Fundamentals of Physics-Informed Neural Networks Applied to Solve the Reynolds Boundary Value Problem


Division of Machine Elements, Luleå University of Technology, SE-971 87 Luleå, Sweden
Lubricants 2021, 9(8), 82; https://doi.org/10.3390/lubricants9080082
Submission received: 31 July 2021
/
Revised: 11 August 2021
/
Accepted: 14 August 2021
/
Published: 19 August 2021
(This article belongs to the Special Issue Machine Learning in Tribology)
Abstract
:This paper presents a complete derivation and design of a physics-informed neural network (PINN) applicable to solve initial and boundary value problems described by linear ordinary differential equations. The objective with this technical note is not to develop a numerical solution procedure which is more accurate and efficient than standard finite element- or finite difference-based methods, but to give a fully explicit mathematical description of a PINN and to present an application example in the context of hydrodynamic lubrication. It is, however, worth noticing that the PINN developed herein, contrary to FEM and FDM, is a meshless method and that training does not require big data which is typical in machine learning.
1. Introduction
There are various categories of artificial neural networks (ANN) and a physics-informed neural network (PINN), see [1] for a recent review on the matter, is a neural network trained to solve both supervised and unsupervised learning tasks while satisfying some given laws of physics, which may be described in terms of nonlinear partial differential equations (PDE). For example, the balance of momentum and conservation laws in solid- and fluid mechanics and various types of initial value problems (IVP) and boundary value problems (BVP), see e.g., [2,3]. The application of a PINN (of this type) to solve differential equations, renders meshless numerical solution procedures [4], and an important feature from a machine learning perspective, is that it is not a data-driven approach requiring a large set of training data to learn the solution.
In fluid mechanics, under certain assumptions, i.e., that the fluid is incompressible, iso-viscous, the balance of linear momentum and the continuity equation, for flows in narrow interfaces reduces to the classical Reynolds equation [5]. For more recent work establishing lower-dimensional models in a similar manner, see e.g., [6,7,8]. The present work describes how a PINN can be adapted and trained to solve both initial and boundary value problems, described by ordinary differential equations, numerically. The theoretical description starts by presenting the neural