by Theorem 5 that can be proved following the similar proof procedures of Theorems 1 and 2, and the details are omitted for concision.
Theorem 5.
If and only if at least one of latent strength and stress are different from unity, then the MLEs of uniquely exist and are given by:
and
where and are solutions of the following equations:
Using the invariant property of maximum likelihood estimation, the MLE of under unequal parameters is given by
3.2.2. Asymptotic Confidence Interval for
The observed Fisher information matrix of is given by
where the second derivatives can be obtained directly, and the detailed expressions are omitted for concision.
Following a similar procedure to obtain Theorem 4 and substituting by , given an arbitrary , an ACI of can be developed as follows:
where
and
An alternative ACI of can be obtained by
where by delta method via Taylor’s expansion.
Similarly, the BCI of under unequal inner shape parameter case can be still obtained through a procedure such as Algorithm 1 and the details are omitted for concision.
4. Pivotal-Based Inference for
In this subsection, pivotal quantities will be derived by using the stress sample from BurrXII and strength sample from BurrXII, and then the pivotal quantities-based estimators for will be uniquely established through Theorems 6–8.
Theorem 6.
Let be the strength sample of (3) from BurrXII. Then
and
are statistically independent and follow the chi-square distributions with and degrees of freedom, respectively. Hence, and are pivotal quantities for and .
Proof.
See Appendix D. □
Theorem 7.
Let be the stress sample of (3) from BurrXII. Then
and
where is jth order statistic of Y, are statistically independent and have the chi-square distributions with and degrees of freedom, respectively. Hence, and are pivotal quantities for and ,
Proof.
See Appendix E. □
To develop estimators for model parameters and based on pivotal quantities, Lemma 1 is needed and provided below.
Lemma 1.
For arbitrary values of a and b with , the function increases in t.
Proof.
See Appendix F. □
Corollary 1.
Pivotal quantities and are increasing functions.
Proof.
See Appendix G. □
4.1. Case 1: Pivotal-Based Inference under Common Inner Shape Parameter
When both inner shape parameters , let , , and . Because and are independent, Theorems 6 and 7 imply the pivotal quantity,
has the chi-square distribution with degree of freedom. Moreover, from Corollary 1 that is an increasing function of .
For a given , the equation has an unique solution, labeled by that can be obtained using the bisection method or the R function ‘uniroot’. The solution is a generalized pivotal quantity to estimate . Meanwhile, from Theorem 6, and
Following the substitution method of Weerahandi [27], a generalized pivotal quantity, denoted by , to estimate can be uniquely obtained by substituting for in and the result can be represented as follows:
where is the observation of sample . It should be mentioned that the distribution of is free from any unknown parameters in its original expression and reduces to when . Therefore, is a generalized pivotal quantity for . Similarly, from Theorem 7, a generalized pivotal quantity for parameter can be derived as
A generalized pivotal quantity for can be developed as
The procedure shown in Algorithm 2 is given to obtain a generalized confidence interval (GCI) of via using the pivotal-based estimation method under the common inner shape parameter case.
| Algorithm 2: Pivotal-based estimation for with the common parameter. |
|
Remark 1.
Using pivotal quantity , for arbitrary , a GCI exact confidence interval for λ is given by
where denotes the right-tail γth quantile of the chi-square distribution with k degrees of freedom.
Meanwhile, the GCI exact confidence regions for and can be constructed from , and as follows:
and
Remark 2.
Consider the following null hypothesis and alternative hypothesis ,
For arbitrary , the decision rule to reject the null hypothesis in can be expressed by
respectively.
4.2. Case 2: Pivotal-Based Inference under Unequal Inner Shape Parameters
When both inner shape parameters , let , , and From Theorems 6 and 7, one can directly have
Theorem 8.
Let and be independent strength and stress variables of (3) from BurrXII and BurrXII, respectively. Denote pivotal quantities,
and
Then,
- are statistically independent;
- are statistically independent.
Similar to the process in Section 3, for given and , denote and as the solutions of equations and , respectively. Using the substitution method of Weerahandi [27], the generalized pivotal quantities for and can be constructed, respectively, by
with and
whereas,
Therefore, a generalized pivotal quantity for can be expressed as,
Meanwhile, the aforementioned generalized estimates of can be obtained via following the procedures of Algorithm 3.
| Algorithm 3: Pivotal-based estimation for when |
|
Similarly, some applications are also presented below.
Remark 3.
For arbitrary , the exact confidence intervals of and are given by:
respectively. Furthermore, exact confidence regions for and are constructed by
and
respectively.
Remark 4.
For , consider the following null hypothesis and alternative hypothesis ,
Therefore, under the significance level , the decision rule to reject the null hypothesis in for and can be expressed as
and
respectively.
Remark 5.
It is worth mentioning that the value of s from the s-out-of-k G system must be at least 2 for computational purposes; otherwise, the aforementioned pivotal quantities and cannot be constructed. In this case, the strength variables can be viewed as a random sample of size n from lifetime distribution with CDF . As an alternative approach, one can use the following pivotal quantities,
and
where if and otherwise. , are the order statistic of in ascending order, and and have the chi-square distributions with and degrees of freedom, respectively. Therefore, previous generalized point and confidence interval estimates could also be developed.
5. Testing Problem on Model Identification
The MSR parameter for a multicomponent system has been studied based on Burr XII distributions under both cases of common and unequal inner shape parameters. Practically, it may be important to test whether the inner shape parameters, and , from two Burr XII distributions are equal or not. Therefore, a likelihood ratio test along with hypothesis is presented as follows:
As , the likelihood ratio statistic has the following property:
where . Hence, the likelihood ratio test for vs. can be established by using the test statistic of and the reject region is given by
where satisfies size of the test.
6. Illustration via Numerical Studies
6.1. Simulation Studies
The goal of this subsection is to investigate the quality of the novelty generalized estimate of and compare the quality the novelty generalized estimate of with the typical MLE. In the simulation design, we will evaluate the performance of point estimation and interval estimation based on different estimation methods. Then, we suggest a most competitive estimation method for evaluating the target parameter of . All findings in the simulation study will be summarized in the Discussion Subsection. Let present any aforementioned estimate for . The performance evaluation will be investigated by the following criteria quantities:
- for point estimator
- –
- mean square error (MSE), which will be computed by ;
- –
- average absolute bias (AB), which will be calculated by ;
- for confidence interval estimator
- –
- coverage probability (CP) of a confidence interval estimator for , which is defined as the relative frequency of the estimated confidence intervals containing the true value of the parameter;
- –
- average width (AW) of a confidence interval estimator for , which is defined as the average length of the estimated confidence intervals.
