Automated Defect Analysis of Additively Fabricated Metallic Parts Using Deep Convolutional Neural Networks


Abstract
:1. Introduction
- Selective manual segmentation: Acquiring manually segmented images are costly. Therefore, the images that are selected to be manually segmented by the domain experts should contain information that is likely to be found in the entire dataset. For example, if the scanned sample contains pores and cracks, the selected training slices should have different types of pores and cracks and their combination to use human expertise as much as possible [3].
- Evaluation measures: The criteria that determine how far (close) the network output is from the ground truth. The optimizer tries to minimize (maximize) these criteria during the training phase [8].
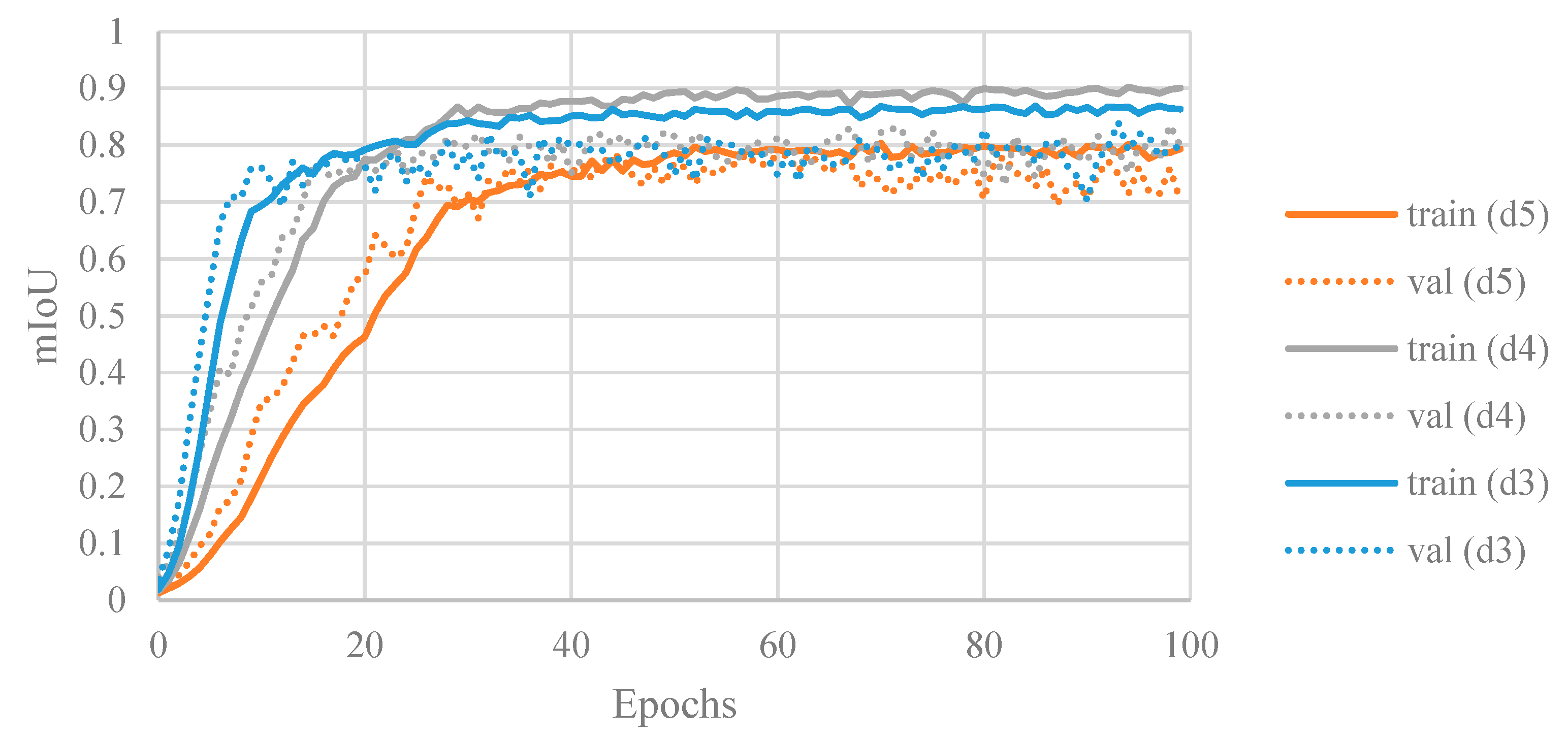
- Effect of network depth
- Random weight initialization
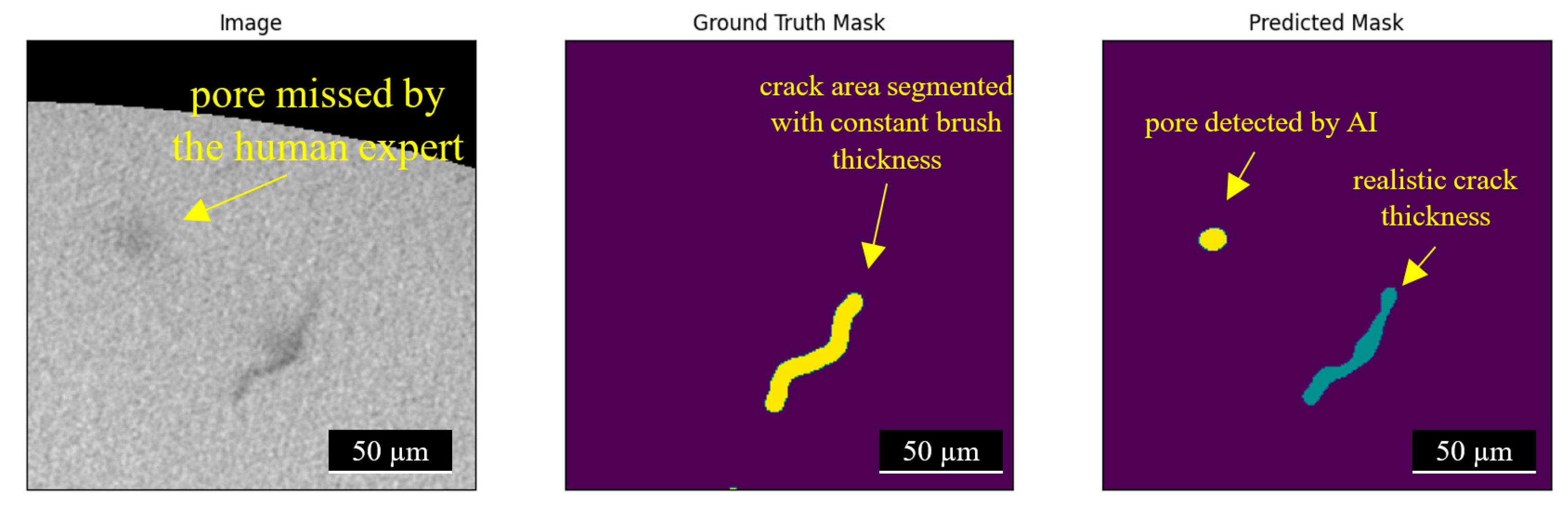
- Accuracy of the manually labeled data compared to network prediction
2. Materials and Methods
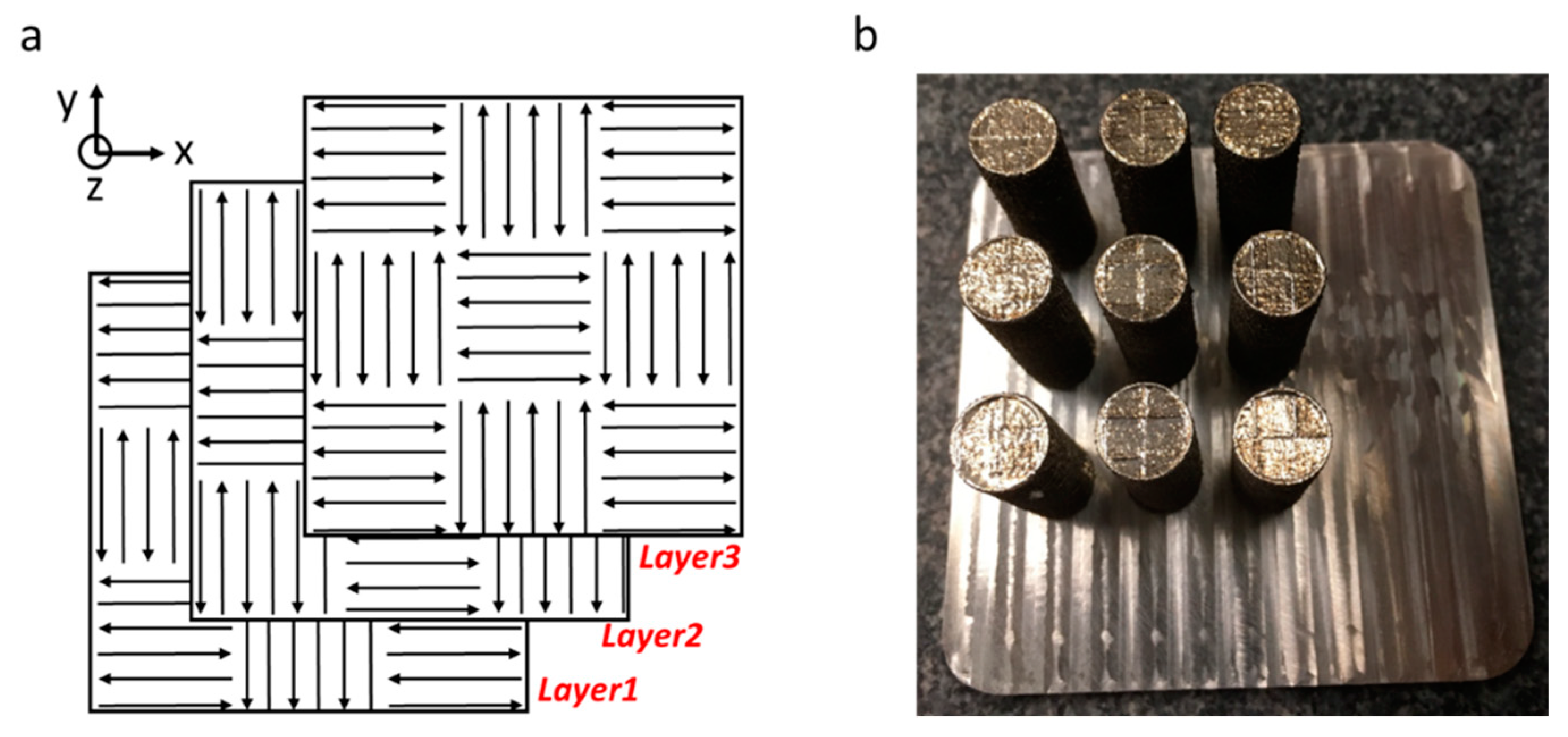