network’s architecture and it is first applied to solve an initial value problem, which is described by a first order ODE, which can be solved analytically so that the validity of the solution can be thoroughly assessed. Thereafter, it is used to obtain a PINN for the classical one-dimensional Reynolds equation, which is a boundary value problem governing, e.g., the flow of lubricant between the runner and the stator in a 1D slider bearing. The novelty and originality of the present work lays in the explicit mathematical description of the cost function, which constitutes the physics-informed feature of the ANN, and the associated gradient with respect to the networks weights and bias. Important features of this particular numerical solution procedure, that is publicly available here: [9], are that it is not data driven, i.e., no training data need to be provided and that it is a meshless method [4].
2. PINN Architecture
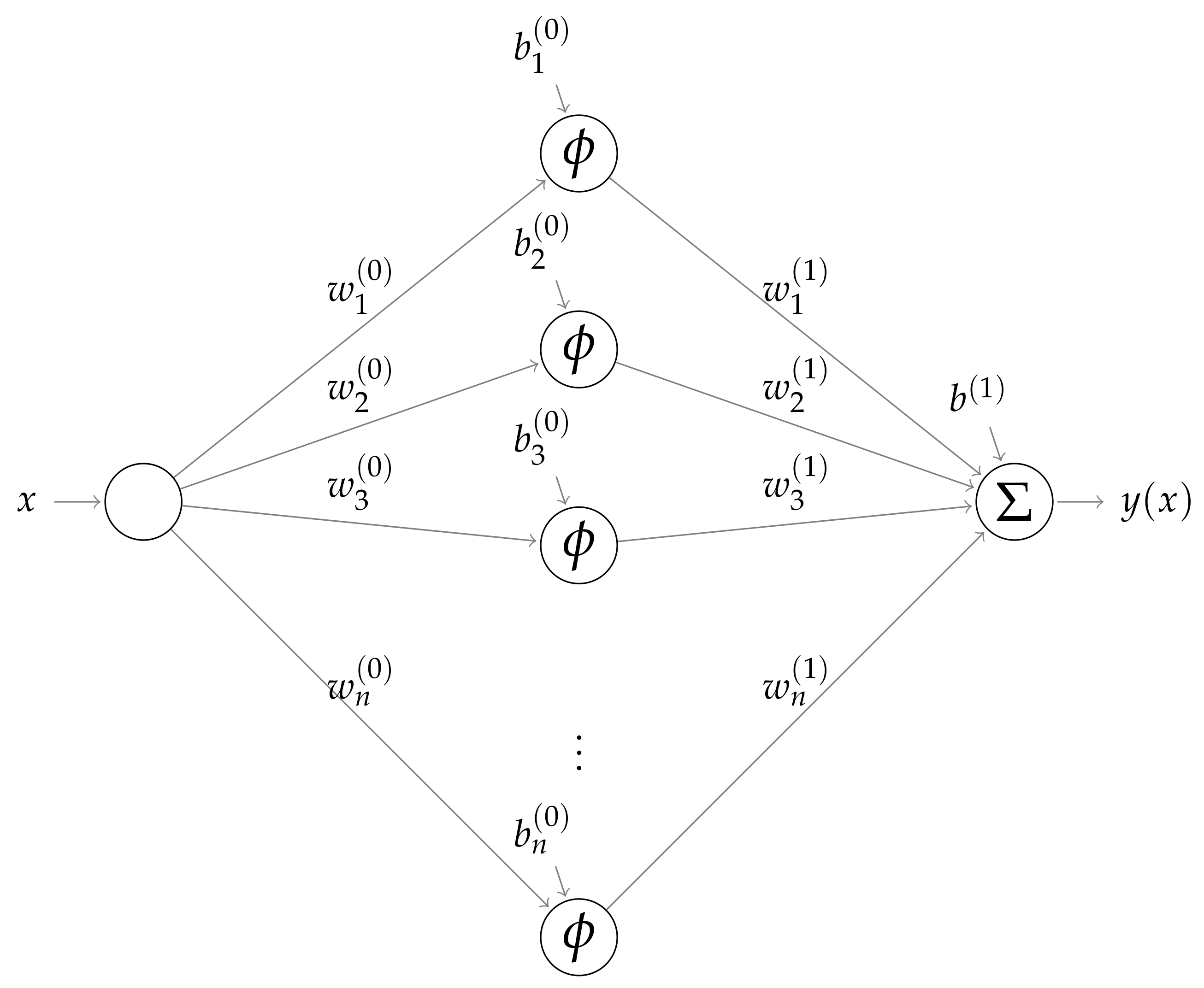
Knowing the characteristics of the solution to the differential equation under consideration is very helpful when designing the PINN architecture, including structure, number of hidden layers, activation function, etc. For this reason, the PINN developed here has one input node x (the independent variable representing the spatial coordinate), one hidden layer consisting of N nodes and one output node y (the dependent variable representing pressure). Figure 1 depicts a graphical illustration of the present architecture, which when trained solves both the IVP example and the Reynolds BVP considered here.
The Sigmoid function, i.e.,
which is mapping to and exhibits the property
is employed as activation function for the hidden layer. This means that the neural network has trainable parameters. That is, the weights and bias for the nodes in the hidden layer and the weights , , for each synapses connecting them with the output node, plus the bias applied there.
Based on this particular architecture, the output of each node in the first hidden layer is,
The output value is then given by applying the Sigmoid activation function scaled by the weight from the node in the second layer and yields
Let us now construct the cost function which the network will be trained to minimise. While the cost function appearing in a typical machine learning procedure is just the quadratic difference between the predicted and the target values, it will here be defined by means of the operators and . The cost function applied here reads
where defines the average value of f, and this is exactly the feature that makes an ANN “physics informed”, i.e., a PINN.