Simulation parameter inputs include for both Burr XII distributions, s and k for the multicomponent G system and sample size n. Some different values of , s and k that are closed to the multicomponent G system based on Burr XII model fitting parameters to the real dataset presented in the next section will be used for the current simulation study. The sample sizes n considered are from small, medium and large. For each combination of simulation input parameters, the simulation was conducted for 10,000 runs. All aforementioned different estimates for were calculated, and the associated criteria quantities were obtained based on 10,000 simulation runs. The results are reported in Table 1, Table 2, Table 3, Table 4 and Table 5, where is MLE, is a natural generalized estimator and is a Fisher Z transformation-based estimator, ACI is based on maximum likelihood estimation method, GCI is based on generalized pivotal quantity, and the confidence level for interval estimators is given as .
Table 1 and Table 3 show that ABs and MSEs of point estimators for decrease as sample sizes n increase for a given and a set of model parameters, as changes from (3,7) to (5,10) for a given sample size n and a set of model parameters, or as the combination of sample sizes n increases and the changes of from (3,7) to (5,19) for a given set of model parameters, regardless of common or unequal inner shape parameters. These observations can serve as the numerical verification of consistency properties of the estimators considered. It was noted that both the likelihood and pivotal estimates have a satisfactory performance in terms of the AB and MSE. For a given effective sample size combining n and and a set of model parameters, MLE has smaller AB and MSE than the pivotal quantities-based generalized point estimators, and , regardless of equal or unequal inner shape parameters. Table 2 and Table 4 show that the AWs of ACIs and GCIs are becoming smaller and the associated CPs are increasing as sample sizes increase for a given set of model parameters and regardless of equal or unequal inner shape parameter case. In general, CPs for GCIs are closer to the nominal level than those of the ACIs via the delta method. When , CPs of ACIs via the delta method seriously underestimate the nominal level.
The simulated AWs and CPs for the ACIs based on parametric bootstrap percentile are placed in Table 5, which shows AWs are decreasing and CPs are increasing when the effective sample sizes increase for given a set of model parameters. From Table 2, Table 4 and Table 5, it can be noted that the ACIs from parametric bootstrap percentile method have CPs much closer to the nominal level than ACIs based on the delta method and generalized pivotal quantity. Therefore, one can draw conclusions from the simulation results that the MLE point estimate along with ACI based on parametric bootstrap percentile would be suggested. Meanwhile, the generalized pivotal quantity method could be used to provide good ACI instead of using the parametric bootstrap percentile to save computational time.
6.2. Discussion
In summary, we have the following findings from the simulation study:
- 1.
- 2.
- The AWs of ACIs and GCIs in Table 2 and Table 4 are decreased and the associated CPs are increasing as the sample size increases. The delta method is conservative due to the property of normality approximation. We note that the CP underestimates the nominal confidence level in Table 2 and Table 4. In particular, the nominal confidence level is seriously underestimated for the case of .
- 3.
- To improve the drawback of underestimating the nominal confidence level, the parametric bootstrap method is suggested to obtain an ACI of for the maximum likelihood estimation. Additionally, the generalized pivotal quantity method is suggested to improve the performance of interval inference. Table 5 shows that the CP based on the parameter bootstrap method is closer to the nominal confidence level. The generalized pivotal quantity method can provide a good ACI for estimating with a satisfactory CP, too.
The parametric bootstrap method can provide a good ACI for instead of using the delta method. However, the parametric bootstrap method is time-consuming to implement. The generalized pivotal quantity method can be an alternative to the parametric bootstrap percentile to save computational time. In practice, practitioners could not have enough to determine the conditions of or before using the proposed estimation methods. When practitioners lack the knowledge to determine the conditions of or , using the maximum likelihood estimation method with the generalized pivotal quantity method to obtain the point and interval estimates for under the condition of is suggested.
6.3. Real Data Illustration
As the largest synthetic lake in California, Shasta Reservoir is located on the upper Sacramento River in northern California. The monthly water capacity of the Shasta reservoir over the months of August, September, and December from 1980 to 2015, which was accessed on September 19, 2021, is used in this section for the illustration of the processes considered. The dataset was also considered by Wang et al. [16] for the Rayleigh stress–strength model.
It is assumed that the water level would not lead to excessive drought if the water capacity of reservoir in December is less than the water capacity for at least two Augusts within the next five years. Specifically, we want to infer the reliability that at least three years within next five years the water capacity in August is not less than the water capacity in the previous December. In this study, , , . Hence, is the capacity of December 1980, and are the capacities of August from 1981 to 1985; is the capacity of December 1986, are the capacities of August from 1987 to 1991, and so on. For the easy fitting of water capacities with BurrXII, all the water capacities are divided by 3,014,878 (the maximum of water capacity) and the transformed data are obtained as follows:
For the above-transformed data, one can refer to Kizilaslan and Nadar [11] for more details, and the complete monthly water capacity of the Shasta reservoir in California, USA between 1981 to 1985 is provided in Appendix H.
