
Optimized XGBoost Model with Small Dataset for Predicting Relative Density of Ti-6Al-4V Parts Manufactured by Selective Laser Melting


Abstract
:1. Introduction
2. Method
2.1. Experimental Dataset
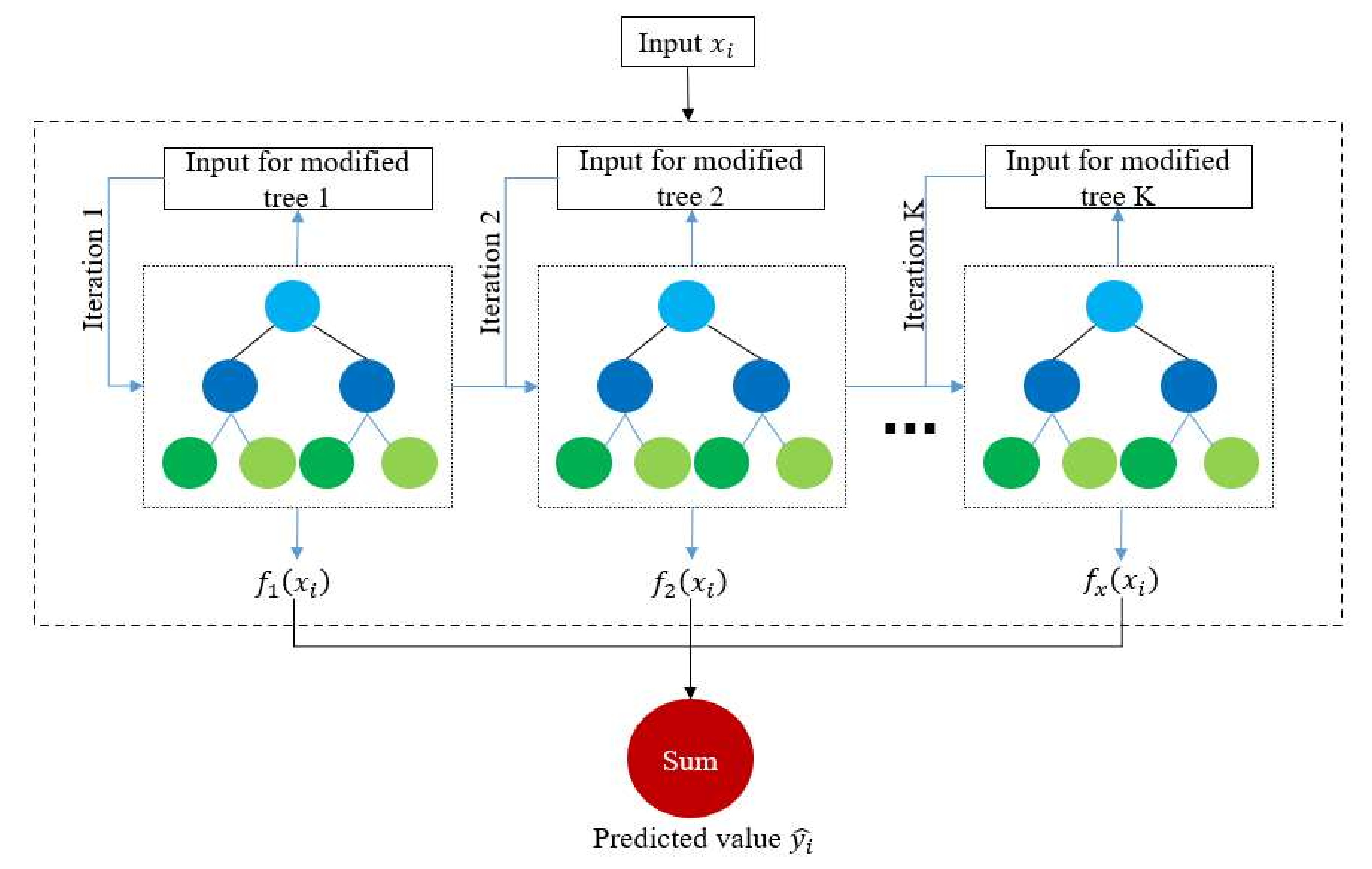
2.2. XGBoost Model
