A Method for Clustering and Analyzing Vessel Sailing Routes Efficiently from AIS Data Using Traffic Density Images


Abstract
:1. Introduction
2. Literature Review
3. Research Methodology
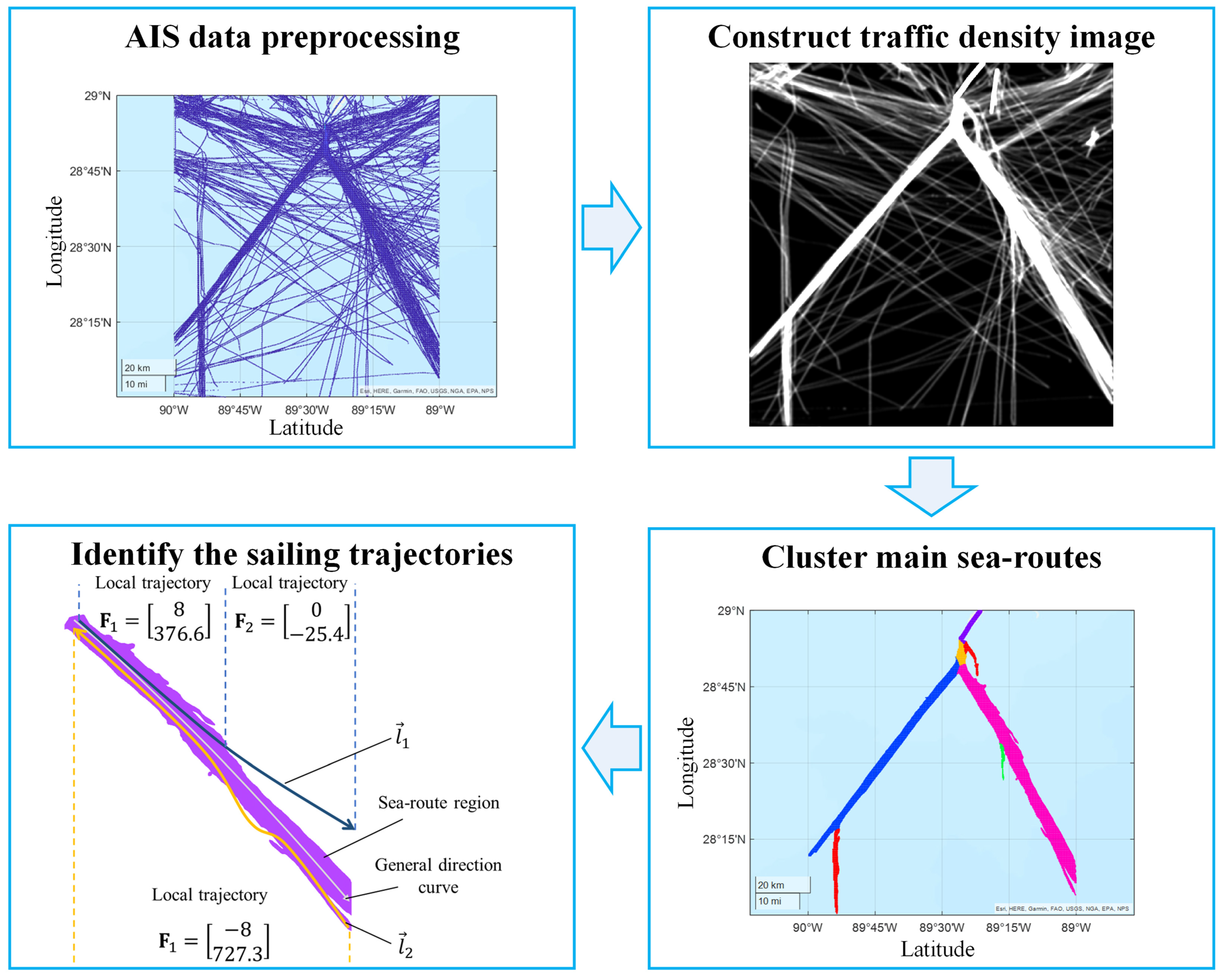
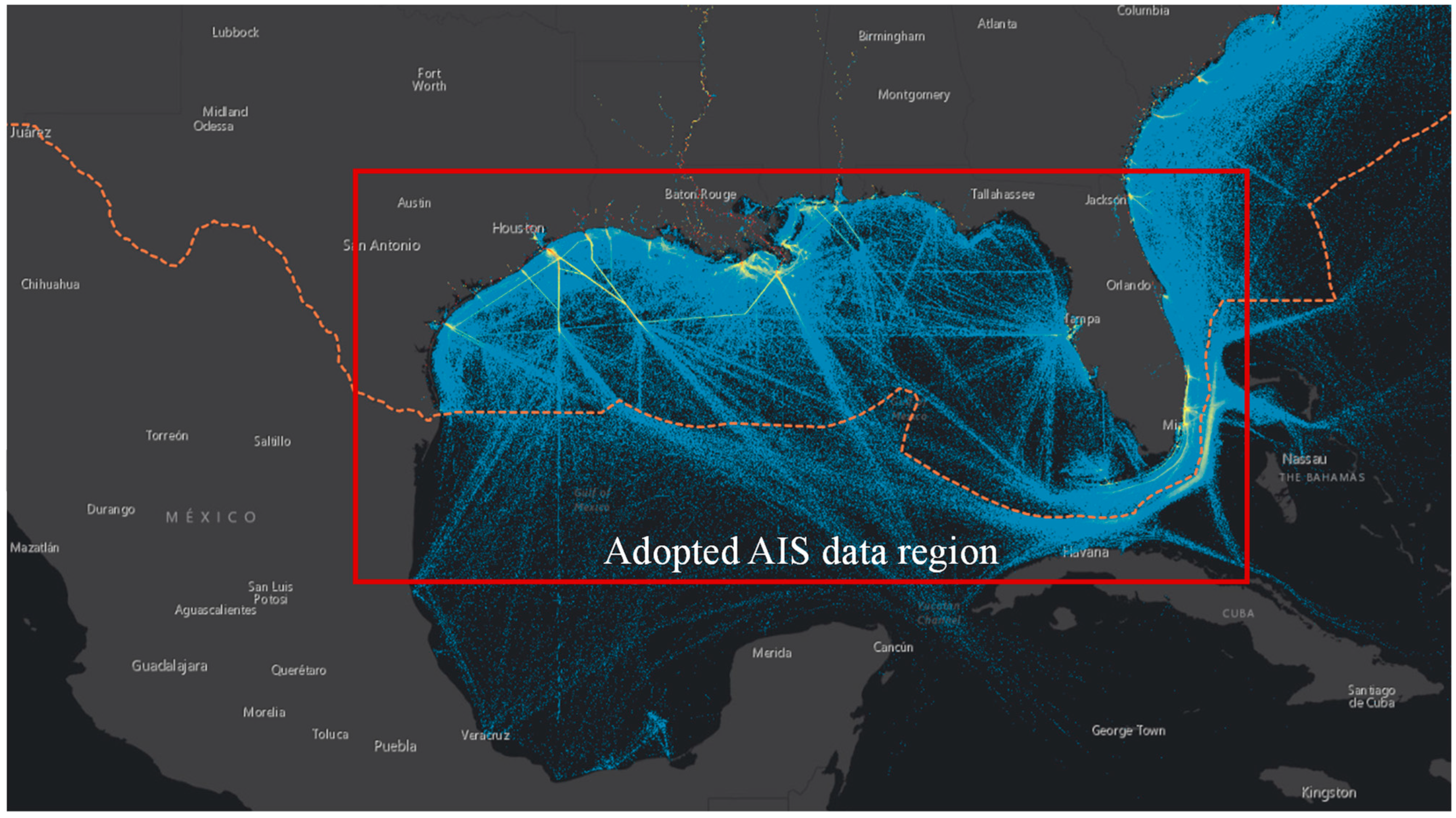
3.1. AIS Data Preprocessing
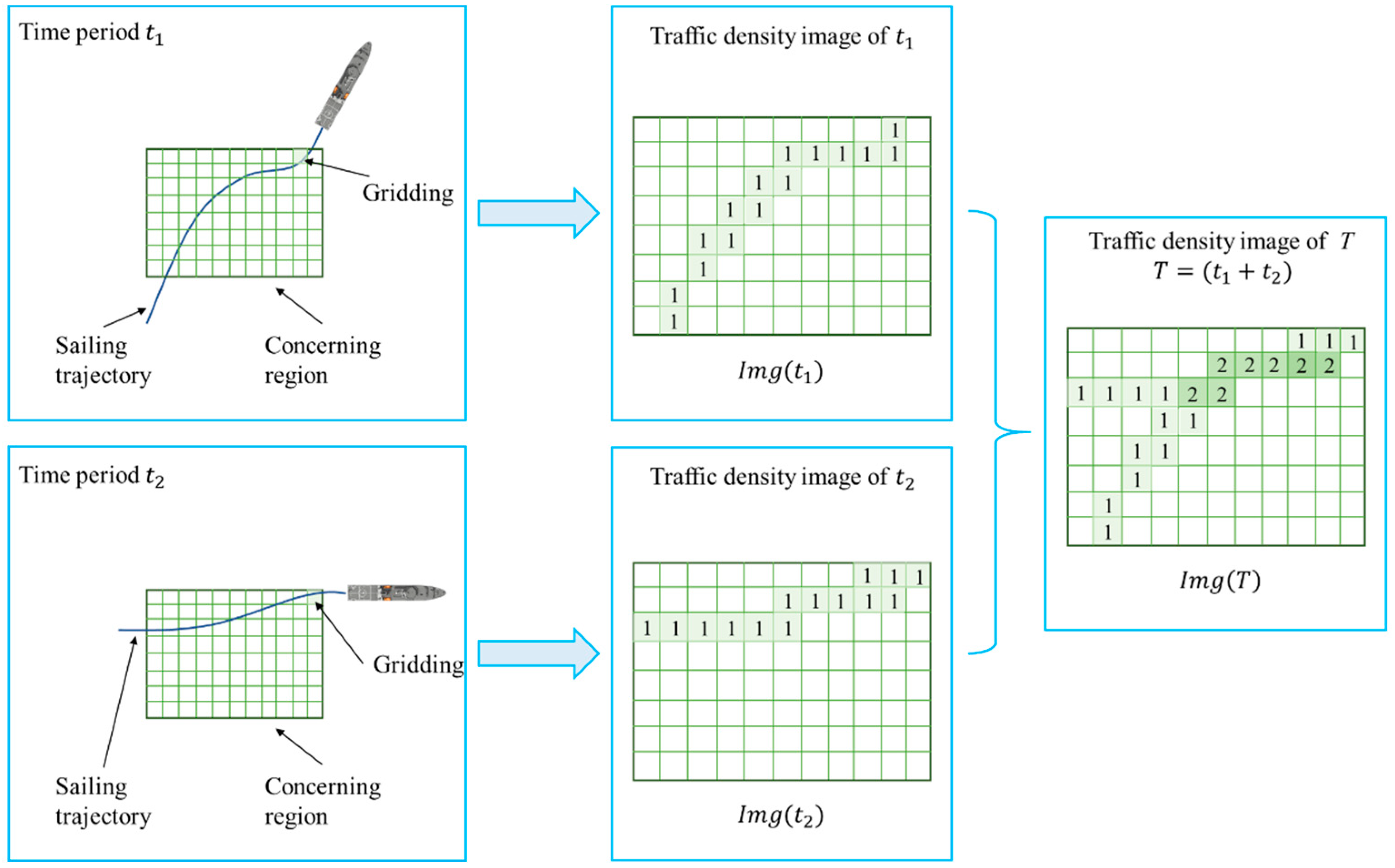
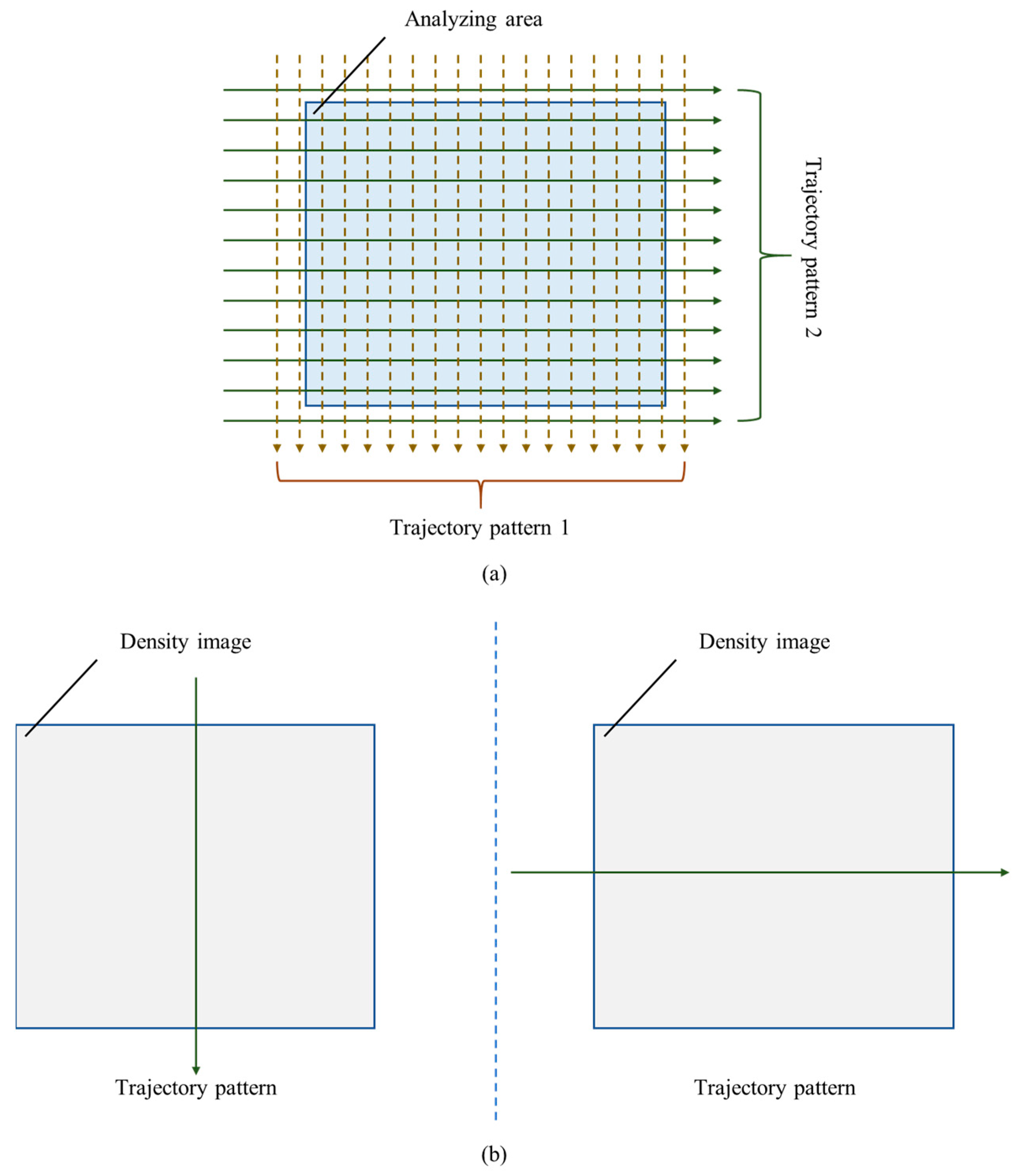
3.2. Construct Traffic Density Image
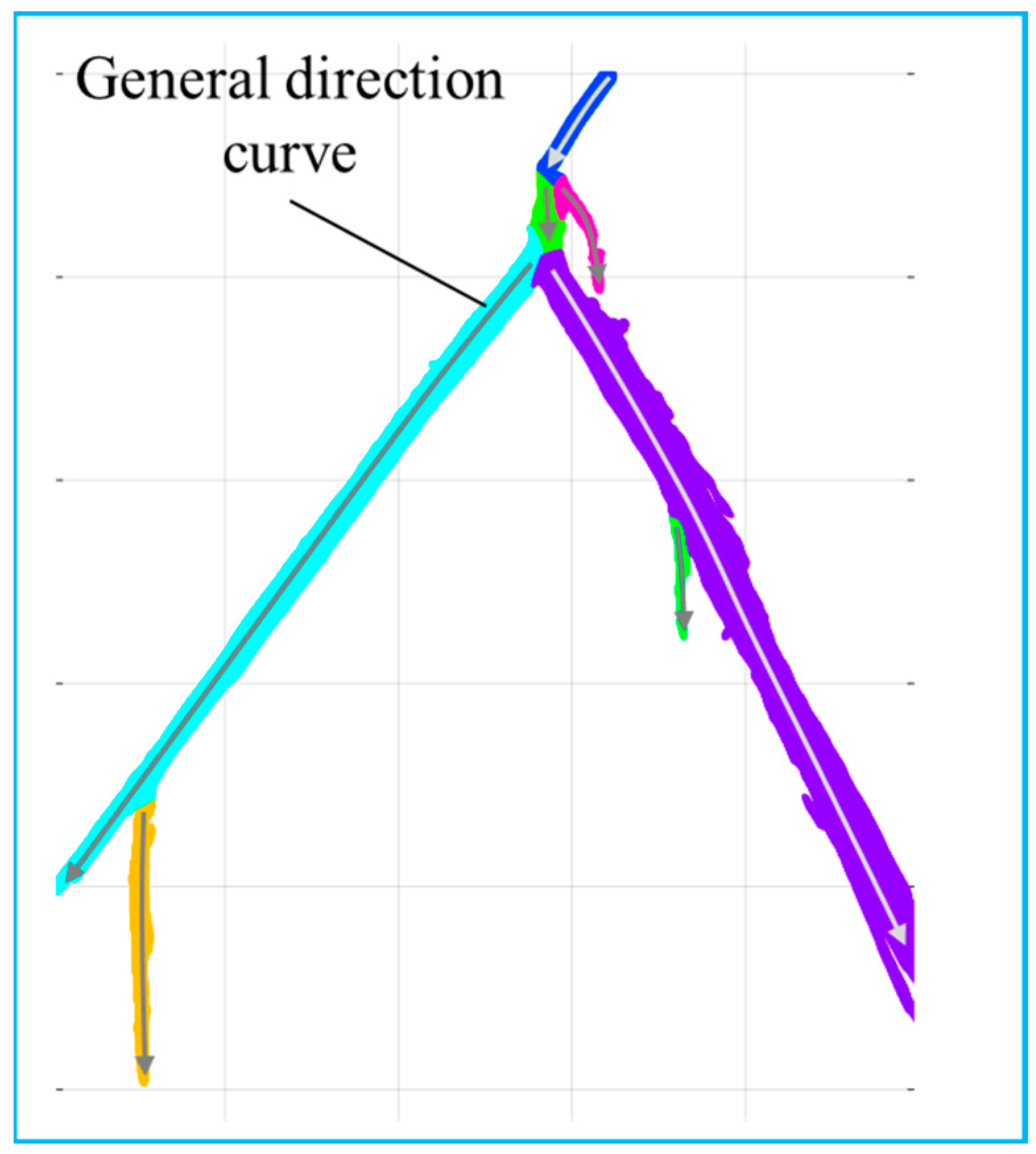
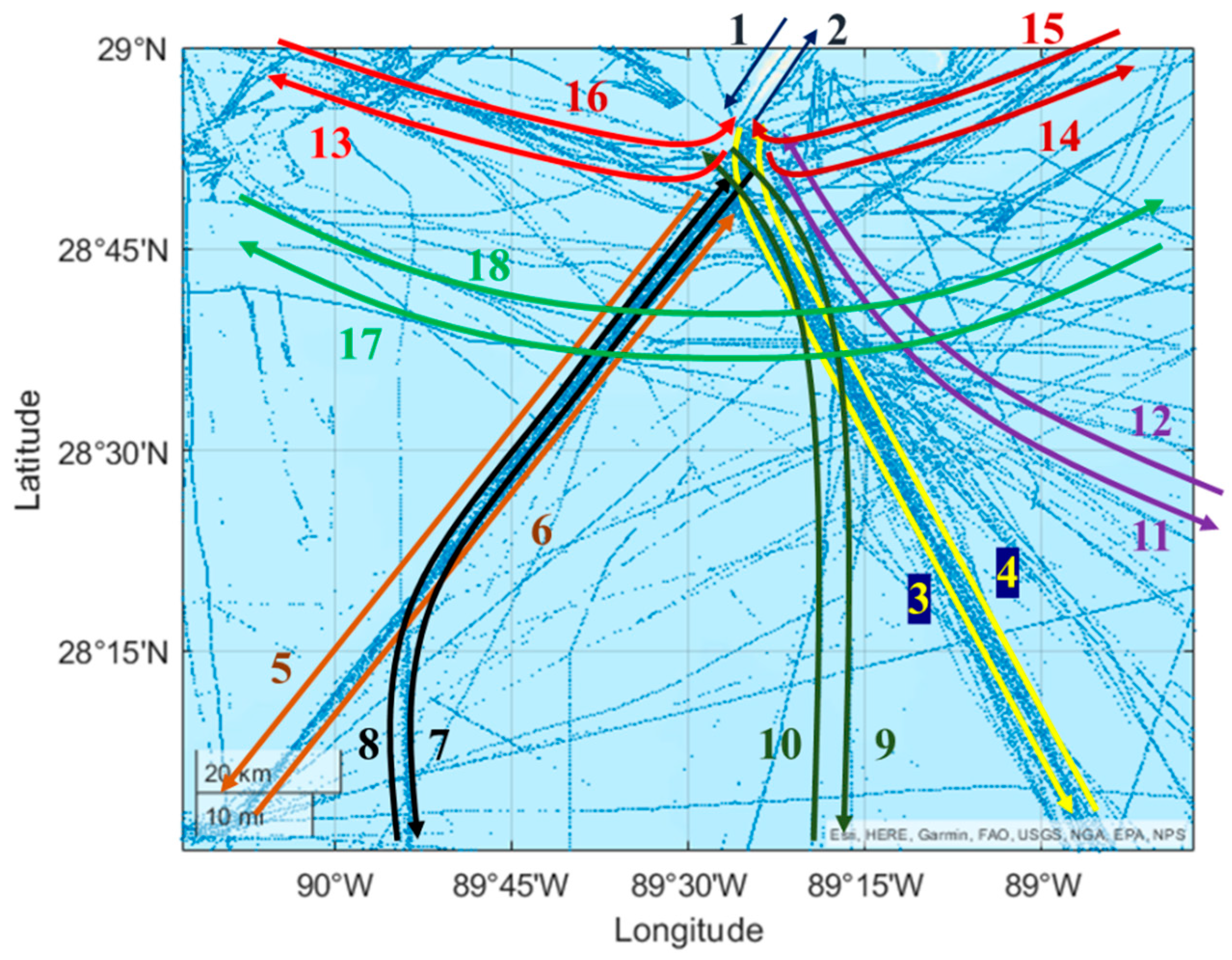
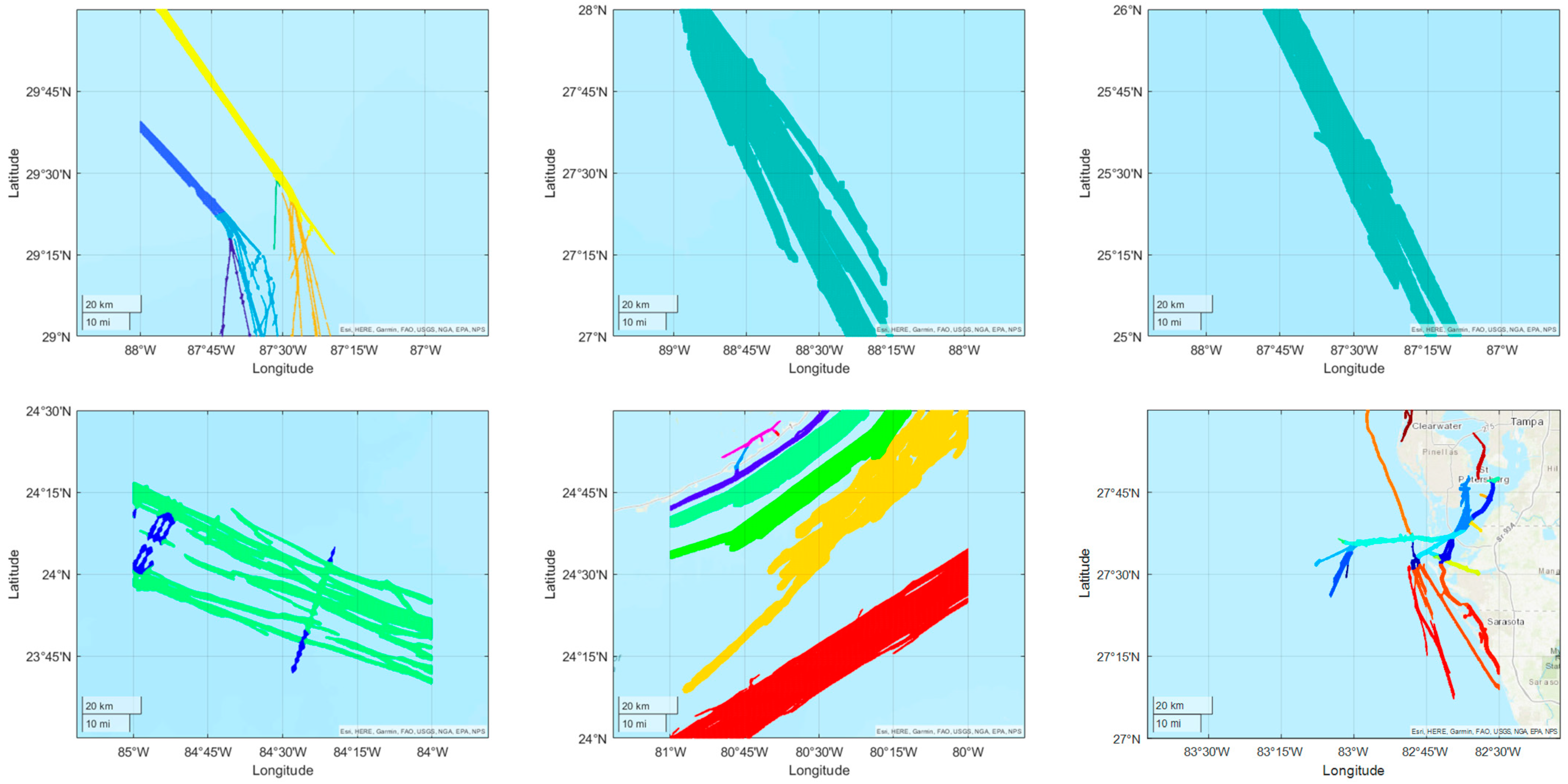
3.3. Cluster Main Sea Routes
- Step 1: cluster regions based on sailing course
- Step 2: check regions based on spatial location and density