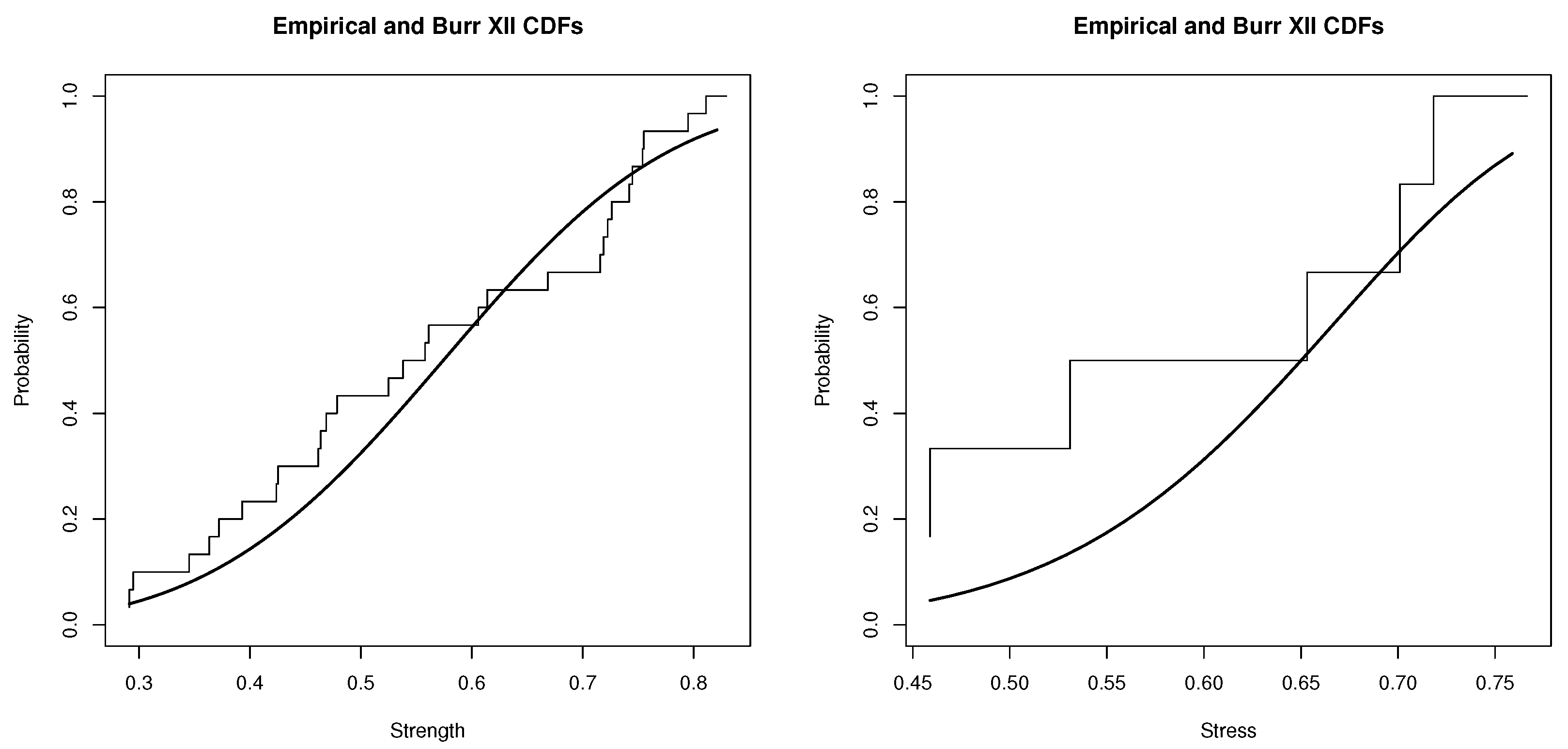
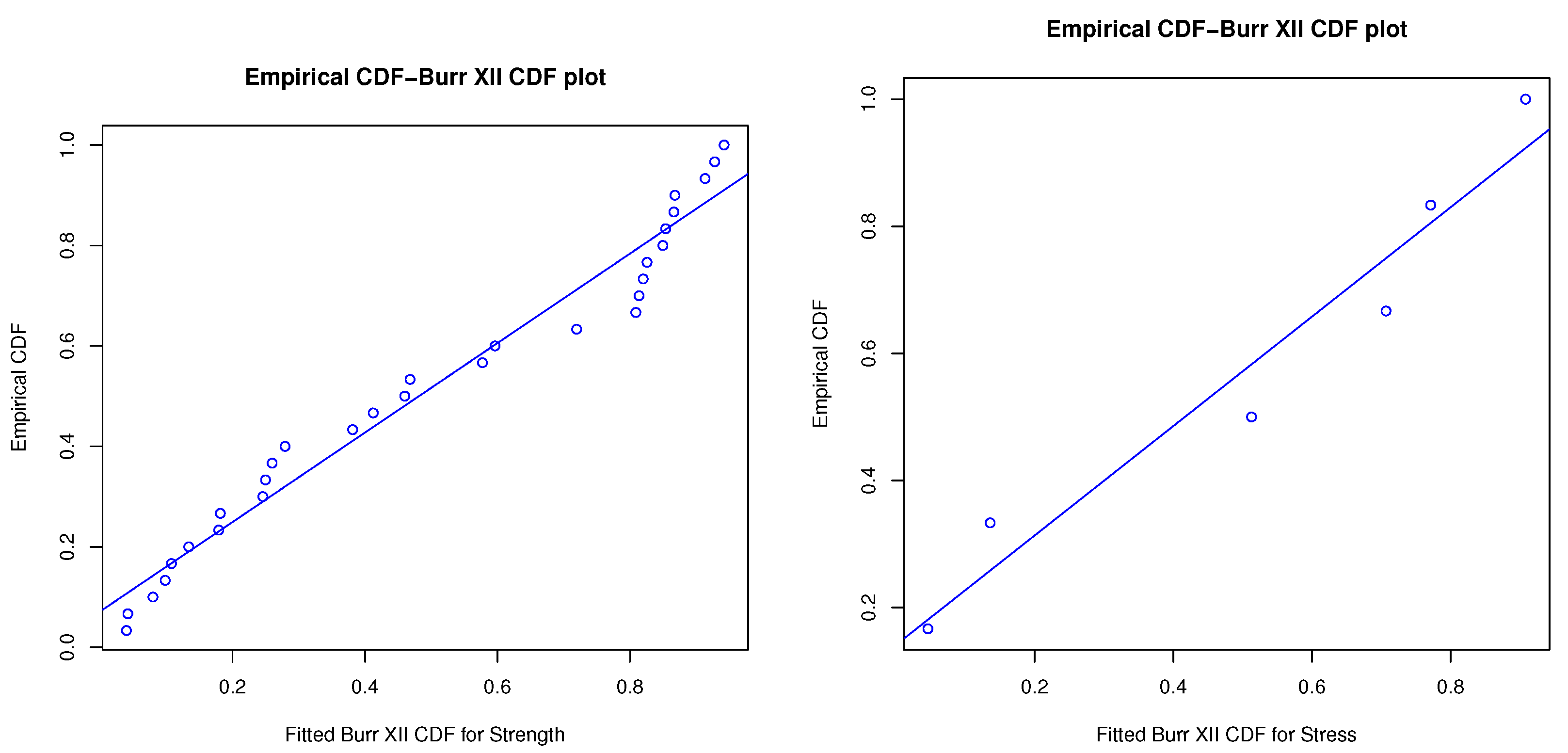
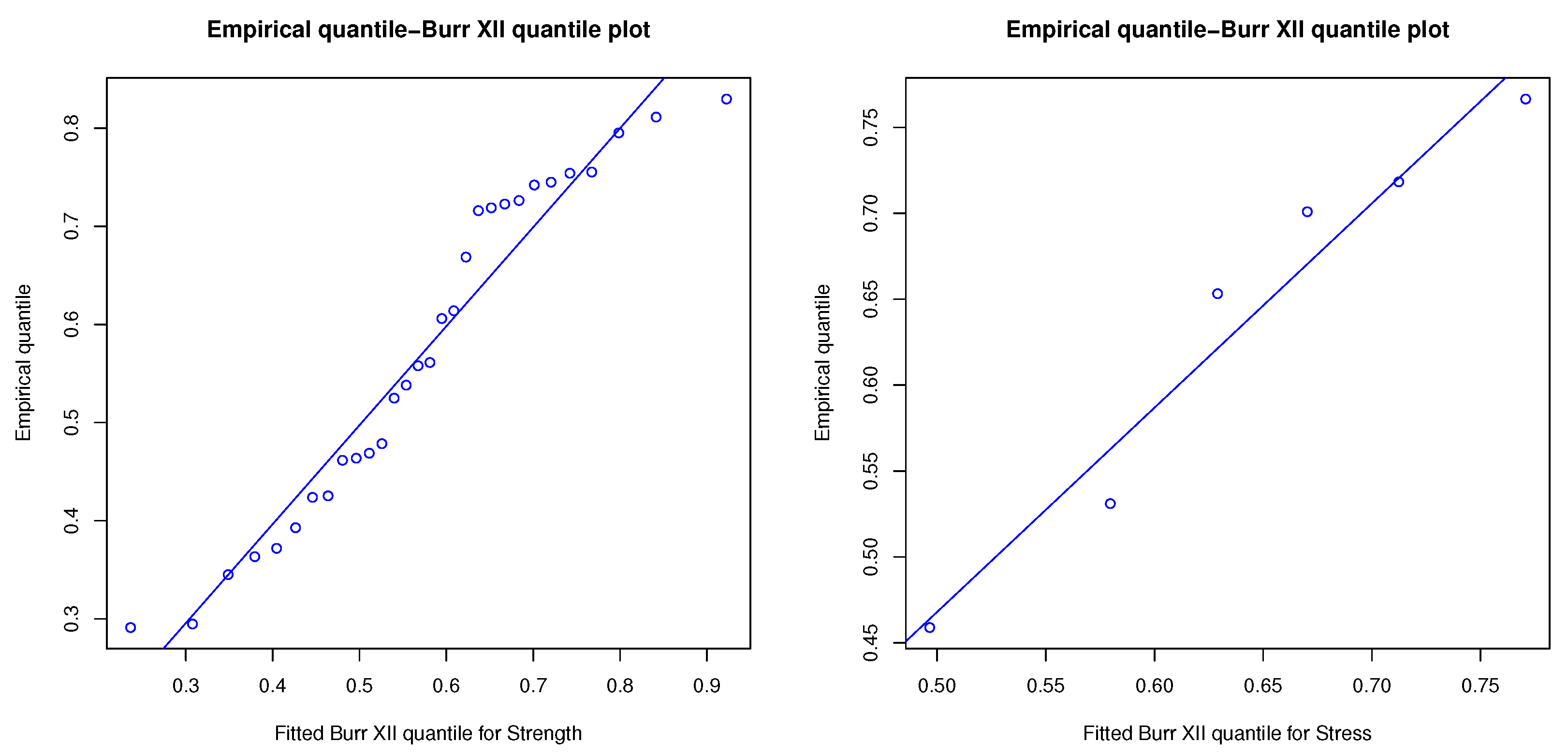
The Burr XII distribution is applied to fit these real-life data via using the Kolmogorov–Smirnov (K–S) test with two-sided reject region. The results for strength and stress data have distances and the corresponding p-values (within brackets), and , respectively. Additionally, the plots of empirical cumulative and Burr XII distributions overlay. Probability–probability (P–P) and Quantile–Quantile (Q–Q) plots are shown in Figure 1, Figure 2 and Figure 3. P–P plot is a probability plot for evaluating how closely of a dataset fitting a specified model or how closely two datasets agree. Q-Q plot is a graphic method for evaluating if two datasets come from populations with a common distribution. Figure 2 shows two P-P plots to present the empirical CDFs of the strength (left side) and the stress (right side) versus the theoretical CDF of Burr XII. The imposed linear regressions over P-P plots in Figure 2 are significant with R-squared, 0.9664 and 0.9459, for the complete strength and stress samples, respectively and the imposed linear regressions over Q-Q plots in Figure 3 are also significant with R-squared, 0.9461 and 0.9502, for the complete strength and stress samples, respectively. Therefore, the Burr XII distribution can be used as a proper probability model to address the transformed datasets well.
Based on previous complete strength and stress data, a MSR censored observation of the 3-out-of-5 G system can be constructed as
The associated point and interval estimates for the MSR parameter are presented in Table 6, where the significance level of is taken to be . The interval lengths are obtained as 0.4077, 0.4949 and 0.6077 for the ACI, GCI and BCI, respectively, under and as 0.3678, 0.5189 and 0.5791 for ACI, GCI and BCI, respectively, under . It is observed that the point estimates are close to each other and the ACI of performs better than the others in terms of interval length.