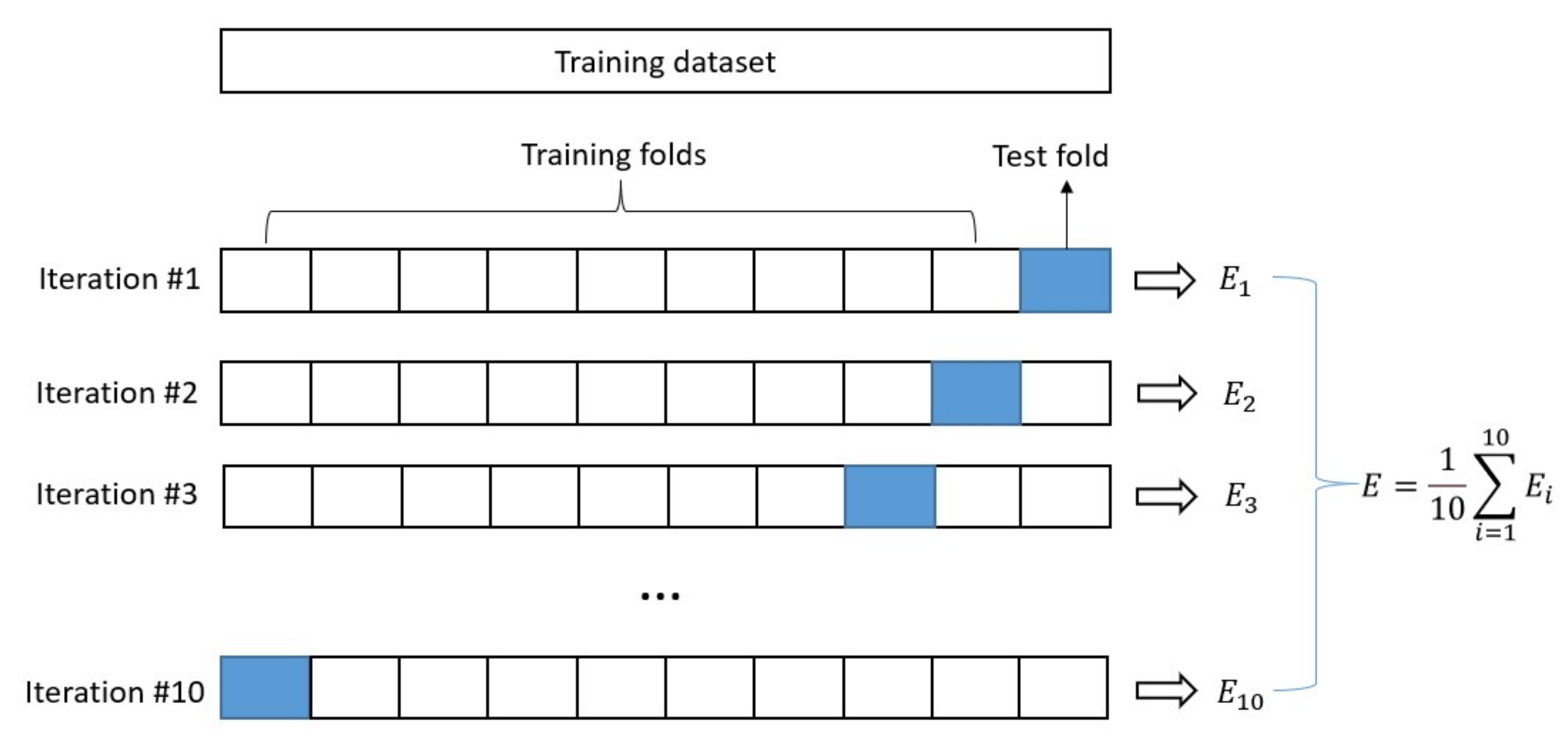
2.3. Hyperparameter Optimization with GridsearchCV Method
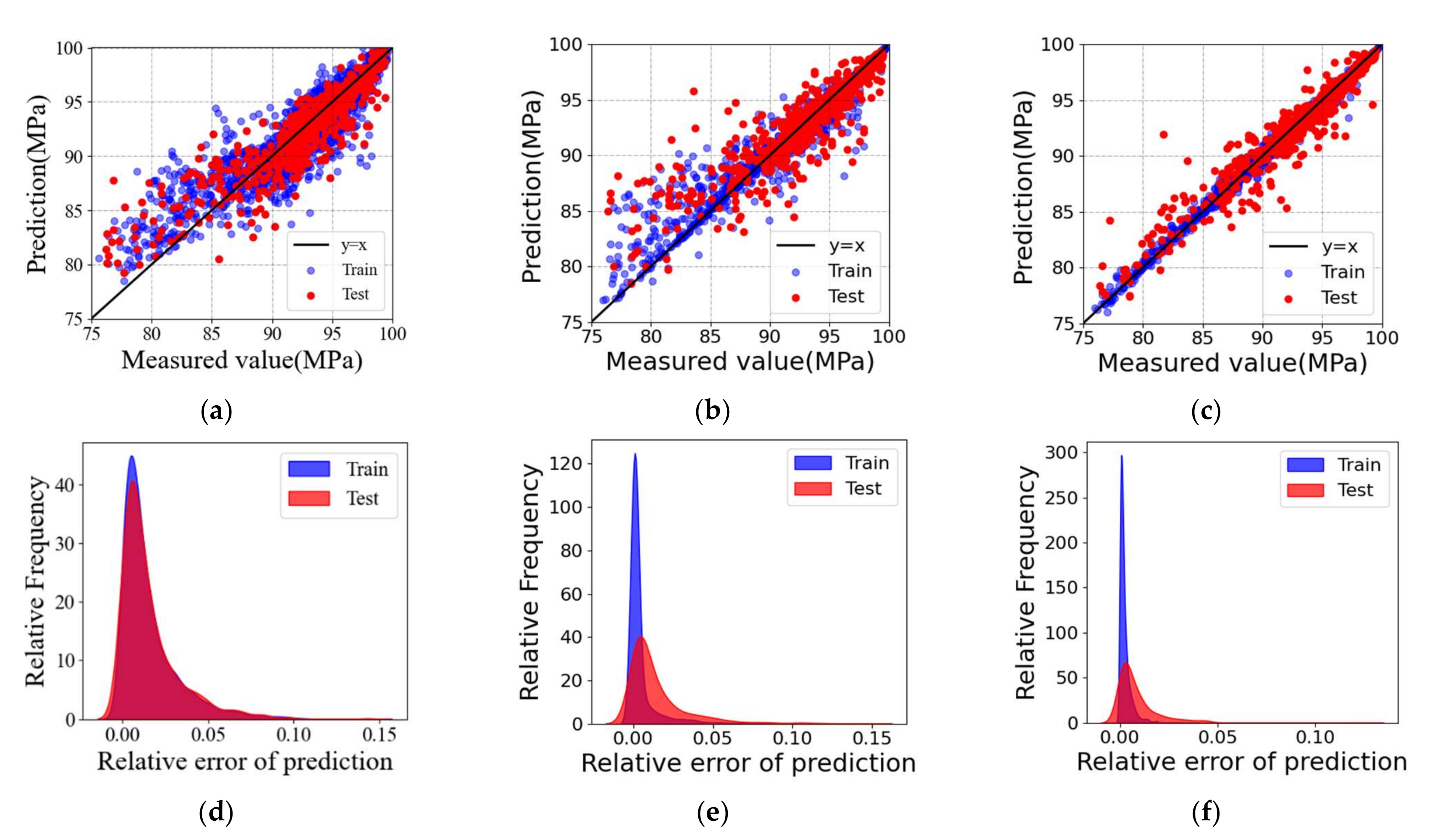
3. Results and Discussion
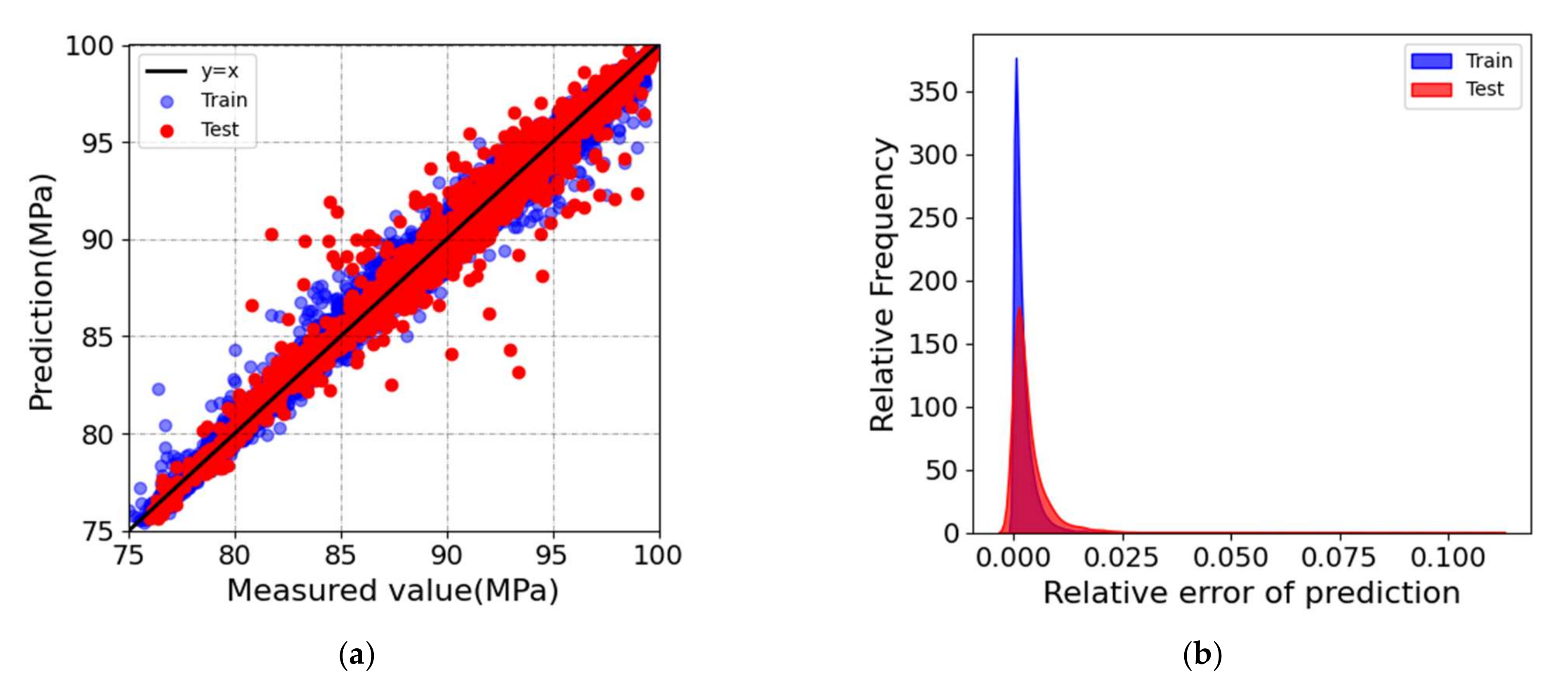
3.1. Performance of the Optimized XGBoost Model
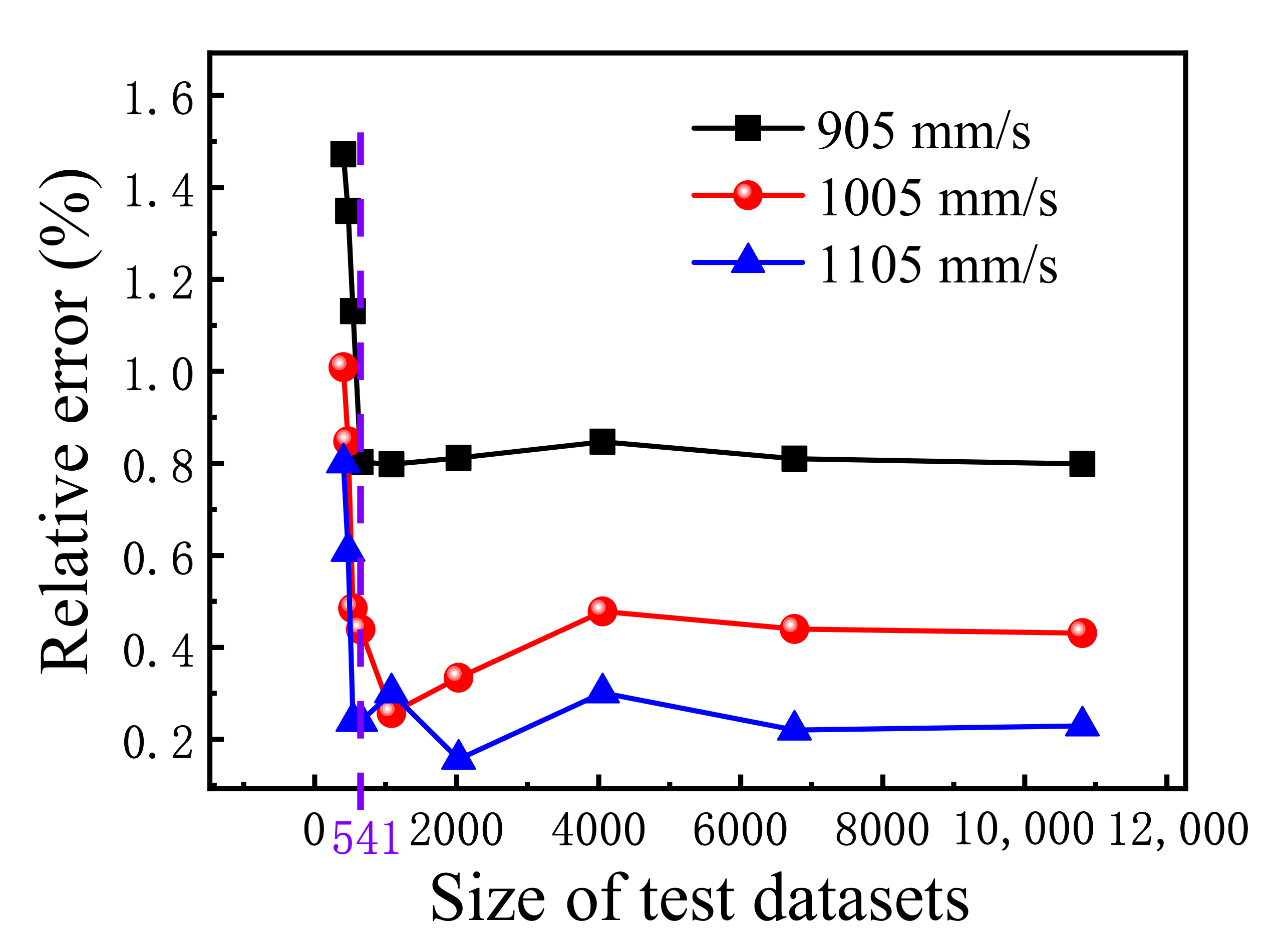
3.2. Influence of Dataset Sizes
3.3. Comparing the Predictive Ability with That of Other ML Models under Small Dataset
4. Conclusions
- (1)
- The trained optimized XGBoost model can effectively provide accurate correspondence between the relative density of the SLMed Ti-6Al-4V parts by SLM and the processing parameters.
- (2)
- As the dataset size decreases, when the size of the test dataset is larger than 541, the prediction accuracy changes slightly, but when the size of the test dataset is smaller than 541, the prediction accuracy drops sharply, at which point the model has lost its predictive ability.
- (3)
- The present optimized XGBoost model outperforms the ANN and SVR models with respect to the accuracy and generality in predicting the relative density of the SLMed Ti-6Al-4V parts under a small dataset.