Since is a differential operator the cost function contains derivatives of the network output (4). In order to obtain an expression of the cost function, in terms of the input x, the weights w and bias b, the network output (4), must be differentiated twice with respect to (w.r.t.) x. This can be accomplished by some kind of automatic differentiation (AD) (also referred to as algorithmic differentiation, computer differentiation, auto-differentiation or simply autodiff), which is a computerised methodology based on the chain rule, which can be applied to efficiently and accurately evaluate derivatives of numeric functions, see e.g., [10,11]. The present work instead applies symbolic differentiation to clearly explain all the essential details of the PINN. Indeed, differentiating one yield
and, because of (2), a consecutive differentiation then yields
Moreover, finding the set of weights and bias minimising the cost function requires its partial derivatives w.r.t. to each weight and bias defining the PINN. In the subsections below, we will present how to achieve this, by first considering a first order differential equation with an analytical solution, and, thereafter, we will consider the classical Reynolds equation which is a second order (linear) ODE that describes laminar flow of incompressible and iso-viscous fluids in narrow interfaces.
3. A First Order ODE Example
Let us consider the first order ODE, describing the initial value problem (IVP) given by
with the exact solution . By means of (6), a cost function suitable for solving (8) may be generated by
The solution of (8) can be obtained by implementing a training routine which iteratively finds the set of weights w and bias b that minimises (9) (and similarly for (19) minimising (17)). The most well-known of these is the Gradient Decent method attributed to Cauchy, who first suggested it in 1847 [12]. For an overview, see, e.g., [13].
As mentioned in the previous section, the derivatives of (4) w.r.t. to the weights w and bias b are required to find them, and automatic differentiation is, normally, employed to perform the differentiation. However, here we carry out symbolic differentiation to demonstrate exactly the explicit expressions that constitute the gradient of the cost function. Indeed, by taking the partial derivatives we obtain
Moreover, the derivatives of the cost function (5) w.r.t. to the weights and bias are also required. For the derivative w.r.t. for the first order ODE (8), this means that
To complete the analysis, we also need expressions for the derivatives of w.r.t. , , and . By the chain rule, the following expressions can be obtained, viz.
What remains now is to obtain expressions for and the partial derivatives of , w.r.t. to the weights and bias. Let us start with . With given by (4) we directly have
which, in turn, means that
The PINN (following the architecture presented above) was implemented as computer program in MATLAB. The program was employed to obtain a numerical solution to the IVP in (8), using the parameters in Table 1.
The weights and bias were initialised using randomly generated and uniformly distributed numbers in the interval , while the weights were initially set to zero and the bias to one, to ensure fulfilment of the initial condition ().
4. A PINN for the Classical Reynolds Equation
The Reynolds equation for a one-dimensional flow situation, where the lubricant is assumed to be incompressible and iso-viscous, is a second order Boundary Value Problem (BVP), which in dimensionless form can be formulated as
where , and H is the dimensionless film thickness, if it is assumed that the pressure y at the boundaries is zero. For the subsequent analysis it is, however, more suitable work with a condensed form which can be obtained by defining the operators and as
The Reynolds BVP given by (16) can then be presented as
where .
For the Reynolds BVP, the cost function (5) becomes
and from the analysis presented for the IVP in Section 3 above, we have all the “ingredients” except for the partial derivatives of and w.r.t. to the weights and bias. For , based on (7) and (12), we obtain
where the third derivative of the Sigmoid function (1) is required. It yields
For we obtain
and we now have all the “ingredients” required to fully specify (19). To test the performance of the PINN, a Reynolds BVP was specified for a linear slider with dimensionless film thickness defined by
This means that and and that the exact solution is
see, e.g., [14].
The PINN (following the architecture suggested herein) was implemented in MATLAB and a numerical solution to (16) was obtained using the parameters in Table 3. As for the IVP, addressed in the previous section, the weights and bias were, again, initialised using randomly generated numbers, uniformly distributed in , while the weights and the bias was initially set to zero, to ensure fulfilment of the boundary conditions.