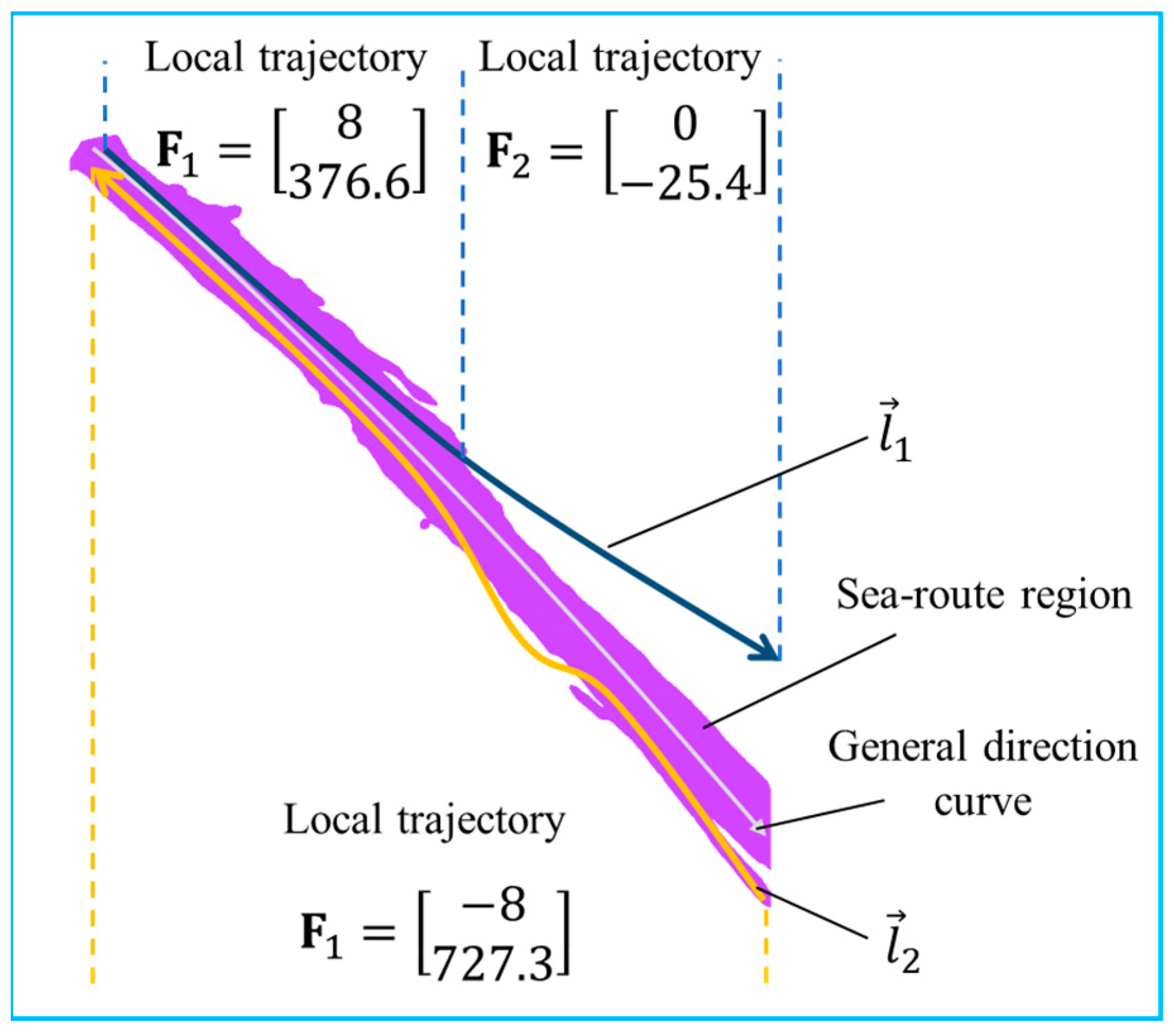
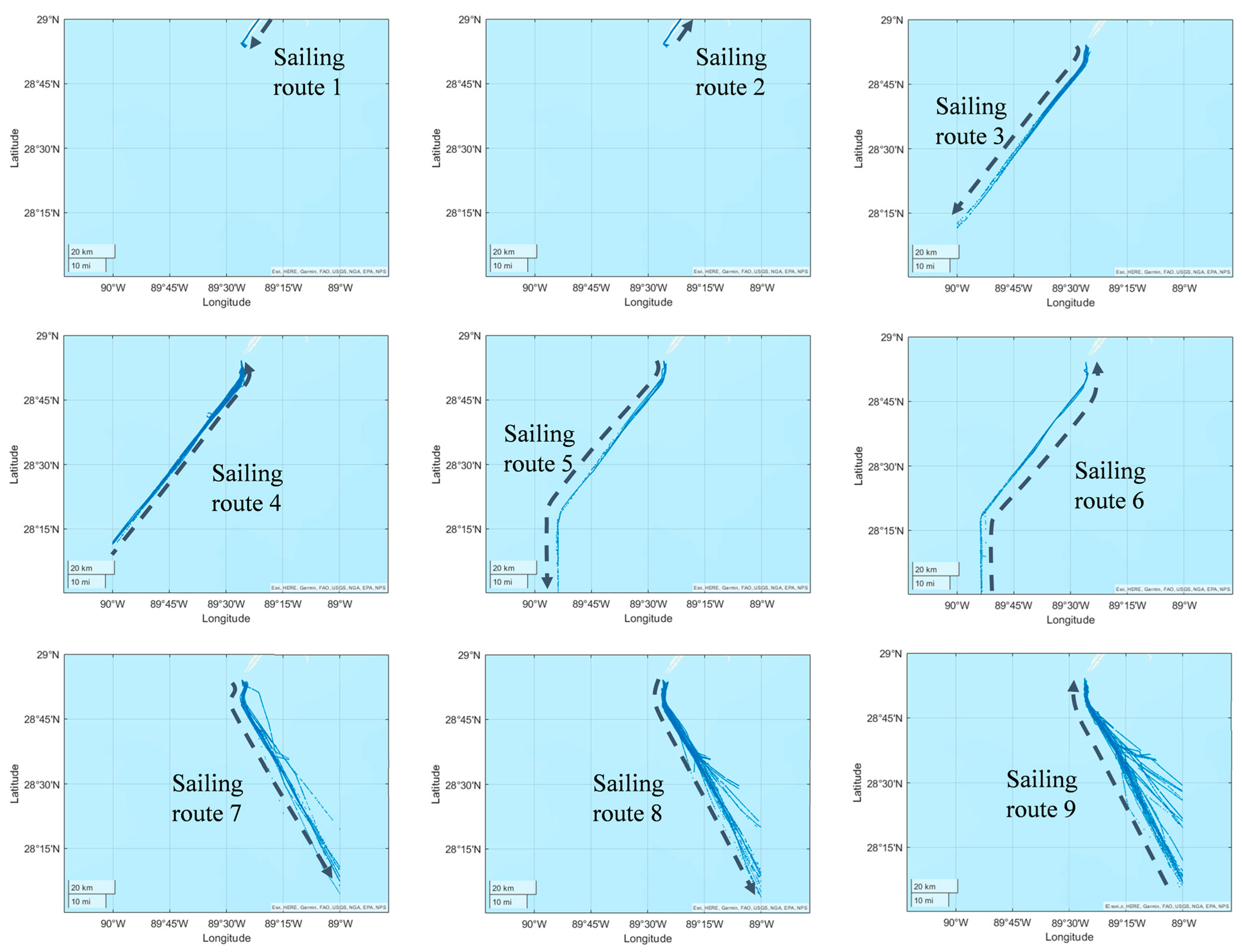
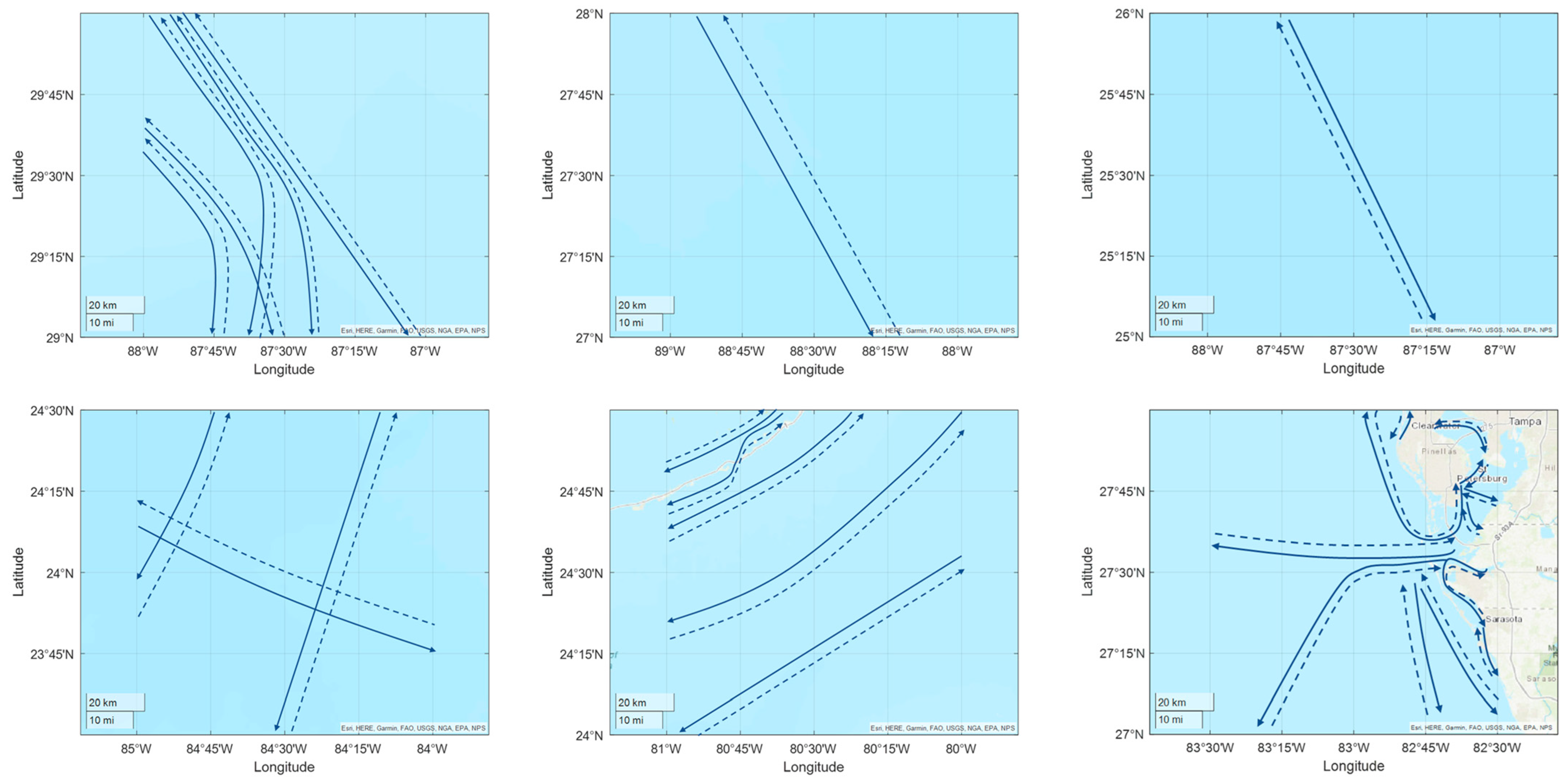
3.4. Identify the Sailing Trajectory
- The representative AIS trajectory (or trajectory segmentation) of a sea route region should belong to the corresponding sea route region.
- The Hausdorff distance [44] between the representative AIS trajectory and the general direction curve should be less than a given threshold.
| Algorithm 1: Reference patterns of main sea routes |
| Input: Main sea routes ; Distance matrix of sea routes . Output: Reference patterns . |
| 1. Let ; 2. Choose -th sea route region, let and add to ; 3. Choose sea route regions with the minimum distance between -th sea route region as ; 3.1 When , let , else, go to step 4; 3.2 Let and add to ; 3.3 Choose sea route regions except for with the minimum distance between -th sea route region as ; 3.4 When , use the recursive method to analyze the rest of sea route regions until is obtained, else, go to step 3.5; 3.5 Let , go to step 3.2; 4. Let , go to step 2; 5. For each sequence in , successively add 0 to the sequence from beginning to end, obtain ; 6. Output ; |
- The proposed method uses the traffic density image to transform the clustering problem of complex AIS trajectories into an image processing problem, and the traffic density images of different time periods can be directly added together to obtain the traffic density image of the total period with a fixed dimension, which can effectively solve the curse of dimensionality.
- The proposed method only calculates the similarity between the given AIS trajectory and the constructed reference patterns. The similarity between trajectories is not required in this method, which significantly shortens the clustering operation time for large-scale AIS data compared to commonly used density-based methods.
- The proposed method can effectively consider local and global features of trajectories and deal with complex AIS data with different vessel densities and sailing patterns. In addition, the noise data can also be eliminated.