Furthermore, for comparison of the equivalence between strength and stress inner shape parameters, and , the likelihood ratio statistic and p-value are calculated as and , respectively. The results show that there is no significant statistical evidence to reject the null hypothesis, at 0.05 significance level. Hence, the strength and stress are suggested to have Burr XII distributions with equal inner shape parameter and for this current monthly capacity data application.
7. Concluding Remarks
The reliability inference for a multicomponent stress–strength model has been studied based on the Burr XII distributions. The existence and uniqueness of maximum likelihood estimators of the strength and stress parameters are established and the generalized pivotal quantity-based estimators have been constructed under common and unequal inner shape parameter situations. Meanwhile, confidence intervals have also been provided using asymptotic normal distribution along with delta technique, bootstrap percentile and generalized pivotal sampling, respectively. Generally, simulation results show that bootstrap percentile procedure produces better ACI than the other two in terms of coverage probability for all cases. When two inner shape parameters are equal, asymptotic normal distribution along with delta method and generalized pivotal sampling are very competitive with each other in terms of coverage probability. However, the maximum likelihood method provides better point estimators than the generalized pivotal sampling method in terms of MSE and AB. Overall, the proposed procedures work quite well under the given sampling scheme, except for the ACI based on delta method for the case of unequal inner shape parameters.