2.1. Material and Fabrication
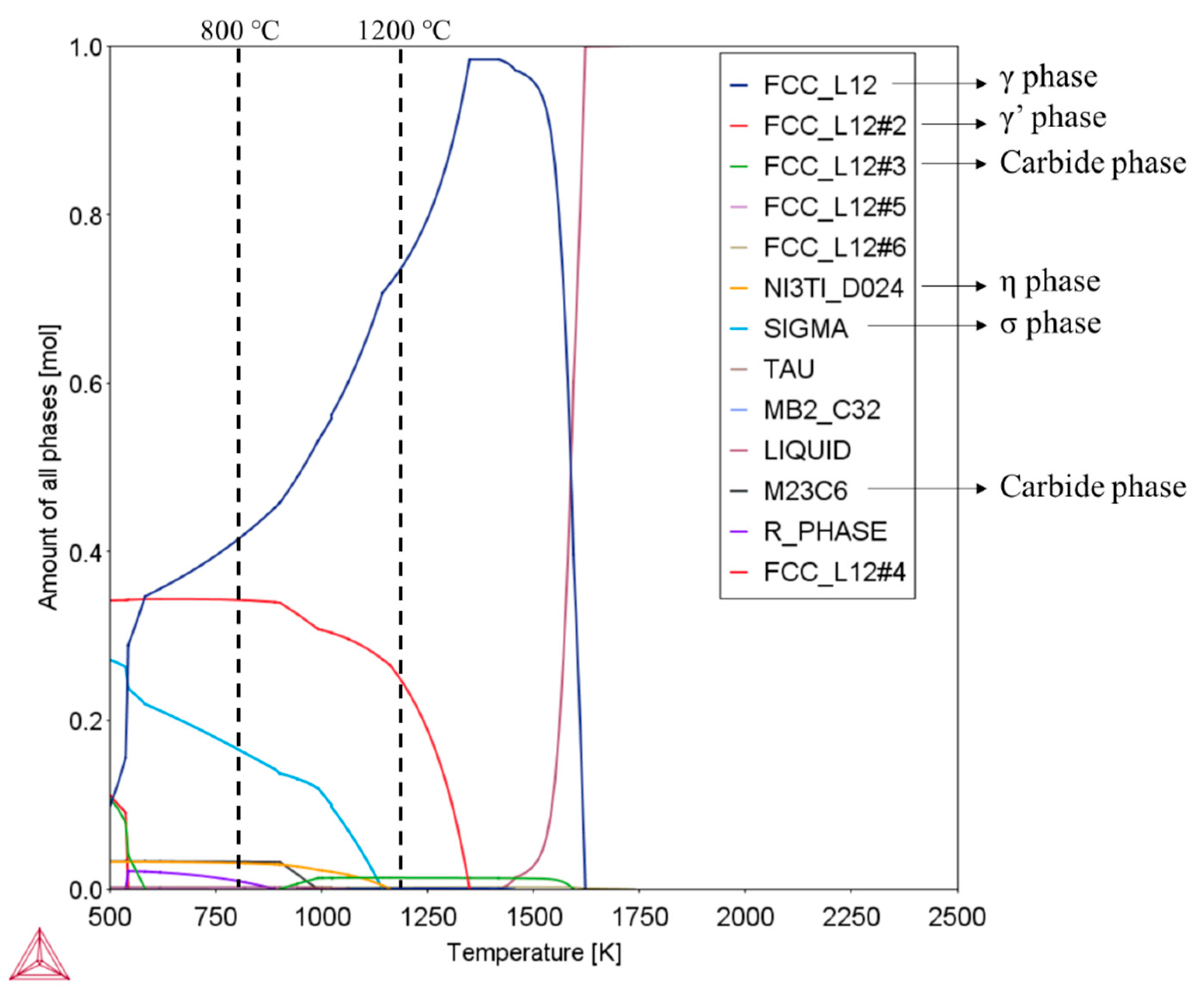
2.2. Phase Constituents and Microstructures
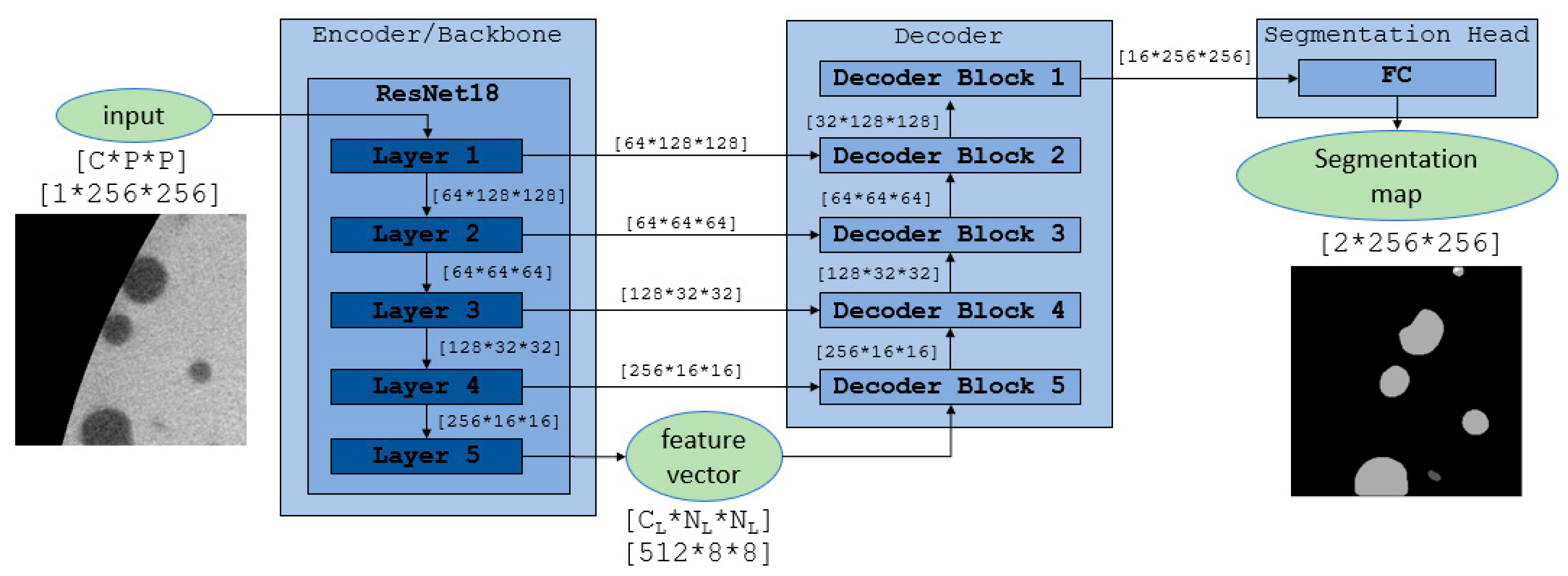
3. CNN-Based Architecture
4. Automated Defect Analysis
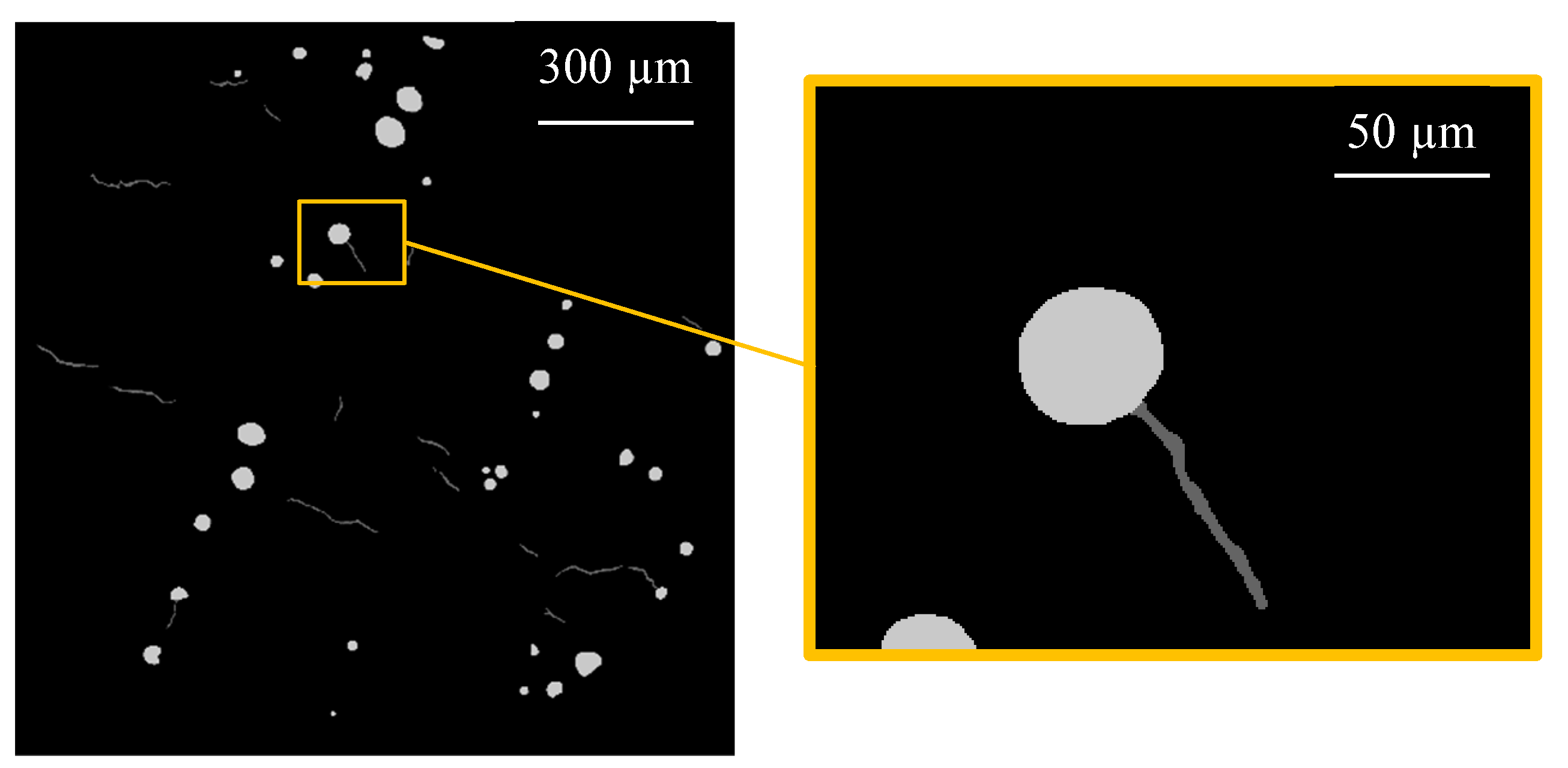
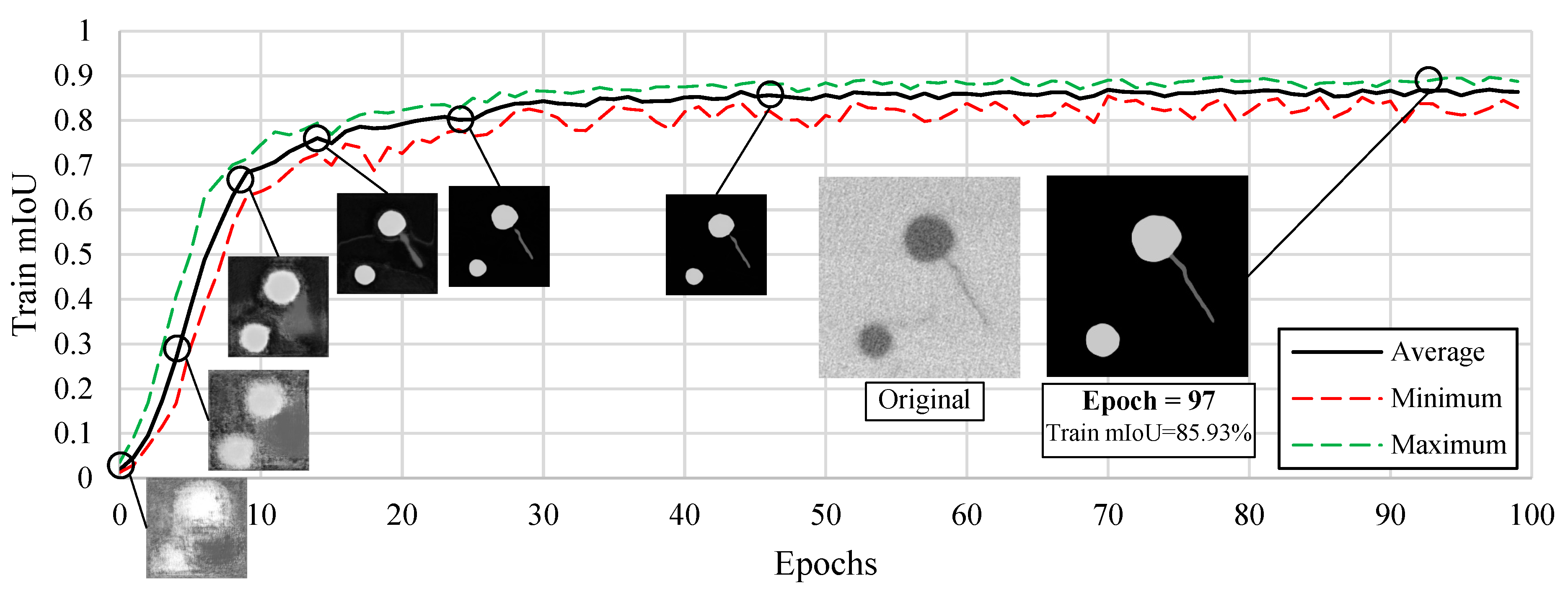
4.1. Manual Image Segmentation
4.2. Data Preparation
4.3. Performance Metric