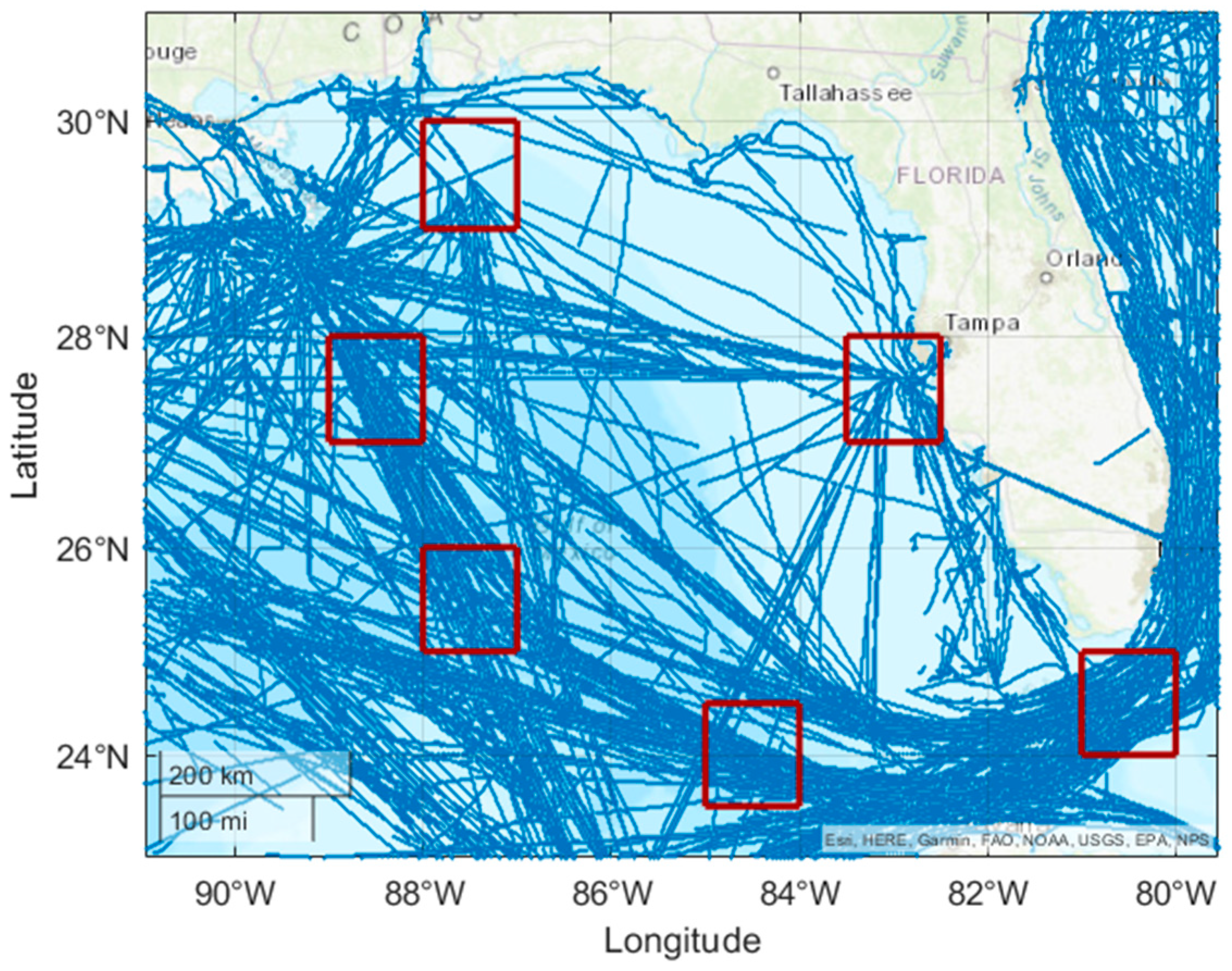
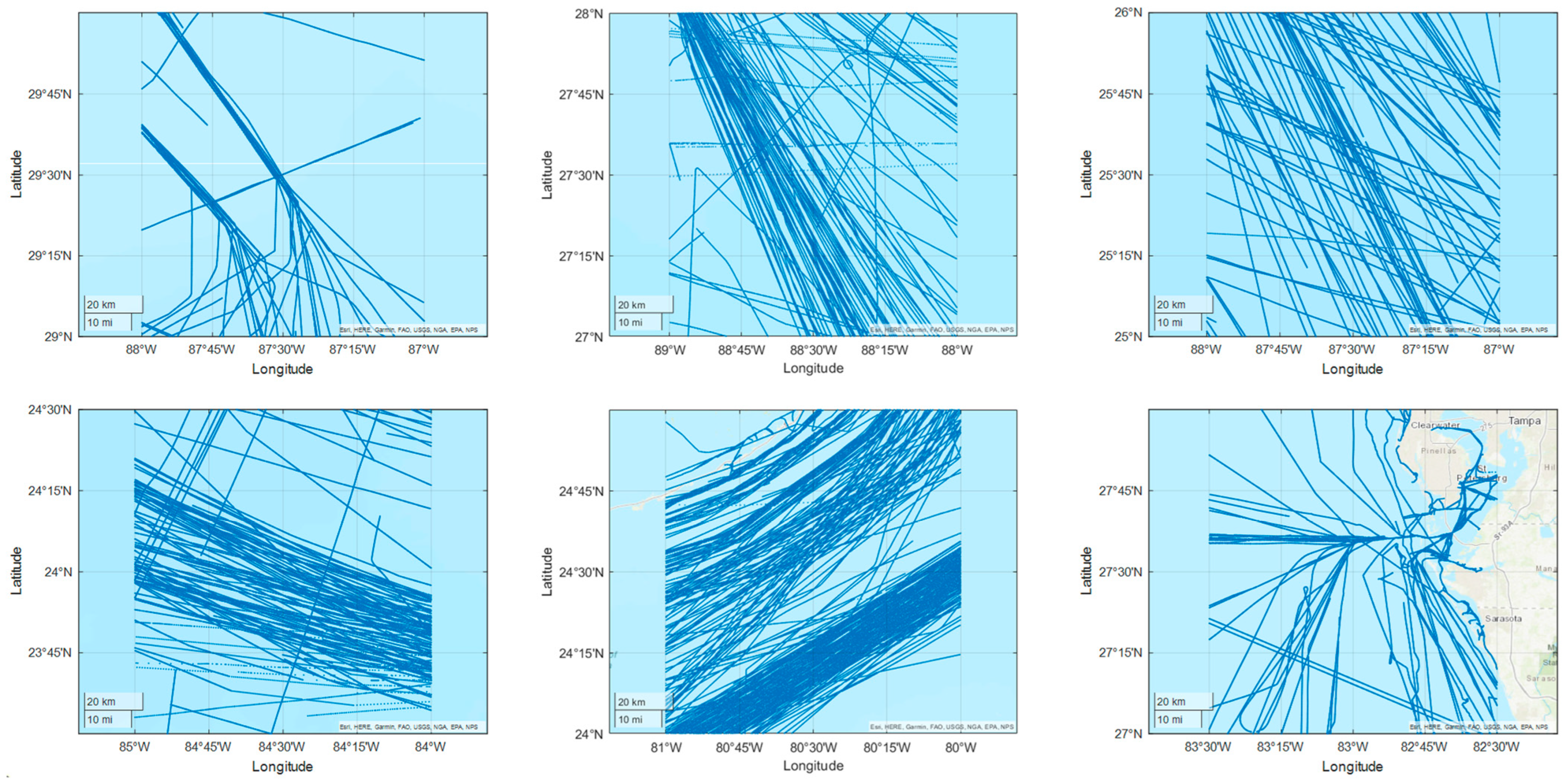
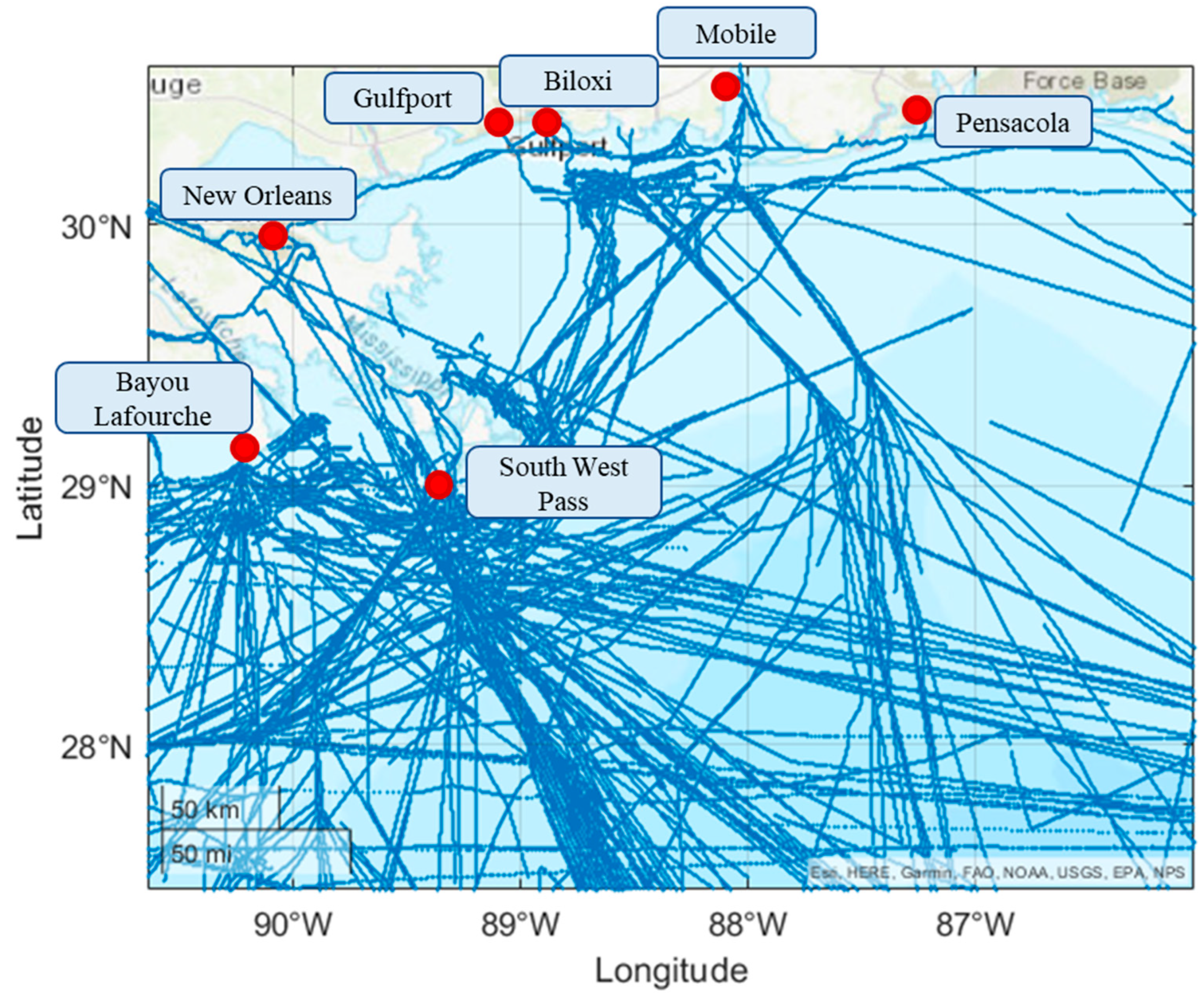
4. Case Studies and Results
4.1. Performance Comparison Experiment
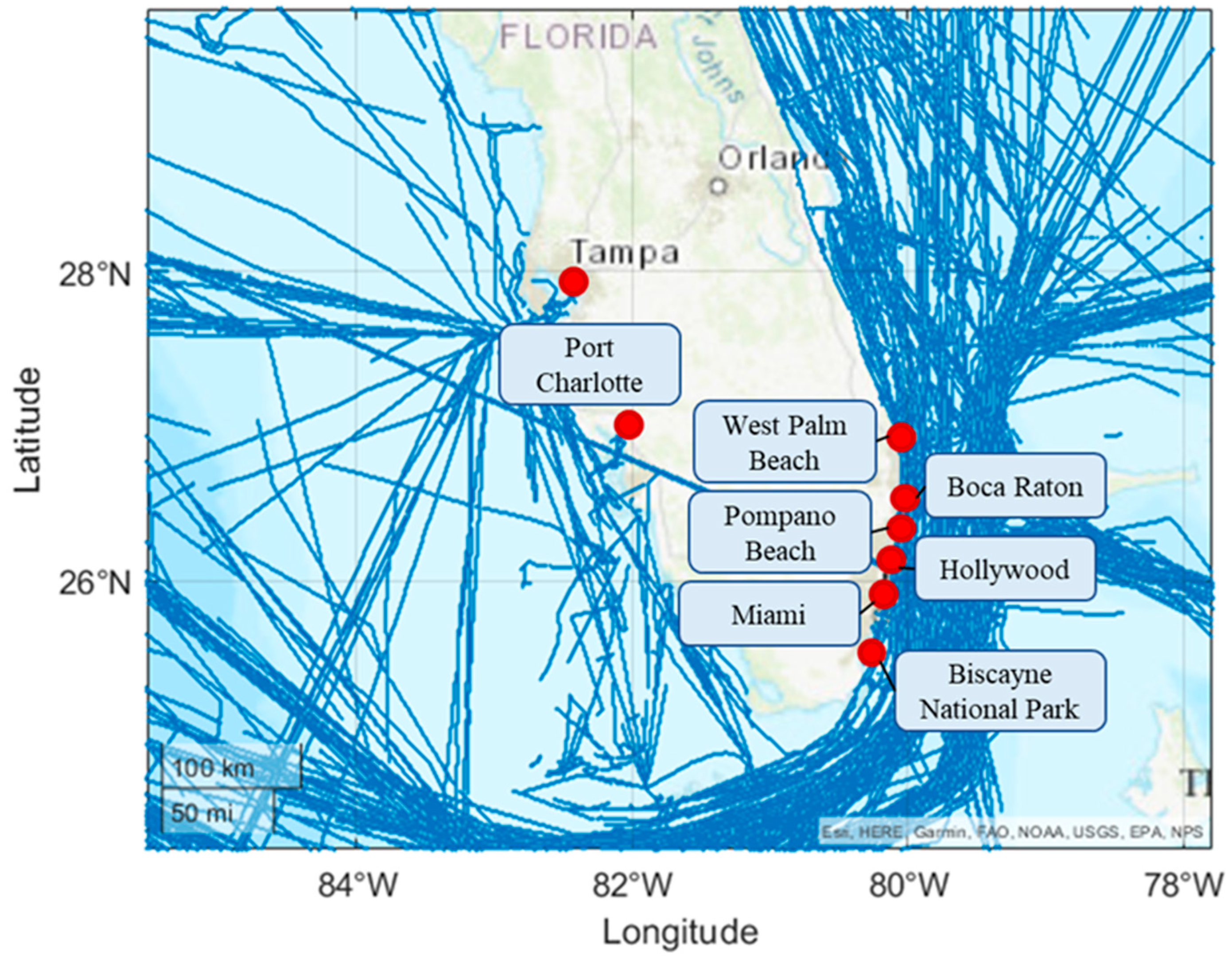
4.2. Time–Space Domain Covering Experiment
5. Discussion
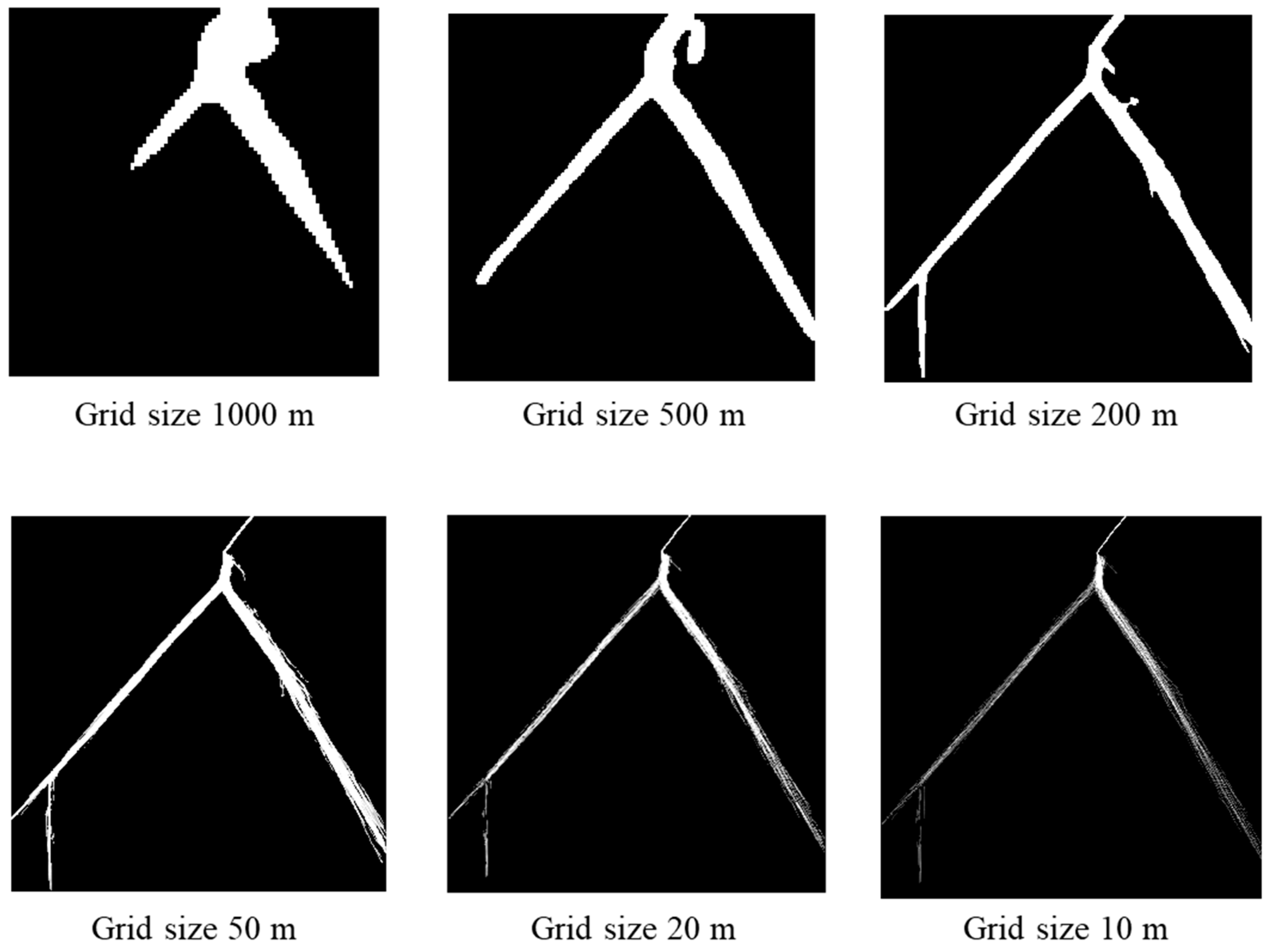
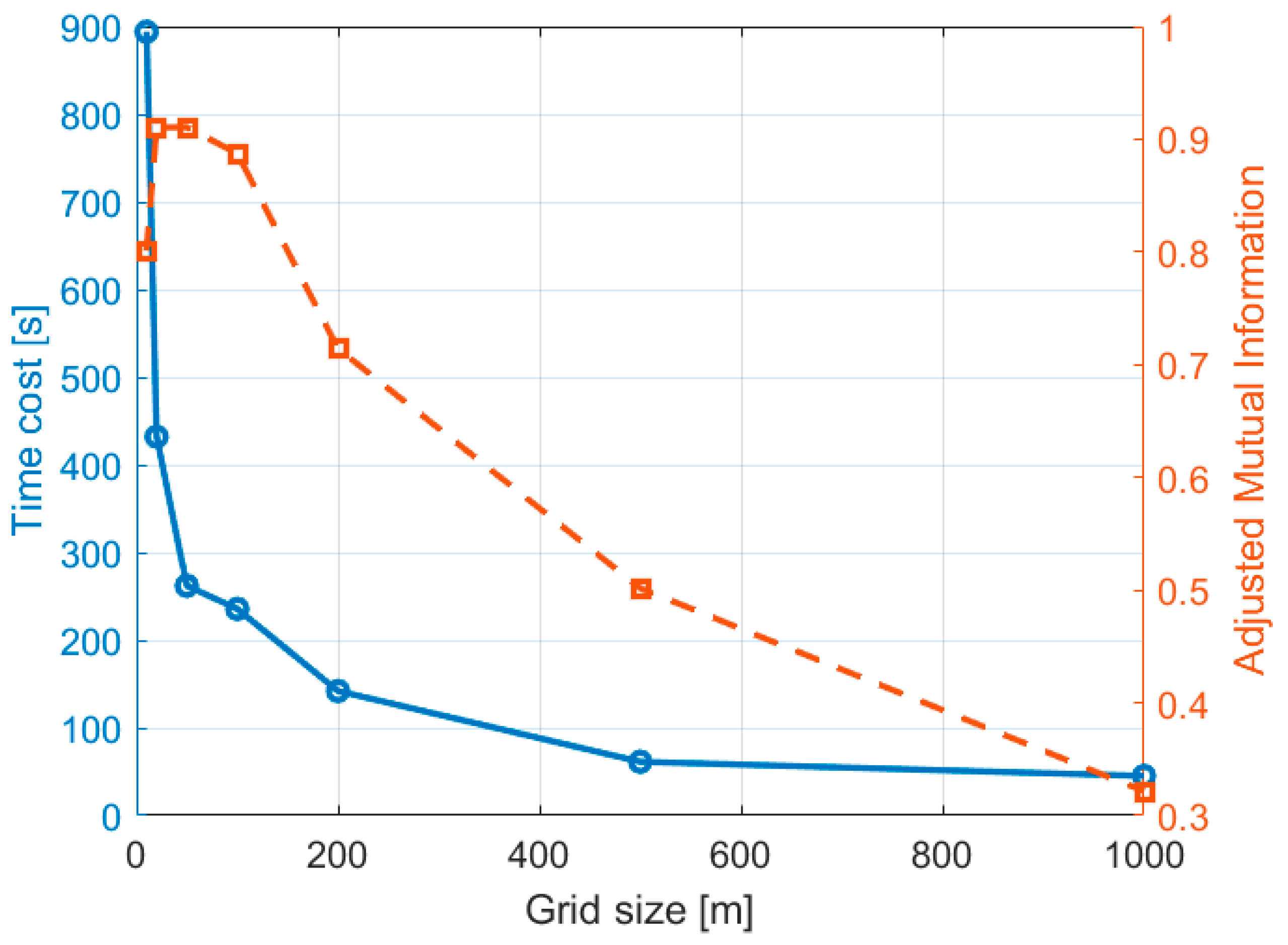
5.1. Parameter Setting
5.2. Practical Implications
5.3. The Limitations of This Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yan, R.; Wang, S.; Cao, J.; Sun, D. Shipping Domain Knowledge Informed Prediction and Optimization in Port State Control. Transp. Res. Part B Methodol. 2021, 149, 52–78. [Google Scholar] [CrossRef]
- Zhang, C.; Bin, J.; Wang, W.; Peng, X.; Wang, R.; Halldearn, R.; Liu, Z. AIS data driven general vessel destination prediction: A random forest based approach. Transp. Res. Part C-Emerg. Technol. 2020, 118, 102729. [Google Scholar] [CrossRef]
- Shen, C.; Shi, Y.; Buckham, B. Path-Following Control of an AUV: A Multi objective Model Predictive Control Approach. IEEE Trans. Control Syst. Technol. 2019, 27, 1334–1342. [Google Scholar] [CrossRef]
- Zhang, T.; Fu, M.; Song, W.; Yang, Y.; Wang, M. Trajectory Planning Based on Spatio-Temporal Map With Collision Avoidance Guaranteed by Safety Strip. IEEE Trans. Intell. Transp. Syst. 2022, 23, 1030–1043. [Google Scholar] [CrossRef]
- Chen, J.; Chen, H.; Zhao, Y.; Li, X. FB-BiGRU: A Deep Learning model for AIS-based vessel trajectory curve fitting and analysis. Ocean Eng. 2022, 266, 112898. [Google Scholar] [CrossRef]
- Xiao, Z.; Fu, X.; Zhang, L.; Goh, R.S.M. Traffic Pattern Mining and Forecasting Technologies in Maritime Traffic Service Networks: A Comprehensive Survey. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1796–1825. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, J.; Chen, H.; Zhao, Y.; Wang, H. A TDV attention-based BiGRU network for AIS-based vessel trajectory prediction. iScience 2023, 26, 106383. [Google Scholar] [CrossRef] [PubMed]
- Anneken, M.; Fischer, Y.; Beyerer, J. Evaluation and comparison of anomaly detection algorithms in annotated datasets from the maritime domain. In Proceedings of the 2015 SAI Intelligent Systems Conference (IntelliSys), London, UK, 10–11 November 2015; pp. 169–178. [Google Scholar]
- Rong, H.; Teixeira, A.; Soares, C.G. Data mining approach to shipping route characterization and anomaly detection based on AIS data. Ocean Eng. 2020, 198, 106936. [Google Scholar] [CrossRef]
- Yang, D.; Wu, L.; Wang, S.; Jia, H.; Li, K.X. How big data enriches maritime research—A critical review of Automatic Identification System (AIS) data applications. Transp. Rev. 2019, 39, 755–773. [Google Scholar] [CrossRef]
- Bo, L.; Souza, E.; Matwin, S.; Sydow, M. Knowledge-based Clustering of Ship Trajectories Using Density-based Approach. In Proceedings of the IEEE International Conference on Big Data, Washington, DC, USA, 27–30 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 603–608. [Google Scholar]
- Yan, W.; Rong, W.; Zhang, A.N.; Yang, D. Vessel Movement Analysis and Pattern Discovery Using Density-based Clustering Approach. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; IEEE: Piscataway, NJ, USA, 2017; pp. 3798–3806. [Google Scholar]
- Zhang, G.; Zhang, J. Trajectory Clustering Based on Trajectory Structure and Longest Common Subsequence. DEStech Trans. Comput. Sci. Eng. 2018. [Google Scholar] [CrossRef]
- Zhao, L.; Shi, G. A trajectory clustering method based on Douglas-Peucker compression and density for marine traffic pattern recognition. Ocean Eng. 2019, 172, 456–467. [Google Scholar] [CrossRef]