Although the current work is developed using a Type-II censoring scheme, it can be extended to other censoring schemes such as the progressively Type-II censoring scheme or progressively first-failure Type-II censoring scheme with proper modification of pivotal quantities for the progressively Type-II or progressively first-failure Type-II censored samples. For further study, the moment estimation and the maximum product of spacing estimation seem also interesting to pursue new inferential results and will be discussed in future. The authors are currently working on these possible projects.
Author Contributions
Y.L., T.-R.T., L.W., I.P.C.T. equally contributed in writing this manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
The study is supported by the grant projects of Ministry of Science and Technology, Taiwan MOST 110-2221-E-032-034-MY2. The work of Liang Wang is supported by the National Natural Science Foundation of China (No. 12061091) and the Yunnan Fundamental Research Projects (No. 202101AT070103).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Complete monthly water capacity data of the Shasta Reservoir from 1981 to 1985 is given in Appendix G. The observed complete strength data and observed complete stress data were given in the first paragraph in Section 6.2.
Acknowledgments
The authors would like to thank the editor and reviewers for their helpful comments and suggestions, which improved this paper significantly.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 1
Let and be known and . It is trivial that as . Let , , and . It can be shown that
We can obtain that
Since at least one of , , and is not empty, it can be shown that . Therefore, at least one positive real solution to . Meanwhile, it can be shown that . Therefore, has uniquely solution.
Appendix B. Proof of Theorem 2
Let , and . Given a positive value of , the MLEs, and , for and can be obtained through the following,
Replacing and in , by and , respectively, the MLE, of can be derived via the solution to
Let
Using same arguments as that proposed by Lio and Tsai [20] and Wingo [22], it can be shown that for and
The MLEs of , and are uniquely defined.
Appendix C. Proof of Theorem 4
Using the Taylor series expansion and the Mean Value Theorem for derivative, can be written as,
where and denotes the matrices of the first and second derivatives for with respect to , and is some proper value between and . Then, expression (A6) could be rewritten as
which implies that when using from Theorem 3. Moreover, from (A6), since the variance of can be written as
Using Theorem 3 and delta method [28],
and Theory 4 is proved.
Appendix D. Proof of Theorem 6
For given positive integer , are the first s order statistics of size k from BurrXII(). Hence, can be viewed as the Type-II censored data from standard exponential distribution with mean one. Due to the memoryless property of the standard exponential distribution, the quantities are random sample from the standard exponential distribution with mean one. Lawless [29] provided more information regarding the memoryless property and exponential distribution.
For , let , one could conduct from Stephens [30] and Viveros and Balakrishnan [31] that are order statistics from the uniform distribution between 0 to 1 with sample size . Moreover, are also independent with .
Using theory of sampling distribution, it is observed directly that quantity follows a chi-square distribution with degrees of freedom, which is independent with being chi-square distributed with degrees of freedom. Therefore, using the independent property of , it can be shown that
comes from a chi-square distribution with degrees of freedom, and:
follows chi-square distribution with degrees of freedom. and are statistically independent. Therefore, the assertion is completed.
Appendix E. Proof of Theorem 7
Let be the order statistic of . Then are order statistics from standard exponential distribution with mean one. Following the same proof procedure of Theorem 6, Theorem 7 can be derived.
Appendix F. Proof of Lemma 1
Taking derivative of with respect to , one directly has
Showing is increasing function of with is equivalent to proving the following inequality
Let for . Since
one directly has that function when . However, for , since and , it is noted that
increases in t and the assertion is completed.
Appendix G. Proof of Corollary 1
Using the definitions of notations and , It can be shown that
and
From Lemma 1, it is seen that the numerator of (A7) increase in and the associated denominator of (A8) decrease in . Therefore, pivotal quantity is increasing function. Similarly, Lemma 1 implies that is increasing functions.
Appendix H. Complete Monthly Water Capacity Data of the Shasta Reservoir

{kind=link}
{kind=link}
{kind=link}
Table A1.
Capacity data of Shasta reservoir from the years 1981 to 1985.
| Date | Storage AF | Date | Storage AF | Date | Storage AF |
|---|---|---|---|---|---|
| January 1981 | 3,453,500 | September 1982 | 3,486,400 | May 1984 | 4,294,400 |
| February 1981 | 3,865,200 | October 1982 | 3,433,400 | June 1984 | 4,070,000 |
| March 1981 | 4,320,700 | November 1982 | 3,297,100 | July 1984 | 3,587,400 |
| April 1981 | 4,295,900 | December 1982 | 3,255,000 | August 1984 | 3,305,500 |
| May 1981 | 3,994,300 | January 1983 | 3,740,300 | September 1984 | 3,240,100 |
| June 1981 | 3,608,600 | February 1983 | 3,579,400 | October 1984 | 3,155,400 |
| July 1981 | 3,033,000 | March 1983 | 3,725,100 | November 1984 | 3,252,300 |
| August 1981 | 2,547,600 | April 1983 | 4,286,100 | December 1984 | 3,105,500 |
| September 1981 | 2,480,200 | May 1983 | 4,526,800 | January 1985 | 3,118,200 |
| October 1981 | 2,560,200 | June 1983 | 4,471,200 | February 1985 | 3,240,400 |
| November 1981 | 3,336,700 | July 1983 | 4,169,900 | March 1985 | 3,445,500 |
| December 1981 | 3,492,000 | August 1983 | 3,776,200 | April 1985 | 3,546,900 |
| January 1982 | 3,556,300 | September 1983 | 3,616,800 | May 1985 | 3,225,400 |
| February 1982 | 3,633,500 | October 1983 | 3,458,000 | June 1985 | 2,856,300 |
| March 1982 | 4,062,000 | November 1983 | 3,395,400 | July 1985 | 2,292,100 |
| April 1982 | 4,472,700 | December 1983 | 3,457,500 | August 1985 | 1,929,200 |
| May 1982 | 4,507,500 | January 1984 | 3,405,200 | September 1985 | 1,977,800 |
| June 1982 | 4,375,400 | February 1984 | 3,789,900 | October 1985 | 2,083,100 |
| July 1982 | 4,071,200 | March 1984 | 4,133,600 | November 1985 | 2,173,900 |
| August 1982 | 3,692,400 | April 1984 | 4,342,700 | December 1985 | 2,422,100 |
The website:https://cdec.water.ca.gov/dynamicapp/QueryMonthly?s=SHA, which was accessed on 19 September 2021.