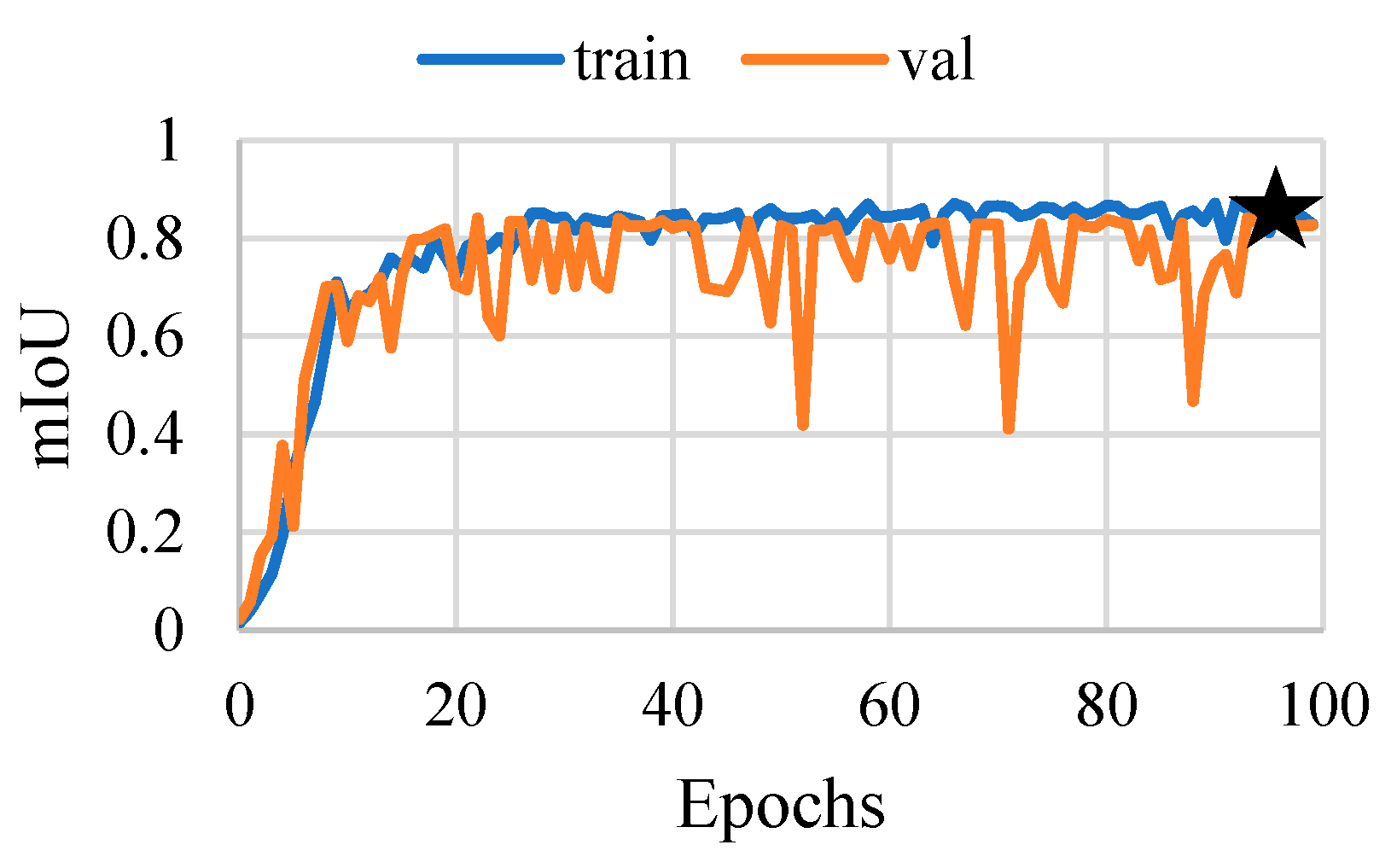
4.4. Training
- Data augmentation settings: patch size, normalization;
- Network settings: depth, backbone, layer structure, decoder structure, segmentation head, normalization, regularization;
- Training settings: learning rate, size of training/validation/test set, optimizer, loss function, weight initialization.