- Zhao, L.; Shi, G. A Novel Similarity Measure for Clustering Vessel Trajectories Based on Dynamic Time Warping. J. Navig. 2018, 72, 290–306. [Google Scholar] [CrossRef]
- Li, H.; Liu, J.; Yang, Z.; Liu, R.W.; Wu, K.; Wan, Y. Adaptively constrained dynamic time warping for time series classification and clustering. Inf. Sci. 2020, 534, 97–116. [Google Scholar] [CrossRef]
- Zhen, R.; Jin, Y.; Hu, Q.; Shao, Z.; Nikitakos, N. Maritime Anomaly Detection within Coastal Waters Based on Vessel Trajectory Clustering and Naïve Bayes Classifier. J. Navig. 2017, 70, 648–670. [Google Scholar] [CrossRef]
- Wang, L.; Chen, P.; Chen, L.; Mou, J. Ship AIS Trajectory Clustering: An HDBSCAN-Based Approach. J. Mar. Sci. Eng. 2021, 9, 566. [Google Scholar] [CrossRef]
- Wei, Z.; Meng, X.; Li, X.; Zhang, X.; Gao, Y. Vessel manoeuvring hot zone recognition and traffic analysis with AIS data. Ocean Eng. 2022, 266, 112858. [Google Scholar] [CrossRef]
- Efrat; Guibas; Har-Peled, S.; Mitchell; Murali. New Similarity Measures between Polylines with Applications to Morphing and Polygon Sweeping. Discret. Comput. Geom. 2002, 28, 535–569. [Google Scholar] [CrossRef]
- Tang, C.; Wang, H.; Wang, Z.; Zeng, X.; Yan, H.; Xiao, Y. An improved OPTICS clustering algorithm for discovering clusters with uneven densities. Intell. Data Anal. 2021, 25, 1453–1471. [Google Scholar] [CrossRef]
- Zhou, Y.; Daamen, W.; Vellinga, T.; Hoogendoorn, S.P. Ship classification based on ship behavior clustering from AIS data. Ocean Eng. 2019, 175, 176–187. [Google Scholar] [CrossRef]
- Liu, C.; Liu, J.; Zhou, X.; Zhao, Z.; Wan, C.; Liu, Z. AIS data-driven approach to estimate navigable capacity of busy waterways focusing on ships entering and leaving port. Ocean Eng. 2020, 218, 108215. [Google Scholar] [CrossRef]
- Zhang, W.; Goerlandt, F.; Montewka, J.; Kujala, P. A method for detecting possible near miss ship collisions from AIS data. Ocean Eng. 2015, 107, 60–69. [Google Scholar] [CrossRef]
- Gao, M.; Shi, G.Y. Ship-handling behavior pattern recognition using AIS sub-trajectory clustering analysis based on the T-SNE and spectral clustering algorithms. Ocean Eng. 2020, 205, 106919. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise; AAAI Press: Washington, DC, USA, 1996. [Google Scholar]
- Khan, M.M.R.; Siddique, M.A.B.; Arif, R.B.; Oishe, M.R. ADBSCAN: Adaptive Density-Based Spatial Clustering of Applications with Noise for Identifying Clusters with Varying Densities. In Proceedings of the 2018 4th International Conference on Electrical Engineering and Information & Communication Technology (iCEEiCT), Dhaka, Bangladesh, 13–15 September 2018; pp. 107–111. [Google Scholar]
- Yang, Y.; Li, Z.; Wang, W.; Tao, D. An adaptive semi-supervised clustering approach via multiple density-based information. Neurocomputing 2017, 257, 193–205. [Google Scholar] [CrossRef]
- Liu, F.; Zhang, Z. Adaptive density trajectory cluster based on time and space distance. Phys. A Stat. Mech. Its Appl. 2017, 484, 41–56. [Google Scholar] [CrossRef]
- Liu, Y.; Ma, Z.; Yu, F. Adaptive density peak clustering based on K-nearest neighbors with aggregating strategy. Knowl. Based Syst. 2017, 133, 208–220. [Google Scholar]
- Marques, J.C.; Orger, M.B. Clusterdv, a simple density-based clustering method that is robust, general and automatic. Bioinformatics 2018, 35, 2125–2132. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Liu, Y.; Ma, L.; Ji, C. Maritime traffic flow clustering analysis by density based trajectory clustering with noise. Ocean Eng. 2022, 249, 111001. [Google Scholar] [CrossRef]