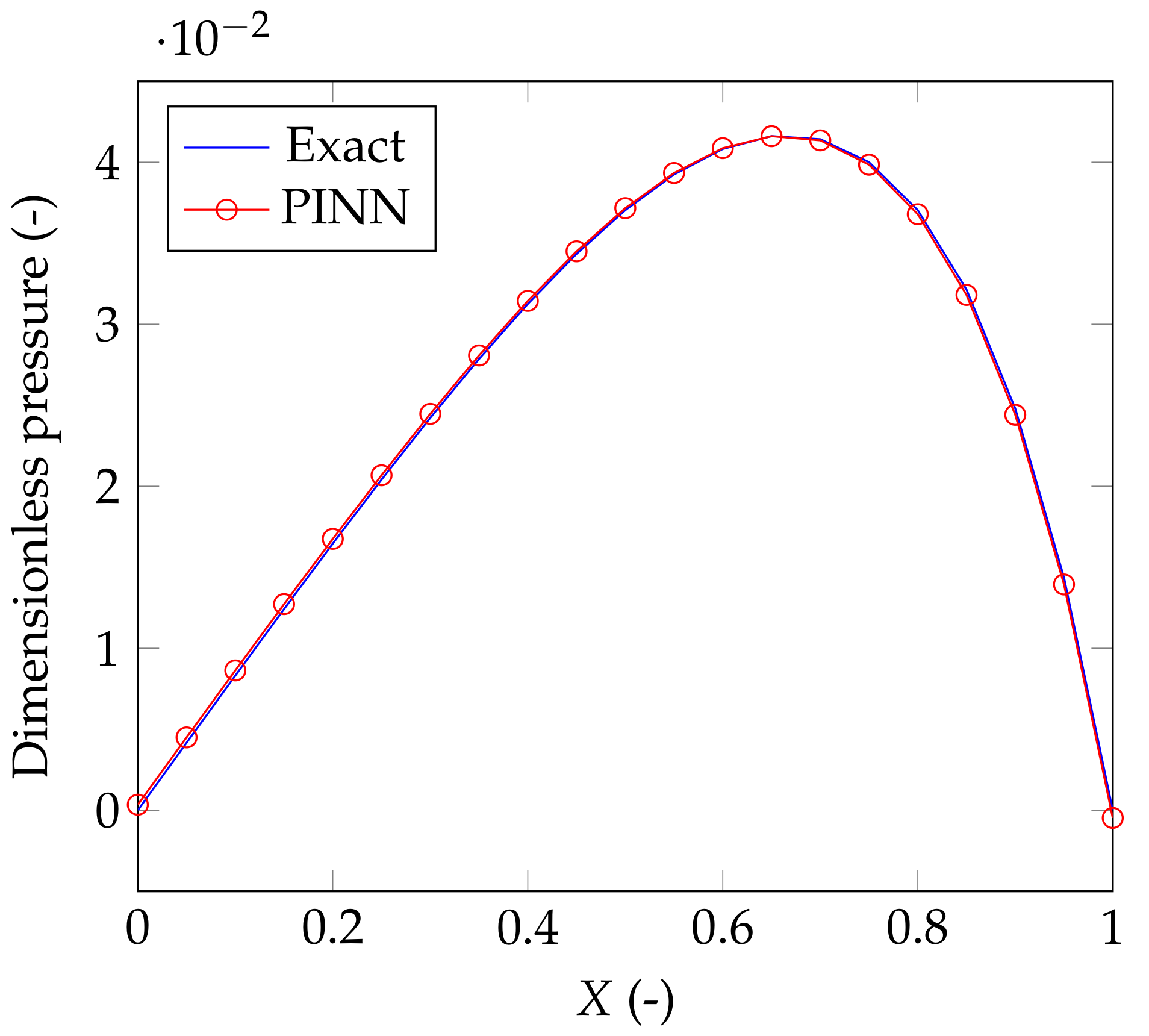
Figure 3 depicts solution predicted by the PINN (red line with circle markers) and the exact solution obtained by integration (blue continuous line).
We note that, with these weights and bias, the trained network’s prediction of the solution to the Reynolds BVP exhibits the overall error
while and .
Remark 1.