5. Results and Discussion
- Error in experimental porosity measurement using Archimedes principle;
- Voids not being captured in XCT;
- Error in manual segmentation for generating training data;
- Network being incapable of performing the segmentation correctly.
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ghadimi, H.; Jirandehi, A.P.; Nemati, S.; Guo, S. Small-sized specimen design with the provision for high-frequency bending-fatigue testing. Fatigue Fract. Eng. Mater. Struct. 2021, 44, 3517–3537. [Google Scholar] [CrossRef]
- Sengur, A.; Budak, U.; Akbulut, Y.; Karabatak, M.; Tanyildizi, E. 7—A Survey on Neutrosophic Medical Image Segmentation, in Neutrosophic Set in Medical Image Analysis; Guo, Y., Ashour, A.S., Eds.; Academic Press: Cambridge, MA, USA, 2019; pp. 145–165. [Google Scholar]
- Liang, J.; Zhou, Z.; Shin, J. Systems, Methods, and/or Media, for Selecting Candidates for Annotation for Use in Training a Classifier. U.S. Patents 10,956,785, 31 October 2019. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Stan, T.; Thompson, Z.T.; Voorhees, P.W. Optimizing convolutional neural networks to perform semantic segmentation on large materials imaging datasets: X-ray tomography and serial sectioning. Mater. Charact. 2020, 160, 110119. [Google Scholar] [CrossRef]
- Torbati-Sarraf, H.; Niverty, S.; Singh, R.; Barboza, D.; De Andrade, V.; Turaga, P.; Chawla, N. Machine-Learning-based Algorithms for Automated Image Segmentation Techniques of Transmission X-ray Microscopy (TXM). JOM 2021, 73, 2173–2184. [Google Scholar] [CrossRef]
- Wen, H.; Huang, C.; Guo, S. The Application of Convolutional Neural Networks (CNNs) to Recognize Defects in 3D-Printed Parts. Materials 2021, 14, 2575. [Google Scholar] [CrossRef]
- Csurka, G.; Larlus, D.; Perronnin, F. What is a good evaluation measure for semantic segmentation? In Proceedings of the BMVC, Bristol, UK, 9–13 September 2013. [Google Scholar]
- Ettefagh, A.H.; Zeng, C.; Guo, S.; Raush, J. Corrosion behavior of additively manufactured Ti-6Al-4V parts and the effect of post annealing. Addit. Manuf. 2019, 28, 252–258. [Google Scholar]
- Gokcekaya, O.; Ishimoto, T.; Hibino, S.; Yasutomi, J.; Narushima, T.; Nakano, T. Unique crystallographic texture formation in Inconel 718 by laser powder bed fusion and its effect on mechanical anisotropy. Acta Mater. 2021, 212, 116876. [Google Scholar] [CrossRef]
- Marchese, G.; Parizia, S.; Rashidi, M.; Saboori, A.; Manfredi, D.; Ugues, D.; Lombardi, M.; Hryha, E.; Biamino, S. The role of texturing and microstructure evolution on the tensile behavior of heat-treated Inconel 625 produced via laser powder bed fusion. Mater. Sci. Eng. A 2020, 769, 138500. [Google Scholar] [CrossRef]
- Wilson-Heid, A.E.; Qin, S.; Beese, A.M. Multiaxial plasticity and fracture behavior of stainless steel 316L by laser powder bed fusion: Experiments and computational modeling. Acta Mater. 2020, 199, 578–592. [Google Scholar] [CrossRef]
- Lassègue, P.; Salvan, C.; De Vito, E.; Soulas, R.; Herbin, M.; Hemberg, A.; Godfroid, T.; Baffie, T.; Roux, G. Laser powder bed fusion (L-PBF) of Cu and CuCrZr parts: Influence of an absorptive physical vapor deposition (PVD) coating on the printing process. Addit. Manuf. 2021, 39, 101888. [Google Scholar] [CrossRef]
- Dovgyy, B.; Simonelli, M.; Pham, M.-S. Alloy design against the solidification cracking in fusion additive manufacturing: An application to a FeCrAl alloy. Mater. Res. Lett. 2021, 9, 350–357. [Google Scholar] [CrossRef]