- Tang, C.; Chen, M.; Zhao, J.; Liu, T.; Liu, K.; Yan, H.; Xiao, Y. A novel ship trajectory clustering method for Finding Overall and Local Features of Ship Trajectories. Ocean Eng. 2021, 241, 110108. [Google Scholar] [CrossRef]
- Yan, Z.; Xiao, Y.; Cheng, L.; He, R.; Ruan, X.; Zhou, X.; Li, M.; Bin, R. Exploring AIS data for intelligent maritime routes extraction. Appl. Ocean Res. 2020, 101, 102271. [Google Scholar] [CrossRef]
- Bailey, N. Training, technology and AIS: Looking beyond the box. In Proceedings of the Seafarers International Research Centre’s Fourth International Symposium, Lisboa, Portugal, 6–9 January 2005. [Google Scholar]
- Paredes-Oliva, I.; Castell-Uroz, I.; Barlet-Ros, P.; Dimitropoulos, X.; Solé-Pareta, J. Practical anomaly detection based on classifying frequent traffic patterns. In Proceedings of the 2012 Proceedings IEEE INFOCOM Workshops, Orlando, FL, USA, 25–30 March 2012; pp. 49–54. [Google Scholar]
- Fletcher, S.J. Chapter 12–Numerical Modeling on the Sphere. In Data Assimilation for the Geosciences, 2nd ed.; Fletcher, S.J., Ed.; Elsevier: Amsterdam, The Netherlands, 2023; pp. 485–555. [Google Scholar] [CrossRef]
- Zhao, L.; Shi, G.; Yang, J. Ship Trajectories Pre-processing Based on AIS Data. J. Navig. 2018, 71, 1210–1230. [Google Scholar] [CrossRef]
- Yan, Z.; Cheng, L.; He, R.; Yang, H. Extracting ship stopping information from AIS data. Ocean Eng. 2022, 250, 111004. [Google Scholar] [CrossRef]
- Yan, Z.; He, R.; Ruan, X.; Yang, H. Footprints of fishing vessels in Chinese waters based on automatic identification system data. J. Sea Res. 2022, 187, 102255. [Google Scholar] [CrossRef]
- Yan, Z.; Xiao, Y.; Cheng, L.; Chen, S.; Zhou, X.; Ruan, X.; Li, M.; He, R.; Ran, B. Analysis of Global Marine Oil Trade Based on Automatic Identification System (AIS) Data. J. Transp. Geogr. 2020, 83, 1026–1037. [Google Scholar] [CrossRef]
- Gahfarrokhi, J.K.; Abolghasemi, M. Fast VI-CFAR Ship Detection in HR SAR Data. In Proceedings of the 2020 28th Iranian Conference on Electrical Engineering (ICEE), Tabriz, Iran, 4–6 August 2020; pp. 1–5. [Google Scholar]
- Jain, A.K.; Farrokhnia, F. Unsupervised Texture Segmentation Using Gabor Filters. Pattern Recognit. 1991, 24, 1167–1186. [Google Scholar] [CrossRef]
- Huttenlocher, D.P.; Klanderman, G.A.; Rucklidge, W.J. Comparing images using the Hausdorff distance. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 850–863. [Google Scholar] [CrossRef]
- Hasan, L.; Al-Ars, Z. Performance Improvement of the Smith-Waterman Algorithm. In Proceedings of the Annual Workshop on Circuits, Systems and Signal Processing, Veldhoven, The Netherlands, 29–30 November 2007. [Google Scholar]
- Wang, X.; Xu, Y. An Improved Index for Clustering Validation Based on Silhouette Index and Calinski-Harabasz Index; IOP Publishing: Bristol, UK, 2019; p. 052024. [Google Scholar]
- Chen, J.; Chen, H.; Chen, Q.; Song, X.; Wang, H. Vessel sailing route extraction and analysis from satellite-based AIS data using density clustering and probability algorithms. Ocean Eng. 2023, 280, 114627. [Google Scholar] [CrossRef]
- Sunarmo, A.A.; Sumpeno, S. Clustering Spatial Temporal Distribution of Fishing Vessel Based lOn VMS Data Using K-Means. In Proceedings of the 2020 3rd International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 24–25 November 2020. [Google Scholar]
- Tang, R.; Fong, S. Clustering big IoT data by metaheuristic optimized mini-batch and parallel partition-based DGC in Hadoop. Future Gener. Comput. Syst. 2018, 86, 1395–1412. [Google Scholar] [CrossRef]
- Chen, Z.; Li, B.; Tian, L.F.; Chao, D. Automatic detection and tracking of ship based on mean shift in corrected video sequences. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017. [Google Scholar]