- (4)
- The optimized XGBoost model has strong practicability under a small dataset. Using this method, the SLM operators can accurately estimate the relative density of the products based on the input processing parameters before printing, without spending a great deal of experience and time.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Wei, Y.C.; Tian, M.J.; Huang, C.Y.; Wang, S.W.; Li, X.; Hu, Q.R.; Yuan, M.Q. Topological study about failure behavior and energy absorption of honeycomb structures under various strain rates. Def. Technol. 2022, Online. [Google Scholar] [CrossRef]
- Tan, F.B.; Song, J.L.; Wang, C.; Fan, Y.B.; Dai, H.W. Titanium clasp fabricated by selective laser melting, CNC milling, and conventional casting: A comparative in vitro in vitro study. J. Prosthodont. Res. 2019, 63, 58–65. [Google Scholar] [CrossRef] [PubMed]
- Jafari, D.; Wits, W.W. The utilization of selective laser melting technology on heat transfer devices for thermal energy conversion applications: A review. Renew. Sustain. Energy. Rev. 2018, 91, 420–442. [Google Scholar] [CrossRef]
- Ataee, A.; Li, Y.; Brandt, M.; Wen, C. Ultrahigh-strength titanium gyroid scaffolds manufactured by selective laser melting (SLM) for bone implant applications. Acta Mater. 2018, 158, 354–368. [Google Scholar] [CrossRef]
- Van Hooreweder, B.; Apers, Y.; Lietaert, K.; Kruth, J.P. Improving the fatigue performance of porous metallic biomaterials produced by Selective Laser Melting. Acta Biomater. 2017, 47, 193–202. [Google Scholar] [CrossRef]
- Gogolewski, D.; Kozior, T.; Zmarzły, P.; Mathia, T.G. Morphology of Models Manufactured by SLM Technology and the Ti6Al4V Titanium Alloy Designed for Medical Applications. Materials 2021, 14, 6249. [Google Scholar] [CrossRef]
- Liu, Q.C.; Elambasseril, J.; Sun, S.J.; Leary, M.; Brandt, M.; Sharp, P.K. The effect of manufacturing defects on the fatigue behaviour of Ti-6Al-4V specimens fabricated using selective laser melting. Adv. Mater. Res. 2014, 891, 1519–1524. [Google Scholar] [CrossRef]
- Kempen, K.; Vrancken, B.; Buls, S.; Thijs, L.; Humbeeck, J.V.; Kruth, J.P. Selective laser melting of crack-free high density M2 high speed steel parts by baseplate preheating. J. Manuf. Sci. Eng. 2014, 136, 061026. [Google Scholar] [CrossRef]
- Li, R.; Liu, J.; Shi, Y.; Wang, L.; Jiang, W. Balling behavior of stainless steel and nickel powder during selective laser melting process. Int. J. Adv. Manuf. Technol. 2012, 59, 1025–1035. [Google Scholar] [CrossRef]
- Furumoto, T.; Ogura, R.; Hishida, K.; Hosokawa, A.; Koyano, T.; Abe, S.; Ueda, T. Study on deformation restraining of metal structure fabricated by selective laser melting. J. Mater. Process. Technol. 2017, 245, 207–214. [Google Scholar] [CrossRef]
- Zhao, X.; Li, S.; Zhang, M.; Liu, Y.; Sercombe, T.B.; Wang, S.; Hao, Y.; Yang, R.; Murr, L.E. Comparison of the microstructures and mechanical properties of Ti-6Al-4V fabricated by selective laser melting and electron beam melting. Mater. Des. 2016, 95, 21–31. [Google Scholar] [CrossRef]
- Cunningham, R.; Narra, S.P.; Montgomery, C.; Beuth, J.; Rollett, A.D. Synchrotron-based X-ray microtomography characterization of the effect of processing variables on porosity formation in laser power-bed additive manufacturing of Ti-6Al-4V. JOM 2017, 69, 479–484. [Google Scholar] [CrossRef]
- Han, J.; Yang, J.; Yu, H.; Yin, J.; Gao, M.; Wang, Z.; Zeng, X. Microstructure and mechanical property of selective laser melted Ti6Al4V dependence on laser energy density. Rapid Prototyp. J. 2017, 23, 217–226. [Google Scholar] [CrossRef]
- Yang, Y.; Lu, J.B.; Luo, Z.Y.; Wang, D. Accuracy and density optimization in directly fabricating customized orthodontic production by selective laser melting. Rapid Prototyp. J. 2012, 18, 482–489. [Google Scholar] [CrossRef]