- Kaira, C.S.; Yang, X.; De Andrade, V.; De Carlo, F.; Scullin, W.; Gursoy, D.; Chawla, N. Automated correlative segmentation of large Transmission X-ray Microscopy (TXM) tomograms using deep learning. Mater. Charact. 2018, 142, 203–210. [Google Scholar] [CrossRef]
- Ma, B.; Ban, X.; Huang, H.; Chen, Y.; Liu, W.; Zhi, Y. Deep Learning-Based Image Segmentation for Al-La Alloy Microscopic Images. Symmetry 2018, 10, 107. [Google Scholar] [CrossRef] [Green Version]
- Tekawade, A.; Sforzo, B.A.; Matusik, K.E.; Kastengren, A.L.; Powell, C.F. High-fidelity geometry generation from CT data using convolutional neural networks. In SPIE Optical Engineering + Applications; SPIE: Bellingham, WA, USA, 2019; Volume 11113. [Google Scholar]
- Evsevleev, S.; Paciornik, S.; Bruno, G. Advanced Deep Learning-Based 3D Microstructural Characterization of Multiphase Metal Matrix Composites. Adv. Eng. Mater. 2020, 22, 1901197. [Google Scholar] [CrossRef]
- Chen, D.; Guo, D.; Liu, S.; Liu, F. Microstructure Instance Segmentation from Aluminum Alloy Metallographic Image Using Different Loss Functions. Symmetry 2020, 12, 639. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; De Andrade, V.; Scullin, W.; Dyer, E.L.; Kasthuri, N.; De Carlo, F.; Gürsoy, D. Low-dose X-ray tomography through a deep convolutional neural network. Sci. Rep. 2018, 8, 2575. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, Y.; Wu, Z.; Hartley, W.D.; Sietins, J.M.; Williams, C.; Yu, H.Z. Unraveling pore evolution in post-processing of binder jetting materials: X-ray computed tomography, computer vision, and machine learning. Addit. Manuf. 2020, 34, 101183. [Google Scholar] [CrossRef]
- Wu, Z.; Yang, T.; Deng, Z.; Huang, B.; Liu, H.; Wang, Y.; Chen, Y.; Stoddard, M.C.; Li, L.; Zhu, Y. Automatic Crack Detection and Analysis for Biological Cellular Materials in X-Ray In Situ Tomography Measurements. Integr. Mater. Manuf. Innov. 2019, 8, 559–569. [Google Scholar] [CrossRef] [Green Version]
- Ferguson, M.; Ak, R.; Lee, Y.-T.T.; Law, K.H. Detection and Segmentation of Manufacturing Defects with Convolutional Neural Networks and Transfer Learning. Smart Sustain. Manuf. Syst. 2018, 2, 20180033. [Google Scholar] [CrossRef] [PubMed]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. arXiv 2016, arXiv:1606.06650. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.W.; Heng, P.A. H-DenseUNet: Hybrid Densely Connected UNet for Liver and Tumor Segmentation From CT Volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [PubMed]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv 2021, arXiv:2105.15203. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision Transformers for Dense Prediction. arXiv 2021, arXiv:2103.13413. [Google Scholar]
- Hegazy, M.A.A.; Cho, M.H.; Cho, M.H.; Lee, S.Y. U-net based metal segmentation on projection domain for metal artifact reduction in dental CT. Biomed. Eng. Lett. 2019, 9, 375–385. [Google Scholar] [CrossRef]
- Cho, P.; Yoon, H.-J. Evaluation of U-net-based image segmentation model to digital mammography. In Medical Imaging 2021: Image Processing; SPIE: Bellingham, WA, USA, 2021. [Google Scholar]
- Maxwell, A.E.; Bester, M.S.; Guillen, L.A.; Ramezan, C.A.; Carpinello, D.J.; Fan, Y.; Hartley, F.M.; Maynard, S.M.; Pyron, J.L. Semantic Segmentation Deep Learning for Extracting Surface Mine Extents from Historic Topographic Maps. Remote Sens. 2020, 12, 4145. [Google Scholar] [CrossRef]
- Zhang, D.; Niu, W.; Cao, X.; Liu, Z. Effect of standard heat treatment on the microstructure and mechanical properties of selective laser melting manufactured Inconel 718 superalloy. Mater. Sci. Eng. A 2015, 644, 32–40. [Google Scholar] [CrossRef]