The formulation of the PINN presented here is applicable as a numerical solution procedure for the Reynolds BVP (16) and it does not consider the effect of cavitation. Exactly how the effect of cavitation can be included is, however, out of the scope of this paper.
5. Concluding Remarks
A physics-informed neural network (PINN) applicable to solve initial and boundary value problems has been established. The PINN was applied to solve an initial value problem described by a first order ordinary differential equation and to solve the Reynolds boundary value problem, described by a second order ordinary differential equation. Both these problems were selected since they can be solved analytically, and the error analysis showed that the predictions returned by the PINN was in good agreement with the analytical solutions for the specifications given. The advantage of the present approach is, however, neither accuracy nor efficiency when solving these linear equations, but that it presents a meshless method and that it is not data driven. This concept may, of course, be generalised, and it is hypothesised that future research in this direction may lead to more accurate and efficient in solving related but nonlinear problems than currently available routines.
Funding
The author acknowledges support from VR (The Swedish Research Council): DNR 2019-04293.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The author declares no conflict of interest.
References
- Karniadakis, G.E.; Kevrekidis, I.G.; Perdikaris, L.L.P.; Wang, S.; Yang, L. Physics-informed machine learning. Nat. Rev. Phys. 2021, 3, 422–440. [Google Scholar] [CrossRef]
- Bai, X.D.; Wang, Y.; Zhang, W. Applying physics informed neural network for flow data assimilation. J. Hydrodyn. 2020, 32, 1050–1058. [Google Scholar] [CrossRef]
- Lu, L.; Meng, X.; Mao, Z.; Karniadakis, G.E. DeepXDE: A deep learning library for solving differential equations. SIAM Rev. 2021, 63, 208–228. [Google Scholar] [CrossRef]
- Liu, G.R. Mesh Free Methods: Moving beyond the Finite Element Method; Taylor & Francis: Boca Raton, FL, USA, 2003. [Google Scholar]
- Reynolds, O. On the theory of lubrication and its application to Mr. Beauchamps tower’s experiments, including an experimental determination of the viscosity of olive oil. Philos. Trans. R. Soc. Lond. A 1886, 177, 157–234. [Google Scholar]
- Almqvist, A.; Burtseva, E.; Pérez-Rà fols, F.; Wall, P. New insights on lubrication theory for compressible fluids. Int. J. Eng. Sci. 2019, 145, 103170. [Google Scholar] [CrossRef]
- Almqvist, A.; Burtseva, E.; Rajagopal, K.; Wall, P. On lower-dimensional models in lubrication, part a: Common misinterpretations and incorrect usage of the reynolds equation. Proc. Inst. Mech. Eng. Part J J. Eng. Tribol. 2020, 235, 1692–1702. [Google Scholar] [CrossRef]
- Almqvist, A.; Burtseva, E.; Rajagopal, K.; Wall, P. On lower-dimensional models in lubrication, part b: Derivation of a reynolds type of equation for incompressible piezo-viscous fluids. Proc. Inst. Mech. Eng. Part J J. Eng. Tribol. 2020, 235, 1703–1718. [Google Scholar] [CrossRef]
- Almqvist, A. Physics-Informed Neural Network Solution of 2nd Order Ode:s. MATLAB Central File Exchange. Retrieved 31 July 2021. Available online: https://www.mathworks.com/matlabcentral/fileexchange/96852-physics-informed-neural-network-solution-of-2nd-order-ode-s (accessed on 7 July 2020).
- Neidinger, R.D. Introduction to automatic differentiation and MATLAB object-oriented programming. SIAM Rev. 2010, 52, 545–563. [Google Scholar] [CrossRef] [Green Version]
- Baydin, A.G.; Pearlmutter, B.A.; Radul, A.A.; Siskind, J.M. Automatic differentiation in machine learning: A survey. J. Mach. Learn. Res. 2018, 18, 1–43. [Google Scholar]
- Cauchy, A.M. Méthode générale pour la résolution des systèmes d’équations simultanées. Comp. Rend. Sci. Paris 1847, 25, 536–538. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Almqvist, A.; Pérez-Ràfols, F. Scientific Computing with Applications in Tribology: A Course Compendium. 2019. Available online: http://urn.kb.se/resolve?urn=urn:nbn:se:ltu:diva-72934 (accessed on 26 July 2021).