- Perevoshchikova, N.; Rigaud, J.; Sha, Y.; Heilmaier, M.; Finnin, B.; Labelle, E.; Wu, X. Optimisation of selective laser melting parameters for the Ni-based superalloy IN-738 LC using Doehlert’s design. Rapid Prototyp. J. 2017, 23, 881–892. [Google Scholar] [CrossRef] [Green Version]
- Tang, S.; Zhang, G.; Yang, H.; Li, Y.; Liu, W.K.; Guo, X. MAP123: A data-driven approach to use 1D data for 3D nonlinear elastic materials modeling. Comput. Method. Appl. M 2019, 357, 112587. [Google Scholar] [CrossRef]
- Xie, X.; Bennett, J.; Saha, S.; Lu, Y.; Cao, J.; Liu, W.K.; Gan, Z. Mechanistic data-driven prediction of as-built mechanical properties in metal additive manufacturing. NPJ. Comput. Mater. 2021, 7, 1–12. [Google Scholar] [CrossRef]
- Qi, X.; Chen, G.; Li, Y.; Cheng, X.; Li, C. Applying neural-network-based machine learning to additive manufacturing: Current applications, challenges, and future perspectives. Engineering 2019, 5, 721–729. [Google Scholar] [CrossRef]
- Ye, S.; Huang, W.Z.; Li, M.; Feng, X.Q. Deep learning method for determining the surface elastic moduli of microstructured solids. Extreme Mech. Lett. 2021, 44, 101226. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In KDD’16, Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. ISBN 978-1-4503-4232-2. [Google Scholar]
- Chakraborty, D.; Elzarka, H. Advanced machine learning techniques for building performance simulation: A comparative analysis. J. Build. Perform. Simul. 2019, 12, 193–207. [Google Scholar] [CrossRef]
- Wang, W.; Shi, Y.; Lyu, G.; Deng, W. Electricity consumption prediction using XGBoost based on discrete wavelet transform. In Proceedings of the 2nd International Conference on Artificial Intelligence and Engineering Applications (AIEA 2017), Guilin, China, 23 September 2017. [Google Scholar]
- Duan, J.; Asteris, P.G.; Nguyen, H.; Bui, X.N.; Moayedi, H. A novel artificial intelligence technique to predict compressive strength of recycled aggregate concrete using ICA-XGBoost model. Eng. Comput.-Ger. 2021, 37, 3329–3346. [Google Scholar] [CrossRef]
- Dong, W.; Huang, Y.; Lehane, B.; Ma, G. XGBoost algorithm-based prediction of concrete electrical resistivity for structural health monitoring. Autom. Constr. 2020, 114, 103155. [Google Scholar] [CrossRef]
- Lim, S.; Chi, S. Xgboost application on bridge management systems for proactive damage estimation. Adv. Eng. Inf. 2019, 41, 100922. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Z.; Wu, D. Prediction of melt pool temperature in directed energy deposition using machine learning. Addit. Manuf. 2021, 37, 101692. [Google Scholar] [CrossRef]
- Peng, X.; Wu, S.; Qian, W.; Bao, J.; Hu, Y.; Zhan, Z.; Guo, G.; Withers, P.J. The potency of defects on fatigue of additively manufactured metals. Int. J. Mech. Sci. 2022, 221, 107185. [Google Scholar] [CrossRef]
- Ye, S.; Li, B.; Li, Q.; Zhao, H.P.; Feng, X.Q. Deep neural network method for predicting the mechanical properties of composites. Appl. Phys. Lett. 2019, 115, 161901. [Google Scholar] [CrossRef]
- Nguyen, D.S.; Park, H.S.; Lee, C.M. Optimization of selective laser melting process parameters for Ti-6Al-4V alloy manufacturing using deep learning. J. Manuf. Process. 2020, 55, 230–235. [Google Scholar] [CrossRef]
- Yu, Z.; Ye, S.; Sun, Y.; Zhao, H.; Feng, X.Q. Deep learning method for predicting the mechanical properties of aluminum alloys with small data sets. Mater. Today Commun. 2021, 28, 102570. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Alonso, J.M.; Alvarruiz, F.; Desantes, J.M.; Hernández, L.; Hernández, V.; Moltó, G. Combining neural networks and genetic algorithms to predict and reduce diesel engine emissions. IEEE. Trans. Evol. Comput. 2007, 11, 46–55. [Google Scholar] [CrossRef]