- Jahangiri, M. Different effects of γ′ and η phases on the physical and mechanical properties of superalloys. J. Alloys Compd. 2019, 802, 535–545. [Google Scholar] [CrossRef]
- Kiss, A.M.; Fong, A.Y.; Calta, N.P.; Thampy, V.; Martin, A.A.; Depond, P.J.; Wang, J.; Matthews, M.J.; Ott, R.T.; Tassone, C.J.; et al. Laser-Induced Keyhole Defect Dynamics during Metal Additive Manufacturing. Adv. Eng. Mater. 2019, 21, 1900455. [Google Scholar] [CrossRef]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Ciresan, D.; Giusti, A.; Gambardella, L.; Schmidhuber, J. Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images. In Proceedings of the NIPS, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R.B. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Convolutional feature masking for joint object and stuff segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3992–4000. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the CVPR, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Yakubovskiy, P. Segmentation Models Pytorch; GitHub Repository: San Francisco, CA, USA, 2020. [Google Scholar]
- Slotwinski, J.A.; Garboczi, E.J.; Hebenstreit, K.M. Porosity Measurements and Analysis for Metal Additive Manufacturing Process Control. J. Res. Natl. Inst. Stand. Technol. 2014, 119, 494–528. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Elements | Al | B | C | Co | Cr | Fe | Mg | N | Nb | Ni | Si | Ta | Ti | W | Zr |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Contents (wt.%) | 1.9 | 0.01 | 0.15 | 19.2 | 22.3 | 0.1 | <0.1 | 0.01 | 1.0 | Bal. | 0.1 | 1.5 | 3.6 | 2.0 | 0.11 |
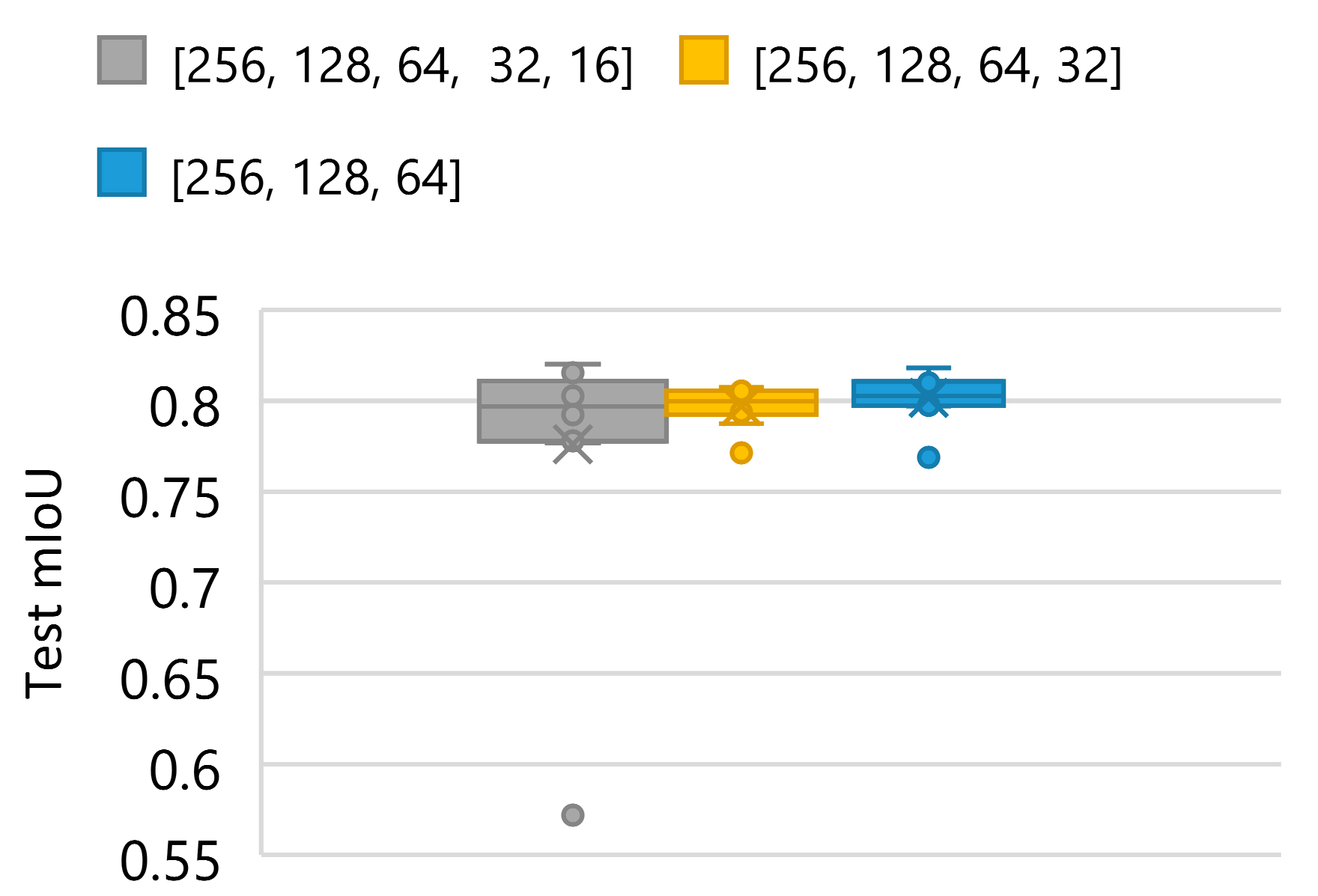
| Depth | Decoder Channels | Number of Parameters | Training Time [min] | Reconstruction Time [sec/slice] | Overall Performance on Test Set [mIoU ± σ] | Best Performance on Test Set | ||
|---|---|---|---|---|---|---|---|---|
| Train mIoU | Val. mIoU | Test mIoU | ||||||
| 5 | (256, 128, 64, 32, 16) | 14,328,354 | ~25 | 1.64 | 0.7933 ± 0.0196 | 0.7992 | 0.9050 | 0.8156 |
| 4 | (256, 128, 64, 32) | 13,344,770 | ~25 | 1.75 | 0.7944 ± 0.0071 | 0.9078 | 0.9240 | 0.8090 |
| 3 | (256, 128, 64) | 12,838,338 | ~50 | 2.34 | 0.8016 ± 0.0127 | 0.8593 | 0.8409 | 0.8181 |
| Segmentation Method | Manual Segmentation | Preprocessing | Training | Reconstruction | Total |
|---|---|---|---|---|---|
| Manual | 1000 h (>5 weeks) | N/A | N/A | N/A | 5 weeks |
| Automated (Supervised) | 1–2 h (for 2 training slices) | 2-4 h | 5-15 h | 1 h | Less than 20 h |
| Defect Type | Volume Fraction |
|---|---|
| Crack | 0.00426696 |
| Pore | 0.0222326 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nemati, S.; Ghadimi, H.; Li, X.; Butler, L.G.; Wen, H.; Guo, S. Automated Defect Analysis of Additively Fabricated Metallic Parts Using Deep Convolutional Neural Networks. J. Manuf. Mater. Process. 2022, 6, 141. https://doi.org/10.3390/jmmp6060141
Nemati S, Ghadimi H, Li X, Butler LG, Wen H, Guo S. Automated Defect Analysis of Additively Fabricated Metallic Parts Using Deep Convolutional Neural Networks. Journal of Manufacturing and Materials Processing. 2022; 6(6):141. https://doi.org/10.3390/jmmp6060141
Chicago/Turabian StyleNemati, Saber, Hamed Ghadimi, Xin Li, Leslie G. Butler, Hao Wen, and Shengmin Guo. 2022. "Automated Defect Analysis of Additively Fabricated Metallic Parts Using Deep Convolutional Neural Networks" Journal of Manufacturing and Materials Processing 6, no. 6: 141. https://doi.org/10.3390/jmmp6060141