- Rong, H.; Teixeira, A.P.; Soares, C.G. Maritime traffic probabilistic prediction based on ship motion pattern extraction. Reliab. Eng. Syst. Saf. 2022, 217, 108061. [Google Scholar] [CrossRef]
- Yu, J.; Wan, Q.; Liu, Q.; Chen, X.; Li, Z. A Novel Ship Detector Based on Gaussian Mixture Model and K-Means Algorithm. In International Conference on Applications and Techniques in Cyber Security and Intelligence ATCI 2018: Applications and Techniques in Cyber Security and Intelligence; Springer International Publishing: Cham, Switzerland, 2019. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Performance | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Clusters | Silhouette Coefficient | Calinski–Harabasz Index | Davies–Bouldin Index | Adjusted Rand Score | Adjusted Mutual Information | V-Measure | Mallows Score | Time Cost | |
| k-means [48] (Affandi et al., 2020) | 6 | 0.4571 | 26,987.0236 | 1.0514 | 0.2300 | 0.3798 | 0.3798 | 0.5354 | 12.7614 s |
| Minibatch [49] (Tang and Fong, 2018) | 240 | 0.3815 | 17,812.3450 | 0.8272 | 0.2947 | 0.4732 | 0.4732 | 0.5125 | 37.5809 s |
| Mean shift [50] (Chen et al., 2017) | 2 | 0.5666 | 18,505.3470 | 1.1534 | 0.1876 | 0.2715 | 0.2715 | 0.5461 | 786.6635 s |
| OPTICS [51] (Rong et al., 2022) | 240 | −0.4389 | 1072.4056 | 1.8995 | 0.0363 | 0.2293 | 0.2293 | 0.4897 | 524.7466 s |
| Spectral clustering [25] (Gao and Shi, 2020) | 240 | 0.3768 | 4467.0755 | 1.3781 | 0.1959 | 0.4987 | 0.4987 | 0.5095 | 170.5076 s |
| Gaussian mixture [52] (Yu et al., 2018) | 49 | −0.0381 | 3469.1872 | 2.5320 | 0.1255 | 0.4110 | 0.4110 | 0.5032 | 600.3050 s |
| Fast-DBSCAN [47] (Chen et al., 2023) | 203 | −0.2005 | 1705.9510 | 1.5039 | 0.3139 | 0.3880 | 0.3879 | 0.5081 | 309.6005 s |
| Ours | 52 | −0.8649 | 783.2227 | 24.9302 | 0.7638 | 0.8874 | 0.8875 | 0.8123 | 235.7099 s |
| Methods | Time Cost | |||
|---|---|---|---|---|
| AIS Data from 1 January to 7 January | AIS Data from 1 January to 14 January | AIS Data from 1 January to 21 January | AIS Data from 1 January to 1 February | |
| k-means (Affandi et al., 2020 [48]) | 12.7614 s | 13.0473 s | 16.9655 s | 26.7114 s |
| Minibatch (Tang and Fong, 2018 [49]) | 6.9864 s | 8.6478 s | 12.5502 s | 16.8571 s |
| Mean shift (Chen et al., 2017 [50]) | 786.6635 s | 5377.7543 s | 9728.5147 s | 15,910.2940 s |
| OPTICS (Rong et al., 2022 [51]) | 524.7466 s | 765.9809 s | 2688.7135 s | 9731.3116 s |
| Spectral clustering (Gao and Shi, 2020 [25]) | 170.5076 s | / | / | / |
| Gaussian mixture (Yu et al., 2018 [52]) | 600.3050 s | 909.2754 s | 1432.8670 s | 1760.0464 s |
| Fast-DBSCAN (Chen et al., 2023 [47]) | 309.6005 s | 378.3306 s | 1317.4696 s | 4476.4033 s |
| Ours | 235.7099 s | 305.6329 s | 427.8843 s | 584.1705 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mou, F.; Fan, Z.; Li, X.; Wang, L.; Li, X. A Method for Clustering and Analyzing Vessel Sailing Routes Efficiently from AIS Data Using Traffic Density Images. J. Mar. Sci. Eng. 2024, 12, 75. https://doi.org/10.3390/jmse12010075
Mou F, Fan Z, Li X, Wang L, Li X. A Method for Clustering and Analyzing Vessel Sailing Routes Efficiently from AIS Data Using Traffic Density Images. Journal of Marine Science and Engineering. 2024; 12(1):75. https://doi.org/10.3390/jmse12010075
Chicago/Turabian StyleMou, Fangli, Zide Fan, Xiaohe Li, Lei Wang, and Xinming Li. 2024. "A Method for Clustering and Analyzing Vessel Sailing Routes Efficiently from AIS Data Using Traffic Density Images" Journal of Marine Science and Engineering 12, no. 1: 75. https://doi.org/10.3390/jmse12010075