- Shi, X.; Ma, S.; Liu, C.; Chen, C.; Wu, Q.; Chen, X.; Lu, J. Performance of high layer thickness in selective laser melting of Ti6Al4V. Materials 2016, 9, 975. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, M.; Wang, Z.; Gao, M.; Zeng, X. Layer thickness dependence of performance in high-power selective laser melting of 1Cr18Ni9Ti stainless steel. J. Mater. Process. Technol. 2015, 215, 142–150. [Google Scholar] [CrossRef]
- Dadbakhsh, S.; Hao, L. Effect of layer thickness in selective laser melting on microstructure of Al/5 wt.% powder consolidated parts. Transfus. Apher. Sci. 2014, 2014, 106129. [Google Scholar]
- Butler, K.T.; Davies, D.W.; Cartwright, H.; Isayev, O.; Walsh, A. Machine learning for molecular and materials science. Nature 2018, 559, 547–555. [Google Scholar] [CrossRef] [PubMed]
- Nielsen, D. Tree Boosting with XGBoost-Why Does XGBoost Win “Every” Machine Learning Competition? Master Thesis, Norwegian University of Science and Technology, Trondheim, Norway, 2016. [Google Scholar]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Jiang, X.Y.; Xia, W.L.; Lou, D.J.; Ren, X.P.; Shao, S.; Li, H.Q.; Liu, S.Y.; Fang, X.Y. Effect of scanning speed on internal defects and mechanical properties of Ti-6A1-4V alloy processed by selective laser melting. Mater. Mech. Eng. 2020, 44, 41–45. (In Chinese) [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Element | Al | V | Fe | C | N | O | H | Ti | Others |
|---|---|---|---|---|---|---|---|---|---|
| wt. % | 5.50–6.50 | 3.50–4.50 | 0.25 | 0.08 | 0.03 | 0.13 | 0.0125 | Balance | 0.50 |
| Process Parameters | Unit | Value |
|---|---|---|
| Laser scanning speed | mm/s | 800, 900, 1000, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000, 2100, 2200, 2300, 2400, 2500 |
| Laser power | W | 80, 90, 95, 100, 105, 110, 115, 120, 130, 135, 140, 145, 150, 155, 160, 165, 170, 175, 180 |
| Hatch distance | μm | 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100 |
| Power layer thickness | μm | 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80 |
| Item | Range of Values | Tolerance |
|---|---|---|
| 1–10 | 1 | |
| 0.01–0.3 | 0.02 | |
| K | 100–600 | 50 |
| 0–0.05 | 0.01 | |
| 0–1 | 0.1 |
| Training Dataset (Set) | Test Dataset (Set) | MAE | RMSE | |
|---|---|---|---|---|
| 48,648 | 10,811 | 0.4768 | 0.6245 | 0.9699 |
| 27,027 | 6757 | 0.4815 | 0.6344 | 0.9696 |
| 16,216 | 4055 | 0.5194 | 0.7179 | 0.9643 |
| 8108 | 2028 | 0.6001 | 0.9917 | 0.9513 |
| 4324 | 1082 | 0.6871 | 1.1797 | 0.9428 |
| 2594 | 649 | 0.8011 | 1.7171 | 0.9184 |
| 2162 | 541 | 0.8889 | 2.1495 | 0.8930 |
| 1621 | 406 | 0.9870 | 2.2707 | 0.8840 |
| 486 | 122 | 1.5577 | 5.1405 | 0.7632 |
| Test | SVR | DNN | Optimized XGBoost |
|---|---|---|---|
| MAE | 1.3344 | 0.8576 | 0.8011 |
| RMSE | 4.8646 | 1.7316 | 1.7171 |
| 0.7687 | 0.7849 | 0.9184 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, M.; Jiang, W.-G.; Qin, Q.-H.; Liu, Y.-C.; Li, M.-L. Optimized XGBoost Model with Small Dataset for Predicting Relative Density of Ti-6Al-4V Parts Manufactured by Selective Laser Melting. Materials 2022, 15, 5298. https://doi.org/10.3390/ma15155298
Zou M, Jiang W-G, Qin Q-H, Liu Y-C, Li M-L. Optimized XGBoost Model with Small Dataset for Predicting Relative Density of Ti-6Al-4V Parts Manufactured by Selective Laser Melting. Materials. 2022; 15(15):5298. https://doi.org/10.3390/ma15155298
Chicago/Turabian StyleZou, Miao, Wu-Gui Jiang, Qing-Hua Qin, Yu-Cheng Liu, and Mao-Lin Li. 2022. "Optimized XGBoost Model with Small Dataset for Predicting Relative Density of Ti-6Al-4V Parts Manufactured by Selective Laser Melting" Materials 15, no. 15: 5298. https://doi.org/10.3390/ma15155298