References
- Eryilmaz, S. Phase type stress-strength models with reliability applications. Commun.-Stat.-Simul. Comput. 2018, 47, 954–963. [Google Scholar] [CrossRef]
- Kundu, D.; Kundu, D. Estimation of R = P(Y < X) for three-parameter Weibull distribution. Stat. Prob. Lett. 2009, 79, 1839–1846. [Google Scholar]
- Krishnamoorthy, K.; Lin, Y. Confdence limits for stress-strength reliability involving Weibull models. J. Stat. Plan. Inference 2010, 140, 1754–1764. [Google Scholar] [CrossRef]
- Mokhlis, N.A.; Ibrahim, E.J.; Ibrahim, E.J. Stress-strength reliability with general form distributions. Commun.-Stat.-Theory Methods 2017, 46, 1230–1246. [Google Scholar] [CrossRef]
- Wang, B.; Geng, Y.; Zhou, J. Inference for the generalized exponential stress-strength model. Appl. Math. Model. 2018, 53, 267–275. [Google Scholar] [CrossRef]
- Bhattacharyya, G.K.; Johnson, R.A. Estimation of reliability in multicomponent stresss-trength model. J. Am. Stat. Assoc. 1974, 69, 966–970. [Google Scholar] [CrossRef]
- Dey, S.; Mazucheli, J.; Anis, M.Z. Estimation of reliability of multicomponent stress-strength for a Kumaraswamy distribution. Commun.-Stat.-Theory Methods 2017, 46, 1560–1572. [Google Scholar] [CrossRef]
- Kayal, T.; Tripathi, Y.M.; Dey, S.; Wu, S.J. On estimating the reliability in a multicomponent stress-strength model based on Chen distribution. Commun.-Stat.-Theory Methods 2020, 49, 2429–2447. [Google Scholar] [CrossRef]
- Kizilaslan, F. Classical and Bayesian estimation of reliability in a multicomponent stress-strength model based on a general class of inverse exponentiated distributions. Stat. Pap. 2018, 59, 1161–1192. [Google Scholar] [CrossRef]
- Kizilaslan, F. Classical and Bayesian estimation of reliability in a multicomponent stress-strength model based on the proportional reversed hazard rate model. Math. Comput. Sim. 2017, 136, 36–62. [Google Scholar] [CrossRef]
- Kizilaslan, F.; Nadar, M. Estimation of reliability in a multicomponent stress-strength model based on a bivariate Kumaraswamy distribution. Stat. Pap. 2018, 59, 307–340. [Google Scholar] [CrossRef]
- Nadar, M.; Kizilaslan, F. Estimation of reliability in a multicomponent stress-strength model based on a Marshall-Olkin bivariate Weibull distribution. IEEE Trans. Reliab. 2016, 65, 370–380. [Google Scholar] [CrossRef]
- Rao, G.S. Estimation of reliability in multicomponent stress-strength model based on Rayleigh distribution. ProbStat. Forum. 2012, 5, 150–161. [Google Scholar]
- Rao, G.S.; Aslam, M.; Kundu, D. Burr type XII distribution parametric estimation and estimation of reliability of multicomponent stress-strength. Commun.-Stat.-Theory Methods 2015, 44, 4953–4961. [Google Scholar] [CrossRef]
- Sauer, L.; Lio, Y.; Tsai, T.-R. Reliability inference for the multicomponent system based on progressively type II censoring samples from generalized Pareto distributions. J. Math. 2020, 8, 8071176. [Google Scholar]
- Wang, L.; Lin, H.; Ahmadi, K.; Lio, Y. Estimation of stress-strength reliability for multicomponent system with Rayleigh data. J. Energies 2021, 14, 7917. [Google Scholar] [CrossRef]
- Burr, I.W. Cumulative frequency functions. Ann. Math. Stat. 1946, 13, 215–232. [Google Scholar] [CrossRef]
- Tadikamalla, P.R. A look at the Burr and related distributions. Int. Stat. Rev. 1980, 48, 337–344. [Google Scholar] [CrossRef]
- Kumar, D. The Burr type XII distribution with some statistical properties. J. Data Sci. 2017, 16, 509–534. [Google Scholar] [CrossRef]
- Lio, Y.L.; Tsai, T.-R. Estimation of δ = P(X < Y) for Burr XII distribution based on the progressively first failure-censored samples. J. Appl. Stat. 2012, 39, 309–322. [Google Scholar]
- Wingo, D.R. Maximum likelihood methods for fitting the Burr type XII distribution to life test data. Biom. J. 1983, 25, 77–84. [Google Scholar] [CrossRef]
- Wingo, D.R. Maximum likelihood methods for fitting the Burr type XII distribution to multiply (progressively) censored life test data. Metrika 1993, 40, 203–210. [Google Scholar] [CrossRef]
- Wu, J.W.; Yu, H.Y. Statistical inference about the shape parameter of the Burr type XII distribution under the failure-censored sampling plan. Appl. Math. Comput. 2005, 163, 443–482. [Google Scholar] [CrossRef]
- Zimmer, W.J.; Keats, J.B.; Wang, F.K. The Burr XII distribution in reliability analysis. J. Qual. Technol. 1998, 30, 386–394. [Google Scholar] [CrossRef]
- Efron, B. The Jackknife, the Bootstrap, and Other Resampling Plans, CBMSNSF Regional Conference Series in Applied Mathematics; SIAM: Philadelphia, PA, USA, 1982; Volume 38. [Google Scholar]
- Hall, P. Theoretical comparison of bootstrap confidence intervals. Ann. Stat. 1988, 16, 927–953. [Google Scholar] [CrossRef]
- Weerahandi, S. Generalized Inference in Repeated Measures: Exact Methods in MANOVA and Mixed Models; Wiley: New York, NY, USA, 2004. [Google Scholar]
- Xu, J.; Long, J.S. Using the Delta Method to Construct Confidence Intervals for Predicted Probabilities, Rates, and Discrete Changes; Lecture Notes; Indiana University: Bloomington, IN, USA, 2005. [Google Scholar]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data, 2nd ed.; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Stephens, M.A. Tests for the exponential distribution. In Goodness-of-Fit Techniques; D’Agostino, R.B., Stephens, M.A., Eds.; Marcel Dekker: New York, NY, USA, 1986; pp. 421–459. [Google Scholar]
- Viveros, R.; Balakrishnan, N. Interval estimation of parameters of life from progressively censored data. Technometrics 1994, 36, 84–91. [Google Scholar] [CrossRef]
Figure 1.