Figure 1.
Architecture of the PINN employed to solve the IVP and BVP considered here.

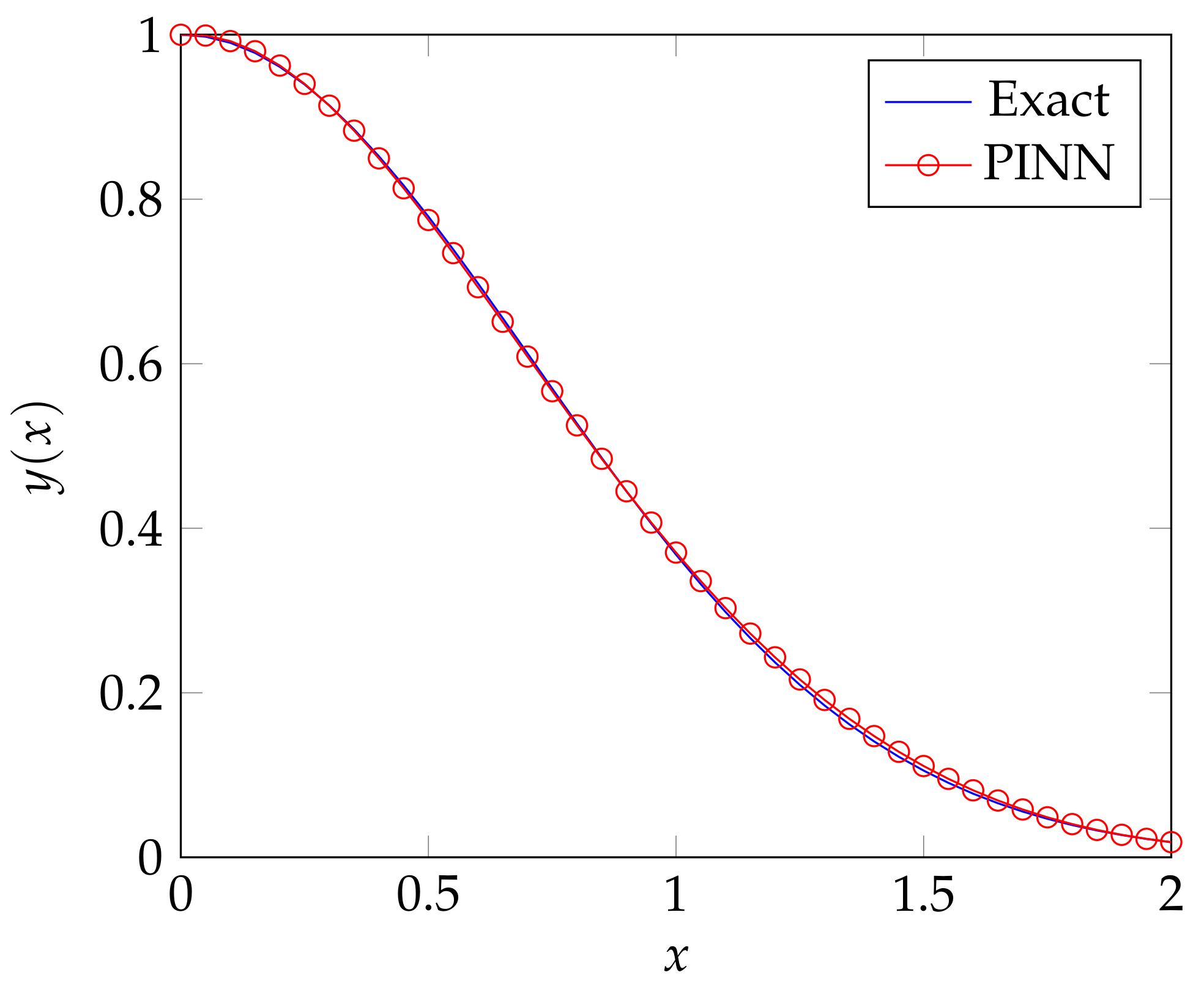
Figure 2.