Empirical and fitted Burr XII distributions based on real data.

Figure 2.
Probability to probability plot based on real data.

Figure 3.
Quantity to quantity plots based on real data.

Table 1.
The AB and MSE of for S1: and S2: .
| n | ||||||||
|---|---|---|---|---|---|---|---|---|
| AB | MSE | AB | MSE | AB | MSE | |||
| S1 | (3,7) | 5 | 0.0198 | 0.0131 | 0.0835 | 0.0253 | 0.0805 | 0.0274 |
| 10 | 0.0107 | 0.0057 | 0.0816 | 0.0131 | 0.0773 | 0.0115 | ||
| 30 | 0.0030 | 0.0017 | 0.0486 | 0.0042 | 0.0470 | 0.0038 | ||
| 50 | 0.0021 | 0.0010 | 0.0377 | 0.0024 | 0.0367 | 0.0023 | ||
| 100 | 0.0009 | 0.0005 | 0.0274 | 0.0012 | 0.0268 | 0.0012 | ||
| (5,10) | 5 | 0.0066 | 0.0139 | 0.0858 | 0.0118 | 0.0816 | 0.0101 | |
| 10 | 0.0023 | 0.0071 | 0.0614 | 0.0059 | 0.0594 | 0.0054 | ||
| 30 | 0.0006 | 0.0024 | 0.0362 | 0.0021 | 0.0357 | 0.0020 | ||
| 50 | 0.0001 | 0.0014 | 0.0105 | 0.0019 | 0.0213 | 0.0015 | ||
| 100 | 0.0005 | 0.0007 | 0.0086 | 0.0015 | 0.0096 | 0.0014 | ||
| S2 | (3,7) | 5 | 0.0217 | 0.0204 | 0.1377 | 0.0353 | 0.1325 | 0.0318 |
| 10 | 0.0120 | 0.0094 | 0.1114 | 0.0225 | 0.1069 | 0.0206 | ||
| 30 | 0.0032 | 0.0029 | 0.0726 | 0.0092 | 0.0699 | 0.0085 | ||
| 50 | 0.0024 | 0.0017 | 0.0611 | 0.0062 | 0.0591 | 0.0058 | ||
| 100 | 0.0010 | 0.0009 | 0.0506 | 0.0040 | 0.0492 | 0.0038 | ||
| (5,10) | 5 | 0.0025 | 0.0203 | 0.1215 | 0.0237 | 0.1239 | 0.0235 | |
| 10 | 0.0002 | 0.0104 | 0.0944 | 0.0142 | 0.0948 | 0.0140 | ||
| 30 | 0.0003 | 0.0035 | 0.0592 | 0.0056 | 0.0587 | 0.0054 | ||
| 50 | 0.0005 | 0.0021 | 0.0469 | 0.0035 | 0.0464 | 0.0034 | ||
| 100 | 0.0004 | 0.0011 | 0.0344 | 0.0019 | 0.0339 | 0.0019 | ||
Table 2.
The AW and CP of for S1: and S2: .
| n | (3,7) | (5,10) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ACI | GCI | ACI | GCI | ||||||
| AW | CP | AW | CP | AW | CP | AW | CP | ||
| S1 | 5 | 0.3238 | 0.7645 | 0.3345 | 0.8258 | 0.3706 | 0.7791 | 0.4171 | 0.9531 |
| 10 | 0.2439 | 0.8455 | 0.2684 | 0.8302 | 0.2805 | 0.8445 | 0.3079 | 0.9507 | |
| 30 | 0.1458 | 0.8997 | 0.1593 | 0.9012 | 0.1717 | 0.8988 | 0.1852 | 0.9560 | |
| 50 | 0.1143 | 0.9141 | 0.1237 | 0.9133 | 0.1346 | 0.9088 | 0.1532 | 0.9532 | |
| 100 | 0.0812 | 0.9235 | 0.0881 | 0.9230 | 0.0963 | 0.9214 | 0.1308 | 0.9505 | |
| S2 | 5 | 0.4233 | 0.7470 | 0.4468 | 0.8317 | 0.4964 | 0.7692 | 0.4666 | 0.8711 |
| 10 | 0.2986 | 0.8215 | 0.3495 | 0.8431 | 0.3285 | 0.8269 | 0.3599 | 0.8721 | |
| 30 | 0.1787 | 0.8653 | 0.2188 | 0.8521 | 0.1988 | 0.8671 | 0.2224 | 0.8843 | |
| 50 | 0.1394 | 0.8782 | 0.1728 | 0.8851 | 0.1586 | 0.8710 | 0.1751 | 0.8978 | |
| 100 | 0.0979 | 0.8955 | 0.1244 | 0.8965 | 0.1108 | 0.8766 | 0.1254 | 0.9235 | |
Table 3.
The AB and MSE of for S3: and S4: .
| n | ||||||||
|---|---|---|---|---|---|---|---|---|
| AB | MSE | AB | MSE | AB | MSE | |||
| S3 | (3,7) | 5 | 0.0257 | 0.0369 | 0.1474 | 0.0320 | 0.1620 | 0.0381 |
| 10 | 0.0154 | 0.0202 | 0.1148 | 0.0199 | 0.1209 | 0.0219 | ||
| 30 | 0.0081 | 0.0072 | 0.0715 | 0.0078 | 0.0729 | 0.0082 | ||
| 50 | 0.0049 | 0.0045 | 0.0560 | 0.0048 | 0.0567 | 0.0049 | ||
| 100 | 0.0020 | 0.0022 | 0.0400 | 0.0025 | 0.0403 | 0.0025 | ||
| (5,10) | 5 | 0.0011 | 0.0250 | 0.1276 | 0.0249 | 0.1365 | 0.0286 | |
| 10 | 0.0010 | 0.0137 | 0.0956 | 0.0141 | 0.0990 | 0.0151 | ||
| 30 | 0.0009 | 0.0048 | 0.0562 | 0.0050 | 0.0569 | 0.0051 | ||
| 50 | 0.0010 | 0.0030 | 0.0446 | 0.0031 | 0.0449 | 0.0032 | ||
| 100 | 0.0015 | 0.0015 | 0.0450 | 0.0016 | 0.0451 | 0.0016 | ||
| S4 | (3,7) | 5 | 0.0004 | 0.0102 | 0.1126 | 0.0230 | 0.1189 | 0.0261 |
| 10 | 0.0002 | 0.0056 | 0.0751 | 0.0101 | 0.0767 | 0.0106 | ||
| 30 | 0.0019 | 0.0020 | 0.0407 | 0.0028 | 0.0409 | 0.0028 | ||
| 50 | 0.0010 | 0.0012 | 0.0312 | 0.0016 | 0.0313 | 0.0016 | ||
| 100 | 0.0003 | 0.0006 | 0.0216 | 0.0008 | 0.0216 | 0.0008 | ||
| (5,10) | 5 | 0.0005 | 0.0052 | 0.0737 | 0.0106 | 0.0756 | 0.0112 | |
| 10 | 0.0009 | 0.0027 | 0.0495 | 0.0044 | 0.0499 | 0.0045 | ||
| 30 | 0.0003 | 0.0009 | 0.0261 | 0.0012 | 0.0262 | 0.0012 | ||
| 50 | 0.0001 | 0.0005 | 0.0197 | 0.0007 | 0.0198 | 0.0007 | ||
| 100 | 0.0002 | 0.0003 | 0.0196 | 0.0004 | 0.0199 | 0.0004 | ||
Table 4.
The AW and CP of for S3: and S4: .
| n | (3,7) | (5,10) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ACI | GCI | ACI | GCI | ||||||
| AW | CP | AW | CP | AW | CP | AW | CP | ||
| S3 | 5 | 0.4951 | 0.7405 | 0.5819 | 0.8754 | 0.8442 | 0.6828 | 0.5075 | 0.8856 |
| 10 | 0.3685 | 0.7709 | 0.4572 | 0.8797 | 0.2587 | 0.6993 | 0.3845 | 0.8892 | |
| 30 | 0.2218 | 0.7926 | 0.2877 | 0.8820 | 0.1526 | 0.7170 | 0.2326 | 0.8925 | |
| 50 | 0.1735 | 0.8008 | 0.2272 | 0.8836 | 0.1187 | 0.7131 | 0.1810 | 0.8964 | |
| 100 | 0.1237 | 0.8030 | 0.1630 | 0.8854 | 0.0841 | 0.7180 | 0.0965 | 0.9015 | |
| S4 | 5 | 0.1570 | 0.4553 | 0.3910 | 0.8427 | 0.0819 | 0.3017 | 0.2574 | 0.8465 |
| 10 | 0.1047 | 0.4597 | 0.2651 | 0.8439 | 0.0552 | 0.3613 | 0.1693 | 0.8476 | |
| 30 | 0.0586 | 0.4705 | 0.1437 | 0.8439 | 0.0311 | 0.3813 | 0.0898 | 0.8462 | |
| 50 | 0.0455 | 0.4746 | 0.1091 | 0.8456 | 0.0239 | 0.3789 | 0.0667 | 0.8481 | |
| 100 | 0.0322 | 0.4769 | 0.0751 | 0.8463 | 0.0168 | 0.3834 | 0.0354 | 0.8495 | |
Table 5.
The AW and CP of the BCI of .
| n | (3,7) | (5,10) | |||
|---|---|---|---|---|---|
| AW | CP | AW | CP | ||
| (5.15, 7.76, 10.25, 7.76) | 5 | 0.4880 | 0.9049 | 0.4782 | 0.9031 |
| 10 | 0.3521 | 0.9297 | 0.3687 | 0.9218 | |
| 30 | 0.2062 | 0.9421 | 0.2267 | 0.9400 | |
| 50 | 0.1606 | 0.9446 | 0.1779 | 0.9410 | |
| 100 | 0.1135 | 0.9464 | 0.1543 | 0.9453 | |
| (7.63, 4.24, 19.97, 4.24) | 5 | 0.3939 | 0.8991 | 0.3946 | 0.8954 |
| 10 | 0.2739 | 0.9262 | 0.3021 | 0.9186 | |
| 30 | 0.1585 | 0.9440 | 0.1861 | 0.9396 | |
| 50 | 0.1231 | 0.9484 | 0.1458 | 0.9420 | |
| 100 | 0.0870 | 0.9486 | 0.1047 | 0.9496 | |
| (7.63, 4.24, 19.97, 7.76) | 5 | 0.6670 | 0.8892 | 0.5459 | 0.9418 |
| 10 | 0.5261 | 0.9004 | 0.4251 | 0.9452 | |
| 30 | 0.3264 | 0.9402 | 0.2643 | 0.9455 | |
| 50 | 0.2578 | 0.9494 | 0.2088 | 0.9482 | |
| 100 | 0.1840 | 0.9528 | 0.1508 | 0.9496 | |
| (10.25, 4.24, 5.65, 7.76) | 5 | 0.4134 | 0.8576 | 0.2320 | 0.8471 |
| 10 | 0.2636 | 0.8676 | 0.1768 | 0.8901 | |
| 30 | 0.1658 | 0.9484 | 0.1118 | 0.9262 | |
| 50 | 0.1309 | 0.9492 | 0.0889 | 0.9382 | |
| 100 | 0.0944 | 0.9500 | 0.0639 | 0.9452 | |
Table 6.
The estimates of based on the real dataset from 3-out-of-5 G System.
| ACI | GCI | BCI |
| ACI | GCI | BCI |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Lio, Y.; Tsai, T.-R.; Wang, L.; Cecilio Tejada, I.P. Inferences of the Multicomponent Stress–Strength Reliability for Burr XII Distributions. Mathematics 2022, 10, 2478. https://doi.org/10.3390/math10142478
AMA Style
Lio Y, Tsai T-R, Wang L, Cecilio Tejada IP. Inferences of the Multicomponent Stress–Strength Reliability for Burr XII Distributions. Mathematics. 2022; 10(14):2478. https://doi.org/10.3390/math10142478
Chicago/Turabian StyleLio, Yuhlong, Tzong-Ru Tsai, Liang Wang, and Ignacio Pascual Cecilio Tejada. 2022. "Inferences of the Multicomponent Stress–Strength Reliability for Burr XII Distributions" Mathematics 10, no. 14: 2478. https://doi.org/10.3390/math10142478
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.