The solution to the IVP (8), predicted by the PINN (red line with circle markers) and the exact solution obtained by integration (blue continuous line).
Figure 2.
The solution to the IVP (8), predicted by the PINN (red line with circle markers) and the exact solution obtained by integration (blue continuous line).

Figure 3.
The solution achieved by the ANN (red line with circle markers) and the exact solution obtained by integration (blue continuous line).
Figure 3.
The solution achieved by the ANN (red line with circle markers) and the exact solution obtained by integration (blue continuous line).


{kind=link}
{kind=link}
{kind=link}
Table 1.
Parameters used to defined the PINN to for the IVP in (8).
| Parameter | Description | Value |
|---|---|---|
| # of grid points for the solution domain | 41 | |
| # of training batches (# or corrections during 1 Epoch) | 1000 | |
| # of Epochs (1 Epoch contains training batches) | 100 | |
| Learning rate coefficient (relaxation for the update) | 0.01 | |
| N | # of nodes/neurons in the hidden layer | 10 |
Table 2.
Parameters used to defined the PINN for the IVP (8).
| Node | ||||
|---|---|---|---|---|
| 1 | 1.8500 | −0.5946 | −3.5805 | 0.3055 |
| 2 | 1.8588 | 1.5974 | 0.9712 | |
| 3 | 0.3025 | 1.9241 | 0.8921 | |
| 4 | 1.4546 | 0.3742 | −0.9955 | |
| 5 | 0.5065 | 1.2535 | −0.1430 | |
| 6 | −1.0898 | −1.0199 | −1.1067 | |
| 7 | −0.8302 | 0.3519 | −1.1668 | |
| 8 | 0.3789 | 1.6502 | 0.1754 | |
| 9 | 2.5012 | 0.7657 | 1.2955 | |
| 10 | 2.2743 | 1.4172 | 1.2787 |
Table 3.
Parameters used to defined the ANN to for the Reynolds equation.
| Parameter | Description | Value |
|---|---|---|
| # of grid points for the solution domain | 21 | |
| K | Slope parameter for the Reynolds equation | 1 |
| # of training batches (# or corrections during 1 epoch) | 2000 | |
| # of Epochs (1 epoch contains training batches) | 600 | |
| Learning rate coefficient (relaxation for the update) | 0.005 | |
| N | # of nodes/neurons in the hidden layer | 10 |
Table 4.
Parameters used to defined the ANN.
| Node | ||||
|---|---|---|---|---|
| 1 | 0.0557 | 1.9808 | −0.2186 | −0.0641 |
| 2 | −6.3047 | 6.1664 | 0.1220 | |
| 3 | −9.3674 | 11.4571 | 0.3843 | |
| 4 | −4.5473 | 3.3266 | 0.0305 | |
| 5 | −2.4464 | −1.9884 | 0.1188 | |
| 6 | −0.1365 | −0.1674 | 0.4155 | |
| 7 | 0.8581 | 0.5253 | 0.5089 | |
| 8 | 1.0901 | 2.0858 | 0.3348 | |
| 9 | 0.2085 | 0.2523 | −0.2024 | |
| 10 | −3.2168 | 5.9722 | −0.9899 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Almqvist, A. Fundamentals of Physics-Informed Neural Networks Applied to Solve the Reynolds Boundary Value Problem. Lubricants 2021, 9, 82. https://doi.org/10.3390/lubricants9080082
AMA Style
Almqvist A. Fundamentals of Physics-Informed Neural Networks Applied to Solve the Reynolds Boundary Value Problem. Lubricants. 2021; 9(8):82. https://doi.org/10.3390/lubricants9080082
Chicago/Turabian StyleAlmqvist, Andreas. 2021. "Fundamentals of Physics-Informed Neural Networks Applied to Solve the Reynolds Boundary Value Problem" Lubricants 9, no. 8: 82. https://doi.org/10.3390/lubricants9080082
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.